3D版的VLA:从3D VLA、SpatialVLA到PointVLA——3D点云版的DexVLA,在动作专家中加入3D数据
前言
之前写这篇文章的时候,就想解读下3D VLA来着,但一直因为和团队并行开发具身项目,很多解读被各种延后
更是各种出差,比如从25年3月下旬至今,连续出差三轮,绕中国半圈,具身占八成
- 第一轮 珠三角,长沙出发,深圳 广州/佛山
- 第二轮 京津冀及山东,长沙出发,保定 北京 济南 青岛
- 第三轮 长三角,青岛出发,上海 南京 今天下午回到长沙
而出差过程中接到的多个具身订单中,有一个人形开发订单涉及要遥操,而3D版的VLA也是一种备选方案「详见此文《从宇树摇操avp_teleoperate到unitree_IL_lerobot:如何基于宇树人形进行二次开发》的开头」
故回到长沙后,便准备解读下3D VLA来了,但既然解读3D VLA了,那就干脆把相关3D版本的VLA一并解读下——特别是PointVLA 且我顺带建了一个PointVLA的复现落地群,欢迎私我一两句简介 以加入
如此,便有了本文
第一部分 3D VLA
第二部分 SpatialVLA
// 待更
第三部分 PointVLA: 将三维世界引入视觉-语言-动作模型
3.1 提出背景与相关工作
25年3.10日,来自1Midea Group、2Shanghai University、3East China Normal University等机构的研究者们提出了PointVLA
这个团队的节奏还挺快的,他们在过去半年多还先后发布了TinyVLA、Diffusion-VLA、DexVLA
| TinyVLA | 24年9月 | 1. Midea Group 2. East China Normal University 3. Shanghai University 4.Syracuse University 5. Beijing Innovation Center of Humanoid Robotics | Junjie Wen1,∗ , Yichen Zhu2,∗,† , Jinming Li3 , Minjie Zhu1 , Kun Wu4 , Zhiyuan Xu5 , Ning Liu2 , Ran Cheng2 , Chaomin Shen1,† , Yaxin Peng3 , Feifei Feng2 , and Jian Tang5 |
| Diffusion-VLA | 24年12月 | 1 East China Normal University, 2 Midea Group, 3 Shanghai University | Junjie Wen1,2,∗, Minjie Zhu1,2,∗, Yichen Zhu2,†,*, Zhibin Tang2, Jinming Li2,3, Zhongyi Zhou1,2,Chengmeng Li2,3, Xiaoyu Liu2,3, Yaxin Peng3, Chaomin Shen1, Feifei Feng2 |
| DexVLA | 25年2月 | 1 Midea Group 2 East China Normal University | Junjie Wen12∗ Yichen Zhu1∗† Jinming Li1 Zhibin Tang1 Chaomin Shen2, Feifei Feng1 |
| PointVLA | 25年3月 | 1 Midea Group 2 Shanghai University 3 East China Normal University | Chengmeng Li1,2,∗ Yichen Zhu1,∗,† Junjie Wen3 Yan Peng2 Yaxin Peng2,† Feifei Feng1 |
3.1.1 引言
如原论文中所说,机器人基础模型,特别是视觉-语言-动作(Vision-Language-Action,VLA)模型[4, 5, 25, 45, 46],在使机器人能够感知、理解和与物理世界交互方面展现了卓越的能力
- 这些模型利用预训练的视觉-语言模型(VLMs)[3, 8, 20, 30, 42] 作为处理视觉和语言信息的骨干,将其嵌入到一个共享的表示空间中,并随后将其转化为机器人动作
这个过程使机器人能够以有意义的方式与其环境交互 - VLA 模型的强大性能在很大程度上依赖于其训练数据的规模和质量。例如,Open-VLA[25] 使用4k 小时的开源数据集进行训练,而更先进的模型如π0 则利用10k 小时的专有数据,从而显著提升了性能
- 除了这些大规模的基础模型外,许多项目还通过物理机器人上的真实人类演示收集了大量数据集。例如,AgiBot-World[6] 发布了一个包含数百万条轨迹的大型数据集,展示了复杂的人形交互
然,大多数现有的机器人基础模型[4, 5, 21, 25, 46]都是基于二维视觉输入进行训练的[23, 35]。这构成了一个关键的局限性,因为人类感知和与世界互动是在三维空间中进行的。训练数据中缺乏全面的三维空间信息阻碍了机器人对其环境形成深刻理解的能力。可这,对于那些需要精确的空间感知、深度感知和物体操作的任务来说,这一点尤其关键
对此,他们提出了PointVLA,一种将点云集成到预训练的视觉-语言-动作模型中的新框架
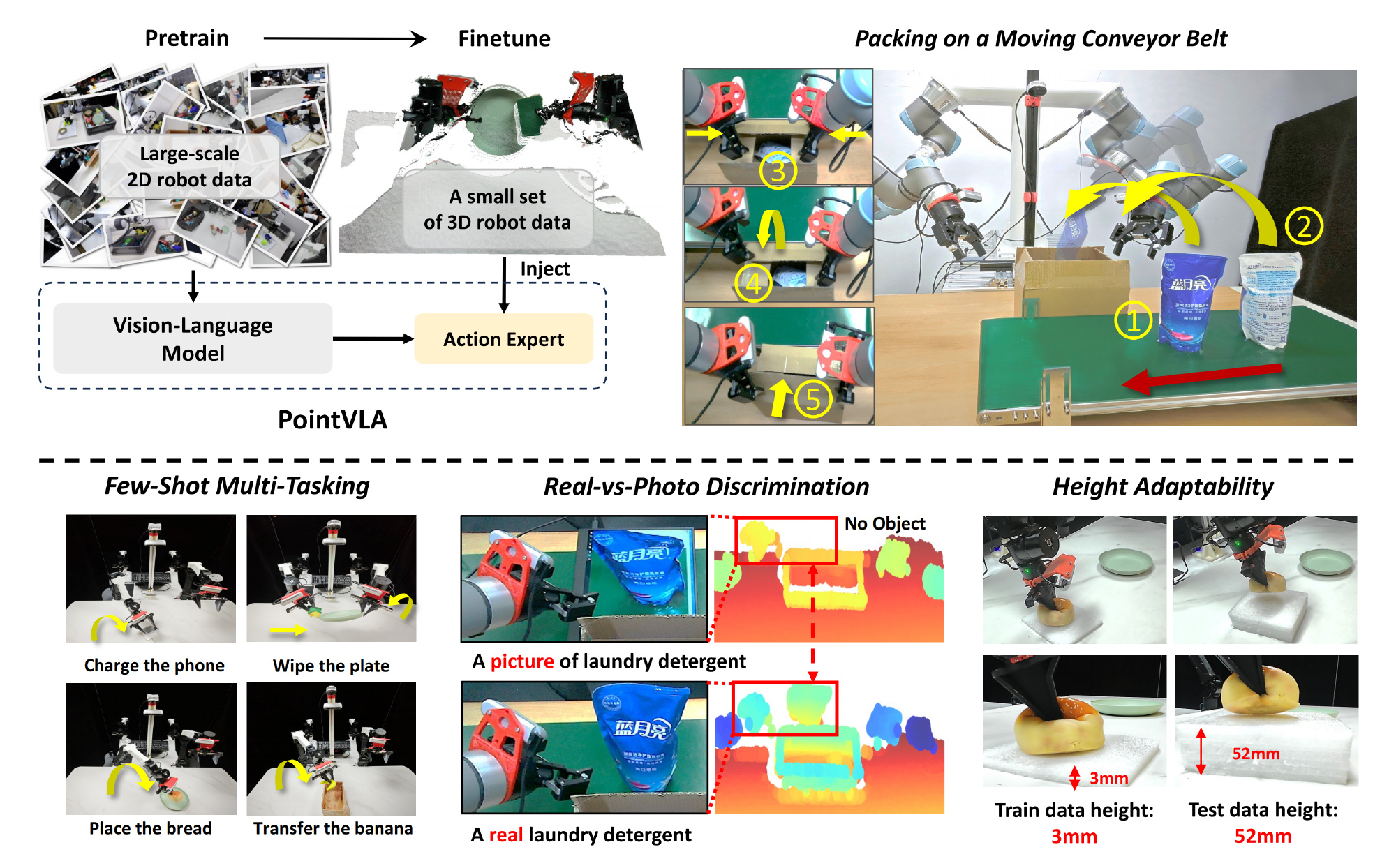
- 且考虑到新的3D机器人数据显著少于预训练的2D数据。在这种情况下,关键是不要破坏已建立的2D特征表示。故他们提出了一个3D模块化块,该块将点云信息直接注入到动作专家中
如此,通过保持视觉-语言骨干网络的完整性,确保了2D视觉-文本嵌入的保留——并仍然是可靠的信息来源 - 此外,他们力求将对动作专家特征空间的干扰降到最低。通过跳跃块分析,他们确定了测试时不太关键的层,即让动作专家中这些“用处较小”层的特征嵌入更适应新模态。在确定了这些较不重要的块后,他们通过加性方法注入提取的3D特征
3.1.2 相关工作
对于视觉-语言-动作模型
近年来的研究越来越多地关注于开发基于大规模机器人学习数据集训练的通用机器人策略[11,14,23,27,35]。视觉-语言-动作(VLA)模型已经成为训练此类策略的一种有前途的方法[4,9,12,13,24,33,36,40,45,46,48,54,55]。VLA扩展了视觉-语言模型(VLM)——这些模型通过基于互联网规模的大型图像和文本数据集进行预训练[1,8,20,28–30,42,53,58,59]——以实现机器人控制[44]
毕竟这种方法提供了几个关键优势:
- 利用大规模具有数十亿参数的视觉-语言模型骨干能够从大量的机器人数据集中进行有效学习
- 同时重用来自互联网规模数据的预训练权重增强了视觉-语言代理(VLAs)理解多样化语言指令以及对新颖物体和环境的泛化能力,使它们在实际机器人应用中具有高度适应性。机器人学习与三维模态
在三维场景中学习鲁棒的视觉运动策略[7,15–17,19,22,37,39,41,49–52]是机器人学习中的一个重要领域
- 现有方法如3DVLA[17]提出了综合框架,将多样化的三维任务(如泛化、视觉问答(VQA)、三维场景理解和机器人控制)整合到统一的视觉-语言-动作模型中
然而,3DVLA的一个局限性是其在机器人控制实验中依赖模拟,这导致了显著的模拟到真实的差距 - 其他研究,如3D扩散策略[51],表明使用外部三维输入(例如来自外部摄像机)可以提高模型对不同光照条件和对象属性的泛化能力
iDP3[50] 则进一步增强了三维视觉编码器并将其应用于人形机器人,在具有自我视角和外部摄像机视角的多样环境中实现了鲁棒性能 - 然而,丢弃现有的二维机器人数据或者完全用新增的三维视觉输入重新训练基础模型,将会耗费大量的计算资源
However, discarding existing 2D robot data or completely retraining the founda-tion model with added 3D visual input would be computa-tionally expensive and resource-intensive.
一个更实用的解决方案是开发一种方法,将三维视觉输入作为补充知识源集成到经过良好预训练的基础模型中,从而在不影响训练模型性能的情况下获得新模态的好处
3.1.3 预备知识:PointVLA相当于3D点云版的DexVLA
VLA的强大源于其底层的VLM,这是一个经过海量互联网数据训练的强大骨干网络。这种训练使得图像和文本表示能够在共享的嵌入空间中实现有效对齐
VLM作为模型的“头脑”,处理指令和当前视觉输入以理解任务状态。随后,一个“动作专家”模块将VLM的状态信息转化为机器人动作
而PointVLA构建于DexVLA [46]的基础上
- DexVLA采用了一个具有20亿参数的Qwen2-VL [2,43]视觉语言模型(VLM)作为其主干,以及一个具有10亿参数的ScaleDP [57](一种扩散策略变体)作为其动作专家
- DexVLA经历了三个训练阶段:
一个为期100小时的跨实体训练阶段(阶段1),随后是实体特定训练(阶段2),以及一个可选的针对复杂任务的任务特定训练(阶段3)
所有三个阶段都使用2D视觉输入。尽管这些VLA模型在多样化的操作任务中表现出色,但它们对2D视觉的依赖限制了它们在需要3D理解的任务中的表现,例如通过照片进行物体欺骗或在不同桌子高度之间的泛化
3.2 将点云注入到VLA中
3.2.1 3D点云注入器的整体架构
如之前所述,VLA模型通常在大规模二维机器人数据集上进行预训练。一个关键的观察是支撑他们方法的核心是现有2D预训练语料库与新兴3D机器人数据集之间数据规模的固有差异
- 具体而言,他们认为3D传感器数据(例如点云、深度图)的体量相比于2D视觉-语言数据集小了几个数量级,这是由于机器人研究历史上对2D感知的广泛关注所致。这种差异需要一种方法,既能保留从2D预训练中学习到的丰富视觉表示,又能有效整合稀疏的3D数据
- 一种解决这一挑战的简单策略是直接将3D视觉输入转换为3D视觉token,并将其融合到大型语言模型(LLM)中——这种方法已被许多3D VLM采用,例如LLaVA-3D [56]
然而,目前的视觉-语言模型在小规模3D数据集上微调时表现出有限的3D理解能力,这一局限性由两个因素加剧:
- 2D像素与3D几何结构之间的显著领域差异
- 以及与图像 - 文本和纯文本语料库的丰富相比,高质量的 3D 文本配对数据十分稀缺
为了解决这些问题,他们提出了一种范式,将3D点云数据视为补充的条件信号,而不是主要的输入模式。这种策略将3D处理与核心的2D视觉编码器分离,从而在保留预训练的2D表示完整性的同时,使模型能够利用几何线索
且通过设计,他们的方法减轻了对2D知识的灾难性遗忘,并降低了对有限3D数据过拟合的风险。点云注入器的模型架构
点云注入器的整体架构如下图图2(右)所示
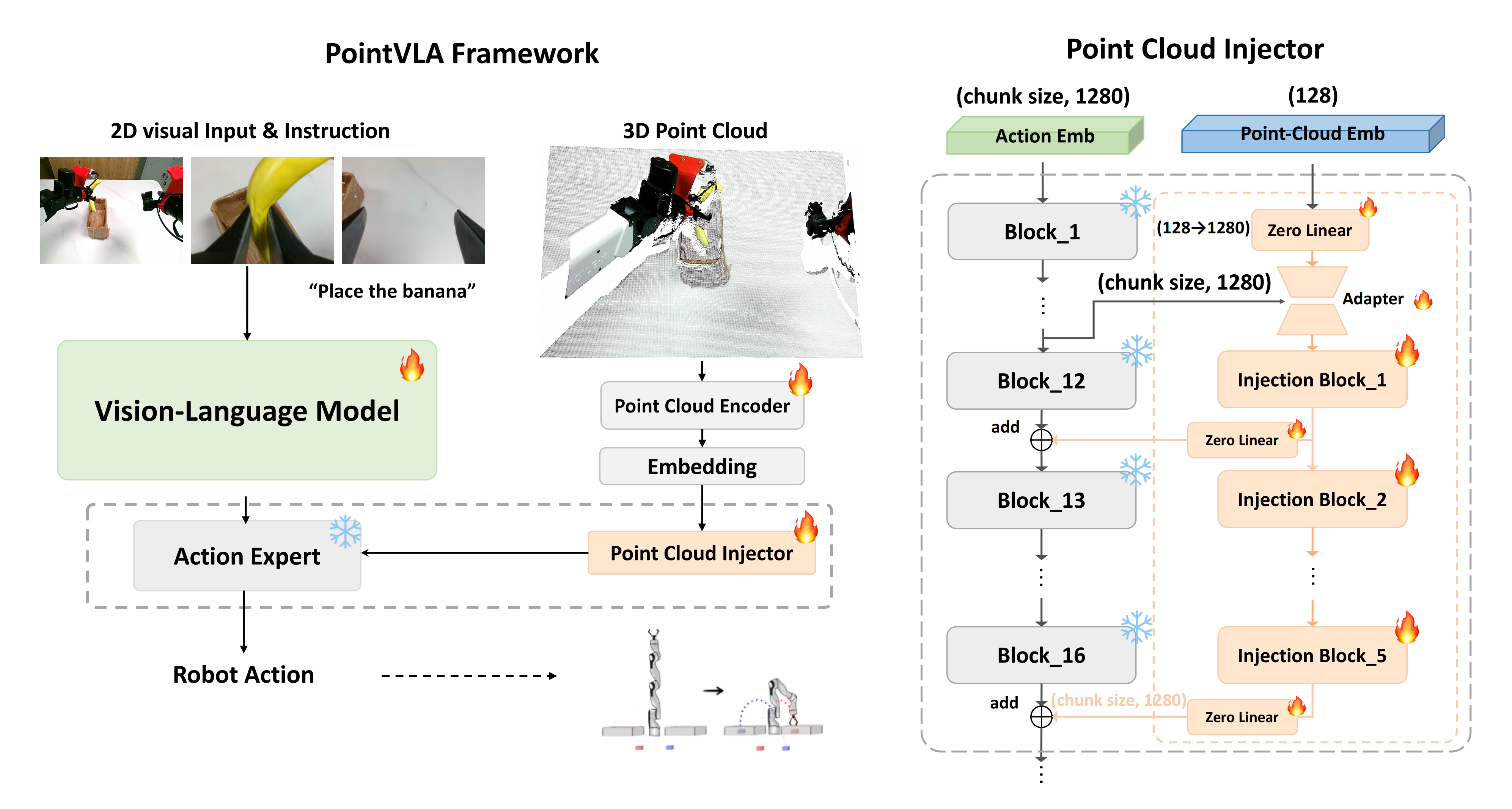
- 具体来说,对于传入的点云嵌入,他们首先将通道维度转换以匹配基础动作专家的通道维度。由于点云的动作嵌入可能较大——具体取决于块大小,他们设计了一个动作嵌入瓶颈来压缩动作专家的信息,同时使其与3D点云嵌入对齐
即Since the action embeddingfrom the point cloud can be large, depending on the chunksize, we design an action embedding bottleneck to compressthe information from the action expert while aligning it withthe 3D point cloud embedding. - 对于动作专家中的选定块,他们首先为每个块应用一个MLP层作为适配器,然后通过加法操作将点云嵌入注入到模型中
值得注意的是,他们会避免将3D特征注入到动作专家的每个块中,主要有两个原因
首先,由于所需的条件块,计算成本将高得无法接受
其次,注入不可避免地会改变受影响块的模型表示
鉴于此,他们的目标是尽量减少有限的 3D 视觉知识对源自 2D 视觉输入的预训练动作嵌入的干扰,故他们进行了分析以确定在推理过程中可以跳过的模块,同时又不影响性能
最后,他们仅将 3D 特征注入到这些不太关键的模块中
3.2.2 点云编码器
与DP3 [51] 和iDP3 [50] 中的观察一致,他们也发现预训练的3D视觉编码器会阻碍性能,通常会阻止在新环境中成功学习机器人行为
- 因此,他们采用了一种简化的分层卷积架构。上层卷积层提取低级特征,而下层卷积块学习高级场景表示。在层之间采用最大池化以逐渐减少点云密度
- 最后,再将特征进行拼接。从每个卷积块中提取的特征嵌入被整合为一个统一的嵌入,封装了多层次的三维表示知识。提取的点云特征嵌入被保留以供后续使用
总之,该架构与iDP3编码器相似。当然了,他们认为,采用更先进的点云编码器可能会进一步提高模型性能
3.2.3 在哪些块注入点云?跳过块分析
如前所述,将点云注入动作专家的每个模块并不理想,因为这会增加计算成本并扰乱从大量2D 基于视觉的机器人数据中学习到的原始动作表示
因此,他们分析了动作专家中哪些模块不太关键——即在推理过程中可以跳过而不影响性能的模块。这个方法在概念上与图像生成、视觉模型和大型语言模型中使用的技术一致[10,18, 26, 38]
- 具体来说,我们使用DexVLA [46] 中的折衬衫任务作为分析的案例研究。请注意,DexVLA 配备了一个包含10 亿参数的动作专家,具有32 个扩散transformer模块
评估遵循相同的指标:平均得分,这是一个长时任务的标准度量[4, 31, 46]——通过将任务分为多个步骤并根据步骤完成情况评估性能 - 他们首先每次跳过一个模块,并在下图中总结了他们的发现
实验表明,前11个模块对模型至关重要——跳过任何一个模块都会导致性能显著下降。特别是,当跳过11层之前的模块时夹具无法紧密闭合,使得模型难以完成任务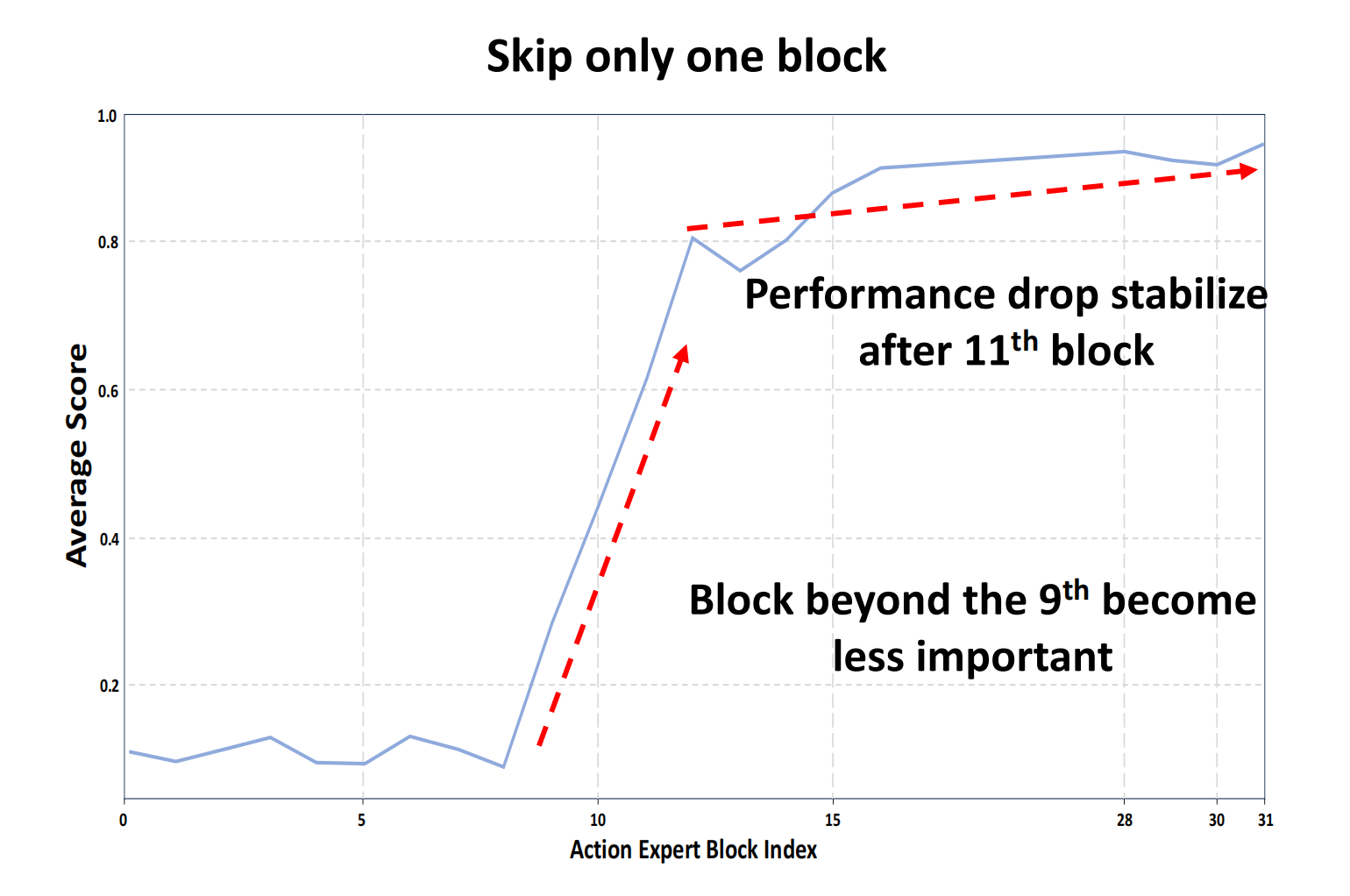
然而,从第11个模块开始,跳过单个模块是可以接受的,直到最后一个模块。这表明,经过训练后,第11到31模块对性能的贡献较少 - 为了进一步研究哪些模块适合点云注入,他们从第11模块开始进行了多模块跳过分析,如图3(右)所示
他们发现,在模型无法完成任务之前,可以跳过最多五个连续模块。这表明可以通过特定模块将3D表示选择性地注入到动作专家中,从而在不显著影响性能的情况下优化效率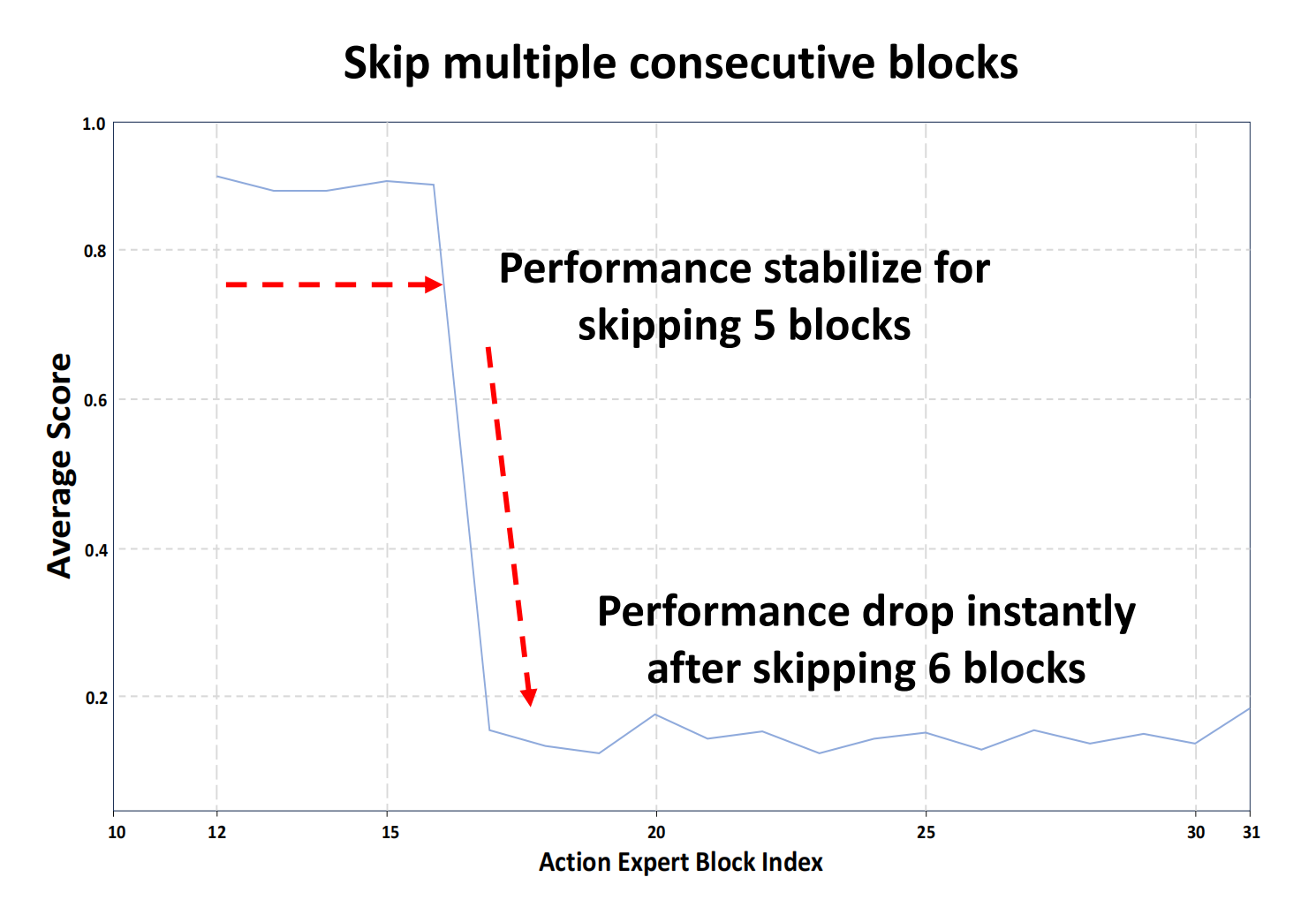
因此,当引入新数据时,他们将所有3D条件模块设置为可训练。且冻结原始动作专家中的所有模块,除了最后的层,这些层被调整以适应具体实施的输出
最终,他们仅训练了五个额外的注入模块,这些模块在推理过程中轻量且快速,使得他们的方法具有极高的成本效益
3.3 实验
3.3.1 实验设置
他们在两种实体上进行了真实机器人实验:
- 双臂 UR5e
两个 UR5e 机器人,每个配备一个 Robotiq 平行夹爪,和一个腕部安装的摄像头——数据以15Hz的频率采集。且使用RealSense D435i 摄像头作为腕部摄像头
另在两臂之间安装了一个俯视摄像头
相当于,此设置共有三个摄像头视角以及一个14维的配置和动作空间 - 双臂 AgileX
两个 6 自由度的 AgileX 机械臂,每个机械臂配备一个腕部摄像头——数据以30Hz 采集。我们使用 RealSense D435i 摄像头作为腕部摄像头
和一个基座摄像头——使用 RealSense L515 摄像头来收集点云数据
此配置具有 14 维的配置和动作空间,相当于总共由三个摄像头支持
之后,将 VLM 模型设置为可训练状态,因为模型需要学习新的语言指令
- 在这两个实验中,他们使用来自 DexVLA [46] 的第一阶段预训练权重,并对他们的模型进行微调。且使用与DexVLA 第二阶段训练相同的训练超参数,并使用最后一次检查点用于评估以避免选择性偏好
- 过程中,将所有任务的块大小设置为50
在他们的实验中,他们对比了包括扩散策略(DP)[9],3D扩散策略(DP3)[51],ScaleDP-1B [57],一种将扩散策略扩展到10亿参数的变体,Octo [34],OpenVLA[25],以及DexVLA [46]
请注意,由于PointVLA是基于DexVLA构建的,因此DexVLA可以被视为PointVLA在未结合3D点云数据情况下的消融版本
3.3.2 少样本多任务处理
如下图图5所示,他们设计了四个少样本任务:充电手机、擦盘子、放置面包、运输水果。物体被随机放置在一个小范围内,我们报告了每种方法的平均成功率
- 充电手机:机器人拾取一部智能手机并将其放置在无线充电器上。手机的尺寸测试了动作的精确性,而其脆弱性需要小心处理
- 擦盘子:机器人同时拾取一个海绵和一个盘子,用海绵擦拭盘子,评估双手操作技能
- 放置面包:机器人拾取一片面包并将其放置在一个盘子上。面包下面的一层薄泡沫用来测试高度泛化能力
- 运输水果:机器人拾取一个随机方向的香蕉并将其放置在一个位于中央的箱子里
由于作者旨在验证模型的少样本多任务能力,故他们为每个任务收集了20个示例,总计80个示例。物体的位置在一个小范围内随机化。这些任务评估了模型在不同场景中管理独立和协调机器人运动的能力。所有数据均以30Hz采集
从实验结果来看,他们宣称的他们的方法优于所有基线方法
- 且值得注意的是,扩散策略在大多数情况下都失败了,这可能是因为每个任务的样本量太小,导致动作表示空间变得纠缠——这一观察与先前文献中的发现一致[47]
- 此外,即使增加模型大小(ScaleDP-1B),也未能带来显著的改进
- 尽管数据有限,DexVLA 展现了强大的少样本学习能力;然而,其性能与 PointVLA 相当或稍逊
- PointVLA 中点云数据的整合实现了更高效的样本学习,突出了将三维信息整合到模型中的必要性。更重要的是,他们的结果证实了PointVLA的方法成功地保留了从二维预训练的VLA中学习的能力
相关文章:

3D版的VLA:从3D VLA、SpatialVLA到PointVLA——3D点云版的DexVLA,在动作专家中加入3D数据
前言 之前写这篇文章的时候,就想解读下3D VLA来着,但一直因为和团队并行开发具身项目,很多解读被各种延后 更是各种出差,比如从25年3月下旬至今,连续出差三轮,绕中国半圈,具身占八成 第一轮 …...
‘ java: 未结束的字符串文字,java: 不是语句,怎么解决)
java: 需要‘)‘ java: 未结束的字符串文字,java: 不是语句,怎么解决
java: 需要’)’ IDE运行当中因为字符串中的JSON串,导致编码不对,IDEA编码识别错误,编译不过,程序运行不起来,解决办法。 第一步,进行修改编码进行尝试 第二步,继续修改编码...

HarmonyOS:使用Refresh组件实现页面下拉刷新上拉加载更多
一、前言 可以进行页面下拉操作并显示刷新动效的容器组件。 说明 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。该组件从API Version 12开始支持与垂直滚动的Swiper和Web的联动。当Swiper设置loop属性为true时&…...

HarmonyOS应用开发的工程目录结构
AppScope > app.json5 应用级的配置信息 AppScope > resources 这个目录下的base>element用于存放全局使用的基本元素,如字符串、颜色和布尔值。base>media目录则存储媒体、动画和布局等资源文件。如果模块下的resources的有同样的资源,那么…...

详解关于VS配置好Qt环境之后但无法打开ui界面
目录 找到Qt安装目录中designer.exe的路径 找到vs中的解决方案资源管理器 右键ui文件,找到打开方式 点击添加 然后把前面designer.exe的路径填到程序栏中,点击确定 然后设置为默认值,并点击确定 当在vs中配置好Qt环境之后,但…...

【JDBC-54.2】深入理解SQL注入攻击及JDBC防护方案
1. SQL注入攻击概述 SQL注入(SQL Injection)是当今Web应用程序中最常见、最危险的安全漏洞之一。它利用了应用程序对用户输入数据处理不当的缺陷,攻击者通过在输入字段中插入恶意的SQL代码片段,欺骗服务器执行非预期的SQL命令。 …...

PCDN通过个人路由器,用更靠近用户的节点来分发内容,从而达到更快地网络反应速度
PCDN(P2P CDN)的核心思想正是利用个人路由器、家庭宽带设备等分布式边缘节点,通过就近分发内容来降低延迟、提升网络响应速度,同时降低传统CDN的带宽成本。以下是其技术原理和优势的详细分析: 1. 为什么PCDN能更快&…...

【软件测试】bug 篇
本章思维导图: 1. 软件测试的生命周期 软件测试贯穿于整个软件的生命周期 流程阶段需求分析测试计划测试设计/开发测试执行测试评估上线运行维护具体工作内容1. 阅读需求文档 2. 标记可测试需求 3. 确定测试类型1. 制定测试范围 2. 选择测试工具 3. 分配资源1. 编写…...

java -jar指定类加载
在 Java 中,使用 java -jar 命令运行 JAR 文件时,默认会加载 JAR 文件的 MANIFEST.MF 文件中指定的 Main-Class。如果你想在运行时指定一个类来加载,可以通过以下方式实现: 方法 1:直接指定类路径和类名 如果你不想使用…...

MVC 模式深度解析与 Spring 框架实践研究
MVC 模式深度解析与 Spring 框架实践研究 摘要 MVC(Model-View-Controller)模式作为软件工程中最重要的架构模式之一,通过将应用逻辑划分为模型、视图和控制器三个独立组件,实现了代码的高内聚低耦合,显著提升了软件的可维护性和可扩展性。本文从 MVC 模式的核心思想出发…...
:从 virtio_blk 看虚拟总线驱动模型的真实落地)
驱动开发硬核特训 · Day 11(下篇):从 virtio_blk 看虚拟总线驱动模型的真实落地
🔍 B站相应的视屏教程: 📌 内核:博文视频 - 总线驱动模型实战全解析 敬请关注,记得标为原始粉丝。 🔧 在上篇中,我们已经从理论视角分析了“虚拟总线驱动模型”在 Linux 驱动体系中的独特定位。…...

Java实现快速排序算法
用「整理书架」理解快速排序原理 想象你有一堆杂乱的书需要按大小排序,快速排序的步骤可以类比为: 1. 选一本“基准书”(比如最右侧的书) 2. 把书分成三堆: - 左边:比基准小的书 - 中间:基…...
)
3.3.2 应用层协议设计protobuf(二进制序列化协议)
文章目录 3.3.2 应用层协议设计protobuf(二进制序列化协议)1. 什么是协议设计什么是协议为什么说进程间通信就需要协议,而不是客户端与服务端之间为什么需要自己设计协议 2. 判断消息的完整性->区分消息的边界1.固定长度2. 特定符号3. 固定…...

软件测试过程模型:v模型、w模型、x模型、H模型
软件测试流程 获取测试需求编写测试计划制定测试方案开发和设计测试用例执行测试提交缺陷报告测试分析与评审提交测试报告准备下一版本测试 软件测试过程模型 v模型 【V模型是线性的操作方式】 优点: 验收测试的标准是用户的需求,用户需求对应指导…...

设计模式-代理模式
虚代理 根据需要创建对象...

cocos Spine资源及加载
COCOS Spine 资源加载 创建 Canvas 以及Camera 再进行spine 拖入 提供40个实战酷炫技能spine文件: Spine文件下载...

约翰·麦卡锡:我的人工智能之梦
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 约翰麦卡锡:我的人工智能之梦 一、引言:计算机科学的传奇人物…...

Scrapy结合Selenium实现搜索点击爬虫的最佳实践
一、动态网页爬取的挑战 动态网页通过JavaScript等技术在客户端动态生成内容,这使得传统的爬虫技术(如requests和BeautifulSoup)无法直接获取完整的内容。具体挑战包括: 数据加载异步化:数据并非一次性加载ÿ…...
 导出、导入补充>)
Oracle数据库数据编程SQL<9.3 数据库逻辑备份和迁移Data Pump (EXPDP/IMPDP) 导出、导入补充>
Oracle Data Pump 是 Oracle 10g 引入的高效数据迁移工具,相比传统的 EXP/IMP 工具,它提供了更强大的功能和显著的性能提升。以下是对 EXPDP 和 IMPDP 工具的全面讲解。 目录 一、高级功能扩展 1. 数据过滤与转换 2. 加密与安全 二、性能调优进阶 1. 并行处理优化 2. …...
)
Vue 3 + TypeScript 实现一个多语言国际化组件(支持语言切换与内容加载)
文章目录 一、项目背景与功能概览二、项目技术架构与依赖安装2.1 技术栈2.2 安装依赖 三、国际化组件实现3.1 创建 i18n 实例3.2 配置 i18n 到 Vue 应用3.3 在组件中使用国际化内容3.4 支持语言切换 四、支持类型安全4.1 添加类型支持4.2 自动加载语言文件 一、项目背景与功能概…...

RK3506+net9+VS2022跨平台调试C#程序
下载GetVsDbg.sh ,这脚本会下载一个压缩包,然后解压缩,设置x权限等等。但是目标板子连不上,就想办法获取到下载路径,修改这个脚本,显示这个下载链接后,复制一下,用电脑下下来 修改好…...

c# 反射及优缺点
在C#中,反射(Reflection)是一种强大的机制,允许程序在运行时检查其自身的结构(如类型、属性、方法等),以及动态地调用对象的方法或访问其属性。反射主要用于那些在编译时不知道具体类型信息&…...

基于SpringBoot的在线教育系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...
决策树|节点纯度与熵)
吴恩达深度学习复盘(16)决策树|节点纯度与熵
决策树简介 决策树算法在很多应用中被使用,机器学习比赛中会经常见到,但在流行病学领域未受到太多关注。 决策树示例 —— 猫的分类 以经营猫收养中心为例,通过动物的耳朵形状、脸型、是否有胡须等特征,来训练一个分类器判断动…...

C++基础精讲-07
文章目录 1. const对象2. 指向对象的指针3. 对象数组4. c中const常见用法总结4.1 修饰常量4.2 修饰指针4.3 修饰函数参数4.4 修饰函数返回值4.5 修饰成员函数4.6 const对象 5. 赋值运算符函数(补充)5.1 概念5.2 默认赋值运算符函数局限5.3 解决办法 1. c…...

100个有用的AI工具 之 生成透明图像LayerDiffuse
Stable Diffusion是开源图像生成界的扛把子,最强的地方在于它的可控性,通过ControlNet,和一系列插件,可以非常精准地控制图像生成的需求。 今天介绍的是SD的一个插件LayerDiffuse,它可以帮助我们用SD生成透明的png图层。我们在用PS抠图的时候,对于头发、毛绒边这种图是非…...

springboot和springcloud的区别
1. 目的与功能 1)Spring Boot: 主要用于快速构建独立的、生产级的 Spring 应用程序。它通过自动配置和嵌入式服务器等特性,简化了微服务的开发、启动和部署,使开发者能够专注于业务逻辑而非繁琐的配置。Spring Boot是一个快速开发的框架,旨在简化Java应用程序的开…...

前端操作document的小方法,主要功能-获取当前页面全部的a标签页,并根据链接中必要的字段进行判断,然后把这些链接放入iframe去打开
首先是一些小方法,有一个问题就是在不同源的页面中无法获取iframe中的dom const isInIframe window.parent ! window.self; console.log(是否在 iframe 中:, isInIframe); console.log(来源页面:, document.referrer); const isSame new URL(document.referrer).o…...

RocketMQ 03
今天是2025/04/14 21:58 day 20 总路线请移步主页Java大纲相关文章 今天进行RocketMQ 6,7,8 个模块的归纳 最近在忙毕设,更新有点慢,见谅 首先是RocketMQ 的相关内容概括的思维导图 6. 安全机制 6.1 ACL 访问控制 核心功能 权限分级:通过…...

基于项目管理的轻量级目标检测自动标注系统【基于 YOLOV8】
🐱 AILabeler 是一个轻量级目标检测标注系统,专为 YOLO 系列模型设计,支持图像上传、标注框管理、类别设置、自动标注(YOLOv8)、导出多格式训练数据等功能。 项目已经发布至https://github.com/as501226107/AILabeler&…...

针对 Java从入门到精通 的完整学习路线图、各阶段技术点、CTO进阶路径以及经典书籍推荐。内容分阶段展开,兼顾技术深度与职业发展
以下是针对 Java从入门到精通 的完整学习路线图、各阶段技术点、CTO进阶路径以及经典书籍推荐。内容分阶段展开,兼顾技术深度与职业发展。 一、学习路线图分阶段详解 阶段1:Java基础入门(3-6个月) 目标:掌握Java核心…...
)
深度学习总结(13)
选择损失函数 为问题选择合适的损失函数,这是极其重要的。神经网络会采取各种方法使损失最小化,如果损失函数与成功完成当前任务不完全相关,那么神经网络最终的结果可能会不符合你的预期。因此,一定要明智地选择损失函数…...

AI测试引擎中CV和ML模型的技术架构
技术架构概述 1. 数据采集层 此层负责收集各种类型的数据,为后续的模型训练和测试提供基础。对于CV模型,主要采集图像、视频数据,可来源于摄像头、图像数据库等;对于ML模型,采集结构化数据(如表格数据)、非结构化数据(如文本数据)等,数据来源包括业务系统日志、传感…...

业务架构发展历史及相关技术应用介绍
1,单体架构 企业处于发展初期阶段,业务的开发量与用户的访问量较少的情况下,通常情况会将业务编写在一个应用中,由一个web容器完成部署调用。如下图,一个应用中所有的功能模块写在一个war包中,功能模块的代…...

Java栈与队列深度解析:结构、实现与应用指南
一、栈与队列核心概念对比 特性栈 (Stack)队列 (Queue)数据原则LIFO(后进先出)FIFO(先进先出)核心操作push(入栈)、pop(出栈)、peek(查看栈顶)offer(入队)、poll(出队)、peek(查看队首)典型应用函数调用栈、括号匹配、撤销操作任…...

CentOS DVD完整版与Minimal版的区别
文章目录 一、体积与内置软件:从“大而全”到“小而精”二、安装体验:开箱即用 vs 高度定制三、适用场景:桌面与服务器的分水岭四、后续配置:时间成本的权衡五、性能与资源占用六、推荐新手下载完整版建议: 在 CentOS…...

AI日报 - 2025年4月13日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | OpenAI CFO称AGI可能已到来 Sarah Friar透露Sam Altman认为AGI潜力尚未完全发挥,引发行业热议 ▎💼 商业动向 | OpenAI开发新型AI工程师A-SWE 超越Copilot,能独立完成应用构建、…...

有哪些基于solidity的应用
🔥 Solidity 常见应用分类(附例子) 🏦 1. DeFi(去中心化金融) Solidity 的最大应用场景之一。 项目功能示例合约逻辑Uniswap去中心化交易所(AMM)流动性池、定价算法、swap函数Aave /…...

mybatis--多对一处理/一对多处理
多对一处理(association) 多个学生对一个老师 对于学生这边,关联:多个学生,关联一个老师[多对一] 对于老师而言,集合,一个老师有多个学生【一对多】 SQL: 测试环境搭建 1.导入依…...

中兴B860AV3.2-U-晶晨S905L3B芯片-安卓9.0-2+8G-线刷固件包
中兴B860AV3.1-U/B860AV3.2-U--晶晨S905L3B芯片-安卓9.0-28G-线刷固件包 线刷方法:(新手参考借鉴一下) 1、准备好一根双公头USB线刷刷机线,长度30-50CM长度最佳,同时准备一台电脑; 2、电脑上安…...

资源分配不均,如何优化
优化资源分配需要关注资源需求评估精准性、资源调度合理性、实时监控与反馈机制、沟通协调的高效性以及持续改进的管理理念。其中,资源需求评估精准性最为关键。精准的资源需求评估意味着对项目各阶段所需资源的准确把控,这能有效防止资源过剩或短缺现象…...

Kimi-VL 解读:高效 MoE 视觉语言模型VLM,兼顾长上下文与高分辨率
写在前面:一起读多模态大模型Kimi-VL Moonshot AI 推出了 Kimi-VL,一个高效的、开源的、基于混合专家(MoE)架构的视觉语言模型。Kimi-VL 旨在解决上述痛点,它具备以下几个核心特点: 高效 MoE 架构:语言解码器采用 MoE 架构,在保持强大能力的同时,显著降低了推理时的激…...

2024团体程序设计天梯赛L3-1 夺宝大赛
L3-037 夺宝大赛 分数 30 作者 陈越 单位 浙江大学 夺宝大赛的地图是一个由 nm 个方格子组成的长方形,主办方在地图上标明了所有障碍、以及大本营宝藏的位置。参赛的队伍一开始被随机投放在地图的各个方格里,同时开始向大本营进发。所有参赛队从一个方格…...

SpringBoot DevTools:开发工具与热部署机制
文章目录 引言一、Spring Boot DevTools概述二、自动重启机制2.1 工作原理2.2 自定义重启触发器 三、LiveReload支持3.1 浏览器自动刷新3.2 与前端框架集成 四、属性默认值调整4.1 缓存配置4.2 日志配置 五、远程开发支持5.1 配置远程应用5.2 使用远程客户端 总结 引言 在Java…...

PyCharm 开发工具 修改字体大小及使用滚轮没有反应
PyCharm 开发工具 修改字体大小及使用滚轮没有反应 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是有学习/理解关联性,希望对您有用~ PyCharm 开发工具 修改字体大小及…...

小刚说C语言刷题——每日一题东方博宜1000熟悉OJ环境
1.题目描述 2.参考代码(C语言版) #include <stdio.h> int main(void) { //定义两个整型变量num1和num2 int num1,num2; int sum;//定义两个数的和sum //下面语句表示输入两个数字 scanf("%d%d",&num1,&num2); sumnum1num…...

Ubuntu安装Docker容器,通过Tomcat部署项目
温馨提示:本教程不是最完美的,只能说是填鸭式教育,仅仅让你快速部署Docker的tomcat项目。 *******命令行需要一行一行操作哟!!!******* 一、检查Ubuntu本地的Tomcat能发正常打开项目 1.1 检查本地tomcat是…...

ubuntu22.04安装zabbix7.0
一、安装repository wget https://repo.zabbix.com/zabbix/7.0/ubuntu/pool/main/z/zabbix-release/zabbix-release_latest_7.0ubuntu24.04_all.deb dpkg -i zabbix-release_latest_7.0ubuntu24.04_all.deb apt update二、安装Zabbix server,Web前端,ag…...

AIGC工具平台-建筑平面图3D渲染
本模块是一款智能化的建筑设计辅助工具,可将任意房屋平面设计图快速转换为高品质3D渲染效果图,让建筑设计更加直观、高效。用户无需复杂的3D建模操作,仅需上传房屋平面图,系统即可一键生成符合实际尺度的3D渲染效果,精…...
)
OpenGL学习笔记(立方体贴图、高级数据、高级GLSL)
目录 立方体贴图天空盒环境映射斯涅尔定律(Snells Law)菲涅尔效应(Fresnel Effect)动态环境贴图 高级数据分批顶点属性复制缓冲 高级GLSL顶点着色器变量片段着色器变量接口块Uniform缓冲对象Uniform块布局使用Uniform缓冲测试 Git…...