ollama修改配置使用多GPU,使用EvalScope进行模型压力测试,查看使用负载均衡前后的性能区别
文章目录
- 省流结论
- 机器配置
- 不同量化模型占用显存
- 1. 创建虚拟环境
- 2. 创建测试jsonl文件
- 3. 新建测试脚本
- 3. 默认加载方式,单卡运行模型
- 3.1 7b模型输出213 tok/s
- 3.1 32b模型输出81 tok/s
- 3.1 70b模型输出43tok/s
- 4. 使用负载均衡,多卡运行
- 4.1 7b模型输出217tok/s
- 4.2 32b模型输出83 tok/s
- 4.3 70b模型输出45 tok/s
- 5. 结论
由于ollama默认调用模型,模型实例会运行在一张卡上,如果有几张显卡,模型只会永远跑在第一张卡上,除非显存超出,然后才会将模型跑在第二张卡,这造成了资源很大的浪费。网上通过修改ollama.service的配置,如下:
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
修改之后可以负载均衡,显存平均分配在集群中的每张卡上,但是我不太了解这种方式是否会提升模型吞吐量?和默认的调用单卡实例有啥区别呢?
因此我决定使用EvalScope进行模型性能测试,从而查看这两种方式区别有多大。
EvalScope简介:
EvalScope是魔搭社区官方推出的模型评测与性能基准测试框架,内置多个常用测试基准和评测指标,如MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH和HumanEval等;支持多种类型的模型评测,包括LLM、多模态LLM、embedding模型和reranker模型。EvalScope还适用于多种评测场景,如端到端RAG评测、竞技场模式和模型推理性能压测等。此外,通过ms-swift训练框架的无缝集成,可一键发起评测,实现了模型训练到评测的全链路支持。
省流结论
我修改ollama的配置环境,使用负载均衡,发现输出tok并没有增加很多,性能几乎没有提升。我看网上使用负载均衡会提升吞吐量,经过我的测试,发现配置修改前后性能差不多。
但是负载均衡毕竟可以使用多GPU,感觉也挺不错。
机器配置
使用显卡如下,4张L20。
懒得查资料,问了gpt 4o,抛开显存不谈,L20的算力性能约等于哪个消费级显卡?
它说:L20 性能 ≈ RTX 4080。介于4080和4090之间。
| 参数 | NVIDIA L20 | RTX 4080 | RTX 4090 |
|---|---|---|---|
| 架构 | Ada Lovelace | Ada Lovelace | Ada Lovelace |
| CUDA 核心数 | 11,776 | 9,728 | 16,384 |
| Tensor 核心数 | 368 | 304 | 512 |
| 基础频率 | 1,440 MHz | 2,205 MHz | 2,235 MHz |
| Boost 频率 | 2,520 MHz | 2,505 MHz | 2,520 MHz |
| FP16 Tensor Core | 119.5 TFLOPS | 97.4 TFLOPS | 165.2 TFLOPS |
| FP32 算力 | 59.8 TFLOPS | 49.1 TFLOPS | 82.6 TFLOPS |
| TDP 功耗 | 275W | 320W | 450W |
不同量化模型占用显存
deepseek-r1量化的几个模型显存占用:
deepseek-r1:7b大概需要5.5G的显存
deepseek-r1:32b大概需要21.2G的显存
deepseek-r1:70b大概需要43G的显存
我们使用evalscope的perf进行模型性能压力测试
evalscope的perf主要用于模型性能压测(吞吐量、速度)
🔍 作用:
用于测试你部署的模型在高并发或大输入下的响应能力和性能,比如:每秒处理多少条请求?并发处理能力怎么样?最慢 / 最快 / 平均响应时间是多少?
📊 输出内容:
吞吐率(tokens/s)平均响应延迟(ms)流式输出响应时间等
1. 创建虚拟环境
首先使用conda新建虚拟环境,之后安装依赖:
pip install evalscope # 安装 Native backend (默认)
# 额外选项
pip install 'evalscope[opencompass]' # 安装 OpenCompass backend
pip install 'evalscope[vlmeval]' # 安装 VLMEvalKit backend
pip install 'evalscope[rag]' # 安装 RAGEval backend
pip install 'evalscope[perf]' # 安装 模型压测模块 依赖
pip install 'evalscope[app]' # 安装 可视化 相关依赖
pip install 'evalscope[all]' # 安装所有 backends (Native, OpenCompass, VLMEvalKit, RAGEval)
如果个别的包由于无法连接github下载导致安装错误,可以手动下载依赖,手动安装。
2. 创建测试jsonl文件
我们需要写一个简单测试的jsonl文件。
新建open_qa.jsonl文件,我的测试jsonl文件内容如下:
{"question": "什么是深度学习?"}
{"question": "请介绍一下量子纠缠。"}
{"question": "图像恢复是什么?"}
{"question": "解释一下牛顿第三定律。"}
{"question": "《红楼梦》讲述了什么内容?"}
{"question": "地球为什么有四季变化?"}
{"question": "黑洞是如何形成的?"}
{"question": "什么是注意力机制(Attention Mechanism)?"}
{"question": "二战的主要原因有哪些?"}
{"question": "如何提高自然语言处理模型的泛化能力?"}
{"question": "什么是摩尔定律?它现在还有效吗?"}
{"question": "请简述贝叶斯定理及其应用。"}
{"question": "中国的四大发明是什么?"}
{"question": "什么是元宇宙(Metaverse)?"}
{"question": "请解释区块链的基本原理。"}
{"question": "DNA 是什么?它的结构特点是什么?"}
{"question": "介绍一下古希腊哲学的主要流派。"}
{"question": "什么是强化学习?它与监督学习有何区别?"}
{"question": "太阳内部发生了什么物理过程?"}
{"question": "人工智能会取代人类的工作吗?"}
{"question": "解释电磁感应现象及其应用。"}
{"question": "什么是熵?它在信息论中代表什么?"}
{"question": "5G 网络有哪些核心技术?"}
{"question": "请说明气候变化的主要原因。"}
{"question": "什么是图神经网络(GNN)?"}
3. 新建测试脚本
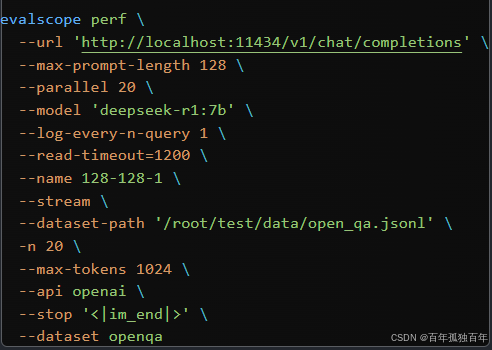
新建test_perf_deepseek.sh文件,内容如下,测试的是7b模型:
如果测试其他模型,修改–model的参数
修改–dataset-path的路径,改为你存放
open_qa.jsonl的路径
evalscope perf \--url 'http://localhost:11434/v1/chat/completions' \--max-prompt-length 128 \--parallel 20 \--model 'deepseek-r1:7b' \--log-every-n-query 1 \--read-timeout=1200 \--name 128-128-1 \--stream \--dataset-path '/root/test/data/open_qa.jsonl' \-n 20 \--max-tokens 1024 \--api openai \--stop '<|im_end|>' \--dataset openqa
参数说明:
--url: 请求的URL地址,例如:http://localhost:11434/v1/chat/completions,这是本地部署的模型API接口。--max-prompt-length: 单个请求中prompt的最大长度限制,这里是128个token。--parallel: 并行请求的任务数量,这里是20,意味着同时发起20个请求进行性能测试。--model: 使用的模型名称,这里是deepseek-r1:7b。--log-every-n-query: 每隔多少个请求打印一次日志,这里是每1个请求都打印一次。--read-timeout: 单个请求的最长等待时间(秒),超过这个时间会认为请求超时。这里设置为1200秒(20分钟),适合长时间响应的情况。--name: 当前测试的名称/标识,用于记录结果或日志标记。这里为128-128-1,可能是自定义的配置标识(如max_prompt/max_tokens/batch_size之类)。--stream: 是否启用流式处理。开启后,将使用流式响应模式接收生成结果(比如OpenAI的stream=True),适合处理大输出或加速响应体验。--dataset-path: 指定本地数据集的路径,这里是/root/test/data/open_qa.jsonl,通常为JSON Lines格式的数据集。-n: 请求总数,这里是20,表示总共发送20个请求进行测试。--max-tokens: 模型在生成时最多生成的token数量,这里为1024。--api: 使用的API协议或服务类型,这里是openai风格的API(即参数格式符合OpenAI Chat API标准)。--stop: 指定生成的停止标记,这里是<|im_end|>,用于控制生成结果在遇到该标记时停止。--dataset: 使用的数据集名称或类型标识,这里是openqa,常用于区分测试任务或用于内部适配。
3. 默认加载方式,单卡运行模型
测试命令如下,测试的模型:
测试不同的模型,修改这个–model参数
测试7b:deepseek-r1:7b
测试32b:deepseek-r1:32b
测试70b:deepseek-r1:70b
3.1 7b模型输出213 tok/s
显存占用如下,由于我先启动了32b和70b模型,最后启动了7b模型,可以看到前两张卡运行了两个模型。
第三张卡运行的是7b模型。
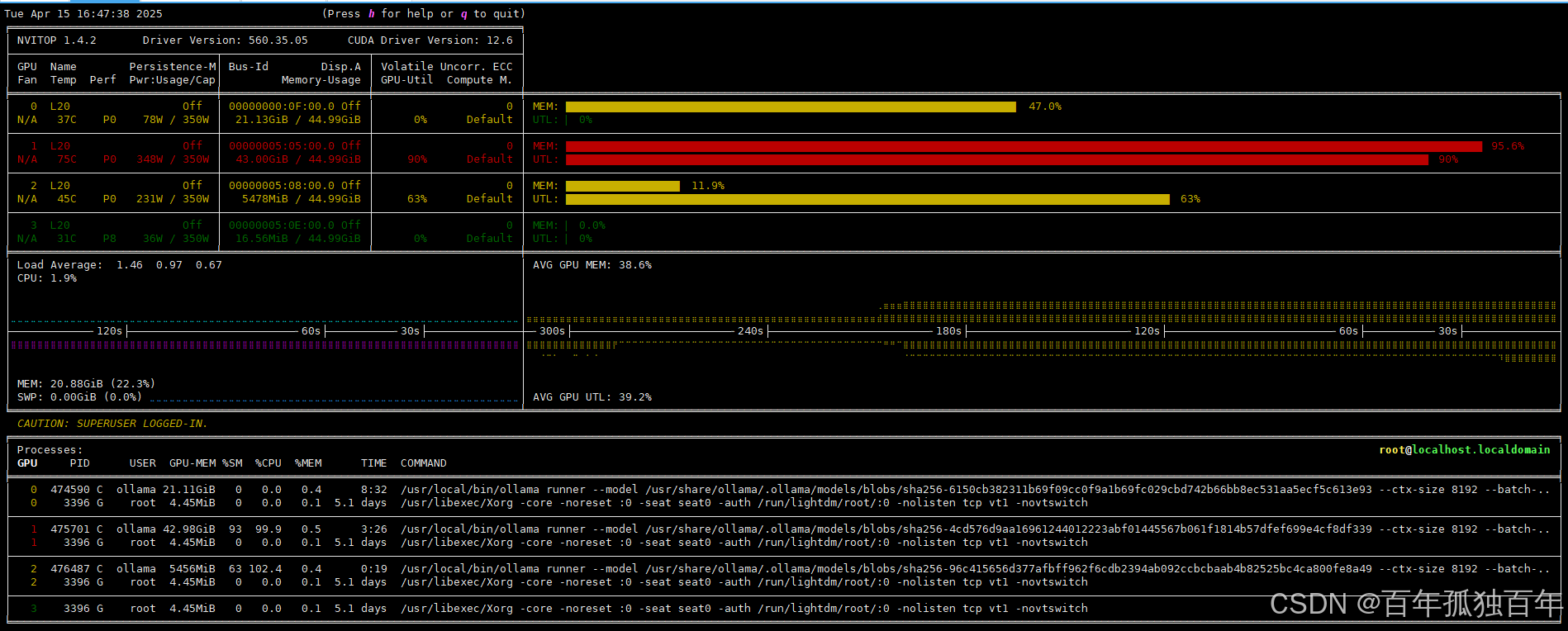
不使用负载均衡,使用ollama默认的调用方式,使用单张卡进行推理,deepseek-r1:7b测试结果如下,可以看到每秒输出的token大概有213。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 69.5776 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 213.79 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 216.7363 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.2874 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 39.6962 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 26.5699 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.0776 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 743.75 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0178 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 739.25 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_091602/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 09:17:12,411 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1328 | 0.0173 | 13.8207 | 7 | 490 | 9.5719 |
| 25% | 12.052 | 0.0177 | 25.8903 | 8 | 664 | 14.3005 |
| 50% | 27.0828 | 0.0179 | 42.0287 | 10 | 772 | 18.1264 |
| 66% | 39.8597 | 0.018 | 53.5647 | 11 | 897 | 29.8181 |
| 75% | 44.5788 | 0.018 | 62.9357 | 12 | 1024 | 33.9352 |
| 80% | 45.7624 | 0.0181 | 64.1272 | 14 | 1024 | 56.3658 |
| 90% | 54.2245 | 0.0182 | 65.4349 | 14 | 1024 | 56.5702 |
| 95% | 62.9888 | 0.0183 | 69.5807 | 14 | 1024 | 56.6541 |
| 98% | 62.9888 | 0.0184 | 69.5807 | 14 | 1024 | 56.6541 |
| 99% | 62.9888 | 0.0188 | 69.5807 | 14 | 1024 | 56.6541 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+3.1 32b模型输出81 tok/s
显存占用,可以看到就单卡运行
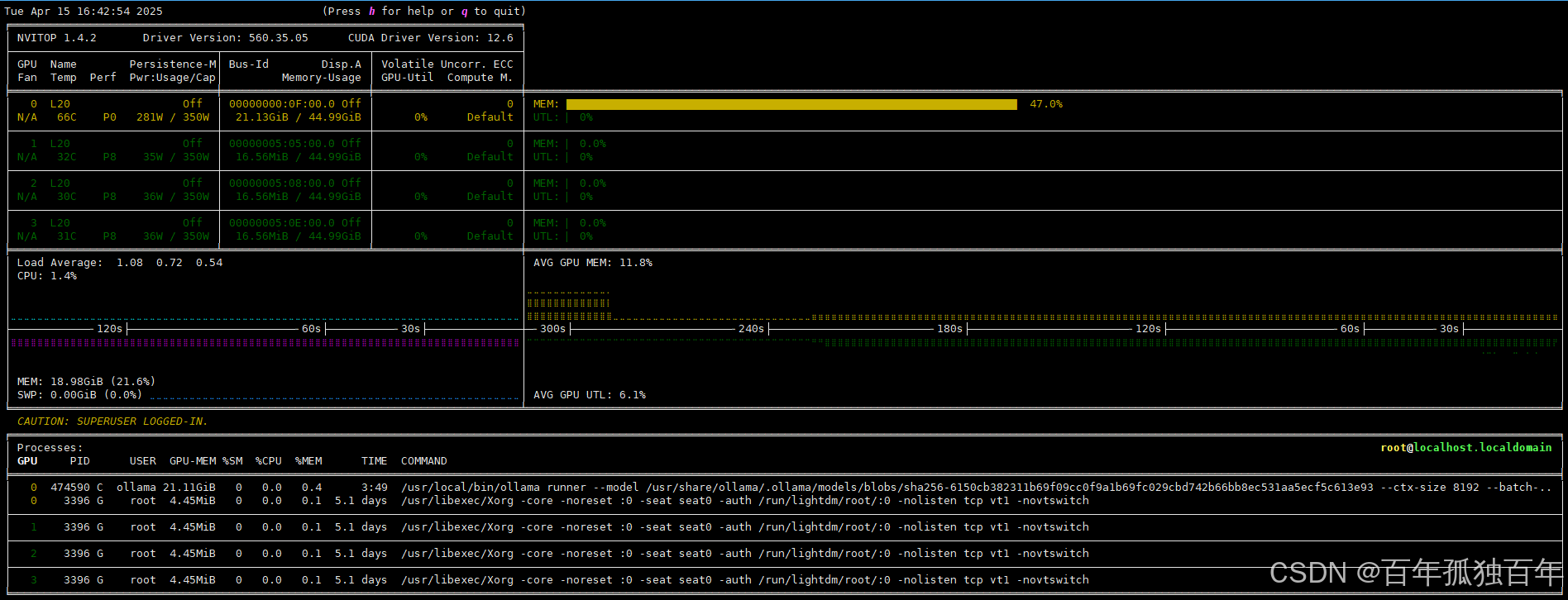
测试的deepseek-r1:32b模型,每秒输出token有81。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 215.884 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 81.5021 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 82.4517 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0926 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 122.059 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 81.843 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1421 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 879.75 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0461 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 872.05 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_092445/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 09:28:26,988 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1992 | 0.0432 | 41.9602 | 7 | 664 | 4.52 |
| 25% | 40.2375 | 0.0454 | 81.6553 | 8 | 797 | 4.7959 |
| 50% | 87.3562 | 0.0465 | 135.0661 | 10 | 892 | 7.5815 |
| 66% | 113.3376 | 0.0466 | 153.0112 | 11 | 1020 | 10.1626 |
| 75% | 137.7377 | 0.0467 | 182.9889 | 12 | 1024 | 11.4105 |
| 80% | 143.7239 | 0.0467 | 184.4415 | 14 | 1024 | 22.1322 |
| 90% | 168.787 | 0.0468 | 212.6837 | 14 | 1024 | 22.247 |
| 95% | 183.1294 | 0.0469 | 215.8822 | 14 | 1024 | 22.2935 |
| 98% | 183.1294 | 0.0471 | 215.8822 | 14 | 1024 | 22.2935 |
| 99% | 183.1294 | 0.0488 | 215.8822 | 14 | 1024 | 22.2935 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+3.1 70b模型输出43tok/s
显存占用如下,可以看到当运行32b模型时,由于再唤醒70b模型需要占用42.9G的显存,单卡48G的显存显然不够用的,因此会调用下一张卡。
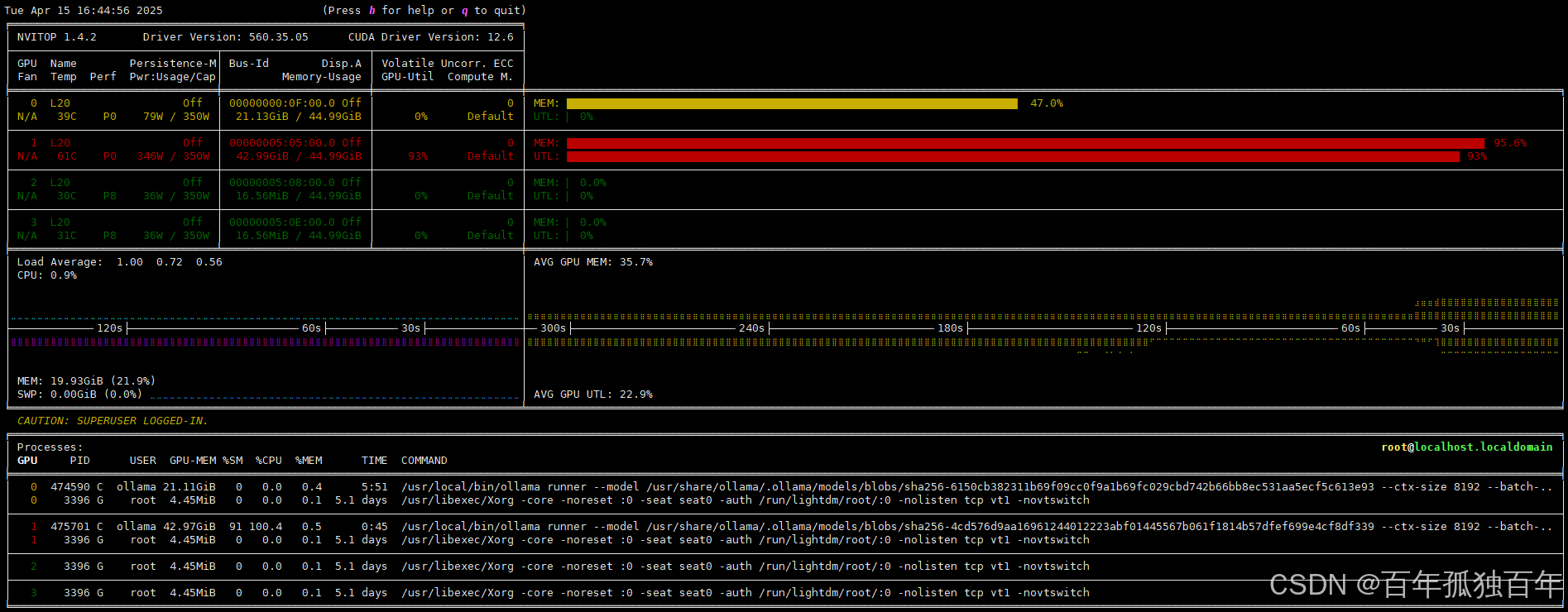
测试的deepseek-r1:70b模型,每秒输出token只有43。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 376.5257 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 43.2029 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 43.8934 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0531 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 206.8567 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 139.3129 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.4626 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 13.0 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 813.35 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0854 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 791.3 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_111007/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 11:16:35,963 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.358 | 0.0788 | 83.4586 | 10 | 476 | 2.2468 |
| 25% | 83.7387 | 0.0813 | 124.8847 | 12 | 695 | 2.7196 |
| 50% | 126.7937 | 0.0847 | 212.0645 | 14 | 1024 | 3.8596 |
| 66% | 211.6319 | 0.085 | 269.4886 | 14 | 1024 | 4.8287 |
| 75% | 214.0528 | 0.0853 | 298.9557 | 14 | 1024 | 5.9358 |
| 80% | 216.7131 | 0.0854 | 301.3438 | 15 | 1024 | 12.2285 |
| 90% | 276.0923 | 0.0858 | 347.9994 | 16 | 1024 | 12.2702 |
| 95% | 299.2182 | 0.0862 | 376.5222 | 18 | 1024 | 12.2703 |
| 98% | 299.2182 | 0.1646 | 376.5222 | 18 | 1024 | 12.2703 |
| 99% | 299.2182 | 0.17 | 376.5222 | 18 | 1024 | 12.2703 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+4. 使用负载均衡,多卡运行
4.1 7b模型输出217tok/s
测试的deepseek-r1:7b模型,每秒输出token变成217。
奇怪,使用负载均衡之后,吐出的tok数量并没有增加很多啊,甚至和单张卡输出tok几乎差不多,我看网上说会增加的。
这是为什么?我也不知道。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 68.8518 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 217.409 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 220.3864 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.2905 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 40.9902 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 27.764 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1033 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 748.45 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0178 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 742.25 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_145249/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 14:54:01,950 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1713 | 0.0172 | 13.0051 | 7 | 579 | 10.83 |
| 25% | 12.5773 | 0.0177 | 27.2219 | 8 | 709 | 15.7196 |
| 50% | 29.3214 | 0.0179 | 45.6927 | 10 | 755 | 19.3558 |
| 66% | 42.2444 | 0.018 | 52.9042 | 11 | 897 | 31.1884 |
| 75% | 46.6769 | 0.018 | 64.2114 | 12 | 1012 | 33.106 |
| 80% | 52.7525 | 0.0181 | 65.1415 | 14 | 1024 | 57.1314 |
| 90% | 54.2956 | 0.0182 | 66.5091 | 14 | 1024 | 57.1984 |
| 95% | 64.2614 | 0.0183 | 68.8467 | 14 | 1024 | 57.4499 |
| 98% | 64.2614 | 0.0185 | 68.8467 | 14 | 1024 | 57.4499 |
| 99% | 64.2614 | 0.0195 | 68.8467 | 14 | 1024 | 57.4499 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+4.2 32b模型输出83 tok/s
测试的deepseek-r1:32b模型,每秒输出token有83左右,单卡输出为83,可以说几乎没区别。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 210.3824 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 83.3245 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 84.2989 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0951 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 116.6855 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 76.7932 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1313 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 876.5 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0458 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 870.55 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_162240/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 16:26:11,509 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1945 | 0.0429 | 45.1571 | 7 | 645 | 4.9526 |
| 25% | 36.8916 | 0.0451 | 73.0001 | 8 | 807 | 5.6556 |
| 50% | 81.7751 | 0.0463 | 119.9128 | 10 | 958 | 8.1476 |
| 66% | 117.7298 | 0.0464 | 159.4871 | 11 | 1007 | 10.6849 |
| 75% | 129.4489 | 0.0464 | 174.0512 | 12 | 1024 | 12.8373 |
| 80% | 134.1872 | 0.0464 | 176.8538 | 14 | 1024 | 22.1902 |
| 90% | 166.9573 | 0.0465 | 208.7023 | 14 | 1024 | 22.3439 |
| 95% | 174.1963 | 0.0466 | 210.3796 | 14 | 1024 | 22.5919 |
| 98% | 174.1963 | 0.0467 | 210.3796 | 14 | 1024 | 22.5919 |
| 99% | 174.1963 | 0.0469 | 210.3796 | 14 | 1024 | 22.5919 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+4.3 70b模型输出45 tok/s
测试的deepseek-r1:70b模型,每秒输出token变成45左右。和单卡的43差不多,似乎性能也没有增加。
为什么?不清楚。
占用显存如下所示,可以看到不像之前占用一张卡,如果显存超过了,启动下一张卡。使用负载均衡可以将显存平均分配到每一张卡上,需要每张卡都出一点力。
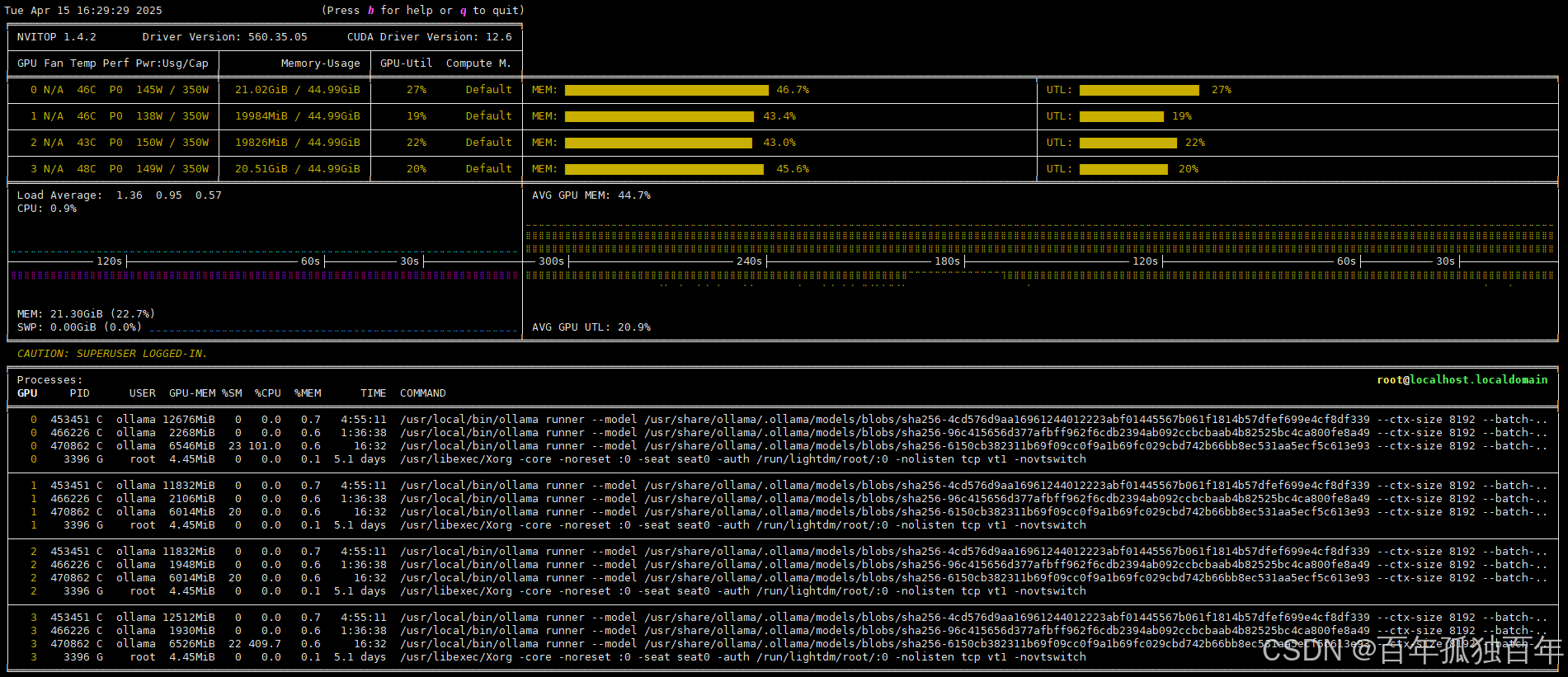
性能测试如下:
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 350.0327 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 45.4586 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 46.2014 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0571 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 185.3367 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 120.6031 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.2389 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 13.0 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 795.6 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0837 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 772.95 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_115239/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 11:58:30,043 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.3932 | 0.08 | 55.6919 | 10 | 482 | 2.5115 |
| 25% | 51.2654 | 0.0819 | 95.2744 | 12 | 617 | 3.0284 |
| 50% | 135.0597 | 0.0819 | 172.4987 | 14 | 1024 | 4.5089 |
| 66% | 170.2825 | 0.082 | 254.2084 | 14 | 1024 | 6.0887 |
| 75% | 214.4321 | 0.082 | 270.23 | 14 | 1024 | 11.3 |
| 80% | 252.6452 | 0.082 | 297.0692 | 15 | 1024 | 11.5983 |
| 90% | 256.9616 | 0.0822 | 338.1322 | 16 | 1024 | 12.1382 |
| 95% | 270.4241 | 0.0824 | 350.0368 | 18 | 1024 | 12.1909 |
| 98% | 270.4241 | 0.1634 | 350.0368 | 18 | 1024 | 12.1909 |
| 99% | 270.4241 | 0.1639 | 350.0368 | 18 | 1024 | 12.1909 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
5. 结论
使用负载均衡之后,7b模型吞吐量从213变为217,32b模型从81到83,70b模型从43到45。
可以说几乎没有提升,因为每次运行,结果会有上下浮动,所以说差不多。
相关文章:

ollama修改配置使用多GPU,使用EvalScope进行模型压力测试,查看使用负载均衡前后的性能区别
文章目录 省流结论机器配置不同量化模型占用显存1. 创建虚拟环境2. 创建测试jsonl文件3. 新建测试脚本3. 默认加载方式,单卡运行模型3.1 7b模型输出213 tok/s3.1 32b模型输出81 tok/s3.1 70b模型输出43tok/s 4. 使用负载均衡,多卡运行4.1 7b模型输出217t…...

vue3 setup vite 配置跨域了proxy,部署正式环境的替换
在开发环境中使用 Vite 的 proxy 配置来解决跨域问题是一种常见的做法。然而,在部署到正式环境时,通常需要对接口地址进行调整,具体是否需要更改接口名称取决于你的部署环境和后端服务的配置。以下是几种常见的情况和建议: 1. 正…...
环境配置)
目标检测:YOLOv11(Ultralytics)环境配置
1、前言 YOLO11是Ultralytics公司YOLO系列实时目标检测器的最新迭代版本,它以尖端的准确性、速度和效率重新定义了可能实现的性能。在之前YOLO版本取得的显著进步基础上,YOLO11在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务中…...

如何高效压缩GIF动图?
GIF动图因其兼容性强、易于传播的特点,成为网络交流的热门选择。然而,过大的文件体积常常导致加载缓慢、分享困难等问题。本文将为您详细介绍几种实用的GIF压缩技巧,帮助您在保持画面质量的同时显著减小文件大小。 压缩方法 1. 在线压缩工具…...

视频融合平台EasyCVR可视化AI+视频管理系统,打造轧钢厂智慧安全管理体系
一、背景分析 在轧钢厂,打包机负责线材打包,操作人员需频繁进入内部添加护垫、整理包装、检修调试等。例如,每班产线超过300件,12小时内人员进出打包机区域超过300次。若员工安全意识薄弱、违规操作,未落实安全措施就…...
)
通过命令行操作把 本地IDE 项目上传到 GitHub(小白快速版)
通过命令行操作把 本地IDE 项目上传到 GitHub(小白版) 你是不是在用 本地IDE 做项目,但不知道怎么把自己的代码上传到 GitHub?今天我们用最简单的命令行方式(不用 SSH、不用复杂配置)教你一步一步把本地项…...

【c语言基础学习】qsort快速排序函数介绍与使用
在C语言中,qsort 函数用于对数组进行快速排序。以下是详细的使用方法及示例: 一、函数原型 #include <stdlib.h>void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *) );二、参数说明 参数说明base指向…...
)
今日github AI科技工具汇总(20250415更新)
以下是2025年4月15日GitHub上值得关注的AI科技工具汇总及趋势分析,结合最新开源动态与开发者社区热点整理: 一、AI编程工具重大更新 GitHub Copilot Agent Mode 全量发布 核心功能:在VS Code中启用后,可自主完成多文件代码重构、测试驱动开发(TDD)及自修复编译错误,支持…...
:广告创意审核的法律红线与平台规则)
程序化广告行业(88/89):广告创意审核的法律红线与平台规则
程序化广告行业(88/89):广告创意审核的法律红线与平台规则 在程序化广告的广阔领域中,不断学习和掌握行业规范是我们稳步前行的基石。一直以来,我都期望与大家携手共进,深入探索这个行业的奥秘。今天&…...
)
前端VUE框架理论与应用(4)
一、计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护。例如: <div id="example">{{ message.split().reverse().join() }}</div> 在这个地方,模板不再是简单的声明式逻辑。你…...

【经验分享】基于Calcite+MyBatis实现多数据库SQL自动适配:从原理到生产实践
基于CalciteMyBatis实现多数据库SQL自动适配:从原理到生产实践 一、引言:多数据库适配的行业痛点 在当今企业IT环境中,数据库异构性已成为常态。根据DB-Engines最新调研,超过78%的企业同时使用两种以上数据库系统。这种多样性带…...

通信算法之265: 无人机系统中的C2链路
在无人机系统设计中,我们经常听到C2链路这个名词,到底什么是C2链路呢?为什么说C2链路是无人机系统中非常重要的环节。 转载: 无人机技术是各种科技技术水平综合发展的结果,包括空气动力,机械设计…...

浙江大学:DeepSeek如何引领智慧医疗的革新之路?|48页PPT下载方法
导 读INTRODUCTION 随着人工智能技术的飞速发展,DeepSeek等大模型正在引领医疗行业进入一个全新的智慧医疗时代。这些先进的技术不仅正在改变医疗服务的提供方式,还在提高医疗质量和效率方面展现出巨大潜力。 想象一下,当你走进医院ÿ…...
)
Codeforces Round 1017 (Div. 4)
Codeforces Round 1017 (Div. 4) A. Trippi Troppi AC code: void solve() { string a, b, c; cin >> a >> b >> c;cout << a[0] << b[0] << c[0] << endl; } B. Bobritto Bandito 思路: 倒推模拟即可,…...

bash的特性-bash中的引号
在Linux或Unix系统中,Bash(Bourne Again SHell)作为最常用的命令行解释器之一,提供了强大的功能来处理各种任务。正确使用引号是掌握Bash脚本编写的基础技能之一,它决定了如何解析字符串、变量替换以及特殊字符的行为。…...

ubuntu上SSH防止暴力破解帐号密码
在知道设备ip的情况下,使用 Fail2Ban防止暴力破解 sudo apt install fail2ban 配置 SSH 防护规则 sudo gedit /etc/fail2ban/jail.local jail.local内容如下: [sshd] enabled true port ssh logpath /var/log/auth.log # Ubuntu/Debian maxret…...
)
【Bluedroid】A2DP Sink播放流程源码分析(二)
接上一篇继续分析:【Bluedroid】A2DP Sink播放流程源码分析(一)_安卓a2dp sink播放流程-CSDN博客 AVDTP接收端(Sink)流事件处理 bta_av_sink_data_cback 是 Bluedroid 中 A2DP Sink 角色的 AVDTP 数据回调函数,负责处理接收端的…...

【Code】《代码整洁之道》笔记-Chapter16-重构SerialDate
第16章 重构SerialDate 如果你找到JCommon类库,深入该类库,其中有个名为org.jfree.date的程序包。在该程序包中,有个名为SerialDate的类,我们即将剖析这个类。 SerialDate的作者是David Gilbert。David显然是一位经验丰富、能力…...

redis 内存中放哪些数据?
在 Java 开发中,Redis 作为高性能内存数据库,通常用于存储高频访问、低延迟要求、短期有效或需要原子操作的数据。以下是 Redis 内存中常见的数据类型及对应的使用场景,适合面试回答: 1. 缓存数据(高频访问,降低数据库压力) 用户会话(Session):存储用户登录状态、临时…...

【Python使用】嘿马云课堂web完整实战项目第4篇:封装异常处理,封装JSON返回值【附代码文档】
教程总体简介:项目概述 项目背景 项目的功能构架 项目的技术架构 CMS 什么是CMS CMS需求分析与工程搭建 静态门户工程搭建 SSI服务端包含技术 页面预览开发 4 添加“页面预览”链接 页面发布 需求分析 技术方案 测试 环境搭建 数据字典 服务端 前端 数据模型 页面原…...

「数据可视化 D3系列」入门第三章:深入理解 Update-Enter-Exit 模式
深入理解 Update-Enter-Exit 模式 一、数据绑定三态:Update、Enter、Exit三种状态的直观理解 二、基础概念1. Update 选区 - 处理已有元素2. Enter 选区 - 处理新增数据3. Exit 选区 - 处理多余元素 三、完整工作流程四、三种状态的底层原理数据绑定过程解析键函数&…...
)
中间件--ClickHouse-5--架构设计(分布式架构,列式压缩存储、并行计算)
1、整体架构设计 ClickHouse 采用MPP(大规模并行处理)架构,支持分布式计算和存储,其核心设计目标是高性能列式分析。 (1)、存储层 列式存储: 数据按列存储(而非传统行式存储&#…...

AgentGPT 在浏览器中组装、配置和部署自主 AI 代理 入门介绍
AI MCP 系列 AgentGPT-01-入门介绍 Browser-use 是连接你的AI代理与浏览器的最简单方式 AI MCP(大模型上下文)-01-入门介绍 AI MCP(大模型上下文)-02-awesome-mcp-servers 精选的 MCP 服务器 AI MCP(大模型上下文)-03-open webui 介绍 是一个可扩展、功能丰富且用户友好的…...
:Backpropagation、mamba、RNN)
【开源项目】Excel手撕AI算法深入理解(三):Backpropagation、mamba、RNN
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git 一、Backpropagation 1. 反向传播的本质 反向传播是通过链式法则计算损失函数对网络参数的梯度的高效算法,目的是用梯度下降优化参数。其核心思想是: 前向传播…...

uniapp的通用页面及组件基本封装
1.基本布局页面 适用于自定义Navbar头部 <template><view class"bar" :style"{height : systemInfo.statusBarHeight px, background: param.barBgColor }"></view><view class"headBox" :style"{ height: param.h…...

Ubuntu和Debian 操作系统的同与异
首先需要说明:Ubuntu 是基于 Debian 操作系统开发的。它们之间的关系如下 起源与发展:Debian 是一个社区驱动的开源 Linux 发行版,始于 1993 年,是最早的 Linux 发行版之一,以其稳定性和自由软件政策著称。Ubuntu 是基…...

【android bluetooth 协议分析 21】【ble 介绍 1】【什么是RPA】
通俗易懂地讲解一下 BLE(低功耗蓝牙)中的 Resolvable Private Address(RPA,可解析私有地址)。 1. 一句话理解 RPA 是一种“临时的、隐私保护的蓝牙设备地址”,别人无法随便追踪你,但“授权的设…...

狂神SQL学习笔记九:MyISAM 和 lnnoDB 区别
show create database school –查看创建数据库的语句 show create table student – 查看student数据表的定义语句 desc student –显示表的结构 MYISAMINNODB事务支持不支持支持数据行锁定不支持支持行锁定外键不支持支持全文索引支持不支持表空间的大小较小较大&#x…...

深度学习--神经网络的构造
在当今数字化时代,深度学习已然成为人工智能领域中最为耀眼的明星。而神经网络作为深度学习的核心架构,其构造方式决定了模型的性能与应用效果。本文将深入探讨深度学习神经网络的构造,带您领略这一前沿技术的奥秘。 一、神经网络基础概念…...

Jenkins 代理自动化-dotnet程序
两种方式 容器部署 本地部署 容器部署 可自动实现,服务器重启,容器自动运行 主要将dockerfile 写好 本地部署 1.服务器重启自动运行代理 参考下面的链接,只是把程序换成 java程序,提前确认好需要的jdk版本 Ubuntu20.04 设置开机…...

【区块链+ 人才服务】“CERX Network”——基于 FISCO BCOS 的研学资源交换网络 | FISCO BCOS 应用案例
CERX Network (Consortium-based Education Resource Exchanging Network) 是定位于面向高校科学研究与教学 的分布式研学资产交换网络, 构建一个用于数据、 算法模型、 论文和课程的研学资源价值流转平台。项目以 FISCO BCOS 联盟链为底层平…...
)
中间件--ClickHouse-6--SQL基础(类似Mysql,存在差异)
ClickHouse语言类似Mysql,如果熟悉Mysql,那么学习ClickHouse的语言还是比较容易上手的。 1、建表语法(CREATE TABLE) (1)、表引擎(Engine) MySQL: 默认使用 InnoDB 引…...

[MSPM0开发]MSPM0G3507番外一:关于使用外部高速晶振HFXT后程序可能不运行的问题
一、问题描述 如下图所示,MSPM0G3507时钟树配置为使用外部HFXT(外部高速晶振)作为HSCLK时钟源。 配置结果MCLK 40MHz。 另外配置PB22为输出模式,控制外部LED亮灭。 在main.c中主要代码如下: 主要完成延时并翻转LED控…...

2025年计算机领域重大技术突破与行业动态综述
——前沿技术重塑未来,开发者如何把握机遇? 2025年第一季度,全球计算机领域迎来多项里程碑式进展,从量子计算到人工智能,从芯片设计到网络安全,技术革新与产业融合持续加速。本文梳理近三个月内最具影响力…...
)
我的机器学习之路(初稿)
文章目录 一、机器学习定义二、核心三要素三、算法类型详解1. 监督学习(带标签数据)2. 无监督学习(无标签数据)3. 强化学习(决策优化)(我之后主攻的方向) 四、典型应用场景五、学习路线图六、常见误区警示七…...

交易模式革新:Eagle Trader APP上线,助力自营交易考试效率提升
近年来,金融行业随着投资者需求的日益多样化,衍生出了众多不同的交易方式。例如,为了帮助新手小白建立交易基础,诞生了各类跟单社区;而与此同时,一种备受瞩目的交易方式 —— 自营交易模式,正吸…...

emotn ui桌面tv版官网-emotn ui桌面使用教程
在智能电视和盒子的使用中,出色的桌面系统能大幅提升体验,Emotn UI桌面TV版便是其中的佼佼者。 访问Emotn UI桌面TV版官网,首页简洁清晰,“产品介绍”“下载中心”等板块一目了然。官网对其功能优势详细阐述,在“下载中…...

Django之modelform使用
Django新增修改数据功能优化 目录 1.新增数据功能优化 2.修改数据功能优化 在我们做数据优化处理之前, 我们先回顾下传统的写法, 是如何实现增加修改的。 我们需要在templates里面新建前端的页面, 需要有新增还要删除, 比如说员工数据的新增, 那需要有很多个输入框, 那html…...

Hadoop:大数据时代的基石
在当今数字化浪潮中,数据量呈爆炸式增长,企业和组织面临着前所未有的数据处理挑战。从社交媒体的海量信息到物联网设备的实时数据,如何高效地存储、管理和分析这些数据成为了一个关键问题。Apache Hadoop 作为大数据处理领域的核心框架&#…...

定制开发还是源码搭建?如何快速上线同城外卖跑腿APP?
在“万物皆可同城配送”的时代,同城外卖跑腿APP成为众多创业者和本地服务商的热门选择。无论是打造本地生活服务平台,还是拓展快送业务,拥有一款功能完善、体验流畅的外卖跑腿APP,已经成为进入市场的标配。 然而,对于…...

How AI could empower any business - Andrew Ng
How AI could empower any business - Andrew Ng References 人工智能如何为任何业务提供支持 empower /ɪmˈpaʊə(r)/ vt. 授权;给 (某人) ...的权力;使控制局势;增加 (某人的) 自主权When I think about the rise of AI, I’m reminded …...

SpringBoot-基础特性
1.SpringApplication 1.1.自定义banner 类路径添加banner.txt或设置spring.banner.location就可以定制 banner 1.2.自定义 SpringApplication import org.springframework.boot.Banner; import org.springframework.boot.SpringApplication; import org.springframework.bo…...

系统环境变量有什么实际作用,为什么要配置它
系统环境变量有什么实际作用,为什么要配置它 系统环境变量具有以下重要实际作用: 指定程序路径:操作系统通过环境变量来知晓可执行文件、库文件等的存储位置例如,当你在命令提示符或终端中输入一个命令时,系统会根据环境变量PATH中指定的路径去查找对应的可执行文件。如果…...

C++ | STL之list详解:双向链表的灵活操作与高效实践
引言 std::list 是C STL中基于双向链表实现的顺序容器,擅长高效插入和删除操作,尤其适用于频繁修改中间元素的场景。与std::vector不同,std::list的内存非连续,但提供了稳定的迭代器和灵活的元素管理。本文将全面解析std::list的…...

Spring Cloud 服务间调用深度解析
前言 在构建微服务架构时,服务间的高效通信是至关重要的。Spring Cloud 提供了一套完整的解决方案来实现服务间的调用、负载均衡、服务发现等功能。本文将深入探讨 Spring Cloud 中服务之间的调用机制,并通过源码片段和 Mermaid 图表帮助读者更好地理解…...

什么是时间复杂度和空间复杂度?
什么是时间复杂度和空间复杂度? 时间复杂度:衡量代码运行时间随输入规模增大而增长的速度。简单来说,就是“代码跑多快”。 空间复杂度:衡量代码运行时额外占用的内存空间随输入规模增大而增长的速度。简单来说,就是“代码用多少内存”。 我们通常用 大 O 表示法(Big O N…...

算法思想之分治-快排
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之分治-快排 发布时间:2025.4.15 隶属专栏:算法 目录 算法介绍核心步骤优化策略 例题颜色分类题目链接题目描述算法思路代码实现 排序数组题目链接题目描述算法思路代码实现 数组中的…...

25.4.15学习总结
问题: 邮箱验证码通过公钥加密后发到前端,在前端用私钥解密验证可行吗? 结论: 在前端使用私钥解密通过公钥加密的邮箱验证码在技术上是可行的,但存在严重的安全风险,不建议采用。 问题分析 非对称加密的…...
)
小程序获取用户总结(全)
获取方式 目前小程序获取用户一共有3中(自己接触到的),但由于这个API一直在改,所以不确定后期是否有变动,还是要多关注官方公告。 方式一 使用wx.getUserInfo 实例: wxml 文件<button open-type="getUserInfo" bindgetuserinfo="onGetUserInfo&quo…...

如何成为一名嵌入式软件工程师?
如何成为一名嵌入式软件工程师? 01明确岗位的角色与定位 嵌入式软件工程师主要负责开发运行在特定硬件平台上的软件,这些软件通常与硬件紧密集成,以实现特定的功能。 不仅需要精通编程语言(如C/C、Java等)和软件开发工…...