SmolVLM2: The Smollest Video Model Ever(二)
这是对论文《SmolVLM: Redefining small and efficient multimodal models》的整理与翻译

SmolVLM:重新定义小型高效的多模态模型
拥抱脸、斯坦福大学

图1 小而强大:SmolVLM与其他最先进的小型视觉语言模型(VLM)的比较。图像结果来自OpenCompass OpenVLM排行榜(段等人,2024年)。
摘要
大型视觉语言模型(VLMs)性能卓越,但需要大量计算资源,这限制了它们在移动和边缘设备上的部署。较小的视觉语言模型通常沿用大型模型的设计选择,比如广泛的图像标记化,这导致GPU内存使用效率低下,并且在设备上应用的实用性受到限制。
我们推出SmolVLM,这是一系列专为资源高效推理而设计的紧凑型多模态模型。我们系统地探索了针对低计算开销优化的架构配置、标记化策略和数据整理方法。通过这些探索,我们确定了关键的设计选择,这些选择能在最小的内存占用下显著提升图像和视频任务的性能。
我们最小的模型SmolVLM - 256M在推理时使用的GPU内存不到1GB,尽管开发时间相差18个月,但它的性能优于参数规模比它大300倍的Idefics-80B模型。我们最大的模型有22亿个参数,其性能可与使用两倍GPU内存的最先进视觉语言模型相媲美。SmolVLM模型不仅适用于静态图像,还展现出强大的视频理解能力。
我们的结果强调,战略性的架构优化、激进但高效的标记化以及精心整理的训练数据,能够显著提升多模态性能,有助于在更小的规模上实现实用、节能的部署。
代码:https://github.com/huggingface/smollm
权重:https://huggingface.co/HuggingFaceTB
演示:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM2
博客:https://huggingface.co/blog/smolvlm2
VLM浏览器:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM-500M-Instruct-WebGPU
苹果:HuggingSnap on the App Store
arXiv:2504.05299v1 [cs.AI] 2025年4月7日

图2 SmolVLM架构。图像被分割成子图像,从视频中采样帧,然后编码为视觉特征。这些特征首先通过像素混洗操作重新排列,然后使用多层感知器(MLP)投影映射到语言模型(LLM)的输入空间作为视觉令牌。视觉令牌随后与文本嵌入(橙色/红色)连接/交织。这个组合序列被输入到语言模型中以生成文本输出。
1 引言
视觉语言模型(VLMs)在能力和应用方面发展迅速(阿希姆等人,2023年;白等人,2023年;拜尔等人,2024年;陈等人,2024c;麦金齐等人,2024年),推动了跨模态推理(刘等人,2024a,2023年)和文档理解(阿帕拉拉朱等人,2021年;费斯等人,2024a;利瓦西诺斯等人,2025年;纳萨尔等人,2025a)领域的突破。然而,这些改进通常伴随着大量的参数和高昂的计算需求。
自早期的大规模视觉语言模型,如拥有80亿参数的Flamingo(阿拉亚克等人,2022a)和Idefics(洛朗松等人,2023年)展示出其能力以来,较小规模的新模型逐渐出现。然而,由于为大型模型所做的架构决策,这些较小规模的模型往往仍然需要大量内存。例如,Qwen2-VL(王等人,2024a)和InternVL 2.5(陈等人,2024b)提供了较小的变体(10亿-20亿参数),但计算开销仍然很大。相反,Meta(杜比等人,2024年)和谷歌(Gemma 3)的模型将视觉能力保留给大规模模型。
即使最初注重效率的PaliGemma(拜尔等人,2024年),在其第二次发布时(施泰纳等人,2024年)规模也显著扩大。相比之下,Moondream(科拉帕蒂,2024年)持续专注于在保持效率的同时提高性能,而H2OVL - Mississippi(加利布等人,2024年)明确针对设备端部署。高效处理对于视频理解任务尤为关键,以Apollo(佐哈尔等人,2024b)为例,其中内存管理至关重要。此外,推理时推理型语言模型会生成更多令牌,增加了计算成本(DeepSeek - AI,2025年;OpenAI等人,2024年)。因此,每个令牌的效率对于确保模型在现实世界中的实用性变得至关重要。我们的贡献如下:
紧凑而强大的模型:我们推出SmolVLM,这是一系列强大的小型多模态模型,证明了精心的架构设计可以在不牺牲能力的情况下大幅降低资源需求。
高效的GPU内存使用:我们最小的模型在推理时使用的GPU随机存取存储器(RAM)不到1GB,显著降低了设备端部署的门槛。
系统的架构探索:我们全面研究了架构选择的影响,包括编码器 - 语言模型参数平衡、标记化方法、位置编码和训练数据组成,确定了在紧凑型视觉语言模型中最大化性能的关键因素。
边缘设备上强大的视频理解能力:我们展示了SmolVLM模型在视频任务上具有有效的泛化能力,在具有挑战性的基准测试(如Video - MME)中取得了有竞争力的分数,突出了它们适用于各种多模态场景以及实时、设备端应用的特点。
完全开源的资源:为了促进可重复性并推动进一步研究,我们发布了所有模型权重、数据集、代码,以及一个展示在智能手机上进行推理的移动应用程序。
2 更小型的模型架构
我们基于图2中的架构系统地探索小型多模态模型的设计选择,在该架构中,编码后的图像被汇聚并投影到SmolLM2骨干网络中。我们首先分析最优的计算分配,表明较小的视觉编码器与紧凑型语言模型相辅相成(§2.1)。扩展上下文长度能够以最小的开销实现更高的图像分辨率(§2.2),并且像素混洗进一步减少了视觉令牌的数量。最后,我们通过特定文档的图像分割和有针对性的令牌压缩,高效地处理高分辨率图像和视频(§2.3)。这些方法共同为小型语言 - 多模态模型(LMMs)提供了一个统一、高性能且经济高效的方案。
2.1 如何在视觉和语言塔之间分配计算资源?
视觉语言模型利用视觉编码器(见图2)生成“视觉令牌”,然后将其输入到语言模型中。我们研究了紧凑型视觉语言模型中视觉编码器和语言模型(LMs)之间的最优容量分配。具体来说,我们将三个SmolLM2变体(1.35亿、3.6亿和17亿参数)与两个SigLIP编码器(?)配对:一个紧凑的9300万参数的SigLIP-B/16和一个更大的4.28亿参数的SigLIP-SO400M。通常,大型视觉语言模型会不成比例地将参数分配给语言模型;然而,随着语言模型规模的缩小,情况并非如此。
这里的 “配对” 指的是在构建 SmolVLM 模型时,将不同参数规模的 SmolLM2 语言模型变体与不同的 SigLIP 视觉编码器进行组合。这种配对操作旨在探索视觉编码器和语言模型之间的最优容量分配,以提升紧凑型视觉语言模型(VLM)的性能,具体如下:
- 模型架构融合:在多模态模型中,视觉编码器负责将图像或视频信息转化为视觉特征,语言模型则基于这些视觉特征和文本输入进行理解、推理和生成文本。将特定的 SmolLM2 变体与 SigLIP 编码器配对,就是把二者整合到同一个模型架构中,使视觉编码器生成的 “视觉令牌” 能够输入到与之配对的 SmolLM2 语言模型中进行联合处理。例如,将 9300 万参数的 SigLIP-B/16 与 1.35 亿参数的 SmolLM2 组合,SigLIP-B/16 先对图像进行编码得到视觉特征并转化为视觉令牌,然后传递给 SmolLM2,SmolLM2 会结合这些视觉令牌和文本信息进行后续处理,如视觉问答、图像描述生成等任务。
- 研究参数平衡影响:通过尝试不同的 SmolLM2 变体和 SigLIP 编码器的配对方式,研究人员可以分析不同参数规模的视觉编码器和语言模型组合对模型整体性能的影响。如实验结果表明,较小的语言模型(1.35 亿参数)搭配较大的视觉编码器(4.28 亿参数的 SigLIP-SO400M)时,性能会下降,而搭配较小的视觉编码器(9300 万参数的 SigLIP-B/16)更合适;对于较大的语言模型(17 亿参数),更大的视觉编码器(SigLIP-SO400M)能带来性能提升且参数增加相对可接受。这种研究有助于确定在紧凑型多模态模型中,如何平衡视觉和语言部分的参数配置,以实现高效的计算分配和更好的性能表现。

图3 SmolVLM配置的性能分析。(左)视觉编码器和语言模型大小的影响。与SigLIP - B/16(9300万参数)相比,较小的语言模型(1.35亿参数)从更大的视觉编码器(SigLIP - SO - 400M,4.28亿参数)中获益较少,而较大的语言模型则从强大的编码器中获得更多收益。(中左)随着上下文长度从2k增加到16k令牌,性能显著提升。(中右)最优像素混洗因子(PS = 2与PS = 4)因模型大小而异。(右)帧平均会降低视频性能,随着平均帧数的增加,性能迅速下降。指标为平均CIDEr(图像字幕)和准确率(视觉问答)。
图3(左)证实,当最小的语言模型(1.35亿参数)使用大型编码器时,性能会显著下降,这突出了编码器 - 语言模型平衡的低效性。在中等规模的语言模型(3.6亿参数)下,更大的编码器使性能提高了11.6%,但参数却大幅增加了66%,因此紧凑型编码器更为可取。只有在最大规模的语言模型(17亿参数)下,更大的编码器仅使参数增加了10%。
发现1:紧凑型多模态模型受益于平衡的编码器 - 语言模型参数分配,为了提高效率,较小的视觉编码器更为可取。
2.2 如何有效地将图像传递给语言模型?
遵循洛朗松等人(2024年)的方法,我们采用自注意力架构,其中来自视觉编码器的视觉令牌与文本令牌连接,并由语言模型联合处理(例如,FROMAGe(科赫等人,2023年)、BLIP - 2(李等人,2023a))。这种设计所需的上下文比SmolLM2中使用的2k令牌限制要多得多,因为使用SigLIP - B/16编码的单个512×512图像需要1024个令牌。为了解决这个问题,我们按照刘等人(2024c)的方法,将RoPE基数从10k增加到273k,从而扩展了上下文容量,并在长上下文数据(Dolma书籍(索尔达尼等人,2024年)、The Stack(科切特科夫等人,2022年))和短上下文数据源(FineWeb - Edu(佩内多等人,2024年)、DCLM(李等人,2024a)以及SmolLM2中的数学数据)的混合数据上对模型进行微调。

图4 像素混洗。重新排列编码后的图像,以空间分辨率换取增加的通道深度。这在保持信息密度的同时减少了视觉令牌的数量。
虽然对于17亿参数的语言模型,在16k令牌下微调是稳定的,但较小的模型(1.35亿、3.6亿参数)在超过8k令牌时会遇到困难。我们对22亿参数的SmolVLM进行的实验证实,在高达16k令牌的情况下性能持续提升(图3,中间)。因此,我们为SmolVLM采用16k令牌的上下文,为较小的变体采用8k令牌的限制。
发现2:紧凑型视觉语言模型从扩展的上下文长度中显著受益。
仅扩展上下文窗口是不够的。最近的视觉语言模型(例如,MM1(麦金齐等人,2024年)、MiniCPM - V(姚等人,2024年)、InternVL(陈等人,2024c))将自注意力架构与令牌压缩技术(佐哈尔等人,2024b;洛朗松等人,2024年)相结合,以高效地适应更长的序列并降低计算开销。
一种特别有效的压缩方法是像素混洗(空间到深度),最初是为超分辨率任务提出的(施等人,2016年),最近被Idefics3采用。像素混洗将空间特征重新排列到额外的通道中,降低了空间分辨率,但增加了表示密度(图4)。这将视觉令牌的总数减少了\(r^{2}\)倍,其中r是混洗比率。然而,较高的比率会将较大的空间区域合并为单个令牌,损害了需要精确定位的任务,如光学字符识别(OCR)。像InternVL和Idefics3这样的模型使用r = 2来平衡压缩和空间保真度。相比之下,我们的实验(图3,右)表明,较小的视觉语言模型受益于更激进的压缩(r = 4),因为减少的令牌数量减轻了注意力开销并改善了长上下文建模。
发现3:小型视觉语言模型受益于更激进的视觉令牌压缩。
2.3 如何有效地编码图像和视频?
在图像和视频之间平衡令牌分配对于高效的多模态建模至关重要:图像受益于更高的分辨率和更多的令牌以保持保真度,而视频通常每帧需要较少的令牌以有效地处理更长的序列。
为了实现这一点,我们成功采用了受UReder(叶等人,2023年)和SPHINX(林等人,2023b)启发的图像分割策略,将高分辨率图像分割成多个子图像以及原始图像的缩小版本。这种方法在不产生过多计算开销的情况下有效地保持了图像质量。然而,对于视频,我们发现受刘等人(2024f)启发的帧平均等策略会对性能产生负面影响。如图3(右)所示,合并多个帧会显著降低OpenCompass - Video的结果,特别是在较高的平均因子(2、4、8)下。因此,帧平均被排除在SmolVLM的最终设计之外,视频帧被重新缩放为图像编码器的分辨率。
发现4:对于小型模型,图像分割可提升视觉任务的性能,而视频帧平均则不会。
3 Smol指令微调
Smol指令微调需要仔细考虑视觉(§3.1)和文本标记化(§3.2),以及在严格计算约束下进行多模态建模的统一方法。学习位置令牌和结构化提示可稳定训练并提高OCR性能,但数据组成仍然至关重要:重用语言模型指令微调(LLM - SFT)的数据集会对小型视觉语言模型产生负面影响(§3.3),过多的思维链(Chain - of - Thought)数据会超出有限的容量(§3.4),适度的视频序列长度可平衡效率和性能(§3.5)。总体而言,这些见解突出了针对SmolVLM有效扩展多模态指令微调至关重要的针对性策略。
3.1 学习令牌与字符串令牌
SmolVLM的一个主要设计考虑因素是有效地编码分割后的子图像位置(?)。最初,我们尝试使用简单的字符串令牌(例如,<row_1_col_2>),这导致训练早期出现停滞,我们称之为“OCR损失困境”,其特征是损失突然下降,但OCR性能却没有相应提升(图5,左和中)。

图5 标记化策略比较。(左)训练损失曲线展示了在较小模型中使用基于字符串的令牌时出现的“OCR损失困境”。(中)综合评估指标显示,使用学习令牌(橙色)(?)的得分始终更高。(右)OpenCompass-Image与OpenCompass-Video的散点图:学习令牌在得分较高的区域占主导地位,特别是在以图像为主的任务中。
为了解决训练过程中的不稳定性问题,我们引入了位置令牌,这显著改善了训练收敛情况并减少了停滞现象。虽然较大的模型对使用原始字符串位置相对鲁棒,但较小的模型从位置令牌中受益匪浅,在OCR准确性方面取得了显著提高,并且在各种任务中的泛化能力也得到了改善。图5(中)显示,在多个图像和文本基准测试中,学习位置令牌始终优于简单的字符串位置。此外,图5(右)表明,使用学习令牌的模型在OpenCompass - Image和OpenCompass - Video评估中得分始终更高,这突出了结构化位置标记化在紧凑型多模态模型中的有效性。
发现5:对于紧凑型视觉语言模型,学习位置令牌优于原始文本令牌。
3.2 结构化文本提示和媒体分割
我们评估了系统提示和明确的媒体引入/结束前缀如何逐步提高SmolVLM在图像(左)和视频(右)基准测试中的性能,如图6所示。每个小提琴图代表给定配置的三个检查点。
系统提示
我们在开头添加简洁的指令,以在零样本推理时阐明任务目标并减少歧义。例如,对话数据集使用“你是一个有用的对话助手”这样的提示,而以视觉为重点的任务则使用“你是一个视觉智能体,应该提供简洁的答案”。每个子图中的第二个小提琴图(图6)显示,纳入这些系统提示后性能有明显提升,在以图像为中心的任务中尤为明显。

图6 训练策略对SmolVLM性能的累积影响。该可视化展示了将不同的标记化和提示工程策略依次应用于SmolVLM基础模型时,性能改进的进展情况。(左)图像基准测试结果显示,每添加一种策略,性能都有持续提升。(右)视频基准测试结果揭示了类似的模式,且性能提升更为显著。
媒体引入/结束Token
为了清晰地划分视觉内容,我们在图像和视频片段周围引入文本标记(例如,“这里有一张图像...”和“这里是从视频中采样的N帧...”)。结束令牌随后过渡回文本指令(例如,“鉴于这张图像/视频……”)。第三个小提琴图表明,这种策略在视频任务中显著提高了性能(在视频任务中更容易出现多帧混淆的情况),并且在图像任务中仍能带来可衡量的改进。
屏蔽用户提示
借鉴阿拉勒等人(2025)的技术,我们在监督微调过程中探索了用户提示屏蔽,以此作为减少过拟合的一种方法。图6中的右小提琴图显示,与未屏蔽的基线(蓝色)相比,屏蔽用户查询(橙色)在图像和视频任务中均提高了性能。在多模态问答中,这种效果尤为显著,因为问题往往具有重复性,模型很容易记住这些问题。因此,屏蔽操作迫使SmolVLM依赖于与任务相关的内容,而不是表面上的重复,从而促进更好的泛化。
发现6:系统提示和媒体引入/结束令牌显著提高了紧凑型视觉语言模型的性能,尤其是在视频任务中。在监督微调(SFT)期间,仅对补全部分进行训练。
3.3 来自LLM-SFT的文本数据重用的影响
一种看似直观的做法是重用来自大型语言模型最终监督微调阶段的文本数据,期望获得分布内的提示和更高质量的语言输入。然而,图7(左)显示,在较小的多模态架构中纳入LLM - SFT文本数据(SmolTalk),在视频任务中性能可能会降低多达3.7%,在图像任务中可能会降低6.5%。我们将这种负迁移归因于数据多样性的降低,这超过了重用文本带来的任何好处。与佐哈尔等人(2024b)的观点一致,因此我们在训练混合数据中严格保持14%的文本比例。这些发现强调了精心平衡的数据管道的重要性,而不是直接将大规模SFT文本用于小型多模态模型。
发现7:添加来自SFT混合的文本被证明比新的文本SFT数据更差。

图7 训练策略对小型多模态模型的影响。(左)重用来自LLM - SFT的文本数据(SmolTalk)会降低较小模型在图像和视频任务中的得分。(中)极小比例(0.02% - 0.05%)的思维链(CoT)数据可产生最佳结果,而更多的CoT使用会降低性能。(右)将平均视频时长增加超过3.5分钟会导致视频和图像任务的回报递减。
3.4 为紧凑型模型优化思维链整合
思维链(CoT)提示在训练过程中向模型展示明确的推理步骤,通常可以增强大型模型的推理能力。然而,它对较小的多模态架构的影响尚不清楚。为了研究这一点,我们改变了整合到Mammoth数据集(岳等人,2024b)中的CoT数据的比例,该数据集涵盖文本、图像和视频任务。图7(中)显示,纳入极小比例(0.02 - 0.05%)的CoT示例会略微提高性能,但更高的比例会显著降低结果,尤其是在图像任务中。这些观察结果表明,过多面向推理的文本数据会超出较小视觉语言模型的有限容量,从而损害它们的视觉表示能力。因此,紧凑型模型从非常稀疏地包含CoT数据中受益最大,而不是像在大规模架构中通常那样广泛使用。
发现8:过多的CoT数据会损害紧凑型模型的性能。
3.5 视频序列长度对模型性能的影响
在训练过程中增加视频时长可以提供更丰富的时间上下文,但会带来更高的计算成本。为了确定最佳时长,我们在平均视频长度从1.5分钟到3.5分钟的范围内训练SmolVLM。图7(右)表明,随着视频时长接近约3.5分钟,视频和图像基准测试的性能都有明显提升,这可能是由于更有效的跨模态特征学习。将视频时长延长超过3.5分钟带来的进一步收益微乎其微,这表明相对于增加的计算成本,回报在逐渐减少。因此,适度延长视频序列可以显著提高小型模型的性能,而过长的序列在计算成本上并不成正比。
发现9:在训练过程中适度增加视频时长可以提高紧凑型视觉语言模型在视频和图像任务上的性能。
4 实验结果
我们构建了三种SmolVLM变体,以适应不同的计算环境:
SmolVLM - 256M:我们最小的模型,结合了9300万参数的SigLIP - B/16和1.35亿参数的SmolLM2(阿拉勒等人,2025)。运行时使用不到1GB的GPU随机存取存储器(GRAM),使其成为资源受限的边缘应用的理想选择。
SmolVLM - 500M:一个中等规模的模型,同样采用9300万参数的SigLIP - B/16,但与更大的3.6亿参数的SmolLM2配对。它平衡了内存效率和性能,适用于资源适中的边缘设备。
SmolVLM - 2.2B:最大的变体,配备4亿参数的SigLIP - SO400M和17亿参数的SmolLM2骨干网络。该模型在保持可部署在高端边缘系统的同时,最大化了性能。

图8 数据详情。视觉(左)和视频(右)训练数据集的详细信息,按模态和子类别细分。
4.1 训练数据
模型训练分两个阶段进行:(1)视觉阶段;(2)视频阶段。视觉训练阶段使用了洛朗松等人(2024)中使用的数据集的新混合,并添加了MathWriting(热尔韦等人,2024)。这种混合经过平衡,以强调视觉和结构化数据的解释,同时保持对推理和解决问题能力的关注。视觉组件包括文档理解、图像字幕、视觉问答(其中2%用于多图像推理)、图表理解、表格理解和视觉推理任务。为了保持模型在基于文本的任务中的性能,我们保留了适量的常识问答和基于文本的推理与逻辑问题,其中包含数学和编码挑战。
视频微调阶段按照佐哈尔等人(2024b)的经验,保持14%的文本数据和33%的视频数据以实现最佳性能。对于视频数据,我们从LLaVA - video - 178k(张等人,2024)、Video - STAR(佐哈尔等人,2024a)、Vript(杨等人,2024)和ShareGPT4Video(陈等人,2023)中采样视觉描述和图像字幕,从Vista - 400k(任等人,2024)中采样时间理解数据,从MovieChat(宋等人,2024)和FineVideo(法雷等人,2024)中采样叙事理解数据。多图像数据从M4 - Instruct(刘等人,2024a)和Mammoth(郭等人,2024)中采样。文本样本来自(徐等人,2024)。
为了更详细地描述,图8提供了我们在视觉和视频微调阶段使用的训练数据分布的详细概述。
4.2 评估细节
我们使用VLMEvalKit(段等人,2024)评估SmolVLM,以确保可重复性。完整的结果可在网上获取。目前,OpenVLM排行榜涵盖239种不同的视觉语言模型和31种不同的多模态基准测试。此外,我们绘制了性能与运行评估所需的随机存取存储器(RAM)的关系图。我们认为,模型大小通常被用作运行模型所需计算成本的代理,但对于视觉语言模型来说,这具有误导性,因为架构对模型运行成本的影响很大;在我们看来,RAM使用是一个更好的代理。对于SmolVLM,在256M和500M模型中,这意味着将图像的最长边调整为1920,在2.2B模型中调整为1536。
4.3 小尺寸下的强大性能
我们根据模型大小评估SmolVLM的性能,将三个变体(256M、500M和2.2B)与高效的最先进开源模型进行比较。表1总结了在九个具有挑战性的视觉语言基准测试和五个视频基准测试中的结果。我们在表中突出显示了具有10亿激活参数的MolmoE 7B(戴特克等人,2024)(MolmoE - A1B - 7B)在视觉任务中的表现,以及InternVL2 - 2B(陈等人,2024c)在视频任务中的表现。图1展示了更广泛的竞争模型。

效率和内存占用
与大得多的模型相比,SmolVLM展示出卓越的计算效率。256M变体进行单图像推理仅需0.8GB的VRAM,500M变体需1.2GB,2.2B变体需4.9GB,远低于MolmoE - A1B - 7B所需的27.7GB。即使与参数规模相似的模型相比,SmolVLM也明显更高效:Qwen2VL - 2B需要13.7GB VRAM,InternVL2 - 2B需要10.5GB VRAM,这表明仅参数数量并不能决定计算需求。在批量大小为64时,SmolVLM的内存使用仍然合理:256M为15.0GB,500M为16.0GB,2.2B为49.9GB。这些结果突出了SmolVLM在GPU受限环境中部署的巨大优势。
规模扩展带来的整体收益
增加SmolVLM的参数数量在所有评估的基准测试中都持续带来显著的性能提升。最大的模型(2.2B)在总体得分上达到最高,为59.8%,其次是中等规模的500M变体(51.0%)和最小的256M变体(44.0%)。值得注意的是,即使是最小的SmolVLM - 256M在几乎所有基准测试中都显著超过了大得多的Idefics 80B模型(见图1),这强调了在较小规模下有效的视觉能力。少数例外情况,特别是MMMU(29.0%对42.3%)和AI2D(46.4%对56.3%),突出了在某些基准测试中,大型语言模型骨干的强大语言推理能力仍然至关重要。有趣的是,像OCRBench这样以视觉为导向的任务也从扩展语言模型容量中显著受益,从256M(52.6%)提升到500M(61.0%)时,得分提高了近10分。这些结果强调,更大的语言模型提供了增强的上下文管理和改进的多模态推理能力,这对语言密集型和以视觉为中心的任务都有益。
与其他紧凑型视觉语言模型的比较

图1通过比较OpenCompass基准测试性能与每图像的GPU内存消耗,将SmolVLM - 2.2B与近期的小型视觉语言模型进行了定位。SmolVLM - 2.2B在MathVista(51.5)和ScienceQA(90.0)上取得了显著的强性能,同时保持了仅4.9GB VRAM的极低GPU使用量。
相比之下,需要显著更多计算资源的模型,如Qwen2VL - 2B和InternVL2 - 2B,在性能上并没有明显优势。具体而言,Qwen2VL - 2B在AI2D(74.7对70.0)和ChartQA(73.5对68.8)上略高于SmolVLM - 2.2B,但在MathVista(48.0对51.5)和ScienceQA(78.7对90.0)上表现较差。
同样,InternVL2 - 2B在ScienceQA(94.1对90.0)和MMStar(49.8对46.0)上得分更高,但VRAM成本超过两倍。进一步的比较突出了在模型大小、内存占用和特定任务性能之间的明显权衡。
MiniCPM - V2(28亿参数)在大多数基准测试中表现不如SmolVLM - 2.2B。其他模型,如Moondream2和PaliGemma(参数都在20 - 30亿左右)在不同任务中表现出显著差异:例如,Moondream2在ChartQA(72.2)上得分不错,仅使用3.9GB VRAM,但在MMMU(29.3)上表现大幅落后。
相反,PaliGemma在ScienceQA(94.3)上表现出色,但在ChartQA(33.7)上表现不佳。这种可变性强调了专门的训练对每个任务的影响。
视频基准测试
表1提供了在五个不同视频基准测试(Video - MME、MLVU、MVBench、TempCompass和WorldSense)中的全面结果。SmolVLM - 2.2B在Video - MME(52.1)和WorldSense(36.2)上表现尤为出色,超过了大得多的模型,如Qwen2 VL - 7B(在WorldSense上为32.4),展示了在复杂多模态视频理解任务中的强大能力。
SmolVLM - 500M变体也表现出强大的性能,在TempCompass(49.0)和WorldSense(30.6)上取得了有竞争力的分数,突出了在适合边缘设备部署的规模下复杂的时间推理和对现实世界视觉的理解能力。尽管SmolVLM变体的参数数量紧凑,但它们始终在高效资源利用和令人印象深刻的准确性之间取得平衡,进一步证明了它们适用于资源受限的场景。
表1 SmolVLM变体在视觉语言任务中的基准测试比较。三个规模(256M、500M和22亿参数)的SmolVLM模型与高效开源模型在单图像、多任务和视频基准测试中的性能比较。SmolVLM模型在保持显著较低的RAM使用量的同时展示出强大的准确性,突出了它们在资源受限的多模态场景中的计算效率。

4.4 设备端性能
为了全面评估SmolVLM的部署实用性,我们在两个代表性硬件平台(NVIDIA A100和NVIDIA L4 GPU)上对不同批量大小的吞吐量进行了基准测试(见图9)。我们的评估突出了SmolVLM适用于设备端和边缘部署场景的特点。
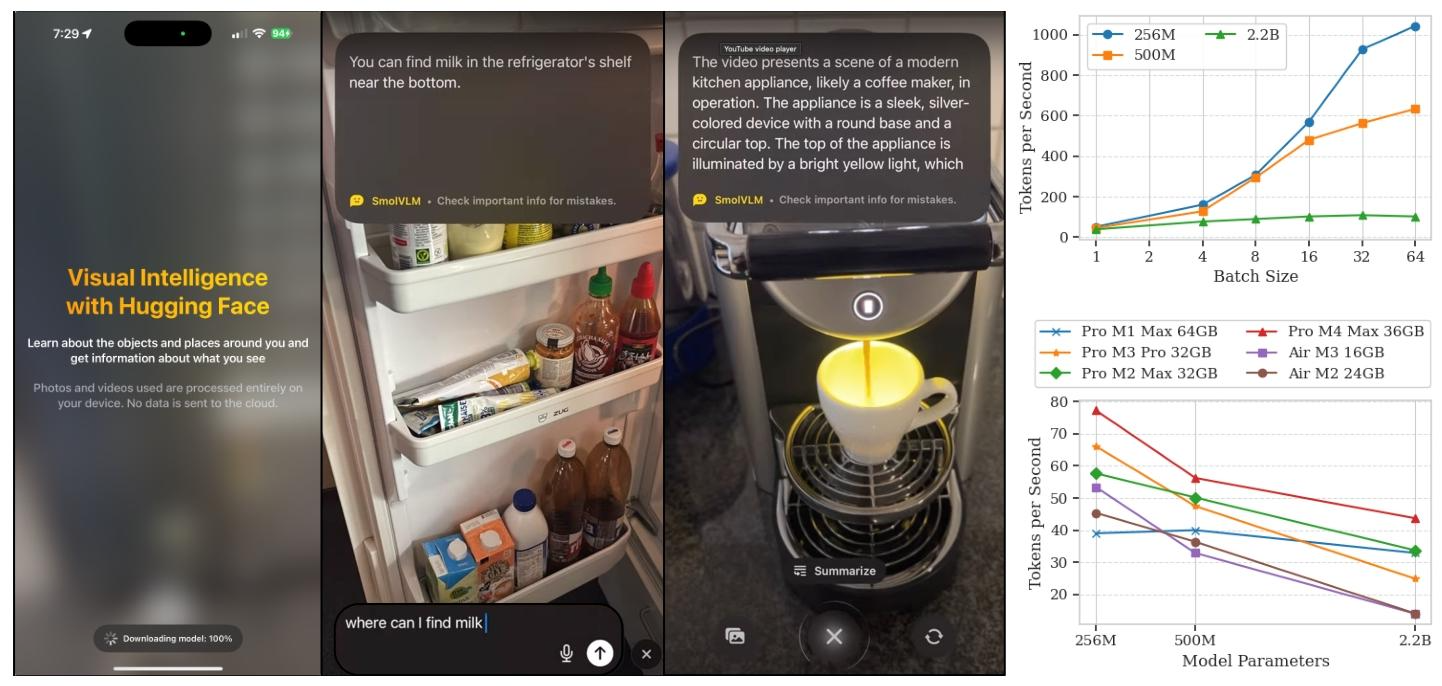
图9 SmolVLM在边缘设备上的应用。(左)HuggingSnap应用程序的示例,SmolVLM可以在消费级手机上本地运行。例如,可以通过移动界面进行交互,以检测物体并回答问题。(右)在NVIDIA A100 GPU(顶部)和不同的消费级个人电脑(底部)上,不同批量大小和模型变体的每秒令牌吞吐量。
在A100 GPU上,最小的SmolVLM - 256M变体实现了令人印象深刻的吞吐量,从批量大小为1时的每秒0.8个样本扩展到批量大小为64时的每秒16.3个样本。500M变体类似地从每秒0.7个样本扩展到每秒9.9个样本,而最大的2.2B变体的扩展较为温和(从每秒0.6个样本到每秒1.7个样本),这表明其计算需求较高。
在L4 GPU上的评估进一步强调了SmolVLM与边缘设备的兼容性。在这里,256M变体在批量大小为8时达到每秒2.7个样本的峰值吞吐量,随后由于内存限制而下降。500M和2.2B变体在较低的批量大小(分别为每秒1.4个样本和每秒0.25个样本)达到峰值,这突出了它们即使在更严格的硬件条件下的效率。
最后,我们在发布时提供了几个优化的ONNX(开放神经网络交换)导出,促进了跨平台兼容性,并拓宽了在消费级硬件目标上的部署机会。
值得注意的是,我们展示了通过WebGPU在浏览器环境中本地高效运行这些模型的能力,256M变体在14英寸MacBook最后,我们在发布时提供了几个优化的ONNX(开放神经网络交换)导出,促进了跨平台兼容性,并拓宽了在消费级硬件目标上的部署机会。
值得注意的是,我们展示了通过WebGPU在浏览器环境中本地高效运行这些模型的能力,256M变体在14英寸MacBook Pro(M4 Max)上每秒可实现高达80个解码令牌。
4.5 下游应用
除了我们自己的评估,SmolVLM还在更广泛的研究社区开发的各种下游应用中得到了应用,这凸显了它在现实世界、资源受限场景中的效率。
ColSmolVLM:设备端多模态推理:ColSmolVLM利用了专为设备端部署而设计的较小的SmolVLM变体(256M和500M参数),正如Hugging Face最近的工作中所详述的那样(Faysse等人,2024b)。这些紧凑型模型能够在移动设备、消费级笔记本电脑甚至基于浏览器的环境中直接进行高效的多模态推理,显著降低了计算需求和运营成本。
Smol Docling:超紧凑型文档处理:Smol Docling是SmolVLM的一个超紧凑型256M参数变体,专门针对端到端的多模态文档转换任务进行了优化(Nassar等人,2025b)。通过采用称为DocTags的特殊表示形式,Smol Docling能够有效地捕获各种文档类型(包括商业文档、学术论文和专利)中的内容、上下文和空间关系。其紧凑的架构在性能上与大得多的视觉语言模型相当,凸显了它在计算资源受限场景中的适用性。
BioVQA:生物医学视觉问答:BioVQA利用SmolVLM紧凑而高效的架构来解决生物医学领域的视觉问答任务(Lozano等人,2025)。小型的SmolVLM模型在解释医学图像方面展示出了有前景的能力,通过基于视觉数据为临床问题提供准确答案来协助医疗保健专业人员。在医疗保健环境中,快速、可靠的图像解释至关重要,而计算资源可能有限,这种能力尤其有价值。BioVQA暂时还未开源(2025.4.10),文章链接在:
https://arxiv.org/pdf/2503.22727
5 相关工作
5.1 第一代视觉语言模型
早期的多模态模型主要通过扩展参数取得了显著进展,但它们高昂的计算需求限制了实际部署。例如,Flamingo(Alayrac等人,2022b)是一个拥有80亿参数的视觉语言模型(VLM),它将一个冻结的70亿参数的语言模型(Hoffmann等人,2022)与一个采用门控交叉注意力和感知器重采样器(Jaegle等人,2021)的视觉编码器集成在一起,以实现高效的令牌压缩。尽管Flamingo在无需特定任务微调的情况下具有最先进的少样本能力,但其大规模带来了重大的部署挑战。
Hugging Face的Idefics(Laurençon等人,2023)采用了Flamingo的架构,提供了90亿和80亿参数的模型,进一步例证了大规模多模态训练的方法。相比之下,BLIP - 2(Li等人,2023a)提出了一种更节省参数的模块化设计,通过冻结视觉编码器和语言模型,引入了一个轻量级的查询变换器(Q - Former),将视觉特征转换为与语言兼容的令牌。这种方法显著减少了可训练参数,在视觉问答(VQA)任务(Antol等人,2015;Goyal等人,2017)上以大约少54倍的可训练参数超越了Flamingo的性能,从而为更高效的多模态架构铺平了道路。
同样,LLaVA(大型语言与视觉助手)(Liu等人,2023)将预训练的CLIP(Radford等人,2021)ViT图像编码器连接到LLaMA/Vicuna语言主干(Touvron等人,2023;Zheng等人,2024),并在指令跟随数据集(?)上对组合模型进行微调。由此产生了一个具有13亿参数的多模态聊天机器人,具备类似GPT - 4V的能力(Achiam等人,2023),LLaVA在视觉对话性能方面取得了显著成果。然而,尽管它比Flamingo更小、更快,但在实时交互中仍需要大量的GPU内存,并且继承了底层语言模型上下文窗口(通常为2048个令牌)的限制。
指令跟随数据集(Instruction - Following Datasets)是用于训练模型理解和执行各种指令的数据集,在自然语言处理和多模态模型训练中具有关键作用。
- 数据构成:包含大量由指令和相应期望输出组成的样本对。以多模态模型训练为例,可能是 “描述图片中动物的动作” 指令,搭配特定动物动作图片和对应的描述文本;在语言模型训练里,指令可能是 “将这段文字总结成一句话” 以及对应的原文和总结文本。
- 作用机制:模型通过学习这些样本对,掌握不同指令的语义和意图,进而在遇到新指令时,能依据已有经验生成合理输出。如模型在学习了众多图像描述指令样本后,面对新图片时,能按指令要求准确描述其中内容。
- 应用场景:广泛应用于提升模型的交互能力,让模型像智能助手一样准确回应指令。还用于增强模型在特定领域的任务执行能力,在医疗领域,可训练模型理解 “分析这张 X 光片并指出异常” 等指令,辅助医生诊断 。
最近的研究积极探索了各种设计选择、训练策略和数据配置,以增强视觉语言模型(VLMs)。例如,Idefics2(Laurençon等人,2024)与它的前身相比,引入了架构和训练数据方面的改进,推进了开源视觉语言模型的能力。同时,Cambrian1(Tong等人,2024)研究了基本设计原则和扩展行为,旨在实现更高效的架构。像Eagle(Shi等人,2024)及其继任者Eagle2(Li等人,2025b)这样的项目优化了特定的架构组件,以提高性能和效率为目标。此外,最近的努力,如Apollo(Zohar等人,2024b)将多模态架构从静态图像扩展到视频理解,进一步丰富了方法的多样性。
5.2 注重效率的视觉语言模型
像InternVL(Chen等人,2024c,b)和Qwen - VL(Bai等人,2023,2025;Wang等人,2024a)这样的大型模型引入了架构创新,以提高计算效率。InternVL将一个60亿参数的视觉变换器(ViT)与一个80亿参数的语言“中间件”对齐,形成了一个140亿参数的模型,在多个视觉和多模态任务中取得了最先进的结果。这种平衡的架构缩小了模态差距,实现了强大的多模态感知和生成能力。
同样,Qwen - VL将Qwen语言模型与专门的视觉模块集成,利用带字幕的边界框数据来增强视觉定位和文本识别能力。尽管它在多语言和多模态性能方面表现出色,但Qwen - VL对于高分辨率输入会生成极长的令牌序列,增加了内存需求。
在较小规模的模型中,像PaliGemma、Moondream2和MiniCPM - V在有限的参数预算内展示了令人印象深刻的多模态能力。PaliGemma(Team等人,2024)仅拥有30亿参数(来自SigLIP-So(Zhai等人,2023)的4亿参数视觉编码器和20亿参数的Gemma语言模型),有效地涵盖了广泛的多模态任务。
然而,其紧凑的视觉接口可能会限制详细的视觉分析。Moondream2仅有18亿参数,将SigLIP视觉特征与微软的Phi - 1.5语言模型(Li等人,2023b)配对,在图像描述、OCR、计数和分类等任务中展示出有竞争力的性能,非常适合边缘和移动应用。
MiniCPM - V(Hu等人,2024)专为设备端场景设计,通过感知器风格的适配器集成了一个4亿参数的视觉编码器和一个75亿参数的语言模型。这个紧凑型模型在选定的基准测试中显著实现了GPT - 4V级别的性能。
Deepseek VL和Deepseek VL2(Lu等人,2024a;Wu等人,2024)的参数范围分别为20 - 70亿和40 - 270亿,进一步说明了对适用于资源受限环境的高效而强大的多模态模型的日益关注。总体而言,这些模型展示了在实际场景中部署有效、实时多模态人工智能的可行性不断提高。
5.3 多模态令牌化和压缩策略
高效的令牌化显著降低了视觉语言模型(VLMs)中的计算和内存需求。早期的方法是单独编码每个像素或图像块,对于分辨率为16×16的224×224图像,会产生196个令牌的冗长序列。最近的策略在保留关键细节的同时压缩视觉数据。
像Flamingo和Idefics2(Alayrac等人,2022b;Laurençon等人,2024)使用的感知器重采样器(Jaegle等人,2021)以及BLIP - 2的Q - Former(Li等人,2023a)这样的学习模块,将输入压缩成一小部分潜在令牌。
虽然这些方法在缩短序列方面有效,但可能会限制在像OCR(Singh等人,2019;Biten等人,2019)这样的细粒度任务上的性能。通过图像块池化和像素混洗进行空间压缩越来越受欢迎。
InternVL v1.5和Idefics3(Chen等人,2024c,b;Laurençon等人,2023)使用2×2像素混洗,将令牌数量减少了四倍,同时保持了OCR能力。
像Qwen - VL - 2(Wang等人,2024a)这样的模型采用多尺度表示,并通过卷积和Transformer模块进行选择性令牌丢弃。自适应方法,如UReder和DocOwl中的图像切片,根据任务复杂性动态调整令牌数量,但会牺牲一些全局上下文。
5.4 具有视频处理能力的视觉语言模型
将视觉语言模型(VLMs)从图像扩展到视频,由于时间维度的增加,显著提高了复杂性,扩大了令牌数量和计算需求。
早期的模型,如VideoLLaVA(Lin等人,2023a)统一了图像和视频训练,将视频帧特征与静态图像对齐(?),在包括MSRVTT(Xu等人,2016)、MSVD(Chen和Dolan,2011)、TGIF(Li等人,2016)和ActivityNet(Caba Heilbron等人,2015)等基准测试中,显著超越了像Video - ChatGPT(Maaz等人,2023)这样的前身。
在多模态模型领域,将视频帧特征与静态图像对齐是提升模型对不同视觉模态理解能力的关键技术。早期模型 VideoLLaVA 在这方面做出了探索,主要通过统一视觉表示和共享视觉编码器等方式来实现两者的对齐:
- 统一视觉表示:VideoLLaVA 将图像和视频的视觉表示统一到语言特征空间,使得模型可以从统一的视觉表征中学习,让大型语言模型(LLM)能同时理解图像和视频 。在训练过程中,把图像和视频数据混合在一起,让模型学习不同数据在同一特征空间下的表示。例如在一个包含多种图像和视频的训练集中,模型通过学习将图像和视频帧的特征映射到相同的特征维度和语义空间中,使得两者在表示上具有一致性,进而实现对齐。
- 共享视觉编码器:利用共享的视觉编码器来处理图像和视频。由于图像和视频在本质上都是视觉信息,共享的视觉编码器可以提取它们共有的视觉特征 。以卷积神经网络(CNN)或 Transformer - based 的视觉编码器为例,无论是静态图像还是视频中的每一帧,都经过这个相同的编码器进行特征提取。这样,从图像和视频帧中提取到的特征在特征空间上具有相似性,为后续的对齐奠定基础。在处理 MSRVTT 数据集中的图像和视频时,使用同一个视觉编码器,使得图像和视频帧的特征在同一特征空间中进行表达,从而达到对齐的效果。
- 投影层前对齐策略:在将视觉特征投影到语言模型可处理的空间之前进行对齐 。大多数现有方法将图像和视频编码到不同的特征空间,这使得语言模型难以学习它们之间的交互。VideoLLaVA 在投影之前,将图像和视频的特征进行对齐,让语言模型能从统一的视觉表示中学习,更好地理解多模态信息。
与此同时,Video - STaR(Zohar等人,2024a)引入了第一种自训练方法,利用现有的带标签视频数据集对大型多模态模型进行指令调整。
最近的模型在处理长格式视频内容方面提高了效率和有效性。时间偏好优化(TPO)(Li等人,2025a)采用带有局部化和全面时间定位的自训练方法,在LongVideoBench、MLVU和Video - MME等基准测试中取得了改进。
Oryx MLLM(Liu等人,2024g)通过其OryxViT编码器动态压缩视觉令牌,在任务中平衡了效率和精度。VideoAgent(Wang等人,2024b)将长格式视频理解建模为一个决策过程,利用大型语言模型(LLM)作为代理,迭代地识别和编译关键信息以进行问答。
VideoLLaMA3(Zhang等人,2025)使其视觉编码器适应可变分辨率,并使用多任务微调来增强视频理解能力。
Video - XL(Shu等人,2024)引入了视觉摘要令牌(VST)和课程学习,以高效处理长达数小时的视频。同样,Kangaroo(Liu等人,2024b)利用课程训练逐步扩展输入分辨率和帧数,在各种基准测试中取得了顶级性能。
Apollo(Zohar等人,2024b)最近对视频语言多模态模型(Video - LMMs)进行了深入探索,展示了对性能影响最大的架构和训练计划。通过这样做,它展示了在训练和推理过程中可以实现的显著效率提升。Apollo在LongVideoBench、MLVU和Video - MME(Zhou等人,2024;Fu等人,2024)等基准测试中,以适度的参数规模取得了最先进的结果。
6 结论
我们推出了SmolVLM,这是一系列内存高效的视觉语言模型,参数范围从2.56亿到22亿。值得注意的是,即使是我们最小的变体在推理时所需的GPU内存也不到1GB,但却超越了仅在18个月前的最先进的80亿参数模型(Laurençon等人,2023)。
我们的发现强调了一个关键见解:在资源丰富条件下优化的大型视觉语言模型架构缩小规模后,在推理过程中会导致不成比例的高内存需求,与专门设计的架构相比几乎没有优势。
相比之下,SmolVLM的设计理念明确优先考虑紧凑的架构创新、激进但谨慎的令牌化方法以及高效的训练策略,从而能够以一小部分计算成本实现强大的多模态能力。
我们公开了所有模型权重、训练数据集和训练代码,以鼓励可重复性、透明度和持续创新。我们希望SmolVLM将激发下一代轻量级、高效的视觉语言模型,为以最小功耗实现实时多模态推理开辟新的可能性。
相关文章:
)
SmolVLM2: The Smollest Video Model Ever(二)
这是对论文《SmolVLM: Redefining small and efficient multimodal models》的整理与翻译 SmolVLM:重新定义小型高效的多模态模型 拥抱脸、斯坦福大学 图1 小而强大:SmolVLM与其他最先进的小型视觉语言模型(VLM)的比较。图像结果来…...

如何通过前端表格控件实现自动化报表?1
背景 最近伙伴客户的项目经理遇见一个问题,他们在给甲方做自动化报表工具,项目已经基本做好了,但拿给最终甲方,业务人员不太买账,项目经理为此也是天天抓狂,没有想到合适的应对方案。 现阶段主要面临的问…...
)
数据库8(函数,变量)
1.数据类型 char(10):不足十个字符,用空格补全,数据定长;非统一字符编码,一个汉字要占两位char(2) nchar(10):不足十个字符,用空格补全,数据定长;统一字符编码,一个汉字占一位 nch…...
——电位器式传感器等效电路分析)
电阻式传感器(三)——电位器式传感器等效电路分析
(1)电位器式传感器的基本工作原理 将机械位移或其他可转换为位移变化的非电量转换为与其有一定函数关系的电阻变化,从而引起输出电压变化。 类型 基本结构 旋转型 直线型 非线性型 (2)电位器式传感器的等效电路分析 电位器式传感器的核…...
:初步认识Java 集成 LLM 的技术架构)
LangChain4j(1):初步认识Java 集成 LLM 的技术架构
LangChain 作为构建具备 LLM 能力应用的框架,虽在 Python 领域大放异彩,但 Java 开发者却只能望洋兴叹。LangChain4j 正是为解决这一困境而诞生,它旨在借助 LLM 的强大效能,增强 Java 应用,简化 LLM 功能在Java应用中的…...

力扣刷题——1339.分裂二叉树的最大乘积
给你一棵二叉树,它的根为 root 。请你删除 1 条边,使二叉树分裂成两棵子树,且它们子树和的乘积尽可能大。 由于答案可能会很大,请你将结果对 10^9 7 取模后再返回。 示例 1: 输入:root [1,2,3,4,5,6] 输…...

Pytest+Allure+Excel接口自动化测试框架实战
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1. Allure 简介 简介 Allure 框架是一个灵活的、轻量级的、支持多语言的测试报告工具,它不仅以 Web 的方式展示了简介的测试结果,而且允…...

交易所开发全流程解析:KYC与U盾在安全合规中的战略价值
——2025年加密资产交易平台的技术架构与风控体系深度实践 一、交易所开发的核心技术架构与流程 1. 系统定位与合规基础 交易所开发需首先明确中心化(CEX)、去中心化(DEX)或混合架构的定位。中心化交易所(如币安&…...

简单了解一下Unity的Resources.UnloadUnusedAssets
基本概念 Resources.UnloadUnusedAssets()是Unity提供的一个内存管理方法,用于卸载当前未被任何GameObject引用的资源,包括贴图、材质、网格、音频等资源。 在Unity中,资源在加载后会占用内存,而当这些资源不再被场景中的对象引…...

ECMAScript 7~10 新特性
ECMAScript 7 新特性 ECMAScript 6 新特性(一) ECMAScript 6 新特性(二) ECMAScript 7~10 新特性(本文) 1. 数组方法 Array.prototype.includes() 用来检测数组中是否包含指定元素,返回布尔值&…...

leetcode_1. 两数之和_java
1. 两数之和https://leetcode.cn/problems/two-sum/ 1、题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你…...
)
Mysql索引(四)
1、B树:B树即平衡查找树,一般理解为平衡多路查找树,也称为B-树、B_树。是一种自平衡树状数据结构,能对存储的数据进行O(log n)的时间复杂度进行查找、插入和删除; 1)每个节点占用一个盘块的磁盘空间&#x…...

力扣——【1991. 找到数组的中间位置】
#前缀和思想 主要利用递推的思想,将数列的前n!项和存到一个新数列中,递推公式可能需要自己推导 一个数列的值等于另一个数列的第i个元素加上这一个数列的第i-1个元素 同时需要初始化这个数列的第一个元素另一个数列的第一个元素 #思路 本…...
上安装 Docker)
在 Linux 系统(ubuntu/kylin)上安装 Docker
在 Linux 系统上安装 Docker 的步骤如下(以 Ubuntu/Debian 和 CentOS/RHEL 为例): 请用./check-config config检查内核是否支持,necessarily 必须全部enable。 以下是脚本自行复制运行: #!/usr/bin/env sh set -eEXITCODE=0# bits of this were adapted from lxc-checkco…...
)
【实证分析】数智化转型对制造企业全要素生产率的影响及机制探究(1999-2023年)
数智化转型是实现数字经济与实体经济深度融合,推动制造企业高质量可持续发展的必然选择,也是加快新质生产力发展的重要抓手。参照宋冬林(2025)的做法,对来自科技进步与对策《数智化转型对制造企业全要素生产率的影响及机制探究——基于中国制…...

lower_bound
在C中,lower_bound 返回的是一个迭代器(iterator),而不是直接的下标位置。因此,为了得到数组中的索引(即 pos1),你需要用返回的迭代器减去数组的起始地址(num)…...

biblatex 的 Biber 警告:tex文件运行无法生成参考文献和目录
原因:使用了 biblatex 管理参考文献,但未运行 biber 生成参考文献数据。 解决:更新 LaTeX Workshop 配置 修改你的 settings.json,添加 biber 工具并更新编译流程: {"latex-workshop.latex.tools&…...

解锁 MCP:模型上下文协议的介绍与应用,技术解析与应用场景
欢迎来到涛涛聊AI,这几天MCP很火,咱们一起学习下吧。 一、什么是 MCP MCP,即 Model Context Protocol(模型上下文协议),是由 Anthropic 推出的一个具有创新性的开放协议 。它的核心目标是统一 LLM 应用与外部数据源和工具之间的通信方式,为 AI 开发打造标准化的上下文…...

十二种存储器综合对比——《器件手册--存储器》
存储器 名称 特点 用途 EEPROM 可电擦除可编程只读存储器,支持按字节擦除和写入操作,具有非易失性,断电后数据不丢失。 常用于存储少量需要频繁更新的数据,如设备配置参数、用户设置等。 NOR FLASH 支持按字节随机访问&…...

对重大保险风险测试的算法理解
今天与同事聊到重大保险风险测试,借助下面链接的文章, 谈IFRS 17下的重大保险风险测试 - 知乎 谈一下对下图这个公式的理解。 尤其是当看到下面这段文字的解释时,感觉有些算法上的东西,需要再澄清一些。 首先,上面文…...

App Cleaner Pro for Mac 中 Mac软件卸载工具
App Cleaner Pro for Mac 中 Mac软件卸载工具 一、介绍 App Cleaner & Uninstaller Pro Mac破解,是一款Mac软件卸载工具,残余垃圾清除工具!可以卸载应用程序或只删除不需要的服务文件,甚至可以删除以前删除的应用程序中的文…...

【操作系统】线程同步:原理、方法与实践
一、线程同步的核心概念 1.1 为什么需要线程同步? 在多线程环境中,当多个线程并发访问共享资源(如内存、文件、数据库等)时,可能会引发数据竞争(Race Condition),导致数据不一致或…...

vue实现二维码生成器和解码器
vue实现二维码生成器和解码器 1.生成基本二维码:根据输入的value生成二维码。 2.可定制尺寸:通过size调整大小。 3.颜色和背景色:设置二维码颜色和背景。 4.静区(quiet zone)支持:通过quietZone调整周围的…...

p2p的发展
PCDN(P2P内容分发网络)行业目前处于快速发展阶段,面临机遇与挑战并存的局面。 一、发展机遇 技术融合推动 边缘计算与5G普及:5G的高带宽、低延迟特性与边缘计算技术结合,显著提升PCDN性能,降低延迟&#x…...

DeepSeek提示词实战大全:提示词合集和使用技巧
大家好,我是大 F,深耕AI算法十余年,互联网大厂技术岗。 知行合一,不写水文,喜欢可关注,分享AI算法干货、技术心得。 更多文章可关注《大模型理论和实战》、《DeepSeek技术解析和实战》,一起探索技术的无限可能! 【数据集篇】更多阅读: 大语言模型常见任务及评测数据集…...

23种设计模式生活化场景,帮助理解
以下是 23种设计模式的生活化场景 及其核心对比,通过日常例子和比喻帮助理解它们的本质区别和应用场景: 创建型模式(5种) 1. 工厂方法(Factory Method) • 场景:快餐店的点餐系统。 • 问题&a…...

Kotlin 学习-方法和参数类型
/*** kotlin 的方法有三种* */fun main() {/*** 方法一* 1.普通类的成员方法申明与调用* (1)需要先构建出实例对象,才能访问成员方法* (2)实例对象的构建只需要在类名后面加上()* */Person().test()/*** 方法二&#x…...

Java 解析日期格式各个字段含义温习
背景 今天解析了一个不常见的日期格式 「10-Mar-2025 16:30:47.869」,对应的 Java 日期格式是 dd-MMM-yyyy HH:mm:ss.SSS ,而且跟 Local 语言环境有关。 本文记录这个简单的解析过程,顺便回忆一下日期格式各个字段。毕竟平时只用了常见的 y…...

OpenBayes 一周速览|1分钟生成完整音乐,DiffRhythm人声伴奏一键搞定; Stable Virtual Camera重塑3D视频创作
公共资源速递 5 个数据集: * 302 例罕见病病例数据集 * DRfold2 RNA 结构测试数据集 * NaturalReasoning 自然推理数据集 * VenusMutHub 蛋白质突变小样本数据集 * Bird Vs Drone 鸟类与无人机图像分类数据集 2 个模型: * Qwen2.5-0mni * Llama…...

SpringBoot 数据库MySql的读写分离 多数据源 Shardingsphere高并发优化
介绍 传统的 MySQL 架构中,所有的数据库操作(包括读操作和写操作)都在同一个数据库实例上进行。随着应用程序的规模增长,单一数据库实例可能会成为瓶颈,无法满足高并发的需求。为了优化性能,可以将数据库的…...

SQLI漏洞公开报告分析
文章目录 1. 闭合 )2. 邀请码|POST参数|时间盲注 | **PostgreSQL**3. POST|order by参数|布尔盲注|Oracle4. SOAP请求|MSSQL|布尔盲注5. MySQL 时间盲注漏洞6. GET|普通回显注入7. ImpressCMS 1.4.2 | CVE | POST | 布尔盲注8. Mysql | post | 布尔/时间盲注9. 登录口 | post |…...

并行和并发有什么区别?
1. 定义 并行是在同一时刻执行多个任务。并发是在相同的时间段内执行多个任务,任务可能交替执行,通过调度实现。 2. 区别 执行方式: 并发:多个任务交替进行,任务并不一定同时执行,只是在同一时间段内处理…...

Elasticsearch 全面解析
Elasticsearch 全面解析 前言一、简介核心特性应用场景 二、核心原理与架构设计1. 倒排索引(Inverted Index)2. 分片与副本机制(Sharding & Replication)3. 节点角色与集群管理 三、核心特点1. 灵活的查询语言(Que…...

SQL 中的 NULL 处理
NULL 在 SQL 中表示缺失、未知或不适用的数据值,它与空字符串或零值不同。SQL 对 NULL 有特殊的处理规则: NULL 的基本特性 比较运算:任何与 NULL 的比较都返回 UNKNOWN(既不是 TRUE 也不是 FALSE) SELECT * FROM tab…...

2025常用的ETL 产品推荐:助力企业激活数据价值
在当今数字化时代,企业面临着海量数据的挑战与机遇,ETL(Extract, Transform, Load)工具作为数据整合与分析的关键环节,其重要性日益凸显。ETL 厂商众多,各有优势,本文将从多个维度进行分析&…...

深入解析:Python 爬取淘宝商品券后价
在电商领域,淘宝作为国内领先的电商平台,拥有海量的商品和丰富的优惠活动。对于技术开发者来说,获取淘宝商品的券后价是实现电商应用功能的重要环节。本文将详细介绍如何通过淘宝开放平台的 API 接口获取商品的券后价,并提供实际的…...

25.4.10学习总结
关于消除警告 警告: Loading FXML document with JavaFX API of version 23.0.1 by JavaFX runtime of version 17.0.6 对应这条警告,我的处理方式是,将IDEA的默认javaFX的库换成自己下载的javaFX的库。 我用的javaFX的库如下: javaFX-24…...

【XML基础-2】深入理解XML中的语义约束:DTD详解
XML(可扩展标记语言)作为数据交换的标准格式,在Web服务和应用程序间数据传递中扮演着重要角色。而确保XML文档结构正确性和语义一致性的关键,就在于文档类型定义(DTD)。本文将全面解析DTD的概念、语法结构、…...

SkyWalking + ELK 全链路监控系统整合指南
一、架构设计图 二、核心组件部署 1. SkyWalking 集群部署 yaml: # docker-compose-skywalking.yml version: 3.8services:oap:image: apache/skywalking-oap-server:9.7.0ports:- "11800:11800" # gRPC- "12800:12800" # HTTPenvironment:SW_STORAGE: …...

LeetCode hot 100—编辑距离
题目 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 示例 示例 1: 输入:word1 "horse", word2 &q…...

SAP系统年终结算出错
问题描述:2024年采购订单发票校验过账到2024年时提示错误如下: 问题原因:2024年全部未结束的采购申请和订单被结转到2025年。 解决方法:用事务代码FMJ3冲销此采购订单结转。...
示例:祝福程序)
在 Dev-C++中编译运行GUI 程序介绍(二)示例:祝福程序
在 Dev-C中编译运行GUI 程序介绍(二)示例:祝福程序 前期见: 在 Dev-C中编译运行GUI 程序介绍(一)基础 https://blog.csdn.net/cnds123/article/details/147019078 示例1、祝福程序 本文中的这个祝福程序是…...

Uniapp使用onShow语法报before initialization
一、错误原因分析 函数未完成初始化时被调用 • 当你在 onShow 生命周期中调用 getUserMessagePlan() 时,如果该函数的定义位于调用代码的下方(如示例中的顺序),JavaScript 引擎会因 变量提升规则 抛出此错误。 • 示例代码结构&a…...
-初治患者诊疗中应用的研究报告)
大模型在儿童急性淋巴细胞白血病(ALL)-初治患者诊疗中应用的研究报告
目录 一、绪论 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与内容 二、大模型技术与儿童 ALL 相关知识 2.1 大模型技术原理与特点 2.2 儿童 ALL 的病理生理与诊疗现状 三、术前风险预测与手术方案制定 3.1 术前数据收集与预处理 3.2 大模型预测术前风险 3.…...

如何选择适合机床的丝杆支撑座型号?
在机床中选择丝杆支撑座型号时,需综合考虑机械性能、安装条件及应用需求,接下来我们一起来看看详细的选型指南! 1、适配性:丝杆支撑座应与所使用的滚珠丝杆完全适配,确保两者在尺寸、规格、性能等方面相互匹配。 2…...

「The Road to Web3 Cloud」香港活动回顾|波卡的 Web3 Cloud 愿景
在区块链基础设施的发展浪潮中,Polkadot 正在迈出决定性的一步:打造一个属于 Web3 的 “云服务平台”。如果说 Bitcoin 创造了一个计算器,以太坊创造了一个计算机,那么 Polkadot 正在做的则是构建链上的 “云服务器”。它的目标是…...

PostgreSQL-容器运行时索引修复
在 Docker 中运行的 PostgreSQL 数据库如果索引损坏,可以通过以下步骤进行修复。索引损坏可能会导致查询性能下降或数据不一致,因此需要及时处理。 1. 进入 PostgreSQL 容器 首先,进入运行 PostgreSQL 的 Docker 容器: <BASH&…...

Vanna + qwq32b 实现 text2SQL
Vanna 是一个开源的 Text-2-SQL 框架,主要用于通过自然语言生成 SQL 查询,它基于 RAG(Retrieval-Augmented Generation,检索增强生成)技术。Vanna 的核心功能是通过训练一个模型(基于数据库的元数据和用户提…...

100V5A同步降压大功率芯片WD5105:高效电源管理的卓越之选
100V5A同步降压大功率芯片WD5105:高效电源管理的卓越之选 在现代电子设备的复杂电源架构中,对高效、稳定且可靠的电源管理芯片需求日益增长。WD5105作为一款100V5A同步降压大功率芯片,凭借其出色的性能、全面的保护机制以及广泛的应用适应性…...

springboot中测试python脚本:ProcessBuilder
目录 一.添加Jython依赖 二.使用步骤 1. 创建 ProcessBuilder 实例 2. 设置工作目录(可选) 3. 合并错误流(可选) 4. 启动进程 5. 处理输入输出流 6. 等待进程完成 7.完整案例 三.注意事项 ProcessBuilder是jdk提供的脚本…...