PyTorch 学习笔记
环境:python3.8 + PyTorch2.4.1+cpu + PyCharm
参考链接:
快速入门 — PyTorch 教程 2.6.0+cu124 文档
PyTorch 文档 — PyTorch 2.4 文档
快速入门
导入库
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor加载数据集
使用 FashionMNIST 数据集。每个 TorchVision 都包含两个参数: 分别是 修改样本 和 标签。
# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data", # 数据集存储的位置train=True, # 加载训练集(True则加载训练集)download=True, # 如果数据集在指定目录中不存在,则下载(True才会下载)transform=ToTensor(), # 应用于图像的转换列表,例如转换为张量和归一化
)# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data",train=False, # 加载测试集(False则加载测试集)download=True,transform=ToTensor(),
)
创建数据加载器
batch_size = 64# Create data loaders.
# DataLoader():batch_size每个批次的大小,shuffle=True则打乱数据
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader: # 遍历训练数据加载器,x相当于图片,y相当于标签print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break ![]()
创建模型
为了在 PyTorch 中定义神经网络,我们创建一个继承 来自 nn.模块。我们定义网络的各层 ,并在函数中指定数据如何通过网络。要加速 作,我们将其移动到 CUDA、MPS、MTIA 或 XPU 等加速器。如果当前加速器可用,我们将使用它。否则,我们使用 CPU。__init__forward
#使用加速器,并打印当前使用的加速器(当前加速器可用则使用当前的,否则使用cpu)
# device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu" # torch2.4.2并没有accelerator这个属性,2.6的才有,所以注释掉
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device")# 检查 CUDA 是否可用
print("CUDA available:", torch.cuda.is_available())# Define model
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork().to(device) #torch2.4.2并没有accelerator这个属性,2.6的才有,所以注释掉不用
# model = NeuralNetwork()
print(model)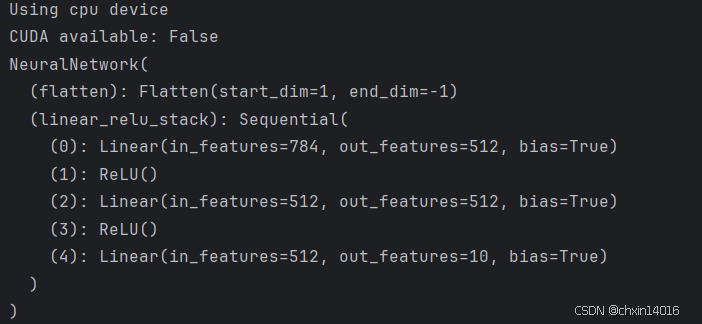
优化模型参数
要训练模型,我们需要一个损失函数和一个优化器:
loss_fn = nn.CrossEntropyLoss() # 损失函数,nn.CrossEntropyLoss()用于多分类
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 优化器,用于更新模型的参数,以最小化损失函数'''
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
优化器用PyTorch 提供的随机梯度下降(Stochastic Gradient Descent, SGD)优化器
model.parameters():将模型的参数传递给优化器,优化器会根据这些参数计算梯度并更新它们
lr=1e-3:学习率(learning rate),控制每次参数更新的步长
(较大的学习率可能导致训练不稳定,较小的学习率可能导致训练速度变慢)
'''在单个训练循环中,模型对训练集进行预测(分批提供给它),并且 反向传播预测误差以调整模型的参数:
'''
训练模型(单个epoch)
dataloader:数据加载器,用于按批次加载训练数据
model :神经网络模型
loss_fn :损失函数,用于计算预测值与真实值之间的误差
optimizer :优化器,用于更新模型参数
'''
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)model.train() # 将模型设置为训练模式(启用 dropout 和 batch normalization 的训练行为)for batch, (X, y) in enumerate(dataloader): # 遍历 dataloader 中的每个批次,获取输入 X 和标签 yX, y = X.to(device), y.to(device) # 将数据移动到指定设备(如 GPU 或 CPU)# Compute prediction error# 计算预测损失,同时也是前向传播pred = model(X) # 模型的预测值,即模型的输出loss = loss_fn(pred, y) # 计算损失:y为实际的类别标签# Backpropagation 反向传播和优化# 梯度清零应在每次反向传播之前执行,以避免梯度累积(先用optimizer.zero_grad())loss.backward() # 计算梯度optimizer.step() # 使用优化器更新模型参数optimizer.zero_grad() # 清除之前的梯度(清零梯度,为下一轮计算做准备)# 梯度清零应在每次反向传播之前执行,以避免梯度累积(在计算模型预测值前先用optimizer.zero_grad())if batch % 100 == 0: # 每 100 个批次打印一次损失值和当前处理的样本数量loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")进度条显示:
- 如果数据集较大,训练过程可能较慢。可以使用
tqdm库添加进度条,提升用户体验。例如:from tqdm import tqdm for batch, (X, y) in enumerate(tqdm(dataloader, desc="Training")):...
我们还根据测试集检查模型的性能,以确保它正在学习:
# 测试模型
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的总样本数num_batches = len(dataloader) # 测试数据加载器(dataloader)的总批次数model.eval() # 设置为评估模式,这会关闭 dropout 和 batch normalization 的训练行为test_loss, correct = 0, 0 # 累积测试损失和正确预测的样本数with torch.no_grad(): # 禁用梯度计算,使用 torch.no_grad() 上下文管理器,避免计算梯度,从而节省内存并加速计算for X, y in dataloader:X, y = X.to(device), y.to(device) # 将数据加载到指定设备pred = model(X) # 模型预测test_loss += loss_fn(pred, y).item() # 累积损失correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累积正确预测数# correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更简洁test_loss /= num_batches # 平均损失correct /= size # 准确率print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累积正确预测数 # correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更简洁 '''pred.argmax(1): pred 是模型的输出(通常是未经过 softmax 的 logits,形状为 [batch_size, num_classes])。 argmax(1) 表示在第二个维度(即类别维度)上找到最大值的索引,返回一个形状为 [batch_size] 的张量,表示每个样本的预测类别。pred.argmax(1) == y: y 是真实标签(形状为 [batch_size]),表示每个样本的真实类别。 这一步会比较预测的类别和真实类别,返回一个布尔张量,形状为 [batch_size],其中每个元素表示对应样本的预测是否正确。.type(torch.float): 将布尔张量转换为浮点数张量(True 转为 1.0,False 转为 0.0).sum(): 对浮点数张量求和,得到预测正确的样本总数.item(): 将结果从张量转换为 Python 的标量(整数) '''
- 举例一:
pred是模型的输出:torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]])
y是真实标签:torch.tensor([0, 1])import torchpred = torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]]) y = torch.tensor([0, 1])correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(correct) # 输出: 2.0 -> 转换为整数后为 2
- 举例二:
import torch# 模型输出(未经过 softmax 的 logits) pred = torch.tensor([[2.0, 1.0, 0.1], # 第一个样本的预测分数[0.5, 3.0, 0.2], # 第二个样本的预测分数[1.2, 0.3, 2.5]]) # 第三个样本的预测分数# 真实标签 y = torch.tensor([0, 1, 2]) # 第一个样本的真实类别是 0,第二个是 1,第三个是 2# 计算预测正确的样本数 correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(f"预测正确的样本数: {correct}") # 预测正确的样本数: 3'''逐步分析 对每个样本的预测分数取最大值的索引,得到预测类别: pred.argmax(1) # 输出: tensor([0, 1, 2])比较预测类别和真实标签,得到布尔张量: pred.argmax(1) == y # 输出: tensor([True, True, True]).type(torch.float): 将布尔张量转换为浮点数张量: (pred.argmax(1) == y).type(torch.float) # 输出: tensor([1.0, 1.0, 1.0]).sum(): 对浮点数张量求和,得到预测正确的样本总数: (pred.argmax(1) == y).type(torch.float).sum() # 输出: tensor(3.0).item():将结果从张量转换为 Python 标量: (pred.argmax(1) == y).type(torch.float).sum().item() # 输出: 3在这个例子中,模型对所有 3 个样本的预测都正确,因此预测正确的样本数为 3。 ''' # 如果知道总样本数,可以进一步计算准确率:# 总样本数 total = len(y)# 准确率 accuracy = correct / total print(f"准确率: {accuracy * 100:.2f}%")
训练过程分多次迭代 (epoch) 进行。在每个 epoch 中,模型会学习 参数进行更好的预测。
然后打印模型在每个 epoch 的准确率和损失,
期望看到 准确率Accuracy增加,损失Avg loss随着每个 epoch 的减少而减少:
# 跑5轮,每轮皆是先训练,然后测试
epochs = 5
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Done!")输出:
Epoch 1
-------------------------------
loss: 2.308106 [ 64/60000]
loss: 2.292096 [ 6464/60000]
loss: 2.280747 [12864/60000]
loss: 2.273108 [19264/60000]
loss: 2.256617 [25664/60000]
loss: 2.240094 [32064/60000]
loss: 2.229981 [38464/60000]
loss: 2.204926 [44864/60000]
loss: 2.201917 [51264/60000]
loss: 2.178733 [57664/60000]
Test Error: Accuracy: 46.1%, Avg loss: 2.164820 Epoch 2
-------------------------------
loss: 2.178193 [ 64/60000]
loss: 2.160645 [ 6464/60000]
loss: 2.110801 [12864/60000]
loss: 2.129119 [19264/60000]
loss: 2.078400 [25664/60000]
loss: 2.029629 [32064/60000]
loss: 2.044328 [38464/60000]
loss: 1.972220 [44864/60000]
loss: 1.980023 [51264/60000]
loss: 1.920835 [57664/60000]
Test Error: Accuracy: 56.2%, Avg loss: 1.906657 Epoch 3
-------------------------------
loss: 1.938616 [ 64/60000]
loss: 1.902610 [ 6464/60000]
loss: 1.797264 [12864/60000]
loss: 1.844325 [19264/60000]
loss: 1.726765 [25664/60000]
loss: 1.688332 [32064/60000]
loss: 1.695883 [38464/60000]
loss: 1.605903 [44864/60000]
loss: 1.628846 [51264/60000]
loss: 1.532240 [57664/60000]
Test Error: Accuracy: 59.8%, Avg loss: 1.541237 Epoch 4
-------------------------------
loss: 1.604458 [ 64/60000]
loss: 1.563167 [ 6464/60000]
loss: 1.426733 [12864/60000]
loss: 1.503305 [19264/60000]
loss: 1.376496 [25664/60000]
loss: 1.381424 [32064/60000]
loss: 1.371971 [38464/60000]
loss: 1.312882 [44864/60000]
loss: 1.342990 [51264/60000]
loss: 1.244696 [57664/60000]
Test Error: Accuracy: 62.7%, Avg loss: 1.268371 Epoch 5
-------------------------------
loss: 1.344515 [ 64/60000]
loss: 1.318664 [ 6464/60000]
loss: 1.166471 [12864/60000]
loss: 1.275481 [19264/60000]
loss: 1.146058 [25664/60000]
loss: 1.179018 [32064/60000]
loss: 1.171105 [38464/60000]
loss: 1.129168 [44864/60000]
loss: 1.163182 [51264/60000]
loss: 1.077062 [57664/60000]
Test Error: Accuracy: 64.7%, Avg loss: 1.097442 Done!保存模型
保存模型的常用方法是序列化内部状态字典(包含模型参数):
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")加载模型
加载模型的过程包括重新创建模型结构和加载 state 字典放入其中。
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth", weights_only=True))查看安装的PyTorch版本
方法一:cmd终端查看
终端中输入:
>>>python
>>>import torch
>>>torch.__version__ //注意version前后是两个下划线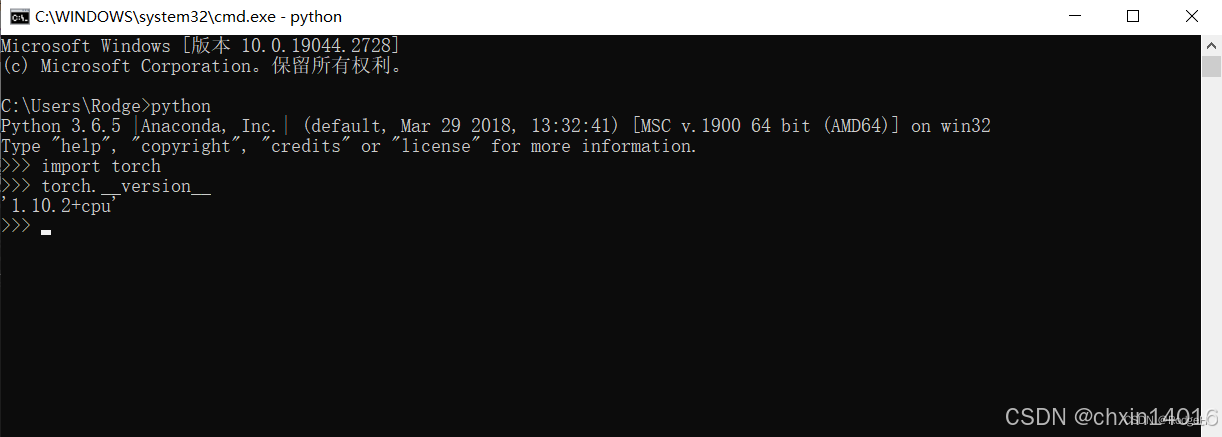
方法二:PyCharm查看
打开Pycharm,在Python控制台中输入:
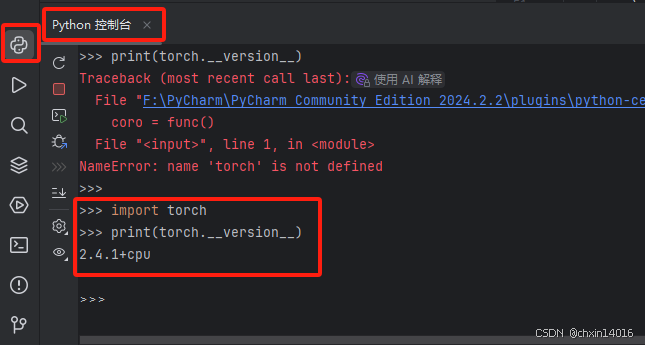
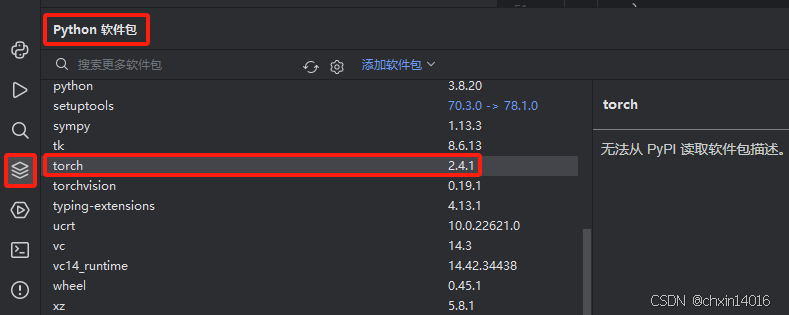
或者在Pycharm的“Python软件包”中查看:
相关文章:

PyTorch 学习笔记
环境:python3.8 PyTorch2.4.1cpu PyCharm 参考链接: 快速入门 — PyTorch 教程 2.6.0cu124 文档 PyTorch 文档 — PyTorch 2.4 文档 快速入门 导入库 import torch from torch import nn from torch.utils.data import DataLoader from torchvision …...

MCP基础学习计划:从MCP入门到项目构建的全面指南
文章简介 ai生成的学计划有的连接是无效的,想着边学习边找输出文章,后续会继续链接更新 在人工智能和大语言模型(LLM)的快速发展下,掌握Model Context Protocol(MCP)成为提升AI应用能力的关键。…...
)
NO.77十六届蓝桥杯备战|数据结构-单调队列|质量检测(C++)
什么是单调队列? 单调队列,顾名思义,就是存储的元素要么单调递增要么单调递减的队列。注意,这⾥的队列和普通的队列不⼀样,是⼀个双端队列。单调队列解决的问题 ⼀般⽤于解决滑动窗⼝内最⼤值最⼩值问题,以…...

【有啥问啥】深入浅出讲解 Teacher Forcing 技术
深入浅出讲解 Teacher Forcing 技术 在序列生成任务(例如机器翻译、文本摘要、图像字幕生成等)中,循环神经网络(RNN)以及基于 Transformer 的模型通常采用自回归(autoregressive)的方式生成输出…...

redis数据迁移之通过redis-dump镜像
这里写目录标题 一、redis-dump 镜像打包1.1 安装windows docker1.2 idea项目创建1.3 idea镜像打包 二、redis数据迁移2.1 数据导出2.2 数据导入 一、redis-dump 镜像打包 没有找到可用的redis-dump镜像,需要自己打包一下,这里我是在idea直接打包的 1.…...

Redis哨兵模式下执行sentinel failover mymaster命令可能导致什么风险,如何避免
在 Redis 哨兵模式下执行 SENTINEL FAILOVER mymaster 命令会强制触发主节点切换(手动故障转移),虽然这是合法的管理操作,但可能带来以下风险及规避方法: 一、潜在风险 数据丢失风险 原因:主节点可能在故障…...

软考案例分析实例答题模板
案例分析(全部为主观问答题, 总 5 大题, 第一题必选, 剩下 4 选 2, 每题 25 分, 共75分) 第一题: 案例分析——某企业信息架构优化项目 案例材料: 某企业是一家从事电子商务的大型企业, 随着业务规模的不断扩大, 现有的信息架 构已无法满足企业快速发展的需求。 企业…...

Docker+Jenkins+Gitee自动化项目部署
前置条件 docker安装成功 按照下面配置加速 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-mirrors": ["https://register.librax.org"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker一、…...

olib开源图书
8.olib开源图书 该软件作者已开源,开源地址:开源地址:https://github.com/shiyi-0x7f/o-lib 点击该软件,使用管理员权限打开,进入界面可以搜索图书并下载pdf文件。 蓝奏云下载:https://wwph.lanzout.com/…...

react: styled-components实现原理 标签模版
styled-components是针对react中一个前端广泛使用的css-in-js样式库B站 利用标签模版 利用ES6中的 标签模版文档标签模板其实不是模板,而是函数调用的一种特殊形式。“标签”指的就是函数,紧跟在后面的模板字符串就是它的参数。 let a 5; let b 10;…...

AI大模型从0到1记录学习 day15
14.3.5 互斥锁 1)线程安全问题 线程之间共享数据会存在线程安全的问题。 比如下面这段代码,3个线程,每个线程都将g_num 1 十次: import time import threading def func(): global g_num for _ in range(10): tmp g_num 1 # ti…...

macbook pro查询并修改命令提示符的格式
环境 MacBook Pro 描述 我的命令提示符总是: # 前面总是多了(base) (base) yutaoyutaodeMacBook-Pro ~ % vim .zshrc (base) yutaoyutaodeMacBook-Pro ~ % source .zshrc # 期望改成下面这样: yutaoyutaodeMacBook-Pro ~ % 找…...
)
Baumer工业相机堡盟工业相机如何处理偶发十万分之一或百万分之一几率出现的黑图现象(C#)
Baumer工业相机堡盟工业相机如何处理偶发十万分之一或百万分之一几率出现的黑图现象(C#) Baumer工业相机Baumer工业相机出现黑图的技术背景硬件层面软件层面环境因素 实际案例演示:BaumerVCXG-53M.I.XT 防护相机项目使用环境项目反馈问题项目…...

基于Resemblyzer 声纹识别门禁系统设计
一、整体结构与思路 这份程序的核心目的是: 用麦克风录音 ➜ 识别说话人是谁 ➜ 图形化展示 ➜ 语音播报反馈 它主要由 4 个部分组成: 全局配置和依赖加载 语音采集和声纹提取逻辑 图形界面与交互(PyQt5) 语音播报反馈系统 …...

分布式数据库LSM树
LSM树的核心结构与操作流程 Log-Structured Merge Tree,日志 结构化 合并 树。 追加写:永远不改,就算是update操作,也是追加写,一直新生成文件。 刷盘触发:追加到一定程序,比如到了几M…...

2143 最少刷题数
2143 最少刷题数 ⭐️难度:中等 🌟考点:2022、前缀和、省赛、二分 📖 📚 import java.util.Scanner; import java.util.Arrays;public class Main2 {public static void main(String[] args) {Scanner sc new Sca…...

Ansible:playbook 使用when和ith_items
文章目录 playbook使用 whenplaybook 使用迭代 with_items迭代嵌套子变量 if 和 for在template中使用了,在playbook中加以区分,因此使用when进行条件判断,with_items进行循环迭代 playbook使用 when when语句,可以实现条件测试。…...

python爬取1688.item_search_best-查询榜单列表返回数据说明
在当今数字化时代,电商平台的数据蕴含着巨大的商业价值。1688作为国内领先的B2B电商平台,其商品搜索榜单数据能够为供应商、采购商以及市场研究人员提供诸多洞察。本文将详细介绍如何使用Python爬取1688的商品搜索榜单数据,并对返回数据进行说…...
KMP+滑动窗口+链表+栈+队列)
数据结构(一)KMP+滑动窗口+链表+栈+队列
数据结构-链表 单链表 #include<iostream> using namespace std; const int N 100010; int head,e[N],ne[N],idx; void init() {head -1;idx 0; } void add_to_head(int x) {e[idx] x;ne[idx] head;head idx;idx; } void add(int k,int x) {e[idx] x;ne[id…...

C语言 数据结构 【队列】动态模拟实现
引言 用动态方式模拟实现队列的各个接口 一、队列的结构与概念 概念:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列…...

Python | 第十三章 | 多态 | 魔术方法 | 静态方法 | 抽象类
P130 多态练习题(1)2025/2/21 一、isinstance函数 基本说明: isinstance()用于判断对象是否为某个类或其子类的对象基本语法:isinstance(object,classinfo)解读形参: object:对象 classinfo:可以是类名、基本类型或者由它们组成…...

线程安全问题的原因与解决方案总结
目录 一 什么是线程安全? 二 线程安全问题的实例 三 线程安全问题的原因 1.多个线程修改共享数据 2.抢占式执行 3.修改操作不是原子的 4.内存可见性问题 5.指令重排序 四 解决方案 1.同步代码块 2.同步方法 3.加锁lock解决问题 一 什么是线程安全&…...

设计模式-模版方法
目录 什么是模版方法? 怎么理解抽象类的算法骨架? Burn功能骨架 战士类 法师类 什么是模版方法? 借助抽象类定义算法的骨架,再由具体子类实现算法的特定步骤。这种设计模式让算法的整体结构得以固定,同时又能让不…...

c# 运用策略模式与模板方法模式实例
策略模式 策略模式的核心在于定义一系列算法,把它们封装起来,并且让它们能够相互替换。策略模式让算法的变化独立于使用算法的客户端。在这个方法里,策略模式的体现如下: convertFunc 参数:这是一个委托类型的参数&a…...

基于51单片机的3路温度报警器proteus仿真
地址: https://pan.baidu.com/s/1qrCpGuzZRbeFVVjaGMffQA 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...

llama-factory微调qwen2.5-vl
本文不生产技术,只做技术的搬运工!!! 前言 目前大模型百花齐放,微调方法复杂多样,且教程复杂,工程端想要进行垂域模型适配困难重重,本篇博客详细介绍了qwen2.5-vl的全流程微调过程,包括环境配置、数据集制作、模型训练、模型导出、模型部署、模型推理等过程,希望对工…...

淘宝历史价格采集合规指南:官方 API + 轻量爬虫混合方案
在电商数据分析领域,获取淘宝商品的历史价格数据对于企业制定价格策略、进行竞品分析以及消费者洞察市场价格波动趋势都具有重要意义。然而,由于淘宝平台对数据安全和合规性的严格要求,历史价格采集工作需要在合法合规的框架内进行。本文将详…...

文档控件DevExpress Office File API v24.2亮点:不再支持非Windows系统
DevExpress Office File API是一个专为C#, VB.NET 和 ASP.NET等开发人员提供的非可视化.NET库。有了这个库,不用安装Microsoft Office,就可以完全自动处理Excel、Word等文档。开发人员使用一个非常易于操作的API就可以生成XLS, XLSx, DOC, DOCx, RTF, CS…...

TDengine.C/C++ 连接器
简介 C/C 开发人员可以使用 TDengine 的客户端驱动,即 C/C 连接器(以下都用 TDengine 客户端驱动表示),开发自己的应用来连接 TDengine 集群完成数据存储、查询以及其他功能。TDengine 客户端驱动的 API 类似于 MySQL 的 C API。…...

什么是混合搜索Hybrid Search?
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创AI未来! 🚀 混合搜索通常指一种结合多种搜索方法或技术的搜索策略,旨在提供更…...

滤波器:模拟滤波器和数字滤波器的区别
滤波器是一种用于从信号中去除不需要的频率成分,只保留所需频率成分的电子设备或算法。根据实现方式的不同,滤波器主要分为模拟滤波器和数字滤波器两大类。以下是对这两种滤波器的详细比较: 一、实现方式与原理 模拟滤波器 实现方式…...

AudioRecord 录制pcm转wav
pcm转wav PCM 格式校验pcm 添加 wav 头信息WAVWAV 格式检验小端序? 参考地址 PCM 格式校验 /*** 专业PCM文件验证(支持动态参数与多格式)* param silenceThreshold 静音检测阈值(0.0~1.0),默认90%零值为静…...

625SJBH网上便利店的设计与实现
1前 言 目前,网络正以一种前所未有的冲击力在影响着人类的活动,包括人类的生产和日常生活。网络的诞生和发展,颠覆了传统的信息传播方式,冲破了存在于传统交流方式中时间和空间的种种壁垒,极大地改变了人类从物质到精…...

如何开发英语在线训练小程序:从0到1的详细步骤
在数字化学习的浪潮下,英语在线训练小程序凭借便捷、高效的学习模式,成为众多英语学习者的得力助手。如果你也想开发一款独具特色的英语在线训练小程序,不妨参考以下步骤,开启你的小程序开发之旅。 一、前期规划 (…...

java设计模式-装饰者模式
装饰者模式(Decorator) 定义 1、动态的将新功能附加到对象上,在对象功能扩展方面,他比继承更有弹性,也体现了开闭原则(OCP) 2、这里提到的动态的将新功能附加到对象和OCP原则,在后面应用实际上会以代码的形式体现。 //饮料 // 饮…...
我提了一个 Androidx IssueTracker
问题 在运行 gradle plugin 插件的 transform R8 阶段出现了报错 Caused by: com.android.tools.r8.internal.xk: java.lang.NullPointerException: Cannot invoke “String.length()” because “” is null 报错日志 FAILURE: Build failed with an exception.* What went w…...

spring mvc @ResponseBody 注解转换为 JSON 的原理与实现详解
ResponseBody 注解转换为 JSON 的原理与实现详解 1. 核心作用 ResponseBody 是 Spring MVC 的一个注解,用于将方法返回的对象直接序列化为 HTTP 响应体(如 JSON 或 XML),而不是通过视图解析器渲染为视图(如 HTML&…...

RK3588芯片NPU的使用:Windows11 Docker中运行MobileNet模型以及部署到开发板进行目标检测
本文的目标 本文将在RKNN Docker环境(见本系列的第二篇文章)中练习MobileNet图像分类示例,并通过adb工具部署到RK3588开发板。 MobileNet简介请参考上一篇文章。 开发环境说明 主机系统:Windows11目标设备:搭载RK35…...
)
智能仓储数字孪生Demo(Unity实现)
一、项目背景与行业痛点 医药流通行业仓储管理面临三大核心挑战: 合规性风险:GSP(药品经营质量管理规范)对温湿度、药品批次追溯的严苛要求,传统人工记录易出错效率瓶颈:库区布局复杂,人工巡检…...

Qt上hook钩子的使用,监测键盘和鼠标。
演示平台:windows。 编译环境:Qt5.12.2 MinGW 64-bit Windows API: ///加载钩子 /*** SetWindowsHookEx 函数解释* int idHook 所监控的挂钩类型* HOOKPROC lpfn 监控信息的处理函数* HINSTANCEhMod 监控信息的动态链接位置 nullptr则与本线…...

Android12源码编译之预置Android Studio项目Android.mk文件编写
1、在AndroidManifest.xml文件中添加package"com.sprd.silentinstalldemo"属性,因为新版本的Android Studio默认生成的AndroidManifest.xml是没有这个属性值的 <?xml version"1.0" encoding"utf-8"?> <manifest xmlns:an…...

微服务注册中心选择指南:Eureka vs Consul vs Zookeeper vs Nacos
文章目录 引言微服务注册中心概述什么是服务注册与发现选择注册中心的标准 常见的微服务注册中心1. Eureka1.1 理论基础1.2 特点1.3 示例代码 2. Consul2.1 理论基础2.2 特点2.3 示例代码 3. Zookeeper3.1 理论基础3.2 特点3.3 示例代码 4. Nacos4.1 理论基础4.2 特点4.3 示例代…...

pg_waldump无法定位WAL文件问题
目录 排查pg_waldump无法定位WAL文件问题的步骤1. 确认WAL文件路径配置2. 检查WAL文件名格式3. 验证文件存在性4. 检查文件权限5. 时间线历史文件检查6. 使用pg_controldata验证状态7. 尝试指定完整路径 典型错误场景及解决方案 排查pg_waldump无法定位WAL文件问题的步骤 1. 确…...

Mysql安装
Mysql安装 1. windows安装1.1 官网下载1.2 安装 1. windows安装 1.1 官网下载 官网下载 选择对于版本,然后跳转到下载页 1.2 安装...

Windows版-RabbitMQ自动化部署
一键完成Erlang环境变量配置(ERLANG_HOME系统变量) 一键完成RabbitMQ环境变量配置(RabbitMQ系统变量) 实现快速安装部署RabbitMQ PS: 需提前下载安装: - otp_win64_25.0.exe (Erlang) - rabbit…...

spring mvc的拦截器HandlerInterceptor 接口详解
HandlerInterceptor 接口详解 1. 接口方法说明 方法作用执行时机返回值/注意事项preHandle请求处理前拦截在控制器方法执行前调用返回 false 中断后续流程;返回 true 继续执行postHandle控制器方法执行后拦截在控制器方法返回结果后,视图渲染前调用无返…...

Linux平台内存泄漏检测工具介绍: ASan vs Valgrind
目录: 前言Valgrind 介绍在Ubuntu上安装Valgrind 核心主要功能Valgrind 基本用法1. --leak-checkfull2. --show-leak-kindsall3. --track-originsyes4. 其他常用选项--tool<name>--log-file<filename>-v / --verbose--error-exitcode<n> 示例命令…...

c# 数据结构 链表篇 有关单链表的一切
本人能力有限,本文仅作学习交流与参考,如有不足还请斧正 目录 0.单链表好处 0.5.单链表分类 1.无虚拟头节点情况 图示: 代码: 头插/尾插 删除 搜索 遍历全部 测试代码: 全部代码 2.有尾指针情况 尾插 全部代码 3.有虚拟头节点情况 全部代码 4.循环单链表 几个…...

二叉树层平均值:层序遍历+队列解法详解
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[3.00000,14.50000,11.00000] 解释:第 0 层的平均值为 …...

解决 Docker Swarm 集群节点故障:从问题剖析到修复实战
解决 Docker Swarm 集群节点故障:从问题剖析到修复实战 在使用 Docker Swarm 构建容器编排集群时,可能会遭遇各种难题。本文将分享一次处理 Docker Swarm 集群节点故障的实战经历,涵盖问题出现的缘由、详细剖析以及完整的解决步骤࿰…...