人工智能通识速览(Part3. 强化学习)

三、强化学习
1. 基本概念
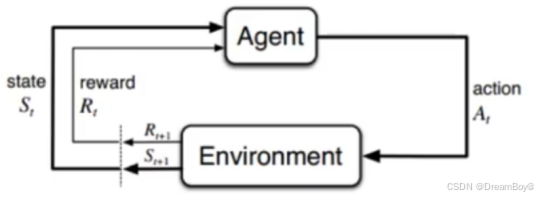
强化学习是机器学习中的一个重要领域,它涉及智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励。以下是关于强化学习的详细介绍:
-
智能体:是一个能够感知环境并采取行动的实体,如机器人、自动驾驶汽车或游戏中的角色等。
-
环境(st):智能体所处的外部世界,它会根据智能体的行动产生相应的反馈,包括奖励信号和新的状态。
-
状态:描述环境在某一时刻的信息,智能体根据当前状态来决定采取何种行动。
-
行动(at):智能体可以执行的操作,例如在游戏中移动、跳跃,机器人的前进、转弯等。
-
奖励(rt):环境给予智能体的反馈信号,用于衡量智能体的行动在实现目标方面的好坏程度。智能体的目标是通过选择合适的行动来最大化长期累积奖励。
- 轨迹:在一个回合中智能体所观测到的所有的状态,动作奖励。
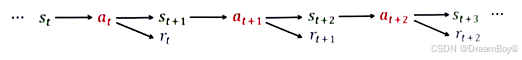
- 随机性:强化学习过程中的随机性主要来自动作的随机性和状态的随机性。动作的随机性来自策略函数的随机性,状态的随机性来自状态转移的随机性。
-
状态空间:所有可能存在的状态集合, 记为S
-
动作空间:所有可能的动作的集合,记为A,
- 状态转移:智能体从当前时刻t的状态转换到下一时刻状态的过程。状态转移可以是确定的,也可以是不确定的。
-
状态转移函数:描述状态转移过程的函数
-

- 策略:智能体根据状态选择动作的策略。包含随机性策略和确定性策略。强化学习的目标是学习一个好的策略函数,在指定环境下做出使得回报期望最大的动作。
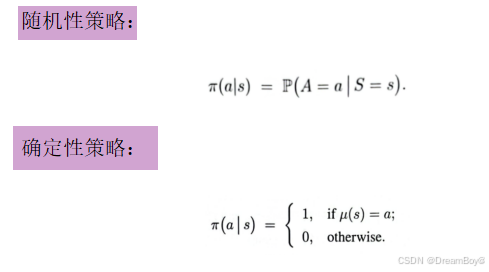
- 回报(累计奖励):一个回合结束所有奖励的总和。强化学习的目标是优化最大化回报,而不是最大化当前奖励。在强化学习的过程中只有执行过的动作产生的奖励是已知的,其余奖励是未知的,但是计算回报需要计算所有奖励的总和,未来奖励的未知性质,导致其并不完全可信,故需要给未知回报一个折扣。
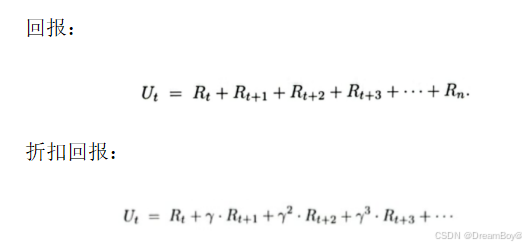 \
\- 有限期MDP:存在终止状态的马尔可夫决策过程。
- 无限期MDP:不存在终止状态的马尔可夫决策过程。为了使无限期的MDP的回报是有界的,需要使用小于1的折扣率。
- 价值函数:反应现状的好坏,值越大,表示现状越有利,是回报的期望。
-
动作价值函数:我们对回报求期望,以反应现状好坏,我们以策略函数π选择动作。动作价值函数的值依赖于当前的动作,状态,与选择的策略函数。
-
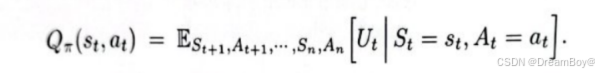
-
最优动作价值函数:使用最优的策略函数,屏蔽策略函数的影响。最优动作价值函数的值,依赖于当前的状态,动作。
-
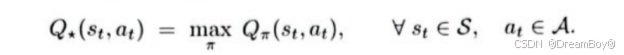
-
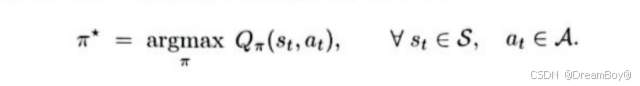
- 状态价值函数:不关注动作,将动作作为随机变量,求回报的期望。消除了动作的影响。状态价值函数依赖于当前的状态与策略函数。
马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process,MDP)是一种用于描述决策过程的数学模型,在强化学习等领域有着广泛的应用。以下是对它的详细介绍:
定义与基本要素

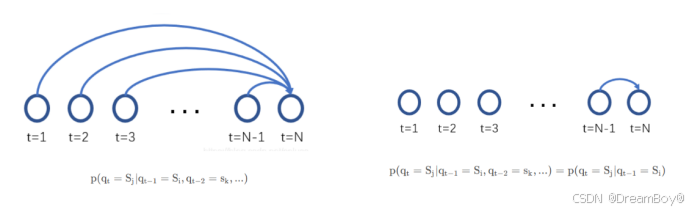
马尔可夫性质

策略与价值函数

求解方法
- 动态规划方法:包括策略迭代和价值迭代。策略迭代先初始化一个策略,然后交替进行策略评估和策略改进步骤,直到找到最优策略;价值迭代则直接通过迭代计算价值函数来求解最优策略。
- 基于模型的强化学习方法:先学习环境的模型,即估计状态转移概率和奖励函数,然后利用模型来规划最优策略,如使用动态规划方法在模型上进行求解。
- 无模型强化学习方法:不需要显式地学习环境模型,而是通过与环境的直接交互来学习最优策略,如前面提到的基于值函数的方法(如 DQN)和基于策略梯度的方法(如 A2C、A3C、PPO 等)。
2. 学习过程

3. 算法类型
-
基于值函数的方法:如深度 Q 网络(DQN)及其扩展。这类方法通过学习一个值函数(如 Q 函数)来估计在每个状态下采取不同行动的长期价值,然后选择具有最高价值的行动。
-
基于策略梯度的方法:例如 A2C、A3C、PPO 等算法。它们直接对策略进行参数化,并通过梯度上升的方式来优化策略,使得策略能够最大化预期累积奖励。
-
无模型强化学习和有模型强化学习:无模型强化学习算法(如上述的 DQN、A2C 等)不直接学习环境的模型,而是通过与环境的交互来学习最优策略;有模型强化学习则先学习环境的模型,然后利用这个模型来规划最优行动序列。
4. 应用领域
-
机器人控制:用于机器人的运动控制、任务执行等,如机器人的导航、抓取物体等任务。
-
游戏:训练智能体在各种游戏中达到高水平的表现,如 Atari 游戏、围棋、象棋等。
-
自动驾驶:决策车辆的行驶速度、转向角度等,以实现安全高效的驾驶。
-
资源管理:如数据中心的资源分配、网络带宽分配等,以优化系统性能和资源利用率。
-
医疗:用于医疗决策,如治疗方案的选择、药物剂量的调整等,以提高治疗效果和患者的预后。
5. 贪心策略
贪心策略是强化学习中用于平衡探索(exploration)和利用(exploitation)的一种常用策略

执行过程
- 探索:当智能体决定进行探索时,它会在动作空间中随机选择一个动作来执行。这样做的目的是为了让智能体能够发现那些可能被忽视但实际上具有更高价值的动作,避免陷入局部最优解。例如,在一个机器人导航任务中,智能体可能会随机选择一些不常用的路径,以探索是否存在更短或更安全的路线。
- 利用:当智能体选择利用时,它会根据当前的知识和经验,选择那个在当前状态下被认为是最优的动作,即具有最高估计价值的动作。这是基于智能体已经学习到的信息来最大化即时奖励的一种方式。例如,在玩游戏时,如果智能体已经发现某种操作在当前场景下通常能获得高分,它就会倾向于选择这个操作。
参数调整
- 在实际应用中,\(\epsilon\)的值通常会随着学习过程的进行而动态调整。在学习的初期,为了鼓励智能体充分探索环境,\(\epsilon\)会被设置为一个较大的值,使得智能体有更多机会尝试不同的动作。随着学习的推进,智能体对环境有了一定的了解,为了更多地利用已经学到的知识,\(\epsilon\)会逐渐减小,让智能体更倾向于选择最优动作。例如,在训练一个自动驾驶模型时,开始时会让车辆更多地随机探索不同的驾驶方式,随着训练的深入,逐渐减少随机探索,让车辆更多地依据已经学习到的最优策略来行驶。
6. 常见算法
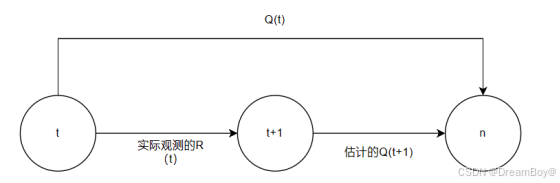
TD算法(temproal difference)
时间差分算法,模型估计t时刻到n时刻的Q(t),并实际观测t时刻到t+1时刻的R(t),基于实际观测到的R(t),估计Q(t+1),使用梯度下降算法,使得Q(t)逼近R(t)+Q(t+1)。TD算法包括Q-learning ,DQN等算法。


- 优点:TD 算法不需要环境的模型信息,直接从与环境的交互中学习,具有较好的通用性和灵活性;它可以在线学习,即在与环境交互的过程中实时更新值函数,不需要等待整个 episode 结束,因此学习效率较高;同时,TD 算法在处理连续状态空间和连续时间问题时也有较好的表现。
- 应用:TD 算法在强化学习的各种应用中都有广泛的使用,如机器人控制、游戏、自动驾驶等领域。它可以用于估计最优策略下的状态价值函数或动作价值函数,为智能体的决策提供依据,帮助智能体学习到最优的行为策略,以最大化长期累积奖励。
Q-Learning
简单的Q-learning 算法以表格的形式呈现,使用一个Q表去表示最优价值函数,使用查表的方式获取不同状态下的选择不同状态能够带来的价值,Q表行索引是状态,列索引是不同的动作,表中的值为不同状态下,选择不同动作能够带来的回报。智能体根据Q表选择对应状态下,回报值最大动作作为将要执行的动作。
- Q - Learning 基于贝尔曼方程,通过学习一个 Q 函数(动作价值函数)来评估在每个状态下采取每个动作的长期价值。Q 函数Q(s, a)表示在状态s下采取动作a,然后遵循最优策略所能获得的长期累积奖励的期望。
- 其核心思想是让智能体在环境中不断进行试验和探索,根据环境反馈的奖励信号来逐步调整 Q 函数的值,使得 Q 函数能够准确地反映出每个状态 - 动作对的价值,最终找到最优策略。

Q表通过异策略的方式更新,Q表的初始状态可以随机获取,也可以设为全零。Q表的更新过程如下。




收集经验与表格更新的过程可以同步进行,每获取一次经验就迭代更新一次Q表,也可以先获取经验,再更新Q表。Q-learning的局限在于表格的大小使得动作空间与状态空间必须是离散并且有限的。


算法特点
-
无模型学习:不需要事先知道环境的状态转移概率和奖励函数等模型信息,直接通过与环境的交互来学习最优策略,因此具有很强的通用性,能适应各种不同的环境。
-
离线学习:Q - Learning 是一种离线学习算法,这意味着它可以在学习过程中使用过去收集到的经验数据进行学习,而不需要实时地与环境进行交互。这使得智能体可以在不影响环境的情况下,对已经经历过的情况进行反复学习和优化,提高学习效率和策略的质量。
-
收敛性:在一定条件下,Q - Learning 算法能够收敛到最优的 Q 函数,从而找到最优策略。然而,收敛速度可能会受到环境的复杂性、参数设置以及初始 Q 值的影响。
应用领域
-
机器人控制:用于机器人的路径规划、动作控制等任务,使机器人能够通过学习在不同环境中采取最优的动作序列来完成任务,如机器人在未知环境中寻找目标、避开障碍物等。
-
游戏领域:训练智能体在各种游戏中学习最优的玩法策略,如 Atari 游戏、围棋、象棋等。智能体通过不断地与游戏环境交互,学习如何根据游戏的当前状态选择最佳的动作,以获得最高的得分或赢得游戏。
-
资源管理:在资源分配、调度等问题中,Q - Learning 可以用于学习最优的资源分配策略,以最大化系统的性能或效益。例如,在网络通信中,智能体可以学习如何根据网络的当前状态(如带宽占用、节点负载等)来分配网络资源,以提高网络的传输效率和可靠性。
DQN
深度 Q 网络(Deep Q - Network,DQN)是一种将深度学习与强化学习相结合的算法,它在 Q - Learning 的基础上,利用深度神经网络来逼近 Q 函数,从而能够处理高维的状态空间和动作空间。以下是对 DQN 的详细介绍:
算法原理
- DQN 的核心思想是使用一个深度神经网络(称为 Q 网络)来学习 Q 函数。网络的输入是环境的状态,输出是每个动作对应的 Q 值。通过在环境中不断进行试验和学习,利用 Q - Learning 的更新规则来调整神经网络的参数,使得 Q 网络能够准确地估计出每个状态 - 动作对的价值。
算法结构
- Q 网络:通常由多个卷积层和全连接层组成。卷积层用于处理图像等具有空间结构的状态信息,提取特征;全连接层则将提取的特征映射到动作空间上,输出每个动作的 Q 值。
- 目标网络:为了使学习过程更加稳定,DQN 引入了目标网络。目标网络的结构与 Q 网络相同,但参数更新相对缓慢。它用于计算目标 Q 值,避免了 Q 值估计的偏差和振荡,提高了算法的收敛性。

关键技术
- 经验回放:通过存储和随机采样经验样本,使得智能体能够利用过去的经验进行学习,并且可以打破数据之间的时间相关性,减少训练数据中的噪声,提高算法的稳定性和收敛速度。
- 目标网络:引入目标网络来解耦 Q 值估计中的当前网络和目标网络,避免了因直接使用当前网络估计目标 Q 值而导致的估计偏差和振荡问题,使得学习过程更加稳定,有助于算法收敛到更优的解。
算法特点
- 处理高维数据:能够处理高维的状态空间,如图像、视频等数据,通过深度学习的特征提取能力,自动从原始数据中学习到有效的特征表示,从而能够在复杂的环境中进行学习和决策。
- 端到端学习:实现了从原始状态输入到动作输出的端到端学习,无需人工设计特征工程,减少了对领域知识的依赖,提高了算法的通用性和灵活性。
- 较好的泛化能力:通过大规模的数据训练和深度神经网络的强大表示能力,DQN 能够学习到具有较好泛化能力的策略,在未见过的环境状态下也能做出合理的决策。
应用领域
- 游戏领域:在各种电子游戏中取得了显著的成果,如 Atari 游戏、星际争霸等。能够让智能体学习到高超的游戏技巧,甚至超越人类玩家的水平。
- 自动驾驶:用于自动驾驶车辆的决策和控制,如根据道路场景、交通信号等信息做出加速、减速、转向等决策。
- 机器人控制:可以应用于机器人的各种任务控制,如机器人的导航、操作物体等,使机器人能够适应复杂多变的环境,完成各种复杂的任务。
SARSA
SARSA(State - Action - Reward - State - Action)是一种基于时间差分(TD)的强化学习算法,属于同策略(on - policy)算法,主要用于解决马尔可夫决策过程中的最优策略学习问题。以下是对它的详细介绍:
算法原理
- SARSA 和 Q - Learning 一样,都是为了学习一个动作价值函数 (Q(s,a)),不过二者在更新方式上存在差异。SARSA 依据智能体当前所遵循的策略来选择动作,在每个时间步更新动作价值函数时,会考虑到下一个状态以及根据当前策略在该状态下选择的下一个动作。

关键要素解释
-
同策略特性:SARSA 属于同策略算法,意味着在更新 Q 值时所采用的策略和选择动作时的策略是相同的。这种特性使得 SARSA 在学习过程中会对探索时产生的策略进行优化,更侧重于学习当前正在使用的策略。
-
探索与利用的平衡:通常借助 贪心策略来平衡探索和利用。在学习初期,设置较大的 epsilon值,让智能体有更多机会去探索新的状态和动作;随着学习的推进,逐渐减小 epsilon值,使智能体更多地利用已经学习到的知识。
与 Q - Learning 的对比
-

-
策略特性:Q - Learning 学习的是最优策略,即使在探索过程中采取了随机动作,也会朝着最优策略的方向进行更新;SARSA 则更关注当前正在执行的策略,会对探索过程中产生的策略进行优化,可能会陷入局部最优,但在某些情况下能更安全地学习,比如在环境中存在危险状态时。
应用领域
-
机器人路径规划:在机器人寻找从起点到目标点的最优路径问题中,SARSA 可以学习到在不同环境状态下的最优动作序列,同时考虑到探索过程中的安全性。
-
资源分配问题:例如在网络资源分配、云计算资源调度等场景中,根据系统的当前状态和资源需求,学习如何分配资源以最大化系统的性能或者效益。
-
游戏策略学习:在一些简单的游戏中,SARSA 可以帮助智能体学习到合适的游戏策略,通过不断地与游戏环境交互和更新策略来提高游戏得分。
相关文章:
)
人工智能通识速览(Part3. 强化学习)
三、强化学习 1. 基本概念 强化学习是机器学习中的一个重要领域,它涉及智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励。以下是关于强化学习的详细介绍: 智能体:是一个能够感知环境并采取行动…...

深度解析LinkedList工作原理
引言 在 Java 编程中,集合框架是处理数据存储和操作的强大工具。LinkedList 作为其中的重要成员,为我们提供了一种灵活的列表实现方式。与 ArrayList 基于数组的实现不同,LinkedList 采用链表结构,这使得它在某些操作上具有独特的…...
)
excel的逻辑类型函数(主要包括if、and、or、not、xor、iserror、iferror、true、false、ifs、ifna、switch)
目录 1. IF 函数2. AND 函数3. OR 函数4. NOT 函数5. XOR 函数6. ISERROR 函数7. IFERROR 函数8. TRUE 与 FALSE9. IFS 函数10. IFNA 函数11. SWITCH 函数 1. IF 函数 功能: 根据指定条件判断结果,如果条件为 TRUE,则返回一个值;…...

数据驱动金融韧性升级,开启数据交换“新范式”:构建“实时、国产化强适配”的数据交换与共享平台
在金融行业,数据不只是“资产”,更是贯穿风控、合规、营销与运营的核心“生命线”。而在数字化加速与信创战略并行推进的当下,金融行业对于“实时数据流通”的需求从未如此迫切。 面对业务复杂性提升、国产化替代加速,以及监管科…...
)
cpp自学 day20(文件操作)
基本概念 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通过文件可以将数据持久化 C中对文件操作需要包含头文件 <fstream> 文件类型分为两种: 文本文件 - 文件以文本的ASCII码形式存储在计算机中二进制文件 - 文件以文本的…...

Qt饼状图在图例上追踪鼠标落点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、饼状图的关键接口二、关键代码1.鼠标移动事件2.核心判断逻辑 总结 前言 最近做了一个项目,需要当鼠标在饼状图上移动的时候展示Slice的内容&am…...

ZKmall开源商城服务端验证:Jakarta Validation 详解
ZKmall开源商城基于Spring Boot 3构建,其服务端数据验证采用Jakarta Validation API(原JSR 380规范),通过声明式注解与自定义扩展机制实现高效、灵活的数据校验体系。以下从技术实现、核心能力、场景优化三个维度展开解析&#…...
)
操作系统概述(3)
批处理系统 1.单道批处理系统 单道批处理系统是成批地处理作用,并且始终只有一道作业在内存中的系统。优点:提高系统资源的利用率和系统吞吐量。缺点:系统中的资源得不到充分利用。 2.多道批处理系统 引入多道程序设计技术,是…...
:基础用法与 Object.keys() 的核心区别)
深入理解 Object.entries():基础用法与 Object.keys() 的核心区别
深入理解 Object.entries():基础用法与 Object.keys() 的核心区别 一、Object.entries() 是什么? Object.entries() 是 JavaScript 中的一个内置方法,用于将对象的 可枚举属性(自身的、非继承的)转换为一个数组。…...
)
GitHub 趋势日报 (2025年04月06日)
GitHub 趋势日报 (2025年04月06日) 本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星语言1microsoft/markitdownPython tool for converting files and office documents to Markdown.⭐ 548Py…...

Visual Studio 中使用 Clang 作为 C/C++ 编译器时,设置优化选项方法
在 Visual Studio 中使用 Clang 作为 C/C 编译器时,可以通过以下方法设置优化选项: 方法 1:通过项目属性设置(推荐) 右键项目 → 属性 配置属性 → C/C → 优化 优化:选择优化级别 /O0 - 禁用优化&#x…...

现场测试的特点与测试设备的基本要求
在各类测试场景中,现场测试有着不可替代的作用。不过,它也面临着诸多难题,对测试设备也有着特殊要求。今天,咱们就深入探讨一下现场测试的特点与测试设备的基本要求。 现场测试的特点 场地电磁环境噪声问题 建议环境噪声低于…...

构建一个最简单的UDP服务器和客户端并逐行解析
目录 1.服务器 (1)基本概念 (2)代码实现 3.逐行解析 1) 2) 3) 4) 5) 6) 7) 8) 1. response.getBytes(): 2.response.get…...

LeetCode 1638 统计只差一个字符的子串
标题:LeetCode 算法题 - 统计只差一个字符的子串数目 在算法学习的过程中,我们经常会遇到一些有趣的字符串问题。今天就来探讨一道这样的题目:给定两个字符串 s 和 t ,找出 s 中的非空子串的数目,这些子串满足替换一个…...

DAY 39 leetcode 18--哈希表.四数之和
题号18 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复): 和…...

关于lombok的异常快速解决办法
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...

Android SELinux权限使用
Android SELinux权限使用 一、SELinux开关 adb在线修改seLinux(也可以改配置文件彻底关闭) $ getenforce; //获取当前seLinux状态,Enforcing(表示已打开),Permissive(表示已关闭) $ setenforce 1; //打开seLinux $ setenforce 0; //关闭seLinux二、命令查看sel…...

JavaWeb注解的原理
WebServlet("/mayikt") 是 Java Servlet 3.0 及以上版本中引入的注解,用于简化 Servlet 的配置。其原理和与 Servlet 映射关系的知识点如下: 1. 注解的作用与原理 核心功能: WebServlet 注解的作用是将当前类声明为一个 Servlet&am…...

类和对象—多态
目录 1、多态的概念2、多态的条件3、向上转型3.1 概念3.2 使用场景 4、向下转型5、多态的优缺点 1、多态的概念 多态,通俗来讲就是多种形态,即对于同样的行为,不同的对象去完成会产生不同的状态。比如动物都会吃东西,小狗和小猫都…...

vscode启动vite+Vue3项目调试功能,QQ浏览器为例
1、增加launch.json配置 {// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid830387"version": "0.2.0","configurations": [{"type&quo…...

Spring MVC 的执行流程以及运行原理
一.什么是 MVC? MVC 是 Model 、 View 和 Controller 的缩写,分别代表 Web 应用程序中的 3 种职责, MVC 是一种软件设计规范。它将业务逻辑、数据、显示分离的方法来组织代码,降低了视图与业 务逻辑之间的…...

08-Spring MVC 请求处理流程全解析
Spring MVC 请求处理流程全解析(从 DispatcherServlet 到 Controller) Spring MVC 是构建 Web 应用的基础框架,而其中最核心的组件就是 DispatcherServlet,它作为整个请求流程的入口和协调者,掌控了从接收请求、分发到…...

pikachu靶场搭建教程,csfr实操
靶场安装 靶场下载地址 百度网盘下载地址和密码 百度网盘 请输入提取码 0278 github靶场下载地址 https://gitcode.com/Resource-Bundle-Collection/c7cc1 安装前提 这两个文件夹的配置文件都要进行更改修改数据库密码 D:\phpstudy_pro\WWW\pikachu\inc D:\phpstudy_pro…...

MCP + 数据库,一种比 RAG 检索效果更好的新方式!
大家好,欢迎来到 code秘密花园,我是 ConardLi。 在今天这一期,我们将一起学习一种基于 MCP 提高大模型检索外部知识精度的新思路,实测比 RAG 效果要好很多。 目前市面上讲 MCP 的教程比较多,但大多数都是一些概念性的…...

图像处理中的梯度计算、边缘检测与凸包特征分析技术详解
前言 书接上文 OpenCV图像处理实战全解析:镜像、缩放、矫正、水印与降噪技术详解-CSDN博客文章浏览阅读1.1k次,点赞38次,收藏29次。本文系统解析OpenCV图像处理五大实战场景:镜像反转的三种坐标变换模式,图像缩放的尺…...
)
TDengine 与 taosAdapter 的结合(一)
一、引言 在当今数字化时代,数据量呈爆发式增长,尤其是物联网、工业互联网等领域产生的海量时序数据,对数据存储和处理提出了极高要求。TDengine 作为一款高性能、开源的时序数据库,专为这些场景设计并优化,在时序数据…...

23种设计模式-行为型模式-模板方法
文章目录 简介场景解决代码关键优化点 总结 简介 模板方法是一种行为设计模式,它在超类中定义了一个算法的框架,允许子类在不修改结构的情况下重写算法的特定步骤。 场景 假如你正在开发一款分析文档的数据挖掘程序。用户需要向程序输入各种格式&…...

Django异步执行任务django-background-tasks
1、安装 pip install django-background-tasks 2、注册服务 INSTALLED_APPS [...background_task, ]3、生成表 // 生成迁移 python manage.py makemigrations //运行迁移 python manage.py migrate 4、创建文件,模拟任务 from background_task import backgrou…...

从零设计React-Markdown组件的实现方案
从零设计React-Markdown组件的实现方案 现在,把这些步骤整理成代码结构。首先是解析器类,用正则表达式分割文本为Token,然后生成AST。接着,编写一个React组件,接收Markdown字符串,解析成AST,遍历AST生成对应的React元素。处理代码高亮需要引入第三方库,但用户不允许用现…...

如何在React中集成 PDF.js?构建支持打印下载的PDF阅读器详解
本文深入解析基于 React 和 PDF.js 构建 PDF 查看器的实现方案,该组件支持 PDF 渲染、图片打印和下载功能,并包含完整的加载状态与错误处理机制。 完整代码在最后 一个PDF 文件: https://mozilla.github.io/pdf.js/web/compressed.tracemo…...

React-Markdown 组件底层实现原理详解
如何在 React 中渲染 Markdown 文档 React-Markdown 组件底层实现原理详解 一、核心架构:基于 Unified.js 的编译流水线 React-Markdown 的底层实现依赖于 Unified.js 这一开源内容处理系统,其核心是一个可插拔的编译流水线。整个过程分为四个阶段&…...
)
基于单片机的防火防盗报警系统设计(论文+源码)
2.1系统的功能及方案设计 本次课题为基于单片机的防火防盗报警系统,其系统采用STC89C52单片机为控制器,并结合SIM800短信模块,DS18B20温度检测模块,MQ-2烟雾检测模块,红外人体检测模块,按键模块,…...
)
NO.72十六届蓝桥杯备战|搜索算法-DFS|选数|飞机降落|八皇后|数独(C++)
P1036 [NOIP 2002 普及组] 选数 - 洛谷 组合型枚举,路径⾥⾯记录选择数的「总和」。在选出k 个数之后,判断「是否是质数」 #include <bits/stdc.h> using namespace std;const int N 25; int n, k; int a[N];int ret; int path; //记录路径中所…...

网络Socket编程基于UDP协议模拟简易网络通信
一、预备知识 网络编程(Network Programming)是指编写程序来实现计算机网络之间的通信。这通常涉及到使用套接字(sockets)来建立连接、发送和接收数据。 (一)套接字 套接字(Socket࿰…...

rust 使用select退出线程
#[derive(Serialize, Deserialize, Debug, Clone, PartialEq)] pub struct Capture {clear: bool, // ????????interface: String, // ??times: u64, // ?? }pub async fn cmd_capture(State(web_env): State<ArcWebEnv>,Json(args): Json<C…...

C++学习day7
思维导图: 使用vector实现一个简单的本地注册登录系统 注册:将账号密码存入vector里面,注意防重复判断 登录:判断登录的账号密码是否正确 #include <iostream> #include <cstring> #include <cstdlib> #includ…...

【学习笔记】CoACD: 基于碰撞感知凹性与树搜索的近似凸分解
CoACD 基于碰撞感知凹性与树搜索的近似凸分解 CoACD 官方文档 CoACD(Convex Approximation of Complex Decompositions)是一种用于将复杂网格分解为多个凸包的算法, 专为 3D 网格设计了近似凸分解算法,强调在保持物体间潜在碰撞条件的同时减…...

Three.js 系列专题 6:后处理与特效
内容概述 后处理(Post-Processing)是在渲染完成后对画面进行额外的处理,以实现模糊、辉光、颜色校正等效果。Three.js 通过 EffectComposer 提供后处理支持。本专题还将简要介绍着色器和粒子系统,为更复杂的特效打基础。 学习目标 掌握 EffectComposer 的基本使用。实现辉…...

2025 年江苏保安员职业资格考试经验分享
江苏保安行业发展成熟,2025 年考试注重对考生综合素养的考查。报考条件常规,但对诚信记录有额外关注,如有不良信用记录可能影响报考资格。 报名在江苏省各地级市公安局指定点进行,提交资料包括身份证、学历证、个人诚信报告&am…...

亚马逊算法重构消费市场:解码2024年Q1北美站热搜商品的底层逻辑
在跨境电商迈入精细化运营时代的背景下,亚马逊平台最新发布的《2024年Q1零售搜索趋势报告》揭示了算法驱动下的消费新图景。数据显示,北美站点月均超300万人次重复搜索特定品类商品,健康生活、智能家居等五大领域形成持续增长极。这份由亚马逊…...

powershell绑定按钮事件的两种方式
写一个powershell的简单GUI做本地任务,试验出2个方法: 方法1: function btn1_click {write-host $text1.Text -ForegroundColor Green -BackgroundColor Black }$btn1.Add_Click({btn1_click})方法2: $btn2_click {write-host $…...

LearnOpenGL——OIT
教程地址:简介 - LearnOpenGL CN 简介 原文链接:LearnOpenGL - Introduction 前言 在混合(Blending)章节中,我们介绍了颜色混合的主题。混合是在3D场景中实现透明表面的方法。简而言之,透明度涉及到在计算…...

【蓝桥杯】Python大学A组第十五届省赛
1.填空题 1.1.拼正方形 问题描述 小蓝正在玩拼图游戏,他有个的方块和个的方块,他需要从中挑出一些来拼出一个正方形。 比如用个和个的方块可以拼出一个的正方形;用个的方块可以拼出一个的正方形。 请问小蓝能拼成的最大的正方形的边长为多少。 import math # 2*2的个数 a =…...

使用JS+HTML+CSS编写提词器实例
手搓提词器网页版,有些BUG但是基本功能使用没有问题,有需要的可复制粘贴,BUG自行修复。下面直接进入代码: <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><me…...

人工智能基础知识详解:从概念到前沿技术与应用
在数字化浪潮席卷全球的今天,人工智能(Artificial Intelligence,简称AI)已不再是科技前沿的神秘概念,而是融入我们日常工作的实用工具。从智能语音助手到自动驾驶汽车,从医疗影像诊断到生成式艺术创作&…...

重温经典,畅享怀旧游戏盛宴
FC街机是一款专为安卓设备设计的经典游戏合集应用,它将玩家熟悉的红白机(FC)游戏体验带到了移动设备上。这款应用不仅提供了丰富的游戏选择,还通过优化的界面和操作,让玩家能够随时随地享受经典游戏的乐趣。 游戏非常…...

CPU 压力测试命令大全
CPU 压力测试命令大全 以下是 Linux/Unix 系统下常用的 CPU 压力测试命令和工具,可用于测试 CPU 性能、稳定性和散热能力。 1. 基本压力测试命令 1.1 使用 yes 命令 yes > /dev/null & # 启动一个无限循环进程 yes > /dev/null & # 启动第二个进…...
)
Windows 系统下用 VMware 安装 CentOS 7 虚拟机超详细教程(包含VMware和镜像安装包)
前言 资源 一、准备工作 (一)下载 VMware Workstation (二)下载 CentOS 7 镜像 二、安装 VMware Workstation(比较简单,按下面走即可) 三、创建 CentOS 7 虚拟机 四、安装 CentOS 7 系统…...

QLineEdit的提交前验证
QLineEdit是pyqt中常用的输入控件,默认情况下,它可以接受键盘输入的任何可打印字符。有时候,我们需要在用户提交前对其输入的内容先行验证,当用户输入不符合预期时予以清空,这就需要对QLineEdit控件进行以下操作&#…...
】初识epoll)
【Linux高级IO(二)】初识epoll
目录 1、epoll的接口 2、epoll原理 3、epoll工作方式 1、epoll的接口 #include <sys/epoll.h> 1、int epoll_create(int size) :创建epoll模型 返回值是一个文件描述符,创建一个struct file结构体,指向epoll模型,返回的…...