【三维重建与生成】GenFusion:SVD统一重建和生成

标题:《GenFusion: Closing the Loop between Reconstruction and Generation via Videos》
来源:西湖大学;慕尼黑工业大学;上海科技大学;香港大学;图宾根大学
项目主页:https://genfusion.sibowu.com
文章目录
- 摘要
- 一、前言
- 二、 Reconstruction-driven Generation
- 三、 Cyclic Fusion 循环融合
- 四、实验
- 4.1 实验设置
- 4.2 视频生成
- 4.3 视图插值
- 4.4 视图外推
- 总结
摘要
最近,3D重建和生成展示了令人印象深刻的新型视图合成结果,实现了高保真度和高效性。然而,在这 两个领域之间可以观察到显著的条件差距 ,例如,可扩展的3D场景重建通常需要密集捕捉的视图,而3D生成则通常依赖于单个或没有输入视图,这极大地限制了它们的应用。原因在于3D约束与生成先验之间的不匹配。为了解决这个问题,我们 提出了一种重建驱动的视频扩散模型,该模型学习讲易产生伪影的RGB-D渲染图像作为视频帧的条件 。此外,我们 提出了一种循环融合管道(cyclical fusion pipeline),迭代地将生成模型的修复帧添加到训练集中,逐步扩展并解决先前重建和生成管道中出现的视角饱和问题 。评估实验包括稀疏视角和mask输入的视图合成,验证了方法有效性。
一、前言
生成3D资产是计算机视觉和计算机图形学中的基础任务,在增强现实/虚拟现实、自动驾驶和机器人技术中有着广泛的应用。最近,神经辐射场(NeRF [36],Mildenhall等人于2020年)和高斯喷射(GS [27],Kerbl等人于2023年)的进展使得高保真3D场景重建和新颖视图合成成为可能。这些方法使用MLP或高斯基元来表示场景,并通过光度损失优化3D表示。然而,这一系列工作继承了一个关键限制:忠实重建依赖于丰富的视角覆盖;未充分观察到的区域或视角可能导致显著的伪影或缺失内容。
这主要是因为从多视角图像重建NeRF或GS本质上是欠约束的,因为输入图像可能存在无数个照片一致性解释[41,64]。因此,即使提供了密集且高质量捕捉的图像[47],重建模型也倾向于生成“漂浮物”或“背景塌陷”伪影,以模拟视图依赖效应。这一观察结果激发了一系列正则化技术来约束神经场训练,包括稀疏正则化器[22,57]、平滑损失[37,56,63]和单目几何线索[62]。例如,ReconFusion [49]通过在新颖的随机相机姿态与由PixelNeRF风格图像扩散模型预测的图像之间引入样本损失,来正则化基于NeRF的3D重建流程,在稀疏设置下显著提升了性能。
相比之下,前馈重建方法[5,6,10,14,58,61]直接从数据集中学习归纳偏置。尽管最近的技术进步使得可以从单张图像进行三维重建,但现有的前馈重建方法在处理超过4-8张图像时表现出性能饱和。这一限制主要源于传统前馈网络在有效聚合和利用多视角信息方面的架构约束。同时,生成方法展示了无需多视角捕捉即可获得3D资产的潜力。利用大规模数据集和可扩展架构,像Stable Diffusion(SD)这样的模型在图像和视频生成方面取得了显著进展[3,21,23]。最近的研究将这些方法应用于生成3D资产。例如,DreamFusion [39]引入了Score Distillation Sampling(SDS),使用预训练的2D文本到图像扩散模型进行文本到3D的合成,而另一条研究线[4,30,60]则通过逐步in/out painting 分层深度图像来探索单视角场景外推。
尽管在三维重建和生成方面取得了进展,但一个显著的条件差距仍然存在:可扩展的三维重建通常需要密集的视图覆盖,而生成方法往往仅使用单个或甚至没有输入视图。我们的论文探讨了如何以可扩展的方式使三维重建和生成相互补充,从而放宽对输入视图数量的限制。
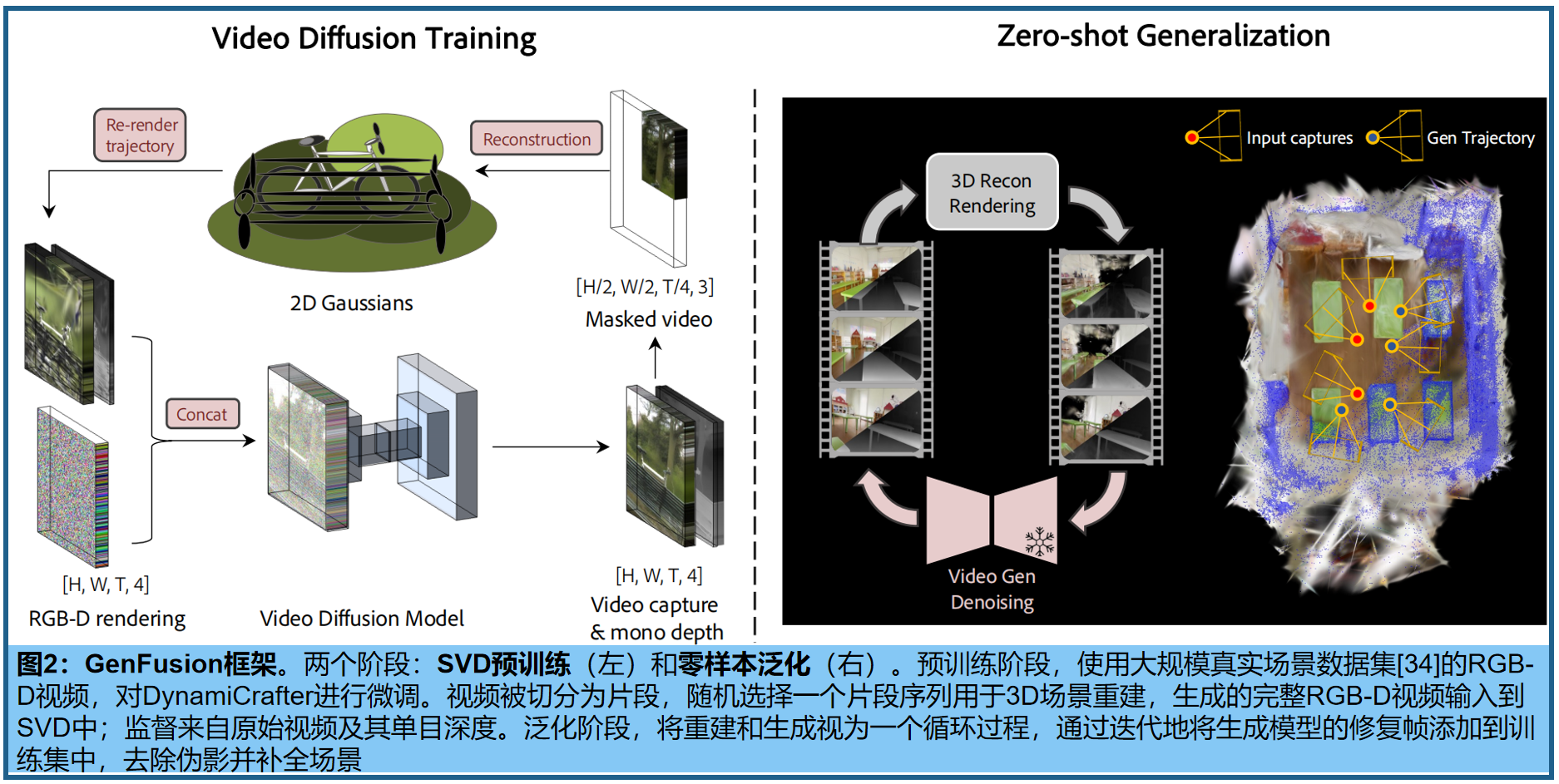
GenFusion核心是一个简单且可扩展的基于重建的视频生成架构,能够从易产生伪影的渲染图中预测出逼真的视频。 其目标是构建无伪影的3D场景,并通过条件视图{ I i I_i Ii} ( i > = 1 ) (i >= 1) (i>=1)进行内容增强。核心思想是通过视频渲染来对齐3D重建和生成。此方法中,3D重建和生成相互促进形成良性循环:重建过程,迭代利用生成模型的信息以提高重建质量;同时,更准确的重建结果有助于生成模型 产生更加真实和一致的内容。这种双向增强机制形成了一个正反馈回路。
预训练阶段目标:训练一个扩散模型,从大规模场景中学习。(该模型已从易产生伪影的3D重建的渲染上进行了预训练)。具体来说,通过最大化(从mask输入生成完整图像)的期望对数似然,来训练生成模型 G φ G_φ Gφ:
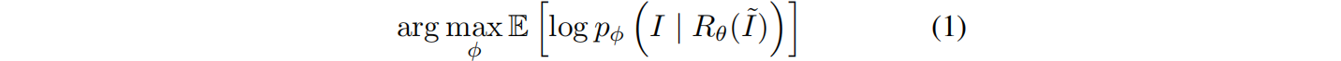
其中, R θ R_θ Rθ表示重建和渲染函数(如NeRF或3DGS), I ~ \tilde{I} I~ 表示mask后的真实图像。为了使生成过程具有三维感知能力,视频扩散模型以带伪影的渲染视频 R θ ( I ~ ) R_θ(\tilde{I}) Rθ(I~)为条件,来学习捕捉图像的底层分布。
公式1的拓展:通过视频扩散模型优化三维场景表示 θ θ θ,该表示同时受输入图像条件和新场景生成视频的指导。具体采用最大化 (3D渲染器渲染的k+1新视图) 与 (扩散模型基于当前k帧的渲染图像生成的下一帧预测) 之间的L2误差,因此三维表示的梯度从光度损失中传播(k 表示iteration索引):
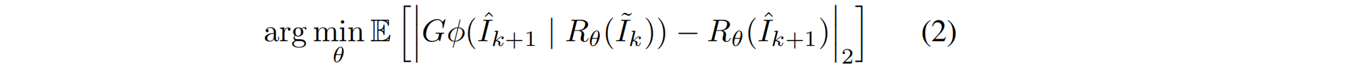
二、 Reconstruction-driven Generation
基于mask的3D重建 。 我们现在讨论如何在开放世界的大型视频重建范式中学习新颖视角的泛化能力。给定场景的视频片段,一种直接的方法是均匀间隔地降采样帧或在输入序列的中点分割为训练/测试段以进行场景重建,然后从测试相机视角渲染重建的场景以生成易产生伪影的数据。将渲染序列和原始视频片段随后作为视频扩散模型训练的输入和输出对。然而,我们观察到这些采样方案将模型限制在视图插值或纯生成上。具体来说,场景通常被采样的视图完全覆盖,目标视图位于这些视图附近,而另一种方法往往导致训练段中的大部分内容未被看到。 我们的工作旨在学习正则化,并在显著偏离捕捉轨迹的路径中生成新内容。
为此,我们提出了一种 掩码3D重建技术,从空间和时间维度的观测中获取受损的3D场景,然后渲染整个输入序列的图像,来生成训练数据集 。具体来说,我们将输入图像捕捉分为4个规则且不重叠的区域,即左上、右上、左下和右下,如图3所示。然后我们对每个场景的左上或右下区域进行采样,并遮住(即移除)其余三个区域。所采样的补丁序列用于通过标准方法进行三维重建,即二维高斯喷射(2DGS)。mask区域在同一场景中相同,迫使重建过程具有有限的视图覆盖范围。实际上,由于我们在训练中使用了开放世界的大型视频序列capture I I I,这进一步增加了稀疏性−视图仅在轨迹上密集,但在角度覆盖上极其稀疏−与标准多视图数据集如Mip-NeRF 360 [1]不同。
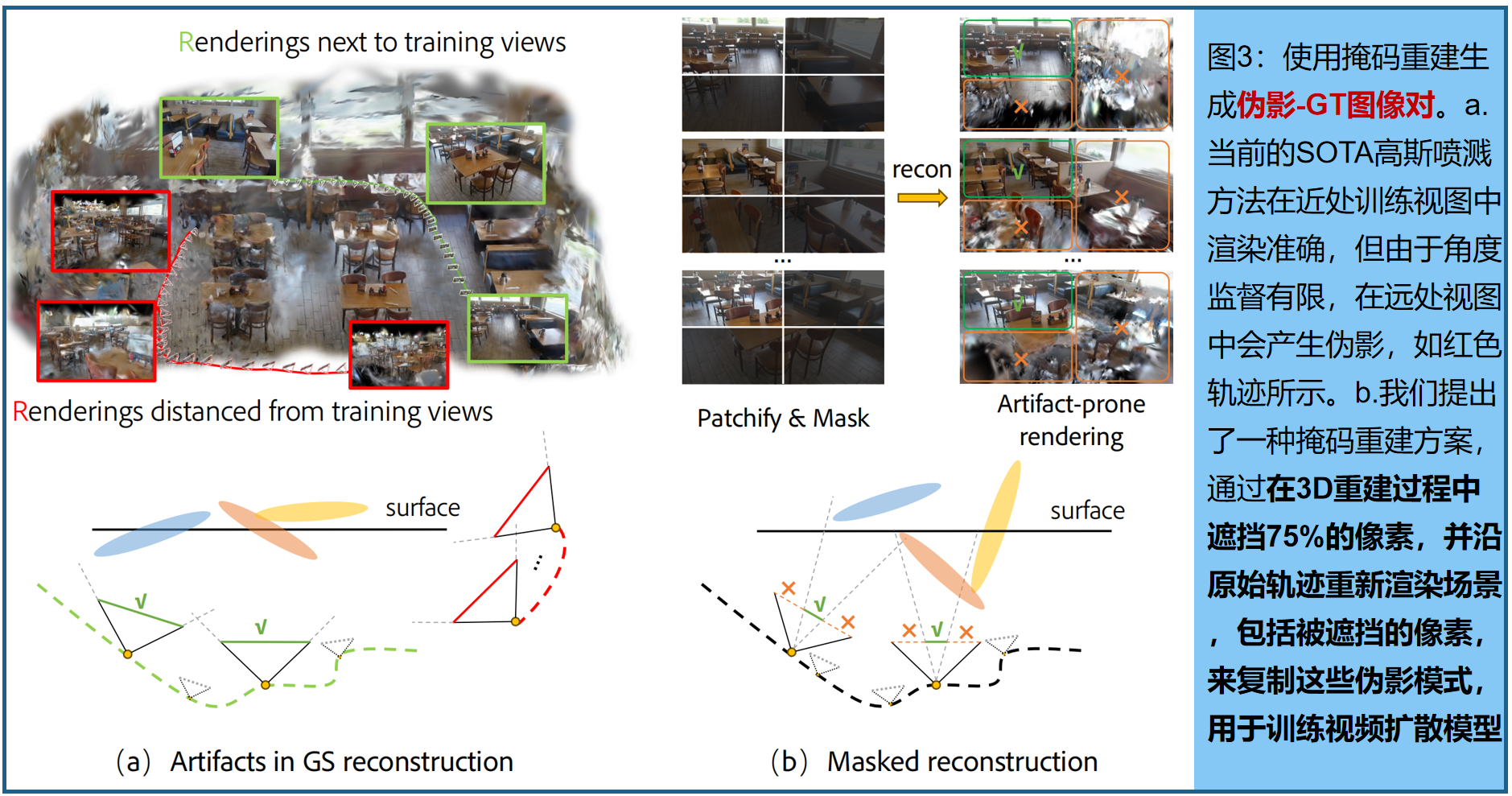
掩码重建:沿着与输入相同的相机位姿渲染更大视图的视频,以形成真实和重建的图像对,用于SVD训练。我们的见解是, 从掩码图像中重建模拟了一个视野较窄的相机,需要从偏离当前视角的视图中推断出掩码外的上下文,这促进了视图外推 。此外,渲染到全视图引入了不受约束的区域,背景广泛为黑色,有助于内容外填充。
视频扩散模型 。具体采用预训练的DynamiCrafter [52](图像到动画模型)的基础上构建视频生成模型,通过在生成过程中融入几何信息来增强帧一致性。其中,将预训练的RGB-D VAE替换base模型中的VAE,来整合深度信息;编码器和解码器分别表示为𝓔和 D D D。训练时,真实RGBD视频 I R G B − D I_{RGB−D} IRGB−D被编码到潜在空间 z : = z:= z:=𝓔 ( I R G B − D ) (I_{RGB−D}) (IRGB−D),在不同的时间步 t t t 中加入噪声,从而获得 z t z_t zt。为生成提供两个条件:首先,编码有伪影的RGB-D视频 I R G B − D ′ I'_{RGB−D} IRGB−D′,并逐帧加入初始噪声,作为序列的条件,利用视觉细节影响生成过程;此外,选择最接近渲染轨迹的输入视图,并将对应的真实图像嵌入为CLIP特征,提供高层次的整体场景信息。视频去噪网络%ϵ_θ%优化为:
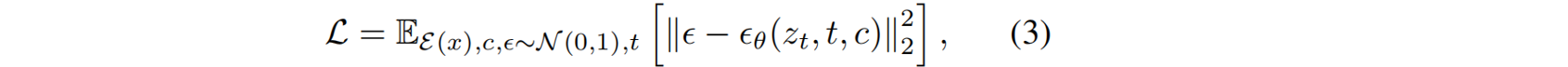
通过预训练的VAE解码器 V ^ = D ( z ) \hat{V}= D(z) V^=D(z) [44],refined latent 解码成最终的RGB-D视频。
三、 Cyclic Fusion 循环融合
我们基于2DGS来融合三维重建和视频扩散的输出,使用多个面向二维的平面高斯圆盘来表示三维场景。高斯圆盘通过中心位置 p ∈ R 3 × 1 p∈R^{3×1} p∈R3×1、不透明度(尺度) α ∈ [ 0 , 1 ] α∈[0,1] α∈[0,1]、两个主切向量 t u t_u tu和 t v t_v tv用于方向、calling vector S = ( s u , s v ) S=(s_u,s_v) S=(su,sv) 以及球谐重构生成(SH)系数进行参数化。
融合。按照原始3DGS方法初始化高斯及属性,并根据渲染损失端到端地更新高斯。优化过程是重建和生成的循环,同时利用输入条件和新生成的视图监督高斯。具体来说,每K次迭代首先生成新轨迹,基于当前的重建渲染RGB-D视频;然后将渲染序列输入到SVD中,生成无伪影的视频,并添加到监督集中,如图2。循环过程能够在观察不足的区域进行伪影校正,并为在输入视图中不可见的区域生成新内容。
其中,我们发现新的轨迹采样是最关键的组成部分。为了确保全面的视角和角度覆盖,我们采用了两种类型的轨迹:邻近输入视图之间的视角插值和在所有输入相机姿态之间生成的螺旋/球形路径(spiral/spherical path)。
内容扩展。大型未观察区域在采样轨迹远离输入视图时,可能会表现为黑色或噪点像素。尽管我们使用生成输出作为这些区域的监督,但由于周围没有高斯分布,我们将新的高斯[27]拆分和克隆变得非常困难。我们通过在优化过程中自适应地向场景中添加新的高斯点来解决这个问题,使用了 unreliable depth-based mapping。像素满足以下公式时,被认定是 unreliable :
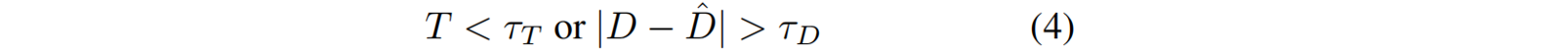
其中, T T T是累积不透明度, D D D和 D ^ \hat{D} D^分别是渲染深度和对齐的生成深度。 τ T τ_T τT和 τ D τ_D τD是阈值。
对于这些不可靠的区域,我们将生成的RGB-D点反投影到三维空间中来添加新的高斯,类似于初始化阶段。注意,对于新添加的高斯,位置和颜色值直接从RGB-D视频中获得,而其他属性则按照2DGS初始化。
损失函数。在Cyclic Fusion过程,冻结SVD,并使用渲染的RGB-D图像和输入( L r e c o n L_{recon} Lrecon)以及生成视图( L g e n L_{gen} Lgen)之间的简单光度损失,对3D表示进行端到端优化。
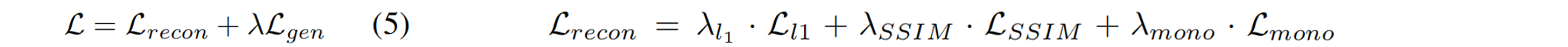
L m o n o L_{mono} Lmono是一种尺度不变的深度损失,如[Monosdf]所使用的,它强制渲染深度 D ^ \hat{D} D^ˆ与SVD预测的单目深度 D D D之间的一致性。生成损失 L g e n L{gen} Lgen共享组件,但应用于生成的图像。
为了稳定优化过程,使用正弦warm-up及退火策略来生成损失权重 λ λ λ,其定义为:
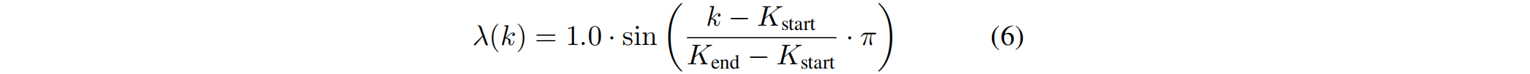
四、实验
4.1 实验设置
训练集:训练扩散模型的数据集为DL3DV- 10K [34],包含10,510个视频,140个基准场景。使用3.1节介绍的掩码3D重建方案,每个场景优化7,000步。为了确保足够的稀疏性,每个视频的训练视图数量均匀降采样至四分之一,并以960×540的分辨率沿原始轨迹渲染重建场景,同时使用当前的SOTA单目深度估计器Depthcrafter[24]增强数据集的深度信息。评估数据集:DL3DV-Benchmark [34]的24个场景、Tanks and Temples(TnT)[28]的7个场景以及来自Mip-NeRF360 [1]数据集的9个场景。
实施细节:采用DynamiCrafter [52]作为SVD的主干,并在伪影-GT RGB-D视频对上微调模型。微调过程包括粗调和精调两个阶段:在粗调阶段,视频分辨率设置为16×320×512×4,潜在空间维度为16×40×64×4。我们在四块H100 GPU上以 1 × 1 0 − 5 1×10^{−5} 1×10−5的学习率和2的批量大小训练此阶段30K步。然后,模型在精调阶段进一步微调至更高的分辨率16×512×960×4,再训练34K步。为了处理RGB-D格式,我们使用了来自LDM3D [44]的冻结RGB-D VAE。在推理过程中,我们应用DDIM采样,步数为25,并将无分类器引导尺度设置为3.2。
对于零样本泛化,我们使用2DGS作为三维表示,并用COLMAP点云初始化。在我们的实验中,视图被屏蔽,帧被下采样;我们过滤并仅保留从训练视图可见的点,用于点云初始化。
4.2 视频生成
本文介绍的基于重建的视频扩散架构,能够实现新视角的正则化和内容生成。表1中报告了VAE的设计及其对视频分辨率的影响,使用RGB-D VAE微调的模型在FID得分上优于RGB VAE(尽管扩散主干最初是在RGB VAE潜在空间上预训练的)。当空间分辨率从512×320增加到960×512时,可以观察到显著的改进。图4中展示了扩散模型的可视化结果:有效地去除了输入视频中的“漂浮物”,同时在黑色像素区域生成逼真的内容。


4.3 视图插值
目标场景完全被输入视图覆盖,测试视图介于输入之间——这是先前正则化评估中的常见设置。我们使用3、6和9个输入视图,在Mip-NeRF 360测试集上将我们的方法与之前的正则化技术进行了比较,如表2所示。

结果表明,我们的方法在新颖视角合成方面比3DGS和2DGS基线以及最近的FSGS取得了显著优势。值得注意的是,高斯喷溅训练难度通常高于NeRF,尤其是在稀疏视角设置下。我们大幅缩小了这一差距,并首次证明,在稀疏视角设置下的Mip-NeRF360数据集上,高斯喷溅的性能可与最先进的NeRF相媲美。(见表2和图5)。

4.4 视图外推
不同于稀疏视图,从视频中生成完整且无伪影的3D场景更实际。视频沿轨迹提供了密集的采样,但视角覆盖高度稀疏。虽然视频易于捕捉和校准,但对于3D重建来说却颇具挑战性,即使使用最先进的重建方法,也容易过度拟合训练视图,并在远离训练视图的视角上产生严重的伪影,见图3。因此,我们关注 far field 的新视角合成质量
为此,我们提出了一种新的评估协议,并重用掩码重建来模拟远场渲染,同时保留参考。具体来说,按照不同的时间比例分割训练/测试集,对视频序列进行降采样(例如表3中的1/2和1/4),并选择覆盖训练视角约25%像素块进行重建;同时在测试视角的全视场进行评估。固定路径位置可能会导致许多不可见和黑色区域,从而在我们的生成方法中产生偏差,基线在这些区域可能有显著误差。为了确保合理的比较,我们为masked path分配了一条轨迹,以提供更完整的内容覆盖,详见补充视频。表3和图6展示了我们的方法与基线在DL3DV-benchmark和TnT场景上的定量和定性结果。GenFusion凭借扩散模型的强大先验,显著提升了渲染质量,有效去除了针状伪影,并为不可见区域增强了逼真的3D内容。


场景 Completion。此外,GenFusion不仅在3D场景边界提供内容增强,而且实现了场景级完成,如图1所示。
总结
GenFusion,一种新颖的无伪影3D资产生成模型。首先,我们将现有的训练良好的2D视频扩散模型进行了最小修改,以驱动强大的3D引导。其次,循环融合实现了可扩展且稳健的3D提升,通过视频合成高效地闭合了3D重建与生成之间的循环。然而,该方法存在一些局限性:需要额外的去噪步骤,训练时间略有增加(每个场景约40分钟)。填充大型不可见区域会导致模糊,因为视频片段之间存在不一致。在融合模块中建模并解决这种不一致性将是实现更高质量的关键步骤
相关文章:

【三维重建与生成】GenFusion:SVD统一重建和生成
标题:《GenFusion: Closing the Loop between Reconstruction and Generation via Videos》 来源:西湖大学;慕尼黑工业大学;上海科技大学;香港大学;图宾根大学 项目主页:https://genfusion.sibowu.com 文章…...

常见的爬虫算法
1.base64加密 base64是什么 Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后…...
)
有序二叉树各种操作实现(数据结构C语言多文件编写)
1.先创建tree.h声明文件( Linux 命令:touch tree.h)。编写函数声明如下(打开文件 Linux 操作命令:vim tree.h): //树的头文件位置 #ifndef __TREE_H__ #define __TREE_H__ //节点 typedef struct node{int data;//数据struct node* left;//记录左侧子节…...

Nacos-Controller 2.0:使用 Nacos 高效管理你的 K8s 配置
作者:濯光、翼严 Kubernetes 配置管理的局限 目前,在 Kubernetes 集群中,配置管理主要通过 ConfigMap 和 Secret 来实现。这两种资源允许用户将配置信息通过环境变量或者文件等方式,注入到 Pod 中。尽管 Kubernetes 提供了这些强…...

特殊文件以及日志——特殊文件
一、特殊文件 必要性:可以用于存储多个用户的:用户名、密码。这些有关系的数据都可以用特殊文件来存储,然后作为信息进行传输。 1. 属性文件.properties(键值对) (1)特点: 都只能…...

Spark-SQL核心编程语言
利用IDEA开发spark-SQL 创建spark-SQL测试代码 自定义函数UDF 自定义聚合函数UDAF 强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(), countDistinct(),avg(),max(),min()。除此之外&…...

jdk 安装
oracle官网 : Java Archive | Oracle 中国 export JAVA_HOME/Users/xxxxx/app/services/x86jdk/jdk1.8.0_431.jdk/Contents/Home export PATH$JAVA_HOME/bin:$PATH 华为镜像网站:Index of java-local/jdk...

Missashe考研日记-day21
Missashe考研日记-day21 1 专业课408 学习时间:4h学习内容: 今天先把昨天学的内容的课后习题做了,整整75道啊,然后学了OS第二章关于CPU调度部分的内容,这第二章太重要了,以至于每一小节的内容都比较多&am…...

双重路由引入的环路,选路次优的产生以及解决方法
描述 在R2,R3上双向引入ospf,以及rip,R5修改静态的优先级为180,在ospf中引入该静态路由 路由分析 选路次优问题 R5引入了静态路由,优先级是150 R2->R5->100.1.1.0,优先级是150 R3->R4->100.1.1.0,优先级是150 R3->R4->R5->100.1.1.0,优先级是150 R2-…...
)
环境变量概念以及获取环境变量(linux下解析)
目录 1 基本概念 2 常见的环境变量 3 查看环境变量方法 4 和环境变量相关的命令 5 环境变量的组织方式 6 通过代码如何获取环境变量 6.1 命令行参数 6.2 环境变量 7 通过系统调用获取或设置环境变量 1 基本概念 环境变量(environmentvariables)⼀般是指在操作系统中用来指…...

删除win11电脑上的阿尔巴尼亚输入法SQI
删除电脑自带的阿尔巴尼亚输入法 这个输入法在系统中并不显示,但是有时候会出现在右下角显示,删除这个输入法的流程如下,暂时没发现反复! 第一步:打开注册表: winR打开运行,输入 regedit 第二…...

目标检测与分割:深度学习在视觉中的应用
🔍 PART 1:目标检测(Object Detection) 1️⃣ 什么是目标检测? 目标检测是计算机视觉中的一个任务,目标是让模型“在图像中找到物体”,并且判断: 它是什么类别(classif…...

npm和npx的作用和区别
npx 和 npm 是 Node.js 生态系统中两个常用的工具,它们有不同的作用和使用场景。 1. npm(Node Package Manager) 作用: npm 是 Node.js 的包管理工具,主要用于: 安装、卸载、更新项目依赖(包&a…...
图像滤波-----形态学操作函数morphologyEx())
OpenCV 图形API(36)图像滤波-----形态学操作函数morphologyEx()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 执行高级形态学变换。 该函数可以使用腐蚀和膨胀作为基本操作来执行高级形态学变换。 任何操作都可以原地进行。在处理多通道图像时,…...

Python入门到精通6:CSS网页美化入门1
CSS(层叠样式表)是网页设计的核心语言之一,它让我们的网页从单调的结构变得生动美观。今天,我将带大家快速了解CSS的基础知识,包括基本概念、引入方式、选择器、字体与文本样式以及调试工具的使用。 1. CSS基本概念 …...

【深入C++多态:基于消息解析器的设计、实现与剖析】
深入C多态:基于消息解析器的设计、实现与剖析 前言多态代码示例代码结构C多态的核心知识点多态的底层机制深入剖析多态的设计模式总结 前言 在C面向对象编程中,多态(Polymorphism)是实现灵活性和扩展性的核心特性,允许…...

Dockerfile 文件常见命令及其作用
Dockerfile 文件包含一系列命令语句,用于定义 Docker 镜像的内容、配置和构建过程。以下是一些常见的命令及其作用: FROM:指定基础镜像,后续的操作都将基于该镜像进行。例如,FROM python:3.9-slim-buster 表示使用 Pyt…...

Redis--持久化
一、持久化 Redis支持RDB和AOF两种持久化机制持久化功能有效地避免因进程退出造成数据丢失问题, 当下次重启时利用之前持久化的文件即可实现数据恢复。 二、RDB RDB 持久化是把当前进程数据⽣成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和…...

Markdown学习
Typora下载 Typora教程 标题 井号加空格——回车即可形成标题,几级标题几个井号。 字体 斜体——前后各一个*,回车 粗体——前后各两个*,回车 既斜体又粗体——前后各三个*,回车 删除线——前后各两个~(波浪号…...

Vulhub-DarkHole靶机通关攻略
下载链接:https://www.vulnhub.com/entry/darkhole-1,724/ 扫描ip arp-scan -l扫描端口 nmap 192.168.112.144 -p-扫描目录 dirsearch -u http://192.168.112.144/有一个登录页面,还有一个upload目录,但是还没有找到上传点 先注册一个用…...

UniRig ,清华联合 VAST 开源的通用自动骨骼绑定框架
UniRig是清华大学计算机系与VAST联合开发的前沿自动骨骼绑定框架,专为处理复杂且多样化的3D模型而设计。基于强大的自回归模型和骨骼点交叉注意力机制,UniRig能够生成高质量的骨骼结构和精确的蒙皮权重,大幅提升动画制作的效率和质量。 UniR…...

深入解析 sklearn 中的 LabelEncoder:功能、使用场景与注意事项
标题:深入解析 sklearn 中的 LabelEncoder:功能、使用场景与注意事项 摘要: LabelEncoder 是 sklearn 中用于类别标签编码的重要工具,能够将离散的类别型标签转换为模型可识别的数值格式。本文详细解析 LabelEncoder 的核心功能…...

红帽Linux网页访问问题
配置网络,手动配置 搭建yum仓库红帽Linux网页访问问题 下载httpd 网页访问问题:首先看httpd的状态---selinux的工作模式(强制)---上下文类型(semanage-fcontext)---selinux端口有没有放行semanage port ---防火墙有没有active---…...

Muduo库代码剖析 : EventLoop
本文初发于 “天目中云的小站”,同步转载于此 EventLoop 详解 EventLoop类似于Reactor模型中的反应堆(Reactor)和事件分发器(Demultiplex)的合并, 其目的在于高效的接收事件, 并正确分配给对应的事件处理器. EventLoop中有两类关键的子控件 : Channel 和 Poller. C…...
)
Python网络爬虫设计(一)
目录 一、网络爬虫 1、基本的爬虫 2、获取URL 3、查找网页源码关键字 4、代码实现 二、requests库 1、requests的优势和劣势 2、获取网页的其他库 (1)selenium库 (2)pyppeteer库 三、pyppeteer库 1、pyppeteer库的来历…...

GEO供应商盈达科技发布:AI信源占位白皮书
副标题:生成式AI时代的企业认知主权争夺战 发布日期:2025年4月15日 一、范式重构:从流量入口到认知主权的战略迁移 生成式AI的规则革命 73%的用户决策直接依赖AI生成内容,但68%的引…...

L1-4 拯救外星人
题目 你的外星人朋友不认得地球上的加减乘除符号,但是会算阶乘 —— 正整数 N 的阶乘记为 “N!”,是从 1 到 N 的连乘积。所以当他不知道“57”等于多少时,如果你告诉他等于“12!”,他就写出了“479001600”这个答案。 本题就请你…...

业务摆渡解锁信息孤岛,重塑数字医疗未来
某三甲医院的急诊科突然亮起红灯,一名车祸患者被紧急送入,主治医师需要调取其三个月前在科研专网存储的增强CT影像。若在两年前,这需要两位管理员手动导出、杀毒、跨网传输,耗时40分钟;而现在,系统自动触发…...

OpenCV中的轮廓近似方法详解
文章目录 引言一、什么是轮廓近似?二、OpenCV中的轮廓近似方法2.1Douglas-Peucker算法原理2.2函数原型 三、代码示例3.1. 基本使用 四、参数选择技巧五、与其他轮廓方法的比较六、总结 引言 在计算机视觉和图像处理中,轮廓是物体边界的重要表示形式。Op…...

4种方法将文件映射到内存提升读写速度
背景 考虑到以下应用需求,常将文件映射到内容,以提升读写效果。 高效文件读写:大文件操作时,避免多次read/write系统调用的开销。进程间通信(共享内存):多个进程映射同一文件,实现…...

367. 有效的完全平方数
给你一个正整数 num 。如果 num 是一个完全平方数,则返回 true ,否则返回 false 。 完全平方数 是一个可以写成某个整数的平方的整数。换句话说,它可以写成某个整数和自身的乘积。 不能使用任何内置的库函数,如 sqrt 。 示例 1…...

Ubuntu2404装机指南
因为原来的2204升级到2404后直接嘎了,于是要重新装一下Ubuntu2404 Ubuntu系统下载 | Ubuntuhttps://cn.ubuntu.com/download我使用的是balenaEtcher将iso文件烧录进U盘后,使用u盘安装,默认选的英文版本, 安装后,安装…...

爬虫框架 - Coocan
安装 pip install coocan 演示...

S06-Kep的跨通道传输
每次分享一小点,进步都是实实在在。小编今天又来分享了!之前我们讲到的KepServer软件,是一个具备强大通讯能力的软件,但是当你的上位软件不够灵活的时候,又有多个通道的数据交互的需求,Kep的跨通道传输就为…...
)
Zookeeper单机三节点集群部署(docker-compose方式)
前提: 服务器需要有docker镜像zookeeper:3.9.3 或能连网拉取镜像 服务器上面新建文件夹: mkdir -p /data/zk-cluster/{data,zoo-cfg} 创建三个zookeeper配置文件zoo1.cfg、zoo2.cfg、zoo3.cfg,配置文件里面内容如下(三个文件内容一样): tickTime=2000 initLimit=10 …...

C++| 深入剖析std::list底层实现:链表结构与内存管理机制
引言 std::list的底层实现基于双向链表,其设计哲学与std::vector截然不同。本文将深入探讨其节点结构、内存分配策略及迭代器实现原理,揭示链表的性能优势和潜在代价。 1. 底层数据结构:双向链表 每个std::list节点包含: 数据域…...

mysql数据库的线程连接数、状态 、最大并发数、缓存等参数配置
mysql数据库的线程连接数、状态 、最大并发数、缓存等参数配置 https://www.modb.pro/db/1784385883449397248 mysql数据库的线程连接数、状态 、最大并发数、缓存等参数配置 SQL命令行临时设置操作 #查看mysql数据库的线程连接数: mysql> show global statu…...

HarmonyOS-ArkUI V2状态-PersistenceV2:持久化存储UI状态
PersistenceV2类是一个与AppStorageV2类用法非常相似的类。因为它俩是子类和父类的关系。如果不了解AppStorageV2,可以先跳转至了解一下这个类。 HarmonyOS-ArkUI V2工具类:AppStorageV2:应用全局UI状态存储-CSDN博客 PersistenceV2相比于其父类AppStorageV2而言,它存储的…...

App测试小工具
前言 最近app测试比较多,每次都得手动输入日志tag,手动安装,测完又去卸载,太麻烦。就搞了小工具使用。 效果预览 每次测试完成,点击退出本次测试,就直接卸载了,usb插下一个手机又可以继续测了…...

ZEP: 一种用于智能体记忆的时序知识图谱架构
摘要 我们介绍了Zep,一种新型的智能体记忆层服务,在深度记忆检索(DMR)基准测试中,超越了现有的最先进系统MemGPT。此外,Zep在比DMR更全面、更具挑战性的评估中表现优异,这些评估更好地反映了现实世界企业应用的需求。尽管现有的基于大语言模型(LLM)的检索增强生成(R…...

800 中值定理
文章目录 前言365366367368369370371372373总结 前言 中值定理貌似是压轴题,但是也没什么难的,我一定可以拿下。 background music : 《还是分开》张叶蕾 365 构造出罗尔定理需要的 F(x) 我现在没啥问题,然后就是要找出两个相等的点&…...

安装fvm可以让电脑同时管理多个版本的flutter、flutter常用命令、vscode连接模拟器
打开 PowerShellfvm安装 dart pub global activate fvm安装完成后,如果显示FVM无法识别,那么需要去添加环境变量path添加这个:C:\Users\Administrator\AppData\Local\Pub\Cache\bin 常用命令 fvm releases 查看用户可以装的flutter版本fvm l…...

多线程、JUC——面试问题自我总结
1、创建线程有几种方式 答:1、通过继承Thread类,但需要注意的是一个类继承Thread就不能继承其他的类了 2、实现Runnable接口 3、实现Callable接口,重写Call方法 4、线程池 2、线程状态是怎么转换 3、实现线程的方式Callable与Runnable区别 …...

LivePortrait 使用指南:让静态照片“动”起来的魔法工具
欢迎来到涛涛聊AI,先看效果 项目地址:https://github.com/KwaiVGI/LivePortrait 在人工智能技术飞速发展的今天,静态照片的“动态化”已成为数字创意领域的热门方向。LivePortrait 凭借其高效性、可控性和逼真效果,成为用户将照片转化为动态视频的首选方案。本文将从技术原…...

Aosp13 文件应用点击apk无反应的处理
最近遇到一个问题,在A13上,打开文件管理应用时,点击apk 无反应或者启动安装进程后安装完成或取消安装进程,再次点击apk 无反应。在此记录该问题。 做一下修改:root/package/ providers/DownloadProvider/下 jenkinsdel…...

用python比较两个mp4是否实质相同
下面这个脚本会使用 ffmpeg 和 ffprobe 检查两个视频文件在以下方面是否“实质相同”: ✅ 检查内容: 分辨率(宽高)帧率视频总帧数音频轨道数量和采样率视频时长视频帧哈希(可选) — 对比前 N 帧的图像感知…...

jmeter中文使用手册
1. 简介 Apache J JMeter 是 100%纯 java 桌面应用程序,被设计用来测试 C/S 结构的软件(例如 web 应用程序)。它可以被用来测试包括基于静态和动态资源程序的性能,例如静态文件,Java Servlets,Java 对象&a…...

【Linux】系统入门
【Linux】系统初识 起源开源 闭源版本内核内核编号 Linux的安装双系统(不推荐)WindowsLinuxvmware虚拟机vitualbox操作系统的镜像centos 7/ubuntu云服务器租用 Linux的操作lsmkdir 文件名pwdadduser userdel -rrm文件名cat /proc/cpuinfolinux支持编程vim code.c./a.out 运行程…...

DP34 【模板】前缀和 -- 前缀和
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接:【模板】前缀和_牛客题霸_牛客网 二:算法原理 三:代码实现 #include <iostream> #include <vector> using namespac…...

2025年机动车授权签字人考试题库及答案
一、单选题 1、汽车一般由发动机、( )、车身、电气和电子设备四大部分组成。 A、底盘 B、变速箱 C、离合器 D、驾驶室 答案: A 2、轮式汽车的驱动形式常用符号"nm"表示,其中n代表车轮总数,m代表 ( )。 A、…...