土堆教程笔记【PyTorch】
官网:torch — PyTorch 2.6 documentation
Pycharm
解释器
一般搞深度学习都用虚拟环境的解释器,为了满足不同的项目所需要的不同的包的版本。
1. system interpreter表示本地的解释器
也就是你电脑系统里安装的解释器
2. Virtual Environment—Python的虚拟环境
anaconda可以帮我们创建虚拟环境
a. 创建虚拟环境
conda create -n name python = 3.8b. 查看系统中已经存在的环境, * 在哪就是当前在哪个环境。
conda info --envsc. 激活环境
conda activate xxxd. 退出环境
conda deactivate 3. conda Enviroment
Anaconda里面附带安装的Python解释器
PyTorch下载命令
- 输入 ↓ ,查看cuda版本
nvcc -V- 建议挑选conda的而不是wheel的命令,conda支持虚拟环境而且能自动解决依赖问题。
常见问题
- 高版本的解释器在anaconda3虚拟路径文件夹envs下边。
- 不显示In[2],打开终端,↓
pip install ipython- jupyter默认只安装在base环境当中,如果base环境没有安装pytorch,那么jupyter是没有办法使用pytorch的。
方案1:在base环境里安装pytorch
方案2:在pytorch环境里安装jupyter
- 装库时报错Caused by SSLError(SSLZeroReturnError(6, 'TLS/SSL connection has been closed (EOF)
把代理关了。
- 导入PIL时报错找不到模块
module = self._system_import(name, *args, **kwargs)
ImportError: DLL load failed while importing _imaging: 找不到指定的模块。解决方法:卸载了pywin32包
- 报错
LooseVersion = distutils.version.LooseVersion AttributeError: module 'distutils' has no attribute 'version'解决方法:注释掉控制台init方法的4-7和第10行。
- 页面太小问题
修改固态盘的页面大小,最小值是内存的1.5倍,最大值是内存的3倍。
- 调用tensorboard不显示图像
降低tensorboard版本
pip install tensorboard==2.12.0- 在调用pillow的add_image方法时报错
image = image.resize((scaled_width, scaled_height), Image.ANTIALIAS)
AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS'新版本pillow(10.0.0之后)Image.ANTIALIAS 被移除了,取而代之的是Image.LANCZOS or Image.Resampling.LANCZOS,相关描述可以可以在pillow的releasenotes中查到。点进去报错的文件,ANTIALIAS改成LANCZOS就可以了。
在 Jupyter Notebook 中切换/使用 conda 虚拟环境
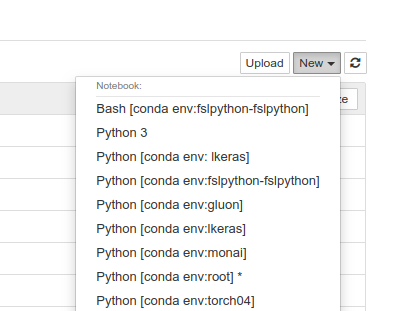
服务器上配置有多个 conda 虚拟环境,在使用jupyter notebook时需要使用其中的一个环境,但是其默认还是使用 base 环境。Jupyter 在一个名为 kernel 的单独进程中运行用户的代码。kernel 可以是不同的 Python 安装在不同的 conda 环境或虚拟环境。
方法1:使用 nb_conda_kernels 添加所有环境(推荐)
conda activate my-conda-env # this is the environment for your project and code
conda install ipykernel
conda deactivateconda activate base # could be also some other environment
conda install nb_conda_kernels
jupyter notebook注意:这里的 conda install nb_conda_kernels 是在 base 环境下操作的。
安装好后,打开 jupyter notebook 就会显示所有的 conda 环境啦,点击随意切换。
方法2:为 conda 环境创建特殊内核
conda create -n my-conda-env # creates new virtual env
conda activate my-conda-env # activate environment in terminal
conda install ipykernel # install Python kernel in new conda env
ipython kernel install --user --name=my-conda-env-kernel # configure Jupyter to use Python kernel
jupyter notebook # run jupyter from system只有 Python 内核会在 conda 环境中运行,系统中的 Jupyter 或不同的 conda 环境将被使用——它没有安装在 conda 环境中。通过调用ipython kernel install将 jupyter 配置为使用 conda 环境作为内核.
windows/mac/linux jupyter notebook 切换默认环境
方法3:在 conda 环境中运行 Jupyter 服务器和内核
conda create -n my-conda-env # creates new virtual env
conda activate my-conda-env # activate environment in terminal
conda install jupyter # install jupyter + notebook
jupyter notebook # start server + kernel这种方法就是为每一个 conda 环境 都安装 jupyter。
Jupyter 将完全安装在 conda 环境中。不同版本的 Jupyter 可用于不同的 conda 环境,但此选项可能有点矫枉过正。
在环境中包含内核就足够了,内核是运行代码的封装 Python 的组件。Jupyter notebook 的其余部分可以被视为编辑器或查看器,并且没有必要为每个环境单独安装它并将其包含在每个 env.yml 文件中。
常用函数
- 查看当前路径的包
dir(torch)- 查看方法的帮助文档
help(torch.cuda.is_available()) / 还有一种方式获取官方文档信息:xxxx ??跳到句首
shift+enter数据加载
DataSet抽象类
提供一种方式去获取数据及其label。
DataLoader类
torch.utils.data.DataLoader是一个迭代器,方便我们去多线程地读取数据,并且可以实现batchsize以及
shuffle 的读取等。为后边的网络提供不同的数据形式。
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
神经网络经常需要对一个数据迭代多次,只有知道当前有多少个数据,进行训练时才知道要训练多少次,才能把整个数据集迭代完。
from torch.utils.data import Dataset
import os
#读取图片
from PIL import Image
class MyDataset(Dataset):
#加载磁盘图片到内存
#路径分成两部分是因为后续还要用蜜蜂的,拼接方便def __init__(self,root_dir,label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir,self.label_dir)#而得到每一张图片的地址self.img_path = os.listdir(self.path)def __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)#读取图片img = Image.open(img_item_path)label = self.label_dirreturn img,labeldef __len__(self):return len(self.img_path)
root_dir = "dataset/train"
label_dir = "ants"
ants_dataset = MyDataset(root_dir,label_dir)
bees_dataset = MyDataset(root_dir,label_dir)
ants_dataset[0]TensorBoard(PyTorch1.1之后)
demo
from torch.utils.tensorboard import SummaryWriter#日志的所在地址
writer = SummaryWriter("D:\PythonProject\Introduction\logs")#第一个参数相当于表头,绘图
for i in range(100):writer.add_scalar('y=x',3 * i, i)writer.close()查看logs
在控制台输入
tensorboard --logdir=logs指定端口,防止当别人也在访问时跟别人冲突
tensorboard --logdir=logs --port=6007注意:如果出现拟合,那么可以删掉logs下边的文件,重新运行。
添加图像
通过打印发现,此类型不适合当作tensorboard的添加图片的输入类型。
PyDev console: using IPython 8.12.2
Python 3.8.20 (default, Oct 3 2024, 15:19:54) [MSC v.1929 64 bit (AMD64)] on win32
img_path = "dataset/train/ants/0013035.jpg"
from PIL import Image
img = Image.open(img_path)
print(type(img))
<class 'PIL.JpegImagePlugin.JpegImageFile'>so,利用Opencv读取图片,获得numpy类型图片数据
利用numpy.array(),对PIL图片进行转换。
Transforms单张图片
输入图像到transforms.py,它像一个工具箱,把一些数据类型转化为tensor(神经网络 的专用数据类型,包装了很多神经网络需要的参数),或者resize.
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
#通过transform.Totensor解决俩问题
#1. transform应该如何使用
#2. 为什么需要一个Tensor的数据类型
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)writer = SummaryWriter('logs')tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# print(tensor_img)
# print(img)
writer.add_image("Tensor_img", tensor_img, 3)
writer.close()图片不显示的把logs下其他的文件删掉,关掉终端打开再重新运行。
归一化----加速收敛
正则化是防止过拟合
让不同的特征在数值上保持一致,避免某些特征对模型的影响过大,从而更好地学习到数据当中的模式和关系。归一化之后,均值为0,标准差为1.

__call__介绍,把对象当函数用。
class Person:def __call__(self, name):print("__call__"+"Hello"+name)def hello(self,name):print("hello"+name)
#__xxx__这种都是内置函数,可以对其进行重写
person = Person()
#__call__可以直接使用对象里加参数,而不用.的方式。
person("zhangsan")
person.hello("lisi")忽略大小写匹配:
settings ----> 搜索case------>Generral下的Code Completion------->取勾Match case
Compose()的用法
Compose()中的参数需要是一个列表,Python中,列表的形式为[xx,xx,xx,xx,...]
在Compose()中,数据需要是transforms类型,所以,Compose(transsforms参数1,transsforms参数2,...)
用于将多个数据预处理操作组合成一个整体的变换,具体而言,按列表顺序进行转换。大小,裁剪,翻转,归一化等。
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
#通过transform.Totensor解决俩问题
#1. transform应该如何使用
#2. 为什么需要一个Tensor的数据类型
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)writer = SummaryWriter('logs')tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# print(tensor_img)
# print(img)
#writer.add_image("Tensor_img", tensor_img, 3)print(tensor_img[0][0][0])
#Normalize,归一化,提供三个均值,三个标准差
tensor_norm = transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
#把图片归一化
img_norm = tensor_norm(tensor_img)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm,2)#Resize
print(img.size)
tran_resize = transforms.Resize((512,512))
#img PIL -> resize -> img_resize PIL
#这个方法需要传入PIL类型的img
img_resize = tran_resize(img)
# img_resize PIL -> toTensor ->img_resize tensor
img_resize = tensor_trans(img_resize)
writer.add_image("Resize", img_resize,0)
print(img_resize)#Compose
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2 , tensor_trans])
trans_resize_2 = trans_compose(img)
writer.add_image("Resize2", trans_resize_2,1)#RandomCrop,随机裁剪
trans_random = transforms.RandomCrop((512,512))
trans_compose_2 = transforms.Compose([trans_random , tensor_trans])
#循环的目的是为了展示随机效果
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("RandomCrop", img_crop,i)
writer.close()torchvision中的数据集的使用
单纯加载数据集CIFAR10 torchvision.datasets — Torchvision master documentation
import torchvisiontrain_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=True)
#打印的是target,就是标签
print(test_set[0])
print(test_set.classes)
img , target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
#对于PIL数据集直接调用这个方法就可以展示图片了
img.show()对数据集变换
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),#因为图片太小了就只进行这一个变换
])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,transform=dataset_transform, download=True)test_set = torchvision.datasets.CIFAR10(root='./data', train=False,transform=dataset_transform, download=True)print(test_set[0])
#输出的是tensor数据类型,那么就可以用tensorboard进行一个显示
writer = SummaryWriter(log_dir='p10')
for i in range(10):img, target = test_set[i]#ctrl+p#此时img是tensor类型的writer.add_image("test_set", img, i)writer.close()在终端输入命令
tensorboard --logdir="p10"如果下载太慢的话,可以打开数据集函数进去复制连接自己下载,然后放在对应的文件夹下。
DataLoader的使用
加载器,可以批量加载
参数:
num_workers : 使用多少进程去加载,但是可能只能linux用,win可能报错BrokenPipeErrror,默认值为0,代表使用主进程进行加载。
drop_last : 最后的余数图片要不要加载,false就是不舍弃的意思
shuffle : 遍历完一遍以后才会打乱,而且是在每轮训练当中打乱,一个epoch打乱一次
target不是标签,是标签存放的位置,标签列表是classes,真正的标签是classes[target]
batchsize打印:
import torch
import torchvision
from torch.utils.data import DataLoader#准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(test_data, batch_size=4, shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片
img ,target = test_data[0]print(img.shape)
print(target)
#data是test_loader里的每一个对象,test_loader是可迭代对象
for data in test_loader:imgs , targets = dataprint(imgs.shape)print(targets)
#输出的tensor是把每个图片的target融合在一起了。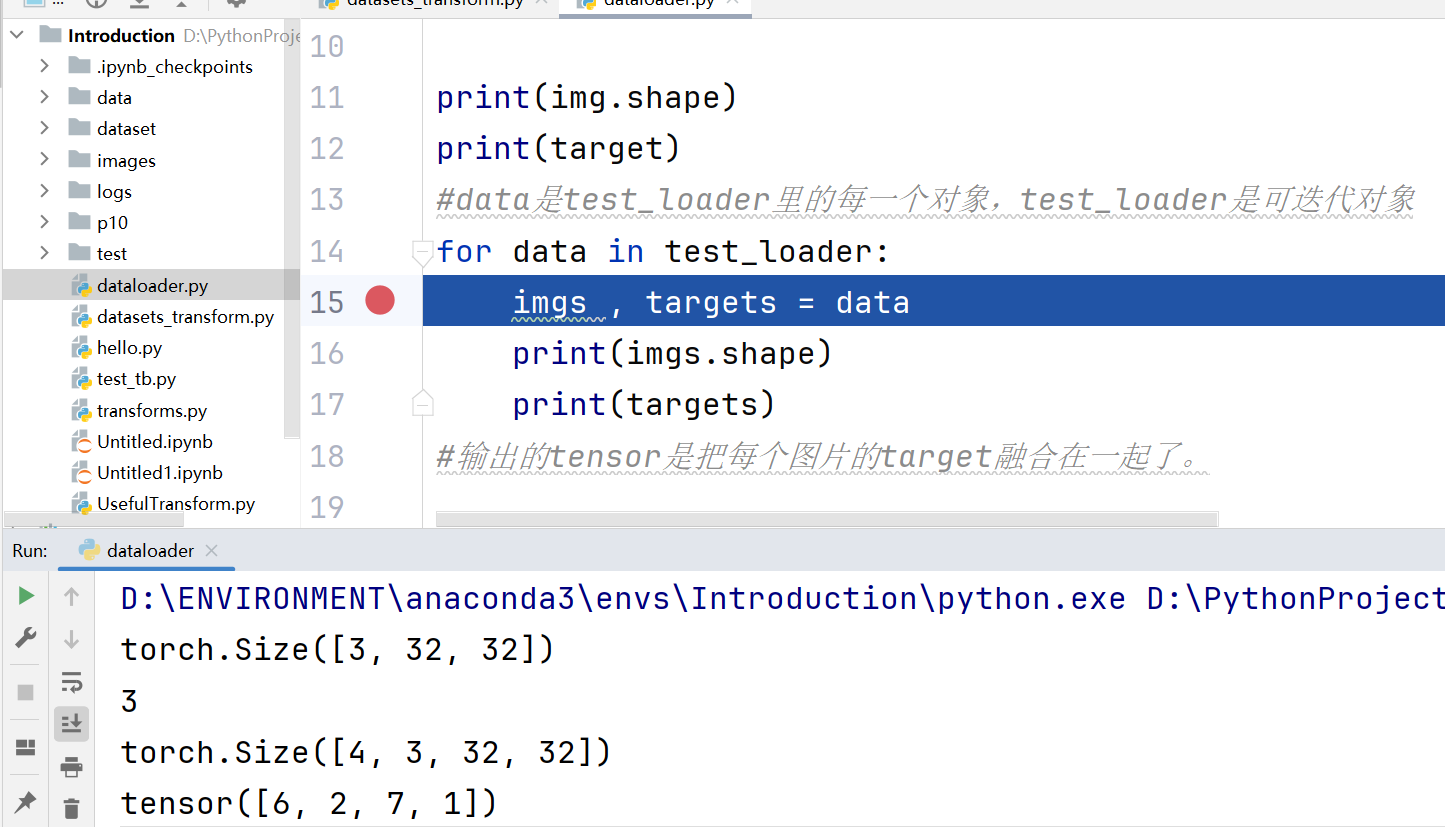
验证shuffle
#验证shuffle
for epoch in range(2):step = 0for data in test_loader:imgs, targets = datawriter.add_images("Epoch:{}".format(epoch), imgs, step)step += 1总代码:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(test_data, batch_size=4, shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片
img ,target = test_data[0]print(img.shape)
print(target)
#data是test_loader里的每一个对象,test_loader是可迭代对象# print(imgs.shape)# print(targets)
#输出的tensor是把每个图片的target融合在一起了。
writer = SummaryWriter(log_dir='./dataloader')
step = 0
for data in test_loader:imgs , targets = datawriter.add_images("test_data", imgs, step)step += 1
#验证shuffle
for epoch in range(2):step = 0for data in test_loader:imgs, targets = datawriter.add_images("Epoch:{}".format(epoch), imgs, step)step += 1writer.close()mini-batch
随机梯度下降
nn.Module
关于神经网络的工具,一般在torch.nn里边。神经网络的基本骨架,一般是被继承的父类
conv2常用参数
padding ----- 填充,更好的利用边缘信息,这样可以平均利用数据,默认是不进行填充的。
bias ------ 偏置参数
padding_mode ------- 填充模式,一般默认是0
dilation -------- 空洞卷积
卷积demo,因为nn.Module函数当中内置了call函数,所以把参数放进对象里,会自动调用forward函数。是在call函数里调用的。
import torch
from torch import nnclass MyNet(nn.Module):def __init__(self):super().__init__()def forward(self, input):output = input + 1return outputmy_net = MyNet()
x =torch.tensor(1.0)
y = my_net(x)
print(y)为什么要调整形状,因为我们一开始打印出来发现只有高和宽,不满足conv2d的api要求输入的形状。
import torchinput = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],[0,1,0],[2,1,0]])
#这个尺寸只有高和宽
print(input.shape)
#torch.Size([5, 5])
print(kernel.shape)
#torch.Size([3, 3])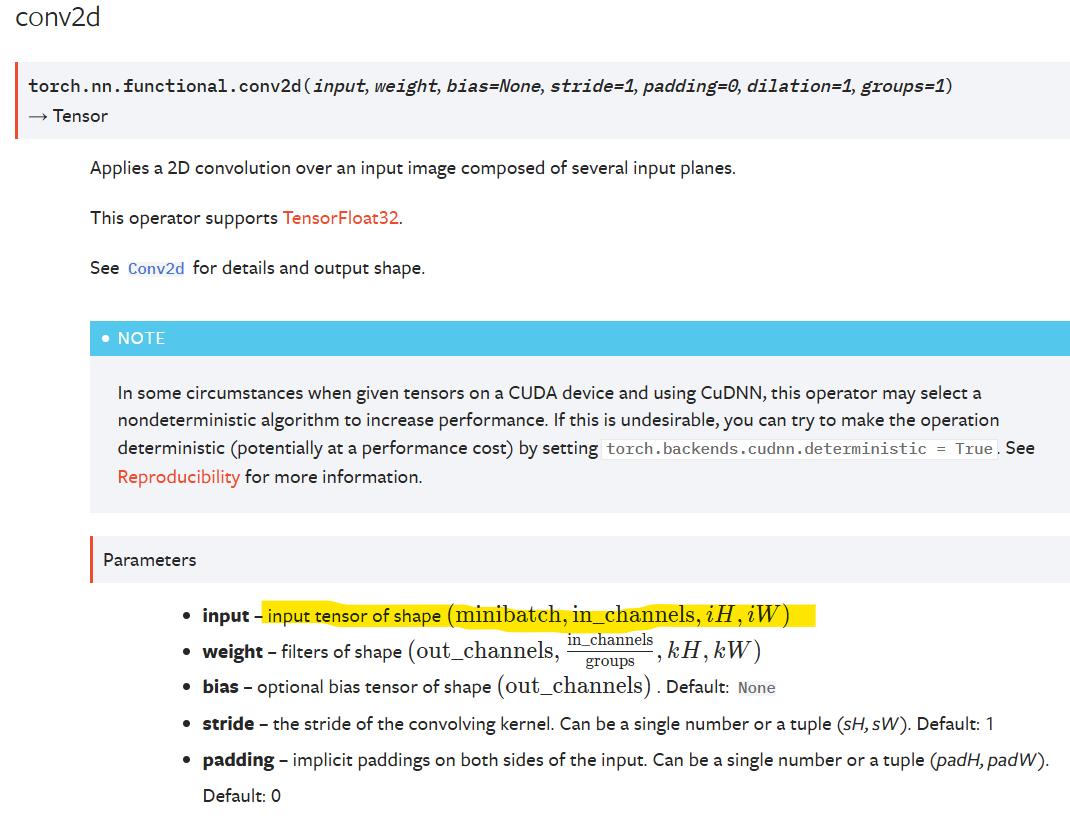
pytorch给我们提供了尺寸变换
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))变换以后就可以利用卷积进行输入
output = F.conv2d(input,kernel,stride=1)
output2 = F.conv2d(input,kernel,stride=2)
print(output)
print(output2)import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data', train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset, batch_size=64)class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv1 = nn.Conv2d(3, 6, 3)def forward(self, x):x = self.conv1(x)return x
my_net = MyNet()
writer = SummaryWriter("./logs")
#可以打印网络结构
#print(my_net)
step = 0
for data in dataloader:imgs, targets = dataoutput = my_net(imgs)print(output.shape)print(imgs.shape)#torch.Size([64, 3, 32, 32])writer.add_images("input", imgs, step)#torch.Size([64, 6, 30, 30])#-1是占位符,会被自动计算那个地方的值是多少output = torch.reshape(output, (-1,3,30,30))writer.add_images("output", output, step)step += 1参数:dilation:空洞卷积,卷积核是隔一个的。
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]
])kernel = torch.tensor([[1,2,1],[0,1,0],[2,1,0]])print(input.shape)
print(kernel.shape)#ctrl+p,提示参数
#(卷积核数量,通道数,,)
#一个卷积核生成一个通道
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))print(input.shape)
print(kernel.shape)output = F.conv2d(input,kernel,stride=1)
output2 = F.conv2d(input,kernel,stride=2)
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output)
print(output2)
print(output3)池化层
https://github.com/vdumoulin/conv_arithmetic
空洞卷积示意图↑
ceil_mode ------- 当卷积核卷出去以后,true,保留,false,不保留
卷积:提取特征
池化:降维
demo
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=4)
input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]
], dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
print(input.shape)
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.maxpool1 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):output = self.maxpool1(x)return output
mynet = MyNet()
#print(mynet(input))
writer = SummaryWriter('./logs_maxpool')
steps = 0
for data in dataloader:imgs,targets = datawriter.add_images("input", imgs, steps)output = mynet(imgs)writer.add_images("output", output, steps)steps += 1writer.close()非线性激活
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterinput = torch.tensor([[1,-0.5],[-1,3]])
output = torch.reshape(input,(-1,1,2,2))
print(output)
dataset = (torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor()))
dataloader = DataLoader(dataset, batch_size=64)
class MyNet(torch.nn.Module):def __init__(self):super(MyNet, self).__init__()self.relu1 = torch.nn.ReLU()self.sigmoid = torch.nn.Sigmoid()def forward(self, x):output = self.sigmoid(x)return output
mynet = MyNet()
writer = SummaryWriter('./logs_relu')
step = 0
for data in dataloader:imgs,targets = datawriter.add_images("input",imgs,step)output = mynet(imgs)writer.add_images("output",imgs,step)step += 1
writer.close()
output = mynet(input)
print(output)Sequential
让代码看起来更简洁。
demo:对cifar10进行简单分类的神经网络,好像是经过一次最大池化,尺寸就减半。
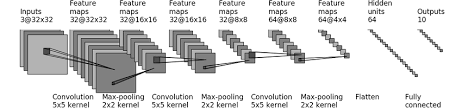
已知输入尺寸和输出尺寸,联立两个公式,可以反解出padding。dilation采用默认的1,就是不进行膨胀。

倒数第二个和倒数第三个,倒数第一个和倒数第二个之间还分别各自有一个线性层。
import torch
from torch import nn
from torch.nn import MaxPool2d, Flatten, Conv2d, Linear
from torch.utils.tensorboard import SummaryWriterclass MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()# self.conv1 = nn.Conv2d(3, 32, kernel_size=5,# padding=2)# self.maxpool1 = nn.MaxPool2d(2)# self.conv2 = nn.Conv2d(32, 32,5, padding=2)# self.maxpool2 = nn.MaxPool2d(2)# self.conv3 = nn.Conv2d(32, 64,5, padding=2)# self.maxpool3 = MaxPool2d(2)# self.flatten = Flatten()# #从图片里看出来的,64*4*4# self.linear1 = nn.Linear(1024,64)# self.linear2 = nn.Linear(64,10)self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)return x
my_net = MyNet()
print(my_net)
input = torch.ones((64, 3, 32, 32))
output = my_net(input)
print(output.shape)
writer = SummaryWriter("./logs_seq")
writer.add_graph(my_net, input)
writer.close()损失函数
L1Loss
import torch
from torch.nn import L1Lossinputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))loss = L1Loss(reduction='sum')
result = loss(inputs,targets)print(result)
#2.MSELoss
loss_mse = nn.MSELoss()
result_mse = loss_mse(result,targets)
print(result_mse)
#1.3333交叉熵
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
#tensor(1.1019)用之前的网络来对数据集进行分类,不过此时的分类是没有意义的,因为还没有经过训练。
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d, Flatten, Conv2d, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=1)
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return xmy_net = MyNet()
loss = nn.CrossEntropyLoss()
for data in dataloader:imgs,targets = dataoutputs = my_net(imgs)result_loss = loss(outputs, targets)print(result_loss)#tensor(2.2306, grad_fn=<NllLossBackward>)
#tensor(2.2557, grad_fn=<NllLossBackward>)
#tensor(2.3920, grad_fn=<NllLossBackward>)
#......# print(outputs)# print(targets)反向传播
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据,方向传播,grad。
一开始是没有梯度的,后来运行完37行,
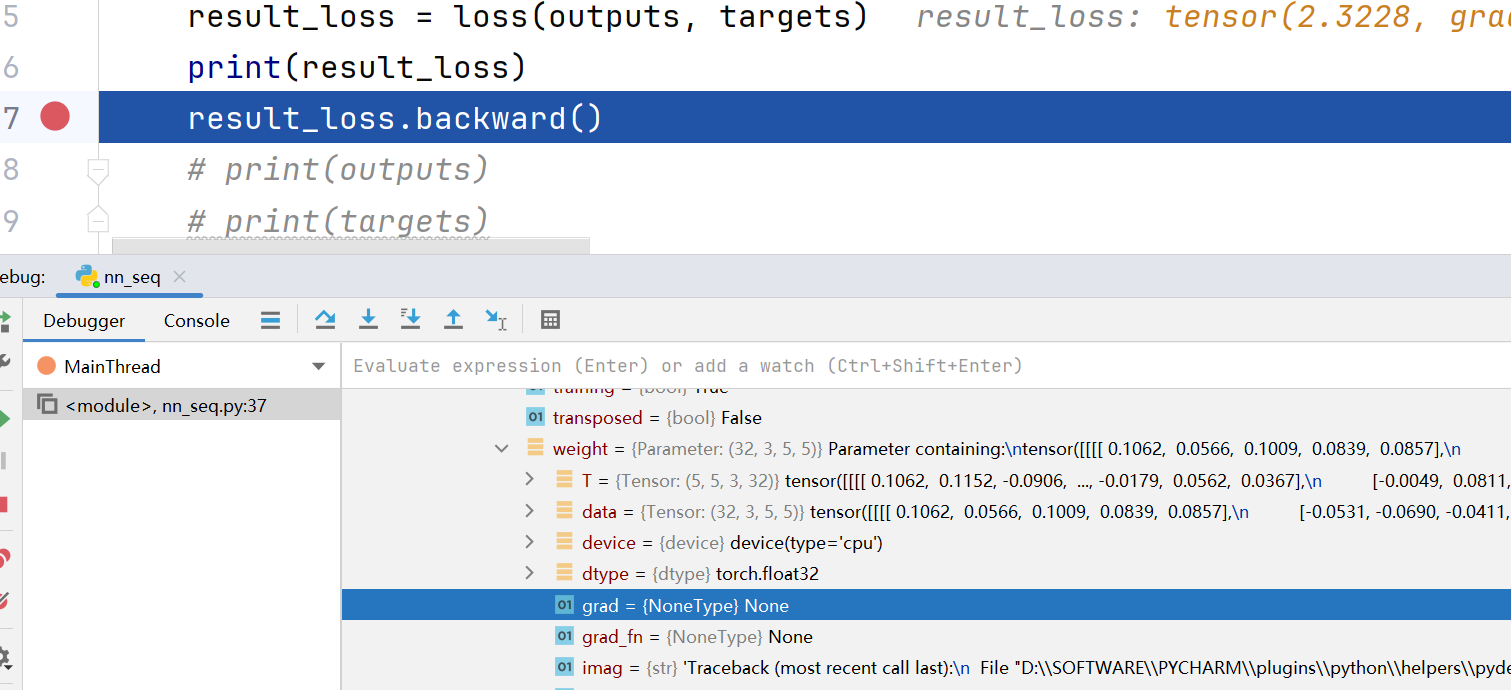
就出现梯度了,有利于反向传播。

优化器
eg:lr是学习速率
optimizer = optim.SGD(model.named_parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([('layer0', var1), ('layer1', var2)], lr=0.0001)demo
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d, Flatten, Conv2d, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=1)
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return xmy_net = MyNet()
optim = torch.optim.SGD(my_net.parameters(), lr=0.01)
loss = nn.CrossEntropyLoss()
for epoch in range(20):running_loss = 0.0for data in dataloader:imgs,targets = dataoutputs = my_net(imgs)result_loss = loss(outputs, targets)#梯度清零optim.zero_grad()#优化器需要每个参数的梯度result_loss.backward()#给每个参数进行调优optim.step()running_loss += result_lossprint(running_loss)
#print(result_loss)现有网络模型的使用以及修改
import torchvision.datasets
from torch import nn
from torchvision import transforms#train_data = torchvision.datasets.ImageNet("./data_image_net",split='train',# download=True,transform=transforms.ToTensor())
vgg16_false = torchvision.models.vgg16(pretrained=False)
#打印的是已经预训练好的网络架构,参数都是在训练之后的
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=False,transform=torchvision.transforms.ToTensor())
#把vgg16当一个前置的网络结构
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000, 10))
print(vgg16_true)
vgg16_false.classifier[6]=nn.Linear(4096, 10)网络模型保存
方式1
模型结构+模型参数
import torch
import torchvisionvgg16 = torchvision.models.vgg16(pretrained=False)
#保存方式1
torch.save(vgg16,"vgg16_method1.pth")加载模型
#保存方式1,加载模型
model = torch.load("vgg16_method1.pth")
print(model)如果是用方式1并且是自定义模型的话,一定要让访问的代码能够访问到模型定义的地方。
方式2---字典类型
模型参数(官方推荐,好像是这样比较小)
#保存方式2
torch.save(vgg16.state_dict(),"vgg16_state_dict.pth")加载模型,字典形式打印出来就看不见网络结构了,也可以再恢复成网络结构的。
#方式2加载方式
#如果你想恢复成网络模型结构
vgg16 = torchvision.models.vgg16(pretrained=False)
model = torch.load("vgg16_state_dict.pth")
print(model)
print(vgg16)模型训练
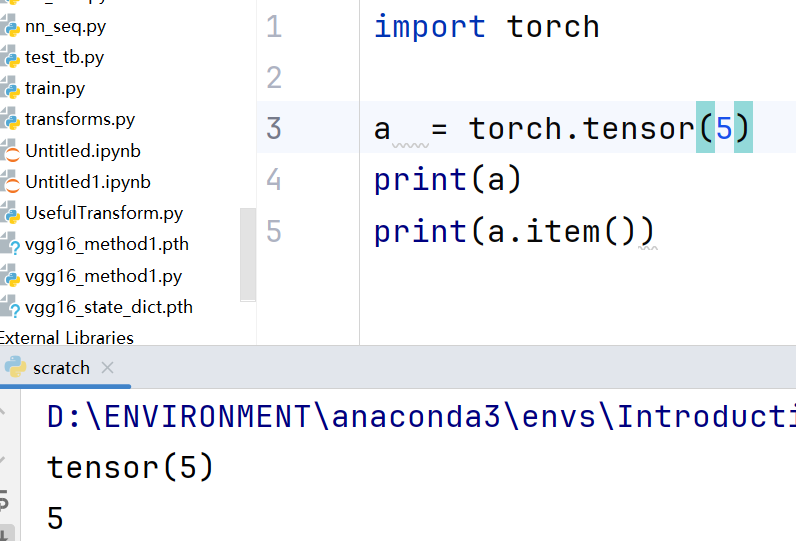
item和本身的区别:
train.py
import torch
import torchvision
from model import *train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度是:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#加载数据集
train_dataloader = torch.utils.data.DataLoader(train_data,batch_size=64,)
#ctrl+d复制本行到下一行
test_dataloader = torch.utils.data.DataLoader(test_data, batch_size=64,)
#创建网络模型
mynet = MyNet()
#损失函数,交叉熵
loss_function = torch.nn.CrossEntropyLoss()
#优化器
optimizer = torch.optim.SGD(mynet.parameters(), lr=0.001, momentum=0.9)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
total_test_step = 0
epoch = 10
for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs,targets = dataoutputs = mynet(imgs)loss = loss_function(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1print("训练次数:{},Loss{}".format(total_train_step,loss.item()))model.py
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
#搭建神经网络
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return x
if __name__ == '__main__':mynet = MyNet()#64张图片input = torch.ones((64,3,32,32))output = mynet(input)print(output.shape)test
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriterfrom model import *train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度是:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#加载数据集
train_dataloader = torch.utils.data.DataLoader(train_data,batch_size=64,)
#ctrl+d复制本行到下一行
test_dataloader = torch.utils.data.DataLoader(test_data, batch_size=64,)
#创建网络模型
mynet = MyNet()
#损失函数,交叉熵
loss_function = torch.nn.CrossEntropyLoss()
#优化器
optimizer = torch.optim.SGD(mynet.parameters(), lr=0.001, momentum=0.9)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter('./logs_train')
for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs,targets = dataoutputs = mynet(imgs)loss = loss_function(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:print("训练次数:{},Loss{}".format(total_train_step,loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)#测试步骤开始total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs , targets = dataoutputs = mynet(imgs)loss = loss_function(outputs, targets)total_test_loss += loss.item() == targetsaccurancy = outputs.argmax(1)total_accuracy+=accurancyprint("整体测试集上的loss:{}".format(total_test_loss))print("整体测试集上的正确率{}".format(total_accuracy))writer.add_scalar("test_loss",total_test_loss, total_test_step)writer.add_scalar("test_accuracy",total_accuracy, total_test_step)total_test_step+=1torch.save(mynet,"mynet_{}.pth".format(i))print("模型已保存")
writer.close()规范tips
当网络中有dropout层等东西的时候,可以调用他们
训练之前
mynet.train()测试之前
mynet.eval()使用GPU训练
思路:在如下几处加入相关代码
- 网络模型
- 数据(输入,标注)
- 损失函数
- .cuda
方法1
if torch.cuda.is_available():loss_function = loss_function.cuda()
if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()方法2
.to(device)
Device = torch.device("cpu")
Device = torch.device("gpu")
#定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#电脑上如果有多张显卡,这样来指定显卡
Torch.device("cuda:0")
Torch.device("cuda:1")
imgs, targets = imgs.to(device), targets.to(device)import torch
import torch.nn as nn
import torchvision
import time
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
#定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return x
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度是:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#加载数据集
train_dataloader = torch.utils.data.DataLoader(train_data,batch_size=64,)
#ctrl+d复制本行到下一行
test_dataloader = torch.utils.data.DataLoader(test_data, batch_size=64,)
#创建网络模型
mynet = MyNet()
mynet.to(device)
#损失函数,交叉熵
loss_function = torch.nn.CrossEntropyLoss()
loss_function.to(device)
# if torch.cuda.is_available():
# loss_function = loss_function.cuda()
#优化器
optimizer = torch.optim.SGD(mynet.parameters(), lr=0.001, momentum=0.9)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter('./logs_train')
start_time = time.time()
for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs,targets = dataimgs, targets = imgs.to(device), targets.to(device)# if torch.cuda.is_available():# imgs = imgs.cuda()# targets = targets.cuda()outputs = mynet(imgs)loss = loss_function(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss{}".format(total_train_step,loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)#测试步骤开始total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs , targets = dataimgs, targets = imgs.to(device), targets.to(device)# if torch.cuda.is_available():# imgs = imgs.cuda()# targets = targets.cuda()outputs = mynet(imgs)loss = loss_function(outputs, targets)total_test_loss += loss.item()accurancy = (outputs.argmax(1) == targets).sum()total_accuracy+=accurancy.item()print("整体测试集上的loss:{}".format(total_test_loss))print("整体测试集上的正确率{}".format(total_accuracy))writer.add_scalar("test_loss",total_test_loss, total_test_step)writer.add_scalar("test_accuracy",total_accuracy, total_test_step)total_test_step+=1torch.save(mynet,"mynet_{}.pth".format(i))print("模型已保存")
writer.close()模型验证
利用已经训练好的模型,给它提供输入。
tips:
png图像是4通道,除了rgb以外ia,还有一个透明通道。
image = image.convert('RGB')demo
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linearclass MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = nn.Sequential(Conv2d(3, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 32, kernel_size=5, padding=2),MaxPool2d(2),Conv2d(32, 64, kernel_size=5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return x
image_path = "./images/dog.png"
image = Image.open(image_path)
print(image)transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
model = torch.load("mynet_9.pth",map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1,3,32,32))
model.eval()
with torch.no_grad():output = model(image)
print(output)
print(output.argmax(1))相关文章:

土堆教程笔记【PyTorch】
官网:torch — PyTorch 2.6 documentation Pycharm 解释器 一般搞深度学习都用虚拟环境的解释器,为了满足不同的项目所需要的不同的包的版本。 1. system interpreter表示本地的解释器 也就是你电脑系统里安装的解释器 2. Virtual Environment—Py…...
 / 十字爆破 (预处理+模拟) / 比那名居的桃子 (滑窗 / 前缀和))
【今日三题】小乐乐改数字 (模拟) / 十字爆破 (预处理+模拟) / 比那名居的桃子 (滑窗 / 前缀和)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 小乐乐改数字 (模拟)十字爆破 (预处理模拟)比那名居的桃子 (滑窗 / 前缀和) 小乐乐改数字 (模拟) 小乐乐改数字…...
注意力机制(第1/4集),背景介绍,以及理解与引入)
各类神经网络学习:(九)注意力机制(第1/4集),背景介绍,以及理解与引入
上一篇下一篇GRU(下集)注意力机制(第2/4集) Attention(注意力机制) 又叫做: attention pooling 简单来说,就是在训练的过程中,已知哪些东西更重要,哪些东西次重要。从而更…...

微软出品的AI Toolkit,在VS Code中使用DeepSeek
文章目录 简介调用DeepSeek 简介 AI Toolkit是微软出品的VS Code智能插件,整合了多种AI大模型,使之可以在VS Code中调用。 在插件栏搜索【AI Toolkit for Visual Studio Code】即可安装。安装完成后,左侧活动栏中会出现【AI Toolkit】的图标…...

随机森林与决策树
随机森林 vs 决策树: 随机森林(Random Forest)和决策树(Decision Tree)都是经典的机器学习算法,但它们在原理、性能和适用场景上有显著差异。以下是关键对比: 1. 决策树(Decision T…...
`方法可能出现的超时问题)
Selenium中`driver.get(htmlfile)`方法可能出现的超时问题
针对Selenium中driver.get(htmlfile)方法可能出现的超时问题,以下是几种改进方案及具体实现方法: 1. 设置页面加载超时时间 通过set_page_load_timeout()方法直接控制页面加载的最大等待时间。若超时,会抛出TimeoutException异常,…...

selenium快速入门
一、操作浏览器 from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By# 设置选项 q1 Options() q1.add_argument("--no-sandbo…...

C++_智能指针
目录 一、智能指针的使用场景、基本概念 (1)因为抛异常而出现的资源泄漏的情况 二、RAII和智能指针的设计思路 三、c标准库智能指针以及使用 (1)几种智能指针的概念 auto_ptr unique_ptr shared_ptr weak_ptr 不是new出来…...

微服务简述
单体架构和微服务架构的区别? 最显著的区别看上去就是单体架构用的同一个数据库,微服务架构用的各自的数据库 单体架构: 所有功能模块(如用户管理、订单处理、支付等)都紧密耦合在一个代码库中。模块之间通过函数调用…...
深度解毒手册:从「撕逼大会」到「人见人爱」的协作秘笈)
研发效能实践:BDD(行为驱动开发)深度解毒手册:从「撕逼大会」到「人见人爱」的协作秘笈
引言:每个研发团队都该养一亩「黄瓜田」——论BDD如何终结「三体人」式需求沟通 🌌 「产品说登录要人脸识别,开发做成了指纹验证,测试按文档测出18个bug,最后发现原型图藏在三年前的邮件附件里…」家人们…...

【第40节】windows编程:仿造MFC版本QQ安全卫士
目录 前言 一、实现功能 二、附加功能 三、开发环境 四、数据库简单字段设计 五、代码架构 六、软件界面 七、功能架构 八、部分功能截图 九、相关实现细节概要 9.1 获取文件信息 9.2 清理电脑垃圾信息 9.2.1 回收站 9.2.2 清理指定数据下的文件 9.3 数据库与网…...
旗下控股子公司“京东方能源”成功挂牌新三板 以科技赋能零碳未来)
BOE(京东方)旗下控股子公司“京东方能源”成功挂牌新三板 以科技赋能零碳未来
2025年4月8日,BOE(京东方)旗下控股子公司京东方能源科技股份有限公司(以下简称“京东方能源”)正式通过全国中小企业股份转让系统审核,成功在新三板挂牌(证券简称:能源科技,证券代码:874526),成为BOE(京东方)自物联网转型以来首个独立孵化并成功挂牌的子公司。此次挂牌是BOE(京…...

【汽车产品开发项目管理——端到端的汽车产品诞生流程】
MPU:集成运算器、寄存器和控制器的中央处理器芯片 MCU:微控制单元,将中央处理器CPU、存储器ROM/RAM、计数器、IO接口及多种外设模块集成在单一芯片上的微型计算机系统。 汽车产品开发项目属性:临时性、独特性、渐进明细性、以目标…...

Visual Studio 2019 配置VTK9.3.1
文章目录 参考博客1、 VTK下载和编译2、vs2019配置vtk9.3.1参考博客 Visual Studio 2022 配置VTK9.3.0 1、 VTK下载和编译 见博客 CMake编译VTK 2、vs2019配置vtk9.3.1 新建一个项目 写入以下代码 #include <vtkActor.h> #include <vtkAssembly.h> #include…...

【含文档+PPT+源码】基于小程序的智能停车管理系统设计与开发
项目视频介绍: 毕业作品基于小程序的智能停车管理系统设计与开发 课程简介: 本课程演示的是一款基于小程序的智能停车管理系统设计与开发,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:…...

科技自立+产业周期:透视人工智能的配置机遇
最近,全球市场因关税政策调整引发震荡,科技板块波动尤为明显。在此背景下,中国人工智能产业经历了一轮回调。 不过,《一点财经》注意到,4月9日上证科创板人工智能指数一度上涨3.7%。拉长周期看,Wind数据显…...

linux网络配置
今天我们来了解一下linux的网络配置,这个是我们进行网络传输的基础,保证网络资源的使用的手段.那么来看. 网络配置原理图: 查看网络ip和网关 windows:ipconfig linux:ifconfig ping测试主机之间网络联通性 ⭐️ip地址要在同一个网段下才…...

机器学习 | 强化学习方法分类汇总 | 概念向
文章目录 📚Model-Free RL vs Model-Based RL🐇核心定义🐇核心区别 📚Policy-Based RL vs Value-Based RL🐇核心定义🐇 核心区别 📚Monte-Carlo update vs Temporal-Difference update…...

git仓库迁移包括提交记录日志
网上找了很多资料都不好用,直到看到一个亲测有效后,整理如下: 1、进入仓库目录下,并且切换到要迁移的分支上 前提是你本地已有旧仓库的代码;如果没有的话,先拉取。 2、更改仓库地址 git remote set-url …...

Docker部署.NetCore8项目
在VS.net新建.netCore8项目,生成项目的发布文件,之后添加Dockerfile,内容如下: FROM mcr.microsoft.com/dotnet/aspnet:8.0 # 设置工作目录 WORKDIR /app # 挂载临时卷(类似于 VOLUME /tmp) VOLUME /tmp …...

xv6部分源码阅读-1
xv6部分源码阅读 前言 在lab2中,我们会为了完成attack这个实验,而花费大量的时间去阅读相关的系统调用源码,以此来分析出我们最终secret所在的页表的位置,而我写lab2中,重点并没有关注其中的逻辑关系,有很…...
)
CentOS中离线安装DockerCompos并用其部署Rabbitmq(使用离线导入导出docker镜像方式)
场景 DockerDockerCompose实现部署jenkins,并实现jenkinsfile打包SpringBootVue流水线项目过程详解、踩坑记录(附镜像资源、离线包资源下载): DockerDockerCompose实现部署jenkins,并实现jenkinsfile打包SpringBootVue流水线项目过程详解、踩坑记录(附镜像资源、离…...

基于 OpenHarmony 5.0 的星闪轻量型设备应用开发——Ch2 OpenHarmony LiteOS-M 内核应用开发
写在前面: 此篇是系列文章《基于 OpenHarmony5.0 的星闪轻量型设备应用开发》的第 2 章。本篇介绍了如何在 OpenHarmony 5.0 框架下,针对 WS63 进行 LiteOS-M 内核应用工程的开发。 为了方便读者学习,需要OpenHarmony 5.0 WS63 SDK 的小伙伴可…...

2025年4月9日-华为暑期实习-第二题-200分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 智能导航系统 问题描述 K小姐生活在一个被称为"未来之城"的智能城市,这个城市拥有高效的无人驾驶运输网络。城市内的智能车辆可以在不同的交通枢纽之间穿行,每个枢…...

抖音视频下载工具
抖音视频下载工具 功能介绍 这是一个基于Python开发的抖音视频下载工具,可以方便地下载抖音平台上的视频内容。 主要特点 支持无水印视频下载自动提取视频标题作为文件名显示下载进度条支持自动重试机制支持调试模式 使用要求 Python 3.10Chrome浏览器必要的P…...

基于大模型预测儿童急性淋巴细胞白血病诱导达完全缓解患者综合治疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 国内外研究现状 二、儿童急性淋巴细胞白血病及大模型相关理论基础 2.1 儿童急性淋巴细胞白血病概述 2.2 大模型技术原理及特点 三、大模型在术前评估中的应用 3.1 患者基本信息与病情数据收集 3.2 大模型对病情严…...

项目合同从专家到小白
文章目录 按项目范围划分项目总承包合同项目单项承包合同项目分包合同 按项目付款方式划分总价合同固定总价合同总价加激励费用合同(FPIF)总价加经济价格调整合同订购单 \ 单边合同 成本补偿合同工料合同(混合型) 基础概念目标成本…...

【windows10】基于SSH反向隧道公网ip端口实现远程桌面
【windows10】基于SSH反向隧道公网ip端口实现远程桌面 1.背景2.SSH反向隧道3.远程连接电脑 1.背景 Windows 10远程桌面协议的简称是RDP(Remote Desktop Protocol)。 RDP是一种网络协议,允许用户远程访问和操作另一台计算机。 远程桌面功…...

学习海康VisionMaster之四边形查找
一:进一步学习了 今天学习下VisionMaster中的四边形查找,这个还是拟合直线的衍生应用,可以同时测量四条直线并且输出交点或者判定是否有交点 二:开始学习 1:什么是四边形查找? 按照传统的算法,…...

菊风RTC 2.0 开发者文档正式发布,解锁音视频新体验!
重磅发布! 开发者们,菊风实时音视频2.0文档已正式发布上线,为您提供更清晰、更高效的开发支持!让菊风实时音视频2.0为您的音视频应用加速~ 菊风实时音视频2.0聚焦性能升级、体验升级、录制服务升级,助力视频通话、语…...

用Python和OpenCV开启图像处理魔法之旅
你是否曾好奇计算机是如何“看懂”这个世界的?从人脸识别到自动驾驶,计算机视觉技术正日益渗透到我们的生活中。而 OpenCV (Open Source Computer Vision Library),作为一个强大的开源计算机视觉库,正是我们探索这个奇妙世界的强大…...
)
初识MySQL · 复合查询(内外连接)
目录 前言: 基本查询回顾 笛卡尔积和子查询 笛卡尔积 内外连接 子查询 单行子查询 多行子查询 多列子查询 from中使用子查询 合并查询 前言: 在前文我们学习了MySQL的基本查询,就是简单的套用了select语句,最多不过是…...
-- Java编程实现)
Devops系列之对接Gerrit的设计与实现(三)-- Java编程实现
一、背景 上文讲述了如何使用shell命令实现创建gerrit项目,本文介绍如何使用java语言编程实现。 二、java语言实现 1、引入jar包 <dependency><groupId>com.urswolfer.gerrit.client.rest</groupId><artifactId>gerrit-rest-java-client…...

深入理解全排列算法:DFS与回溯的完美结合
全排列问题是算法中的经典问题,其目标是将一组数字的所有可能排列组合列举出来。本文将详细解析如何通过深度优先搜索(DFS)和回溯法高效生成全排列,并通过模拟递归过程帮助读者彻底掌握其核心思想。 问题描述 给定一个正整数 n&a…...
)
服务器(一种管理计算资源的计算机)
服务器是在网络环境中提供计算能力并运行软件应用程序的特定IT设备,它在网络中为其他客户机(如个人计算机、智能手机、ATM机等终端设备)提供计算或者应用服务, 一般来说服务器都具备承担响应服务请求、承担服务、保障服务的能力。服务器相比普…...

时态--02--一般过去时
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一般过去时1.肯定句am/is — wasare — were 2.否定句3.⼀般疑问句4.特殊疑问句5.there be 过去式 practice过去分词 一般过去时 1.肯定句 am/is — was are — wer…...
安装LSPosed和应用教程)
WSA(Windows Subsystem for Android)安装LSPosed和应用教程
windows安卓子系统WSA的Lsposed和shamiko的安装教程 WSA(Windows Subsystem for Android)安装LSPosed和应用教程 一、环境准备 在开始之前,请确保: 已经安装好WSA(Windows Subsystem for Android)已经安装好ADB工具下载好LSPosed和Shamiko框架安装包 二、连接WSA 首先需要…...

Opencv计算机视觉编程攻略-第十三节 跟踪视频中的物品
这是opencv系列的最后一节,主要学习视频序列,上一节介绍了读取、处理和存储视频的工具,本文将介绍几种跟踪图像序列中运动物体的算法。可见运动或表观运动,是物体以不同的速度在不同的方向上移动,或者是因为相机在移动…...

10 个最新 CSS 功能已在所有主流浏览器中得到支持
前言 CSS 不断发展,新功能使我们的工作更快、更简洁、更强大。得益于最新的浏览器改进(Baseline 2024),许多新功能现在可在所有主要引擎上使用。以下是您可以立即开始使用的10 CSS新功能。 1. Scrollbar-Gutter 和 Scrollbar-Co…...

[特殊字符] 企业级Docker私有仓库实战:3步搭建Harbor安全仓库,镜像管理从此高效无忧
本文提供 一站式Docker私有仓库部署指南,聚焦企业级镜像管理需求,深入解析Harbor私有仓库的搭建、运维与安全加固全流程。内容涵盖 轻量级Registry快速部署与 Harbor企业级方案对比,手把手演示SSL证书配置、多租户权限控制、镜像漏洞扫描等核…...

一个基于Django的进销存管理系统Demo实现
第一步:创建 Django 项目 bash 复制 django-admin startproject inventory_system cd inventory_system python manage.py startapp erp 第二步:定义数据模型(models.py) python 复制 from django.db import models from d…...
)
wsl2+ubuntu22.04安装blender教程(详细教程)
本章教程介绍,如何在Windows操作系统上通过wsl2+ubuntu安装blender并运行教程。Blender 是一款免费、开源的 3D 创作套件,广泛应用于建模、动画、渲染、视频编辑、特效制作等领域。它由全球开发者社区共同维护,支持跨平台(Windows、macOS、Linux),功能强大且完全…...

netty中的ChannelPipeline详解
Netty中的ChannelPipeline是事件处理链的核心组件,负责将多个ChannelHandler组织成有序的责任链,实现网络事件(如数据读写、连接状态变化)的动态编排和传播。以下从核心机制、执行逻辑到应用场景进行详细解析: 1. 核心结构与组成 双向链表结构 组成单元:ChannelPipeline…...

使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构
使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构 在现代应用程序中,实时数据处理和高并发性能是至关重要的。本文将介绍如何使用 Python 的多进程和 Socket 技术来接收和解析数据,并将处理后的数据推送到 Kafka,从而实现高效的…...
——ListView控件详解)
WinForm真入门(14)——ListView控件详解
一、ListView 控件核心概念与功能 ListView 是 WinForm 中用于展示结构化数据的多功能列表控件,支持多列、多视图模式及复杂交互,常用于文件资源管理器、数据报表等场景。 核心特点: 支持 5种视图模式:Details&…...

FastAPI用户认证系统开发指南:从零构建安全API
前言 在现代Web应用开发中,用户认证系统是必不可少的功能。本文将带你使用FastAPI框架构建一个完整的用户认证系统,包含注册、登录、信息更新和删除等功能。我们将采用JWT(JSON Web Token)进行身份验证,并使用SQLite作…...

【BUG】阿里云服务器数据库远程连接报错
当你遇到 ERROR 2003 (HY000): Cant connect to MySQL server on 47.100.xxx.xx (10061) 错误,这个错误代码 10061 通常意味着客户端无法连接到指定的 MySQL 服务器,原因可能有多种,下面为你分析可能的原因及对应的解决办法。 1. 网络连接问…...

【前端】【React】性能优化三件套useCallback,useMemo,React.memo
一、总览:性能优化三件套 useCallback(fn, deps):缓存函数,避免每次渲染都新建函数。useMemo(fn, deps):缓存值(计算结果),避免重复执行计算。React.memo(Component):缓存组件的渲染…...

Vue3性能优化终极指南:编译策略、运行时调优与全链路监控
一、Vue3性能优化体系框架 1.1 性能优化全景图谱 1.2 关键性能指标定义表 指标测量方式优化目标核心影响因子FCPLighthouse<1.5s资源加载速度LCPPerformance API<2.5s关键资源大小TTIWebPageTest<3.5s主线程阻塞时间Memory UsageChrome DevTools<50MB对象引用策略…...

FISCO BCOS技术架构解析:从多群组设计到性能优化实践
目录 FISCO BCOS整体架构设计 多群组架构与数据隔离机制 交易流程与执行机制 安全架构与隐私保护 性能优化与压测实践 应用案例与生态工具 FISCO BCOS作为中国领先的金融级开源联盟链平台,自2017年由金链盟开源工作组推出以来,已在政务、金融、医疗、版权等众多领域实现…...