向量数据库
目录标题
- 阶段二:核心技术深入学习
- 阶段三:工具与实践
- 1. 基础概念
- 问题:什么是向量数据库?它与传统关系型数据库的区别是什么?
- 问题:向量数据库的核心数据结构是什么?为什么向量适合用于高维数据?
- 问题:什么是向量索引?常见的向量索引算法有哪些?
- 2. 技术实现
- 问题:向量数据库如何实现高效的相似性搜索?
- 问题:你了解哪些开源的向量数据库?它们的优缺点是什么?
- 问题:向量数据库如何处理大规模数据的存储和查询?
- 3. 应用场景
- 问题:向量数据库在哪些场景下有优势?请举例说明。
- 问题:在推荐系统中,如何使用向量数据库来提高效率?
- 4. 实践经验
- 问题:你是否在实际项目中使用过向量数据库?请分享你的经验。
- 问题:如何处理多模态数据(如图像、文本、音频)的向量化存储和检索?
- HNSW算法
- PQ乘积量化算法
- 步骤 1:分割向量
- 步骤 2:对每个子向量进行量化
- 步骤 3:存储量化结果
- 步骤 4:查询时使用量化结果
- 为什么 PQ 高效?
- 举例说明
- Milvus
- 面试可能的问题

-
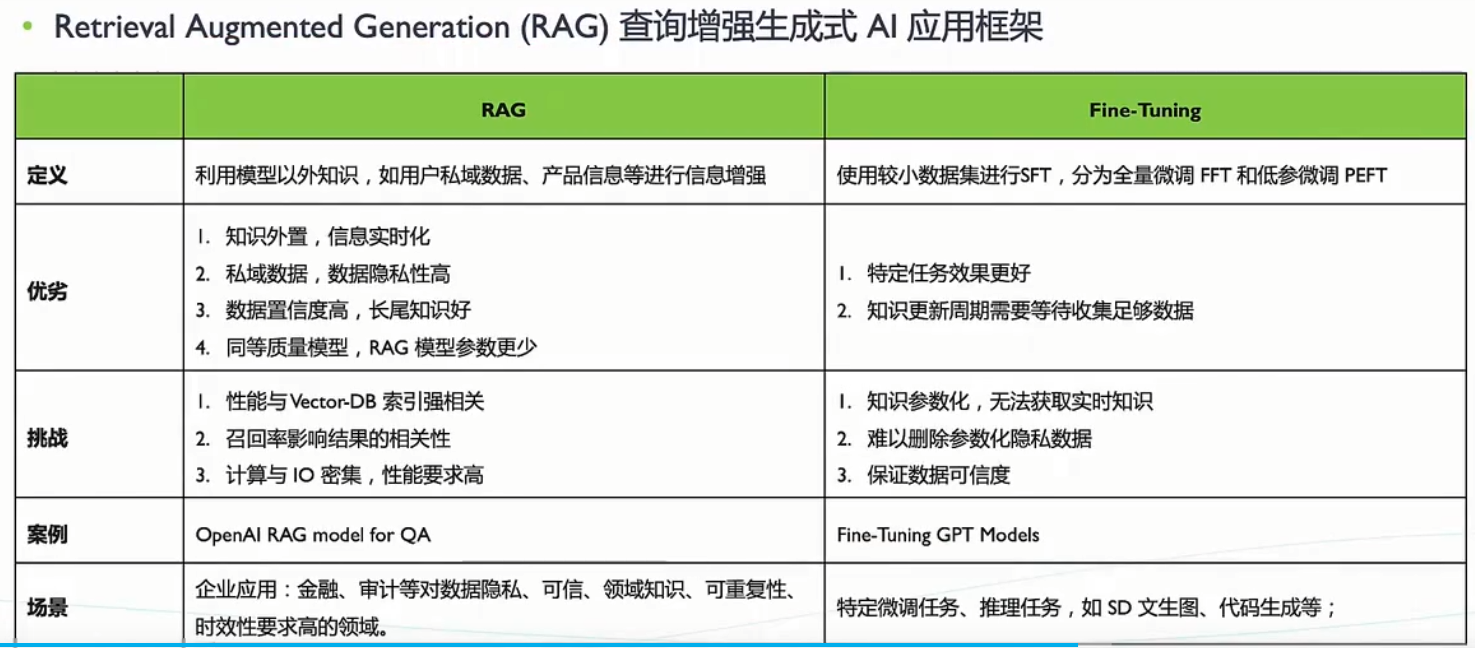
向量检索基础
- 近似最近邻搜索(ANN)原理与算法分类
- 经典算法:IVF(倒排索引)、HNSW(图索引)、PQ(乘积量化)
- 评测指标:召回率、延迟、吞吐量、内存占用
-
数据库与分布式系统基础
- 数据库索引原理(B树、LSM树)
- 分布式存储与计算框架(如Spark、Flink)
阶段二:核心技术深入学习
- 向量数据库核心技术
- 索引结构优化:混合索引(如IVF+HNSW)、层次化索引
- 距离度量:欧氏距离、余弦相似度、自定义度量函数
- 量化技术:标量量化(SQ)、乘积量化(PQ)、4-bit量化(参考HANNS优化)
量化:
-
性能优化与硬件加速
- SIMD指令优化(如AVX-512)
- GPU/NPU加速(如华为NPU在HANNS中的应用)
- 内存与磁盘I/O优化(数据压缩、缓存策略)
-
跨模态检索技术
- 多模态表示学习(CLIP、ALIGN等模型)
- 跨模态对齐(特征映射、对抗学习)
- 分布外(OOD)数据检索优化(参考HANNS-OOD算法)
阶段三:工具与实践
-
主流工具与框架
- 开源库:Faiss(Meta)、Annoy(Spotify)、SCANN(Google)
- 向量数据库:Milvus、Pinecone、Weaviate
- 华为云HANNS算法库(研究其开源实现与技术文档)
-
实践项目
- 复现经典论文(如HNSW、IVFPQ)
- 优化现有算法(如改进量化策略或索引结构)
- 参与Kaggle竞赛(如BigANN Benchmark相关任务)
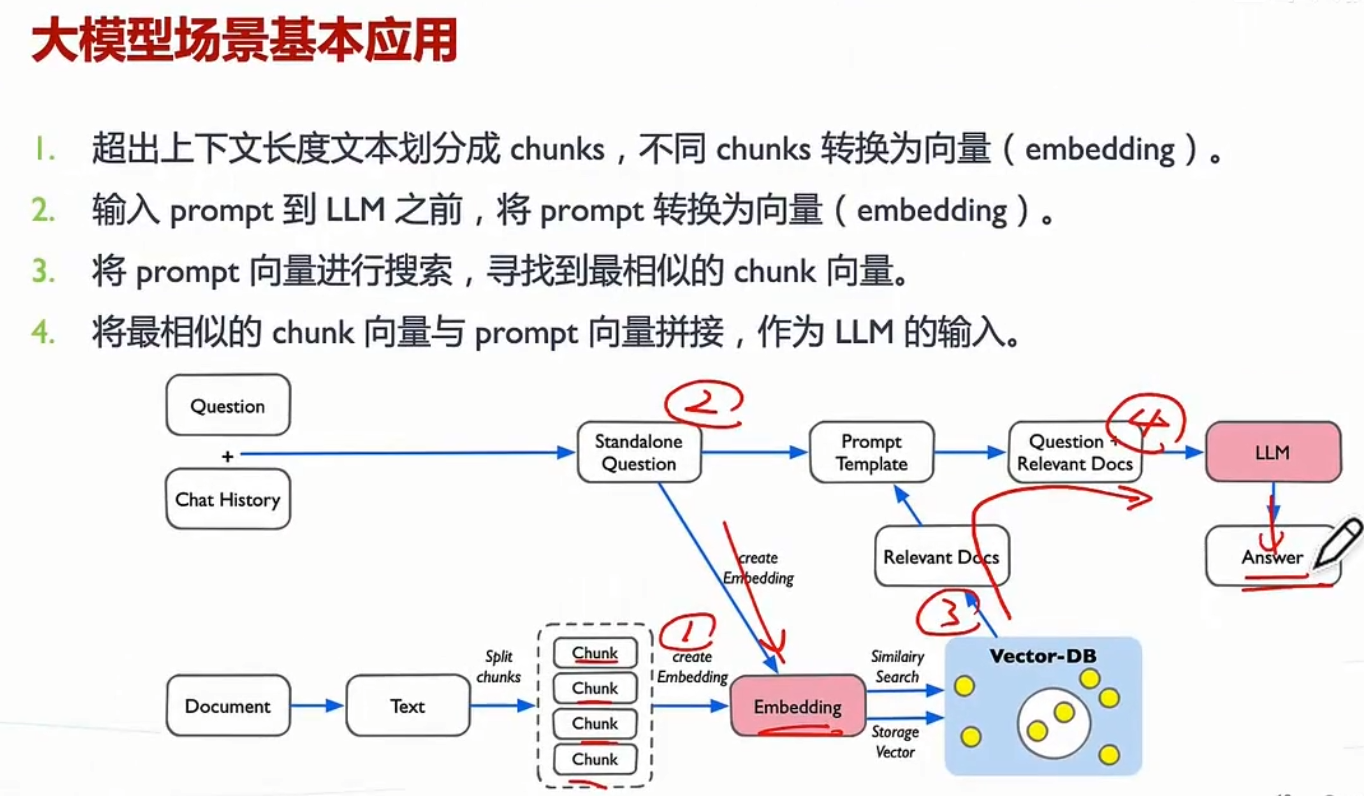
1. 基础概念
问题:什么是向量数据库?它与传统关系型数据库的区别是什么?
-
期望答案:
- 向量数据库是一种专门设计用来存储和查询高维向量数据的数据库系统。这些向量通常是由机器学习模型生成的,它们可以表示各种类型的数据,如文本、图像或音频等非结构化数据的特征。向量数据库允许用户高效地执行相似性搜索,这对于推荐系统、图像识别、语音处理等领域非常重要。
- 与传统关系型数据库的区别:
- 数据模型:关系型数据库存储结构化数据(如表),而向量数据库存储高维向量。
- 查询方式:关系型数据库使用SQL进行精确查询,向量数据库支持相似性搜索(如最近邻搜索)。
- 应用场景:关系型数据库适用于事务处理,向量数据库适用于AI、推荐系统、语义搜索等场景。
-
解决的问题
- 检索∶以图搜图场景,如人脸检索、人脸支付、车牌号码检索、相似商品检索等;
- 分析∶以图分析行为,人脸撞库、人脸对比、场景再现等;
问题:向量数据库的核心数据结构是什么?为什么向量适合用于高维数据?
-
期望答案:
- 核心数据结构是向量(高维数组),通常用于表示嵌入(Embedding)。
- 向量适合高维数据的原因:
- 高维向量可以捕捉复杂特征(如图像、文本、音频的语义信息)。
- 通过向量距离(如余弦相似度、欧氏距离)可以量化数据之间的相似性。


-
考察重点: 候选人对向量及其在高维数据处理中的优势的理解。
问题:什么是向量索引?常见的向量索引算法有哪些?
- 期望答案:
- 向量索引是一种数据结构,用于高效地组织和存储向量数据。由于向量通常是高维的(例如,图像、文本或音频的嵌入向量),直接对这些向量进行搜索会非常耗时。因此,向量索引的作用是通过某种方式对向量进行组织,使得搜索过程更加高效。
- 常见算法:
-
HNSW(Hierarchical Navigable Small World):基于图的索引,构建一个多层图结构,支持高效近似最近邻搜索。

-
IVF(Inverted File):将向量聚类,并在每个聚类中建立索引。
-
FAISS(Facebook AI Similarity Search):基于量化和分层的索引库。
-
KD-Tree:将向量空间递归地划分为二叉树结构。
-
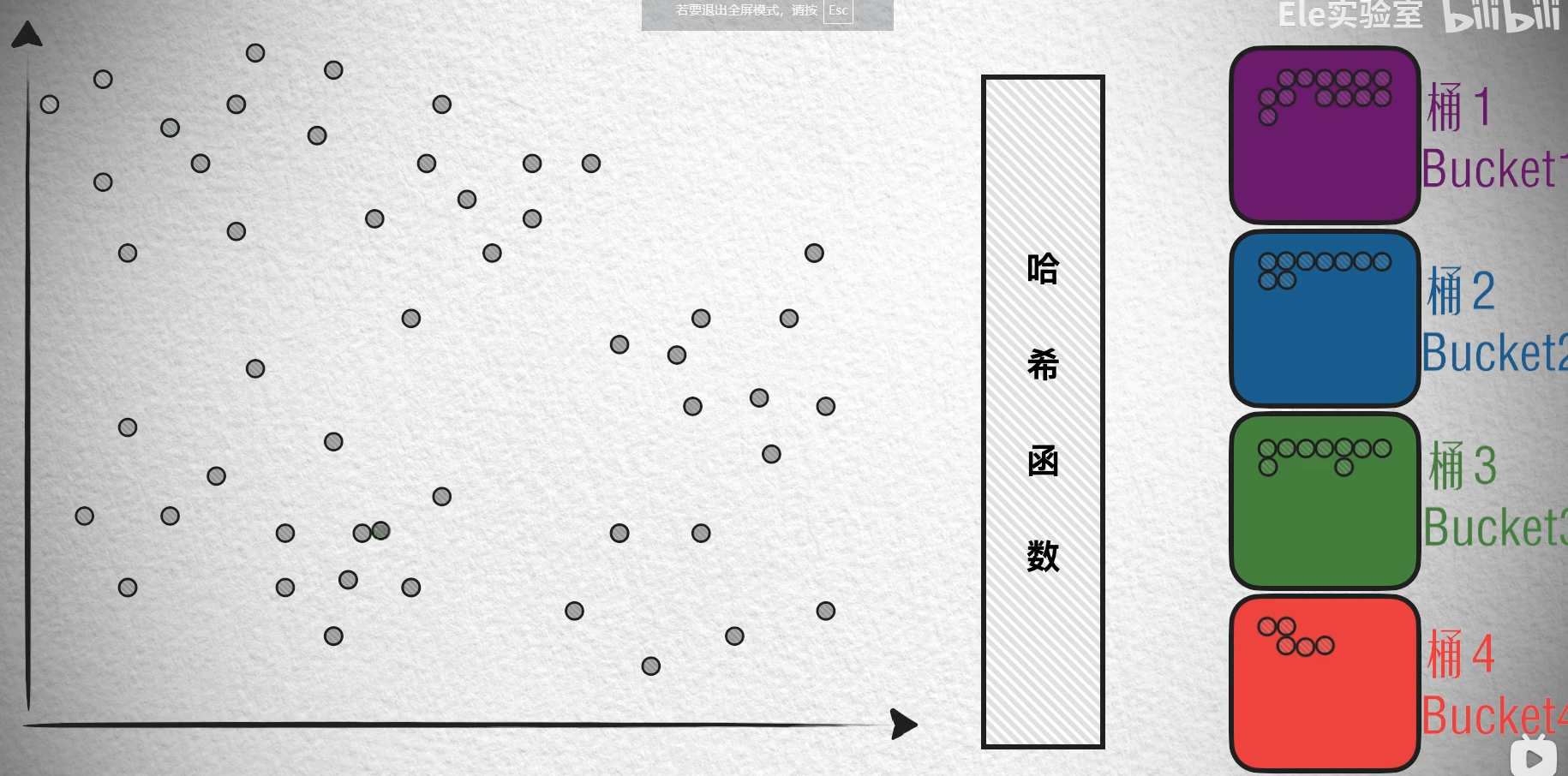
LSH(局部敏感哈希):通过哈希函数将相似的向量映射到同一个桶中。
-
- 考察重点: 候选人对向量索引技术的了解,以及对常用算法的熟悉程度。

2. 技术实现
问题:向量数据库如何实现高效的相似性搜索?
- 期望答案:
- 使用近似最近邻搜索(ANN)算法(ANN 是一类用于在高维空间中快速找到与查询向量最相似的向量的算法。),在保证精度的同时提高搜索效率。
- 常见技术:
- 基于图的算法: 如 HNSW(Hierarchical Navigable Small World)。
- 基于树的算法: 如 KD-Tree、Ball Tree。
- 基于量化的算法: 如 PQ(Product Quantization)、IVF(Inverted File)。
- 基于哈希的算法: 如 LSH(Locality-Sensitive Hashing位置敏感哈希)。
视频链接:b站
- 考察重点: 候选人对ANN算法及其优化技术的理解。
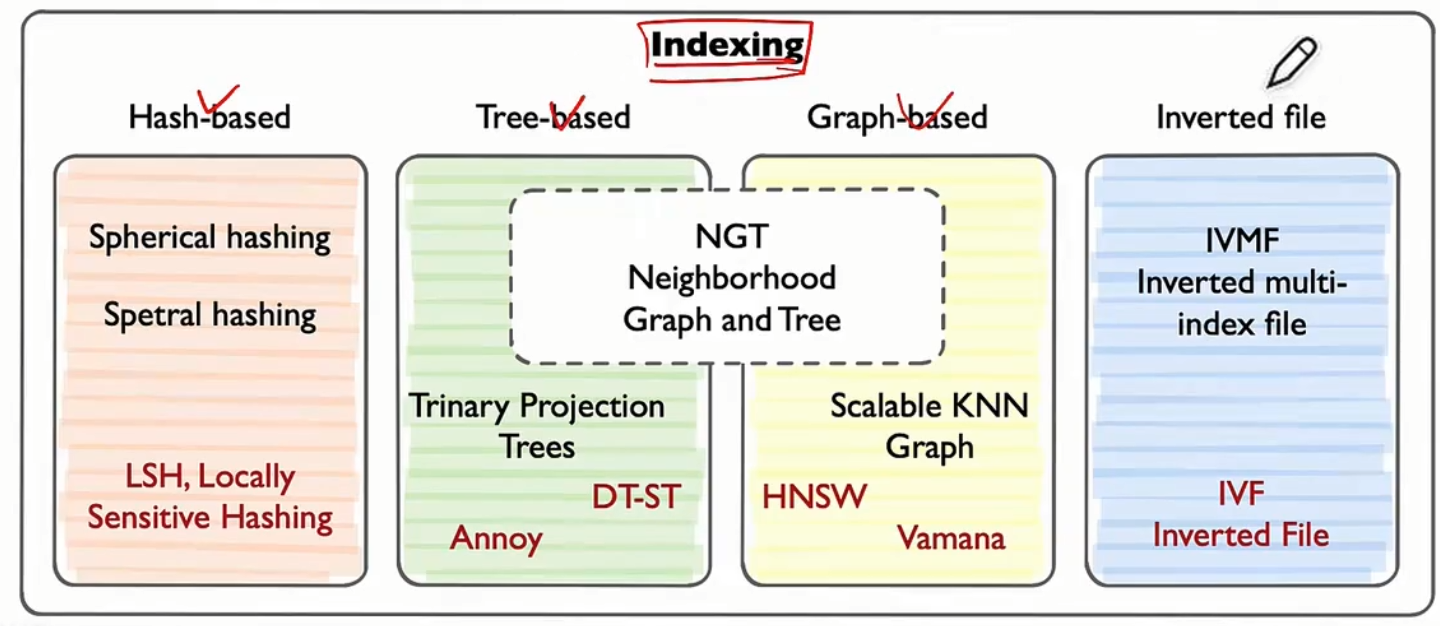
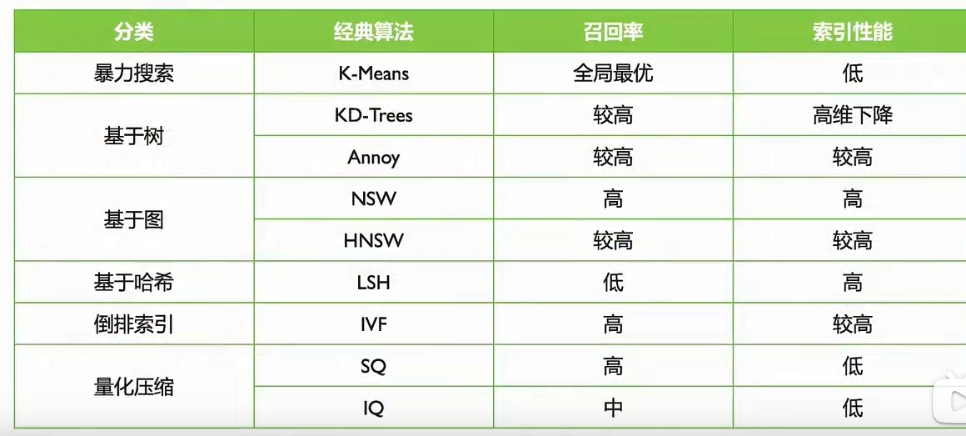
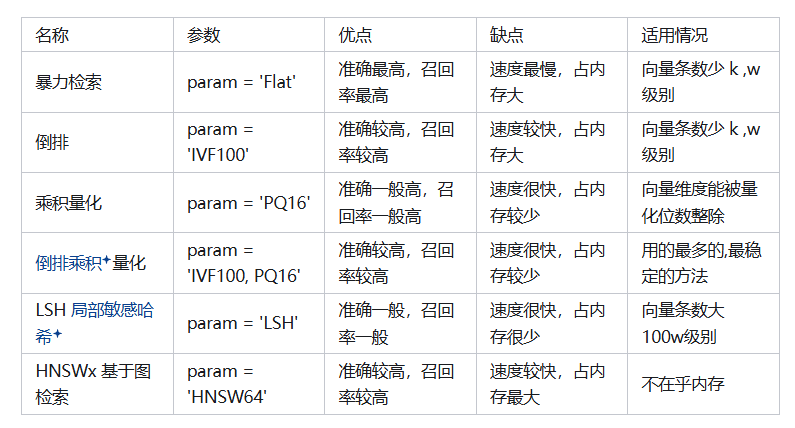
问题:你了解哪些开源的向量数据库?它们的优缺点是什么?
- 期望答案:
- Milvus: 支持分布式部署,功能丰富,但配置复杂。
- Weaviate: 集成语义搜索和AI模型,适合文本数据,但社区较小。
- FAISS: 高效的向量搜索库,但需要自行搭建数据库功能。
- Pinecone: 托管服务,易于使用,但成本较高。
- 考察重点: 候选人对主流向量数据库的了解及其优缺点分析。
问题:向量数据库如何处理大规模数据的存储和查询?
- 期望答案:
- 使用分布式存储(如对象存储、分布式文件系统)扩展存储容量。
- 通过分片(Sharding)和并行计算加速查询。
- 利用索引优化(如HNSW、IVF)减少搜索范围。
- 考察重点: 候选人对大规模数据处理技术的理解。
3. 应用场景
问题:向量数据库在哪些场景下有优势?请举例说明。
- 期望答案:
- 推荐系统: 通过用户和物品的向量表示进行相似性推荐。
- 语义搜索: 将文本转换为向量,支持自然语言查询。
- 图像检索: 通过图像特征向量进行相似图像搜索。
- 异常检测: 通过向量距离识别异常数据。
- 考察重点: 候选人对向量数据库在实际应用中的理解。
问题:在推荐系统中,如何使用向量数据库来提高效率?
- 期望答案:
- 将用户和物品表示为向量(如通过矩阵分解或深度学习模型)。
- 使用向量数据库存储和索引这些向量。
- 通过相似性搜索快速找到与用户兴趣匹配的物品。
- 考察重点: 候选人对推荐系统与向量数据库结合的应用能力。
4. 实践经验
问题:你是否在实际项目中使用过向量数据库?请分享你的经验。
- 期望答案:
- 描述具体项目背景(如推荐系统、语义搜索)。
- 说明使用的向量数据库(如Milvus、FAISS)及其选型原因。
- 分享遇到的挑战(如性能优化、数据规模)及解决方案。
- 考察重点: 候选人的实际项目经验及问题解决能力。
问题:如何处理多模态数据(如图像、文本、音频)的向量化存储和检索?
- 期望答案:
- 使用多模态模型(如CLIP、UniT)将不同模态数据映射到同一向量空间。
- 在向量数据库中统一存储这些向量。
- 通过相似性搜索实现跨模态检索。
- 考察重点: 候选人对多模态数据处理及向量数据库应用的理解。
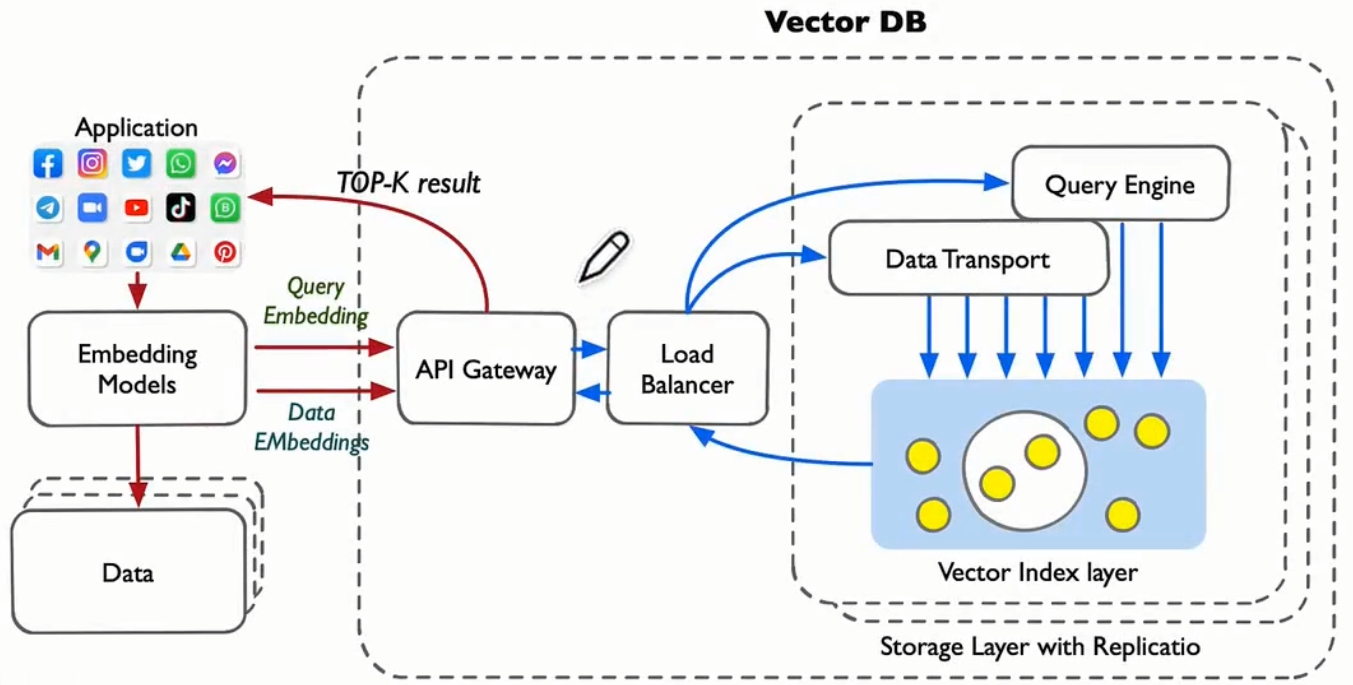
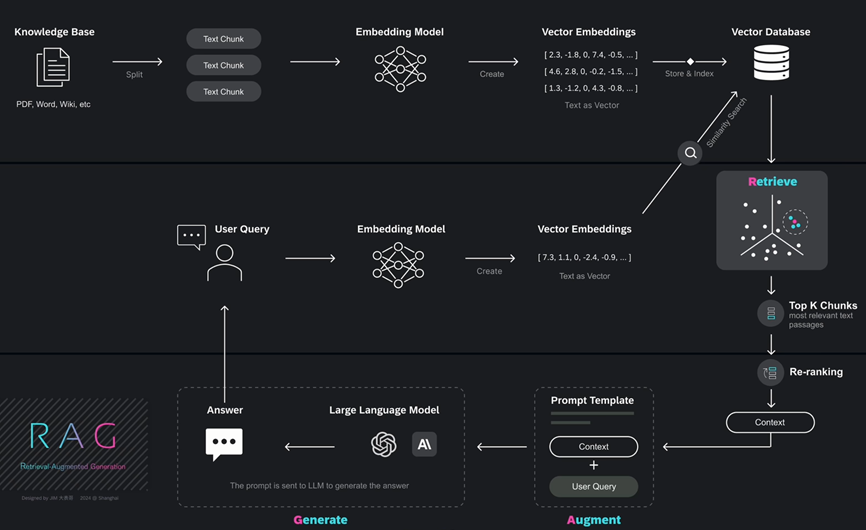
大模型遇到向量检索
- LLM应用离不开Prompt Engine,提示工程离不开向量检索
- 本质语义搜索,从海量数据中找到匹配的内容拼接提示词
- 向量数据库对输入数据Embedding后,使用向量化计算为大模型提供高效的数据存储和查询支撑;
Vector-DB提供存储、记忆能力,大模型提供问题处理和分析能力
- 大模型与Vector-DB深度融合应用为通用人工智能(AGl )的实现提供了可靠路径;
- 大模型新一代AlI处理器,提供数据处理能力;Vector-DB提供Memory存储能力。

HNSW算法
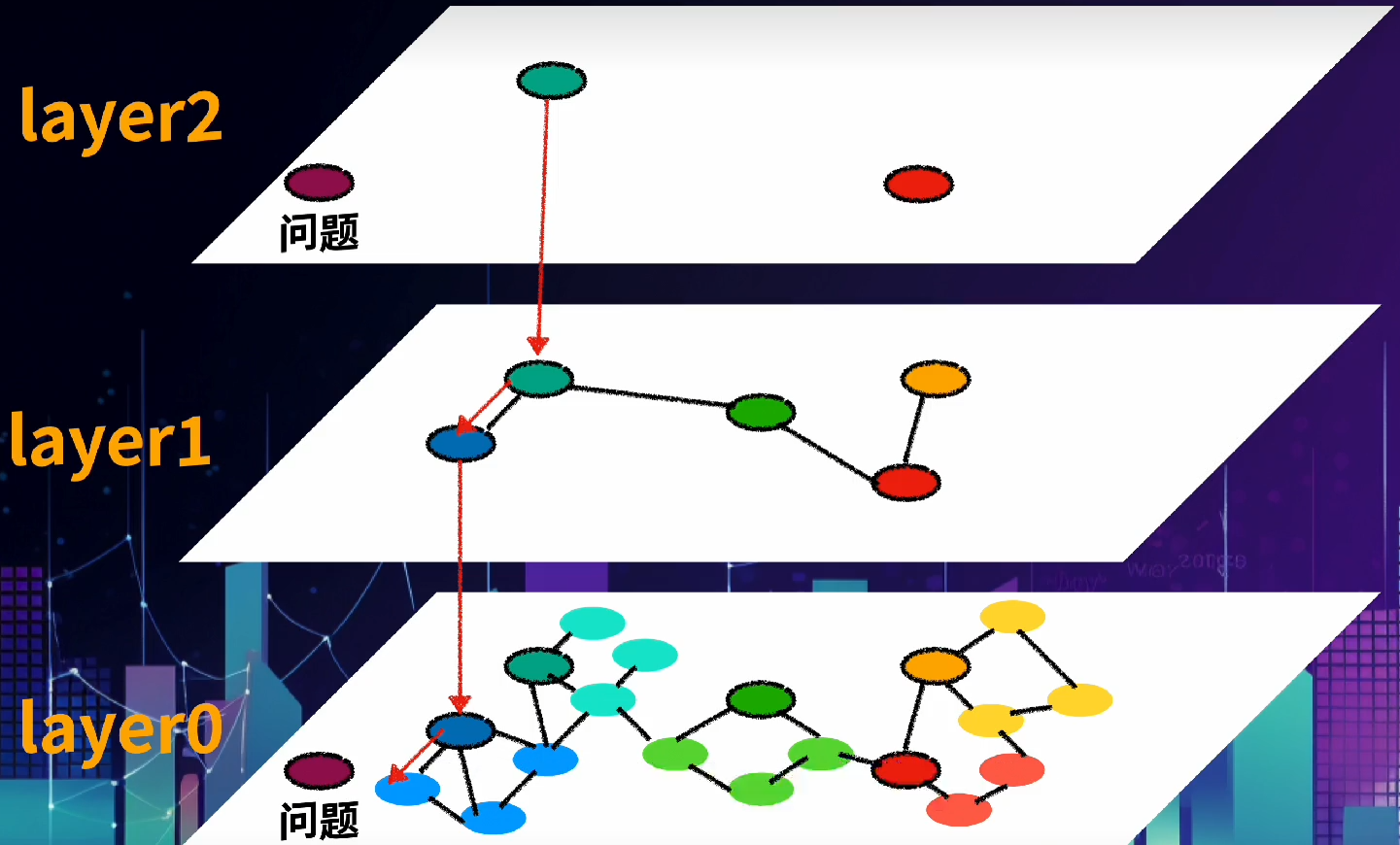
b站视频
(从上往下看)
构图准则:

视频:b站
通过长连接快速导航,然后通过短连接实现精细化搜索。
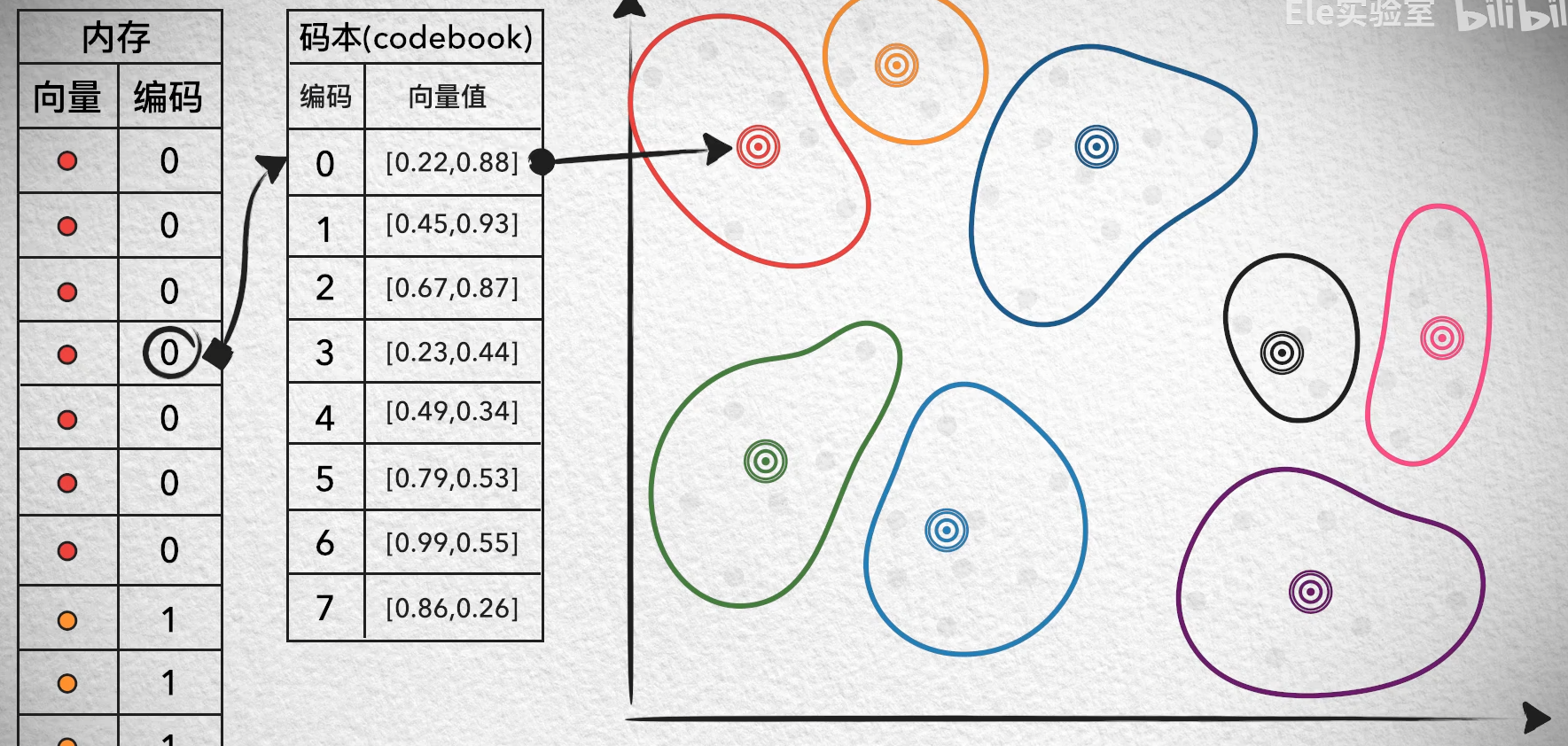
PQ乘积量化算法
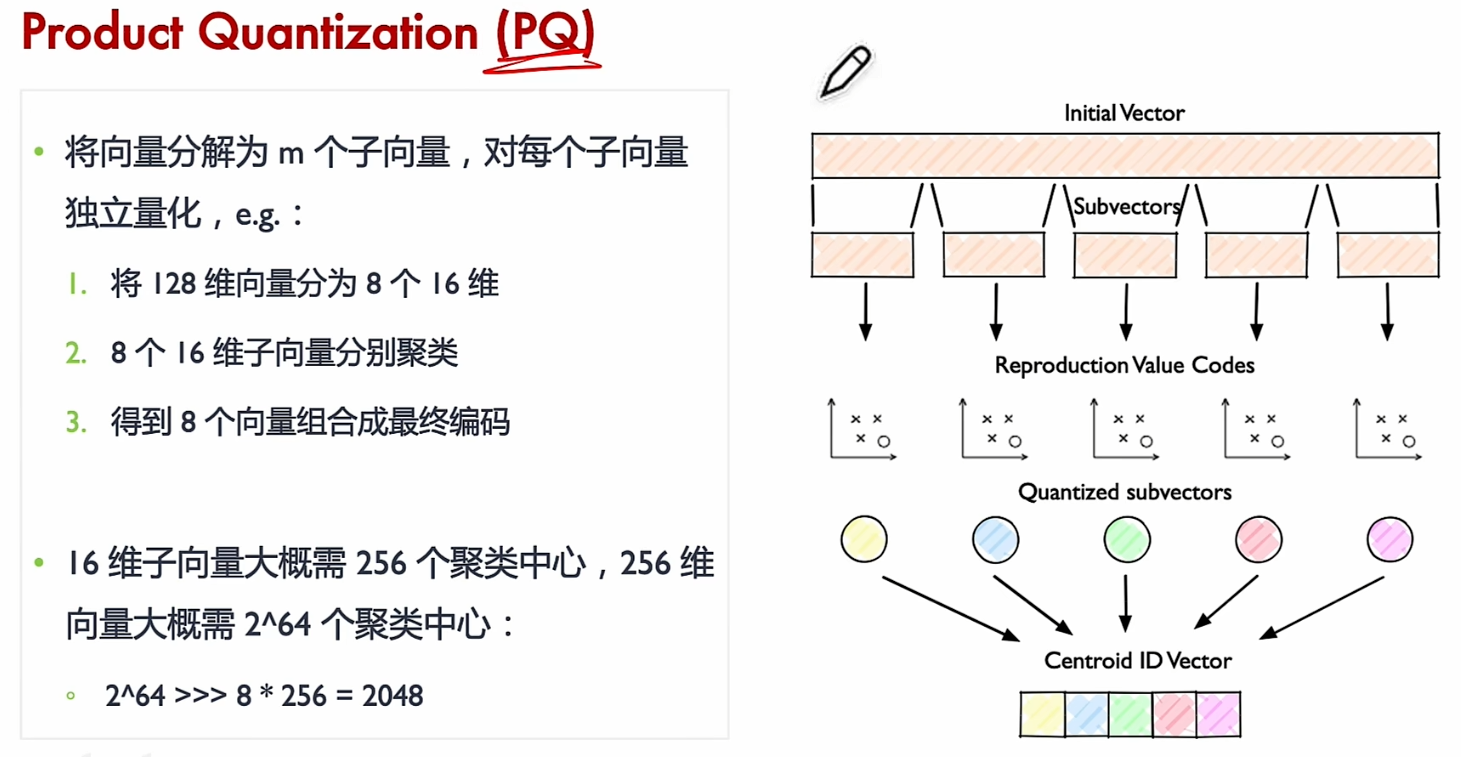
乘积量化(Product Quantization, PQ) 是一种用于高效压缩和检索高维向量数据的算法。
PQ 的核心思想是将高维向量分成若干个子向量(就像将图片分成小块),然后对每个子向量进行独立的量化(压缩)。具体步骤如下:
步骤 1:分割向量
- 假设你有一个 128 维的向量,直接处理它会很复杂。
- 将这个向量分成 m m m 个子向量,比如 m = 8 m=8 m=8,每个子向量就是 16 维。
步骤 2:对每个子向量进行量化
- 对每个 16 维的子向量,使用 K-Means 聚类算法生成一个码本(Codebook)。
- 码本是一个包含 k k k 个“代表向量”的集合,比如 k = 256 k=256 k=256。
- 每个子向量会被映射到码本中与其最接近的代表向量。
- 这样,每个子向量就可以用一个索引(0 到 255)来表示,而不是原始的 16 维数据。
步骤 3:存储量化结果
- 每个子向量被压缩成一个索引(比如一个 8 位的整数)。
- 整个 128 维向量就被压缩成 m m m 个索引,比如 8 个 8 位整数,总共 64 位。
步骤 4:查询时使用量化结果
- 当需要查询与某个向量最相似的向量时:
- 将查询向量也分割成 m m m 个子向量。
- 对每个子向量,计算它与码本中所有代表向量的距离。
- 使用这些距离来快速找到最相似的向量。
为什么 PQ 高效?
- 存储高效: 原始的高维向量被压缩成少量索引,大大减少了存储空间。
- 计算高效: 查询时只需要计算子向量与码本的距离,而不是整个高维向量。
- 搜索快速: 通过预先计算的距离表,可以快速找到最相似的向量。
举例说明
假设我们有一个 128 维的向量,将其分成 8 个子向量,每个子向量 16 维:
- 对每个子向量,使用 K-Means 生成一个包含 256 个代表向量的码本。
- 将每个子向量映射到码本中最接近的代表向量,并用一个 8 位整数表示。
- 最终,整个 128 维向量被压缩成 8 个 8 位整数,总共 64 位。
- 查询时,通过计算子向量与码本的距离,快速找到最相似的向量。
Milvus
Milvus是一个开源向量数据库项目,旨在解决非结构化数据(如图像、视频、音频等)的相似度搜索问题。它通过将这些数据转换为向量,并利用高效的索引算法来实现快速的相似性搜索。
面试可能的问题
- K-Means算法的步骤?

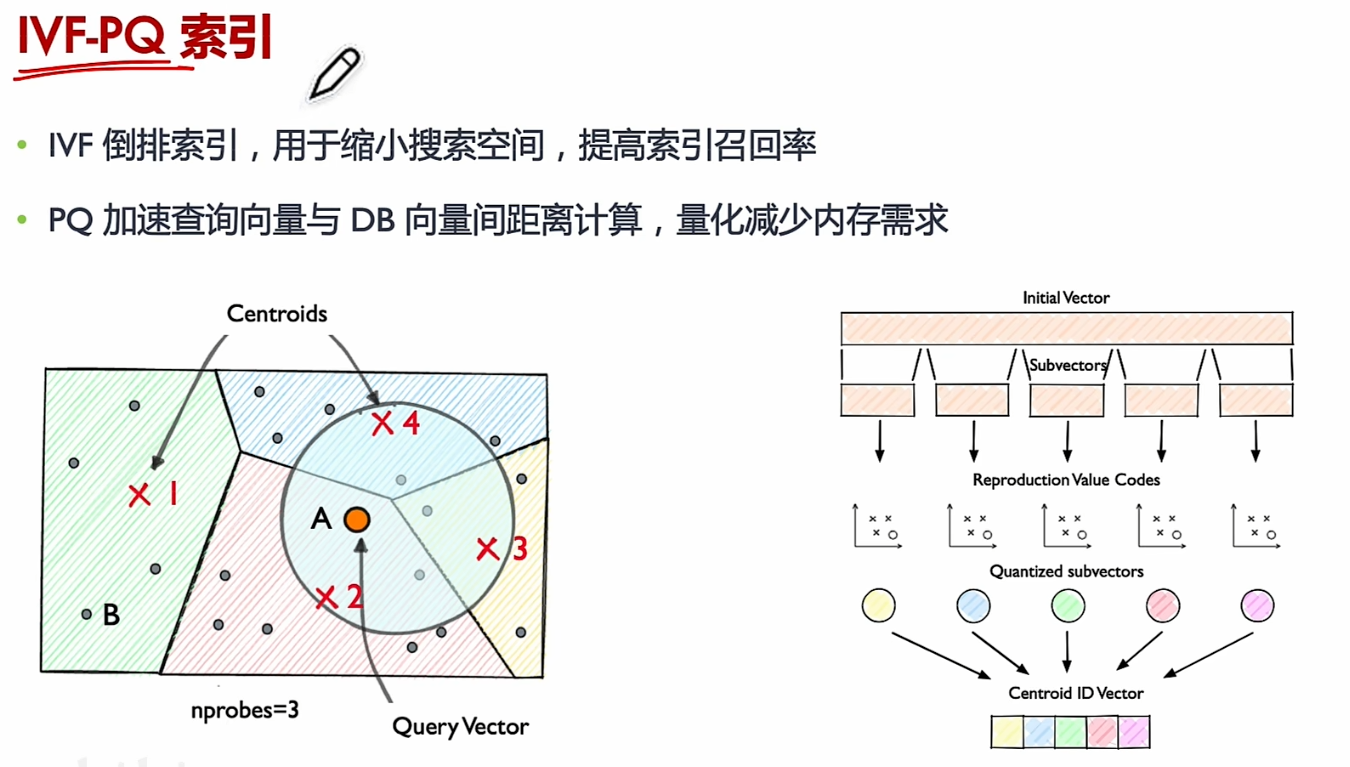
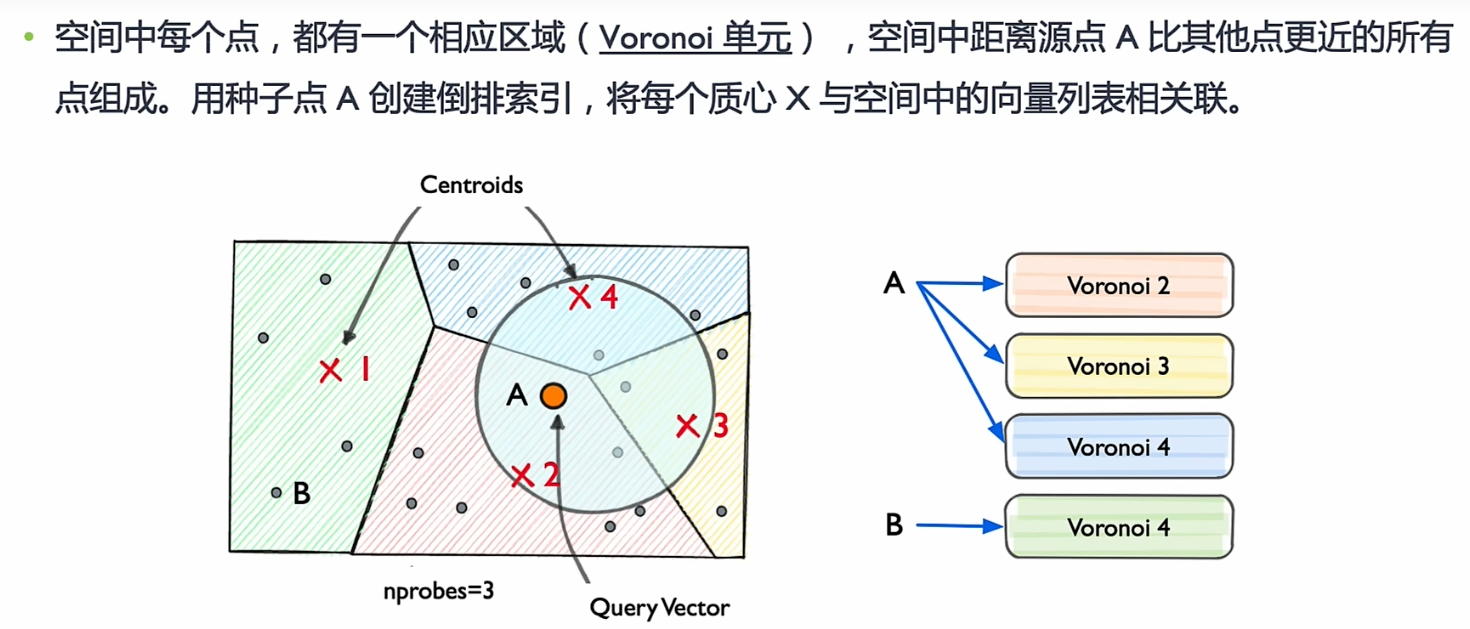
- 倒排索引算法IVF。
为每个向量规定一个置信区域,区域所在的类别即认为该向量属于该类别。
相关文章:

向量数据库
目录标题 阶段二:核心技术深入学习阶段三:工具与实践 1. 基础概念问题:什么是向量数据库?它与传统关系型数据库的区别是什么?问题:向量数据库的核心数据结构是什么?为什么向量适合用于高维数据&…...

《Vue3学习手记2》
今天主要学习Vue3中的数据监视: ps: 代码中的注释写的很详细,这样更有利于理解 watch 作用: 监视数据的变化(和Vue2中watch作用一致) 特点: Vue3中的watch只能监视以下四种数据: ref创建定义的数据(基本类型、对象类型)reactiv…...

zigbee和wifi都是无线通信,最大区别是低功耗,远距离!
zigbee和wifi都属于短距离无线通信技术,都使用了2.4GHz的无线频段,并采用了直接序列扩频传输技术(DSSS)。并广泛应用于人们的生产生活之中。但是,它们之间却存在很大区别。 1、传输速率不同 ①、zigbee传输速率 zigb…...

JavaWeb开发 Servlet底层 Servlet 过滤器 过滤器和拦截器 手写一个限制访问路径的拦截器
目录 万能图 过滤器自我理解 案例 实现Filter 接口 配置文件 web.xml 将过滤器映射到 servlet 用处 拦截器 手写案例 重写 preHandle() 方法 拦截处理 重写 postHandle() 方法 后处理 重写 afterHandle() 方法 完成处理 代码 如何配置拦截器 万能图 还是看一下这张…...
)
Zookeeper三台服务器三节点集群部署(docker-compose方式)
1. 准备工作 - 服务器:3 台服务器,IP 地址分别为 `10.10.10.11`、`10.10.10.12`、`10.10.10.13`。 - 安装 Docker:确保每台服务器已安装 Docker 和 Docker Compose。 - 网络通信:确保三台服务器之间可以通过 IP 地址互相访问,并开放以下端口: - `2181`:Zookeeper 客户…...

从北京到大同,走过600里,跨越1000年。
人们都说,在中国,地下文物看陕西,地上文物看山西,因此在一个月之前就想来山西走一走,看一看,感受一下我泱泱大国的中华千年的历史积淀。 1、出发前的小花絮 于是,就在清明车票开卖的一瞬间&…...
)
鸿蒙NEXT开发全局上下文管理类(ArkTs)
type CacheValue string | number | boolean | object;/*** 全局上下文管理类,用于存储和管理全局数据。* author: 鸿蒙布道师* since: 2025/04/15*/ export class GlobalContext {private static instance: GlobalContext;private _objects new Map<string, C…...

【论文阅读】Orion: Online Backdoor Sample Detection via Evolution Deviance
摘要 现有的后门输入检测策略依赖于一个假设,即正常样本和被投毒样本在模型的特征表示中是可分离的。然而,这一假设可能会被先进的特征隐藏型后门攻击打破。在本文中,我们提出了一种新颖的检测框架,称为Orion(通过进化…...

Redis之缓存雪崩
Redis之缓存雪崩 文章目录 Redis之缓存雪崩一、什么是缓存雪崩1. 定义2.核心原因① 缓存集中过期② 缓存服务故障③ 资源竞争或流量激增 3. 影响 二、缓存雪崩常见解决方案1. 分散缓存过期时间2. 多级缓存架构3. 缓存高可用设计4. 熔断与降级机制5. 缓存预热6. …...

【HarmonyOS 5】AttributeModifier和AttributeUpdater详解
【HarmonyOS 5】AttributeModifier和AttributeUpdater区别详解 一、AttributeModifier和AttributeUpdater的定义和作用 1. AttributeModifier是ArkUI组件的动态属性,提供属性设置功能。开发者可使用attributeModifier方法,通过自定义实现AttributeModi…...

C# + Python混合开发实战:优势互补构建高效应用
文章目录 前言🥏一、典型应用场景1. 桌面应用智能化2. 服务端性能优化3. 自动化运维工具 二、四大技术实现方案方案1:进程调用(推荐指数:★★★★☆)方案2:嵌入Python解释器(推荐指数࿱…...

鸿蒙开发中,@Extend、@Styles 和 @Builder 的区别
在鸿蒙(HarmonyOS)开发中,Extend、Styles 和 Builder 是三种常用的装饰器,用于提升代码复用性和可维护性。以下是它们的详细介绍和示例: 1. Extend:扩展组件样式 说明: 功能:用于…...

poll为什么使用poll_list链表结构而不是数组 - 深入内核源码分析
一:引言 在Linux内核中,poll机制是一个非常重要的I/O多路复用机制。它允许进程监视多个文件描述符,等待其中任何一个进入就绪状态。poll的内部实现使用了poll_list链表结构而不是数组,这个设计选择背后有其深层的技术考量。本文将从内核源码层面深入分析这个设计决…...

从健康干预到成本优化:健康管理系统如何驱动企业降本增效?
在全球经济竞争日益激烈的背景下,企业正面临劳动力成本上升、员工健康问题频发、医疗支出居高不下等多重挑战,在当今商业环境中,企业的降本增效至关重要,而员工的健康状况是影响企业成本和效率的关键因素之一。健康管理系统作为一…...
:高级使用)
12【模块学习】DS18B20(二):高级使用
DS18B20 1、改变采样分辨率2、总线上有多个设备的使用2.1、获取总线上单个设备的ROM码2.2、通过匹配ROM指令使用总线上多个设备 3、项目:4路温度检测LCD显示 1、改变采样分辨率 需要改变采样的分辨率,则需要向暂存器的配置寄存器中写入配置参数。在向寄…...
——什么是人类偏好对齐中的「对齐税」(Alignment Tax)?如何缓解?)
NLP高频面试题(四十三)——什么是人类偏好对齐中的「对齐税」(Alignment Tax)?如何缓解?
一、什么是「对齐税」(Alignment Tax)? 所谓「对齐税」(Alignment Tax),指的是在使人工智能系统符合人类偏好的过程中,所不可避免付出的性能损失或代价。换句话说,当我们迫使AI遵循人类价值观和规范时,AI系统往往无法达到其最大理论性能。这种性能上的妥协和折衷,就…...

线代第二章矩阵第一课:矩阵的概念
一、矩阵的概念 矩阵 i还是表示的是行,j表示的是列;行数未必等于列数 同型矩阵: A,B行数相等,列数相等 矩阵相等: 同型矩阵,且对应元素相等 零矩阵: 所有元素均为0 二、特殊矩阵 方阵 行数…...

如何获取Google Chrome的官方最新下载链接【获取教程】
一、为什么选择官方下载链接 安装谷歌浏览器的最安全方式始终是通过其官方网站。非官方渠道可能存在版本落后、功能缺失,甚至潜藏恶意插件等风险。因此,获取Google Chrome的官方最新下载链接,是保障浏览器安全与性能的重要前提。 此外&…...

软件测试——BUG概念
一、软件测试生命周期 软件测试贯穿于软件的整个生命周期 软件测试的生命周期指测试流程,每个阶段有不同的目标和交付产物 需求分析 从用户角度考虑软件需求是否合理 从技术角度考虑技术上是否可行,是否有优化空间 从测试角度考虑是否存在业务逻辑错误…...
)
Docker安装 (centos)
1.安装依赖包: sudo yum install -y yum-utils device-mapper-persistent-data lvm2 2.删除已有的 Docker 仓库文件(如果有): sudo rm -f /etc/yum.repos.d/docker-ce.repo 3.添加阿里云的 Docker 仓库: sudo yum…...

MySQL数据库 - 存储引擎
存储引擎 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 存储引擎1. MySQL 体系结构2. 存储引擎简介2.1 语法代码演示 3. 存储引擎特点InnoDB介绍特点文件逻辑存储结构 MyISAM介绍特点文件 Memory介绍特点文件 总结 4. 存储引擎…...

【网络篇】UDP协议的封装分用全过程
大家好呀 我是浪前 今天讲解的是网络篇的第二章:UDP协议的封装分用 我们的协议最开始是OSI七层网络协议 这个OSI 七层网络协议 是计算机的大佬写的,但是这个协议一共有七层,太多了太麻烦了,于是我们就把这个七层网络协议就简化为…...

数据结构——布隆过滤器
目录 一、什么是布隆过滤器? 二、布隆过滤器的原理 三、布隆过滤器的特点 一、什么是布隆过滤器? 布隆过滤器是一种空间效率高、适合快速检索的数据结构,用于判断一个元素是否可能存在于一个集合中。它通过使用多个哈希函数和一个位数组来…...

pytorch实现逻辑回归
pytorch实现逻辑回归 数据准备,参数初始化前向计算计算损失计算梯度更新参数 在官网上找到线性函数的公式表达式 import torch from sklearn.datasets import load_iris # from sklearn.model_selection import train_test_split #train_test_split是sklearn中的…...

03-Spring Cloud Gateway 深度解析:从核心原理到生产级网关实践
Spring Cloud Gateway 深度解析:从核心原理到生产级网关实践 一、网关技术演进与 Spring Cloud Gateway 定位 1. 微服务网关的核心价值 作为微服务架构的流量入口,网关承担着 路由转发、流量治理、安全防护 三大核心职能: 统一接入&#…...

Spark-sql编程
创建子模块并添加依赖 在IDEA中创建一个名为Spark-SQL的子模块。 在该子模块的pom.xml文件中添加Spark-SQL的依赖,具体依赖为org.apache.spark:spark-sql_2.12:3.0.0。 编写Spark-SQL测试代码 定义一个User case class,用于表示用户信息…...

K8s 生产落地
深夜收到报警短信,集群突然宕机——这可能是每个运维人最不愿面对的噩梦。生产级Kubernetes集群的部署,远不是几条命令就能搞定的事情。本文将结合真实踩坑经验,从零拆解一个高可用、高安全、可自愈的Kubernetes生产环境该如何落地。 一、架…...

SnailJob:分布式环境设计的任务调度与重试平台!
背景 近日挖掘到一款名为“SnailJob”的分布式重试开源项目,它旨在解决微服务架构中常见的重试问题。在微服务大行其道的今天,我们经常需要对某个数据请求进行多次尝试。然而,当遇到网络不稳定、外部服务更新或下游服务负载过高等情况时,请求…...

通过WebRTC源码入门OpenGL ES
文章目录 基本概念Vertex和Fragment着色器程序 准备工作getUniformLocation/getAttribLocationglVertexAttribPointer 开始绘制Demo实现 OpenGL SE是一套适用于嵌入式设备的图形API,本文主要介绍如何通过OpenGL SE在Android设备上进行图形绘制,同时我会通…...

面试题:请描述一下你在项目中是如何进行性能优化的?针对哪些方面进行了优化,采取了哪些具体的措施?
目录 1.算法和数据结构优化 2.内存管理优化 3.并发编程优化 4.数据库优化 5.网络优化 6.持续优化与监控 7.总结 现在是企业招聘和求职者的金三银四,每每问到这个主观性问题的时候,都不知道怎么回答,下面就我知道的一些总结一下&#x…...

从零实现富文本编辑器#2-基于MVC模式的编辑器架构设计
在先前的规划中我们是需要实现MVC架构的编辑器,将应用程序分为控制器、模型、视图三个核心组件,通过控制器执行命令时会修改当前的数据模型,进而表现到视图的渲染上。简单来说就是构建一个描述文档结构与内容的数据模型,并且使用自…...

SAP S4HANA embedded analytics
SAP S4HANA embedded analytics...
程编程——(7)消息队列)
linux多线(进)程编程——(7)消息队列
前言 现在修真界大家的沟通手段已经越来越丰富了,有了匿名管道,命名管道,共享内存等多种方式。但是随着深入使用人们逐渐发现了这些传音术的局限性。 匿名管道:只能在有血缘关系的修真者(进程)间使用&…...

STM32 HAL库 实现485通信
一、引言 在工业自动化、智能家居等众多领域中,RS - 485 通信因其长距离、高抗干扰能力等优点被广泛应用。STM32F407 是一款性能强大的微控制器,其丰富的外设资源为实现 RS - 485 通信提供了良好的硬件基础。本文将详细介绍基于 STM32F407 HAL 库实现 R…...
)
用 Vue 3 + OpenAI API 实现一个智能对话助手(支持上下文、多角色)
文章目录 一、项目背景与功能介绍二、技术选型与准备工作环境准备 三、智能对话助手的实现第一节:封装 OpenAI 接口请求第二节:构建消息上下文结构第三节:构建对话 UI 组件第四节:滚动自动到底部(可选优化)…...

ollama修改配置使用多GPU,使用EvalScope进行模型压力测试,查看使用负载均衡前后的性能区别
文章目录 省流结论机器配置不同量化模型占用显存1. 创建虚拟环境2. 创建测试jsonl文件3. 新建测试脚本3. 默认加载方式,单卡运行模型3.1 7b模型输出213 tok/s3.1 32b模型输出81 tok/s3.1 70b模型输出43tok/s 4. 使用负载均衡,多卡运行4.1 7b模型输出217t…...

vue3 setup vite 配置跨域了proxy,部署正式环境的替换
在开发环境中使用 Vite 的 proxy 配置来解决跨域问题是一种常见的做法。然而,在部署到正式环境时,通常需要对接口地址进行调整,具体是否需要更改接口名称取决于你的部署环境和后端服务的配置。以下是几种常见的情况和建议: 1. 正…...
环境配置)
目标检测:YOLOv11(Ultralytics)环境配置
1、前言 YOLO11是Ultralytics公司YOLO系列实时目标检测器的最新迭代版本,它以尖端的准确性、速度和效率重新定义了可能实现的性能。在之前YOLO版本取得的显著进步基础上,YOLO11在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务中…...

如何高效压缩GIF动图?
GIF动图因其兼容性强、易于传播的特点,成为网络交流的热门选择。然而,过大的文件体积常常导致加载缓慢、分享困难等问题。本文将为您详细介绍几种实用的GIF压缩技巧,帮助您在保持画面质量的同时显著减小文件大小。 压缩方法 1. 在线压缩工具…...

视频融合平台EasyCVR可视化AI+视频管理系统,打造轧钢厂智慧安全管理体系
一、背景分析 在轧钢厂,打包机负责线材打包,操作人员需频繁进入内部添加护垫、整理包装、检修调试等。例如,每班产线超过300件,12小时内人员进出打包机区域超过300次。若员工安全意识薄弱、违规操作,未落实安全措施就…...
)
通过命令行操作把 本地IDE 项目上传到 GitHub(小白快速版)
通过命令行操作把 本地IDE 项目上传到 GitHub(小白版) 你是不是在用 本地IDE 做项目,但不知道怎么把自己的代码上传到 GitHub?今天我们用最简单的命令行方式(不用 SSH、不用复杂配置)教你一步一步把本地项…...

【c语言基础学习】qsort快速排序函数介绍与使用
在C语言中,qsort 函数用于对数组进行快速排序。以下是详细的使用方法及示例: 一、函数原型 #include <stdlib.h>void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *) );二、参数说明 参数说明base指向…...
)
今日github AI科技工具汇总(20250415更新)
以下是2025年4月15日GitHub上值得关注的AI科技工具汇总及趋势分析,结合最新开源动态与开发者社区热点整理: 一、AI编程工具重大更新 GitHub Copilot Agent Mode 全量发布 核心功能:在VS Code中启用后,可自主完成多文件代码重构、测试驱动开发(TDD)及自修复编译错误,支持…...
:广告创意审核的法律红线与平台规则)
程序化广告行业(88/89):广告创意审核的法律红线与平台规则
程序化广告行业(88/89):广告创意审核的法律红线与平台规则 在程序化广告的广阔领域中,不断学习和掌握行业规范是我们稳步前行的基石。一直以来,我都期望与大家携手共进,深入探索这个行业的奥秘。今天&…...
)
前端VUE框架理论与应用(4)
一、计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护。例如: <div id="example">{{ message.split().reverse().join() }}</div> 在这个地方,模板不再是简单的声明式逻辑。你…...

【经验分享】基于Calcite+MyBatis实现多数据库SQL自动适配:从原理到生产实践
基于CalciteMyBatis实现多数据库SQL自动适配:从原理到生产实践 一、引言:多数据库适配的行业痛点 在当今企业IT环境中,数据库异构性已成为常态。根据DB-Engines最新调研,超过78%的企业同时使用两种以上数据库系统。这种多样性带…...

通信算法之265: 无人机系统中的C2链路
在无人机系统设计中,我们经常听到C2链路这个名词,到底什么是C2链路呢?为什么说C2链路是无人机系统中非常重要的环节。 转载: 无人机技术是各种科技技术水平综合发展的结果,包括空气动力,机械设计…...

浙江大学:DeepSeek如何引领智慧医疗的革新之路?|48页PPT下载方法
导 读INTRODUCTION 随着人工智能技术的飞速发展,DeepSeek等大模型正在引领医疗行业进入一个全新的智慧医疗时代。这些先进的技术不仅正在改变医疗服务的提供方式,还在提高医疗质量和效率方面展现出巨大潜力。 想象一下,当你走进医院ÿ…...
)
Codeforces Round 1017 (Div. 4)
Codeforces Round 1017 (Div. 4) A. Trippi Troppi AC code: void solve() { string a, b, c; cin >> a >> b >> c;cout << a[0] << b[0] << c[0] << endl; } B. Bobritto Bandito 思路: 倒推模拟即可,…...

bash的特性-bash中的引号
在Linux或Unix系统中,Bash(Bourne Again SHell)作为最常用的命令行解释器之一,提供了强大的功能来处理各种任务。正确使用引号是掌握Bash脚本编写的基础技能之一,它决定了如何解析字符串、变量替换以及特殊字符的行为。…...