使用Python从零开始构建生成型TransformerLM并训练
在人工智能的浩瀚宇宙中,有一种神奇的生物,它拥有着强大的语言魔法,能够生成各种各样的文本,仿佛拥有无尽的创造力。它就是——Transformer 模型!Transformer 模型的出现,为人工智能领域带来了一场“语言魔法”的革命。它不仅让机器学会了“说话”,还为人类的生活带来了许多惊喜和便利。今天,就让我们踏上一场关于 Transformer 模型的奇幻之旅,去探索它背后的奥秘吧!
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
文章目录
- 🧠 向所有学习者致敬!
- 🌐 欢迎[点击加入AI人工智能社区](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 引言:从标记到 Transformer 的文本生成之旅
- 第 0 步:设置 —— 库、语料库、标记化、超参数
- 第 0.1 步:导入库
- 第 0.2 步:定义训练语料库
- 第 0.3 步:字符级标记化
- 第 0.4 步:编码语料库
- 第 0.5 步:定义超参数
- 第 1 步:训练数据准备
- 第 1.1 步:创建输入(`x`)和目标(`y`)对
- 第 1.2 步:批处理策略(简化:随机采样)
- 第 2 步:模型组件初始化
- 第 2.1 步:标记嵌入层
- 第 2.2 步:位置编码矩阵
- 第 2.3 步:Transformer 块组件初始化
- 第 2.4 步:最终层初始化
- 第 3 步:定义正向传播(内联 —— 概念块)
- 第 3.1 步:输入嵌入 + 位置编码
- 第 3.2 步:Transformer 块循环(概念)
- 第 3.2.1 步:带掩码的多头自注意力(概念)
- 第 3.2.2 步:添加与归一化 1(第一次注意力后)(概念)
- 第 3.2.3 步:位置级前馈网络(FFN)(概念)
- 第 3.2.4 步:添加与归一化 2(第一次 FFN 后)(概念)
- 第 3.3 步:最终层(概念)
- 第 4 步:训练模型(内联循环)
- 第 4.1 步:定义损失函数
- 第 4.2 步:定义优化器
- 第 4.3 步:训练循环
- 第 5 步:文本生成(内联)
- 第 5.1 步:设置生成种子和参数
- 第 5.2 步:生成循环
- 第 5.3 步:解码生成序列
- 第 6 步:保存模型状态(可选)
- 第 7 步:总结
引言:从标记到 Transformer 的文本生成之旅
回顾:标记化的作用
之前我们研究了像字节对编码(BPE)这样的技术,文本处理的第一步就是标记化。这会把原始文本分解成便于管理的单元(标记)。在这个 notebook 里,为了简单起见,我们采用基本的字符级标记化,即文本中的每个独特字符都成为一个独立的标记。这些标记随后会被映射到独特的数字 ID 上。我们主要关注的是从这些 ID 序列中学习的模型:语言模型。
目标:构建生成型 Transformer
我们的目标是构建一个基于Transformer 架构的基本语言模型。具体来说,我们将构建一个类似 GPT 风格的仅解码器 Transformer。这个模型能够根据前面的标记来预测序列中的下一个标记(在我们这里就是字符)。通过反复预测下一个标记并将它重新输入到输入序列中,模型可以逐字符地生成新的文本序列。
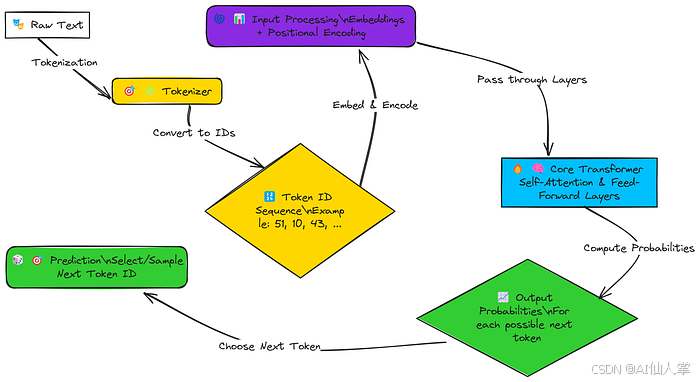
Transformer 架构:关键概念
Transformer 是在“Attention Is All You Need”(Vaswani 等人,2017 年)中提出的,它使用注意力机制来衡量在处理某个标记时不同输入标记的重要性,消除了 RNN/LSTM 中使用的递归需求。我们将要实现的关键组成部分如下:
- 输入嵌入:将数字标记(字符)ID 转换为密集的向量表示。
- 位置编码:向序列中添加关于标记位置的信息。
- 多头自注意力(带掩码):让模型能够关注序列中的前面标记以预测下一个标记。掩码防止关注未来的标记。
- 添加与归一化层:残差连接后跟层归一化,用于稳定训练。
- 逐位置前馈网络:独立地对每个标记表示应用非线性变换。
- 解码器块:多次堆叠这些组件。
- 最终线性层与 Softmax:将最终表示映射回词汇表得分(logits),然后再映射为概率。
本文的方法:
我们将逐步实现这个架构,直接在代码中操作,而不是定义函数或类。每个概念部分会被分解成最小的代码块,并附上极其详细的解释和数学公式(使用 LaTeX)。我们会使用一个小型文本数据集和模型配置,以确保透明度。
第 0 步:设置 —— 库、语料库、标记化、超参数
目标:通过导入 PyTorch,定义文本语料库,执行字符级标记化,设置模型配置(超参数)来准备环境。
第 0.1 步:导入库
解释:我们需要 torch 来进行张量操作、神经网络组件(nn)、激活函数(F)、优化器(optim),以及 math 来进行像注意力缩放中的平方根这样的计算。
# 导入必要的库
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import math
import os# 为了可重复性(可选,但这是个好习惯)
torch.manual_seed(1337)print(f"PyTorch 版本:{torch.__version__}")
print("库已导入。")
第 0.2 步:定义训练语料库
解释:我们将使用《爱丽丝梦游仙境》的同一段摘录作为训练数据。这提供了一个小型但还算现实的文本来源。
# 定义用于训练的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""print(f"训练语料库已定义(长度:{len(corpus_raw)} 个字符)。")
第 0.3 步:字符级标记化
解释:我们创建一个包含语料库中所有独特字符的词汇表。然后我们创建映射:一个是从每个字符到独特整数 ID(char_to_int)的映射,另一个是它的逆映射(int_to_char)。这个独特字符集的大小决定了我们的 vocab_size。
# 找出原始语料库中所有独特的字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)# 创建字符到整数的映射(编码)
char_to_int = { ch:i for i,ch in enumerate(chars) }# 创建整数到字符的映射(解码)
int_to_char = { i:ch for i,ch in enumerate(chars) }print(f"创建了大小为:{vocab_size} 的字符词汇表")
print(f"词汇表:{''.join(chars)}")
# print(f"Char-to-Int 映射:{char_to_int}") # 可选
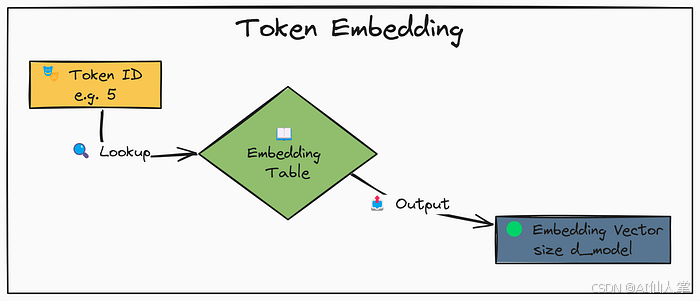
第 0.4 步:编码语料库
解释:使用 char_to_int 映射,将整个原始文本语料库转换为整数标记 ID 序列。这个数字序列就是模型将要处理的实际输入。
# 将整个语料库编码为整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)print(f"将语料库编码为张量,形状为:{full_data_sequence.shape}")
# print(f"前 100 个编码的标记 ID:{full_data_sequence[:100].tolist()}") # 可选
第 0.5 步:定义超参数
解释:设置模型和训练的配置。我们使用从数据中确定的 vocab_size。其他值为了演示保持较小。
d_model:嵌入和内部表示的维度。n_heads:并行注意力计算的数量。n_layers:Transformer 块的数量。d_ff:前馈网络中的隐藏维度。block_size:一次处理的最大序列长度。learning_rate、batch_size、epochs:训练控制参数。device:如果可用,使用 GPU(‘cuda’),否则使用 CPU。
# 定义模型超参数(使用从数据中计算出的 vocab_size)
# vocab_size = vocab_size # 已经从数据中定义
d_model = 64 # 嵌入维度(对于字符稍微增加一点)
n_heads = 4 # 注意力头的数量
n_layers = 3 # Transformer 块的数量
d_ff = d_model * 4 # 前馈网络的内部维度
block_size = 32 # 最大上下文长度(序列长度)
# dropout_rate = 0.1 # 为了简单起见,省略了 dropout 层# 定义训练超参数
learning_rate = 3e-4 # 对于 AdamW,稍小的学习率通常更好
batch_size = 16 # 每步处理 16 个序列
epochs = 5000 # 对于字符级模型增加训练周期以观察学习效果
eval_interval = 500 # 多久打印一次损失# 设备配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 确保 d_model 能被 n_heads 整除
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
d_k = d_model // n_heads # 每个头的键/查询/值的维度print(f"超参数已定义:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_heads: {n_heads}")
print(f" d_k (每个头的维度): {d_k}")
print(f" n_layers: {n_layers}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" learning_rate: {learning_rate}")
print(f" batch_size: {batch_size}")
print(f" epochs: {epochs}")
print(f" 使用设备:{device}")
第 1 步:训练数据准备
目标:将编码后的数据(full_data_sequence)结构化为适合训练下一个标记预测任务的输入(x)和目标(y)对。
第 1.1 步:创建输入(x)和目标(y)对
解释:模型需要学习 P(token_i | token_0, ..., token_{i-1})。我们通过创建长度为 block_size 的序列来实现这一点。对于从 data[i : i+block_size] 取出的每个输入序列 x,相应的目标序列 y 是 x 中每个位置的下一个标记,即 data[i+1 : i+block_size+1]。我们从编码后的语料库中提取所有可能的重叠序列。
# 创建列表以保存所有可能的输入(x)和目标(y)序列,长度为 block_size
all_x = []
all_y = []# 遍历编码后的语料库张量以提取重叠序列
# 我们需要提前停止,以便我们总能获得相同长度的目标序列
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):# 提取长度为 block_size 的输入序列片段x_chunk = full_data_sequence[i : i + block_size]# 提取目标序列片段(向右移动一个位置)y_chunk = full_data_sequence[i + 1 : i + block_size + 1]# 将片段添加到我们的列表中all_x.append(x_chunk)all_y.append(y_chunk)# 将列表中的张量堆叠成单个大张量
# train_x 的形状为 (num_sequences, block_size)
# train_y 的形状为 (num_sequences, block_size)
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)num_sequences_available = train_x.shape[0]
print(f"创建了 {num_sequences_available} 个重叠的输入/目标序列对。")
print(f"train_x 的形状:{train_x.shape}")
print(f"train_y 的形状:{train_y.shape}")# 可选:显示一个输入/目标对并解码它
# sample_idx = 0
# sample_x_ids = train_x[sample_idx].tolist()
# sample_y_ids = train_y[sample_idx].tolist()
# sample_x_chars = ''.join([int_to_char[id] for id in sample_x_ids])
# sample_y_chars = ''.join([int_to_char[id] for id in sample_y_ids])
# print(f"\n样本输入 x[{sample_idx}] ID:{sample_x_ids}")
# print(f"样本目标 y[{sample_idx}] ID:{sample_y_ids}")
# print(f"样本输入 x[{sample_idx}] 字符:'{sample_x_chars}'")
# print(f"样本目标 y[{sample_idx}] 字符:'{sample_y_chars}'")
第 1.2 步:批处理策略(简化:随机采样)
解释:为了避免实现复杂的数据加载器,对于每个训练步骤,我们只需简单地从可用序列(0 到 num_sequences_available - 1)中随机选择 batch_size 个索引。然后我们使用这些索引来获取对应的输入(xb)和目标(yb)序列,从 train_x 和 train_y 中。这模拟了从数据集中随机抽取批次。
# 检查我们是否有足够的序列来满足所需的批次大小
if num_sequences_available < batch_size:print(f"警告:序列数量({num_sequences_available})小于批次大小({batch_size})。调整批次大小。")batch_size = num_sequences_availableprint(f"数据已准备好用于训练。将随机抽取大小为 {batch_size} 的批次。")
第 2 步:模型组件初始化
目标:初始化 Transformer 模型所有层的可学习参数。每个层都被创建为 torch.nn 模块的一个实例,并移动到目标 device 上。
第 2.1 步:标记嵌入层
解释:将整数标记 ID(在我们这里是字符 ID)映射到密集向量。输入 (B, T) -> 输出 (B, T, C),其中 B=批次,T=时间/序列长度,C=d_model。
# 初始化标记嵌入表(查找表)
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)print(f"初始化了标记嵌入层(词汇表:{vocab_size},维度:{d_model})。设备:{device}")
第 2.2 步:位置编码矩阵
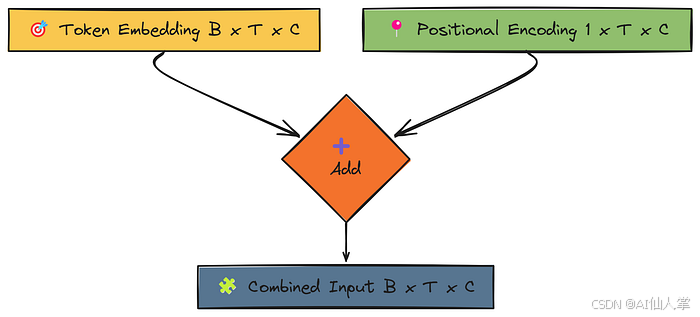
解释:使用正弦和余弦函数创建固定(非学习)向量来编码位置信息,频率各不相同。这个矩阵 (1, block_size, d_model) 将被添加到标记嵌入中。
公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
# 预计算正弦波位置编码矩阵
print("第 2.2 步:创建位置编码矩阵...")# 矩阵用于存储编码:形状为 (block_size, d_model)
positional_encoding = torch.zeros(block_size, d_model, device=device)# 位置索引(0 到 block_size-1):形状为 (block_size, 1)
position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)# 维度索引(0, 2, 4, ...):形状为 (d_model/2)
div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)
# 分母项:1 / (10000^(2i / d_model))
div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))# 计算偶数维度的正弦值
positional_encoding[:, 0::2] = torch.sin(position * div_term)# 计算奇数维度的余弦值
positional_encoding[:, 1::2] = torch.cos(position * div_term)# 添加批次维度:形状为 (1, block_size, d_model)
positional_encoding = positional_encoding.unsqueeze(0)print(f" 位置编码矩阵已创建,形状为:{positional_encoding.shape}。设备:{device}")
第 2.3 步:Transformer 块组件初始化
解释:初始化 n_layers 解码器块所需的所有组件。我们将它们存储在 Python 列表中,索引对应于层号(0 到 n_layers-1)。
print(f"第 2.3 步:初始化 {n_layers} 个 Transformer 层的组件...")# 列表用于存储每层 Transformer 块的层
layer_norms_1 = [] # 第一次 MHA 后的层归一化
layer_norms_2 = [] # 第一次 FFN 后的层归一化
mha_qkv_linears = [] # QKV 投影的组合线性层
mha_output_linears = [] # MHA 的输出线性层
ffn_linear_1 = [] # FFN 中的第一个线性层
ffn_linear_2 = [] # FFN 中的第二个线性层# 遍历层数
for i in range(n_layers):# 第一次 MHA 后的层归一化ln1 = nn.LayerNorm(d_model).to(device)layer_norms_1.append(ln1)# 多头注意力:QKV 投影层qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device) # 通常这里 bias=Falsemha_qkv_linears.append(qkv_linear)# 多头注意力:输出投影层output_linear = nn.Linear(d_model, d_model).to(device)mha_output_linears.append(output_linear)# 第一次 FFN 后的层归一化ln2 = nn.LayerNorm(d_model).to(device)layer_norms_2.append(ln2)# 位置级前馈网络:第一个线性层lin1 = nn.Linear(d_model, d_ff).to(device)ffn_linear_1.append(lin1)# 位置级前馈网络:第二个线性层lin2 = nn.Linear(d_ff, d_model).to(device)ffn_linear_2.append(lin2)print(f" 初始化了第 {i+1}/{n_layers} 层的组件。")print(f"已初始化 {n_layers} 层的组件。")
第 2.4 步:最终层初始化
解释:初始化最后一个块之后应用的最终层归一化和将 Transformer 输出映射回词汇表得分的最终线性层。
print("第 2.4 步:初始化最终层归一化和输出层...")# 最终层归一化
final_layer_norm = nn.LayerNorm(d_model).to(device)
print(f" 初始化了最终层归一化。设备:{device}")# 最终线性层(语言建模头)
output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
print(f" 初始化了最终线性层(到词汇表大小 {vocab_size})。设备:{device}")
第 3 步:定义正向传播(内联 —— 概念块)
目标:详细说明构成 Transformer 正向传播的序列操作。这些概念块将在训练和生成循环中直接执行。
第 3.1 步:输入嵌入 + 位置编码
解释:将输入标记 ID (B, T) 转换为嵌入 (B, T, C) 并添加位置信息。输出 x 的形状为 (B, T, C)。
print("概念第 3.1 步已定义(嵌入 + 位置编码)。在循环中执行。")
第 3.2 步:Transformer 块循环(概念)
解释:概述在循环中迭代 n_layers 次的操作。
第 3.2.1 步:带掩码的多头自注意力(概念)
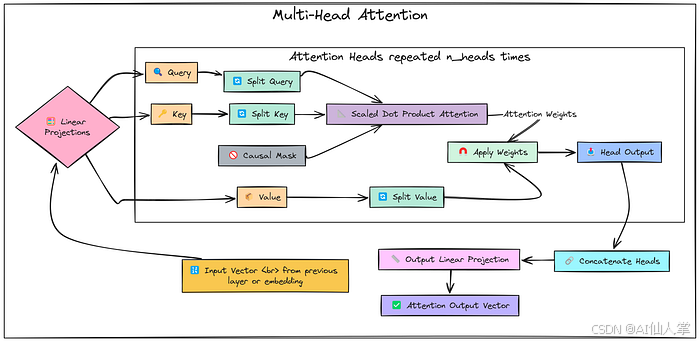
解释:允许每个标记关注前面的标记(包括自身)。
- 将输入
x(B, T, C)投影到 Q、K、V(B, n_heads, T, d_k)。 - 计算缩放点积注意力分数:
Attention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dkQKT+M)V
其中 (M) 是因果掩码(将上三角部分设置为 (-\infty))。 - 将头连接起来并投影回
(B, T, C)。
print("概念第 3.2.1 步已定义(多头注意力)。在层循环中执行。")
第 3.2.2 步:添加与归一化 1(第一次注意力后)(概念)
解释:残差连接(x + AttentionOutput)后跟层归一化。
LayerNorm ( x ) = γ x − μ σ 2 + ϵ + β \text{LayerNorm}(x) = \gamma \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LayerNorm(x)=γσ2+ϵx−μ+β
其中 (\mu, \sigma^2) 是特征维度 (C) 上的均值/方差,而 (\gamma, \beta) 是可学习的缩放/偏移量。
print("概念第 3.2.2 步已定义(添加与归一化 1)。在层循环中执行。")
第 3.2.3 步:位置级前馈网络(FFN)(概念)
解释:在每个位置 (t) 独立应用两次线性变换,中间有一个非线性激活(ReLU)。
FFN ( x ) = Linear 2 ( ReLU ( Linear 1 ( x ) ) ) \text{FFN}(x) = \text{Linear}_2(\text{ReLU}(\text{Linear}_1(x))) FFN(x)=Linear2(ReLU(Linear1(x)))
print("概念第 3.2.3 步已定义(前馈网络)。在层循环中执行。")
第 3.2.4 步:添加与归一化 2(第一次 FFN 后)(概念)
解释:第二次残差连接(Norm1Output + FFNOutput)后跟层归一化。这个输出成为下一层的输入 x。
print("概念第 3.2.4 步已定义(添加与归一化 2)。在层循环中执行。")
第 3.3 步:最终层(概念)
解释:对最后一个块的输出应用最终层归一化,然后将其投影到词汇表得分 (B, T, V)。
print("概念第 3.3 步已定义(最终层)。在层循环之后执行。")
第 4 步:训练模型(内联循环)
目标:迭代调整模型参数以最小化预测误差(损失)。
第 4.1 步:定义损失函数
解释:使用交叉熵损失函数,适用于多类分类(预测下一个字符 ID)。它需要 logits (N, V) 和目标 (N)。我们将 (B, T, V) 重塑为 (B*T, V),(B, T) 重塑为 (B*T)。
# 定义损失函数
criterion = nn.CrossEntropyLoss()print(f"第 4.1 步:已定义损失函数:{type(criterion).__name__}")
第 4.2 步:定义优化器
解释:使用 AdamW 优化器。将所有初始化层的可学习参数收集到一个列表中,供优化器管理。
# 收集所有需要梯度的模型参数
all_model_parameters = list(token_embedding_table.parameters())
for i in range(n_layers):all_model_parameters.extend(list(layer_norms_1[i].parameters()))all_model_parameters.extend(list(mha_qkv_linears[i].parameters()))all_model_parameters.extend(list(mha_output_linears[i].parameters()))all_model_parameters.extend(list(layer_norms_2[i].parameters()))all_model_parameters.extend(list(ffn_linear_1[i].parameters()))all_model_parameters.extend(list(ffn_linear_2[i].parameters()))
all_model_parameters.extend(list(final_layer_norm.parameters()))
all_model_parameters.extend(list(output_linear_layer.parameters()))# 定义 AdamW 优化器
optimizer = optim.AdamW(all_model_parameters, lr=learning_rate)print(f"第 4.2 步:已定义优化器:{type(optimizer).__name__}")
print(f" 管理 {len(all_model_parameters)} 个参数组/张量。")# 在循环外部创建自注意力的下三角掩码
# 形状:(1, 1, block_size, block_size)
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
第 4.3 步:训练循环
解释:迭代 epochs 次。在每一步中:选择批次,执行正向传播(执行概念步骤 3.1-3.3),计算损失,清零梯度,反向传播,更新权重。
print(f"\n第 4.3 步:开始 {epochs} 个周期的训练循环...")# 列表用于记录损失
losses = []# 将层设置为训练模式(例如,对于可能的 dropout,尽管这里省略了)
# 这在没有 dropout/batchnorm 的情况下实际上什么也不做,但这是个好习惯
for i in range(n_layers):layer_norms_1[i].train()mha_qkv_linears[i].train()mha_output_linears[i].train()layer_norms_2[i].train()ffn_linear_1[i].train()ffn_linear_2[i].train()
final_layer_norm.train()
output_linear_layer.train()
token_embedding_table.train()# 训练循环
for epoch in range(epochs):# --- 1. 批次选择 ---indices = torch.randint(0, num_sequences_available, (batch_size,))xb = train_x[indices].to(device) # 输入批次形状:(B, T)yb = train_y[indices].to(device) # 目标批次形状:(B, T)# --- 2. 正向传播(内联执行)---B, T = xb.shape # B = batch_size, T = block_sizeC = d_model # 嵌入维度# 第 3.1 步:嵌入 + 位置编码token_embed = token_embedding_table(xb) # (B, T, C)pos_enc_slice = positional_encoding[:, :T, :] # (1, T, C)x = token_embed + pos_enc_slice # (B, T, C)# 第 3.2 步:Transformer 块for i in range(n_layers):# 这个块的输入x_input_block = x # --- MHA ---# 在 MHA 之前应用层归一化(预归一化变体 —— 常见)x_ln1 = layer_norms_1[i](x_input_block)# QKV 投影qkv = mha_qkv_linears[i](x_ln1) # (B, T, 3*C)# 分割头qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3) # (B, n_heads, T, 3*d_k)q, k, v = qkv.chunk(3, dim=-1) # (B, n_heads, T, d_k)# 缩放点积注意力attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5) # (B, n_heads, T, T)# 应用因果掩码(使用预先计算的掩码,切片到 T)attn_scores_masked = attn_scores.masked_fill(causal_mask[:,:,:T,:T] == 0, float('-inf'))attention_weights = F.softmax(attn_scores_masked, dim=-1) # (B, n_heads, T, T)# 注意力输出attn_output = attention_weights @ v # (B, n_heads, T, d_k)# 连接头attn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C) # (B, T, C)# 输出投影mha_result = mha_output_linears[i](attn_output) # (B, T, C)# 添加与归一化 1(残差连接将输出添加到原始输入)x = x_input_block + mha_result # 残差连接 1# 注意:我们将 LN1 移到 MHA *之前*(预归一化)# --- FFN ---# FFN 的输入x_input_ffn = x # 在 FFN 之前应用层归一化(预归一化变体)x_ln2 = layer_norms_2[i](x_input_ffn)# FFN 层ffn_hidden = ffn_linear_1[i](x_ln2) # (B, T, d_ff)ffn_activated = F.relu(ffn_hidden)ffn_output = ffn_linear_2[i](ffn_activated) # (B, T, C)# 添加与归一化 2(残差连接将输出添加到 FFN 输入)x = x_input_ffn + ffn_output # 残差连接 2# 注意:我们将 LN2 移到 *FFN 之前*(预归一化)# 这个块的输出 'x' 成为下一个块的输入 'x_input_block'# 第 3.3 步:最终层(循环之后)# 应用最终层归一化(预归一化风格,应用于最终投影之前)final_norm_output = final_layer_norm(x) # (B, T, C)logits = output_linear_layer(final_norm_output) # (B, T, vocab_size)# --- 3. 计算损失 ---B_loss, T_loss, V_loss = logits.shapelogits_for_loss = logits.view(B_loss * T_loss, V_loss) targets_for_loss = yb.view(B_loss * T_loss)loss = criterion(logits_for_loss, targets_for_loss)# --- 4. 清零梯度 ---optimizer.zero_grad()# --- 5. 反向传播 ---loss.backward()# --- 6. 更新参数 ---optimizer.step()# --- 日志记录 ---current_loss = loss.item()losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 个周期,损失:{current_loss:.4f}")print("--- 训练循环已完成 ---")
第 5 步:文本生成(内联)
目标:使用训练好的模型参数逐字符生成新文本,从种子上下文开始。
第 5.1 步:设置生成种子和参数
解释:定义生成的起始字符,并指定要生成多少个字符。我们将种子字符(在这里是 ‘t’)转换为其标记 ID。
print("\n--- 第 5 步:文本生成 ---")# 种子字符
seed_chars = "t"
# 将种子字符转换为标记 ID
seed_ids = [char_to_int[ch] for ch in seed_chars]# 创建初始上下文张量
# 形状:(1, len(seed_ids)) -> 批次维度 = 1
generated_sequence = torch.tensor([seed_ids], dtype=torch.long, device=device)
print(f"初始种子序列:'{seed_chars}' -> {generated_sequence.tolist()}")# 定义要生成的新标记(字符)数量
num_tokens_to_generate = 200
print(f"将生成 {num_tokens_to_generate} 个新标记...")
第 5.2 步:生成循环
解释:迭代 num_tokens_to_generate 次。在每次迭代中:
- 准备当前上下文(最后
block_size个标记)。 - 使用 已训练 的模型参数执行正向传播(在评估模式下 —— 使用
torch.no_grad()禁用梯度计算以提高效率)。 - 获取 最后一个 时间步的 logits。
- 应用 softmax 获得概率。
- 根据概率采样下一个标记 ID。
- 将新的标记 ID 添加到
generated_sequence中。
# 将层设置为评估模式(如果使用了 dropout/batchnorm,这很重要)
# 这会禁用 dropout。我们手动进行,因为没有使用 nn.Module 类。
for i in range(n_layers):layer_norms_1[i].eval()mha_qkv_linears[i].eval()mha_output_linears[i].eval()layer_norms_2[i].eval()ffn_linear_1[i].eval()ffn_linear_2[i].eval()
final_layer_norm.eval()
output_linear_layer.eval()
token_embedding_table.eval()# 禁用生成时的梯度计算
with torch.no_grad():# 循环生成标记for _ in range(num_tokens_to_generate):# --- 1. 准备输入上下文 ---# 取最后 block_size 个标记作为上下文current_context = generated_sequence[:, -block_size:] # 形状:(1, min(current_len, block_size))B_gen, T_gen = current_context.shape C_gen = d_model# --- 2. 正向传播 ---# 嵌入 + 位置编码token_embed_gen = token_embedding_table(current_context) # (B_gen, T_gen, C_gen)pos_enc_slice_gen = positional_encoding[:, :T_gen, :] x_gen = token_embed_gen + pos_enc_slice_gen # (B_gen, T_gen, C_gen)# Transformer 块for i in range(n_layers):x_input_block_gen = x_gen# 预归一化 MHAx_ln1_gen = layer_norms_1[i](x_input_block_gen)qkv_gen = mha_qkv_linears[i](x_ln1_gen)qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)# 使用预先计算的掩码,切片到当前上下文长度 T_genattn_scores_masked_gen = attn_scores_gen.masked_fill(causal_mask[:,:,:T_gen,:T_gen] == 0, float('-inf'))attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)attn_output_gen = attention_weights_gen @ v_genattn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)mha_result_gen = mha_output_linears[i](attn_output_gen)x_gen = x_input_block_gen + mha_result_gen # 残差 1# 预归一化 FFNx_input_ffn_gen = x_genx_ln2_gen = layer_norms_2[i](x_input_ffn_gen)ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)ffn_activated_gen = F.relu(ffn_hidden_gen)ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)x_gen = x_input_ffn_gen + ffn_output_gen # 残差 2# 最终层final_norm_output_gen = final_layer_norm(x_gen)logits_gen = output_linear_layer(final_norm_output_gen) # (B_gen, T_gen, vocab_size)# --- 3. 获取最后一个时间步的 logits ---logits_last_token = logits_gen[:, -1, :] # 形状:(B_gen, vocab_size)# --- 4. 应用 softmax ---probs = F.softmax(logits_last_token, dim=-1) # 形状:(B_gen, vocab_size)# --- 5. 采样下一个标记 ---next_token = torch.multinomial(probs, num_samples=1) # 形状:(B_gen, 1)# --- 6. 添加采样标记 ---generated_sequence = torch.cat((generated_sequence, next_token), dim=1)print("\n--- 生成完成 ---")
第 5.3 步:解码生成序列
解释:使用 int_to_char 映射将生成的标记 ID 序列转换回人类可读的字符。
# 获取第一个(也是唯一一个)批次项的生成序列
final_generated_ids = generated_sequence[0].tolist()# 将 ID 列表解码回字符串
decoded_text = ''.join([int_to_char[id] for id in final_generated_ids])print(f"\n最终生成的文本(包括种子):")
print(decoded_text)
第 6 步:保存模型状态(可选)
由于我们的 Transformer 模型是以内联方式实现的,使用的是单独的组件变量,而不是 PyTorch nn.Module,因此我们需要手动将所有参数收集到一个状态字典中,然后才能保存。
# 创建一个目录来保存模型(如果它不存在)
os.makedirs('saved_models', exist_ok=True)# 创建一个状态字典来保存所有模型参数
state_dict = {'token_embedding_table': token_embedding_table.state_dict(),'positional_encoding': positional_encoding, # 这不是一个参数,只是一个张量'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],'mha_qkv_linears': [linear.state_dict() for linear in mha_qkv_linears],'mha_output_linears': [linear.state_dict() for linear in mha_output_linears],'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],'ffn_linear_1': [linear.state_dict() for linear in ffn_linear_1],'ffn_linear_2': [linear.state_dict() for linear in ffn_linear_2],'final_layer_norm': final_layer_norm.state_dict(),'output_linear_layer': output_linear_layer.state_dict(),# 保存超参数以重建模型'config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'d_ff': d_ff,'block_size': block_size},# 保存分词器信息以便文本生成'tokenizer': {'char_to_int': char_to_int,'int_to_char': int_to_char}
}# 保存状态字典
torch.save(state_dict, 'saved_models/transformer_model.pt')
print("模型已成功保存到 'saved_models/transformer_model.pt'")
要稍后加载模型,可以这样做:
# 加载保存的状态字典
loaded_state_dict = torch.load('saved_models/transformer_model.pt', map_location=device)# 提取配置和分词器信息
config = loaded_state_dict['config']
vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
block_size = config['block_size']
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']# 重新创建模型组件
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_state_dict['token_embedding_table'])positional_encoding = loaded_state_dict['positional_encoding'].to(device)# 初始化层列表
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []# 加载每层的组件
for i in range(n_layers):# 层归一化 1ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)# MHA QKV 线性qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device)qkv_linear.load_state_dict(loaded_state_dict['mha_qkv_linears'][i])mha_qkv_linears.append(qkv_linear)# MHA 输出线性output_linear = nn.Linear(d_model, d_model).to(device)output_linear.load_state_dict(loaded_state_dict['mha_output_linears'][i])mha_output_linears.append(output_linear)# 层归一化 2ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)# FFN 线性 1lin1 = nn.Linear(d_model, d_ff).to(device)lin1.load_state_dict(loaded_state_dict['ffn_linear_1'][i])ffn_linear_1.append(lin1)# FFN 线性 2lin2 = nn.Linear(d_ff, d_model).to(device)lin2.load_state_dict(loaded_state_dict['ffn_linear_2'][i])ffn_linear_2.append(lin2)# 最终层归一化
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])# 输出线性层
output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
output_linear_layer.load_state_dict(loaded_state_dict['output_linear_layer'])print("模型已成功加载!")
第 7 步:总结
这个 notebook 提供了一个字符级仅解码器 Transformer 语言模型的极其详细的逐步内联实现。通过避免使用函数和类,我们展示了训练和文本生成中涉及的粒度操作。
我们涵盖了以下内容:
- 设置与分词:准备环境,定义文本语料库,执行字符级分词(创建字符映射并编码语料库),设置超参数。
- 数据准备:将编码后的语料库结构化为输入/目标对,用于下一个标记预测。
- 模型初始化:创建所有必要的
torch.nn层(嵌入、线性层、层归一化)的实例,并预先计算位置编码。 - 正向传播(内联):详细说明并执行从嵌入、位置编码、多个 Transformer 块(带掩码的多头自注意力和前馈网络,包括残差连接和层归一化 —— 使用预归一化结构)到最终输出层的流程。
- 训练:实现训练循环,包括批次采样、正向传播执行、交叉熵损失计算、反向传播以及通过 AdamW 优化器更新参数。
- 文本生成:通过从种子开始,迭代执行正向传播(在
torch.no_grad()内),根据输出概率采样下一个标记,并将其添加到序列中,最终将生成的 ID 解码回文本,展示了自回归生成过程。
虽然非常冗长,但这种方法清晰地展示了 Transformer LM 中的基本机制和数据流。实际应用中,人们会大量使用函数和类来提高模块化、可重用性和可读性,但这种内联方法作为一个详细的教育分解示例还是很有价值的。
相关文章:
使用Python从零开始构建生成型TransformerLM并训练
在人工智能的浩瀚宇宙中,有一种神奇的生物,它拥有着强大的语言魔法,能够生成各种各样的文本,仿佛拥有无尽的创造力。它就是——Transformer 模型!Transformer 模型的出现,为人工智能领域带来了一场“语言魔…...

xtrabackup备份
安装: https://downloads.percona.com/downloads/Percona-XtraBackup-8.0/Percona-XtraBackup-8.0.35-30/binary/tarball/percona-xtrabackup-8.0.35-30-Linux-x86_64.glibc2.17.tar.gz?_gl1*1ud2oby*_gcl_au*MTMyODM4NTk1NS4xNzM3MjUwNjQ2https://downloads.perc…...

2.3 Spark运行架构与流程
Spark运行架构与流程包括几个核心概念:Driver负责提交应用并初始化作业,Executor在工作节点上执行任务,作业是一系列计算任务,任务是作业的基本执行单元,阶段是一组并行任务。Spark支持多种运行模式,包括单…...

【Pandas】pandas DataFrame head
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行 pandas.DataFrame.head pandas.DataFrame.head 是一个方法,用于返回 DataFrame 的前几行。这个方法非常有用,特别是在需要快速查看 DataFrame 的前…...

从递归入手一维动态规划
从递归入手一维动态规划 1. 509. 斐波那契数 1.1 思路 递归 F(i) F(i-1) F(i-2) 每个点都往下展开两个分支,时间复杂度为 O(2n) 。 在上图中我们可以看到 F(6) F(5) F(4)。 计算 F(6) 的时候已经展开计算过 F(5)了。而在计算 F(7)的时候,还需要…...

鸿蒙HarmonyOS埋点SDK,ClkLog适配鸿蒙埋点分析
ClkLog埋点分析系统,是一种全新的、开源的洞察方案,它能够帮助您捕捉每一个关键数据点,确保您的决策基于最准确的用户行为分析。技术人员可快速搭建私有的分析系统。 ClkLog鸿蒙埋点SDK通过手动埋点的方式实现HarmonyOS 原生应用的前端数据采…...

HarmonyOS:HMPermission权限请求框架
前段时间利用空余时间写了一个权限请求库:HMPermission。 一,简介 HMPermission 是鸿蒙系统上的一款权限请求框架,封装了权限请求逻辑,采用链式调用的方式请求权限,简化了权限请求的代码。 二,使用方法 …...

【书籍】DeepSeek谈《持续交付2.0》
目录 一、深入理解1. 核心理念升级:从"自动化"到"双环模型"2. 数字化转型的五大核心能力3. 关键实践与案例4. 组织与文化变革5. 与其它框架的关系6. 实际应用建议 二、对于开发实习生的帮助1. 立刻提升你的代码交付质量(技术验证环实…...

Spring AOP 扫盲
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
部署Embedding模型bge-m3【简单版本】)
银河麒麟v10(arm架构)部署Embedding模型bge-m3【简单版本】
硬件 服务器配置:鲲鹏2 * 920(32c) 4 * Atlas300I duo卡 参考文章 https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d 鲲鹏昇腾Atlas300Iduo部署Embedding模型和Rerank模型并连接Dify(自…...

如何通过流程管理优化企业运营?
流程管理的本质是“用确定性的规则应对不确定性的业务”。 那么,具体该如何通过流程管理来优化企业的运作呢?以下是一些关键步骤和思路,或许能给到一些启发。 1. 从流程梳理开始:摸清现状,找准问题 想要管理好企业的…...
:AXI GPIO)
ZYNQ笔记(四):AXI GPIO
版本:Vivado2020.2(Vitis) 任务:使用 AXI GPIO IP 核实现按键 KEY 控制 LED 亮灭(两个都在PL端) 一、介绍 AXI GPIO (Advanced eXtensible Interface General Purpose Input/Output) 是 Xilinx 提供的一个可…...

Java学习手册:JVM、JRE和JDK的关系
在Java生态系统中,JVM(Java虚拟机)、JRE(Java运行时环境)和JDK(Java开发工具包)是三个核心概念。它们共同构成了Java语言运行和开发的基础。理解它们之间的关系对于Java开发者来说至关重要。本文…...

Java 并发-newFixedThreadPool
前言 为什么选择使用多线程?一种场景是在数据和业务处理能力出现瓶颈时,而服务器性能又有空闲,通常是cpu空闲,这时使用多线程就能很好的解决问题,而又无需加硬件,实际使用中,线程池又是最为常用…...

C# task任务异步编程提高UI的响应性
方式1:async/await模式 private async void button1_Click(object sender, EventArgs e){try{var result await Task.Run(() > CalculateResult());label1.Text result.ToString();}catch (Exception ex){label1.Text $"Error: {ex.Message}";}}pri…...

Spring Bean生命周期执行流程详解
文章目录 一、什么是Spring Bean生命周期?工作流程图:二、Bean生命周期执行流程验证1.编写测试代码验证结果2.源码追溯Bean初始化回调过程 一、什么是Spring Bean生命周期? Spring Bean生命周期是指从Bean的创建到销毁的整个过程,…...
)
windows 安装 pygame( pycharm)
一、安装流程 1.查看python版本 2.检查是否安装pip 3.下载pygame安装文件 下载地址:https://pypi.org/project/pygame/#files 选择合适的版本(我选择的是 python3.7 windows 64bit): 4.使用pip安装pygame 将下载好的whl文件移动到…...

Envoy网关实例异常重启排查总结
一、事件背景 于10月24日凌晨业务租户有业务应用发版上线,中午收到pod连续5分钟重启严重告警,登录管理节点查看异常重启的应用网关pod日志,存在内核段错误报错信息导致进程终止并触发监控检查异常并重启; 该报错主要是访问的内存超出了系统…...
——ListBox控件详解)
WinForm真入门(13)——ListBox控件详解
WinForm ListBox 详解与案例 一、核心概念 ListBox 是 Windows 窗体中用于展示可滚动列表项的控件,支持单选或多选操作,适用于需要用户从固定数据集中选择一项或多项的场景。 二、核心属性 属性说明Items管理列表项的集合,支持动…...

【Linux网络编程】UDP Echo Server的实现
本文专栏:Linux网络编程 目录 一,Socket编程基础 1,IP地址和端口号 端口号划分范围 理解端口号和进程ID 源端口号和目的端口号 理解Socket 2,传输层的典型代表 3,网络字节序 4,Socket编程接口 s…...
控件)
8.3.5 ToolStripContainer(工具栏容器)控件
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 ToolStripContainer控件是一个容器,可以包含菜单和工具条、状态栏。 在设计窗体中放入一个ToolStripContainer࿱…...

代码随想录-06-二叉树-05.05 N叉树的层序遍历
N叉树的层序遍历 #模板题 题目描述 给定一个 N 叉树,返回其节点值的_层序遍历_。(即从左到右,逐层遍历)。 树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。 具体思路 …...

【NEPVR】《A Lightweight Palm Vein Recognition Algorithm NEPVR》
[1]马莉,刘子良,谭振林,等.一种轻量级掌静脉识别算法NEPVR[J].计算机技术与发展,2024,34(12):213-220.DOI:10.20165/j.cnki.ISSN1673-629X.2024.0248. 文章目录 1、背景2、相关工作3、创新点4、NEPVR 手掌静脉识别算法5、实验结果及分析6、总结 / 未来工作 1、背景 手掌静脉独…...

牟乃夏《ArcGIS Engine地理信息系统开发教程》学习笔记1
(适合GIS开发入门者,通俗解析核心知识点) 目录 一、ArcGIS Engine是什么? 二、ArcGIS Engine能做什么? 三、ArcGIS Engine与ArcObjects的区别 四、开发资源与学习路径 五、对象模型图(OMD)…...

架构师论文《论模型驱动软件开发方法在智能制造转型实践中的应用》
摘要: 本人现任某大型装备制造企业智能制造研究院首席架构师,主导集团级数字化工厂平台建设。面对多品种小批量生产模式下普遍存在的交付周期超预期(平均延期21天)、设备综合效率OEE不足65%的痛点,我司于2021年启动基…...

探索MCP.so:AI生态的创新枢纽
今天在研究MCP时发现了一个还不错的网站,分享给大家。后续会基于这些mcp servers做一些有趣的应用。 在人工智能飞速发展的当下,AI与各类工具、数据源的协同合作变得愈发关键。MCP.so这个平台,正悄然成为AI领域的重要枢纽,为众多开发者和AI爱好者打开了新的大门。 MCP,即…...

JVM底层详解
JVM底层详解 目录 JVM概述JVM内存模型垃圾回收机制类加载过程JIT编译JVM调优JVM监控与故障排查JVM与多线程JVM与性能优化JVM发展历程与未来JVM实战案例分析JVM高级特性JVM安全机制JVM与容器化 一、JVM概述 1.1 什么是JVM Java虚拟机(Java Virtual Machine&…...

多点:分布式升级助力新零售转型,成本节省超80% | OceanBase 案例
本文作者:多点数据库DBA团队 编者按:多点是零售行业数字(智)化的先行者,为全球企业提供创新的数字化解决方案。然而,在数字化转型的过程中,多点原有的数据库架构逐渐暴露出架构复杂、成本上升等…...

Java权限修饰符深度解析
Java权限修饰符深度解析与最佳实践 一、权限修饰符总览 Java提供四种访问控制修饰符,按访问范围从宽到窄排序如下: 修饰符类内部同包类不同包子类全局范围public✔️✔️✔️✔️protected✔️✔️✔️❌默认(无)✔️✔️❌❌pr…...

RocketMQ和kafka 的区别
一、数据可靠性与容错机制 数据可靠性 RocketMQ支持同步刷盘和同步复制,确保消息写入磁盘后才返回确认,单机可靠性高达10个9,即使操作系统崩溃也不会丢失数据159。而Kafka默认采用异步刷盘和异步复制,虽然吞吐量高,但极…...

分布式限流器框架 eval-rate-limiter
分布式限流器框架 eval-rate-limiter 文章目录 分布式限流器框架 eval-rate-limiter前言设计流程图 核心方法tryAcquire 获取通信证增加访问次数 incrementRequestCount生成分布式 key generateRateLimiterKey 测试测试代码结果Redis 客户端 前言 基于 redis 实现的分布式限流…...

使用Docker部署Java项目的完整指南
前言 Docker是一个轻量级的容器化平台,可将应用及其依赖打包成标准化单元,实现快速部署和环境隔离。本文以Spring Boot项目为例,演示如何通过Dockerfile部署Java应用。 准备工作 本地环境 安装Docker Desktop(官网下载࿰…...

机器学习数据需求与应用分析
监督学习、无监督学习和强化学习作为机器学习的核心范式,对数据条件的需求存在显著差异。以下是具体分析: 一、监督学习的数据条件 数据要求 监督学习需要带标签(labeled)的数据集,即每个输入样本都有对应的目标输出&a…...
✅)
【机器学习算法】基于python商品销量数据分析大屏可视化预测系统(完整系统源码+数据库+开发笔记+详细启动教程)✅
目录 一、项目背景 二、技术思路 三、算法介绍 四、项目创新点 五、开发技术介绍 六、项目展示 一、项目背景 本项目基于Python技术栈构建了"商品销量数据分析与预测系统",通过自动化爬取淘宝商品多维数据(价格、销量、评价、品类等&a…...

springboot集成springcloud vault读值示例
接上三篇 Vault---机密信息管理工具安装及常用示例 Vault机密管理工具集群配置示例 vault签发根证书、中间证书、ca证书流程记录 项目里打算把所有密码都放到vault里管理,vault提供了springcloud vault用来在springboot里连接vault,启动加载vault里的值放…...

BERT 模型是什么
BERT 模型是什么? BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的深度学习模型,由Google于2018年提出。它在自然语言处理领域取得了显著成就,成为众多NLP任务的基础。 …...

三元电池正极材料除杂工艺介绍
三元电池正极材料的除杂工艺对于提高电池性能、安全性和稳定性至关重要。以下是对三元电池正极材料除杂工艺的详细介绍: 物理除杂工艺 磁选 原理:利用磁场对磁性杂质的吸引作用实现分离。在三元电池正极材料生产中,常混入铁、钴、镍等磁性金…...

wx212基于ssm+vue+uniapp的科创微应用平台小程序
开发语言:Java框架:ssmuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:M…...

Multi Agents Collaboration OS:数据与知识协同构建数据工作流自动化
1-背景 传统数据系统与业务数字化的开发与维护面临诸多挑战:行业知识获取壁垒高、需求变化快导致开发周期长、系统复杂度高以及人力与资源投入成本巨大。同时,用户在使用过程中也常遇到痛点:手动录入数据繁琐低效、数据分散于各模块难以整合…...

elemenPlus中,如何去掉el-input中 文本域 textarea自带的边框和角标
1、去掉角标 :deep(.el-textarea__inner) {resize: none !important; // 去除右下角图标 }2、去除边框,并自定义背景色 <el-inputref"textareaRef"v-model"tempContent":style"{--el-border-color: rgba(255,255,255,0.0),--el-input-…...

Excel 动态比较两列数据:实现灵活的数据验证
目录 动态比较两列数据的需求动态公式的实现使用INDIRECT和ROW函数公式解释应用 动态公式的优点 快速添加一列公式的技巧使用快捷键Ctrl D使用VBA宏自动化使用“表格”功能自动填充 实际应用场景数据验证动态报告数据清洗 注意事项总结 在数据处理和分析中,Excel 是…...

谷歌推出可免费使用的Firebase Studio:Gemini全栈AI开发利器
谷歌刚刚发布了Firebase Studio,这是其打造的一款沉浸式代码开发平台,旨在与Cursor、Lovable、Bolt和V0等工具竞争。如果你是一名网页开发者,可能只知道Firebase是谷歌的数据库工具。 但现在,它已远不止于此。 Firebase已发展成一个完整的生态系统,如今能帮助你从头到尾…...
)
spark(二)
本节课接上节课继续对于RDD进行学习,首先是对于创建RDD的不同方式,接着学习了RDD的三种转换算子:Value类型、双Value类型、Key-Value类型,以及各个转换算子的不同使用方式。 学习到如下的区别: map 与 mapPartitions…...

Fay 数字人部署环境需求
D:\ai\Fay>python main.py pygame 2.6.1 (SDL 2.28.4, Python 3.11.9) Hello from the pygame community. https://www.pygame.org/contribute.html [2025-04-11 00:10:16.7][系统] 注册命令... [2025-04-11 00:10:16.8][系统] restart 重启服务 [2025-04-11 00:10:16.8][…...
)
【Harmony】端云一体化(云函数)
一、云函数的概述 1、什么是云函数 官方解释 云函数是一项Serverless计算服务,提供FaaS(Function as a Service)能力,一方面云函数将开发测试的对象聚焦到函数级别,可以帮助您大幅简化应用开发与运维相关的事务&…...

利用大模型和聚类算法找出 Excel 文件中重复或相似度高的数据,并使用 FastAPI 进行封装的详细方案
以下是一个利用大模型和聚类算法找出 Excel 文件中重复或相似度高的数据,并使用 FastAPI 进行封装的详细方案: 方案流程 数据读取:从 Excel 文件中读取数据。文本向量化:使用大模型将文本数据转换为向量表示。聚类分析:运用聚类算法对向量进行分组,将相似度高的数据归为…...

通过远程桌面连接wsl2中安装的ubuntu24.04
要介绍的这种方式其实跟直接用wsl来执行命令差不多,是在终端去操作ubuntu。WSL2 默认只提供命令行界面,本文安装xrdp后通过windows远程桌面连接过去。 1、更新软件包列表 sudo apt update 确保你的软件包列表是最新的,否则可能找不到某些包…...

对接和使用国内稳定无水印的 Suno API
随着 AI 的应用日益广泛,各种 AI 程序已经融入我们的日常生活。从最早的写作,到医疗、教育,如今甚至扩展到了音乐领域。 Suno 是一个专注于高质量 AI 歌曲和音乐创作的平台。用户只需输入简单的文本提示词,便可以按照流派风格和歌…...
_38)
LeetCode算法题(Go语言实现)_38
我将按照您提供的文档结构为您整理二叉树最近公共祖先(LCA)问题的解决方案: 一、代码实现 type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode }func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {if root nil ||…...

Linux学习笔记 1
1.发展史 略...... 2.xshell的使用方法 2.1登录 ssh root公网地址 输入密码,用 uname -r 指令来鉴定是否登录成功。之后就可以进行命令行操作了。 alt enter 全屏、退出 设置多用户指令,新建用户 adduser 名字 passwd 密码 销毁用户…...