Elasticsearch 官网阅读学习笔记01
Elasticsearch 官网阅读学习笔记01
-
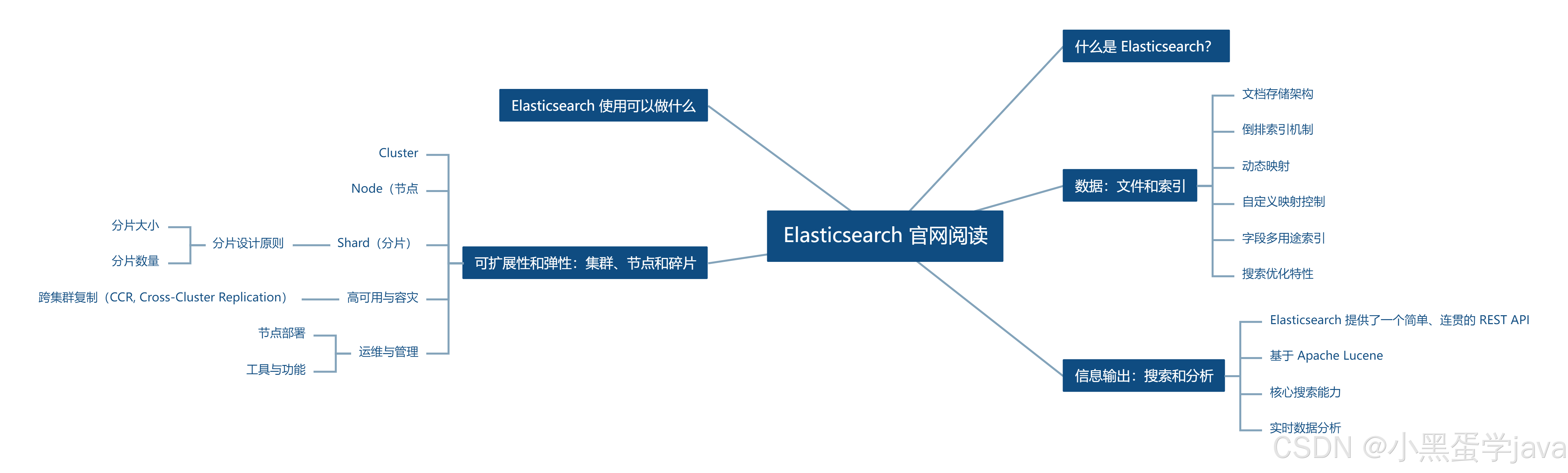
什么是 Elasticsearch?
- Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。
- Elasticsearch 可为所有类型的数据提供近乎实时的搜索和分析。无论您拥有的是结构化或非结构化文本、数值数据还是地理空间数据
-
Elasticsearch 使用可以做什么
- 在应用程序或网站中添加搜索框
- 存储和分析日志、指标和安全事件数据
- 使用 Elasticsearch 作为存储引擎,实现业务工作流程自动化
- 将 Elasticsearch 作为地理信息系统 (GIS) 来管理、整合和分析空间信息
-
数据:文件和索引
-
关键内容提取
-
Elasticsearch 是一种分布式文档存储。Elasticsearch 存储的是序列化为 JSON 文档的复杂数据结构,而不是以列数据行的形式存储信息
-
文档存储后,会在 1 秒钟内编制索引并进行完全实时搜索Elasticsearch 使用一种称为倒排索引的数据结构,支持非常快速的全文检索
-
索引可以看作是文档的优化集合,而每个 文档又是字段的集合 ,即包含数据的键值对
-
Elasticsearch 会为每个字段中的所有数据建立索引,每个索引字段都有一个专用的优化数据结构。
- 文本字段存储在倒排索引中
- 数字和地理字段存储在 BKD 树中
-
启用动态映射后,Elasticsearch 会自动检测新字段并将其添加到索引中
-
定义映射可以作什么
- 区分全文字符串字段和精确值字符串字段
- 进行特定语言的文本分析
- 优化字段以进行部分匹配
- 使用自定义日期格式
- 使用 geo_point(用于存储单个地理坐标点(经纬度),例如:一个商店的位置、用户的实时坐标等。 适合场景:快速查询“附近的地点”、计算两点距离、聚合地理位置数据。) 和 geo_shape (用于存储复杂的地理形状(如多边形、线、圆形等),例如:国家边界、配送区域、地理围栏。 适合场景:判断地理空间关系(如“某个点是否在某个区域内”或“两个区域是否相交”)。)等无法自动检测的数据类型
-
-
总结:
-
文档存储架构
- 分布式文档存储,数据以序列化JSON文档形式存储
- 支持跨节点分布式存储,数据可被集群内任意节点实时访问
- 近实时搜索(1秒内完成索引)
-
倒排索引机制
-
核心数据结构支持快速全文搜索
-
通过记录单词与文档的映射关系实现快速检索
-
所有字段默认被索引,不同字段类型使用不同数据结构:
- 文本字段 → 倒排索引
- 数值/地理位置 → BKD树
-
-
动态映射(Schema-less)
- 自动检测字段类型(布尔值、数值、日期、字符串等)
- 自动添加新字段到索引
- 适合快速探索数据的场景
-
自定义映射控制
-
可覆盖自动映射规则,实现更精确控制:
- 区分全文检索(text)与精确值(keyword)字段
- 执行语言特定的文本分析
- 优化部分匹配
- 自定义日期格式
- 支持特殊类型(geo_point/geo_shape)
-
-
字段多用途索引
-
持同一字段不同索引方式:
- 文本字段同时用于全文搜索和排序/聚合
- 多语言分析器处理混合语言内容
-
索引和分析链在查询时保持一致
-
-
搜索优化特性
- 查询文本会经过与索引时相同的分析处理
- 字段级数据结构优化查询性能
- 支持复杂数据类型的地理空间查询
-
-
-
信息输出:搜索和分析
-
基于 Apache Lucene 搜索引擎库的全套搜索功能。
-
Elasticsearch 提供了一个简单、连贯的 REST API,用于管理集群以及索引和搜索数据
-
简短说明 REST请求 RESTful 风格
-
资源导向 : 所有数据/服务抽象为资源,通过URI唯一标识 示例:
/users/123 表示ID为123的用户资源 -
HTTP方法映射操作
-
通过标准HTTP方法实现CRUD:
-
GET → 获取资源 -
POST → 创建资源 -
PUT → 更新资源 -
DELETE → 删除资源
-
-
-
-
说明应用程序可以通过简单网络请求获取到数据
-
Elasticsearch 客户端:Java、JavaScript、Go、.NET、PHP、Perl、Python 或 Ruby
-
-
数据搜索
-
Elasticsearch REST API 支持结构化查询、全文本查询以及将二者结合起来的复杂查询
- 结构化查询类似于在 SQL 中构建的查询类型。例如,您可以搜索 employee 索引中的 gender 和 age 字段,并根据 hire_date 字段对匹配结果进行排序
- 全文查询可查找与查询字符串匹配的所有文档,并按相关性(即与搜索条件的匹配程度)排序返回。
-
支持 支持高性能地理和数值查询。
-
查询方式
- Elasticsearch 的综合 JSON 风格查询语言( 查询 DSL )访问所有这些搜索功能
- 内部构建 SQL 风格 的查询
- JDBC 和 ODBC 驱动程序可让大量第三方应用程序通过 SQL 与 Elasticsearch 进行交互。
-
-
分析数据
- 概述 : Elasticsearch 聚合使您能够建立复杂的数据摘要,并深入了解关键指标、模式和趋势
-
总结:
- 核心搜索能力
- 支持结构化查询(类SQL)与全文搜索(基于相关性排序)
- 提供短语搜索、模糊匹配、前缀搜索及自动补全功能
- 专为地理空间/数值数据优化,支持高性能地理查询
- 提供Query DSL(JSON风格)和SQL双查询模式
- 支持JDBC/ODBC驱动实现第三方工具集成
- 实时数据分析
- 聚合分析功能可生成多维数据洞察:
▪ 统计聚合(数量/平均值/中位数)
▪ 时间趋势分析(如按月统计)
▪ 制造商分布等商业洞察 - 搜索与聚合在单请求中同步执行
- 分析结果实时更新,支持动态数据可视化
-
-
可扩展性和弹性:集群、节点和碎片
核心概念
-
Cluster(集群)
- 分布式架构,支持横向扩展和高可用性。
- 自动分配数据和查询负载到所有节点。
- 节点增减时自动重平衡分片(Shard)分布。
-
Node(节点)
- 集群中的单个服务器,可动态加入或移除。
- 节点越多,集群容量和查询能力越强(冗余性提升)。
-
Shard(分片)
-
逻辑索引(Index)由多个物理分片组成。
-
分片分为两类:
- Primary Shard(主分片) :存储文档的唯一副本,数量在索引创建时固定。
- Replica Shard(副本分片) :主分片的冗余副本,提供数据保护和读请求负载均衡,数量可动态调整。
-
分片分布在多个节点上,实现冗余和性能优化。
-
2. 分片设计原则
-
分片大小
- 推荐范围:几GB到几十GB(时间序列数据建议20-40GB)。
- 过大问题:集群重平衡时迁移时间变长。
- 过小问题:维护开销高(如大量小分片导致查询性能下降)。
-
分片数量
- 主分片数:索引创建时确定,不可修改。
- 副本分片数:可随时调整,不影响读写操作。
- 分片与堆内存关系:每GB堆内存建议不超过20个分片(避免“海量分片”问题)。
- 测试验证:需根据实际数据和查询场景测试最佳配置。
3. 高可用与容灾
-
跨集群复制(CCR, Cross-Cluster Replication)
-
作用:主集群(Active Leader)到备用集群(Passive Follower)的热备份,支持故障转移和地理邻近读请求。
-
模式:
- 主集群处理写请求,副本集群只读。
- 主集群故障时,副本集群可接管。
-
4. 运维与管理
-
节点部署
- 节点间需高可靠、低延迟连接(建议同数据中心或邻近数据中心)。
- 避免单点故障(多区域部署需结合CCR)。
-
工具与功能
- Kibana:集群管理控制中心,集成安全、监控、管理功能。
- 索引生命周期管理:自动管理数据(如滚动更新、归档)。
- 数据汇总(Rollups) :优化历史数据存储与查询效率。
-
相关文章:

Elasticsearch 官网阅读学习笔记01
Elasticsearch 官网阅读学习笔记01 什么是 Elasticsearch? Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Elasticsearch 可为所有类型的数据提供近乎实时的搜索和分析。无论您拥有的是结构化或非结构化文本、数值数据还是地理空间数据 Elastic…...

玩转Docker | 使用Docker搭建Van-Nav导航站
玩转Docker | 使用Docker搭建Van-Nav导航站 前言一、Van-Nav介绍van-nav 简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署Van-Nav服务下载镜像创建容器检查容器状态检查服务端口安全设置四、访问Van-Nav应用访问Van-Nav首页登录后台管理五、添…...

若依 前后端部署
后端:直接把代码从gitee上拉去到本地目录 (https://gitee.com/y_project/RuoYi-Vue ) 注意下redis连接时password改auth 后端启动成功 前端:运行前首先确保安装了node环境,随后执行: !!一定要用管理员权限…...

笔记:头文件与静态库的使用及组织方式
笔记:头文件与静态库的使用及组织方式 1. 头文件的作用 接口声明:提供函数、类、变量等标识符的声明,供其他模块调用。编译依赖:编译器需要头文件来验证函数调用和类型匹配。避免重复定义:通过包含保护(如…...

PostgreSQL-常用命令
PostgreSQL 提供了丰富的命令行工具和 SQL 命令,用于管理和操作数据库。以下是一些常用的命令和操作: 1. 数据库管理 创建数据库 CREATE DATABASE dbname; 删除数据库 DROP DATABASE dbname; 列出所有数据库 \l SELECT datname FROM pg_database;…...
 中实现 Cookie 持久化并保持同一会话)
如何在 Postman(测试工具) 中实现 Cookie 持久化并保持同一会话
在开发基于 Spring Boot 的 Web 应用时,使用 Session 存储验证码等敏感信息是常见的做法。然而,在调试接口时,你可能会遇到这样一个问题:第一次请求接口时存入的验证码在第二次请求时无法获取,原因往往是两个请求所使用…...
——微信小程序学习笔记)
粘性定位(position:sticky)——微信小程序学习笔记
1. 简介 CSS 中的粘性定位(Sticky positioning)是一种特殊的定位方式,它可以使元素在滚动时保持在视窗的特定位置,类似于相对定位(relative),但当页面滚动到元素的位置时,它会表现得…...

谷歌浏览器极速安装指南
目录 📋 准备工作 步骤一:访问官网 🌐 步骤二:获取安装包 ⬇️ 步骤三:一键安装 🖱️ 步骤四:首次启动设置 ⚙️ 步骤五:开始探索! 🌟 💬 …...
【2024年最新IEEE Trans】模糊斜率熵Fuzzy Slope entropy及5种多尺度,应用于状态识别、故障诊断!
引言 2024年11月,研究者在测量领域国际顶级期刊《IEEE Transactions on Instrumentation and Measurement》(IF 5.6,JCR 1区,中科院二区)上发表科学研究成果,以“Optimized Fuzzy Slope Entropy: A Comple…...

无人机击落技术难点与要点分析!
一、技术难点 1. 目标探测与识别 小型化和低空飞行:现代无人机体积小、飞行高度低(尤其在城市或复杂地形中),雷达和光学传感器难以有效探测。 隐身技术:部分高端无人机采用吸波材料或低可探测设计,进…...

Flink的数据流图中的数据通道 StreamEdge 详解
本文从基础原理到代码层面逐步解释 Flink 的数据通道 StreamEdge,尽量让初学者也能理解。 主要思路:从概念开始,逐步深入到实现细节,并结合伪代码来逐步推导。 第一步:什么是 StreamEdge? StreamEdge 是 F…...
图像滤波-----均值滤波(模糊处理)函数blur())
OpenCV 图形API(25)图像滤波-----均值滤波(模糊处理)函数blur()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用归一化的方框滤波器模糊图像。 该函数使用以下核来平滑图像: K 1 k s i z e . w i d t h k s i z e . h e i g h t [ 1 1 ⋯ …...

基于频率约束条件的最小惯量需求评估,包括频率变化率ROCOF约束和频率最低点约束matlab/simulink
基于频率约束条件的最小惯量评估,包括频率变化率ROCOF约束和频率最低点约束matlab/simulink 1建立了含新能源调频的频域仿真传函模型,虚拟惯量下垂控制 2基于构建的模型,考虑了不同调频系数,不同扰动情况下的系统最小惯量需求...
)
.pdf,.docx,.doc文档在一页纸上显示4页内容(详细步骤)
生活中常见一页纸上显示4页内容,我们熟知的是打印文件时,选择“每页4版”,但如果也是为了方便阅读,想要设置成一张纸上显示4页内容,又该怎么做呢?下面分享.docx和.pdf文档,一张纸上显示4页内容的…...
求解移动机器人路径规划,MATLAB代码)
基于CNN-BiLSTM-GRU的深度Q网络(Deep Q-Network,DQN)求解移动机器人路径规划,MATLAB代码
一、深度Q网络(Deep Q-Network,DQN)介绍 1、背景与动机 深度Q网络(DQN)是深度强化学习领域的里程碑算法,由DeepMind于2013年提出。它首次在 Atari 2600 游戏上实现了超越人类的表现,解决了传统…...

高并发场景下的 Java 性能优化
在当今数字化时代,高并发场景已成为众多 Java 应用面临的常态,如电商大促、在线直播等活动期间,系统需承受巨大的访问压力。因此,Java 性能优化在高并发场景下显得尤为重要。传统的人工编写代码优化方式不仅耗时费力,还…...

Java 设计模式:观察者模式详解
Java 设计模式:观察者模式详解 观察者模式(Observer Pattern)是一种行为型设计模式,它定义了对象之间的一对多依赖关系,当一个对象的状态发生变化时,所有依赖它的对象都会收到通知并自动更新。这种模式广泛…...

Linux vagrant 导入Centos
前言 vagrant 导入centos 虚拟机 前提要求 安装 virtualbox 和vagrant<vagrant-disksize> (Linux 方式 Windows 方式) 创建一键部署centos 虚拟机 /opt/vagrant 安装目录/opt/VirtualBox 安装目录/opt/centos8/Vagrantfile (可配置网络IP,内存…...

linux Ubuntu 如何删除文件,错误删除后怎么办?
一、删除文件的常用方法 命令行删除 普通删除:rm 文件名 (示例:rm old_file.txt) 强制删除(无提示):rm -f 文件名 (示例:rm -f locked_file.txt) 删除目录…...

【前端】事件循环专题
引入 以下情况是为什么呢? //q1 for (var i 0; i < 3; i) {setTimeout(() > {console.log(i);}, 1000); } // console: // 3 // 3 // 3//q2 let name;setTimeout(() > {name name;console.log(name); }, 1000);if (name) {name newname;console.log(n…...

3DMAX笔记-UV知识点和烘焙步骤
1. 在展UV时,如何点击模型,就能选中所有这个模型的uv 2. 分多张UV时,不同的UV的可以设置为不同的颜色,然后可以通过颜色进行筛选。 3. 烘焙步骤 摆放完UV后,要另存为一份文件,留作备份 将模型部件全部分成…...

【深度学习】PyTorch实现VGG16模型及网络层数学原理
一、Demo概述 代码已附在文末 1.1 代码功能 ✅ 实现VGG16网络结构✅ 在CIFAR10数据集上训练分类模型 1.2 环境配置 详见【深度学习】Windows系统Anaconda CUDA cuDNN Pytorch环境配置 二、各网络层概念 2.1 卷积层(nn.Conv2d) nn.Conv2d(in_cha…...

Spring 事务
29.Spring管理事务的方式有几种? Spring中的事务分为编程式事务和声明式事务。 编程式事务是在代码中硬编码,通过 TransactionTemplate或者 TransactionManager 手动管理事务,事务范围过大会出现事务未提交导致超时,比较适合分布…...
GPT - TransformerDecoderBlock
本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Lay…...
(C语言完结篇))
【C语言】预处理(预编译)(C语言完结篇)
一、预定义符号 前面我们学习了C语言的编译和链接。 在C语言中设置了一些预定义符号,其可以直接使用,预定义符号也是在预处理期间处理的。 如下: 可以看到上面的预定义符号,其都有两个短下划线,要注意的是ÿ…...

【Kubernetes】Kubernetes 如何进行日志管理?Fluentd / Loki / ELK 适用于什么场景?
由于 Kubernetes 运行在容器化的环境中,应用程序和系统日志通常分布在多个容器和节点上,传统的日志管理方法(例如直接访问每个节点的日志文件)在 Kubernetes 中不适用。 因此,Kubernetes 引入了集中式日志管理方案&am…...

从 SaaS 到 MCP:构建 AI Agent 生态的标准化服务升级之路
从 SaaS 到 MCP:构建 AI Agent 生态的标准化服务升级之路 —— 以数据连接器 dslink 的技术改造实践为例 引言:AI Agent 时代的 SaaS 服务范式转型 在生成式 AI 爆发式发展的 2025 年,AI Agent 已从概念验证走向企业级应用落地,…...

Linux 入门五:Makefile—— 从手动编译到工程自动化的蜕变
一、概述:Makefile—— 工程编译的 “智能指挥官” 1. 为什么需要 Makefile? 手动编译的痛点:当工程包含数十个源文件时,每次修改都需重复输入冗长的编译命令(如gcc file1.c file2.c -o app),…...

CST入门教程:如何从SYZ参数提取电容C和电感L --- 双端口
上期解释了单端口计算S参数,然后后处理很容易提取L或C,已经满足基本需求。 这期我们看复杂一点的情况,电路中放两个端口,比如S2P: 或集总电路: 或导入SPICE: 两个端口的Y和Z参数就是四个量了,Y…...

桌面版本及服务器版本怎么查看网络源软件包的url下载路径
服务器版本: ### 利用yumdownloader工具 - 首先安装yum-utils软件包,它包含yumdownloader工具。执行命令: bash yum install yum-utils - 安装完成后,使用yumdownloader --urls <package_name>命令来获取软件包的下载UR…...

汽车零部件产线节能提效,工业网关解锁数据采集 “密码”
在汽车零部件生产领域,高效的生产监控与精准的数据采集至关重要。工业网关作为智能工厂的关键枢纽,正发挥着不可替代的作用,助力产线实现电表等多种仪表数据的采集与高效监控。 背景简析 汽车零部件产线涉及众多设备与环节,各类电…...

量化策略分类、优劣势及对抗风险解析
一、常见量化策略分类及优劣势 1. 趋势跟踪策略(Trend Following) 原理:通过捕捉价格趋势(如均线突破、动量指标)进行交易。 代表模型:海龟交易法则、Dual Thrust。 优势: 在强趋势市场&am…...

Linux调试工具——gdb/cgdb
📝前言: 这篇文章我们来讲讲Linux调试工具——gdb/cgdb: 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏:C学习笔记,C…...

SQLite + Redis = Redka
Redka 是一个基于 SQLite 实现的 Redis 替代产品,实现了 Redis 的核心功能,并且完全兼容 Redis API。它可以用于轻量级缓存、嵌入式系统、快速原型开发以及需要事务 ACID 特性的键值操作等场景。 功能特性 Redka 的主要特点包括: 使用 SQLi…...

使用 Terraform 部署 Azure landing zone
Azure 登陆区是架构完善的环境,遵循 Microsoft 针对 Azure 云架构的最佳实践。它们为团队运行工作负载提供了良好管理的基础,从而提供了可扩展性并促进了云的采用。 如果您有兴趣部署 Azure 登陆区,Terraform 是一个不错的选择。本教程概述的…...

【搭建博客网站】老旧笔记本“零成本逆袭”
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言博客网站搭建免费域名本地主机安装虚拟机安装宝塔及配置花生壳内网穿透 磁盘扩容 …...

XHR、FetchAxios详解网络相关大片文件上传下载
以下是 XHR(XMLHttpRequest) 与 Fetch API 的全面对比分析,涵盖语法、功能、兼容性等核心差异: 一、语法与代码风格 XHR(基于事件驱动) 需要手动管理请求状态(如 onreadystatechange 事件)和错误处理,代码冗长且易出现回调地狱。 const xhr = new XMLHttpRequest(); x…...
)
共享内存(与消息队列相似)
目录 共享内存概述 共享内存函数 (1)shmget函数 功能概述 函数原型 参数解释 返回值 示例 结果 (2)shmat函数 功能概述 函数原型 参数解释 返回值 (3)shmdt函数 功能概述 函数原型 参数解释…...

【3D开发SDK】HOOPS SDKS如何在BIM行业运用?
Tech Soft 3D提供了支持核心功能的软件开发工具,使开发人员可以使用Windows,Linux,OSX和移动平台等广泛的平台来构建巨大而复杂的建筑和BIM应用程序。HOOPS SDK支持多种格式的CAD导入和3D查看技术。这些技术受到了Trimble,RIB&…...

纳米软件矿用电源模块自动化测试方案分享
矿用电源模块主要是用于矿井等危险环境的一种电源系统,它可以为矿井中的仪器提供充足的电力支持。由于矿用电源经常用在危险环境中,因此对于矿用电源的稳定性要求极为严格。 纳米软件矿用电源模块自动化测试方案 测试需求分析 矿用电源模块作为矿井作业…...

pycharm中安装Charm-Crypto
一、安装依赖 1、安装gcc、make、perl sudo apt-get install gcc sudo apt-get install make sudo apt-get install perl #检查版本 gcc -v make -v perl -v 2、安装依赖库m4、flex、bison(如果前面安装过pypbc的话,应该已经装过这些包了) sudo apt-get update sudo apt…...

RTX30系显卡运行Tensorflow 1.15 GPU版本
30系显卡只支持cuda11.0及以上版本,但很多tensorflow项目用的仍然是1.1x版本,这些版本需要cuda10或者以下版本,这就导致在30系显卡上无法正常运1.1x版本的tensorflow,最近几天我也因为这个问题头疼不已,网上一番搜索…...

adb|scrcpy的安装和配置方法|手机投屏电脑|手机声音投电脑|adb连接模拟器或手机
adb|scrcpy的安装和配置方法手机投屏电脑|手机声音投电脑|adb连接模拟器或手机或电视 引言 在数字设备交织的现代生活中,adb(Android Debug Bridge)与 scrcpy 宛如隐匿的强大工具,极大地拓展了我们操控手机、模拟器乃至智能电视等…...
:Chat、流式与文生图模型功能)
LangChain4j(2):Chat、流式与文生图模型功能
本文将探讨 LangChain4j 的聊天对话、流式对话以及文生图这三种常见且实用的功能,以及实际代码示例 一、聊天对话(ChatLanguageModel) 在 LangChain4j 中,使用ChatLanguageModel进行基本的聊天对话简单直观。以下是一段示例代码&a…...

Uniapp当中的async/await的作用
一、原始代码的行为(使用 async/await) const getUserMessagePlan async () > {// 等待两个异步操作完成const tabsList await message.getTagesList(); // 等待获取标签列表const tagsStateList await message.getTagsStateList(); // 等…...

JS包装类型Array
reduce()函数 没有起始值的执行过程 有初始值的执行过程 计算对象 是对象数组的情况 数组类型 方法...

Cursor + MCP让Blender实现自动建模
先决条件 Blender 3.0 或更新版本 Python 3.10 或更高版本 uv Blender安装 && 插件安装 下载Blender,版本最好是3.x以上的版本,选择适合自己的平台,地址:Download — blender.org 安装插件 从https://g…...

websocket深入-webflux+websocket
文章目录 背景版本约定配置文件代码使用webflux使用websocket配置文件handler基类实现类注册路由 背景 基于更复杂的情况和更高的开发要求,我们可能会遇到必须同时要使用webflux和websocket的情况。 版本约定 JDK21Springboot 3.2.0Fastjson2lombok 配置文件 &…...
)
LangChain-输出解析器 (Output Parsers)
输出解析器是LangChain的重要组件,用于将语言模型的原始文本输出转换为结构化数据。本文档详细介绍了输出解析器的类型、功能和最佳实践。 概述 语言模型通常输出自然语言文本,但在应用开发中,我们经常需要将这些文本转换为结构化的数据格式…...

wsl2+ubuntu22.04安装blenderproc教程
本章教程,介绍如何在windows操作系统上通过wsl2+Ubuntu22.04上安装blenderproc。 一、pipi安装方式 推荐使用minconda3安装Python环境。 pip install Blenderproc二、源码安装 1、下载源码 git clone https://github.com/DLR-RM/BlenderProc2、安装依赖 cd BlenderProc &am…...