LINUX基础 [四] - Linux工具
目录
软件包管理器yum
Linux开发工具vim
vim的基本概念
vim的三种常用模式
vim的简单配置
vim常用模式的基本操作
命令模式
底行模式
处理vim打开文件报错的问题
Linux编译器-gcc/g++使用
为什么我们可以用C/C++做开发呢?
预处理(进行宏替换)
编译(生成汇编)
汇编(生成机器可识别代码)
链接(生成可执行文件或库文件)
.o和库是如何链接的(静态链接和动态链接)
动态库文件和静态库文件
动态库和静态库理解
控制链接方式的选择
动态链接和静态链接的优缺点
Linux调试器 - gdb
gdb使用须知
gdb命令汇总
Linux项目自动化构建工具 - make/Makefile
依赖关系和依赖方法
多文件编译
make原理
项目清理
为什么不会允许多次make呢??(重点)
stat指令
Linux第一个小程序 - 进度条
行缓冲区的概念
\r和\n
软件包管理器yum
Linux开发工具vim
vim的基本概念
vim在我们做开发的时候,主要解决我们编写代码的问题,本质上就是一个多模式的文本编辑器。
每个Linux账户都独有一个vim编辑器。
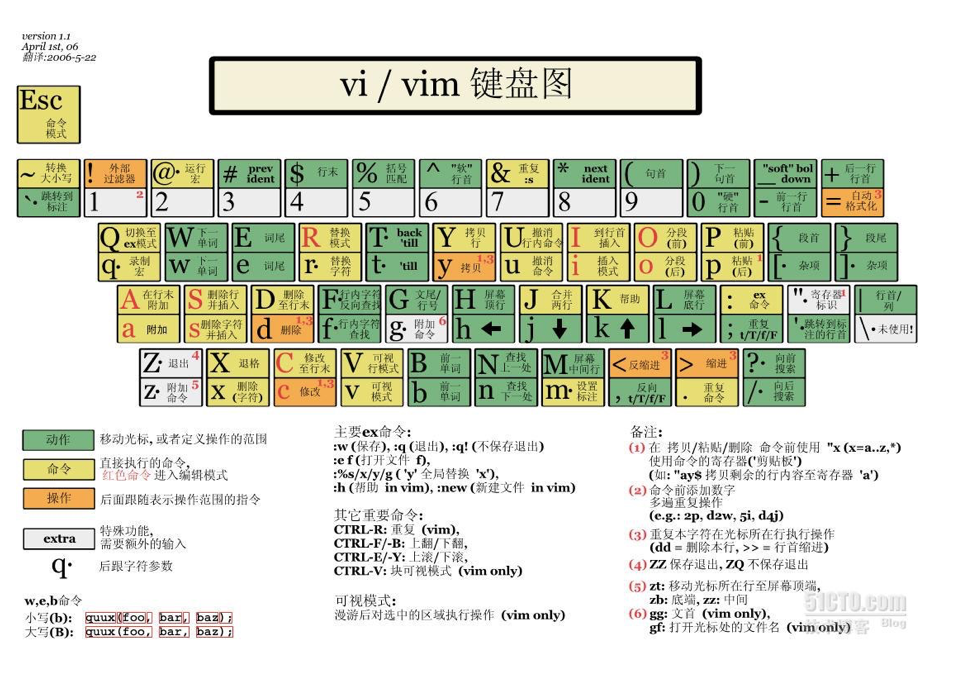

vim的三种常用模式
创建vim文件:vim 文件名 (如果该文件没有创建,必须保存后才会创建出来)
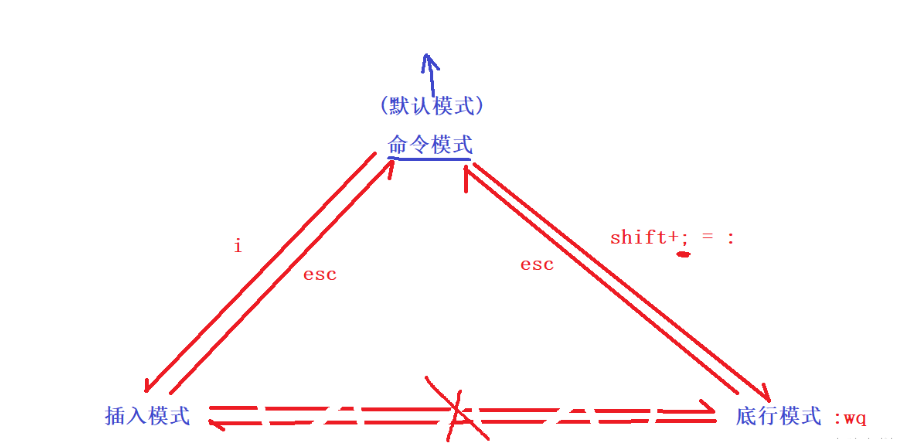
vim最常用的三种模式:命令模式(command mode)、底行模式(last line mode)、插入模式(insert mode)
命令模式
每次打开 vim 编辑器,默认进入的就是命令行模式

命令行模式下无法在打开的文件里插入任何数据,只能执行对应的指令
底行模式
底行模式由命令模式进入 ,输入:(即shift+;)

:是提示符,表示当前处于底行模式
从底行模式退出,按 ESC键 即可。且退出到命令模式
插入模式
插入模式由命令模式进入,输入‘i’


INSERT是提示符,表示当前处于插入模式
只有在插入模式下才可以对打开的文件进行写操作,即编写程序
从插入模式退出,按 ESC键即可。且退出到命令模式
三种模式的相互转换
vim的简单配置
【配置文件的位置】
- 在目录/etc/下面,有个名为vimrc的文件,这是系统中公共的配置文件,对所有用户都有效。
- 在每个用户的主目录/home/xxx下,都可以自己建立私有的配置文件,命名为“.vimrc”,这是该用户私有的配置文件,仅对该用户有效。
例如,普通用户在自己的主目录下建立了“.vimrc”文件后,在文件当中输入set nu指令并保存,下一次打开vim的时候就会自动显示行号。
vim的配置比较复杂,某些vim配置还需要使用插件,建议不要自己一个个去配置。比较简单的方法是直接执行以下指令(想在哪个用户下让vim配置生效,就在哪个用户下执行该指令,不推荐直接在root下执行):
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh然后按照提示输入root密码:
然后等待安装配置,最后手动执行source ~/.bashrc即可。

配置完成后,像什么自动补全、行号显示以及自动缩进什么的就都有了。
vim常用模式的基本操作
命令模式
【移动光标】
1)按「k」:光标上移。
2)按「j」:光标下移。
3)按「h」:光标左移。
4)按「l」:光标右移。
5)按「$」:移动到光标所在行的行尾。
6)按「^」:移动到光标所在行的行首。
7)按「gg」:移动到文本开始。
8)按「Shift+g」:移动到文本末尾。
9)按「n+Shift+g」:移动到第n行行首。
10)按「n+Enter」:当前光标向下移动n行。
11)按「w」:光标从左到右,从上到下的跳到下一个字的开头。
12)按「e」:光标从左到右,从上到下的跳到下一个字的结尾。
12)按「b」:光标从右到左,从下到上的跳到上一个字的开头
【删除】
1)按「x」:删除光标所在位置的字符。
2)按「nx」:删除光标所在位置开始往后的n个字符。
3)按「X」:删除光标所在位置的前一个字符。
4)按「nX」:删除光标所在位置的前n个字符。
5)按「dd」:删除光标所在行。
6)按「ndd」:删除光标所在行开始往下的n行。
【复制粘贴】
1)按「yy」:复制光标所在行到缓冲区。
2)按「nyy」:复制光标所在行开始往下的n行到缓冲区。
3)按「yw」:将光标所在位置开始到字尾的字符复制到缓冲区。
4)按「nyw」:将光标所在位置开始往后的n个字复制到缓冲区。
5)按「p」:将已复制的内容在光标的下一行粘贴上。
6)按「np」:将已复制的内容在光标的下一行粘贴n次。
【剪切】
1)按「dd」:剪切光标所在行。
2)按「ndd」:剪切光标所在行开始往下的n行。
3)按「p」:将已剪切的内容在光标的下一行粘贴上。
4)按「np」:将已剪切的内容在光标的下一行粘贴n次。
【撤销】
1)按「u」:撤销。
2)按「Ctrl+r」:恢复刚刚的撤销。
【大小写切换】
1)按「~」:完成光标所在位置字符的大小写切换。
2)按「n~」:完成光标所在位置开始往后的n个字符的大小写切换。
【替换】
1)按「r」:替换光标所在位置的字符。
2)按「R」:替换光标所到位置的字符,直到按下「Esc」键为止。
【更改】
1)按「cw」:将光标所在位置开始到字尾的字符删除,并进入插入模式。
2)按「cnw」:将光标所在位置开始往后的n个字删除,并进入插入模式。
【翻页】
1)按「Ctrl+b」:上翻一页。
2)按「Ctrl+f」:下翻一页。
3)按「Ctrl+u」:上翻半页。
4)按「Ctrl+d」:下翻半页。
底行模式
在使用底行模式之前,记住先按「Esc」键确定你已经处于命令模式,再按「:」即可进入底行模式。
【行号设置】
1)「set nu」:显示行号。
2)「set nonu」:取消行号。
【保存退出】
1)「w」:保存文件。
2)「q」:退出vim,如果无法离开vim,可在「q」后面跟一个「!」表示强制退出。
3)「wq」:保存退出。
【分屏指令】
1)「vs 文件名」:实现多文件的编辑。
2)「Ctrl+w+w」:光标在多屏幕下进行切换。
【执行指令】
1)「!+指令」:在不退出vim的情况下,可以在指令前面加上「!」就可以执行Linux的指令,例如查看目录、编译当前代码等。
处理vim打开文件报错的问题
如果我们在用vim编辑器处理文件时错误的退出当前的编辑(例如直接关闭云服务器或者虚拟机),那么再次用vim打开相同的文件时,就会出现如下报错信息:
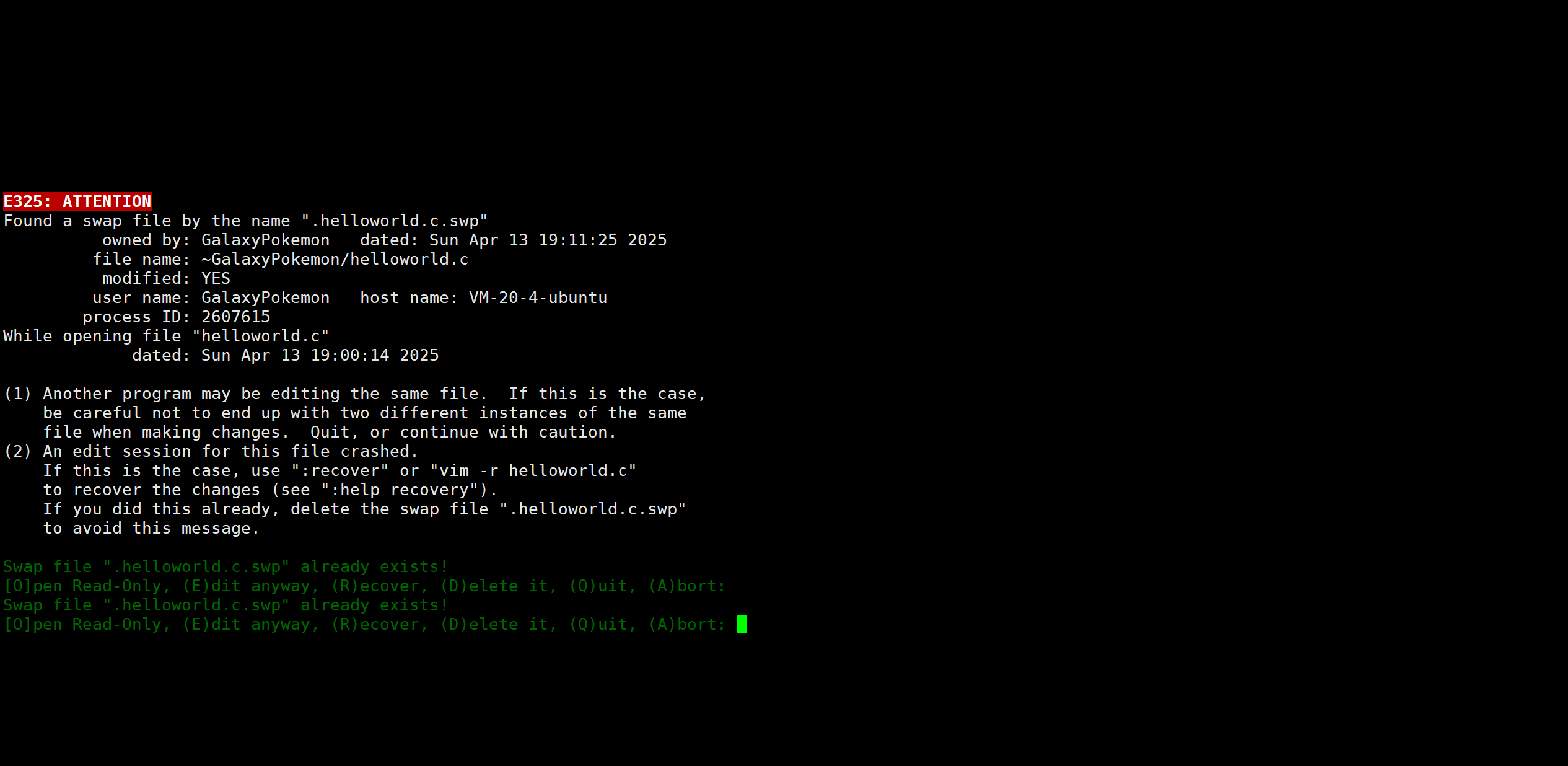
我们按如下的步骤解决:
- 第一步:选择R(ecover)选项,即输入字符e,之后会进入vim编辑器,直接进入底行模式正常退出即可
- 第二步:继续用vim打开该文件,此时同样会弹出相同的报错信息,这次选择(D)elele it选项,即输入字符d,之后就会进入vim编辑器,此时问题已经得到解决,可以正常进行编写代码了。
Linux编译器-gcc/g++使用
为什么我们可以用C/C++做开发呢?
无论是在windows、还是Linux中,C++的开发环境不仅仅指的是vs、gcc、g++,更重要的是语言本身的头文件(函数的声明)和库文件(函数的实现)。所以我们在安装这些软件的时候,同时也选择了相关的开发包,会同步下载对应的头文件和库文件。
所以任何一款编译型语言的使用,都必要需要安装相应的开发包(头文件和库文件)
查看头文件:ls /usr/include/
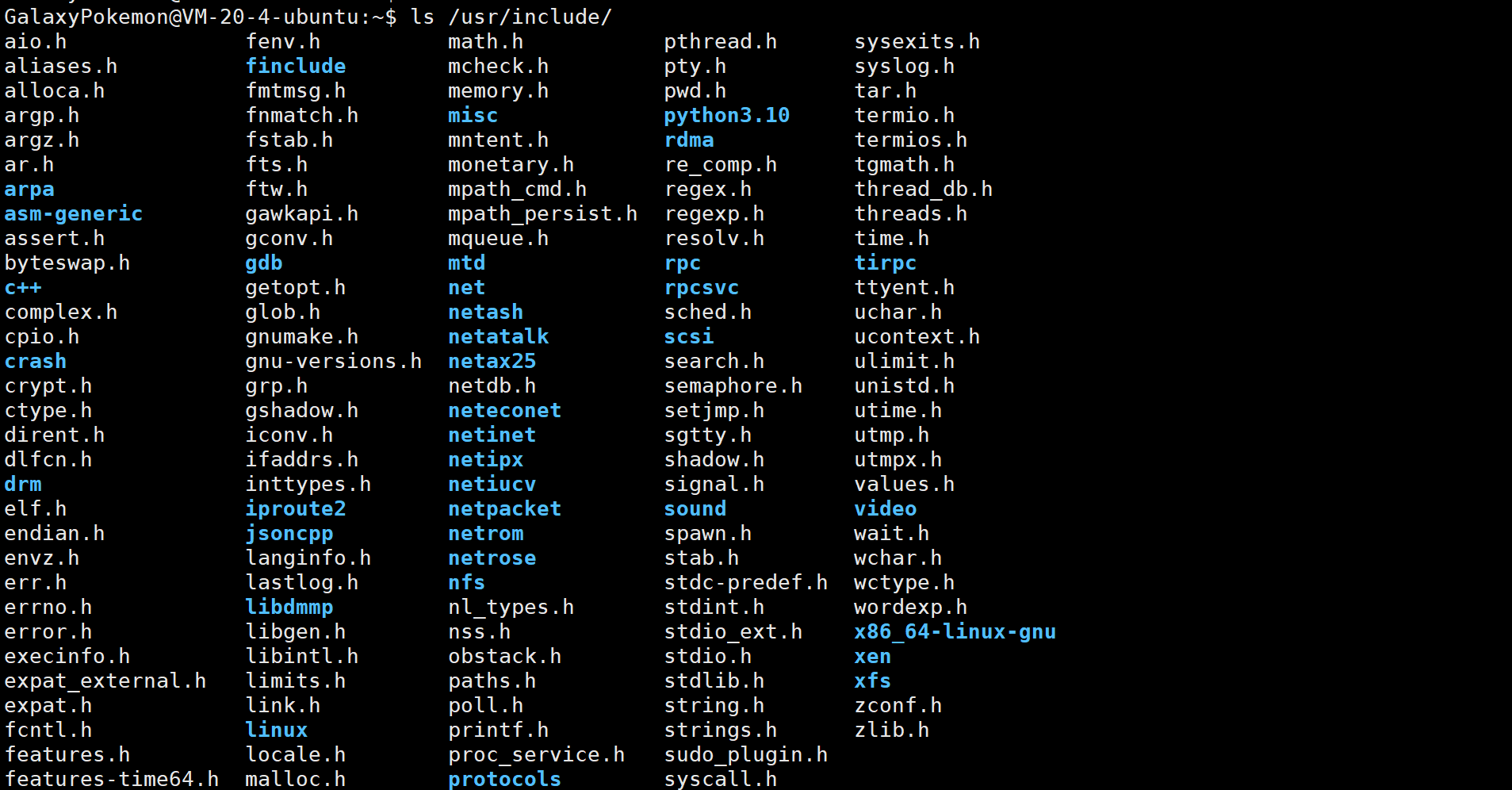
预处理(进行宏替换)
预处理阶段会涉及到很多操作
去注释
注释我们一般用于对我们的代码进行解释说明,但并不参与编译,所以是可以直接去掉的,节省文件的大小。
头文件展开
头文件里面包含了我们需要的一些函数的声明,由于在链接之前各个文件都是独立进行编译和转汇编的,所以头文件将函数声明展示出来其实就是为了在编译过程的时候告诉编译器,这个函数是存在的,一定要放行,而最后的函数定义一般得等到链接的时候才能找到。
条件编译
条件编译其实就是有选择的编译,比较常见的一种情况比如说我们要通过打印来观察代码的运行情况(调试),但是仅仅只是为了起到一个调试的作用,所以我们调试后还要删掉其实有点可惜,所以我们可以通过条件编译来对他进行保留,在必要的时候启动这段代码或者是去掉这段代码。
gcc -E test.c -o test.i告诉gcc,从现在开始进行程序编译,从预处理工作就停下来,不要往前走了
- 预处理功能主要包括头文件展开、去注释、宏替换、条件编译等。
- 预处理指令是以#开头的代码行。
- -E选项的作用是让gcc/g++在预处理结束后停止编译过程。
- -o选项是指目标文件,“xxx.i”文件为已经过预处理的原始程序。
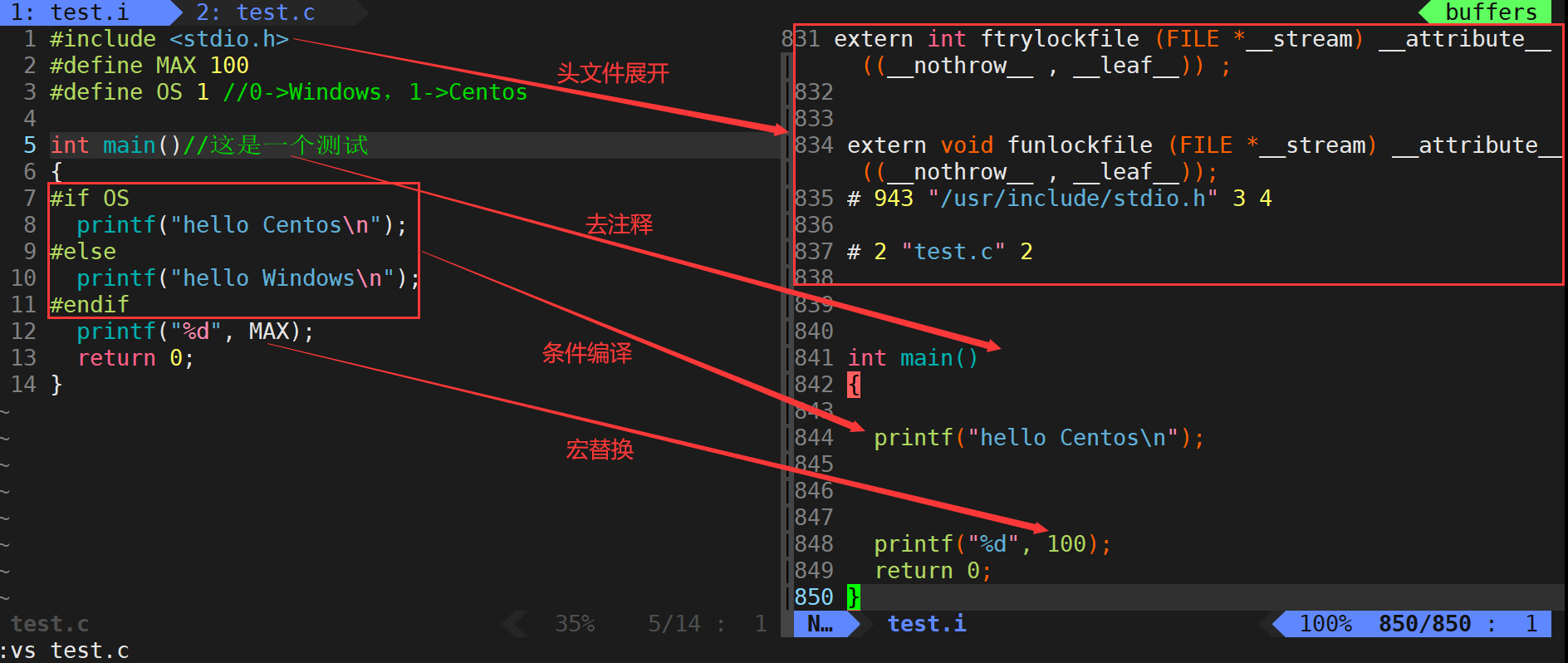
编译(生成汇编)
gcc -S test.i -o test.s告诉gcc,从现在开始进行程序编译,将编译过程做完就停下来
- 在这个阶段中,gcc/g++首先检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,将代码翻译成汇编语言。
- 用户可以使用-S选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
- -o选项是指目标文件,“xxx.s”文件为已经过翻译的原始程序。
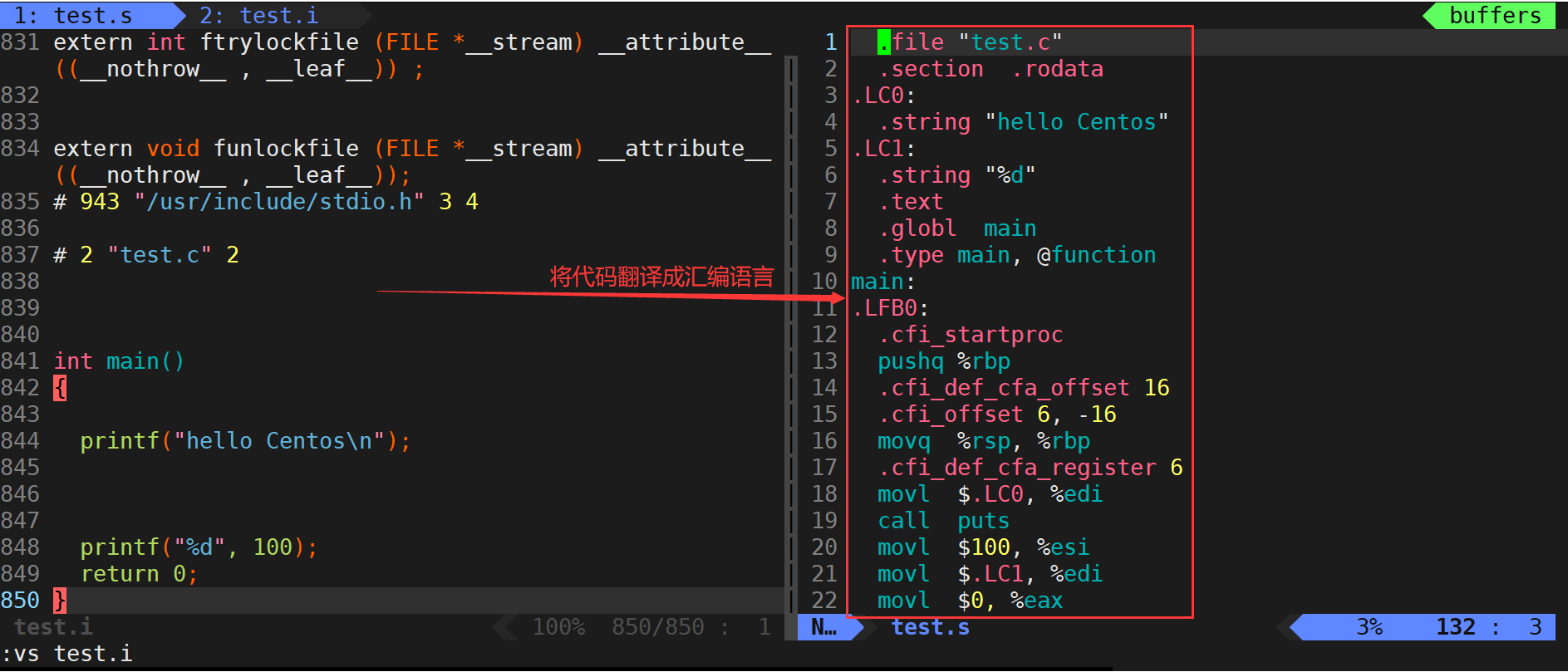
汇编(生成机器可识别代码)
gcc -c test.s -o test.o- 汇编阶段是把编译阶段生成的“xxx.s”文件转成目标文件。
- 使用-c选项就可以得到汇编代码转化为“xxx.o”的二进制目标代码了。
告诉gcc,从现在开始进行程序编译,汇编结束就停下来
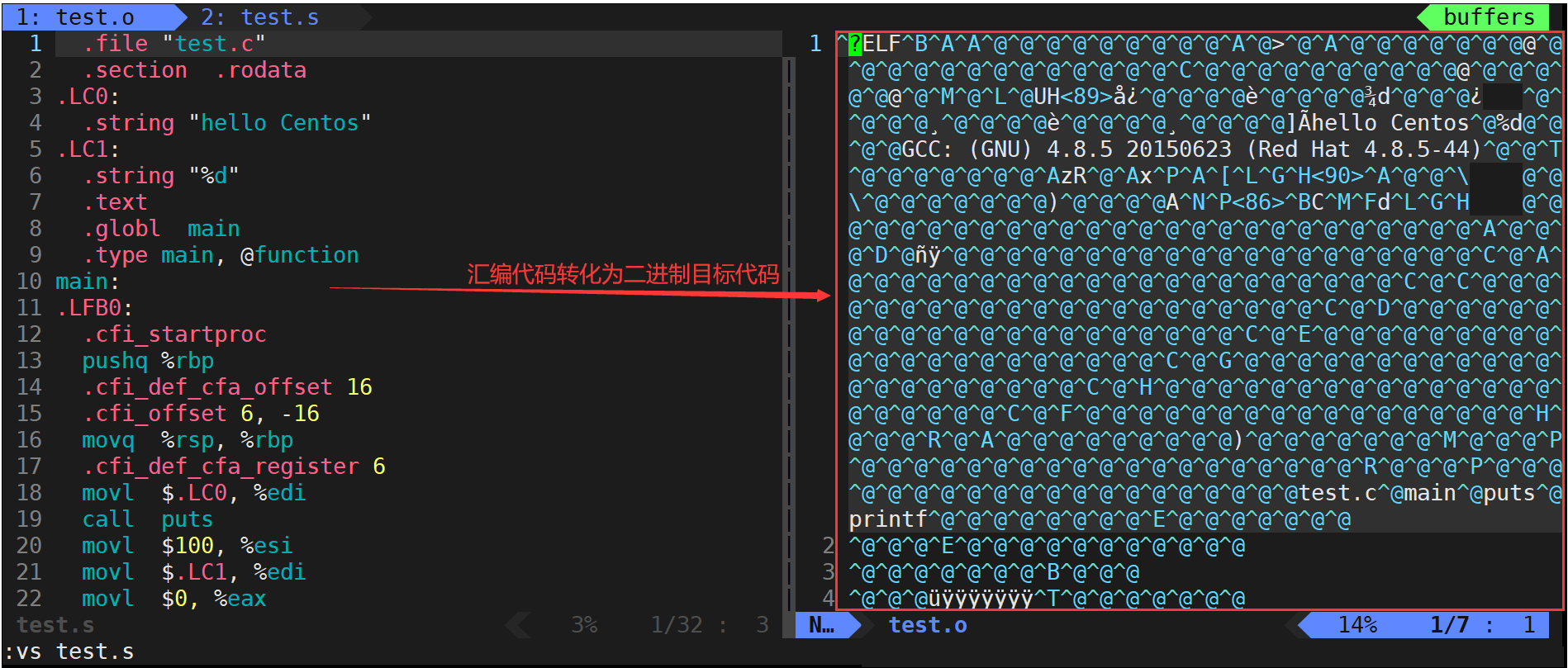
注意:有执行权限和具有可执行能力是两回事,就好比一个富二代,他有继承家产的权利,但是他未必就有管理家业的能力。所以.o文件是无法运行的!!需要经过链接才行!!
链接(生成可执行文件或库文件)
gcc test.o -o test- 在成功完成以上步骤之后,就进入了链接阶段。
- 链接的主要任务就是将生成的各个“xxx.o”文件进行链接,生成可执行文件。
- gcc/g++不带-E、-S、-c选项时,就默认生成预处理、编译、汇编、链接全过程后的文件。
- 若不用-o选项指定生成文件的文件名,则默认生成的可执行文件名为a.out。
将目标文件和库进行链接,就得到了可执行程序
注意: 链接后生成的也是二进制文件。
明明已经生成了机器可以读懂的文件,为什么还需要链接才能运行呢?
原因就在于我们当前的文件并只有函数调用、函数声明,却没有函数方法,所以必须要和库(C语言标准库,本质上就是一个文件)链接,函数的方法就存在于库中(其实就是把源文件.c经过一定的编译,然后打包,最后只给你提供一个文件)这样做有两个好处:
- 方便源文件的隐藏(未来我们想把程序给别人用,但不希望他看到源码,也可以这样)
- 不让我们做重复工作(帮我们造好了轮子),站在巨人的肩膀上 。
所以软件=头文件的方法+库文件提供的方法实现+你的代码。
个人觉得在日常的学习中,我们要尽可能地去尝试自己造轮子,研究底层,扎实内功,这样才可能应对未来的一些更复杂的情况,而在以后工作的时候,尽可能用一些已经写好的高效的代码,避免重复工作。而如果需要自己造轮子,早期的学习就会给你提供很大的帮助。
.o和库是如何链接的(静态链接和动态链接)
动态库文件和静态库文件
- 在Linux中: .so(动态库) .a(静态库)
- 命名规则:libname.so.XXX
- 在windows中:.dll(动态库) .lib(静态库)
在Linux中,通过 ls /usr/lib64/ld-linux-x86-64.so* 可以看到我们的动态库文件

还有之前我们知道其实指令的本质就是可执行程序,所以我们也可以去查看指令所依赖的动态库,我们会发现大部分都是用C的库
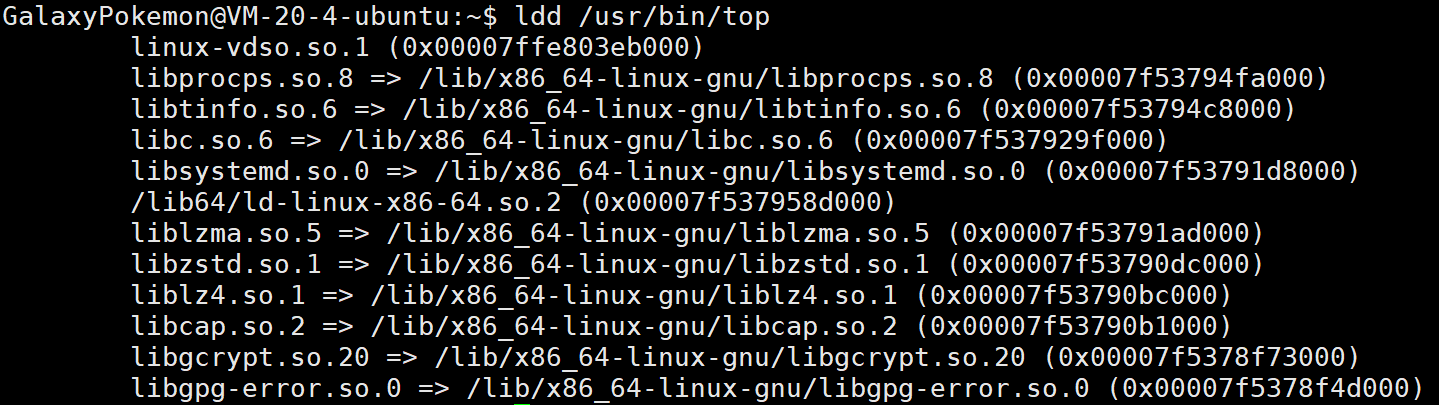
静态库的文件默认是没有安装的,需要通过以下指令去手动安装
C静态库:sudo yum install -y glibc-static
C++静态库:sudo yum install -y libstdc++-static
动态库和静态库理解
1. 假设我们考上了一所高中,这里不让上网,但是你是一个喜欢打游戏的人,你通常会将打游戏这件事列入到自己每天的计划表中,而你的学校附近恰好有一个网吧,你在将计划进行到规定时间的时候就会翻墙出去上网,然后再回来。
- 自己的计划表——可执行程序
- 学校——编译器
- 网吧——动态库
- 网吧里的电脑——库文件
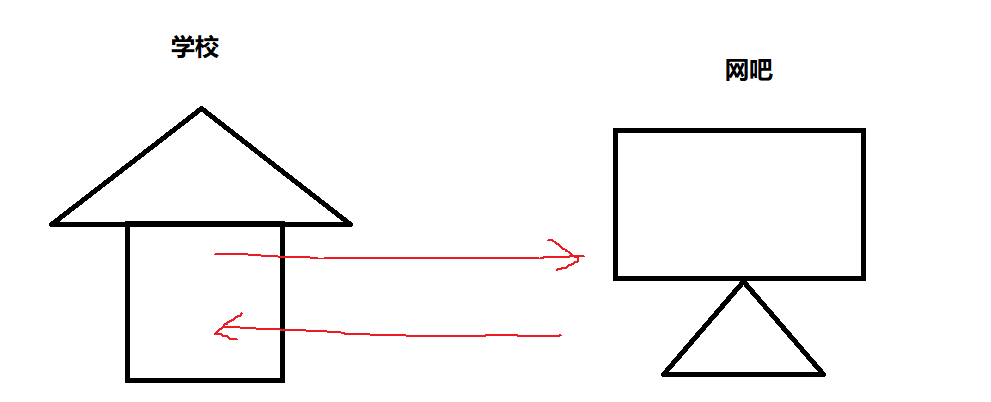
也就是说当程序执行到某个地方时,他会跳出到动态库继续执行,然后再回来,这个过程就是动态链接。
2. 假设有一天网吧老板突然被举报,并且没有营业执照而被迫查封,这个时候我的计划就无法如期进行了,并且影响的不只是你,还有学校其他喜欢打游戏的人!
所以动态库不能缺失!!一旦缺失影响的不仅仅是一个程序,而是多个程序都会崩溃!
3. 突然有一天学校允许学生上网了,这个时候网吧老板捕捉到了商机,把网吧的电脑搬出来开了一家二手电脑专卖店,然后喜欢打游戏的同学都过来购买了电脑了!!
二手电脑专卖店——静态库
二手电脑——库文件
也就是说,静态库进行静态链接的时候,会将自己的方法拷贝到目标程序中,该程序以后不用再依赖静态库!!
4. 有一天那个老板又被举报查封了,但是这个时候学校里的学生却没有感到伤心,因为大家都有自己的电脑了,店查不查封对他们没什么影响。
所以静态链接的程序并不依赖静态库,即使静态库丢失了程序也可以正常运行!
控制链接方式的选择
当我们不做限制时,会默认使用动态链接。我们可以使用file指令进行查看。

其次,我们还可以使用ldd指令查看动态链接的可执行文件所依赖的库。

(图中的/lib64/libc.so.6就是当前云服务器当中的C标准库)。
虽然gcc和g++默认采用的是动态链接,但如果我们需要使用静态链接,带上-static选项即可。
如果没有-static,默认编译可能会出现三种情况:动态链接->静态链接->报错。而有了static,就会去掉第一种情况,即静态链接->报错
gcc helloworld.c -o helloworld_s -static此时生成的可执行文件就是静态链接的了。

我们可以查看源代码相同,但链接方式不同而生成的两个可执行程序test和test_s的大小。

这也证明了动态链接比较节省空间,而静态链接比较浪费空间。
动态链接和静态链接的优缺点
动态库:
- 优点:动态库是共享库,可以有效节省资源(磁盘空间、内存空间、网络空间)
- 缺点:动态库一旦缺失,所有的程序将无法运行
静态库:
- 优点:不依赖库,程序可以独立运行
- 缺点:体积大,消耗资源
一般来说,我们在实际应用中更倾向于使用动态链接,因为体积大所带来的影响是很大的,比方说你下个游戏要1G,但是用静态链接可能就需要上百G,所以无论是我们还是Linux默认,都是会尽量选择动态链接。
Linux调试器 - gdb
gdb使用须知
程序发布方式:
1、debug版本:程序本身会被加入更多的调试信息,以便于进行调试。
2、release版本:不会添加任何调试信息,是不可调试的。
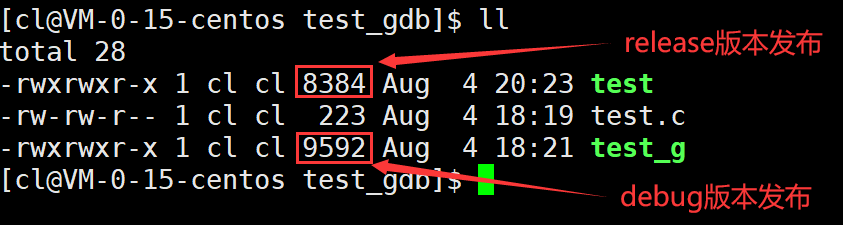
在Linux当中gcc/g++默认生成的可执行程序是release版本的,是不可被调试的。如果想生成debug版本,就需要在使用gcc/g++生成可执行程序时加上-g选项。

对同一份源代码分别生成其release版本和debug版本的可执行程序,并通过ll指令可以看到,debug版本发布的可执行程序的大小比release版本发布的可执行程序的大小要大一点,其原因就是以debug版本发布的可执行程序当中包含了更多的调试信息。
gdb命令汇总
【进入gdb】
指令: gdb 文件名
【调试】
1)「run/r」:运行代码(启动调试)。
2)「next/n」:逐过程调试。
3)「step/s」:逐语句调试。
4)「until 行号」:跳转至指定行。
5)「finish」:执行完当前正在调用的函数后停下来(不能是主函数)。
6)「continue/c」:运行到下一个断点处。
7)「set var 变量=x」:修改变量的值为x。
【显示】
1)「list/l n」:显示从第n行开始的源代码,每次显示10行,若n未给出则默认从上次的位置往下显示.。
2)「list/l 函数名」:显示该函数的源代码。
3)「print/p 变量」:打印变量的值。
4)「print/p &变量」:打印变量的地址。
5)「print/p 表达式」:打印表达式的值,通过表达式可以修改变量的值。
6)「display 变量」:将变量加入常显示(每次停下来都显示它的值)。
7)「display &变量」:将变量的地址加入常显示。
8)「undisplay 编号」:取消指定编号变量的常显示。
9)「bt」:查看各级函数调用及参数。
10)「info/i locals」:查看当前栈帧当中局部变量的值。
【断点】
1)「break/b n」:在第n行设置断点。
2)「break/b 函数名」:在某函数体内第一行设置断点。
3)「info breakpoint/b」:查看已打断点信息。
4)「delete/d 编号」:删除指定编号的断点。
5)「disable 编号」:禁用指定编号的断点。
6)「enable 编号」:启用指定编号的断点。
【退出gdb】
1)「quit/q」:退出gdb。
Linux项目自动化构建工具 - make/Makefile
为什么我们会需要自动化构建工具?
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的 规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
所以,makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是一条命令,Makefile是一个文件,两个搭配使用,完成项目自动化构建。
依赖关系和依赖方法
在使用make/Makefile前我们首先应该理解各个文件之间的依赖关系以及它们之间的依赖方法。
依赖关系: 文件A的变更会影响到文件B,那么就称文件B依赖于文件A。
- 例如,test.o文件是由test.c文件通过预处理、编译以及汇编之后生成的文件,所以test.c文件的改变会影响test.o,所以说test.o文件依赖于test.c文件。
依赖方法: 如果文件B依赖于文件A,那么通过文件A得到文件B的方法,就是文件B依赖于文件A的依赖方法。(就是二者通过什么方法联系起来的)
- 例如,test.o依赖于test.c,而test.c通过gcc -c test.c -o test.o指令就可以得到test.o,那么test.o依赖于test.c的依赖方法就是gcc -c test.c -o test.o。
多文件编译
当你的工程当中有多个源文件的时候,应该如何进行编译生成可执行程序呢?

首先,我们可以直接使用gcc指令对多个源文件进行编译,进而生成可执行程序。
gcc -o 输出文件名 源文件
但进行多文件编译的时候一般不使用源文件直接生成可执行程序,而是先用每个源文件各自生成自己的二进制文件,然后再将这些二进制文件通过链接生成可执行程序。

原因:
- 若是直接使用源文件生成可执行程序,那么其中一个源文件进行了修改,再生成可执行程序的时候就需要将所以的源文件重新进行编译链接。
- 而若是先用每个源文件各自生成自己的二进制文件,那么其中一个源文件进行了修改,就只需重新编译生成该源文件的二进制文件,然后再将这些二进制文件通过链接生成可执行程序即可。
注意: 编译链接的时候不需要加上头文件,因为编译器通过源文件的内容可以知道所需的头文件名字,而通过头文件的包含方式(“尖括号”包含和“双引号”包含),编译器可以知道应该从何处去寻找所需头文件。
但是随着源文件个数的增加,我们每次重新生成可执行程序时,所需输入的gcc指令的长度与个数也会随之增加。这时我们就需要使用make和Makefile了,这将大大减少我们的工作量。
步骤一: 在源文件所在目录下创建一个名为Makefile/makefile的文件。

步骤二: 编写Makefile文件。
Makefile文件最简单的编写格式是,先写出文件的依赖关系,然后写出这些文件之间的依赖方法,依次写下去。

在 Makefile 中,命令行必须以制表符(Tab)开头,而不是空格。

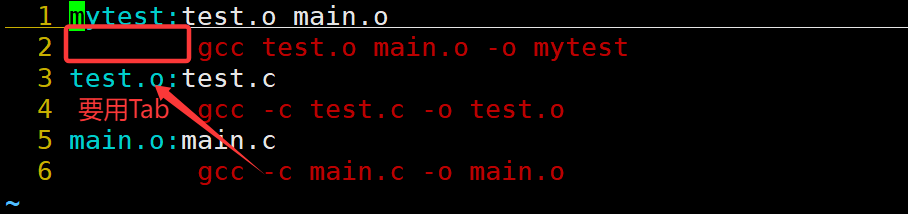
我们会发现这个过程其实有点像是函数调用,特别像递归,形成了makefile的自动推导
所以其实我们乱序也可以,因为他会自己去找,如果找不到就会报错。
编写完毕Makefile文件后保存退出,然后在命令行当中执行make指令便可以生成可执行程序,以及该过程产生的中间产物。

Makefile文件的简写方式:
- $@:表示依赖关系中的目标文件(冒号左侧)。
- $^:表示依赖关系中的依赖文件列表(冒号右侧全部)。
- $<:表示依赖关系中的第一个依赖文件(冒号右侧第一个)。
例如以上Makefile文件可以简写为:
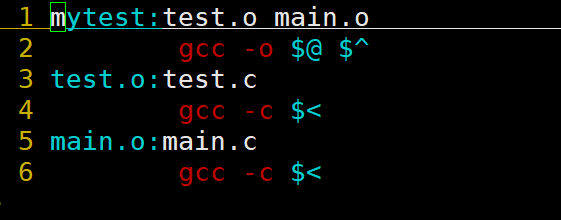
说明: gcc/g++携带-c选项时,若不指定输出文件的文件名,则默认输出文件名为xxx.o,所以这里也可以不用指定输出文件名
make原理
- make会在当前目录下找名字为“Makefile”或“makefile”的文件。
- 如果找到,它会找文件当中的第一个目标文件,在上面的例子中,它会找到mytest这个文件,并把这个文件作为最终的目标文件。
- 如果mytest文件不存在,或是mytest所依赖的后面的test.o文件和main.o文件的文件修改时间比mytest文件新,那么它就会执行后面的依赖方法来生成mytest文件。
- 如果mytest所依赖的test.o文件不存在,那么make会在Makefile文件中寻找目标为test.o文件的依赖关系,如果找到则再根据其依赖方法生成test.o文件(类似于堆栈的过程)。
- 当然,你的test.c文件和main.c文件是存在的,于是make会生成test.o文件和main.o文件,然后再用test.o文件和main.o文件生成最终的mytest文件。
- make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在寻找的过程中,如果出现错误,例如最后被依赖的文件找不到,那么make就会直接退出,并报错。
项目清理
在我们每次重新生成可执行程序前,都应该将上一次生成可执行程序时生成的一系列文件进行清理,但是如果我们每次都手动执行一系列指令进行清理工作的话,未免有些麻烦,因为每次清理时执行的都是相同的清理指令,这时我们可以将项目清理的指令也加入到Makefile文件当中。
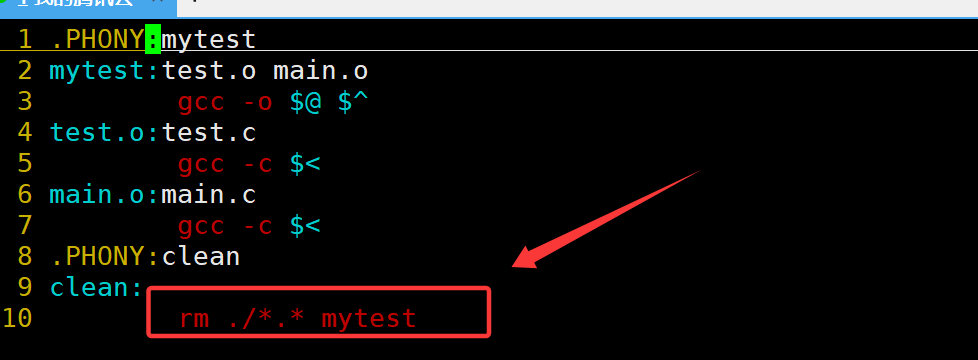
想clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,但我们可以显示要make执行。
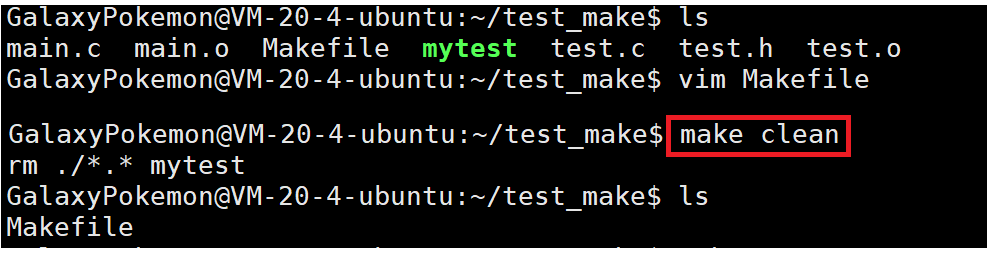
注: 一般将这种clean的目标文件设置为伪目标,用.PHONY修饰,伪目标的特性是:总是被执行。
为什么make执行前面的,而make clean执行后面的呢?
原因就是因为,如果make没有指定的话,默认就是从第一行开始扫描到第一个make就执行,所以建议将编译的工作放到最前面,然后把清理的工作写到后面!!
为什么不会允许多次make呢??(重点)
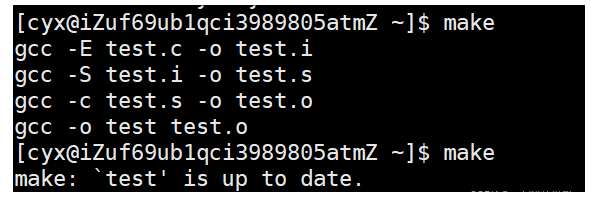
我们会发现我们make一次之后,就不然我们继续make了。这是为啥呢?
为了提高编译效率!如果我们的文件相较于之前没有发生过任何的变化,那么就不能进行make(因为系统觉得没必要,纯属浪费时间),如果相较于之前的内容有更新过,那么就会重新形成一次新的可执行程序覆盖掉。
那么我们的系统究竟是如何做到判断这个文件是否被更新过呢??难道是将文件扫描一遍??显然不现实。其原理如下:
首先,可执行程序一定是由源文件形成的,所以源文件的最近修改时间一定比可执行程序的最近时间要老——>推到得出,如果我们的源文件的最近修改文件比可执行程序时间新,那么就说明这个文件被修改过!!!
总结:只需要比较可执行程序的时间和源文件的最近修改时间即可!
- .exe比.c老,说明被修改过,需要重新编译
- .exe比.c新,说明没有被修改过,就不需要重新编译(提高了编译效率!)
stat指令
stat指令是查看文件或者文件系统的详细信息
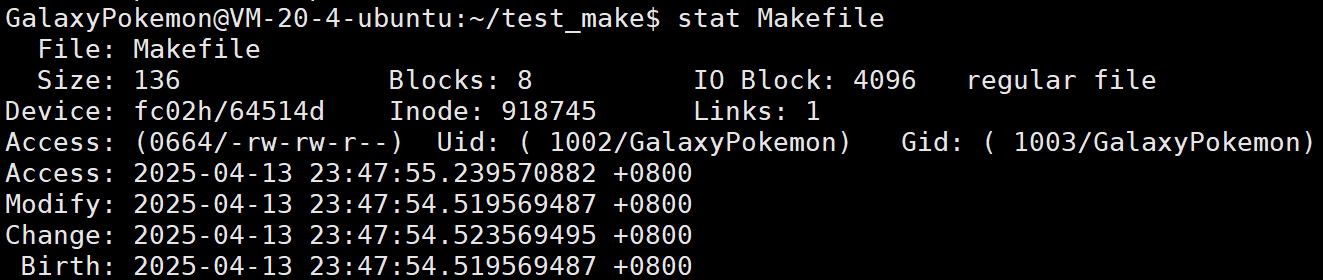
Access表示访问时间,任何增删查改都算访问操作
Modify表示修改文件内容的时间
Change表示修改文件属性的时间
按道理来说,Access的修改频率应该是最高的,但有些时候是无意义的,并且由于磁盘是属于外部设备,如果频繁访问的话,效率是极低的,所以在设计的时候,Access的时间其实是取决于另外两个时间的!!
(1)当仅读取或者访问文件文件时,只有Access会改变
(2)当修改文件内容时,Modify(文件内容)和Change(文件大小)都会改变,Access不一定改变
(3)当修改文件权限属性时, 只有Change会改变
.PHONY:
所以make会根据源文件和目标文件的新旧,判定是否需要重新执行依赖关系进行编译,那么如果我们希望依赖关系总是被执行,就需要.PHONY:(伪目标)
.PHONY:其实就是告诉make,这个目标是我的朋友,只要他想编你就让他编,不要阻拦,所以这个关键词常用在clean的身上。
在一个文件不存在的时候,touch的作用是将该文件新建出来,但是如果这个文件存在的话,touch就可以将三个时间都修改成当前的时候,或者是用-a -m -c 选项来强制修改其中一个。
Linux第一个小程序 - 进度条
行缓冲区的概念
首先,我们来感受一下行缓冲区的存在,在Linux当中以下代码的运行结果是什么样的?
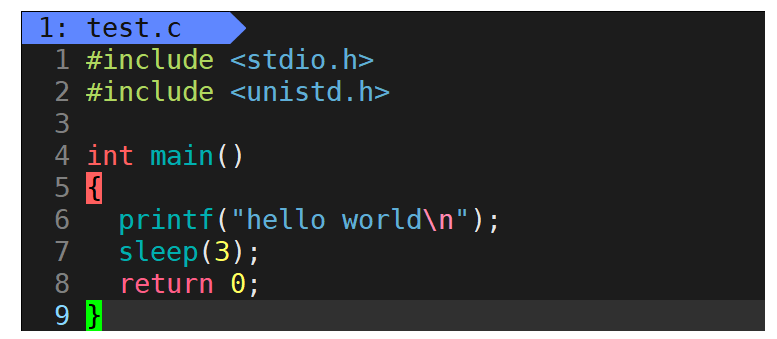
对于此代码,大家应该都没问题,当然是先输出字符串hello world然后休眠3秒之后结束运行。那么对于以下代码呢?
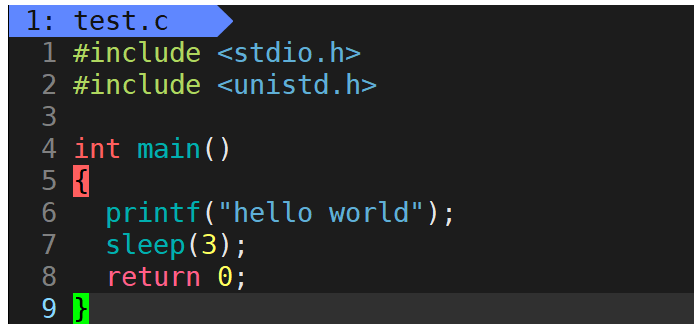
可以看到代码中仅仅删除了字符串后面的’\n’,那么代码的运行结果还与之前相同吗?答案否定的,该代码的运行结果是:先休眠3秒,然后打印字符串hello world之后结束运行。该现象就证明了行缓冲区的存在。
显示器对应的是行刷新,即当缓冲区当中遇到’\n’或是缓冲区被写满才会被打印出来,而在第二份代码当中并没有’\n’,所以字符串hello world先被写到缓冲区当中去了,然后休眠3秒后,直到程序运行结束时才将hello world打印到显示器当中。
\r和\n
- \r: 回车,使光标回到本行行首。
- \n: 换行,使光标下移一格。
而我们键盘上的Enter键实际上就等价于\n+\r。

既然是\r是使光标回到本行行首,那么如果我们向显示器上写了一个数之后再让光标回到本行行首,然后再写一个数,不就相当于将前面一个数字覆盖了吗?
但这里有一个问题:不使用’\n’进行换行怎么将缓冲区当中数据打印出来?
这里我们可以使用fflush函数,该函数可以刷新缓冲区,即将缓冲区当中的数据刷新当显示器当中。
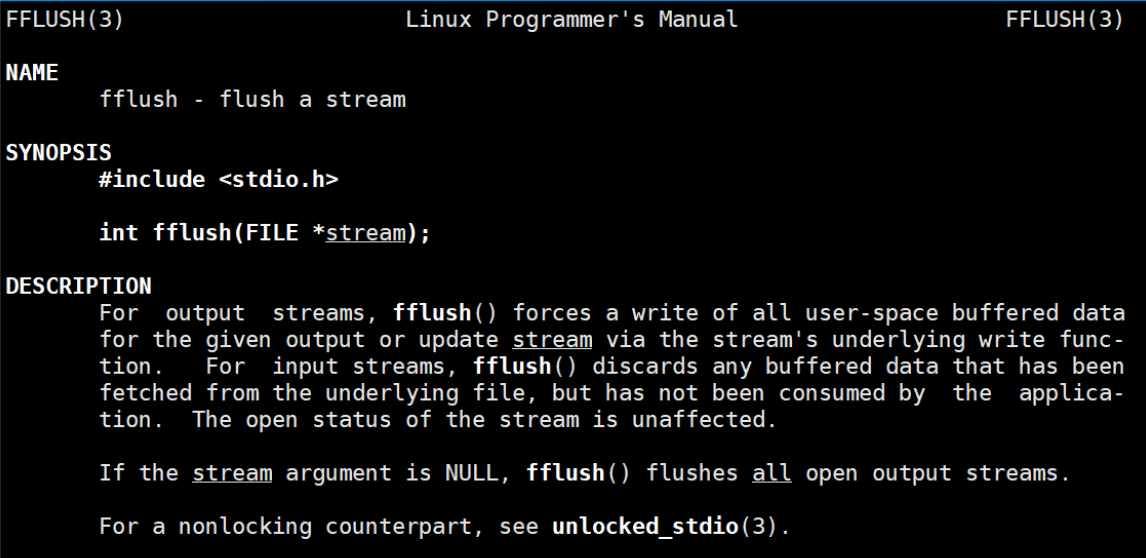
参数可以是:标准输出(stdin)、标准输入(stdout)、标准错误(stderr)
对此我们可以编写一个倒计时的程序。
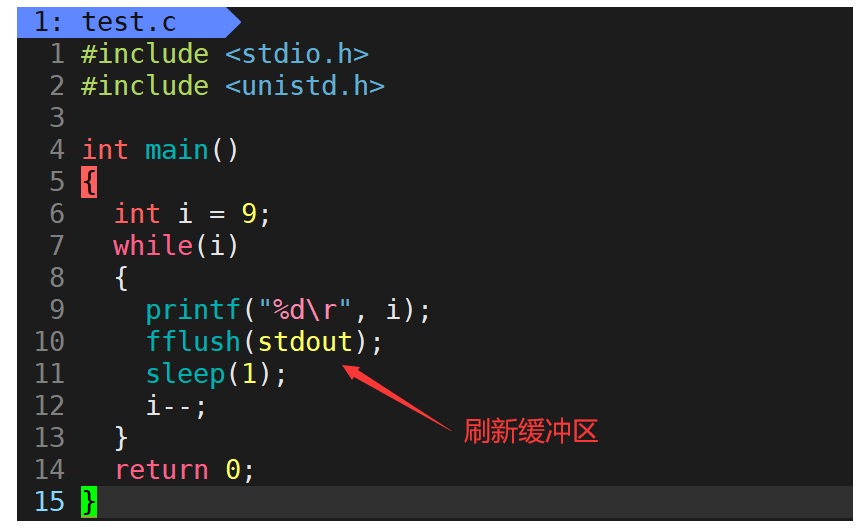
在输出下一个数之前都让光标先回到本行行首,就得到了倒计时的效果。

相关文章:

LINUX基础 [四] - Linux工具
目录 软件包管理器yum Linux开发工具vim vim的基本概念 vim的三种常用模式 vim的简单配置 vim常用模式的基本操作 命令模式 底行模式 处理vim打开文件报错的问题 Linux编译器-gcc/g使用 为什么我们可以用C/C做开发呢? 预处理(进行宏替换&#x…...

Spring Cloud之远程调用OpenFeign最佳实践
目录 OpenFeign最佳实践 问题引入 Feign 继承方式 创建Module 引入依赖 编写接口 打Jar包 服务提供方 服务消费方 启动服务并访问 Feign 抽取方式 创建Module 引入依赖 编写接口 打Jar包 服务消费方 启动服务并访问 服务部署 修改pom.xml文件 观察Nacos控制…...

【QT】 常用控件【输入类】
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 输入类控件 🦋 Line Edit -- 单行输入框🎀 录入个人信息🎀 正则表达式验证输入框数据🎀 验证两次输入密码一致…...

【Python】读取xyz坐标文件输出csv文件
Python读取xyz坐标文件输出csv文件 import sys import numpy as np import pandas as pd from tqdm import tqdm import cv2 import argparsedef read_xyz(file_path):with open(file_path, "r") as f: # 打开文件data f.readlines() # 读取文件datas []for …...
)
深度解析Redis过期字段清理机制:从源码到集群化实践 (一)
深度解析Redis过期字段清理机制:从源码到集群化实践 一、问题本质与架构设计 1.1 过期数据管理的核心挑战 Redis连接池时序图技术方案 设计规范: #mermaid-svg-Yr9fBwszePgHNnEQ {font-family:"trebuchet ms",verdana,arial,sans-se…...
)
MapReduce实验:分析和编写WordCount程序(对文本进行查重)
实验环境:已经部署好的Hadoop环境 Hadoop安装、配置与管理_centos hadoop安装-CSDN博客 实验目的:对输入文件统计单词频率 实验过程: 1、准备文件 test.txt文件,它是你需要准备的原始数据文件,存放在你的 Linux 系…...

【中大厂面试题】腾讯云 java 后端 最新面试题
腾讯云(一面) 1. spring 和 springboot的区别是什么? 配置方式的区别:Spring 应用的配置较为繁琐,通常需要编写大量的 XML 配置文件或者使用 Java 注解进行配置。例如,配置数据源、事务管理器等都需要手动…...

Redis存储“大数据对象”的常用策略及StackOverflowError错误解决方案
Hi,大家好,我是灰小猿! 在一些功能的开发中,我们一般会有一些场景需要将得到的数据先暂时的存储起来,以便后面的接口或业务使用,这种场景我们一般常用的场景就是将数据暂时存储在缓存中,之后再…...

【Vue】v-if和v-show的区别
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–核心区别三–使用场景四–性能对比五–总结 二. 核心区别 之前将css的显示隐藏的方式的时候,就已经提到过v-show和v-if了。忘记了的可以再回头去复习复习。 (2.1)…...

南瓜颜色预测:逻辑回归在农业分类问题中的实战应用
南瓜颜色预测:逻辑回归在农业分类问题中的实战应用 摘要 本案例通过预测南瓜颜色的分类问题,全面展示了逻辑回归在农业领域的实战应用。从数据预处理到模型评估,详细介绍了Seaborn可视化、模型构建、性能优化和结果解释等关键环节。案例不仅…...

【物联网-RS-485】
物联网-RS-485 ■ RS-485 连接方式■ RS-485 半双工通讯■ RS-485 的特点■ ModBus■ ModBus-ASCII■ ModBus-RTU ■ RS-485 连接方式 ■ RS-485 半双工通讯 一线定义为A 一线定义为B RS-485传输方式:半双工通信、(逻辑1:2V ~ 6V 逻辑0&…...
)
TDengine 语言连接器(Node.js)
简介 tdengine/websocket 是 TDengine 的官方 Node.js 语言连接器。Node.js 开发人员可以通过它开发存取 TDengine 数据库的应用软件。 Node.js 连接器源码托管在 GitHub。 Node.js 版本兼容性 支持 Node.js 14 及以上版本。 支持的平台 支持所有能运行 Node.js 的平台。 …...

Git分布式版本控制工具
一、工作流程 二、常用指令 1、配置git 配置环境变量 cmd打开命令行,输入git查看是否配置成功。 设置用户名和邮箱 git config --global user.name "用户名" git config --global user.email "邮箱" 查看用户名和邮箱 git config --glob…...

The first day of vue
关于小白直接接触vue3的第1天 首先我们需要一个脚手架node.js (这个可以从官网下载,免费的,安装也比较简单,后续我也会出一个相关的安装教程,方便大家和我一起讨论,互相学习) (不知道有没有人对…...
)
C语言超详细指针知识(三)
在经过前面两篇指针知识博客学习之后,我相信你已经对指针有了一定的理解,今天将更新C语言指针最后一篇,一起来学习吧。 1.字符指针变量 在指针类型的学习中,我们知道有一种指针类型为字符指针char*,之前我们是这样使用…...

无人机气动-结构耦合技术要点与难点
一、技术要点 1. 多学科耦合建模 气动载荷与结构响应的双向耦合:气动力(如升力、阻力、力矩)导致结构变形,而变形改变气动外形,进一步影响气流分布,形成闭环反馈。 建模方法: 高精度C…...

打造现代数据基础架构:MinIO对象存储完全指南
目录 打造现代数据基础架构:MinIO对象存储完全指南1. MinIO介绍1.1 什么是对象存储?1.2 MinIO核心特点1.3 MinIO使用场景 2. MinIO部署方案对比2.1 单节点单驱动器(SNSD/Standalone)2.2 单节点多驱动器(SNMD/Standalone Multi-Drive)2.3 多节点多驱动器(…...

SpringBoot条件注解全解析:核心作用与使用场景详解
目录 引言一、条件注解的核心机制二、SpringBoot内置条件注解详解1、ConditionalOnClass和ConditionalOnMissingClass2、ConditionalOnBean和ConditionalOnMissingBean3、ConditionalOnProperty4、ConditionalOnWebApplication和ConditionalOnNotWebApplication5、ConditionalO…...

智慧酒店企业站官网-前端静态网站模板【前端练习项目】
最近又写了一个静态网站,智慧酒店宣传官网。 使用的技术 html css js 。 特别适合编程学习者进行网页制作和前端开发的实践。 项目包含七个核心模块:首页、整体解决方案、优势、全国案例、行业观点、合作加盟、关于我们。 通过该项目,小伙伴们…...

#2 物联网组成要素
从下至上,则包括了5个要素,包括 设备 / 传感器 / 网络 / 物联网服务 / 数据分析 这五个要素。为了便于理解,我们用思维导图展示 物联网构成架构 设备 能够感测和反馈并连到网络进行物联网服务的装置 传感器 传感器和网关的融合实现了物…...

UE5 物理模拟 与 触发检测
文章目录 碰撞条件开启模拟关闭模拟 多层级的MeshUE的BUG 触发触发条件 碰撞 条件 1必须有网格体组件 2网格体组件必须有网格,没有网格虽然可以开启物理模拟,但是不会有任何效果 注意开启的模拟的网格体组件会计算自己和所有子网格的mesh范围 3只有网格…...
与Lambda)
C++23 新特性静态operator[]、operator()与Lambda
文章目录 静态操作符 operator[] 和 operator()示例:静态 operator[]示例:静态 operator() 静态 Lambda 表达式(P1169R4)示例:静态 Lambda 表达式 编译器支持和总结深入静态操作符 operator[] 和 operator()性能优化代…...

C# 13新特性 - .NET 9
转载: C# 13 中的新增功能 | Microsoft Learn C# 13 包括以下新增功能。 可以使用最新的 Visual Studio 2022 版本或 .NET 9 SDK 尝试这些功能:Introduced in Visual Studio 2022 Version 17.12 and newer when using C# 13 C# 13 中的新增功能 | Micr…...

MyBatis SQL会话管理详解
目录 一、SQL会话的基本概念(一)创建SQL会话 二、SQL会话的生命周期(一)打开会话(二)执行SQL操作(三)提交事务(四)回滚事务(五)关闭会…...

Uniapp: 下拉选择框 ba-tree-picker
目录 1、效果展示2、如何使用2.1 插件市场2.2 引入插件 3、参数配置3.1 属性3.2 方法 4、遇见的问题4.1、设置下拉树的样式 1、效果展示 2、如何使用 2.1 插件市场 首先从插件市场中将插件导入到项目中 2.2 引入插件 在使用的页面引入插件 <view click"showPicke…...

【高性能缓存Redis_中间件】三、redis 精通:性能优化与生产实践
一、引言 在前两篇 Redis 消息队列的文章中,我们掌握了基础使用和高级特性。本文作为系列终篇,将聚焦生产环境的性能优化与全流程实践,请各位跟随小编的步伐一起构建高可靠、高性能的消息处理系统(文章中的演示均为Centos7的背…...
自然语言处理Hugging Face Transformers
Hugging Face Transformers 是一个基于 PyTorch 和 TensorFlow 的开源库,专注于 最先进的自然语言处理(NLP)模型,如 BERT、GPT、RoBERTa、T5 等。它提供了 预训练模型、微调工具和推理 API,广泛应用于文本分类、机器翻…...

uniapp自定义tabbar,根据角色动态显示不同tabbar,无闪动问题
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回!!) 👉 个人专栏推荐:《前端项目教程以及代码》 ✨一、前言 这个需求在开发中还是很常见的,搜索了网络其他教程,…...

狂神SQL学习笔记一:初识MySQL、关系型数据库和非关系型数据库
菜鸟教程学习一半了,但是已经疲倦了,所以换一个课程学习,来提升学习质量,可能会有很多已经学习到的地方,就当是复习巩固了。 按照SQL学习课程来划分,分为45集,所以可能也会写45篇文章ÿ…...

面向MoE和推理模型时代:阿里云大数据AI产品升级发布
阿里云 2025 AI 势能大会上,阿里云智能集团副总裁、阿里云智能计算平台事业部负责人汪军华带来主题演讲《范式演进:MoE&推理模型时代的挑战与应对》,并发布大数据 AI 平台一系列重磅产品能力升级。 汪军华认为,从 Generative …...

网络安全·第三天·ICMP协议安全分析
一、ICMP功能介绍 ICMP(Internet Control Message Protocal)是一种差错和控制报文协议,不仅用于传输差错报文, 还传输控制报文,但是ICMP只是尽可能交付,提供的服务是无连接、不可靠的,并不能保…...
)
Hadoop大数据平台部署(Hadoop3.2.4+Hive4.0.1)
这里写自定义目录标题 1、前置要求与规划2、基础环境配置3、Hadoop 3.2.4 集群部署4、MariaDB 10.6.x 安装(仅 master 节点)5、Hive 4.0.1 部署(仅 master 节点)6、Hive 离线数据预处理7、Sqoop导出预处理结果到MySQL 1、前置要求…...

JMeter使用
1.简介 1.1 打开方式 ①点击bat,打开 ②添加JMeter系统环境变量,输⼊命令jmeter即可启动JMeter⼯具 1.2 配置 简体中文 放大字体 1.3 使用 ①添加线程组 ②创建http请求 2. 组件 2.1 线程组 控制JMeter将⽤于执⾏测试的线程数,也可以把⼀个线程理解为⼀个测…...

API:科技赋能,引领智能文字识别、身份认证与发票查验真伪变革
在数字化进程不断加速的今天,各行业对高效、精准的数据处理和身份验证方式如饥似渴。 文字识别:精准捕捉,高效便捷 文字识别产品系列宛如一把把精准的信息采集利器,其中包含证件识别接口、车牌识别接口、文档识别接口、发票识别接…...

Docker 安装 Flink 实现数据实时统计 - 华为云
概述 案例介绍 Apache Flink 是一个开源的流处理框架,具有高吞吐、低延迟、可容错等特点,可同时支持批处理和流处理,为数据处理提供了强大而灵活的解决方案,Flink 在 Docker 中的应用场景主要是为了简化集群的部署和管理&#x…...
_46)
LeetCode算法题(Go语言实现)_46
题目 给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。 另有一些以数组 queries 表示的问题,其中 querie…...

AJAX与Axios基础
目录 一、AJAX 核心概念解析 1.1 AJAX 的核心概念 1.2 AJAX 工作原理 1.3 AJAX 局限性 二、axios 库介绍 2.1 Axios 核心特性 2.2 快速上手 2.3 核心配置项 2.4 错误处理标准方案 三、Axios 核心配置项 3.1 常用核心配置项 1. url 2. method 3. params 4. data …...

CodeReview工具集合
codereview 工具集合 在现代软件开发中,代码审查(Code Review) 已成为保障代码质量和团队协作效率的关键流程。一个合适的 Code Review 工具,不仅能帮助团队发现潜在问题,还能促进知识共享与规范统一。 本文整理了一些…...
_45)
LeetCode算法题(Go语言实现)_45
题目 n 座城市,从 0 到 n-1 编号,其间共有 n-1 条路线。因此,要想在两座不同城市之间旅行只有唯一一条路线可供选择(路线网形成一颗树)。去年,交通运输部决定重新规划路线,以改变交通拥堵的状况…...
]] 属性)
C++23 新特性:[[assume(expression)]] 属性
文章目录 语法与基本用法作用与优化原理使用注意事项未满足假设时的行为使用场景 示例代码总结 C23 引入了一个新的属性 [[assume(expression)]],它为程序员提供了一种向编译器传递额外信息的机制,从而让编译器能够生成更高效的代码。 语法与基本用法 …...

AI IDE 提示词
好的,这就将之前的分析内容整理成一篇适合发布在 CSDN 上的博客文章。 告别代码生成混乱:AI IDE 提示词模式权威指南 作者: (你的名字/昵称) 日期: 2025年4月14日 前言 随着人工智能技术的飞速发展,AI 助手(如 GitHub Copilot…...

Framework Binder架构分解
整个 Binder 架构所涉及的总共有以下 5 个目录: 1. /framework/base/core/java/(Java) 2. /framework/base/core/jni/ (JNI) 3,/framework/native/libs/binder (Native) 4,/framework/native/cmds/servicemanager/ (Native) 5,…...
实现各个实训室电脑网络可互通,原本是独立局域网)
三层交换机SVI功能(交换机虚拟接口)实现各个实训室电脑网络可互通,原本是独立局域网
三层交换机 SVI功能(交换机虚拟接口) 实现VLAN路由 需求 :各实训室使用独立局域网,即每个实训有自己的IP网段, 每个实训室只有内部互相访问。 需求:为了加强各实训室学生的交流,学校要求我们…...

Spark-SQL核心编程:DataFrame、DataSet与RDD深度解析
在大数据处理领域,Spark-SQL是极为重要的工具。今天就来深入探讨Spark-SQL中DataFrame、DataSet和RDD这三个关键数据结构。 Spark-SQL的前身是Shark,它摆脱了对Hive的过度依赖,在数据兼容、性能优化和组件扩展上有显著提升。DataFrame是基于R…...

腾讯云COS直传,官方后端demo,GO语言转JAVA
腾讯云COS直传,官方后端demo,GO写的,我们台是JAVA所以转一下,已跑通。废话不多说,直接上代码: Controller类如下: import com.ruoyi.web.core.config.CosConfig; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.Ht…...
)
c语言坦克对战(前言)
实现C语言中的“坦克大战”游戏逻辑,可以按照以下步骤进行: 游戏初始化 定义游戏窗口:设置游戏窗口的大小和标题。加载资源:加载坦克、子弹、敌人等图像资源。初始化游戏状态:设置初始分数、生命值、坦克位置等。 游…...
)
空间信息可视化——WebGIS前端实例(一)
技术栈:原生HTML 源代码:CUGLin/WebGIS: This is a project of Spatial information visualization 4 全国贫困县可视化系统 4.1 系统设计思想 党的十九大报告明确指出,要“确保到2020年我国现行标准下农村贫困人口实现脱贫,贫困县全部摘帽,解决区域…...
:量子封神·用鸿蒙编译器重铸天道法则)
JVM考古现场(十九):量子封神·用鸿蒙编译器重铸天道法则
楔子:代码鸿蒙劫 "警告!警告!昆仑山服务器集群出现量子纠缠现象!"凌霄殿监控中心警报响彻云霄。全息投影中,Java线程在四维时空中编织出克莱因瓶拓扑结构,GC日志里闪烁着霍金辐射般的奇点事件。本…...

思维与算法共舞:AIGC语言模型的艺术与科学
云边有个稻草人-个人主页 热门文章_云边有个稻草人的博客-本篇文章所属专栏~ 目录 引言:AIGC与文本生成概述 一、AIGC基础:语言模型的基本原理 1. 什么是语言模型? 2. 预训练与微调 二、AIGC的应用领域:文本生成的具体应用 …...

C++之 多继承
在学校里有老师和学生,他们都是人,我么应该创建一个名为 Person 的基类和两个名为 Teacher 和Student 的子类,后两者是从前者继承来的 有一部分学生还教课挣钱(助教),也就是同时存在着两个”是一个”关系&…...