医学成像中的对比语言-图像预训练模型(CLIP):一项综述|文献速递-深度学习医疗AI最新文献
Title
题目
CLIP in medical imaging: A survey
医学成像中的对比语言-图像预训练模型(CLIP):一项综述
01
文献速递介绍
尽管在过去十年中视觉智能领域取得了重大进展(何恺明等人,2016;塔尔瓦宁和瓦尔波拉,2017;多索维茨基等人,2020;刘等人,2021,2022b),但视觉模型通常仅在视觉模态的注释和任务上进行训练(龙内贝格尔等人,2015;何恺明等人,2017;伊森塞等人,2021;何恺明等人,2021)。尽管其中一些方法已经达到了人类水平的性能,但由于缺乏与人类认知的对齐,它们在分布外的性能仍远不能令人满意(彼得森等人,2019;巴特勒迪等人,2020;盖尔霍斯等人,2020;彼得斯和克里格斯克特,2021)。相比之下,文本监督的形式在语义上自然丰富,并且相应的语言模型,尤其是如今的大型语言模型(图夫龙等人,2023;熊等人,2023;张等人,2023a),通常包含大量的人类水平知识。因此,将文本监督整合到视觉任务中是很直观的想法。 受对比预训练的启发,拉德福德等人(2021)提出了对比语言 - 图像预训练(CLIP),它从文本监督中学习可解释的视觉表示。与大多数仅针对视觉的对比预训练方法(陈等人,2020a;卡龙等人,2021;兹邦塔尔等人,2021)不同,CLIP 同时利用了视觉和语言信息。具体来说,它将文本字幕视为图像的一种语言视角,并期望它与图像在本质上是一致的。因此,它在潜在空间中尽可能拉近成对的图像和文本表示。通过这种方式,图像 - 文本对通过 CLIP 的视觉和文本编码器进行对齐,从而大量的知识被编码在视觉编码器中。受益于图像 - 文本对齐,CLIP 从文本监督中学习了广泛的知识,并已被证明在许多领域都很有用,包括图像生成(温克等人,2022;拉梅什等人,2022;于等人,2022;龙巴赫等人,2022)、分割(李等人,2022a;饶等人,2022;罗等人,2023)、检测(班加拉特等人,2022;林和龚,2023)和分类(周等人,2022b,c;王等人,2023b)。 最近,CLIP 在医学成像领域也受到了越来越多的关注(埃斯拉米等人,2021;王等人,2022e;金等人,2024)。图 1 的左图展示了医学成像领域中与 CLIP 相关论文的增长趋势,从 2021 年下半年到 2023 年下半年呈现出数倍的增长,尤其是在 2023 年呈现出蓬勃发展的趋势。这可以归因于它能够使神经网络与人类认知对齐,满足了医疗保健领域人工智能对可解释性的需求(劳里岑等人,2020;乔亚和关,2020;谢等人,2021)。尽管先前的研究试图通过额外的专家级注释来提高可解释性,例如边界框(罗等人,2022;欧阳等人,2020;谷田等人,2023;米勒等人,2023)和分割掩码(梅塔等人,2018;周等人,2019),但收集这些注释既费力又耗时(拉希米等人,2021;王等人,2022b;曲等人,2023),这使得它们难以大规模应用。相反,在临床实践中由医学专业人员常规生成和收集的文本报告(黄等人,2021;王等人,2022a;谢等人,2023)以很少的额外成本提供了有价值的专家级知识,这使得 CLIP 成为一个更有前景的解决方案。 动机:尽管许多研究致力于为医学图像分析定制 CLIP,但这种定制带来了一些仍未解决的新挑战。为了鼓励和促进医学成像领域中基于 CLIP 的研究,对现有文献进行综述将是有益的。因此,我们广泛回顾了该领域 200 多种现有方法,以提供有见地的综述。 搜索策略:我们在包括谷歌学术、DBLP、arXiv 和 IEEE Xplore 等学术平台上进行搜索。利用“CLIP”、“图像 - 文本对齐”和“医学成像”等关键词,我们的初步探索涵盖了各种来源,如高影响力的期刊论文、会议/研讨会论文以及仍在评审中的预印本。我们排除了仅将 CLIP 用作基线方法的研究以及不专注于医学成像的研究。鉴于在稳定扩散(龙巴赫等人,2022)取得成功后,CLIP 文本编码器已成为扩散模型(卡泽鲁尼等人,2023)中的关键组件,我们也排除了主要关注扩散模型而非 CLIP 的论文。此外,手术视频和超声等成像模态通常以视频片段的形式呈现。因此,一些专注于这些模态的研究被错误检索到,即使它们没有使用与 CLIP 相关的技术。这些误检索的研究经过人工审查后被排除,而确实采用了 CLIP 的相关研究则被保留。应用这些选择标准后,我们确定了总共 224 篇用于本次综述的论文。按各自使用的成像模态分类的所选论文分布如图 1 的右图所示,其中基于 X 射线的研究占大多数。 分类方法:为了简化我们对医学成像领域中与 CLIP 相关工作的讨论,在本次综述中,我们将它们分为两类,即(1)改进的 CLIP 预训练和(2)由 CLIP 驱动的应用,如图 2 所示。第一类研究侧重于将 CLIP 的预训练范式从网络爬取的图像字幕对调整为医学图像及其相应的报告。第二类研究倾向于直接采用预训练的 CLIP 模型,以提高深度学习模型在各种临床任务中的可解释性和鲁棒性,例如胸部疾病诊断和多器官分割(蒂乌等人,2022;佩莱格里尼等人,2023;刘等人,2023g)。 相关综述:有一些与我们的综述范围相似的同期综述。 例如,什雷斯塔等人(2023)的一篇综述论文侧重于医学视觉语言预训练。他们的综述与我们的综述之间的区别在于:(1)他们主要探索各种视觉语言预训练架构,包括掩码预测(卡雷等人,2021)、对比(黄等人,2021)、匹配预测(穆恩等人,2022)和混合架构(王等人,2021a),对 CLIP 风格的对比预训练的关注较少;(2)他们主要关注大规模预训练,缺乏对临床任务的讨论。由于缺乏大规模的公共医学图像 - 文本数据集,他们的综述的影响可能有限。相比之下,我们的综述深入探讨了由 CLIP 驱动的应用,由于对数据的要求较低且对现实世界临床任务具有更多价值,这些应用在现实环境中更可行。此外,阿扎德等人(2023)探索了医学成像中的基础模型,他们的综述论文中也包括了 CLIP。与我们的综述论文的主要区别在于,他们主要涵盖仅视觉、仅语言和视觉 - 语言基础模型,而我们专门关注 CLIP,这是一种视觉 - 语言基础模型。此外,他们的综述也缺乏对临床应用的讨论,而我们对此进行了广泛的涵盖。因此,我们的综述(与上述两篇综述论文相比)将在技术和临床应用方面提供更有见地和更深入的综述。 贡献:总之,我们的贡献如下: - 据我们所知,本文是对医学成像中 CLIP 的首次综述,旨在为这个快速发展领域的潜在研究提供及时的总结和见解。 - 我们全面涵盖了现有研究,并提供了一个多层次的分类方法,以满足读者的不同需求。 - 此外,我们讨论了该领域的问题和开放性问题。我们还指出了新的趋势,并提出了进一步探索的未来方向。 论文结构:本文的其余部分组织如下。第 2 节提供了 CLIP 及其变体的初步知识。在第 3 节中,我们从关键挑战和相应解决方案的角度,对如何使 CLIP 适应医学成像领域进行了系统分析。第 4 节涵盖了预训练 CLIP 的各种临床应用,并将由 CLIP 驱动的方法与早期方法/解决方案进行了比较。第 6 节进一步讨论了现有局限性以及潜在的研究方向。我们最后在第 7 节中对本文进行总结。
Abatract
摘要
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfullyintroduces text supervision to vision models. It has shown promising results across various tasks due to itsgeneralizability and interpretability. The use of CLIP has recently gained increasing interest in the medicalimaging domain, serving as a pre-training paradigm for image–text alignment, or a critical component indiverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, thissurvey offers an in-depth exploration of the CLIP within the domain of medical imaging, regarding both refinedCLIP pre-training and CLIP-driven applications. In this paper, we (1) first start with a brief introduction tothe fundamentals of CLIP methodology; (2) then investigate the adaptation of CLIP pre-training in the medicalimaging domain, focusing on how to optimize CLIP given characteristics of medical images and reports; (3)further explore practical utilization of CLIP pre-trained models in various tasks, including classification, denseprediction, and cross-modal tasks; and (4) finally discuss existing limitations of CLIP in the context of medicalimaging, and propose forward-looking directions to address the demands of medical imaging domain. Studiesfeaturing technical and practical value are both investigated. We expect this survey will provide researcherswith a holistic understanding of the CLIP paradigm and its potential implications. The project page of thissurvey can also be found on Github
对比语言-图像预训练(CLIP)是一种简单却有效的预训练范式,它成功地将文本监督引入到视觉模型中。由于其具有通用性和可解释性,在各种任务中都取得了令人瞩目的成果。最近,CLIP在医学成像领域的应用越来越受到关注,它既可以作为图像-文本对齐的预训练范式,也可以作为各种临床任务中的关键组成部分。为了帮助人们更深入地理解这一充满前景的方向,本次综述对医学成像领域中的CLIP进行了深入探究,内容涵盖了精细的CLIP预训练以及由CLIP驱动的各种应用。在本文中,我们:(1)首先简要介绍CLIP方法的基本原理;(2)接着研究CLIP预训练在医学成像领域的适应性,重点关注如何根据医学图像和报告的特点对CLIP进行优化;(3)进一步探讨CLIP预训练模型在各类任务中的实际应用,这些任务包括分类任务、密集预测任务以及跨模态任务;(4)最后讨论CLIP在医学成像背景下存在的局限性,并提出具有前瞻性的方向,以满足医学成像领域的需求。我们对具有技术价值和实践价值的研究都进行了考察。我们期望本次综述能为研究人员提供对CLIP范式及其潜在影响的全面理解。本次综述的项目页面也可以在GitHub上找到。
Background
背景
CLIP-related research has advanced rapidly in recent years. In thissection, we provide a brief overview of CLIP, as well as its generalizability and multiple variants. Additionally, we summarize datasets ofmedical image–text pairs that are publicly available and usable to CLIP.
2.1. Contrastive language-image pre-training
CLIP (Contrastive Language-Image Pre-training) is a pre-trainingmethod developed by OpenAI, designed to bridge the gap betweenimages and texts. It jointly optimizes a vision encoder and a textencoder, ensuring that image–text pairs are closely aligned in a sharedlatent space. Unlike other methods that rely on extensive manual supervision or complex structures, CLIP follows the principle of Occam’sRazor (Blumer et al., 1987), favoring simplicity for effective results.Architecture.In terms of its architecture, CLIP seamlessly integrates a vision model with a language model. The visual componentcan be based on either ResNet (He et al., 2016) or Vision Transformer(ViT) (Dosovitskiy et al., 2020), while the language encoder is rooted ina transformer-based model like BERT (Kenton and Toutanova, 2019).As illustrated in Fig. 3, it receives a batch of images and their corresponding text descriptions as input in each iteration. Following theencoding process, the embeddings are normalized and mapped to ajoint image–text latent space. That is, the input images and texts areencoded into 𝐼 ∈ R𝑁×𝐷 and 𝑇 ∈ R𝑁×𝐷, respectively, where 𝑁 denotesbatch size and 𝐷 represents embedding dimensionality.
近年来,与对比语言-图像预训练模型(CLIP)相关的研究发展迅速。在本节中,我们将简要概述CLIP,包括它的通用性以及多种变体。此外,我们还将总结可供CLIP使用的公开的医学图像-文本对数据集。 ### 2.1 对比语言-图像预训练 CLIP(对比语言-图像预训练)是由OpenAI开发的一种预训练方法,旨在弥合图像和文本之间的差距。它联合优化一个视觉编码器和一个文本编码器,确保图像-文本对在共享的潜在空间中紧密对齐。与其他依赖大量人工监督或复杂结构的方法不同,CLIP遵循奥卡姆剃刀原则(布鲁默等人,1987),倾向于通过简洁的方式获得有效的结果。 架构:就其架构而言,CLIP将视觉模型与语言模型无缝集成。视觉组件可以基于残差网络(ResNet)(何恺明等人,2016)或视觉Transformer(ViT)(多索维茨基等人,2020),而语言编码器则基于像BERT(肯顿和图托纳娃,2019)这样的基于Transformer的模型。如图3所示,在每次迭代中,它接收一批图像及其相应的文本描述作为输入。在编码过程之后,嵌入向量会被归一化并映射到一个联合的图像-文本潜在空间中。也就是说,输入的图像和文本分别被编码为(I \in \mathbb{R}^{N \times D})和(T \in \mathbb{R}^{N \times D}),其中(N)表示批量大小,(D)表示嵌入向量的维度。
Conclusion
结论
In conclusion, we have presented the first review of the CLIP inmedical imaging. Starting by introducing the foundational conceptsthat underpin CLIP’s success, we then delve into an extensive literature review from two aspects: refined CLIP pre-training methodsand diverse CLIP-driven applications. For refined CLIP pre-trainingmethods, our survey offers a structured taxonomy based on the uniquechallenges that CLIP pre-training owns in the medical imaging domain, aiming to chart a clear pathway for researchers to advancethis field progressively. In exploring diverse CLIP-driven applications,we compare CLIP-related approaches against those solely vision-drivenmethods, emphasizing the added value that pre-trained CLIP modelscould bring. Notably, through thoughtful design, they could serve asvaluable supplementary supervision signals, significantly enhancing theperformance across various tasks. Beyond simply reviewing existingstudies in these two sections, we also discuss common issues, layingthe groundwork for future directions. By illuminating the potential andchallenges of employing CLIP in medical imaging, we aim to pushthe field forward, encouraging innovation and paving the way forhuman-aligned medical AI.
总之,我们首次对对比语言-图像预训练模型(CLIP)在医学成像领域的应用进行了综述。我们从介绍支撑CLIP成功的基础概念入手,然后从两个方面深入进行广泛的文献综述:改进的CLIP预训练方法以及多样的由CLIP驱动的应用。 对于改进的CLIP预训练方法,我们的调研基于CLIP在医学成像领域预训练所面临的独特挑战,提供了一个结构化的分类体系,旨在为研究人员逐步推动这一领域的发展规划一条清晰的道路。在探索多样的由CLIP驱动的应用时,我们将与CLIP相关的方法与那些仅由视觉驱动的方法进行了比较,强调了预训练的CLIP模型所能带来的附加价值。值得注意的是,通过精心的设计,它们可以作为有价值的补充监督信号,显著提升各种任务的性能。 除了简单地回顾这两个部分的现有研究之外,我们还讨论了常见问题,为未来的研究方向奠定基础。通过阐明在医学成像中使用CLIP的潜力和挑战,我们旨在推动该领域的发展,鼓励创新,并为符合人类需求的医学人工智能铺平道路。
Figure
图
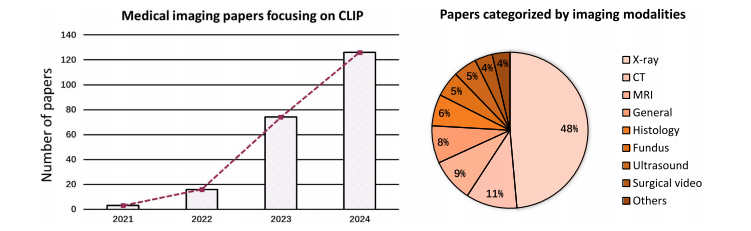
Fig. 1. Left: Rapid increase in medical imaging papers focusing on CLIP. **Right:** Distribution of papers included in this survey, classified by different imaging modalities. Studiesleveraging CLIP for developing generalist medical AI are classified as ‘‘General’’. Imaging modalities rarely used, including placenta, dermoscopy, and electrocardiograms, aregrouped under ‘‘Others’’.
图1. 左侧:专注于对比语言-图像预训练模型(CLIP)的医学成像领域论文数量迅速增长。右侧:本综述所纳入论文按不同成像模态分类的分布情况。利用CLIP开发通用医学人工智能的研究被归类为“通用”类别。较少使用的成像模态,包括胎盘成像、皮肤镜检查以及心电图检查等,被归在“其他”类别下。
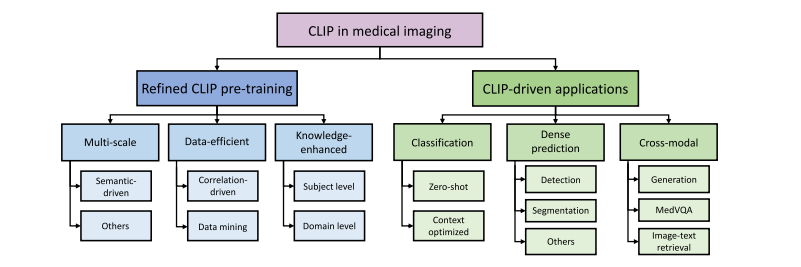
Fig. 2. Taxonomy of studies focusing on CLIP in the field of medical imaging.
图2. 医学成像领域中专注于对比语言-图像预训练模型(CLIP)的研究分类。
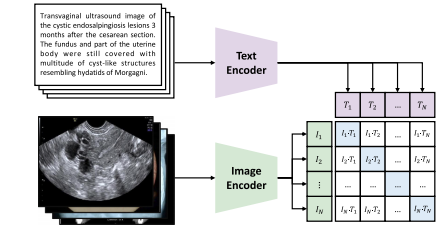
Fig. 3. Illustration of CLIP in medical imaging, with an example from the PMC-OA dataset
图3. 医学成像中对比语言-图像预训练模型(CLIP)的图示说明,以来自PubMed 中心开放获取(PMC-OA)数据集的一个例子进行展示 。
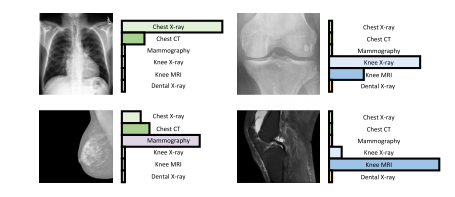
Fig. 4. Illustration of CLIP’s generalizability via domain identification.
图4:通过领域识别来展示对比语言-图像预训练模型(CLIP)通用性的图示。
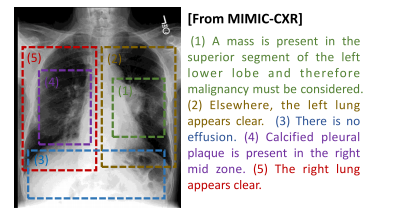
Fig. 5. Demonstration of multi-scale features of medical image–text pairs. The medicalreport is composed of several sentences, with each sentence focusing on region-levelfeatures instead of global-level features. Sentences are independent of each other, andhold different levels of significance.
图5:医学图像-文本对的多尺度特征示例。医学报告由若干句子组成,每一个句子关注的是区域层面的特征,而非全局层面的特征。这些句子相互独立,并且具有不同程度的重要性。
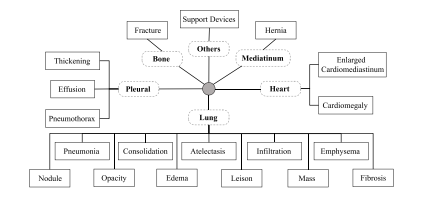
Fig. 6. An illustration of hierarchical dependencies among clinical findings in chest Xrays (sourced from Huang et al. (2023d)). Solid boxes indicate clinical findings whiledotted boxes represent organs or tissues
图6:胸部X光片中临床检查结果之间层级依存关系的图示(源自黄等人(2023d)的研究)。实线框表示临床检查结果,而虚线框代表器官或组织。
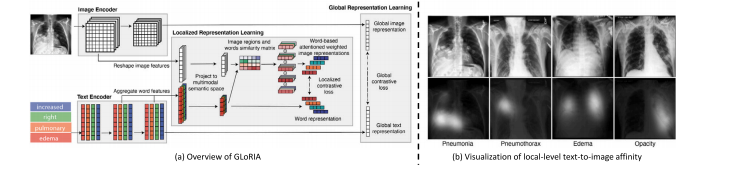
Fig. 7. Illustration of the semantic-driven contrast proposed by GLoRIA (Huang et al., 2021). (a) Overview of GLoRIA, which performs multi-scale image–text alignment based oncross-modal semantic affinity. (b) Visualization of the semantic affinity learned by GLoRIA.
图7:由GLoRIA(黄等人,2021)提出的语义驱动对比的图示。(a)GLoRIA的概述,它基于跨模态语义亲和性来执行多尺度图像-文本对齐。(b)由GLoRIA学习到的语义亲和性的可视化展示。
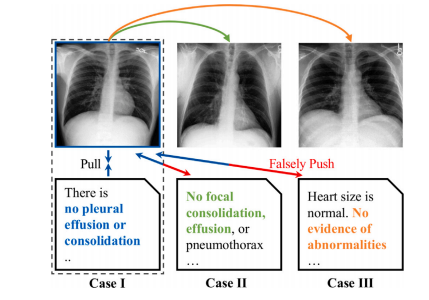
Fig. 8. Illustration of false-negative pairs (Liu et al., 2023a). In CLIP pre-training, apositive pair is defined as an image and its corresponding report, whereas all otherreports are considered negatives. This can result in false negatives, where semanticallysimilar reports from different subjects are mistakenly considered as negative pairs.
图8:假阴性对的图示(刘等人,2023a)。在对比语言-图像预训练模型(CLIP)的预训练过程中,正样本对被定义为一张图像及其对应的报告,而所有其他报告则被视为负样本。这可能会导致假阴性情况的出现,即来自不同主体但语义相似的报告被错误地认定为负样本对。
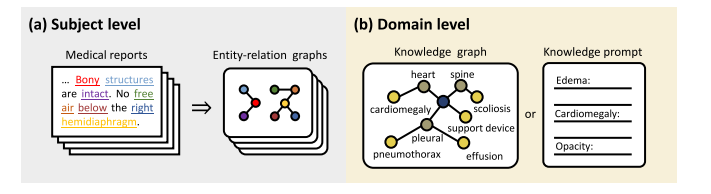
Fig. 9. Illustration of knowledge enhancement at different levels (with the chest X-ray as an example). (a) At the subject level, external knowledge aids in converting medicalreports into entity-relation graphs, which elucidate the causal relationships among medical entities in the report. (b) At the domain level, the domain knowledge is presented asa knowledge graph or descriptive knowledge prompt, directly providing human prior guidance for pre-training
图9:不同层面的知识增强示例(以胸部X光片为例)。(a)在主体层面,外部知识有助于将医学报告转化为实体-关系图,该图阐释了报告中医学实体之间的因果关系。(b)在领域层面,领域知识以知识图谱或描述性知识提示的形式呈现,直接为预训练提供人类先验指导。
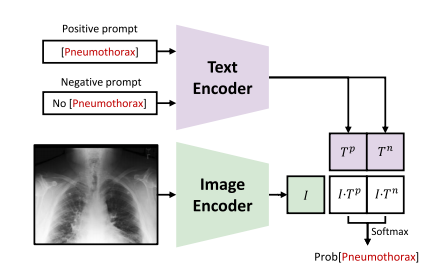
Fig. 10. Illustration of the positive/negative prompt engineering for zero-shot diseasediagnosis. The diagnosis of Pneumothorax is demonstrated here, while other potentialdiseases can also be diagnosed in this way
图10:用于零样本疾病诊断的正/负提示工程图示。此处展示了气胸的诊断过程,其他潜在疾病也可以通过这种方式进行诊断。
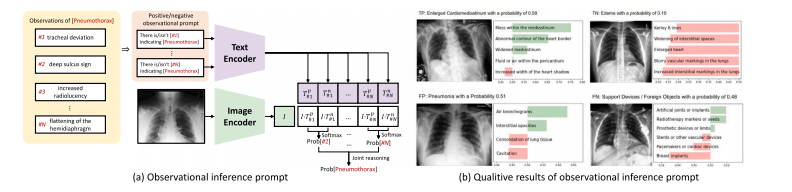
Fig. 11. Overview of Xplainer. (a) Illustration of the observational inference prompt proposed by Xplainer. The diagnosis of Pneumothorax is demonstrated here, while otherpotential diseases can also be implemented in this way. (b) The qualitative results of Xplainer.
图11:Xplainer概述。(a)Xplainer提出的观察性推理提示图示。此处展示了气胸的诊断过程,其他潜在疾病也可以通过这种方式来实现诊断。(b)Xplainer的定性结果。
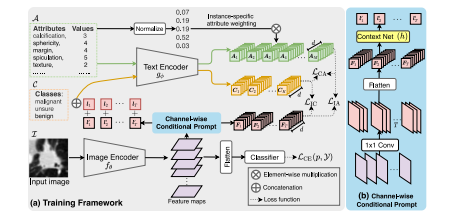
Fig. 12. Context optimization for lung nodule classification.Source: From Lei et al. (2023c)
图12:肺结节分类的上下文优化。来源: 出自雷等人(2023c)的研究
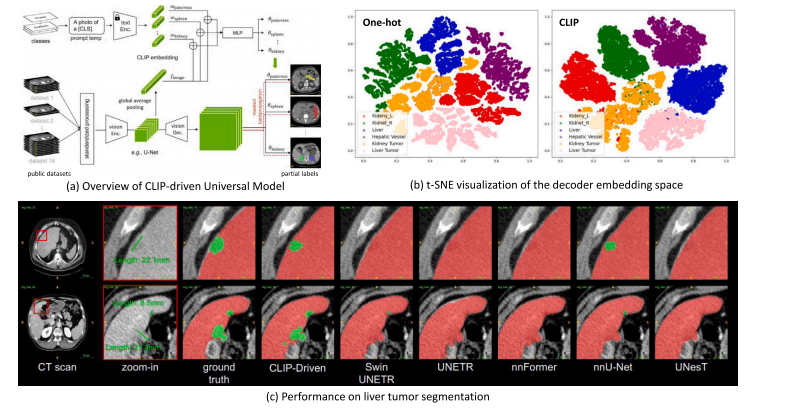
Fig. 13. (a) Overview of CLIP-driven segmentation model for universal segmentation (Liu et al., 2023g). (b) t-SNE visualization of the decoder embedding space between one-shottask encoding and CLIP label encoding. (c) Performance on liver tumor segmentation (green for tumor and red for organ).
图13:(a)用于通用分割的由对比语言-图像预训练模型(CLIP)驱动的分割模型概述(刘等人,2023g)。(b)单样本任务编码和解码器嵌入空间与CLIP标签编码之间的t分布随机邻域嵌入(t-SNE)可视化。(c)肝脏肿瘤分割的性能表现(肿瘤为绿色,器官为红色)。
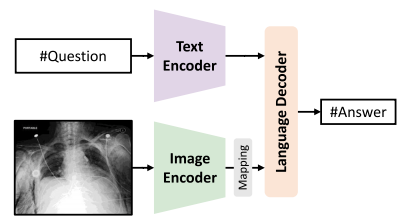
Fig. 14. Illustration of CLIP-driven methods for open-ended MedVQA
图14:由对比语言-图像预训练模型(CLIP)驱动的用于开放式医学视觉问答(MedVQA)方法的图示。
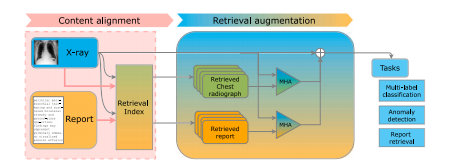
Fig. 15. Architecture overview of X-TRA.Source: From van Sonsbeek and Worring(2023)
图15:X-TRA的架构概述。来源: 出自范·松斯贝克和沃林(2023年)的研究
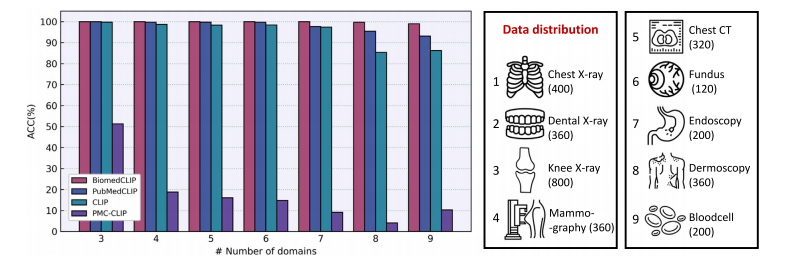
Fig. 16. Quantitative analysis of different CLIP models on the task of domain identification. Pre-trained CLIP models were asked to discriminate the domain of each input imagevia zero-shot inference, which can, to some extent, reflect their understanding of general biomedical knowledge
图16:不同对比语言-图像预训练模型(CLIP)在领域识别任务上的定量分析。要求经过预训练的CLIP模型通过零样本推理来判别每个输入图像的领域,这在一定程度上能够反映它们对一般生物医学知识的理解
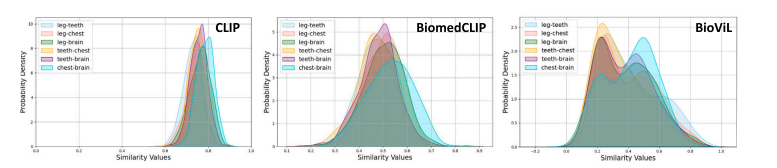
Fig. 17. Comparison between non-domain-specific and domain-specific pre-training. CLIP (OpenAI) tends to present high inter-disease similarity, which is significantly alleviatedin BiomedCLIP and BioViL, revealing the irrationality of adopting CLIP (OpenAI) in medical applications.
图17:非特定领域预训练和特定领域预训练之间的对比。CLIP(OpenAI公司的版本)往往表现出较高的疾病间相似度,而这种情况在BiomedCLIP和BioViL中得到了显著改善,这表明在医学应用中采用CLIP(OpenAI公司的版本)存在不合理性。
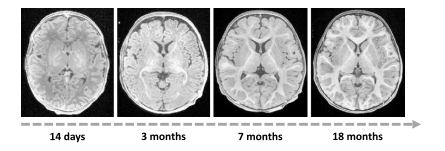
Fig. 18. Illustration of changes in both brain morphology and intensity contrastthroughout infancy
图18: 婴儿期大脑形态和强度对比度变化的图示。
Table
表
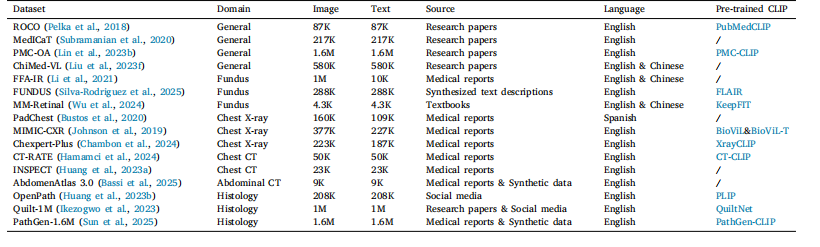
Table 1Summary of publicly available medical image–text datasets
表1 公开可用的医学图像-文本数据集概述
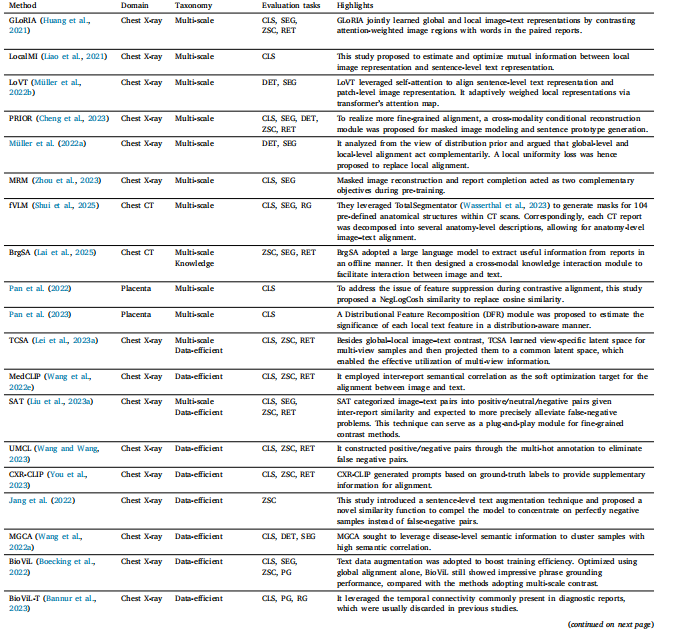
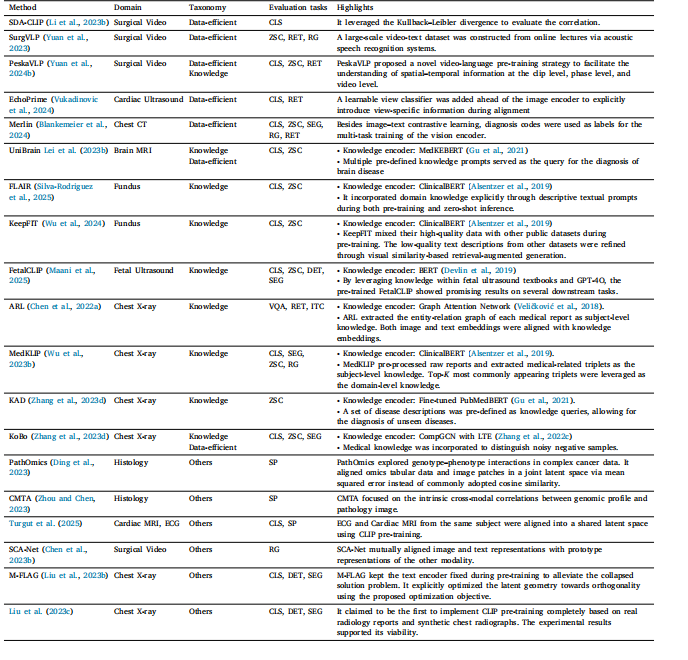
Table 2Overview of representative studies focusing on improving CLIP pre-training framework. CLS: classification; ZSC: zero-shot classification; SEG: segmentation; DET: detection; RET:retrieval; VQA: visual question answering; PG: phrase grounding; RG: report generation; ITC: image–text classification; SP: survival prediction.
表2 专注于改进对比语言-图像预训练模型(CLIP)预训练框架的代表性研究概述。CLS:分类;ZSC:零样本分类;SEG:分割;DET:检测;RET:检索;VQA:视觉问答;PG:短语定位;RG:报告生成;ITC:图像-文本分类;SP:生存预测。
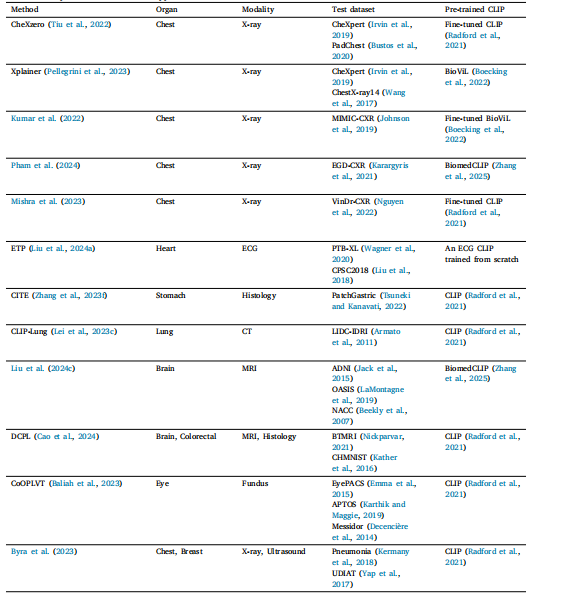
Table 3Overview of representative classification applications.
表3 代表性分类应用概述。
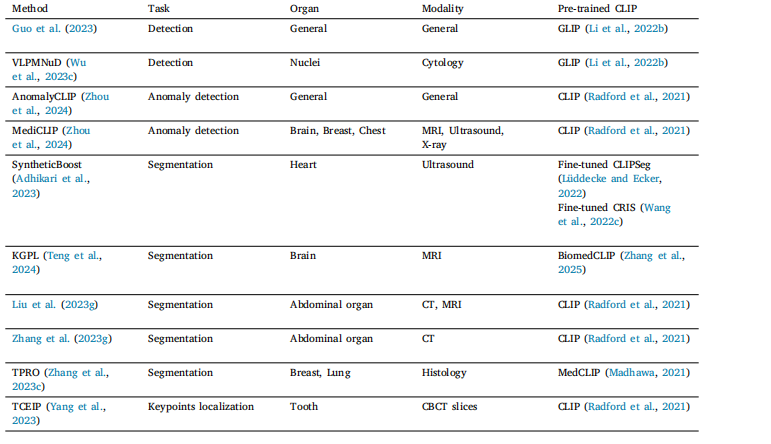
Table 4Overview of representative dense prediction applications.
表4 代表性密集预测应用概述。
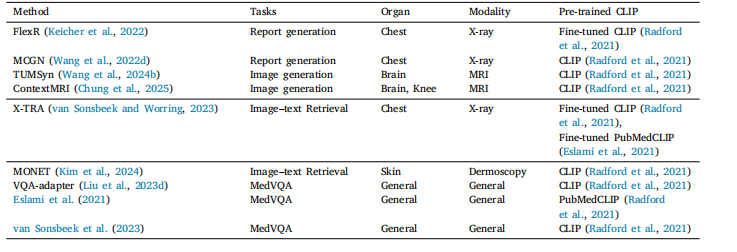
Table 5Overview of representative cross-modality applications
表5 代表性跨模态应用概述。

Table 6Comparison of Multi-modality Large Language Model (MLLM) and CLIP. Fiveaspects, including implementation efficiency, adaptability to different tasks, and userfriendliness were investigated.
表6 多模态大语言模型(MLLM)与对比语言-图像预训练模型(CLIP)的比较。从实施效率、对不同任务的适应性以及用户友好性等五个方面进行了研究。
相关文章:
:一项综述|文献速递-深度学习医疗AI最新文献)
医学成像中的对比语言-图像预训练模型(CLIP):一项综述|文献速递-深度学习医疗AI最新文献
Title 题目 CLIP in medical imaging: A survey 医学成像中的对比语言-图像预训练模型(CLIP):一项综述 01 文献速递介绍 尽管在过去十年中视觉智能领域取得了重大进展(何恺明等人,2016;塔尔瓦宁和瓦尔…...

KEGG注释脚本kofam2kegg.py--脚本010
采用kofam结合kegg官网htxt进行注释 用法: python kofam2kegg.py kofam.out ath00001.keg my_kegg_output code: import sys from collections import defaultdictdef parse_kofam_file(kofam_file):ko_to_genes defaultdict(list)with open(kofam_file) as f:…...

hevc编码芯片学习-VLSI实现
在Fan等工作中,根据特定算法设计了整像素运动估计引擎,最终的BD-Rate损失非常小,但是硬件开销比较大,搜索算法缺少灵活性,本次设计优化了硬件设计架构, 微代码 取像素 压缩 水平参考像素存储器 寻址控制 转…...

选导师原理
总述 一句话总结:是雷一定要避,好的一定要抢。方向契合最好,不契合适当取舍。 首先明确自身需求: 我要学东西!青年导师,好沟通,有冲劲,高压力。 我要摆烂!中老年男性教…...

2.5亿像素卷帘快门CMOS大幅面扫描相机
规格说明书 主要特征 ◎ 卷帘快门CMOS 传感器 ◎ 2.46 亿像素分辨率 ◎ 全分辨率最高帧率达5fps ◎ 高灵敏度及低噪声 ◎ ROI 区域设置 ◎ 曝光时间灵活控制(外触发,自由运行) ◎ 输出像素格式8/10/12bit 可选 ◎ 自动坏像素校正、平场校正…...
友元和内部类)
CD27.【C++ Dev】类和对象(18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...

企业级硬盘的测试流程
测试硬盘流程 找一个有Linux操作系统的服务器,配置好管理ip的接口,连接上linux服务器,执行lsblk命令来查看设备的情况 使用mkfs命令格式化要测试的硬盘,格式化之前务必把数据进行备份,可以使用blkid命令查看硬盘的文件…...

std::enable_shared_from_this 模板类的作用是什么?
我们以Connection类的shared智能指针为例说明,std::enable_shared_from_this<Connection> 是一个标准库模板类,它的作用是让一个类的对象能够安全地生成指向自身的 std::shared_ptr,即使该对象最初是通过普通指针或其他方式创建的。 作…...

鸿蒙开发-ArkUi控件使用
2.0控件-按钮 2.1.控件-文本框 Text(this.message).fontSize(40) // 设置文本的文字大小.fontWeight(FontWeight.Bolder) // 设置文本的粗细.fontColor(Color.Red) // 设置文本的颜色------------------------------------------------------------------------- //设置边框Tex…...

大数据学习栈记——MongoDB编程
本文介绍NoSQL技术:MongoDB用Java来连接数据库,执行常见的数据库操作,使用环境:IntelliJ IDEA、Ubuntu24.04。 配置Maven 我们需要使用“MongoDB Driver”,所以先打开“MongoDB Java Driver”项目,但是提…...
:A Machine-Learning-Guided Framework for Fault-Tolerant DNNs)
体系结构论文(六十七):A Machine-Learning-Guided Framework for Fault-Tolerant DNNs
A Machine-Learning-Guided Framework for Fault-Tolerant DNNs DATE 2024 研究动机 深度神经网络(DNN)虽然对某些扰动具有天然的容错性,但在面对硬件故障(如软错误、老化、环境干扰等)时,仍会出现输出错…...

qt designer 创建窗体选择哪种屏幕大小
1. 新建窗体时选择QVGA还是VGA 下面这个图展示了区别 这里我还是选择默认,因为没有特殊需求,只是在PC端使用...

游戏引擎学习第225天
只能说太难了 回顾当前的进度 我们正在进行一个完整游戏的开发,并在直播中同步推进。上周我们刚刚完成了过场动画系统的初步实现,把开场动画基本拼接完成,整体效果非常流畅。看到动画顺利呈现,令人十分满意,整个系统…...

sql工具怎么选最适合自己的?
sql工具怎么选? 为什么大多数主流工具又贵又难用?有没有一款免费好用的sql工具?像大多数朋友经常用的sql工具应该都遇到过这种情况,用着用着收到了来自品牌方的律师函,或者处理数据时经常卡死,再或者不支持…...

css实现一键换肤
实现一键换肤的时候,我们除了动态替换引用的css文件,还可以通过使用css变量的方式,达到所需效果。 首先我们来了解css变量,css变量以--开头,引用时va(--变量名),例 :root{--default-color: #fff; } .box{b…...
从算法仿真到工程源码实现-第八节-波束图)
波束形成(BF)从算法仿真到工程源码实现-第八节-波束图
一、概述 本节对MVDR、LCMV、LMS等算法的波束图进行仿真。 二、MVDR代码仿真 2.1 mvdr代码 clc; clear; M 18; % 天线数 lambda 10; d lambda / 2; L 100; %快拍数 thetas [10]; % 期望信号入射角度 thetai [-30 30]; % 干扰入射角度 n [0:M-1]; vs exp(-1j * 2…...

静态代码深度扫描详解
静态代码深度扫描是一种通过分析源代码结构、语法、语义及潜在逻辑,在不运行程序的情况下全面检测代码缺陷、安全漏洞和质量问题的技术。它通过结合数据流分析、控制流分析、符号执行等高级技术,实现对代码的深度理解,帮助开发团队在早期发现…...
)
LC25. K 个一组翻转链表(自己用)
25. K 个一组翻转链表 Java代码: 思路:利用虚拟头节点结合反转链表实现 Code: class Solution {public ListNode reverseKGroup(ListNode head, int k) {ListNode dummy new ListNode(0);if (head null || k 1)return head;ListNode…...

Spring事务同步器在金融系统中的应用:从风控计算到交易投递
一句话总结 通过 TransactionSynchronization 机制,成功将投行交易系统的可靠性提升至金融级要求,并在对公贷款风控中实现高效资源管理。未来,事务管理将不仅仅是“提交”与“回滚”的二元选择,而是向智能化、实时化演进的核心基础设施。 1. 架构设计 1.1 整体架构图 2.…...

sealos跳转到cusor安装出错
第一次打开cursor安装出错怎么办 我出现这个问题的解决方式是重新下载并且切换目录解决...
)
【CUDA 】第3章 CUDA执行模型——3.5循环展开(1)
CUDA C编程笔记 第三章 CUDA执行模型3.5 循环展开3.5.1 展开的规约 待解决的问题: 第三章 CUDA执行模型 3.5 循环展开 循环展开是一种循环优化的技术,通过减少分支出现频率循环维护指令。 循环主体代码被多次编写,任何封闭的循环可以把迭代…...

AndroidStudio编译报错 Duplicate class kotlin
具体的编译报错信息如下: Duplicate class kotlin.collections.jdk8.CollectionsJDK8Kt found in modules kotlin-stdlib-1.8.10 (org.jetbrains.kotlin:kotlin-stdlib:1.8.10) and kotlin-stdlib-jdk8-1.6.21 (org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.6.21) D…...

LeetCode hot 100—搜索二维矩阵
题目 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 fa…...
)
栈与队列习题分享(精写)
最小栈 题解 一、题目描述 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。 void push(int val) 将元素 val 推入堆栈。 void pop() 删除堆栈顶部的元素。 int…...

Kotlin 集合过滤全指南:all、any、filter 及高级用法
在 Kotlin 中,集合过滤是数据处理的核心操作之一。无论是简单的条件筛选,还是复杂的多条件组合,Kotlin 都提供了丰富的 API。本文将详细介绍 filter、all、any、none 等操作符的用法,并展示如何在实际开发中灵活运用它们。 1. 基础…...
)
【lerobot】3-开源SO-100 主从臂的舵机位置校正、遥控操作(ubuntu系统)
官方从零教程:https://github.com/huggingface/lerobot/blob/main/examples/10_use_so100.md 8-lerobot aloha装配完毕如何进行遥操作 需要先完成的 组装好了so-100 2个机械臂下载安装了lerobot的代码环境:固定好主从臂,通过usb链接到同一个…...

影刀RPA证书题库包含初级、中级、高级和AP初级
影刀rpa初级证书选择题答案,影刀证书答案,影刀rpa考试,影刀初级考试,影刀初级考试选择题 原因 以前的在线题库https://exam.ezrpa.store/是为了方便更新题目和使用的,但经过实际使用发现大部分人“不会用”࿱…...
)
LR(0)
LR0就是当我处在自动机为红色这些结束状态的时候,这些红色状态就代表我们识别到了一个句柄,那现在的问题就是识别到了句柄,那要不要对他进行归约?LR0就是我不管当前指针指向的终结符是什么,我都拿它做规约 这里的二号状…...
)
基于 Python 和 OpenCV 技术的疲劳驾驶检测系统(2.0 全新升级,附源码)
大家好,我是徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。 🍅文末获取源码联系🍅 2025年最全的计算机软件毕业设计…...

Matplotlib库详解
Matplotlib 是 Python 里一个特别常用的绘图库,它能帮你创建各种各样的可视化图形,像折线图、柱状图、散点图等。对于数据可视化、数据分析和科学研究而言,它是非常重要的工具。接下来我会以初学者的视角,为你详细介绍 Matplotlib…...

daz dForce to UE 的原理分析
dForce是物理模拟,不是关键帧动画: dForce是一个物理引擎。当你运行模拟时,Daz Studio会根据你设置的物理属性(如裙子的重量、布料的硬度、摩擦力)、环境因素(如重力、风力)以及与角色的碰撞&am…...

速卖通商品详情API接口:功能、应用与开发指南
前言 在全球跨境电商蓬勃发展的背景下,速卖通(AliExpress)作为阿里巴巴旗下的国际电商平台,凭借丰富的商品种类和庞大的用户群体,成为众多商家和开发者拓展海外市场的首选平台。为了满足商家和开发者对商品数据的深度…...

4月14日星期一今日早报简报微语报早读
4月14日星期一,农历三月十七,早报#微语早读。 1、全国田径大奖赛接力摘金,苏炳添的传奇将延续至全运会; 2、中国红基会:2024年全年总收支12.85亿元; 3、我国2025年电影总票房已突破250亿 位居全球第一&a…...
)
快速排序(非递归版本)
引言 在排序算法的世界里,快速排序以其高效的性能脱颖而出。它采用分治法的思想,通过选择基准元素将数组分为两部分,递归地对左右两部分进行排序。然而,递归实现的快速排序在处理大规模数据时可能会导致栈溢出的问题。为了解决这…...

Ubuntu20.04 设置开机自启
参考: Ubuntu20.04 设置开机自启_ubuntu进bos系统-CSDN博客...

添加登录和注册功能
先写前端再写后端 前提:ideavue3mybatisspringBoot3前后端分离实现对一张表的增删改查(完整代码版)-CSDN博客 项目地址 1.添加一个Login.vue视图 <template><div class"login_container"><div class"login…...

弱口令爆破
1.简单介绍 弱口令是指一些简单易猜的密码,可通过社工方式和一些爆破工具进行破解,以下介绍一款爆破工具的用法。burpsuite简称BP,一款可以利用字典破解账户密码的工具。 2.部署网站 可以使用PHPstudy的Apache服务,也可以使用I…...
)
springboot调用python文件,在ubuntu上部署,踩坑之旅(已部署成功)
项目介绍 springboot 调用python文件,python调用另一个数据文件,然后计算出结果,看似简单,实际上有很多坑,因为涉及到python的三方库,有时候下载不下来,有时候版本不匹配,折腾了好久…...

Android studio消息同步机制:消息本地存储,服务器交互减压
文章目录 后端(Flask)代码前端(Android Studio Java)代码 消息同步机制: 手机端可以将消息存储在本地数据库中,减少与服务器的交互压力。同时,通过序列号机制,手机端可以与服务器同步消息&#…...

前端常用组件库全览与推荐
📌 一、组件库生态全景图 🚀 二、React 生态组件库推荐 名称简介官网Ant Design阿里出品,企业级 UI 系统,设计规范完整,适合后台系统https://ant.designMaterial UIGoogle Material Design 实现,样式响应式…...

视觉算法+雾炮联动:开创智能降尘新时代
在许多工业环境中,尤其是那些涉及大量物料搬运和处理的地方,如工厂或仓库,扬尘问题是一个普遍存在的挑战。这不仅影响了工作人员的工作条件,还可能构成健康和安全隐患。为了改善这一状况,不少业主采用了物理方法来减少…...

【Pandas】pandas DataFrame items
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

易境通WMS系统代理仓解决方案:让代理仓管理无后顾之忧!
易境通WMS系统代理仓解决方案:让代理仓管理无后顾之忧! 对于海外仓企业而言,除了自有仓库外,为了业务发展还会同时代理其他仓库,于是经常会面临主仓代理仓数据同步问题及费用问题。此外,由于个仓库分布较广…...

【智驾中的大模型 -2】VLM 在自动驾驶中的应用
1. 前言 随着端到端 AI 和多模态学习的迅猛发展,VLM(视觉-语言模型)在自动驾驶领域中的应用正逐渐成为一个备受瞩目的重要研究方向。VLM 凭借其强大的融合能力,将视觉(如高清晰度的摄像头图像、精准的雷达数据&#x…...

L1-104 九宫格
L1-104 九宫格 - 团体程序设计天梯赛-练习集 九宫格是一款数字游戏,传说起源于河图洛书,现代数学中称之为三阶幻方。游戏规则是:将一个 99 的正方形区域划分为 9 个 33 的正方形宫位,要求 1 到 9 这九个数字中的每个数字在每一行…...
-part2)
图像预处理(OpenCV)-part2
4 边缘填充 为什么要填充边缘呢?我们以下图为例。 原图旋转后的图 可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进…...

SpringAI-ollama
SpringAi主要依赖 System Prompt :设置提示词 用来预设角色 ConversationMemory: 对话集 RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接 Function Calling 用来调用自己的api <dependencyManagement>&…...

如何在Windows 10系统中查看已连接WiFi密码-亲测可用-优雅草卓伊凡
如何在Windows 10系统中查看已连接WiFi密码-亲测可用-优雅草卓伊凡 通过系统设置查看 点击屏幕左下角的“开始”按钮,打开“设置”应用。在“设置”应用中,点击“网络和 Internet”。在“网络和 Internet”页面中,点击“WLAN”,…...

蓝耘赋能通义万相 2.1:用 C++ 构建高效 AI 视频生成生态
开篇:AI 视频生成新时代的号角 通义万相 2.1:AI 视频生成的领军者 核心技术揭秘 功能特点展示 与其他模型的全面对比 C:高效编程的基石 C 的发展历程与特性 C 在 AI 领域的广泛应用 通义万相 2.1 与 C 的完美融合 融合的意义与价值 …...

tmpfs的监控筛选/dev/shm下的shmem创建
一、背景 在一个比较注重性能的系统上,共享内存的使用肯定非常普遍。为了能更好的了解系统里共享内存的使用,比如创建、删除等操作,我们是可以对其进行监控的。 这篇博客以共享内存的创建监控为例来介绍如何监控共享内存。 这里有一个概念…...