机器学习 Day09 线性回归
1.线性回归简介
线性回归知识讲解
- 定义与公式
- 定义:线性回归是利用回归方程(函数)对自变量(特征值)和因变量(目标值)之间关系进行建模的分析方式 。自变量只有一个时是单变量回归,超过一个就是多元回归。
- 公式:
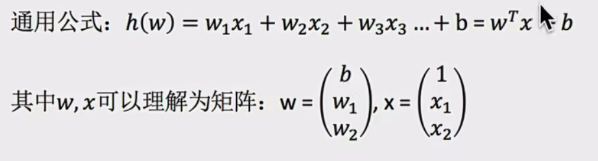
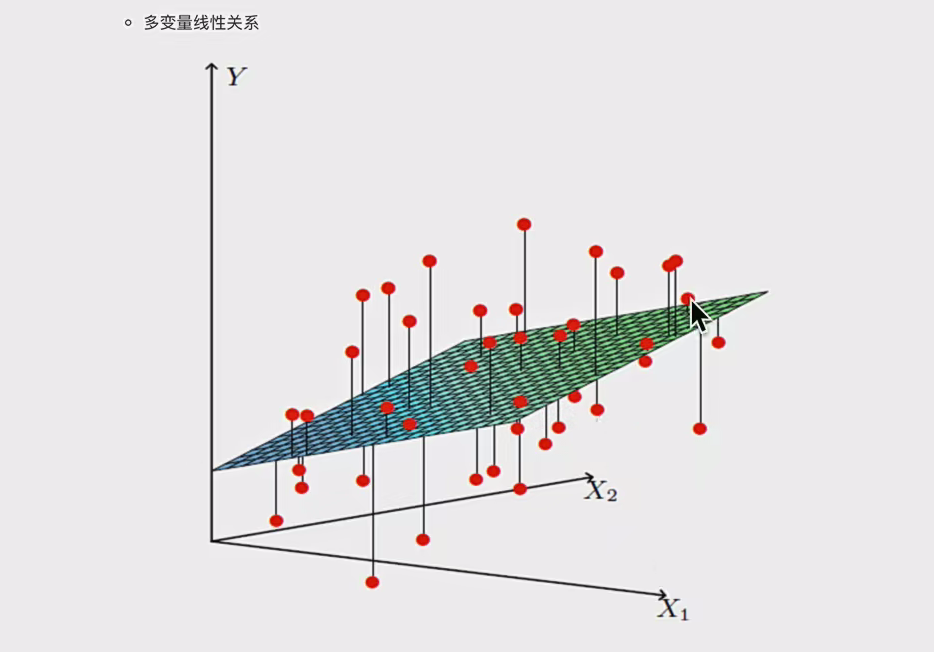
- 特征与目标的关系分析 线性回归模型分线性关系和非线性关系。单变量线性关系中,像房子面积和房子价格,从图中散点分布能看出大致呈直线趋势,说明两者存在线性相关关系,可通过线性回归方程拟合这条直线来描述它们之间的数量关系,进而预测房价等 。非线性关系则不呈现这种直线特征,其关系更复杂。比如:
再比如非线性关系: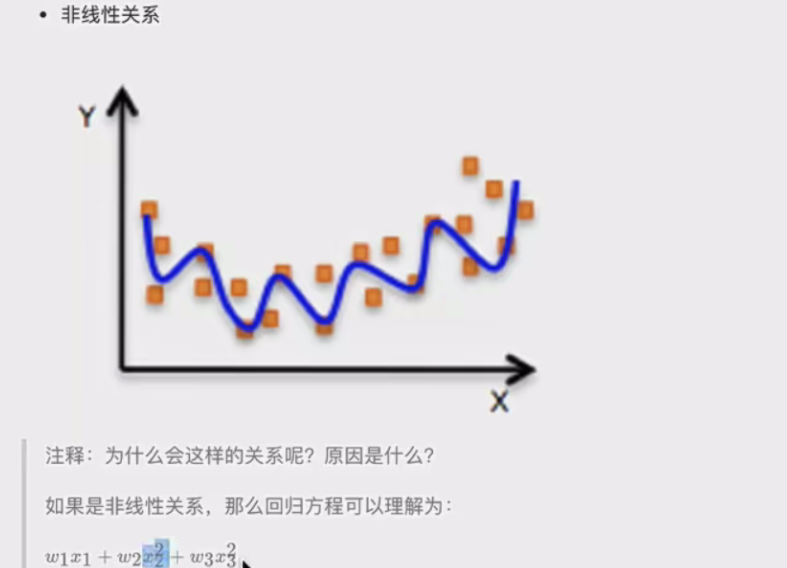
2.回归的损失和优化:
- 损失函数
- 定义:总损失
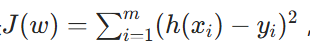 ,其中yi是第i个训练样本真实值 ,h(xi)是第i个训练样本特征值组合预测函数 。它衡量了预测值与真实值之间的误差,通过最小化这个损失函数,能让模型预测更准确,也被称为最小二乘法。(其实还有其他定义这个误差的办法)
,其中yi是第i个训练样本真实值 ,h(xi)是第i个训练样本特征值组合预测函数 。它衡量了预测值与真实值之间的误差,通过最小化这个损失函数,能让模型预测更准确,也被称为最小二乘法。(其实还有其他定义这个误差的办法)
- 定义:总损失
- 优化算法
- 正规方程
- 公式:
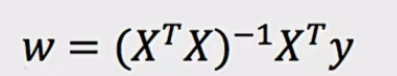 ,X为特征值矩阵(就是我们的数据,不包括标签值),y为目标值矩阵 。可直接求解得到使损失最小的参数w。
,X为特征值矩阵(就是我们的数据,不包括标签值),y为目标值矩阵 。可直接求解得到使损失最小的参数w。 - 缺点:当特征过多过复杂时,计算逆矩阵求解速度慢,甚至可能无法得到结果。所以正规方程适合小规模数据,梯度下降适合大规模数据
- 正规方程的推导:其实第一行最后一项是xw-y(n*1)矩阵每行平方求和,简写为那样

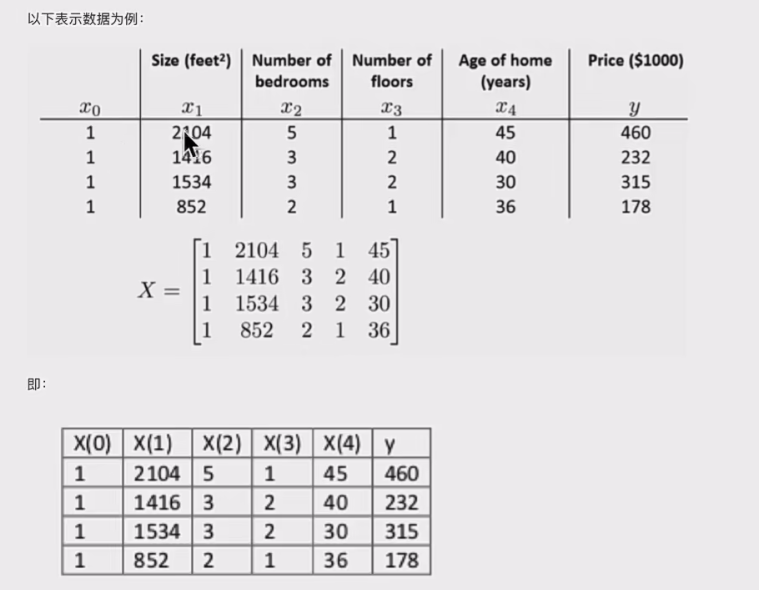
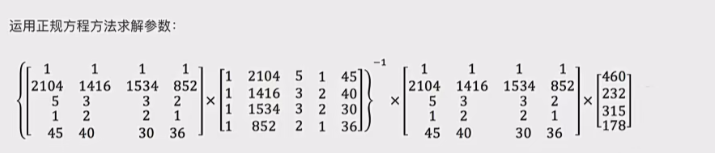
- 案例:
- 公式:
- 梯度下降
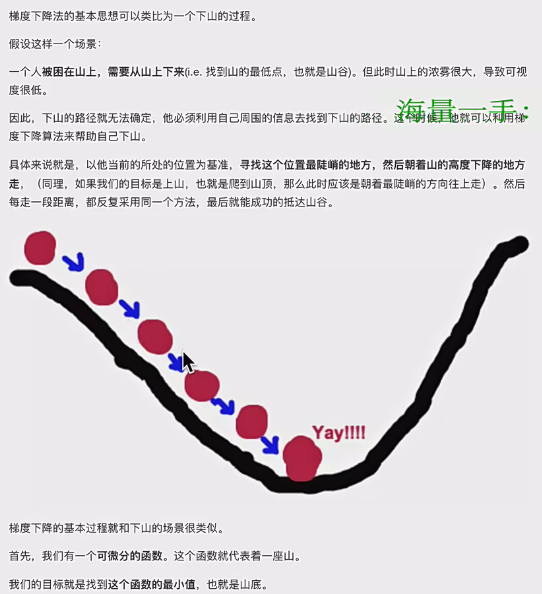
- 基本思想:类比下山过程,以当前位置为基准,寻找最陡峭方向(即梯度方向),朝着梯度相反方向走(因为梯度方向是函数上升最快方向,其反方向是下降最快方向),重复此过程找到函数最小值 。其实就是我们运筹学中讲过的优化办法的框架中方向的特定情况(牛顿法):1.确定初始位置 2.确定方向t 3.确定步长a 4.确定终止条件,迭代公式为当前位置=过去位置+at,梯度下降就是方向是梯度。
- 梯度概念:单变量函数中,梯度是函数微分,代表给定点切线斜率;多变量函数中,梯度是向量,其方向是函数上升最快方向 。
- 公式:
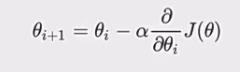 。其中a是学习率(步长),控制每次更新的幅度 ,a太大会错过最低点,太小则收敛缓慢;梯度前乘负号,是为了朝着梯度相反方向(即函数下降最快方向)更新参数。
。其中a是学习率(步长),控制每次更新的幅度 ,a太大会错过最低点,太小则收敛缓慢;梯度前乘负号,是为了朝着梯度相反方向(即函数下降最快方向)更新参数。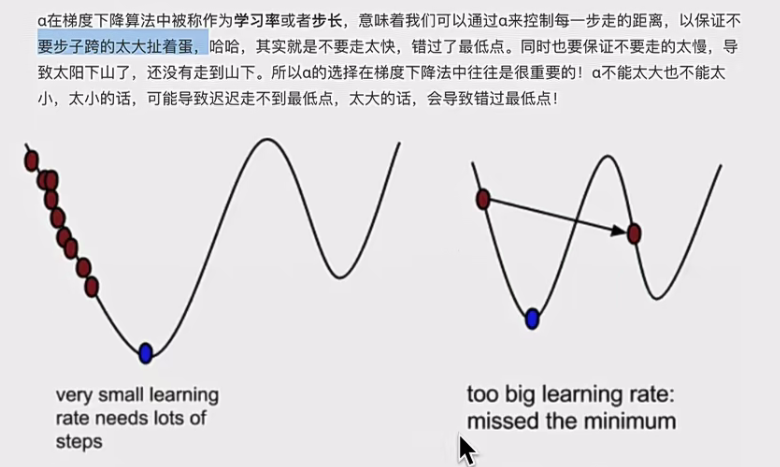
- 案例:

- 基本思想:类比下山过程,以当前位置为基准,寻找最陡峭方向(即梯度方向),朝着梯度相反方向走(因为梯度方向是函数上升最快方向,其反方向是下降最快方向),重复此过程找到函数最小值 。其实就是我们运筹学中讲过的优化办法的框架中方向的特定情况(牛顿法):1.确定初始位置 2.确定方向t 3.确定步长a 4.确定终止条件,迭代公式为当前位置=过去位置+at,梯度下降就是方向是梯度。
- 正规方程
3.梯度下降法详解

3.1推导流程:

3.2分类
梯度下降法家族算法总结6
- 全梯度下降算法(FG)
- 原理:计算训练集所有样本误差并求平均作为目标函数,利用所有样本计算损失函数关于参数theta的梯度,权重向量沿梯度反方向移动。公式为:
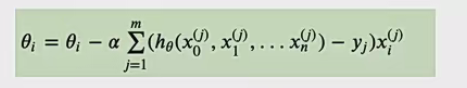
- 优缺点:优点是能准确朝着最优解方向更新;缺点是计算所有样本梯度,速度慢,无法处理超内存数据集,不能在线更新模型。
- 原理:计算训练集所有样本误差并求平均作为目标函数,利用所有样本计算损失函数关于参数theta的梯度,权重向量沿梯度反方向移动。公式为:
- 随机梯度下降算法(SG)
- 原理:每次只代入计算一个样本目标函数的梯度来更新权重,不断重复,直至损失函数值满足停止条件 。迭代公式为(无求和了):
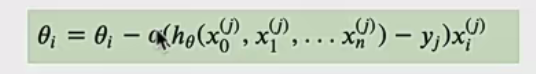
- 优缺点:优点是简单高效,可避免收敛到局部最优解;缺点是仅用单个样本迭代,遇噪声易陷入局部最优解 。
- 原理:每次只代入计算一个样本目标函数的梯度来更新权重,不断重复,直至损失函数值满足停止条件 。迭代公式为(无求和了):
- 小批量梯度下降算法(mini - batch)(结合FG和SG,随机拿出部分样本全部用于计算)
- 原理:从训练样本集随机抽取小样本集(batch_size 个样本 ),在小样本集上采用全梯度下降迭代更新权重 。迭代公式为:(从i到i+x-1求和说明就是选取了x个样本)

- 特点:是 FG 和 SG 的折中方案,batch_size 常设为 2 的幂次方利于 GPU 加速 ,batch_size = 1 时为 SG,batch_size = n(样本总数)时为 FG 。
- 原理:从训练样本集随机抽取小样本集(batch_size 个样本 ),在小样本集上采用全梯度下降迭代更新权重 。迭代公式为:(从i到i+x-1求和说明就是选取了x个样本)
- 随机平均梯度下降算法(SAG)
- 原理:内存中维护每个样本旧梯度,随机选样本更新其梯度,其他样本梯度不变,求所有梯度平均值更新参数 。迭代公式为
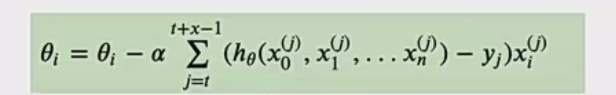
- 优缺点:计算成本与 SG 相当,但收敛速度快得多,兼具随机性与确定性,计算成本低于 mini - batch sgd 。
- 原理:内存中维护每个样本旧梯度,随机选样本更新其梯度,其他样本梯度不变,求所有梯度平均值更新参数 。迭代公式为
4.API介绍(和其他一样,先会生成一个对象,然后再用对象的方法)以及回归评估
4.1 API介绍偏置就是那个回归方程中的常数,SGD函数里边的正则化和loss函数以后会讲,这里采用的loss是我们讲的最小二乘法。

SGDRegressor(max_iter=1000)表示最多迭代1000次
4.2回归误差如何衡量:

MSE是最小二乘法的目标函数!!!

4.3 案例:
正归法案例:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_errordef linear_model1():"""线性回归:正规方程:return:None"""# 1.获取数据data = load_boston()# 2.数据集划分x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)# 3.特征工程-标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(正规方程)estimator = LinearRegression()estimator.fit(x_train, y_train)# 5.模型评估# 5.1 获取系数等值y_predict = estimator.predict(x_test)print("预测值为:\n", y_predict)print("模型中的系数为:\n", estimator.coef_)print("模型中的偏置为:\n", estimator.intercept_)# 5.2 评价# 均方误差error = mean_squared_error(y_test, y_predict)print("误差为:\n", error)return None梯度下降法案例:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_errordef linear_model2():"""线性回归:梯度下降法:return:None"""# 1.获取数据data = load_boston()# 2.数据集划分x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)# 3.特征工程-标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(梯度下降)estimator = SGDRegressor(max_iter=1000)estimator.fit(x_train, y_train)# 5.模型评估# 5.1 获取系数等值y_predict = estimator.predict(x_test)print("预测值为:\n", y_predict)print("模型中的系数为:\n", estimator.coef_)print("模型中的偏置为:\n", estimator.intercept_)# 5.2 评价# 均方误差error = mean_squared_error(y_test, y_predict)print("误差为:\n", error)return None6.欠拟合和过拟合
- 定义
- 过拟合:模型在训练集上拟合效果好,但在测试集上表现差 ,原因是模型过于复杂,捕捉到了训练数据中的噪声和特殊细节 。
- 欠拟合:模型在训练集和测试集上拟合效果都不好 ,是因为模型过于简单,无法学习到数据中的规律 。
- 原因及解决办法
- 欠拟合
- 原因:学习到的数据特征过少 。
- 解决办法:添加其他特征项,如 “组合”“泛化”“相关性” 特征 ,以及上下文、平台特征等;添加多项式特征,提升模型泛化能力 。
- 过拟合
- 原因:原始特征过多,存在嘈杂特征 ,模型为兼顾各测试数据点变得复杂 。
- 解决办法:重新清洗数据;增大训练量;采用正则化;减少特征维度 。
- 欠拟合
- 正则化(过拟合的处理)
- 概念:在训练过程中,让算法尽量减少某些影响模型复杂度或异常数据多的特征的作用 ,通过调整参数优化结果,而非直接识别特定特征影响 。
- 类别
- L2 正则化:使部分权重W趋近于 0 ,削弱特征影响 ,对应 Ridge (岭)回归 。
- L1 正则化:使部分权重W直接为 0 ,删除特征影响 ,对应 LASSO 回归 。
7.正则化详解(这些回归都是不同类型的损失函数,前面讲的梯度下降法是求解最优值的办法。)

一些补充:
关于l1正则化lasso回归的导数:
知道api即可,着重讲岭回归,因为经常用。。很少用普通的回归。
正则就相当于惩罚力度,越大则权重越小,就能处理过拟合。


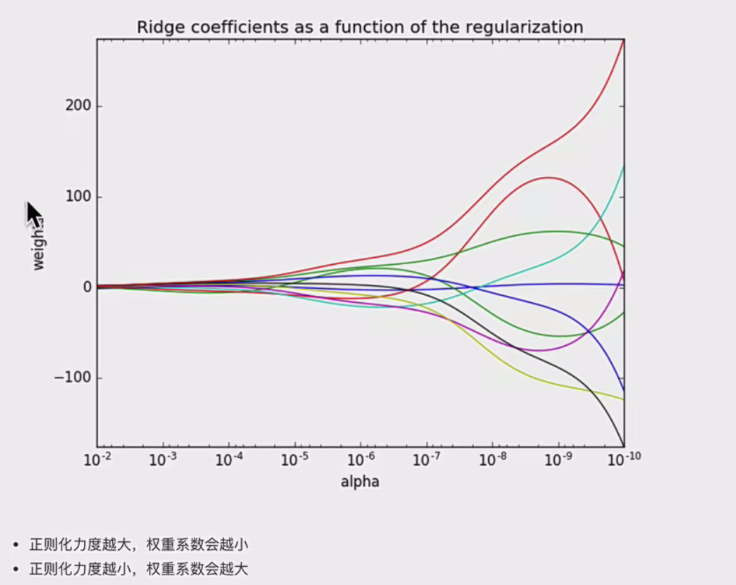
8.岭回归详解

这个api函数可以自己进行标准化。
案例:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_errordef linear_model3():"""线性回归:岭回归:return:"""# 1.获取数据data = load_boston()# 2.数据集划分x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)# 3.特征工程-标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(岭回归)estimator = Ridge(alpha=1)estimator.fit(x_train, y_train)# 5.模型评估# 5.1 获取系数等值y_predict = estimator.predict(x_test)print("预测值为:\n", y_predict)print("模型中的系数为:\n", estimator.coef_)print("模型中的偏置为:\n", estimator.intercept_)# 5.2 评价# 均方误差error = mean_squared_error(y_test, y_predict)print("误差为:\n", error)return Noneif __name__ == '__main__':linear_model3()9.模型的加载和保存
很简单就是调用函数就行。后面是路径

还是上面的案例:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
import joblibdef load_dump_demo():"""模型保存和加载:return:"""# 1.获取数据data = load_boston()# 2.数据集划分x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)# 3.特征工程-标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.fit_transform(x_test)# 4.机器学习-线性回归(岭回归)# 4.1 模型训练estimator = Ridge(alpha=1)estimator.fit(x_train, y_train)# 4.2 模型保存joblib.dump(estimator, "./data/test.pkl")# 4.3 模型加载estimator = joblib.load("./data/test.pkl")# 5.模型评估# 5.1 获取系数等值y_predict = estimator.predict(x_test)print("预测值为:\n", y_predict)print("模型中的系数为:\n", estimator.coef_)print("模型中的偏置为:\n", estimator.intercept_)# 5.2 评价# 均方误差error = mean_squared_error(y_test, y_predict)print("误差为:\n", error)return Noneif __name__ == '__main__':load_dump_demo()相关文章:

机器学习 Day09 线性回归
1.线性回归简介 线性回归知识讲解 定义与公式 定义:线性回归是利用回归方程(函数)对自变量(特征值)和因变量(目标值)之间关系进行建模的分析方式 。自变量只有一个时是单变量回归,…...

2025高频面试算法总结篇【字符串】
文章目录 直接刷题链接直达如何找出一个字符串中的最大不重复子串给定一个数,删除K位得到最大值字符串的排列至少有K个重复字符的最长子串 直接刷题链接直达 如何找出一个字符串中的最大不重复子串 滑动窗口 --> 滑动窗口直到最后一个元素,每当碰到重…...
)
JavaScript性能优化(上)
1. 减少 DOM 操作 减少 DOM 操作是优化 JavaScript 性能的重要方法,因为频繁的 DOM 操作会导致浏览器重绘和重排,从而影响性能。以下是一些具体的策略和技术,可以帮助有效减少 DOM 操作: 1.1. 批量更新 DOM 亲切与母体ÿ…...
)
数据结构与算法——链表OJ题详解(1)
文章目录 一、前言二、OJ题分享2.1移除链表元素——非val尾插法2.2反转链表2.2.1头插法2.2.2三指针法 2.3链表的中间结点——快慢指针法2.4合并两个有序链表2.4.1空链表法2.4.2非空链表法 2.5链表的回文结构2.5.1投机取巧数组法2.5.2反转链表法 三、总结 一、前言 前几天博主已…...

sedex认证2025年变化重点
近日,SEDEX突然宣布:2025年7月1日起,全通知审核正式退出历史舞台,取而代之的是至少3周窗口期的半通知突击审核。这场被业内称为“供应链透明化革命”的调整,或将重塑全球工厂合规生态。 三大变化划重点: 1…...
)
Scala课后总结(8)
集合计算高级函数 过滤(filter) 从集合里挑出符合特定条件元素组成新集合 。比如从整数集合里选出偶数, list.filter(x > x % 2 0) ,就是筛选出能被2整除的元素。 转化/映射(map) 对集合每个元素应…...
物联网版)
老硬件也能运行的Win11 IoT LTSC (OEM)物联网版
#记录工作 Windows 11 IoT Enterprise LTSC 2024 属于物联网相关的版本。 Windows 11 IoT Enterprise 是为物联网设备和场景设计的操作系统版本。它通常针对特定的工业控制、智能设备等物联网应用进行了优化和定制,以满足这些领域对稳定性、安全性和长期支持的需求…...

蓝桥杯冲刺题单--二分
二分 知识点 二分: 1.序列二分:在序列中查找(不怎么考,会比较难?) 序列二分应用的序列必须是递增或递减,但可以非严格 只要r是mid-1,就对应mid(lr1)/2 2.答…...

计网 2025/4/8
CDMA? CRC循环冗余检验 PPP协议的帧格式 字节填充(异步传输、7E->7D5E)零比特填充(同步传输、确保不会出现连续6个1) CSMA/CD协议 多点接入载波监听碰撞检测 一些概念: 争用期 一些公式: 最短有效帧…...

java设计模式-工厂模式
工厂模式 简单工厂模式 请看类: org.xwb.springcloud.factory.simple.PizzaStore 1、简单工厂模式是属于创建型模式,是工厂模式的一种,简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实力。简单来工厂模式就是工厂模式家族中最简单最…...

2025年客运从业资格证备考刷题题库
题库中通常包含大量的题目,以全面覆盖考试的知识点。通过做大量的题目,考生可以熟悉各种考试题型和命题方式,提高答题的速度和准确性,同时也能发现自己在知识掌握上的薄弱环节,有针对性地进行复习和强化训练。 1、驾驶…...

Zephyr、FreeRTOS、RT-Thread 任务创建对比分析
一、任务模型与核心概念 特性ZephyrFreeRTOSRT-Thread任务术语线程(Thread)任务(Task)线程(Thread)执行单元线程(单地址空间)任务(共享内存空间)线程&#x…...

RK-realtime Linux
rk3562实时性数据:最大76us rk3568实时性数据:最大126us rk3588实时性数据:最大30us 注意事项 (1)RK3568 需要使用RT版本的BL31,实时性能更好 a)rkbin需要更新到最新,且包含这个补丁:...
之1)
Ubuntu 22 Linux上部署DeepSeek+RAG知识库操作详解(Dify方式)之1
一、安装Docker 1. 更新你的包索引 首先,确保你的包列表是最新的。打开终端并运行以下命令: sudo apt update 2. 安装必要的依赖项 安装Docker之前,你需要安装一些必要的依赖项。运行以下命令来安装它们: sudo apt install apt…...

将飞帆制作的网页作为 div 集成到自己的网页中
并且自己的网页可以和飞帆中的控件相互调用函数。效果: 上链接 将飞帆制作的网页作为 div 集成到自己的网页中 - 文贝 进入可以复制、运行代码...
AABB/OBB碰撞检测)
【C++游戏引擎开发】《几何算法》(3)AABB/OBB碰撞检测
一、AABB(轴对齐包围盒) 1.1 定义 最小点: m i n = ( x min , y min , z min ) \mathbf{min} = (x_{\text{min}}, y_{\text{min}}, z_{\text{min}}) min=(xmin,ymin,zmin)最大点: m a x = ( x max , y max , z max ) \mathbf{max} = (x_{\text{max}}, y_{\text{…...

基于人工智能的高中教育评价体系重构研究
基于人工智能的高中教育评价体系重构研究 一、引言 1.1 研究背景 在科技飞速发展的当下,人工智能技术已广泛渗透至各个领域,教育领域亦不例外。人工智能凭借其强大的数据处理能力、智能分析能力和个性化服务能力,为教育评价体系的创新与发…...
、CGAL(几何计算)的安装与使用指南)
【C++游戏引擎开发】数学计算库GLM(线性代数)、CGAL(几何计算)的安装与使用指南
写在前面 两天都没手搓实现可用的凸包生成算法相关的代码,自觉无法手搓相关数学库,遂改为使用成熟数学库。 一、GLM库安装与介绍 1.1 vcpkg安装GLM 跨平台C包管理利器vcpkg完全指南 在PowerShell中执行命令: vcpkg install glm# 集成到系…...
)
Python 字典和集合(常见的映射方法)
本章内容的大纲如下: 常见的字典方法 如何处理查找不到的键 标准库中 dict 类型的变种set 和 frozenset 类型 散列表的工作原理 散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的 顺序,等等) 常见的映射方法 映射类型…...
对比)
Qt 自带的QSqlDatabase 模块中使用的 SQLite 和 SQLite 官方提供的 C 语言版本(sqlite.org)对比
Qt 自带的 QSqlDatabase 模块中使用的 SQLite 和 SQLite 官方提供的 C 语言版本(sqlite.org)在核心功能上是相同的,但它们在集成方式、API 封装、功能支持以及版本更新上存在一些区别。以下是主要区别: 1. 核心 SQLite 引擎 Qt 的…...

按键长按代码
这些代码都存放在定时器中断中。中断为100ms中断一次。 数据判断,看的懂就看吧...

zk源码—3.单机和集群通信原理一
大纲 1.单机版的zk服务端的启动过程 (1)预启动阶段 (2)初始化阶段 2.集群版的zk服务端的启动过程 (1)预启动阶段 (2)初始化阶段 (3)Leader选举阶段 (4)Leader和Follower启动阶段 1.单机版的zk服务端的启动过程 (1)预启动阶段 (2)初始化阶段 单机版zk服务端的启动&…...

车企数字化转型:从“制造工厂”到“移动科技平台”的升维路径
一、战略重构:政策与产业变革的双重倒逼 中国《智能网联汽车技术路线图2.0》明确要求2030年L4级自动驾驶新车渗透率达20%,而麦肯锡数据显示,全球车企数字化投入占比已从2018年的7%跃升至2025年的18%。当前车企面临三大核心挑战:用…...
-https-server-openssl)
C++-Mongoose(2)-https-server-openssl
OpenSSL生成HTTPS自签名证书 - 简书 1.Openssl windowsubuntu下载http://www.openssl.vip/download1.VS2019编译OpenSSL 2.VS2019编译第一个OpenSSL项目 1.ubuntu编译OpenSSL 3.0 2.编写第一个OpenSSL 1.windows下编译OpenSSL 安装vs2019 perl nasm安装activePerl…...

nginx正向代理https
一、需求 公司内部服务器向外访问腾讯接口:https://qyapi.weixin.qq.com/cgi-bin,不能使用http直接访问。并且不支持域名,还需要设置互联网出口-出向白名单ip。 如何在尽量少改动代码的情况下实现应用的出向访问链接,考虑使用正向…...
浅讲)
Flask中的蓝图(Blueprint)浅讲
BluePrint Flask中的蓝图(Blueprint)是一种强大的组织工具,能够将大型应用拆分为可重用的模块化组件 1. 模块化组织 用途:将应用按功能拆分为独立模块,提升代码可维护性。示例: # user/views.py fr…...

虚拟表、TDgpt、JDBC 异步写入…TDengine 3.3.6.0 版本 8 大升级亮点
近日,TDengine 3.3.6.0 版本正式发布。除了此前已亮相的时序数据分析 AI 智能体 TDgpt,本次更新还带来了多个针对性能与易用性的重要增强:虚拟表全面上线,支持更灵活的一设备一表建模;JDBC 写入机制全新升级࿰…...

大型语言模型智能应用Coze、Dify、FastGPT、MaxKB 对比,选择合适自己的LLM工具
大型语言模型智能应用Coze、Dify、FastGPT、MaxKB 对比,选择合适自己的LLM工具 Coze、Dify、FastGPT 和 MaxKB 都是旨在帮助用户构建基于大型语言模型 (LLM) 的智能应用的平台。它们各自拥有独特的功能和侧重点,以下是对它们的简要对比: Coz…...

WEB安全--XSS--DOM破坏
一、前言 继XSS基础篇后,我们知道了三种类型的XSS,这篇文章主要针对DOM型XSS的原理进行深入解析。 二、DOM型XSS原理 2.1、什么是DOM 以一个形象的比喻: 网页就像是一座房子,而 **DOM** 就是这座房子的“蓝图”或者“结构图”。…...

持续集成:GitLab CI/CD 与 Jenkins CI/CD 的全面剖析
一、引言 在当今快速迭代的软件开发领域,持续集成(Continuous Integration,CI)已成为保障软件质量、加速开发流程的关键实践。通过频繁地将代码集成到共享仓库,并自动进行构建和测试,持续集成能够尽早发现并解决代码冲突和缺陷。而 GitLab CI/CD 和 Jenkins CI/CD 作为两…...

Go语言sync.Mutex包源码解读
互斥锁sync.Mutex是在并发程序中对共享资源进行访问控制的主要手段,对此Go语言提供了非常简单易用的机制。sync.Mutex为结构体类型,对外暴露Lock()、Unlock()、TryLock()三种方法,分别用于阻塞加锁、解锁、非阻塞加锁操作(加锁失败…...

FreeRTOS软件定时器
软件定时器就是"闹钟",你可以设置闹钟, 用软件定时器的话USE_TIMER要设置为1 在30分钟后让你起床工作每隔1小时让你例行检查机器运行情况 软件定时器也可以完成两类事情: 在"未来"某个时间点,运行函数周期…...

Selenium三大等待
一、强制等待 1.设置完等待后不管有没有找到元素,都会执行等待,等待结束后才会执行下一步 2.实例: driver webdriver.Chrome()driver.get("https://www.baidu.com")time.sleep(3) # 设置强制等待driver.quit() 二、隐性等待 …...

【Ansible自动化运维】一、初步了解,开启自动化运维之旅
在当今数字化时代,随着企业 IT 基础设施规模的不断扩大,传统的手工运维方式逐渐显得力不从心。自动化运维技术应运而生,其中 Ansible 凭借其简洁易用、功能强大的特点,成为众多运维工程师和开发人员的首选工具。本篇文章将从基础概…...

雪花算法、md5加密
雪花算法生成ID是一个64位长整型(但是也可以通过优化简短位数) 组成部分: 时间戳 机器ID 序列号 用途: 分布式系统唯一ID生成:解决数据库自增ID在分布式环境下的唯一性问题、避免UUID的无序性和性能问题 有序性…...

micro介绍
micro介绍 Micro 的首要特点是易于安装(它只是一个静态的二进制文件,没有任何依赖关系)和易于使用Micro 支持完整的插件系统。插件是用 Lua 编写的,插件管理器可自动为你下载和安装插件。使用简单的 json 格式配置选项࿰…...

电视盒子 刷armbian
参考 中兴电视盒子中兴B860AV3.2-M刷Armbian新手级教程-CSDN博客 1.刷安卓9 带root版本 a. 下载安卓线刷包 链接:https://pan.baidu.com/s/1hz87_ld2lJea0gYjeoHQ8A?pwdd7as 提取码:d7as b.拆机短接 3.安装usbburning工具 使用方法 ,…...
lerobot开源项目so100新版本全流程操作(操作记录))
(七)lerobot开源项目so100新版本全流程操作(操作记录)
目录 《项目简介》 一、环境配置 1、创建虚拟环境 2、克隆项目并安装所需包 二、主从臂硬件准备 1、舵机配置 (1)分别查看主从臂的开发板端口号 (2)分别设置主从臂的舵机 2、组装主从臂 3、查看主从臂端口号和相机端…...

智慧景区能源管理解决方案,为旅游“升温”保驾护航
景区能源管理 当下痛点 1 高峰期用电负荷大 节假日和旅游旺季等高峰期用电需求增大,电力供应不足、电网负荷过大; 2 设备维护困难 景区内电力设备多且散,包括发电机组、变电站、配电设备等,维护和管理困难,特别是…...

LCR 056. 两数之和 IV - 输入二叉搜索树
文章目录 题意思路代码 题意 题目链接 思路 代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), …...

AI搜索+法律咨询:在「事实重构」与「程序正义」的博弈场
已经写了股票和医疗相关的内容,今天聊一下AI搜索和法律结合的应用场景。AI搜索不替用户做选择,却让我们握住了法律武器的说明书。 一、AI重构事实:技术理想与法律现实的碰撞 1、案例切入:AI能否还原车祸责任比…...

多模态大模型重塑自动驾驶:技术融合与实践路径全解析
目录 1、 引言:AI与自动驾驶的革命性融合 2、五大领先多模态模型解析 2.1 Qwen2.5-Omni:全模态集大成者 2.2. LLaVA:视觉语言理解专家 2.3. Qwen2-VL:长视频理解能手 2.4. X-InstructBLIP:跨模态理解框架 2.5. …...

海阳科技IPO:业务独立性、业绩稳定性、财务规范性存致命缺陷
三角形是最稳定的结构,它既是完美的相互制衡,又是有力的彼此支撑。 ——佚名 引 言 IPO审议指标、要求、规定众多,有无一个直接简单的公式?该公式可以直接将造假等“低劣”IPO项目排除在外? 在《奕泽财经》看来…...

PyTorch 与 Python 装饰器及迭代器的比较与应用
在深度学习和 Stable Diffusion(SD)训练过程中,PyTorch 不仅依赖于 Python 的基础特性,而且通过扩展和封装这些特性,提供了更高效、便捷的训练和推理方式。本文将从装饰器和迭代器两个方面详细解释 Python 中的原生实现…...
(基础概念)Spark从入门到实战:核心原理与大数据处理实战案例)
大数据(5)(基础概念)Spark从入门到实战:核心原理与大数据处理实战案例
目录 一、背景介绍1. 为什么需要Spark?2. Spark的诞生: 二、Spark核心原理1. 四大核心特性2. 核心架构3. 执行流程 三、Spark实战案例案例1:单词计数(WordCount)案例2:实时流处理&…...

Ubuntu小练习
文章目录 一、远程连接1、通过putty连接2、查看putty运行状态3、通过Puuty远程登录Ubuntu4、添加新用户查看是否添加成功 5、用新用户登录远程Ubuntu6、使用VNC远程登录树莓派 二、虚拟机上talk聊天三、Opencv1、简单安装版(适合新手安装)2、打开VScode特…...

运行Spark会出现恶问题
1. 依赖冲突问题:Spark依赖众多组件,如Scala、Hadoop等。不同版本的依赖之间可能存在兼容性问题,导致Spark无法正常运行。比如,特定版本的Spark可能要求与之匹配的Scala版本,若使用了不兼容的Scala版本,会在…...

uniapp大文件分包
1. 在pages.json中配置 "subPackages":[{"root":pagesUser,"pages":[{"path":mine/xxx,"style":xxx },{"path":mine/xxx,"style":xxx}]},{"root":pagesIndex,"pages":[{"p…...

Git 源码打包、迁移、恢复和备份
介绍 Git 项目打包方式,适用于源码交付、迁移、备份等场景。 一 Git 仓库的两种类型 在实际项目开发与交付中,常接触 的 两种 Git 仓库: 仓库类型是否包含源码适用场景普通仓库是本地开发、运行、构建裸仓库否代码托管、只读交付、备份 普…...

Linux 内核网络协议栈中的 struct packet_type:以 ip_packet_type 为例
在 Linux 内核的网络协议栈中,struct packet_type 是一个核心数据结构,用于注册特定协议类型的数据包处理逻辑。它定义了如何处理特定协议的数据包,并通过协议类型匹配机制实现协议分发。本文将通过分析 ip_packet_type 的定义和作用,深入探讨其在网络协议栈中的重要性。 …...