C++中数组的概念
文章目录
- 一、数组的定义
- 二、什么是一维数组?
- 2.1 一维数组的声明
- 2.2 一维数组的初始化
- 2.3 一维数组的使用
- 三、什么是一维数组的数组名?
- 四、一维数组与指针的关系
- 五、数组指针和指针数组的区别
- 5.1 指针数组(array of pointers)
- 5.2 数组指针(pointer to array)
- 六、函数参数中使用数组指针
- 6.1 为什么用数组指针?
- 6.1 一维数组 + 数组指针
- 6.3 多维数组 + 数组指针
- 七、指向数组的指针数组
- 7.1 概念介绍
- 7.2 示例解析
- 八、二维数组的定义和使用
- 8.1 二维数组的定义
- 8.2 二维数组的初始化方式
- 8.3 访问二维数组元素和二维数组的大小
- 8.4 二维数组作为函数参数传递
- 九、二维数组的数组名
- 9.1 数组名到底是什么?
- 9.2 a 的类型是什么?
- 9.3 二维数组名的实际用途
- 十、一维数组模拟二维数组
- 十一、二维数组与指针的转换
- 11.1 二维数组和指针的关系
- 11.2 指针与数组的转换
- 11.3 二维数组与指针数组的区别
- 11.4 二维数组与指针结合使用的实际应用
一、数组的定义
在 C++ 中,数组(Array)是一种用于存储固定大小、相同类型元素的容器。数组在内存中是连续存储的,因此可以通过索引快速访问每一个元素。
二、什么是一维数组?
一维数组是相同类型的数据元素的线性集合,在内存中是连续存储的。
2.1 一维数组的声明
类型名 数组名[数组大小];
示例:
int scores[5]; // 声明一个可以保存5个整数的一维数组
2.2 一维数组的初始化
完全初始化:
int scores[5] = {90, 85, 78, 92, 88};
部分初始化(未写的部分默认为 0):
int scores[5] = {90, 85}; // 相当于 {90, 85, 0, 0, 0}
自动推导大小:
int scores[] = {90, 85, 78}; // 系统自动推断大小为3
2.3 一维数组的使用
访问数组元素:
std::cout << scores[0]; // 访问第一个元素(注意索引从0开始)
scores[2] = 100; // 修改第三个元素
注意事项:
- 数组大小固定,不能动态变化。
- 数组索引从 0 开始,到 n-1 结束。
- 访问越界会导致未定义行为,不要访问 scores[5]。
- 数组名本质上是一个指向第一个元素的指针
三、什么是一维数组的数组名?
在 C++ 中,一维数组的数组名其实表示的是数组第一个元素的地址。
比如:
int arr[5] = {10, 20, 30, 40, 50};
这里的 arr 就相当于 &arr[0],是一个指向第一个元素的指针。
举例说明:
#include <iostream>
using namespace std;int main() {int arr[5] = {10, 20, 30, 40, 50};cout << "arr = " << arr << endl; // 输出数组名,其实是地址cout << "&arr[0] = " << &arr[0] << endl; // 也是地址cout << "*arr = " << *arr << endl; // 解引用,输出第一个元素:10cout << "arr[2] = " << *(arr + 2) << endl; // 使用指针方式访问第三个元素return 0;
}
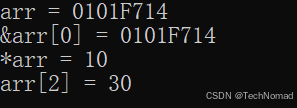

虽然数组名表现得像指针,但它不是普通的指针变量:
int* p = arr; // 正确
arr = p; // ❌ 错误,数组名不能作为左值
也就是说,数组名是不能被赋值的,它在声明时就绑定到那块连续内存了。
总结一句话:一维数组的数组名本质是一个指向首元素的指针常量,在很多情况下可以像指针一样使用,但它不是一个可以改变的变量。
3.1 数组名与&arr和&arr[0]的区别
先看三者的含义:

假设有下面的数组:
int arr[5] = {10, 20, 30, 40, 50};
3.2 arr 和 &arr[0] 的区别?
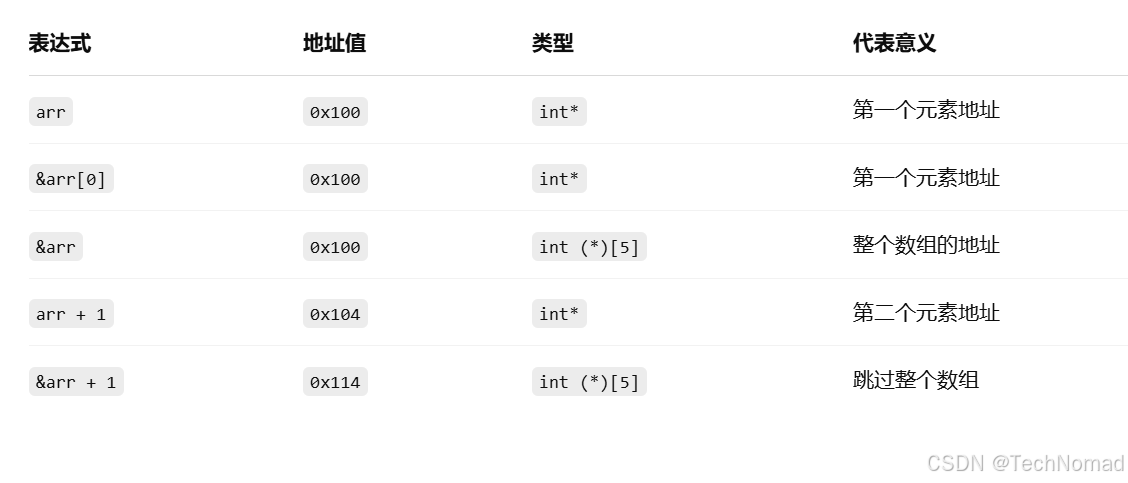
- 相同点:它们的值是一样的,都是首元素的地址。
- 不同点:它们的类型不同!
arr // 类型是 int*
&arr[0] // 类型也是 int*
虽然类型相同,语义稍有区别:
- arr 是数组名,表示“数组首元素的地址”
- &arr[0] 是明确取“第一个元素的地址”
3.3 &arr 是什么?
- &arr 表示“整个数组的地址”
- 它的类型是:int (*)[5],即“指向长度为5的数组的指针”
这个指针不是指向某个元素,而是指向整个数组块!
举个例子:
#include <iostream>
using namespace std;int main() {int arr[5] = {10, 20, 30, 40, 50};cout << "arr = " << arr << endl;cout << "&arr[0] = " << &arr[0] << endl;cout << "&arr = " << &arr << endl;cout << "arr + 1 = " << arr + 1 << endl;cout << "&arr[0] + 1 = " << &arr[0] + 1 << endl;cout << "&arr + 1 = " << &arr + 1 << endl;return 0;
}
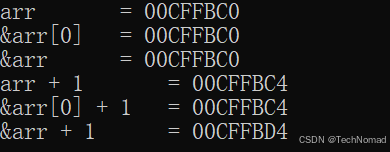
输出分析(假设起始地址为 0x100):

内存图示(假设int是4字节):
地址 内容
0x100 arr[0] = 10
0x104 arr[1] = 20
0x108 arr[2] = 30
0x10C arr[3] = 40
0x110 arr[4] = 50arr / &arr[0] → 0x100
&arr → 0x100,类型不同但地址一样
arr + 1 → 0x104
&arr + 1 → 0x100 + 20(整个数组的地址+1个数组块)
总结对比表:
四、一维数组与指针的关系
在 C++ 中,一维数组名其实就是一个指向首元素的指针,所以可以用指针来访问数组中的元素。
示例:数组和指针的基本结合用法
#include <iostream>
using namespace std;int main() {int arr[5] = { 10, 20, 30, 40, 50 };int* p = arr; // 指针p指向数组首元素cout << "用数组方式:arr[2] = " << arr[2] << endl;cout << "用指针方式:*(p + 2) = " << *(p + 2) << endl;return 0;
}
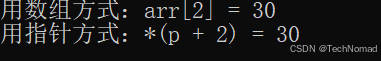
用指针遍历数组:
int arr[5] = {1, 2, 3, 4, 5};
int* p = arr;for (int i = 0; i < 5; ++i) {cout << *(p + i) << " ";
}
或者使用指针本身进行++操作:
int* end = arr + 5; // 指向最后一个元素的下一个地址
while (p < end) {cout << *p << " ";++p;
}
数组与指针的对比:

把数组传给函数(本质上传的是指针)
void printArray(int* p, int size) {for (int i = 0; i < size; ++i) {cout << p[i] << " ";}
}int main() {int arr[3] = {10, 20, 30};printArray(arr, 3); // arr会退化为指针传给函数
}
等价于:
void printArray(int arr[], int size); // 实际上跟 int* 一样
注意事项:
数组名是一个指针常量,它的值(指向地址)不能修改,而普通指针可以:
int arr[5];
int* p = arr;
p = p + 1; // OK
arr = arr + 1; // ❌ 错误:数组名不可修改
用指针访问时要特别小心越界,指针不像数组访问有明显的范围检查。
五、数组指针和指针数组的区别
5.1 指针数组(array of pointers)
指针数组:数组里面每个元素是指针。
定义方式:
int* pArr[3]; // 一个数组,包含3个 int* 类型的元素
pArr 是一个有 3 个元素的数组,每个元素是 int* 指针。
场景举例:多个指向不同变量的指针
#include <iostream>
using namespace std;int main() {int a = 10, b = 20, c = 30;int* pArr[3] = { &a, &b, &c };for (int i = 0; i < 3; ++i) {cout << *pArr[i] << " "; // 输出:10 20 30}return 0;
}
5.2 数组指针(pointer to array)
数组指针:一个指向整个数组的指针。
定义方式:
int (*p)[5]; // 一个指向长度为5的int数组的指针
p 是一个指针,它指向一个 int[5] 的数组。
场景举例:传递整个数组的地址
#include <iostream>
using namespace std;int main() {int arr[5] = { 1, 2, 3, 4, 5 };int (*p)[5] = &arr; // p 指向整个数组cout << (*p)[2] << endl; // 输出3,相当于 arr[2]return 0;
}
语法对比表:

更直观理解(类比):

六、函数参数中使用数组指针
6.1 为什么用数组指针?
普通的数组参数比如:
void func(int arr[]) { ... }
在函数中其实就是 退化成 int* 指针,你拿不到原始数组的长度等信息。而数组指针能保留「整块数组」的概念。
6.1 一维数组 + 数组指针
#include <iostream>
using namespace std;void printArray(int (*p)[5]) {for (int i = 0; i < 5; ++i) {cout << (*p)[i] << " ";}
}int main() {int arr[5] = { 10, 20, 30, 40, 50 };printArray(&arr); // 注意传的是 &arr,不是 arrreturn 0;
}
为什么要用 &arr?
- arr → 是 int*
- &arr → 是 int (*)[5](数组指针)
- 这和函数的参数 int (*p)[5] 类型匹配
6.3 多维数组 + 数组指针
#include <iostream>
using namespace std;void print2D(int (*p)[4], int rows) {for (int i = 0; i < rows; ++i) {for (int j = 0; j < 4; ++j) {cout << p[i][j] << " ";}cout << endl;}
}int main() {int arr[3][4] = {{1, 2, 3, 4},{5, 6, 7, 8},{9, 10, 11, 12}};print2D(arr, 3); // arr 自动转换成 int(*)[4]return 0;
}
总结数组指针函数参数写法:

七、指向数组的指针数组
7.1 概念介绍
指向数组的指针数组就是:一个数组,里面的每个元素是指针,这些指针指向数组。
拆词理解:
- 数组 → 有一组元素
- 指针数组→ 每个元素是个指针(T*)
- 指向数组的指针数组 → 每个指针指向一个数组(如 int (*)[3])
#include <iostream>
using namespace std;int main() {int a[3] = { 1, 2, 3 };int b[3] = { 4, 5, 6 };int c[3] = { 7, 8, 9 };// 定义:指向3个元素的数组的指针,每一个元素都是一个数组int (*pArr[3])[3]; // pArr 是一个指针数组,包含3个指向数组的指针pArr[0] = &a;pArr[1] = &b;pArr[2] = &c;for (int i = 0; i < 3; ++i) {for (int j = 0; j < 3; ++j) {cout << (*pArr[i])[j] << " ";}cout << endl;}return 0;
}
对比其他相关定义:
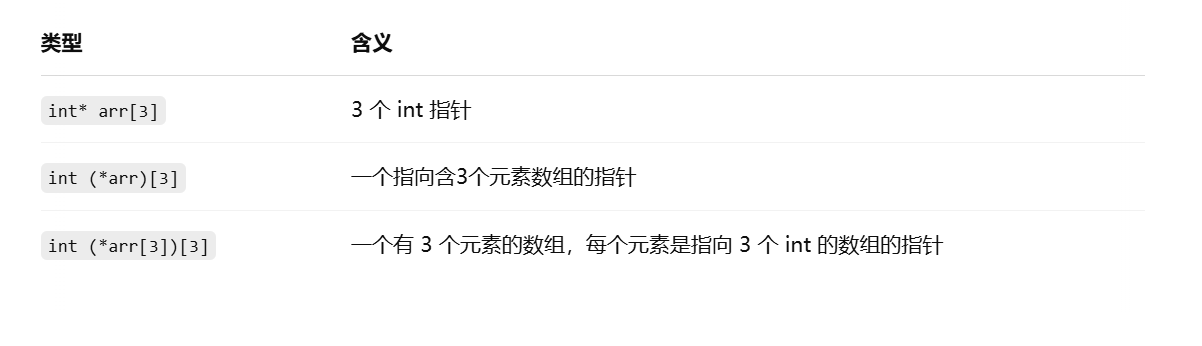
阅读技巧:从变量名“pArr”开始读:
int (*pArr[3])[3];
读法:
- pArr[3] → 数组,含3个元素
- → 元素是指针
- (*pArr[3])[3] → 每个指针指向一个 int[3] 数组
7.2 示例解析
int *(*f())[3];
步骤一:从标识符 f 开始读,我们按照“由内向外,遇到括号先处理”的原则来解析。
拆解顺序:
- 最里层是 f() → f 是一个函数,接受 无参数。
- (*f()) → 返回的是一个指针。
- (*f())[3] → 这个指针指向一个包含 3 个元素的数组。
- int *(f())[3] → 这个数组的元素类型是 int。
所以完整意思是:f 是一个函数,没有参数,返回一个指针,这个指针指向一个有 3 个元素的数组,而这个数组的每个元素是 int*。换句话说就是f 返回int* 类型的指针组成的数组(长度为 3)的指针。
举个例子(实际使用)
#include <iostream>
using namespace std;int* arr1[3] = {nullptr, nullptr, nullptr};int* (*f())[3] {return &arr1; // 返回指向数组的指针
}int main() {int* (*p)[3] = f();// 访问 p[0][0], p[0][1], etc.
}
小结口诀(读复杂声明):
- 从变量名(标识符)开始读
- 遇到 () 说明是函数
- 遇到 [] 说明是数组
- * 是指针,看结合谁
int (*(*x())[5])(); //函数返回数组,数组里是函数指针
我们从 x 开始读,遵循优先级规则。
拆解步骤:
- x() → x 是一个函数,没有参数。
- (*x()) → 返回一个指针
- (*x())[5] → 这个指针指向一个有 5 个元素的数组
- (*x())[5] 中每个元素是:(*x())[i]
- (*x())i → 说明每个元素是函数指针
- int (*(*x())[5])() → 每个函数指针,指向的函数返回 int,参数未知
总结一句话:x 是一个函数(无参数),它返回一个指针,这个指针指向一个长度为 5 的数组,数组里的每个元素是返回 int 的函数指针。
举个例子(实际用法)
#include <iostream>
using namespace std;int func1() { return 1; }
int func2() { return 2; }
int func3() { return 3; }
int func4() { return 4; }
int func5() { return 5; }int (*funcArray[5])() = {func1, func2, func3, func4, func5};int (*(*x())[5])() {return &funcArray; // 返回指向函数指针数组的指针
}int main() {auto funcs = x(); // funcs 是 int (*[5])()for (int i = 0; i < 5; ++i) {cout << funcs[0][i]() << " "; // 注意:funcs 是指向数组的指针,先解引用}return 0;
}
八、二维数组的定义和使用
8.1 二维数组的定义
二维数组定义的一般形式是:
类型说明符 数组名[常量表达式1][常量表达式2]
定义了一个三行四列的数组,数组名为a其元素类型为整型,该数组的元素个数为3*4,即:

二维数组a是按行进行存放的,先存放a[0]行,再存放a[1]行、a[2]行,并且每行有四个元素,也是依次存放的。
8.2 二维数组的初始化方式
1. 行列都写出来:
int a[2][3] = {{1, 2, 3},{4, 5, 6}
};
2. 不写行数,让编译器推断:
int a[][3] = {{1, 2, 3},{4, 5, 6}
}; // 自动推断为 a[2][3]
列数必须指定,因为内存布局要连续
8.3 访问二维数组元素和二维数组的大小
#include <stdio.h>
#include <stdlib.h>int main() {//int a[3][4] = {1, 2, 3}; //前三个元素初始化为1,2,3,后面的元素默认初始化为0int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};int n = sizeof(a) / sizeof(a[0][0]); //二维数组的个数int line = sizeof(a) / sizeof(a[0]); //行数=二维数组总大小除以一行的大小int clu = sizeof(a[0]) / sizeof(a[0][0]); //列数:行大小除以一个元素的大小printf("%d %d %d\n", n, line, clu);return 0;
}

8.4 二维数组作为函数参数传递
1. 固定列数传递
void print(int arr[][3], int rows) {for (int i = 0; i < rows; ++i)for (int j = 0; j < 3; ++j)cout << arr[i][j] << " ";
}
2. 使用指针传递
void print(int (*arr)[3], int rows) {for (int i = 0; i < rows; ++i)for (int j = 0; j < 3; ++j)cout << arr[i][j] << " ";
}
九、二维数组的数组名
9.1 数组名到底是什么?
在 C++ 中,数组名(如 a)本质上是一个常量指针,但又稍有不同:
- 对于 一维数组,a 会自动退化为指向首元素的指针(类型是 int*)
- 对于 二维数组,a 也会退化,但是指向“行”的指针!
9.2 a 的类型是什么?
举个例子:
int a[2][3] = {{1, 2, 3},{4, 5, 6}
};

内存结构示意图(int a[2][3])
a → &a[0] → a[0][0] a[0][1] a[0][2] | a[1][0] a[1][1] a[1][2]
- a 的类型是 int (*)[3],是指向含3个int的一维数组的指针
- 所以 a + 1 会跳过一整行,也就是 3 * sizeof(int) 字节
实验:打印地址
cout << a << endl; // 地址1:等价于 &a[0]
cout << a + 1 << endl; // 地址2:等价于 &a[1]
cout << &a[0][0] << endl; // 地址3:首元素地址
9.3 二维数组名的实际用途
你可以把二维数组名当作函数参数传递,比如:
void print(int (*arr)[3], int rows) {for (int i = 0; i < rows; ++i)for (int j = 0; j < 3; ++j)cout << arr[i][j] << " ";
}
然后这样调用:
print(a, 2); // 传入二维数组名 a
所以二维数组名 a,在表达式中会退化为指向一维数组(行)的指针,其类型是 int (*)[列数]。
如下示例:
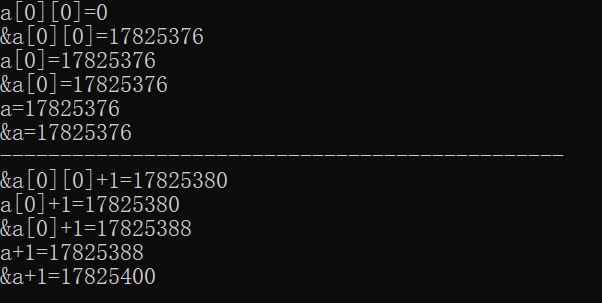
#include <stdio.h>
#include <stdlib.h>int main() {int a[2][3] = {0};printf("a[0][0]=%d\n", a[0][0]); //第0行第0个元素printf("&a[0][0]=%d\n", &a[0][0]); //第0行第0个元素的地址printf("a[0]=%d\n", a[0]); //代表第0行一维数据的数组名, a[0]=&a[0][0]printf("&a[0]=%d\n", &a[0]); //第0行的地址printf("a=%d\n", a); //二维数组的数组名,代表二维数组,也代表首行地址printf("&a=%d\n", &a); //二维数组的地址printf("-----------------------------------------------\n");printf("&a[0][0]+1=%d\n", &a[0][0]+1); //元素地址加1,跨过一个元素printf("a[0]+1=%d\n", a[0]+1); //元素地址加1,跨过一个元素printf("&a[0]+1=%d\n", &a[0]+1); //行地址加1,跨过一行printf("a+1=%d\n", a+1); //行地址加1,跨过一行printf("&a+1=%d\n", &a+1); //二维数组地址加1,跨过整个数组return 0;
}
输出结果:
十、一维数组模拟二维数组
假设我们有一个二维数组 a[3][4],我们可以将它映射为一个一维数组,这样就能够在内存中按行排列数据。
- 理解数组的内存布局:二维数组 a[3][4] 其实是一个 3 行 4 列的数组,它在内存中是按行优先(Row-major)存储的:
a[0][0], a[0][1], a[0][2], a[0][3]
a[1][0], a[1][1], a[1][2], a[1][3]
a[2][0], a[2][1], a[2][2], a[2][3]
- 映射为一维数组:我们将 a[3][4] 映射为一个一维数组 b[12],它的元素依然保持行优先顺序存储。
数组模拟图:

示例代码:一维数组模拟二维数组
#include <iostream>
using namespace std;int main() {int rows = 3, cols = 4;int b[12]; // 一维数组,模拟 3x4 的二维数组// 模拟二维数组赋值for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {b[i * cols + j] = i * cols + j + 1; // 填充 1~12 的值}}// 打印模拟的二维数组for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {cout << b[i * cols + j] << " "; // 模拟访问二维数组}cout << endl;}return 0;
}
代码说明:
模拟二维数组赋值:
- b[i * cols + j] 计算当前元素在一维数组中的索引,这里 i 是行索引,j 是列索引。
- i * cols + j 的方式保证了数据是按行优先顺序存储的。
打印模拟的二维数组:
- b[i * cols + j] 用来模拟访问二维数组 a[i][j]。
十一、二维数组与指针的转换
11.1 二维数组和指针的关系
二维数组其实是一个指向数组的指针,而指针的行为与数组紧密相关。在 C++ 中,二维数组和指针之间有很多有趣的转换方式。
假设我们有一个二维数组 a[3][4],它是一个包含 3 行 4 列的数组。
int a[3][4] = {{1, 2, 3, 4},{5, 6, 7, 8},{9, 10, 11, 12}
};
11.2 指针与数组的转换
1. 指向二维数组的指针
对于一个二维数组 a[3][4],它在内存中是按行优先顺序存储的,数组名 a 代表的是指向第一行的指针。我们可以定义一个指向一维数组的指针来访问二维数组。
// 指向包含 4 个元素的数组的指针
int (*ptr)[4] = a; // 这里的 a 就是一个指向包含 4 个 int 元素的数组的指针cout << ptr[0][0] << endl; // 输出 1,即访问第一行的第一个元素
cout << ptr[1][2] << endl; // 输出 7,即访问第二行的第三个元素
解释:ptr 是一个指向 int[4] 类型数组的指针,指向 a[0],即数组的第一行。
2. 将二维数组转换为指向单个元素的指针
二维数组的元素就是一维数组(即数组的某一行),可以通过指向元素的指针来访问:
// 指向二维数组中单个元素的指针
int* ptrElem = &a[1][2]; // 指向第二行第三列的元素cout << *ptrElem << endl; // 输出 7
解释:ptrElem 是指向单个 int 元素的指针,指向 a[1][2],即二维数组中的第 2 行第 3 列的元素。
3. 使用指针遍历二维数组
使用指针来遍历二维数组是很常见的操作,可以通过不同方式来模拟数组访问。
int* ptr = &a[0][0]; // 指向数组的首元素for (int i = 0; i < 3; ++i) {for (int j = 0; j < 4; ++j) {cout << *(ptr + i * 4 + j) << " "; // 计算出对应的地址偏移}cout << endl;
}
4. 使用数组指针的方式遍历
int (*ptr)[4] = a; // 指向包含4个元素的数组的指针for (int i = 0; i < 3; ++i) {for (int j = 0; j < 4; ++j) {cout << ptr[i][j] << " "; // 访问每一行的元素}cout << endl;
}
5. 通过 ptr + i * 4 + j 访问
int* ptr = &a[0][0];for (int i = 0; i < 3; ++i) {for (int j = 0; j < 4; ++j) {cout << *(ptr + i * 4 + j) << " "; // 通过地址偏移来访问}cout << endl;
}
解释:ptr + i * 4 + j 是通过指针偏移来访问二维数组元素的方式。这里 i * 4 用来计算行的偏移,j 用来计算列的偏移。
11.3 二维数组与指针数组的区别
有时候可能会把指针数组和指向数组的指针搞混。
- 指向数组的指针:是一个指针,指向一个一维数组(即数组的一行)。
- 指针数组:是一个数组,数组中的每个元素都是指向单个元素的指针。
示例:指向数组的指针
int a[3][4]; // 二维数组
int (*ptr)[4] = a; // 指向一维数组的指针
示例:指针数组
int* ptr[3]; // 指向 int 的指针数组
ptr[0] = &a[0][0]; // 指向 a[0][0]
ptr[1] = &a[1][0]; // 指向 a[1][0]
ptr[2] = &a[2][0]; // 指向 a[2][0]
11.4 二维数组与指针结合使用的实际应用
二维数组可以作为参数传递给函数,可以使用指针来接受这个参数。
void print(int (*arr)[4], int rows) {for (int i = 0; i < rows; ++i) {for (int j = 0; j < 4; ++j) {cout << arr[i][j] << " ";}cout << endl;}
}int main() {int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};print(a, 3); // 传递二维数组
}
使用指针动态分配二维数组:
int** arr = new int*[3]; // 为3行分配内存
for (int i = 0; i < 3; ++i) {arr[i] = new int[4]; // 为每一行分配4列
}// 释放内存
for (int i = 0; i < 3; ++i) {delete[] arr[i];
}
delete[] arr;
相关文章:

C++中数组的概念
文章目录 一、数组的定义二、什么是一维数组?2.1 一维数组的声明2.2 一维数组的初始化2.3 一维数组的使用 三、什么是一维数组的数组名?四、一维数组与指针的关系五、数组指针和指针数组的区别5.1 指针数组(array of pointers)5.2…...
)
996引擎-源码学习:Cocos2d-Lua 的 class(classname, ...)
996引擎-源码学习:Cocos2d-Lua 的 class(classname, ...) 一、核心方法调用顺序用户调用入口完整调用链二、__create 工厂方法的三种情形情形1:父类为函数(自定义工厂)情形2:父类为Cocos原生类情形3:父类为普通Lua表三、方法职责与内存管理对照表四、正确使用示例示例1…...
)
@linux系统SSL证书转换(Openssl转换PFX)
在Linux中,你可以使用OpenSSL工具将PFX/P12格式的证书转换为单独的CRT(证书)、KEY(私钥)文件以及提取证书链 1. 提取私钥文件(.key) openssl pkcs12 -in your_certificate.pfx -nocerts -out private.key -nodes系统会…...

flask返回json或者中文字符串不要编码
在 Flask 中返回中文字符串时,如果希望浏览器直接显示中文(而非编码后的 Unicode 转义字符如 \uXXXX),需确保以下两点: 正确设置 HTTP 响应的字符集(如 utf-8)。 避免 Flask 默认的 JSON 序列化转义中文字符。 以下是具体实现方法: 方法 1:直接返回纯文本(非 JSON) …...

打造船岸“5G+AI”智能慧眼 智驱力赋能客船数智管理
项目介绍 船舶在航行、作业过程中有着严格的规范要求,但在实际航行与作业中往往会因为人为的疏忽,发生事故,导致人员重大伤亡和财产损失; 为推动安全治理模式向事前预防转型,实现不安全状态和行为智能预警,…...

【Proteus仿真】【32单片机-A007】PT100热敏温度检测系统设计
目录 一、主要功能 二、使用步骤 三、硬件资源 四、软件设计 五、实验现象 联系作者 一、主要功能 1、LCD1602显示当前检测的温度值以及温度阈值 2、超过上限温度,降温模块启动 3、PT100热敏电阻测量-60C-135C 4、按键设置温度阈值 5、超过阈值࿰…...

MPDrive:利用基于标记的提示学习提高自动驾驶的空间理解能力
25年4月来自南方科技大学、百度、英国 KCL和琶洲实验室(广东 AI 和数字经济实验室)的论文“MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving”。 自动驾驶视觉问答(AD-VQA)…...

PhotoShop学习08
1.应用滤镜 PhotoShop提供了很多滤镜,借助滤镜可以打造很多有趣的效果。滤镜可以通过点击菜单栏的滤镜,并选择滤镜库进入滤镜调整界面。 进入到滤镜库后,左侧是实时进行预览的图片,右侧可以选择滤镜效果,最右边可以调…...
)
Photoshop2025最新版v26超详细图文安装教程(附安装包)
前言 Photoshop是一款基于位图的图像处理软件,专注于对已有图像的编辑、修复、合成及特效制作。其核心功能包括图层管理、色彩校正、选区工具、滤镜效果等,支持多种颜色模型(如RGB、CMYK、CIELAB)和文件格式(如.PSD、…...

Plusar集群搭建-Ubuntu20.04-Winterm
1 背景 已经部署了Pulsar集群在生产上,新项目需要用到Pulsar。对Pulsar不熟,故搭建练手。 环境:Windows10vmwareUbuntu20.04,ssh工具使用的Winterm。 使用的是root账户,ubuntu防火墙都ufw disable了。 2 参考文档 集…...

Qt与C++数据类型转换
本文深入探讨Qt与C中相似但不同的数据类型处理技巧。 一、QString与std::string的相互转换 1. QString → std::string 方法1:使用toStdString()(推荐) QString qstr "你好,Qt世界"; std::string str qstr.toStdS…...

Excel处理控件Aspose.Cells指南:如何查看、编辑和删除 Excel 元数据
本文是如何使用Aspose.Cells的在线工具和编码解决方案查看、编辑和删除 Excel 元数据的综合指南。无论您是寻找快速Excel 元数据查看器的普通用户,还是寻求强大的Excel 元数据编辑器的开发人员,本指南都能满足您的需求。您可以选择使用简单的在线转换器来…...

Rust 在汽车 MCU 编程中的进展及安全特性剖析
在当今汽车行业,软件定义汽车的趋势正深刻改变着汽车的设计与用户体验。随着汽车电子系统复杂性的不断提升,对汽车微控制器(MCU)编程的安全性、可靠性和效率提出了更高要求。Rust 作为一种新兴的编程语言,凭借其独特的…...

Pytorch 第十四回:神经网络编码器——变分自动编解码器
Pytorch 第十四回:神经网络编码器——变分自动编解码器 本次开启深度学习第十四回,基于Pytorch的神经网络编码器。本回分享VAE变分自动编码器。在本回中,通过minist数据集来分享如何建立一个变分自动编码器。接下来给大家分享具体思路。 本次…...

hive排序函数
在 Hive 中,排序可以通过几种不同的方法来实现,通常依赖于 ORDER BY 或 SORT BY 等函数。这里简要介绍这几种排序方法: 1. ORDER BY ORDER BY 用于对结果集进行全局排序。它会将所有数据加载到一个节点进行排序,因此可能会导致性能问题,尤其是在数据量很大的时候。 语法…...

Android测试王炸:Appium + UI Automator2
Android平台主流开源框架简介 在Android平台上,有多个开源且好用的自动化测试框架。以下是几个被广泛使用和认可的框架: 1.1 Appium Appium是一个跨平台的移动测试工具,支持iOS和Android上的原生、混合及移动Web应用。 它使用了供应商提供的…...

用Python打造增强现实的魔法:实时对象叠加系统全解析
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

const let var 在react jsx中的使用方法 。
在 JavaScript 里,const 和 let 都是 ES6(ES2015)引入的用于声明变量的关键字,它们和之前的 var 关键字有所不同。下面为你详细介绍 const 和 let 的区别: 1. 块级作用域 const 和 let 都具备块级作用域,…...

C++隐式转换的机制、风险与消除方法
引言 C作为一门强类型语言,类型安全是其核心特性之一。 然而,隐式转换(Implicit Conversion)的存在既为开发者提供了便利,也可能成为程序中的“隐藏炸弹”。 一、隐式转换的定义与分类 1.1 什么是隐式转换…...

Python 为什么要保留显式的 self ?
当你在类中定义方法时,Python要求第一个参数必须表示当前对象实例。当你调用obj.method(),Python 本质上会将它转换为ClassName.method(obj)。 所以你需要通过self参数显式接收这个实例,才能访问该对象的属性和其他方法。如果不加self&#…...

Linux 性能调优之CPU认知
写在前面 博文内容为《性能之巅 系统、企业与云可观测性(第2版)》CPU 章节课后习题答案整理内容涉及: CPU 术语,指标认知CPU 性能问题分析解决CPU 资源负载特征分析应用程序用户态CPU用量分析理解不足小伙伴帮忙指正对每个人而言,真正的职责只有一个:找到自我。然后在心中…...

认识vue中的install和使用场景
写在前面 install 在实际开发中如果你只是一个简单的业务实现者,那么大部分时间你是用不到install的,因为你用到的基本上都是别人封装好的插件、组件、方法、指令等等,但是如果你需要给公司的架构做建设,install就是你避不开的一个…...

C++Cherno 学习笔记day17 [66]-[70] 类型双关、联合体、虚析构函数、类型转换、条件与操作断点
b站Cherno的课[66]-[70] 一、C的类型双关二、C的union(联合体、共用体)三、C的虚析构函数四、C的类型转换五、条件与操作断点——VisualStudio小技巧 一、C的类型双关 作用:在C中绕过类型系统 C是强类型语言 有一个类型系统,不…...

3.神经网络
神经网络 神经元与大脑 神经网络神经元的结构: 输入(Input):接收来自前一层神经元的信息。 权重(Weights):每个输入都有一个权重,表示其重要性。 加权和(Weighted Sum&a…...

CentOS 7安装Python3.12
文章目录 使用pyenv安装python3.12一、gitub下载pyenv二、升级GCC三.升级openssl这样python3.12.9就完成安装在CentOS上啦! 使用pyenv安装python3.12 一、gitub下载pyenv https://github.com/pyenv/pyenv 按照README,pyenv教程安装即可 二、升级GCC 安…...

微服务无感发布实践:基于Nacos的客户端缓存与故障转移机制
微服务无感发布实践:基于Nacos的客户端缓存与故障转移机制 背景与问题场景 在微服务架构中,服务的动态扩缩容、滚动升级是常态,而服务实例的上下线需通过注册中心(如Nacos)实现服务发现的实时同步。但在实际生产环境…...
)
5.2 自定义通知操作按钮(UNNotificationAction)
在本地推送通知中添加自定义操作按钮可以增强用户交互性,让用户无需打开应用就能执行一些快速操作。本节将详细介绍如何在SwiftUI应用中实现这一功能。 基本概念 UNNotificationAction 和 UNNotificationCategory 是UserNotifications框架中用于定义通知交互的核心…...

Python与链上数据分析:解锁区块链数据的潜力
Python与链上数据分析:解锁区块链数据的潜力 引言 区块链技术的兴起不仅改变了金融行业,也为数据分析领域带来了全新的机遇。链上数据(On-chain Data)是区块链网络中公开透明的交易记录和活动数据,它为我们提供了一个独特的视角,去观察用户行为、市场趋势以及网络健康状…...

数字化转型:未来已来,企业如何抢占先机?
近年来,“数字化转型”从一个技术热词逐渐演变为各行各业的“必选项”。无论是全球市场还是中国市场,数字化浪潮正以不可逆的姿态重塑商业生态。据IDC预测,到2028年,中国数字化转型市场规模将突破7300亿美元,全球投资规…...

Web3游戏全栈开发实战指南:智能合约与去中心化生态构建全解析
在GameFi市场规模突破千亿美元的当下,去中心化游戏系统开发正面临技术架构升级与生态融合的双重机遇。本文基于Solidity、Rust等多链智能合约开发经验,结合Truffle、Hardhat等主流框架,深度解析如何构建高性能、高收益的链游生态系统。 一、…...

Windows 图形显示驱动开发-WDDM 2.0功能_IoMmu 模型
概述 输入输出内存管理单元 (IOMMU) 是一个硬件组件,它将支持具有 DMA 功能的 I/O 总线连接到系统内存。 它将设备可见的虚拟地址映射到物理地址,使其在虚拟化中很有用。 在 WDDM 2.0 IoMmu 模型中,每个进程都有一个虚拟地址空间࿰…...
)
uniapp微信小程序基于wu-input二次封装TInput组件(支持点击下拉选择、支持整数、电话、小数、身份证、小数点位数控制功能)
一、 最终效果 二、实现了功能 1、支持输入正整数---设置specifyTypeinteger 2、支持输入数字(含小数点)---设置specifyTypedecimal,可设置decimalLimit来调整小数点位数 3、支持输入手机号--设置specifyTypephone 4、支持输入身份证号---设…...

Java 大厂面试题 -- JVM 深度剖析:解锁大厂 Offe 的核心密钥
最近佳作推荐: Java大厂面试高频考点|分布式系统JVM优化实战全解析(附真题)(New) Java大厂面试题 – JVM 优化进阶之路:从原理到实战的深度剖析(2)(New&#…...

小白入门JVM、字节码、类加载机制图解
前提知识~ JDK 基本介绍 JDK 的全称(Java Development Kit Java 开发工具包)JDK JRE java 的开发工具[java, javac,javadoc,javap 等]JDK 是提供给Java 开发人员使用的,其中包含了java 的开发工具,也包括了JRE。可开发、编译、调试…… JRE 基本介绍…...

新能源汽车动力性与经济性优化中的经典数学模型
一、动力性优化数学模型 动力性优化的核心目标是提升车辆的加速性能、最高车速及爬坡能力,主要数学模型包括: 1. 车辆纵向动力学模型 模型方程: 应用场景: 计算不同工况下的驱动力需求匹配电机扭矩与减速器速比案例ÿ…...
有什么作用?)
高级java每日一道面试题-2025年3月25日-微服务篇[Nacos篇]-Nacos中的命名空间(Namespace)有什么作用?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos中的命名空间(Namespace)有什么作用? 我回答: 在Java高级面试中,关于Nacos中的命名空间(Namespace)的作用,是一个考察候选人对微服务架构和配…...

5.JVM-G1垃圾回收器
一、什么是G1 二、G1的三种垃圾回收方式 region默认2048 三、YGC的过程(Step1) 3.1相关代码 public class YGC1 {/*-Xmx128M -XX:UseG1GC -XX:PrintGCTimeStamps -XX:PrintGCDetails -XX:UnlockExperimentalVMOptions -XX:G1LogLevelfinest128m5% 60%6.4M 75M*/private stati…...

变量、数据、值类型引用类型的存储方式
代码写了也有2年了,对于这些基础的程序名词,说出口也是模棱两可,心里很不爽,很多基础还是模糊不清,清算一下...... Example值类型: int x 10; 变量:“x”是一个标识符,它对应着栈…...

分布式和微服务的区别
1. 定义 在讨论分布式系统和微服务的区别之前,我们先明确两者的定义: 分布式系统:是一组相互独立的计算机,通过网络协同工作,共同完成某个任务的系统。其核心在于资源的分布和任务的分解。 微服务架构:是…...

数组的常见算法一
注: 本文来自尚硅谷-宋红康仅用来学习备份 6.1 数值型数组特征值统计 这里的特征值涉及到:平均值、最大值、最小值、总和等 **举例1:**数组统计:求总和、均值 public class TestArrayElementSum {public static void main(String[] args)…...

Leedcode刷题 | Day27_贪心算法01
一、学习任务 455.分发饼干代码随想录376. 摆动序列53. 最大子序和 二、具体题目 1.455分发饼干455. 分发饼干 - 力扣(LeetCode) 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对…...

springboot集成kafka,后续需要通过flask封装restful接口
Spring Boot与Kafka的整合 在现代软件开发中,消息队列是实现服务解耦、异步消息处理、流量削峰等场景的重要组件。Apache Kafka是一个分布式流处理平台,它具有高吞吐量、可扩展性和容错性等特点。Spring Boot作为一个轻量级的、用于构建微服务的框架&am…...

MYSQL数据库语法补充2
一,数据库设计范式(原则) 数据库设计三大范式: 第一范式: 保证列的原子性(列不可再分) 反例:联系方式(手机,邮箱,qq) 正例: 手机号,qq,邮箱. 第二范式: 要有主键,其他列依赖于主键列,因为主键是唯一的,依赖了主键,这行数据就是唯一的. 第三范式: 多表关联时,在…...

Flask返回文件方法详解
在 Flask 中返回文件可以通过 send_file 或 send_from_directory 方法实现。以下是详细方法和示例: 1. 使用 send_file 返回文件 这是最直接的方法,适用于返回任意路径的文件。 from flask import Flask, send_fileapp = Flask(__name__)@app.route("/download")…...
)
随机数据下的最短路问题(Dijstra优先队列)
题目描述 给定 NN 个点和 MM 条单向道路,每条道路都连接着两个点,每个点都有自己编号,分别为 1∼N1∼N 。 问你从 SS 点出发,到达每个点的最短路径为多少。 输入描述 输入第一行包含三个正整数 N,M,SN,M,S。 第 22 到 M1M1 行…...

CPP杂项
注意:声明类,只是告知有这个类未完全定义,若使用类里具体属性,要么将访问块(函数之类)放到定义后,要么直接完全定义 C 友元函数/类的使用关键点(声明顺序为核心) 1. 友元…...

Idea将Java工程打包成war包并发布
1、问题概述? 项目开发之后,我们需要将Java工程打包成war后缀,并进行发布。之前在网上看到很多的文章,但是都不齐全,今天将提供一个完整的实现打包war工程,并发布的文章,希望对大家有所帮助,主要解决如下问题: 1、war工程需要满足的相关配置 2、如何解决项目中的JDK…...

多级缓存模型设计
为了有效避免缓存击穿、穿透和雪崩的问题。最基本的缓存设计就是从数据库中查询数据时,无论数据库中是否存在数据,都会将查询的结果缓存起来,并设置一定的有效期。后续请求访问缓存时,如果缓存中存在指定Key时,哪怕对应…...

SGLang实战:从KV缓存复用到底层优化,解锁大模型高效推理的全栈方案
在当今快速发展的人工智能领域,大型语言模型(LLM)的应用已从简单对话扩展到需要复杂逻辑控制、多轮交互和结构化输出的高级任务。面对这一趋势,如何高效地微调并部署这些大模型成为开发者面临的核心挑战。本文将深入探讨SGLang——这一专为大模型设计的高…...

【中大厂面试题】腾讯 后端 校招 最新面试题
操作系统 进程和线程的区别 本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销&am…...