【消息队列kafka_中间件】一、快速入门分布式消息队列
在当今大数据和分布式系统盛行的时代,消息队列作为一种关键的中间件技术,发挥着举足轻重的作用。其中,Apache Kafka 以其卓越的性能、高可扩展性和强大的功能,成为众多企业构建分布式应用的首选消息队列解决方案。本篇文章将带你深入了解 Kafka 的基础概念、架构原理、核心组件,并通过实际代码示例,让你快速上手 Kafka,揭开分布式消息队列的神秘面纱。
一、Kafka 简介与背景
Kafka 最初是由 LinkedIn 公司开发,用于处理公司内部大规模的实时数据流。随着其开源并在社区的不断发展壮大,Kafka 已成为一款广泛应用于大数据处理、实时流计算、日志收集与处理、系统解耦等众多领域的分布式消息队列系统。
与传统消息队列相比,Kafka 具有显著的优势。它能够支持超高的吞吐量,每秒可以处理数十万甚至数百万条消息,这使得它在应对海量数据传输时表现出色。同时,Kafka 具备低延迟的特性,消息的生产和消费延迟可以控制在毫秒级,满足了许多对实时性要求极高的应用场景。此外,Kafka 的分布式架构设计使其具有强大的可扩展性,能够轻松应对不断增长的数据处理需求。
二、关键概念剖析
2.1 生产者(Producer)
生产者是 Kafka 系统中负责发送消息的组件。在实际应用中,生产者通常是由业务系统中的某个模块或服务担当,它将业务数据封装成 Kafka 能够识别的消息格式,并发送到指定的主题(Topic)中。
以 Java 语言为例,以下是一个简单的 Kafka 生产者代码示例:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// 设置生产者属性Properties props = new Properties();// Kafka集群地址,格式为host1:port1,host2:port2,...props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 键的序列化方式,这里使用字符串序列化props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 值的序列化方式,同样使用字符串序列化props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 创建生产者实例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 要发送的消息内容String messageKey = "key1";String messageValue = "Hello, Kafka!";// 创建消息对象,指定主题和键值对ProducerRecord<String, String> record = new ProducerRecord<>("test - topic", messageKey, messageValue);try {// 发送消息并获取响应RecordMetadata metadata = producer.send(record).get();System.out.println("Message sent successfully to partition " + metadata.partition() +" with offset " + metadata.offset());} catch (Exception e) {e.printStackTrace();} finally {// 关闭生产者,释放资源producer.close();}}
}2.2 消费者(Consumer)
消费者负责从 Kafka 主题中读取消息并进行处理。Kafka 的消费者是以消费者组(Consumer Group)的形式存在的,同一消费者组内的消费者共同消费主题中的消息,通过负载均衡的方式提高消息处理的效率。不同消费者组之间相互独立,每个消费者组都可以完整地消费主题中的所有消息。
以下是一个 Java 语言的 Kafka 消费者代码示例:
import org.apache.kafka.clients.consumer.*;
import java.util.Arrays;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// 设置消费者属性Properties props = new Properties();// Kafka集群地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 消费者组ID,同一组内的消费者共享消费偏移量props.put(ConsumerConfig.GROUP_ID_CONFIG, "test - group");// 键的反序列化方式,这里使用字符串反序列化props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 值的反序列化方式,同样使用字符串反序列化props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 自动提交消费偏移量,默认true,建议设置为false,手动管理偏移量以确保数据不丢失props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");// 创建消费者实例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题consumer.subscribe(Arrays.asList("test - topic"));try {while (true) {// 拉取消息,设置拉取超时时间为100毫秒ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println("Received message: " +"topic = " + record.topic() +", partition = " + record.partition() +", offset = " + record.offset() +", key = " + record.key() +", value = " + record.value());}// 手动提交消费偏移量consumer.commitSync();}} catch (Exception e) {e.printStackTrace();} finally {// 关闭消费者,释放资源consumer.close();}}
}2.3 主题(Topic)
主题是 Kafka 中消息分类存储的逻辑概念,类似于数据库中的表。每个主题可以包含多个分区(Partition),生产者发送的消息会被存储到指定的主题中,消费者则通过订阅主题来获取消息。在实际应用中,通常会根据不同的业务类型或数据类型创建不同的主题。例如,在一个电商系统中,可以创建 “order - topic” 用于存储订单相关的消息,“user - behavior - topic” 用于存储用户行为数据相关的消息等。
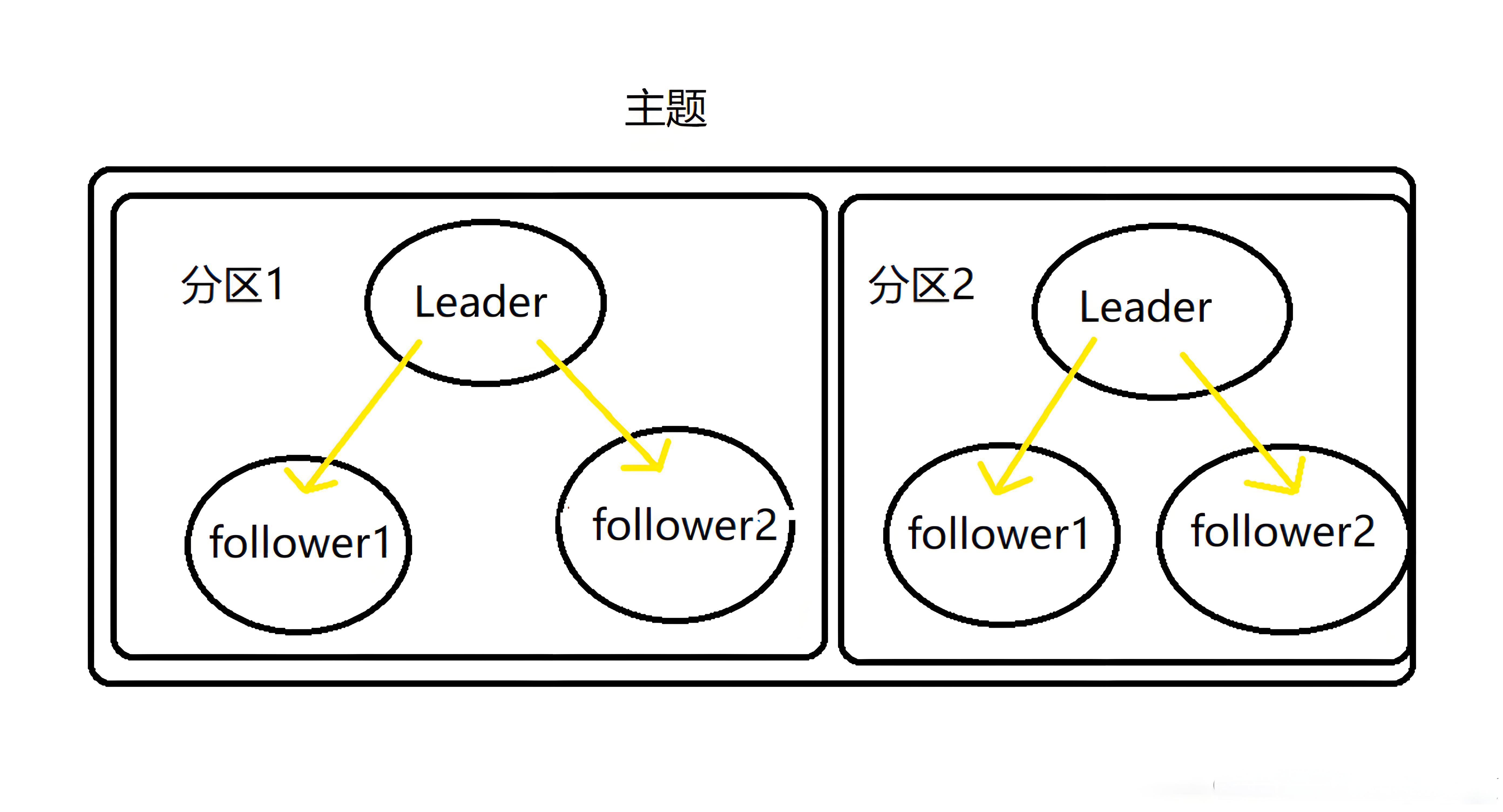
2.4 分区(Partition)
分区是 Kafka 实现高吞吐量和可扩展性的关键机制。每个主题可以被划分为多个分区,这些分区分布在 Kafka 集群的不同 Broker 节点上。当生产者发送消息时,Kafka 会根据一定的策略将消息分配到主题的某个分区中。常见的分区策略有按消息键的 Hash 值分配(如果消息带有键)和轮询分配(如果消息没有键)。
分区的好处主要有以下几点:首先,通过将数据分散存储在多个分区上,可以提高数据存储和读取的并行度,从而提升整体的吞吐量。例如,在一个拥有多个 Broker 节点的集群中,每个 Broker 可以同时处理不同分区的读写请求,大大加快了数据处理速度。其次,分区还可以实现数据的冗余备份。Kafka 会为每个分区创建多个副本,其中一个副本作为领导者(Leader)副本,负责处理读写请求,其他副本作为跟随者(Follower)副本,从领导者副本同步数据。当领导者副本所在的 Broker 节点发生故障时,Kafka 会自动从跟随者副本中选举出一个新的领导者副本,确保数据的可用性和一致性。
三、Kafka 集群架构
Kafka 集群由多个 Broker 节点组成,每个 Broker 节点实际上就是一个 Kafka 服务器进程。这些 Broker 节点共同协作,实现了 Kafka 的分布式存储和消息处理功能。
在 Kafka 集群中,Zookeeper 扮演着至关重要的角色。Zookeeper 是一个分布式协调服务,它负责管理 Kafka 集群的元数据信息,包括 Broker 节点的注册与发现、主题与分区的元数据管理、分区领导者副本的选举等。具体来说,当一个新的 Broker 节点加入集群时,它会向 Zookeeper 注册自己的信息,Zookeeper 会将这些信息同步给其他 Broker 节点,使得整个集群能够感知到新节点的加入。在主题与分区管理方面,Zookeeper 存储了每个主题的分区信息,包括分区的数量、每个分区的领导者副本和跟随者副本所在的 Broker 节点等。当某个分区的领导者副本出现故障时,Zookeeper 会触发领导者选举过程,从跟随者副本中选举出一个新的领导者副本,确保分区的正常工作。
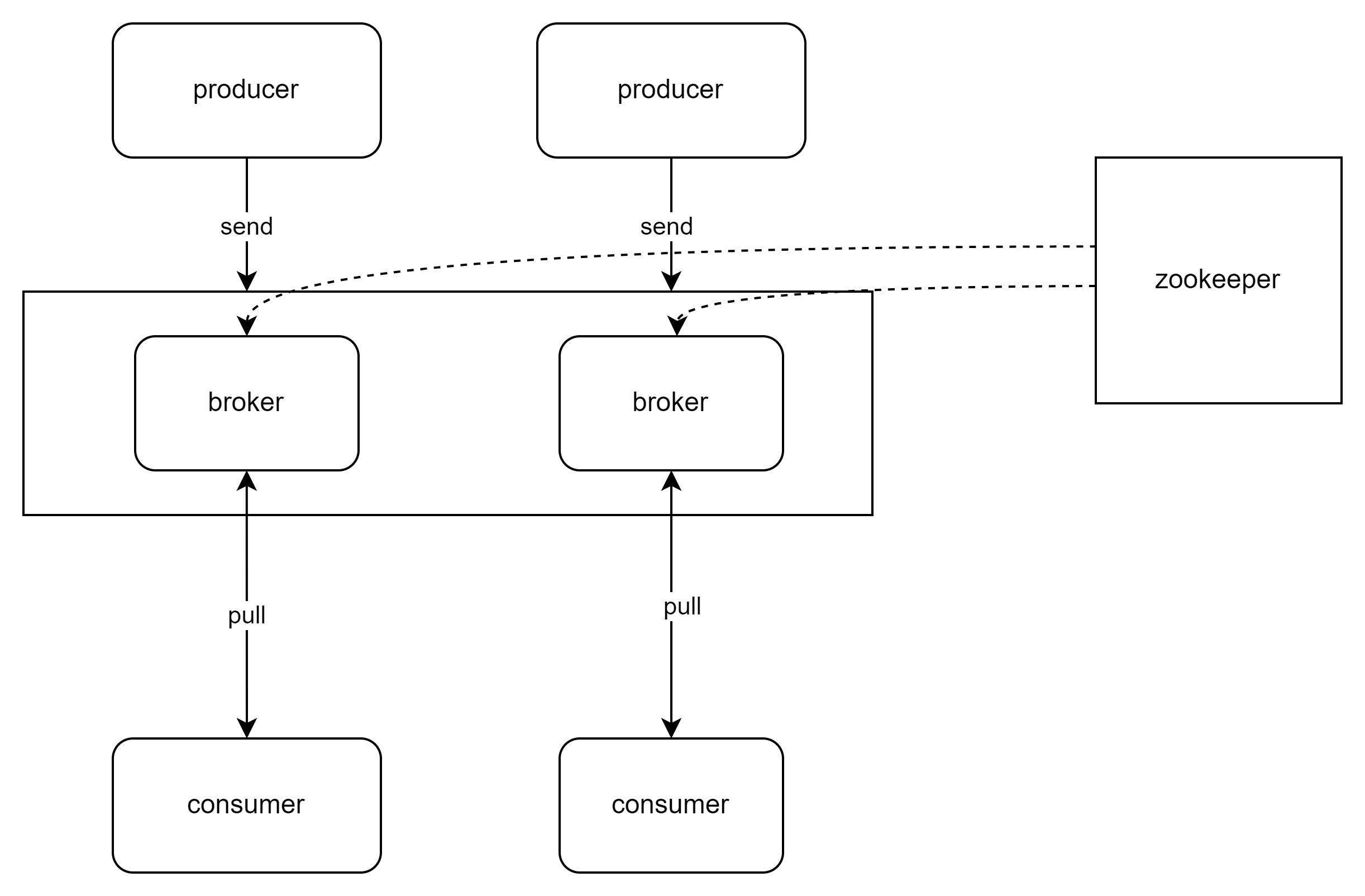
如上图所示,Kafka 集群中的多个 Broker 节点通过 Zookeeper 进行协调和管理。生产者和消费者通过与 Broker 节点进行通信来发送和接收消息,而 Zookeeper 则在幕后负责维护集群的一致性和稳定性。
四、安装与环境搭建
4.1 下载 Kafka
首先,从 Apache Kafka 官方网站(Apache Kafka)下载 Kafka 的安装包。目前 Kafka 的最新版本可以在官网上找到,选择适合自己操作系统的安装包进行下载。例如,对于 Linux 系统,可以下载.tgz格式的压缩包。
4.2 解压安装包
下载完成后,使用解压命令将安装包解压到指定目录。假设将安装包下载到了/downloads目录下,解压命令如下:
tar -xzf kafka_2.13 - 3.3.1.tgz -C /usr/local/上述命令将 Kafka 安装包解压到了/usr/local/目录下,解压后的目录名称为kafka_2.13 - 3.3.1,其中2.13是 Scala 的版本号,3.3.1是 Kafka 的版本号。
4.3 配置环境变量
为了方便在命令行中使用 Kafka 的命令工具,需要将 Kafka 的bin目录添加到系统的环境变量中。在 Linux 系统中,可以编辑~/.bashrc文件,在文件末尾添加以下行:
export PATH=$PATH:/usr/local/kafka_2.13 - 3.3.1/bin然后执行以下命令使环境变量生效:
source ~/.bashrc4.4 配置 Kafka
Kafka 的主要配置文件位于其安装目录下的config文件夹中,其中最重要的配置文件是server.properties。在这个文件中,可以配置 Kafka 的各种参数,如 Kafka 监听的端口、日志存储路径、连接 Zookeeper 的地址等。
以下是一些常见的配置参数及说明:
# Kafka监听的端口,默认9092
listeners=PLAINTEXT://localhost:9092
# 日志存储路径,可以配置多个路径,用逗号分隔
log.dirs=/tmp/kafka - logs
# 连接Zookeeper的地址,格式为host1:port1,host2:port2,...
zookeeper.connect=localhost:2181
# 每个分区的副本因子,即每个分区有多少个副本,建议设置为大于1的奇数,以确保容错
num.partitions=1
replica.fetch.max.bytes=10485764.5 启动 Zookeeper 与 Kafka
在完成 Kafka 配置后,需要先启动 Zookeeper,因为 Kafka 依赖 Zookeeper 进行集群管理。在 Kafka 安装目录下,执行以下命令启动 Zookeeper:
bin/zookeeper - server - start.sh config/zookeeper.properties上述命令会使用config/zookeeper.properties配置文件启动 Zookeeper 服务。启动成功后,终端会输出一些启动日志信息,显示 Zookeeper 已正常运行并监听在指定端口(默认为 2181)。
接着,启动 Kafka 服务,执行命令:
bin/kafka - server - start.sh config/server.properties此命令通过config/server.properties配置文件启动 Kafka 服务器进程。启动过程中,日志会显示 Kafka 加载配置、注册到 Zookeeper 等信息。当看到类似 “[KafkaServer id=0] started” 的日志时,表明 Kafka 已成功启动。
4.6 使用 Kafka 命令行工具验证安装
Kafka 提供了丰富的命令行工具,方便我们进行各种操作与验证。例如,使用以下命令创建一个新的主题:
bin/kafka - topics.sh --create --bootstrap - servers localhost:9092 --replication - factor 1 --partitions 1 --topic new - topic参数说明:
- --create:表示执行创建主题操作。
- --bootstrap - servers localhost:9092:指定 Kafka 集群地址,这里是本地的 9092 端口。
- --replication - factor 1:设置主题的副本因子为 1,即每个分区只有一个副本。在生产环境中,为了数据冗余与容错,通常设置为大于 1 的奇数,如 3 或 5。
- --partitions 1:指定主题的分区数量为 1。根据业务需求可调整,若业务数据量较大且对并行处理要求高,可设置多个分区。
- --topic new - topic:指定要创建的主题名称为new - topic。
创建成功后,可使用以下命令查看当前 Kafka 集群中的所有主题:
bin/kafka - topics.sh --list --bootstrap - servers localhost:9092该命令会列出所有已创建的主题名称,若能看到刚刚创建的new - topic,则说明主题创建成功。
还可以使用生产者和消费者命令行工具进行消息的发送与接收测试。首先,启动一个生产者终端,执行命令:
bin/kafka - console - producer.sh --bootstrap - servers localhost:9092 --topic new - topic启动后,终端会等待输入消息。此时,输入任意消息内容并回车,消息就会被发送到new - topic主题中。
然后,在另一个终端启动消费者,执行命令:
bin/kafka - console - consumer.sh --bootstrap - servers localhost:9092 --topic new - topic --from - beginning--from - beginning参数表示从主题的起始位置开始消费消息。
启动消费者后,就能看到之前生产者发送的消息,这表明 Kafka 的基本功能正常,安装与环境搭建成功。
通过这些命令行工具的操作,不仅验证了安装,也进一步熟悉了 Kafka 的基本使用方式。你将发现其在分布式消息处理领域的强大功能,无论是构建大规模数据处理系统,还是实现复杂业务系统的解耦与异步通信,Kafka 都能成为有力的技术支撑。
相关文章:

【消息队列kafka_中间件】一、快速入门分布式消息队列
在当今大数据和分布式系统盛行的时代,消息队列作为一种关键的中间件技术,发挥着举足轻重的作用。其中,Apache Kafka 以其卓越的性能、高可扩展性和强大的功能,成为众多企业构建分布式应用的首选消息队列解决方案。本篇文章将带你深…...

【Axure元件分享】移动端滑动拨盘地区级联选择器
在移动端产品设计中,地区级联选择器(省/市/区)是用户信息录入场景的核心组件,尤其在电商收货地址、政务信息填报等高频业务中直接影响表单转化率。本文将介绍一款基于Axure的三级动态联动机型地区选择器,通过仿真级联滚…...

宁德时代25年校招演绎数字推理SHL测评题库题型及真题分析
非常感谢您对宁德时代的关注。祝贺您通过宁德时代校园招聘的专业面试环节,现邀请您参与完成以下测评。本轮共两份测评,每份测评对您的最终结果都非常重要,请务必在收到测评后48小时内完成!本测评需要进行远程监考,如果您无法或不愿…...

Python-Django+vue宠物服务管理系统功能说明
❥(^_-) 上千个精美定制模板,各类成品Java、Python、PHP、Android毕设项目,欢迎咨询。 ❥(^_-) 程序开发、技术解答、代码讲解、文档,💖文末获取源码+数据库+文档💖 💖软件下载 | 实战案例 💖文章底部二维码,可以联系获取软件下载链接,及项目演示视频。 本项目…...
)
洛谷普及B3691 [语言月赛202212] 狠狠地切割(Easy Version)
题目:[语言月赛202212] 狠狠地切割(Easy Version) 题号:B3691 难度:普及一 末尾包含对二分法优化的详细解释 题目分析 最后一句应该是本题的考查关键,关于筛选算法的时间优化, 但从功能理论上,我找到了…...
)
FPGA_BD Block Design学习(一)
PS端开发流程详细步骤 1.第一步:打开Vivado软件,创建或打开一个工程。 2.第二步:在Block Design中添加arm核心,并将其配置为IP核。 3.第三步:配置arm核心的外设信息,如DDR接口、时钟频率、UART接口等。 …...

Collection vs Collections:核心区别与面试指南
Collection vs Collections:核心区别与面试指南 一、本质区别(核心记忆点) 维度CollectionCollections身份集合框架的根接口操作集合的工具类包位置java.utiljava.util是否可实例化❌ 接口✅ 类(但构造器私有,不可实…...

sqlite3基本语句
创建表 CREATE TABLE student ( id INTEGER PRIMARY KEY, -- 学号,主键 name TEXT NOT NULL, -- 姓名,不能为空 age INTEGER, -- 年龄 gender TEXT -- 性别 ); SQLite常用数据类型 主键 …...

jupyter notebook 显示conda虚拟环境
使用 nb_conda_kernels 安装 nb_conda_kernels:这个包可以自动从你的 Conda 环境中发现并列出内核。 conda activate base # 确保你在 base 环境或任何其他环境中安装 conda install nb_conda_kernels显示jupyternotebook当前所在的位置。...
岗位笔试机考题)
华为海思IC前端中后端(COTXPU)岗位笔试机考题
近期华为海思即将开始IC设计实现实习岗位机考。小编今天给大家分享下华为海思相关机考题目。 华为海思2025届校招笔试面试经验分享 每年IC秋招笔试其实也是从题库中随机抽出一些题。 华为海思2025届校招笔试面试经验分享华为海思机考主要分三个方向,分别是物理方向…...

HarmonyOS NEXT 实现滑动拼图验证码功能
大家好,我是 V 哥。 在 Gitee 上看到一个用 Java 实现的 HarmonyOS 滑动拼图验证码功能,已经太老了,鸿蒙开发推荐使用 ArkTS 语言,V 哥来改造一下。 以下是基于 ArkTS 的实现方案。由于鸿蒙系统的特性差异,这里提供核…...

【XML基础-1】深入理解XML:介绍、语法规则与实际应用
XML(可扩展标记语言)作为数据表示和交换的标准格式,自1998年问世以来已成为现代计算领域不可或缺的一部分。本文将全面介绍XML的基础概念、详细语法规则以及它在各领域中的实际应用。 1. 什么是XML? XML(eXtensible …...

STM32 HAL库扩大USB CDC的输入缓冲区
STM32 HAL库,使用USB, 扩大输入暂存区的方法 使用STM32的USB通讯CubeMX建立配置Serial Wire时钟配置USB配置时钟频率设置代码编写运行效果总结使用STM32的USB通讯 STM32可以不用使用串口转换直接和USB通讯。这给串口调试提供了极大的方便。编程,我使用了STM32CubeIDE编程。这…...

迭代器模式深度解析与实战案例
一、模式定义 迭代器模式(Iterator Pattern) 是一种行为设计模式,提供一种方法顺序访问聚合对象的元素,无需暴露其底层表示。核心思想是将遍历逻辑从聚合对象中分离,实现 遍历与存储的解耦。 二、核心组件 组件作用…...

Kotlin协程实用模版合集
目录 ✅ Kotlin 协程实用模板合集(适合 Android 项目) 📦 1. 基础挂起函数封装(Repository 层) ⚙️ 2. ViewModel 中使用协程 状态处理 ⏱️ 3. 带超时控制的挂起操作 🤝 4. 并发请求合并࿰…...

基于Flask的Windows事件ID查询系统开发实践
基于Flask的Windows事件ID查询系统开发实践 一、项目背景与功能概述 Windows操作系统的事件日志系统记录了数百种不同的事件ID,每个ID对应特定的系统事件。本文介绍如何构建一个基于Web的事件ID查询系统,主要实现以下功能: 数据可视化展示…...

机器人编程基础---C语言中的运算符
C语言中的运算符 算术运算符关系运算符逻辑运算符位运算符C语言提供了多种运算符来执行不同的操作。 算术运算符 + 加法- 减法* 乘法/ 除法% 取模(求余)++ 自增-- 自减int a = 10, b = 5; int sum = a + b;...

设计模式之迭代器模式:遍历的艺术与实现
引言 迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象中各个元素的方法,而又不暴露其底层实现。迭代器模式将遍历逻辑与聚合对象解耦,使得我们可以用统一的方式处理不同的集合结构。…...

React七案例中
代码下载 地图找房模块 顶部导航栏 封装NavHeader组件实现城市选择,地图找房页面的复用,在 components 目录中创建组件 NavHeader,把之前城市列表写过的样式复制到 NavHeader.scss 下,在该组件中封装 antd-mobile 组件库中的 N…...

消息中间件篇——RabbitMQ,Kafka
RabbitMQ 如何保证消息不丢失? 生产者确认机制 消息持久化 消费者确认机制 RabbitMQ如何保证消息不丢失? RabbitMQ的重复消费问题如何解决? RabbitMQ中死信交换机(RabbitMQ延迟队列有了解过吗?) 延迟队列…...

HOW - 实现 useClickOutside 或者 useClickAway
场景 在开发过程中经常遇到需要点击除某div范围之外的区域触发回调:比如点击 dialog 外部区域关闭。 手动实现 import { useEffect } from "react"/*** A custom hook to detect clicks outside a specified element.* param ref - A React ref object…...

青少年编程考试 CCF GESP Python七级认证真题 2025年3月
Python 七级 2025 年 03 月 题号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 答案 B C A B B A A B C A B B A B A 1 单选题(每题 2 分,共 30 分) 第 1 题 下列哪个选项是python中的关键字? A. function B. class C. method D. object…...

兆讯MH2103系列pin to pin替代STM32F103,并且性能超越
MH2103 是一款高性能的 32 位微控制器,由兆讯恒达推出,主要用于替代 STM32F103 系列产品。以下是关于 MH2103 芯片的详细介绍: 技术规格 内核与主频: 采用高性能 32 位 Cortex-M3 内核,最高工作频率可达 216 MHz。支…...

h5使用dsBridge与原生app通信--桥方法
dsBridge是一个轻量级的 JS 和原生 App 的通信桥梁库,使用起来比原生方便不少支持: 1.H5 调用 Native 方法(JS → Native) 2.Native 调用 H5 方法(Native → JS) 3.支持参数传递和异步回调 4.支持 Android、iOS、以…...

package.json配置项积累
peerDependencies 用途:peerDependencies 主要用于声明一个包在其宿主项目中期望安装的依赖版本。它通常用于确保插件或库与特定版本的其他库兼容。 行为: 在 npm v7之前,如果宿主项目未安装 peerDependencies 中列出的依赖,则不…...

Python安装软件包报错 fatal error: Python.h: No such file or directory
Python安装软件包报错 fatal error: Python.h: No such file or directory Failed to import transformers.integrations.integration_utils because of the following error (look up to see its traceback): Failed to import transformers.modeling_utils because of the f…...
)
数据结构与算法-图论-复习1(单源最短路,全源最短路,最小生成树)
1. 单源最短路 单一边权 BFS 原理:由于边权为单一值,可使用广度优先搜索(BFS)来求解最短路。BFS 会逐层扩展节点,由于边权相同,第一次到达某个节点时的路径长度就是最短路径长度。 用法:适用…...

uniapp:微信小程序,一键获取手机号
<button open-type"getPhoneNumber" getphonenumber"getphonenumber">一键获取</button> <script>export default {methods: {getphonenumber(e){uni.login({provider: weixin,success: (res)> {console.log(res);},});},}} </scr…...

协作焊接机器人
一、核心定义与核心特点 1. 定义 协作焊接机器人是基于协作机器人本体(具备力传感、轻量化、安全停机等特性),集成焊接电源、焊枪、视觉 / 电弧传感器等模块,实现人机共融焊接作业的自动化设备。其核心在于: 安全协作:支持与焊工共同工作,无需物理隔离;柔性适配:快速…...

SpringBoot和微服务学习记录Day2
微服务 微服务将单体应用分割成更小的的独立服务,部署在不同的服务器上。服务间的关联通过暴露的api接口来实现 优点:高内聚低耦合,一个模块有问题不影响整个应用,增加可靠性,更新技术方便 缺点:增加运维…...

【CornerTag组件详解:优雅的角标设计与实现】
CornerTag组件详解:优雅的角标设计与实现 组件完整代码 <template><divclass"corner-tag":style"{background: bgColor,padding: ${paddingY}px 0,fontSize: fontSize px,...customStyle}"><slot /></div> </tem…...

Mybatis-缓存详解
什么是缓存? 存在内存中的临时数据 将用户经常查询的数据放在缓存中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题 经…...

WHAT - React useId vs uuid
目录 uuiduseId适用场景语法示例注意事项 复杂示例示例:动态表单列表 useId解读重点 useId vs uuid一句话总结对比表格示例对比useId 用于表单uuid() 用在 UI 会出问题uuid 的适合场景 总结建议 uuid 在 WHAT - Math.random?伪随机? 中我们…...
)
Leetcode 跳跃游戏 II (贪心算法)
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - 1] 的最…...

银河麒麟V10 Ollama+ShellGPT打造Shell AI助手——筑梦之路
环境说明 1. 操作系统版本: 银河麒麟V10 2. CPU架构:X86 3. Python版本:3.12.9 4. 大模型:mistral:7b-instruct 准备工作 1. 编译安装python 3.12 # 下载python 源码wget https://www.python.org/ftp/python/3.12.9/Python-3.12.9.tg…...

【物联网】GPT延时
文章目录 前言一、GPT实现延时1. 定时器介绍2. I.MX6ull GPT定时器介绍1)GPT定时器工作原理2)GPT的输入捕获3)GPT的输出比较 3. 高精度延时实现1)实现思路 前言 使用 GPT 实现延时控制以及基于 PWM 实现蜂鸣器发声与频率调节这两…...

【套题】大沥2019年真题——第4题
04.数字圈 题目描述 当我们写数字时会发现有些数字有封闭区域,有的数字没有封闭区域。 数字 0 有一个封闭区域,数字 1、2、 3 都没有封闭区域,数字 4 有一个封闭区域,数字 5 没有封闭区域,数字 6 有一个封闭区域&#…...

idea 安装 proxyai 后的使用方法
1. 可以默认使用ProxyAi 安装后使用如下配置可以进行代码提示 配置 使用示例 2. 这里有必要说一下,这里要选择提供服务的ai 选择后才可以使用ProxyAI或者Custom openAI 3. 可以使用custom openAi, 要自行配置 1)配置 code completions 这是header …...

构建实时、融合的湖仓一体数据分析平台:基于 Delta Lake 与 Apache Iceberg
1. 执行摘要 挑战: 传统数据仓库在处理现代数据需求时面临诸多限制,包括高昂的存储和计算成本、处理海量多样化数据的能力不足、以及数据从产生到可供分析的端到端延迟过高。同时,虽然数据湖提供了低成本、灵活的存储,但往往缺乏…...

数据库的MVCC机制详解
MVCC(Multi-Version Concurrency Control,多版本并发控制)是数据库系统中常用的并发控制机制,它允许数据库在同一时间点保存数据的多个版本,从而实现非阻塞的读操作,提高并发性能。 MVCC的核心思想是&…...

未来与自然的交响:蓉城生态诗篇
故事背景 故事发生在中国四川成都,描绘了未来城市中科技与自然共生的奇迹。通过六个极具创意的生态场景,展现人类如何以诗意的方式重构与自然的连接,在竹海保育、文化传承、能源循环等维度编织出震撼心灵的未来图景。 故事内容 当晨雾在竹纤维…...

【愚公系列】《高效使用DeepSeek》062-图书库存管理
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

汽车软件开发常用的建模工具汇总
目录 往期推荐 1.Enterprise Architect(EA) 2.MATLAB/Simulink 3.TargetLink 4.Rational Rhapsody 5.AUTOSAR Builder 6.PREEvision 总结 往期推荐 2025汽车行业新宠:欧企都在用的工具软件ETAS工具链自动化实战指南<一&am…...
)
六、继承(二)
1 继承与友元 如果一个基类中存在友元关系,那么这个友元关系能不能继承呢? 例: #include <iostream> using namespace std; class Student; class Person { public:friend void Display(const Person& p, const Student& s)…...
连接达梦数据库并写入读取数据)
flink部署使用(flink-connector-jdbc)连接达梦数据库并写入读取数据
flink介绍 1)Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。 2)在实时计算或离线任务中,往往需要…...

【Rust开发】Rust快速入门,开发出Rust的第一个Hello World
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

Flink框架:批处理和流式处理与有界数据和无界数据之间的关系
本文重点 从数据集的类型来看,数据集可以分为有界数据和无界数据两种,从处理方式来看,有批处理和流处理两种。一般而言有界数据常常使用批处理方式,无界数据往往使用流处理方式。 有界数据和无界数据 有界数据有一个明确的开始和…...
)
基于 Spring Boot 瑞吉外卖系统开发(四)
基于 Spring Boot 瑞吉外卖系统开发(四) 新增分类 新增分类UI界面,两个按钮分别对应两个UI界面 两个页面所需的接口都一样,请求参数type值不一样,type1为菜品分类,type2为套餐分类。 请求方法都为POST。…...

患者根据医生编号完成绑定和解绑接口
医疗系统接口文档 一、Controller 层 1. InstitutionDoctorController 医疗机构和医生相关的控制器,提供机构查询、医生查询、绑定解绑医生等功能。 RestController RequestMapping("/institution-doctor") public class InstitutionDoctorController…...

Flutter性能优化终极指南:从JIT到AOT的深度调优
一、Impeller渲染引擎调优策略 1.1 JIT预热智能预编译 // 配置Impeller预编译策略 void configureImpeller() {ImpellerEngine.precacheShaders(shaders: [lib/shaders/skinned_mesh.vert,lib/shaders/particle_system.frag],warmupFrames: 30, // 首屏渲染前预编译帧数cach…...