数据库架构全解析:MyCat、MHA、ProxySQL 的原理、功能与实例
前言 :
在分布式数据库架构中,分库分表、高可用性(HA)和查询优化是核心需求。本文将深入解析三款主流工具:MyCat(分布式数据库中间件)、MHA(MySQL高可用方案)、ProxySQL(高性能数据库代理),从设计原理、核心功能、适用场景等维度对比分析,并结合实例示范帮助开发者理解落地细节。
数据库的发展历史可以追溯到20世纪60年代,经历了多个重要的阶段和技术创新。以下是数据库发展的主要历程:
数据库发展简史:
1. 早期数据库(20世纪60年代)
-
层次数据库(Hierarchical Databases)
- 1960年代,IBM开发了层次数据库系统,如 IBM Information Management System (IMS)。这种数据库使用树状结构存储数据,主要用于大型机系统,适合处理具有固定层次关系的数据(如企业资源规划系统)。
- 特点:数据结构固定,查询效率高,但灵活性差。
-
网状数据库(Network Databases)
- 1969年,CODASYL(Conference on Data Systems Languages)发布了网状数据库标准,代表产品是 CODASYL DBTG。这种数据库使用图结构来表示数据之间的关系。
- 特点:比层次数据库更灵活,但仍然需要复杂的导航操作。
2. 关系型数据库(1970年代)
- 理论基础:1970年,IBM研究员 E. F. Codd 提出了关系型数据库模型,奠定了现代数据库的基础。他提出了关系代数和关系模型,强调数据的逻辑结构和独立性。
- 实现:1974年,IBM开发了 System R,这是第一个实现关系型数据库的原型。
- 商业化:
- 1979年,Oracle(最初名为 Oracle V1)成为第一个商业化的关系型数据库系统。
- 1980年代,其他关系型数据库如 SQL Server 和 DB2 也相继推出。
3. MySQL的出现(1995年)
- 开发背景:MySQL由 Michael Widenius 和 David Axmark 开发,最初是一个轻量级的数据库,主要用于 Web 应用。
- 特点:开源、高性能、易用性,迅速在互联网行业流行。
- 应用:广泛用于 Web 开发(如 LAMP 架构:Linux、Apache、MySQL、PHP)。
4. NoSQL数据库(2000年代末)
- 背景:随着互联网应用的爆炸式增长,传统关系型数据库在处理大规模数据和高并发时遇到了瓶颈。
- 特点:
- 非关系型:不使用表结构,而是采用键值对、文档、列族或图结构。
- 分布式:通过分布式架构实现高扩展性和高可用性。
- CAP定理:在一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)之间进行权衡。
- 代表产品:
- 键值数据库:Redis、Memcached(适用于缓存和简单数据存储)。
- 文档数据库:MongoDB(适用于灵活的 JSON 文档存储)。
- 列族数据库:Cassandra、HBase(适用于大规模时间序列数据)。
- 图数据库:Neo4j(适用于复杂关系数据,如社交网络)。
5. NewSQL数据库(2010年代)
- 背景:NewSQL 数据库结合了关系型数据库的事务处理能力和 NoSQL 数据库的扩展性。
- 特点:
- 支持 ACID 事务(原子性、一致性、隔离性、持久性)。
- 提供水平扩展能力,适合大规模分布式系统。
- 代表产品:
- Google Spanner:分布式关系型数据库,支持全球分布式事务。
- CockroachDB:开源的分布式 SQL 数据库,受 Spanner 启发。
- Amazon Aurora:AWS 提供的高性能、高可用的云数据库服务。
6. 现代数据库趋势(2020年代)
- 云原生数据库:如 Amazon Aurora、Google Cloud Spanner、阿里云 PolarDB,提供弹性扩展和自动管理。
- 多模数据库:支持多种数据模型(如关系型、文档、键值、图)的统一数据库,如 ArangoDB。
- AI 驱动的数据库:结合机器学习优化查询性能和资源管理,如 Google 的 SQLFlow 和 TensorFlow 集成。
总结
数据库技术从早期的层次和网状数据库,到关系型数据库的普及,再到 NoSQL 和 NewSQL 的兴起,经历了多次重大变革。每种数据库类型都有其特定的应用场景和优势,现代数据库的发展正朝着云原生、多模和智能化方向迈进。
数据库中间件MyCat、MHA、ProxySQL:
一、MyCat:分布式数据库的“路由器”
1. 定位与核心价值
- 定位:基于 Java 开发的开源数据库中间件,介于应用层和数据库层之间,实现分库分表、读写分离、分布式事务等功能,屏蔽底层数据库细节。
- 核心价值:将单机数据库扩展为分布式集群,解决数据量/流量爆炸时的扩展性问题,适用于互联网高并发、海量数据场景(如电商订单、用户中心)。
2. 核心原理与架构
-
架构层级思维导图:
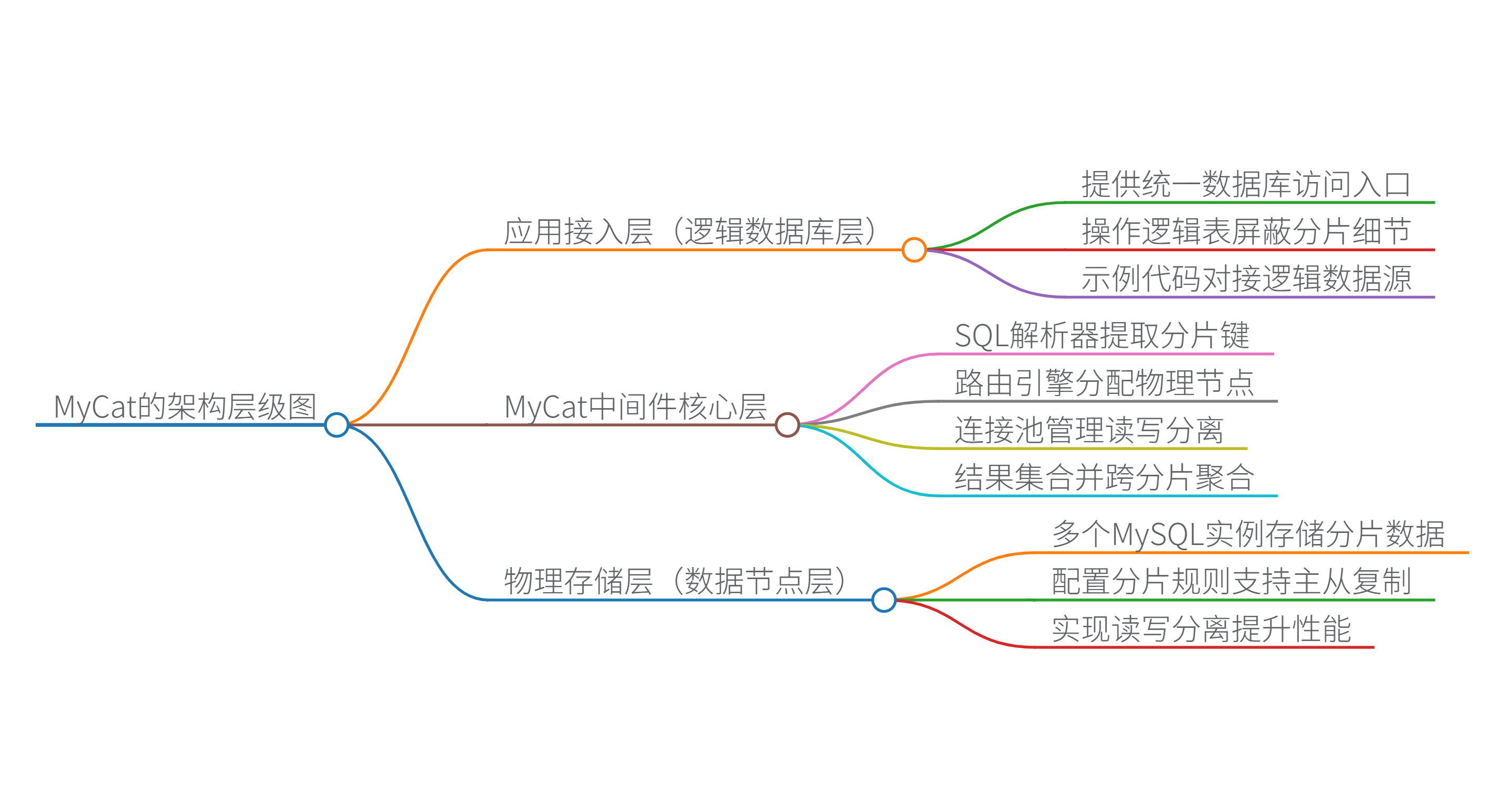
(注:图示为逻辑架构,实际需结合具体部署)
-
核心模块:
- SQL 解析器:将 SQL 语句拆解为 AST(抽象语法树),识别表名、分片键、操作类型等。
- 路由规则引擎:根据分片策略(如哈希分片、范围分片、枚举分片)决定 SQL 路由到哪个分片节点。
- 连接池:管理与后端数据库的连接,支持连接复用和负载均衡。
- 结果集合并:聚合多个分片的查询结果(如分页、排序、聚合函数),返回给应用层。
-
分片策略:
- 垂直分片:按业务模块拆分(如用户库、订单库)。
- 水平分片:按数据特征拆分(如按用户 ID 哈希分到多个库表)。
3. 核心功能
- 分库分表:支持全局表(各分片同步数据,如字典表)、ER 分片(关联表按主外键分片)。
- 读写分离:根据 SQL 类型(SELECT/INSERT/UPDATE/DELETE)路由到主库或从库。
- 分布式事务:支持基于 XA 协议的强一致事务,或柔性事务(最终一致性)。
- 兼容性:模拟 MySQL 协议,应用无需修改代码即可接入,支持跨数据库(MySQL、Oracle、PostgreSQL 等)。
4. 优缺点与适用场景
- 优点:
- 开箱即用,支持复杂分片逻辑,适合业务快速迭代。
- 兼容 MySQL 协议,对应用透明。
- 缺点:
- 引入中间件层,增加系统复杂度和网络开销。
- 分片键设计一旦确定难以修改,需提前规划数据模型。
- 适用场景:
- 数据量超过单库瓶颈(如单表超千万行)。
- 需要读写分离、分库分表的分布式系统(如电商、社交平台)。
5. 实例示范:用户表水平分片配置
假设业务需求:用户表(user_info)按 user_id 哈希分片到 2 个数据库(db_0、db_1),每个库包含 2 个表(user_info_0、user_info_1)。
步骤 1:配置分片规则(rule.xml)
<rule> <name>hash_user_id</name> <ruleType>1</ruleType> <columns>user_id</columns> <algorithm>mod-long</algorithm>
</rule>
<function> <name>mod-long</name> <class>io.mycat.route.function.PartitionByMod</class> <property>count>2</property> <!-- 分片数量为 2,user_id % 2 决定数据节点 -->
</function>
步骤 2:定义逻辑库与表(schema.xml)
<schema name="test_schema" checkSQLschema="false"> <table name="user_info" dataNode="dn0,dn1" rule="hash_user_id" />
</schema>
<dataNode name="dn0" dataHost="host0" database="db_0" />
<dataNode name="dn1" dataHost="host1" database="db_1" />
<dataHost name="host0" maxCon="1000" minCon="10" balance="0"> <heartbeat>select user()</heartbeat> <writeHost host="master0" url="192.168.1.10:3306" user="root" password="123456" />
</dataHost>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"> <heartbeat>select user()</heartbeat> <writeHost host="master1" url="192.168.1.11:3306" user="root" password="123456" />
</dataHost>
步骤 3:启动 MyCat 并测试路由
- 连接 MyCat(默认端口 8066):
mysql -u mycat -p123456 -h 127.0.0.1 -P 8066 - 插入数据验证分片:
INSERT INTO user_info (user_id, username) VALUES (1, 'user1'); -- user_id=1 % 2 = 1,路由到 dn1(db_1) INSERT INTO user_info (user_id, username) VALUES (2, 'user2'); -- user_id=2 % 2 = 0,路由到 dn0(db_0) - 登录物理数据库查看表数据,确认分片规则生效。
二、MHA:MySQL 高可用性的“守护者”
- 架构层级思维导图:

1. 定位与核心价值
- 定位:基于 Perl 开发的 MySQL 高可用性解决方案,专注于主从架构下的故障自动切换,确保主库宕机时快速提升从库为新主库,减少服务中断时间。
- 核心价值:解决传统主从架构中故障切换依赖人工的问题,实现自动化、可靠的 HA 机制,适用于对可用性要求极高的业务(如交易、支付系统)。
2. 核心原理与架构
- 架构组件:
- Manager 节点:监控主从集群状态,执行故障检测和切换逻辑(通常部署在独立服务器)。
- Node 节点:每个 MySQL 实例(主/从库)上运行的脚本,提供状态汇报和切换执行功能。
- 依赖条件:主从复制(需开启 GTID 或二进制日志)、SSH 互信(Manager 需远程操作 Node 节点)。
- 故障切换流程:
- Manager 检测到主库宕机,通过
ping命令和 MySQL 协议双重验证。 - 筛选出拥有最新数据的从库(基于 relay log 应用进度)。
- 在新主库上应用所有未同步的 relay log,确保数据一致性。
- 更新其他从库指向新主库,通知应用层切换连接地址(需配合 DNS 或配置中心)。
- Manager 检测到主库宕机,通过
3. 核心功能
- 快速故障切换:秒级检测(可配置检测间隔),分钟级完成切换(取决于日志应用时间)。
- 数据一致性保障:切换前补全所有 relay log,避免主从数据不一致(需关闭
sync_binlog=0等风险配置)。 - 多节点支持:支持一主多从架构,可配置候选主库优先级。
4. 优缺点与适用场景
- 优点:
- 专注 MySQL 高可用,轻量高效,资源消耗低。
- 社区成熟,支持 GTID 模式(简化复制管理)。
- 缺点:
- 仅支持主从架构,不解决分片问题。
- 切换过程中可能出现短暂服务中断(需配合连接池重试机制)。
- 适用场景:
- 以 MySQL 为主库的主从集群,需高可用性(如金融、实时交易系统)。
- 业务规模中等,暂不需要分库分表,但需保障主库故障时的自动容灾。
5. 实例示范:一主两从集群故障切换
假设集群节点:
- 主库:192.168.1.10(port 3306)
- 从库1:192.168.1.11(port 3306,候选主库)
- 从库2:192.168.1.12(port 3306)
- MHA Manager:192.168.1.20(需安装 Perl 及 MHA 工具包)
步骤 1:配置主从复制(所有节点)
- 主库开启 GTID(
my.cnf):[mysqld] server-id=1 gtid_mode=ON enforce_gtid_consistency=1 - 从库配置复制(以从库1为例):
CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION=1; START SLAVE;
步骤 2:配置 MHA 配置文件(mha.cnf)
[server default]
manager_workdir=/var/log/mha
manager_log=/var/log/mha/manager.log
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover # 自定义切换后更新 IP 脚本
ssh_user=root
repl_user=repl
repl_password=repl
[server1]
hostname=192.168.1.10
port=3306
[server2]
hostname=192.168.1.11
port=3306
candidate_master=1 # 标记为优先候选主库
[server3]
hostname=192.168.1.12
port=3306
步骤 3:启动 MHA 并验证
- 检查 SSH 互信与复制状态:
masterha_check_ssh --conf=mha.cnf # 确保 Manager 可无密登录所有节点 masterha_check_repl --conf=mha.cnf # 验证主从复制正常 - 启动 Manager 进程:
nohup masterha_manager --conf=mha.cnf & - 模拟主库故障(关闭主库服务):
ssh 192.168.1.10 'systemctl stop mysql' - 观察切换日志,确认从库1提升为主库:
-- 连接新主库(192.168.1.11),查看 GTID 状态 SHOW MASTER STATUS; # 确保 Log_slave_updates=ON,且无 Slave 相关状态
三、ProxySQL:高性能数据库的“流量调节器”
- 架构层级思维导图:
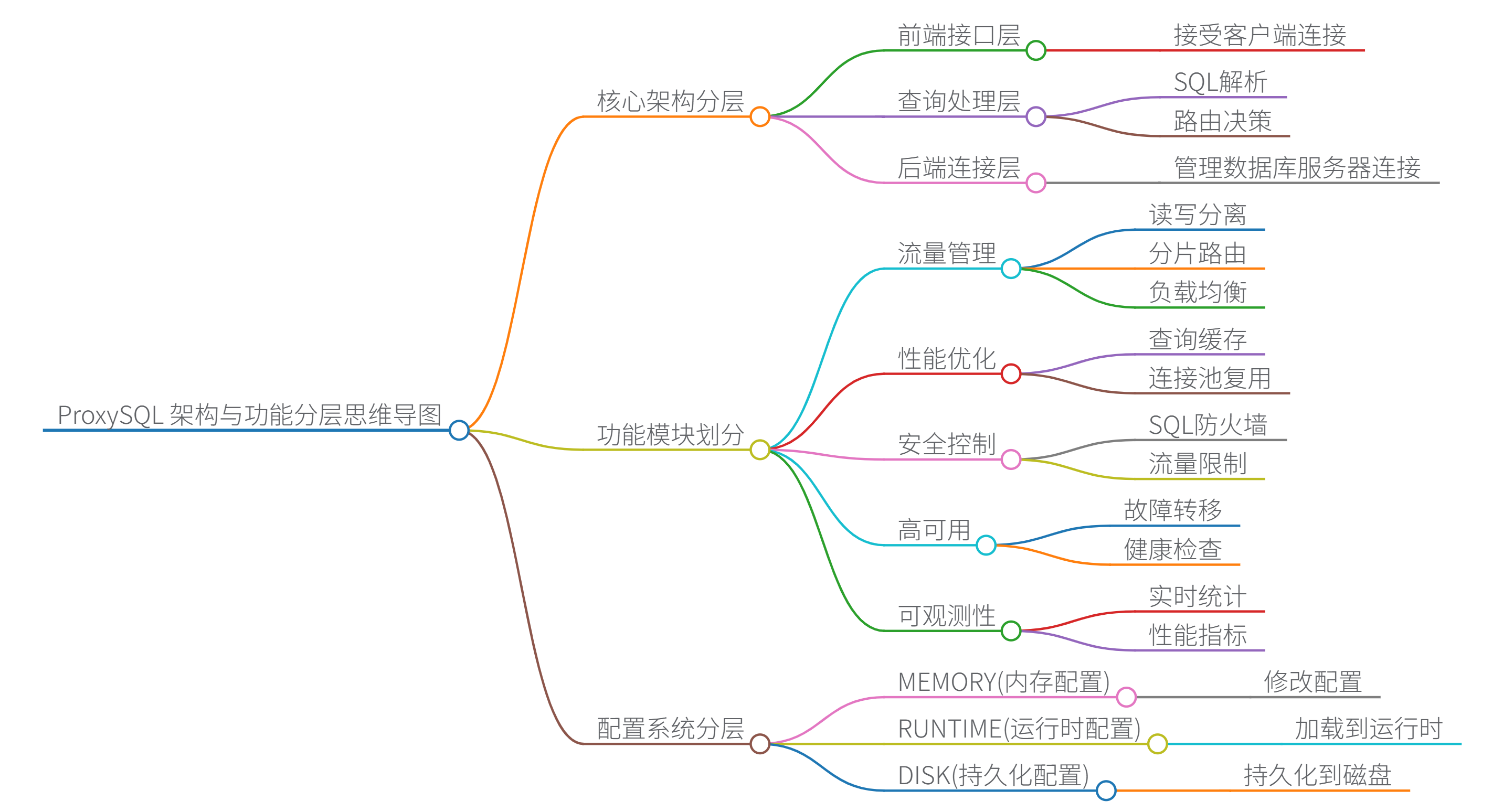
1. 定位与核心价值
- 定位:基于 C++ 开发的高性能数据库代理,支持连接池管理、查询优化、流量控制,可部署在应用与数据库之间,降低连接开销和提升查询效率。
- 核心价值:解决高并发场景下连接数爆炸、慢查询拖垮数据库等问题,适用于需要精细化流量管理的场景(如秒杀、高并发 API)。
2. 核心原理与架构
- 架构特性:
- 分层架构:
- 管理节点(Admin Interface):通过 MySQL 协议连接,动态配置路由规则、连接池参数等(数据存储在内存和磁盘)。
- 运行节点(Runtime):处理实际流量,基于配置进行查询路由和连接管理。
- 连接池机制:
- 为每个后端数据库维护独立连接池,支持最大/最小连接数、连接超时等参数。
- 连接复用:避免频繁创建/销毁连接,减少数据库压力(尤其适合短连接场景)。
- 分层架构:
- 查询优化能力:
- 查询缓存:缓存 SELECT 语句结果(需显式开启,支持 TTL 和大小限制)。
- 语法分析:识别读写语句,实现精准的读写分离(如根据表名、SQL 模式路由)。
- 负载均衡:支持轮询、权重、延迟感知等策略分配读请求到从库。
3. 核心功能
- 连接池管理:降低连接数峰值,避免数据库被连接打满(如限制每个应用的最大连接数)。
- 动态路由:通过正则表达式或 SQL 模式匹配,实现细粒度路由(如将
SELECT * FROM users固定路由到从库)。 - 监控与统计:记录查询耗时、连接池状态、慢查询日志,支持与 Prometheus、Grafana 集成。
- 事务支持:完整传递事务语句到后端数据库,确保事务原子性。
4. 优缺点与适用场景
- 优点:
- 高性能(内存级处理,单节点可支持数万 QPS),资源占用低。
- 灵活的动态配置,无需重启即可修改路由规则。
- 缺点:
- 不支持分库分表,仅作为代理层优化(需与 MyCat 等中间件配合使用)。
- 查询缓存功能较弱,复杂查询缓存命中率低。
- 适用场景:
- 高并发读场景(如抢购、实时报表),需降低数据库连接压力。
- 读写分离架构中,需精细化流量控制和连接管理。
5. 实例示范:读写分离与连接池配置
假设后端数据库:
- 主库(写):192.168.1.10:3306
- 从库1(读):192.168.1.11:3306
- 从库2(读):192.168.1.12:3306
步骤 1:启动 ProxySQL 并连接 Admin 接口
# 启动 ProxySQL(默认 Admin 端口 6032,数据端口 6033)
proxysql -d
# 连接 Admin 接口(默认用户名/密码:admin/admin)
mysql -u admin -padmin -h 127.0.0.1 -P 6032
步骤 2:配置后端节点(分写节点组和读节点组)
-- 写节点组(hostgroup_id=1)
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (1, '192.168.1.10', 3306, 100);
-- 读节点组(hostgroup_id=2)
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (2, '192.168.1.11', 3306, 50), (2, '192.168.1.12', 3306, 50);
步骤 3:配置路由规则(按 SQL 类型路由)
-- SELECT 语句路由到读节点组(hostgroup=2)
INSERT INTO mysql_query_rules (rule_id, active, match_digest, destination_hostgroup)
VALUES (1, 1, '^SELECT .*', 2);
-- 写语句路由到写节点组(hostgroup=1)
INSERT INTO mysql_query_rules (rule_id, active, match_digest, destination_hostgroup)
VALUES (2, 1, '^(INSERT|UPDATE|DELETE) .*', 1);
-- 加载规则到运行时并持久化
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
步骤 4:配置连接池参数(限制后端节点连接数)
-- 写节点最大连接数 200
UPDATE mysql_server_groups SET max_connections=200 WHERE hostgroup_id=1;
-- 读节点最大连接数 500
UPDATE mysql_server_groups SET max_connections=500 WHERE hostgroup_id=2;
LOAD MYSQL SERVER GROUPS TO RUNTIME;
SAVE MYSQL SERVER GROUPS TO DISK;
步骤 5:压测与监控
- 通过 ProxySQL 数据端口(6033)连接应用:
mysql -u app_user -papp_pass -h 127.0.0.1 -P 6033 - 使用
sysbench压测读请求,观察监控数据:-- 查看各节点连接数和请求量 SELECT * FROM stats_mysql_servers; -- 查看慢查询日志(需配置慢查询阈值) SELECT * FROM stats_mysql_slow_log;
四、对比与选型建议
| 维度 | MyCat | MHA | ProxySQL |
|---|---|---|---|
| 核心定位 | 分布式数据库中间件(分库分表) | MySQL 高可用(主从故障切换) | 数据库代理(连接池+查询优化) |
| 核心功能 | 分片、读写分离、分布式事务 | 自动故障检测、主从切换 | 连接池、查询路由、流量控制 |
| 支持数据库 | 多数据库(MySQL、Oracle 等) | 仅 MySQL | 仅 MySQL(支持 MariaDB、Percona) |
| 部署复杂度 | 较高(需设计分片策略) | 中等(需配置 SSH 互信、主从复制) | 低(动态配置,轻量部署) |
| 适用场景 | 海量数据分布式架构 | 主从架构高可用性保障 | 高并发连接管理与查询优化 |
| 典型案例 | 电商订单系统、用户中心 | 金融交易系统、核心数据库集群 | 高并发 API 服务、秒杀系统 |
五、总结
- MyCat 是分布式数据库的“基建工具”,通过分库分表解决数据扩展问题,需提前规划分片策略(如实例中的哈希分片配置)。
- MHA 是 MySQL 高可用的“刚需方案”,通过自动化故障切换保障主从集群的可靠性,适合对可用性敏感的核心业务(如实例中的 GTID 模式切换)。
- ProxySQL 是高性能场景的“优化利器”,通过连接池和动态路由降低数据库压力,适合高并发读写分离场景(如实例中的读写规则配置)。
实际部署中,三者可组合使用:MyCat 负责分片,MHA 保障分片内高可用,ProxySQL 优化应用到中间件的连接和查询。选择时需结合业务规模——小项目可先用 ProxySQL 优化连接,中等规模用 MHA 保障 HA,数据量爆炸时引入 MyCat 分片。技术选型的核心是“合适”,而非“全能”,通过实例落地可更高效地验证方案可行性。
以下是结合 MyCat、MHA、ProxySQL 的分布式数据库架构图,展示三者在系统中的角色和协作关系:
分布式数据库架构图(MyCat + MHA + ProxySQL)
┌───────────────┐│ 应用层 │└───────────────┘│▼┌───────────────┐│ ProxySQL 代理 │ (连接池管理、查询优化)└───────────────┘│▼┌───────────────┐│ MyCat 中间件 │ (分库分表、读写分离)└───────────────┘│┌───────────────┼───────────────┐│ ▼ │▼ ▼ ▼┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 分片集群1 │ │ 分片集群2 │ │ 分片集群N │└─────────────┘ └─────────────┘ └─────────────┘│ │ │▼ ▼ ▼┌─────────────┬─────────────┐ ┌─────────────┬─────────────┐│ 主库 (M) │ 从库 (S) │ │ 主库 (M) │ 从库 (S) │├──────┬───────┼──────┬───────┤ ├──────┬───────┼──────┬───────┤│ ▼ │ ▼ │ ▼ │ ▼├───────MHA───────┼───────MHA───────┤│ Manager 节点 │ (故障检测与切换)└─────────────────┘
图例说明:
-
分层架构:
- 应用层:业务系统通过数据库连接(如 JDBC/MySQL 驱动)访问 ProxySQL。
- ProxySQL 层:作为数据库代理,管理应用的连接池,根据 SQL 类型(读/写)路由到 MyCat,并优化查询流量(如负载均衡、慢查询缓存)。
- MyCat 层:分布式中间件,解析 SQL 并按分片规则(如哈希、范围)路由到具体的分片集群(如
user_id分片到集群 1 或 2)。 - 分片集群层:每个分片是独立的主从集群(M-S),由 MHA 保障高可用性。主库处理写请求,从库处理读请求(通过 MyCat 或 ProxySQL 分流)。
- MHA 层:Manager 节点监控所有分片集群的主从状态,当主库故障时自动提升从库为新主库,确保数据一致性。
-
核心数据流:
- 写请求:应用 → ProxySQL(识别写操作)→ MyCat(解析分片规则)→ 目标分片的主库(M)。
- 读请求:应用 → ProxySQL(识别读操作)→ MyCat(路由到从库)→ 目标分片的从库(S)。
- 高可用保障:MHA Manager 定期检测主库状态,主库宕机时触发切换,更新从库指向新主库,并通过配置中心/DNS 通知应用层切换连接地址。
-
关键组件交互:
- MyCat 与 ProxySQL:ProxySQL 可部署在 MyCat 前端,降低应用到中间件的连接开销;也可直接部署在数据库前端(MyCat 后端),优化中间件到数据库的连接。
- MHA 与分片集群:每个分片集群独立部署 MHA(或共享 Manager 节点),确保单个分片内的主从切换不影响其他分片。
架构特点:
- 扩展性:通过 MyCat 水平分片,支持数据量和流量的线性扩展。
- 高可用性:MHA 保障每个分片集群的主从故障切换,结合 ProxySQL 的连接重试机制,减少服务中断时间。
- 性能优化:ProxySQL 的连接池复用和查询路由降低数据库压力,适合高并发场景。
此架构适用于数据量庞大、需高可用性和高性能的分布式系统(如电商、社交平台核心数据库)。实际部署时可根据业务规模调整节点数量和部署方式(如 ProxySQL 集群、MyCat 多实例负载均衡)。

相关文章:

数据库架构全解析:MyCat、MHA、ProxySQL 的原理、功能与实例
前言 : 在分布式数据库架构中,分库分表、高可用性(HA)和查询优化是核心需求。本文将深入解析三款主流工具:MyCat(分布式数据库中间件)、MHA(MySQL高可用方案)、ProxySQL…...

【hadoop】Hive数据仓库安装部署
一、MySQL的安装与配置 换源: 最下面附加部分 1、在master上直接使用yum命令在线安装MySQL数据库: sudo yum install mysql-server 途中会询问是否继续,输入Y并按回车。 2、启动MySQL服务: sudo service mysqld start 3、设…...

Unity Addressables资源生命周期自动化监控技术详解
一、Addressables资源生命周期管理痛点 1. 常见资源泄漏场景 泄漏类型典型表现检测难度隐式引用泄漏脚本持有AssetReference未释放高异步操作未处理AsyncOperationHandle未释放中循环依赖泄漏资源相互引用无法释放极高事件订阅泄漏未取消事件监听导致对象保留高 2. 传统管理…...

Linux网络编程——深入理解TCP的可靠性、滑动窗口、流量控制、拥塞控制
目录 一、前言 二、流量控制 三、TCP的滑动窗口 1、原理 2、机制 3、数据重发 Ⅰ、只是确认应答包(ACK)丢了 Ⅱ、发送数据包丢失 4、缓冲区结构 四、TCP的拥塞控制 1、慢启动 2、拥塞避免 3、快速重传 4、快速恢复 五、延迟应答 六、捎带应答 七、再谈TCP的面…...

Manifold-IJ 2022.1.21 版本解析:IntelliJ IDEA 的 Java 增强插件指南
Manifold-IJ-2022.1.21 可能是 IntelliJ IDEA 的一个插件或相关版本,特别是与 Manifold 这个增强 Java 开发体验的框架相关的组件。 很多时候没有网络环境,而又需要这个插件。 Manifold-IJ 2022.1.21下载:https://pan.quark.cn/s/ad907344c…...

linux内核
一 初识linux内核 1.1操作系统和内核简介 操作系统的精确定义并没有一个统一的标准,这里我认为操作系统是指整个系统负责完成最基本功能和系统管理的那些部分 这些部分包括内核,设备驱动程序,启动引导程序,基本的文件管理工具和…...
求解移动机器人路径规划,MATLAB代码)
基于CNN-LSTM-GRU的深度Q网络(Deep Q-Network,DQN)求解移动机器人路径规划,MATLAB代码
一、深度Q网络(Deep Q-Network,DQN)介绍 1、背景与动机 深度Q网络(DQN)是深度强化学习领域的里程碑算法,由DeepMind于2013年提出。它首次在 Atari 2600 游戏上实现了超越人类的表现,解决了传统…...

C++23新特性:显式对象形参与显式对象成员函数
文章目录 一、背景与动机二、语法与基本使用三、优势与应用场景(一)简化代码(二)提升模板编程灵活性(三)与Lambda表达式结合 四、限制与注意事项五、总结 C23标准引入了一项重要的语言特性——显式对象形参…...

leetcode_242. 有效的字母异位词_java
242. 有效的字母异位词https://leetcode.cn/problems/valid-anagram/ 1、题目 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词(字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次…...

【Docker基础】容器技术详解:生命周期、命令与实战案例
文章目录 一、什么是容器?二、为什么需要容器三、容器的生命周期容器状态容器OOM容器异常退出容器异常退出容器暂停 四、容器命令命令清单详细介绍 五、容器操作案例容器的状态迁移容器批量操作容器交互模式attached 模式detached 模式interactive 模式 容器 与 宿主…...
架构)
电子电气架构 --- 为配备区域计算的下一代电子/电气(E/E)架构
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

python基础:位置互换
n int(input()) for _ in range(n):line input().strip()line list(line)for i in range(1,len(line)1):if i%2 0:line[i-2], line[i-1] line[i-1],line[i-2] print(.join(line))以下分不同数据类型说明 Python 实现奇偶互换的方法: 字符串的奇偶位互换 若字…...

51单片机Day03---让一个LED灯闪烁
目录 1.研究原理图: 2.一些小知识(重定义的使用): (1)在单片机中,unsigned int 常用于以下场景: (2)unsigned char: 3.思路构造:…...

城电科技 | 从概念到落地:如何打造真正的智慧零碳园区?
在科技飞速发展的当下,智慧零碳园区成为了引领未来发展的重要范式。那么,究竟什么是智慧零碳园区呢? 智慧零碳园区,是借助前沿信息技术,把物联网、云计算、大数据等技术深度融入园区管理及产业运营,以此达…...

oracle常见问题处理集锦
oracle常见问题处理集锦 oracle常见问题处理集锦ORA:28000 the count is locked oracle常见问题处理集锦 ORA:28000 the count is locked ORA-28000: 账户已被锁定 这个错误表示你尝试登录的 Oracle 数据库用户账户已被锁定,常见原因包括: 多次密码输错…...

Java-JDBC入门程序、预编译SQL
一. JDBC JDBC:Java DataBase Connectivity 就是使用Java语言操作关系型数据库的一套API 本质:sun公司官方定义一套操作所有关系型数据库的规范,即接口;各个数据库厂商去实现这套接口,提供数据库驱动jar包。我们可以使…...

【SQL】基于多源SQL 去重方法对比 -- 精华版
【SQL】基于SQL 去重方法对比 -- 精华版 一、引言二、基于SQL去重方法完整对比1. MySQL去重方法及优劣势1.1 DISTINCT关键字1.2 GROUP BY子句1.3 UNION系列操作1.4 子查询 自关联 2. Hive去重方法及优劣势2.1 DISTINCT关键字2.2 GROUP BY子句2.3 ROW_NUMBER窗口函数2.4 …...

list的使用以及模拟实现
本章目标 1.list的使用 2.list的模拟实现 1.list的使用 在stl中list是一个链表,并且是一个双向带头循环链表,这种结构的链表是最优结构. 因为它的实现上也是一块线性空间,它的使用上是与string和vector类似的.但相对的因为底层物理结构上它并不像vector是线性连续的,它并没有…...

java继承练习
//创建父类public class Employee {private String id;private String name;private double salary;public Employee() {}public Employee(String id, String name, double salary) {this.id id;this.name name;this.salary salary;}public String getId() {return id;}pu…...

猫咪如厕检测与分类识别系统系列【一】 功能需求分析及猫咪分类特征提取
开发背景 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的…...

sparkcore编程算子
今天是Spark Core编程算子 Value类型算子 1. map 将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。Map算子是分区内一个数据一个数据的执行,类似于串行操作。 特点: - 主要目的将数据源中的数据进行…...
)
【EI会议】第三届机器人与软件工程前沿国际会议(FRSE 2025)
第三届机器人与软件工程前沿国际会议(FRSE 2025)将于2025年8月8日-10日在中国张家界召开。会议由清华大学自动化系主办,长沙理工大学、湖南科技大学、吉首大学、AC学术中心协办。 一、会议信息 大会官网:www.icfrse.org 会议时…...

机器人系统仿真--1.机器人模型URDF
添加机器人地盘...
与PLC、驱动器协同发展研究:突破数据困境与指令精确控制(3))
具身机器人中AI(DEEPSEEK)与PLC、驱动器协同发展研究:突破数据困境与指令精确控制(3)
具身机器人中AI(DEEPSEEK)与PLC、驱动器协同发展研究:突破数据困境与指令精确控制(1)-CSDN博客 具身机器人中AI(DEEPSEEK)与PLC、驱动器协同发展研究:突破数据困境与指令精确控制&a…...

+++++背到厌倦。持续更新
Spring IoC 的工作流程: 读取 BeanDefinition: Spring 容器启动时,会读取 Bean 的配置信息 (例如 XML 配置文件、注解或 Java 代码),并将这些配置信息转换为 BeanDefinition 对象。创建 Bean 实例: 根据 BeanDefinition 中的信息,Spring 容器…...

修改 docker 工作目录
一、停掉 containerd、cri-docker、docker systemctl stop containerd systemctl stop cri-docker systemctl stop docker 二、拷贝 docker 工作目录下的所有文件到新路径 rsync -aP /var/lib/docker/ /docker/data/ 三、daemon.json 添加新工作目录路径 {"registry-…...

51c嵌入式~继电器~合集1
我自己的原文哦~ https://blog.51cto.com/whaosoft/13775821 一、继电器应用细节 继电器的应用,相信大家都知道,在电路中只要给它供电、断电也就可以工作了。本文讨论它的应用细节。 现在流行的接法 图中,继电器的线圈经过Q1作为开关&am…...

舵机:机器人领域的“关节革命者”
机器人的技术,每一个细微的进步都可能引领一场行业变革。而在这场变革中,舵机作为机器人关节的核心部件,正悄然上演着一场革命性的应用风暴。从简单的关节运动到复杂的姿态控制,舵机以其卓越的性能和无限的可能,重新定…...

飞书集成衡石ChatBot实战:如何10分钟搭建一个业务数据问答机器人?
让数据查询像聊天一样简单 在快节奏的业务环境中,数据查询的实时性和便捷性至关重要。传统BI工具需要复杂的操作,而衡石ChatBot结合飞书,让业务人员只需在聊天窗口提问,就能立刻获取数据反馈,真正实现“零门槛”数据分…...
)
高并发环境下超发现象的详细分析,包含场景示例、影响分析及解决方案(悲观锁、乐观锁、分布式锁)
以下是针对高并发环境下超发现象的详细分析,包含场景示例、影响分析及解决方案: 高并发下的超发详解 1. 超发现象定义 超发(Over-issuance)指在并发操作中,系统实际发放的资源(如商品库存)超过…...

Git 分支整合策略:Cherry-pick、Merge、Rebase 三者之间对比
Git 分支整合策略详解:Cherry-pick、Merge、Rebase 在日常的 Git 多分支协作开发中,代码合并是常见操作。Git 中主要提供以下三种方式来合并或迁移分支的提交: Cherry-pick:精确挑选部分提交复制到当前分支;Merge&am…...

嵌入式八股---计算机网络篇
前言 这块主要是结合着LWIP去理解计算机网络中常见的面试题 OSI四层/五层/七层模型 OSI分层(7层):物理层、数据链路层、网络层、传输层、会话层(http)、表示层(加密)、应用层。 TCP/IP分层(4层):网络接口层…...

使用 3D Layout 和 Icepak 进行 PCB、DCIR 和热分析
在本教程中,您将学习如何使用 3D Layout 执行 DCIR,然后使用功率损耗数据执行热分析。热分析将使用电子桌面 Icepak 进行。SIwave 及其嵌入式 icepak 可用于执行相同的分析,但有一个例外。电子桌面 Icepak 是一款功能齐全的 3D 工具。用户可以…...

UE5 Windows游戏窗口置顶
参考资料:UE5 UE4 项目设置全局置顶_ue4运行设置置顶-CSDN博客 修改完build.cs后,关掉重新生成解决方案。(不然可能编译报错,在这卡了半个小时) 不知道怎么用C的,可以用这个 Topmost - Keep Editor/Game w…...

【Linux】进程管理
一、程序与进程区别 1.程序: 存放在磁盘文件可执行文件(静态存在) 特点 静态性:程序是静态的,它只是一组指令的集合,在未被执行时,不会占用计算机的运行资源,也不会产生任何实际的…...

Android Studio PNG转SVG方法总结
在 Android Studio 中,将 PNG 位图转换为 SVG 矢量图并非直接内置的功能,但你可以通过以下步骤实现目标: 方法 1:使用在线转换工具 访问在线转换网站 推荐工具: CloudConvert Vector Magic OnlineConvertFree 上传…...

第6篇:Linux程序访问控制FPGA端LEDR<四>
Q:如何设计.c程序代码控制FPGA端外设LEDR动态显示? A:我们来设计程序实现简易计数器:将上一期点亮LEDR的程序代码*LEDR_ptr 0x2aa 改为 *LEDR_ptr *LEDR_ptr 1,读取LEDR端口的data寄存器,将寄存器值递增…...

DP扰码模块verilog仿真
在DisplayPort 1.4协议中,为了减少EMI,在8B/10B编码之前,需进行扰码Scramble。扰码用到了16-bit LFSR,表达式如下。 LFSR每移位8个bit后,用最高有效 8 位以相反的位顺序与一个字节数据进行异或从而实现数据加扰/解扰。…...

协作焊接机器人的应用场景
协作焊接机器人凭借其灵活性、安全性和高效性,在多个领域有着广泛的应用场景,以下是一些主要的方面: 汽车制造 车身焊接:在汽车车身生产线上,协作焊接机器人可与工人协同工作,完成车身各部件的焊接任务。例…...

深入解析计算机操作系统的底层架构与核心模块功能
深入解析计算机操作系统的底层架构与核心模块功能 一、操作系统底层架构总览 操作系统处于计算机系统的核心地位,是计算机硬件与用户之间的关键纽带,承担着资源管理者的重要角色。它负责统筹管理计算机的各类资源,如CPU、内存、存储设备以及…...

Elasticsearch 官网阅读学习笔记01
Elasticsearch 官网阅读学习笔记01 什么是 Elasticsearch? Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Elasticsearch 可为所有类型的数据提供近乎实时的搜索和分析。无论您拥有的是结构化或非结构化文本、数值数据还是地理空间数据 Elastic…...

玩转Docker | 使用Docker搭建Van-Nav导航站
玩转Docker | 使用Docker搭建Van-Nav导航站 前言一、Van-Nav介绍van-nav 简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Van-Nav服务下载镜像创建容器检查容器状态检查服务端口安全设置四、访问Van-Nav应用访问Van-Nav首页登录后台管理五、添…...

若依 前后端部署
后端:直接把代码从gitee上拉去到本地目录 (https://gitee.com/y_project/RuoYi-Vue ) 注意下redis连接时password改auth 后端启动成功 前端:运行前首先确保安装了node环境,随后执行: !!一定要用管理员权限…...

笔记:头文件与静态库的使用及组织方式
笔记:头文件与静态库的使用及组织方式 1. 头文件的作用 接口声明:提供函数、类、变量等标识符的声明,供其他模块调用。编译依赖:编译器需要头文件来验证函数调用和类型匹配。避免重复定义:通过包含保护(如…...

PostgreSQL-常用命令
PostgreSQL 提供了丰富的命令行工具和 SQL 命令,用于管理和操作数据库。以下是一些常用的命令和操作: 1. 数据库管理 创建数据库 CREATE DATABASE dbname; 删除数据库 DROP DATABASE dbname; 列出所有数据库 \l SELECT datname FROM pg_database;…...
 中实现 Cookie 持久化并保持同一会话)
如何在 Postman(测试工具) 中实现 Cookie 持久化并保持同一会话
在开发基于 Spring Boot 的 Web 应用时,使用 Session 存储验证码等敏感信息是常见的做法。然而,在调试接口时,你可能会遇到这样一个问题:第一次请求接口时存入的验证码在第二次请求时无法获取,原因往往是两个请求所使用…...
——微信小程序学习笔记)
粘性定位(position:sticky)——微信小程序学习笔记
1. 简介 CSS 中的粘性定位(Sticky positioning)是一种特殊的定位方式,它可以使元素在滚动时保持在视窗的特定位置,类似于相对定位(relative),但当页面滚动到元素的位置时,它会表现得…...

谷歌浏览器极速安装指南
目录 📋 准备工作 步骤一:访问官网 🌐 步骤二:获取安装包 ⬇️ 步骤三:一键安装 🖱️ 步骤四:首次启动设置 ⚙️ 步骤五:开始探索! 🌟 💬 …...
【2024年最新IEEE Trans】模糊斜率熵Fuzzy Slope entropy及5种多尺度,应用于状态识别、故障诊断!
引言 2024年11月,研究者在测量领域国际顶级期刊《IEEE Transactions on Instrumentation and Measurement》(IF 5.6,JCR 1区,中科院二区)上发表科学研究成果,以“Optimized Fuzzy Slope Entropy: A Comple…...

无人机击落技术难点与要点分析!
一、技术难点 1. 目标探测与识别 小型化和低空飞行:现代无人机体积小、飞行高度低(尤其在城市或复杂地形中),雷达和光学传感器难以有效探测。 隐身技术:部分高端无人机采用吸波材料或低可探测设计,进…...