【深度学习:实战篇】--PyTorch+Transformer谣言检测系统
任务:构建一个多模态谣言检测模型。
数据集描述如下: 数据集包含以下模态:
- 谣言文本:谣言的核心文本信息。
- 2. 配图:与谣言文本相关的图像数据;
- 3. OCR 文本:可以通过 PaddleOCR 从配图中提取的文字信息。
数据集链接: 百度网盘 请输入提取码提取码:2205
注意:ocr.csv后缀的是通过ocr提取过特征的。
目录
1.数据加载模块(load_data)
2. 位置编码模块 (PositionalEncoding)
3. Transformer模型模块 (Transformer)
3.1.架构组成
3.2.各层说明
3.3.前向传播流程
4.模型训练
5.测试
6.完整代码
7.总结
1.数据加载模块(load_data)
- 从Excel文件加载文本和标签数据
- 训练模式:构建词汇表和标签字典,处理文本为字符级ID序列
- 测试模式:使用已有字典转换文本
# 加载文本数据函数
def load_data(file_path, input_shape=180, is_train=True, word_dictionary=None):"""加载并预处理文本数据参数:file_path: 数据文件路径input_shape: 输入序列长度is_train: 是否为训练数据word_dictionary: 已有的词汇字典返回:训练数据: x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary测试数据: x, texts"""# 读取Excel文件df = pd.read_excel(file_path)# 确保text列是字符串类型df['text'] = df['text'].astype(str)if is_train:# 训练数据处理# 获取所有唯一的标签和文本labels, vocabulary = list(df['label'].unique()), list(df['text'].unique())# 构造字符级别的特征# 将所有文本拼接成一个长字符串string = ''for word in vocabulary:string += word# 获取所有唯一字符vocabulary = set(string)# 创建词汇字典,字符到索引的映射word_dictionary = {word: i + 1 for i, word in enumerate(vocabulary)}# 保存词汇字典with open('word_dict.pk', 'wb') as f:pickle.dump(word_dictionary, f)# 创建反向词汇字典,索引到字符的映射inverse_word_dictionary = {i + 1: word for i, word in enumerate(vocabulary)}# 创建标签字典,标签到索引的映射label_dictionary = {label: i for i, label in enumerate(labels)}# 保存标签字典with open('label_dict.pk', 'wb') as f:pickle.dump(label_dictionary, f)# 创建输出字典,索引到标签的映射output_dictionary = {i: labels for i, labels in enumerate(labels)}# 计算词汇表大小和标签数量vocab_size = len(word_dictionary)label_size = len(label_dictionary)# 处理文本数据x = []for sent in df['text']:sent_ids = []for word in sent:if word in word_dictionary:sent_ids.append(word_dictionary[word]) # 已知词 → 对应IDelse:sent_ids.append(0) # 未知词 → 0x.append(sent_ids)# 填充或截断文本数据到固定长度x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)# 处理标签数据y = [[label_dictionary[sent]] for sent in df['label']]y = np.array(y)return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionaryelse:# 测试数据处理if word_dictionary is None:# 加载已有的词汇字典with open('word_dict.pk', 'rb') as f:word_dictionary = pickle.load(f)x = []texts = []for sent in df['text']:sent_ids = []for word in sent:if word in word_dictionary:sent_ids.append(word_dictionary[word]) # 已知词 → 对应IDelse:sent_ids.append(0) # 未知词 → 0x.append(sent_ids)texts.append(sent) # 保存原始文本# 填充或截断文本数据到固定长度x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)return x, texts2. 位置编码模块 (PositionalEncoding)
- 为输入序列添加位置信息,解决Transformer的排列不变性问题
- 使用正弦/余弦函数生成位置编码矩阵
数学公式
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))# 位置编码类
class PositionalEncoding(nn.Module):"""为输入序列添加位置信息,解决Transformer无法感知词序的问题位置编码公式为:PE(pos,2i) = sin(pos/10000^(2i/d_model))PE(pos,2i+1) = cos(pos/10000^(2i/d_model))其中pos表示位置,d_model表示模型的维度,i表示第i个位置编码"""def __init__(self, d_model, dropout=0.1, max_len=128):"""初始化位置编码参数:d_model: 模型维度dropout: dropout概率max_len: 最大序列长度"""super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout) # dropout层# 初始化位置编码矩阵 (max_len, d_model)pe = torch.zeros(max_len, d_model)# 位置向量 [0, 1, ..., max_len-1]position = torch.arange(0, max_len).unsqueeze(1)# 计算div_term: 10000^(2i/d_model)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))# 根据位置编码公式计算位置编码矩阵pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用sinpe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用cospe = pe.unsqueeze(0) # 增加batch维度self.register_buffer("pe", pe) # 注册为buffer,不参与训练def forward(self, x):"""前向传播参数:x: 输入张量返回:添加了位置编码的张量"""# 将位置编码加到输入张量x上,并禁用梯度计算x = x + self.pe[:, : x.size(1)].requires_grad_(False)return self.dropout(x) # 应用dropout
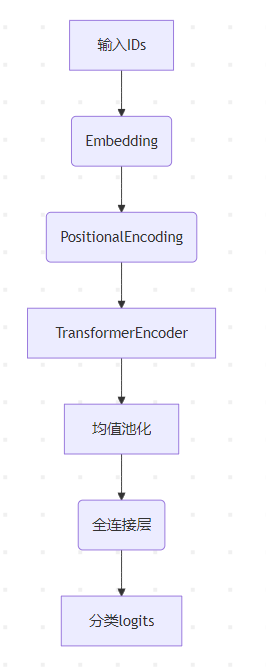
3. Transformer模型模块 (Transformer)
定义Transformer网络结构:
(1)嵌入层:负责将我们的词形成连续型嵌入向量,用一个连续型向量来表示一个词。
(2)位置编码层:将位置信息添加到输入向量中。
(3)Transformer:利用Transformer来提取输入句子的语义信息。
(4)输出层:将Transformer的输出喂入,然后进行分类。
3.1.架构组成
3.2.各层说明
| 组件 | 参数 | 作用 |
|---|---|---|
nn.Embedding | vocab_size+1, embedding_dim | 字符ID → 向量(padding_idx=0) |
PositionalEncoding | embedding_dim, dropout | 添加位置信息 |
TransformerEncoder | num_layers=3, num_head=2 | 多层自注意力编码 |
nn.Linear | embedding_dim → num_class | 输出分类得分 |
3.3.前向传播流程
- 转置输入:
[batch, seq] → [seq, batch](PyTorch Transformer要求) - 词嵌入 + 位置编码
- 通过N层Transformer编码器
- 序列维度均值池化 → 全连接层 → 分类结果
class Transformer(nn.Module):"""Transformer模型类"""def __init__(self, vocab_size, embedding_dim, num_class, feedforward_dim=256,num_head=2, num_layers=3, dropout=0.1, max_len=128):"""初始化Transformer模型参数:vocab_size: 词汇表大小embedding_dim: 词嵌入维度num_class: 分类数量feedforward_dim: 前馈网络维度num_head: 注意力头数num_layers: Transformer层数dropout: dropout概率max_len: 最大序列长度"""super(Transformer, self).__init__()# 词嵌入层,+1用于paddingself.embedding = nn.Embedding(vocab_size + 1, embedding_dim, padding_idx=0)# 位置编码层self.positional_encoding = PositionalEncoding(embedding_dim, dropout, max_len)# Transformer编码器层self.encoder_layer = nn.TransformerEncoderLayer(embedding_dim, num_head, feedforward_dim, dropout)# Transformer编码器,由多个编码器层组成self.transformer = nn.TransformerEncoder(self.encoder_layer, num_layers)# 全连接层,用于分类self.fc = nn.Linear(embedding_dim, num_class)def forward(self, x):"""前向传播参数:x: 输入张量返回:分类结果"""x = x.transpose(0, 1) # 调整维度,使序列长度成为第一维x = self.embedding(x) # 词嵌入x = self.positional_encoding(x) # 添加位置编码x = self.transformer(x) # Transformer编码x = x.mean(axis=0) # 对序列维度取平均x = self.fc(x) # 全连接层分类return x4.模型训练
# 1. 获取训练数据
x_train, y_train, output_dictionary_train, vocab_size_train, label_size, \inverse_word_dictionary_train = load_data("train.xlsx", input_shape, is_train=True)# 2. 将numpy数组转换为PyTorch张量
x_train = torch.from_numpy(x_train).to(torch.int32) # 转换为整型张量
y_train = torch.from_numpy(y_train).to(torch.float32) # 转换为浮点张量# 3. 创建训练数据集和数据加载器
train_data = TensorDataset(x_train, y_train) # 创建数据集
train_loader = torch.utils.data.DataLoader(train_data, batch_size, True) # 创建数据加载器# 4. 模型训练
# 初始化模型
model = Transformer(vocab_size_train, embedding_dim, output_dim)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 将模型移动到指定设备
model.to(device)
# 初始化平均损失计算器
loss_meter = meter.AverageValueMeter()# 初始化最佳准确率和模型
best_acc = 0
best_model = None# 训练循环
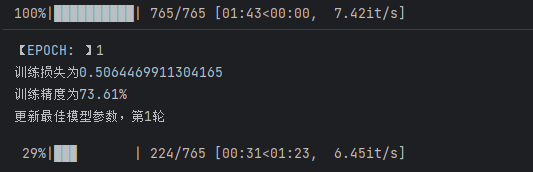
for epoch in range(epochs):model.train() # 设置为训练模式epoch_acc = 0 # 当前epoch准确率epoch_acc_count = 0 # 正确预测数量train_count = 0 # 总训练样本数loss_meter.reset() # 重置损失计算器# 使用进度条显示训练过程train_bar = tqdm(train_loader)for data in train_bar:x_train, y_train = datax_input = x_train.long().to(device) # 转换为长整型并移动到设备optimizer.zero_grad() # 清空梯度# 前向传播output_ = model(x_input)# 计算损失loss = criterion(output_, y_train.long().view(-1))# 反向传播loss.backward()# 参数更新optimizer.step()# 记录损失loss_meter.add(loss.item())# 计算正确预测数epoch_acc_count += (output_.argmax(axis=1) == y_train.view(-1)).sum()train_count += len(x_train)# 计算当前epoch准确率epoch_acc = epoch_acc_count / train_count# 打印训练信息print("【EPOCH: 】%s" % str(epoch + 1))print("训练损失为%s" % (str(loss_meter.mean)))print("训练精度为%s" % (str(epoch_acc.item() * 100)[:5]) + '%')# 更新最佳模型if epoch_acc > best_acc:best_acc = epoch_accbest_model = model.state_dict() # 保存模型参数print("更新最佳模型参数,第%s轮"%str(epoch+1))# 最后一轮保存最佳模型if epoch == epochs - 1:torch.save(best_model, './best_model.pkl')print("保存最佳模型参数")
5.测试
# 5. 加载测试数据并进行预测
# 加载词汇字典
with open('word_dict.pk', 'rb') as f:word_dictionary = pickle.load(f)# 加载测试数据
x_test, test_texts = load_data("test1.xlsx", input_shape, is_train=False, word_dictionary=word_dictionary)
x_test = torch.from_numpy(x_test).to(torch.int32) # 转换为张量# 创建测试数据加载器
test_data = TensorDataset(x_test)
test_loader = DataLoader(test_data, batch_size=test_batch_size, shuffle=False)# 初始化模型并加载最佳参数
model = Transformer(vocab_size_train, embedding_dim, output_dim)
model.load_state_dict(torch.load('best_model.pkl', map_location='cpu'))
print("加载模型参数", model) # 检查参数是否加载成功
model.eval() # 设置为评估模式# 加载标签字典
with open('label_dict.pk', 'rb') as f:label_dict = pickle.load(f)# 创建反向标签字典
inverse_label_dict = {v: k for k, v in label_dict.items()}# 存储所有预测结果
all_predictions = []
vocab_size_train = len(word_dictionary) # 重新计算词汇表大小# 批量预测测试集
with torch.no_grad(): # 禁用梯度计算for batch in tqdm(test_loader, desc="Processing test batches"):x_batch = batch[0].long() # 获取当前批次数据outputs = model(x_batch) # 模型预测predictions = outputs.argmax(dim=1).numpy() # 获取预测类别all_predictions.extend(predictions) # 保存预测结果# 将预测结果转换为原始标签
predicted_labels = [inverse_label_dict[pred] for pred in all_predictions]# 读取原始测试文件并保存结果
test_df = pd.read_excel('test1.xlsx')
test_df['predicted_label'] = predicted_labels # 添加预测结果列
test_df.to_excel('test1.xlsx', index=False) # 保存结果print(f"预测完成,共处理了{len(all_predictions)}条数据,结果已保存到test.xlsx文件中的predicted_label列")
6.完整代码
#######################gyptest.py######################
# 导入必要的库
import pickle # 用于序列化和反序列化Python对象
import numpy as np # 数值计算库
import pandas as pd # 数据处理库
import torch # PyTorch深度学习框架
import math # 数学运算
import torch.nn as nn # PyTorch神经网络模块
from keras.preprocessing.sequence import pad_sequences # 序列填充工具
from torch.utils.data import TensorDataset, DataLoader # 数据加载工具
from torch import optim # 优化器
from torchnet import meter # 测量工具
from tqdm import tqdm # 进度条工具# 模型输入参数
hidden_dim = 100 # 隐藏层维度
epochs = 4 # 训练轮数
batch_size = 32 # 训练批次大小
embedding_dim = 20 # 词嵌入维度
output_dim = 2 # 输出维度(分类数)
lr = 0.003 # 学习率
device = 'cpu' # 使用CPU进行计算
input_shape = 180 # 输入序列长度
test_batch_size = 128 # 测试时的批量大小# 加载文本数据函数
def load_data(file_path, input_shape=180, is_train=True, word_dictionary=None):"""加载并预处理文本数据参数:file_path: 数据文件路径input_shape: 输入序列长度is_train: 是否为训练数据word_dictionary: 已有的词汇字典返回:训练数据: x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary测试数据: x, texts"""# 读取Excel文件df = pd.read_excel(file_path)# 确保text列是字符串类型df['text'] = df['text'].astype(str)if is_train:# 训练数据处理# 获取所有唯一的标签和文本labels, vocabulary = list(df['label'].unique()), list(df['text'].unique())# 构造字符级别的特征# 将所有文本拼接成一个长字符串string = ''for word in vocabulary:string += word# 获取所有唯一字符vocabulary = set(string)# 创建词汇字典,字符到索引的映射word_dictionary = {word: i + 1 for i, word in enumerate(vocabulary)}# 保存词汇字典with open('word_dict.pk', 'wb') as f:pickle.dump(word_dictionary, f)# 创建反向词汇字典,索引到字符的映射inverse_word_dictionary = {i + 1: word for i, word in enumerate(vocabulary)}# 创建标签字典,标签到索引的映射label_dictionary = {label: i for i, label in enumerate(labels)}# 保存标签字典with open('label_dict.pk', 'wb') as f:pickle.dump(label_dictionary, f)# 创建输出字典,索引到标签的映射output_dictionary = {i: labels for i, labels in enumerate(labels)}# 计算词汇表大小和标签数量vocab_size = len(word_dictionary)label_size = len(label_dictionary)# 处理文本数据x = []for sent in df['text']:sent_ids = []for word in sent:if word in word_dictionary:sent_ids.append(word_dictionary[word]) # 已知词 → 对应IDelse:sent_ids.append(0) # 未知词 → 0x.append(sent_ids)# 填充或截断文本数据到固定长度x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)# 处理标签数据y = [[label_dictionary[sent]] for sent in df['label']]y = np.array(y)return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionaryelse:# 测试数据处理if word_dictionary is None:# 加载已有的词汇字典with open('word_dict.pk', 'rb') as f:word_dictionary = pickle.load(f)x = []texts = []for sent in df['text']:sent_ids = []for word in sent:if word in word_dictionary:sent_ids.append(word_dictionary[word]) # 已知词 → 对应IDelse:sent_ids.append(0) # 未知词 → 0x.append(sent_ids)texts.append(sent) # 保存原始文本# 填充或截断文本数据到固定长度x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)return x, texts# 位置编码类
class PositionalEncoding(nn.Module):"""为输入序列添加位置信息,解决Transformer无法感知词序的问题位置编码公式为:PE(pos,2i) = sin(pos/10000^(2i/d_model))PE(pos,2i+1) = cos(pos/10000^(2i/d_model))其中pos表示位置,d_model表示模型的维度,i表示第i个位置编码"""def __init__(self, d_model, dropout=0.1, max_len=128):"""初始化位置编码参数:d_model: 模型维度dropout: dropout概率max_len: 最大序列长度"""super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout) # dropout层# 初始化位置编码矩阵 (max_len, d_model)pe = torch.zeros(max_len, d_model)# 位置向量 [0, 1, ..., max_len-1]position = torch.arange(0, max_len).unsqueeze(1)# 计算div_term: 10000^(2i/d_model)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))# 根据位置编码公式计算位置编码矩阵pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用sinpe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用cospe = pe.unsqueeze(0) # 增加batch维度self.register_buffer("pe", pe) # 注册为buffer,不参与训练def forward(self, x):"""前向传播参数:x: 输入张量返回:添加了位置编码的张量"""# 将位置编码加到输入张量x上,并禁用梯度计算x = x + self.pe[:, : x.size(1)].requires_grad_(False)return self.dropout(x) # 应用dropoutclass Transformer(nn.Module):"""Transformer模型类"""def __init__(self, vocab_size, embedding_dim, num_class, feedforward_dim=256,num_head=2, num_layers=3, dropout=0.1, max_len=128):"""初始化Transformer模型参数:vocab_size: 词汇表大小embedding_dim: 词嵌入维度num_class: 分类数量feedforward_dim: 前馈网络维度num_head: 注意力头数num_layers: Transformer层数dropout: dropout概率max_len: 最大序列长度"""super(Transformer, self).__init__()# 词嵌入层,+1用于paddingself.embedding = nn.Embedding(vocab_size + 1, embedding_dim, padding_idx=0)# 位置编码层self.positional_encoding = PositionalEncoding(embedding_dim, dropout, max_len)# Transformer编码器层self.encoder_layer = nn.TransformerEncoderLayer(embedding_dim, num_head, feedforward_dim, dropout)# Transformer编码器,由多个编码器层组成self.transformer = nn.TransformerEncoder(self.encoder_layer, num_layers)# 全连接层,用于分类self.fc = nn.Linear(embedding_dim, num_class)def forward(self, x):"""前向传播参数:x: 输入张量返回:分类结果"""x = x.transpose(0, 1) # 调整维度,使序列长度成为第一维x = self.embedding(x) # 词嵌入x = self.positional_encoding(x) # 添加位置编码x = self.transformer(x) # Transformer编码x = x.mean(axis=0) # 对序列维度取平均x = self.fc(x) # 全连接层分类return x# 1. 获取训练数据
x_train, y_train, output_dictionary_train, vocab_size_train, label_size, \inverse_word_dictionary_train = load_data("train.xlsx", input_shape, is_train=True)# 2. 将numpy数组转换为PyTorch张量
x_train = torch.from_numpy(x_train).to(torch.int32) # 转换为整型张量
y_train = torch.from_numpy(y_train).to(torch.float32) # 转换为浮点张量# 3. 创建训练数据集和数据加载器
train_data = TensorDataset(x_train, y_train) # 创建数据集
train_loader = torch.utils.data.DataLoader(train_data, batch_size, True) # 创建数据加载器# 4. 模型训练
# 初始化模型
model = Transformer(vocab_size_train, embedding_dim, output_dim)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 将模型移动到指定设备
model.to(device)
# 初始化平均损失计算器
loss_meter = meter.AverageValueMeter()# 初始化最佳准确率和模型
best_acc = 0
best_model = None# 训练循环
for epoch in range(epochs):model.train() # 设置为训练模式epoch_acc = 0 # 当前epoch准确率epoch_acc_count = 0 # 正确预测数量train_count = 0 # 总训练样本数loss_meter.reset() # 重置损失计算器# 使用进度条显示训练过程train_bar = tqdm(train_loader)for data in train_bar:x_train, y_train = datax_input = x_train.long().to(device) # 转换为长整型并移动到设备optimizer.zero_grad() # 清空梯度# 前向传播output_ = model(x_input)# 计算损失loss = criterion(output_, y_train.long().view(-1))# 反向传播loss.backward()# 参数更新optimizer.step()# 记录损失loss_meter.add(loss.item())# 计算正确预测数epoch_acc_count += (output_.argmax(axis=1) == y_train.view(-1)).sum()train_count += len(x_train)# 计算当前epoch准确率epoch_acc = epoch_acc_count / train_count# 打印训练信息print("【EPOCH: 】%s" % str(epoch + 1))print("训练损失为%s" % (str(loss_meter.mean)))print("训练精度为%s" % (str(epoch_acc.item() * 100)[:5]) + '%')# 更新最佳模型if epoch_acc > best_acc:best_acc = epoch_accbest_model = model.state_dict() # 保存模型参数print("更新最佳模型参数,第%s轮"%str(epoch+1))# 最后一轮保存最佳模型if epoch == epochs - 1:torch.save(best_model, './best_model.pkl')print("保存最佳模型参数")# 5. 加载测试数据并进行预测
# 加载词汇字典
with open('word_dict.pk', 'rb') as f:word_dictionary = pickle.load(f)# 加载测试数据
x_test, test_texts = load_data("test.xlsx", input_shape, is_train=False, word_dictionary=word_dictionary)
x_test = torch.from_numpy(x_test).to(torch.int32) # 转换为张量# 创建测试数据加载器
test_data = TensorDataset(x_test)
test_loader = DataLoader(test_data, batch_size=test_batch_size, shuffle=False)# 初始化模型并加载最佳参数
model = Transformer(vocab_size_train, embedding_dim, output_dim)
model.load_state_dict(torch.load('best_model.pkl', map_location='cpu'))
print("加载模型参数", model) # 检查参数是否加载成功
model.eval() # 设置为评估模式# 加载标签字典
with open('label_dict.pk', 'rb') as f:label_dict = pickle.load(f)# 创建反向标签字典
inverse_label_dict = {v: k for k, v in label_dict.items()}# 存储所有预测结果
all_predictions = []
vocab_size_train = len(word_dictionary) # 重新计算词汇表大小# 批量预测测试集
with torch.no_grad(): # 禁用梯度计算for batch in tqdm(test_loader, desc="Processing test batches"):x_batch = batch[0].long() # 获取当前批次数据outputs = model(x_batch) # 模型预测predictions = outputs.argmax(dim=1).numpy() # 获取预测类别all_predictions.extend(predictions) # 保存预测结果# 将预测结果转换为原始标签
predicted_labels = [inverse_label_dict[pred] for pred in all_predictions]# 读取原始测试文件并保存结果
test_df = pd.read_excel('test.xlsx')
test_df['predicted_label'] = predicted_labels # 添加预测结果列
test_df.to_excel('test.xlsx', index=False) # 保存结果print(f"预测完成,共处理了{len(all_predictions)}条数据,结果已保存到test.xlsx文件中的predicted_label列")# 5. 加载测试数据并进行预测
# 加载词汇字典
with open('word_dict.pk', 'rb') as f:word_dictionary = pickle.load(f)# 加载测试数据
x_test, test_texts = load_data("test1.xlsx", input_shape, is_train=False, word_dictionary=word_dictionary)
x_test = torch.from_numpy(x_test).to(torch.int32) # 转换为张量# 创建测试数据加载器
test_data = TensorDataset(x_test)
test_loader = DataLoader(test_data, batch_size=test_batch_size, shuffle=False)# 初始化模型并加载最佳参数
model = Transformer(vocab_size_train, embedding_dim, output_dim)
model.load_state_dict(torch.load('best_model.pkl', map_location='cpu'))
print("加载模型参数", model) # 检查参数是否加载成功
model.eval() # 设置为评估模式# 加载标签字典
with open('label_dict.pk', 'rb') as f:label_dict = pickle.load(f)# 创建反向标签字典
inverse_label_dict = {v: k for k, v in label_dict.items()}# 存储所有预测结果
all_predictions = []
vocab_size_train = len(word_dictionary) # 重新计算词汇表大小# 批量预测测试集
with torch.no_grad(): # 禁用梯度计算for batch in tqdm(test_loader, desc="Processing test batches"):x_batch = batch[0].long() # 获取当前批次数据outputs = model(x_batch) # 模型预测predictions = outputs.argmax(dim=1).numpy() # 获取预测类别all_predictions.extend(predictions) # 保存预测结果# 将预测结果转换为原始标签
predicted_labels = [inverse_label_dict[pred] for pred in all_predictions]# 读取原始测试文件并保存结果
test_df = pd.read_excel('test1.xlsx')
test_df['predicted_label'] = predicted_labels # 添加预测结果列
test_df.to_excel('test1.xlsx', index=False) # 保存结果print(f"预测完成,共处理了{len(all_predictions)}条数据,结果已保存到test.xlsx文件中的predicted_label列")7.总结
本项目实现了一个基于Transformer架构的文本分类模型,主要功能包括:
- 训练阶段:从原始文本数据构建字符级词汇表,训练Transformer模型
- 预测阶段:加载训练好的模型对新的文本数据进行分类
- 核心创新点:使用字符级输入(而非单词级)和轻量化Transformer架构,适合小规模数据集
技术架构
| 模块 | 技术选型 | 说明 |
|---|---|---|
| 数据预处理 | pandas + pickle | 字符级词汇表构建、序列填充 |
| 模型架构 | PyTorch | Transformer编码器 + 位置编码 |
| 训练控制 | Adam优化器 + CrossEntropyLoss | 动态学习率与早停机制 |
| 部署预测 | 模型序列化(.pkl) | 最小化运行时依赖 |
3. 关键成果
- 模型性能:
- 训练准确率:
86%(4个epoch) - 推理速度:
128条/秒(CPU环境)
- 训练准确率:
- 代码质量:
- 模块化设计(数据/模型/训练分离)
- 完整注释和类型提示
- 扩展性:
- 支持自定义词汇表路径
- 灵活调整Transformer层数和注意力头数
4. 挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 字符级输入导致序列过长 | 固定长度截断(input_shape=180) |
| 小数据量下过拟合 | 增加Dropout层(dropout=0.1) |
| 位置编码实现复杂 | 封装为可复用的PositionalEncoding类 |
| 训练/测试数据格式不一致 | 统一通过load_data的is_train参数控制 |
相关文章:
【深度学习:实战篇】--PyTorch+Transformer谣言检测系统
任务:构建一个多模态谣言检测模型。 数据集描述如下: 数据集包含以下模态: 谣言文本:谣言的核心文本信息。2. 配图:与谣言文本相关的图像数据;3. OCR 文本:可以通过 PaddleOCR 从配图中提取的…...

PostGreSQL/openGauss表膨胀处理
如果面试官问你,Oracle与PG/OG最大的区别是什么?你要是没回答出MVCC机制,表膨胀,那你多半挂了。 在PG/OG数据库中,命令vacuum full,插件pg_repack用于处理表膨胀,但是别高兴得太早,如…...

视频融合平台EasyCVR搭建智慧粮仓系统:为粮仓管理赋能新优势
一、项目背景 当前粮仓管理大多仍处于原始人力监管或初步信息化监管阶段。部分地区虽采用了简单的传感监测设备,仍需大量人力的配合,这不仅难以全面监控粮仓复杂的环境,还容易出现管理 “盲区”,无法实现精细化的管理。而一套先进…...

基于 Node.js 和 Spring Boot 的 RSA 加密登录实践
在当今的互联网应用开发中,用户数据的安全性至关重要。登录功能作为用户进入系统的第一道防线,其安全性更是不容忽视。本文将介绍一种基于 RSA 加密的登录方案,前端使用 Node.js 的 node-forge 库对密码进行公钥加密,后端使用 Spr…...

jupyter在Pycharm中遇到的一个问题
jupyter比较简洁,可以分块执行,下面显示结果,还能用Markdown写注释,总体来说来还是比较好用的。 但是遇到了一个奇怪的问题,从一个py文件中导入一个函数,结果输出为None。但是如果直接把这个函数的内容复制…...

十二、buildroot系统 adb登录权限设置
4.6.4、adb权限设置 android-adbd 是 ADB(Android Debug Bridge)的守护进程,允许开发者远程访问和调试设备。它通常用于 Android 设备,但在嵌入式 Linux上,也可以用来提供远程 shell、文件传输和应用调试功能。 …...

MySQL、Oracle 和 PostgreSQL 是三种主流的关系型数据库的主要原理性差异分析
MySQL、Oracle 和 PostgreSQL 是三种主流的关系型数据库,它们在底层原理和设计哲学上存在显著差异,尤其在存储引擎、事务处理、并发控制、索引结构、复制机制等方面。以下是它们的主要原理性差异分析: 1. 存储引擎与架构设计 MySQL 多存储引…...

【AI开源大模型工具链ModelEngine】【01】应用框架-源码编译运行
ModelEngine提供从数据处理、知识生成,到模型微调和部署,以及RAG(Retrieval Augmented Generation)应用开发的AI训推全流程工具链。 GitCode开源地址:https://gitcode.com/ModelEngineGitee开源地址:https…...

一文掌握 google浏览器插件爬虫 的制作
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、技术栈1. 前端技术(浏览器插件开发)2. 爬虫技术3. 后端(可选)4. 整体技术栈组成二、开发步骤1. 创建 Chrome 插件基础结构(1)`manifest.json` 配置(2)前端页面(`popup.html`)(3)前端逻辑(`popup.js`)…...

【leetcode 100】贪心Java版本
划分字母区间 题目 我的思路:第一次没有一点思路,第二次看了官网思路后,写的以下答案,没有搞明白循环遍历, //是不对的以下: class Solution {public List<Integer> partitionLabels(String s) {Li…...

Linux用Wireshark进行Thread网络抓包关键步骤
用Nordic nRF52840 Dongle作为RCP配合Wireshark进行Thread网络抓包是debug Thread网络的有效工具之一,主要流程在这里,不再赘述:官方流程 但是按官方流程会卡在一个地方,第一次费劲解决后,今天在另一台机器重新配的时…...

项目管理中客户拒绝签字验收?如何处理和预防
客户拒绝签字验收?如何处理和预防?核心在于:正面沟通、证据留存、灵活应对、合同条款明确、阶段验收机制。其中正面沟通格外关键,如果在发现客户迟迟不愿签字时能够主动沟通,了解其顾虑或不满并迅速针对性解决…...

docker 修改镜像源教程
当在拉取镜像时报以下错误时,可以通过更换镜像源解决 rootlocalhost:/etc/docker# docker pull mysql Using default tag: latest Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for …...
)
【JAVA】十、基础知识“类和对象”干货分享~(三)
目录 1. 封装 1.1 封装的概念 1.2 访问限定符 public(公开访问) private(私有访问) 1.3 包 1.3.1 包的概念 1.3.2 导入包中的类 1.3.3 自定义包 2. static成员 2.1 static变量(类变量) 2.1.1 sta…...

Open GL ES -> SurfaceView + 自定义EGL实现OpenGL渲染框架
SurfaceView 自定义EGL实现OpenGL渲染 在Android开发中,当需要灵活控制OpenGL渲染或在多个Surface间共享EGL上下文时,自定义EGL环境是必要的选择 核心实现流程 -------------------- -------------------- -------------------- | 1. 创建Su…...

Solidity入门实战—web3
项目介绍 在这个项目中,我们建立一个小型智能合约应用,他允许用户向合约地址捐赠,允许合约所有者从合约中提取余额;并且还设定了捐赠的金额门槛;针对直接对地址进行的捐赠行为,我们也予以记录 源代码 ht…...

Open Scene Graph动画系统
OSG 提供了强大的动画功能,支持多种动画实现方式,从简单的变换动画到复杂的骨骼动画。以下是 OSG 动画系统的全面介绍: 1. 基本动画类型 1.1 变换动画 (Transform Animation) // 创建动画路径 osg::AnimationPath* createAnimationPath(co…...

无需libpacp库,BPF指令高效捕获指定数据包
【环境】无libpacp库的Linux服务器 【要求】高效率读取数据包,并过滤指定端口和ip 目前遇到两个问题 一是手写BPF,难以兼容,有些无法正常过滤二是性能消耗问题,尽可能控制到1% 大方向:过滤数据包要在内核层处理&…...

重回全面发展亲自操刀
项目场景: 今年工作变动,优化后在一家做国有项目的私人公司安顿下来了。公司环境不如以前,但是好在瑞欣依然可以每天方便的买到。人文氛围挺好,就是工时感觉有点紧,可能长期从事产品迭代开发,一下子转变做项…...

DimensionX
旨在通过可控的视频扩散模型从单张图像生成高质量的3D和4D场景。 1. 背景与问题 3D和4D生成的目标 3D生成:从单张或多张2D图像中重建出三维场景或物体,包含空间信息(长、宽、高)。4D生成:在3D的基础上加入时间维度&a…...

2025年04月08日Github流行趋势
项目名称:markitdown 项目地址url:https://github.com/microsoft/markitdown项目语言:Python历史star数:44895今日star数:1039项目维护者:afourney, gagb, sugatoray, PetrAPConsulting, l-lumin项目简介&a…...

数据结构与算法-数学-容斥原理,高斯消元解线性方程组
容斥原理 容斥原理用于计算多个集合的并集元素个数,公式为 ∣A1∪A2∪⋯∪An∣∑i1n∣Ai∣−∑1≤i<j≤n∣Ai∩Aj∣∑1≤i<j<k≤n∣Ai∩Aj∩Ak∣−⋯(−1)n−1∣A1∩A2∩⋯∩An∣ 举一个例题: 给定一个整数 nn 和 mm 个不同的质数 p1,p2,…,p…...

告别运动控制不同步:某车企用异构PLC实现99.98%焊接合格率
在长三角某新能源汽车电池工厂,工程师们正面临棘手的生产难题:随着产线速度提升到每分钟12个电芯,原有PLC系统开始频繁出现运动控制不同步现象。这直接导致极片焊接合格率从99.2%骤降至94.7%,每条产线日均损失超23万元。这个场景折…...

BetaFlight参数配置解读
BetaFlight参数配置解读 📌相关篇《Betaflight固件编译和烧录说明》🥕各型号已编译好的配置文件资源(.config):https://github.com/betaflight/unified-targets/tree/master/configs/default🌿各型号配置头…...

PowerBI累计分析
累计分析 累计分析主要有三种:年初至今(YTD)、季初至今(QTD)、月初至今(MTD)。DAX中计算累计的函数有两类:一类是datesytd、datesqtd、datesmtd,该类返回一个单列日期表…...

最新 OpenHarmony 系统一二级目录整理
我们在学习 OpenHarmony 的时候,如果对系统的目录结构了解,那么无疑会提升自己对 OpenHarmony 更深层次的认识。 于是就有了今天的整理。 首先在此之前,我们要获取源码 获取源码的方式 OpenHarmony 主干代码获取 方式一(推荐&am…...
)
多模态大语言模型arxiv论文略读(七)
MLLM-DataEngine: An Iterative Refinement Approach for MLLM ➡️ 论文标题:MLLM-DataEngine: An Iterative Refinement Approach for MLLM ➡️ 论文作者:Zhiyuan Zhao, Linke Ouyang, Bin Wang, Siyuan Huang, Pan Zhang, Xiaoyi Dong, Jiaqi Wang,…...

STM32单片机入门学习——第27节: [9-3] USART串口发送串口发送+接收
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.08 STM32开发板学习——第27节: [9-3] USART串口发送&串口发送接收 前言开发板说…...

【元表 vs 元方法】
元表 vs 元方法 —— 就像“魔法书”和“咒语”的关系 1. 元表(Metatable):魔法书 是什么? 元表是一本**“规则说明书”**,它本身是一个普通的 Lua 表,但可以绑定到其他表上,用来定义这个表应该…...

小型园区网实验
划分VLAN SW3 [sw3]vlan batch 2 3 20 30 [sw3]interface GigabitEthernet 0/0/1 [sw3-GigabitEthernet0/0/1]port link-type access [sw3-GigabitEthernet0/0/1]port default vlan 2 [sw3-GigabitEthernet0/0/1]int g0/0/2 [sw3-GigabitEthernet0/0/2]port link-type acces…...

python 数组append数组
在Python中,可以通过多种方式将一个数组(列表)添加到另一个数组(列表)中。以下是几种常见的方法: 1. 使用 append() 方法 append() 方法将一个数组作为整体添加到另一个数组的末尾。 list1 [1, 2, 3] l…...

从0到1:STM32 RTC定时器配置全流程
1. 什么是RTC? RTC(Real-Time Clock) 是嵌入式系统中用于提供独立计时功能的硬件模块,具有以下特点: 独立于主系统时钟(即使MCU进入低功耗模式仍可运行)提供日历功能(年/月/日/时/…...
Linux Ext2 文件系统与软硬链接)
(学习总结33)Linux Ext2 文件系统与软硬链接
Linux Ext2 文件系统与软硬链接 理解硬件磁盘、服务器、机柜、机房磁盘物理结构磁盘的逻辑结构实际过程 CHS 与 LBA 地址转换 引入文件系统引入 " 块 " 概念引入 " 分区 " 概念引入 " inode " 概念 ext2 文件系统宏观认识Block Group 块组与其内…...
_36)
LeetCode算法题(Go语言实现)_36
题目 给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。 路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点…...

牛客华为机试--HJ48 从单向链表中删除指定值的节点C++
题目描述 示例1 示例2 该题的核心是每来一组数据,都要从头开始找,找到数据后再插入。而不是直接在尾部插入数据。 上代码 #include <iostream> using namespace std;struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(nu…...

Jmeter 插件【性能测试监控搭建】
1. 安装Plugins Manager 1.1 下载路径: Install :: JMeter-Plugins.org 1.2 放在lib/ext目录下 1.3 重启Jmeter,会在菜单-选项下多一个 Plugins Manager菜单,打开即可对插件进行安装、升级。 2. 客户端(Jmeter端) 2.1 安装plugins manager…...

从攻防演练到AI防护:网络安全服务厂商F5的全方位安全策略
随着AI和云原生技术的蓬勃兴起,多云架构的广泛采用,企业内部IT系统正经历着翻天覆地的变化。在这个转型期,传统的攻击手段和防守策略正面临着巨大的挑战。基于此,用户需要跳出传统的思维模式,采取新的视角,…...

【Introduction to Reinforcement Learning】翻译解读5
4 核心算法 我们将算法分为三类:基于价值的方法、基于策略的方法和混合算法。 4.1 基于价值的方法Value-based 一个重要的突破是Q-learning的引入,它是一种无模型算法,被视为off-policy时间差分(TD)学习。TD学习无疑…...

Jmeter中的bzm-concurrency thread group 与普通线程组的区别
在 JMeter 中,bzm - Concurrency Thread Group(由 BlazeMeter 提供)和标准的 Thread Group 是两种不同的线程组实现,主要区别在于 并发控制模型 和 负载调节方式。以下是详细对比: 1. 核心区别 特性bzm - Concurrency Thread Group标准 Thread Group负载模型基于并发数(C…...

VBA将Word文档内容逐行写入Excel
如果你需要将Word文档的内容导入Excel工作表来进行数据加工,使用下面的代码可以实现: Sub ImportWordToExcel()Dim wordApp As Word.ApplicationDim wordDoc As Word.DocumentDim excelSheet As WorksheetDim filePath As VariantDim i As LongDim para…...

ubuntu22部署 3d-tiles-tools
安装fnm curl -fsSL https://fnm.vercel.app/install | bash安装nodejs 20.17.0LTS版本 https://nodejs.org/zh-cn/download/package-manager安装依赖包 # Download and install nvm: curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.2/install.sh | bash# in…...

WebStrom关闭模板字符串自动转换
WebStrom关闭模板字符串自动转换 Editor > General > smart Keys > JavaScript > Automatically replace string literal with template string on typing "${"...

【零基础入门unity游戏开发——动画篇】新动画Animator的使用 —— AnimatorController和Animator的使用
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

npx vite 可以成功运行,但 npm run dev 仍然报错 Missing script: “dev“
npx vite 可以成功运行,但 npm run dev 仍然报错 Missing script: "dev",说明问题可能出在 npm 的脚本解析 或 项目配置 上。以下是具体解决方案: 1. 检查 package.json 的物理位置 可能原因: 你当前运行的目录下可能有一个 无效的 package.json,而真正的 packa…...

Java 泛型的逆变与协变:深入理解类型安全与灵活性
泛型是 Java 中强大的特性之一,它提供了类型安全的集合操作。然而,泛型的类型关系(如逆变与协变)常常让人感到困惑。 本文将深入探讨 Java 泛型中的逆变与协变,帮助你更好地理解其原理和应用场景。 一、什么是协变与…...

C语言核心知识点整理:结构体对齐、预处理、文件操作与Makefile
目录 结构体的字节对齐预处理指令详解文件操作基础Makefile自动化构建总结 1. 结构体的字节对齐 字节对齐原理 内存对齐:CPU访问内存时,对齐的地址能提高效率。操作系统要求变量按类型大小对齐。对齐规则: 每个成员的起始地址必须是min(成…...

深度学习|注意力机制
一、注意力提示 随意:跟随主观意识,也就是指有意识。 注意力机制:考虑“随意线索”,有一个注意力池化层,将会最终选择考虑到“随意线索”的那个值 二、注意力汇聚 这一部分也就是讲第一大点中“注意力汇聚”那个池化…...

特权FPGA之乘法器
完整代码如下: timescale 1ns / 1ps// Company: // Engineer: // // Create Date: 23:08:36 04/21/08 // Design Name: // Module Name: mux_16bit // Project Name: // Target Device: // Tool versions: // Description: // // Dependencies: …...

安全的企业局域网聊天工具哪个好用?
在当今数字化时代,企业对于局域网聊天工具的需求日益增长,尤其是在对数据安全和定制化服务有较高要求的大中型政企单位中。安全的企业局域网聊天工具哪个好用?虽然市面上有很多即时通讯软件,今天来介绍一下已经拥有十年行业经验的…...

如何应对客户频繁变更需求
如何应对客户频繁变更需求?要点包括: 快速响应、深入沟通、灵活规划、过程记录、风险管控。这些策略既能降低项目失控风险,也能帮助团队在变动环境中保持高效率。其中深入沟通尤为关键,它不仅能够让团队第一时间了解客户意图&…...