劫持SUID程序提权彻底理解Dirty_Pipe:从源码解析到内核调试
DirtyPipe(CVE-2022-0847)漏洞内核调试全流程指南
本文主要面向对内核漏洞挖掘与调试没有经验的初学者,结合 CVE-2022-0847——著名的 Dirty Pipe 漏洞,带你从零开始学习 Linux 内核调试、漏洞复现、原理分析与漏洞利用。该漏洞危害极大,并且概念简单明了,无需复杂前置知识即可理解和复现。
文章涵盖以下主要内容:
- 环境搭建与调试准备:介绍如何编译带调试信息的内核、搭建模拟漏洞的实验环境,以及如何利用 QEMU 和 gdb 进行内核动态调试。
- 内核源码阅读与调试技巧:详细解析 Linux 系统调用、文件操作与管道机制,讲解如何借助源码阅读和调试技巧来深刻理解内核的工作原理及漏洞成因。
- 从底层彻底理解dirty_pipe漏洞的利用原理:从管道的页缓存机制、零拷贝技术和相关内核数据结构出发,揭示 Dirty Pipe 漏洞的根本原因以及为何这一漏洞能够实现任意写覆盖。
- Dirty_pipe漏洞复现与内核动态调试分析:提供一个完整的漏洞复现流程及示例代码,展示如何利用 pipe 与 page cache 的交互缺陷实现对只读文件的越权覆盖,并通过内核调试验证漏洞利用过程。
- 解决和解释Dirty_Pipe在复现过程中的疑问:总结漏洞利用过程中常见的问题与疑问,并给出详细的解释和调试技巧,帮助读者理解每一步骤的关键原理与细节。
- 通过Dirty_pipe劫持劫持SUID二进制文件进行提权:最后讲解如何单独依靠这漏洞进行root提权!
一、调试编译模拟漏洞环境搭建
环境搭建的调试脚本已经上传github:Brinmon/KernelStu
1. 内核准备
源码下载路径:Index of /pub/linux/kernel/v5.x/
编译教程:kernel pwn从小白到大神(一)-先知社区
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.8.1.tar.gz
tar -xvf linux-5.8.1.tar.gz
cd linux-5.8.1/
sudo apt-get update
sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils qemu flex libncurses5-dev libssl-dev bc bison libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev libelf-dev dwarves zstd
#make menuconfig 命令需要依赖库,下面的
sudo apt-get install libncurses5-dev libncursesw5-dev
make menuconfig #图形化配置配置文件cp .config .config.bak
#避免make 的时候报错,直接将.config内的CONFIG_SYSTEM_TRUSTED_KEYS字段置空不然会报错
sed -i 's/^\(CONFIG_SYSTEM_TRUSTED_KEYS=\).*/\1""/' .config
#还需要给Makefile添加 -0O选项避免编译优化
#最后多核编译就可以了
make -j$(nproc) bzImage
检查勾选配置:
- Kernel hacking —> Kernel debugging
- Kernel hacking —> Compile-time checks and compiler options —> Compile the kernel with debug info
- Kernel hacking —> Generic Kernel Debugging Instruments –> KGDB: kernel debugger
- kernel hacking —> Compile the kernel with frame pointers(找不到)
WSL直接编译:

速度嘎嘎快!
2. 文件系统准备
构建最小根文件系统(基于BusyBox)
wget https://busybox.net/downloads/busybox-1.36.0.tar.bz2
tar -xvf busybox-1.36.0.tar.bz2
cd busybox-1.36.0
make defconfig
make menuconfig # 选中 "Build static binary (no shared libs)"
make -j$(nproc) && make install
配置磁盘镜像
配置rcS文件:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
mount -t tmpfs tmpfs /tmp
mkdir /dev/pts
mount -t devpts devpts /dev/ptsecho -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"# 创建文件并设置权限(root可读写,其他用户只读)
echo "This is a secret file!" > /secret.txt
chmod 644 /secret.txt # 644 = rw-r--r--
chown root:root /secret.txtsetsid cttyhack setuidgid 1000 sh
poweroff -d 0 -f
3. 工具链准备
安装Qemu:
apt install qemu qemu-utils qemu-kvm virt-manager libvirt-daemon-system libvirt-clients bridge-utils
安装pwndbg:
nix profile install github:pwndbg/pwndbg --extra-experimental-features nix-command --extra-experimental-features flakes
gdb.sh
pwndbg -q -ex "target remote localhost:1234" \-ex "add-auto-load-safe-path /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1" \-ex "file /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/vmlinux" \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/open.c:1184" \ #open打开的文件结构体,查看file \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/pipe.c:882" \ #pipe创建的管道结构体,查看结构体地址 \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/pipe.c:536" \ #pipe_write为管道结构体赋予可以合并标记 \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/mm/filemap.c:1995" \ #splice获取到的文件结构体,查看file \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/mm/filemap.c:2029" \ #generic_file_buffered_read获取只读文件的page \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/lib/iov_iter.c:372" \ #文件结构体的page直接替换了管道结构体的page未重新初始化是否可以续写 \-ex "b /home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/pipe.c:463" \ #向管道写入数据,发现可以在管道page续写,但是由于该page实际指向了只读文件的实际page,所以可以实现文件越权写 \-ex "c"
start.sh
#!/bin/sh
qemu-system-x86_64 \-m 128M \-kernel ./bzImage \-initrd ./rootfs_new.cpio \-monitor /dev/null \-append "root=/dev/ram rdinit=/sbin/init console=ttyS0 oops=panic panic=1 quiet nokaslr loglevel=7" \-cpu kvm64,+smep \-smp cores=2,threads=1 \-nographic \-s
二、Linux内核源码阅读和调试技巧
Linux系统调用syscall源码实现搜索技巧
系统调用实现原理
Linux 系统调用是用户空间与内核交互的核心接口,其实现依赖于架构相关的中断机制(如 x86 的int 0x80或syscall指令)和系统调用表(sys_call_table)。每个系统调用通过唯一的系统调用号索引,对应内核中的sys_xxx函数。例如,open系统调用在内核中对应fs/open.c中的sys_open函数。
添加系统调用号
arch/x86/entry/syscalls/syscall_64.tbl
在linux源码中寻找到这个,手动添加系统调用号!
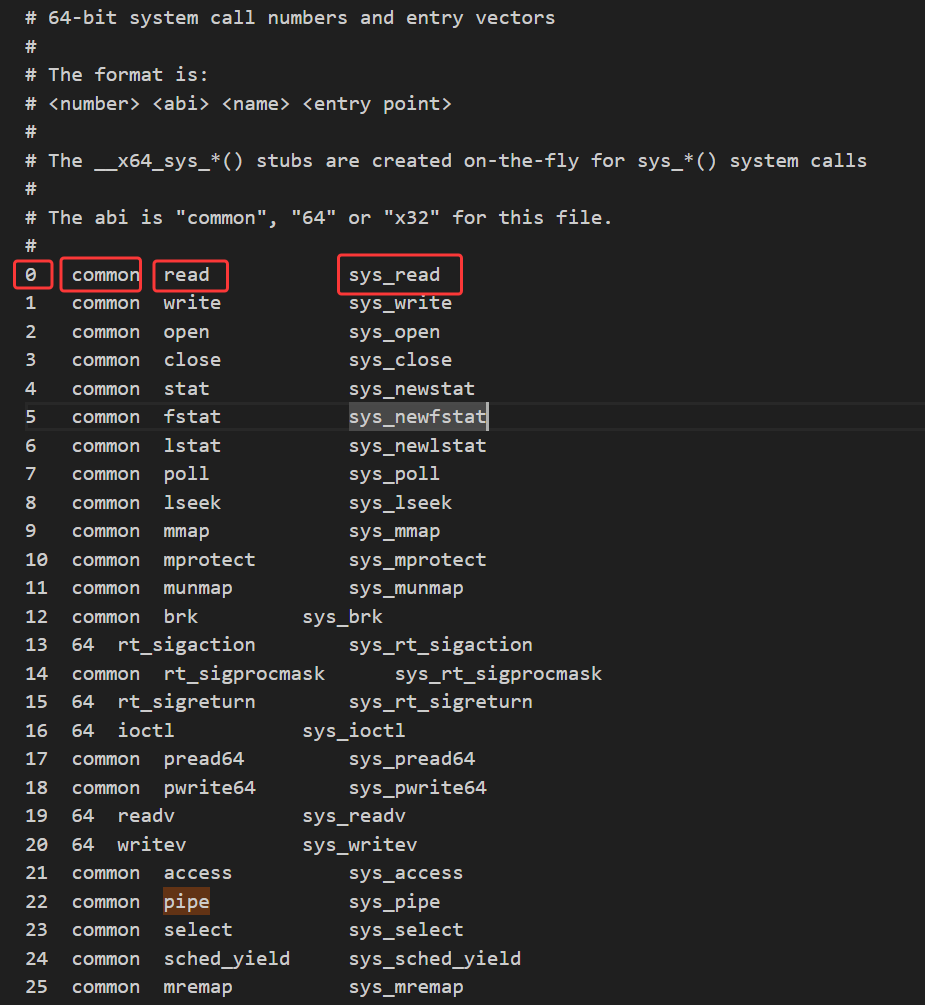
0 common read sys_read
第一列是系统调用号,第二列表示该系统调用适用的架构类型(如common表示通用架构),第三列是系统调用的名称(在用户空间使用的名称),第四列是内核中对应的系统调用实现函数名。若要添加新的系统调用号,需按照此格式在文件中新增一行,并确保系统调用号的唯一性。
声明系统调用
系统调用的声明通常位于include/linux/syscalls.h文件中。以read系统调用为例,其声明如下:
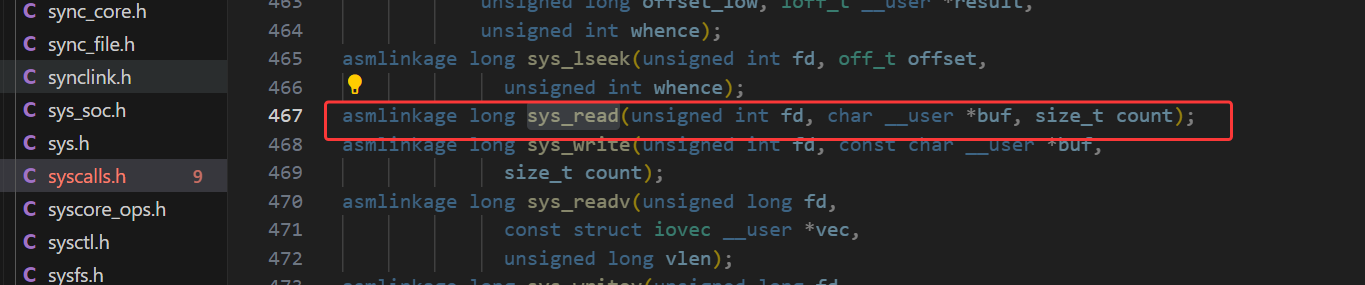
asmlinkage long sys_read(unsigned int fd, char __user *buf, size_t count);
asmlinkage关键字用于指示编译器该函数是从汇编代码调用的,这在系统调用中很常见,因为系统调用的入口点通常由汇编代码处理。函数声明明确了系统调用的返回类型(这里是long)、参数类型及名称。其中,char __user *类型表示指向用户空间内存的指针,用于确保内核在访问该指针时进行必要的安全检查,防止内核非法访问用户空间内存。
定义系统调用
系统调用的实现代码位置较为灵活。若不想修改makefile文件的配置,可将系统调用的实现放置在kernel/sys.c文件中。当然,为了更好的代码组织和管理,系统调用号也可分类放置在不同的文件夹中:
1. 核心系统调用目录
**(1) **kernel/:功能类型:进程管理、信号处理、定时器等核心功能。
**(2) **fs/:功能类型:文件系统操作、文件读写、目录管理等。
**(3) **mm/:功能类型:内存管理、映射、堆分配等。
**(4) **net/:功能类型:网络通信、套接字操作。
**(5) **ipc/ :功能类型:进程间通信(IPC)。
SYSCALL_DEFINE 宏解析,系统调用号实现的具体,SYSCALL_DEFINE** 宏** 的书写规范与核心规则:
// 使用SYSCALL_DEFINEx宏(x=参数个数),x:参数数量(1~6)
// name:系统调用名称(用户态调用的名称,如 read)。
// 参数书写格式:每个参数需明确类型和变量名。用户空间指针必须标记 __user(如 char __user *, buf)
// 参数名称和参数类型要分别作为宏定义的一个参数!
SYSCALL_DEFINEx(name, type1, arg1, type2, arg2, ...)
{
....
}
根据这个方法可以找到read系统调用的函数实现:
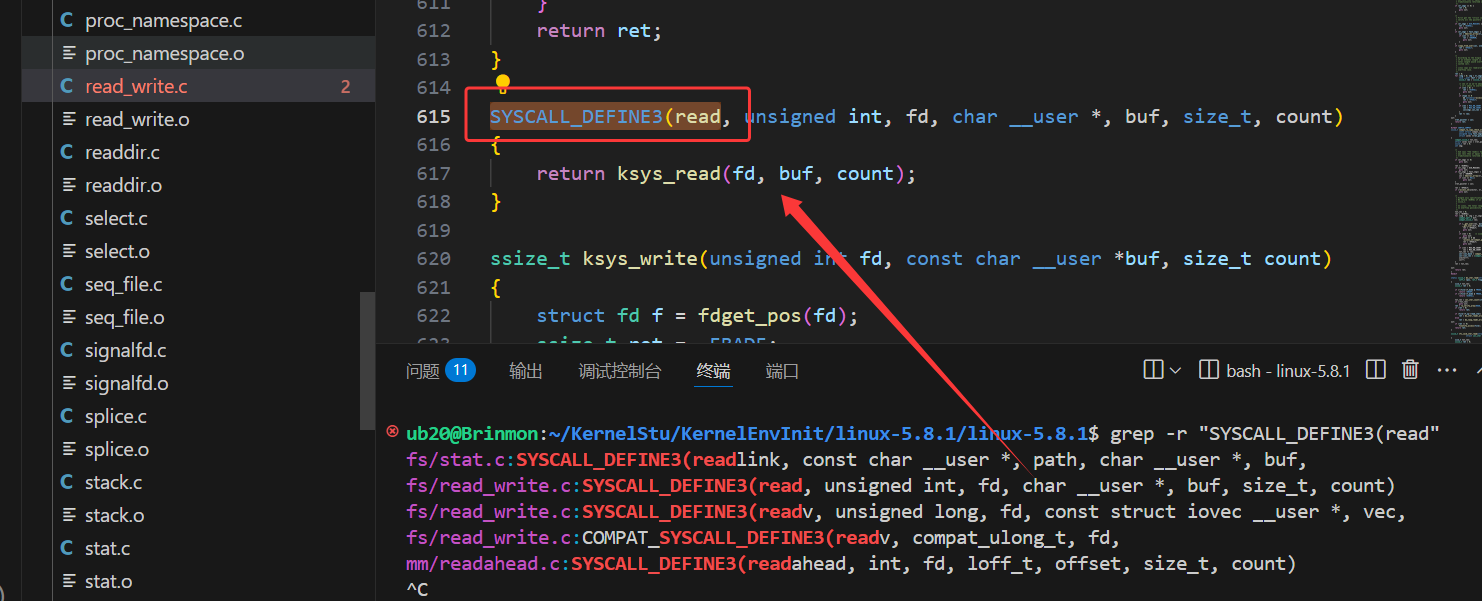
grep -r "SYSCALL_DEFINE3(read,.*"
动态调试定位f_op文件结构体的操作函数源码
f_op 结构体原理
struct file_operations(简称f_op)定义了文件操作的函数指针,如open、read、write等。内核通过file->f_op调用这些函数,具体实现由文件系统(如 ext4、NFS)或设备驱动提供。
例如,在 ext4 文件系统中,当用户空间执行open操作打开一个文件时,内核会根据该文件对应的file结构体中的f_op指针,找到并调用 ext4 文件系统中定义的open操作函数。这个函数会处理诸如检查文件权限、打开文件描述符等具体操作。在设备驱动场景下,对于块设备驱动,其f_op中的read和write函数会负责与硬件设备进行数据交互,将数据从设备读取到内核缓冲区或从内核缓冲区写入设备。
可以查看一下write的源码实现发现调用了,file->f_op->write_iter函数但是无法找到其源码实现!
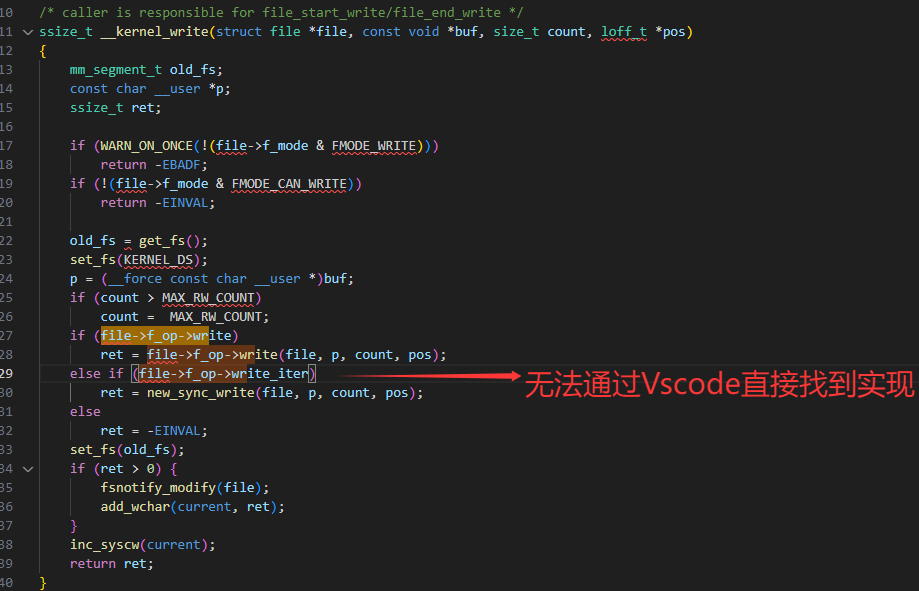
下面结合源码进行讲解。假设我们要分析ext4文件系统中read操作的f_op函数实现。首先,在fs/ext4/file.c文件中,可以找到ext4_file_operations结构体的定义:
#/home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/ext4/file.cconst struct file_operations ext4_file_operations = {.llseek = ext4_llseek,.read_iter = ext4_file_read_iter,.write_iter = ext4_file_write_iter,.iopoll = iomap_dio_iopoll,.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT.compat_ioctl = ext4_compat_ioctl,
#endif.mmap = ext4_file_mmap,.mmap_supported_flags = MAP_SYNC,.open = ext4_file_open,.release = ext4_release_file,.fsync = ext4_sync_file,.get_unmapped_area = thp_get_unmapped_area,.splice_read = generic_file_splice_read,.splice_write = iter_file_splice_write,.fallocate = ext4_fallocate,
};
这里,.read_iter成员指向了ext4文件系统中read操作的具体实现函数ext4_file_read_iter。当用户空间执行read系统调用时,内核在处理过程中,若涉及到ext4文件系统的文件,就会通过file->f_op->read_iter来调用ext4_file_read_iter函数,从而完成read操作的具体功能,如从磁盘读取数据并填充到用户提供的缓冲区中。
GDB动态调试定位f_op 结构体所使用的函数
定位一下:pipe_buf_confirm函数
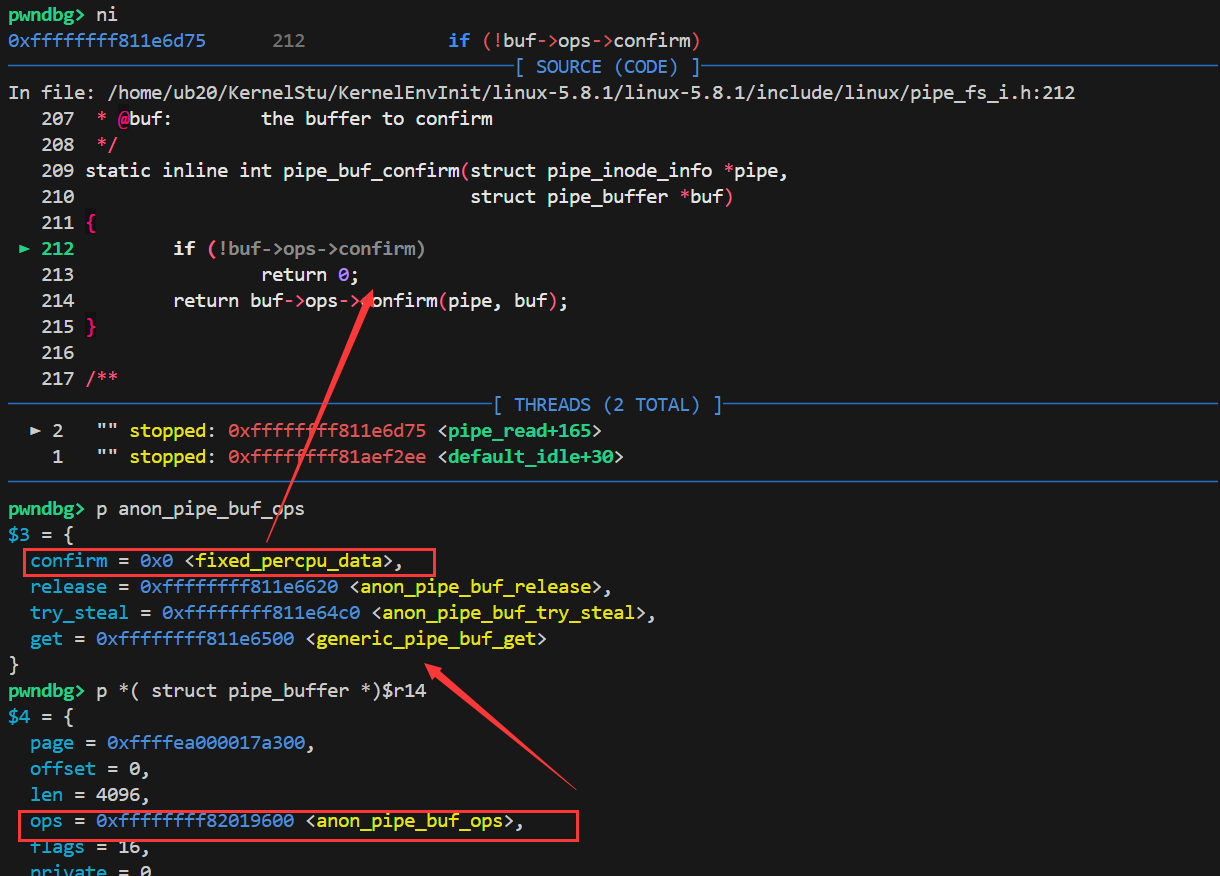
在源码下完断点之后,来到该调用的位置,在使用gdb命令就饿可以定位到buf->ops的具体值,从而在源码中定位函数的具体实现!
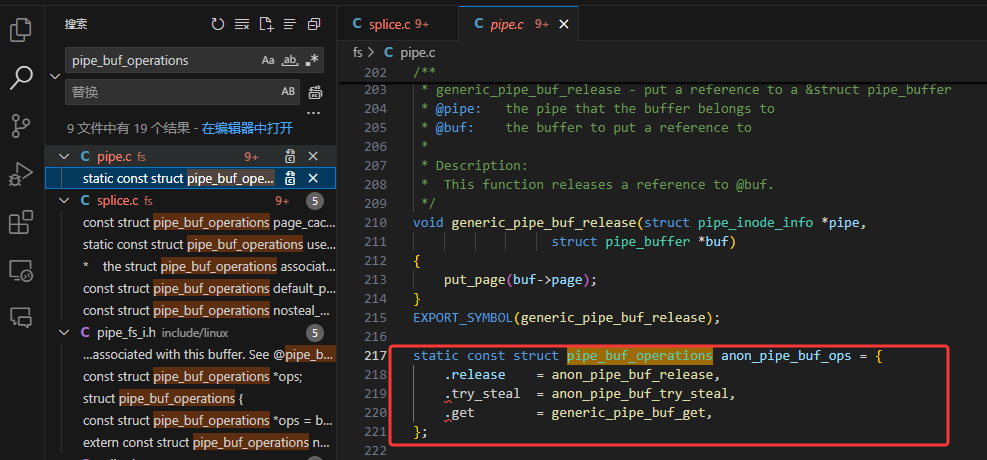
#/home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/pipe.c
static const struct pipe_buf_operations anon_pipe_buf_ops = {.release = anon_pipe_buf_release,.try_steal = anon_pipe_buf_try_steal,.get = generic_pipe_buf_get,
};
Linux内核源码结合AI进行动态调试分析技巧
编译完成内核之后,可借助 AI 工具为内核源码添加代码注释,但需注意不能改变 Linux 源码的结构。由于动态调试时是直接索引到源码,如果改变源码的代码行数或者增加过多文本数量,都会打乱调试时的源码定位。因此,在使用 AI 添加提示词时,应将注释加在每行代码的后面。
常用的提示词,也可以自己优化:
给代码添加中文注释,只在每行代码的后面添加中文注释,如果遇到已有的注释则不修改:
{
}
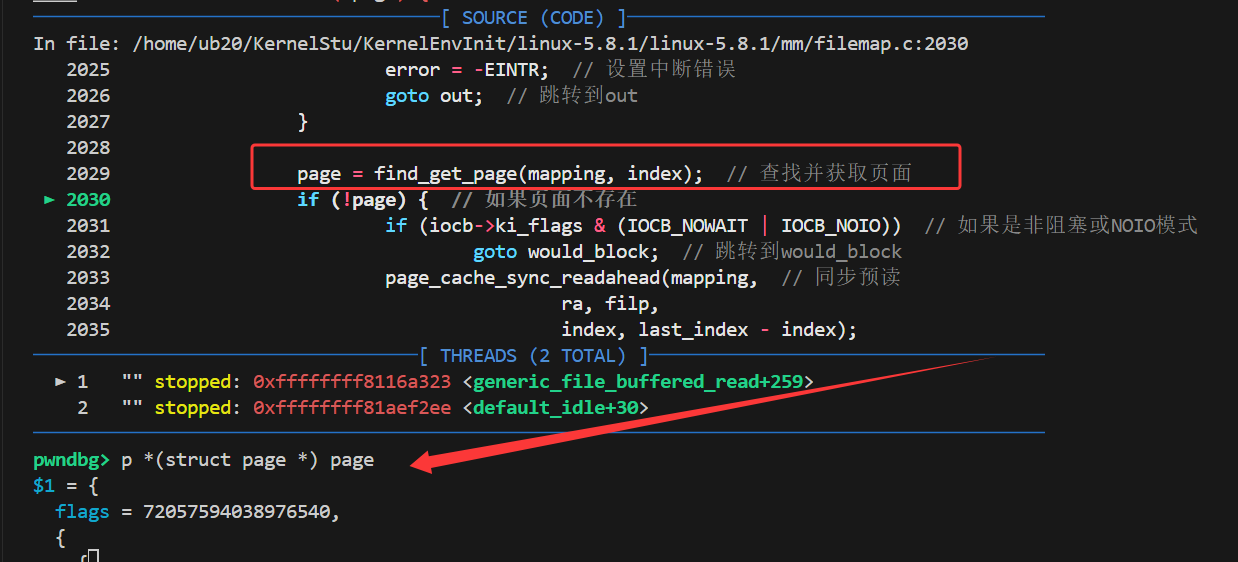
在使用gdb调试源码时,常用的命令如下:
- n :执行下一行源码,但不进入函数内部(如果当前行有函数调用)。
- ni :执行下一条汇编指令,同样不进入函数内部(若当前指令涉及函数调用)。
- s :进入当前行调用的源码函数内部,便于深入调试函数实现。
- si :进入call调用的函数内部,且以汇编指令级别的方式进行单步调试。
为了让gdb能正确索引到内核源码,需要修改.gdbinit文件添加源码索引。例如:
set disassembly-flavor intel
dir /home/ub20/LibcSource/glibc-2.31/
set disassembly-flavor intel命令设置gdb的反汇编风格为 Intel 格式,这样在调试时显示的汇编代码更易阅读。
三、从底层彻底理解dirty_pipe漏洞的利用原理
syscall pipe : Linux 中的管道Pipe是什么?
在 Linux 系统中,pipe是一种进程间通信(IPC,Inter-Process Communication)机制。它允许两个或多个进程通过一个共享的缓冲区来传递数据,实现进程之间的通信。从系统调用的角度来看,通过pipe系统调用可以创建一个管道。
在终端中输入man 2 pipe可以查看其详细手册:
讲解系统调用函数pipe的源码实现
当调用pipe系统调用时,它会在内核中创建一个管道对象,并返回两个文件描述符,一个用于写入(通常称为写端,fd[1]),另一个用于读取(通常称为读端,fd[0])。数据从写端写入管道,然后可以从读端读取出来,遵循先进先出(FIFO,First-In-First-Out)的原则。
grep -r "SYSCALL_DEFINE1(pipe.*" #注释SYSCALL_DEFINE后门的数字代表参数的数量,第一个参数为系统调用号的名称!

从内核代码角度看,pipe系统调用的定义如下:
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{return do_pipe2(fildes, 0);
}
这里的SYSCALL_DEFINE1宏定义了一个接受一个参数的系统调用,该参数fildes是一个指向用户空间数组的指针,用于存储返回的文件描述符。实际的管道创建工作由do_pipe2函数完成:
/** sys_pipe() is the normal C calling standard for creating* a pipe. It's not the way Unix traditionally does this, though.*/
static int do_pipe2(int __user *fildes, int flags)
{struct file *files[2];int fd[2];int error;error = __do_pipe_flags(fd, files, flags);if (!error) {if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {fput(files[0]);fput(files[1]);put_unused_fd(fd[0]);put_unused_fd(fd[1]);error = -EFAULT;} else {fd_install(fd[0], files[0]);fd_install(fd[1], files[1]);}}return error;
}
do_pipe2函数首先调用__do_pipe_flags来创建管道,并获取两个文件描述符。如果创建成功,它会尝试将这两个文件描述符复制到用户空间的fildes数组中。若复制失败,函数会清理已分配的资源并返回错误。
进一步深入内核实现,__do_pipe_flags函数会调用create_pipe_files,最终调用到get_pipe_inode函数,该函数负责创建管道的核心数据结构:
可以追踪到系统调用链:do_pipe2->__do_pipe_flags->create_pipe_files->get_pipe_inode
#/home/ub20/KernelStu/KernelEnvInit/linux-5.8.1/linux-5.8.1/fs/pipe.c
static struct inode * get_pipe_inode(void)
{struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);struct pipe_inode_info *pipe;
...pipe = alloc_pipe_info();//申请一个结构体if (!pipe)goto fail_iput;inode->i_pipe = pipe;pipe->files = 2;pipe->readers = pipe->writers = 1;inode->i_fop = &pipefifo_fops;
...
}
get_pipe_inode函数主要完成以下几个关键步骤:
- 创建伪文件系统(pipefs)中的 inode:通过new_inode_pseudo函数创建一个属于pipefs文件系统的inode,该inode代表了管道对象在内核中的存储节点。
- 分配管道核心结构体:调用alloc_pipe_info函数分配一个pipe_inode_info结构体,该结构体包含了管道的状态信息,如读写计数器、缓冲区指针等。
- 初始化管道读写计数器:将pipe->readers和pipe->writers初始化为 1,表示管道的读写端都已准备就绪。
讲解Linux管道Pipe在内核中的管理机制
在Linux内核中,管道(Pipe)通过struct pipe_inode_info和struct pipe_buffer两个核心结构体实现进程间通信(IPC)的底层管理。
1. 环形缓冲区与指针管理
struct pipe_inode_info {
...unsigned int head; // 环形缓冲区写指针unsigned int tail; // 环形缓冲区读指针unsigned int max_usage;unsigned int ring_size;
...struct page *tmp_page; // 临时页缓存(用于零拷贝优化)
...struct pipe_buffer *bufs; // 管道缓冲区数组(核心!)
...
};
在内核实现中,管道缓存空间总长度一般为 65536 字节,以页为单位进行管理,总共 16 页(每页大小为 4096 字节)。这些页面在物理内存中并不连续,而是通过数组进行管理,从而形成一个环形链表。其中,维护着两个关键的指针:
- head:指向最新生产的缓冲区位置,即数据写入的位置。
- tail:指向开始消费的缓冲区位置,即数据读取的位置。
- max_usage:表示管道中可使用的最大缓冲区槽位数。
- ring_size:管道缓冲区的总数,通常是 2 的幂次方,默认情况下,Linux 内核中管道的缓冲区数量为 16 个(PIPE_DEF_BUFFERS)。
- tmp_page:用于缓存已释放的页面。
- bufs:是一个循环数组,用于管理管道缓冲区。每个缓冲区的大小为一页(在常见的系统中,一页大小默认是0x1000字节)。
2. 内存页与缓冲区数组
struct pipe_buffer {struct page *page; // 直接指向物理内存页(漏洞利用目标unsigned int offset, len;//页内偏移,有效数据长度const struct pipe_buf_operations *ops; // 操作函数表unsigned int flags; // 状态标志unsigned long private; // 私有数据
};
管道数据存储在离散的物理内存页中,通过struct pipe_buffer数组(bufs)管理:
bufs数组:数组中的每个元素对应一个内存页(struct page),通过page字段直接指向物理页帧。这样,内核可以直接定位到存储管道数据的物理内存位置。- 非连续内存管理:页之间无需连续,内核通过数组索引实现逻辑上的环形链表。这种非连续内存管理方式,充分利用了内存空间,避免了因连续内存分配困难而导致的资源浪费。在进行数据读写时,内核根据head和tail指针在bufs数组中的索引,找到对应的缓冲区进行操作,同时通过环形链表的逻辑,实现数据的循环读写。例如,当head指针到达数组末尾时,下一次写入会回到数组开头,继续填充缓冲区。
管道本质是一个由内核维护的环形缓冲区,通过head和tail指针实现高效的数据读写:
可以看一个Pipe缓冲区的实际示意图:
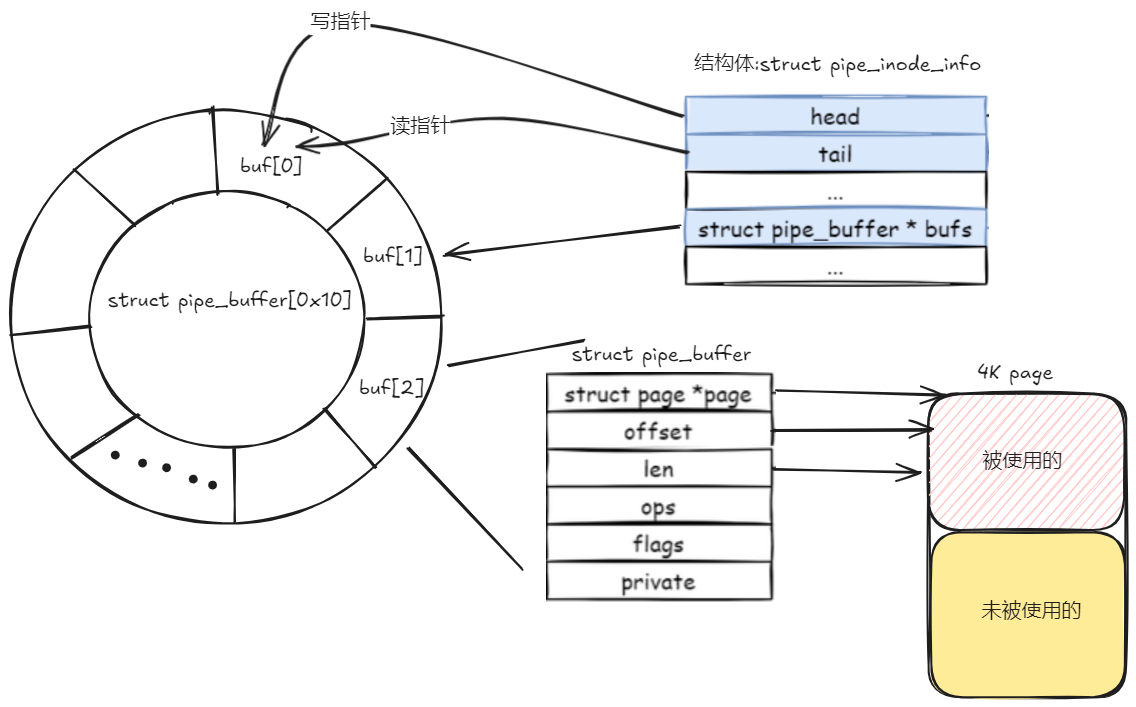
这张图片展示了一个 pipe 的基本数据结构,具体是如何通过循环缓冲区(circular buffer)来管理数据传输。
或者参考一下这个结构图:
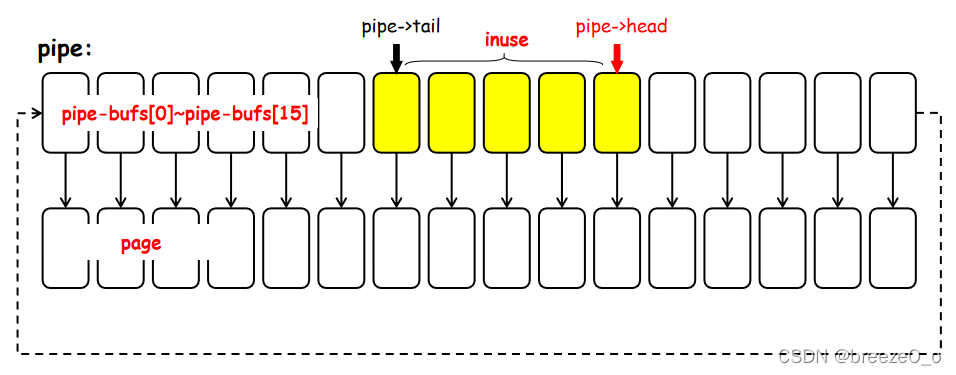
- pipe->
bufs[0]** 到 pipe->**bufs[15]:这是管道的 16 个缓冲区,每个缓冲区对应一个pipe_buffer结构体。 - pipe->tail 和 pipe->head:
pipe->tail指向当前读取位置,pipe->head指向当前写入位置。缓冲区中的黄色区域表示当前正在被使用的缓冲区(inuse),即当前正在读取或写入的部分。 - 页面管理:每个
pipe_buffer结构体对应一个 4KB 的页面,图中显示了这些页面的分布情况,并标记了哪些部分是正在被使用的。
讲解Linux管道Pipe如何进行数据写入和读取
当我们使用read和write向pipe进行数据写入和读取的时候,read和write会寻找到pipe_write和pipe_read进行数据写入和读取!
根据前面的管道结构体的讲解可知,pipe_write和pipe_read进行数据操作的时候实际都是对pipe->buf的内容进行写入和读取!
pipe_write写入流程
数据写入管道的操作由内核中的pipe_write函数负责。在数据写入过程中,pipe_write会调用copy_page_from_iter函数来完成从用户空间到内核管道缓冲区的实际数据复制。下面对pipe_write函数的执行流程进行详细拆解:
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{struct file *filp = iocb->ki_filp; // 获取文件指针struct pipe_inode_info *pipe = filp->private_data; // 获取管道信息
...head = pipe->head; // 获取当前头指针
...if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // 检查缓冲区是否可合并
...ret = copy_page_from_iter(buf->page, offset, chars, from); // 复制数据到缓冲区
...struct pipe_buffer *buf = &pipe->bufs[head & mask]; // 获取当前缓冲区
...pipe->head = head + 1; // 移动头指针...buf = &pipe->bufs[head & mask]; // 获取新缓冲区buf->page = page; // 设置缓冲区页buf->ops = &anon_pipe_buf_ops; // 设置缓冲区操作buf->offset = 0; // 设置偏移量buf->len = 0; // 初始长度为0
...if (is_packetized(filp)) // 如果是数据包模式buf->flags = PIPE_BUF_FLAG_PACKET; // 设置数据包标志elsebuf->flags = PIPE_BUF_FLAG_CAN_MERGE; // 设置可合并标志pipe->tmp_page = NULL; // 清空临时页
...copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); // 复制数据到页
...return ret; // 返回实际写入的字节数
}
写入流程:数据按页写入bufs[head],更新head指针;若缓冲区满,写进程进入睡眠。
在pipe_write函数写入数据过程中,获取管道的写指针head,通过head & mask的运算,在pipe->bufs数组中定位当前用于写入的缓冲区buf。这里的mask是根据管道缓冲区总数计算得出的掩码,用于实现环形缓冲区的循环访问。最后调用copy_page_from_iter函数,将用户空间的数据从from迭代器中复制到内核分配的页面中,完成数据写入操作。
写入标记:
if (is_packetized(filp)) // 如果是数据包模式buf->flags = PIPE_BUF_FLAG_PACKET; // 设置数据包标志elsebuf->flags = PIPE_BUF_FLAG_CAN_MERGE; // 设置可合并标志
可以发现这里当第一次向管道写入数据的时候会将pipe->bufs[i]->flags字段赋值为PIPE_BUF_FLAG_CAN_MERGE,如果是网络数据通过pipe传输的话就会赋值PIPE_BUF_FLAG_PACKET;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // 检查缓冲区是否可合并
...ret = copy_page_from_iter(buf->page, offset, chars, from); // 复制数据到缓冲区
如果想继续在管道写入数据会首先检查buf->flags字段和buf->page是否有剩余空间,再次调用pipe_write可以继续向这个buf->page写入数据!
相关文章:

劫持SUID程序提权彻底理解Dirty_Pipe:从源码解析到内核调试
DirtyPipe(CVE-2022-0847)漏洞内核调试全流程指南 本文主要面向对内核漏洞挖掘与调试没有经验的初学者,结合 CVE-2022-0847——著名的 Dirty Pipe 漏洞,带你从零开始学习 Linux 内核调试、漏洞复现、原理分析与漏洞利用。该漏洞危害极大,并且概念简单明了,无需复杂前置知…...

React 组件样式
在这里插入图片描述 分为行内和css文件控制 行内 通过CSS中类名文件控制...

嵌入式人工智能应用-第三章 opencv操作3 图像平滑操作 下
5 高斯噪声(Gaussian Noise) 高斯噪声(Gaussian Noise)是一种符合正态(高斯)分布的随机噪声,广泛存在于传感器采集、信号传输等场景中。以下是关于高斯噪声的详细说明、添加方法及滤波方案。 …...

OSPF的接口网络类型【复习篇】
OSPF在不同网络环境下默认的不同工作方式 [a3]display ospf interface g 0/0/0 # 查看ospf接口的网络类型网络类型OSPF接口的网络类型(工作方式)计时器BMA(以太网)broadcast ,需要DR/BDR的选举hello:10s…...

maven编译jar踩坑[sqlite.db]
背景: 最近在项目中搞多数据源切换的job,在src/resource下有初始化的sqlite默认文件供后续拷贝使用,在测试阶段没有什么问题,但是一部署到服务器上运行就有问题。 报错现象: 找不到这个sqlite.db文件或者文件格式有问题&#x…...

【软考系统架构设计师】软件工程
1、 软件开发生命周期 软件定义时期:包括可行性研究和详细需求分析过程,任务是确定软件开发工程必须完成的总目标,具体分为问题定义、可行性研究、需求分析等 软件开发时期:软件的设计与实现,分为概要设计、详细设计、…...

蓝桥杯单片机刷题——ADC测量电位器的电压
设计要求 通过PCF8591的ADC通道测量电位器RB2的输出电压,并使用套件上提供的USB转串口功能,完成下列程序设计要求。 串口每次接收包含5个字符的字符串, 1)若接收的5个字符中有字符’a’或’A’,则数码管显示一位小数…...
:DataFrame 数据清洗与预处理 (下) - 类型转换、格式化、文本与日期处理)
零基础上手Python数据分析 (12):DataFrame 数据清洗与预处理 (下) - 类型转换、格式化、文本与日期处理
写在前面 上一篇博客,我们学习了如何使用 Pandas 处理数据分析中最常见的 “脏数据”:缺失值、重复值和异常值。 这为我们处理数据质量问题打下了坚实的基础。 然而,数据清洗的挑战远不止于此。 在实际数据中,我们还会经常遇到 数据类型不一致、数据格式不规范、文本数据混…...

免费下载 | 2025清华五道口:“十五五”金融规划研究白皮书
《2025清华五道口:“十五五”金融规划研究白皮书》的核心内容主要包括以下几个方面: 一、五年金融规划的重要功能与作用 凝聚共识:五年金融规划是国家金融发展的前瞻性谋划和战略性安排,通过广泛听取社会各界意见,凝…...
)
制造一只电子喵 (qwen2.5:0.5b 微调 LoRA 使用 llama-factory)
AI (神经网络模型) 可以认为是计算机的一种新的 “编程” 方式. 为了充分利用计算机, 只学习传统的编程 (编程语言/代码) 是不够的, 我们还要掌握 AI. 本文以 qwen2.5 和 llama-factory 举栗, 介绍语言模型 (LLM) 的微调 (LoRA SFT). 为了方便上手, 此处选择使用小模型 (qwen2…...

Java中parallelStream并行流使用指南
Java中parallelStream并行流使用指南 在 Java 中,parallelStream() 是 Java 8 引入的一个用于并行处理集合数据的工具,它基于 Fork/Join框架 实现,能够自动将任务拆分成子任务并利用多核处理器并行执行。以下是对 parallelStream的详细说明和…...

Python及C++中的列表
一、Python中的列表(List) Python的列表是动态数组,内置于语言中,功能强大且易用,非常适合算法竞赛。 1. 基本概念 定义:列表是一个有序、可变的序列,可以存储任意类型的元素(整数…...

mybatis plus 分页查询出来数据后对他二次 修改数据 封装返回
mybatis plus 分页查询出来数据后对他二次 修改数据 封装返回 /*** 搜索问卷** param keyword* param pageNo* param pageSize* return*/AutoLog(value "v_survey-搜索")ApiOperation(value"v_survey-搜索", notes"v_survey-搜索")GetMapping(v…...

海洋大地测量基准与水下导航系列之八我国海洋水下定位装备发展现状
中国国家综合PNT体系建设重点可概括为“51N”,“5”指5大基础设施,包括重点推进下一代北斗卫星导航系统、积极发展低轨导航增强系统、按需发展水下导航系统、大力发展惯性导航系统、积极探索脉冲星导航系统;“1”是实现1个融合发展࿰…...

基于单片机的电梯智能识别电动车阻车系统设计与实现
标题:基于单片机的电梯智能识别电动车阻车系统设计与实现 内容:1.摘要 随着电动车在日常生活中的普及,将电动车带入电梯带来的安全隐患日益凸显,如引发火灾等。本研究的目的是设计并实现一种基于单片机的电梯智能识别电动车阻车系统。方法上,…...

什么是柜台债
柜台债(柜台债券业务)是指通过银行等金融机构的营业网点或电子渠道,为投资者提供债券买卖、托管、结算等服务的业务模式。它允许个人、企业及机构投资者直接参与银行间债券市场的交易,打破了以往仅限机构参与的壁垒。以下是综合多…...

.py文件和.ipynb文件的区别:完整教程
一、概述 Python开发者常用的两种文件格式.py和.ipynb各有特点,本教程将通过对比分析、代码示例和场景说明,帮助开发者全面理解二者的区别与联系。 二、核心区别对比 1. 文件格式本质 特性.ipynb文件.py文件文件类型JSON结构化文档纯文本文件存储内容…...

Python中NumPy的逻辑和比较
在数据科学和科学计算领域,NumPy是一个不可或缺的Python库。它提供了高效的多维数组对象以及丰富的数组操作函数,其中逻辑和比较操作是NumPy的核心功能之一。通过灵活运用这些操作,我们可以轻松实现数据筛选、条件判断和复杂的数据处理任务。…...

tt_Docker
快速上手 查看 Docker 服务运行状态;查看本地镜像;从 Docker Hub 拉取基础镜像, 我们此处选择 ubuntu:18.04 镜像;再次查看本地镜像;使用 ubuntu:18.04 镜像构建容器,并交互式运行容器;在容器内部执行 LS 命令;退出容器;查看本地容器实例;再次启动停止的…...

虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?
虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解? code review! 文章目录 虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?理解这句话的关键点1.类(…...

compose map 源码解析
目录 TileCanvas ZoomPanRotateState ZoomPanRotate 布局,手势处理完了,就开始要计算tile了 MapState TileCanvasState telephoto的源码已经分析过了.它的封装好,扩展好,适用于各种view. 最近又看到一个用compose写的map,用不同的方式,有点意思.分析一下它的实现流程与原…...

IDEA202403 常用设置【持续更新】
文章目录 1、设置maven2、设置JDK3、菜单栏固定展示4、连接Gitee第一步、安装插件第二步、Gitee账号配置 IDEA 是程序员的编程利器,需要具备其的各种配置,提高工作效率。Java项目启动,两个关键设置:Maven 和 JDK设置。 1、设置mav…...

从零开始开发纯血鸿蒙应用之语音输入
从零开始开发纯血鸿蒙应用 〇、前言一、认识 speechRecognizer1、使用方式2、依赖权限3、结果回写 二、实现语音识别功能1、创建语音识别引擎2、设置事件监听3、启动识别4、写入音频数据5、操作控制 三、总结 〇、前言 除了从图片中识别文本外,语音输入也是一种现代…...

c++ STL常用工具的整理和思考
蓝桥杯后,我整理了这些常用的C STL工具 作为一个算法竞赛的中等生,以前总觉得STL“花里胡哨”,不如自己写数组和循环踏实。但这次蓝桥杯发现,合理用STL能省很多时间,甚至避免低级错误。下面是我总结的常用知识点和踩过…...

Go:复合数据结构
数组 定义:数组是固定长度、元素数据类型相同的序列 。元素通过索引访问,索引从 0 到数组长度减 1 。可用len函数获取元素个数 。 初始化:默认元素初始值为类型零值(数字为 0 ) 。可使用数组字面量初始化,…...
)
SQL 语句基础(增删改查)
文章目录 一、SQL 基础概念1. SQL 简介2. 数据库系统的层次结构 二、SQL 语句分类1. DDL(Data Definition Language 数据定义语言)1.1 CREATE1.1.1 创建数据库1.1.2 创建数据表1.1.3 创建用户 1.2 ALTER1.2.1 AlTER 添加字段名1.2.2 ALTER 修改字段名1.2…...

【蓝桥杯 CA 好串的数目】题解
题目链接 考虑令 p r e [ i ] pre[i] pre[i] 表示 [ p r e [ i ] , i ] [pre[i], i] [pre[i],i] 是连续非递减子串,这可以类似双指针 O ( n ) O(n) O(n) 预处理: std::vector<int> pre(n); for (int r 1, l 0; r < n; r) {if (s[r] ! s[…...
——Linux命令)
Oracle for Linux安装和配置(11)——Linux命令
11.1. Linux命令 Linux是目前比较常用和流行的操作系统,现在很多生产环境就会用到它。随着其功能、性能、稳定性和可靠性等方面的日渐增强和完善,加之其成本上的优势,其市场占有率逐日攀升,也得到越来越多广大用户的关注和青睐。但作为一种操作系统,其安装、配置、管理和…...

Linux基础7
一、逻辑卷管理 查看所有物理卷:pvs 查看当前系统卷组:vgs 查看所有逻辑卷:lvs 新创建系统卷组:vgcreate [参数] [volume name] url/sdb[1-2] eg:vgcreate vg_Test /dev/sdb{1,2} >…...

C#打开文件及目录脚本
如果每天开始工作前都要做一些准备工作,比如打开文件或文件夹,我们可以使用代码一键完成。 using System.Diagnostics; using System.IO;namespace OpenFile {internal class Program{static void Main(string[] args){Console.WriteLine("Hello, …...

Docker 镜像 的常用命令介绍
拉取镜像 $ docker pull imageName[:tag][:tag] tag 不写时,拉取的 是 latest 的镜像查看镜像 查看所有本地镜像 docker images or docker images -a查看完整的镜像的数字签名 docker images --digests查看完整的镜像ID docker images --no-trunc只查看所有的…...

Python数组学习之旅:数据结构的奇妙冒险
Python数组学习之旅:数据结构的奇妙冒险 第一天:初识数组的惊喜 阳光透过窗帘缝隙洒进李明的房间,照亮了他桌上摊开的笔记本和笔记本电脑。作为一名刚刚转行的金融分析师,李明已经坚持学习Python编程一个月了。他的眼睛因为昨晚熬夜编程而微微发红,但脸上却挂着期待的微…...

Vue 3 和 Vue 2 的区别及优点
Vue.js 是一个流行的 JavaScript 框架,广泛用于构建用户界面和单页应用。自 Vue 3 发布以来,很多开发者开始探索 Vue 3 相较于 Vue 2 的新特性和优势。Vue 3 引入了许多改进,优化了性能、增强了功能、提升了开发体验。本文将详细介绍 Vue 2 和…...

特殊定制版,太给力了!
今天给大家分享一款超棒的免费录屏软件,真的是录屏的好帮手! 这款软件功能可以录制 MP4、AVI、WMV 格式的标清、高清、原画视频,满足你各种需求。 云豹录屏大师 多功能录屏神器 它的界面特别简洁,上手超快,用起来很顺…...

Vue事件修饰符课堂练习
Vue事件修饰符课堂练习 题目:基于 Vue 2.0,使用事件修饰符 .stop、.prevent、.capture、.self 和 .once,为按钮绑定 click 事件,并展示每个修饰符的作用。 要求: 创建一个 Vue 实例,并绑定到一个 HT…...

Y1——ST表
知识点 ST表 只能询问,不能修改 ST表的预处理: 使用了DP的思想,设a是要求区间最值的数列,f(i,j)表示从第i个数起连续2^j个数中的最大值 状态转移方程 f [ i , j ]max( f [ i , j-1 ], f [ i 2 ^ j-1,j - 1]) 建立ST表 vo…...

Python Cookbook-5.14 给字典类型增加排名功能
任务 你需要用字典存储一些键和“分数”的映射关系。你经常需要以自然顺序(即以分数的升序)访问键和分数值,并能够根据那个顺序检查一个键的排名。对这个问题,用dict 似乎不太合适。 解决方案 我们可以使用 dict 的子类,根据需要增加或者重…...

第二十二: go与k8s、docker相关编写dockerfile
实战演示k8s部署go服务,实现滚动更新、重新创建、蓝绿部署、金丝雀发布-CSDN博客 go 编写k8s命令: 怎么在go语言中编写k8s命令 • Worktile社区 k8s中如何使用go 在K8s编程中如何使用Go-阿里云开发者社区 go build - o : -o:指定输出文件…...

Servlet、HTTP与Spring Boot Web全面解析与整合指南
目录 第一部分:HTTP协议与Servlet基础 1. HTTP协议核心知识 2. Servlet核心机制 第二部分:Spring Boot Web深度整合 1. Spring Boot Web架构 2. 创建Spring Boot Web应用 3. 控制器开发实践 4. 请求与响应处理 第三部分:高级特性与最…...

事件过滤器
1.简介 事件过滤器是指在程序分发到event事件之前进行的一次高级拦截。 2.使用步骤 给控件安装事件过滤器重写eventfilter事件 3.具体实现 3.1安装事件过滤器 代码: //给label1安装事件过滤器ui->label->installEventFilter(this); 3.2重写eventfilter…...

AI识别与雾炮联动:工地尘雾治理新途径
利用视觉分析的AI识别用于设备联动雾炮方案 背景 在建筑工地场景中,人工操作、机械作业以及环境因素常常导致局部出现大量尘雾。传统监管方式存在诸多弊端,如效率低、资源分散、监控功能单一、人力效率低等,难以完美适配现代工程需求。例如…...
)
Kubernetes nodeName Manual Scheduling practice (K8S节点名称绑定以及手工调度)
Manual Scheduling 在 Kubernetes 中,手动调度框架允许您将 Pod 分配到特定节点,而无需依赖默认调度器。这对于测试、调试或处理特定工作负载非常有用。您可以通过在 Pod 的规范中设置 nodeName 字段来实现手动调度。以下是一个示例: apiVe…...

Nacos注册中心
Nacos注册中心 本地环境搭建 准备挂载的文件夹 在拉取 Nacos 镜像之前,在 E:\docker 文件夹下,创建一个 /nacos 文件夹,等会运行容器时,用于将 Nacos 容器中的配置文件、持久化文件挂载出来,防止容器重启时数据丢失…...
,还有CAUSAL_LM,QUESTION_ANS)
除了 `task_type=“SEQ_CLS“`(序列分类),还有CAUSAL_LM,QUESTION_ANS
task_type="SEQ_CLS"是什么意思:QUESTION_ANS 我是qwen,不同模型是不一样的 SEQ_CLS, SEQ_2_SEQ_LM, CAUSAL_LM, TOKEN_CLS, QUESTION_ANS, FEATURE_EXTRACTION. task_type="SEQ_CLS" 通常用于自然语言处理(NLP)任务中,SEQ_CLS 是 Sequence Classif…...

二战蓝桥杯所感
🌴 前言 今天是2025年4月12日,第十六届蓝桥杯结束,作为二战的老手,心中还是颇有不甘的。一方面,今年的题目比去年简单很多,另一方面我感觉并没有把能拿的分都拿到手,这是我觉得最遗憾的地方。不…...

深度解析自动化工作流工具:n8n 与 Dify 的对比分析
深度解析自动化工作流工具:n8n 与 Dify 的对比分析 随着企业数字化转型的加速,自动化工具在提高工作效率、降低人工成本方面扮演着越来越重要的角色。市面上有多种自动化工作流工具可供选择,其中 n8n 和 Dify 是两个备受关注的开源和商业产品…...

深度剖析Python中的生成器:高效迭代的秘密武器
深度剖析Python中的生成器:高效迭代的秘密武器 在Python的编程世界里,生成器(Generator)是一个强大而又迷人的特性,它为开发者提供了一种高效处理大量数据的方式,尤其在涉及到迭代操作时,能显著…...

Mac 下载 PicGo 的踩坑指南
Mac 下载 PicGo 的踩坑指南 一、安装问题 下载地址:https://github.com/Molunerfinn/PicGo/releases 下载之后直接安装即可,此时打开会报错:Picgo.app 文件已损坏,您应该将它移到废纸篓。 这是因为 macOS 为了保护用户不受恶意…...

网页布局汇总
1. 盒模型 容器大小 内容大小 内边距(padding) 边框大小 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0">&l…...

基于 Maven 构建的 Thingsboard 3.8.1 项目结构
一、生命周期(Lifecycle) Maven 的生命周期定义了项目构建和部署的各个阶段,图中列出了标准的生命周期阶段: clean:清理项目,删除之前构建生成的临时文件和输出文件。validate:验证项目配置是否…...