COD任务论文--MAMIFNet
摘要
提示:论文机翻
由于难以从复杂背景中区分高度相似的目标,伪装物体检测(COD)仍然是计算机视觉领域的一项具有挑战性的任务。现有的伪装物体检测方法往往在场景理解和信息利用方面存在困难,导致精度不足,从而引发背景误动作、目标定位损失和边缘模糊等问题。为了应对这些挑战,我们提出了一种名为 “掩码和注意力调制信息聚焦网络(MAMIFNet)”的新方法,旨在改进空间-频率融合域中的 COD。MAMIFNet 引入了掩码和注意力调制快速傅立叶卷积(MAM-FFC)算子,通过跨域掩码和注意力机制,自适应地增强跨空间和频率域的全局和局部信息。该算子可实现更全面的场景理解,减少大范围误激活和目标区域丢失等区域性错误。为了进一步优化场景信息的利用,在 MAM-FFC 运算器的基础上引入了关键线索感知模块(CCPM)。CCPM 精炼目标前景焦点和前景-背景对比度,挖掘辨别线索以提高目标定位和边缘检测的准确性。在四个基准数据集上进行的实验评估证明了所提出的方法具有竞争力的性能,验证了其在 COD 中的有效性。
小结:从摘要来看,提出了一个MAMIFNet,主要在空间-频率融合域中创新。两个重要内容MAM-FFC和CCPM
文章目录
- 摘要
- Introduction
- 相关工作
- 方法
- 概述
- 1.掩码和注意力调制快速傅立叶卷积(MAM-FFC)
- Detail enhanced module细节加强模块 (DEM)
- Panoramic information perception module全景信息感知模块 (PIPM)
- Critical cue perception module关键线索预测模块 (CCPM)
- 损失函数
- 拟议算法的数据流
- 实验
- 总结
Introduction
【首先讲了应用,讲了生物启发法,但是详细介绍了空间域-频域的方法】
仅空间域的方法[8],[9],[10],[11],[11],[12],[13],[14],[15],[15],[16],[17]采用卷积内核来捕获当地细节,并间接地在深网中汇总了全局信息。但是,这些内核的有限接收领域限制了全球信息获取,从而影响了场景的理解准确性。
备注:所谓空间域就是正常卷积,局限在于感受野问题,但是会通过叠加卷积扩大感受野,同事牺牲复杂度
为了解决这个问题,探索性研究介绍了频域信息[18],[19],[20],[21],受图像Denoising [22],图像恢复[23],多源图像融合[24],[25],[26],[27],[27],[27]和超分辨率[27]和超级分辨率[28],[29]的启发。转换空间信息后,频域直接在频域中的频率域方法[18]。在有效捕获全球功能的同时,这种方法通常会导致域转换过程中关键空间细节的丢失,从而影响场景的理解准确性。
备注:图像频域表示灰度在平面空间上的梯度。图像的频域可以这么理解,灰度图变化快的称谓高频,包括轮廓、纹理信息;低频也就是灰度缓慢地变化,图像中的大部分内容
空间频率融合方法[19],[20],[21]整合了来自频率和空间域的信息。这种方法有效地平衡了全球功能和本地信息;但是,简单的直接融合策略可能会在特征空间中引入混乱和冗余,可能会影响场景的理解准确性。这三种方法(纯空间域,纯频域和空间频率融合方法)的常见缺点是它们的场景理解能力受损,这阻碍了在复杂背景中区分相似目标的能力。这种障碍会导致许多背景误导和目标定位损失,特别是对于多个,遮挡或超大的目标和水下反射,如图1(红色框)所示。此外,这些方法通常采用简单的操作来获取线索,例如未分化的全景特征或基本的前景/背景特征。场景信息的这种未实现的不足通常会导致伪装对象的扭曲或模糊的边缘轮廓,如图1(黄色框)所示。

现有 COD 方法面临的共同挑战包括 (1) 有效感知和融合更丰富的全局信息与局部纹理细节,以实现更准确的场景理解;(2) 充分利用这些增强的场景理解信息来挖掘隐藏的细微差别。
contributions:
(1)
MAM-FFC 运算器通过掩蔽和注意调制机制过滤、增强和融合频率和空间域的关键信息。这能增强对场景的理解,实现全面感知,减少大范围区域识别错误,如背景误激活和目标区域丢失。【MAM-FFC 运算器核心方法与作用】
(2)
CCPM 模块通过深度挖掘潜在的场景线索,充分利用场景信息中隐藏的代表性特征,减少伪装物体边缘的不恰当损失,从而完善目标定位。【ccpm的作用】
(3)
在四个基准数据集上进行的实验评估表明,我们的模型表现出极具竞争力的性能,验证了其在 COD 中的有效性。
相关工作
【SOD和COD不再梳理,论文中还提到了快速傅立叶卷积,有篇论文20CVPR就叫Fast fourier convolution】
FFC [46] 是一种创新的卷积算子,其特点是利用傅立叶变换原理,在深度神经网络卷积层中加强远距离依赖性处理和多尺度信息融合。它将不同尺度的信息,包括本地空间数据和通过傅立叶变换得到的半全局到全局频率信息,整合到一个运算单元中。这种聚合实现了卷积单元内局部和非局部感受野的跨尺度融合,增强了对图像或视频中复杂特征的捕捉。此外,FFC 的设计便于无缝替换现有网络中的标准卷积层,无需额外调整,计算效率可与传统卷积相媲美。经验验证表明,FFC 在图像分类、视频动作识别和人体关键点检测等各种视觉任务中都有显著的性能提升。其出色的局部和非局部融合能力还被有效地应用于像素敏感的低级视觉任务,如超分辨率[28]、图像复原[23]和图像内绘[47]、[48]。
方法
概述
MAMIFNet 通过密集部署我们提出的掩码和注意力调制快速傅立叶卷积(MAM-FFC 3.2)算子,实现了空间和频率域信息的有效融合。这些算子在空间-频率融合域中实现了掩码和注意力机制,使网络能够在每一层捕捉到丰富的场景理解信息,从而为准确的伪装物体检测奠定了基础。
如图 2 所示,MAMIFNet 采用两阶段自下而上的渐进式检测策略。在第一阶段,(空间域)骨干网络和 K-Ways 融合模块协同完成空间特征聚合。具体来说,对于输入图像 I € R^HxWx3.
主干网络首先输出四个多尺度空间特征{S_j,€ R^{H_jxW_jxC_j},|j= 1, 2, 3, 4},然后通过 K-Ways 融合模块将其整合为增强的空间域特征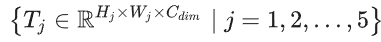
在第二阶段(空间-频率融合域),网络在空间-频率融合域采用渐进式优化策略进行特征转换和推理。最初,PIPM部署在最深层(第 5 层),以生成初步预测:
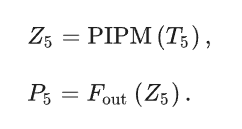
随后,DEM模块对浅层特征进行了细化
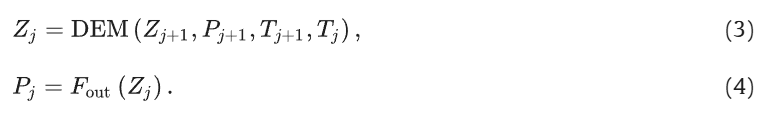
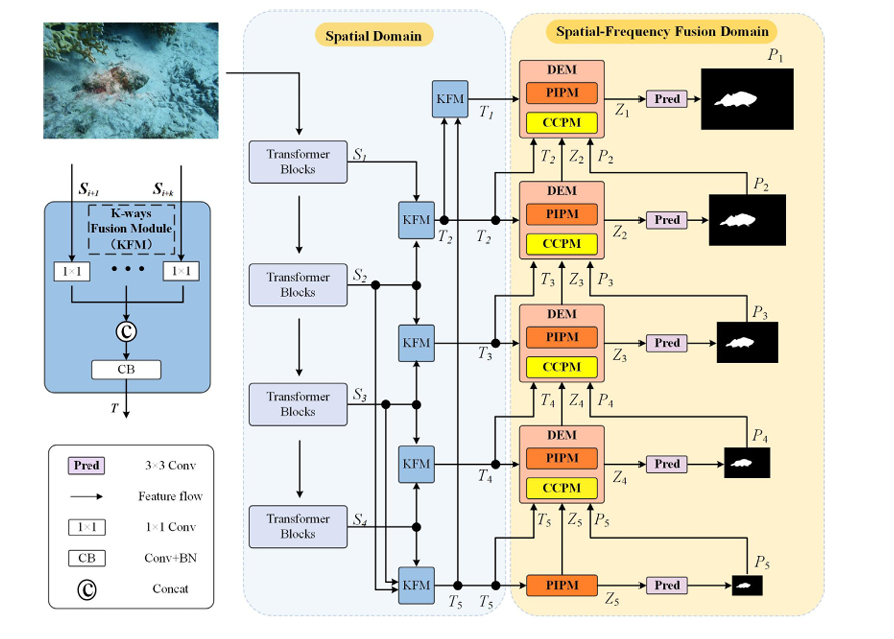
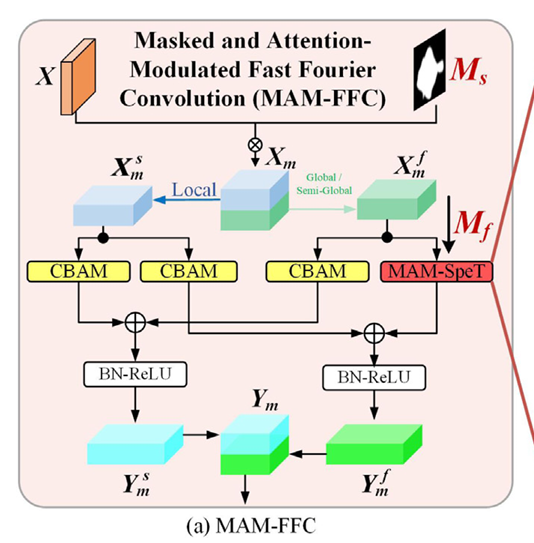
图 2. 该图说明了 MAMIFNet 的框架,它由两个阶段组成。在初始阶段,主干网络负责提取全面的空间特征表征。随后,空间信息被转换到空间-频率融合域,在该域中进行推理,以准确定位伪装物体。这一转换和分析过程是通过级联 DEM(由 PIPM 和 CCPM 组成)模块实现的,所有这些模块都是通过 MAM-FFC 堆栈实现的。图 3 详细描述了 MAM-FFC 的内部结构,图 4 则进一步阐述了 DEM 及其内部 PIPM 和 CCPM 的结构组成。
对应网络forward代码看整体架构
layer = self.backbone(x) # Transformer blocks# KFM,K-Ways fusion,就是cat和卷积组合s2 = self.fu0(layer[0], layer[1]) #s2 1,64,96,96s3 = self.fu1(layer[1], layer[2]) #s3 1,64,48,48s4 = self.fu2(layer[2], layer[3]) #s4 1,64,24,24s5 = self.fu4( layer[1],layer[2],layer[3]) #s5 1,64,24,24s1 = self.fu3(s2, s5) #s1 1,64,192,192# PIPM 其中关键运用了MAM_FFC_Layert5 = self.pipm5(s5) #t5 1,64,24,24 粗图predict5 = self.predict_conv(t5) #predict5 1,64,24,24# DEM 比价复杂,一系列卷积,上采样,乘加以及MAM_FFC_Layer组合dem4, predict4 = self.dem4(s4, s5, t5, predict5)dem3, predict3 = self.dem3(s3,s4, dem4, predict4)dem2, predict2 = self.dem2(s2,s3, dem3, predict3)dem1, predict1 = self.dem1(s1,s2, dem2, predict2)# rescalepredict5 = F.interpolate(predict5, size=x.size()[2:], mode='bilinear', align_corners=True)predict4 = F.interpolate(predict4, size=x.size()[2:], mode='bilinear', align_corners=True)predict3 = F.interpolate(predict3, size=x.size()[2:], mode='bilinear', align_corners=True)predict2 = F.interpolate(predict2, size=x.size()[2:], mode='bilinear', align_corners=True)predict1 = F.interpolate(predict1, size=x.size()[2:], mode='bilinear', align_corners=True)return predict5, predict4, predict3, predict2, predict1
DEM 模块由两个核心部分组成:全景信息感知模块 (PIPM) 和关键线索感知模块 (CCPM)。全景信息感知模块**(PIPM)**采用简化版的 MAM-FFC(命名为 MAM-FFCs)。它只保留了跨域注意机制。这为相邻层的浅层空间信息提供了空间-频率融合域特征的全景视角。CCPM 采用完整的 MAM-FFC 运算符,同时具有跨域屏蔽和注意力机制。它专注于深层特征中的特定区域,并从这些区域中提取关键线索。然后在 DEM 中整合两个组件的输出。这种整合会产生精细的特征表示,从而更准确地检测出伪装物体。值得注意的是,最深层 PIPM 与 DEM 在结构上保持一致。关键区别在于其输出–它直接生成粗略的目标位置预测,为浅层 DEM 中的 CCPM 提供区域先验指导。
备注:提到之前没有提到的模块,K-Ways fusion module,PIPM,DEM,可以看出来DEM={PIPM+CCPM}
1.掩码和注意力调制快速傅立叶卷积(MAM-FFC)
【总体说明MAM-FFC】如图 3(a)所示,我们提出的 MAM-FFC 算子作为 MAMIFNet 的基石,通过跨域掩码和关注机制增强了 FFC 的基本框架。该架构由两个并行分支组成:主要在空间域运行的局部分支 和
主要在频率域运行的全局/半全局分支,它们共同生成多维空间-频率融合域的输出特性。
备注:主要说明MAM-FFC双分支结构,在空间域搞局部;在频域搞全局或半全局,至于这个半全局可以去看《Fast Fourier Convolution》
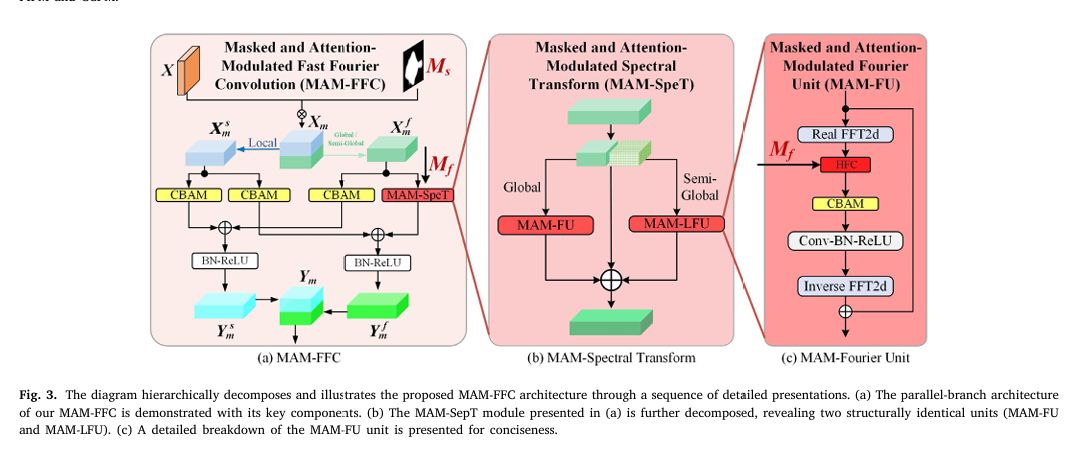
【浅分说明MAM-FFC 还包含了什么】MAM-FFC 扩展了 Vanilla FFC 的基本框架 [46],纳入了双域掩码【暂时不知道什么意思,猜测全局和局部相关】和注意力机制【CBAM】,以增强特征提取能力。在掩码机制设计中,我们为空间域和频率域开发了专门的方法。在空间域,伪装物体的精确定位需要关注特定的区域信息。为此,我们利用深层的粗略估计作为空间掩码来突出潜在的目标区域,同时抑制背景干扰。在频率域,生物学研究[7]表明,伪装物体主要通过高频特征(如纹理和边缘)而非低频成分(如颜色和光照)与背景区分开来。最近的研究[18]、[21]进一步验证了这一发现。因此,我们在频域中应用一般掩码滤波[49] 来选择性地过滤和增强高频鉴别特征。在此基础上,我们在空间域和频率域引入注意力机制 [50],以自适应地关注和增强融合域中的关键信息。4.5.1 中的实验表明,双域注意力设计的对称性对于模型的检测准确性和鲁棒性至关重要。这是因为它可以自适应地感知和增强空间-频率融合域中的重要信息,从而使 MAM-FFC 模型能够更精确地探测伪装物体的边界。
备注:构成的两个关键点——双域掩码和注意力机制
我们在 1-4 层的 CCPM 模块中实现了完整的 MAM-FFC 结构。为了实现高效的特征转换,我们设计了一个简化版本(MAM-FFCs),只保留了 PIPM 模块的关注机制。第 1-4 层的 PIPM 只关注特征域转换,而最深的 PIPM(第 5 层)则额外生成粗略估计,以指导较浅的层。
备注:保留脑子一会看CCPM,现在关注简化版的MAM-FFCs,只保留了 PIPM 模块的关注机制
在网络中,我们为不同的特征处理任务设计了两种 MAM-FFC 变体: 完整版(包含跨域掩码和注意力机制)部署在 CCPM 中,用于挖掘深层特征指定区域内的关键线索。简化版 MAM-FFCs(仅保留跨域关注机制)应用于 PIPM,以捕捉浅层的全景特征。这两种变体在 1-4 层的 DEM 中进行协作,在整合后生成精细的特征表征。值得注意的是,虽然最深层(第 5 层)的 PIPM 采用了相同的简化结构,但它还执行了一项额外的任务–生成粗略的目标位置预测,为完整的 MAM-FF 提供建议的焦点区域 (Ms),为浅层 CCPM 中的完整 MAM-FFC 提供建议焦点区域。
备注:也就是说MAM-FFC在后面 CCPM和PIPM中使用?
MAM-FFC操作的输入特征X ∈Rh*w*c与空间掩码Ms∈Rh*w*1 初始元素元素相乘,结果为Xm∈Rh*w*c,这一步骤旨在聚焦前景信息,同时抑制背景干扰:
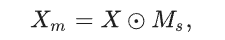
在Ms中,数值为 1 的区域表示感兴趣的区域,而数值为 0 的区域则不予考虑。
代码如下(示例):
input = torch.randn(1, 128, 384, 384).cuda()
mask = torch.randn(1, 1, 384, 384)
mask = torch.sigmoid(mask).cuda()
fc = input * mask #输入特征与空间掩码相乘
接下来,Xm呗分为两部分Xm={X_ms ,X_mf },其中,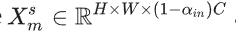
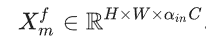
关于系数属于[0,1]这个区间,这些成分分别通过本地分支和非本地分支进行处理,输出结果是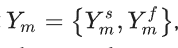
系数设为0.5【这里的想法与FFC一样哦】过程表示为:
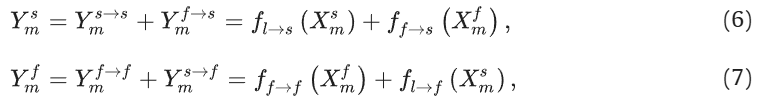
借助FFC的图理解就是:
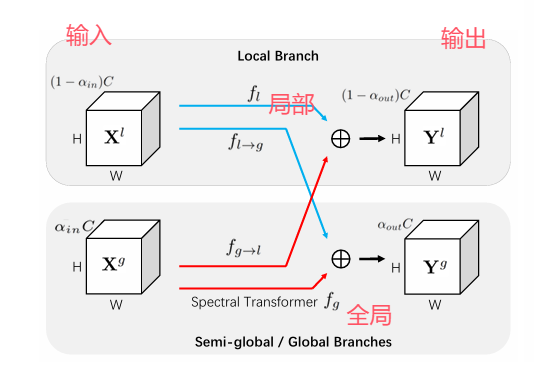
思路一样,但是实现路径不一样在式子中,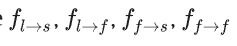
对于涉及局部信息的前三条路径(除f_f->f),我们采用了标准卷积,然后是 CBAM [50] 注意机制:
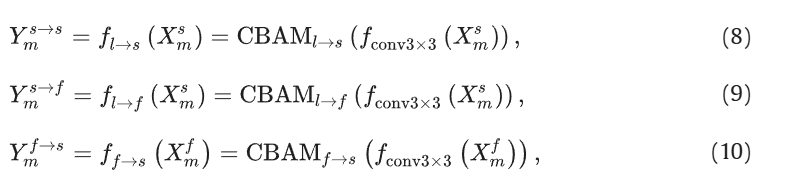
也就是注意力机制和卷积结合的方法。
f_{f->f} 我们利用频谱变换模块来捕捉非本地信息。以 MAM-FU 为例,其核心操作如下:
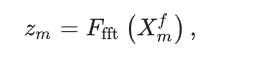
Ffft指的是快速傅里叶变换,并且引入一个频域掩码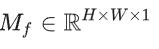
以过滤与背景相关的频率:
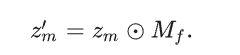
MAM-FFC 模块的频域遮蔽机制从三个关键领域汲取灵感:生物系统、频率分析和神经网络。生物学研究[7]表明,有效的伪装是通过最小化目标与其周围环境之间的关键区别来实现的,尤其是高频成分,如纹理图案和边缘特征,而不是低频元素,如颜色和光照。研究[18]、[21]进一步证实了高频信息在伪装检测中的关键作用。此外,神经网络研究还发现,卷积神经网络(CNN)对低频信息表现出更高的灵敏度,同时在更深的网络层中逐渐减弱微妙的高频细节[51]。基于这些见解,我们在 MAM-FFC 架构中实施了频域掩码Mf在 MAM-FFC 架构内实施频域掩码,以专门针对和增强辨别特征。掩码Mf通过以下公式生成,其中超参数调节选定频率成分的带宽:
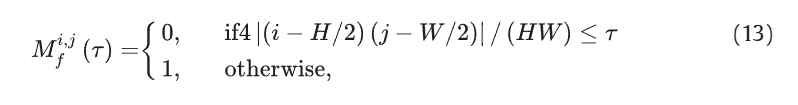
对滤波后的频域 信息Zm` 通过CBAM进行自适应加权,并随后映射回空间域:
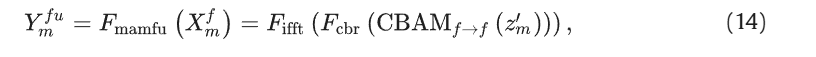
其中,Fcbf代表一系列的卷积,批归一化和relu激活操作,Fifft是逆傅里叶转换。
对于MAM-LFU有相似的操作:
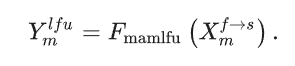
最后非局部分支:
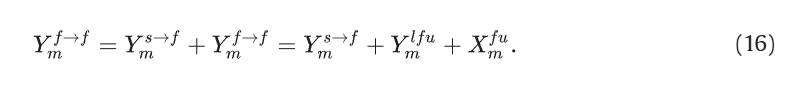
通过综合设计,MAM-FFC 协同整合了空间域和频率域的遮蔽和注意机制,为后续的 PIPM 和 CCPM 模块奠定了坚实的基础。这种双域融合架构能有效捕捉并增强分辨特征,最终提高网络在复杂场景中分辨伪装物体的能力。
码中MAM_FFC_Layer模块是 MAM - FFC 算子的具体体现。
它由多个MAM_FFC_Block模块组成,每个MAM_FFC_Block模块包含MAM_FFCResnetBlock模块。
在MAM_FFCResnetBlock中,MAM_FFC_BN_ACT模块对输入特征进行处理,通过MAM_FFC模块将输入特征分为局部和全局两部分,进行不同的卷积和频域处理操作,实现特征的融合与增强,符合论文中 MAM - FFC 算子的功能描述。
代码如下(示例):
class MAM_FFC_Layer(torch.nn.Module):def __init__(self,dim, # Number of input/output channels.kernel_size=3, # Convolution kernel size.ratio_gin=0.5,ratio_gout=0.5,fre_m=0.25,):super().__init__()self.padding = kernel_size // 2self.mam_ffc_act1 = MAM_FFC_Block(dim=dim, kernel_size=kernel_size, activation=nn.ReLU,padding=self.padding, ratio_gin=ratio_gin, ratio_gout=ratio_gout, fre_m =fre_m)self.mam_ffc_act2 = MAM_FFC_Block(dim=dim, kernel_size=kernel_size, activation=nn.ReLU,padding=self.padding, ratio_gin=ratio_gin, ratio_gout=ratio_gout, fre_m =fre_m)def forward(self, gen_ft, spa_mask=None, fname=None):x = self.mam_ffc_act1(gen_ft, spa_mask, fname=fname)x = self.mam_ffc_act2(x, spa_mask, fname=fname)return x
class MAM_FFC_Block(torch.nn.Module):def __init__(self,dim, # Number of output/input channels.kernel_size, # Width and height of the convolution kernel.padding,ratio_gin=0.5,ratio_gout=0.5,activation='linear', # Activation function: 'relu', 'lrelu', etc.fre_m=0.25,):super().__init__()if activation == 'linear':self.activation = nn.Identityelse:self.activation = nn.ReLUself.padding = paddingself.kernel_size = kernel_sizeself.mam_ffc_block = MAM_FFCResnetBlock(dim=dim,padding_type='reflect',norm_layer=nn.BatchNorm2d,activation_layer=self.activation,dilation=1,ratio_gin=ratio_gin,ratio_gout=ratio_gout, fre_m =fre_m)self.concat_layer = ConcatTupleLayer()def forward(self, gen_ft, spa_mask=None, fname=None):x = gen_ft.float()x_l, x_g = x[:, :-self.mam_ffc_block.conv1.mam_ffc.global_in_num], x[:, -self.mam_ffc_block.conv1.mam_ffc.global_in_num:]id_l, id_g = x_l, x_ginput_x = (x_l, x_g)x_l, x_g = self.mam_ffc_block(input_x,spa_mask, fname=fname)x_l, x_g = id_l + x_l, id_g + x_gx = self.concat_layer((x_l, x_g))return x + gen_ft.float()
class MAM_FFCResnetBlock(nn.Module):def __init__(self, dim, padding_type, norm_layer, activation_layer=nn.ReLU, dilation=1,spatial_transform_kwargs=None, inline=False, ratio_gin=0.5, ratio_gout=0.5 ,fre_m =0.25,):super().__init__()self.conv1 = MAM_FFC_BN_ACT(dim, dim, kernel_size=3, padding=dilation, dilation=dilation,norm_layer=norm_layer,activation_layer=activation_layer,padding_type=padding_type,ratio_gin=ratio_gin, ratio_gout=ratio_gout, fre_m =fre_m)self.inline = inlinedef forward(self, x, spa_mask =None,fname=None):if self.inline:x_l, x_g = x[:, :-self.conv1.mam_ffc.global_in_num], x[:, -self.conv1.mam_ffc.global_in_num:]else:# x_l, x_g = x if type(x) is tuple else (x, 0)x_l, x_g = x if type(x) is tuple else (x, 0)id_l, id_g = x_l, x_gx_l, x_g = self.conv1((x_l, x_g),spa_mask, fname=fname)x_l, x_g = id_l + x_l, id_g + x_gout = x_l, x_gif self.inline:out = torch.cat(out, dim=1)return out
class MAM_FFC_BN_ACT(nn.Module):def __init__(self, in_channels, out_channels,kernel_size, ratio_gin, ratio_gout,stride=1, padding=0, dilation=1, groups=1, bias=False,norm_layer=nn.BatchNorm2d, activation_layer=nn.Identity,padding_type='reflect',enable_lfu=True, fre_m =0.25,**kwargs):super(MAM_FFC_BN_ACT, self).__init__()self.mam_ffc = MAM_FFC(in_channels, out_channels, kernel_size,ratio_gin, ratio_gout, stride, padding, dilation,groups, bias, enable_lfu, padding_type=padding_type, fre_m =fre_m,**kwargs)lnorm = nn.Identity if ratio_gout == 1 else norm_layergnorm = nn.Identity if ratio_gout == 0 else norm_layerglobal_channels = int(out_channels * ratio_gout)self.bn_l = lnorm(out_channels - global_channels)self.bn_g = gnorm(global_channels)lact = nn.Identity if ratio_gout == 1 else activation_layergact = nn.Identity if ratio_gout == 0 else activation_layerself.act_l = lact(inplace=True)self.act_g = gact(inplace=True)def forward(self, x,spa_mask =None, fname=None):x_l, x_g = self.mam_ffc(x, spa_mask,fname=fname)x_l = self.act_l(self.bn_l(x_l))x_g = self.act_g(self.bn_g(x_g))return x_l, x_g
class MAM_FFC(nn.Module):def __init__(self, in_channels, out_channels, kernel_size,ratio_gin, ratio_gout, stride=1, padding=0,dilation=1, groups=1, bias=False, enable_lfu=True,padding_type='reflect', gated=False, fre_m =0.25,**spectral_kwargs):super(MAM_FFC, self).__init__()assert stride == 1 or stride == 2, "Stride should be 1 or 2."self.stride = stridein_cg = int(in_channels * ratio_gin)in_cl = in_channels - in_cgout_cg = int(out_channels * ratio_gout)out_cl = out_channels - out_cg# groups_g = 1 if groups == 1 else int(groups * ratio_gout)# groups_l = 1 if groups == 1 else groups - groups_gself.ratio_gin = ratio_ginself.ratio_gout = ratio_goutself.global_in_num = in_cgmodule = nn.Identity if in_cl == 0 or out_cl == 0 else nn.Conv2dself.convl2l = module(in_cl, out_cl, kernel_size,stride, padding, dilation, groups, bias, padding_mode=padding_type)self.cbam_l2l = CBAMLayer(out_cl)module = nn.Identity if in_cl == 0 or out_cg == 0 else nn.Conv2dself.convl2g = module(in_cl, out_cg, kernel_size,stride, padding, dilation, groups, bias, padding_mode=padding_type)self.cbam_l2g = CBAMLayer(out_cg)module = nn.Identity if in_cg == 0 or out_cl == 0 else nn.Conv2dself.convg2l = module(in_cg, out_cl, kernel_size,stride, padding, dilation, groups, bias, padding_mode=padding_type)self.cbam_g2l = CBAMLayer(out_cl)module = nn.Identity if in_cg == 0 or out_cg == 0 else MAM_SpectralTransformself.convg2g = module(in_cg, out_cg, stride, 1 if groups == 1 else groups // 2, enable_lfu, fre_m =fre_m,**spectral_kwargs)self.gated = gatedmodule = nn.Identity if in_cg == 0 or out_cl == 0 or not self.gated else nn.Conv2dself.gate = module(in_channels, 2, 1)def forward(self, x, spa_mask=None,fname=None):x_l, x_g = x if type(x) is tuple else (x, 0)out_xl, out_xg = 0, 0if self.gated:total_input_parts = [x_l]if torch.is_tensor(x_g):total_input_parts.append(x_g)total_input = torch.cat(total_input_parts, dim=1)gates = torch.sigmoid(self.gate(total_input))g2l_gate, l2g_gate = gates.chunk(2, dim=1)else:g2l_gate, l2g_gate = 1, 1if spa_mask is not None:x_l_fc = x_l * spa_maskx_g_fc = x_g * spa_maskelse:x_l_fc = x_lx_g_fc = x_gif self.ratio_gout != 1:convl2l =self.cbam_l2l(self.convl2l(x_l_fc))convg2l =self.cbam_g2l(self.convg2l(x_g_fc))out_xl = convl2l + convg2l * g2l_gateif self.ratio_gout != 0:spec_x = self.convg2g(x_g, spa_mask)convl2g = self.cbam_l2g(self.convl2g(x_l_fc))out_xg = convl2g * l2g_gate + spec_xreturn out_xl, out_xg
Detail enhanced module细节加强模块 (DEM)
细节增强模块(DEM)是我们网络的核心组件,通过 MAM-FFC 运算符的不同变体协调 PIPM 和 CCPM 之间的互补互动,如图 4(a) 所示。通过这种独特的架构,DEM 实现了检测结果的逐层细化,在全局背景的指导下发挥局部优化过程的作用。该模块可完善粗略的深层预测图P_j+1,通过整合相邻的深层和浅层信息,生成更精细的浅层预测图Pj
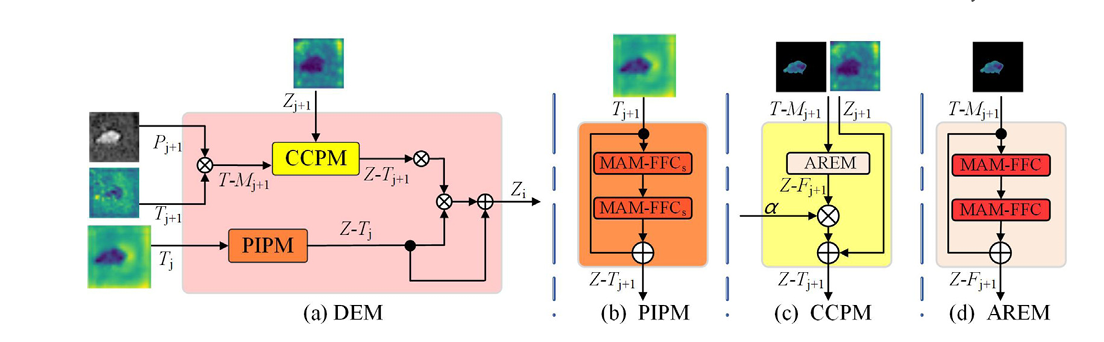
【总的来看,DEM 作用就是融合相邻两层特征,整合pipm5以及粗预测结果】
DEM 的关键部分在于我们设计的 CCPM 模块,它利用了P_j+1作为指导,从深层j+1提取关键线索Tj+1和相应的多维深度融合信息特征Zj+1。这些线索随后与浅层特征Tj合并由 DEM 中的另一个组件 PIPM 提取,以完善预测图Pj+1,从而得到更精确的Pj
如下表所示:
备注:这里写了DEM的构成,两个关键PIPM和CCPM后面详细介绍
class DEM(nn.Module):def __init__(self, channel):super(DEM, self).__init__()self.channel = channel# self.channel2 = channelself.up = nn.Sequential(nn.Conv2d(self.channel, self.channel, 7, 1, 3),nn.BatchNorm2d(self.channel), nn.ReLU(), nn.UpsamplingBilinear2d(scale_factor=2))self.input_map = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2), nn.Sigmoid())# ???????self.increase_input_map = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=1))self.output_map = nn.Conv2d(self.channel, 1, 7, 1, 3) #用于生成最终的预测结果或某种掩码。self.beta1 = nn.Parameter(torch.ones(1))self.beta2 = nn.Parameter(torch.ones(1))self.conv2 = nn.Conv2d(in_channels=self.channel, out_channels=self.channel, kernel_size=3, padding=1,stride=1)self.conv_cur_dep1 = Basic_Conv(self.channel, self.channel, 3, 1, 1)self.conv_cur_dep2 = Basic_Conv(in_channels=self.channel, out_channels=self.channel, kernel_size=3,padding=1, stride=1)self.conv_cur_dep3 = Basic_Conv(in_channels=self.channel, out_channels=self.channel, kernel_size=3,padding=1, stride=1)self.pipm = MAM_FFC_Layer(self.channel, ratio_gin=0.5, ratio_gout=0.5,fre_m=0.0) #MAM_FFC_Layer 模块处理当前层级的特征self.arem = MAM_FFC_Layer(self.channel, ratio_gin=0.5,ratio_gout=0.5,fre_m=0.25) #MAM_FFC_Layer 模块处理依赖层级的特征def cgpm(self, dep_x_dual, dep_mask, input_map):t_dep_feature = dep_x_dual #将输入的依赖特征 dep_x_dual 赋值给 t_dep_feature。fc_dep_feature = self.arem(dep_mask, input_map) #对依赖掩码 dep_mask 和输入映射 input_map 进行处理,得到处理后的依赖特征 fc_dep_featuredep_feature = self.beta2 * fc_dep_feature + t_dep_feature #将处理后的依赖特征 fc_dep_feature 与原始依赖特征 t_dep_feature 进行加权求和return dep_featuredef forward(self, cur_x_spa,dep_x_spa, dep_x_dual, in_map):# x; current-level features 1,64,24,24# y: higher-level features 1,64,12,12# in_map: higher-level prediction ,1,1,12,12# 对输入的特征进行尺寸检查和调整:if dep_x_dual.shape[3:]!=cur_x_spa.shape[3:]:dep_x_dual = self.up(dep_x_dual)if dep_x_spa.shape[3:]!=cur_x_spa.shape[3:]:dep_x_spa = self.up(dep_x_spa)if in_map.shape[3:] != cur_x_spa.shape[3:]:# dep_x_dual = self.up(dep_x_dual)input_map = self.input_map(in_map)else:input_map = in_mapdep_mask= dep_x_spa * input_map # 计算依赖掩码 dep_mask,将依赖特征 dep_x_spa 与输入映射 input_map 相乘# cur_mask = cur_x_spa * input_map # ????????????????????????????????# dep_x_dual 1,64,24,24# in_map: higher-level prediction ,1,1,24,24dep_feature = self.cgpm(dep_x_dual, dep_mask, input_map)cur_feature = self.pipm(cur_x_spa)refine1 = dep_feature * cur_feature + cur_featurerefine2 = self.conv_cur_dep1(refine1)refine2 = self.conv_cur_dep2(refine2)refine2 = self.conv_cur_dep3(refine2) #行三次卷积操作,进一步精炼特征output_map = self.output_map(refine2)return refine2, output_map
Panoramic information perception module全景信息感知模块 (PIPM)
如图 4(b)所示,PIPM 在 DEM 中的主要功能是将相邻图层的浅层空间域信息转换为多维光谱空间融合域信息,提供全景透视审查信息Tj。将相邻图层的浅层空间域信息转换为多维光谱空间融合域,提供全景透视审查信息Z-Tj。其结构由两个专门的 MAM-FFC 算子(MAM-FFC)的残差堆栈组成,其特点是在频域和空间域处理中都不存在跨域掩蔽机制。
通过这种设计,PIPM 主要关注潜在的兴趣区域,如伪装物体与背景之间的边界附近区域。然而,由于简化了 MAM-FFC 算子设计,且缺乏有效的跨域遮蔽机制,PIPM 的注意力分布往往集中在目标边缘两侧,相对分散,限制了其精确度。因此,我们设计了 CCPM 作为补充模块,以增强模型对伪装物体边缘的精确感知能力。
提示:在DEM中PIPM 就是MAM_FFC_Layer(self.channel, ratio_gin=0.5, ratio_gout=0.5,fre_m=0.0)
在整个网络架构中,PIPM 起着双重作用。在前四层中,它是 DEM 的基本组成部分,而在第五层中【前面提到的t5 = self.pipm5(s5) 】,它又是一个独立的模块。虽然这个最深的 PIPM 保持了相同的架构设计,但它以最低的空间分辨率运行,不仅能像其 DEM 对应模块一样捕捉全景透视场景信息,更重要的是,它还能生成初步的伪装对象预测。在这些预测的基础上,网络为下层的检测过程提供重要的指导信息,并逐步优化,以生成更精确的分割结果。
class PIPM5(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1):super(PIPM5, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels,kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation)self.norm_cfg = {'type': 'BN', 'requires_grad': True}_, self.bn = build_norm_layer(self.norm_cfg, out_channels)self.pipm = MAM_FFC_Layer(out_channels, ratio_gin=0.5,ratio_gout=0.5,fre_m=0.0)def forward(self, x):x = self.conv(x)x = self.bn(x)x = F.relu(x, inplace=True)x = self.pipm(x)return x
Critical cue perception module关键线索预测模块 (CCPM)
现有研究[18]、[20]表明,特征图中前景区域与背景之间的差异并不是均匀分布的,只有某些特征具有重要的区分信息。基于这一认识,我们认为有效的线索感知机制不应局限于简单地提取整个前景区域的特征,而应侧重于识别和增强具有内在分辨特性的关键线索。
为此,CCPM 采用了三阶段渐进式处理策略:首先提取与前景区域相对应的空间-频率融合域特征,然后通过自适应调制因子增强这些特征,最后将调制后的特征重新整合到全局特征图中,从而在关键的前景线索、非关键信息和背景特征之间建立强烈的对比。这种渐进式处理机制确保了模块能够逐步提炼出最具辨别力的特征信息。CCPM(如图 4©所示)作为 DEM 模块中的协作优化组件,在其 AREM(如图 4(d)所示)中部署了两层完整的 MAMF-FFC 算子(包含跨域掩码和注意力机制)。这弥补了 PIPM 缺少遮挡机制的不足,实现了精确的注意力集中和目标边界检测结果的优化。具体来说,其数学表达式如下:首先,重点空间域特征Z-Mj+1,从输入的粗略预测图中获取Pj+1和空间域信息Tj+1表示为:
随后,通过 AREM 模块(如图 4(d)所示),聚焦区域内隐藏的分辨信息,进行深度挖掘,输出判别特征Z-Fj+1,在空间-频率融合域输出判别特征

此外,为了增强鉴别信息和非关键信息之间的对比度,该模块引入了自适应调制因子
并将其与深层的融合域特征进行整合:
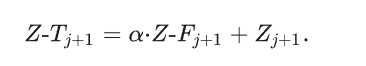
提示:具体在DEM的def cgpm中对应
通过这一过程,DEM 模块提高了伪装物体检测预测的准确性和细节,为在复杂背景中检测伪装物体提供了高效、精确的解决方案。
损失函数
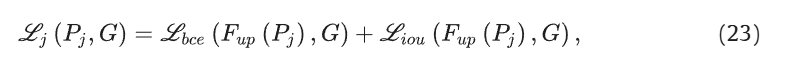
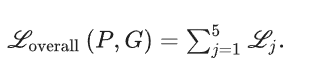
【依旧是 binary cross-entropy (BCE) loss和intersection over union (IoU) loss , 计算是多层损耗的总和】
拟议算法的数据流
MAMIFNet 算法 1 采用了一种自下而上的渐进式伪装物体检测策略。首先,输入图像通过主干网络处理,生成多尺度空间特征,然后通过 K-Ways 融合模块进行整合。在最深的一层,PIPM 将复合空间特征转换为空间-频率融合域特征,然后进行卷积运算,生成初始粗预测图。对于后续层,DEM 处理深层的特征和预测,将其与当前层的特征相结合,最终在第 1 层输出最精细的预测图。在整个过程中,MAM-FFC 操作是基础运算器,而 PIPM 和 CCPM 模块分别负责全局和局部信息处理。它们的输出被整合到 DEM 中,实现多尺度和多领域信息融合。这种分层设计使网络能够逐步完善检测结果,从粗略的全局预测过渡到精确的局部细节,从而在复杂环境中实现高精度伪装物体检测。

实验
细节:图像被调整为 384 × 384 的分辨率;图像增强是通过随机水平翻转和颜色抖动进行的。优化采用随机梯度下降法(SGD),动量为 0.9,权重衰减为5x10-4;初始学习率为1×10-3,训练了 60 个历元(设置总历元数为 100,并采用提前停止策略),整个训练过程耗时约 6 小时。与同期 SARNet [17] 100 个历元训练耗时 8 小时和 SDRNet [54] 100 个历元训练耗时 12 小时相比,我们的模型在训练效率和性能之间取得了平衡。测试时,输入图像的大小也调整为 384 × 384,以便进行模型推理
评价标准: Structure-measure [55], Mean E-measure [56], and Weighted F-measure [57], and Mean Absolute Error (M)
结果:
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
相关文章:

COD任务论文--MAMIFNet
摘要 提示:论文机翻 由于难以从复杂背景中区分高度相似的目标,伪装物体检测(COD)仍然是计算机视觉领域的一项具有挑战性的任务。现有的伪装物体检测方法往往在场景理解和信息利用方面存在困难,导致精度不足,…...

基于MCP协议调用的大模型agent开发04
目录 MCP客户端Client开发流程 uv工具 uv安装流程 uv的基本用法介绍 MCP极简客户端搭建流程 MCP客户端接入OpenAI、DeepSeek在线模型流程 参考来源及学习推荐: Anthropic MCP发布通告:https://www.anthropic.com/news/model-context-protocol MC…...

ComfyUI_Echomimic部署问题集合
本博客总结自己在从WebUI转到ComfyUI的过程配置Echomimic遇到的一些问题和解决方法。 默认大家已经成功安装ComfyUI,我之前装的是ComfyU桌面版,现在用的是B站秋葉大佬的整合包。但内核都一样,错误也是通用的。遇到问题时,应该先去…...

音频转文本:如何识别音频成文字
Python脚本:MP4转MP3并语音识别为中文 以下是一个完整的Python脚本,可以将MP4视频转换为MP3音频,然后使用语音识别模型将音频转换为中文文本。 准备工作 首先需要安装必要的库: pip install moviepy pydub SpeechRecognition openai-whisper完整脚本 import os from m…...

脑科学与人工智能的交叉:未来智能科技的前沿与机遇
引言 随着科技的迅猛发展,脑科学与人工智能(AI)这两个看似独立的领域正在发生深刻的交汇。脑机接口、神经网络模型、智能机器人等前沿技术,正带来一场跨学科的革命。这种结合不仅推动了科技进步,也在医疗、教育、娱乐等…...
)
Linux | I.MX6ULL外设功能验证(11)
01 CSI 摄像头测试 I.MX6ULL 终结者开发板引出了一路 CSI 的摄像头接口,支持【007】的 OV5640 摄像头模块。首先我们连接OV5640 摄像头模块到开发板上,如下图所示(大家在连接的时候一定要注意方向,摄像头朝向开发板的内侧,千万不要接反):...

AI助手:Claude
一、简介 Claude 是由 Anthropic 公司开发的一款人工智能助手,类似于 OpenAI 的 ChatGPT。它以 Anthropic 提出的“宪法式 AI(Constitutional AI)”为核心设计理念,强调安全性、透明性和可控性。以下是对 Claude 的一个简要介绍&…...

vue项目proxy代理的方式
以下是一个详细的 Vue 项目配置 Proxy 代理 的示例和说明,用于解决开发环境跨域问题: 1. 基础代理配置 vue.config.js 配置文件 // vue.config.js module.exports {devServer: {proxy: {// 代理所有以 /api 开头的请求/api: {target: http://localhos…...

多项目并行时如何避免资源冲突
多项目并行时避免资源冲突需做到:精确的资源规划与调度、建立统一的资源管理体系、设置清晰的优先级策略、实时监控资源使用状况、优化团队沟通与协调。其中,精确的资源规划与调度尤其重要,它决定了项目资源能否高效利用,防止资源…...
次方)
求x的c(n,m)次方
近期看到一类很有趣的题啊,其最基础的表现形式为求 mod P的值。 所以我们来拿一道小例题讲讲。 题面:给定 x,n,m,求: mod 1000003471的值。 首先我们注意到,题目给定的模数1000003471为质数,根据费马…...

VS Code 的 .S 汇编文件里面的注释不显示绿色
1. 确认文件语言模式 打开 .S 文件后,查看 VS Code 右下角的状态栏,确认当前文件的识别模式(如 Assembly、Plain Text 等)。如果显示为 Plain Text 或其他非汇编模式: 点击状态栏中的语言模式(如 Plain Te…...

Apipost自定义函数深度实战:灵活处理参数值秘籍
在开发过程中,为了更好地处理传递给接口的参数值,解决在调试过程中的数据处理问题,我们经常需要用到函数处理数据。 过去,我们通过预执行脚本来处理数据,先添加脚本,然后将处理后的结果再赋值给请求参数。…...
驱动直流电机和步进电机)
ADI的BF561双核DSP怎么做开发,我来说一说(十)驱动直流电机和步进电机
作者的话 ADI的双核DSP,最早的一颗是Blackfin系列的BF561,这颗DSP我用了很久,比较熟悉,且写过一些给新手的教程。 硬件准备 ADZS-BF561-EZKIT开发板:ADI原厂评估板 AD-ICE20000仿真器:ADI现阶段性能最好…...

JS包装类型Object
包装类型 1 对象 Object 声明普通对象 学习静态方法,只能由Object自己调用 1.获得所有属性 2.获得所有属性值 3.对象拷贝...

【C++初阶】--- vector容器功能模拟实现
1.什么是vector? 在 C 里,std::vector 是标准模板库(STL)提供的一个非常实用的容器类,它可以看作是动态数组 2.成员变量 iterator _start;:指向 vector 中第一个元素的指针。 iterator _finish;&#x…...

FreeRTOS项目工程完善指南:STM32F103C8T6系列
FreeRTOS项目工程完善指南:STM32系列 本文是FreeRTOS STM32开发系列教程的一部分。我们将完善之前移植的FreeRTOS工程,添加串口功能并优化配置文件。 更多优质资源,请访问我的GitHub仓库:https://github.com/Despacito0o/FreeRTO…...

多值字典表设计:优雅处理一对多关系的数据库方案
在数据库设计中,我们经常需要处理一对多的关系数据。传统做法是创建关联表,但有时这种方式会显得过于复杂。今天,我将分享一种简单而实用的多值字典表设计方案,它适用于那些不需要对单个值进行复杂操作的场景。 为什么需要多值字典表? 在许多应用场景中,我们需要存储一…...

如何在Linux系统Docker部署Dashy并远程访问内网服务界面
## 简介 Dashy 是一个开源的自托管的导航页配置服务,具有易于使用的可视化编辑器、状态检查、小工具和主题等功能。你可以将自己常用的一些网站聚合起来放在一起,形成自己的导航页。一款功能超强大,颜值爆表的可定制专属导航页工…...
脉冲生成Bresenham算法)
GRBL运动控制算法(五)脉冲生成Bresenham算法
前言 在数控系统和运动控制领域,脉冲信号的精确生成是实现高精度位置控制的核心。GRBL作为一款高效、开源的嵌入式运动控制固件,其底层脉冲生成机制直接决定了步进电机的运动平滑性、响应速度及整体性能。而这一机制的核心,正是经典的Bresen…...

Java学习手册:Java发展历史与版本特性
Java作为全球最流行的编程语言之一,其发展历程不仅见证了技术的演进,也反映了软件开发模式的变革。从1995年的首次发布到如今的持续更新,Java始终保持着强大的生命力和广泛的影响力。本文将简要回顾Java的发展历程,并重点介绍其关…...

25年时代电服社招入职Verify测评SHL题库语言理解数字推理考什么?
宁德时代语言理解 语言理解部分主要考察应聘者的语言表达和逻辑思维能力,题型包括阅读理解、逻辑填空和语句排序。阅读理解要求应聘者快速捕捉文章的主旨和细节信息,能够迅速把握文章的核心观点;逻辑填空需要在给定的语句中填入最合适的词汇…...

【C++】右值引用、移动语义与完美转发
左值、右值是C常见的概念,那么什么是右值引用,移动语义,完美转发呢?本UP带大家了解一下C校招常问的C11新特性。 左值与右值 左值:明确存储未知、可以取地址的表达式 右值:临时的、即将被销毁的ÿ…...

AIGC3——AIGC的行业应用与生产力变革:医疗、教育、影视与工业设计的突破
引言 人工智能生成内容(AIGC)技术正在深刻改变多个行业的生产方式,从医疗诊断到影视创作,从个性化教育到工业设计,其应用不仅提升了效率,还创造了全新的工作模式。本文将聚焦医疗、教育、影视、工业设计四…...
之旅——启航①)
Java从入门到“放弃”(精通)之旅——启航①
🌟Java从入门到“放弃 ”精通之旅🚀 今天我将要带大家一起探索神奇的Java世界!希望能帮助到同样初学Java的你~ (๑•̀ㅂ•́)و✧ 🔥 Java是什么?为什么这么火? Java不仅仅是一门编程语言,更…...

Web前端之Vue+Element实现表格动态不同列合并多行、localeCompare、forEach、table、push、sort、Map
MENU 效果图公共数据数据未排序时(需要合并的行数据未处于相邻位置)固定合并行(写死)动态合并行方法(函数)执行 效果图 公共数据 Html <el-table :data"tableData" :span-method"chang…...
)
JavaScript(JS进阶)
目录 00闭包 01函数进阶 02解构赋值 03通过forEach方法遍历数组 04深入对象 05内置构造函数 06原型 00闭包 <!-- 闭包 --><html><body><script>// 定义:闭包内层函数(匿名函数)外层函数的变量(s&…...

学习51单片机Day02---实验:点亮一个LED灯
目录 1.先看原理图 2.思考一下(sbit的使用): 3.给0是要让这个LED亮(LED端口设置为低电平) 4.完成的代码 1.先看原理图 比如我们要让LED3亮起来,对应的是P2^2。 2.思考一下(sbit的使用&…...

线性回归模型--California房价预测
#利用线性回归模型california房价预测 #调用API from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression,SGDRe…...

c++进阶之----异常
1. 异常处理的基本概念 异常处理是 C 中一种用于处理运行时错误的机制,允许程序在遇到错误时优雅地处理问题,而不是直接崩溃。异常处理的核心是通过 try、catch 和 throw 关键字来实现,它允许程序在遇到错误时优雅地处理问题,而不…...

SmolDocling:一种超紧凑的视觉语言模型,用于端到端多模态文档转换
paper地址:SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion Huggingface地址:SmolDocling-256M-preview 代码对应的权重文件:SmolDocling-256M-preview权重文件 一、摘要 以下是文章摘要的总结: SmolDocling 是一…...

多模态大模型在目标检测领域的最新进展
1. 技术融合创新 多模态数据融合: 传感器融合:整合图像、激光雷达(LiDAR)、毫米波雷达等数据,提升检测精度和鲁棒性。例如,在自动驾驶中,通过融合视觉与LiDAR数据,实现三维目标检测…...

KWDB创作者计划—KWDB技术重构:重新定义数据与知识的神经符号革命
引言:数据洪流中的范式危机 在AI算力突破千卡集群、大模型参数量级迈向万亿的时代,传统数据库系统正面临前所未有的范式危机。当GPT-4展现出跨领域推理能力,AlphaFold3突破蛋白质预测精度时,数据存储系统却仍在沿用基于关系代数的…...

我开源了一个“宝藏”开源项目
我开源了一个“宝藏”开源项目 - AI需求分析项目 | 适合交作业和学习 🚀 前言 大家好!最近在学习软件工程和大模型应用开发的过程中,我发现许多学生都遇到了需求分析AI的题目。把一份需求文档转化为用户故事、实体关系或数据库设计ÿ…...
)
从零实现Agent智能体配置使用(Ragflow)
从零实现Agent智能体配置使用(Ragflow) 1. 创建智能体2. 配置智能体2.1 配置问题识别2.2 配置问题分类2.3 不同问题进行单独配置2.4 保存Agent 3. 体验效果 1. 创建智能体 2. 配置智能体 2.1 配置问题识别 2.2 配置问题分类 2.3 不同问题进行单独配置 当…...

Fluent VOF水下固体火箭发射仿真
本案例利用VOF模型对水下固体火箭(10m水深)发动机点火初期的流场进行了仿真。该案例所用模型为假设模型,且缺少相关燃气参数,仅作计算设置参考。通过此案例后续跨可以对不同水深、不同模型的工况展开类似仿真计算。 1 假设说明 …...

电脑死机/锁屏后死机无法唤醒
电脑死机/锁屏后死机无法唤醒 导航 文章目录 电脑死机/锁屏后死机无法唤醒导航一、系统日志分析二、电源管理与睡眠模式问题1、禁用快速启动2、调整电源计划(开启高性能模式&关闭硬盘休眠)若是没有禁用睡眠和关闭显示器方法一:方法二&am…...

爱普生可编程晶振SG8201CJ和SG8200CJ在胃镜机器人发挥重要作用
在医疗机器人技术高速发展的今天,胃镜机器人作为胃肠道疾病诊断与治疗的创新设备,正逐渐改变传统诊疗模式。其复杂精密的系统需要精准的时间同步与稳定的信号输出,胃镜机器人是一种先进的医疗设备,用于无创性地检查胃部疾病。与传…...

按规则批量修改文件名称,支持替换或删除文件名称中的内容
文件重命名的需求在我们工作中是非常常见的一个需求,也非常的重要的一个需求,我相信很多小伙伴在工作中都会碰到需要进行文件重命名的场景。今天就给大家介绍一个文件重命名的方法,支持多种方式批量修改文件名称。功能非常的强大,…...

scrum详细理解
Scrum与传统瀑布模型区别 瀑布模型:需要花费几个月来规划产品----->在花费几个月时间进行研发----->产品测试、评审----->最终发布产品 缺点:①如果市场需求发生变化,研发的产品可能无法满足市场需求 ②产品规划必须早于后续工作之…...
——AVL树(平衡二叉搜索树))
数据结构(五)——AVL树(平衡二叉搜索树)
目录 前言 AVL树概念 AVL树的定义 AVL树的插入 右旋转 左旋转 左右双旋 右左双旋 插入代码如下所示 AVL树的查找 AVL树的遍历 AVL树的节点个数以及高度 判断平衡 AVL树代码如下所示 小结 前言 前面我们在数据结构中介绍了二叉搜索树,其中提到了二叉搜…...

Linux文件传输:让数据飞起来!
一、前置任务 为了便于实验,我用母盘的虚拟机克隆出两台虚拟机来模拟两台主机进行文件传输 查询两台主机的IP BL1 192.168.163.130/24 BL2 192.168.88.129/24 二、文件传输 scp命令 不填选项正常显示进度的传输-q静默传输-r递归传输(用于传输目录及目…...

repo仓库文件清理
1. repo 仓库内文件清理 # 清理所有Git仓库中的项目 repo forall -c git clean -dfx # 重置所有Git 仓库中的项目 repo forall -c git reset --hard 解释: repo forall -c git clean -dfx: repo forall 是一个用于在所有项目中执行命令的工具。-c 后…...

MyBatis-Plus 的 FieldStrategy 属性
前几天做个需求的时候,有几个字段在更新的时候,可能为空。想着MyBatis-Plus有注解可以直接使用,就找寻了一下。此处记录一下。我用的MyBatis-Plus的版本是 3.5.1。版本之间对于 TableField 中的方法定义有些区别,但大体相差不大。…...

解锁塔能科技,开启工厂绿色转型与可持续发展双引擎
在全球积极推进可持续发展的大背景下,能源的高效利用与节能减排,已成为各行各业迈向高质量发展进程中无法回避的核心任务。工厂作为能源消耗大户与污染排放重点源头,其绿色转型迫在眉睫,这不仅关乎企业自身的长远发展,…...

c++进阶--智能指针
大家好,今天我们来学习一下c中的智能指针部分。 智能指针的使⽤及其原理 1. 智能指针的使⽤场景分析 下⾯程序中我们可以看到,new了以后,我们也delete了,但是因为抛异常导,后⾯的delete没有得到执⾏,所以…...

五种常用的web加密算法
文章目录 五种常用Web加密算法实战及原理详解1. AES (高级加密标准)原理详解应用场景实战代码(Node.js) 2. RSA (非对称加密)原理详解应用场景实战代码(Node.js) 3. SHA-256 (安全哈希算法)原理详解应用场景实战代码(浏…...

LeetCode 题目 「二叉树的右视图」 中,如何从「中间存储」到「一步到位」实现代码的优化?
背景简介 在 LeetCode 的经典题目 「二叉树的右视图」 中,我们需要返回从右侧看一棵二叉树时所能看到的节点集合。每一层我们只能看到最右边的那个节点。 最初,我采用了一个常规思路:层序遍历 每层单独保存节点值 最后提取每层最后一个节…...

MySQL——存储过程、索引
一、存储过程 1、存储过程使用的场景 例如:有一个购物网站,要验证查询商品的性能,测试之前肯定要准备大量的测试数据,如果是通过 执行 insert 语句一条一条进行插入,效率很低。这种情况下,写一个存储过程…...

【项目管理】第9章 项目范围管理
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 (二)知识笔记 第9章 项目范围管理 1.管理基础 1.1 产品范围…...

无人机隐身技术难点要点!
全频段雷达隐身 频段覆盖挑战:传统隐身材料(如铁氧体、掺杂半导体)多针对特定频段(如X波段),难以应对米波至毫米波的宽频段探测。 低频段突破:低频雷达(如米波雷达)波长…...