【深度学习:理论篇】--Pytorch基础入门
目录
1.Pytorch--安装
2.Pytorch--张量
3.Pytorch--定义
4.Pytorch--运算
4.1.Tensor数据类型
4.2.Tensor创建
4.3.Tensor运算
4.4.Tensor--Numpy转换
4.5.Tensor--CUDA(GPU)
5.Pytorch--自动微分 (autograd)
5.1.backward求导
5.1.1.标量Tensor求导
5.1.2.非标量Tensor求导
5.2.autograd.grad求导
5.3.求最小值
1.Pytorch--安装
配置环境经常是让各位同学头痛不已又不得不经历的过程,那么本小节就给大家提供一篇手把手安装PyTorch的教程。
首先,进入pytorch官网,点上方get started进入下载
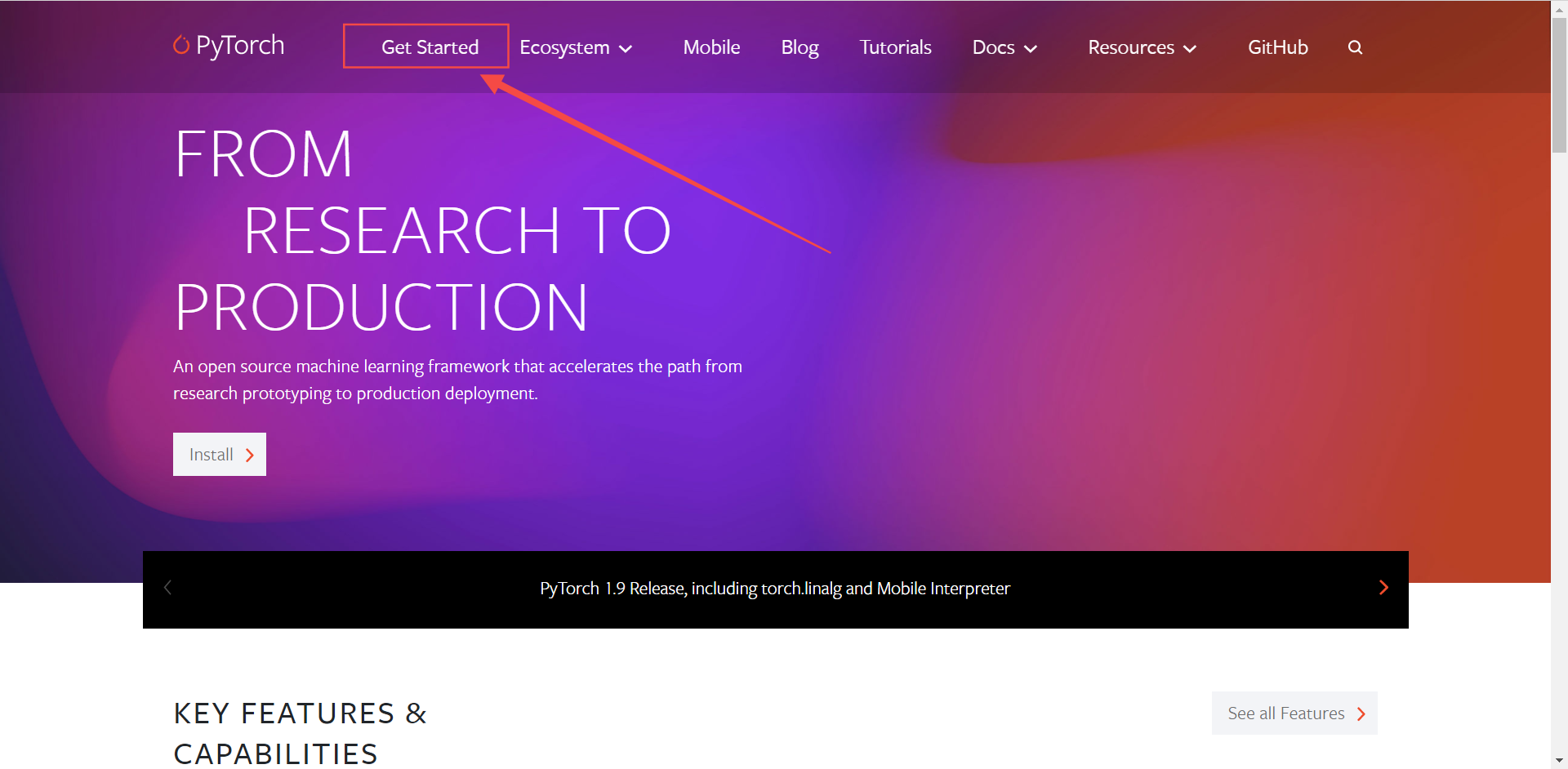
根据你的操作系统选择对应的版本,安装方式,CUDA版本等等。

这里作者的设备是window10,python3.8的运行环境,由于设备是AMD显卡不支持CUDA因此选择了CPU版本,后面关于CUDA是什么、有什么用我们会单独出一期教程讲解。
如果已经下载了anaconda 可以使用conda安装,没有下载就使用Pip安装,然后打开cmd将生成的命令语句复制到cmd上。
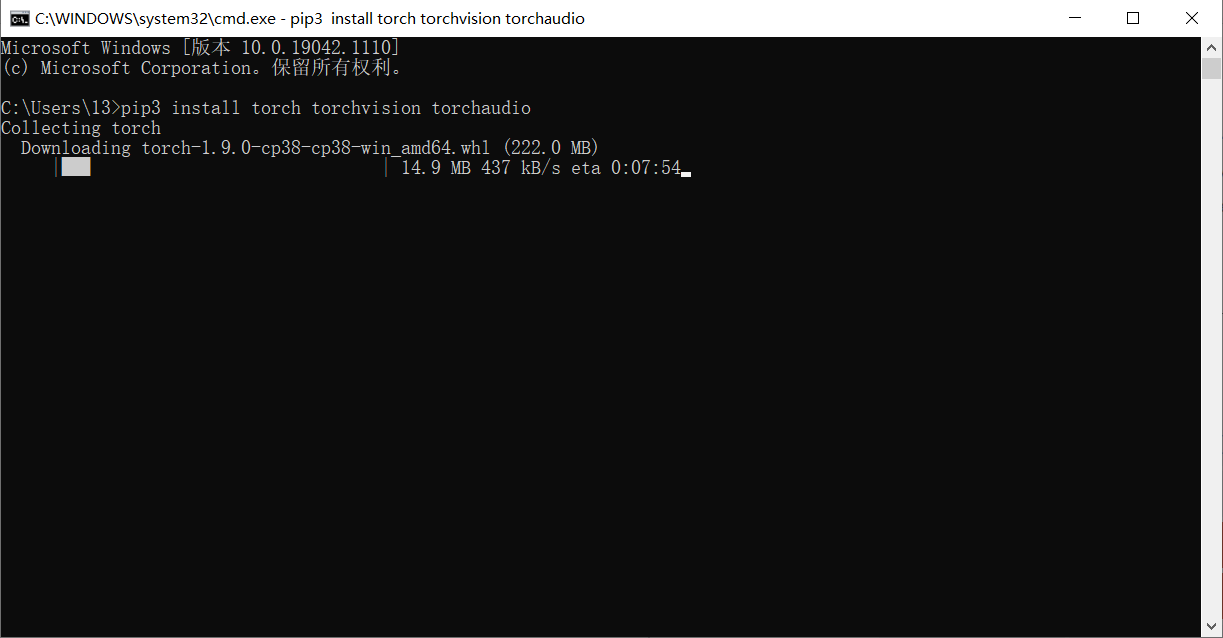
这里直接用 pip install 下载会比较慢,这边我们可以将源换掉,个人比较推荐阿里源和清华源
1pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/假如喜欢其他源的也可以换成其他源,将指令的网址换一下就好了
阿里云 Simple Index
中国科技大学 Verifying - USTC Mirrors
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 Simple Index
中国科学技术大学 Verifying - USTC Mirrors
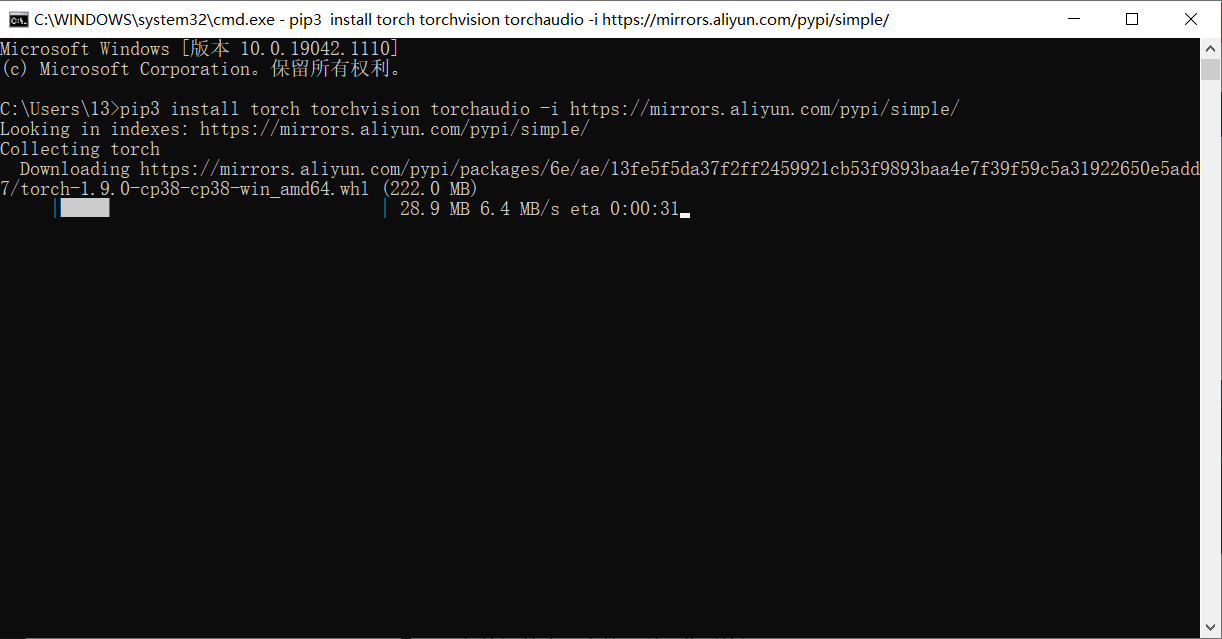
这里用了 -i 临时换源的方法,只对这次安装有效,如果你想一劳永逸的话请使用上面提到的换源方法。
![]()
出现这样的字段说明安装成功了
测试一下:
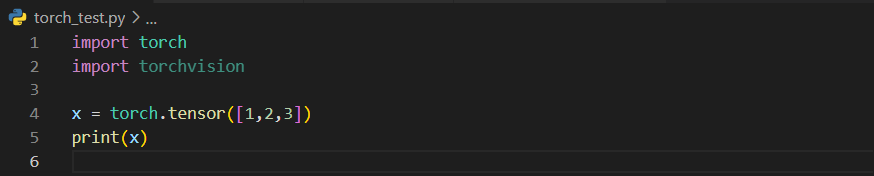
没有报错可以正常输出。
当时我们上面的操作是直接安装到真实环境中,我们更推荐你使用anaconda创建一个独立的环境
虚拟环境的创建,使用命令行:
1conda create -n pytorch(虚拟环境名) python=3.6激活环境:
1activate pytorch也可以使用pycharm创建:
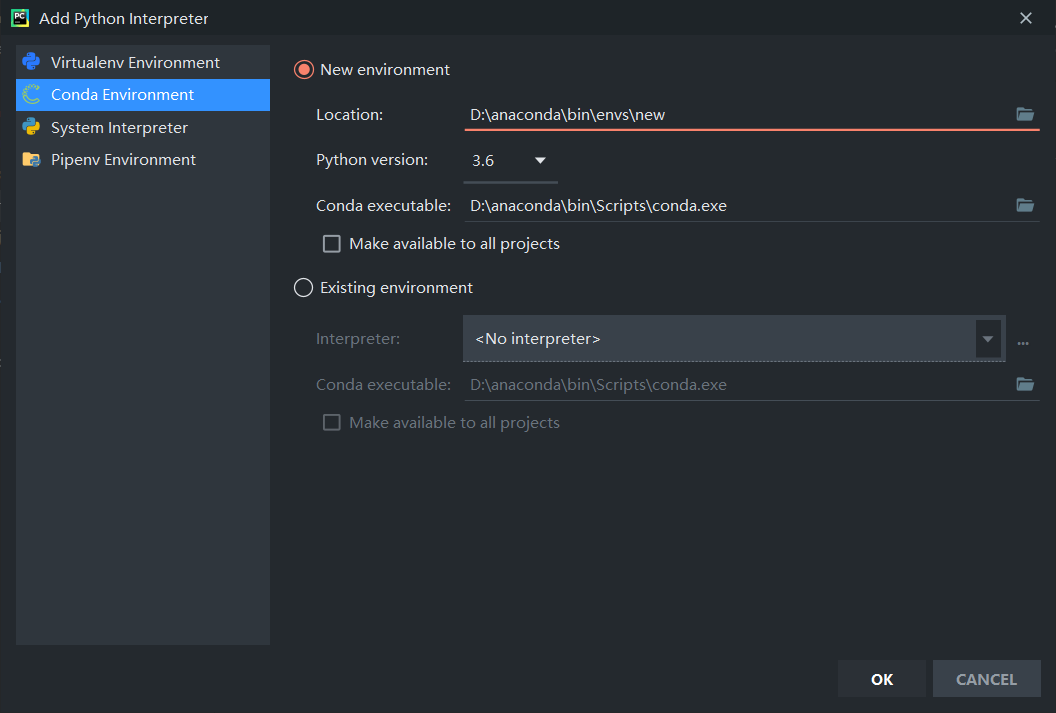
在这里选择环境名称和python版本。虽然虚拟环境很方便,但是对于有多个版本python的用户来说安装包的时候一定要在相应的python版本下的script的目录下进行pip,尽量使用pycharm安装,除非找不到或者安装很慢。因为一不小心容易把环境搞崩。
使用对应命令完成安装


2.Pytorch--张量
无论是 Tensorflow 还是我们接下来要介绍的 PyTorch 都是以**张量(tensor)**为基本单位进行计算的学习框架,第一次听说张量这个词的同学可能都或多或少困惑这究竟是个什么东西,那么在正式开始学习 PyTorch 之前我们还是花些时间简单介绍一下张量的概念。
学过线性代数的童鞋都知道,矩阵可以进行各种运算,比如:
- 矩阵的加法:

- 矩阵的转置:
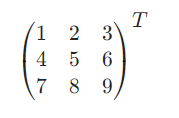
- 矩阵的点乘:

为了方便存储矩阵及进行矩阵之间的运算,大神们抽象出了 PyTorch 库,PyTorch 库中有一个类叫torch.Tensor,这个类存储了一个矩阵变量,并且有一系列方法用于对这个矩阵进行各种运算。上面的这些矩阵运算都可以通过 torch.Tensor 类的相应方法实现。
比如上面的矩阵加法:
import torch # 引入torch类
x = torch.rand(5, 3) # 生成一个5*3的矩阵x,矩阵的每个元素都是0到1之间的随机数,x的类型就是torch.Tensor,x里面存了一个5*3的矩阵
y = torch.zeros(5, 3, dtype=torch.float) # 生成一个5*3的矩阵y,矩阵的每个元素都是0,每个元素的类型是long型,y的类型就是torch.Tensor,y里面存了一个5*3的矩阵
y.add_(x) # 使用y的add_方法对y和x进行运算,运算结果保存到y上面的x、y的类型都是 torch.Tensor,Tensor 这个单词一般可译作“张量”。但是上面我们进行的都是矩阵运算,为什么要给这个类型起名字叫张量呢,直接叫矩阵不就行了吗?张量又是什么意思呢?
这是因为:通常我们不但要对矩阵进行运算,我们还会对数组进行运算(当然数组也是特殊的矩阵),比如两个数组的加法:
但是在机器学习中我们更多的是会对下面这种形状进行运算:
大家可以把这种数看作几个矩阵叠在一起,这种我们暂且给它取一个名字叫“空间矩阵”或者“三维矩阵”。 因此用**“矩阵”不能表达所有我们想要进行运算的变量**,所以,我们使用张量把矩阵的概念进行扩展。这样普通的矩阵就是二维张量,数组就是一维张量,上面这种空间矩阵就是三维张量,类似的,还有四维、五维、六维张量

那么上面这种三维张量怎么表达呢?
一维张量[1,2,3],:
torch.tensor([1,2,3]) 二维张量: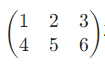 :
:
torch.tensor([[1,2,3],[4,5,6]])聪明的同学可能发现了,多一个维度,我们就多加一个 []。
所以为什么叫张量而不是矩阵呢?就是因为我们通常需要处理的数据有零维的(单纯的一个数字)、一维的(数组)、二维的(矩阵)、三维的(空间矩阵)、还有很多维的。PyTorch 为了把这些各种维统一起来,所以起名叫张量。
张量可以看作是一个多维数组。标量可以看作是0维张量,向量可以看作1维张量,矩阵可以看作是二维张量。比如我们之前学过的 NumPy,你会发现 tensor 和 NumPy 的多维数组非常类似。
创建 tensor:
x = torch.empty(5, 3)
x = torch.rand(5, 3)
x = torch.zeros(5, 3, dtype=torch.long)
x = torch.tensor([5.5, 3])
x = x.new_ones(5, 3, dtype=torch.float64)
y = torch.randn_like(x, dtype=torch.float)获取 tensor 的形状:
print(x.size())
print(x.shape)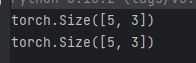
tensor 的各种操作:
y = torch.rand(5, 3)
print(x + y) # 加法形式一
print(torch.add(x, y)) # 加法形式二
# adds x to y
y.add_(x) # 加法形式三
print(y)PyTorch 中的 tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等,总之,凡是你能想到的操作,在 PyTorch 里都有对应的方法去完成。
3.Pytorch--定义
PyTorch 是一个基于 python 的科学计算包,主要针对两类人群:
- 作为 NumPy 的替代品,可以利用 GPU 的性能进行计算
- 作为一个高灵活性,速度快的深度学习平台
张量 Tensors
Tensor(张量),类似于 NumPy 的 ndarray ,但不同的是 Numpy 不能利用GPU加速数值计算,对于现代的深层神经网络,GPU通常提供更高的加速,而 Numpy 不足以进行现代深层学习。
而 Tensor 可以利用gpu加速数值计算,要在gpu上运行pytorch张量,在构造张量时使用device参数将张量放置在gpu上。
4.Pytorch--运算
4.1.Tensor数据类型
Tensor张量是Pytorch里最基本的数据结构。直观上来讲,它是一个多维矩阵,支持GPU加速,其基本数据类型如下
| 数据类型 | CPU Tensor | GPU Tensor |
|---|---|---|
| 8位无符号整型 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8位有符号整型 | torch.CharTensor | torch.cuda.CharTensor |
| 16位有符号整型 | torch.ShortTensor | torch.cuda.ShortTensor |
| 32位有符号整型 | torch.IntTensor | torch.cuda.IntTensor |
| 64位有符号整型 | torch.LongTensor | torch.cuda.LongTensor |
| 32位浮点型 | torch.FloatTensor | torch.cuda.FloatTensor |
| 64位浮点型 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 布尔类型 | torch.BoolTensor | torch.cuda.BoolTensor |
4.2.Tensor创建
torch.empty():创建一个没有初始化的 5 * 3 矩阵:
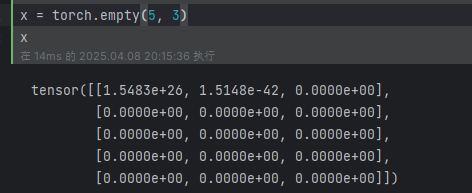
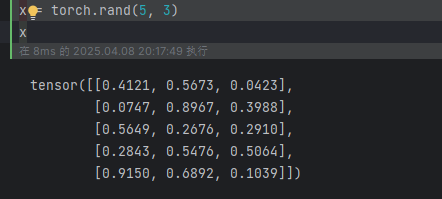
torch.rand(5, 3):创建一个随机初始化矩阵:
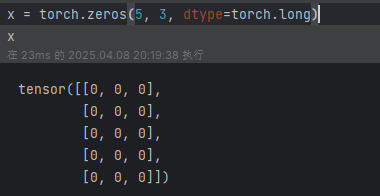
torch.zeros(5, 3, dtype=torch.long):构造一个填满 0 且数据类型为 long 的矩阵:
4.3.Tensor运算
| 函数 | 作用 | 注意事项 |
|---|---|---|
torch.abs(A) | 计算张量 A 的绝对值 | 输入输出张量形状相同。 |
torch.add(A, B) | 张量相加(A + B),支持标量或张量 | 支持广播机制(如 A.shape=(3,1), B.shape=(1,3))。 |
torch.clamp(A, min, max) | 裁剪 A 的值到 [min, max] 范围内 | 常用于梯度裁剪(如 grad.clamp(min=-0.1, max=0.1))。 |
torch.div(A, B) | 相除(A / B),支持标量或张量 | 整数除法需用 // 或 torch.floor_divide。 |
torch.mul(A, B) | 逐元素乘法(A * B),支持标量或张量 | 与 torch.mm(矩阵乘)区分。 |
torch.pow(A, n) | 计算 A 的 n 次幂 | n 可为标量或同形状张量。 |
torch.mm(A, B) | 矩阵乘法(A @ B),要求 A.shape=(m,n), B.shape=(n,p) | 不广播,需手动转置(如 B.T)。 |
torch.mv(A, B) | 矩阵与向量乘(A @ B),A.shape=(m,n), B.shape=(n,) | 无需转置 B,结果形状为 (m,)。 |
A.item() | 将单元素张量转为 Python 标量(如 int/float) | 仅限单元素张量(如 loss.item())。 |
A.numpy() | 将张量转为 NumPy 数组 | 需在 CPU 上(A.cpu().numpy())。 |
A.size() / A.shape | 查看张量形状(同义) | 返回 torch.Size 对象(类似元组)。 |
A.view(*shape) | 重构张量形状(不复制数据) | 总元素数需一致(如 A.view(-1, 2))。 |
A.transpose(0, 1) | 交换维度(如矩阵转置) | 高维张量可用 permute(如 A.permute(2,0,1))。 |
A[1:] | 切片操作(同 NumPy) | 支持高级索引(如 A[A > 0])。 |
A[-1, -1] = 100 | 修改指定位置的值 | 避免连续赋值(可能触发复制)。 |
A.zero_() | 将张量所有元素置零(原地操作) | 带下划线的函数(如 add_())表示原地修改。 |
torch.stack((A,B), dim=-1) | 沿新维度拼接张量(升维) | A 和 B 形状需相同(如 stack([A,B], dim=0) 结果形状 (2,...))。 |
torch.diag(A) | 提取对角线元素(输入矩阵→输出向量) | 若 A 为向量,则输出对角矩阵。 |
torch.diag_embed(A) | 将向量嵌入对角线生成矩阵(非对角线置零) | 输入向量形状 (n,),输出矩阵形状 (n, n)。 |
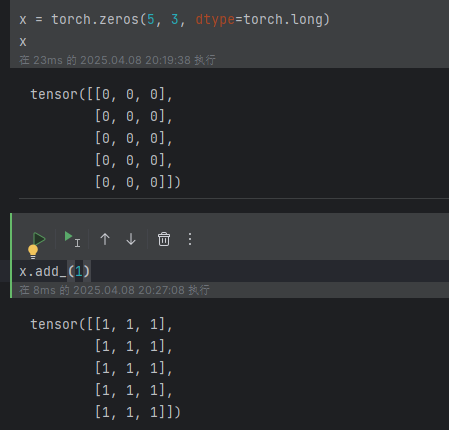
⭐ ⭐ ⭐ :所有的带_符号的函数都会对原数据进行修改,可以叫做原地操作
例如:X.add_()
事实上 PyTorch 中对于张量的计算、操作和 Numpy 是高度类似的。
例如:通过索引访问数据:(第二列)
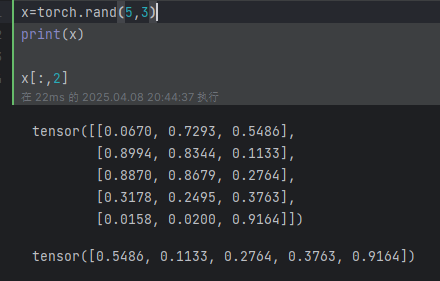
对 Tensor 的尺寸修改,可以采用 torch.view() ,如下所示:
x = torch.randn(4, 4)
y = x.view(16)
# -1 表示给定列维度8之后,用16/8=2计算的另一维度数
z = x.view(-1, 8)
print("x = ",x)
print("y = ",y)
print("z = ",z)
print(x.size(), y.size(), z.size())
x = tensor([[-0.3114, 0.2321, 0.1309, -0.1945],
[ 0.6532, -0.8361, -2.0412, 1.3622],
[ 0.7440, -0.2242, 0.6189, -1.0640],
[-0.1256, 0.6199, -1.5032, -1.0438]])
y = tensor([-0.3114, 0.2321, 0.1309, -0.1945, 0.6532, -0.8361, -2.0412, 1.3622,
0.7440, -0.2242, 0.6189, -1.0640, -0.1256, 0.6199, -1.5032, -1.0438])
z = tensor([[-0.3114, 0.2321, 0.1309, -0.1945, 0.6532, -0.8361, -2.0412, 1.3622],
[ 0.7440, -0.2242, 0.6189, -1.0640, -0.1256, 0.6199, -1.5032, -1.0438]])
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
如果 tensor 仅有一个元素,可以采用 .item() 来获取类似 Python 中整数类型的数值:
x = torch.randn(1)
print(x)
print(x.item())tensor([-0.7328])
-0.7328450083732605
4.4.Tensor--Numpy转换
Tensor-->Numpy:
a = torch.ones(5)
print(a)
b = a.numpy()
print(b)

两者是共享同个内存空间的,例子如下所示,修改 tensor 变量 a,看看从 a 转换得到的 Numpy 数组变量 b 是否发生变化。
a.add_(1)
print(a)
print(b)
![]()
Numpy-->Tensor:
转换的操作是调用 torch.from_numpy(numpy_array) 方法。例子如下所示:
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)

4.5.Tensor--CUDA(GPU)
Tensors 可以通过 .to 方法转换到不同的设备上,即 CPU 或者 GPU 上。例子如下所示:
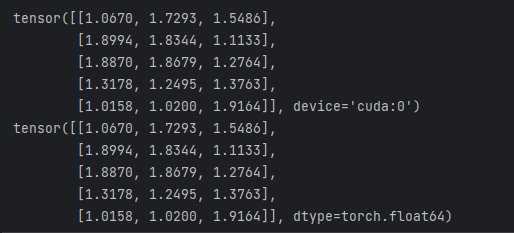
# 当 CUDA 可用的时候,可用运行下方这段代码,采用 torch.device() 方法来改变 tensors 是否在 GPU 上进行计算操作
if torch.cuda.is_available():device = torch.device("cuda") # 定义一个 CUDA 设备对象y = torch.ones_like(x, device=device) # 显示创建在 GPU 上的一个 tensorx = x.to(device) # 也可以采用 .to("cuda") z = x + yprint(z)print(z.to("cpu", torch.double)) # .to() 方法也可以改变数值类型
5.Pytorch--自动微分 (autograd)
对于 Pytorch 的神经网络来说,非常关键的一个库就是 autograd ,它主要是提供了对 Tensors 上所有运算操作的自动微分功能,也就是计算梯度的功能。它属于 define-by-run 类型框架,即反向传播操作的定义是根据代码的运行方式,因此每次迭代都可以是不同的。
| 概念/方法 | 作用 | 典型应用场景 |
|---|---|---|
requires_grad=True | 启用张量的梯度追踪,记录所有操作历史 | 训练参数(如模型权重 nn.Parameter) |
.backward() | 自动计算梯度,结果存储在 .grad 属性中 | 损失函数反向传播 |
.grad | 存储梯度值的属性(与张量同形状) | 查看或手动更新梯度(如优化器步骤) |
.detach() | 返回一个新张量,从计算图中分离(requires_grad=False) | 冻结部分网络或避免梯度计算(如特征提取) |
torch.no_grad() | 上下文管理器,禁用梯度计算和追踪 | 模型评估、推理阶段 |
Function 类 | 定义自动微分规则,每个操作对应一个 Function 节点 | 自定义反向传播逻辑(继承 torch.autograd.Function) |
.grad_fn | 指向创建该张量的 Function 节点(用户创建的张量为 None) | 调试计算图结构 |
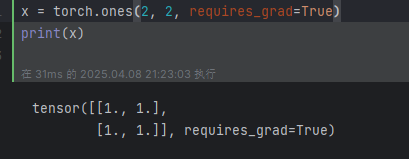
开始创建一个 tensor, 并让 requires_grad=True 来追踪该变量相关的计算操作:
5.1.backward求导
5.1.1.标量Tensor求导
import numpy as np
import torch# 标量Tensor求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor(-2.0, requires_grad=True)#定义x是自变量,requires_grad=True表示需要求导
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a*torch.pow(x,2)+b*x+c
y.backward() # backward求得的梯度会存储在自变量x的grad属性中
dy_dx =x.grad
dy_dx
![]()
5.1.2.非标量Tensor求导
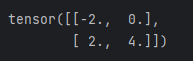
# 非标量Tensor求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
y.backward(gradient=gradient)
dy_dx =x.grad
dy_dx# 使用标量求导方式解决非标量求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
z=torch.sum(y*gradient)
z.backward()
dy_dx=x.grad
dy_dx
5.2.autograd.grad求导
import torch#单个自变量求导
# 求 f(x) = a*x**4 + b*x + c 的导数
x = torch.tensor(1.0, requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x, 4) + b * x + c
#create_graph设置为True,允许创建更高阶级的导数
#求一阶导
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
#求二阶导
dy2_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0]
#求三阶导
dy3_dx3 = torch.autograd.grad(dy2_dx2, x)[0]
print(dy_dx.data, dy2_dx2.data, dy3_dx3)# 多个自变量求偏导
x1 = torch.tensor(1.0, requires_grad=True)
x2 = torch.tensor(2.0, requires_grad=True)
y1 = x1 * x2
y2 = x1 + x2
#只有一个因变量,正常求偏导
dy1_dx1, dy1_dx2 = torch.autograd.grad(outputs=y1, inputs=[x1, x2], retain_graph=True)
print(dy1_dx1, dy1_dx2)
# 若有多个因变量,则对于每个因变量,会将求偏导的结果加起来
dy1_dx, dy2_dx = torch.autograd.grad(outputs=[y1, y2], inputs=[x1, x2])
dy1_dx, dy2_dx
print(dy1_dx, dy2_dx)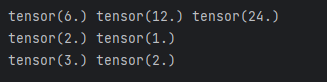
5.3.求最小值
#例2-1-3 利用自动微分和优化器求最小值
import numpy as np
import torch# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0, requires_grad=True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x], lr=0.01) #SGD为随机梯度下降
print(optimizer)def f(x):result = a * torch.pow(x, 2) + b * x + creturn (result)for i in range(500):optimizer.zero_grad() #将模型的参数初始化为0y = f(x)y.backward() #反向传播计算梯度optimizer.step() #更新所有的参数
print("y=", y.data, ";", "x=", x.data)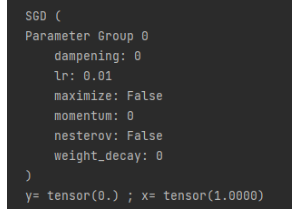
相关文章:

【深度学习:理论篇】--Pytorch基础入门
目录 1.Pytorch--安装 2.Pytorch--张量 3.Pytorch--定义 4.Pytorch--运算 4.1.Tensor数据类型 4.2.Tensor创建 4.3.Tensor运算 4.4.Tensor--Numpy转换 4.5.Tensor--CUDA(GPU) 5.Pytorch--自动微分 (autograd) 5.1.back…...

C++中数组的概念
文章目录 一、数组的定义二、什么是一维数组?2.1 一维数组的声明2.2 一维数组的初始化2.3 一维数组的使用 三、什么是一维数组的数组名?四、一维数组与指针的关系五、数组指针和指针数组的区别5.1 指针数组(array of pointers)5.2…...
)
996引擎-源码学习:Cocos2d-Lua 的 class(classname, ...)
996引擎-源码学习:Cocos2d-Lua 的 class(classname, ...) 一、核心方法调用顺序用户调用入口完整调用链二、__create 工厂方法的三种情形情形1:父类为函数(自定义工厂)情形2:父类为Cocos原生类情形3:父类为普通Lua表三、方法职责与内存管理对照表四、正确使用示例示例1…...
)
@linux系统SSL证书转换(Openssl转换PFX)
在Linux中,你可以使用OpenSSL工具将PFX/P12格式的证书转换为单独的CRT(证书)、KEY(私钥)文件以及提取证书链 1. 提取私钥文件(.key) openssl pkcs12 -in your_certificate.pfx -nocerts -out private.key -nodes系统会…...

flask返回json或者中文字符串不要编码
在 Flask 中返回中文字符串时,如果希望浏览器直接显示中文(而非编码后的 Unicode 转义字符如 \uXXXX),需确保以下两点: 正确设置 HTTP 响应的字符集(如 utf-8)。 避免 Flask 默认的 JSON 序列化转义中文字符。 以下是具体实现方法: 方法 1:直接返回纯文本(非 JSON) …...

打造船岸“5G+AI”智能慧眼 智驱力赋能客船数智管理
项目介绍 船舶在航行、作业过程中有着严格的规范要求,但在实际航行与作业中往往会因为人为的疏忽,发生事故,导致人员重大伤亡和财产损失; 为推动安全治理模式向事前预防转型,实现不安全状态和行为智能预警,…...

【Proteus仿真】【32单片机-A007】PT100热敏温度检测系统设计
目录 一、主要功能 二、使用步骤 三、硬件资源 四、软件设计 五、实验现象 联系作者 一、主要功能 1、LCD1602显示当前检测的温度值以及温度阈值 2、超过上限温度,降温模块启动 3、PT100热敏电阻测量-60C-135C 4、按键设置温度阈值 5、超过阈值࿰…...

MPDrive:利用基于标记的提示学习提高自动驾驶的空间理解能力
25年4月来自南方科技大学、百度、英国 KCL和琶洲实验室(广东 AI 和数字经济实验室)的论文“MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving”。 自动驾驶视觉问答(AD-VQA)…...

PhotoShop学习08
1.应用滤镜 PhotoShop提供了很多滤镜,借助滤镜可以打造很多有趣的效果。滤镜可以通过点击菜单栏的滤镜,并选择滤镜库进入滤镜调整界面。 进入到滤镜库后,左侧是实时进行预览的图片,右侧可以选择滤镜效果,最右边可以调…...
)
Photoshop2025最新版v26超详细图文安装教程(附安装包)
前言 Photoshop是一款基于位图的图像处理软件,专注于对已有图像的编辑、修复、合成及特效制作。其核心功能包括图层管理、色彩校正、选区工具、滤镜效果等,支持多种颜色模型(如RGB、CMYK、CIELAB)和文件格式(如.PSD、…...

Plusar集群搭建-Ubuntu20.04-Winterm
1 背景 已经部署了Pulsar集群在生产上,新项目需要用到Pulsar。对Pulsar不熟,故搭建练手。 环境:Windows10vmwareUbuntu20.04,ssh工具使用的Winterm。 使用的是root账户,ubuntu防火墙都ufw disable了。 2 参考文档 集…...

Qt与C++数据类型转换
本文深入探讨Qt与C中相似但不同的数据类型处理技巧。 一、QString与std::string的相互转换 1. QString → std::string 方法1:使用toStdString()(推荐) QString qstr "你好,Qt世界"; std::string str qstr.toStdS…...

Excel处理控件Aspose.Cells指南:如何查看、编辑和删除 Excel 元数据
本文是如何使用Aspose.Cells的在线工具和编码解决方案查看、编辑和删除 Excel 元数据的综合指南。无论您是寻找快速Excel 元数据查看器的普通用户,还是寻求强大的Excel 元数据编辑器的开发人员,本指南都能满足您的需求。您可以选择使用简单的在线转换器来…...

Rust 在汽车 MCU 编程中的进展及安全特性剖析
在当今汽车行业,软件定义汽车的趋势正深刻改变着汽车的设计与用户体验。随着汽车电子系统复杂性的不断提升,对汽车微控制器(MCU)编程的安全性、可靠性和效率提出了更高要求。Rust 作为一种新兴的编程语言,凭借其独特的…...

Pytorch 第十四回:神经网络编码器——变分自动编解码器
Pytorch 第十四回:神经网络编码器——变分自动编解码器 本次开启深度学习第十四回,基于Pytorch的神经网络编码器。本回分享VAE变分自动编码器。在本回中,通过minist数据集来分享如何建立一个变分自动编码器。接下来给大家分享具体思路。 本次…...

hive排序函数
在 Hive 中,排序可以通过几种不同的方法来实现,通常依赖于 ORDER BY 或 SORT BY 等函数。这里简要介绍这几种排序方法: 1. ORDER BY ORDER BY 用于对结果集进行全局排序。它会将所有数据加载到一个节点进行排序,因此可能会导致性能问题,尤其是在数据量很大的时候。 语法…...

Android测试王炸:Appium + UI Automator2
Android平台主流开源框架简介 在Android平台上,有多个开源且好用的自动化测试框架。以下是几个被广泛使用和认可的框架: 1.1 Appium Appium是一个跨平台的移动测试工具,支持iOS和Android上的原生、混合及移动Web应用。 它使用了供应商提供的…...

用Python打造增强现实的魔法:实时对象叠加系统全解析
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

const let var 在react jsx中的使用方法 。
在 JavaScript 里,const 和 let 都是 ES6(ES2015)引入的用于声明变量的关键字,它们和之前的 var 关键字有所不同。下面为你详细介绍 const 和 let 的区别: 1. 块级作用域 const 和 let 都具备块级作用域,…...

C++隐式转换的机制、风险与消除方法
引言 C作为一门强类型语言,类型安全是其核心特性之一。 然而,隐式转换(Implicit Conversion)的存在既为开发者提供了便利,也可能成为程序中的“隐藏炸弹”。 一、隐式转换的定义与分类 1.1 什么是隐式转换…...

Python 为什么要保留显式的 self ?
当你在类中定义方法时,Python要求第一个参数必须表示当前对象实例。当你调用obj.method(),Python 本质上会将它转换为ClassName.method(obj)。 所以你需要通过self参数显式接收这个实例,才能访问该对象的属性和其他方法。如果不加self&#…...

Linux 性能调优之CPU认知
写在前面 博文内容为《性能之巅 系统、企业与云可观测性(第2版)》CPU 章节课后习题答案整理内容涉及: CPU 术语,指标认知CPU 性能问题分析解决CPU 资源负载特征分析应用程序用户态CPU用量分析理解不足小伙伴帮忙指正对每个人而言,真正的职责只有一个:找到自我。然后在心中…...

认识vue中的install和使用场景
写在前面 install 在实际开发中如果你只是一个简单的业务实现者,那么大部分时间你是用不到install的,因为你用到的基本上都是别人封装好的插件、组件、方法、指令等等,但是如果你需要给公司的架构做建设,install就是你避不开的一个…...

C++Cherno 学习笔记day17 [66]-[70] 类型双关、联合体、虚析构函数、类型转换、条件与操作断点
b站Cherno的课[66]-[70] 一、C的类型双关二、C的union(联合体、共用体)三、C的虚析构函数四、C的类型转换五、条件与操作断点——VisualStudio小技巧 一、C的类型双关 作用:在C中绕过类型系统 C是强类型语言 有一个类型系统,不…...

3.神经网络
神经网络 神经元与大脑 神经网络神经元的结构: 输入(Input):接收来自前一层神经元的信息。 权重(Weights):每个输入都有一个权重,表示其重要性。 加权和(Weighted Sum&a…...

CentOS 7安装Python3.12
文章目录 使用pyenv安装python3.12一、gitub下载pyenv二、升级GCC三.升级openssl这样python3.12.9就完成安装在CentOS上啦! 使用pyenv安装python3.12 一、gitub下载pyenv https://github.com/pyenv/pyenv 按照README,pyenv教程安装即可 二、升级GCC 安…...

微服务无感发布实践:基于Nacos的客户端缓存与故障转移机制
微服务无感发布实践:基于Nacos的客户端缓存与故障转移机制 背景与问题场景 在微服务架构中,服务的动态扩缩容、滚动升级是常态,而服务实例的上下线需通过注册中心(如Nacos)实现服务发现的实时同步。但在实际生产环境…...
)
5.2 自定义通知操作按钮(UNNotificationAction)
在本地推送通知中添加自定义操作按钮可以增强用户交互性,让用户无需打开应用就能执行一些快速操作。本节将详细介绍如何在SwiftUI应用中实现这一功能。 基本概念 UNNotificationAction 和 UNNotificationCategory 是UserNotifications框架中用于定义通知交互的核心…...

Python与链上数据分析:解锁区块链数据的潜力
Python与链上数据分析:解锁区块链数据的潜力 引言 区块链技术的兴起不仅改变了金融行业,也为数据分析领域带来了全新的机遇。链上数据(On-chain Data)是区块链网络中公开透明的交易记录和活动数据,它为我们提供了一个独特的视角,去观察用户行为、市场趋势以及网络健康状…...

数字化转型:未来已来,企业如何抢占先机?
近年来,“数字化转型”从一个技术热词逐渐演变为各行各业的“必选项”。无论是全球市场还是中国市场,数字化浪潮正以不可逆的姿态重塑商业生态。据IDC预测,到2028年,中国数字化转型市场规模将突破7300亿美元,全球投资规…...

Web3游戏全栈开发实战指南:智能合约与去中心化生态构建全解析
在GameFi市场规模突破千亿美元的当下,去中心化游戏系统开发正面临技术架构升级与生态融合的双重机遇。本文基于Solidity、Rust等多链智能合约开发经验,结合Truffle、Hardhat等主流框架,深度解析如何构建高性能、高收益的链游生态系统。 一、…...

Windows 图形显示驱动开发-WDDM 2.0功能_IoMmu 模型
概述 输入输出内存管理单元 (IOMMU) 是一个硬件组件,它将支持具有 DMA 功能的 I/O 总线连接到系统内存。 它将设备可见的虚拟地址映射到物理地址,使其在虚拟化中很有用。 在 WDDM 2.0 IoMmu 模型中,每个进程都有一个虚拟地址空间࿰…...
)
uniapp微信小程序基于wu-input二次封装TInput组件(支持点击下拉选择、支持整数、电话、小数、身份证、小数点位数控制功能)
一、 最终效果 二、实现了功能 1、支持输入正整数---设置specifyTypeinteger 2、支持输入数字(含小数点)---设置specifyTypedecimal,可设置decimalLimit来调整小数点位数 3、支持输入手机号--设置specifyTypephone 4、支持输入身份证号---设…...

Java 大厂面试题 -- JVM 深度剖析:解锁大厂 Offe 的核心密钥
最近佳作推荐: Java大厂面试高频考点|分布式系统JVM优化实战全解析(附真题)(New) Java大厂面试题 – JVM 优化进阶之路:从原理到实战的深度剖析(2)(New&#…...

小白入门JVM、字节码、类加载机制图解
前提知识~ JDK 基本介绍 JDK 的全称(Java Development Kit Java 开发工具包)JDK JRE java 的开发工具[java, javac,javadoc,javap 等]JDK 是提供给Java 开发人员使用的,其中包含了java 的开发工具,也包括了JRE。可开发、编译、调试…… JRE 基本介绍…...

新能源汽车动力性与经济性优化中的经典数学模型
一、动力性优化数学模型 动力性优化的核心目标是提升车辆的加速性能、最高车速及爬坡能力,主要数学模型包括: 1. 车辆纵向动力学模型 模型方程: 应用场景: 计算不同工况下的驱动力需求匹配电机扭矩与减速器速比案例ÿ…...
有什么作用?)
高级java每日一道面试题-2025年3月25日-微服务篇[Nacos篇]-Nacos中的命名空间(Namespace)有什么作用?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos中的命名空间(Namespace)有什么作用? 我回答: 在Java高级面试中,关于Nacos中的命名空间(Namespace)的作用,是一个考察候选人对微服务架构和配…...

5.JVM-G1垃圾回收器
一、什么是G1 二、G1的三种垃圾回收方式 region默认2048 三、YGC的过程(Step1) 3.1相关代码 public class YGC1 {/*-Xmx128M -XX:UseG1GC -XX:PrintGCTimeStamps -XX:PrintGCDetails -XX:UnlockExperimentalVMOptions -XX:G1LogLevelfinest128m5% 60%6.4M 75M*/private stati…...

变量、数据、值类型引用类型的存储方式
代码写了也有2年了,对于这些基础的程序名词,说出口也是模棱两可,心里很不爽,很多基础还是模糊不清,清算一下...... Example值类型: int x 10; 变量:“x”是一个标识符,它对应着栈…...

分布式和微服务的区别
1. 定义 在讨论分布式系统和微服务的区别之前,我们先明确两者的定义: 分布式系统:是一组相互独立的计算机,通过网络协同工作,共同完成某个任务的系统。其核心在于资源的分布和任务的分解。 微服务架构:是…...

数组的常见算法一
注: 本文来自尚硅谷-宋红康仅用来学习备份 6.1 数值型数组特征值统计 这里的特征值涉及到:平均值、最大值、最小值、总和等 **举例1:**数组统计:求总和、均值 public class TestArrayElementSum {public static void main(String[] args)…...

Leedcode刷题 | Day27_贪心算法01
一、学习任务 455.分发饼干代码随想录376. 摆动序列53. 最大子序和 二、具体题目 1.455分发饼干455. 分发饼干 - 力扣(LeetCode) 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对…...

springboot集成kafka,后续需要通过flask封装restful接口
Spring Boot与Kafka的整合 在现代软件开发中,消息队列是实现服务解耦、异步消息处理、流量削峰等场景的重要组件。Apache Kafka是一个分布式流处理平台,它具有高吞吐量、可扩展性和容错性等特点。Spring Boot作为一个轻量级的、用于构建微服务的框架&am…...

MYSQL数据库语法补充2
一,数据库设计范式(原则) 数据库设计三大范式: 第一范式: 保证列的原子性(列不可再分) 反例:联系方式(手机,邮箱,qq) 正例: 手机号,qq,邮箱. 第二范式: 要有主键,其他列依赖于主键列,因为主键是唯一的,依赖了主键,这行数据就是唯一的. 第三范式: 多表关联时,在…...

Flask返回文件方法详解
在 Flask 中返回文件可以通过 send_file 或 send_from_directory 方法实现。以下是详细方法和示例: 1. 使用 send_file 返回文件 这是最直接的方法,适用于返回任意路径的文件。 from flask import Flask, send_fileapp = Flask(__name__)@app.route("/download")…...
)
随机数据下的最短路问题(Dijstra优先队列)
题目描述 给定 NN 个点和 MM 条单向道路,每条道路都连接着两个点,每个点都有自己编号,分别为 1∼N1∼N 。 问你从 SS 点出发,到达每个点的最短路径为多少。 输入描述 输入第一行包含三个正整数 N,M,SN,M,S。 第 22 到 M1M1 行…...

CPP杂项
注意:声明类,只是告知有这个类未完全定义,若使用类里具体属性,要么将访问块(函数之类)放到定义后,要么直接完全定义 C 友元函数/类的使用关键点(声明顺序为核心) 1. 友元…...

Idea将Java工程打包成war包并发布
1、问题概述? 项目开发之后,我们需要将Java工程打包成war后缀,并进行发布。之前在网上看到很多的文章,但是都不齐全,今天将提供一个完整的实现打包war工程,并发布的文章,希望对大家有所帮助,主要解决如下问题: 1、war工程需要满足的相关配置 2、如何解决项目中的JDK…...

多级缓存模型设计
为了有效避免缓存击穿、穿透和雪崩的问题。最基本的缓存设计就是从数据库中查询数据时,无论数据库中是否存在数据,都会将查询的结果缓存起来,并设置一定的有效期。后续请求访问缓存时,如果缓存中存在指定Key时,哪怕对应…...

SGLang实战:从KV缓存复用到底层优化,解锁大模型高效推理的全栈方案
在当今快速发展的人工智能领域,大型语言模型(LLM)的应用已从简单对话扩展到需要复杂逻辑控制、多轮交互和结构化输出的高级任务。面对这一趋势,如何高效地微调并部署这些大模型成为开发者面临的核心挑战。本文将深入探讨SGLang——这一专为大模型设计的高…...