机器学习 Day10 逻辑回归
1.简介

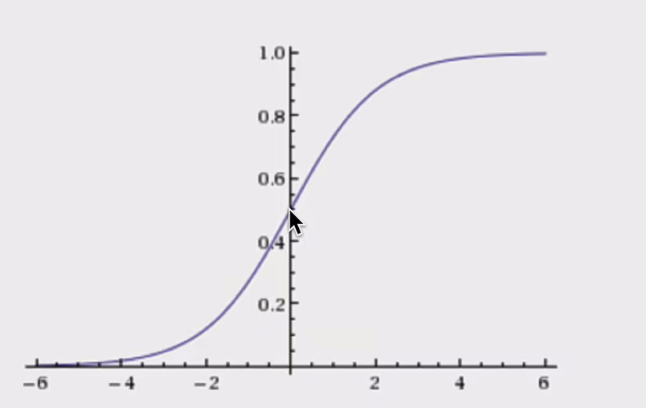
流程就是:



就是我们希望回归后激活函数给出的概率越是1和0.
2.API介绍
sklearn.linear_model.LogisticRegression 是 scikit-learn 库中用于实现逻辑回归算法的类,主要用于二分类或多分类问题。以下是对其重要参数的详细介绍:
2.1. API函数
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C = 1.0)
因为逻辑回归是先回归再使用激活函数,所以也涉及过拟合问题,所以后边会有正则化以及处罚力度。
2.2. 参数说明
- solver:用于优化问题的算法,可选参数为
{'liblinear', 'sag', 'saga', 'newton - cg', 'lbfgs'}。- 默认值:
'liblinear'。对于小数据集,'liblinear'是不错的选择 。 - 大数据集适用:
'sag'和'saga'对于大型数据集计算速度更快。 - 多类问题处理:对于多类问题,只有
'newton - cg'、'sag'、'saga'和'lbfgs'可以处理多项损失;'liblinear'仅限于 “one - versus - rest”(一对多)分类 。
- 默认值:
- penalty:指定正则化的种类 。通过对模型参数进行约束,防止模型过拟合。常见的正则化类型如
'l1'(lasso回归)、'l2'等(岭回归),不同类型对参数的约束方式有差异。 - C:正则化力度的倒数 。默认值:
1.0。C 值越小,正则化力度越强,模型越倾向于简单化,防止过拟合;C 值越大,正则化力度越弱,模型复杂度可能更高 。
2.3. 其他特性
- 默认将类别数量少的当做正例。
LogisticRegression方法相当于SGDClassifier(loss="log", penalty=" "),即损失函数是对数似然损失的回归,(这个api是回归里的api,默认是最小二乘法,是Day09里的)SGDClassifier实现了普通的随机梯度下降学习,而LogisticRegression(实现了SAG,随机平均梯度法 )在一些情况下能更高效地收敛,尤其对于大规模数据。
3.肿瘤预测案例


import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import ssl# 解决SSL验证问题
ssl._create_default_https_context = ssl._create_unverified_context# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)# 2.基本数据处理
# 2.1 缺失值处理
data = data.replace(to_replace="?", value=np.NaN)
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:, 1:10]
y = data["Class"]
# 2.3 分割数据
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 3.特征工程(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4.机器学习(逻辑回归)
estimator = LogisticRegression()
estimator.fit(x_train, y_train)# 5.模型评估
y_predict = estimator.predict(x_test)
print("预测结果:", y_predict)
score = estimator.score(x_test, y_test)
print("模型得分:", score)names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class'] data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)从提供的链接读取数据集时,若不指定
names,默认会将文件第一行数据当作列名,但该数据集可能无此默认列名信息,通过手动指定names列表,能准确对应各列含义,方便后续基于列名进行数据处理、特征提取等操作 。
提出疑问: 我们仅仅考虑准确率是不行的,我们相比准确率更加关注的是在所有样本中,是否能把所有是癌症患者检测出来,这是我们很关注的,所以评估分类模型还有一下评估办法也很重要(KNN也可以用)
4.分类模型评估方法

labels和target_names对应是为了让结果显示的更加容易观察。
但是有如下问题:如果我们有99个癌症,1个非癌症,不管如何预测为癌症,这样的话预测准确率就是99%,这样好吗,这个模型如果在其他数据上会出大错,因为全部预测为了癌症哈哈哈,这就是样本不均衡问题,一会我们会讲样本不均衡数据该怎么样做到样本均衡但是现在我们要看其他的评估指标来用于样本不均衡问题:
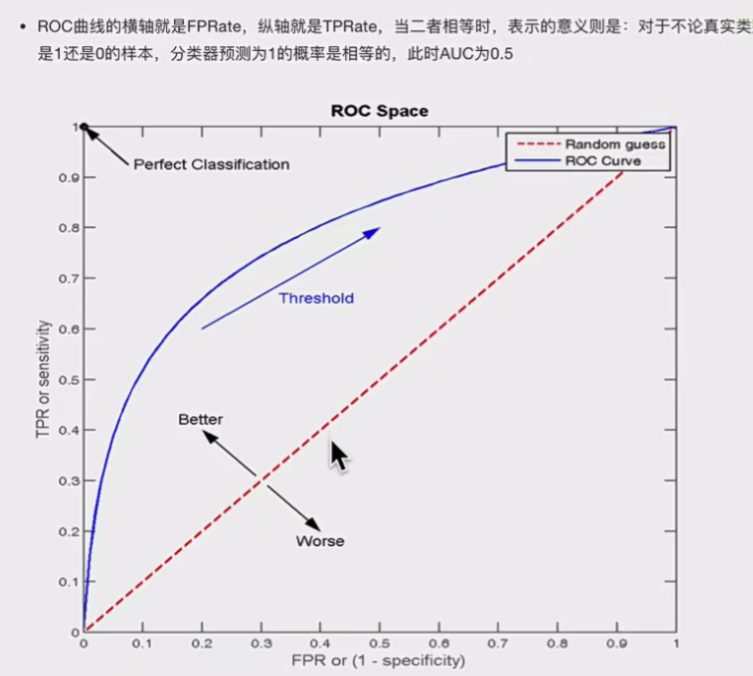
TPR就是召回率,就是模型识别正确能力,FPR就是模型识别错误的能力,下一节会详解ROC曲线是如何绘制的。

即AUC=0.5,模型就是瞎蒙
总结:

5.AUC如何绘制
就是你给我传入真实值(y_test)和预测值(y_pre),让它们一一对应起来,逻辑回归其实会转化概率,即每个预测值都会带有一个概率,我们让这些成对数据按照概率排序(概率仅用来排序,而具体的概率数值并不直接影响TPR和FPR的计算)
然后从第一个开始,我们将每个对预测结果都视为正(其实不一定为正),将原本的正/0进行比对,带入混淆矩阵,计算TRP与FRP作为一对,依次绘图即可:
比如原始真实数据是:![]()
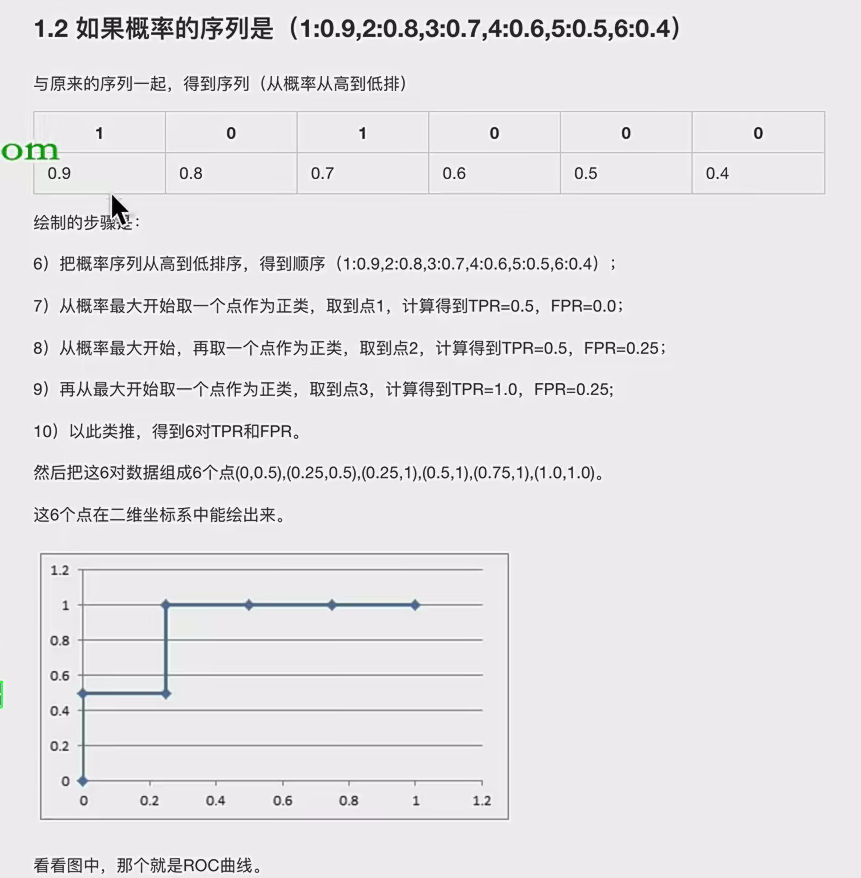
可以看到概率仅仅是排序作用,你正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),这就是为什么ROC越靠左上越好。概率对ROC曲线的影响。而且每次计算都是将预测值视为正值,带入混淆矩阵,即:
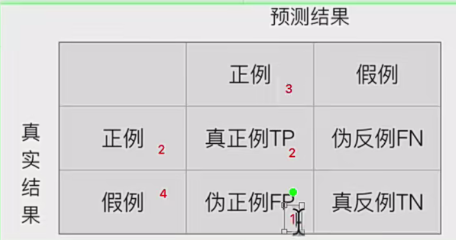
每次选取总是会填在预测结果的第一列(均视为正例),实际是什么决定天真第几行。
看我想到的一些深远的问题:
1.概率问题:正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),所以ROC看重的是排序能力。
2.阈值不影响ROC绘制:

6.对于类别不平衡数据处理
6.1准备:
python中lmblearn库专门用来处理类别不平衡问题 。
1. 类别不平衡问题概述
类别不平衡是指数据集中不同类别的样本数量差异很大的情况。一个三分类问题,其中:
类别0: 64个样本(1.28%)
类别1: 262个样本(5.24%)
类别2: 4674个样本(93.48%)
这种极端不平衡会导致模型偏向多数类,忽视少数类。
2. 创建不平衡数据集
使用datasets库里的
make_classification函数创建人工不平衡数据集:from sklearn.datasets import make_classification import matplotlib.pyplot as plt# 创建5000个样本,2个特征,3个类别的不平衡数据集 X, y = make_classification(n_samples=5000,n_features=2, # 特征总数n_informative=2, # 有意义的特征数n_redundant=0, # 冗余特征数n_repeated=0, # 重复特征数n_classes=3, # 类别数n_clusters_per_class=1, # 每个类别的簇数weights=[0.01, 0.05, 0.94], # 各类别比例random_state=0 # 随机种子 )特征总数需要等于后面的有意义,冗余,重复特征数3. 查看类别分布
使用
Counter函数可以查看各类别样本数量:from collections import Counter print(Counter(y)) # 输出: Counter({2: 4674, 1: 262, 0: 64})
6.2处理办法

相关文章:

机器学习 Day10 逻辑回归
1.简介 流程就是: 就是我们希望回归后激活函数给出的概率越是1和0. 2.API介绍 sklearn.linear_model.LogisticRegression 是 scikit-learn 库中用于实现逻辑回归算法的类,主要用于二分类或多分类问题。以下是对其重要参数的详细介绍: 2.1.…...

Hadoop的序列化和反序列化
//1 package com.example.sei;import org.apache.hadoop.io.Writable;import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;//学生类,姓名,年龄 //支持hadoop的序列化 //1.要实现Writable接口 //2.补充一个空参构造 publi…...

Altera Cyclone EP1C20F400C8N FPGA 阿尔特拉 介绍
在可编程逻辑器件领域,Altera 的 Cyclone 系列 FPGA 以其低成本、低功耗和灵活的 I/O 支持而著称。EP1C20F400C8N 作为 Cyclone I 家族中规模最大的成员之一,提供约 20 060 个逻辑单元,面向通信、工业控制、视频处理等多种嵌入式应用场景。…...
)
VTK随笔十四:QT与VTK的交互示例(平移)
VTK(Visualization Toolkit)是一个开源的软件系统,用于三维计算机图形学、图像处理和可视化。它提供了丰富的工具和类来处理三维数据和交互。在 VTK 中,拾取操作通常通过 vtkCellPicker 或 vtkPointPicker 等类来实现。 本文将展示…...
)
用户注册(阿里云手机验证码)
阿里云开通三网106短信 ①、在阿里云市场搜索“短信”,开通三网短信,并可以查看其中的请求示例(java PHP^) 并在个人中心的管理控制台中查到,获取其中的AppKey AppCode ②、接口开发 service-user模块中依赖spr…...

【BFT帝国】20250409更新PBFT总结
2411 2411 2411 Zhang G R, Pan F, Mao Y H, et al. Reaching Consensus in the Byzantine Empire: A Comprehensive Review of BFT Consensus Algorithms[J]. ACM COMPUTING SURVEYS, 2024,56(5).出版时间: MAY 2024 索引时间(可被引用): 240412 被引:…...

学习海康VisionMaster之边缘交点
一:进一步学习了 今天学习下VisionMaster中的边缘交点,这个还是拟合直线的衍生应用,可以同时测量两条直线并且输出交点或者判定是否有交点 二:开始学习 1:什么是边缘交点? 按照传统的算法,必须…...
评估板与上位机的初步调试)
公司级项目-AD9914扫频源(三)评估板与上位机的初步调试
硬件平台搭建1-评估板与上位机 第一阶段,先使用评估板配套的上位机软件进行控制,学习一下各种功能的实现方式和寄存器配置方式。 硬件连接 需要的设备仪器包括:多路直流稳压电源、信号发生器、示波器、电脑。 按照图中的方式进行连接&am…...

技术优化实战解析:Stream重构与STAR法则应用指南
目录 一、真实案例背景:老代码的"历史厚重感" 二、屎山代码解剖课:这些写法到底烂在哪? 三、Stream流式重构:给老代码做个大保健 2.1 重构后代码实现 2.2 核心API技术拆解 2.3 进阶优化技巧 三、STAR法则技术文档…...

基于Qt的串口通信工具
程序介绍 该程序是一个基于Qt的串口通信工具,专用于ESP8266 WiFi模块的AT指令配置与调试。主要功能包括: 1. 核心功能 串口通信:支持串口开关、参数配置(波特率、数据位、停止位、校验位)及数据收发。 AT指令操作&a…...

Xilinx FPGA XCZU5EV‑2FBVB900I Zynq UltraScale+™ MPSoC EV 系列
XCZU5EV‑1FBVB900I XCZU5EV‑2FBVB900E XCZU5EV‑1FBVB900I 是 Xilinx Zynq UltraScale™ MPSoC EV 系列中功能最为丰富的器件之一,采用 16 nm FinFET 工艺,封装为 31 mm 31 mm、900‑ball FCBGA(FBVB900)。该系列在传统的…...

如何更改OCP与metadb集群的连接方式 —— OceanBase运维管理
背景 许多用户都会借助OCP平台来进行OceanBase集群的运维与监控,且因为考虑单节点的OCP部署,在遇故障时可能会短时间出现无法管控 OceanBase集群,多数用户倾向于采用多节点方式来部署OCP,即 OCP的 metadb集群也是三节点的集群部署…...

Databricks: Why did your cluster disappear?
You may found that you created a cluster many days ago, and you didnt delete it, but it is disapear. Why did this happen? Who deleted the cluster? Actually, 30 days after a compute is terminated, it is permanently deleted automaticlly. If your workspac…...

深入解析Java内存与缓存:从原理到实践优化
一、Java内存管理:JVM的核心机制 1. JVM内存模型全景图 ┌───────────────────────────────┐ │ JVM Memory │ ├─────────────┬─────────────────┤ │ Thread │ 共享…...

macos下 ragflow二次开发环境搭建
参考官网链接 https://ragflow.io/docs/dev/launch_ragflow_from_source虚拟环境 git clone https://github.com/infiniflow/ragflow.git cd ragflow/ # if not pipx, please install it at first pip3 install pipxpipx install uv uv sync --python 3.10 --all-extras 安装 …...

从 Excel 到你的表格应用:条件格式功能的嵌入实践指南
一、引言 在日常工作中,面对海量数据时,如何快速识别关键信息、发现数据趋势或异常值,是每个数据分析师面临的挑战。Excel的条件格式功能通过自动化的视觉标记,帮助用户轻松应对这一难题。 本文将详细介绍条件格式的应用场景&am…...

安徽京准:NTP网络时钟服务器功能及同步模式的介绍
安徽京准:NTP网络时钟服务器功能及同步模式的介绍 安徽京准:NTP网络时钟服务器功能及同步模式的介绍 1、NTP网络时钟服务器概念: NTP时钟服务器,表面意思是时间计量工具的服务设备,其在现代工业中是用于对客户端设备…...

基于ueditor编辑器的功能开发之百度编辑器自带的查找和替换功能无法对目标文字进行滚动定位修复
在查找百度编辑器的查找和替换功能,发现当页面文字过多,用户在检索文字点击上一个下一个的时候,滚动条不跟随滚动了 分析了ueditor关于searchpalce方法的处理时,他会在目标文字的前面插入一个span标签用户获取当前需要高亮的文字节…...

MYSQL——SQL语句到底怎么执行
查询语句执行流程 MySQL 查询语句执行流程 查询缓存(Query Cache) MySQL内部自带了一个缓存模块,默认是关闭的。主要是因为MySQL自带的缓存应用场景有限。 它要求SQL语句必须一摸一样表里面的任何一条数据发生变化时,该表所有缓…...

[蓝桥杯 2022 省 B] 李白打酒加强版
题目链接: 思路: ①定义dp数组,f[i][j][k],表示经过 i 店, 遇到 j 花, 还有 k 酒。如果酒的数量超过了花的数量,那么一定喝不完。因此,k 不能超过 M。 ②从店推过来,f[…...

计算机视觉——图像金字塔与目标图像边缘检测原理与实践
一、两个图像块之间的相似性或距离度量 1.1 平方差和(SSD) 平方差和(SSD) 是一种常用的图像相似性度量方法。它通过计算两个图像在每个对应位置的像素值差的平方和来衡量两个图像之间的整体差异。如果两个图像在每个位置的像素值…...

复现QGIS-MCP教程
由于Claude国内下载不了尝试使用Cursor 下载安装Cursor Cursor - The AI Code Editor 本示例安装的是0.46版本 UV安装 简介 安装 安装成功 配置环境变量 验证 下载代码 git clone gitgithub.com:jjsantos01/qgis_mcp.git QGIS插件安装 文件拷贝 您需要将 qgis_mcp_plu…...

人工智能图像识别Spark Core
Spark Core 一.spark运行架构 1.运行架构 Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作…...

决策树+泰坦尼克号生存案例
决策树简介 学习目标 1.理解决策树算法的基本思想 2.知道构建决策树的步骤 【理解】决策树例子 决策树算法是一种监督学习算法,英文是Decision tree。 决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中…...

怎么查看苹果手机和ipad的设备信息和ios udid
你知道吗?我们每天使用的iPhone和iPad,其实隐藏着大量详细的硬件与系统信息。除了常见的系统版本和序列号外,甚至连电池序列号、摄像头序列号、销售地区、芯片型号等信息,也都可以轻松查到! 如果你是开发者、维修工程…...

智能驱动教育变革:人工智能在高中教育中的实践路径与创新策略
一、引言 随着信息技术的飞速发展,人工智能(Artificial Intelligence, AI)已成为推动社会进步的重要力量。在教育领域,人工智能的应用正逐渐改变着传统的教学模式和方法,为教育现代化注入了新的活力。高中教育作为教育…...

TCP 和 UDP 可以使用同一个端口吗?
TCP 和 UDP 可以使用同一个端口吗? 前言 在深入探讨 TCP 和 UDP 是否可以使用同一个端口之前,我们首先需要理解网络通信的基本原理。网络通信是一个复杂的过程,涉及到多个层次的协议和机制。在 OSI 模型中,传输层是负责端到端数…...

MySQL事务管理
MySQL事务管理 事务的概念 事务由一条或多条SQL语句组成,这些语句在逻辑上存在相关性,共同完成一个任务,事务主要用于处理操作量大,复杂度高的数据。比如转账就涉及多条SQL语句,包括查询余额(select&…...

通过 SSH 方式访问 GitHub 仓库
我们来一步一步讲解如何让 Git 通过 SSH 方式访问 GitHub 仓库,包括从零开始的详细步骤,适用于大多数系统(Linux、macOS、Windows Git Bash)。 注意最好只用 Git bash 比较好!他能够直接在 Windows 系统上面使用一些 L…...

数据库学习
DDL(数据定义语言)、DML(数据操纵语言)、DQL(数据查询语言)和DCL(数据控制语言)。 DDL用于创建、删除和修改数据库对象,如表和数据库;DML涉及数据的增删改操…...

DeepSeek在安全领域的应用案例全景解析
DeepSeek作为人工智能领域的标杆技术,已在网络安全、公共安全、工业安全、军事防护等领域形成系统性应用。以下从六大核心场景展开分析,结合技术实现与行业标杆案例,呈现其多维度的安全赋能价值。 一、网络安全防护体系创新 威胁检测与响应闭环安胜"星盾"平台:通…...

AI驱动SEO关键词精准定位
内容概要 在传统SEO实践中,关键词定位往往依赖人工经验与有限的数据样本,导致策略滞后性与覆盖盲区并存。随着AI技术的深度介入,这一过程正经历系统性重构:从搜索意图的智能识别到关键词的自动化挖掘,算法模型通过分析…...

邮件营销:如何巧妙平衡发送频率与客户体验
在邮件营销领域,发送频率和客户体验就像跷跷板的两端,需要精心平衡。如果邮件发得太多,客户可能会觉得烦,甚至取消订阅,对品牌产生不好的印象;但如果发得太少,客户又容易把你忘了,错…...

Acrel-1000DP分布式光伏监控系统在嘉兴亨泰新能源有限公司2996.37KWP分布式光伏项目中的应用
摘 要:分布式光伏发电系统其核心特点是发电设备靠近用电负荷中心,通常安装在屋顶、建筑立面或闲置空地上,截至2025年,分布式光伏发电系统在全球和中国范围内取得了显著发展,成为能源转型和可持续发展的重要推动力量。国…...

vue3中左右布局两个个组件使用vuedraggable实现左向右拖动,右组件列表可上下拖动
需求:左侧是个菜单组件,有对应的表单类型。 右侧是渲染组件,点击左侧菜单或者拖动即可渲染出对应的组件 项目中采用vuedraggable实现拖拽功能。 具体实现是使用elementplus的组件,然后根据tagName的类型去渲染不同的组件。 首先…...

gevent 高并发、 RabbitMQ 消息队列、Celery 分布式的案例和说明
1. gevent 高并发请求示例 gevent:基于协程的Python库,通过异步非阻塞模式实现高并发请求。例如,同时抓取100个网页时,无需等待每个请求完成,提升效率。 import gevent from gevent import monkey monkey.patch_…...

直线模组在电子行业具体的应用
在工业自动化高速发展的今天,直线模组作为重要的传动和控制元件,凭借其高效、精准、稳定的特性。在众多行业中得到了广泛应用,尤其是在电子行业中,通过提供精确的运动控制和定位,帮助提高电子制造过程的效率、质量和自…...

Ubuntu 24.04启用root账户
1.启用ubuntu中的root账号 ubuntu默认是禁用了root账号的,需要手动开始root权限 # 设置root账号密码 sudo passwd root # 用以下命令启用 root 账户: sudo usermod -aG sudo rootsu - root 然后输入你之前设置的 root 密码。 一旦你成功登录为 root 用户&#x…...
)
【ES系列】Elasticsearch简介:为什么需要它?(基础篇)
🔥 本文将详细介绍Elasticsearch的前世今生,以及为什么它在当今的技术栈中如此重要。本文是ES起飞之路系列的基础篇第一章,适合想要了解ES的读者。 文章目录 一、什么是Elasticsearch?1. ES的定义2. ES的核心特性2.1 分布式存储2.2 实时搜索2.3 高可用性2.4 RESTful API3.…...
—— 最佳实践之身份认证)
SvelteKit 最新中文文档教程(19)—— 最佳实践之身份认证
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...
删除某一个分区数据)
Droris(强制)删除某一个分区数据
Doris如果想删除某一个分区的数据,可以这么操作: DROP PARTITION [IF EXISTS] partition_name [FORCE]需要注意的是: 必须为使用分区的表保留至少一个分区。执行DROP PARTITION一段时间后,可以通过RECOVER语句恢复被删除的分区:…...

Meta 最新 AI 模型系列 ——Llama 4
Meta 发布了最新 AI 模型系列 ——Llama 4,这是其 Llama 家族的最新成员。 在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek…...

软考 系统架构设计师系列知识点 —— 设计模式之工厂模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 https://baike.baidu.com/item/%E5%B7%A5%E5%8E%82%E6%A8%A1%E5%BC%8F?fromModulelemma_search-box 设计模式-工厂方法模式࿰…...

Jetpack Compose 状态保存机制全面解析:让UI状态持久化
在Android开发中,Jetpack Compose 的状态管理是一个核心话题,而状态保存则是确保良好用户体验的关键。本文将深入探讨Compose中各种状态保存技术,帮助你在配置变更和进程重建时保持UI状态。 一、基础保存:rememberSaveable reme…...

阿里云原生AI网关Higress:架构解析与应用实践
摘要 随着云原生与AI技术的深度融合,API网关作为流量治理的核心组件,正面临新的挑战与机遇。阿里云开源的Higress网关,凭借其“三网合一”(流量网关、微服务网关、安全网关)的高集成能力,以及面向AI场景的…...

如何在数据仓库中集成数据共享服务?
目录 1. Snowflake 数据共享服务:云端的最佳实践 2. 数据共享服务的重要性 3. 麦聪 QuickAPI:企业本地的理想选择 4. 云端与本地的互补 总结 数据共享服务是现代数据仓库的核心功能,能够提升协作效率、降低成本并释放数据潜力。 以 Sno…...

spark RDD相关概念和运行架构
核心概念 - RDD定义:弹性分布式数据集,是Spark中基础数据处理抽象,具弹性、不可变、可分区及并行计算特性。 弹性 存储的弹性:内存与磁盘的自动切换; 容错的弹性:数据丢失可以自动恢复; 计算…...

2025.04.09【Sankey】| 生信数据流可视化精讲
文章目录 引言Sankey图简介R语言中的Sankey图实现安装和加载networkD3包创建Sankey图的数据结构创建Sankey图绘制Sankey图 结论 引言 在生物信息学领域,数据可视化是理解和分析复杂数据集的关键工具之一。今天,我们将深入探讨一种特别适用于展示数据流动…...

《系统分析师-案例实践篇-16-22章总结》
案例实践篇...

spark core
Executor的核心功能 运行任务:Executor负责运行组成Spark应用的任务,并将结果返回给驱动器进程。 缓存管理:Executor通过自身的块管理器为用户程序中要求缓存的RDD提供内存或存储。 Master和Worker的角色 Master:负责资源调度和分…...