【第三十一周】ViT 论文阅读笔记
ViT
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- Patch Embedding
- Patch + Position Embedding
- Transformer Encoder
- MLP Head
- 整体架构
- CNN的归纳偏置
- 代码实现
- 实验结果
- 总结
摘要
本篇博客介绍了Vision Transformer(ViT),这是一种突破性的图像分类模型,其核心思想是将图像分割为固定大小的块(如16×16像素),并将这些块序列化后输入标准的Transformer架构,从而替代传统卷积神经网络(CNN)对视觉特征的局部归纳偏置依赖 。针对图像数据难以直接适配序列模型的问题,ViT提出图像块嵌入(Patch Embedding)技术,通过线性投影将每个块展平为向量,并引入可学习的位置编码(Position Embedding)保留空间信息,同时添加分类标识符(Class Token)以聚合全局特征。ViT采用多层Transformer Encoder堆叠,通过自注意力机制捕捉跨区域的全局依赖,最终由MLP Head输出分类结果。实验表明,当在大规模数据集(如JFT-300M)预训练后,ViT在ImageNet等任务上超越同期CNN模型,且训练资源需求更低。其优势在于全局建模能力与模型扩展性,但依赖大量预训练数据且计算复杂度随分辨率呈平方增长。未来改进方向包括轻量化设计、动态位置编码优化,以及结合局部-全局注意力机制以提升实际场景的实用性。
Abstract
This blog introduces Vision Transformer (ViT), a groundbreaking image classification model that replaces the local inductive bias of traditional convolutional neural networks (CNNs) by segmenting images into fixed-size patches (e.g., 16×16 pixels) and processing them as sequential inputs through a standard Transformer architecture. To address the challenge of adapting grid-structured images to sequence-based modeling, ViT employs patch embedding to linearly project flattened patches into vectors, learnable positional embeddings to encode spatial relationships, and a class token to aggregate global features. By stacking multiple Transformer encoder layers with self-attention mechanisms, ViT captures long-range dependencies across image regions, culminating in classification predictions via an MLP head. Experiments demonstrate that when pretrained on large-scale datasets like JFT-300M, ViT outperforms contemporary CNNs on tasks such as ImageNet while requiring fewer computational resources. Despite its advantages in global feature modeling and scalability, ViT heavily relies on extensive pretraining data and suffers from quadratic computational complexity relative to input resolution. Future research may focus on lightweight architectures, dynamic positional encoding, and hybrid local-global attention mechanisms to enhance its practicality in real-world applications.
文章信息
Title:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Author:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
Source:https://arxiv.org/abs/2010.11929
引言
在ViT的提出之前,基于自注意力的架构,特别是 Transformers ,已成为自然语言处理领域的首选模型,主要的方法是在大型文本语料上进行预训练,然后在较小的任务特定数据集上进行微调。Transformer的计算效率高(并行计算)、可扩展性强,且随着模型和数据集的增长,性能仍然没有饱和的迹象。
然而,在计算机视觉领域,卷积架构仍占主导地位。受 NLP 成功的启发,一些作品尝试将类似 CNN 的架构与自注意力相结合,也有一些作品尝试完全取代卷积,但后一种模型虽然理论上有效,但由于使用了专门的注意力模式,因此尚未在现代硬件加速器上有效扩展。
CNN依赖两种先验知识——局部性(Locality)和平移不变性(Translation Equivariance),这使得CNN在小数据集上表现优异,但也限制了其全局建模能力。CNN的逐层卷积操作难以直接建模图像中远距离像素或区域之间的关系。
ViT摒弃了卷积操作,消除了视觉任务中的归纳偏置,将图像分割为固定大小的块(Patch),通过线性投影转化为序列输入,完全依赖自注意力机制建模全局关系。
方法
在 ViT 的设计中,尽可能与原始的 Transformer 结构保持一致,这种简单的设计的一个好处是可以使用现有的 Transformer 架构的高效实现。
ViT 的网络架构如下图所示:

ViT 的架构简单来说有三部分组成:
- Linear Projection of Flattened Patches(Embedding层,将二维图像转换为适合Transformer处理的序列数据)
- Transformer Encoder(通过自注意力机制和前馈网络提取全局特征)
- MLP Head(最终用于分类的层结构)
ViT总体流程:
对于输入图像,先按照预先指定的尺寸进行分割,分割后的小图像是 patch ,然后每个patch经过 Linear Projection of Flattened Patches层进行embeding,得到 patch embedding。然后对每个 patch embedding 分别加上对应 patch 的位置编码 position embedding,并拼接(concat)上一个 cls token (cls token 来自BERT,用于最终的分类层的输入)的信息。上述得到的信息输入到 Transformer encoder (堆叠的多层,每层的结构一致,参数独立)中提取全局信息。经过堆叠的Transformer encoder后,cls token 可以得到整图(所有patch)的信息,所以其输出作为分类层 MLP head 的输入,进行类别概率计算。
ViT的流程动图如下:

Patch Embedding
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。为方便描述网络中的数据流,本博客在具体的数据上都以ViT-B/16为例(patch大小为16*16)。
首先将输入的图片按照预先指定的patch大小分割为若干patch,如输入图片大小为 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3,划分后有 ( 224 ∗ 224 ) / ( 16 ∗ 16 ) = 196 (224*224)/(16*16)= 196 (224∗224)/(16∗16)=196 个 patch。每个patch大小为 16 × 16 × 3 16\times16\times3 16×16×3,通过映射得到一个长度为768的向量,数据形状变化:[16, 16, 3] -> [768]。
在实际的实现中,是通过卷积来完成上述操作的。

使用卷积核为 16 ∗ 16 16*16 16∗16,stride=16,padding=0,卷积核个数为 768 的卷积操作,可将原图的 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3 转化为 14 ∗ 14 ∗ 768 14*14*768 14∗14∗768,然后将 H 个 W 两个维度展平得到二维矩阵,形状为 196*768,其中 196 是patch token 的个数,768 是 token 的维度。
Q:为何要处理成Patch
A:主要有以下两个原因:
第一,减少计算量,在Transformer中,假设输入的序列长度为N,则经过attention时计算复杂度为 O ( N 2 ) O(N^2) O(N2),因为注意力机制下,每个token都要和包括自己在内的所有token做一次attention score计算。在ViT中,分割的每个Patch作为一个token输入到Transformer encoder,序列长度 N = ( H × W ) / P 2 N=(H\times W)/{P^2} N=(H×W)/P2,其中P是patch的大小,patch越大,序列越短,计算量越小。
第二,和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。比如,相邻的两个像素格子间的取值往往是相似的。因此并不需要特别精准的计算粒度(比如把P设为1)。
Patch + Position Embedding
与BERT一样,ViT 中 Transformer 的输入需要有位置信息(position embeding)和 class token([class]token是一个可训练的参数,数据格式和之前计算的patch token一样)。
得到的 patch token 先与 class token 进行 concat 拼接: Cat([1, 768], [196, 768]) -> [197, 768]。然后加上可训练Position Embedding,是直接在token上进行sum运算,前后数据格式不变。
对于Position Embedding,在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。

Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,Encoder Block其具体结构如下图左侧所示。

Encoder Block主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理。
- 多头自注意力(Multi-Head Self-Attention),捕捉不同位置patch间的依赖关系。
- Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth)。
- MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]。
MLP Head
Transformer Encoder前后的数据格式不变,在其后还有一个layer norm。对于MLP,其输入为提取出的[class]token生成的对应结果,即[197, 768]中抽取出[class]token对应的[1, 768],MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。
整体架构
下面是ViT-B/16的详细网络结构

论文中计算的数学表达如下:
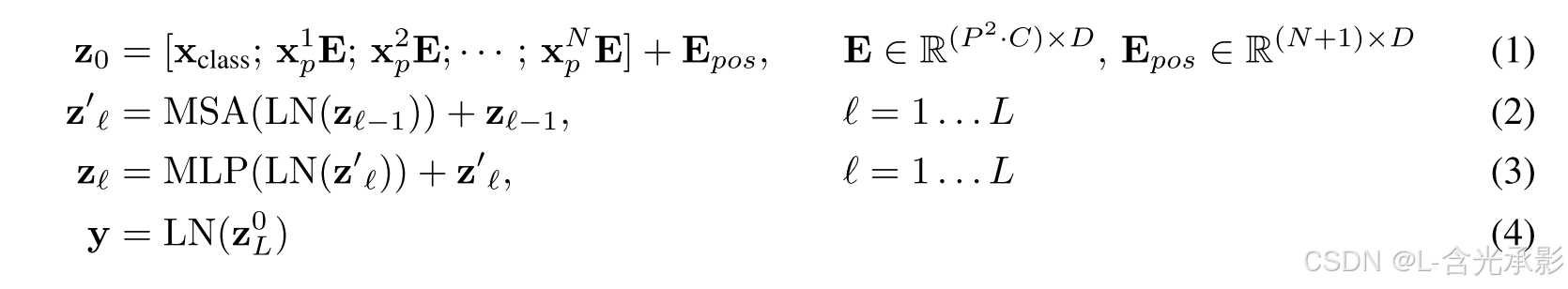
其中, x p i x_p^i xpi表示第i个patch, E E E和 E p o s E_{pos} Epos分别表示Token Embedding和Positional Embedding, Z 0 Z_0 Z0是Transformer Encoder的输入,公式(2)是计算multi-head attention的过程,公式(3)是计算MLP的过程,公式(4)是最终分类任务,LN表示是一个简单的线性分类模型, Z L 0 Z_L^0 ZL0是得到的 cls token 对应的输出结果。
CNN的归纳偏置
归纳偏置就是一种假设,或者说一种先验知识。有了这种先验,就能知道哪一种方法更适合解决哪一类任务。所以归纳偏置是一种统称,不同的任务其归纳偏置下包含的具体内容不一样。
对图像任务来说,它的归纳偏置有以下两点:
- 空间局部性(locality) :假设一张图片中,相邻的区域是有相关特征的。比如太阳和天空就经常一起出现。
- 平移等边性(translation equivariance):无论是先做卷积还是先做平移,其结果都是一样的,即 f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x))。
基于这两种先验知识,CNN成为了图像任务最佳的方案之一。卷积核能最大程度保持空间局部性(保存相关物体的位置信息)和平移等边性,使得在训练过程中,最大限度学习和保留原始图片信息。
而本文介绍的ViT没有使用卷积(除了在patch embedding时),完全丢弃了图像的归纳偏置。
代码实现
下面的代码来自rwightman的实现,这也是被官方认可的实现。
patch embedding的实现:
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):"""初始化 PatchEmbed 模块Args:img_size (int or tuple): 输入图像的尺寸,默认为 224patch_size (int or tuple): 图像块的尺寸,默认为 16in_c (int): 输入图像的通道数,默认为 3embed_dim (int): 嵌入维度,默认为 768norm_layer (nn.Module): 归一化层,默认为 None"""super().__init__()# 将图像尺寸转换为元组形式img_size = (img_size, img_size)# 将图像块尺寸转换为元组形式patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_size# 计算网格尺寸self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])# 计算图像块的数量self.num_patches = self.grid_size[0] * self.grid_size[1]# 定义卷积层,用于将图像分割成图像块并进行嵌入self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)# 定义归一化层,如果提供了则使用,否则使用恒等映射self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):"""前向传播Args:x (torch.Tensor): 输入图像张量,形状为 [B, C, H, W]Returns:torch.Tensor: 处理后的张量,形状为 [B, num_patches, embed_dim]"""# 获取输入图像的形状B, C, H, W = x.shape# 检查输入图像的尺寸是否与模型设置的尺寸一致assert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# 通过卷积层将图像分割成图像块并进行嵌入# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)# 进行归一化处理x = self.norm(x)return x
使用卷积层将图像分割成多个图像块,并将每个图像块映射到一个固定维度的嵌入向量。
Attention模块:实现多头自注意力机制(Multi-Head Self-Attention),用于捕捉输入序列中不同位置之间的依赖关系。
class Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):"""初始化 Attention 模块Args:dim (int): 输入 token 的维度num_heads (int): 注意力头的数量,默认为 8qkv_bias (bool): 是否使用偏置项,默认为 Falseqk_scale (float): 缩放因子,默认为 Noneattn_drop_ratio (float): 注意力矩阵的丢弃概率,默认为 0.proj_drop_ratio (float): 投影层的丢弃概率,默认为 0."""super(Attention, self).__init__()self.num_heads = num_heads# 计算每个注意力头的维度head_dim = dim // num_heads# 计算缩放因子,如果未提供则使用默认值self.scale = qk_scale or head_dim ** -0.5# 定义线性层,用于生成查询(Q)、键(K)和值(V)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)# 定义注意力矩阵的丢弃层self.attn_drop = nn.Dropout(attn_drop_ratio)# 定义投影层self.proj = nn.Linear(dim, dim)# 定义投影层的丢弃层self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):"""前向传播Args:x (torch.Tensor): 输入张量,形状为 [batch_size, num_patches + 1, total_embed_dim]Returns:torch.Tensor: 处理后的张量,形状为 [batch_size, num_patches + 1, total_embed_dim]"""# 获取输入张量的形状B, N, C = x.shape# 通过线性层生成查询(Q)、键(K)和值(V)# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# 分离查询(Q)、键(K)和值(V)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# 计算注意力分数# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scale# 对注意力分数进行 softmax 操作,得到注意力矩阵attn = attn.softmax(dim=-1)# 对注意力矩阵进行丢弃操作attn = self.attn_drop(attn)# 根据注意力矩阵对值(V)进行加权求和# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)# 通过投影层进行线性变换x = self.proj(x)# 对投影层的输出进行丢弃操作x = self.proj_drop(x)return x
MLP模块:由两个全连接层和一个激活函数组成,通过对输入进行线性变换和非线性激活,得到输出。
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):"""初始化 MLP 模块Args:in_features (int): 输入特征的维度hidden_features (int): 隐藏层特征的维度,默认为 Noneout_features (int): 输出特征的维度,默认为 Noneact_layer (nn.Module): 激活函数层,默认为 nn.GELUdrop (float): 丢弃概率,默认为 0."""super().__init__()# 如果未提供输出特征的维度,则使用输入特征的维度out_features = out_features or in_features# 如果未提供隐藏层特征的维度,则使用输入特征的维度hidden_features = hidden_features or in_features# 定义第一个全连接层self.fc1 = nn.Linear(in_features, hidden_features)# 定义激活函数层self.act = act_layer()# 定义第二个全连接层self.fc2 = nn.Linear(hidden_features, out_features)# 定义丢弃层self.drop = nn.Dropout(drop)def forward(self, x):"""前向传播Args:x (torch.Tensor): 输入张量Returns:torch.Tensor: 处理后的张量"""# 通过第一个全连接层x = self.fc1(x)# 通过激活函数层x = self.act(x)# 进行丢弃操作x = self.drop(x)# 通过第二个全连接层x = self.fc2(x)# 进行丢弃操作x = self.drop(x)return x
Block模块:实现 Transformer 编码器中的一个块,包含多头自注意力机制和多层感知机。对输入进行归一化处理,然后依次通过多头自注意力机制和多层感知机,最后使用残差连接将输入和输出相加。
class Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):"""初始化 Block 模块Args:dim (int): 输入特征的维度num_heads (int): 注意力头的数量mlp_ratio (float): MLP 隐藏层维度与输入维度的比例,默认为 4.qkv_bias (bool): 是否使用偏置项,默认为 Falseqk_scale (float): 缩放因子,默认为 Nonedrop_ratio (float): 丢弃概率,默认为 0.attn_drop_ratio (float): 注意力矩阵的丢弃概率,默认为 0.drop_path_ratio (float): 随机深度丢弃概率,默认为 0.act_layer (nn.Module): 激活函数层,默认为 nn.GELUnorm_layer (nn.Module): 归一化层,默认为 nn.LayerNorm"""super(Block, self).__init__()# 定义第一个归一化层self.norm1 = norm_layer(dim)# 定义注意力模块self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# 定义随机深度丢弃层,如果丢弃概率大于 0 则使用,否则使用恒等映射self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()# 定义第二个归一化层self.norm2 = norm_layer(dim)# 计算 MLP 隐藏层的维度mlp_hidden_dim = int(dim * mlp_ratio)# 定义 MLP 模块self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):"""前向传播Args:x (torch.Tensor): 输入张量Returns:torch.Tensor: 处理后的张量"""# 先进行归一化,再通过注意力模块,最后加上随机深度丢弃和残差连接x = x + self.drop_path(self.attn(self.norm1(x)))# 先进行归一化,再通过 MLP 模块,最后加上随机深度丢弃和残差连接x = x + self.drop_path(self.mlp(self.norm2(x)))return x
VisionTransformer模块:实现完整的 Vision Transformer 模型,包括图像块嵌入、位置编码、Transformer 编码器和分类头。具体做法为:将输入图像通过PatchEmbed模块转换为嵌入向量,添加位置编码后,通过多个Block模块进行特征提取,最后通过分类头进行分类。
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): 输入图像的尺寸,如果是整数则表示正方形图像的边长patch_size (int, tuple): 图像分块的尺寸,如果是整数则表示正方形分块的边长in_c (int): 输入图像的通道数,通常彩色图像为3num_classes (int): 分类任务的类别数embed_dim (int): 嵌入向量的维度depth (int): 变压器(Transformer)的层数num_heads (int): 多头注意力机制中的头数mlp_ratio (int): 多层感知机(MLP)隐藏层维度与嵌入维度的比例qkv_bias (bool): 是否在查询(Q)、键(K)、值(V)的线性变换中使用偏置qk_scale (float): 自定义的查询和键的缩放因子,如果未设置则使用默认值representation_size (Optional[int]): 如果设置,则启用并将表示层(预对数层)的维度设置为该值distilled (bool): 模型是否包含蒸馏令牌和头,如DeiT模型drop_ratio (float): 随机失活(Dropout)的概率attn_drop_ratio (float): 注意力机制中的随机失活概率drop_path_ratio (float): 随机深度(Stochastic Depth)的概率embed_layer (nn.Module): 用于图像分块嵌入的层norm_layer: (nn.Module): 归一化层"""super(VisionTransformer, self).__init__()# 分类任务的类别数self.num_classes = num_classes# 特征维度,与嵌入维度保持一致,便于与其他模型统一接口self.num_features = self.embed_dim = embed_dim# 令牌数量,如果使用蒸馏则为2(分类令牌和蒸馏令牌),否则为1(分类令牌)self.num_tokens = 2 if distilled else 1# 如果未提供归一化层,则使用默认的LayerNorm层,设置eps为1e-6norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)# 如果未提供激活函数层,则使用默认的GELU激活函数act_layer = act_layer or nn.GELU# 图像分块嵌入层,将输入图像分割成多个分块并进行嵌入self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)# 分块的数量num_patches = self.patch_embed.num_patches# 分类令牌,可学习的参数,形状为 [1, 1, embed_dim]self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 蒸馏令牌,如果使用蒸馏则为可学习的参数,形状为 [1, 1, embed_dim],否则为Noneself.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None# 位置嵌入,可学习的参数,形状为 [1, num_patches + num_tokens, embed_dim]self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))# 位置嵌入后的随机失活层self.pos_drop = nn.Dropout(p=drop_ratio)# 随机深度衰减规则,从0到drop_path_ratio线性插值生成depth个值dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)]# 变压器块序列,包含多个Block层self.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])# 归一化层,用于对变压器块的输出进行归一化self.norm = norm_layer(embed_dim)# 表示层(预对数层)if representation_size and not distilled:# 如果设置了表示层维度且不使用蒸馏,则启用表示层self.has_logits = True# 更新特征维度为表示层维度self.num_features = representation_size# 表示层,包含一个线性层和一个Tanh激活函数self.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:# 否则不启用表示层,使用恒等映射self.has_logits = Falseself.pre_logits = nn.Identity()# 分类头self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()# 蒸馏头,如果使用蒸馏则为线性层,否则为Noneself.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# 权重初始化# 位置嵌入的权重使用截断正态分布初始化,标准差为0.02nn.init.trunc_normal_(self.pos_embed, std=0.02)if self.dist_token is not None:# 蒸馏令牌的权重使用截断正态分布初始化,标准差为0.02nn.init.trunc_normal_(self.dist_token, std=0.02)# 分类令牌的权重使用截断正态分布初始化,标准差为0.02nn.init.trunc_normal_(self.cls_token, std=0.02)# 应用自定义的权重初始化函数self.apply(_init_vit_weights)def forward_features(self, x):"""前向传播特征提取部分Args:x (torch.Tensor): 输入图像,形状为 [B, C, H, W]Returns:torch.Tensor: 特征向量,如果使用蒸馏则返回分类令牌和蒸馏令牌的特征向量"""# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:# 如果不使用蒸馏,将分类令牌和分块嵌入拼接x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:# 如果使用蒸馏,将分类令牌、蒸馏令牌和分块嵌入拼接x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)# 位置嵌入并进行随机失活x = self.pos_drop(x + self.pos_embed)# 通过变压器块序列x = self.blocks(x)# 归一化x = self.norm(x)if self.dist_token is None:# 如果不使用蒸馏,返回分类令牌的特征向量return self.pre_logits(x[:, 0])else:# 如果使用蒸馏,返回分类令牌和蒸馏令牌的特征向量return x[:, 0], x[:, 1]def forward(self, x):"""前向传播函数Args:x (torch.Tensor): 输入图像,形状为 [B, C, H, W]Returns:torch.Tensor: 分类结果,如果使用蒸馏则返回分类结果和蒸馏结果的平均值"""# 提取特征x = self.forward_features(x)if self.head_dist is not None:# 如果使用蒸馏,分别通过分类头和蒸馏头x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# 训练时返回分类结果和蒸馏结果return x, x_distelse:# 推理时返回分类结果和蒸馏结果的平均值return (x + x_dist) / 2else:# 如果不使用蒸馏,通过分类头得到分类结果x = self.head(x)return x
实验结果
论文中训练了三种模型,如下表:

ViT与传统的CNN网络的比较:

VIT和卷积神经网络相比,表现基本一致,ViT的训练成本更低。
采用了不同数量的数据集,对VIT进行训练,效果如下:

当数据集较小时,ViT的效果不如CNN,但随着训练数据的增多,ViT的效果会逐步超越ViT。
总结
Vision Transformer(ViT)通过将图像分割为固定大小的图像块并转化为序列数据,结合可学习的位置编码与全局分类标识符(Class Token),利用多层Transformer Encoder的自注意力机制实现图像特征的全局建模,最终通过MLP Head输出分类结果。其核心工作流程以图像块嵌入为起点,通过位置编码赋予空间信息,在Transformer中逐层融合跨区域的语义关联,最终由Class Token汇聚全局信息完成分类。ViT的优势在于突破卷积的局部限制、实现长距离依赖建模,且模型扩展性强,但依赖大规模预训练数据且计算复杂度随图像分辨率陡增。未来研究可探索轻量化设计、局部-全局注意力结合、动态位置编码优化,以及跨模态与多任务的高效适配,进一步推动视觉Transformer在复杂场景下的实用化进程。ViT的成功不仅验证了Transformer在视觉任务中的普适性,更为跨模态统一模型开辟了新路径。
相关文章:

【第三十一周】ViT 论文阅读笔记
ViT 摘要Abstract文章信息引言方法Patch EmbeddingPatch Position EmbeddingTransformer EncoderMLP Head整体架构CNN的归纳偏置 代码实现实验结果总结 摘要 本篇博客介绍了Vision Transformer(ViT),这是一种突破性的图像分类模型ÿ…...
静电放电防护方案)
射频(RF)静电放电防护方案
方案简介 射频(RF)是 Radio Frequency 的缩写,表示可以辐射到空间的电磁频率,频率 范围从 300kHz~300GHz 之间。射频就是射频电流,简称 RF,它是一种高频交流变化 电磁波的简称。射频天线是一…...
)
【redis进阶三】分布式系统之主从复制结构(1)
目录 一 为什么要有分布式系统? 二 分布式系统涉及到的非常关键的问题:单点问题 三 学习部署主从结构的redis (1)创建一个目录 (2)进入目录拷贝两份原有redis (3)使用vim修改几个选项 (4)启动两个从节点服务器 (5)建立复制,要想配…...
)
排序(1)
排序(1) 日常生活中,有很多场景都会用到排序。比如你买东西,在购物软件就有几种展现方式,按照评论数量给你排序出来,让你选,还是说按照价钱高低排序出来让你选。 排序其实是一种为了更好解决问…...

NR 5G中的N5接口
N5接口的定义: Reference point between the PCF and an AF or TSN AF. 即N5 PCF和AF之间的参考点。 AF Application Function 应用功能,指应用层的各种服务,可以是运营商内部的应用如Volte AF(类似4G的Volte As)、也可以是第三方的AF&…...

STM32自学进阶指南:从入门到精通的成长路径 | 零基础入门STM32第九十九步
主题内容教学目的/扩展视频自学指导通过数据手册和搜索引擎查找资料,独立解决问题以积累经验和提升能力。自学过程中应保持敬畏之心,不断总结未知领域,持续进步。师从洋桃电子,杜洋老师 📑文章目录 一、自学指导全景图1.1 学习路线对比1.2 关键学习策略二、待探索技术领域…...

利用 Python 进行股票数据可视化分析
在金融市场中,股票数据的可视化分析对于投资者和分析师来说至关重要。通过可视化,我们可以更直观地观察股票价格的走势、交易量的变化以及不同股票之间的相关性等。 Python 作为一种功能强大的编程语言,拥有丰富的数据处理和可视化库…...

用 Vue.js 构建基础购物车:从 0 到 1 的实战解析
在当今数字化购物的浪潮中,购物车功能已成为电商平台不可或缺的一部分。它不仅承担着记录用户所选商品的重任,还需提供流畅的交互体验和精准的计算逻辑。本文将深入探讨如何利用 Vue.js 这一强大的 JavaScript 框架,逐步搭建一个基础但功能完…...
)
MapSet常用的集合类(二叉搜索树,哈希表)
Set集合 Set的核心特点: Set继承了Collection。 保存的元素不会重复。 保存的元素不能修改。 保存的元素无序,和List不同,如果有两个:List {1,2,3},List {2,1,3}&…...

五种IO模型
1、通信的本质: 通过网络通信的学习,我们能够理解网络通信的本质是进程间通信,而进程间通信的本质就是IO。 IO也就是input和output。当读取条件不满足的时候,recv会阻塞。write写入数据时,会将数据拷贝到缓冲区中&am…...

路由器开启QOS和UPNP的作用
QOS 的作用 保障关键业务带宽:可根据网络应用的重要性分配带宽。比如在家庭网络中,当多人同时使用网络时,将视频会议等实时性要求高的关键业务设置为高优先级,确保其能获得足够带宽,避免卡顿,而文件下载等…...

学习MySQL的第九天
纸上得来终觉浅 绝知此事要躬行 数据处理的增删查改 一、添加数据 添加数据有两种方式,一种是一条一条的添加数据,另一种是通过对其他表的查询,将查询的结果插入到表中;第一种方式又可以分为三种方式:…...

怎么免费下载GLTF/GLB格式模型文件,还可以在线编辑修改
现在非常流行glb格式模型,和gltf格式文件,可是之类模型网站非常非常少 1,咱们先直接打开http://glbxz.com 官方glb下载网站 glbxz.com 2 可以搜索,自己想要的模型关键词 3,到自己想下载素材页面 4,…...

高效数据拷贝方法总结
1.系统/语言层面的高效拷贝 内存拷贝优化 使用memcpy(C/C)或类似函数进行大块内存拷贝 利用SIMD指令(如AVX/SSE)进行向量化拷贝 2.零拷贝技术 文件映射(mmap) - 将文件映射到内存空间 发送文件描述符而非数据本身(Unix域套接字) 使用sendfile系统调用(文件到套接字直接传…...

C 语言 第八章 文件操作
目录 文件操作 文件和流的介绍 C 输入 & 输出 C 文件的读写 创建/打开文件 写入文件 fputc 函数 fputs 函数 fprintf 函数 实例: 读取文件 fgets函数 实例: 关闭文件 文件操作 文件和流的介绍 变量、数组、结构体等数据在运行时存储于内存…...

开发一款游戏需要哪些岗位角色参与?
常见分类 1. 游戏策划(Game Designer) 核心职责:设计游戏的玩法、规则、内容和整体体验。 具体工作: 系统设计:设计游戏的战斗、经济、成长、社交等核心系统。 数值设计:平衡角色属性、装备数值、经济系…...
)
大模型面经 | 手撕多头注意力机制(Multi-Head Attention)
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...

二叉树的初步学习
前言 对于二叉树的学习不想其他数据结构一样,直接学习他的结构的构建。单纯的一个二叉树在实际中没什么作用,除非是加了限制条件的,比如大名鼎鼎的红黑树。但是对于初学者而言,刚开始就学习红黑树,会让你刚接触就想放…...

Tkinter菜单和工具栏的设计
在这一章中,我们将深入探讨如何在Tkinter应用程序中设计菜单和工具栏。菜单和工具栏是桌面应用程序中常见的界面元素,它们为用户提供了便捷的操作方式。通过这一章的学习,您将能够在您的Tkinter应用中添加菜单栏和工具栏,提升用户体验。 6.1 菜单栏的设计 菜单栏是应用程…...

windows中搭建Ubuntu子系统
windows中搭建虚拟环境 1.配置2.windows中搭建Ubuntu子系统2.1windows配置2.1.1 确认启用私有化2.1.2 将wsl2设置为默认版本2.1.3 确认开启相关配置2.1.4重启windows以加载更改配置 2.2 搭建Ubuntu子系统2.2.1 下载Ubuntu2.2.2 迁移位置 3.Ubuntu子系统搭建docker环境3.1安装do…...

Docker 部署 Kafka 完整指南
Docker 部署 Kafka 完整指南 本指南将详细介绍如何使用 Docker 部署 Kafka 消息队列系统,包括单节点和集群模式的部署方式。 1. 单节点部署 (Zookeeper Kafka) 1.1 创建 docker-compose.yml 文件 version: 3.8services:zookeeper:image: bitnami/zookeeper:3.8…...
)
java学习总结(if switch for)
一.基本结构 1.单分支if int num 10; if (num > 5) {System.out.println("num 大于 5"); } 2.双分支if-else int score 60; if (score > 60) {System.out.println("及格"); } else {System.out.println("不及格"); } 3.多分支 int…...
)
解释:指数加权移动平均(EWMA)
指数加权移动平均(EWMA, Exponential Weighted Moving Average) 是一种常用于时间序列平滑、异常检测、过程控制等领域的统计方法。相比普通移动平均,它对最近的数据赋予更高权重,对旧数据逐渐“淡化”。 ✅ 一、通俗理解 想象你…...

open harmony多模组子系统分析
multimodalinput是open harmony的核心输入子系统,负责统一管理触摸屏,键盘,鼠标,手势,传感器等多种 输入源,提供标准化事件分发机制。其核心 目标是通过统一的事件处理框架,实现跨设备ÿ…...

Hello Java!
1. Java发展史 1.1 计算机编程语言分类 机器语言:电子机器能够直接识别的语言,无需经过翻译,计算机内部就有相应的电路来完成它;从使用的角度来看,机器语言是最低级的语言。 机器语言。指令以二进制代码形式存在。 汇…...

vue 入门:生命周期
文章目录 vue组件的生命周期创建阶段更新阶段销毁阶段生命周期钩子函数 vue组件的生命周期 创建阶段、销毁阶段:只会执行一次更新阶段:会执行多次 创建阶段 beforeCreate 在实例初始化之后,数据观测(data observer)…...

C#容器源码分析 --- Dictionary<TKey,TValue>
Dictionary<TKey, TValue> 是 System.Collections.Generic 命名空间下的高性能键值对集合,其核心实现基于哈希表和链地址法(Separate Chaining)。 .Net4.8 Dictionary<TKey,TValue>源码地址: dictionary…...

yum的基本操作和vim指令
在我们的手机端或者Windows上下载软件,可以在相应的应用商店或者官网进行下载,这样对于用户来说十分的方便和便捷。而在Linux上,也有类似的安装方式,我们来一一了解一下。 Linux安装软件的3种方法 源代码安装 在Linux下安装软件…...

MCU刷写——HEX与S19文件互转详解及Python实现
工作之余来写写关于MCU的Bootloader刷写的相关知识,以免忘记。今天就来聊聊Hex与S19这这两种文件互相转化,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走…...

深入探讨避免MQ消息重复消费的策略与实现
引言 随着微服务架构的流行,消息队列(Message Queue, MQ)作为系统间异步通信的重要手段,被广泛应用于各种场景。然而,在使用MQ的过程中,一个不容忽视的问题是消息可能被重复消费。这不仅可能导致数据不一致…...
:SM3 摘要算法)
定制一款国密浏览器(8):SM3 摘要算法
上一章我们讲到了铜锁和 BoringSSL,本章从最简单的国密算法 SM3 摘要算法入手,说明一下 SM3 算法的移植要点。 SM3 算法本身并不复杂,详细算法说明参考《GB∕T 32905-2016信息安全技术 SM3密码杂凑算法》这份文档。因为铜锁开源项目有实现代码,直接照搬过来。 将 crypto/…...

【Docker基础】Compose 使用手册:场景、文件与命令详解
文章目录 一、什么是 Docker Compose二、为什么需要 Docker Compose三、Docker Compose 使用步骤 / 核心功能步骤核心功能: 四、Docker Compose 的使用场景五、Docker Compose 文件(docker-compose.yml)文件语法版本文件基本结构及常见指令常…...

RT-2论文深度解读:视觉-语言-动作统一模型的机器人泛化革命
1. 核心问题与挑战 传统机器人学习存在两大瓶颈: 数据效率低下:依赖特定场景的机器人操作数据(如抓取、推压),收集成本高泛化能力局限:模型仅能完成训练中出现过的任务,无法应对长尾场景 RT-…...

git 提交标签
Git 提交标签 提交消息格式: <type>: <description> (示例:git commit -m "feat: add user login API") 标签适用场景feat新增功能(Feature)。fix修复 Bug(Bug fix&…...
)
学习率(Learning Rate)
学习率(Learning Rate)是深度学习中最关键的超参数之一,它控制模型在每次参数更新时的“步长大小”。简单来说:它决定了模型从错误中学习的“速度”。 直观比喻 想象你在山顶蒙眼下山(找最低点)࿱…...

李宏毅NLP-3-语音识别part2-LAS
语音识别part2——LAS Listen Listen主要功能是提取内容信息,去除说话人差异和噪声 。编码器(Encoder)结构,输入是声学特征,经过 Encoder 处理后,输出为高级表示,这些高级表示可用于后续语音识别…...

游戏引擎学习第222天
回顾昨天的过场动画工作 我们正在制作一个游戏,目标是通过直播的方式完成整个游戏的开发。在昨天的工作中,我享受了制作过场动画的过程,所以今天我决定继续制作多个层次的过场动画。 昨天我们已经开始了多层次过场动画的基本制作࿰…...

双系统win11 + ubuntu,如何完全卸载ubuntu系统?
双系统win11 ubuntu,如何完全卸载ubuntu? 注意事项 操作前确保有 Windows 安装介质(USB),以防需要修复对 EFI 分区的操作要格外小心如果使用 BitLocker,可能需要先暂停保护如果遇到问题,可以使用 Windows…...

【T2I】Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
code: https://github.com/NJU-PCALab/RAG-Diffusion Abstract 区域提示,或组成生成,能够实现细粒度的空间控制,在实际应用中越来越受到关注。然而,以前的方法要么引入了额外的可训练模块,因此只适用于特定…...

HarmonyOS:Map Kit简介
一、概述 Map Kit(地图服务) 为开发者提供强大而便捷的地图能力,助力全球开发者实现个性化显示地图、位置搜索和路径规划等功能,轻松完成地图构建工作。您可以轻松地在HarmonyOS应用/元服务中集成地图相关的功能,全方位…...

【从零实现高并发内存池】- 项目介绍、原理 及 内存池详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
学习笔记)
CSS margin(外边距)学习笔记
CSS 中的 margin 属性用于定义元素周围的空白区域,它是一个非常重要的布局工具,可以帮助我们控制元素之间的间距,从而实现更美观和易用的页面布局。以下是对 margin 属性的详细学习笔记。 一、margin 的基本概念 margin 是元素周围的透明区…...
)
【数据集】中国各省低空经济及无人机相关数据集(1996-2025年2月)
低空经济泛指3000米高空以下的飞行经济活动,以民用客运飞行器和无人驾驶航空器为主。低空经济产业是先进飞行器出行(AAM)在城市低空运行的一种变革性和颠覆性的复合新产业,主要以垂直起降型飞机(VTOL)与无人…...

C++动态分配内存知识点!
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 大家好呀,又是分享干货的时间,今天我们来学习一下动态分配内存。 文章目录 1.动态分配内存的思想 2.动态分配内存的概念 2.1内存分配函数 2.2动态内存的申请和释放 2.3内存碎片问…...

哈喽打车 小程序 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 这一次遇到这种风控感觉挺有…...

泛型的二三事
泛型(Generics)是Java语言的一个重要特性,它允许在定义类、接口和方法时使用类型参数(Type Parameters),从而实现类型安全的代码重用。泛型在Java 5中被引入,极大地增强了代码的灵活性和安全性。…...

云计算:数字浪潮中的第三次文明跃迁——从虚拟化到智能协同的范式革命
一、浪潮的序曲:从机械革命到数字原子的觉醒 20世纪中叶,当晶体管的发明点燃信息革命的火种时,人类社会的第三次浪潮已悄然萌芽。托夫勒预言的“信息将成为新的权力核心”,在21世纪初以云计算的形态具象化。这场浪潮的起点&#…...

redis哨兵机制 和集群有什么区别:
主从: 包括一个master节点 和多个slave节点: master节点负责数据的读写,slave节点负责数据的读取,master节点收到数据变更,会同步到slave节点 去实现数据的同步。通过这样一个架构可以去实现redis的一个读写分离。提升…...

java基础2
构造器: 构造器与类同名; 每个类可以有一个以上的构造器; 构造器可以有0个,1个或多个参数; 构造器没有返回值; 构造器总是伴着new一起调用 方法重载: 方法名字一样,参数不一样…...

《算法笔记》3.6小节——入门模拟->字符串处理
1009 说反话 #include <cstdio>int main() {char sen[80][80];int num0;while(scanf("%s",sen[num])!EOF){num;}for (int i num-1; i > 0; --i) {printf("%s ",sen[i]);}printf("%s\n",sen[0]);return 0; }字符串连接 #include <io…...