【图像生成之21】融合了Transformer与Diffusion,Meta新作Transfusion实现图像与语言大一统
论文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
地址:https://arxiv.org/abs/2408.11039
类型:理解与生成
Transfusion模型是一种将Transformer和Diffusion模型融合的多模态模型,旨在同时处理离散数据(如文本)和连续数据(如图像)。该模型由Meta公司开发,能够在单个模型中预测离散文本token并生成连续图像,从而实现了语言建模和图像生成的一体化。
Transfusion模型的核心特点
-
统一的Transformer架构:Transfusion使用单一的Transformer模型来处理文本和图像数据,通过不同的损失函数和注意力机制来实现多模态建模。
-
双重训练目标:对于文本,采用经典的语言建模目标(LM loss),即预测序列中的下一个token;对于图像,则引入扩散模型的目标(DDPM loss),通过预测加噪过程中的噪声分量来逐步生成图像12。
-
模态混合序列:Transfusion将文本和图像数据整合成单一输入序列,使用特殊标记分隔不同模态,确保模型能区分处理对象2。
-
注意力机制的创新:对于文本,保持因果注意力;对于图像patch,引入双向注意力,捕捉空间关系,提升生成质量2。
-
联合损失函数:训练时,将语言建模损失和扩散模型损失加权组合为一个总损失函数
一、摘要
我们介绍了Transfusion,这是一种在离散和连续数据上训练多模态模型的方法。Transfusion将语言建模损失函数(下一个token预测)与扩散相结合,在混合模态序列上训练单个Transformer。我们在文本和图像数据的混合上从头开始预训练多达7B个参数的多个Transfusion模型,建立了关于各种单模态和跨模态基准的缩放规律。我们的实验表明,Transfusion的缩放效果明显优于量化图像和在离散图像标记上训练语言模型。通过引入特定于模态的编码和解码层,我们可以进一步提高Transfusion模型的性能,甚至将每张图像压缩到只有16个patch。我们进一步证明,将我们的Transfusion配方扩展到7B参数和2T多模态令牌可以产生一个模型,该模型可以生成与类似规模的扩散模型和语言模型相当的图像和文本,从而获得两个世界的好处。
二、介绍
多模态生成模型需要能够感知、处理和生成离散元素(如文本或代码)和连续元素(如图像、音频和视频数据)。虽然在下一个令牌预测目标上训练的语言模型主导了离散模态,但扩散模型及其推广Flow matching是生成连续模态的最新技术。已经做出了许多努力来结合这些方法,包括扩展语言模型以使用扩散模型作为工具,无论是明确地还是将预训练的扩散模型移植到语言模型上。在这项工作中,我们表明,通过训练一个模型来预测离散文本标记和扩散连续图像,可以在不损失信息的情况下完全整合这两种模式。
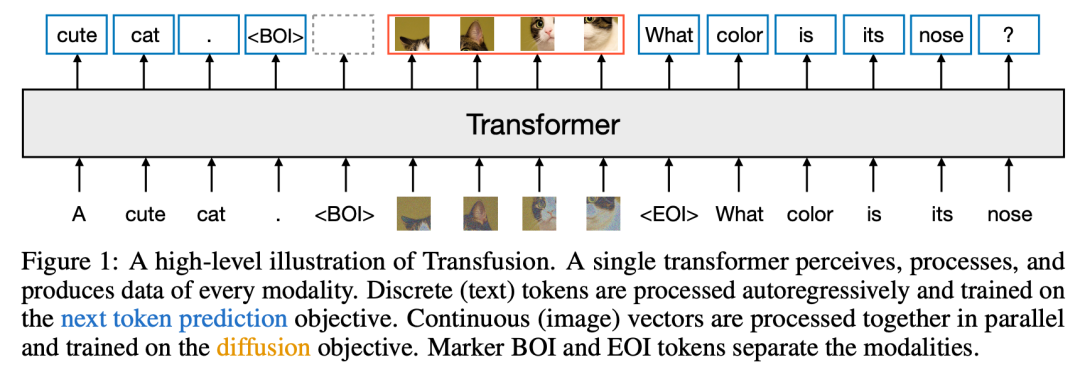
我们介绍了Transfusion,这是一种训练模型的方法,可以无缝生成离散和连续的模态。我们通过在50%的文本和50%的图像数据上预训练一个transformer模型来演示Transfusion,为每种模态使用不同的目标:文本的下一个标记预测和图像的扩散。该模型在每个训练步骤中都暴露于模态和损失函数。Standard embedding layers将文本标记转换为向量,而patchification layer则表示每个图像作为补丁矢量序列。我们对文本标记应用 causal attention,对image patches应用bidirectional attention。为了进行推理,我们引入了一种解码算法,该算法结合了从语言模型生成文本和从扩散模型生成图像的标准实践。图1显示了Transfusion。
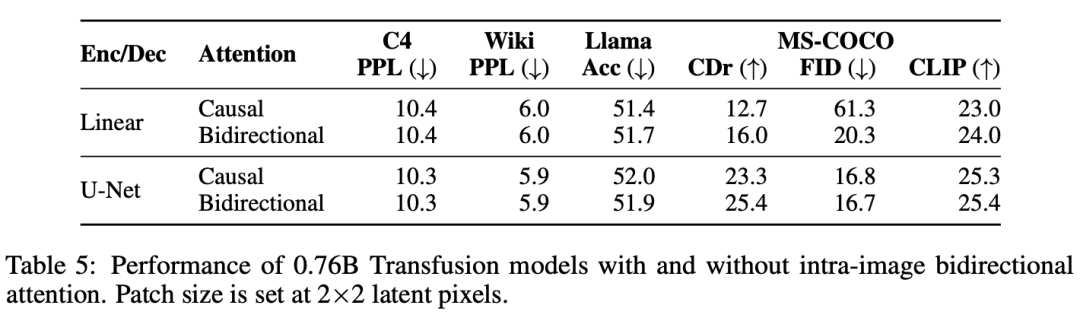
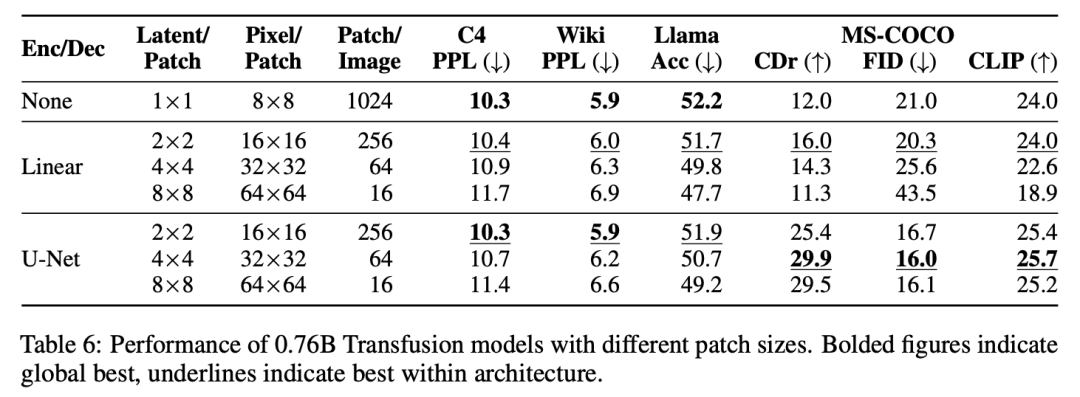
消融实验揭示了Transfusion的关键组成部分和潜在的改进。我们观察到,图像内双向注意力很重要,用因果注意力代替它会损害文本到图像的生成。我们还发现,添加U-Net上下块来编码和解码图像,使Transfusion能够以相对较小的性能损失压缩较大的图像块,从而可能将服务成本降低64倍。

最后,我们证明了Transfusion可以生成与其他扩散模型质量相似的图像。我们从头开始训练一个7B转换器,该转换器在2T令牌上增强了U-Net down/up(0.27B参数):1T文本令牌,以及大约5个epochs 692M图像及其captions迭代,总计1T patches/tokens。图2显示了从模型中采样的一些生成图像。在GenEval基准测试中,我们的模型优于其他流行模型,如DALL-E 2和SDXL;与那些图像生成模型不同,它可以生成文本,在文本基准测试中达到与Llama 1相同的性能水平。因此,我们的实验表明,Transfusion是一种训练真正多模态模型的有前景的方法。
GenEval是专门评估生成式AI模型(如文本到图像生成)性能的基准测试,它定义明确,通过标准化的测试流程,对模型在图像生成质量、指令遵循度、多模态理解等关键指标上进行量化评估。例如,在开源模型Janus-Pro与DALL-E 3、Stable Diffusion的对比中,GenEval的测试结果显示Janus-Pro-7B的准确率高达80%,显著优于竞品。
GenEval的框架设计包含多维度评估体系,覆盖图像生成质量(如分辨率、色彩准确性)、指令响应能力(如地标识别、文字生成)、多模态任务处理(如视觉问答、图像标注)等核心模块。其测试方法结合了自动化指标(如FID分数、CLIP匹配度)与人工评审,确保评估的全面性与可靠性。
三、背景
Transfusion是一个单一的模型,有两个目标:语言建模和扩散(language modeling and diffusion)。这些目标分别代表了离散和连续数据建模的最新技术。本节简要定义了这些目标,以及潜在表示的背景。
3.1 Language Modeling
给定离散令牌序列y=y1...yn,语言模型预测序列P(y)的概率。标准语言模型将P(y)分解为条件概率的乘积如下公式,这创建了一个自回归分类任务,其中每个令牌yi的概率分布是在序列y<i的前缀的条件下,使用由θ参数化的单个分布Pθ进行预测的。该模型可以通过最小化Pθ和数据经验分布之间的交叉熵来优化,从而产生标准的下一个令牌预测目标,俗称LM损失:
![]()
![]()
一旦经过训练,语言模型还可以通过从模型分布Pθ中逐个采样来生成文本,通常使用温度和top-P截断。
温度参数用于控制生成文本的随机性,其值通常介于0.1到2.0之间;
Top-P截断是一种动态限制采样范围的方法,仅考虑概率最高的前P%的词汇
3.2 Diffusion
去噪扩散概率模型(也称为DDPM或扩散模型)的工作原理是学习如何逆转逐渐增加噪声的过程。与通常使用离散标记(y)的语言模型不同,扩散模型在连续向量(x)上运行,使其特别适合涉及图像等连续数据的任务。扩散框架涉及两个过程:一个描述原始数据如何转化为噪声的正向过程,以及模型学习执行的去噪反向过程。
Forward Process。从数学的角度来看,正向过程定义了如何创建噪声数据(作为模型输入)。给定一个数据点x0,Ho等人定义了一个马尔可夫链,该链在T步上逐渐增加高斯噪声,从而产生一个噪声越来越大的序列x1, x2, ..., xT,这个过程的每一步都由
![]()
其中βt根据预定义的噪声时间表随时间增加(见下文)。该过程可以重新参数化,使我们能够使用高斯噪声ε∼N(0,I)的单个样本直接从x0中采样xt:
![]()
![]()
它提供了对原始马尔可夫链的有用抽象。事实上,训练目标和噪声调度器最终都以这些术语表示(和实现)。
Reverse Process。对扩散模型进行训练,以执行逆过程pθ(xt−1|xt),学习逐步对数据进行去噪。有几种方法可以做到这一点;在这项工作中,我们遵循Ho等人的方法,将方程2中的高斯噪声ε建模为步骤t处累积噪声的代理。具体来说,在给定噪声数据xt和时间步长t的情况下,训练一个具有参数θ的模型εθ(·)来估计噪声ε。在实践中,该模型通常在生成图像时以附加的上下文信息c为条件,例如caption。因此,通过最小化均方误差损失来优化噪声预测模型的参数:
![]()
Noise Schedule。在创建有噪声的示例xt时,ᾱt确定了时间步长t的噪声方差。在这项工作中,我们采用了常用的余弦调度器,该调度器在很大程度上遵循sqrt(αt)≈cos(t/T·π/2),并进行了一些调整。
Inference。解码是迭代完成的,每一步都会消除一些噪声。从xT处的纯高斯噪声开始,模型εθ(xT,t,c)预测时间步长t处累积的噪声。然后根据噪声调度对预测的噪声进行缩放,并从xT中去除预测噪声的比例量以产生xT-1。在实践中,推理的时间步比训练少。无分类器引导(CFG)通常用于通过对比基于上下文c的模型预测和无条件预测来改进生成,代价是计算量加倍。
3.3 Latent Image Representation
早期的扩散模型直接在像素空间pixel-space中工作,但这被证明计算成本很高。变分自编码器(VAEs)可以通过将图像编码到低维潜在空间来节省计算。作为深度卷积神经网络实现,现代VAE在重建和正则化损失的组合上进行训练,允许潜在扩散模型(LDM)等下游模型在紧凑的图像块嵌入上高效运行;例如,将每个8×8像素的补丁表示为8维向量。对于自回归语言建模方法,必须对图像进行离散化。离散自编码器,如矢量量化VAE(VQ-VAE),通过引入将连续潜在嵌入映射到离散标记的量化层(和相关的正则化损失)来实现这一点。
四、方法
Transfusion是一种训练单个统一模型以理解和生成离散和连续模态的方法。我们的主要创新是证明,我们可以对不同的模态使用单独的损失——文本的语言建模、图像的扩散——而不是共享的数据和参数。图1显示了Transfusion。
Data Representation。我们实验了两种模式的数据:离散文本和连续图像。每个文本字符串都被标记为来自固定词汇表的离散标记序列,其中每个标记都表示为整数。使用VAE将每个图像编码为潜在patch,其中每个patch表示为连续向量;patch从左到右从上到下排序,以从每张图像中创建patch向量序列。对于混合模态示例,我们在将每个图像序列插入文本序列之前,用特殊的图像开始(BOI)和图像结束(EOI)标记包围每个图像序列;因此,我们得到一个可能包含离散元素(表示文本标记的整数)和连续元素(表示图像块的向量)的单一序列。
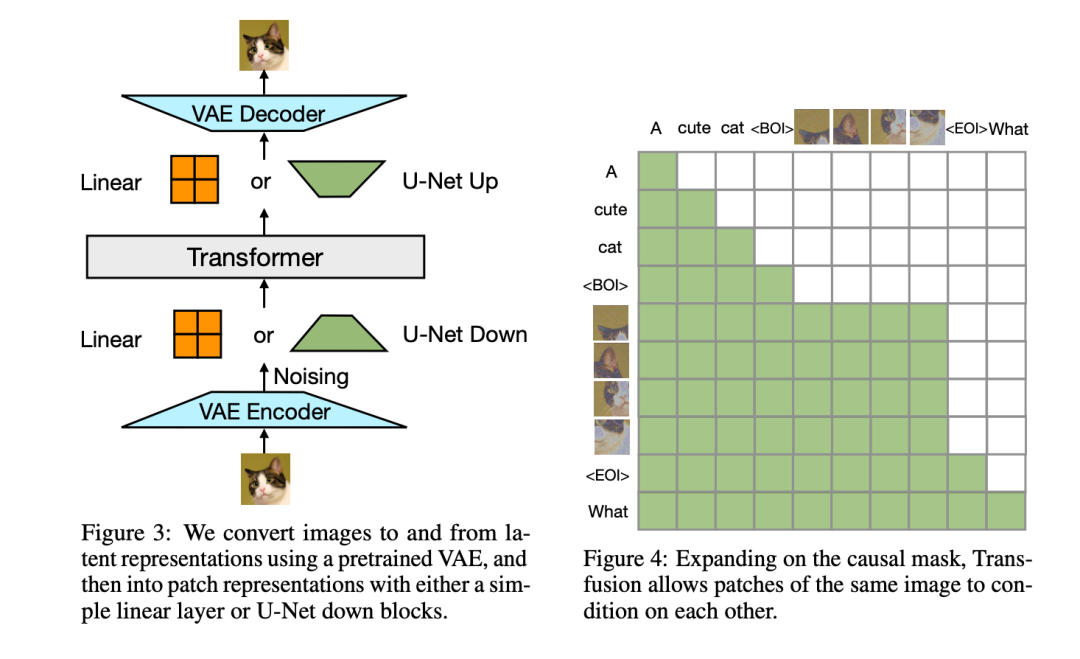
Model Architecture。模型的绝大多数参数属于一个Transformer,该Transformer处理每个序列,而不管模态如何。Transformer将R^d中的一系列高维向量作为输入,并产生相似的向量作为输出。为了将我们的数据转换到这个空间,我们使用具有非共享参数的轻量级模态特定组件。对于文本,这些是嵌入矩阵,将每个输入整数转换为向量空间,将每个输出向量转换为词汇表上的离散分布。对于图像,我们尝试了两种将k×k个patch向量的局部窗口压缩为 single transformer vector的替代方案:(1)简单线性层;(2)UNet上下块,图3显示了整体架构。
Transfusion Attention。语言模型通常使用causal masking来有效地计算单个前向后向传递中整个序列的损失和梯度,而不会从未来的token中泄露信息。虽然文本是自然顺序的,但图像不是,并且通常以不受限制的(双向)注意力进行建模。Transfusion通过对序列中的每个元素应用因果注意力,以及在每个单独图像的元素内应用双向注意力,将两种注意力模式结合在一起。这允许每个图像补丁处理同一图像中的其他补丁,但只处理序列中之前出现的其他图像的文本或补丁。我们发现,启用图像内注意力可以显著提高模型性能。图4显示了 Transfusion attention mask。
Training Objective。为了训练我们的模型,我们将语言建模目标L-LM应用于文本标记的预测,将扩散目标L-DDPM应用于图像块的预测。LM损失按每个标记计算,而扩散损失按每个图像计算,这可能跨越序列中的多个元素(图像块)。具体来说,我们根据扩散过程将噪声ε添加到每个输入的潜像x0中,以在diffusion之前产生xt,然后计算图像级扩散损失。我们通过简单地将每种模态上计算的损失与平衡系数λ相加,将这两种损失结合起来:
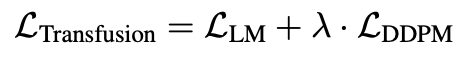
这个公式是一个更广泛想法的具体实例:将离散分布损失与连续分布损失相结合,以优化同一模型。我们将对这一领域的进一步探索,例如用flow matching取代扩散,留给未来的工作。
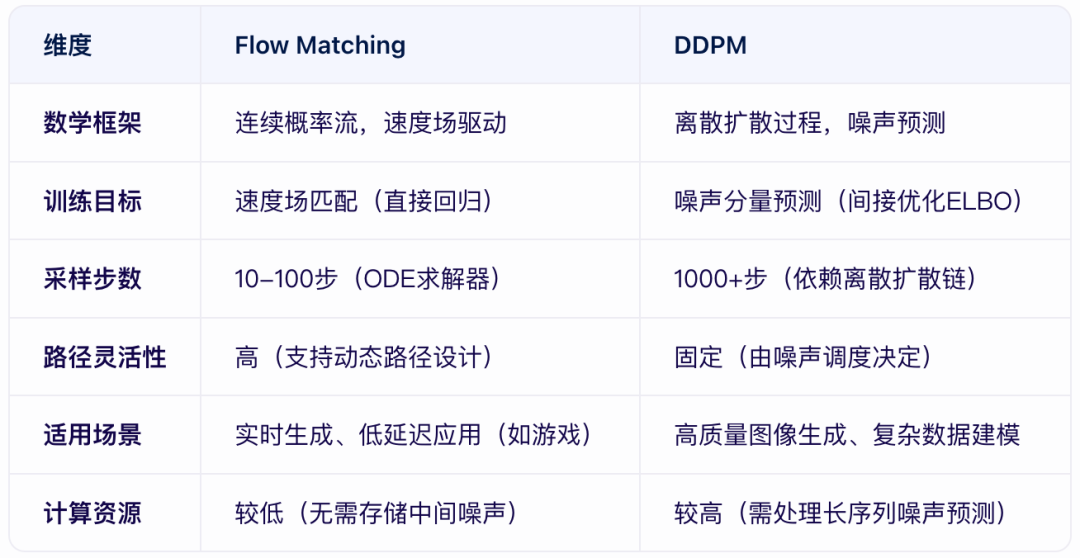
一、Flow Matching的核心原理与应用
1. 数学本质:连续概率流的“路径规划”
类比理解:如同用黏土塑形,Flow Matching通过构建一个连续的速度场(Velocity Field),将随机噪声(先验分布)逐步“引导”至目标图像分布。
技术实现:定义从噪声到数据的平滑路径(如线性插值或动态学习路径)。通过神经网络直接预测每个时空点的速度向量(而非噪声),形成确定性轨迹。满足概率质量守恒(连续性方程),确保转换过程中信息不丢失。
2. 训练与采样优势
模板函数:直接优化速度场与预定义路径的匹配度(均方误差MSE),无需马尔可夫链假设。
采样效率:采用高阶ODE求解器(如RK45),10-100步即可生成高质量图像,支持实时应用(如直播、游戏场景)。
灵活性:允许自定义路径(直线、曲线或动态路径),适合复杂分布建模。二、DDPM的核心原理与应用
1. 数学本质:离散扩散的“噪声逆转”
- 类比理解
:类似沙堡被侵蚀后重建,DDPM通过逐步添加高斯噪声破坏图像,再学习逆转此过程的去噪步骤。
- 技术实现:
前向过程:按固定噪声调度(如线性β_t)将图像逐步转化为纯噪声。
反向过程:用U-Net预测每一步的噪声分量,通过迭代去噪还原图像。2. 训练与采样特点
- 目标函数
:间接优化变分下界(ELBO),依赖马尔可夫链分解。
- 采样效率
:需1000步以上(即使通过DDIM加速仍受限于离散步数)。
- 生成质量
:擅长建模复杂数据(如高分辨率图像),与U-Net结合可捕捉细节。
Flow Matching:
优势场景:需要快速生成(如实时互动、低延迟应用)或路径可控的场景(如风格迁移中的渐变控制)。
案例:条件Flow Matching(CFM)在文本到图像生成中,通过定义噪声与数据间的连续路径,提升生成速度。
DDPM:
优势场景:追求高质量图像生成(如艺术画作、超分辨率重建)或复杂数据分布建模。
案例:Stable Diffusion通过潜在空间扩散生成高分辨率图像,支持文本引导和图像修复。
Inference。为了反映训练目标,我们的解码算法还可以在两种模式之间切换:LM和diffusion。在LM模式下,我们遵循从预测分布中逐个采样的标准做法。当我们对BOI令牌进行采样时,解码算法会切换到扩散模式,在那里我们遵循从扩散模型解码的标准过程。具体来说,我们以n个图像块的形式将纯噪声xT附加到输入序列中(取决于所需的图像大小),并在T步内进行降噪。在每个步骤t,我们进行噪声预测并使用它来产生xt-1,然后覆盖序列中的xt;即,该模型总是以噪声图像的最后一个时间步长为条件,而不能关注之前的时间步长。一旦扩散过程结束,我们将EOI令牌附加到预测图像中,并切换回LM模式。该算法能够生成文本和图像模态的任何混合。
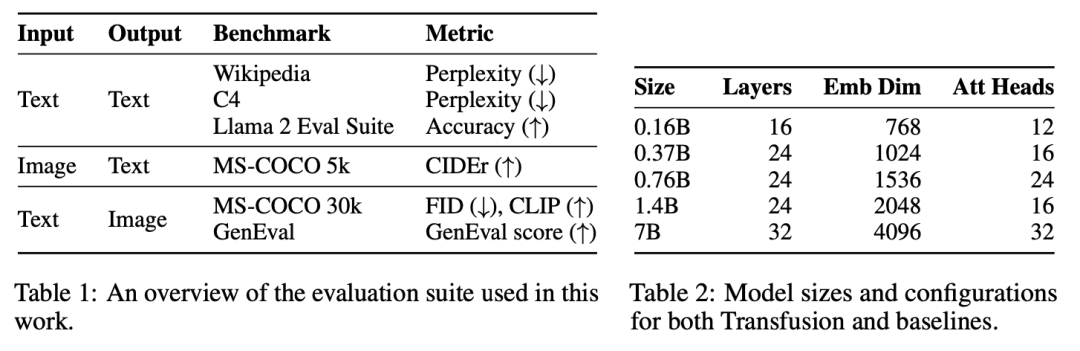
五、实验
我们在一系列对照实验中证明,transfusion是一种可行的、可扩展的训练统一多模态模型的方法。
Evaluation。我们在一系列标准uni-modal\cross-modal benchmarks基准上评估模型性能,如表1所示。包括Wikipedia\MS-COCO,覆盖文生图、与文本生成。指标包括FID、CLIP、Perplexity等。
Baseline。Chameleon和Transfusion之间的关键区别在于,虽然Chameleon将图像离散化并将其作为token进行处理,但Transfusion将图像保持在连续空间中,消除了量化信息瓶颈。
Data。对于我们几乎所有的实验,我们以1:1的token比率从两个数据集中采样0.5T令牌(补丁)。对于文本,我们使用Llama 2标记器和语料库,其中包含跨不同域分布的2T标记。对于图像,我们使用一组3.8亿张获得许可的Shutterstock图像和字幕。每幅图像都经过中心裁剪和调整大小,以产生256×256像素的图像。我们随机排列图像和字幕,80%的时间先排列字幕。
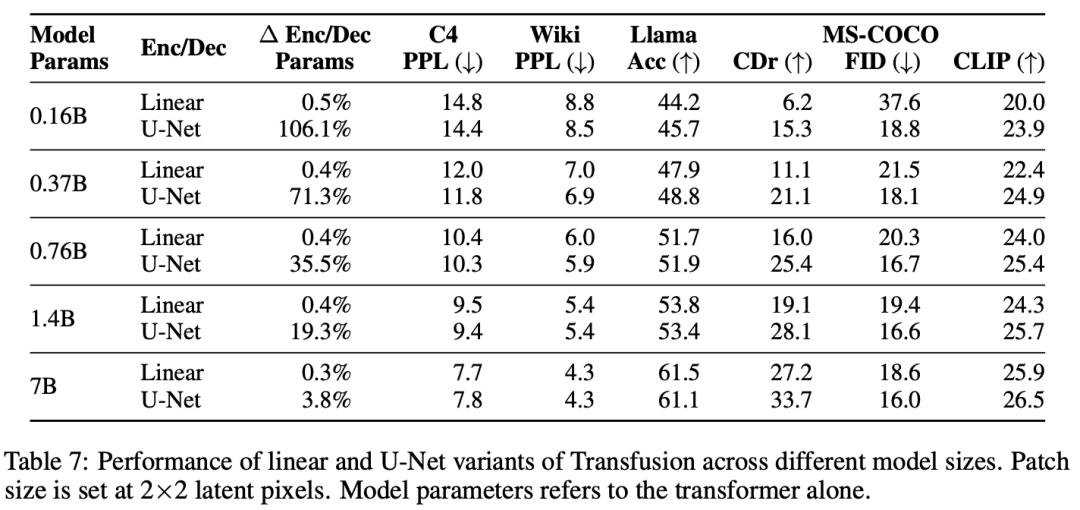
Model Configuration。为了研究缩放趋势,我们按照Llama的标准设置,以五种不同的尺寸(0.16B、0.37B、0.76B、1.4B和7B参数)训练模型。表2详细描述了每种设置。在使用线性补丁编码的配置中,附加参数的数量微不足道,在每个配置中占总参数的不到0.5%。当使用U-Net补丁编码时,这些参数在所有配置中加起来总共为0.27B的额外参数;虽然这是对较小模型的大量参数添加,但这些层仅比7B配置增加了3.8%,几乎与嵌入层中的参数数量相同。
Optimization。我们随机初始化所有模型参数,并使用学习率为3e-4的AdamW(β1=0.9,β2=0.95,ε=1e-8)对其进行优化,warmed up 4000步,使用cosine scheduler衰减到1.5e-5。我们在4096个token的序列上进行训练,每批2M个token,每次250k步,总共达到0.5T个令牌。在我们的大规模实验中,我们在500k步内使用4M令牌的批量进行训练,总共2T令牌。
实验主要探索了Controlled Comparison with Chameleon, Architecture Ablations(Attention Masking,Patch Size,Patch Encoding/Decoding Architecture, Image Noising), Comparison with Image Generation Literature, Image Editing等,具体实验结果如下表分析所示。
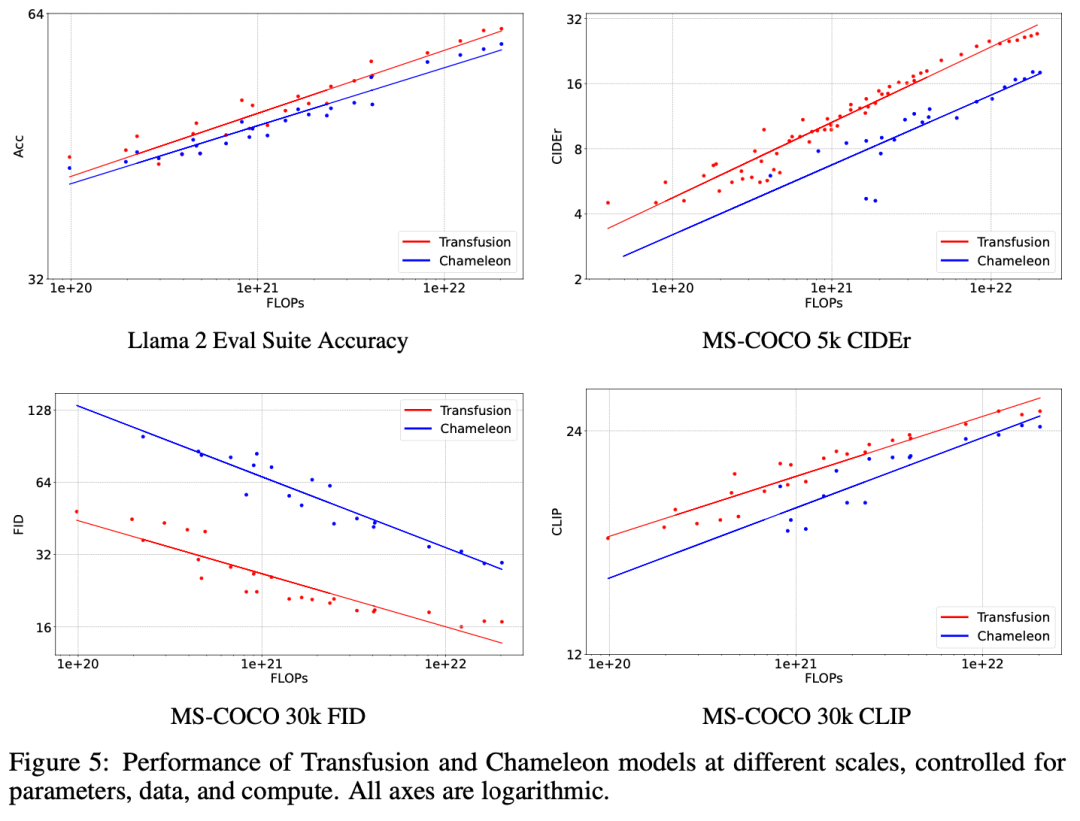
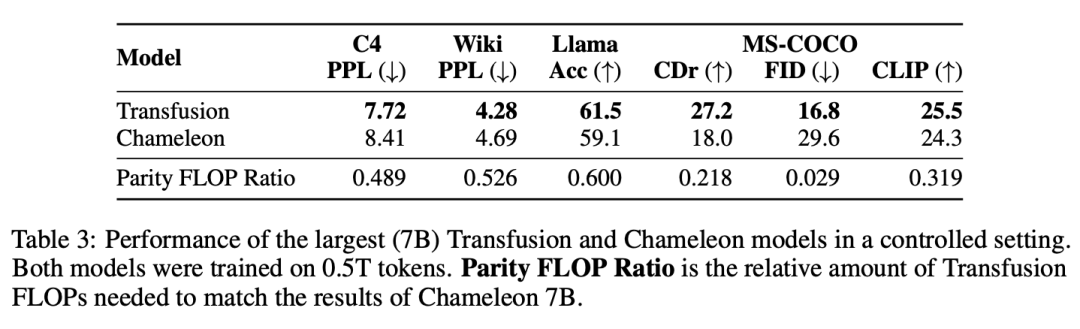
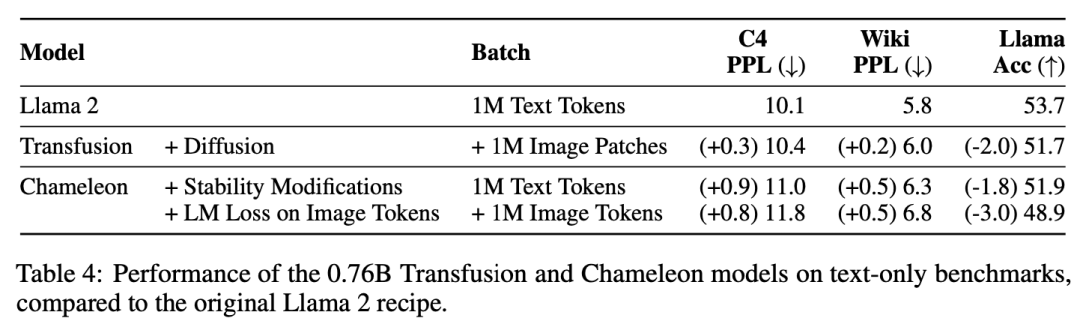
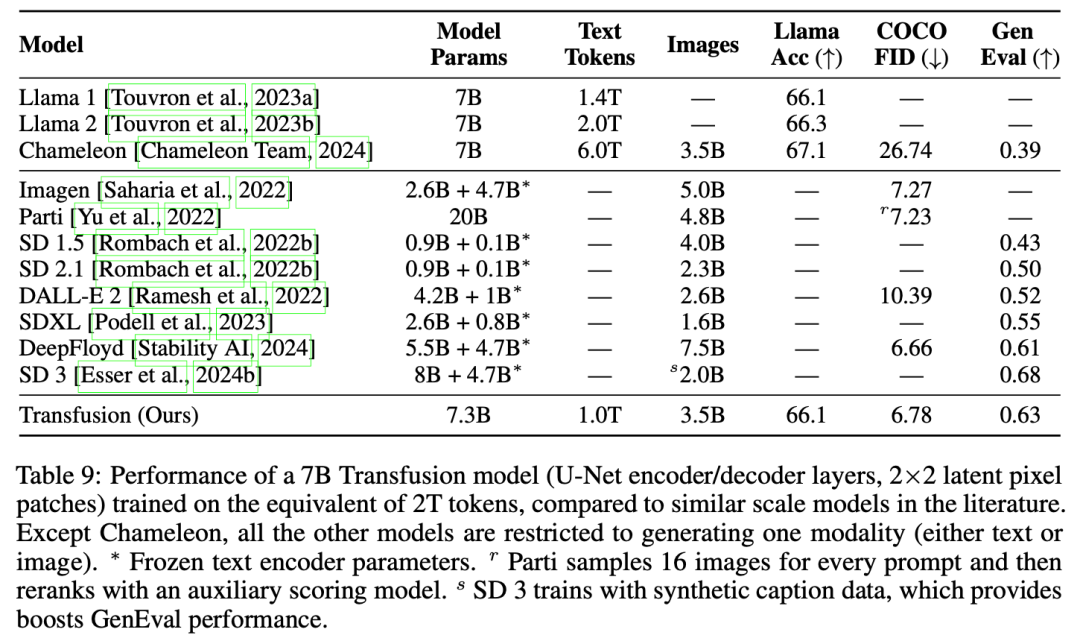

这项工作探讨了如何缩小离散序列建模(下一个token预测)和连续媒体生成(扩散)之间的差距。我们提出了一个简单但以前未被探索的解决方案:在两个目标上训练一个联合模型,将每种模式与其首选目标联系起来。我们的实验表明,Transfusion可以有效地扩展,几乎不产生参数共享成本,同时能够生成任何模态。
相关文章:
【图像生成之21】融合了Transformer与Diffusion,Meta新作Transfusion实现图像与语言大一统
论文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model 地址:https://arxiv.org/abs/2408.11039 类型:理解与生成 Transfusion模型是一种将Transformer和Diffusion模型融合的多模态模型,旨…...

《人件》第二章 办公环境
二、办公环境 电话铃不停的响,打印机维修人员顺道过来聊聊天,复印机不工作了,人事部不停催促更新的能力调查表,下午3点之前就要提交时间表…然后一天就这样过去了。 2.1 家具警察 人们怎么使用空间、需要的桌子空间多大、花多少小…...

哈希表系列一>存在重复元素II 存在重复元素I
目录 题目:解析:存在重复元素 II-->代码:存在重复元素-->代码: 题目: 链接: link 链接: link 解析: 存在重复元素 II–>代码: class Solution {public boolean containsNearbyDuplic…...

文献总结:AAAI2025-UniV2X-End-to-end autonomous driving through V2X cooperation
UniV2X 一、文章基本信息二、文章背景三、UniV2X框架1. 车路协同自动驾驶问题定义2. 稀疏-密集混合形态数据3. 交叉视图数据融合(智能体融合)4. 交叉视图数据融合(车道融合)5. 交叉视图数据融合(占用融合)6…...

LeetCode --- 444 周赛
题目列表 3507. 移除最小数对使数组有序 I 3508. 设计路由器 3509. 最大化交错和为 K 的子序列乘积 3510. 移除最小数对使数组有序 II 一、移除最小数对使数组有序 I & II 由于数组是给定的,所以本题的操作步骤是固定的,我们只要能快速模拟操作的过…...

单片机Day05---静态数码管
目录 一、原理图:编辑 二、思路梳理: 三:一些说明: 1.点亮方式: 2.数组: 3.数字与段码对应: 四:程序实现: 一、原理图: 二、思路梳理: …...

kernel32!GetQueuedCompletionStatus函数分析之返回值得有效性
第一部分://#define STATUS_SUCCESS 0x0返回值为0 } else { // // Set the completion status, capture the completion // information, deallocate the associated IRP, and // attempt to write the…...

gazebo 启动卡死的解决方法汇总
1. 排查显卡驱动是否正常安装 nvidia-smi # 英伟达显卡--------------------------------------------------------------------------------------- | NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 | |------------------------…...

硬件设计-MOS管快速关断的原因和原理
目录 简介: 来源: MOS管快关的原理 先简单介绍下快关的原理: 同电阻时为什么关断时间会更长 小结 简介: 本章主要介绍MOS快速关断的原理和原因。 来源: 有人会问,会什么要求快速关断,而…...

塔能科技解节能密码,工厂成本“效益方程式”精准破题
在全球积极推进可持续发展战略的当下,各行业都在努力探索节能减排、绿色发展的新路径,对于工厂而言,节能早已不是锦上添花的选择,而已成为关乎企业生死存亡与长远发展的核心要素,是实现可持续运营的必由之路。塔能科技…...

swift ui基础
一个朴实无华的目录 今日学习内容:1.三种布局(可以相互包裹)1.1 vstack(竖直):先写的在上面1.1 hstack(水平):先写的在左边1.1 zstack(前后)&…...

格式工厂 v5.18最新免安装绿色便携版
前言 用它来转视频的时候,还能顺便给那些有点小瑕疵的视频修修补补,保证转出来的视频质量杠杠的。更厉害的是,它不只是转换那么简单,还能帮你把PDF合并成一本小册子,视频也能合并成大片,还能随心所欲地裁剪…...

CSPM认证对项目论证的范式革新:从合规审查到价值创造的战略跃迁
引言 在数字化转型浪潮中,全球企业每年因项目论证缺陷导致的损失高达1.7万亿美元(Gartner 2023)。CSPM(Certified Strategic Project Manager)认证体系通过结构化方法论,将传统的项目可行性评估升级为战略…...

TcxCustomCheckComboBoxProperties.EditValueFormat 值说明
TcxCheckStatesValueFormat 类枚举复选框状态对 edit 值的可能解释。以下选项可用。 价值 意义 cvf字幕 编辑值是一个字符串,其中包含两个由分号分隔的子字符串。分号前的子字符串包含灰显项目的标题列表。分号后面的子字符串包含已选中项目的标题列表。请注意&a…...

Spring Boot 测试详解,包含maven引入依赖、测试业务层类、REST风格测试和Mock测试
Spring Boot 测试详解 1. 测试依赖引入 Spring Boot 默认通过以下 Maven 依赖引入测试工具: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</s…...
(C语言完结篇))
【C语言】预处理(下)(C语言完结篇)
一、#和## 1、#运算符 这里的#是一个运算符,整个运算符会将宏的参数转换为字符串字面量,它仅可以出现在带参数的宏的替换列表中,我们可以将其理解为字符串化。 我们先看下面的一段代码: 第二个printf中是由两个字符串组成的&am…...

IIC通信协议
一、概述 IIC协议:是一种各种电子设备之间进行数据交换和通信的串行,半双工通信协议,主要用于近距离,低速的芯片之间的通信。 I2C协议采用双线结构传输数据,由一个数据线&#…...
)
SpringBoot原生实现分布式MapReduce计算(无第三方中间件版)
一、架构设计调整 核心组件替换方案: 注册中心 → 数据库注册表任务队列 → 数据库任务表分布式锁 → 数据库行级锁节点通信 → HTTP REST接口 二、数据库表结构设计 -- 节点注册表 CREATE TABLE compute_nodes (node_id VARCHAR(36) PRIMARY KEY,last_heartbea…...

02-libVLC的视频播放器:播放音视频文件以及网络流
libvlc_new(0, nullptr)功能:创建并初始化libVLC的核心实例,是使用所有libVLC功能的前提。 参数:第一个参数:参数数量(通常设为0)第二个参数:参数列表(通常为nullptr,表示使用默认配置)返回值:成功返回libvlc_instance_t*指针,失败返回nullptr。注意事项:可通过参…...

Autoware源码总结
Autoware源码网站 项目简介 教程 Autoware的整体架构如下图,主要包括传感器sensing、高精地图map data、车辆接口vehicle interface、感知perception(动态障碍物检测detection、跟踪tracking、预测prediction;交通信号灯检测detection、分类c…...

PowerBI 条形图显示数值和百分比
数据表: 三个度量值 销售额 SUM(销量表[销售量])//注意, 因为Y轴显示的产品,会被筛选,所以用ALLSELECTED来获取当前筛选条件下,Y轴显示的产品 百分比 FORMAT(DIVIDE([销售额],CALCULATE([销售额],ALLSELECTED(销量表[产品编码]))),"0…...
)
Sa-Token 自定义插件 —— SPI 机制讲解(一)
前言 博主在使用 Sa-Token 框架的过程中,越用越感叹框架设计的精妙。于是,最近在学习如何给 Sa-Token 贡献自定义框架。为 Sa-Token 的开源尽一份微不足道的力量。我将分三篇文章从 0 到 1 讲解如何为 Sa-Token 自定义一个插件,这一集将是前沿…...

基于 Termux 在移动端配置 Ubuntu 系统并搭建工作环境
本套方案主要参考了以下内容,并根据自身体验进行了修改。 【教程】用Termux搭建桌面级生产力环境Termux安装完整版Linux(Ubuntu)详细步骤 前言 自己的电脑太重,有时候外出不想带,平板生产力有有限。所以一直在折腾用平板替代电脑的事情。之前…...

JAVA SDK通过proxy对接google: GCS/FCM
前言:因为国内调用google相关api需要通过代理访问(不想设置全局代理),所以在代理这里经常遇到问题,先说一下结论 GCS 需要设置全局代理或自定义代理选择器, FCM sdk admin 在初始化firebaseApp时是支持设置的。 GCS: 开始时尝试在…...
)
JAVA EE_多线程-初阶(三)
我对未来没有底气 我也不知道当下该如何做 那就活着,活着就能把日子过下去 ---------陳長生. 1.多线程案例 1.1.单例模式 单例模式是常见的设计模式之一 设计模式:一些编程大佬制定的一些通用代码,再特定的场景下能套用进去,即…...

@PKU秋招互联网产品经理求职分享
从校园到职场 非常荣幸能够在毕业后两年半再次回到燕园。今天,我主要想和大家分享一下我在互联网行业的求职和工作经验。从最初面对职场的迷茫,到现在能够从容应对职场各种挑战,这一路走来积累了不少心得。互联网行业变化迅速,持续…...

uniapp日常总结--uniapp页面跳转方式
uniapp日常总结--uniapp页面跳转方式_uniapp 跳转-CSDN博客...

【能源节约管理系统行业树组件优化总结】
能源节约管理系统行业树组件优化总结 问题背景 在能源节约管理系统中,我们需要一个行业选择组件,以树形结构展示国民经济行业分类数据。由于行业数据量大且层级多,我们采用了懒加载的方式实现。然而,在编辑和详情模式下…...

青少年编程考试 CCF GESP图形化编程 二级认证真题 2025年3月
图形化编程 二级 2025 年 03 月 一、单选题(共 10 题,每题 3 分,共 30 分) 1、2025 年春节有两件轰动全球的事件,一个是 DeepSeek 横空出世,另一个是贺岁片《哪吒 2》票房惊人,入了全球票房榜…...

【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume? Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能…...

十六、Linus网络编程基础
1、Linux 网络的历史发展 早期阶段(1991–1995) 1991年:Linus Torvalds 发布 Linux 内核的初始版本(0.01),此时内核不支持网络功能,仅是一个单机操作系统。1992年:受 BSD …...

【激活函数:神经网络的“调味料】
1. 激活函数:神经网络的“调味料” 想象你在做菜: 没有激活函数:就像只用水煮食材,味道单调(只能拟合线性关系)。加入激活函数:像加了盐、糖、辣椒,让菜有酸甜苦辣(非线…...

006.Gitlab CICD流水线触发
文章目录 触发方式介绍触发方式类型 触发方式实践分支名触发MR触发tag触发手动人为触发定时任务触发指定文件变更触发结合分支及文件变更触发正则语法触发 触发方式介绍 触发方式类型 Gitlab CICD流水线的触发方式非常灵活,常见的有如下几类触发方式: …...

服务器远程端口详解
服务器远程端口详解 一、服务器远程端口的概念与作用 1. 端口的基本定义 服务器远程端口是计算机网络中用于标识不同应用程序或服务的逻辑接口。通过TCP/IP协议栈的"Socket"机制,计算机可以通过软件方式与其他设备建立通信通道。每个端口对应一个16位无…...

如何在 Vue 3 中实现百度地图位置选择器组件
如何在 Vue 3 中实现百度地图位置选择器组件 前言 在开发前端应用时,地图选择器是一个非常常见的需求。尤其是在一些需要用户选择地址的场景,如电商平台、旅游网站、酒店预定等,百度地图组件能提供准确的地理位置服务。在本文中,…...

es6学习02-let命令和const命令
一、let命令 1.let块级作用域: let关键字 VS var关键字 2.for循环计数器很适合let命令 var:整个for循环中一直都是同一个i在做1,最后输出的就是10; let:每循环一次都是多一个i的赋值,最后输出是可以调出…...
TPS63xxx系列DC/DC电源EMI PCB设计方案)
电路方案分析(二十)TPS63xxx系列DC/DC电源EMI PCB设计方案
tips:资料来自网络,仅供学习使用。[TOC](TPS63xxx系列DC/DC电源EMI PCB设计方案) 1.概述 通过TPS63xxx系列DC/DC电源模块来分析降低直流/直流降压/升压转换器辐射 EMI 的来源以及相关PCB设计。 下面都以最常用的TPS63070为例说明: 典型应用…...

DeepSeek大语言模型部署指南:从基础认知到本地实现
目录 一、DeepSeek简介:开源领域的新兴力量 1.1 公司背景与发展历程 1.2 核心产品DeepSeek-R1的技术特点 1.3 行业影响与伦理挑战 二、官方资源获取:全面掌握DeepSeek生态 2.1 官方网站与API服务 2.2 开源代码库资源 2.3 模型部署工具Ollama简介…...

09-设计模式 企业场景 面试题-mk
你之前项目中用过设计模式吗? 需求:设计一个咖啡店点餐系统。 设计一个咖啡类(Coffee),并定义其两个子类(美式咖啡【AmericanCoffee】和拿铁咖啡【LatteCoffee】);再设计一个咖啡店类(CoffeeStore),咖啡店具有点咖啡的功能。具体类图设计如下: 上面的对象都是ne…...
)
达梦数据库-学习-18-ODBC数据源配置(Linux)
一、环境信息 名称值CPU12th Gen Intel(R) Core(TM) i7-12700H操作系统CentOS Linux release 7.9.2009 (Core)内存4G逻辑核数2DM版本1 DM Database Server 64 V8 2 DB Version: 0x7000c 3 03134284194-20240703-234060-20108 4 Msg Versi…...

解决VS2022中scanf报错C4996
这个的原因是因为新版的VS认为scanf不安全,要去使用scanf_s,但在C语言中就需要scanf,所以我们只要以以下步骤解决就可以了。 只要加入宏定义即可 #define _CRT_SECURE_NO_WARNINGS 因为本人已经很少写小案例了,所以就用这个办法…...
Python判断语句全面解析:从基础到高级模式匹配)
Python(11)Python判断语句全面解析:从基础到高级模式匹配
目录 一、条件逻辑的工程价值1.1 真实项目中的逻辑判断1.2 判断语句类型矩阵 二、基础判断深度解析2.1 多条件联合判断2.2 类型安全判断 三、模式匹配进阶应用3.1 结构化数据匹配3.2 对象模式匹配 四、判断语句优化策略4.1 逻辑表达式优化4.2 性能对比测试 五、典型应用场景实战…...

Quartus II的IP核调用及仿真测试
目录 第一章 什么是IP核?第二章 什么是LPM?第一节 设置LPM_COUNTER模块参数第二节 仿真 第三章 什么是PLL?第一节 设置ALTPLL(嵌入式锁相环)模块参数第二节 仿真 第四章 什么是RAM?第一节 RAM_1PORT的调用第…...

如何修改服务器TTL值
Windows默认返回的TTL值为128,Linux为64,我们怎么修改这个值呢? 目录 一. Windows 二. Linux 临时更改 永久更改 一. Windows WinR输入regedit,打开注册表 路径:计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentContro…...

大模型LLM表格报表分析:markitdown文件转markdown,大模型markdown统计分析
整体流程:用markitdown工具文件转markdown,然后大模型markdown统计分析 markitdown https://github.com/microsoft/markitdown 在线体验:https://huggingface.co/spaces/AlirezaF138/Markitdown 安装: pip install markitdown…...

劫持SUID程序提权彻底理解Dirty_Pipe:从源码解析到内核调试
DirtyPipe(CVE-2022-0847)漏洞内核调试全流程指南 本文主要面向对内核漏洞挖掘与调试没有经验的初学者,结合 CVE-2022-0847——著名的 Dirty Pipe 漏洞,带你从零开始学习 Linux 内核调试、漏洞复现、原理分析与漏洞利用。该漏洞危害极大,并且概念简单明了,无需复杂前置知…...

React 组件样式
在这里插入图片描述 分为行内和css文件控制 行内 通过CSS中类名文件控制...

嵌入式人工智能应用-第三章 opencv操作3 图像平滑操作 下
5 高斯噪声(Gaussian Noise) 高斯噪声(Gaussian Noise)是一种符合正态(高斯)分布的随机噪声,广泛存在于传感器采集、信号传输等场景中。以下是关于高斯噪声的详细说明、添加方法及滤波方案。 …...

OSPF的接口网络类型【复习篇】
OSPF在不同网络环境下默认的不同工作方式 [a3]display ospf interface g 0/0/0 # 查看ospf接口的网络类型网络类型OSPF接口的网络类型(工作方式)计时器BMA(以太网)broadcast ,需要DR/BDR的选举hello:10s…...

maven编译jar踩坑[sqlite.db]
背景: 最近在项目中搞多数据源切换的job,在src/resource下有初始化的sqlite默认文件供后续拷贝使用,在测试阶段没有什么问题,但是一部署到服务器上运行就有问题。 报错现象: 找不到这个sqlite.db文件或者文件格式有问题&#x…...