《Python星球日记》第25天:Pandas 数据分析
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
订阅专栏:《Python星球日记》
目录
- 一、引言
- 二、数据分组与聚合
- 1. 分组操作基础
- 按单列分组
- 按多列分组
- 2. 聚合函数
- 单一聚合函数
- 多个聚合函数
- 对不同列应用不同的聚合函数
- 3. 转换与过滤
- 转换操作
- 过滤操作
- 三、排序与排名
- 1. 数据排序
- 按值排序 - sort_values()
- 按索引排序 - sort_index()
- 2. 数据排名
- 处理并列情况
- 四、时间序列分析
- 1. 时间戳与时间段
- 2. 创建时间序列数据
- 3. 时间序列索引与切片
- 4. 重采样
- 5. 移动窗口函数
- 五、实战练习:销售数据分析
- 1. 准备数据
- 2. 分组分析
- 3. 时间序列分析
- 4. 数据可视化
- 六、总结与拓展
- 1. 关键知识点回顾
- 2. 实际应用场景
- 3. 学习资源推荐
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》第24天:Pandas 数据清洗
🌟引言: 欢迎来到Python星球🪐的第25天!
今天我们将深入学习Pandas的高级数据分析功能,包括数据分组、聚合操作、排序与排名以及时间序列分析。这些是数据分析工作中的核心技能,掌握它们将大大提升你的数据处理能力。
一、引言
在前面的学习中,我们已经了解了Pandas的基础知识,包括Series和DataFrame的创建、基本操作和数据清洗等。今天,我们将进一步探索Pandas提供的高级数据分析功能,学习如何从数据中提取更深层次的信息和洞察。
数据分析是数据科学工作流程中的核心环节,而Pandas提供了丰富的工具和函数来支持各种分析需求。通过本文的学习,你将掌握如何对数据进行分组分析、排序排名以及时间序列处理,这些都是实际数据分析项目中经常用到的技能。
首先,让我们导入必要的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
二、数据分组与聚合
数据分组和聚合是数据分析中最常用的操作之一,它允许我们按照某一列或多列的值将数据分为多个组,然后对每组数据应用聚合函数。

1. 分组操作基础
分组操作的核心是groupby()函数,它根据指定的一个或多个列将DataFrame分割成不同的组。
让我们创建一个销售数据示例:
# 创建示例销售数据
data = {'日期': pd.date_range(start='2023-01-01', periods=20, freq='D'),'产品': ['A', 'B', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'],'区域': ['东部', '东部', '南部', '南部', '东部', '西部', '西部', '南部', '东部', '南部','西部', '东部', '南部', '西部', '东部', '南部', '西部', '东部', '南部', '西部'],'销售额': np.random.randint(1000, 5000, size=20),'数量': np.random.randint(10, 100, size=20)
}df = pd.DataFrame(data)
print(df.head())
输出结果:
日期 产品 区域 销售额 数量
0 2023-01-01 A 东部 3416 56
1 2023-01-02 B 东部 4713 67
2 2023-01-03 A 南部 2965 31
3 2023-01-04 B 南部 1743 25
4 2023-01-05 C 东部 4350 78
按单列分组
最简单的分组是按单个列进行分组:
# 按产品分组并计算销售额总和
product_sales = df.groupby('产品')['销售额'].sum()
print(product_sales)
输出结果:
产品
A 14986
B 20165
C 17354
Name: 销售额, dtype: int64
按多列分组
我们也可以按多个列进行分组:
# 按产品和区域分组,计算销售额总和
product_region_sales = df.groupby(['产品', '区域'])['销售额'].sum()
print(product_region_sales)
输出结果:
产品 区域
A 东部 9874南部 2965西部 2147
B 东部 4713南部 11709西部 3743
C 东部 4350南部 4219西部 8785
Name: 销售额, dtype: int64
2. 聚合函数
聚合函数是对分组后的数据执行计算的函数。Pandas提供了多种内置的聚合函数:
单一聚合函数
# 按产品分组,计算销售额的平均值
avg_sales = df.groupby('产品')['销售额'].mean()
print(avg_sales)
输出结果:
产品
A 2997.2
B 4033.0
C 3470.8
Name: 销售额, dtype: float64
多个聚合函数
# 按产品分组,同时计算销售额的多个统计量
sales_stats = df.groupby('产品')['销售额'].agg(['sum', 'mean', 'count', 'max', 'min'])
print(sales_stats)
输出结果:
sum mean count max min
产品
A 14986 2997.2 5 4217 1983
B 20165 4033.0 5 4713 1743
C 17354 3470.8 5 4350 2631
对不同列应用不同的聚合函数
# 对不同列应用不同的聚合函数
agg_result = df.groupby('产品').agg({'销售额': ['sum', 'mean'],'数量': ['count', 'max', 'min']
})
print(agg_result)
输出结果:
销售额 数量 sum mean count max min
产品
A 14986 2997.2 5 89 21
B 20165 4033.0 5 92 25
C 17354 3470.8 5 94 32
3. 转换与过滤
除了聚合,groupby对象还支持转换和过滤操作:
转换操作
转换操作会返回与原DataFrame形状相同的结果:
# 计算每个产品的销售额占该产品总销售额的百分比
df['销售额百分比'] = df.groupby('产品')['销售额'].transform(lambda x: x / x.sum() * 100
)
print(df[['产品', '销售额', '销售额百分比']].head(10))
过滤操作
过滤操作用于筛选满足条件的组:
# 筛选出平均销售额大于3000的产品组
filtered_groups = df.groupby('产品').filter(lambda x: x['销售额'].mean() > 3000)
print(filtered_groups['产品'].unique())
三、排序与排名
数据分析中,排序和排名是非常常用的操作,可以帮助我们更好地理解数据的分布和相对位置。
1. 数据排序
Pandas提供了两种主要的排序方法:按值排序和按索引排序。
按值排序 - sort_values()
# 按销售额降序排序
df_sorted = df.sort_values(by='销售额', ascending=False)
print(df_sorted[['产品', '区域', '销售额']].head())# 按多列排序:先按产品排序,再按销售额降序排序
df_multi_sorted = df.sort_values(by=['产品', '销售额'], ascending=[True, False])
print(df_multi_sorted[['产品', '销售额']].head())
按索引排序 - sort_index()
# 先将产品设为索引,然后按索引排序
df_idx = df.set_index('产品')
df_idx_sorted = df_idx.sort_index()
print(df_idx_sorted.head())
2. 数据排名
排名是一种将数据值转换为其相对位置的方法。Pandas的rank()函数提供了灵活的排名功能:
# 对销售额进行排名
df['销售额排名'] = df['销售额'].rank(ascending=False) # 降序排名,销售额最高的排名为1
print(df[['产品', '销售额', '销售额排名']].sort_values('销售额排名').head())
处理并列情况
当存在相同值时,rank()函数提供多种处理方式:
# 创建包含重复值的Series
s = pd.Series([7, 2, 7, 3, 7, 4])# 不同的处理并列的方式
print("默认(average):", s.rank())
print("min方法:", s.rank(method='min'))
print("max方法:", s.rank(method='max'))
print("first方法:", s.rank(method='first'))
print("dense方法:", s.rank(method='dense'))
输出结果:
默认(average): [4.0, 1.0, 4.0, 2.0, 4.0, 3.0]
min方法: [3.0, 1.0, 3.0, 2.0, 3.0, 3.0]
max方法: [5.0, 1.0, 5.0, 2.0, 5.0, 3.0]
first方法: [3.0, 1.0, 4.0, 2.0, 5.0, 3.0]
dense方法: [3.0, 1.0, 3.0, 2.0, 3.0, 2.0]
四、时间序列分析
时间序列数据是按时间顺序索引的数据,在金融、气象、销售等领域非常常见。Pandas提供了强大的时间序列处理功能。
1. 时间戳与时间段
Pandas有两种主要的时间相关对象:
- Timestamp:表示时间点,类似于Python的
datetime - Period:表示时间段,如"2023年1月"或"2023年第一季度"
# 创建时间戳
ts = pd.Timestamp('2023-01-15 12:30:00')
print(ts)# 创建时间段
period = pd.Period('2023-01', freq='M') # 月度频率
print(period)
2. 创建时间序列数据
我们可以通过多种方式创建时间序列数据:
# 创建日期范围
date_range = pd.date_range(start='2023-01-01', periods=10, freq='D')
print(date_range)# 创建带时间序列索引的数据
ts_data = pd.Series(np.random.randn(10), index=date_range)
print(ts_data)
3. 时间序列索引与切片
时间序列数据可以使用时间进行索引和切片:
# 准备一年的每日数据
daily_data = pd.Series(np.random.rand(365),index=pd.date_range(start='2023-01-01', periods=365, freq='D')
)# 使用时间索引
print(daily_data['2023-02-14']) # 查看特定日期的数据# 时间范围切片
print(daily_data['2023-03-01':'2023-03-07']) # 查看一周的数据# 使用年、月、日等属性进行筛选
march_data = daily_data[daily_data.index.month == 3] # 筛选3月的数据
print(march_data)
4. 重采样
重采样是改变时间序列频率的过程:
- 升采样:从低频到高频(如月→日)
- 降采样:从高频到低频(如日→月)
# 准备每日销售数据
daily_sales = pd.Series(np.random.randint(100, 500, size=365),index=pd.date_range(start='2023-01-01', periods=365, freq='D')
)# 降采样:日→月,求和
monthly_sales = daily_sales.resample('M').sum()
print(monthly_sales)# 降采样:日→周,求平均
weekly_sales = daily_sales.resample('W').mean()
print(weekly_sales.head())# 升采样:月→日,填充
monthly_data = pd.Series([1000, 1200, 1500, 1800, 2100, 2400],index=pd.date_range(start='2023-01-31', periods=6, freq='M')
)
daily_filled = monthly_data.resample('D').ffill() # 前向填充
print(daily_filled.head())
5. 移动窗口函数
移动窗口函数是时间序列分析中非常有用的工具:
# 7天移动平均
sales_7d_ma = daily_sales.rolling(window=7).mean()
print(sales_7d_ma.head(10))# 30天移动平均
sales_30d_ma = daily_sales.rolling(window=30, min_periods=1).mean()
print(sales_30d_ma.head())# 累计统计
cumulative_sales = daily_sales.expanding().sum()
print(cumulative_sales.head())
五、实战练习:销售数据分析
现在,让我们综合运用所学知识,对销售数据进行分析和可视化。
1. 准备数据
import pandas as pd
import numpy as np# 创建更完整的销售数据
np.random.seed(42) # 设置随机种子以确保结果可重现# 创建日期范围:2023年全年
dates = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')# 产品类别
products = ['电子产品', '服装', '食品', '家居']# 创建空的DataFrame
sales_data = []# 生成数据
for date in dates:# 为每个产品生成销售记录for product in products:# 模拟周末销量增加weekend_factor = 1.5 if date.dayofweek >= 5 else 1.0# 模拟季节性变化:夏季(6-8月)电子产品和食品销量增加,冬季(11-2月)服装和家居销量增加seasonal_factor = 1.0if product in ['电子产品', '食品'] and date.month in [6, 7, 8]:seasonal_factor = 1.3elif product in ['服装', '家居'] and date.month in [11, 12, 1, 2]:seasonal_factor = 1.4# 生成销售量quantity = int(np.random.randint(10, 50) * weekend_factor * seasonal_factor)# 生成销售额 (价格在100-500之间)price = np.random.randint(100, 500)amount = quantity * price# 添加到列表sales_data.append({'日期': date,'产品': product,'销量': quantity,'单价': price,'销售额': amount})# 创建DataFrame
sales_df = pd.DataFrame(sales_data)# 显示数据样本
print(sales_df.head())
print(f"数据集大小: {sales_df.shape}")
输出结果:

2. 分组分析
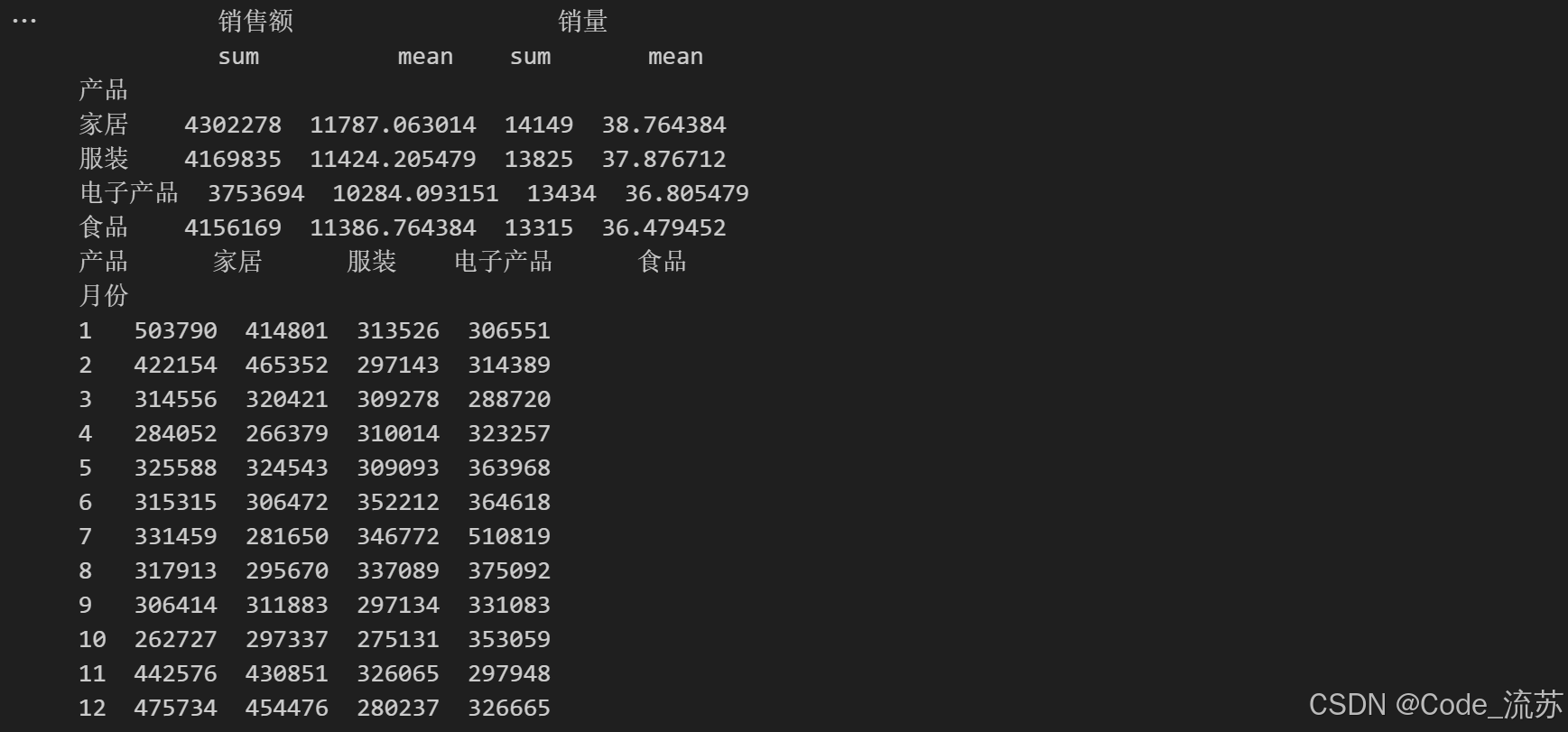
# 按产品分组,计算总销售额和平均销售额
product_summary = sales_df.groupby('产品').agg({'销售额': ['sum', 'mean'],'销量': ['sum', 'mean']
})
print(product_summary)# 按月份和产品分组,计算每月每种产品的总销售额
sales_df['月份'] = sales_df['日期'].dt.month
monthly_product_sales = sales_df.groupby(['月份', '产品'])['销售额'].sum().unstack()
print(monthly_product_sales)
输出结果:
3. 时间序列分析
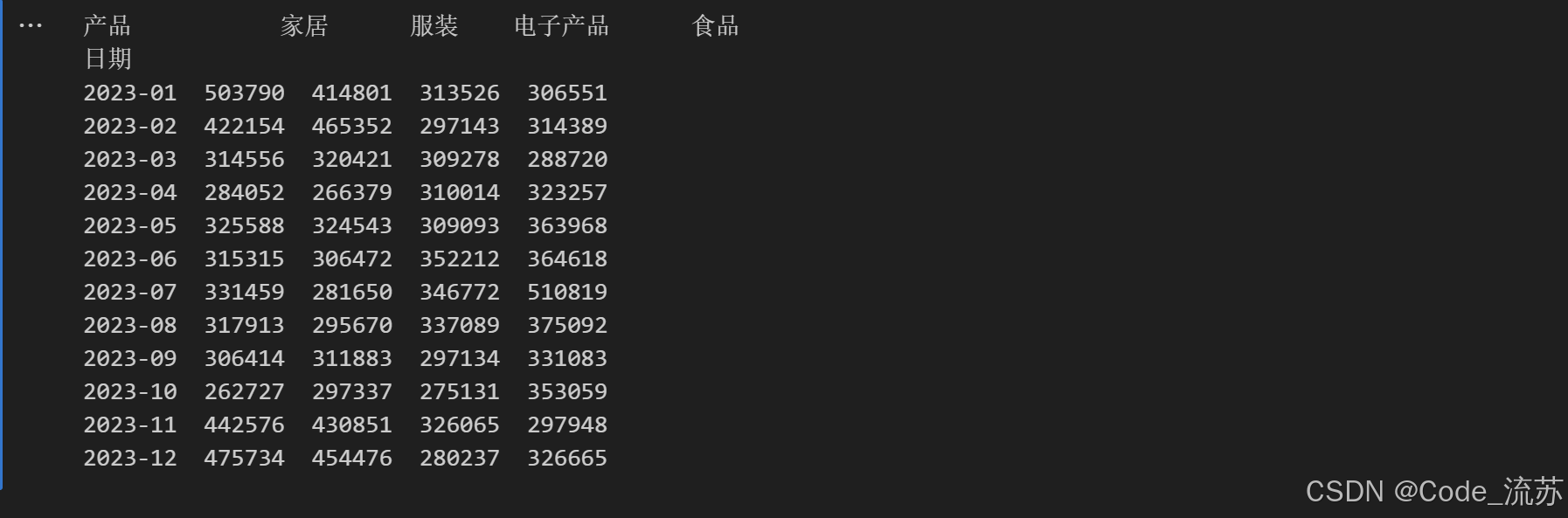
# 将数据按日期和产品分组,计算每日每种产品的总销售额
daily_product_sales = sales_df.groupby(['日期', '产品'])['销售额'].sum().unstack()# 计算7天移动平均
moving_avg = daily_product_sales.rolling(window=7).mean()# 每月销售额趋势
monthly_sales = sales_df.groupby([sales_df['日期'].dt.to_period('M'), '产品'])['销售额'].sum().unstack()
print(monthly_sales)
输出结果:
4. 数据可视化
import matplotlib.pyplot as plt
import seaborn as sns# 设置中文显示(防止中文注释出错,实际图表无中文)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False# 设置图表风格
plt.style.use('seaborn-v0_8-darkgrid')
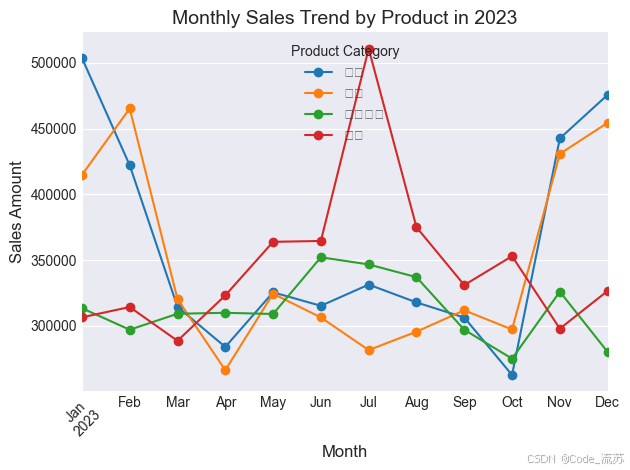
plt.figure(figsize=(14, 8))# 绘制每月产品销售额趋势(Monthly Sales Trend by Product)
monthly_sales.plot(kind='line', marker='o')
plt.title('Monthly Sales Trend by Product in 2023', fontsize=14)
plt.xlabel('Month', fontsize=12)
plt.ylabel('Sales Amount', fontsize=12)
plt.legend(title='Product Category')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('monthly_sales_trend.png', dpi=300)
plt.show()# 绘制产品销售额占比饼图(Sales Proportion by Product)
plt.figure(figsize=(10, 8))
product_total = sales_df.groupby('产品')['销售额'].sum()
plt.pie(product_total, labels=product_total.index, autopct='%1.1f%%', startangle=90, shadow=True, explode=[0.05, 0, 0, 0])
plt.title('Sales Proportion by Product', fontsize=14)
plt.axis('equal')
plt.savefig('product_sales_pie.png', dpi=300)
plt.show()# 绘制季节性变化热力图(Heatmap of Monthly Average Sales by Product)
plt.figure(figsize=(12, 8))
pivot_table = sales_df.pivot_table(index=sales_df['日期'].dt.month,columns='产品',values='销售额',aggfunc='mean'
)
sns.heatmap(pivot_table, annot=True, fmt='.0f', cmap='YlGnBu')
plt.title('Heatmap of Monthly Average Sales by Product', fontsize=14)
plt.xlabel('Product Category', fontsize=12)
plt.ylabel('Month', fontsize=12)
plt.tight_layout()
plt.savefig('monthly_product_heatmap.png', dpi=300)
plt.show()
输出结果:


六、总结与拓展
通过本文的学习,我们掌握了Pandas中的数据分组与聚合、排序与排名以及时间序列分析等高级数据分析技能。这些技能对于从数据中提取有价值的信息至关重要。
1. 关键知识点回顾
- 数据分组:使用
groupby()按一个或多个列对数据进行分组 - 聚合函数:通过
sum()、mean()、count()等函数对分组数据进行聚合计算 - 排序:使用
sort_values()和sort_index()对数据进行排序 - 排名:使用
rank()对数据进行排名,支持多种处理并列情况的方法 - 时间序列处理:包括时间索引、重采样、移动窗口等操作
2. 实际应用场景
- 销售数据分析:按产品、地区、时间等维度分析销售趋势和模式
- 金融数据分析:股票价格时间序列分析,计算移动平均线和波动性
- 用户行为分析:按用户群体分组,分析不同群体的行为特征
- 传感器数据处理:对高频采集的传感器数据进行降采样和异常检测
3. 学习资源推荐
- 官方文档:Pandas官方文档
- 书籍:《Python for Data Analysis》by Wes McKinney
- 在线课程:Coursera的"Data Analysis with Python"
练习题:
- 使用本文介绍的销售数据,按产品和月份分组,计算销售额最高的前3个产品-月份组合。
- 实现一个函数,对时间序列数据检测异常值(比如超过3个标准差的值)。
- 尝试使用groupby和transform计算每个产品的销售额占该产品总销售额的百分比。
希望这篇文章能帮助你更好地理解Pandas的高级数据分析功能。如有问题,欢迎在评论区留言,在下一篇文章中,星球之旅的第26天,我们将探索 Matplotlib 可视化,敬请期待!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》第25天:Pandas 数据分析
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、引言二、数据分组与聚合1. 分组操…...

C++在Linux上生成动态库并调用接口测试
加减乘除demo代码 项目结构 CPP/ ├── calculator.cpp ├── calculator.h ├── main.cpp 头文件 #ifndef CALCULATOR_H #define CALCULATOR_H#ifdef __cplusplus extern "C" {#endifdouble add(double a, double b);double subtract(double a, double b…...
:Cesium相机系统)
Cesium.js(6):Cesium相机系统
Camera表示观察场景的视角。通过操作摄像机,可以控制视图的位置、方向和角度。 帮助文档:Camera - Cesium Documentation 1 setView setView 方法允许你指定相机的目标位置和姿态。你可以通过 Cartesian3 对象来指定目标位置,并通过 orien…...
——线性代数:概述)
机器学习中的数学(PartⅡ)——线性代数:概述
首先引入代数和线性代数的概念: 在将一些直观的、基于经验或直觉的概念转化为严格的数学或逻辑定义时,一种常用方法是构建一组对象和一组操作这些对象的规则,这就是代数。线性代数是研究向量和某些操作向量的规则。 其次从更广泛的意义上定…...

基于双闭环PID控制器的永磁同步电机控制系统匝间故障Simulink仿真
欢迎微♥关注“电击小子程高兴的MATLAB小屋”获取巨额优惠 1.模型简介 本仿真模型基于MATLAB/Simulink(版本MATLAB 2013Rb)软件。建议采用matlab2013 Rb及以上版本打开。(若需要其他版本可联系代为转换,高于该版本的matlab均可正…...

在51单片机上实现平滑呼吸灯:50us定时器PWM实战指南
在51单片机上实现平滑呼吸灯:50us定时器PWM实战指南 引言 本文将详细介绍如何在51单片机平台上,通过精确的50us定时器中断实现无闪烁的呼吸灯效果。相比常见的125us实现方案,50us定时器能提供更高的PWM频率和更细腻的亮度控制。 硬件设计 基本电路配置 主控芯片:SC92F8…...

asm汇编源代码之CPU型号检测
提供1个子程序: 1. CPU型号检测 CPUTYPE 无输入参数,返回值AX指示CPU类型(报歉,当时最新CPU型号只有80486) 函数的返回值详细描述如下 CPUTYPE PROC FAR ;OUT: AX01, 8086; AX02, 80286; AX03, 80386; AX04, 80486 UP; ; more source code at http://www.ahj…...

提高课:数据结构之树状数组
1,楼兰图腾 #include<iostream> #include<cstring> #include<cstdio> #include<algorithm>using namespace std;typedef long long LL;const int N 200010;int n; int a[N]; int tr[N]; int Greater[N], lower[N];int lowbit(int x) {ret…...

python可变对象与不可变对象
文章目录 Python 中的可变对象与不可变对象不可变对象(Immutable Objects)可变对象(Mutable Objects)重要区别 Python 中的可变对象与不可变对象 在 Python 中,对象可以分为可变对象(mutable)和不可变对象(immutable),这是 Python 中非常重要的概念&…...

C++学习之金融类安全传输平台项目git
目录 1.知识点概述 2.版本控制工具作用 3.git和SVN 4.git介绍 5.git安装 6.工作区 暂存区 版本库概念 7.本地文件添加到暂存区和提交到版本库 8.文件的修改和还原 9.查看提交的历史版本信息 10.版本差异比较 11.删除文件 12.本地版本管理设置忽略目录 13.远程git仓…...

果篮问题 Python
# 给你两个长度为 n 的整数数组,fruits 和 baskets,其中 fruits[i] 表示第 i 种水果的 数量,baskets[j] 表示第 j 个篮子的 容量。 # 你需要对 fruits 数组从左到右按照以下规则放置水果: # 每种水果必须放入第一个 容量大于等于 …...

Spring 是如何解决循环依赖的?
在使用 Spring 框架进行开发时,循环依赖是一个常见而棘手的问题。循环依赖指的是两个或多个 bean 之间的相互依赖,导致 Spring 容器无法正常创建这些 bean。下面将深入探讨 Spring 如何解决循环依赖问题,并提供一些最佳实践。 什么是循环依赖…...
)
部署NFS版StorageClass(存储类)
部署NFS版StorageClass存储类 NFS版PV动态供给StorageClass(存储类)基于NFS实现动态供应下载NFS存储类资源清单部署NFS服务器为StorageClass(存储类)创建所需的RBAC部署nfs-client-provisioner的deployment创建StorageClass使用存储类创建PVC NFS版PV动态供给StorageClass(存储…...

深入理解 PyTorch 的 nn.Embedding:词向量映射及变量 weight 的更新机制
文章目录 前言一、直接使用 nn.Embedding 获得变量1、典型场景2、示例代码:3、特点 二、使用 iou_token nn.Embedding(1, transformer_dim) 并访问 iou_token.weight1、典型场景2、示例代码:3、特点 三、第一种方法在模型更新中会更新其值吗?…...

go语言内存泄漏的常见形式
go语言内存泄漏 子字符串导致的内存泄漏 使用自动垃圾回收的语言进行编程时,通常我们无需担心内存泄漏的问题,因为运行时会定期回收未使用的内存。但是如果你以为这样就完事大吉了,哪里就大错特措了。 因为,虽然go中并未对字符串…...

操作系统
操作系统 操作系统(OperatingSystem,OS)是指控制和管理整个计算机系统的硬件和软件资源,并合理地组织调度计算机的工作和资源的分配;以提供给用户和其他软件方便的接口和环境;它是计算机系统中最基本的系统…...
:造化玉碟·用字节码重写因果律的九种方法》)
《JVM考古现场(十八):造化玉碟·用字节码重写因果律的九种方法》
"鸿蒙初判!当前因果链突破十一维屏障——全体码农修士注意,《JVM考古现场(十八)》即将渡劫飞升!" 目录 上卷阴阳交缠 第一章:混沌初开——JVM因果律的量子纠缠 第二章:诛仙剑阵改—…...
)
【2】k8s集群管理系列--包应用管理器之helm(Chart语法深入应用)
一、Chart模板:函数与管道 常用函数: • quote:将值转换为字符串,即加双引号 • default:设置默认值,如果获取的值为空则为默认值 • indent和nindent:缩进字符串 • toYaml:引用一…...

汇编获取二进制
mov_.S mov %r8d,0 nop执行命令: gcc -c mov_.S 会输出 mov_.o 文件:objdump -D mov_.o : mov_.o: 文件格式 elf64-x86-64Disassembly of section .text:0000000000000000 <.text>:0: 44 89 04 25 00 00 00 mov %r8d,0x0…...

《嵌套调用与链式访问:C语言中的函数调用技巧》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、嵌套调用(一)定义(二)实现方式(三)优点(四)缺点 二、链式…...
)
txt、Csv、Excel、JSON、SQL文件读取(Python)
txt、Csv、Excel、JSON、SQL文件读取(Python) txt文件读写 创建一个txt文件 fopen(rtext.txt,r,encodingutf-8) sf.read() f.close() print(s)open( )是打开文件的方法 text.txt’文件名 在同一个文件夹下所以可以省略路径 如果不在同一个文件夹下 ‘…...

前端工程化之新晋打包工具
新晋打包工具 新晋打包工具前端模块工具的发展历程分类初版构建工具grunt使用场景 gulp采用管道机制任务化配置与api简洁 现代打包构建工具基石--webpack基于webpack改进的构建工具rollup 推荐举例说明package.jsonrollup.config.mjsmy-extract-css-rollup-plugin.mjssrc/index…...

Python语言介绍
Python 是一种高级、通用、解释型的编程语言,由 Guido van Rossum 于 1991 年首次发布。其设计哲学强调代码的可读性和简洁性。 Python通过简洁的语法和强大的生态系统,成为当今最受欢迎的编程语言之一。 一、核心特点 Python 是一种解释型、面向对象、…...

关于 Spring Boot 部署到 Docker 容器的详细说明,涵盖核心概念、配置步骤及关键命令,并附上表格总结
以下是关于 Spring Boot 部署到 Docker 容器的详细说明,涵盖核心概念、配置步骤及关键命令,并附上表格总结: 1. Docker 核心概念 概念描述关系镜像(Image)预定义的只读模板,包含运行环境和配置(…...

Tomcat 服务频繁崩溃的排查方法
# Tomcat 服务频繁崩溃排查方法 当Tomcat服务频繁崩溃时,可以按照以下步骤进行系统化排查: ## 1. 检查日志文件 **关键日志位置**: - catalina.out (标准输出和错误) - catalina.log (主日志) - localhost.log (应用相关日志) - host-mana…...

分布式系统-脑裂,redis的解决方案
感谢你的反馈!很高兴能帮到你。关于你提到的“脑裂”(split-brain),这是一个分布式系统中的常见术语,尤其在像 Redis Cluster 这样的高可用集群中会涉及。既然你问到了,我会从头解释“脑裂”的含义、Redis …...

MySQL InnoDB 索引与B+树面试题20道
1. B树和B+树的区别是什么? 数据存储位置: B树:所有节点(包括内部节点和叶子节点)均存储数据。 B+树:仅叶子节点存储数据,内部节点仅存储键值(索引)。 叶子节点结构: B+树:叶子节点通过双向链表连接,支持高效的范围查询。 查询稳定性: B+树:所有查询必须走到叶子…...

深入解析 Spring AI Alibaba 多模态对话模型:构建下一代智能应用的实践指南
一、多模态对话模型的技术演进 1.1 从单一文本到多模态交互 现代AI应用正经历从单一文本交互到多模态融合的革命性转变。根据Gartner预测,到2026年将有超过80%的企业应用集成多模态AI能力。Spring AI Alibaba 对话模型体系正是为这一趋势量身打造,其技…...

2025年ESWA SCI1区TOP:动态分类麻雀搜索算法DSSA,深度解析+性能实测
目录 1.摘要2.麻雀搜索算法SSA原理3.孤立微电网经济环境调度4.改进策略5.结果展示6.参考文献7.代码获取 1.摘要 污染物排放对环境造成负面影响,而可再生能源的不稳定性则威胁着微电网的安全运行。为了在保障电力供应可靠性的同时实现环境和经济目标的平衡ÿ…...

MySQL Error Log
MySQL Error Log Error Log 的开启Error Log 查看Error Log 滚动 MySQL Error Log MySQL主从复制:https://blog.csdn.net/a18792721831/article/details/146117935 MySQL Binlog:https://blog.csdn.net/a18792721831/article/details/146606305 MySQL Ge…...

让DeepSeek API支持联网搜索
引子 DeepSeek官网注册的API token是不支持联网搜索的,这导致它无法辅助分析一些最新的情况或是帮忙查一下互联网上的资料。本文从实战角度提供一种稳定可靠的方法使得DeepSeek R1支持联网搜索分析。 正文 首先登录火山方舟控制台,https://www.volcen…...

SQL 语句说明
目录 数据库和数据表什么是 SQL 语言数据操作语言(DML)1、SELECT 单表查询通过 WHERE 对原始数据进行筛选通过 聚合函数 获取汇总信息通过 ORDER BY 对结果排序通过 GROUP BY 对数据进行分组通过 HAVING 对分组结果进行筛选 2、SELECT 多表查询3、INSERT…...

PostgreSQL内幕探索—基础知识
PostgreSQL内幕探索—基础知识 PostgreSQL(以下简称PG) 起源于 1986 年加州大学伯克利分校的 POSTGRES 项目,最初以对象关系模型为核心,支持高级数据类型和复杂查询功能。 1996 年更名为 PostgreSQL 并开源,逐…...

Springboot项目正常启动,访问资源却出现404错误如何解决?
我在自己的springboot项目中的启动类上同时使用了SprinBootApplication和ComponentScan注解, 虽然项目能够正常启动,但是访问资源后,返回404错误,随后在启动类中输出bean,发现controller创建失败: 而后我将ComponentScan去掉后资源就能访问到了. 原因 SprinBootApplication本身…...
)
MaxPooling层的作用(通俗解释)
MaxPooling层的作用(通俗解释) MaxPooling层是卷积神经网络中非常重要的组成部分,它的主要作用可以用以下几个简单的比喻来理解: 1. 信息压缩器(降维作用) 就像把一张高清照片缩小尺寸一样,M…...

0.DockerCE起步之Linux相关【完善中】
ubuntu用户组&权限&文件/目录 服务启停操作 sudo systemctl start docker # 启动服务3,4 sudo systemctl stop docker # 停止服务 sudo systemctl restart docker ps top 以下内容参考 Vim编辑器 Linux系统常用命令 管理Linux实例软件源 Cron定时任务 在Linux系统上…...
)
树莓派Pico C/C++ OpenOCD调试环境搭建(Windows)
树莓派Pico C/C OpenOCD调试环境搭建(Windows) 参考资料和背景 从上次树莓派Pico C/C 开发环境搭建(一键完成版)后,一直想找个合适调试器,最后测试了多种方案,还是使用另一块树莓派pico作为picoprobe 来调试比较方便,其中参考的…...
【图像生成之21】融合了Transformer与Diffusion,Meta新作Transfusion实现图像与语言大一统
论文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model 地址:https://arxiv.org/abs/2408.11039 类型:理解与生成 Transfusion模型是一种将Transformer和Diffusion模型融合的多模态模型,旨…...

《人件》第二章 办公环境
二、办公环境 电话铃不停的响,打印机维修人员顺道过来聊聊天,复印机不工作了,人事部不停催促更新的能力调查表,下午3点之前就要提交时间表…然后一天就这样过去了。 2.1 家具警察 人们怎么使用空间、需要的桌子空间多大、花多少小…...

哈希表系列一>存在重复元素II 存在重复元素I
目录 题目:解析:存在重复元素 II-->代码:存在重复元素-->代码: 题目: 链接: link 链接: link 解析: 存在重复元素 II–>代码: class Solution {public boolean containsNearbyDuplic…...

文献总结:AAAI2025-UniV2X-End-to-end autonomous driving through V2X cooperation
UniV2X 一、文章基本信息二、文章背景三、UniV2X框架1. 车路协同自动驾驶问题定义2. 稀疏-密集混合形态数据3. 交叉视图数据融合(智能体融合)4. 交叉视图数据融合(车道融合)5. 交叉视图数据融合(占用融合)6…...

LeetCode --- 444 周赛
题目列表 3507. 移除最小数对使数组有序 I 3508. 设计路由器 3509. 最大化交错和为 K 的子序列乘积 3510. 移除最小数对使数组有序 II 一、移除最小数对使数组有序 I & II 由于数组是给定的,所以本题的操作步骤是固定的,我们只要能快速模拟操作的过…...

单片机Day05---静态数码管
目录 一、原理图:编辑 二、思路梳理: 三:一些说明: 1.点亮方式: 2.数组: 3.数字与段码对应: 四:程序实现: 一、原理图: 二、思路梳理: …...

kernel32!GetQueuedCompletionStatus函数分析之返回值得有效性
第一部分://#define STATUS_SUCCESS 0x0返回值为0 } else { // // Set the completion status, capture the completion // information, deallocate the associated IRP, and // attempt to write the…...

gazebo 启动卡死的解决方法汇总
1. 排查显卡驱动是否正常安装 nvidia-smi # 英伟达显卡--------------------------------------------------------------------------------------- | NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 | |------------------------…...

硬件设计-MOS管快速关断的原因和原理
目录 简介: 来源: MOS管快关的原理 先简单介绍下快关的原理: 同电阻时为什么关断时间会更长 小结 简介: 本章主要介绍MOS快速关断的原理和原因。 来源: 有人会问,会什么要求快速关断,而…...

塔能科技解节能密码,工厂成本“效益方程式”精准破题
在全球积极推进可持续发展战略的当下,各行业都在努力探索节能减排、绿色发展的新路径,对于工厂而言,节能早已不是锦上添花的选择,而已成为关乎企业生死存亡与长远发展的核心要素,是实现可持续运营的必由之路。塔能科技…...

swift ui基础
一个朴实无华的目录 今日学习内容:1.三种布局(可以相互包裹)1.1 vstack(竖直):先写的在上面1.1 hstack(水平):先写的在左边1.1 zstack(前后)&…...

格式工厂 v5.18最新免安装绿色便携版
前言 用它来转视频的时候,还能顺便给那些有点小瑕疵的视频修修补补,保证转出来的视频质量杠杠的。更厉害的是,它不只是转换那么简单,还能帮你把PDF合并成一本小册子,视频也能合并成大片,还能随心所欲地裁剪…...

CSPM认证对项目论证的范式革新:从合规审查到价值创造的战略跃迁
引言 在数字化转型浪潮中,全球企业每年因项目论证缺陷导致的损失高达1.7万亿美元(Gartner 2023)。CSPM(Certified Strategic Project Manager)认证体系通过结构化方法论,将传统的项目可行性评估升级为战略…...