李宏毅NLP-3-语音识别part2-LAS
语音识别part2——LAS

Listen
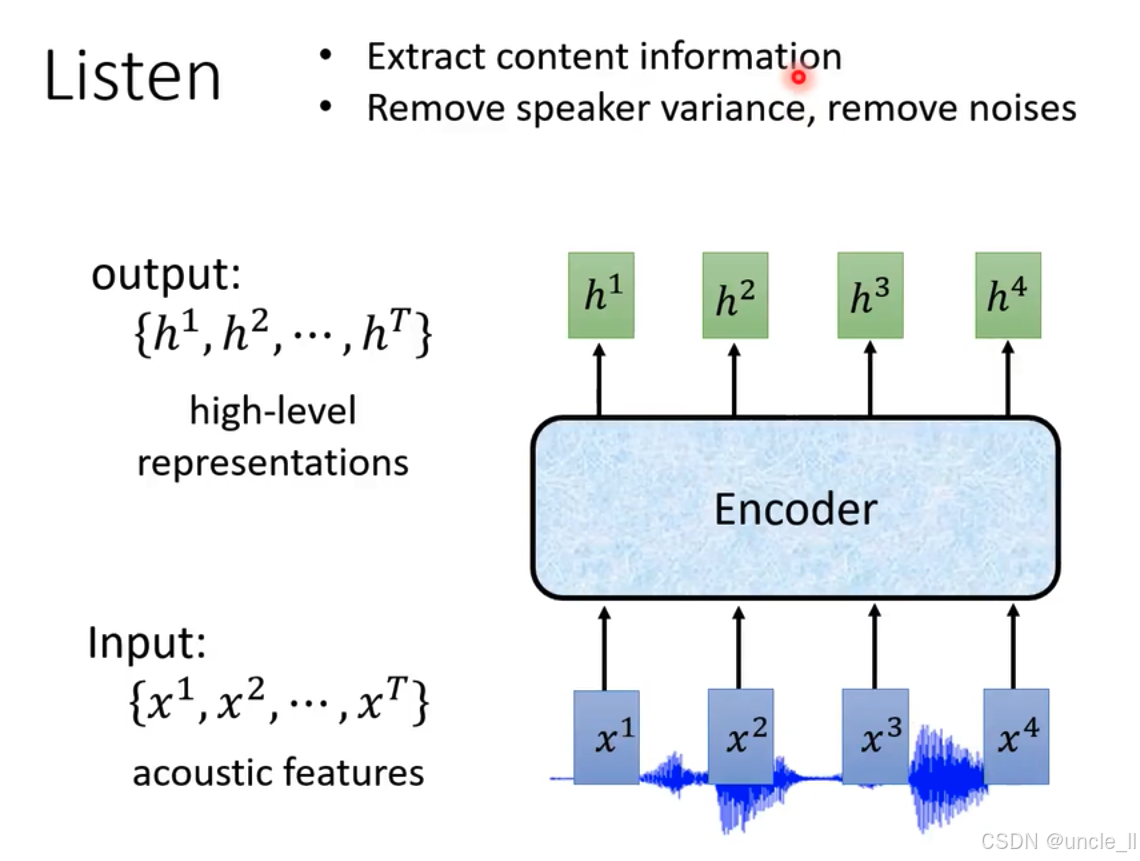
Listen主要功能是提取内容信息,去除说话人差异和噪声 。编码器(Encoder)结构,输入是声学特征,经过 Encoder 处理后,输出为高级表示,这些高级表示可用于后续语音识别等任务 。
encoder有多种实现方式:
- RNN
- 1D CNN
- self-attention
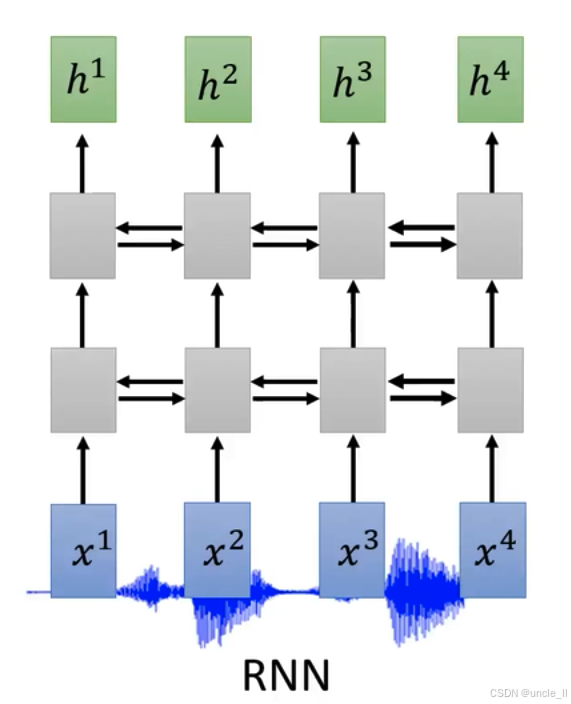
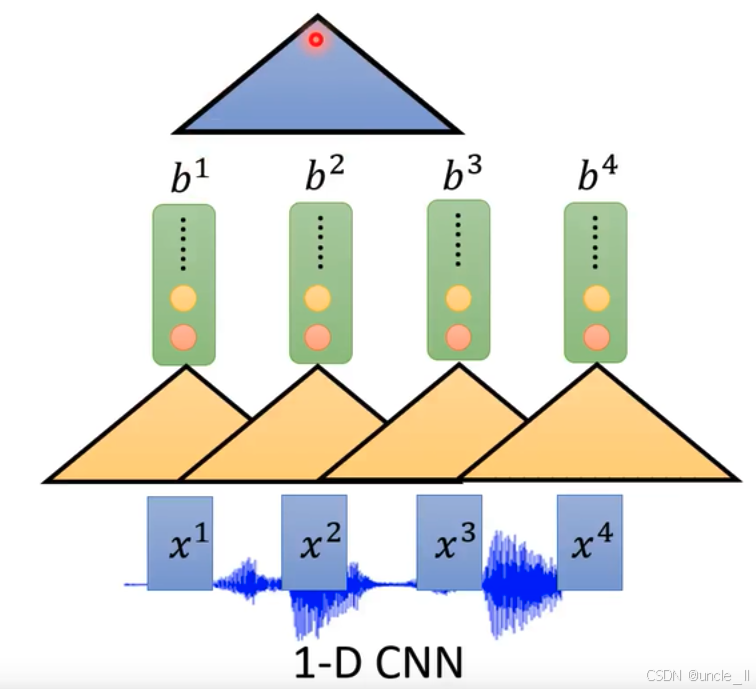
神经网络在语音处理等序列数据任务中应用的要点:
高层滤波器特性
“Filters in higher layer can consider longer sequence” ,意思是在卷积神经网络(CNN)中,高层的滤波器能够考虑更长的序列信息。随着网络层数加深,滤波器感受野增大,可捕捉更广泛的上下文信息 。比如在语音识别中,能整合更长语音片段的特征,提升对复杂语音模式的理解 。
网络组合方式
“CNN+RNN is common” ,指出将卷积神经网络(CNN)和循环神经网络(RNN)结合使用是常见做法。CNN擅长提取局部特征,RNN擅长处理序列的时序信息,二者结合能兼顾语音数据的局部模式提取和整体时序关联建模 ,在语音识别、自然语言处理等领域广泛应用 。
现在更流行的趋势是使用self-attention

自注意力机制能让模型在处理序列数据时,根据不同位置元素间的关联程度分配注意力权重,捕捉长距离依赖关系 。比如在语音识别中,可有效关注语音前后文信息,理解语义 。

为了降低输入的向量,语音处理中回加入下采样(Down Sampling),下采样方法包含:
Pyramid RNN(金字塔循环神经网络 )
- 来源:由Chan等人在ICASSP’16(国际声学、语音和信号处理会议,2016年 )提出。
- 结构特点:输入为声学特征 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4 ,通过多层循环神经网络处理,下层的输出作为上层的输入,呈金字塔式结构。随着层数增加,时间维度上的信息被逐步聚合,最终输出 h 1 h^1 h1、 h 2 h^2 h2 ,实现对语音特征的下采样 。
Pooling over time(时间池化 )
- 来源:由Bahdanau等人在ICASSP’16提出。
- 结构特点:同样以 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4作为声学特征输入,通过时间维度上的池化操作(如最大池化、平均池化等 ),对输入特征进行降采样处理,减少时间维度上的信息冗余,输出 h 1 h^1 h1、 h 2 h^2 h2 。 图中展示的两种方法都是为了在语音处理中有效减少数据量,同时保留关键特征信息 。
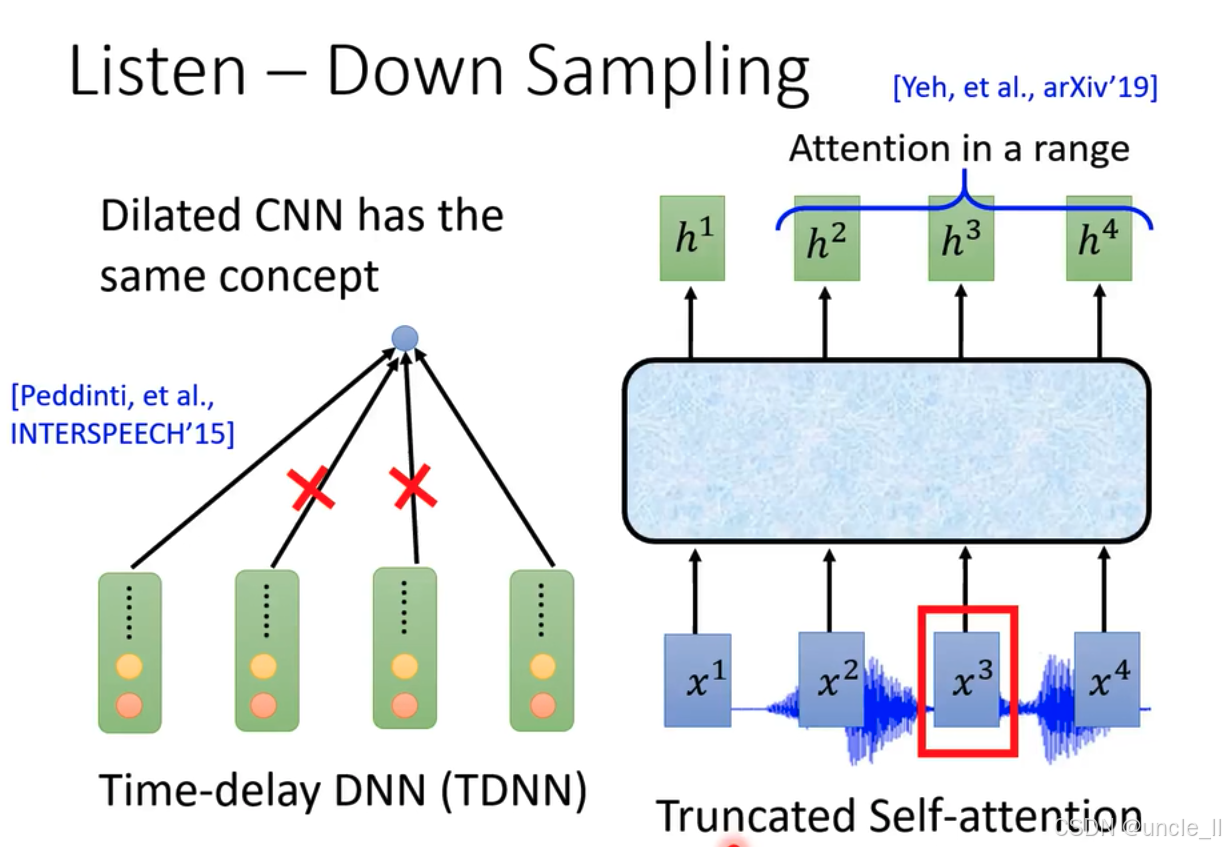
Time - delay DNN (TDNN,时延深度神经网络 )
- 来源:由Peddinti等人在INTERSPEECH’15(国际语音通信协会年会,2015年 )提出。
- 结构特点:图中显示多个绿色模块(代表网络层 )通过黑色箭头连接到一个中心点。TDNN通过在时间维度上设置延迟,能够捕捉语音信号在不同时间步的局部上下文信息,有效处理语音的时序特征,实现对语音特征的下采样 。扩张卷积神经网络(Dilated CNN)与之概念相同,都通过特殊方式扩大感受野来处理序列数据 。
Truncated Self - attention(截断自注意力 )
- 来源:出自Yeh等人在arXiv’19上的研究。
- 结构特点:输入为声学特征 x 1 x^1 x1、 x 2 x^2 x2、 x 3 x^3 x3、 x 4 x^4 x4 ,经过一个浅蓝色模块(代表截断自注意力层 )处理,输出为 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。截断自注意力机制在自注意力基础上,限制注意力计算范围,减少计算量,同时能捕捉语音序列中的重要关联信息,达到下采样目的 。
Attention
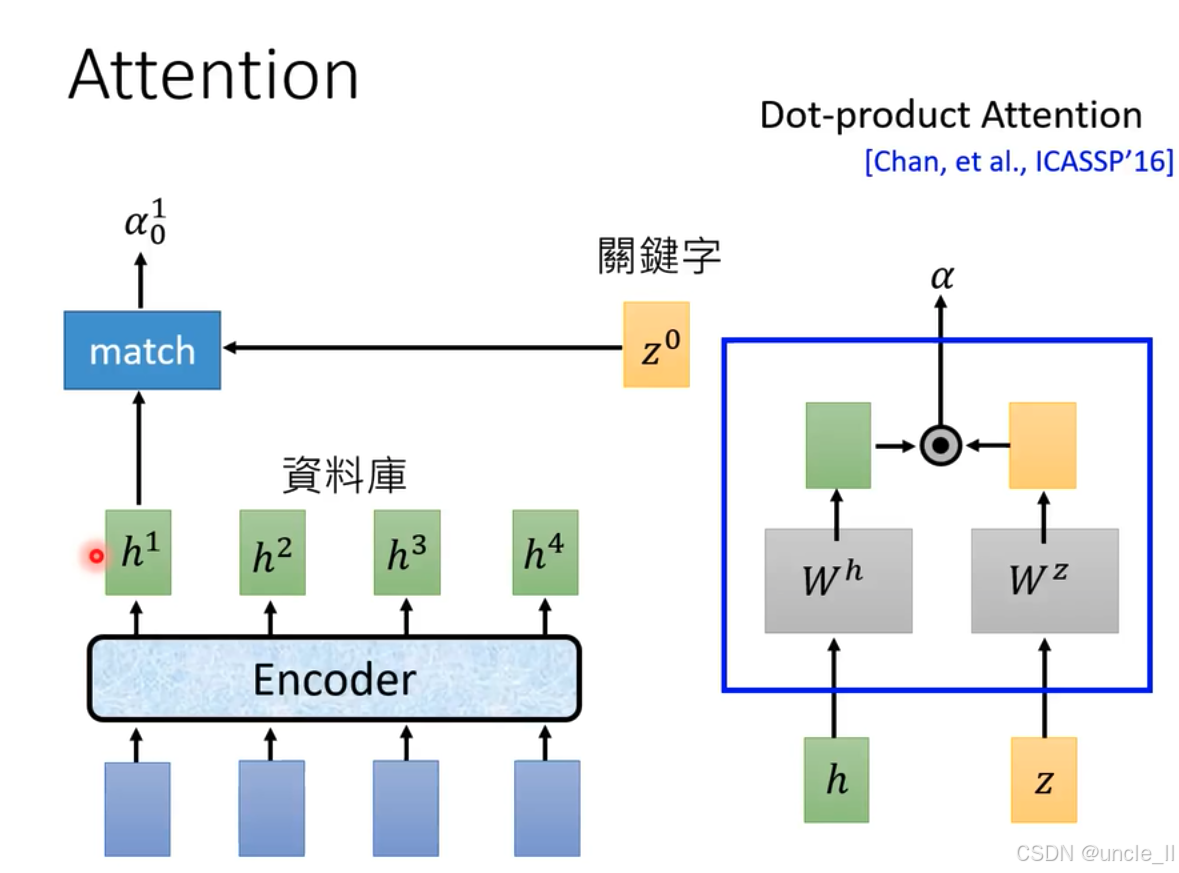
注意力机制(Attention)中的点积注意力(Dot - product Attention) :
- 点积注意力计算:详细展示点积注意力计算过程。输入为特征 h h h和 z z z ,分别经过权重矩阵 W h W^h Wh和 W z W^z Wz线性变换后,进行点积操作(图中圆圈表示 ),得到注意力权重 α \alpha α 。该计算方式出自Chan等人在ICASSP’16(国际声学、语音和信号处理会议,2016年 )的研究 。
- 作用:点积注意力通过这种计算方式,衡量不同特征间关联程度,为后续任务分配注意力权重,在语音识别、自然语言处理等领域用于聚焦关键信息 。
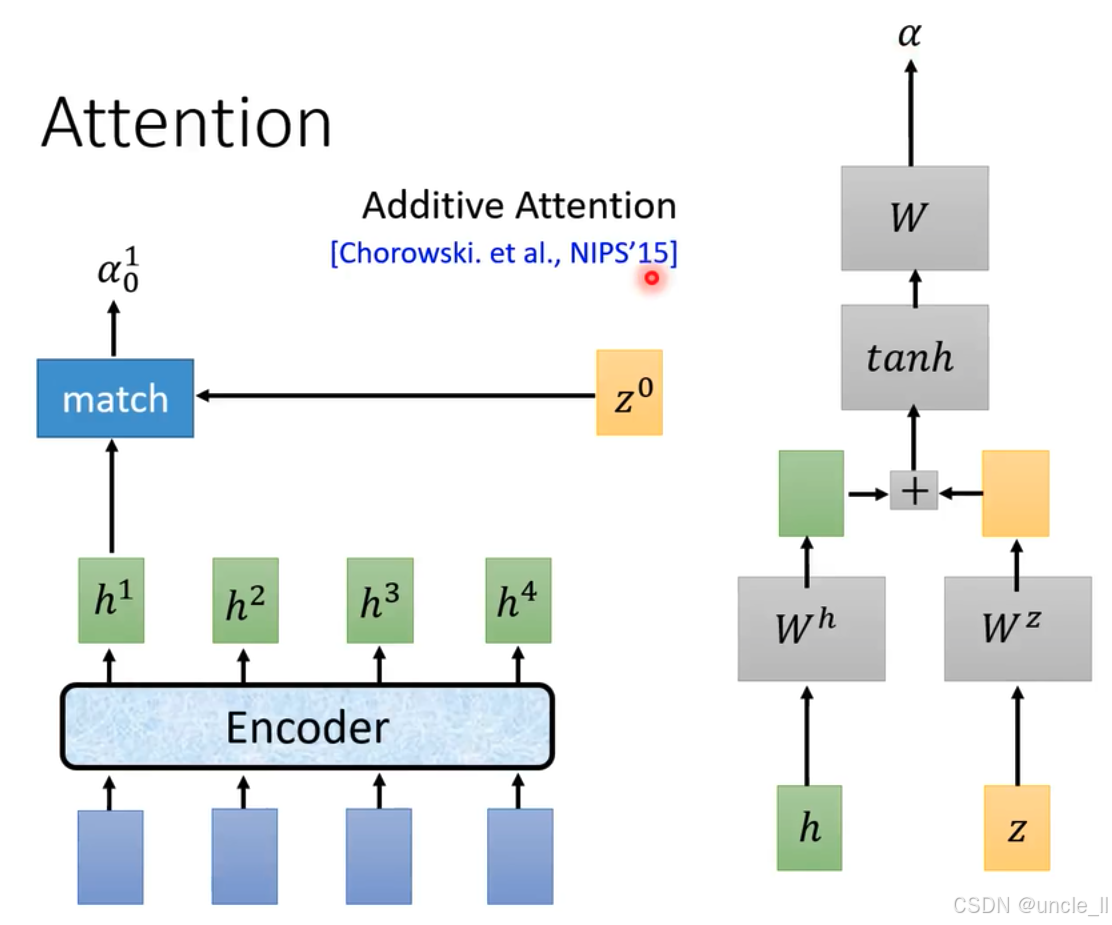
注意力机制(Attention)中的加法注意力(Additive Attention) :
- 加法注意力计算:详细展示加法注意力计算过程。输入为特征 h h h和 z z z ,分别经过权重矩阵 W h W^h Wh和 W z W^z Wz线性变换后,将变换结果相加,再经过 t a n h tanh tanh激活函数处理,最后通过权重矩阵 W W W得到注意力权重 α \alpha α 。该计算方式出自Chorowski等人在NIPS’15(神经信息处理系统大会,2015年 )的研究 。
Spell
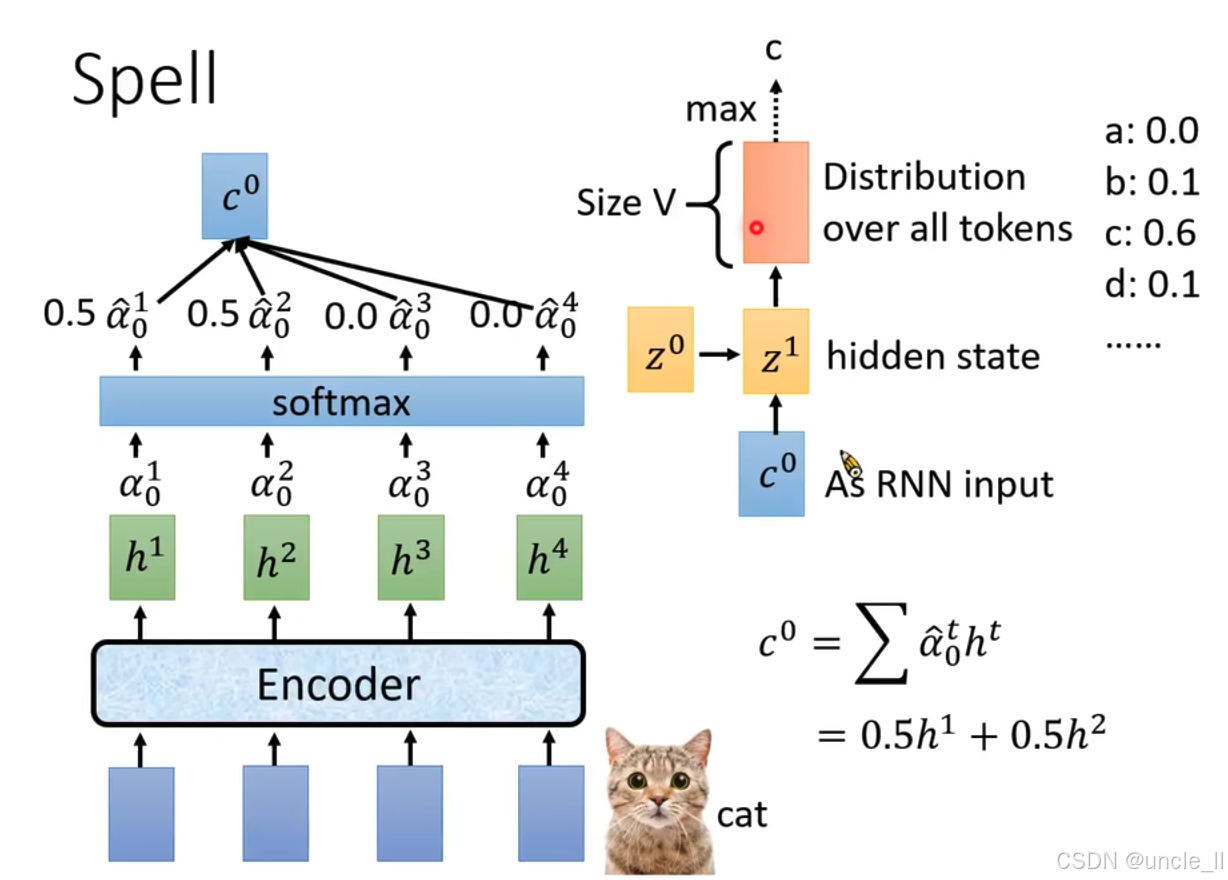 展示了语音识别中“Spell”(解码 )环节的过程:
展示了语音识别中“Spell”(解码 )环节的过程:
- 输入与特征提取:底部蓝色模块是输入,经“Encoder”(编码器 )处理后得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力权重计算:这些特征经过注意力机制计算,得到注意力权重 α 0 1 \alpha_0^1 α01、 α 0 2 \alpha_0^2 α02、 α 0 3 \alpha_0^3 α03、 α 0 4 \alpha_0^4 α04 ,再通过“softmax”函数处理,得到归一化后的权重 α ^ 0 1 \hat{\alpha}_0^1 α^01、 α ^ 0 2 \hat{\alpha}_0^2 α^02、 α ^ 0 3 \hat{\alpha}_0^3 α^03、 α ^ 0 4 \hat{\alpha}_0^4 α^04 ,图中示例为0.5、0.5、0.0、0.0 。
- 上下文向量计算:根据归一化权重计算上下文向量 c 0 c^0 c0 ,公式为 c 0 = ∑ α ^ 0 t h t c^0 = \sum \hat{\alpha}_0^t h^t c0=∑α^0tht ,示例中 c 0 = 0.5 h 1 + 0.5 h 2 c^0 = 0.5h^1 + 0.5h^2 c0=0.5h1+0.5h2 。
- 循环神经网络输入与处理: c 0 c^0 c0作为循环神经网络(RNN)的输入,与隐藏状态 z 0 z^0 z0结合,得到新的隐藏状态 z 1 z^1 z1 。
- 输出与预测:基于新的隐藏状态 z 1 z^1 z1 ,生成所有标记(tokens)上的概率分布,图中“Size V”表示分布的维度(词汇表大小 ),示例给出了标记a、b、c、d等的概率值,用于预测最终的语音识别结果 。
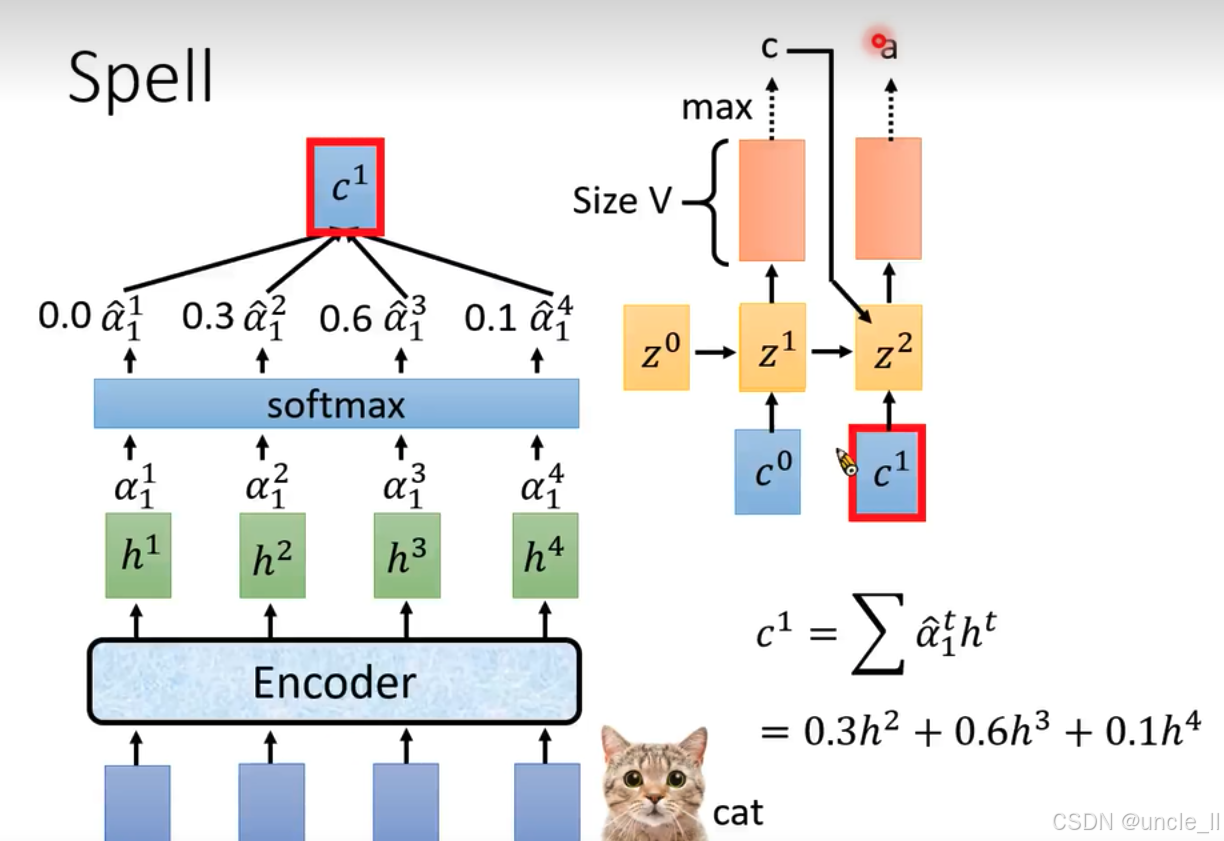
- 输入与特征提取:依旧是底部蓝色模块作为输入,经“Encoder”(编码器 )得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力权重计算:这些特征经注意力机制计算出权重 α 1 1 \alpha_1^1 α11、 α 1 2 \alpha_1^2 α12、 α 1 3 \alpha_1^3 α13、 α 1 4 \alpha_1^4 α14 ,再通过“softmax”函数得到归一化权重 α ^ 1 1 \hat{\alpha}_1^1 α^11、 α ^ 1 2 \hat{\alpha}_1^2 α^12、 α ^ 1 3 \hat{\alpha}_1^3 α^13、 α ^ 1 4 \hat{\alpha}_1^4 α^14 ,图中示例为0.0、0.3、0.6、0.1 。
- 上下文向量计算:根据归一化权重计算新的上下文向量 c 1 c^1 c1 ,公式为 c 1 = ∑ α ^ 1 t h t c^1 = \sum \hat{\alpha}_1^t h^t c1=∑α^1tht ,示例中 c 1 = 0.3 h 2 + 0.6 h 3 + 0.1 h 4 c^1 = 0.3h^2 + 0.6h^3 + 0.1h^4 c1=0.3h2+0.6h3+0.1h4 , c 1 c^1 c1用红色方框特别标出 。
- 循环神经网络迭代: c 1 c^1 c1作为RNN新的输入,与隐藏状态 z 1 z^1 z1结合得到 z 2 z^2 z2 。
- 输出与预测:基于 z 2 z^2 z2生成所有标记(tokens)上的概率分布,“Size V”表示分布维度(词汇表大小 ),通过取概率最大值(“max” )确定预测结果 。
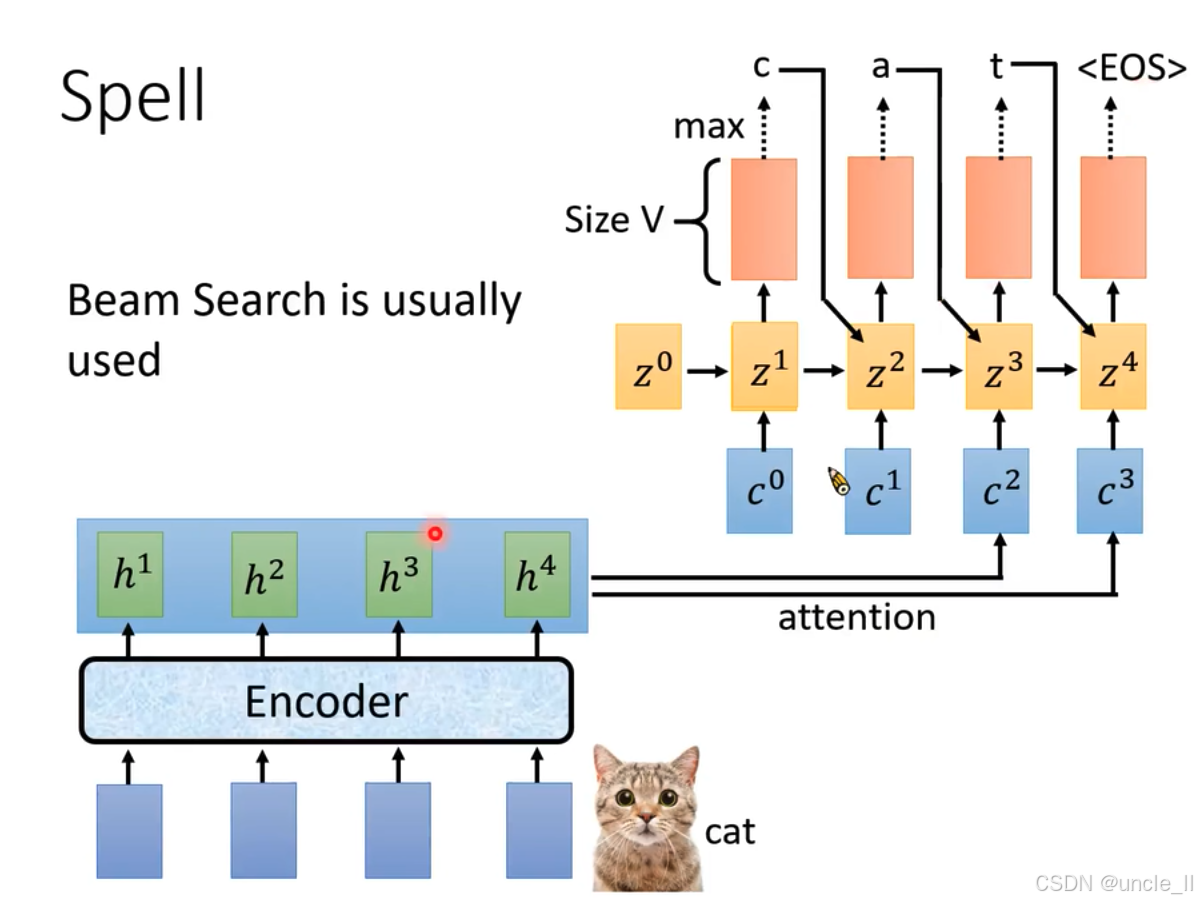
- 输入与特征提取:底部蓝色模块作为输入,经“Encoder”(编码器 )得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力机制:这些特征通过注意力机制,为后续解码提供加权信息 。
- 循环神经网络迭代:展示了循环神经网络隐藏状态的迭代过程,从 z 0 z^0 z0开始,依次结合上下文向量 c 0 c^0 c0、 c 1 c^1 c1、 c 2 c^2 c2、 c 3 c^3 c3 ,得到 z 1 z^1 z1、 z 2 z^2 z2、 z 3 z^3 z3、 z 4 z^4 z4 。
- 输出与预测:基于各隐藏状态生成所有标记(tokens)上的概率分布,“Size V”表示分布维度(词汇表大小 )。通过取概率最大值(“max” )逐步确定预测结果,图中示例依次预测出“c”“a”“t” ,最终识别结果为“cat” 。
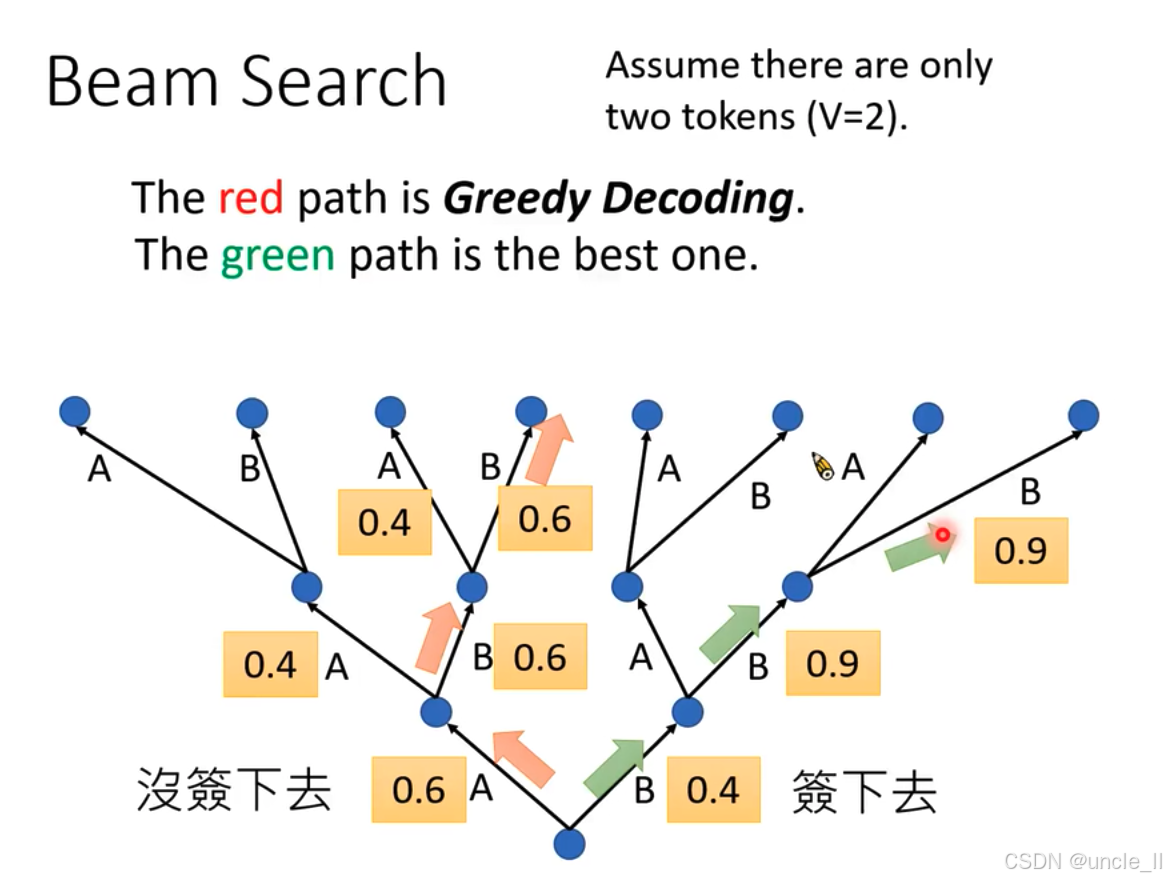
这张图用于说明束搜索(Beam Search)算法,为便于理解做了简化假设,假设词汇表中只有两个标记(tokens),即 V = 2 V = 2 V=2 ,分别用A和B表示 。
路径对比
- 红色路径(Greedy Decoding,贪婪解码 ):每一步都选择当前概率最高的标记。但从全局看,这种策略可能无法得到最优解。图中红色箭头指示其选择路径,每一步只关注当下最大概率,未考虑后续整体情况 。
- 绿色路径:代表全局最优路径。通过综合考虑后续步骤,选择能使最终结果概率最高的路径,图中绿色箭头指示其选择路径 。
概率与选择
图中不同节点间连线上标注的数字(如0.4、0.6、0.9 )表示选择相应路径的概率。在束搜索中,会根据设定的束宽,保留每一步概率较高的若干路径继续搜索,而非像贪婪解码只选当前最优,以此提升找到全局最优解的可能性。 但是实践中无法计算所有的线路。
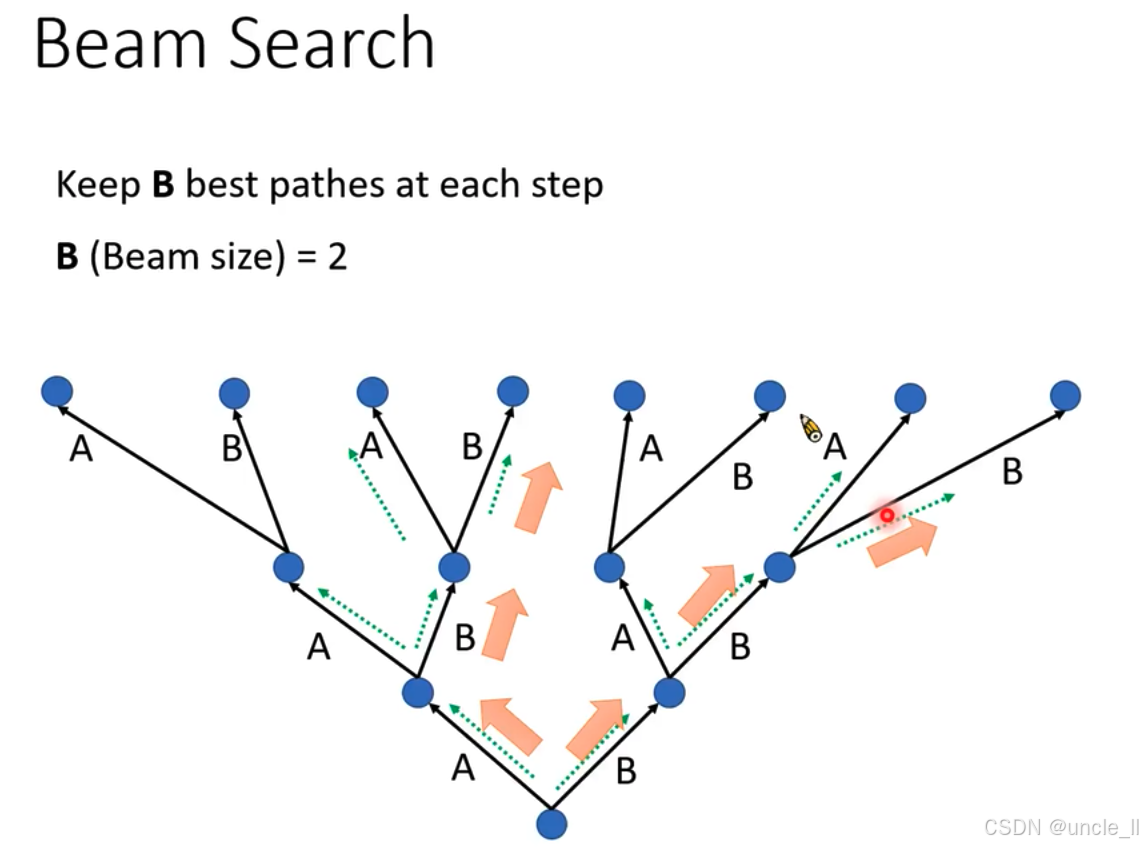
上方文字“Keep B best pathes at each step”说明算法在每一步会保留B条最佳路径 ,这里设定束宽“B (Beam size) = 2” ,即每一步保留两条最优路径继续搜索 。
- 从起始节点开始,每一步根据概率等因素评估各路径优劣,保留概率最高的两条路径(用绿色箭头表示 )继续延伸搜索,舍弃其他路径(用橙色箭头表示 ) 。通过这种方式,在平衡计算量的同时,更有可能找到全局最优解,避免像贪婪解码那样陷入局部最优 。
Train
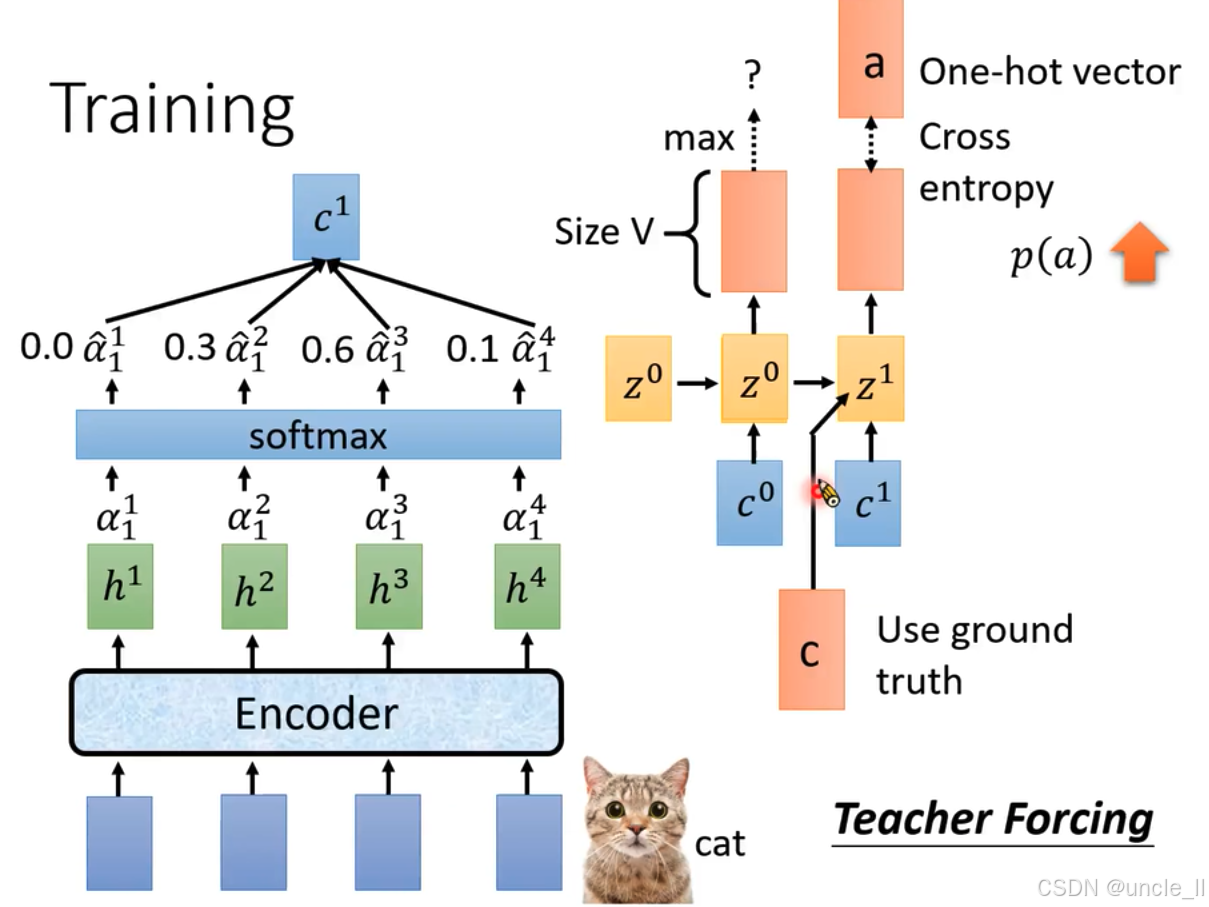
这张图展示了语音识别模型的训练过程,涉及Teacher Forcing(教师强制 )机制:
- 输入与特征提取:底部蓝色模块为输入,经“Encoder”(编码器 )处理后得到特征表示 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 。
- 注意力权重计算:这些特征通过注意力机制计算出权重 α 1 1 \alpha_1^1 α11、 α 1 2 \alpha_1^2 α12、 α 1 3 \alpha_1^3 α13、 α 1 4 \alpha_1^4 α14 ,再经“softmax”函数得到归一化权重 α ^ 1 1 \hat{\alpha}_1^1 α^11、 α ^ 1 2 \hat{\alpha}_1^2 α^12、 α ^ 1 3 \hat{\alpha}_1^3 α^13、 α ^ 1 4 \hat{\alpha}_1^4 α^14 ,图中示例值为0.0、0.3、0.6、0.1 。
- 上下文向量计算:根据归一化权重计算上下文向量 c 1 c^1 c1 ,公式为 c 1 = ∑ α ^ 1 t h t c^1 = \sum \hat{\alpha}_1^t h^t c1=∑α^1tht 。
- 循环神经网络迭代: c 1 c^1 c1与隐藏状态 z 0 z^0 z0结合,得到新隐藏状态 z 1 z^1 z1 。
- 输出与损失计算:基于 z 1 z^1 z1生成所有标记(tokens)上的概率分布,“Size V”表示分布维度(词汇表大小 )。通过“max”操作确定预测结果。真实值用独热向量(One - hot vector)表示,与预测概率分布通过交叉熵(Cross entropy)计算损失 p ( a ) p(a) p(a) 。
- Teacher Forcing机制:在训练循环神经网络时,不使用上一时刻的预测值作为下一时刻的输入,而是直接使用真实的标签值作为输入。这样能让模型在训练时学习到更准确的映射关系,加快收敛速度,避免错误累积,但可能导致模型在测试时对错误预测的鲁棒性较差 。
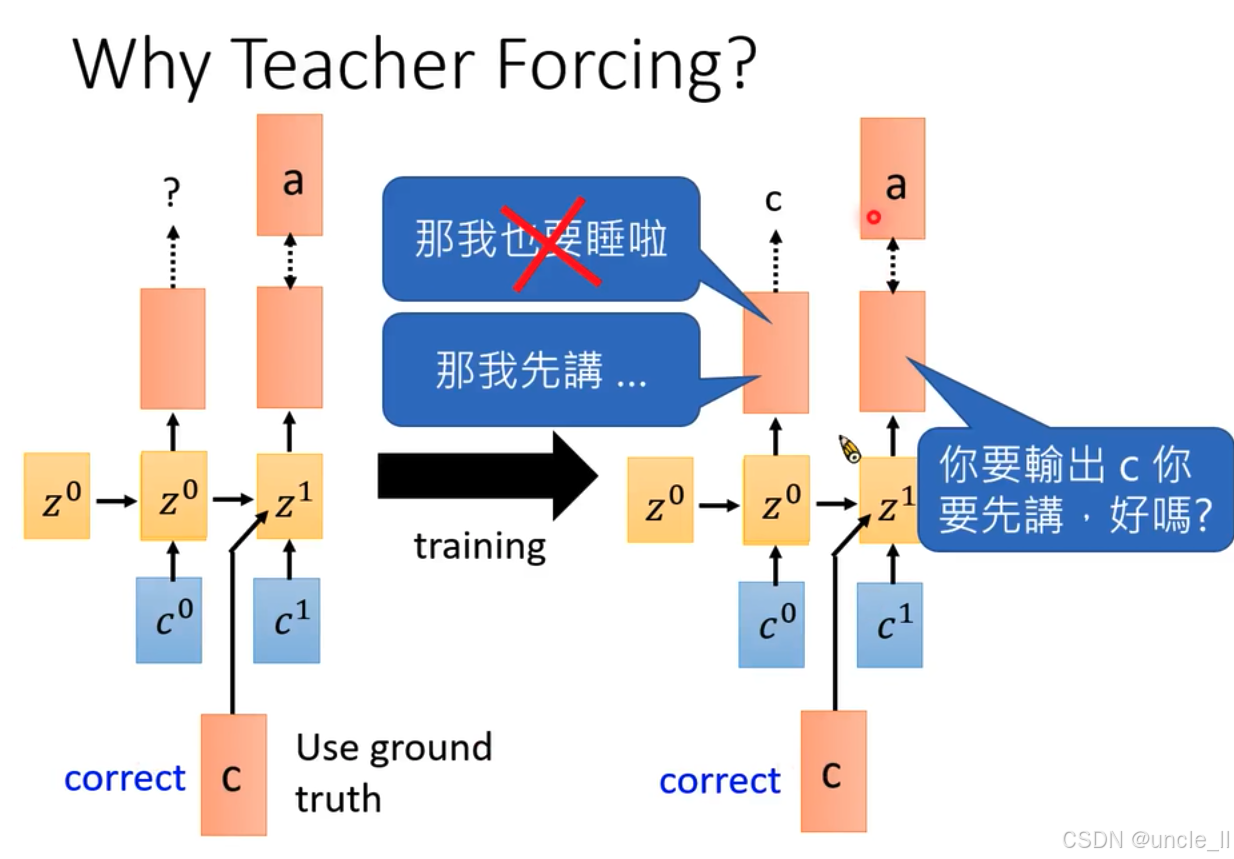
为什么使用教师强制(Teacher Forcing):
- 训练方式:展示了循环神经网络训练时,隐藏状态从 z 0 z^0 z0转变到 z 1 z^1 z1 ,输入为 c 0 c^0 c0和 c 1 c^1 c1 。这里使用真实标签(标注“correct” )作为输入,即Teacher Forcing机制 。上方橙色模块代表输出,其中一个输出旁标注问号“?” ,表示模型预测不确定 。蓝色对话框“那我也要睡啦”被划掉,暗示这种方式避免模型因错误累积而“消极怠工” 。
- 训练方式:同样是隐藏状态从 z 0 z^0 z0到 z 1 z^1 z1 ,输入为 c 0 c^0 c0和 c 1 c^1 c1 ,且使用真实标签(标注“correct” )。蓝色对话框“那我先講…”表示模型使用正确标签信息进行训练 ,另一个对话框“你要輸出c你要先講,好嗎?” ,进一步强调使用真实标签能让模型更好学习正确输出 。
- 对比说明:中间箭头标注“training” ,表示从左侧情况向右侧情况的训练转变,强调Teacher Forcing机制在训练中为模型提供准确信息,避免错误累积,使模型能更有效地学习正确映射关系 。
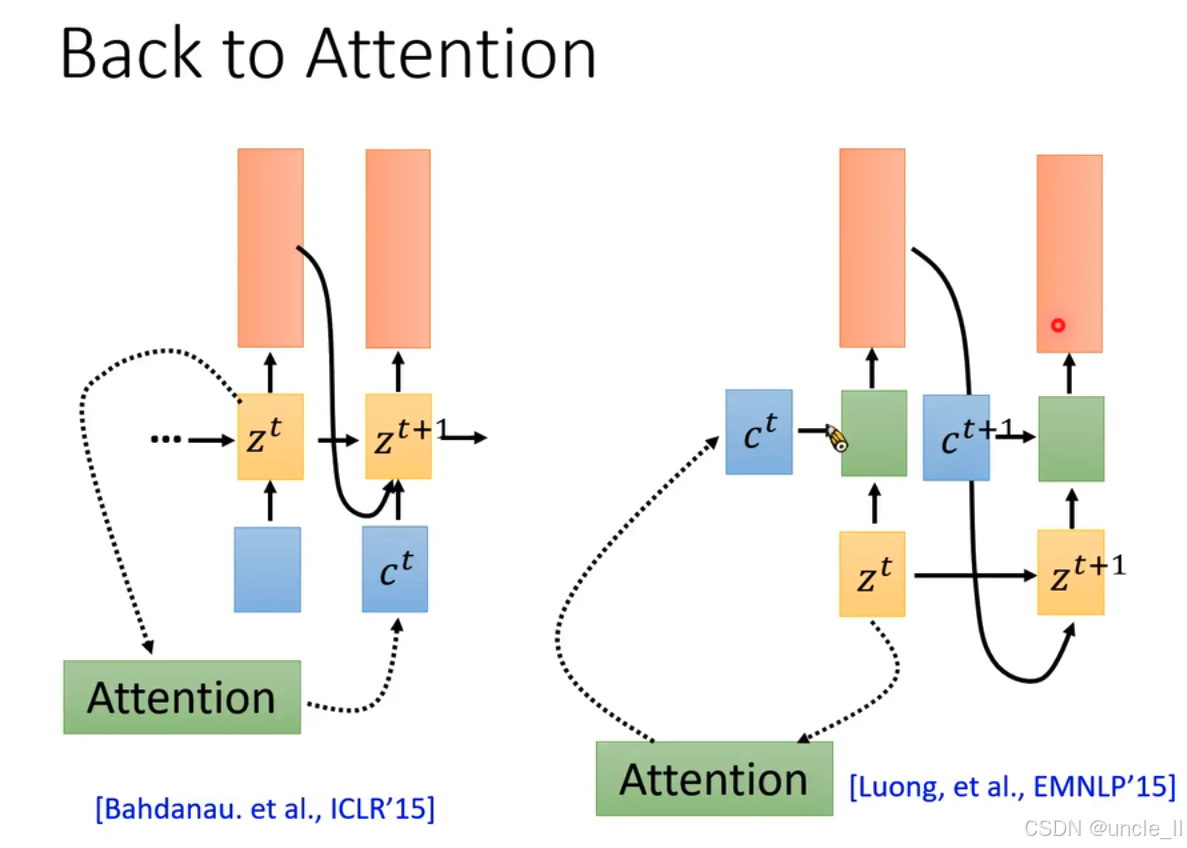
围绕注意力机制,介绍了不同的注意力计算和应用方式:
- 左图:出自Bahdanau等人在ICLR’15的研究。展示了注意力机制的一种结构, z t z^t zt和 z t + 1 z^{t + 1} zt+1为隐藏状态, c t c^t ct是上下文向量,注意力机制(绿色模块)通过虚线箭头与其他模块相连,计算注意力权重并影响隐藏状态更新和输出 。
- 右图:出自Luong等人在EMNLP’15的研究。结构上, z t z^t zt、 z t + 1 z^{t + 1} zt+1、 c t c^t ct、 c t + 1 c^{t + 1} ct+1作用类似,但注意力机制与各模块连接方式有别,体现不同的注意力计算和应用思路 。
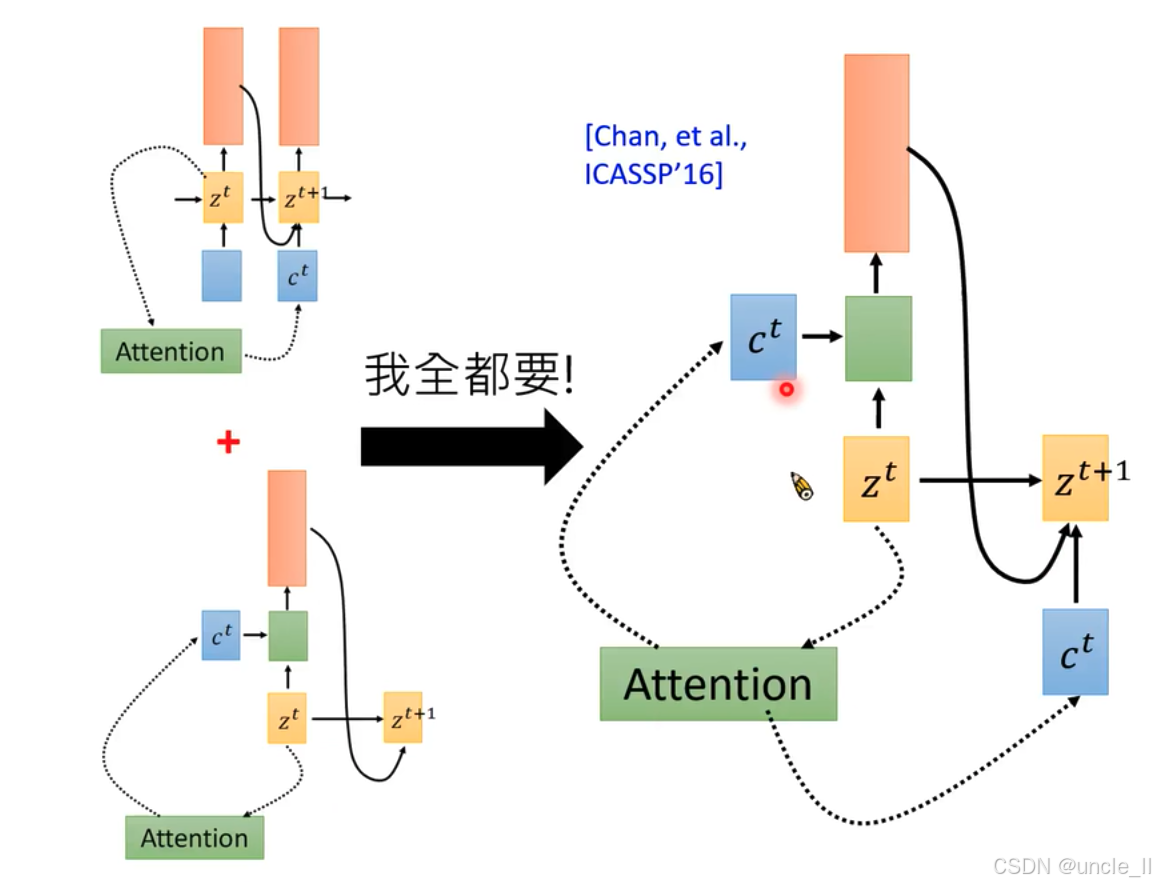
- 二者都要:出自Chan等人在ICASSP’16的研究,是前两者结合(图中“我全都要!” )。综合了不同注意力机制的优势,展示了更复杂的信息交互,隐藏状态 z t z^t zt、 z t + 1 z^{t + 1} zt+1 ,上下文向量 c t c^t ct ,注意力机制模块(绿色 )之间通过虚线箭头紧密连接,体现多方面信息整合用于计算注意力权重,为后续任务提供支持 。
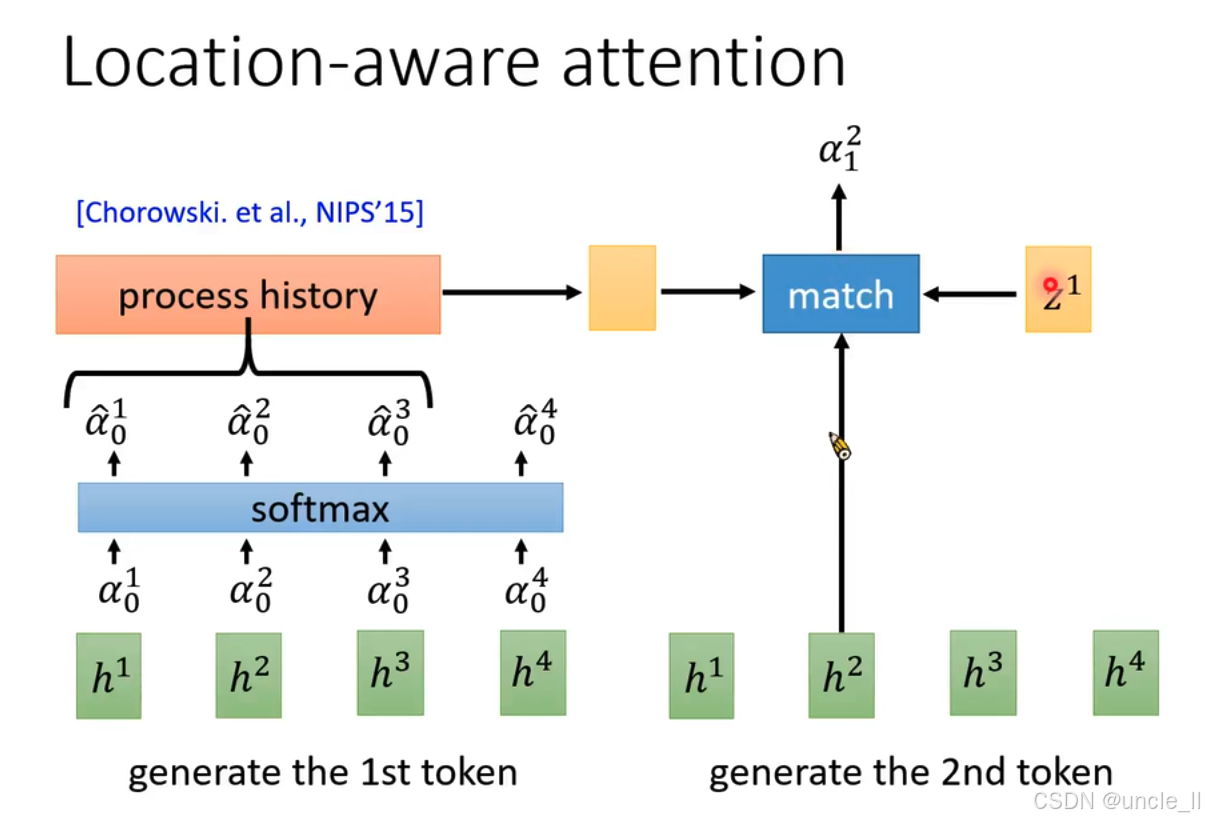
这张图介绍了位置感知注意力(Location - aware attention)机制:
- 生成第一个标记(token) :输入特征 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 ,通过注意力机制计算得到注意力权重 α 0 1 \alpha_0^1 α01、 α 0 2 \alpha_0^2 α02、 α 0 3 \alpha_0^3 α03、 α 0 4 \alpha_0^4 α04 ,经“softmax”函数得到归一化权重 α ^ 0 1 \hat{\alpha}_0^1 α^01、 α ^ 0 2 \hat{\alpha}_0^2 α^02、 α ^ 0 3 \hat{\alpha}_0^3 α^03、 α ^ 0 4 \hat{\alpha}_0^4 α^04 。这些权重用于计算“process history” ,最终生成第一个标记 。
- 生成第二个标记 :输入特征仍为 h 1 h^1 h1、 h 2 h^2 h2、 h 3 h^3 h3、 h 4 h^4 h4 ,结合之前的隐藏状态 z 1 z^1 z1 ,通过“match”操作计算注意力权重 α 1 2 \alpha_1^2 α12 ,用于生成第二个标记 。
- 来源:该机制出自Chorowski等人在NIPS’15(神经信息处理系统大会,2015年 )的研究 。
- 特点:位置感知注意力机制在计算注意力权重时,会考虑输入序列的位置信息,使得模型在生成标记时能更好地捕捉序列中不同位置的特征依赖关系,提升模型在处理序列数据(如语音识别、自然语言处理 )时的性能 。
Performance
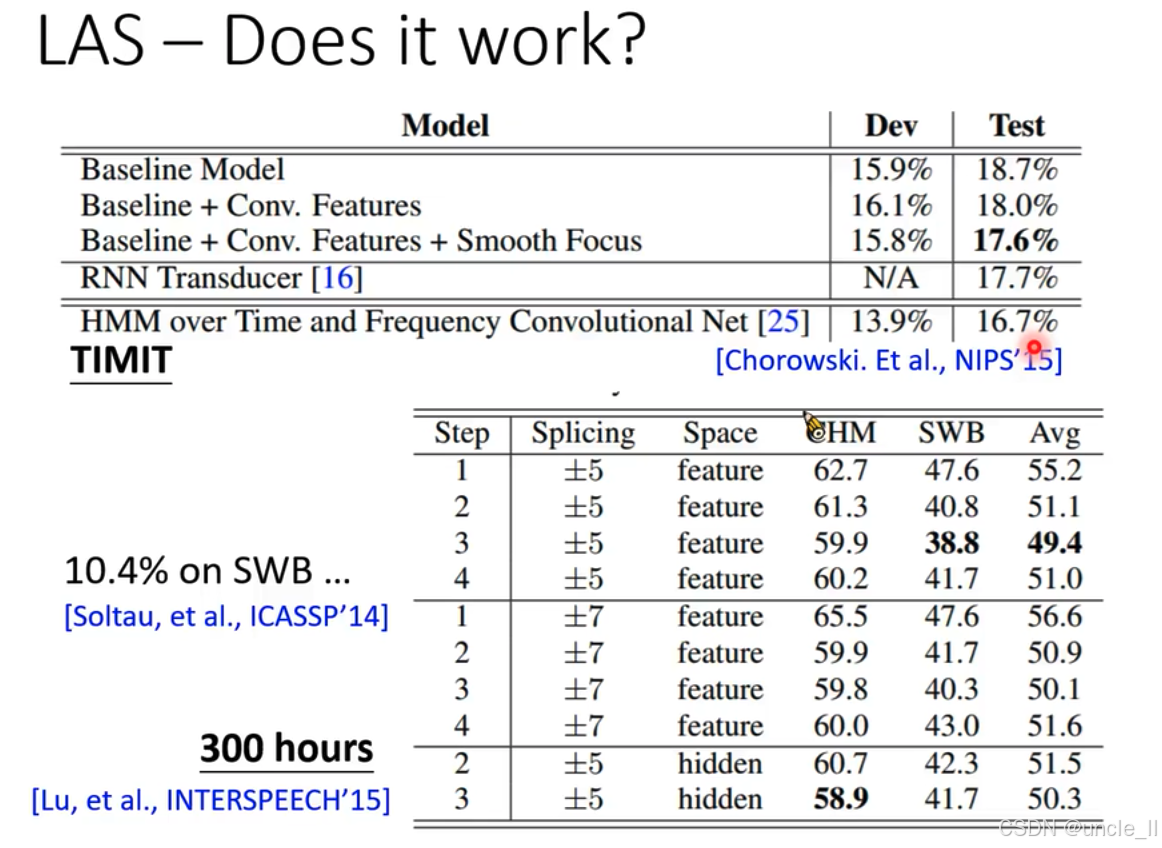
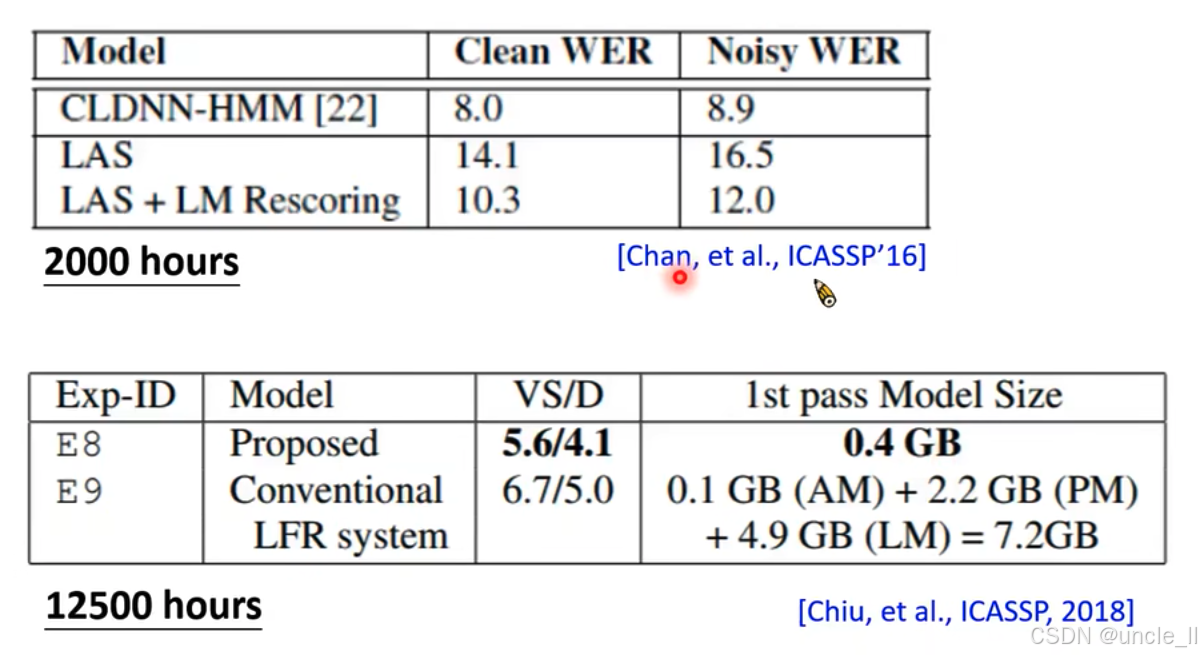
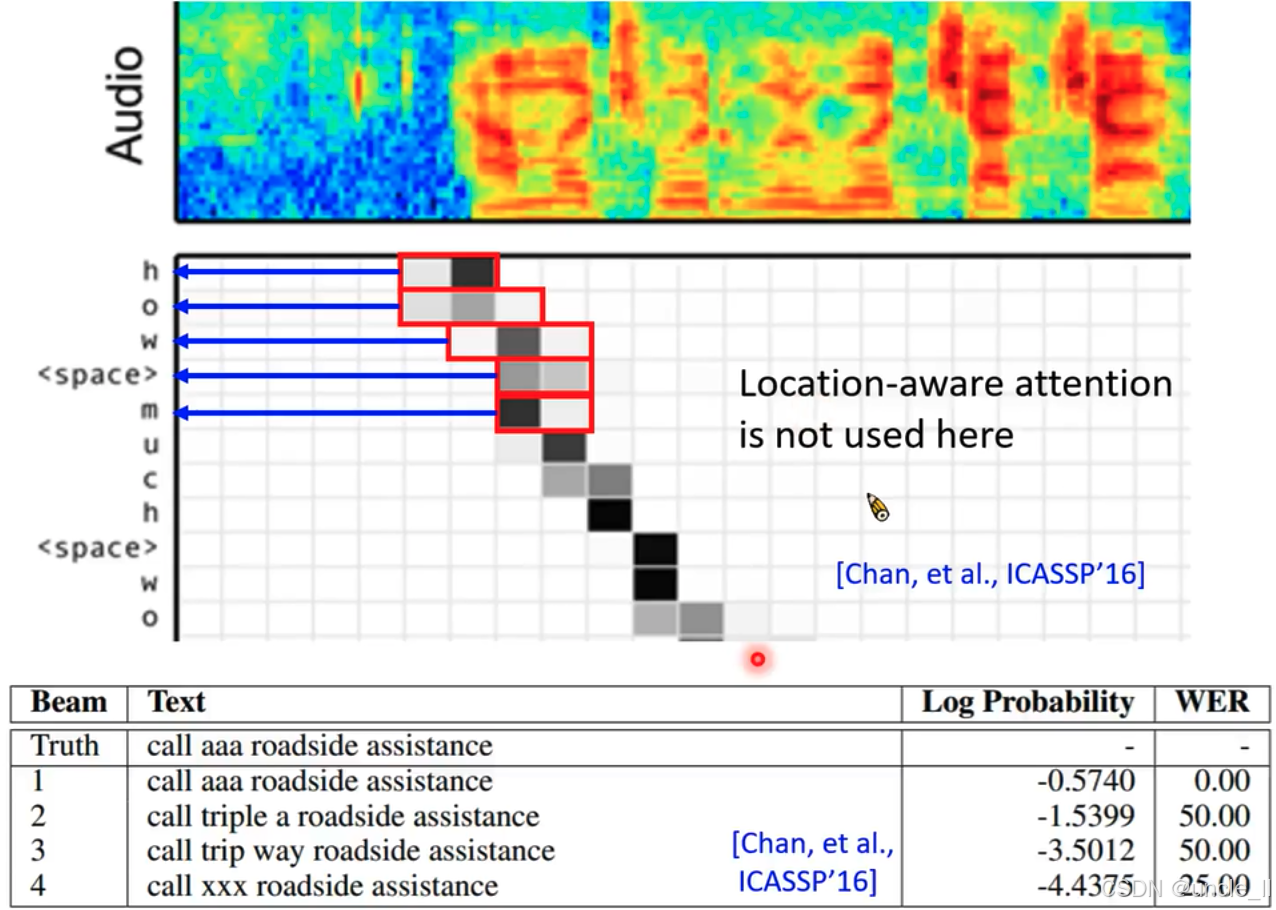
- aaa 和 triple a
- LAS能学到复杂的输入和输出
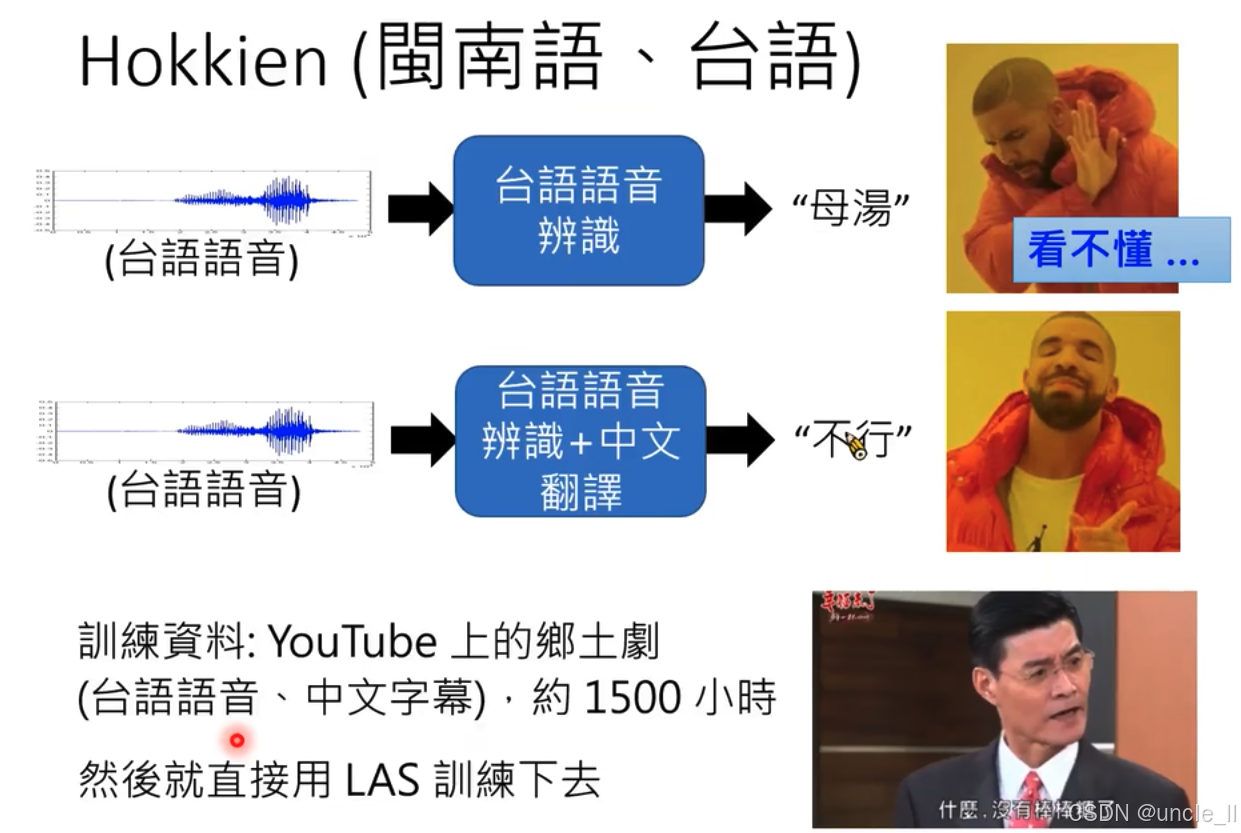
- 闽南语(台语)语音识别及翻译
- 不用考虑背景音乐,音效
Limitation

LAS(Listen, Attend and Spell)模型的局限性:
- LAS模型需听完整个输入语音后,才输出第一个标记(token) 。这意味着在处理语音时,无法即时反馈识别结果,存在延迟。
- 用户期望的是在线语音识别,即能实时、逐字地看到语音识别结果,而LAS模型的处理方式无法满足这一需求 。
相关文章:

李宏毅NLP-3-语音识别part2-LAS
语音识别part2——LAS Listen Listen主要功能是提取内容信息,去除说话人差异和噪声 。编码器(Encoder)结构,输入是声学特征,经过 Encoder 处理后,输出为高级表示,这些高级表示可用于后续语音识别…...

游戏引擎学习第222天
回顾昨天的过场动画工作 我们正在制作一个游戏,目标是通过直播的方式完成整个游戏的开发。在昨天的工作中,我享受了制作过场动画的过程,所以今天我决定继续制作多个层次的过场动画。 昨天我们已经开始了多层次过场动画的基本制作࿰…...

双系统win11 + ubuntu,如何完全卸载ubuntu系统?
双系统win11 ubuntu,如何完全卸载ubuntu? 注意事项 操作前确保有 Windows 安装介质(USB),以防需要修复对 EFI 分区的操作要格外小心如果使用 BitLocker,可能需要先暂停保护如果遇到问题,可以使用 Windows…...

【T2I】Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
code: https://github.com/NJU-PCALab/RAG-Diffusion Abstract 区域提示,或组成生成,能够实现细粒度的空间控制,在实际应用中越来越受到关注。然而,以前的方法要么引入了额外的可训练模块,因此只适用于特定…...

HarmonyOS:Map Kit简介
一、概述 Map Kit(地图服务) 为开发者提供强大而便捷的地图能力,助力全球开发者实现个性化显示地图、位置搜索和路径规划等功能,轻松完成地图构建工作。您可以轻松地在HarmonyOS应用/元服务中集成地图相关的功能,全方位…...

【从零实现高并发内存池】- 项目介绍、原理 及 内存池详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
学习笔记)
CSS margin(外边距)学习笔记
CSS 中的 margin 属性用于定义元素周围的空白区域,它是一个非常重要的布局工具,可以帮助我们控制元素之间的间距,从而实现更美观和易用的页面布局。以下是对 margin 属性的详细学习笔记。 一、margin 的基本概念 margin 是元素周围的透明区…...
)
【数据集】中国各省低空经济及无人机相关数据集(1996-2025年2月)
低空经济泛指3000米高空以下的飞行经济活动,以民用客运飞行器和无人驾驶航空器为主。低空经济产业是先进飞行器出行(AAM)在城市低空运行的一种变革性和颠覆性的复合新产业,主要以垂直起降型飞机(VTOL)与无人…...

C++动态分配内存知识点!
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 大家好呀,又是分享干货的时间,今天我们来学习一下动态分配内存。 文章目录 1.动态分配内存的思想 2.动态分配内存的概念 2.1内存分配函数 2.2动态内存的申请和释放 2.3内存碎片问…...

哈喽打车 小程序 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 这一次遇到这种风控感觉挺有…...

泛型的二三事
泛型(Generics)是Java语言的一个重要特性,它允许在定义类、接口和方法时使用类型参数(Type Parameters),从而实现类型安全的代码重用。泛型在Java 5中被引入,极大地增强了代码的灵活性和安全性。…...

云计算:数字浪潮中的第三次文明跃迁——从虚拟化到智能协同的范式革命
一、浪潮的序曲:从机械革命到数字原子的觉醒 20世纪中叶,当晶体管的发明点燃信息革命的火种时,人类社会的第三次浪潮已悄然萌芽。托夫勒预言的“信息将成为新的权力核心”,在21世纪初以云计算的形态具象化。这场浪潮的起点&#…...

redis哨兵机制 和集群有什么区别:
主从: 包括一个master节点 和多个slave节点: master节点负责数据的读写,slave节点负责数据的读取,master节点收到数据变更,会同步到slave节点 去实现数据的同步。通过这样一个架构可以去实现redis的一个读写分离。提升…...

java基础2
构造器: 构造器与类同名; 每个类可以有一个以上的构造器; 构造器可以有0个,1个或多个参数; 构造器没有返回值; 构造器总是伴着new一起调用 方法重载: 方法名字一样,参数不一样…...

《算法笔记》3.6小节——入门模拟->字符串处理
1009 说反话 #include <cstdio>int main() {char sen[80][80];int num0;while(scanf("%s",sen[num])!EOF){num;}for (int i num-1; i > 0; --i) {printf("%s ",sen[i]);}printf("%s\n",sen[0]);return 0; }字符串连接 #include <io…...

JavaScript:BOM编程
今天我要介绍的是JS中有关于BOM编程的知识点内容:BOM编程; 介绍:BOM全名(Browser Object Model(浏览器对象模型))。 是浏览器提供的与浏览器窗口交互的接口,其核心对象是 window。与…...
开发与应用(二))
用户自定义函数(UDF)开发与应用(二)
五、UDF 在不同平台的应用 5.1 数据库中的 UDF 应用(如 MySQL、PostgreSQL) 在数据库领域,UDF 为开发者提供了强大的扩展能力,使得数据库可以完成一些原本内置函数无法实现的复杂操作。 以 MySQL 为例,假设我们有一…...

C++——继承、权限对继承的影响
目录 继承基本概念 编程示例 1.基类(父类)Person 代码特点说明 权限对类的影响 编辑 编程示例 1. 公有继承 (public inheritance) 2. 保护继承 (protected inheritance) 3. 私有继承 (private inheritance) 重要规则 实际应用 继承基本概…...

Tkinter样式与主题定制
在创建图形用户界面(GUI)应用时,除了功能的实现外,界面的外观和用户体验也非常重要。Tkinter提供了多种方式来定制控件的样式,使应用程序界面更加美观和易用。在这一章中,我们将介绍如何使用Tkinter的样式和…...

CSS 背景属性学习笔记
CSS 背景属性用于定义 HTML 元素的背景效果,包括背景颜色、背景图像、图像平铺方式、图像定位以及图像是否固定等。以下是关于 CSS 背景属性的详细学习笔记。 一、背景颜色(background-color) background-color 属性用于定义元素的背景颜色…...

信息安全管理与评估2023广东省样题答案截图视频
2023年广东省职业院校技能大赛高职组 “信息安全管理与评估”赛项任务书 一、 赛项时间 9:00-13:30,共计4小时30分,含赛题发放、收卷时间。 二、 赛项内容 本次大赛,各位选手需要完成三个阶段的任务,其中第一个阶段需要…...

ubuntu学习day1
linux常用命令 1. 用户相关 1.1 切换用户 su root #切换到root用户 su user #切换到普通用户sudo能赋予普通用户管理者权限,一般不要直接使用root用户进行操作。 1.2 添加用户 useradd 用户名 useradd user1 #添加了用户名为user1的用户但在ubuntu中想要创建普…...

ubuntu22.04-VMware Workstation移动后无法连接网络
1.VMware 中查看NAT模式 2.查看宿主机VMnet8的IP地址 虚拟机里设置成192.168.20.160 , 255.255.255.0, 192.168.20.2 在ubuntu系统中设置如下: 至此可以连上了。...

如何评估大模型的性能?有哪些常用的评估指标?
评估大模型(如大语言模型 LLM)的性能是一个多维度的问题,常常需要结合多个指标从不同角度来考察模型的能力。以下是常见的评估方法和指标: 一、通用评估维度 任务性能(Task Performance) 衡量模型在特定任务上的表现,如问答、翻译、总结等。 语言能力(Linguistic Capa…...

Linux驱动开发-网络设备驱动
Linux驱动开发-网络设备驱动 一,网络设备总体结构1.1 总体架构1.2 NAPI数据处理机制 二,RMII和MDIO2.1 RMII接口2.2 MDIO接口 三,MAC和PHY模块3.1 MAC模块3.2 PHY模块 四,网络模型4.1 网络的OSI和TCP/IP分层模型4.1.1 传输层&…...

CTF web入门之文件包含
web78: include函数执行file引入的文件,如果执行不成功,就高亮显示当前页面的源码。 方法一:filter伪协议 file关键字的get参数传递,php://是一种协议名称,php://filter/是一种访问本地文件的协议,/readc…...

error: failed to run custom build command for `yeslogic-fontconfig-sys v6.0.0`
rust使用plotters时遇到编译错误。 一、错误 error: failed to run custom build command for yeslogic-fontconfig-sys v6.0.0 二、解决方法 我用的是opensuse,使用下面命令可以解决问题。 sudo zypper in fontconfig-devel...

低资源需求的大模型训练项目---调研0.5B大语言模型
一、主流0.5B大语言模型及性能对比 1. Qwen系列(阿里) • Qwen2.5-0.5B:阿里2024年9月开源的通义千问系列最小尺寸模型,支持32K上下文长度和8K生成长度。在中文场景下表现优异,指令跟踪、JSON结构化输出能力突出&…...

信息安全管理与评估广东省2023省赛正式赛题
任务1:网络平台搭建(60分) 题号 网络需求 1 根据网络拓扑图所示,按照IP地址参数表,对DCFW的名称、各接口IP地址进行配置。(10分) 2 根据网络拓扑图所示,按照IP地址参数表,对DCRS的名称进…...

LeetCode.225. 用队列实现栈
用队列实现栈 题目解题思路1. push2. pop3. empty CodeQueue.hQueue.cStack.c 题目 225. 用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现…...

CTF--bp
一、原题: (1)提示:弱密码top1000?z????? (2)原网页: 二、步骤: 1.先打开BP,随便输入一个密码: 2.打开BP,发现password&#…...

01_背包问题
package org.josh; import java.util.*; public class Main { public static void main(String[] args) { Scanner scanner new Scanner(System.in); int n scanner.nextInt(); // 物品数量 long w scanner.nextLong(); // 背包容量,使用long防止溢出 int[] v …...

ps 人像学习
视频: 一ps快捷键 1.1 创建图层 ctrlj 1.2 放大缩小图片的大小 按住alt 滚轮 1.3 移动图片 空格 左键 1.4 撤回 ctrlz 二 精修的第一步是去除斑点,瑕疵, 2.1 污点修复画笔工具 新建一个图层,点击污点修复工具进行修复…...

【AI论文】MM-IFEngine:迈向多模态指令遵循
摘要:指令遵循(IF)能力衡量多模态大语言模型(MLLM)准确理解用户告诉他们的内容以及他们是否做得正确的能力。 现有的多模态指令训练数据很少,基准测试简单,指令原子化,对于要求精确输…...
 单目运算符重载)
【C++初学】课后作业汇总复习(五) 单目运算符重载
本题主要考察-构造函数的定义和操作符重载、友元函数等 根据后缀和程序样例输出,完成分数类和相关函数的定义, 输入: -6 12 8 -16 输出: 1/2 1/1 -1/2 / -1/2 - -1/2 0/1 输入: 3 7 2 6 输出: 1/…...
)
Python基础语法速通(自用笔记)
目录 # 输出直接print就行了 # 次方,除法,取整 # 定义变量直接写就可以,不用写类型 # 基础的while不用写()和{},直接用冒号即可,缩进对齐 # 这里的for循环直接用in就可以,意思是从...中一个…...

Nginx基础讲解
Nginx基础讲解 Nginx 是一款高性能的 HTTP 服务器和反向代理服务器,广泛用于负载均衡、静态资源托管、SSL 终端等场景。以下是对 Nginx 的详细讲解: 1. Nginx 核心概念 事件驱动架构:基于异步非阻塞模型,高效处理高并发连接…...

K8S+Prometheus+Consul+alertWebhook实现全链路服务自动发现与监控、告警配置实战
系列文章目录 k8s服务注册到consul prometheus监控标签 文章目录 系列文章目录前言一、环境二、Prometheus部署1.下载2.部署3.验证 三、kube-prometheus添加自定义监控项1.准备yaml文件2.创建新的secret并应用到prometheus3.将yaml文件应用到集群4.重启prometheus-k8s pod5.访…...

组件安全工程化革命:从防御体系构建到安全基因重塑
文章目录 总起:数字世界的钢铁长城 分论: 一、组件生态的"七宗罪"与安全基因重组 二、百万级流量下的安全工程化实战 三、性能与安全的共生进化论 四、安全工程化全链路解决方案 总束:安全基因驱动的未来图景 五、时代思考…...
大气滚屏网站模板 电气电力设备网站源码下载)
(PC+WAP)大气滚屏网站模板 电气电力设备网站源码下载
源码介绍 (PCWAP)大气滚屏网站模板 电气电力设备网站源码下载。PbootCMS内核开发的网站模板,该模板适用于滚屏网站模板、电气电力设备网站源码等企业,当然其他行业也可以做,只需要把文字图片换成其他行业的即可;PCWAP,…...

发送加密信息的简单实现【Java】
(修改期) 一、代码的引用处 public static SecretKeys generateKeys() throws NoSuchAlgorithmException {: 定义一个公共静态方法,用于生成 AES 和 HMAC 密钥对。 public static String encrypt(String plaintext, SecretKey aesKey, S…...

阿里云域名解析
一、打开域名控制台 PC端浏览器打开阿里云域名控制台:域名控制台,点击"域名解析"。 二、添加解析设置 选择需要解析的域名,点击"解析设置"。 点击"添加记录"。 添加@和www即可。...
)
DNS域名解析服务(正向 反向 主从)
DNS 1.分散式管理: Hosts文件 一改百度就不会访问了 Ip地址 域名 121.226.246.3 www.jd.com 2.我们会搭建一台 域名解析服务器全世界得域名全靠这台服务器进行解析 中央集权制 域名是由多个部分组成的 www.baidu.com .baidu .com是域…...

ROS2---std_msgs基础消息包
std_msgs 是ROS 2(Robot Operating System 2)里的基础消息包,它定义了一系列简单却常用的消息类型,为不同节点间的通信提供了基础的数据格式。 1. 消息包概述 std_msgs 包包含了多种基础消息类型,这些类型用于表示常…...
)
python基础:数据类型转换、运算符(算术运算符、比较运算符、逻辑运算符、三元运算符、位运算符)
目录 一、类型转换 隐式类型转换/自动转换: 显示类型转换/强制转换: 二、运算符 算数运算符: - * / 比较运算符 逻辑/布尔运算符 赋值运算符: 三元运算符 位运算符 [二进制] 运算符优先级 一、类型转换 python变量的类…...

[特殊字符] 终端效率提升指南:zsh + tmux
在日常开发中,一个舒适、高效的终端环境能显著提升工作效率。本文将介绍如何通过配置 oh-my-zsh 和 tmux 打造一个功能强大、便捷实用的终端工具集。无论你是 Linux 新手,还是资深开发者,都能从中获得实用的提升技巧。 🌀 一、终…...

【Linux篇】深入理解文件系统:从基础概念到 ext2 文件系统的应用与解析
文件系统的魔法:让计算机理解并存储你的数据 一. 文件系统1.1 块1.2 分区1.3 inode(索引节点) 二. ext2文件系统2.1 认识文件系统2.2 Block Group (块组)2.2.1 Block Group 的基本概念2.2.2 Block Group 的作用 2.3 块组内部结构2.3.1 超级块(Super Bloc…...

MarkDown 输出表格的方法
MarkDown用来输出表格很简单,比Word手搓表格简单多了,而且方便修改。 MarkDown代码: |A|B|C|D| |:-|-:|:-:|-| |1|b|c|d| |2|b|c|d| |3|b|c|d| |4|b|c|d| |5|b|c|d|显示效果: ABCD1bcd2bcd3bcd4bcd5bcd A列强制左对齐…...

DOM解析XML:Java程序员的“乐高积木式“数据搭建
各位代码建筑师们!今天我们要玩一个把XML变成内存乐高城堡的游戏——DOM解析!和SAX那种"边看监控边破案"的刺激不同,DOM就像把整个乐高说明书一次性倒进大脑,然后慢慢拼装(内存:你不要过来啊&…...

Python 数组里找出子超集
碰见一个问题,有一个大数组,如下所示: xx [[1, 3, 4], [3, 4, 5], [1, 2, 3, 4, 5], [6], [7, 8], [6, 7, 8]]大数组里面有好多小的数组,观察发现,小的数组其实有挺多别的小数组的子集,现在问题来了&…...