人工智能图像识别Spark Core
Spark Core
一.spark运行架构
1.运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
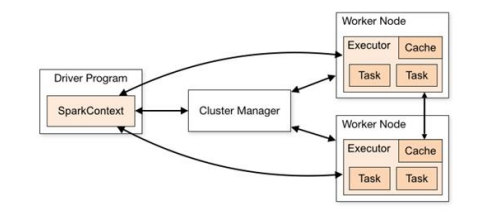
2.核心组件
由上图可以看出,对于 Spark 框架有两个核心组件:
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
将用户程序转化为作业(job)
在 Executor 之间调度任务(task)
跟踪 Executor 的执行情况
通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
3.核心概念
Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:

并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
有向无环图(DAG):

大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。
对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
4.提交流程
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以这里提到的提交流程是基于 Yarn 环境的。
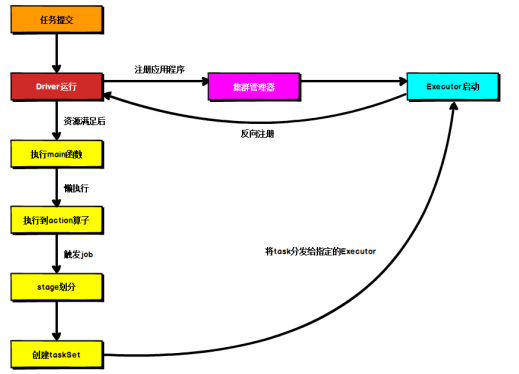
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
Yarn Client 模式
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
Driver 在任务提交的本地机器上运行
Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
ResourceManager 分配container,在合适的 NodeManager 上启动 ApplicationMaster,负责向 ResourceManager 申请 Executor 内存
ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster。
随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程。
Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数。
之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
二.RDD相关概念
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
1.RDD
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
可分区、并行计算
2.核心属性
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。

分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。

RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。

分区器(可选)
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区。
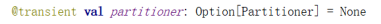
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
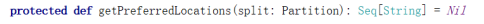
3.执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
1)启动 Yarn 集群环境
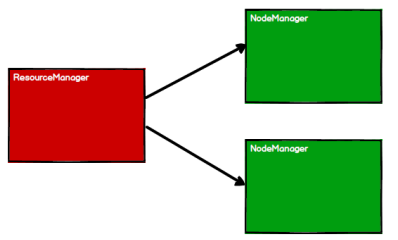
2)Spark 通过申请资源创建调度节点和计算节点

3)Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
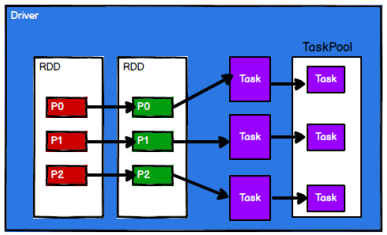
4)调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
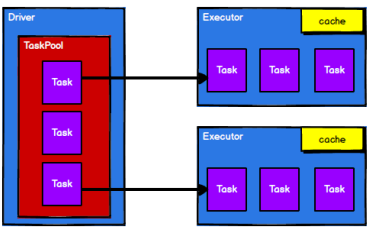
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算。
4.RDD序列化
1) 闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
2) 序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行
3) Kryo 序列化框架
Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。
5.RDD依赖关系
1) RDD 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2) RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。包括打印依赖、shuffle依赖等。
3) RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
4) RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
5) RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。

6) RDD 任务划分
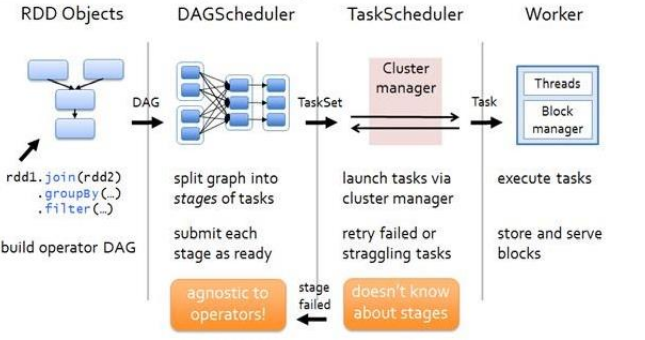
RDD 任务切分中间分为:Application、Job、Stage 和 Task
Application:初始化一个 SparkContext 即生成一个 Application;
Job:一个 Action 算子就会生成一个 Job;
Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
6.RDD持久化
1) RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
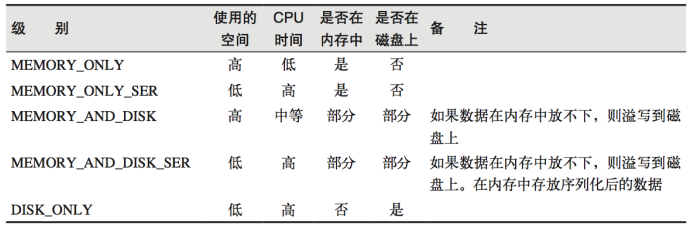
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
2) RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
3) 缓存和检查点区别
·1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
·2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
·3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
7.RDD分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
1)Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余。
2)Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
8.RDD文件读取与保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
text 文件

sequence 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(Flat File)。在 SparkContext 中,可以调用 sequenceFile[keyClass, valueClass](path)。

object 对象文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。可以通过 objectFile[T: ClassTag](path)函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。

三. Spark-Core编程(一)
环境准备
1.Jdk1.8版本
2.Scala2.12版本
3.Idea集成开发环境中需要安装scala插件
环境配置
添加Scala插件
Spark 由 Scala 语言开发的,所以接下来的开发所使用的语言也为 Scala,当前使用的 Spark 版本为 3.0.0,默认采用的 Scala 编译版本为 2.12,所以后续开发时,我们依然采用2.12的scala版本。开发前请保证 IDEA 开发工具中含有 Scala 开发插件
File—Settings—plugins

创建spark实现的WordCount程序
1.创建Maven项目
2.在pom.xml中添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将 Scala 代码编译成 class 文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
保存之后重新加载。
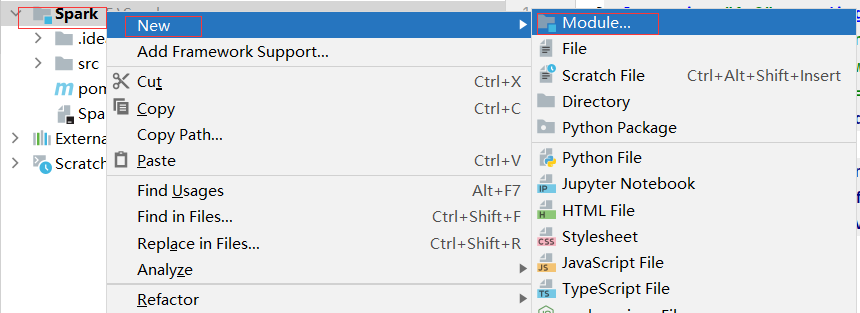
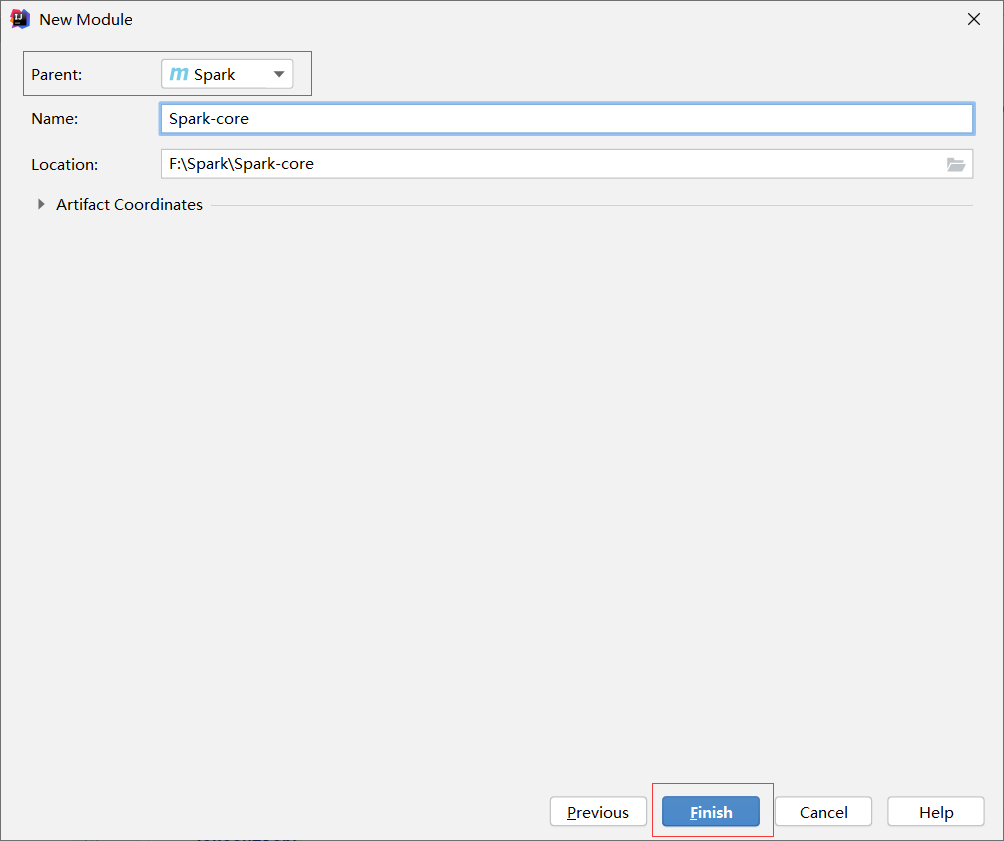
3.创建Spark-core子模块
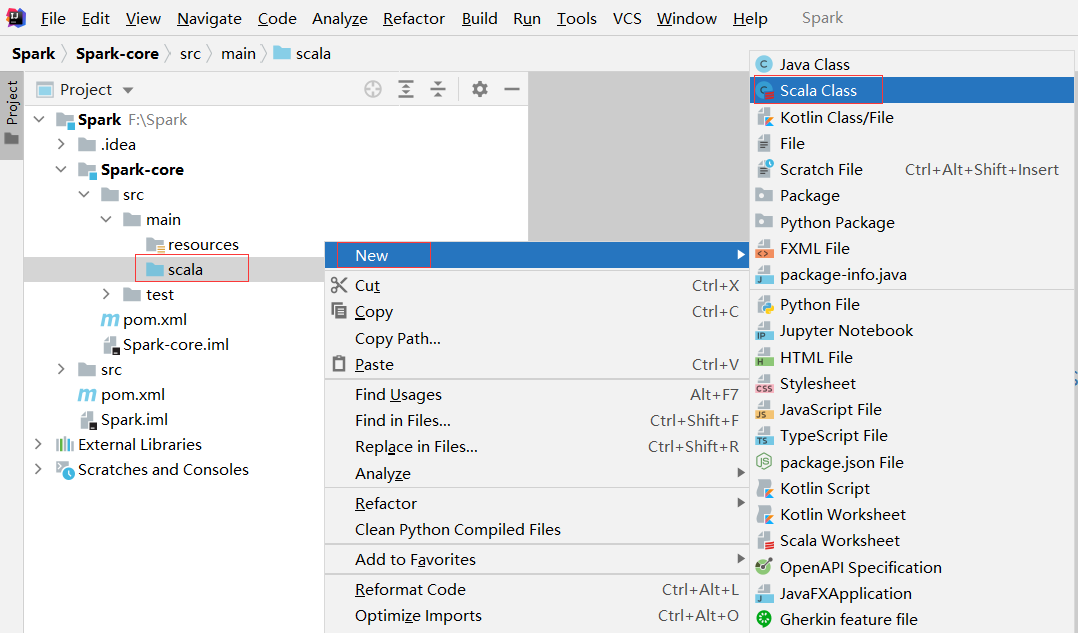
4.将spark-core当中的java文件夹重命名为scala。

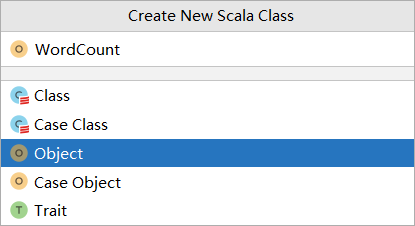
5.在scala文件夹中创建Scala的object程序。
6.编写wordCount的spark程序
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.
textFile("Spark-core/input/word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
}
}
7.在Spark-core中创建名为input的文件夹,在此文件夹中创建word.txt文件,并在文件中添加需要进行统计的语句。
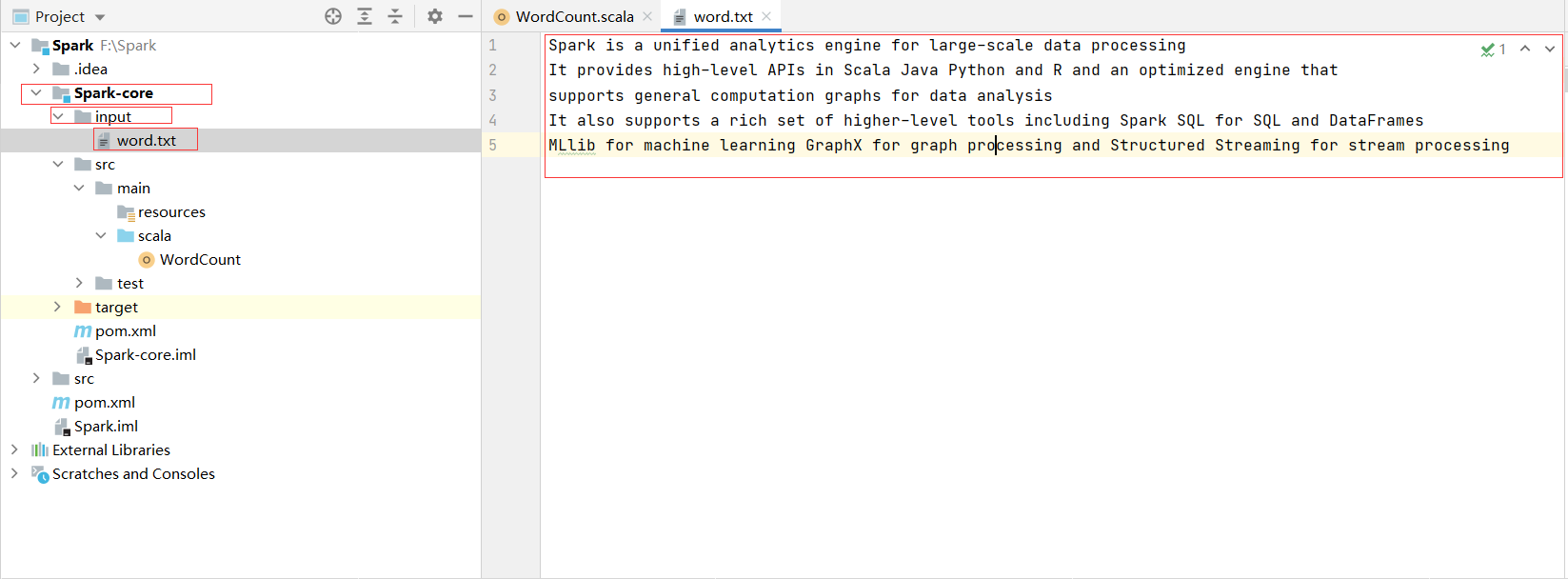
测试文本:
Spark is a unified analytics engine for large-scale data processing
It provides high-level APIs in Scala Java Python and R and an optimized engine that
supports general computation graphs for data analysis
It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames
MLlib for machine learning GraphX for graph processing and Structured Streaming for stream processing
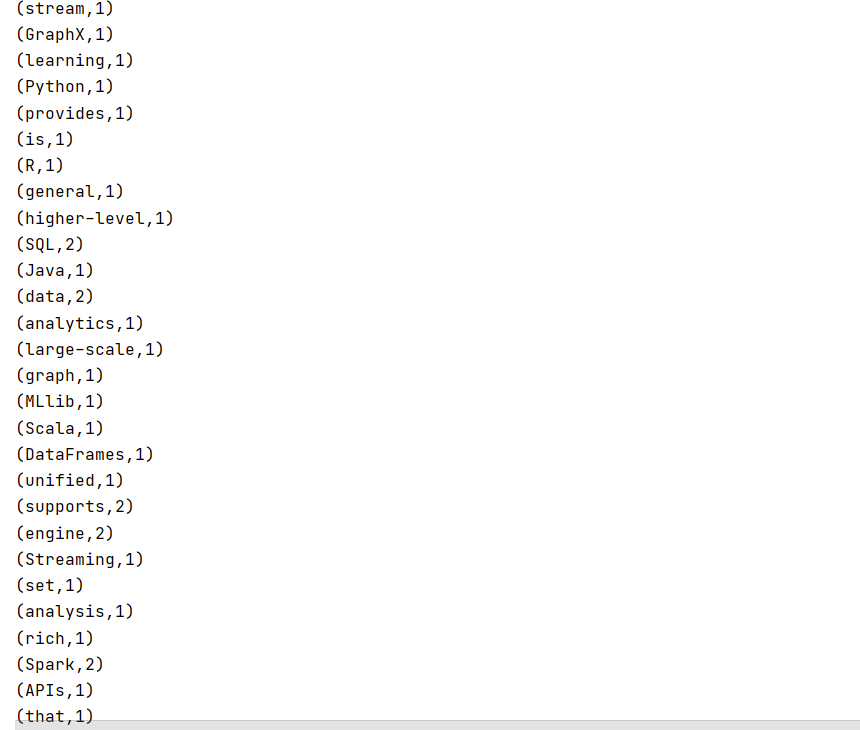
8.运行编写好的WordCount程序
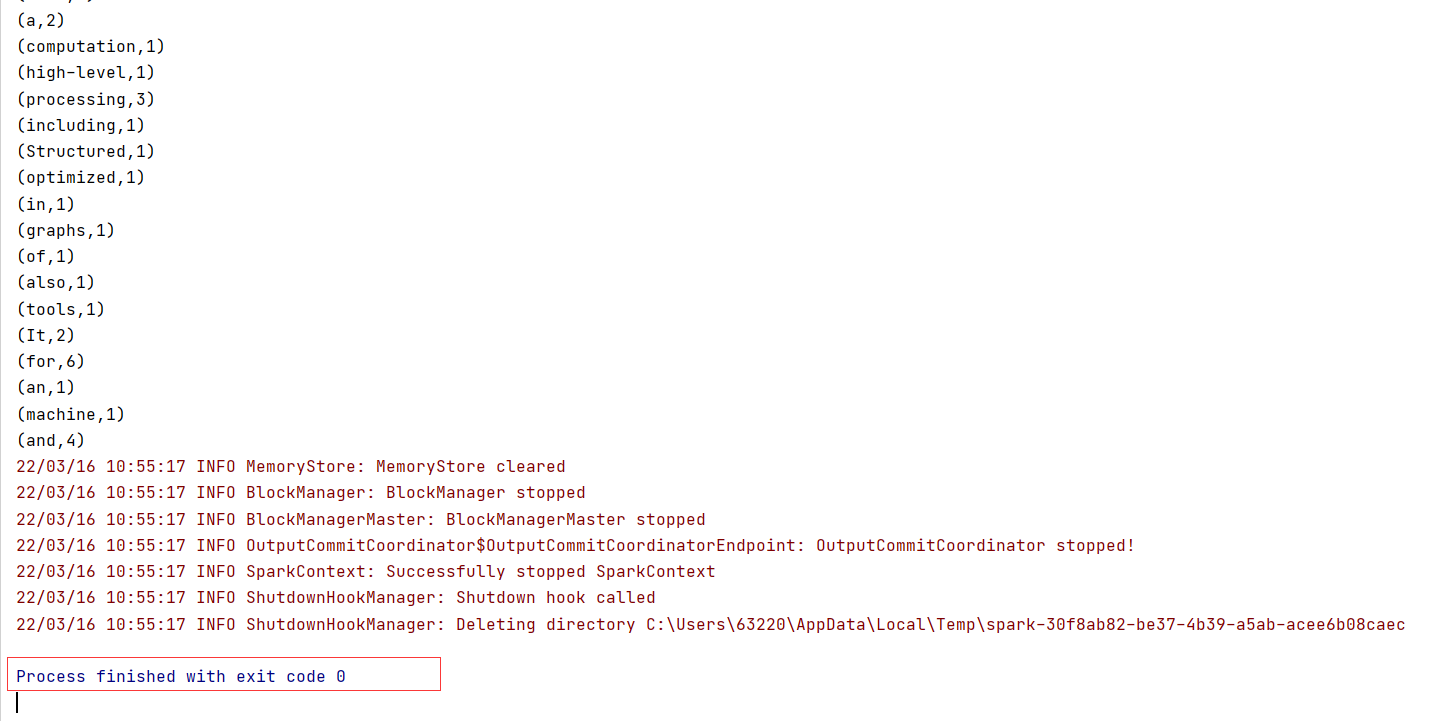
9.配置日志文件
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项
目的 resources 目录中创建 log4j.properties 文件,并添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/ddHH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
10.配置完成后重新执行代码


11.常见问题解决
如果本机操作系统是 Windows,在程序中使用了 Hadoop 相关的东西,比如写入文件到 HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是 windows 系统用到了 hadoop 相关的服 务,解决办法是通过配置关联到 windows 的系统依赖就可以了
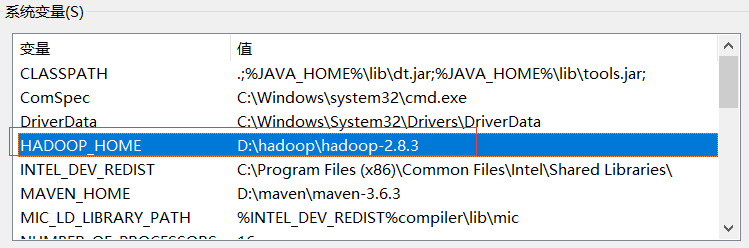
首先确保在本地磁盘中有hadoop的相关内容且配置了环境变量
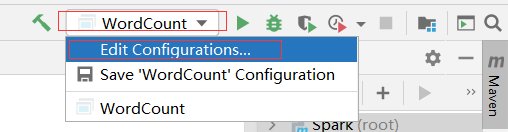
然后在Idea中配置 Run Configuration,添加 HADOOP_HOME 变量
相关文章:

人工智能图像识别Spark Core
Spark Core 一.spark运行架构 1.运行架构 Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作…...

决策树+泰坦尼克号生存案例
决策树简介 学习目标 1.理解决策树算法的基本思想 2.知道构建决策树的步骤 【理解】决策树例子 决策树算法是一种监督学习算法,英文是Decision tree。 决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中…...

怎么查看苹果手机和ipad的设备信息和ios udid
你知道吗?我们每天使用的iPhone和iPad,其实隐藏着大量详细的硬件与系统信息。除了常见的系统版本和序列号外,甚至连电池序列号、摄像头序列号、销售地区、芯片型号等信息,也都可以轻松查到! 如果你是开发者、维修工程…...

智能驱动教育变革:人工智能在高中教育中的实践路径与创新策略
一、引言 随着信息技术的飞速发展,人工智能(Artificial Intelligence, AI)已成为推动社会进步的重要力量。在教育领域,人工智能的应用正逐渐改变着传统的教学模式和方法,为教育现代化注入了新的活力。高中教育作为教育…...

TCP 和 UDP 可以使用同一个端口吗?
TCP 和 UDP 可以使用同一个端口吗? 前言 在深入探讨 TCP 和 UDP 是否可以使用同一个端口之前,我们首先需要理解网络通信的基本原理。网络通信是一个复杂的过程,涉及到多个层次的协议和机制。在 OSI 模型中,传输层是负责端到端数…...

MySQL事务管理
MySQL事务管理 事务的概念 事务由一条或多条SQL语句组成,这些语句在逻辑上存在相关性,共同完成一个任务,事务主要用于处理操作量大,复杂度高的数据。比如转账就涉及多条SQL语句,包括查询余额(select&…...

通过 SSH 方式访问 GitHub 仓库
我们来一步一步讲解如何让 Git 通过 SSH 方式访问 GitHub 仓库,包括从零开始的详细步骤,适用于大多数系统(Linux、macOS、Windows Git Bash)。 注意最好只用 Git bash 比较好!他能够直接在 Windows 系统上面使用一些 L…...

数据库学习
DDL(数据定义语言)、DML(数据操纵语言)、DQL(数据查询语言)和DCL(数据控制语言)。 DDL用于创建、删除和修改数据库对象,如表和数据库;DML涉及数据的增删改操…...

DeepSeek在安全领域的应用案例全景解析
DeepSeek作为人工智能领域的标杆技术,已在网络安全、公共安全、工业安全、军事防护等领域形成系统性应用。以下从六大核心场景展开分析,结合技术实现与行业标杆案例,呈现其多维度的安全赋能价值。 一、网络安全防护体系创新 威胁检测与响应闭环安胜"星盾"平台:通…...

AI驱动SEO关键词精准定位
内容概要 在传统SEO实践中,关键词定位往往依赖人工经验与有限的数据样本,导致策略滞后性与覆盖盲区并存。随着AI技术的深度介入,这一过程正经历系统性重构:从搜索意图的智能识别到关键词的自动化挖掘,算法模型通过分析…...

邮件营销:如何巧妙平衡发送频率与客户体验
在邮件营销领域,发送频率和客户体验就像跷跷板的两端,需要精心平衡。如果邮件发得太多,客户可能会觉得烦,甚至取消订阅,对品牌产生不好的印象;但如果发得太少,客户又容易把你忘了,错…...

Acrel-1000DP分布式光伏监控系统在嘉兴亨泰新能源有限公司2996.37KWP分布式光伏项目中的应用
摘 要:分布式光伏发电系统其核心特点是发电设备靠近用电负荷中心,通常安装在屋顶、建筑立面或闲置空地上,截至2025年,分布式光伏发电系统在全球和中国范围内取得了显著发展,成为能源转型和可持续发展的重要推动力量。国…...

vue3中左右布局两个个组件使用vuedraggable实现左向右拖动,右组件列表可上下拖动
需求:左侧是个菜单组件,有对应的表单类型。 右侧是渲染组件,点击左侧菜单或者拖动即可渲染出对应的组件 项目中采用vuedraggable实现拖拽功能。 具体实现是使用elementplus的组件,然后根据tagName的类型去渲染不同的组件。 首先…...

gevent 高并发、 RabbitMQ 消息队列、Celery 分布式的案例和说明
1. gevent 高并发请求示例 gevent:基于协程的Python库,通过异步非阻塞模式实现高并发请求。例如,同时抓取100个网页时,无需等待每个请求完成,提升效率。 import gevent from gevent import monkey monkey.patch_…...

直线模组在电子行业具体的应用
在工业自动化高速发展的今天,直线模组作为重要的传动和控制元件,凭借其高效、精准、稳定的特性。在众多行业中得到了广泛应用,尤其是在电子行业中,通过提供精确的运动控制和定位,帮助提高电子制造过程的效率、质量和自…...

Ubuntu 24.04启用root账户
1.启用ubuntu中的root账号 ubuntu默认是禁用了root账号的,需要手动开始root权限 # 设置root账号密码 sudo passwd root # 用以下命令启用 root 账户: sudo usermod -aG sudo rootsu - root 然后输入你之前设置的 root 密码。 一旦你成功登录为 root 用户&#x…...
)
【ES系列】Elasticsearch简介:为什么需要它?(基础篇)
🔥 本文将详细介绍Elasticsearch的前世今生,以及为什么它在当今的技术栈中如此重要。本文是ES起飞之路系列的基础篇第一章,适合想要了解ES的读者。 文章目录 一、什么是Elasticsearch?1. ES的定义2. ES的核心特性2.1 分布式存储2.2 实时搜索2.3 高可用性2.4 RESTful API3.…...
—— 最佳实践之身份认证)
SvelteKit 最新中文文档教程(19)—— 最佳实践之身份认证
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...
删除某一个分区数据)
Droris(强制)删除某一个分区数据
Doris如果想删除某一个分区的数据,可以这么操作: DROP PARTITION [IF EXISTS] partition_name [FORCE]需要注意的是: 必须为使用分区的表保留至少一个分区。执行DROP PARTITION一段时间后,可以通过RECOVER语句恢复被删除的分区:…...

Meta 最新 AI 模型系列 ——Llama 4
Meta 发布了最新 AI 模型系列 ——Llama 4,这是其 Llama 家族的最新成员。 在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek…...

软考 系统架构设计师系列知识点 —— 设计模式之工厂模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 https://baike.baidu.com/item/%E5%B7%A5%E5%8E%82%E6%A8%A1%E5%BC%8F?fromModulelemma_search-box 设计模式-工厂方法模式࿰…...

Jetpack Compose 状态保存机制全面解析:让UI状态持久化
在Android开发中,Jetpack Compose 的状态管理是一个核心话题,而状态保存则是确保良好用户体验的关键。本文将深入探讨Compose中各种状态保存技术,帮助你在配置变更和进程重建时保持UI状态。 一、基础保存:rememberSaveable reme…...

阿里云原生AI网关Higress:架构解析与应用实践
摘要 随着云原生与AI技术的深度融合,API网关作为流量治理的核心组件,正面临新的挑战与机遇。阿里云开源的Higress网关,凭借其“三网合一”(流量网关、微服务网关、安全网关)的高集成能力,以及面向AI场景的…...

如何在数据仓库中集成数据共享服务?
目录 1. Snowflake 数据共享服务:云端的最佳实践 2. 数据共享服务的重要性 3. 麦聪 QuickAPI:企业本地的理想选择 4. 云端与本地的互补 总结 数据共享服务是现代数据仓库的核心功能,能够提升协作效率、降低成本并释放数据潜力。 以 Sno…...

spark RDD相关概念和运行架构
核心概念 - RDD定义:弹性分布式数据集,是Spark中基础数据处理抽象,具弹性、不可变、可分区及并行计算特性。 弹性 存储的弹性:内存与磁盘的自动切换; 容错的弹性:数据丢失可以自动恢复; 计算…...

2025.04.09【Sankey】| 生信数据流可视化精讲
文章目录 引言Sankey图简介R语言中的Sankey图实现安装和加载networkD3包创建Sankey图的数据结构创建Sankey图绘制Sankey图 结论 引言 在生物信息学领域,数据可视化是理解和分析复杂数据集的关键工具之一。今天,我们将深入探讨一种特别适用于展示数据流动…...

《系统分析师-案例实践篇-16-22章总结》
案例实践篇...

spark core
Executor的核心功能 运行任务:Executor负责运行组成Spark应用的任务,并将结果返回给驱动器进程。 缓存管理:Executor通过自身的块管理器为用户程序中要求缓存的RDD提供内存或存储。 Master和Worker的角色 Master:负责资源调度和分…...
)
crawl4ai的实践(爬虫)
1.准备环境 !pip install -U crawl4ai !pip install nest_asynciocrawl4ai-setup 验证是否安装成功 # Check crawl4ai version import crawl4ai print(crawl4ai.__version__.__version__) 验证是否可以爬 crawl4ai-doctor 2.简单示例 import asyncio from playwright.as…...

Python从入门到精通全套视频教程免费
概述 📢 所有想学Python的小伙伴看过来!作为深耕编程领域的技术分享者,最新整理了一份Python从0到1的视频教程。 💡亮点 ✅ 保姆级系统路线:从环境搭建、语法精讲,到爬虫/数据分析/AI/Web全栈开发&#…...

Node.js是js语言在服务器编译运行的环境,什么是IP和域名
一句话结论 Node.js 不是语言也不是框架,而是一个让 JavaScript 能运行在服务器端的“环境”(类似 Python 的解释器)。JavaScript 是语言,Node.js 是它的“执行工具”。 🌰 用 Python 类比理解 Python 和 JavaScript …...

checkra1n越狱出现的USB error -10问题解决
使用checkra1n进行越狱是出现: 解决办法(使用命令行进行越狱): 1. cd /Applications/checkra1n.app/Contents/MacOS 2. ./checkra1n -cv 3. 先进入恢复模式 a .可使用爱思助手 b. 或者长按home,出现关机的滑条,同时按住home和电源键&#…...

如何利用 Java 爬虫获取京东商品详情信息
在电商领域,获取商品详情信息对于数据分析、市场研究和用户体验优化具有重要意义。京东作为国内知名的电商平台,提供了丰富的商品详情信息 API 接口。通过 Java 爬虫技术,我们可以高效地调用这些接口,获取商品的详细信息ÿ…...

【spark--scala】--环境配置
文章目录 scalaspark scala 官网下载二进制包 添加环境变量 #set scala export SCALA_HOME/usr/local/src/scala-2.11.8 export PATH$PATH:$SCALA_HOME/binspark 官网下载二进制包 解压后 spark/conf cp slaves.template slaves cp spark-env.sh.template spark-env.sh# s…...

Spark Core学习总结
一、Spark运行架构 1. 核心组件 Driver(驱动器): 执行main方法,负责将用户程序转换为作业(Job)。 调度任务(Task)到Executor,并监控任务执行状态。 通过UI展示作业运行情…...
(PyTorch))
Python深度学习基础——深度神经网络(DNN)(PyTorch)
张量 数组与张量 PyTorch 作为当前首屈一指的深度学习库,其将 NumPy 数组的语法尽数吸收,作为自己处理张量的基本语法,且运算速度从使用 CPU 的数组进步到使用 GPU 的张量。 NumPy 和 PyTorch 的基础语法几乎一致,具体表现为&am…...

前端三件套—CSS入门
上篇文章: 前端三件套—HTML入门https://blog.csdn.net/sniper_fandc/article/details/147070026?fromshareblogdetail&sharetypeblogdetail&sharerId147070026&sharereferPC&sharesourcesniper_fandc&sharefromfrom_link 目录 1 引入CSS …...

mapreduce-案例-简单的数据清洗案例代码
//1.从Mapper继承 //2.重写map方法 //LongWritable,Text:表示初始输入的键值对格式。LongWritable是键的数据类型,Text是值的数据类型 //Text,LongWritable:表示map函数输出的数据的格式。Text是键的数据类型,LongWritable是值的数据类型 public class W…...

为什么PDF文件更适合LLM大模型信息提取?
为什么PDF文件更适合LLM大模型信息提取? 在Dify平台中,我们通过LLM大模型提取上传文件中的指定信息。目前使用的大模型包括qwen2:7b和deepseek-r1:70b。然而,我们发现一个有趣的现象:在提取信息时,PDF文件的表现明显优…...

期权时间价值与隐含波动率怎么选?
期权隐含波动率与时间价值要怎么选?期权隐含波动率IV对期权价格有着巨大的影响。整体来看,期权隐波与期权价格呈正相关关系。当期权隐波从低水平上升时,期权价格也会相应上涨;反之,当隐波下降,期权价格则会…...

LangChain入门指南:调用DeepSeek api
文章目录 1. 什么是LangChain?2. 核心组件3. 为什么选择LangChain?4. 实战案例安装简单chat案例流式交互Prompt模板 5. 简单总结 1. 什么是LangChain? 定义:LangChain是一个用于构建大语言模型(LLM)应用的…...

Cherry Studio配置MCP server
MCP server在很多的app上开始支持了,从以前的claude desktop,到cursor,vscode等等,甚至现在开源的软件也都开始支持mcp协议的配置了.这里主要来说一下如何在cherry studio中配置好mcp的服务. cheery studio 中配置MCP并使用 基础配置过程Blender MCP百度地图GitGithubfilesyst…...

前端快速入门——JavaScript变量、控制语句
1.JavaScript 定义 JavaScript 简称 JS. JavaScript 是一种轻量级、解释型、面向对象的脚本语言。它主要被设计用于在网页上实现动态效果,增加用户与网页的交互性。 作为一种客户端脚本语言,JavaScript 可以直接嵌入 HTML,并在浏览器中执行。…...

[CISSP] [8] 安全模型,设计和能力的原则
开源软件(Open Source Software, OSS) 优点: 透明性高 开源软件的源代码对公众开放,安全专家和用户可以检查其实现,验证是否存在安全隐患。 社区驱动的漏洞发现 有大量开发者和安全研究人员参与代码审查,…...

docker使用
最近为了打vulhub也是搞了好久的docker,搞了半天搞得我头大,结果还是没能成功,不知道为什么起shiro550靶场总是报139的错误,在网上搜了半天也没有解决,有没有师傅救一下喵QaQ 安装就不说了喵,安装完记得换…...

phpexcel导出下拉框,超过255字符不显示的问题处理
用php生成excel模板,并设置下拉框的选项。如果选项太多,可能导致下拉框不显示的问题。下面会给出示例,以及解决方案,支持生成包含大量数据的下拉框。 // $info 为下拉框的数数据,[男,女,保密] function exportDataSel…...

【重构谷粒商城12】npm快速入门
重构谷粒商城12:npm快速入门 前言:这个系列将使用最前沿的cursor作为辅助编程工具,来快速开发一些基础的编程项目。目的是为了在真实项目中,帮助初级程序员快速进阶,以最快的速度,效率,快速进阶…...

【Pandas】pandas DataFrame bool
Pandas2.2 DataFrame Conversion 方法描述DataFrame.astype(dtype[, copy, errors])用于将 DataFrame 中的数据转换为指定的数据类型DataFrame.convert_dtypes([infer_objects, …])用于将 DataFrame 中的数据类型转换为更合适的类型DataFrame.infer_objects([copy])用于尝试…...

Django 在同一域名下使用 NGINX 服务器运行 Django 和 WordPress
在本文中,我们将介绍如何使用 NGINX 服务器在同一域名下同时运行 Django 和 WordPress。我们将使用反向代理和URL重写来实现这一目标。 1. 安装和配置 NGINX 首先,我们需要在服务器上安装并配置 NGINX。请根据您的操作系统类型和版本的要求,…...
—— 子串、普通数组、矩阵)
LeetCode Hot100 刷题笔记(2)—— 子串、普通数组、矩阵
目录 前言 一、子串 1. 和为 K 的子数组 2. 滑动窗口最大值 3. 最小覆盖子串 二、普通数组 4. 最大子数组和 5. 合并区间 6. 轮转数组 7. 除自身以外数组的乘积 8. 缺失的第一个正数 三、矩阵 9. 矩阵置零 10. 螺旋矩阵 11. 旋转图像 12. 搜索二维矩阵 II 前言 一、子串&#…...