【JVM】JVM调优实战
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- JVM调优实战
- 性能优化的步骤
- 第一步(发现问题):性能监控
- 第二步(排查问题):性能分析
- 第三步(解决问题):性能调优
- Jmeter
- 简介
- 使用流程
- 新增线程组
- 新增JMeter元组
- 新增监听器
- 运行并查看结果
- 案例1:调整堆大小提升服务的吞吐量
- 修改tomcatJVM配置
- 初始配置
- 优化配置
- 案例2:JVM优化之JIT优化
- 堆是分配对象的唯一选择吗?
- 传统认知的局限性
- JIT的优化突破:逃逸分析
- 总结
- 编译的开销
- 时间开销
- 空间开销
- 编译开销的平衡艺术
- 即时编译对代码的优化
- 逃逸分析
- 代码举例1:未逃逸对象
- 代码举例2:逃逸对象
- 参数设置
- 代码优化一:栈上分配
- 代码举例
- 代码优化二:同步省略(锁消除)
- 代码举例
- 代码优化三:标量替换
- 代码举例1:基本类型替换
- 参数设置
- 代码举例2:数组成员替换
- 逃逸分析小结
- 案例3:合理配置堆内存
- 推荐配置
- 如何计算老年代存活对象
- 方式1:查看GC日志(无侵入式)
- 方式2:强制触发Full GC(侵入式)
- 注意事项
- 方案对比
- 案例演示
- JVM参数配置
- 代码演示
- 数据分析
- 结论
- 如何估算GC频率
- 新生代与老年代的比例
- 参数设置:手动控制比例
- 参数AdaptiveSizePolicy:动态比例调优
- 验证方式
- 案例4:CPU占用很高的排查方案
- 示例代码
- 问题呈现
- 问题分析
- 解决方案
- 案例5:G1并发GC线程数对性能的影响
- 配置信息
- 硬件配置
- JVM参数设置
- 初始状态
- 优化后
- 总结
- 案例6:调整垃圾回收器对吞吐量的影响
- 初始配置:单核+SerialGC
- 优化配置1:ParallelGC
- 优化配置2:8核
- 优化配置3:G1
- 案例7:日均百万订单如何设置JVM参数
JVM调优实战
性能优化的步骤
首先,来回顾一下调优的基本步骤。
第一步(发现问题):性能监控
性能监控是整个调优过程的基础,必须通过监控工具实时获取系统运行状态。通过监控,可以发现哪些资源(如内存、CPU、磁盘、网络等)存在瓶颈,系统是否频繁发生GC停顿、线程阻塞等问题。 常见的问题如下:
- GC频繁
- CPU负载过高
- OOM
- 内存泄露
- 死锁
- 程序响应时间长
第二步(排查问题):性能分析
- 打印GC日志,通过
GCViewer或GCeasy来分析异常 - 灵活运用命令行工具,如
jstat、jinfo等 - 生成快照文件,使用内存分析工具分析文件
- 使用阿里
Arthas、jconsole以及JVisualVM等GUI工具来实时查看JVM状态 jstack查看堆栈信息
第三步(解决问题):性能调优
- 调优GC:根据分析结果,调整垃圾回收器和相关参数,减少GC停顿时间。例如,切换至G1 GC或使用ZGC(低延迟垃圾回收器)。
- 调优堆内存:根据应用的内存需求,调整堆大小,避免内存溢出或频繁的垃圾回收。
- 调优线程池:通过调整线程池的大小、线程优先级等,确保线程调度的高效性。
- 优化代码:针对代码中的性能瓶颈,进行相应的优化,减少内存泄漏和过多的锁竞争。
- 使用中间件:针对程序中原生的接口,观察是否可以替换为效率更高的中间件,如消息队列等。
Jmeter
简介
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。 它可以用于测试静态和动态资源,例如静态文件、CGI 脚本、Java 对象、数据库、FTP 服务器, 等等。JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。我们这里主要介绍与我们接下来的案例相关的部分。
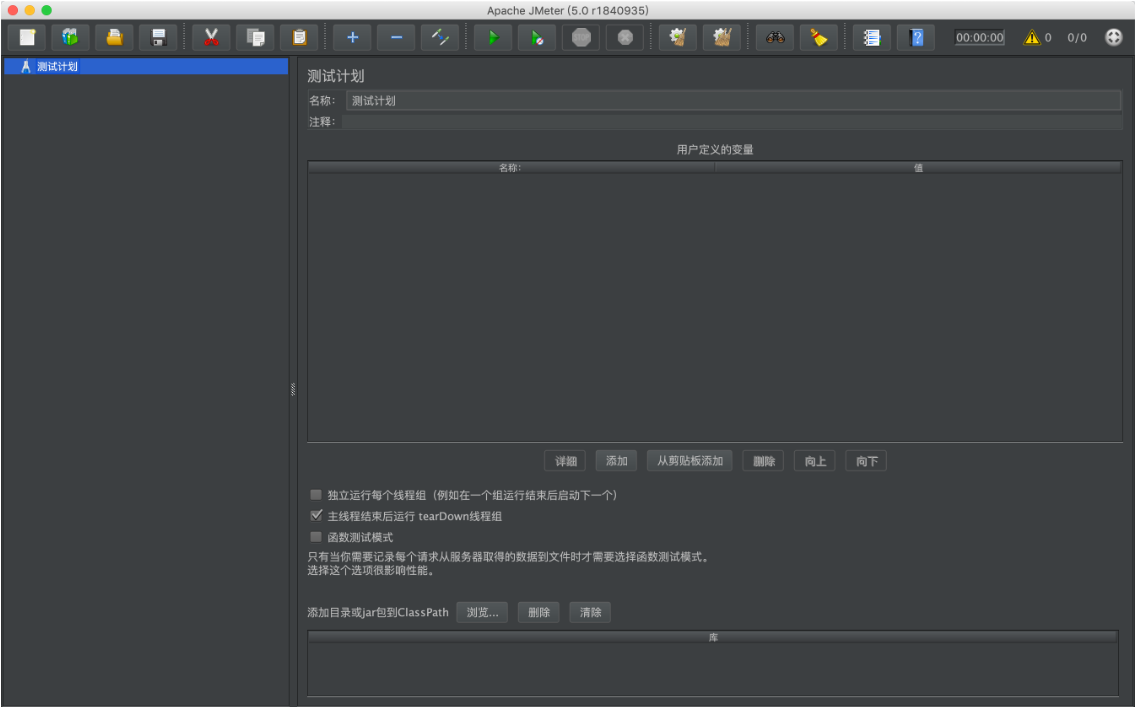
使用流程
新增线程组
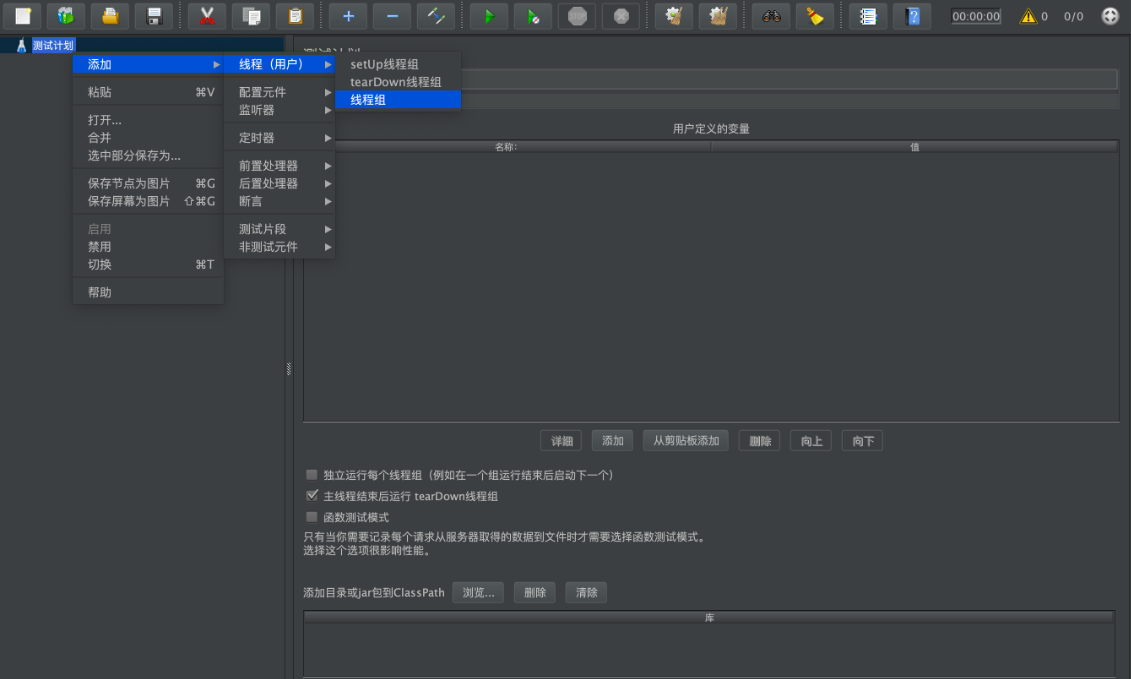
新增JMeter元组
创建各种默认元组及测试元组,填入目标测试静态资源请求和动态资源请求参数及数据。
新增http采样器,采样器用于对具体的请求进行性能数据的采样,如下图所示,这次案例添加HTTP请求的采样。
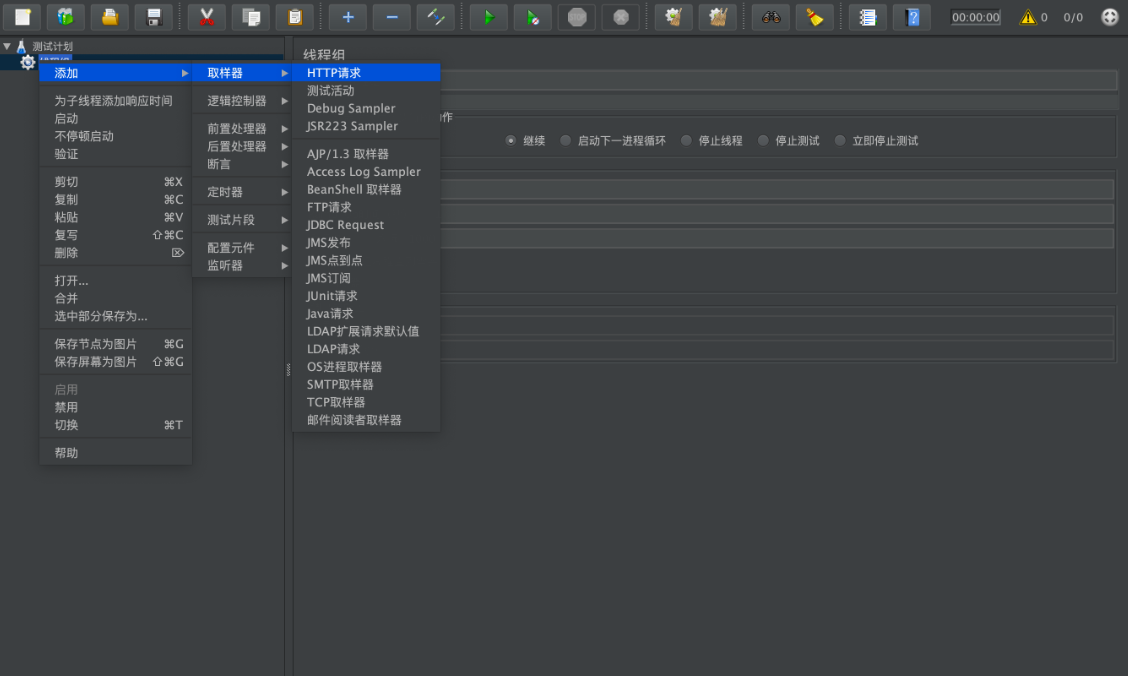
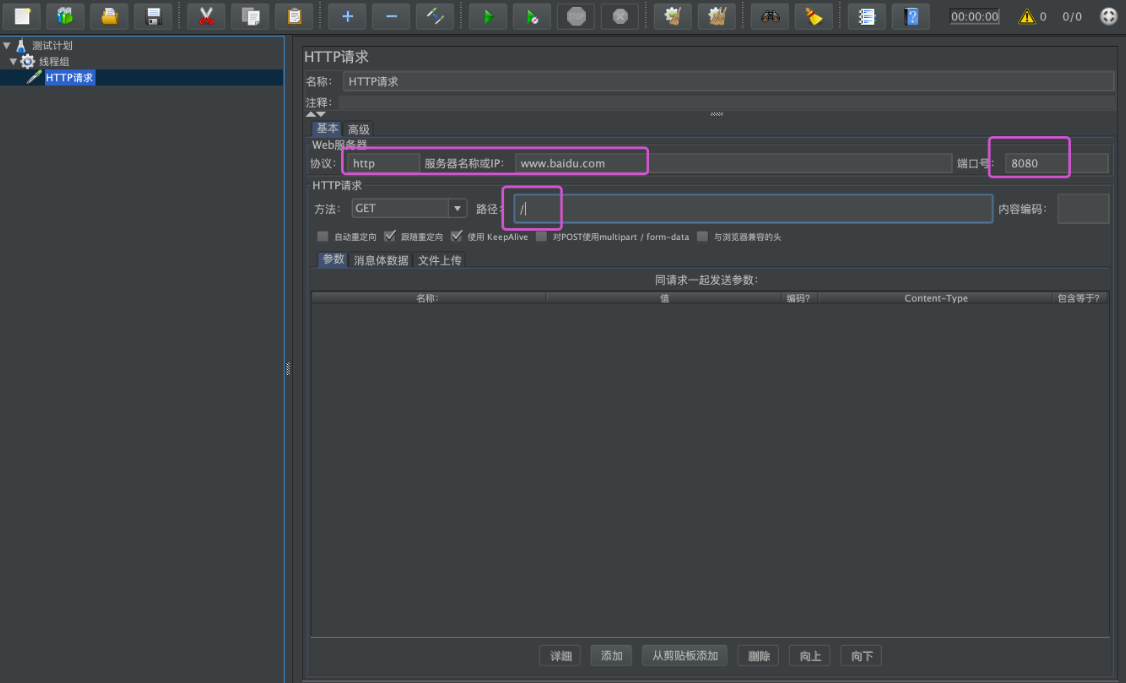
对请求的具体目标进行设置,比如目标服务器地址,端口号,路径等信息,如下图所示,Jmeter会按照设置对目标进行批量的请求。
新增监听器
创建各种形式的结果搜集元组,以便在运行过程及运行结束后搜集监控指标数据。
对于批量请求的访问结果,Jmeter可以以报告的形式展现出来,在监听器中,添加聚合报告,如下图所示:
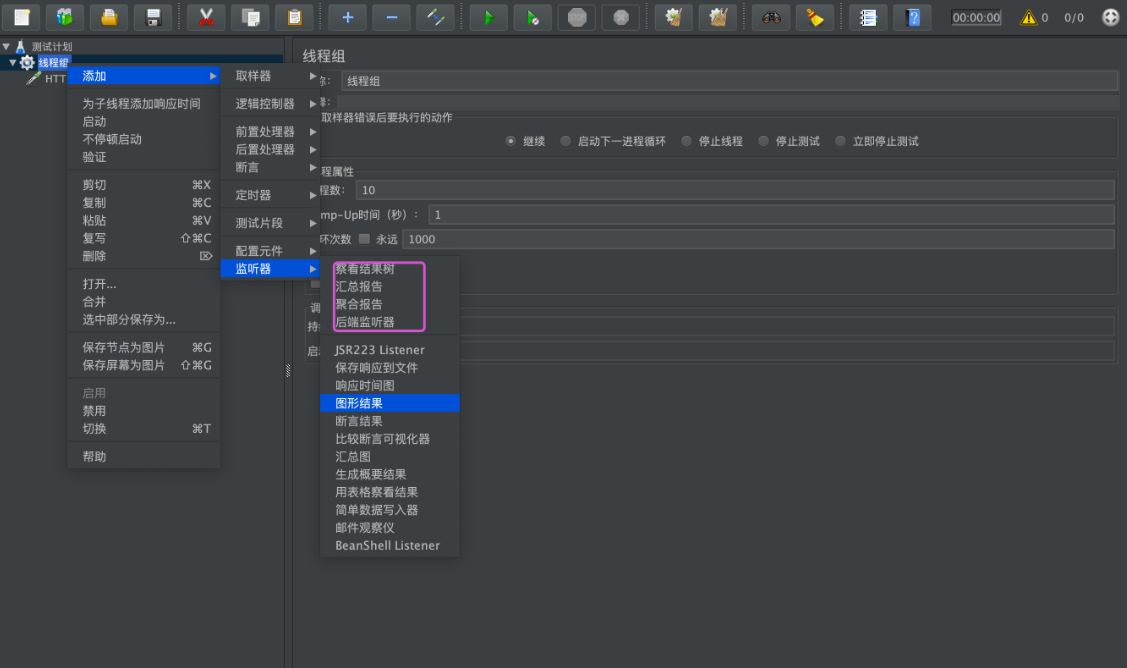
运行并查看结果
调试运行,分析指标数据,挖掘性能瓶颈、评估系统性能状态
案例1:调整堆大小提升服务的吞吐量
修改tomcatJVM配置
生产环境下,Tomcat并不建议直接在catalina.sh里配置变量,而是写在与catalina同级目录(bin目录)下的setenv.sh里。
所以如果我们想要修改jvm的内存配置,那么我们就需要修改setenv.sh文件(默认没有,需新建一个setenv.sh)。
初始配置
setenv.sh文件中写入(大小根据自己情况修改):setenv.sh内容如下:
export CATALINA_OPTS="$CATALINA_OPTS -Xms30m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:SurvivorRatio=8"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx30m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseParallelGC"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDetails"
export CATALINA_OPTS="$CATALINA_OPTS -XX:MetaspaceSize=64m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDateStamps"
export CATALINA_OPTS="$CATALINA_OPTS -Xloggc:/opt/tomcat8.5/logs/gc.log"
我们查看日志信息:

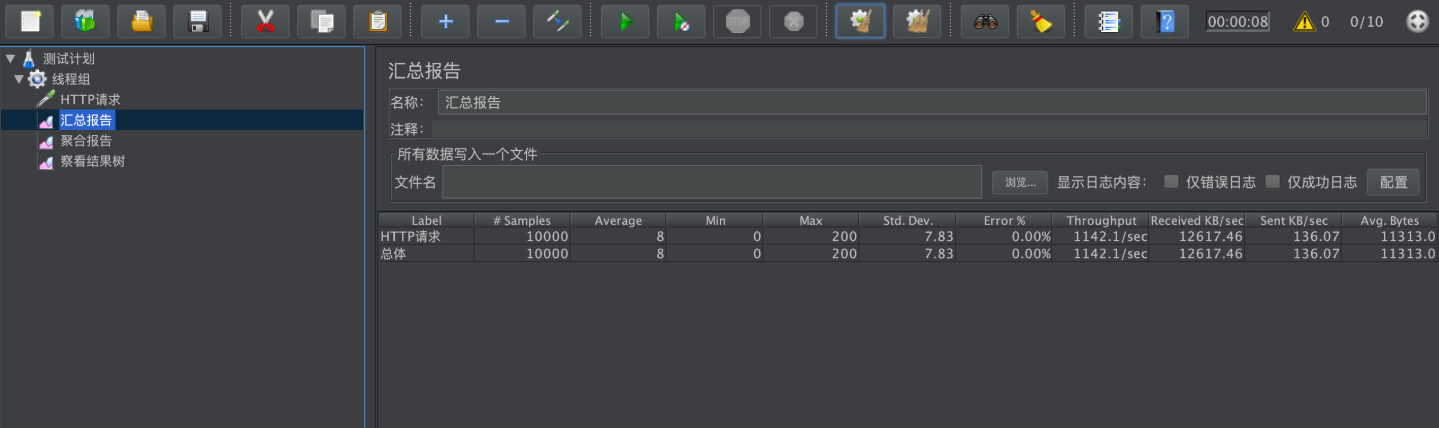
其中存在大量的Full GC日志,查看一下我们Jmeter汇总报告
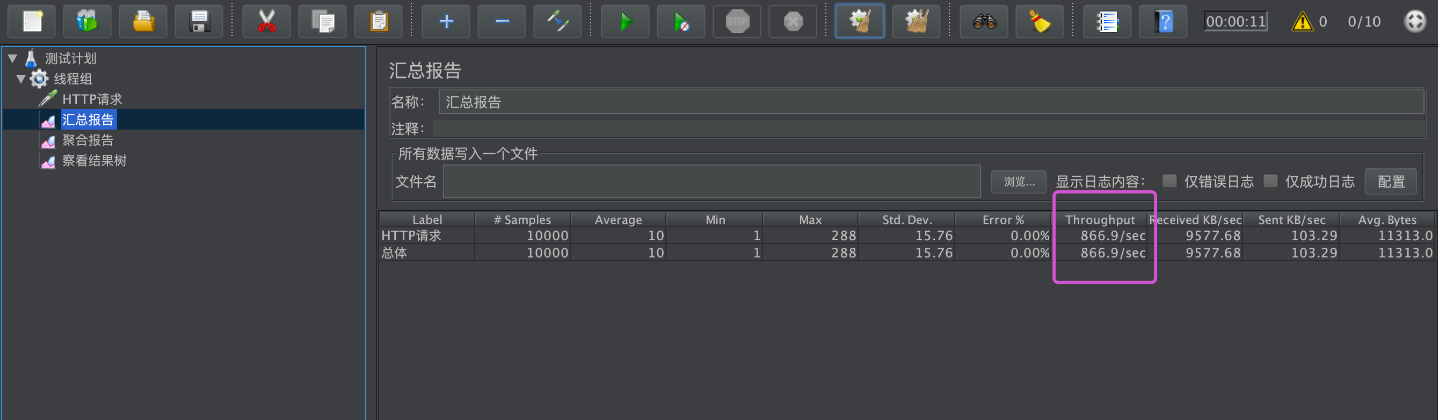
优化配置
接下来我们测试另外一组数据,增加初始化和最大内存:
export CATALINA_OPTS="$CATALINA_OPTS -Xms120m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:SurvivorRatio=8"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx120m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseParallelGC"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDetails"
export CATALINA_OPTS="$CATALINA_OPTS -XX:MetaspaceSize=64m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDateStamps"
export CATALINA_OPTS="$CATALINA_OPTS -Xloggc:/opt/tomcat8.5/logs/gc.log"
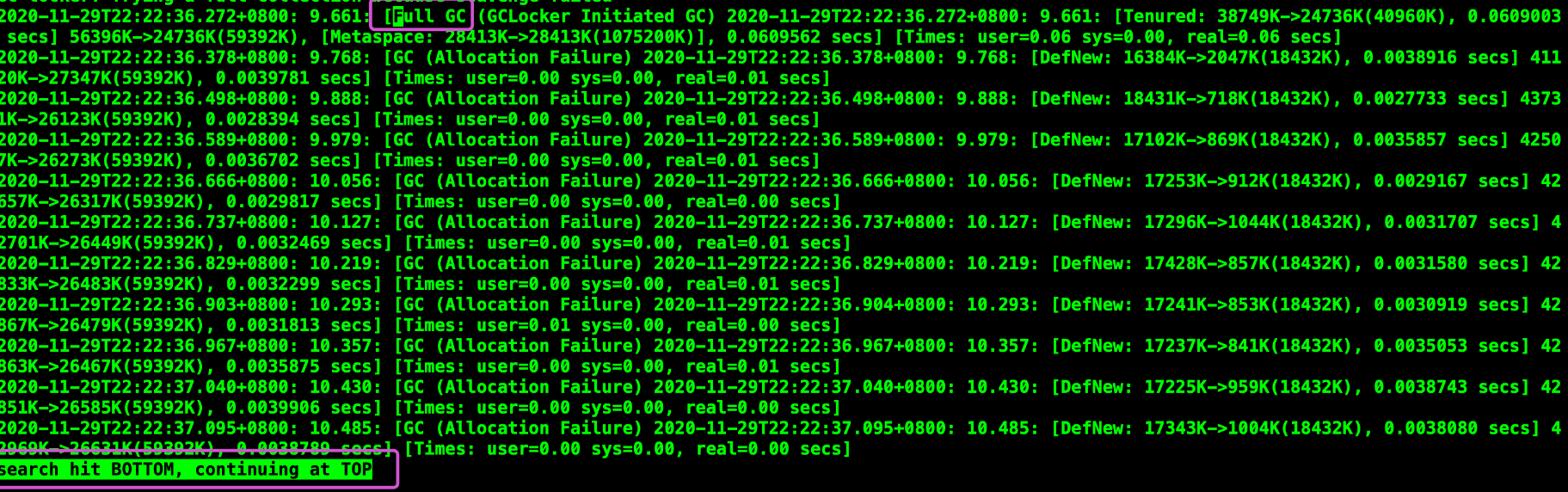
查找Full关键字,发现只有一处FullGC,如下图所示,我们可以看到,增大了初始化内存和最大内存之后,我们的Full次数有一个明显的减少。
查看Jmeter汇总报告,如下图所示:吞吐量变成了1142.1/sec,基本上是有一个明显的提升,这就说明,增加内存之后,服务器的性能有一个明显的提升。
案例2:JVM优化之JIT优化
堆是分配对象的唯一选择吗?
在Java开发者的普遍认知中,对象的实例化必须依赖堆内存分配,这一观点源自Java语言规范对对象存储的早期定义。然而,随着JVM即时编译(JIT)技术的发展,尤其是**逃逸分析(Escape Analysis)**的引入,这一结论正在被颠覆。
传统认知的局限性
- 堆分配的必要性: 对象的生命周期通常跨越方法调用边界,堆内存的动态性和线程共享特性使其成为默认选择。
- 性能代价: 频繁的堆分配会导致内存碎片化、垃圾回收(GC)压力增大,尤其是对短生命周期的小对象而言,GC暂停时间可能成为性能瓶颈。
JIT的优化突破:逃逸分析
JVM的即时编译器通过逃逸分析技术,能够在编译期推断对象的生命周期范围,从而为某些对象提供更高效的分配方式。
总结
虽然堆仍是大部分对象的最终归宿,但JIT通过逃逸分析打破了“堆是唯一选择”的绝对性。对于符合条件的作用域内对象,栈上分配和标量替换能显著减少GC压力,提升程序吞吐量。开发者可通过代码结构优化(如减少全局暴露、缩小对象作用域)主动适配这些特性,释放JVM性能潜力。
编译的开销
即时编译(JIT)技术通过将热点代码转换为本地机器码来提升程序性能,但这一过程并非零成本。编译操作本身会消耗 CPU时间 和 内存空间,理解这些开销是优化JVM性能的关键前提。
时间开销
- 分层编译的代价
JVM采用分层编译(Tiered Compilation) 策略,分为解释执行、C1编译(客户端编译器)、C2编译(服务端编译器)三个阶段:- 解释阶段:快速启动但执行效率低,适合短生命周期方法。
- C1编译(-XX:TieredStopAtLevel=1):生成简单优化代码,编译耗时约 1-10ms/方法。
- C2编译(-XX:TieredStopAtLevel=4):深度优化(如内联、循环展开),编译耗时可达 10-100ms/方法。
- 性能拐点
若热点方法频繁触发再编译(如因去优化[Deoptimization]),累积的编译时间可能抵消性能收益。典型场景:
// 动态类型变化导致去优化
Object val = Math.random() > 0.5 ? "string" : 123;
for (int i = 0; i < 1_000_000; i++) {process(val); // 需多次编译多态签名
}
- 参数调优
- 调整触发编译的阈值:
-XX:CompileThreshold(默认1500次调用) - 关闭非必要编译层级:
-XX:-TieredCompilation(慎用,可能降低峰值性能)
- 调整触发编译的阈值:
空间开销
- 代码缓存(Code Cache)
JIT编译生成的本地机器码存储在固定大小的Code Cache中(默认约240MB):- 溢出风险:缓存满后停止编译,程序退回解释执行,性能断崖下降。
- 监控命令:
jinfo -flag CodeCacheSize <pid> # 查看当前容量
jstat -compiler <pid> # 查看编译方法占比
- 元数据内存占用
- 编译队列:待编译方法队列占用堆外内存(可通过
-XX:CICompilerCount增加编译线程数缓解)。 - 分析数据结构:逃逸分析、内联决策等算法需额外存储方法调用图、控制流等中间数据。
- 编译队列:待编译方法队列占用堆外内存(可通过
- 空间优化策略
- 调整CodeCache大小:
-XX:ReservedCodeCacheSize=512m(建议不超过512MB) - 清理无效编译结果:
-XX:+UseCodeCacheFlushing(JDK 8+默认开启) - 限制激进优化:
-XX:InlineSmallCode=2000(避免大方法内联占用缓存)
- 调整CodeCache大小:
编译开销的平衡艺术
JIT编译的 时间-空间-性能三角矛盾 要求开发者根据场景动态权衡:
- 短周期应用(如命令行工具):关闭C2编译(
-XX:TieredStopAtLevel=3)减少启动延迟。 - 长周期服务(如Web服务器):扩大CodeCache并启用全量优化,追求吞吐量最大化。
通过-XX:+PrintCompilation日志可观察编译耗时,结合-Xlog:codecache=info监控缓存利用率,实现精准调优。
即时编译对代码的优化
JIT编译器通过**逃逸分析(Escape Analysis)**动态追踪对象作用域,触发以下三类关键优化,显著降低堆内存与同步操作的开销。
逃逸分析
原理:在编译期判断对象是否逃逸出当前线程/方法/类的作用域,决定优化策略。
代码举例1:未逃逸对象
public void renderImage() {// 对象未逃逸出方法 ColorProfile profile = new ColorProfile(0.5, 0.2, 0.8); applyFilter(profile); // 仅在方法内使用
}
优化:profile对象满足栈上分配或标量替换条件。
代码举例2:逃逸对象
public class LoggerHolder {private static Logger LOGGER; // 静态字段导致逃逸public static void log(String msg) {LOGGER = new Logger(msg); // 对象逃逸到类作用域外LOGGER.flush();}
}
结果:强制堆分配,无法触发优化。
参数设置
- 开启逃逸分析(JDK 7+默认启用):
-XX:+DoEscapeAnalysis - 逃逸分析日志(调试用):
-XX:+PrintEscapeAnalysis
代码优化一:栈上分配
条件:对象未逃逸出方法作用域。
原理:将对象存储在栈帧中,随方法调用结束自动销毁。
代码举例
public String generateID() {// UUID对象未逃逸 UUID uuid = UUID.randomUUID(); return uuid.toString(); // 仅返回字符串,UUID对象未暴露
}
效果:uuid对象分配在栈上,无GC开销。
代码优化二:同步省略(锁消除)
条件:对象未逃逸出线程作用域。
原理:若锁对象仅被当前线程访问,JIT移除synchronized字节码。
代码举例
public void threadLocalCounter() {Object lock = new Object(); // 对象未逃逸出当前线程 synchronized(lock) { // 锁被消除 counter++; }
}
反编译验证:用javap -v查看字节码,无monitorenter/monitorexit指令。
代码优化三:标量替换
条件:对象未逃逸且可拆解为独立标量(基本类型或极简结构)。
代码举例1:基本类型替换
public double calculateArea(Point p) {// Point对象被拆解为x,y int x = p.x; int y = p.y; return x * y; // 无需保留Point对象
}
参数设置
- 标量替换开关(JDK 7+默认开启):
-XX:+EliminateAllocations
代码举例2:数组成员替换
public void initMatrix() {int[] matrix = new int[4]; // 未逃逸数组 matrix[0] = 1; // 替换为4个int变量 matrix[1] = 2; // ...
}
逃逸分析小结
| 优化类型 | 触发条件 | 性能收益 |
|---|---|---|
| 栈上分配 | 对象未逃逸出方法作用域 | 减少堆内存分配/GC停顿 |
| 同步省略 | 对象未逃逸出线程作用域 | 消除锁竞争开销 |
| 标量替换 | 对象可分解为独立标量 | 降低内存占用,提高CPU缓存命中率 |
注意事项:
- 逃逸分析依赖JIT编译阈值,高频热点方法才能触发优化。
- 过度封装(如滥用DTO对象)可能导致对象意外逃逸,抑制优化。
- 可通过
-XX:+JITDisableStackAllocation强制关闭栈分配(调试用)。
案例3:合理配置堆内存
推荐配置
- Java整个堆大小设置,Xmx 和 Xms设置为老年代存活对象的3-4倍,即FullGC之后的老年代内存占用的3-4倍。
- 方法区(永久代 PermSize和MaxPermSize 或 元空间 MetaspaceSize 和 MaxMetaspaceSize)设置为老年代存活对象的1.2-1.5倍。
- 年轻代Xmn的设置为老年代存活对象的1-1.5倍。
- 老年代的内存大小设置为老年代存活对象的2-3倍。
如何计算老年代存活对象
准确计算老年代存活对象大小是合理设置堆内存、选择垃圾收集器的重要依据,以下提供两种实践方案:
方式1:查看GC日志(无侵入式)
原理:通过GC日志中的老年代容量变化推算长期存活对象。
- 启用详细GC日志
启动参数添加:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
- 关键日志指标解读
观察Full GC后老年代占用(以G1收集器为例):
2024-01-01T12:00:00.123+0800: [GC pause (G1 Humongous Allocation) ... [Eden: 200M(200M)->0B(200M) Survivors: 24M->24M **Old: 1800M->1500M** # 老年代回收后占用 ]
计算逻辑:
存活对象 ≈ Old区回收后占用值(1500M) - 浮动垃圾(需多轮Full GC观察稳定值)
- 日志分析工具
- GCViewer:可视化分析
gc.log中各区域趋势 - grep命令:快速提取老年代数据
- GCViewer:可视化分析
grep "Old: " gc.log | awk -F'Old: ' '{print $2}'
方式2:强制触发Full GC(侵入式)
原理:主动触发Full GC回收可回收对象,通过内存快照获取精确值。
- 手动触发Full GC
- jmap命令触发(立即执行Full GC):
jmap -histo:live <pid> # 触发Full GC并生成直方图(不推荐生产环境)
- **jcmd命令触发**(JDK 7+):
jcmd <pid> GC.run # 执行Full GC
- 查看老年代占用
Full GC完成后,使用jstat获取实时数据:
jstat -gc <pid> 1000 5 # 每秒1次,共5次
输出列说明:
OC(Old Capacity) OU(Old Utilization)
6144.0(MB) 2048.0(MB) # 存活对象约2GB
- 内存dump验证
jmap -dump:live,file=heap.hprof <pid> # Full GC后dump(谨慎使用)
使用MAT工具分析heap.hprof,过滤Old Gen对象:
OQL查询:SELECT * FROM INSTANCEOF java.lang.Object WHERE ${object}@gcInfo.gen == "old"
注意事项
- 生产环境风险:
- Full GC会导致所有线程暂停(STW),禁止在高峰期操作
- 建议在压测环境或维护窗口执行
- 数据误差控制:
- 多次采样取平均值(至少3次Full GC后数据)
- 排除元数据(Metaspace)、CodeCache等非堆影响
- 收集器差异:
- CMS收集器需配合
-XX:+UseCMSCompactAtFullCollection避免碎片误差 - G1收集器优先观察
Region分布(jstat -gccapacity)
- CMS收集器需配合
方案对比
| 维度 | 日志分析 | 强制触发Full GC |
|---|---|---|
| 实时性 | 依赖历史数据 | 即时获取 |
| 侵入性 | 无 | 高(STW暂停) |
| 精度 | 需排除浮动垃圾干扰 | 精确(需排除强引用误差) |
| 适用阶段 | 日常监控 | 容量规划、故障排查 |
案例演示
JVM参数配置
内存初始化为1024M。
-XX:+PrintGCDetails -XX:MetaspaceSize=64m -Xss512K
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap/heapdump3.hprof
-XX:SurvivorRatio=8 -XX:+PrintGCDateStamps -Xms1024M -Xmx1024M -Xloggc:log/gc-oom3.log代码演示
- controller
@RequestMapping("/getData")
public List<People> getProduct(){List<People> peopleList = peopleSevice.getPeopleList();return peopleList;
}
- service
@Service
public class PeopleSevice {@AutowiredPeopleMapper peopleMapper;public List<People> getPeopleList(){return peopleMapper.getPeopleList();}}- mapper
@Repository
public interface PeopleMapper {List<People> getPeopleList();
}- bean
@Data
public class People {private Integer id;private String name;private Integer age;private String job;private String sex;
}
- xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguiigu.jvmdemo.mapper.PeopleMapper"><resultMap id="baseResultMap" type="com.atguiigu.jvmdemo.bean.People"><result column="id" jdbcType="INTEGER" property="id" /><result column="name" jdbcType="VARCHAR" property="name" /><result column="age" jdbcType="VARCHAR" property="age" /><result column="job" jdbcType="INTEGER" property="job" /><result column="sex" jdbcType="VARCHAR" property="sex" /></resultMap><select id="getPeopleList" resultMap="baseResultMap">select id,name,job,age,sex from people</select>
</mapper>
数据分析
项目启动,通过jmeter访问10000次(主要是看项目是否可以正常运行)之后,查看gc状态
jstat -gc pid
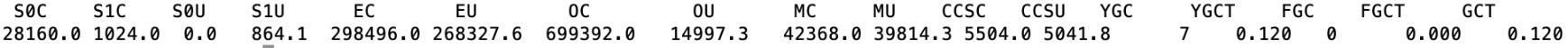
YGC平均耗时: 0.12s * 1000/7 = 17.14ms
FGC未产生
看起来似乎不错,YGC触发的频率不高,FGC也没有产生,但这样的内存设置是否还可以继续优化呢?是不是有一些空间是浪费的呢。
为了快速看数据,我们使用了方式2,通过命令 jmap -histo:live pid 产生几次FullGC,FullGC之后,使用的jmap -heap 来看的当前的堆内存情况。
观察老年代存活对象大小:
jmap -heap pid
或者直接查看GC日志
查看一次FullGC之后剩余的空间大小
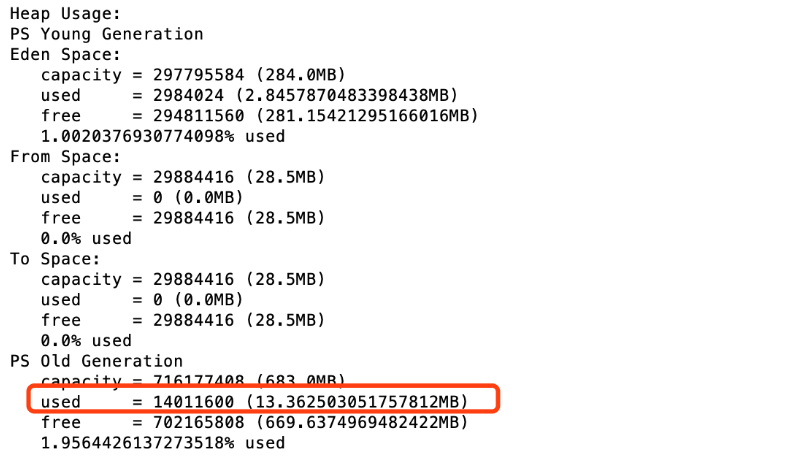
可以看到存活对象占用内存空间大概13.36M,老年代的内存占用为683M左右。 按照整个堆大小是老年代(FullGC)之后的3-4倍计算的话,设置堆内存情况如下:
Xmx=14 * 3 = 42M 至 14 * 4 = 56M 之间
我们修改堆内存状态如下:
-XX:+PrintGCDetails -XX:MetaspaceSize=64m -Xss512K -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=heap/heapdump.hprof -XX:SurvivorRatio=8 -XX:+PrintGCDateStamps
-Xms60M -Xmx60M -Xloggc:log/gc-oom.log
修改完之后,我们查看一下GC状态

请求之后
YGC平均耗时: 0.195s * 1000/68 = 2.87ms
FGC未产生
整体的GC耗时减少。但GC频率比之前的1024M时要多了一些。依然未产生FullGC,所以我们内存设置为60M 也是比较合理的,相对之前节省了很大一块内存空间,所以本次内存调整是比较合理的
依然手动触发Full ,查看堆内存结构
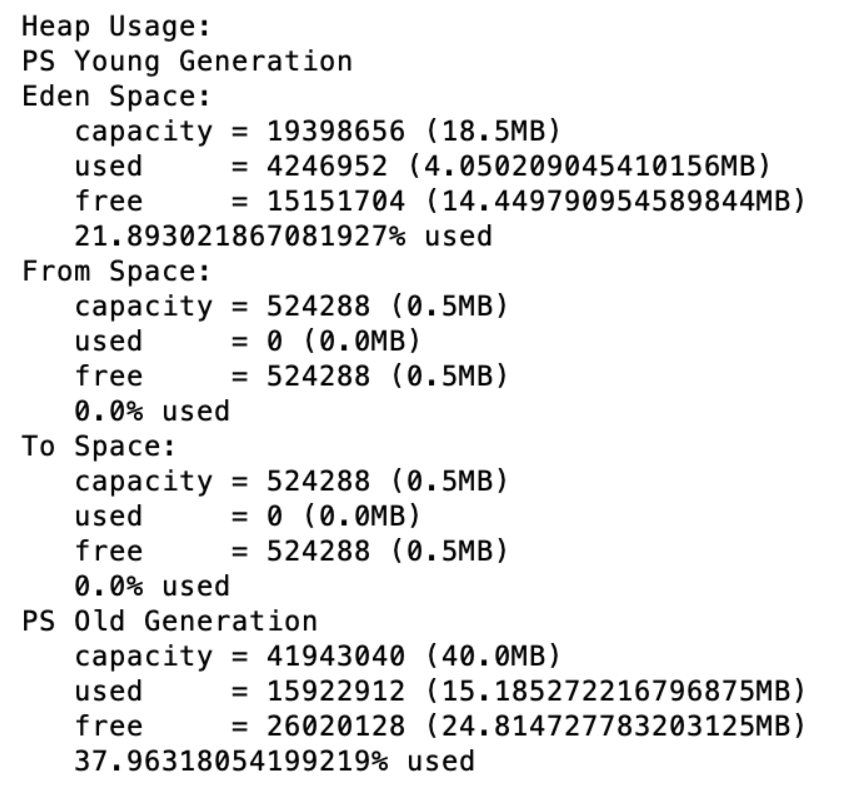
结论
在内存相对紧张的情况下,可以按照上述的方式来进行内存的调优, 找到一个在GC频率和GC耗时上都可接受的一个内存设置,可以用较小的内存满足当前的服务需要。
但当内存相对宽裕的时候,可以相对给服务多增加一点内存,可以减少GC的频率,GC的耗时相应会增加一些。 一般要求低延时的可以考虑多设置一点内存, 对延时要求不高的,可以按照上述方式设置较小内存。
如果在垃圾回收日志中观察到OutOfMemoryError,尝试把Java堆的大小扩大到物理内存的80%~90%。尤其需要注意的是堆空间导致的OutOfMemoryError以及一定要增加空间。
比如说,增加-Xms和-Xmx的值来解决old代的OutOfMemoryError
- 增加-XX:PermSize和-XX:MaxPermSize来解决permanent代引起的OutOfMemoryError(jdk7之前);
- 增加-XX:MetaspaceSize和-XX:MaxMetaspaceSize来解决Metaspace引起的OutOfMemoryError(jdk8之后)
记住一点Java堆能够使用的容量受限于硬件以及是否使用64位的JVM。在扩大了Java堆的大小之后,再检查垃圾回收日志,直到没有OutOfMemoryError为止。如果应用运行在稳定状态下没有OutOfMemoryError就可以进入下一步了,计算活动对象的大小。
如何估算GC频率
正常情况我们应该根据我们的系统来进行一个内存的估算,这个我们可以在测试环境进行测试,最开始可以将内存设置的大一些,比如4G这样,当然这也可以根据业务系统估算来的。
比如从数据库获取一条数据占用128个字节,需要获取1000条数据,那么一次读取到内存的大小就是(128 B/1024 Kb/1024M)* 1000 = 0.122M ,那么我们程序可能需要并发读取,比如每秒读取100次,那么内存占用就是0.122100 = 12.2M ,如果堆内存设置1个G,那么年轻代大小大约就是333M,那么333M80% / 12.2M =21.84s ,也就是说我们的程序几乎每分钟进行两到三次youngGC。这样可以让我们对系统有一个大致的估算。
0.122M * 100 = 12.2M /秒 ---Eden区
1024M * 1/3 * 80% = 273M
273 / 12.2M = 22.38s ---> YGC 每分钟2-3次YGC
新生代与老年代的比例
参数设置:手动控制比例
- 静态比例策略(-XX:NewRatio)
-XX:NewRatio=3 # 老年代:新生代=3:1(默认JDK8=2,JDK11+=2)
场景:对象晋升模式稳定(如批量处理系统),老年代长期占用70%+内存。
- 绝对值分配(-Xmn/-XX:NewSize)
-Xmn2g # 新生代固定2GB(优先级高于NewRatio)
-XX:NewSize=1g -XX:MaxNewSize=4g # 动态区间(需配合自适应策略)
风险:硬编码可能导致老年代溢出(尤其在突发大对象场景)。
- Survivor区调节(-XX:SurvivorRatio)
-XX:SurvivorRatio=8 # Eden:Survivor=8:1:1(默认JDK8=8)
调优依据:
- 对象存活率低(如Web请求):增大Eden区,减少Minor GC频率
- 对象存活率高(如缓存服务):缩小Eden区,避免Survivor溢出
参数AdaptiveSizePolicy:动态比例调优
JVM内置自适应内存调整算法,通过统计GC效率动态平衡各代容量。
- 启用与关闭
-XX:+UseAdaptiveSizePolicy # 默认开启(Parallel Scavenge生效)
-XX:-UseAdaptiveSizePolicy # 关闭后需手动配置
- 运作原理
- 监控指标:Minor GC耗时、对象晋升速率、Survivor溢出次数
- 动态响应:
- 若老年代GC耗时过高 → 扩大新生代,减少晋升压力
- 若Survivor频繁溢出 → 增大Survivor区比例
- 若Eden区GC频率过低 → 收缩Eden区,释放内存给老年代
- 冲突与规避
- 与CMS/G1的兼容性:
- CMS需配合
-XX:+UseCMSCompactAtFullCollection避免碎片干扰 - G1收集器强制禁用AdaptiveSizePolicy(由Region机制替代)
- CMS需配合
- 调优矛盾:
- UseAdaptiveSizePolicy不要和SurvivorRatio参数显示设置搭配使用,一起使用会导致参数失效;
- 由于UseAdaptiveSizePolicy会动态调整 Eden、Survivor 的大小,有些情况存在Survivor 被自动调为很小,比如十几MB甚至几MB的可能,这个时候YGC回收掉 Eden区后,还存活的对象进入Survivor 装不下,就会直接晋升到老年代,导致老年代占用空间逐渐增加,从而触发FULL GC,如果一次FULL GC的耗时很长(比如到达几百毫秒),那么在要求高响应的系统就是不可取的。
- 与CMS/G1的兼容性:
关于堆内存的自适应调节有如下三个参数:调整堆是按照每次20%增长,按照每次5%收缩
young区增长量(默认20%):-XX:YoungGenerationSizeIncrement=<Y>
old区增长量(默认20%):-XX:TenuredGenerationSizeIncrement=<T>
收缩量(默认5%):-XX:AdaptiveSizeDecrementScaleFactor=<D>
验证方式
- jstat动态观测:
jstat -gc <pid> 1000 # 每秒输出各代容量变化
NGCMN(最小新生代) NGCMX(最大新生代) NGC(当前新生代)
4194304.0 6291456.0 5242880.0 # 动态扩容至5GB
- GC日志分析:
[PSYoungGen: 3584K->480K(4096K)] # 新生代调整后容量
[ParOldGen: 10240K->10752K(20480K)]
- 强制内存快照:
jmap -heap <pid> # 查看运行时各代实际容量
案例4:CPU占用很高的排查方案
示例代码
public class JstackDeadLockDemo {/*** 必须有两个可以被加锁的对象才能产生死锁,只有一个不会产生死锁问题*/private final Object obj1 = new Object();private final Object obj2 = new Object();public static void main(String[] args) {new JstackDeadLockDemo().testDeadlock();}private void testDeadlock() {Thread t1 = new Thread(() -> calLock_Obj1_First());Thread t2 = new Thread(() -> calLock_Obj2_First());t1.start();t2.start();}/*** 先synchronized obj1,再synchronized obj2*/private void calLock_Obj1_First() {synchronized (obj1) {sleep();System.out.println("已经拿到obj1的对象锁,接下来等待obj2的对象锁");synchronized (obj2) {sleep();}}}/*** 先synchronized obj2,再synchronized obj1*/private void calLock_Obj2_First() {synchronized (obj2) {sleep();System.out.println("已经拿到obj2的对象锁,接下来等待obj1的对象锁");synchronized (obj1) {sleep();}}}/*** 为了便于让两个线程分别锁住其中一个对象,* 一个线程锁住obj1,然后一直等待obj2,* 另一个线程锁住obj2,然后一直等待obj1,* 然后就是一直等待,死锁产生*/private void sleep() {try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}
}
问题呈现
可以看到,程序依然处于运行状态。现在我们知道是线程死锁造成的问题。

问题分析
那么如果是生产环境的话,是怎么样才能发现目前程序有问题呢?我们可以推导一下,如果线程死锁,那么线程一直在占用CPU,这样就会导致CPU一直处于一个比较高的占用率。所示我们解决问题的思路应该是:
- 首先查看java进程ID
# 查看所有java进程 ID
jps -l

- 根据进程 ID 检查当前使用异常线程的pid
# 根据进程 ID 检查当前使用异常线程的pid
top -Hp 1456
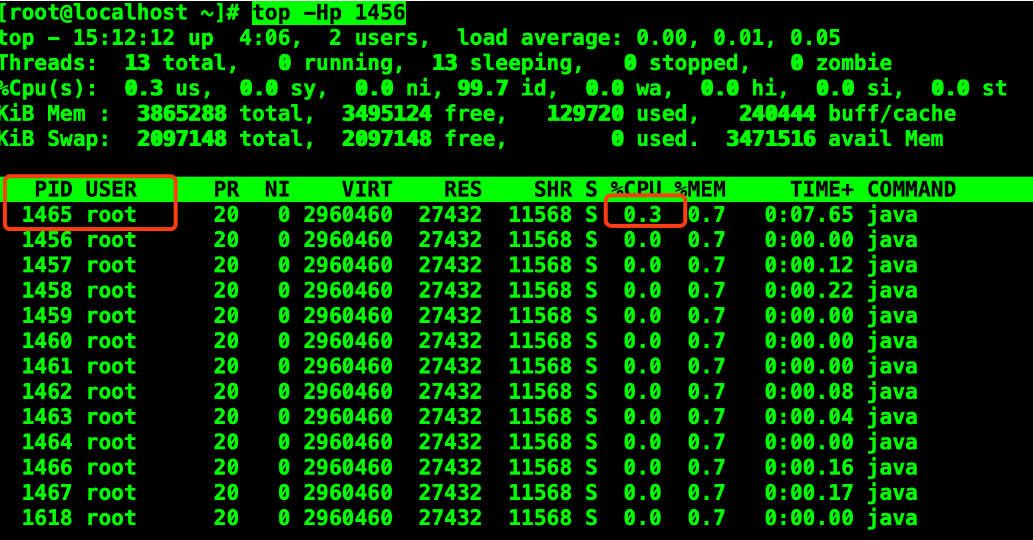
- 把线程pid变为16进制
从上图可以看出来,当前占用cpu比较高的线程 ID 是1465
# 10 进制线程PId 转换为 16 进制
1465 -------> 5b9
# 5b9 在计算机中显示为
0x5b9
- jstack 进程的pid | grep -A20 0x… 得到相关进程的代码 (鉴于我们当前代码量比较小,线程也比较少,所以我们就把所有的信息全部导出来)
jstack 1456 > jstack.log

打开jstack.log文件,查找一下刚刚我们转换完的16进制ID是否存在。
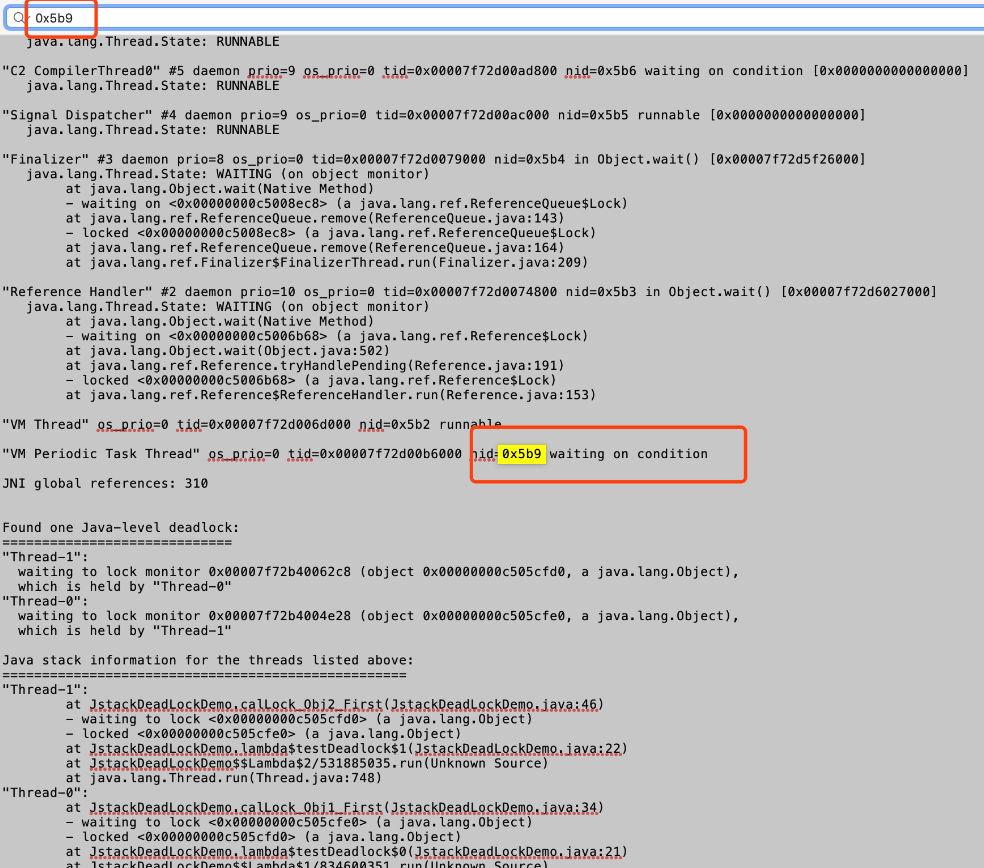
jstack命令生成的thread dump信息包含了JVM中所有存活的线程,里面确实是存在我们定位到的线程 ID ,在thread dump中每个线程都有一个nid,在nid=0x5b9的线程调用栈中,我们发现两个线程在互相等待对方释放资源。
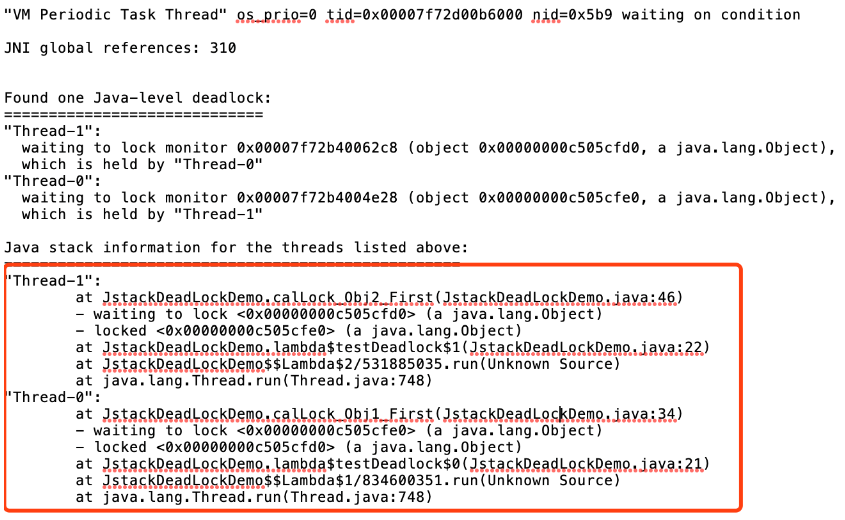
到此就可以检查对应的代码是否有问题,也就定位到我们的死锁问题。
解决方案
- 顺序加锁。
- 采用定时锁,一段时间后,如果还不能获取到锁就释放自身持有的所有锁。
案例5:G1并发GC线程数对性能的影响
配置信息
硬件配置
8核linux
JVM参数设置
export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseG1GC"
export CATALINA_OPTS="$CATALINA_OPTS -Xms30m"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx30m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDetails"
export CATALINA_OPTS="$CATALINA_OPTS -XX:MetaspaceSize=64m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDateStamps"
export CATALINA_OPTS="$CATALINA_OPTS -Xloggc:/opt/tomcat8.5/logs/gc.log"
export CATALINA_OPTS="$CATALINA_OPTS -XX:ConcGCThreads=1"
说明:最后一个参数可以在使用G1GC测试初始并发GCThreads之后再加上。
初始化内存和最大内存调整小一些,目的发生 FullGC,关注GC时间
关注点是:GC次数,GC时间,以及 Jmeter的平均响应时间
初始状态
启动tomcat,查看进程默认的并发线程数:
jinfo -flag ConcGCThreads pid
-XX:ConcGCThreads=1
没有配置的情况下:并发线程数是1。
查看线程状态:
jstat -gc pid

得出信息:
YGC:youngGC次数是1259次
FGC:Full GC次数是6次
GCT:GC总时间是5.556s
Jmeter压测之后的GC状态:

得出信息:
YGC:youngGC次数是1600次
FGC:Full GC次数是18次
GCT:GC总时间是7.919s
由此我们可以计算出来压测过程中,发生的GC次数和GC时间差。
压测过程GC状态:
YGC:youngGC次数是 1600 - 1259 = 341次
FGC:Full GC次数是 18 - 6 = 12次
GCT:GC总时间是 7.919 - 5.556 = 2.363s
Jmeter压测结果如下:
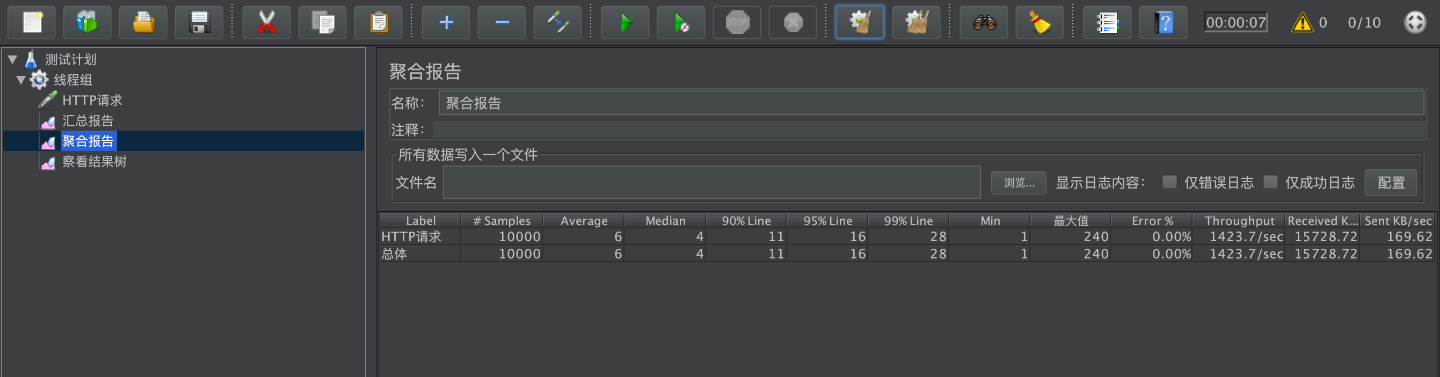
95%的请求响应时间为:16ms
99%的请求响应时间为:28ms
优化后
增加线程配置:
export CATALINA_OPTS="$CATALINA_OPTS -XX:ConcGCThreads=8"
观察GC状态:
jstat -gc pid
YGC:youngGC次数是 1134 次
FGC:Full GC次数是 5 次
GCT:GC总时间是 5.234s
Jmeter压测之后的GC状态:
YGC:youngGC次数是 1347 次
FGC:Full GC次数是 16 次
GCT:GC总时间是 7.149s
压测过程GC状态:
YGC:youngGC次数是 1347 - 1134 = 213次
FGC:Full GC次数是 16 - 5 = 13次
GCT:GC总时间是 7.149 - 5.234 = 1.915s 提供了线程数,使得用户响应时间降低了。
Jmeter压测结果如下:
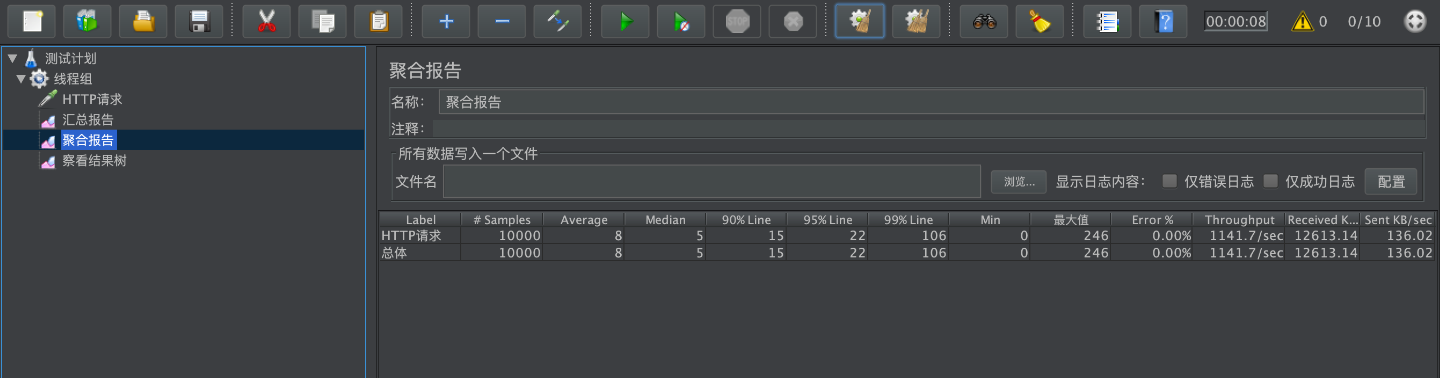
95%的请求响应时间为:15ms
99%的请求响应时间为:22ms
总结
- 在CPU资源充足(空闲率 > 30%)时优先调高
ConcGCThreads。 - 在容器/云环境中,严格限制CPU配额并预留GC线程预算。
- 始终通过A/B测试对比调整前后的吞吐量与P99延迟。
案例6:调整垃圾回收器对吞吐量的影响
初始配置:单核+SerialGC
单核+SerialGC
优化配置1:ParallelGC
export CATALINA_OPTS="$CATALINA_OPTS -Xms60m"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx60m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseParallelGC"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDetails"
export CATALINA_OPTS="$CATALINA_OPTS -XX:MetaspaceSize=64m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDateStamps"
export CATALINA_OPTS="$CATALINA_OPTS -Xloggc:/opt/tomcat8.5/logs/gc6.log"
查看GC状态:

3次FullGC。
查看吞吐量:
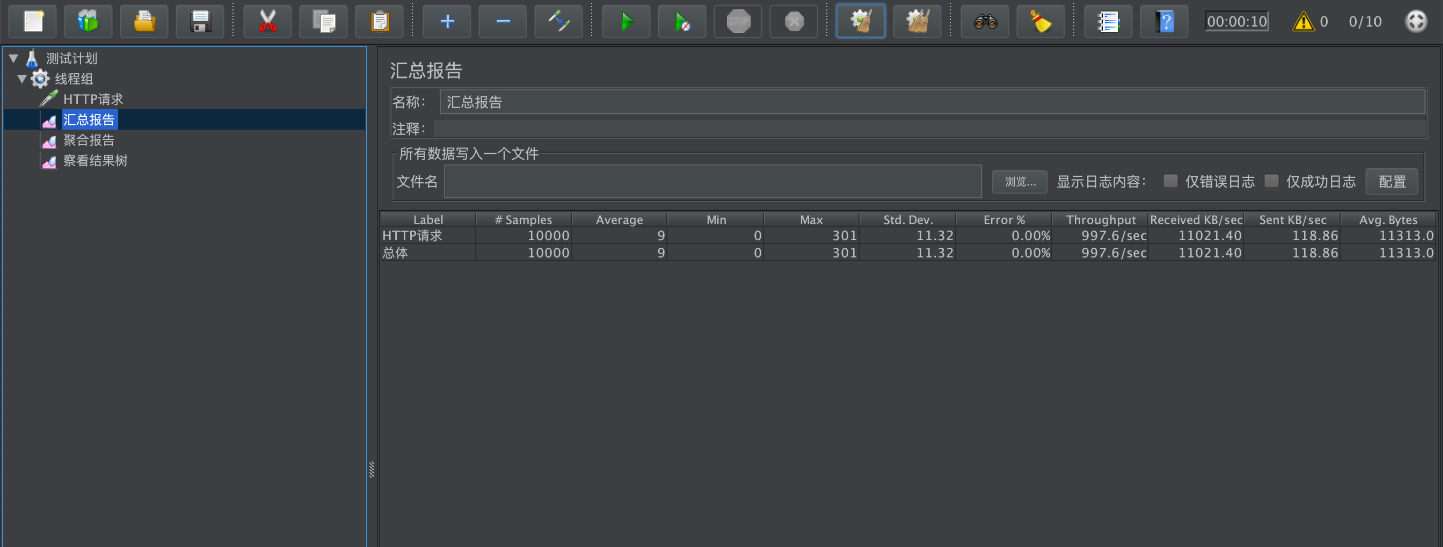
查看吞吐量,997.6/sec。
优化配置2:8核
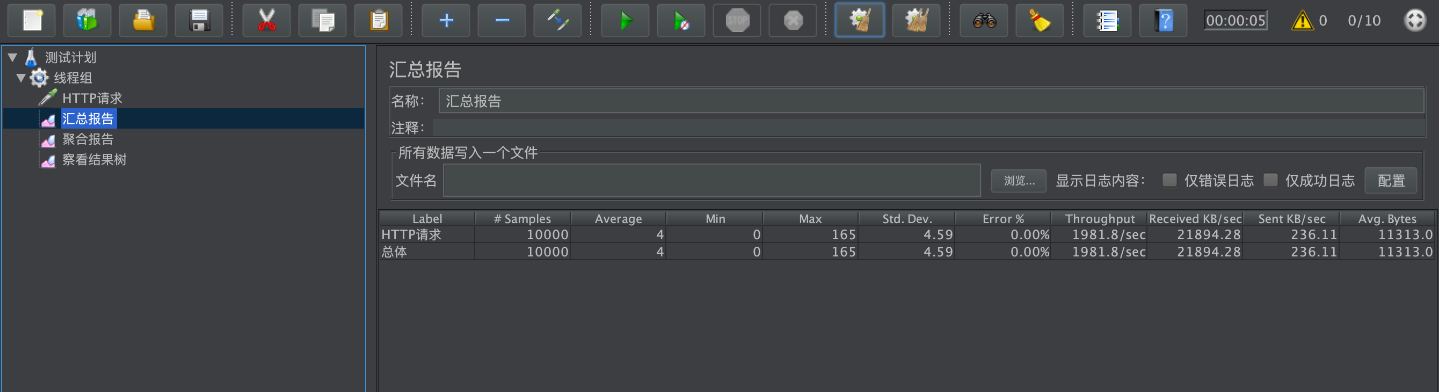
8核状态下的性能表现如下,吞吐量大幅提升,甚至翻了一倍,这说明我们在多核机器上面采用并行收集器对于系统的吞吐量有一个显著的效果。
优化配置3:G1
export CATALINA_OPTS="$CATALINA_OPTS -XX:+UseG1GC"
export CATALINA_OPTS="$CATALINA_OPTS -Xms60m"
export CATALINA_OPTS="$CATALINA_OPTS -Xmx60m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDetails"
export CATALINA_OPTS="$CATALINA_OPTS -XX:MetaspaceSize=64m"
export CATALINA_OPTS="$CATALINA_OPTS -XX:+PrintGCDateStamps"
export CATALINA_OPTS="$CATALINA_OPTS -Xloggc:/opt/tomcat8.5/logs/gc6.log"
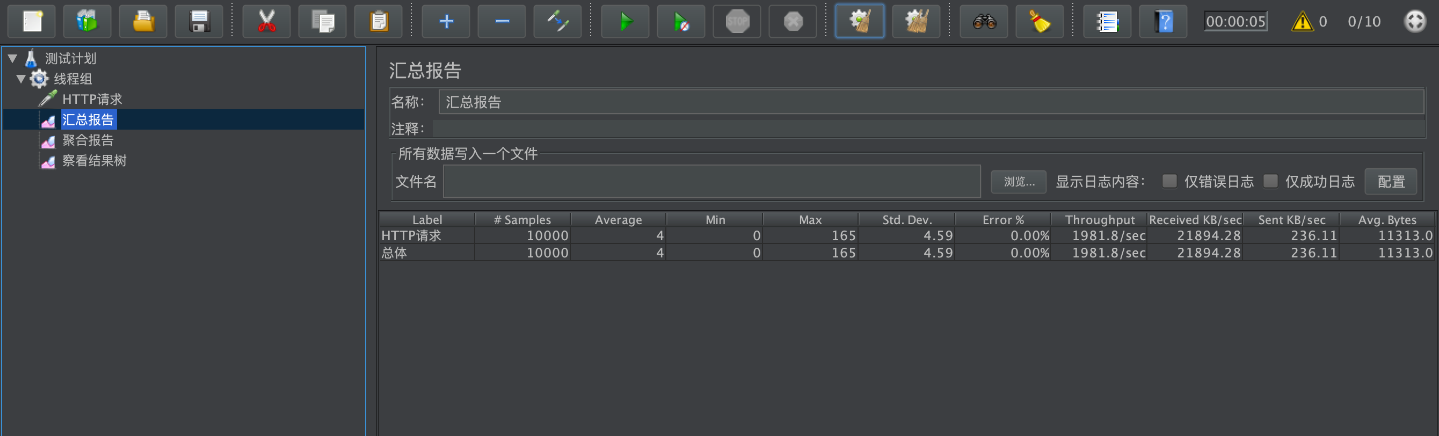
查看GC状态:

没有产生FullGC,效果较之前有提升。
查看压测效果,吞吐量也是比串行收集器效果更佳,而且没有了FullGC。此次优化较为成功。
案例7:日均百万订单如何设置JVM参数
一天百万级订单这个绝对是现在顶尖电商公司交易量级,百万订单一般在4个小时左右产生,我们计算一下每秒产生多少订单,3000000/3600/4 = 208.3单/s,我们大概按照每秒300单来计算。
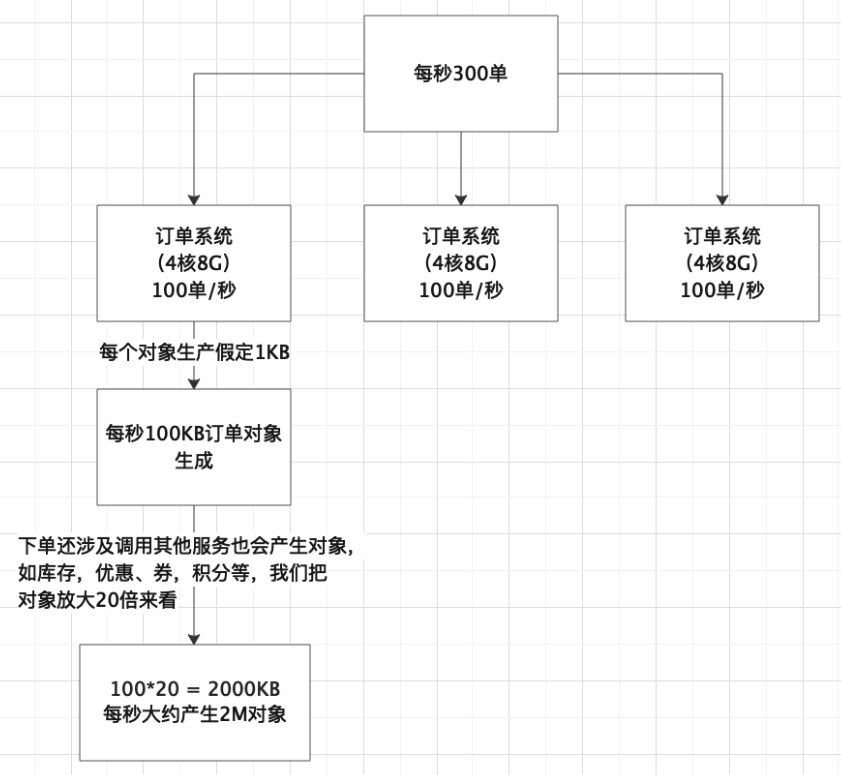
这种系统我们一般至少要三四台机器去支撑,假设我们部署了三台机器,也就是每台每秒钟大概处理完成100单左右,也就是每秒大概有100个订单对象在堆空间的新生代内生成,一个订单对象的大小跟里面的字段多少及类型有关,比如int类型的订单id和用户id等字段,double类型的订单金额等,int类型占用4字节,double类型占用8字节,初略估计下一个订单对象大概1KB左右,也就是说每秒会有100KB的订单对象分配在新生代内。
真实的订单交易系统肯定还有大量的其他业务对象,比如购物车、优惠券、积分、用户信息、物流信息等等,实际每秒分配在新生代内的对象大小应该要再扩大几十倍,我们假设20倍,也就是每秒订单系统会往新生代内分配近2M的对象数据,这些数据一般在订单提交完的操作做完之后基本都会成为垃圾对象。
假设我们选择4核8G的服务器,就可以给JVM进程分配四五个G的内存空间,那么堆内存可以分到三四个G左右,于是可以给新生代至少分配1G,这样算下差不多需要10分钟左右才能把新生代放满触发minor gc,这样的GC频率我们是可以接受的。我们还可以继续调整young区大小。不一定是1:2,这样就可以降低GC频率。这样进入老年代的对象也会降低,减少Full GC频率。

如果系统业务量继续增长那么可以水平扩容增加更多的机器,比如五台甚至十台机器,这样每台机器的JVM处理请求可以保证在合适范围,不至于压力过大导致大量的gc。
假设业务量暴增几十倍,在不增加机器的前提下,整个系统每秒要生成几千个订单,之前每秒往新生代里分配的1M对象数据可能增长到几十M,而且因为系统压力骤增,一个订单的生成不一定能在1秒内完成,可能要几秒甚至几十秒,那么就有很多对象会在新生代里存活几十秒之后才会变为垃圾对象,如果新生代只分配了几百M,意味着一二十秒就会触发一次minor gc,那么很有可能部分对象就会被挪到老年代,这些对象到了老年代后因为对应的业务操作执行完毕,马上又变为了垃圾对象,随着系统不断运行,被挪到老年代的对象会越来越多,最终可能又会导致full gc,full gc对系统的性能影响还是比较大的。
相关文章:

【JVM】JVM调优实战
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...

Linux系统安全-开发中注意哪些操作系统安全
Hey小伙伴们~👋 在Linux开发中,确保操作系统的安全真的太太太重要啦!🛡️ 今天就来和大家聊聊几个超关键的注意事项,记得拿小本本记下来哦!📝 1️⃣ 用户管理与权限控制👥 合理…...

Qt问题之 告别软件因系统默认中文输入法导致错误退出的烦恼
1. 问题 使用Qt进行研发时,遇到一个问题,当在系统默认输入法中文(英文输入法或者搜狗就不会触发闪退)的情况下,选中QTableWidget控件(QTableWidgetItem有焦点,但是不双击)ÿ…...

2025 年“认证杯”数学中国数学建模网络挑战赛 D题 无人机送货规划
在快递和外卖等短途递送小件货物的业务中,无人机或许大有可为。现 有一个城市的快递仓库准备使用若干无人机进行派件,设有若干架无人机从 仓库出发,分别装载了若干快递包裹。每架无人机装载的包裹的收货地点会 被排列为一个目的地列表&#x…...

【2025年认证杯数学中国数学建模网络挑战赛】A题解题思路与模型代码
【2025年认证杯数学建模挑战赛】A题 该题为典型的空间几何建模轨道动力学建模预测问题。 ⚙ 问题一:利用多个天文台的同步观测,确定小行星与地球的相对距离 问题分析 已知若干地面天文台的观测数据:方位角 (Azimuth) 和 高度角 (Altitude)&…...

Redhat红帽 RHCE8.0认证体系课程
课程大小:7.7G 课程下载:https://download.csdn.net/download/m0_66047725/90546064 更多资源下载:关注我 红帽企业 Linux 系统的管理技能已经成为现代数据中心的核心竞争力。 Linux 在支持混合云、跨物理服务器、虚机、私有云和公共云计…...
)
Python 实现的运筹优化系统数学建模详解(最大最小化模型)
一、引言 在数学建模的实际应用里,最大最小化模型是一种极为关键的优化模型。它的核心目标是找出一组决策变量,让多个目标函数值里的最大值尽可能小。该模型在诸多领域,如资源分配、选址规划等,都有广泛的应用。本文将深入剖析最大…...

MySQL快速入门
MySQL快速入门 SQL语句 SQL语句概述 1.SQL 是用于访问和处理数据库的标准的计算机语言。 2.SQL指结构化查询语言,全称是 Structured Query Language。 3.SQL 可以访问和处理数据库。 4.SQL 是一种 ANSI(American National Standards Institute 美国…...
)
离线安装 nvidia-docker2(nvidia-container-toolkit)
很多时候大家都有用docker使用gpu的需求,但是因为网络等原因不是那么好用,这里留了一个给ubuntu的安装包,网络好的话也提供了在线安装方式 安装 nvidia-docker2 1 离线安装 (推荐) unzip解压后进入目录 dpkg -i *.d…...

【自然语言处理】深度学习中文本分类实现
文本分类是NLP中最基础也是应用最广泛的任务之一,从无用的邮件过滤到情感分析,从新闻分类到智能客服,都离不开高效准确的文本分类技术。本文将带您全面了解文本分类的技术演进,从传统机器学习到深度学习,手把手实现一套…...

云原生运维在 2025 年的发展蓝图
随着云计算技术的不断发展和普及,云原生已经成为了现代应用开发和运维的主流趋势。云原生运维是指在云原生环境下,对应用进行部署、监控、管理和优化的过程。在 2025 年,云原生运维将迎来更加广阔的发展前景,同时也将面临着一系列…...
)
Windows系统Python多版本运行解决TensorFlow安装问题(附详细图文)
Windows系统Python多版本运行解决TensorFlow安装问题(附详细图文) 摘要 TensorFlow 无法安装?Python版本太高是元凶! 本文针对Windows系统中因Python版本过高导致TensorFlow安装失败的问题,提供三种降级解决方案&…...

银行业务知识序言
银行业务知识体系全景解析 第一章 金融创新浪潮下的银行业务知识革命 1.1 数字化转型驱动金融业态重构 在区块链、人工智能、物联网等技术的叠加作用下,全球银行业正经历着"服务无形化、流程智能化、风控穿透化"的深刻变革。根据麦肯锡《2023全球银行业…...

《深度剖析分布式软总线:软时钟与时间同步机制探秘》
在分布式系统不断发展的进程中,设备间的协同合作变得愈发紧密和复杂。为了确保各个设备在协同工作时能够有条不紊地进行,就像一场精准的交响乐演出,每个乐器都要在正确的时间奏响音符,分布式软总线中的软时钟与时间同步机制应运而…...

RK3588 android12 适配 ilitek i2c接口TP
一,Ilitek 触摸屏简介 Ilitek 提供多种型号的触控屏控制器,如 ILI6480、ILI9341 等,采用 I2C 接口。 这些控制器能够支持多点触控,并具有优秀的灵敏度和响应速度。 Ilitek 的触摸屏控制器监测屏幕上的触摸事件。 当触摸发生时&a…...
、except(差集)、intersect(交集))
pgsql:关联查询union(并集)、except(差集)、intersect(交集)
pgsql:关联查询union(并集)、except(差集)、intersect(交集)_pgsql except-CSDN博客...

模型材质共享导致的问题
问题:当我选中其中某个网格模型并设置color的时候,相同种类的颜色都被改变,但是打印我选中的网格模型数据其实只有一个。 导致问题的原因: 加载Blender模型修改材质颜色 Blender创建一个模型对象,设置颜色࿰…...

ThinkpPHP生成二维码
导入依赖 composer require endroid/qr-code 封装成函数,传入二维码包含的值,存储路径,二维码大小,二维码边距 private function getCode($content, $directory, $size 300, $margin 10){// 创建二维码对象// $content: 二…...

FLINK框架:流式处理框架Flink简介
在大数据时代,数据的价值不言而喻,谁能利用好数据,谁就掌握了整个行业的先机。面对海量的数据,如何处理数据成为了一个难题。除了海量数据外,实时性也是一个重要的课题,所以流式数据处理便登上了技术舞台&a…...
使用Python从零开始构建生成型TransformerLM并训练
在人工智能的浩瀚宇宙中,有一种神奇的生物,它拥有着强大的语言魔法,能够生成各种各样的文本,仿佛拥有无尽的创造力。它就是——Transformer 模型!Transformer 模型的出现,为人工智能领域带来了一场“语言魔…...

xtrabackup备份
安装: https://downloads.percona.com/downloads/Percona-XtraBackup-8.0/Percona-XtraBackup-8.0.35-30/binary/tarball/percona-xtrabackup-8.0.35-30-Linux-x86_64.glibc2.17.tar.gz?_gl1*1ud2oby*_gcl_au*MTMyODM4NTk1NS4xNzM3MjUwNjQ2https://downloads.perc…...

2.3 Spark运行架构与流程
Spark运行架构与流程包括几个核心概念:Driver负责提交应用并初始化作业,Executor在工作节点上执行任务,作业是一系列计算任务,任务是作业的基本执行单元,阶段是一组并行任务。Spark支持多种运行模式,包括单…...

【Pandas】pandas DataFrame head
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行 pandas.DataFrame.head pandas.DataFrame.head 是一个方法,用于返回 DataFrame 的前几行。这个方法非常有用,特别是在需要快速查看 DataFrame 的前…...

从递归入手一维动态规划
从递归入手一维动态规划 1. 509. 斐波那契数 1.1 思路 递归 F(i) F(i-1) F(i-2) 每个点都往下展开两个分支,时间复杂度为 O(2n) 。 在上图中我们可以看到 F(6) F(5) F(4)。 计算 F(6) 的时候已经展开计算过 F(5)了。而在计算 F(7)的时候,还需要…...

鸿蒙HarmonyOS埋点SDK,ClkLog适配鸿蒙埋点分析
ClkLog埋点分析系统,是一种全新的、开源的洞察方案,它能够帮助您捕捉每一个关键数据点,确保您的决策基于最准确的用户行为分析。技术人员可快速搭建私有的分析系统。 ClkLog鸿蒙埋点SDK通过手动埋点的方式实现HarmonyOS 原生应用的前端数据采…...

HarmonyOS:HMPermission权限请求框架
前段时间利用空余时间写了一个权限请求库:HMPermission。 一,简介 HMPermission 是鸿蒙系统上的一款权限请求框架,封装了权限请求逻辑,采用链式调用的方式请求权限,简化了权限请求的代码。 二,使用方法 …...

【书籍】DeepSeek谈《持续交付2.0》
目录 一、深入理解1. 核心理念升级:从"自动化"到"双环模型"2. 数字化转型的五大核心能力3. 关键实践与案例4. 组织与文化变革5. 与其它框架的关系6. 实际应用建议 二、对于开发实习生的帮助1. 立刻提升你的代码交付质量(技术验证环实…...

Spring AOP 扫盲
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
部署Embedding模型bge-m3【简单版本】)
银河麒麟v10(arm架构)部署Embedding模型bge-m3【简单版本】
硬件 服务器配置:鲲鹏2 * 920(32c) 4 * Atlas300I duo卡 参考文章 https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d 鲲鹏昇腾Atlas300Iduo部署Embedding模型和Rerank模型并连接Dify(自…...

如何通过流程管理优化企业运营?
流程管理的本质是“用确定性的规则应对不确定性的业务”。 那么,具体该如何通过流程管理来优化企业的运作呢?以下是一些关键步骤和思路,或许能给到一些启发。 1. 从流程梳理开始:摸清现状,找准问题 想要管理好企业的…...
:AXI GPIO)
ZYNQ笔记(四):AXI GPIO
版本:Vivado2020.2(Vitis) 任务:使用 AXI GPIO IP 核实现按键 KEY 控制 LED 亮灭(两个都在PL端) 一、介绍 AXI GPIO (Advanced eXtensible Interface General Purpose Input/Output) 是 Xilinx 提供的一个可…...

Java学习手册:JVM、JRE和JDK的关系
在Java生态系统中,JVM(Java虚拟机)、JRE(Java运行时环境)和JDK(Java开发工具包)是三个核心概念。它们共同构成了Java语言运行和开发的基础。理解它们之间的关系对于Java开发者来说至关重要。本文…...

Java 并发-newFixedThreadPool
前言 为什么选择使用多线程?一种场景是在数据和业务处理能力出现瓶颈时,而服务器性能又有空闲,通常是cpu空闲,这时使用多线程就能很好的解决问题,而又无需加硬件,实际使用中,线程池又是最为常用…...

C# task任务异步编程提高UI的响应性
方式1:async/await模式 private async void button1_Click(object sender, EventArgs e){try{var result await Task.Run(() > CalculateResult());label1.Text result.ToString();}catch (Exception ex){label1.Text $"Error: {ex.Message}";}}pri…...

Spring Bean生命周期执行流程详解
文章目录 一、什么是Spring Bean生命周期?工作流程图:二、Bean生命周期执行流程验证1.编写测试代码验证结果2.源码追溯Bean初始化回调过程 一、什么是Spring Bean生命周期? Spring Bean生命周期是指从Bean的创建到销毁的整个过程,…...
)
windows 安装 pygame( pycharm)
一、安装流程 1.查看python版本 2.检查是否安装pip 3.下载pygame安装文件 下载地址:https://pypi.org/project/pygame/#files 选择合适的版本(我选择的是 python3.7 windows 64bit): 4.使用pip安装pygame 将下载好的whl文件移动到…...

Envoy网关实例异常重启排查总结
一、事件背景 于10月24日凌晨业务租户有业务应用发版上线,中午收到pod连续5分钟重启严重告警,登录管理节点查看异常重启的应用网关pod日志,存在内核段错误报错信息导致进程终止并触发监控检查异常并重启; 该报错主要是访问的内存超出了系统…...
——ListBox控件详解)
WinForm真入门(13)——ListBox控件详解
WinForm ListBox 详解与案例 一、核心概念 ListBox 是 Windows 窗体中用于展示可滚动列表项的控件,支持单选或多选操作,适用于需要用户从固定数据集中选择一项或多项的场景。 二、核心属性 属性说明Items管理列表项的集合,支持动…...

【Linux网络编程】UDP Echo Server的实现
本文专栏:Linux网络编程 目录 一,Socket编程基础 1,IP地址和端口号 端口号划分范围 理解端口号和进程ID 源端口号和目的端口号 理解Socket 2,传输层的典型代表 3,网络字节序 4,Socket编程接口 s…...
控件)
8.3.5 ToolStripContainer(工具栏容器)控件
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 ToolStripContainer控件是一个容器,可以包含菜单和工具条、状态栏。 在设计窗体中放入一个ToolStripContainer࿱…...

代码随想录-06-二叉树-05.05 N叉树的层序遍历
N叉树的层序遍历 #模板题 题目描述 给定一个 N 叉树,返回其节点值的_层序遍历_。(即从左到右,逐层遍历)。 树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。 具体思路 …...

【NEPVR】《A Lightweight Palm Vein Recognition Algorithm NEPVR》
[1]马莉,刘子良,谭振林,等.一种轻量级掌静脉识别算法NEPVR[J].计算机技术与发展,2024,34(12):213-220.DOI:10.20165/j.cnki.ISSN1673-629X.2024.0248. 文章目录 1、背景2、相关工作3、创新点4、NEPVR 手掌静脉识别算法5、实验结果及分析6、总结 / 未来工作 1、背景 手掌静脉独…...

牟乃夏《ArcGIS Engine地理信息系统开发教程》学习笔记1
(适合GIS开发入门者,通俗解析核心知识点) 目录 一、ArcGIS Engine是什么? 二、ArcGIS Engine能做什么? 三、ArcGIS Engine与ArcObjects的区别 四、开发资源与学习路径 五、对象模型图(OMD)…...

架构师论文《论模型驱动软件开发方法在智能制造转型实践中的应用》
摘要: 本人现任某大型装备制造企业智能制造研究院首席架构师,主导集团级数字化工厂平台建设。面对多品种小批量生产模式下普遍存在的交付周期超预期(平均延期21天)、设备综合效率OEE不足65%的痛点,我司于2021年启动基…...

探索MCP.so:AI生态的创新枢纽
今天在研究MCP时发现了一个还不错的网站,分享给大家。后续会基于这些mcp servers做一些有趣的应用。 在人工智能飞速发展的当下,AI与各类工具、数据源的协同合作变得愈发关键。MCP.so这个平台,正悄然成为AI领域的重要枢纽,为众多开发者和AI爱好者打开了新的大门。 MCP,即…...

JVM底层详解
JVM底层详解 目录 JVM概述JVM内存模型垃圾回收机制类加载过程JIT编译JVM调优JVM监控与故障排查JVM与多线程JVM与性能优化JVM发展历程与未来JVM实战案例分析JVM高级特性JVM安全机制JVM与容器化 一、JVM概述 1.1 什么是JVM Java虚拟机(Java Virtual Machine&…...

多点:分布式升级助力新零售转型,成本节省超80% | OceanBase 案例
本文作者:多点数据库DBA团队 编者按:多点是零售行业数字(智)化的先行者,为全球企业提供创新的数字化解决方案。然而,在数字化转型的过程中,多点原有的数据库架构逐渐暴露出架构复杂、成本上升等…...

Java权限修饰符深度解析
Java权限修饰符深度解析与最佳实践 一、权限修饰符总览 Java提供四种访问控制修饰符,按访问范围从宽到窄排序如下: 修饰符类内部同包类不同包子类全局范围public✔️✔️✔️✔️protected✔️✔️✔️❌默认(无)✔️✔️❌❌pr…...

RocketMQ和kafka 的区别
一、数据可靠性与容错机制 数据可靠性 RocketMQ支持同步刷盘和同步复制,确保消息写入磁盘后才返回确认,单机可靠性高达10个9,即使操作系统崩溃也不会丢失数据159。而Kafka默认采用异步刷盘和异步复制,虽然吞吐量高,但极…...

分布式限流器框架 eval-rate-limiter
分布式限流器框架 eval-rate-limiter 文章目录 分布式限流器框架 eval-rate-limiter前言设计流程图 核心方法tryAcquire 获取通信证增加访问次数 incrementRequestCount生成分布式 key generateRateLimiterKey 测试测试代码结果Redis 客户端 前言 基于 redis 实现的分布式限流…...