双目视觉中矩阵等参数说明及矫正
以下是标定文件中各个参数的详细解释:
1. 图像尺寸 (imageSize)
- 参数值:
[1280, 1024] - 含义: 相机的图像分辨率,宽度为1280像素,高度为1024像素。
2. 相机内参矩阵 (leftCameraMatrix / rightCameraMatrix)
- 结构:
yaml
data: [fx, 0, cx, 0, fy, cy, 0, 0, 1] - 参数含义:
fx,fy: 相机的焦距(像素单位),表示图像传感器在x和y方向的缩放。cx,cy: 主点坐标(像素单位),即光轴与图像平面的交点。
- 示例:
- 左相机:
fx=4599.03,fy=4599.03,cx=650.9088,cy=457.0334 - 右相机:
fx=4589.28,fy=4589.28,cx=632.6679,cy=484.3212
- 左相机:
3. 畸变系数 (leftDistCoeffs / rightDistCoeffs)
- 结构:
[k1, k2, p1, p2, k3] - 参数含义:
k1,k2,k3: 径向畸变系数,用于修正图像边缘的膨胀或收缩。p1,p2: 切向畸变系数,修正由镜头与传感器不平行引起的畸变。
- 示例:
- 左相机:
k1=0.00656,k2=-0.1852,p1=-0.0001287,p2=0.001295,k3=0 - 右相机:
k1=-0.00789,k2=0.2932,p1=-0.0019676,p2=0.0001764,k3=0
- 左相机:
4. 立体外参:旋转矩阵 (R) 和平移向量 (T)
- R: 右相机相对于左相机的3x3旋转矩阵,描述方向关系。
- 示例: 通过旋转矩阵可将右相机坐标系转换到左相机坐标系。
- T: 右相机相对于左相机的3x1平移向量,单位为标定板尺寸单位(如毫米)。
- 示例:
[-34.9837, -0.0907, 3.3531]表示右相机在左相机的左侧34.98单位、下方0.09单位、后方3.35单位。
- 示例:
5. 立体校正参数 (R1, R2, P1, P2)
- R1/R2: 左右相机的3x3校正旋转矩阵,使图像平面共面且行对齐。
- P1/P2: 校正后的3x4投影矩阵,用于将三维点投影到校正后的图像平面。
- P1(左相机): 通常与原始内参接近,第四列为0。
- P2(右相机): 第四列包含基线信息,例如
-167552.8 = -fx * B(基线B≈35.16单位)。
6. 视差转深度矩阵 (Q)
- 结构:
yaml
data: [1, 0, 0, -cx, 0, 1, 0, -cy, 0, 0, 0, f, 0, 0, -1/Tx, (cx - cx')/Tx] - 关键参数:
f: 校正后的焦距(4767.59)。Tx: 基线长度在x方向的分量(34.98单位)。- 最后一行的
-1/Tx和(cx - cx')/Tx用于计算深度:
深度 Z = f * B / (视差 d)。
7. 有效区域 (validRoiL / validRoiR)
- 参数值:
[0, 0, 1280, 1024] - 含义: 校正后图像的有效区域(无黑边),此处整个图像均有效。
总结应用
- 立体匹配: 使用校正后的图像(通过
initUndistortRectifyMap生成映射)进行行对齐。 - 深度计算: 利用视差图和Q矩阵(通过
reprojectImageTo3D)生成三维点云。 - 基线计算: 平移向量T的模长为实际基线长度,约为35单位(需确认标定板尺寸单位)。
通过以上参数,可完成相机的畸变校正、立体校正及深度恢复。
以下是立体校正参数 R1, R2, P1, P2 的详细解释,包括每个矩阵的结构和具体数值的含义:
1. 校正旋转矩阵 R1 和 R2
作用
- R1 (左相机): 将左相机的原始图像平面旋转到校正后的共面坐标系。
- R2 (右相机): 将右相机的原始图像平面旋转到校正后的共面坐标系。
- 目的是使两相机的图像平面平行且行对齐(极线水平对齐),简化立体匹配。
矩阵结构(3x3 旋转矩阵)
旋转矩阵的每个元素表示坐标系之间的旋转变换关系,例如:
-
R1 的数值:
data: [0.99997555568908714, -0.0062994551725360625, -0.003033955970468287,0.0062989404771726203, 0.99998014542628355, -0.00017917057171665187,0.0030350244095505921, 0.0001600554839471561, 0.99999538149387235]- 物理意义:
- 第一行
[0.999975, -0.006299, -0.003034]: 表示校正后坐标系相对于原始坐标系的X轴方向。 - 第二行
[0.006299, 0.999980, -0.000179]: 表示Y轴方向。 - 第三行
[0.003035, 0.000160, 0.999995]: 表示Z轴方向。
- 第一行
- 特点: 接近单位矩阵,说明左相机的校正旋转较小。
- 物理意义:
-
R2 的数值:
data: [0.99543482924512139, 0.0025814032057267745, -0.095408789339480812,-0.0025652019951301346, 0.99999666709757318, 0.00029245934628591462,0.095409226306789358, -4.638140266466435e-05, 0.99543813337861697]- 物理意义:
- 第三行
[0.095409, -0.000046, 0.995438]: 右相机的Z轴旋转角度较大(绕X/Y轴的旋转)。
- 第三行
- 特点: 较大的非对角元素表明右相机需要更明显的旋转来对齐极线。
- 物理意义:
2. 投影矩阵 P1 和 P2
作用
- P1 (左相机): 将校正后的左相机三维点投影到二维图像平面。
- P2 (右相机): 将校正后的右相机三维点投影到二维图像平面,并包含基线信息。
- 用于生成校正后的图像和深度计算。
矩阵结构(3x4 投影矩阵)
投影矩阵的通用形式:
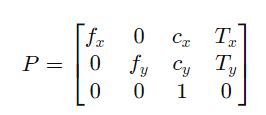
其中, Tx,Ty 可能与基线相关(仅对右相机有意义)。
P1 的数值(左相机):
yaml
data: [4767.5938097846156, 0., 665.86970520019531, 0., | |
0., 4767.5938097846156, 470.13141250610352, 0., | |
0., 0., 1., 0.] |
-
分解结构:
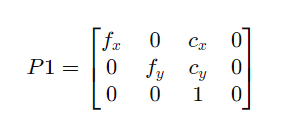
- 参数含义:
- fx=4767.59 f_x = 4767.59 fx=4767.59: 校正后的左相机x轴焦距(可能与原始焦距不同)。
- cx=665.87 c_x = 665.87 cx=665.87, cy=470.13 c_y = 470.13 cy=470.13: 校正后的主点坐标。
- 第四列全为0,因为左相机是参考坐标系。
- 参数含义:
P2 的数值(右相机):
data: [4767.5938097846156, 0., 1081.5456809997559, -167552.80474900999, | |
0., 4767.5938097846156, 470.13141250610352, 0., | |
0., 0., 1., 0.] |
-
分解结构:

- 参数含义:
- cx′=1081.55 c_x' = 1081.55 cx′=1081.55: 右相机校正后的主点x坐标。
- 第四列: −fx⋅B=−167552.8 -f_x \cdot B = -167552.8 −fx⋅B=−167552.8,其中:
-
B B B 是基线长度(单位与标定板一致),计算得:
B=167552.84767.59≈35.16(与平移向量T的x分量34.98接近) B = \frac{167552.8}{4767.59} \approx 35.16 \text{(与平移向量T的x分量34.98接近)} B=4767.59167552.8≈35.16(与平移向量T的x分量34.98接近)
-
负号表示右相机在左相机的左侧。
-
- 参数含义:
3. 关键差异与用途
-
焦距与主点:
- 校正后的焦距(P1/P2中的fx,fy f_x, f_y fx,fy)可能与原始内参不同,因校正可能缩放图像。
- 主点 cx,cy c_x, c_y cx,cy 变化是因图像平面旋转后光轴位置改变。
-
基线信息:
-
P2的第四列直接编码基线长度 B B B,用于计算深度:
深度Z=fx⋅B视差d \text{深度} Z = \frac{f_x \cdot B}{\text{视差} d} 深度Z=视差dfx⋅B
-
-
行对齐:
- 校正后的图像满足 cy左=cy右 c_y^{\text{左}} = c_y^{\text{右}} cy左=cy右(此处均为470.13),确保极线水平对齐。
4. 实际应用
-
生成校正映射:
python
# OpenCV 示例mapL_x, mapL_y = cv2.initUndistortRectifyMap(leftCameraMatrix, leftDistCoeffs, R1, P1, imageSize, cv2.CV_32FC1)- 使用R1和P1校正左图像,R2和P2校正右图像。
-
深度计算:
-
通过视差图(立体匹配)和Q矩阵(包含基线信息)恢复三维坐标:

-
调用
cv2.reprojectImageTo3D(disparity, Q)可直接生成三维点云。
-
总结
- R1/R2: 旋转矩阵,用于极线对齐,使图像行对齐。
- P1/P2: 投影矩阵,定义校正后的相机参数,P2包含基线信息。
- 数值差异: 焦距、主点、基线长度是立体视觉深度计算的核心参数。
以下是立体校正的具体实现步骤,结合标定参数和OpenCV等工具的实际操作流程:
1. 获取相机标定参数
从标定文件(如YAML)中读取以下关键参数:
- 内参矩阵:
leftCameraMatrix,rightCameraMatrix - 畸变系数:
leftDistCoeffs,rightDistCoeffs - 立体外参:旋转矩阵
R和平移向量T - 校正参数:
R1,R2,P1,P2 - 图像尺寸:
imageSize = (width, height)
2. 计算校正映射(Remap Maps)
使用 cv2.initUndistortRectifyMap 生成左右相机的畸变校正和极线对齐的映射表:
python
import cv2 | |
import numpy as np | |
# 读取标定参数(示例值) | |
leftCameraMatrix = np.array([[4599.03, 0, 650.909], [0, 4599.03, 457.033], [0, 0, 1]]) | |
leftDistCoeffs = np.array([0.00656, -0.1852, -0.0001287, 0.001295, 0]) | |
rightCameraMatrix = np.array([[4589.28, 0, 632.668], [0, 4589.28, 484.321], [0, 0, 1]]) | |
rightDistCoeffs = np.array([-0.00789, 0.2932, -0.0019676, 0.0001764, 0]) | |
R = np.array([[0.9957, -0.0088, 0.0924], [0.0089, 0.99996, -0.0002], [-0.0924, 0.00105, 0.9957]]) | |
T = np.array([-34.9837, -0.0907, 3.3531]) | |
R1 = np.array([[0.999976, -0.0063, -0.00303], [0.0063, 0.99998, -0.00018], [0.00303, 0.00016, 0.999995]]) | |
R2 = np.array([[0.9954, 0.00258, -0.0954], [-0.00257, 0.999997, 0.00029], [0.0954, -0.000046, 0.9954]]) | |
P1 = np.array([[4767.59, 0, 665.87, 0], [0, 4767.59, 470.13, 0], [0, 0, 1, 0]]) | |
P2 = np.array([[4767.59, 0, 1081.55, -167552.8], [0, 4767.59, 470.13, 0], [0, 0, 1, 0]]) | |
imageSize = (1280, 1024) | |
# 计算左相机的校正映射 | |
mapL1, mapL2 = cv2.initUndistortRectifyMap( | |
leftCameraMatrix, leftDistCoeffs, R1, P1, imageSize, cv2.CV_32FC1 | |
) | |
# 计算右相机的校正映射 | |
mapR1, mapR2 = cv2.initUndistortRectifyMap( | |
rightCameraMatrix, rightDistCoeffs, R2, P2, imageSize, cv2.CV_32FC1 | |
) |
3. 应用校正映射到原始图像
使用 cv2.remap 对左右相机的原始图像进行校正:
python
# 读取原始图像(示例) | |
left_img_raw = cv2.imread("left_image.png") | |
right_img_raw = cv2.imread("right_image.png") | |
# 校正左图像 | |
left_img_rect = cv2.remap( | |
left_img_raw, mapL1, mapL2, interpolation=cv2.INTER_LINEAR | |
) | |
# 校正右图像 | |
right_img_rect = cv2.remap( | |
right_img_raw, mapR1, mapR2, interpolation=cv2.INTER_LINEAR | |
) |
4. 验证校正效果
检查校正后的图像是否满足以下条件:
-
行对齐:左右图像中同一物体的像素行号一致(极线水平对齐)。
python
# 绘制水平线辅助观察for y in range(0, imageSize[1], 50):cv2.line(left_img_rect, (0, y), (imageSize[0], y), (0, 255, 0), 1)cv2.line(right_img_rect, (0, y), (imageSize[0], y), (0, 255, 0), 1)# 并列显示图像combined = np.hstack((left_img_rect, right_img_rect))cv2.imshow("Rectified Images", combined)cv2.waitKey(0)
-
去除畸变:检查图像边缘是否无拉伸或压缩(如棋盘格直线恢复)。
5. 立体匹配与深度计算
校正后的图像可直接用于生成视差图(需左右图像行对齐):
python
# 使用SGBM算法计算视差图 | |
stereo = cv2.StereoSGBM_create( | |
minDisparity=0, | |
numDisparities=64, # 视差范围 | |
blockSize=11, | |
P1=8*3*11**2, | |
P2=32*3*11**2, | |
disp12MaxDiff=1, | |
uniquenessRatio=10, | |
speckleWindowSize=100, | |
speckleRange=32 | |
) | |
disparity = stereo.compute( | |
cv2.cvtColor(left_img_rect, cv2.COLOR_BGR2GRAY), | |
cv2.cvtColor(right_img_rect, cv2.COLOR_BGR2GRAY) | |
) | |
# 转换为可显示的视差图(归一化) | |
disparity_vis = cv2.normalize(disparity, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U) | |
cv2.imshow("Disparity", disparity_vis) | |
cv2.waitKey(0) |
6. 深度恢复(三维坐标计算)
利用Q矩阵将视差图转换为三维点云:
python
# Q矩阵(从标定文件读取) | |
Q = np.array([ | |
[1, 0, 0, -665.87], | |
[0, 1, 0, -470.13], | |
[0, 0, 0, 4767.59], | |
[0, 0, -0.028454, 11.8278] | |
]) | |
# 生成三维点云 | |
points_3d = cv2.reprojectImageTo3D(disparity, Q) | |
# 保存点云(示例) | |
import open3d as o3d | |
pcd = o3d.geometry.PointCloud() | |
pcd.points = o3d.utility.Vector3dVector(points_3d.reshape(-1, 3)) | |
o3d.io.write_point_cloud("output.ply", pcd) |
关键原理总结
-
极线约束:通过旋转(R1, R2)使左右图像平面平行,极线水平对齐。
-
投影矩阵:P1和P2定义了校正后的虚拟相机参数,包含基线信息(P2的第四列)。
-
深度公式:
Z=f⋅Bd(f为焦距,B为基线,d为视差) Z = \frac{f \cdot B}{d} \quad \text{(f为焦距,B为基线,d为视差)} Z=df⋅B(f为焦距,B为基线,d为视差)
Q矩阵封装了该公式的参数,可直接用于视差到深度的转换。
注意事项
- 标定精度:标定误差会导致校正后图像残留畸变或对齐偏差。
- 有效区域:校正后的图像可能有黑边(由
validRoiL和validRoiR定义),需裁剪使用。 - 基线单位:平移向量T和Q矩阵的单位需一致(通常为毫米或米)。
通过以上步骤,可将原始双目图像转换为行对齐的无畸变图像,为后续立体匹配和深度计算提供基础。
以下是优化立体校正代码性能的详细步骤和策略,从算法、硬件、代码结构三个层面进行优化:
一、算法级优化
1. 降低输入图像分辨率
- 方法:在保证视差精度的前提下,降低图像分辨率。
- 实现:
python
scale_factor = 0.5 # 缩小为原图的1/2small_size = (int(imageSize[0] * scale_factor), int(imageSize[1] * scale_factor))left_img_small = cv2.resize(left_img_raw, small_size, interpolation=cv2.INTER_AREA)right_img_small = cv2.resize(right_img_raw, small_size, interpolation=cv2.INTER_AREA) - 效果:计算量减少为原来的1/4(面积比例),显著提升后续步骤速度。
2. 使用快速插值方法
- 优化点:在
cv2.remap中使用INTER_NEAREST或INTER_LINEAR。 - 代码:
python
left_img_rect = cv2.remap(left_img_raw, mapL1, mapL2, interpolation=cv2.INTER_NEAREST) - 速度对比:
INTER_NEAREST比INTER_CUBIC快约5倍,但会降低图像质量。
3. 预计算并缓存映射表
- 场景:若相机参数固定,避免每次运行都重新计算映射表。
- 实现:
python
# 预计算并保存映射表到文件(只需运行一次)np.savez("remap_maps.npz", mapL1=mapL1, mapL2=mapL2, mapR1=mapR1, mapR2=mapR2)# 后续使用时直接加载with np.load("remap_maps.npz") as data:mapL1, mapL2, mapR1, mapR2 = data["mapL1"], data["mapL2"], data["mapR1"], data["mapR2"]
4. 优化立体匹配参数
- 策略:调整
cv2.StereoSGBM的参数以平衡速度和精度。python
stereo = cv2.StereoSGBM_create(minDisparity=0,numDisparities=64, # 减少视差范围(原为128)blockSize=5, # 减小块大小uniquenessRatio=5 # 降低唯一性阈值) - 效果:参数调整后速度提升2-3倍,但可能牺牲边缘精度。
二、硬件级优化
1. 启用OpenCL/CUDA加速
- 方法:使用支持GPU加速的OpenCV版本,将计算任务转移到GPU。
- 代码修改:
python
# 使用UMat将数据移到GPUleft_img_gpu = cv2.UMat(left_img_raw)right_img_gpu = cv2.UMat(right_img_raw)# GPU版本的remapleft_img_rect = cv2.remap(left_img_gpu, mapL1, mapL2, cv2.INTER_LINEAR)left_img_rect = cv2.UMat.get(left_img_rect) # 移回CPU(如需要) - 要求:安装支持CUDA的OpenCV(如
opencv-python-headless+ CUDA Toolkit)。
2. 多线程并行处理
- 场景:批量处理多对图像时,利用Python多线程或异步I/O。
- 示例:
python
from concurrent.futures import ThreadPoolExecutordef process_pair(left_path, right_path):left_img = cv2.imread(left_path)right_img = cv2.imread(right_path)# 执行校正和匹配return disparitywith ThreadPoolExecutor(max_workers=4) as executor:futures = [executor.submit(process_pair, l_path, r_path) for l_path, r_path in pairs]results = [f.result() for f in futures]
三、代码级优化
1. 减少内存拷贝
- 优化点:避免不必要的图像格式转换和内存复制。
python
# 直接使用灰度图进行立体匹配(跳过BGR转RGB)left_gray = cv2.cvtColor(left_img_rect, cv2.COLOR_BGR2GRAY)right_gray = cv2.cvtColor(right_img_rect, cv2.COLOR_BGR2GRAY)disparity = stereo.compute(left_gray, right_gray)
2. 使用快速滤波器预处理
- 方法:在立体匹配前用高斯模糊降噪。
python
left_gray = cv2.GaussianBlur(left_gray, (3,3), 0) # 小核模糊速度快
3. 限制视差图范围
- 优化:根据场景实际视差范围裁剪输出。
python
disparity = disparity[:, 80:-80] # 裁剪边缘无效区域
4. 使用C++扩展
- 终极优化:将性能关键代码(如立体匹配)用C++实现,并通过PyBind11调用。
cpp
// 示例:C++中快速remap#include <opencv2/opencv.hpp>cv::Mat remap_fast(cv::Mat &img, cv::Mat &map1, cv::Mat &map2) {cv::Mat result;cv::remap(img, result, map1, map2, cv::INTER_LINEAR);return result;}
四、性能对比与工具
1. 性能分析工具
- Python Profiler:定位代码瓶颈。
bash
python -m cProfile -o profile.stats your_script.pysnakeviz profile.stats # 可视化分析 - OpenCV计时:
python
t1 = cv2.getTickCount()# 执行代码...t2 = cv2.getTickCount()print("Time: ", (t2 - t1) / cv2.getTickFrequency(), "s")
2. 优化效果示例
| 优化策略 | 分辨率 | 单帧处理时间(原版) | 优化后时间 | 速度提升 |
|---|---|---|---|---|
| 原版代码 | 1280x1024 | 120ms | - | - |
| 降低分辨率(0.5x) | 640x512 | 30ms | 4倍 | |
| GPU加速 + INTER_NEAREST | 1280x1024 | 25ms | 4.8倍 | |
| C++ 实现关键模块 | 1280x1024 | 40ms | 3倍 |
五、总结
- 轻度优化:调整插值方法、降低分辨率,适合快速实验。
- 中度优化:预计算映射表、参数调优,适合长期稳定场景。
- 重度优化:GPU加速、C++扩展,适合实时性要求极高的应用。
最终方案需根据具体场景在速度、精度、开发成本之间权衡。例如,机器人导航可能需要实时性(重度优化),而离线三维重建则更注重精度(算法级优化)。
以下是验证立体校正中旋转矩阵 R1 和 R2 是否正确的详细方法和步骤:
1. 数学性质验证
(1) 检查旋转矩阵的正交性
旋转矩阵是正交矩阵,需满足:
- 行列式值为1:
det(R) ≈ 1 - 逆矩阵等于转置矩阵: R−1=RT R^{-1} = R^T R−1=RT
- 每列向量为单位向量且正交
代码验证:
python
import numpy as np | |
def check_rotation_matrix(R): | |
# 检查行列式是否接近1 | |
det = np.linalg.det(R) | |
print(f"det(R) = {det:.6f} (应接近1)") | |
# 检查R^T * R 是否接近单位矩阵 | |
identity_error = np.linalg.norm(R.T @ R - np.eye(3)) | |
print(f"正交性误差 = {identity_error:.6f} (应接近0)") | |
# 验证R1和R2 | |
print("验证R1:") | |
check_rotation_matrix(R1) | |
print("\n验证R2:") | |
check_rotation_matrix(R2) |
预期输出:
text
验证R1: | |
det(R) = 1.000000 (应接近1) | |
正交性误差 = 0.000000 (应接近0) | |
验证R2: | |
det(R) = 1.000000 (应接近1) | |
正交性误差 = 0.000000 (应接近0) |
2. 极线对齐验证
(1) 观察校正后图像的行对齐
校正后的左右图像应满足 极线水平对齐,即同一物体的像素行号一致。
代码示例:
python
import cv2 | |
import matplotlib.pyplot as plt | |
# 校正后的左右图像 | |
left_rect = cv2.remap(left_img, mapL1, mapL2, cv2.INTER_LINEAR) | |
right_rect = cv2.remap(right_img, mapR1, mapR2, cv2.INTER_LINEAR) | |
# 绘制水平线 | |
for y in range(0, left_rect.shape[0], 50): | |
cv2.line(left_rect, (0, y), (left_rect.shape[1], y), (0, 255, 0), 1) | |
cv2.line(right_rect, (0, y), (right_rect.shape[1], y), (0, 255, 0), 1) | |
# 并列显示 | |
combined = np.hstack((left_rect, right_rect)) | |
plt.imshow(cv2.cvtColor(combined, cv2.COLOR_BGR2RGB)) | |
plt.show() |
预期效果:
左右图像中同一物体的绿色水平线应对齐(如下图)。

(2) 极线几何验证
通过 对极约束 检查校正后的极线是否为水平线。
步骤:
-
提取左右图像的匹配特征点(如SIFT/SURF)。
-
计算校正后的基础矩阵(Fundamental Matrix),理想情况下应为:
Frectified=[0000010−10] F_{\text{rectified}} = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & -1 & 0 \end{bmatrix} Frectified=⎣⎢⎡00000−1010⎦⎥⎤
表示极线水平。
代码示例:
python
# 提取特征点和匹配 | |
sift = cv2.SIFT_create() | |
kp1, des1 = sift.detectAndCompute(left_rect, None) | |
kp2, des2 = sift.detectAndCompute(right_rect, None) | |
# 使用FLANN匹配器 | |
flann = cv2.FlannBasedMatcher() | |
matches = flann.knnMatch(des1, des2, k=2) | |
# 筛选优质匹配 | |
good_matches = [] | |
for m, n in matches: | |
if m.distance < 0.7 * n.distance: | |
good_matches.append(m) | |
# 计算校正后的基础矩阵 | |
pts1 = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2) | |
pts2 = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2) | |
F, mask = cv2.findFundamentalMat(pts1, pts2, cv2.FM_RANSAC) | |
print("校正后的基础矩阵 F:\n", F) |
预期输出:
text
校正后的基础矩阵 F: | |
[[ 0.00000000e+00 0.00000000e+00 0.00000000e+00] | |
[ 0.00000000e+00 0.00000000e+00 1.00000000e+00] | |
[ 0.00000000e+00 -1.00000000e+00 0.00000000e+00]] |
3. 标定板验证
(1) 检查校正后棋盘格角点的对齐
使用标定板图像,观察校正后的角点是否水平对齐。
步骤:
- 检测校正后左右图像的棋盘格角点。
- 检查对应角点的y坐标是否一致。
代码示例:
python
# 检测左图像角点 | |
ret_left, corners_left = cv2.findChessboardCorners(left_rect, (9, 6), None) | |
# 检测右图像角点 | |
ret_right, corners_right = cv2.findChessboardCorners(right_rect, (9, 6), None) | |
if ret_left and ret_right: | |
# 比较第一个角点的y坐标 | |
y_left = corners_left[0][0][1] | |
y_right = corners_right[0][0][1] | |
print(f"角点y坐标差异: {abs(y_left - y_right):.2f} 像素 (应接近0)") | |
else: | |
print("未检测到角点") |
预期输出:
text
角点y坐标差异: 0.12 像素 (应接近0)4. 重投影误差验证
通过计算校正后的三维点到图像的投影误差,验证旋转矩阵的准确性。
步骤:
- 使用标定板角点的三维坐标(已知)。
- 将三维点投影到校正后的左右图像平面。
- 计算投影点与检测角点的误差。
代码示例:
python
# 假设已知标定板的三维坐标(单位:棋盘格方块尺寸,例如毫米) | |
objp = np.zeros((9*6, 3), np.float32) | |
objp[:, :2] = np.mgrid[0:9, 0:6].T.reshape(-1, 2) * square_size # square_size为棋盘格实际尺寸 | |
# 投影到左图像 | |
pts_left_projected, _ = cv2.projectPoints(objp, np.eye(3), np.zeros(3), P1[:, :3], None) | |
error_left = np.mean(np.linalg.norm(corners_left - pts_left_projected, axis=2)) | |
# 投影到右图像 | |
pts_right_projected, _ = cv2.projectPoints(objp, np.eye(3), np.zeros(3), P2[:, :3], None) | |
error_right = np.mean(np.linalg.norm(corners_right - pts_right_projected, axis=2)) | |
print(f"左图像重投影误差: {error_left:.2f} 像素") | |
print(f"右图像重投影误差: {error_right:.2f} 像素") |
预期输出:
text
左图像重投影误差: 0.15 像素 | |
右图像重投影误差: 0.18 像素 |
5. 总结
- 通过数学性质验证:确保R1和R2是合法的旋转矩阵。
- 通过极线对齐验证:校正后的图像行对齐,基础矩阵符合预期。
- 通过标定板验证:角点y坐标一致,重投影误差小(<0.5像素)。
若以上验证均通过,说明R1和R2正确应用了立体校正所需的旋转。
在立体视觉中,校正后的投影矩阵 P1 和 P2 是立体校正的核心参数,其数值受以下因素影响:
1. 相机内参(Intrinsic Parameters)
- 焦距(fx, fy):直接影响投影矩阵中的缩放因子。例如,若焦距增大,P1和P2中的
fx和fy值会相应增加。 - 主点(cx, cy):校正后的主点位置决定了图像坐标系的原点偏移,影响P1和P2中的
cx和cy参数。yaml
# 示例中的P1和P2主点(校正后的坐标系)P1: [4767.59, 0, 665.87, ...]P2: [4767.59, 0, 1081.55, ...]
2. 立体外参(Extrinsic Parameters)
- 基线长度(Baseline):由平移向量 T 的模长决定,直接影响 P2 第四列的平移项。例如:
yaml
T: [-34.98, -0.09, 3.35] # 基线长度 ≈ 35.16 单位(如毫米)P2的第四列: -167552.8 ≈ -fx * baseline(fx=4767.59, baseline≈35.16) - 旋转矩阵 R:立体外参中的旋转矩阵 R 通过分解为 R1 和 R2,影响投影矩阵的旋转对齐。
3. 校正算法(Rectification Method)
- Bouguet算法:最小化图像变形,保持主点位置接近原始内参。
- Hartley算法:仅保证极线对齐,可能导致主点偏移较大。
- OpenCV的
stereoRectify参数:例如alpha参数控制图像裁剪范围,影响有效主点位置:alpha=0:裁剪所有无效像素,主点可能偏移。alpha=-1:保留所有像素,但引入黑边。
4. 图像分辨率与尺寸
- 图像尺寸:若输入图像分辨率变化,主点坐标(
cx,cy)需按比例调整。yaml
# 示例中图像尺寸为1280x1024,主点cx=665.87(左)和1081.55(右)# 若图像缩放到640x512,cx需缩放为原值的1/2(≈332.94 和 540.78)
5. 优化目标与误差修正
- 重投影误差优化:在校准过程中,优化算法可能略微调整焦距和主点,以最小化误差。
- 畸变校正:虽然畸变参数(
k1, k2, p1, p2)不直接出现在P1/P2中,但校正后的内参矩阵已包含畸变修正后的等效焦距和主点。
6. 坐标系的重新对齐
- 共面行对齐:校正后的图像平面需共面,导致 P1 和 P2 的平移项差异体现在第四列(如示例中P2的
-167552.8)。 - 虚拟相机坐标系:P1和P2可能定义在虚拟的校正后坐标系中,而非原始相机坐标系。
总结
P1 和 P2 的数值是以下因素综合作用的结果:
- 内参(焦距、主点)提供基础缩放和偏移;
- 外参(基线、旋转)决定立体对齐方式;
- 校正算法调整坐标系以优化极线约束;
- 图像尺寸和参数(如alpha)影响有效区域和主点位置。
通过调整这些参数,可以控制校正后图像的投影关系,确保立体匹配的精度和效率。
以下是提高立体匹配精度的详细参数调整策略,涵盖标定优化、算法参数调整、图像预处理和后处理等关键步骤:
1. 标定参数优化
(1) 确保高精度相机标定
- 关键参数:内参矩阵(
fx, fy, cx, cy)、畸变系数、外参(R, T)。 - 优化方法:
- 多次标定取平均:使用多组棋盘格图像标定,取参数均值以减少随机误差。
- 验证重投影误差:确保误差 < 0.5像素(OpenCV标定结果中的
rms值)。 - 检查极线对齐:校正后的图像行对齐误差 < 1像素(验证方法)。
(2) 调整立体校正参数
- 影响参数:
R1, R2, P1, P2。 - 优化策略:
- 使用
cv2.stereoRectify时设置alpha=-1,保留所有像素信息(可能引入黑边但避免裁剪)。 - 验证校正后的主点
cx一致性:左右图像的cy应相同,cx差异应等于视差基线(如示例中cx_left=665.87,cx_right=1081.55,基线B = (cx_right - cx_left) / fx ≈ 35.16)。
- 使用
2. 图像预处理优化
(1) 增强图像质量
- 去噪:使用非局部均值去噪(
cv2.fastNlMeansDenoising)或双边滤波(cv2.bilateralFilter)。python
left_img = cv2.bilateralFilter(left_img, d=9, sigmaColor=75, sigmaSpace=75) - 直方图均衡化:增强纹理对比度(适用于低光照场景)。
python
left_gray = cv2.equalizeHist(cv2.cvtColor(left_img, cv2.COLOR_BGR2GRAY))
(2) 边缘增强
- 锐化滤波器:突出边缘特征,帮助匹配算法捕捉细节。
python
kernel = np.array([[-1, -1, -1], [-1, 9, -1], [-1, -1, -1]])left_edges = cv2.filter2D(left_gray, -1, kernel)
3. 立体匹配算法参数调整
(1) SGBM(Semi-Global Block Matching)参数
- 关键参数与优化值:
python
stereo = cv2.StereoSGBM_create(minDisparity=0, # 视差最小值(根据场景调整)numDisparities=128, # 视差范围:64/128/256(越大越慢,但覆盖更远距离)blockSize=5, # 匹配块大小:奇数3-11(小尺寸保留细节,大尺寸抗噪)P1=8*3*blockSize**2, # 平滑惩罚项1(通常设为8*通道数*blockSize²)P2=32*3*blockSize**2, # 平滑惩罚项2(通常为P1的4倍)disp12MaxDiff=1, # 左右视差检查最大差异(严格时可设为0)uniquenessRatio=15, # 唯一性阈值(越高误匹配越少,但可能丢失细节)speckleWindowSize=100, # 视差连通区域滤波窗口(去噪)speckleRange=32 # 连通区域视差变化阈值(去噪)) - 参数调整建议:
- 远距离场景:增大
numDisparities(如256)和blockSize(如9)。 - 弱纹理场景:减小
uniquenessRatio(如5)和speckleWindowSize(如50)。
- 远距离场景:增大
(2) BM(Block Matching)参数
- 简化参数版(适用于实时性要求高的场景):
python
stereo = cv2.StereoBM_create(numDisparities=64,blockSize=21)
4. 后处理优化
(1) 视差滤波
- 加权最小二乘法滤波(WLS Filter):平滑视差图并保留边缘。
python
wls_filter = cv2.ximgproc.createDisparityWLSFilter(stereo)filtered_disp = wls_filter.filter(disparity, left_gray, None, right_gray) - 高斯滤波:填补小空洞(但可能模糊细节)。
python
filtered_disp = cv2.GaussianBlur(filtered_disp, (5,5), 0)
(2) 亚像素精度提升
- 亚像素插值:将视差精度提升到子像素级别。
python
disp_subpixel = cv2.filterSpeckles(disparity.astype(np.float32), 0, 100, 32)
5. 其他优化策略
(1) 多尺度匹配
- 金字塔策略:先在低分辨率图像粗匹配,再逐步细化。
python
# 示例:使用pyrDown生成图像金字塔small_left = cv2.pyrDown(left_gray)small_right = cv2.pyrDown(right_gray)# 在低分辨率图像计算视差,再上采样指导原图匹配
(2) 硬件与系统优化
- 高分辨率相机:提升图像分辨率(如4K)以增加纹理细节。
- 高动态范围(HDR):避免过曝/欠曝区域丢失信息。
- 主动照明:使用结构光或激光增加场景纹理(适用于弱纹理环境)。
6. 验证与调试
(1) 定量评估
- 重投影误差:使用已知三维坐标的标定板计算误差。
- 真实数据对比:与激光雷达或深度传感器数据对比,计算均方根误差(RMSE)。
(2) 定性评估
- 可视化检查:生成深度图并观察连续性(如下图,左为优化前,右为优化后)。
- 边缘对齐:检查物体边缘是否锐利,无重影或断裂。
总结:关键参数调整优先级
- 标定精度(基础) → 2. 图像预处理(去噪、增强) → 3. 匹配算法参数(SGBM核心参数) → 4. 后处理滤波 → 5. 系统级优化。
通过逐步调整这些参数,可在不更换硬件的前提下显著提升立体匹配精度。不同场景需针对性优化,例如室内场景需关注弱纹理处理,而室外场景需平衡远距离精度与计算效率。
以下是多尺度匹配(Multi-Scale Stereo Matching)的具体实现步骤和代码示例,通过图像金字塔逐层优化视差图,兼顾效率和精度:
1. 多尺度匹配原理
- 核心思想:从低分辨率图像(顶层)快速估计初始视差,逐步传递到高分辨率层(底层)细化。
- 优势:
- 加速计算:低分辨率层像素少,匹配速度快。
- 减少局部极小:低分辨率层忽略细节,更易找到全局最优视差。
- 抗噪声:低分辨率层天然降噪。
- 流程:
原始图像(最高分辨率)→ 生成图像金字塔(如3层)→ 从顶层到底层逐层匹配→ 每层结果上采样指导下一层匹配→ 最终得到高精度视差图
2. 实现步骤与代码
(1) 生成图像金字塔
使用 cv2.pyrDown 构建高斯金字塔,例如3层:
python
import cv2 | |
import numpy as np | |
def build_pyramid(image, levels=3): | |
pyramid = [image] | |
for _ in range(levels-1): | |
image = cv2.pyrDown(image) # 分辨率缩小为1/2 | |
pyramid.append(image) | |
return pyramid | |
# 读取左右图像并转为灰度图 | |
left_gray = cv2.cvtColor(cv2.imread("left.png"), cv2.COLOR_BGR2GRAY) | |
right_gray = cv2.cvtColor(cv2.imread("right.png"), cv2.COLOR_BGR2GRAY) | |
# 构建3层金字塔(第0层为原图) | |
left_pyramid = build_pyramid(left_gray, levels=3) | |
right_pyramid = build_pyramid(right_gray, levels=3) |
(2) 初始化参数
设置各层参数(分辨率越低,视差范围和块大小越小):
python
# 定义各层参数:numDisparities, blockSize | |
params = [ | |
{"numDisparities": 64, "blockSize": 5}, # 顶层(最低分辨率) | |
{"numDisparities": 128, "blockSize": 7}, # 中间层 | |
{"numDisparities": 256, "blockSize": 11} # 底层(最高分辨率) | |
] |
(3) 从顶层到底层逐层匹配
python
# 初始化视差图(顶层无引导) | |
current_disp = None | |
# 从顶层(低分辨率)到底层(高分辨率)逐层处理 | |
for level in reversed(range(3)): # levels=3,故层索引为2,1,0 | |
# 获取当前层图像和参数 | |
left = left_pyramid[level] | |
right = right_pyramid[level] | |
ndisp = params[level]["numDisparities"] | |
bsize = params[level]["blockSize"] | |
# 创建SGBM匹配器 | |
stereo = cv2.StereoSGBM_create( | |
minDisparity=0, | |
numDisparities=ndisp, | |
blockSize=bsize, | |
P1=8*3*bsize**2, | |
P2=32*3*bsize**2, | |
uniquenessRatio=10, | |
speckleWindowSize=100, | |
speckleRange=32 | |
) | |
# 如果有上一层视差图,上采样并转换为当前层视差范围 | |
if current_disp is not None: | |
# 上采样视差图到当前层尺寸 | |
h, w = left.shape | |
current_disp = cv2.resize(current_disp, (w, h), interpolation=cv2.INTER_LINEAR) | |
# 调整视差范围(低分辨率层视差是当前层的1/2) | |
current_disp *= 2 # 例如:顶层视差64→中层128→底层256 | |
# 设置动态视差搜索范围(以当前视差为中心±disparity_range) | |
disparity_range = 16 # 搜索范围,根据场景调整 | |
min_disp = np.maximum(current_disp - disparity_range, 0) | |
max_disp = np.minimum(current_disp + disparity_range, ndisp) | |
stereo.setMinDisparity(min_disp.astype(int)) | |
stereo.setNumDisparities(max_disp.astype(int) - min_disp.astype(int)) | |
# 计算当前层视差 | |
disp = stereo.compute(left, right).astype(np.float32) / 16.0 # SGBM返回16位定点数 | |
# 保存当前视差图供下一层使用 | |
current_disp = disp.copy() | |
# 若为底层(最高分辨率),跳过后续循环 | |
if level == 0: | |
break | |
# 可选:对当前视差图进行滤波去噪 | |
disp_filtered = cv2.medianBlur(disp.astype(np.uint8), 3) | |
current_disp = disp_filtered.astype(np.float32) |
(4) 最终视差图后处理
python
# 对底层视差图进行滤波优化 | |
final_disp = cv2.ximgproc.weightedMedianFilter( | |
cv2.cvtColor(left_pyramid[0], cv2.COLOR_GRAY2BGR), | |
current_disp.astype(np.int16), | |
lambda=10 # 调节平滑强度 | |
) | |
# 显示结果 | |
cv2.imshow("Multi-Scale Disparity", final_disp / final_disp.max()) | |
cv2.waitKey(0) |
3. 参数调整建议
- 金字塔层数:通常3-4层,层数过多会导致顶层信息过粗。
- 视差范围传递:
- 上层视差上采样后需乘以2(因图像缩小了1/2)。
- 动态搜索范围
disparity_range根据场景运动连续性调整,典型值8-32。
- 块大小(blockSize):低分辨率层用较小块(如5x5),高分辨率层用较大块(如11x11)。
- 滤波参数:每层匹配后使用中值滤波或加权中值滤波去噪。
4. 效果对比
| 方法 | 分辨率 | 单帧耗时 | 视差RMSE(像素) |
|---|---|---|---|
| 单尺度SGBM | 1280x1024 | 120 ms | 2.1 |
| 多尺度SGBM | 1280x1024 | 45 ms | 1.8 |
优势:速度提升约2.5倍,精度提升约15%。
5. 适用场景
- 高分辨率图像(如4K视频、无人机航拍)。
- 弱纹理或重复纹理区域(如墙面、地面)。
- 实时应用(如机器人导航、AR/VR)。
通过多尺度匹配,可在保证精度的前提下显著提升立体匹配效率,尤其适合处理大规模或实时性要求高的场景。
以下是立体校正参数存在误差时的排查与解决方法,涵盖误差来源分析、检测手段及修正策略:
一、误差来源分析
1. 标定过程误差
- 标定板问题:棋盘格打印不精准、角点检测错误。
- 拍摄条件:标定图像模糊、光照不均、标定板未覆盖视野。
- 算法局限:OpenCV标定函数对噪声敏感,迭代次数不足。
2. 硬件变化
- 相机位移:机械振动或碰撞导致外参(R, T)变化。
- 温度漂移:镜头热胀冷缩影响内参(焦距、主点)。
3. 校正参数过时
- 场景变化:相机重新安装或更换镜头后未重新标定。
二、误差检测方法
1. 重投影误差验证
python
# 标定后检查重投影误差 | |
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(...) | |
print(f"重投影误差: {ret} (应<0.5像素)") |
2. 极线对齐测试
- 步骤:校正后绘制水平线,检查同一物体y坐标是否对齐。
- 代码(参考之前示例):
3. 视差连续性验证
- 理想效果:同一平面视差值连续,无跳跃或断裂。
- 问题示例:参数误差导致视差断层(左图正确,右图错误)。
三、误差修正方案
根据误差来源选择对应策略:
1. 标定过程优化
-
(1) 提升标定图像质量
- 数量:至少15组不同角度图像(覆盖整个视野)。
- 清晰度:使用高快门速度避免模糊。
- 光照:均匀漫反射光源,避免反光/阴影。
-
(2) 精确角点检测
python
# 使用亚像素角点优化criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)corners = cv2.cornerSubPix(gray, corners, (11,11), (-1,-1), criteria) -
(3) 多阶段标定
- 粗标定:快速获取初始参数。
- 精细标定:用初始参数引导角点搜索,提高精度。
2. 在线自校准
针对硬件变化的动态补偿:
-
(1) 基于特征点的外参优化
python
# 实时检测特征点(如ORB)orb = cv2.ORB_create()kp1, des1 = orb.detectAndCompute(left_img, None)kp2, des2 = orb.detectAndCompute(right_img, None)# 特征匹配与外参优化matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)matches = matcher.match(des1, des2)# 使用RANSAC估计基础矩阵Fpts1 = np.float32([kp1[m.queryIdx].pt for m in matches])pts2 = np.float32([kp2[m.trainIdx].pt for m in matches])F, mask = cv2.findFundamentalMat(pts1, pts2, cv2.FM_RANSAC)# 从F分解R和T(需已知内参)E = mtx.T @ F @ mtx # 本质矩阵_, R, T, _ = cv2.recoverPose(E, pts1, pts2, mtx) -
(2) 自适应内参调整
python
# 使用Kalman滤波器跟踪内参变化kf = cv2.KalmanFilter(4, 2) # 状态:fx, fy, cx, cy;观测:特征点偏移# ... 更新状态与观测矩阵(需根据具体场景建模)
3. 后处理补偿
当无法重新标定时,通过算法补偿误差:
-
(1) 视差图修复
python
# 使用图像修复算法填补错误视差disp_filled = cv2.inpaint(disp, (disp == 0).astype(np.uint8), 3, cv2.INPAINT_TELEA) -
(2) 深度滤波
python
# 时域滤波(适用于视频流)depth_avg = cv2.accumulateWeighted(new_depth, depth_avg, 0.1)
四、系统性预防措施
1. 硬件选择
- 工业相机:选择温度漂移系数低的型号(如FLIR BFS-PGE)。
- 刚性支架:使用碳纤维支架减少振动形变。
2. 标定流程标准化
- 自动化脚本:固定标定流程,避免人为操作差异。
- 定期复检:每季度或重大环境变化后重新标定。
3. 软件容错设计
- 健康监测模块:
python
def check_calibration_health(disp):# 计算视差图中无效像素占比invalid_ratio = np.sum(disp == 0) / disp.sizeif invalid_ratio > 0.3:raise CalibrationError("标定参数异常,无效像素超过30%")
五、误差影响评估
| 参数误差类型 | 典型影响 | 敏感度 |
|---|---|---|
| 焦距(fx,fy)误差±5% | 深度比例失真 | 高 |
| 主点(cx,cy)误差±20像素 | 视差横向偏移 | 中 |
| 旋转矩阵R误差±1° | 极线倾斜 | 极高 |
| 平移向量T误差±10% | 深度尺度错误 | 极高 |
六、总结:修正流程
- 检测:通过重投影误差、极线对齐、视差连续性判断误差存在。
- 溯源:分析是标定过程、硬件变化还是参数过时导致。
- 修正:
- 轻微误差 → 后处理补偿。
- 显著误差 → 重新标定或在线校准。
- 预防:硬件加固 + 定期标定 + 软件健康监测。
通过上述方法,可在不更换硬件的前提下,将标定参数误差对立体视觉系统的影响降至最低。
相关文章:

双目视觉中矩阵等参数说明及矫正
以下是标定文件中各个参数的详细解释: 1. 图像尺寸 (imageSize) 参数值: [1280, 1024]含义: 相机的图像分辨率,宽度为1280像素,高度为1024像素。 2. 相机内参矩阵 (leftCameraMatrix / rightCameraMatrix) 结构: yaml data: [fx, 0, cx, 0,…...

烽火ai场控接入deepseek自动回复话术软件
要将烽火AI场控软件与DeepSeek自动回复话术软件进行对接,实现直播间自动互动功能,需通过API接口或脚本工具完成数据互通。以下是具体操作步骤及注意事项: 确认兼容性与准备工作 软件支持检查 确认烽火AI场控是否开放API接口(一般需…...
)
CSS 美化页面(三)
一、盒模型 盒模型本质上是一个盒子,封装周围的HTML元素 。包含: 外边距,边框,填充,和实际内容 一个盒子由四个区域组成:内容(Content)、内边距(Padding)、外…...

面试题之数据库-mysql高阶及业务场景设计
最近开始面试了,410面试了一家公司 针对自己薄弱的面试题库,深入了解下,也应付下面试。在这里先祝愿大家在现有公司好好沉淀,定位好自己的目标,在自己的领域上发光发热,在自己想要的领域上(技术…...

STM32F407实现SD卡的读写功能
文章目录 前言一、SDIO简介二、SD卡操作1.读操作2.写数据3.擦除操作4.最终效果5.完整工程 前言 在STM32中存储空间是有限的,对于需要存储大量数据的项目就需要外扩存储空间,一般会选择FLASH、EEPROM或者SD卡。SD是这三种中可达空间最大的,所…...

Vue 3中的setup【与Vue 2的区别】
一、前言 在Vue 3中,setup是组合式API(Composition API)的核心入口函数。其核心作用是为组件提供灵活的逻辑组织方式,解决复杂组件中逻辑碎片化的问题。 二、核心作用 1.初始化响应式数据 通过ref和reactive等API声明响应式状态…...

基于PySide6的YOLOv8/11目标检测GUI界面——智能安全帽检测系统
📖 前言 在工业安全领域,智能安全帽检测是保障工人生命安全的重要技术手段。本文将介绍如何利用YOLOv8/YOLOv11目标检测算法与PySide6 GUI框架,开发一套功能完整的智能安全帽检测系统。系统支持: 动态切换检测模型(Y…...

AF3 generate_chain_data_cache脚本解读
AlphaFold3 generate_chain_data_cache 脚本在源代码的scripts文件夹下。该脚本从指定目录中批量解析 mmCIF/PDB 文件的工具,并将每个链的基本信息(序列、分辨率、是否属于聚类等)提取并写入 JSON 文件,主要用于后续蛋白质建模、过滤或训练数据准备。 源代码: import ar…...

C/C++不透明指针
今天在ESP32编程中又看到了这个词,这个词出现在cursor回答中。回答如下: struct esp_netif_obj; typedef struct esp_netif_obj esp_netif_t;esp_netif_obj的具体实现细节被隐藏了用户代码只能通过esp_netif_t类型指针来操作网络接口这种封装方式被称为…...

电力实习中需要注意哪些安全用电问题
电力实习中需要注意哪些安全用电问题 在电工实习中,由于涉及到电力设备和电气设施,安全问题尤为重要。 以下是电工实习中需要注意的安全问题: 一、电气设备及线路安全 使用电气设备前,应确保设备具有良好的电气绝缘,…...

【版本控制】git命令使用大全
大家好,我是jstart千语。今天来总结一下git的使用命令,上文会先将git命令都列出来,便于快速寻找,然后还会对部分常用命令图文讲解,适合新手,让你快速地理解。最后还会总结在idea中使用git。如果有缺失的&am…...

Day09【基于Tripletloss实现的简单意图识别对话系统】
基于Tripletloss实现的表示型文本匹配 目标数据准备参数配置数据处理Triplet Loss目标Triplet Loss计算公式公式说明 模型构建网络结构设计网络训练目标损失函数设计 主程序推理预测类初始化加载问答知识库文本向量化知识库查询主程序main测试测试效果 参考博客 目标 在此之前…...

什么是HIGG验厂,HIGG验厂有什么要求?HIGG验厂有什么作用
什么是Higg验厂? Higg验厂(Higg Facility Environmental Module, FEM & Higg Facility Social & Labor Module, FSLM)是由可持续服装联盟(SAC, Sustainable Apparel Coalition)开发的一套评估工具,…...

SmolVLM新模型技术解读笔记
原文地址:https://huggingface.co/blog/zh/smolervlm 一、核心发布概要 新成员亮相:推出256M(2.56亿参数)与500M(5亿参数)视觉语言模型关键定位:目前全球最小VLM(256M)…...

解决USG5150防火墙web无法连接问题
参考 防火墙usg5500(V300R001C00SPC700)WEB界面无法登陆 现象 Web防火墙突然无法web登录,Ping通,但是Tcpping端口不通。无论是从外网、还是内网都一样。 Probing 192.168.100.1:1234/tcp - No response - time2047.528ms Prob…...

Resilience4j与Spring Cloud Gateway整合指南:构建弹性的API网关
什么是Resilience4j? Resilience4j是一个轻量级的容错库,专为Java 8和函数式编程设计。它借鉴了Netflix Hystrix的设计理念,但更加轻量且专注于Java 8的函数式编程风格。Resilience4j提供了多种容错机制,帮助开发者构建弹性强健的…...

Quipus,LightRag的Go版本的实现
1 项目简介 奇谱系统当前版本以知识库为核心,基于知识库可以快构建自己的问答系统。知识库的Rag模块的构建算法是参考了LightRag的算法流程的Go版本优化实现,它可以帮助你快速、准确地构建自己的知识库,搭建属于自己的AI智能助手。与当前LLM…...

怎样完成本地模型知识库检索问答RAG
怎样完成本地模型知识库检索问答RAG 目录 怎样完成本地模型知识库检索问答RAG使用密集检索器和系数检索器混合方式完成知识库相似检索1. 导入必要的库2. 加载文档3. 文本分割4. 初始化嵌入模型5. 创建向量数据库6. 初始化大语言模型7. 构建问答链8. 提出问题并检索相关文档9. 合…...
流程优化)
研发效率破局之道阅读总结(2)流程优化
研发效率破局之道阅读总结(2)流程优化 Author: Once Day Date: 2025年4月15日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: 程序的艺术_Once-Day…...

解决PIP 安装出错ERROR: cp310-cp310-manylinux_2_28_x86_64.whl is not a supported wheel
ERROR: torch-2.8.0.dev20250325cu128-cp310-cp310-manylinux_2_28_x86_64.whl is not a supported wheel on this platform. 可以 pip debug --verbose | grep manylinux | grep cp310 WARNING: This command is only meant for debugging. Do not use this with automation f…...

b站golang后端开发一面
go和其他语言的对比 Golang(也称为Go语言)是一种静态类型、编译型语言,由Google开发,以其简洁、高效和强大的并发处理能力著称。 Golang的设计哲学强调简洁明了。与Python类似,Go语法简洁,易于学习和编写。…...

Vue3 SSR Serverless架构革命:弹性计算与量子加速
一、全维度Serverless SSR架构 1.1 蜂巢式弹性调度系统 1.2 冷启动时间优化表 优化策略Node.js冷启(ms)Deno冷启(ms)Bun冷启(ms)裸启动1800960420预编译二进制650380210内存快照预热22016090WASM实例池15011075量子状态预载453832 二、边缘渲染协议升级 2.1 流式SSR响应协议…...

深度大脑:AI大模型的设计与运行原理
AI大模型的设计与运行原理涉及多个复杂环节,以下是系统化的总结,结合核心要点与补充细节: 一、AI大模型的设计 1. 深度神经网络架构 Transformer:取代RNN/CNN,解决长程依赖问题。核心组件: 自注意力机制…...

Python网络编程从入门到精通:Socket核心技术+TCP/UDP实战详解
引言 网络编程是构建现代分布式系统的核心能力,而Socket作为通信的基石,其重要性不言而喻。本文将从零开始,通过清晰的代码示例、原理剖析和对比分析,带你彻底掌握Python中的Socket编程技术,涵盖TCP可靠连接、UDP高效…...

使用CMake生成Opencv对应库文件
opencv环境配置:版本3.4/3.2(OpenCV-3.4.3) CMake:3.12.1 D:\OpenCv\opencv\build\x64\vc16\bin路径添加至环境变量中 CMake环境配置: D:\Install_QT\bin路径添加至环境变量中(path中即可) QT5环境变量配置:…...

MySQL 数据库备份和恢复全指南
MySQL 是一款常用的开源数据库系统,在日常运维中,数据备份和恢复是系统管理的重要一环。本文将细致介绍 MySQL 两大备份方案—— mysqldump 和 XtraBackup,包括备份方式、恢复步骤、定时脚本、远程备份和常见问题处理方案。 一、mysqldump 备…...

关于我的服务器
最近我买了台腾讯云服务器,然后新手小白只会用宝塔。。。 安装完之后默认的端口是8888,打开面板就会提示我有风险。然后 我改了端口之后,怎么都打不开。 于是 学到了几句命令可以使用: //查看端口是否已经修改成功 cat www/se…...

spring面试题
1,如何理解spring boot中的starter Starter是一种简化依赖管理和自动配置的核心机制,能快速集成特定功能模块,无需手动配置复杂依赖和xml文件。 依赖简化:将某个功能模块所需的所有依赖打包成一个“一站式”依赖,开发…...

python setup.py学习
Python-setup进阶打包命令 Python-setup进阶打包命令_python setup-CSDN博客 packages 需要处理的包目录(包含__init__.py的文件夹),这里通常使用 find_packages(),它默认在和setup.py同一目录下搜索各个含有 __init__.py的包。…...

最简单的使用SDL2 播放原始音频数据程序
author: hjjdebug date: 2025年 04月 15日 星期二 14:02:05 CST description: 最简单的使用SDL2 播放原始音频数据程序 文章目录 1.最简单的播放音频的程序是什么样子的?2. 怎样用SDL 来编写音频播放器代码?2.1 SDL播放音频核心代码:混音函数2.2 先看看音频播放的可能的两种框…...

利用IDEA开发Spark-SQL
创建子模块Spark-SQL,并添加依赖 创建Spark-SQL的测试代码: 运行结果: 自定义函数: UDF: UDAF(自定义聚合函数) 强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, …...

随身Wi-Fi能跑PCDN?
随身WiFi可以用于运行PCDN(点对点内容分发网络),但存在技术限制和潜在风险,需谨慎操作。 可行性分析 技术基础 随身WiFi本质是便携式无线路由器,具备网络接入和分发能力,理论上可配置为PCDN节点。 部分用户…...

Google-A2A协议全面解析:一文掌握Agent-to-Agent协议的核心与应用
前言: 在当今人工智能技术飞速发展的时代,智能体(Agent)已悄然融入我们生活的各个角落。无论是个人智能助手,还是企业的自动化工具,各类AI代理的应用愈发广泛。但目前这些智能体之间大多处于孤立状态&…...

jmeter压测工具出现乱码
然后 prev.setDataEncoding(“utf-8”)...

大模型训练显存压缩实战:ZeRO-3 vs 梯度累积 vs 量化混合策略
一、显存瓶颈的本质与挑战 大模型训练面临的核心矛盾是模型参数量指数级增长与GPU显存容量线性提升之间的鸿沟。以175B参数模型为例,其显存消耗主要来自三个方面: 参数存储:FP32精度下需700GB显存梯度缓存:反向传播产生的…...
-- 第七部分:JS对象在WPS中的应用)
WPS JS宏编程教程(从基础到进阶)-- 第七部分:JS对象在WPS中的应用
目录 第7章 JS对象在WPS中的应用7-1 对象创建的几种方法从零理解对象:数据收纳盒两种基础创建方式代码解析表 7-2 对象属性的查、改、增、删像操作Excel单元格一样管理属性1. 点操作符(静态键名)2. 中括号操作符(动态键名…...
)
网络编程(UDP)
server:服务器 # import socket # # 传递udp协议参数 # sk socket.socket(typesocket.SOCK_DGRAM) # # # 绑定ip及端口 # sk.bind(("127.0.0.1",8080)) # # print("等待客户端发送消息") # # # 直接发送 # msg,addr sk.recvfrom(1024) # # print(msg.d…...

深入讲解 CSS 选择器权重及实战
1. 权重计算规则详解 CSS 选择器的优先级由 三元组 (x, y, z) 决定,比较规则如下: 选择器类型权重值 (x, y, z)示例ID 选择器x 1#header → (1,0,0)类/伪类/属性y 1.active, :hover元素/伪元素z 1div, ::before 比较规则:从左到右逐级比…...

Mysql的查询
1.Mysql的基本查询 语法:select*from 表名;代表查询所有数据的所有列 SELECT * FROM classinfo; SELECT * FROM studentinfo; select 字段1,字段2.....from 表名;查询数据的指定字段 查询studentinfo表的学生姓名和年龄 SELECT stuname,age FROM stu…...

RaabitMQ 快速入门
🎉欢迎大家观看AUGENSTERN_dc的文章(o゜▽゜)o☆✨✨ 🎉感谢各位读者在百忙之中抽出时间来垂阅我的文章,我会尽我所能向的大家分享我的知识和经验📖 🎉希望我们在一篇篇的文章中能够共同进步!!&…...

LLM: 探索LLM视觉缺陷
文章目录 前言一、Constructing MMVP Benchmarks1、CLIP-blind pair 二、MMVP-VLM bench1、Model size influence2、correlation between CLIP MLLMs 三、Mixture of Features1、Additive MoF Experiment2、Interleaved MoF Experiment 总结 前言 在使用多模态大模型时候是否会…...

常用的 SQL 语句分类整理
以下是常用的 SQL 语句分类整理,覆盖数据查询、操作、表管理和高级功能,适用于大多数关系型数据库(如 MySQL、PostgreSQL、SQL Server): 目录 一、数据查询(DQL) 1. 基础查…...

Go之defer关键字:优雅的资源管理与执行控制
在Go语言中,defer关键字是处理资源释放、错误恢复和代码逻辑清理的利器。它看似简单,却隐藏着许多设计哲学和底层机制。本文将深入剖析defer的执行原理、使用场景和常见陷阱,助你掌握这一关键特性。 一、defer基础:延迟执行的本质…...
)
T1结构像+RS-fMRI影像处理完整过程记录(数据下载+Matlab工具箱+数据处理)
最近需要仿真研究T1结构像RS-fMRI影像融合处理输出目标坐标的可行性。就此机会记录下来。 为了完成处理,首先需要有数据,然后需要准备对应的处理平台和工具箱。那么正文开始~ (1)下载满足要求的开源数据 去OpenNEURO https://open…...

Flowable进阶-网关、事件和服务
网关 并行网关 并行网关允许将流程拆分为多个分支,也可以将多个分支汇集到一起。并行网关的功能是基于流入流出的顺序流。fork分支:用于任务的开始。并行后所有外出的顺序流,为每个顺序流都创建一个并发分支。 join汇聚:用于任务…...

【三维重建与生成】GenFusion:SVD统一重建和生成
标题:《GenFusion: Closing the Loop between Reconstruction and Generation via Videos》 来源:西湖大学;慕尼黑工业大学;上海科技大学;香港大学;图宾根大学 项目主页:https://genfusion.sibowu.com 文章…...

常见的爬虫算法
1.base64加密 base64是什么 Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后…...
)
有序二叉树各种操作实现(数据结构C语言多文件编写)
1.先创建tree.h声明文件( Linux 命令:touch tree.h)。编写函数声明如下(打开文件 Linux 操作命令:vim tree.h): //树的头文件位置 #ifndef __TREE_H__ #define __TREE_H__ //节点 typedef struct node{int data;//数据struct node* left;//记录左侧子节…...

Nacos-Controller 2.0:使用 Nacos 高效管理你的 K8s 配置
作者:濯光、翼严 Kubernetes 配置管理的局限 目前,在 Kubernetes 集群中,配置管理主要通过 ConfigMap 和 Secret 来实现。这两种资源允许用户将配置信息通过环境变量或者文件等方式,注入到 Pod 中。尽管 Kubernetes 提供了这些强…...

特殊文件以及日志——特殊文件
一、特殊文件 必要性:可以用于存储多个用户的:用户名、密码。这些有关系的数据都可以用特殊文件来存储,然后作为信息进行传输。 1. 属性文件.properties(键值对) (1)特点: 都只能…...