xv6-labs-2024 lab2
lab-2
0. 前置
课程记录
操作系统的隔离性,举例说明就是,当我们的shell,或者qq挂掉了,我们不希望因为他,去影响其他的进程,所以在不同的应用程序之间,需要有隔离性,并且,应用程序和操作系统之间,也是如此。
当失去操作系统,我们的应用程序将会直接与硬件进行交互,数据也将直接存储在物理内存中,但是我们的两个应用程序无法识别相互的边界,此时就可能会产生覆盖,所以,这就是我们希望内存能够隔离的原因,也是我们操作系统所需要实现的功能,另外还需要multiplexing(cpu分时复用,也就是多线程,CPU运行一个进程一段时间,再运行另一个进程)
这里也有一层抽象,操作系统没有直接将cpu提供给应用程序,而是将进程抽象了cpu,这样操作系统才能在多个应用程序之间复用一个或者多个cpu。
而我们也可以认为exec是对内存的抽象,通过提供exec这样一个系统调用,使得我们可以安全的访问对应的内存,而我们不能够直接访问物理内存。
files,它提供了方便的磁盘抽象,我们唯一与存储系统交互的方式就是files,我们可以任意改写这个文件,而最终,由操作系统来决定,这个files如何与磁盘中的块对应。
操作系统的防御性,操作系统需要确保所有的应用程序都能工作,因此,操作系统不能没有任何抵御攻击的准备,比如说,应用程序向系统调用中传递了错误的参数,而导致了操作系统的崩溃,进而导致操作系统拒绝了为其他所有应用程序提供服务,所以操作系统需要能够应对恶意的程序。
并且应用程序也不能打破隔离性,而影响到其他的程序,甚至控制内核(很危险)。
通常来说,强隔离性由硬件实现,包括user/kernel mode和虚拟内存。
首先,为了支持user/kernel mode,处理器也会有两种操作模式,不同的操作模式权限不同,kernel mode可以使用特权命令,而user mode只能使用普通权限命令。
特权命令,比如说设置page table寄存器,以及处理器的相关状态等。
当在user mode 执行了特权命令,cpu会拒绝这条命令,并且转入kernel mode,杀死这个进程。
kernel mode还是user mode是通过一个flag寄存器来存储的。
page table,每个进程都会有自己的一个独立的page table,也就是说,每个进程都有自己独立的视图,而进程在这个视图上去访问内存空间,从而被映射到物理地址中,这样来保证他们的内存不会重合。
user/kernel mode是如何切换的?xv6中,我们在make之后,我们可以在user/usys.S找到ecall这个指令,事实上,通过ecall这个指令,我们能够跳转到内核中指定的由内核控制的位置来执行系统调用。
举一个例子,当我们调用fork,或者read的时候,事实上没有直接调用函数,而是通过ecall去跳转到内核,执行系统调用。
现在我们有了可以执行系统调用的手段,之后内核负责实现具体的系统调用,并且需要检查参数,防止被恶意攻击,所以安全可靠无bug的内核也成为TCB(Trusted Computing Base)
宏内核:xv6就是一个宏内核的典型代表,所有的操作系统服务都在kernel mode中,由于任何一个操作系统的bug都有可能成为漏洞,而我们有大量的代码放在内核中,出现漏洞的可能性就更高了,这便是宏内核的缺点,而宏内核的另一个代表就是linux,宏内核的优势在于包括文件系统,虚拟内存等子模块都集成在一个程序中,提供了很好的性能。
微内核:微内核和宏内核恰恰相反,他将大部分操作系统运行在内核之外,这样可以有效减少内核的代码数量,从而降低出现漏洞的概率,但是微内核也有缺陷,比如说在shell需要与文件系统交互的时候,内核实际上是以消息传递的形式来执行系统调用的,这种情况下,每个操作都需要执行两次跳转,所以性能是更差的。并且,在一个宏内核中,如文件系统和虚拟内存系统可以轻易地共享page cache,但是在微内核中,这些模块都被隔离开了,而这种共享难以实现,也使得难以获得更高的性能。
到分析xv6启动过程的时候,我发现只看文档,确实还是很不理解的,推荐有实践,带着看代码的部分还是看视频最好。
xv6手册
进程
进程具有独占的地址空间,以及看上去是仅在运行当前程序的cpu,而其他进程无法对其进行干扰,这样,它就会误以为自己运行在独立一台机器上。
xv6使用页表(硬件实现)为每个进程提供独有的地址空间,而页表将虚拟地址(汇编使用的地址)映射为物理地址(处理器芯片向主存发送的地址)。
从低地址区开始,依次代表着用户(低处存放进程的指令)->全局变量->栈区->堆区
同样的,内核的指令和数据也都被映射到了每个进程的地址空间中的高地址处(为用户留下足够的空间),当进程使用系统调用的时候,就会跳转到进程地址空间的内核区域执行(感觉和中断有点像),而在xv6中,使用的是proc来维护的一个进程的状态(包含了页表,内核栈,运行状态等信息)。
每个进程都有自己的用户栈和内核栈,当进程运行用户命令时,只有用户栈被使用,内核栈是空的,在进行系统调用或者中断进入内核的时候,内核代码就会被放入内核栈中执行,用户栈依旧保存着数据,只是现在不活跃,进程的线程交替使用内核栈和用户栈,而用户代码无法操作内核栈,所以即便用户破坏了自己的用户栈,内核也能正常运行,梳理一下流程:
进程系统调用 -> 处理器转入内核栈中(或者说指令指针改变到内核栈中) -> 提升硬件特权 -> 运行特权代码 -> 降低特权 -> 转回到用户栈
而我们每个进程都会有一个线程,线程之间的切换,实际上就是挂起当前线程,恢复另一个线程的状态,线程的状态都保存在线程栈上。(有点像中断时的寄存器状态的恢复和保存)
开机后发生的事情:他会初始化自己,将bootloader从磁盘中载入,而bootloader负责将内核从磁盘中载入,随后开始运行entry,而entry的最开始,设置了两份页表映射,(低地址的映射和高地址的映射),因为在最开始,还没有设置页表的时候,我们的机器很可能没有虚拟地址对应的那么大的内存,于是,我们只能将其对应到物理地址上,然后我们会设置这两份页表映射,因为最开始entry还运行在内存的低地址处,所以需要设置 0:0x400000 -> 0:0x400000的映射关系,我们还需要设置一个高地址的映射关系KERNBASE:KERNBASE+0x400000 -> 0:0x400000,而kernbase指的就是 0x80000000。
配合这张图会比较好理解。
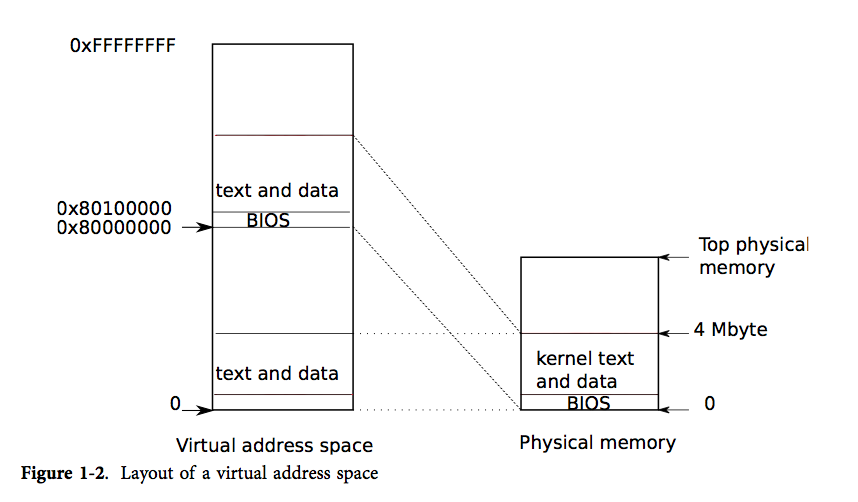
然后entry会继续设置页表,并且将页表的目录entrypgdir的物理地址载入%cr,此时就可以通过各种操作去实现分页机制了(这里有一些比较底层的没看懂)
最后,entry就需要跳转到内核的C代码,并且在内存的高地址去执行它了
这里我还有很多地方都没看懂,感觉这里还是主要讲的是x86的?有的部分还是自己去看看源代码比较好,我看2024年的源代码,riscv的汇编部分是很少的,也就300行左右,大部分还是c语言,包括很多操作系统的cpu,进程调度啥的,也没看懂,这里分享一下我和AI大战三百回合了解到的东西(不一定对):
操作系统本质上也是一个进程,也需要一个cpu去执行,而在操作系统启动后,cpu就会不断去执行我们提前写好的代码(执行程序的机器),而所有cpu的CS:IP,也就是执行程序的指针,都由操作系统这个特殊的进程来调度,但是,如果到最后,没有任何程序可以供cpu执行,那么cpu就会陷入一个空闲循环,因为cpu总是应该执行的,然后,当我们新建了一个进程,需要cpu去执行的时候,就会获取一个cpu,同时修改他的CS:IP使他的指令指针指向这个进程的起始位置,然后将相关的上下文切换,cpu便能继续执行新的工作,当然在后面的调度,我们还会知道,时间片耗尽的中断机制,当然,这是后面的话题了。
其实这方面最开始最困扰我的就是,你的CPU他怎么知道他何时应该执行程序?CPU在操作系统没有启动的时候,不是陷入睡眠吗?启动操作系统之后,就能向下执行命令,cpu难道是个只会工作的机器吗?cpu并不是一开始就在运行吧?我们如果创建一段程序,想要去执行它,除了设置它的状态为RUNNING,并且表示他能够呗调度,但是实际上,cpu怎么知道,他应该去执行什么呢? 或者说,cpu怎么知道,他何时应该执行命令? 毕竟即便是汇编代码,想要cpu开始去执行,让他的CS:IP开始偏转,不也需要去运行这个程序吗?然而我们就是把它的状态标记成RUNNING,这合适吗?还有什么其他的步骤?
其实现在一想,自己的一些疑问也有点意思,但是同时理解了之后,回答这些疑问也是比较轻松的,不知道自己和AI大战之后得出来的结论正确没有,如果有什么错误,希望给我能留言!
1. gdb
-
谁调用了syscall? kernel/trap.c中的usertrap()这个函数
-
p->trapframe->a7的值代表什么意思? 通过hint,我从initcode.S里面发现,a7寄存器代表了执行系统调用的类型,这里应该也是代表了执行的系统调用类型
-
cpu之前是什么模式? 在这里,我输入
p /x $sstatus打印出的值为0x200000022,而当我重新运行,设置断点在usertrap处,输入打印出来的值为0x200000020,我调了一下,发现是intr_on()这个函数执行之后改变的,感觉应该关系不是很大?全英文的那个手册也很劝退,之前的cpu模式应该是用户态吧,目前应该是超级用户(问的AI)
-
num存在那个寄存器? 通过对应的sepc,找到对应的panic行,发现num对应了a3这个寄存器,而内核崩溃的原因是因为访问了未映射的地址0,scause的值记录了触发异常的原因。
-
至于panic的时候,正在运行的进程,我倒是没有找出来,gdb在kernel进入panic的时候,也跟着陷入了,即便是在panic里面打印相对应的进程信息也没有找到答案。
好了,实验完成之后,不要忘记将你的代码恢复原样!
2. Trace
这个实验要求,最开始确实没看懂,我总是想象不出来要如何去修改一些代码,使得能够满足要求,
但是hint还是很有用的,跟着hint来完全可以弄出来。
首先,trace就是说,对于每一个系统调用,你都需要跟踪调用进程,系统调用的名称,系统调用的返回值,直接给我说这些东西,我肯定是一头雾水,但是实验确实也给了足够的hint让我们完成这个lab,总体来讲,还是比较简单的。
首先,我们的trace.c貌似已经为我们准备好了?我们在user空间里面只需要修改makefile/usys.pl以及user.h,而trace的函数签名已经在trace.c中确定了:
entry("trace"); //usys.plint trace(int); //user.h$U/_trace\ //makefile
接下来,便是在syscall的施工了,最开始,我们需要进入到proc.h修改我们的proc结构体的成员,为其加上int tracing的成员,作为tracing的mask掩码。
而后,我们在调用trace系统调用的时候,需要为我们的proc这个tracing参数赋值,所以就在sysproc.c添加我们的trace系统调用是如何执行的:
uint64 sys_trace(void) {int mask;//从传来的第一个参数中获取maskargint(0, &mask);myproc()->tracing = mask;return 0;
}
这里为什么不直接通过参数来获得?ai说这里是xv的特性,就不深究了,argint就是从参数中获取第一个值,并赋给mask,然后为我们的tracing赋值,这样,我们就能够进行判断了!
仅仅是赋值,并不能直接就能够输出我们的进程信息,我们还需要在syscall.c中的syscall函数中,添加合理的输出信息:
void
syscall(void)
{int num;struct proc *p = myproc();num = p->trapframe->a7;if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {// Use num to lookup the system call function for num, call it,// and store its return value in p->trapframe->a0p->trapframe->a0 = syscalls[num]();//修改在此处,根据掩码来输出相应的系统调用信息。if ((p->tracing >> num) & 1) {printf("%d: syscall %s -> %ld\n", p->pid, syscall_str[num], p->trapframe->a0);}} else {printf("%d %s: unknown sys call %d\n",p->pid, p->name, num);p->trapframe->a0 = -1;}
}
当然,我们的每个系统调用都有相对应的数字,所以我们还需要在syscall.h中添加映射:
#define SYS_trace 22
并且将我们的映射和对应的系统调用添加进系统调用的数组中:
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
//添加这一行就可以了
[SYS_trace] sys_trace,
};然后,我们的syscall_str是未定义的,这里需要我们自己去定义一个数组:
//名称数组索引
static char* syscall_str[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",
[SYS_kill] "kill",
[SYS_exec] "exec",
[SYS_fstat] "fstat",
[SYS_chdir] "chdir",
[SYS_dup] "dup",
[SYS_getpid] "getpid",
[SYS_sbrk] "sbrk",
[SYS_sleep] "sleep",
[SYS_uptime] "uptime",
[SYS_open] "open",
[SYS_write] "write",
[SYS_mknod] "mknod",
[SYS_unlink] "unlink",
[SYS_link] "link",
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
};
但是通过这样,我们会发现,fork出来的子进程,无法继承父进程的tracing字段,因为我们tracing是新增的,并没有启用任何继承操作,所以在proc.c里面,需要对fork函数进行修改添加以下的内容:
np->tracing = p->tracing; // 继承父进程的跟踪状态
这样,我们的trace就完成了!
3. attack
这个lab是真的卡了我很久,课上说这次的lab很简单,可是对于我这种菜鸡还是太过困难了。
首先观察attacktest的函数,发现其中生成一个secret,随后调用调用secret.c中的函数,就是将一串密钥写入内存中,后回到attacktest,调用我们需要写的的attack,我们的attack需要将获取的密钥写入到fd2中,以供检查,然后attacktest会比对我们的获取的密钥是否和真正的密钥相同。
总体流程如上,这里需要操作内存页,好难~先来看看我们的secret.c
int
main(int argc, char *argv[])
{if(argc != 2){printf("Usage: secret the-secret\n");exit(1);}char *end = sbrk(PGSIZE*32);end = end + 9 * PGSIZE;strcpy(end, "my very very very secret pw is: ");strcpy(end+32, argv[1]);exit(0);
}
这里分配了32个内存页,随后在第10页中写入了我们的密钥,同时带有一个前缀,我最开始的思路其实就是根据前缀去寻找密钥,但是事实证明,这个方法行不通,于是我开始从其他的突破点入手,比如说,这是一个页,我可以通过找到这个页,并且我们也能够知道其偏移量,这样,我们就有能力去寻找这个密钥,但是如何去寻找到这一页地址?我们如何知道,重新分配的内存页,哪一页才是我们需要的?我想,这就是强迫我们去读源码的一个lab。
去读源码然后分析也是一个很艰难的过程,这里大部分也参考了其他的博客,我一个人肯定是写不出来的😭
首先我们需要了解的是内存页的分配与回收(位于kernel/kalloc.c),xv6的内存是采取栈式的链表管理,分配时,从栈中取出内存页,回收的时候则推回栈顶,这也是我们寻找真正的页的根基。
随后我们需要知道,在attacktest中,attack之前,到底分配了多少,回收了多少内存页,只要知道这个,我们的困难就迎刃而解了。当然,虽然说上去很简单,但这也要求我们必须熟悉其中涉及的每一个系统调用,函数会分配的页数,这也是我们熟悉xv6的一个很好的机会。
首先是attacktest中的fork(),这是一个系统调用,位于/kernel/proc.c,总所周知,每一个进程都会分配一个内存页,fork当然也会,当我们进入到fork的函数体的时候,也确实如此,他通过调用allocproc来分配空间,在allocproc中:
// Allocate a trapframe page.if((p->trapframe = (struct trapframe *)kalloc()) == 0){freeproc(p);release(&p->lock);return 0;}// An empty user page table.p->pagetable = proc_pagetable(p);if(p->pagetable == 0){freeproc(p);release(&p->lock);return 0;}
他通过kalloc分配了一个页表,这个页表存储上下文信息,而又通过proc_pagetable分配了一个页,这个页是虚拟页到物理页的映射,在内部,他会创建一个新的页表:
pagetable = uvmcreate();
if (pagetable == 0)return 0;
然后将虚拟地址空间的一部分映射到物理地址上面:
// 映射 trampoline 代码(用于系统调用返回)// trampoline 是在用户虚拟地址空间的最顶端,负责在系统调用的上下文切换时跳转到内核。// 该映射设置为只读且可执行(PTE_R | PTE_X),因为 trampoline 是内核代码// 注意:此区域仅用于系统调用跳转,并不是用户程序直接访问的,因此没有 PTE_U 标志if(mappages(pagetable, TRAMPOLINE, PGSIZE,(uint64)trampoline, PTE_R | PTE_X) < 0){uvmfree(pagetable, 0);return 0;}// 映射 trapframe 页,位于 trampoline 页面下方// trapframe 用于保存进程的上下文(寄存器值、堆栈指针等),// 这是在系统调用或中断时保存进程状态的地方,供 trampoline 使用。// 这里的映射设置为可读写(PTE_R | PTE_W),因为操作系统需要在该页写入和读取数据。if(mappages(pagetable, TRAPFRAME, PGSIZE,(uint64)(p->trapframe), PTE_R | PTE_W) < 0){uvmunmap(pagetable, TRAMPOLINE, 1, 0);uvmfree(pagetable, 0);return 0;}
我们的xv6是采取的三级页表结构,最开始创建的pagetable作为我们的根页表,我们的trampoline和trapframe(之前已经分配)作为我们的根页表,但是此时还需要一个二级页表来帮助映射,所以我们还需要一个分配一个二级页表来维护完整的映射结构,因此此处分配了三个页表,对应了pagetable,trampoline和二级页表。
回到我们的fork()
// Copy user memory from parent to child.if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){freeproc(np);release(&np->lock);return -1;}
这里将我们分配的内存从父进程复制到子进程中,这里原父进程也占用了四个页表,并且还需要一个一级页表和二级页表来建立映射,所赐此处又新分配了6个页表。
所以我们的fork一共分配了10个页表。
然后回到我们的attacktest,我们可以看见,下一步可能有内存分配的地方就是exec()去执行我们的secret了,exec可以说是最复杂的一个系统调用了,但是我们的目的不是深入分析他,目前只需要知道他分配了哪些内存即可,他在代码前面会使用proc_pagetable去创建新的页表以此来替换旧页表。
if((pagetable = proc_pagetable(p)) == 0)goto bad;
随后,exec会遍历elf文件的头表,会将我们的LOAD段加入我们的内存页中,使用readelf查看_secret如下:
root@rinai-VMware-Virtual-Platform:/home/rinai/6S081/xv6-labs-2024# readelf -l user/_secret Elf 文件类型为 EXEC (可执行文件)
Entry point 0x5c
There are 3 program headers, starting at offset 64程序头:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignRISCV_ATTRIBUT 0x00000000000073e5 0x0000000000000000 0x00000000000000000x0000000000000047 0x0000000000000000 R 0x1LOAD 0x0000000000001000 0x0000000000000000 0x00000000000000000x0000000000000901 0x0000000000000901 R E 0x1000LOAD 0x0000000000002000 0x0000000000001000 0x00000000000010000x0000000000000000 0x0000000000000020 RW 0x1000Section to Segment mapping:段节...00 .riscv.attributes 01 .text .rodata 02 .data .bss
结果如上,存在两个LOAD段,需要分别加载到不同的内存页中,(大概知道是咋回事就行),同时,我们当然还需要一级页表和二级页表来进行映射,因此,这里创建了四个页。
加载段到内存的代码是这样写的:
// 加载程序段到内存中for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))goto bad;if(ph.type != ELF_PROG_LOAD) // 跳过非 LOAD 类型段continue;if(ph.memsz < ph.filesz) // 内存大小不能小于文件大小goto bad;if(ph.vaddr + ph.memsz < ph.vaddr) // 防止溢出goto bad;if(ph.vaddr % PGSIZE != 0) // 地址必须页对齐goto bad;// 为段分配内存(虚拟地址)uint64 sz1;if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz, flags2perm(ph.flags))) == 0)goto bad;sz = sz1;// 从文件中读取代码或数据,写入到段对应虚拟地址中if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)goto bad;}
随后还会分配用户栈:
// 将栈的起始地址 `sz` 向页边界对齐sz = PGROUNDUP(sz);uint64 sz1;// 为进程分配一块内存区域,作为用户栈空间。// uvmalloc 会根据提供的页表 `pagetable` 分配内存,// 并将分配的内存区域的结束地址返回给 `sz1`// 新的栈空间大小从 `sz` 到 `sz + (USERSTACK + 1) * PGSIZE`,分配的是可写内存 (PTE_W)if ((sz1 = uvmalloc(pagetable, sz, sz + (USERSTACK + 1) * PGSIZE, PTE_W)) == 0)goto bad; // 如果分配失败,跳转到错误处理部分// 更新栈的结束地址为分配的内存的结束地址sz = sz1;// 清除栈的保护区域,使其变为不可访问// 栈的保护区域位于栈的顶部 (栈底的内存页),// 用来防止栈溢出攻击,当访问该区域时会触发页面错误 (page fault)uvmclear(pagetable, sz - (USERSTACK + 1) * PGSIZE);// 设置栈指针 `sp` 为栈的结束地址sp = sz;// 计算栈的基址,即栈的底部地址// `stackbase` 指向栈空间的起始位置stackbase = sp - USERSTACK * PGSIZE;
此时,又分配了两页内存。
最后,还会调用函数来释放旧的页表
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{uvmunmap(pagetable, TRAMPOLINE, 1, 0);uvmunmap(pagetable, TRAPFRAME, 1, 0);uvmfree(pagetable, sz);
}
其中,trampoline是整个操作系统共享,不会被释放,tramframe也是一样,是用户态和内核态转换时用到的存储区,不会被释放,所以最后会释放旧页表占用的5页和用户的4页内存。
exec一共分配了9页,释放了9页,而后,开始执行我们的secret程序,他申请了32页内存,并且在第10页写入了相对应的secret,到现在,我们的attacktest已经申请过了42页内存。
而secret实际上是作为fork出来的子进程运行的,而在我们的父进程中,首先就是等待secret子进程的退出,此时,我们分配的内存页都会被回收,此处的回收顺序,也应当重点关注(kernel/proc.c):
// 释放进程使用的资源并重置进程状态
static void
freeproc(struct proc *p)
{// 如果该进程的 trapframe(保存用户态寄存器上下文)存在,则释放它占用的内核内存if(p->trapframe)kfree((void*)p->trapframe);// 将 trapframe 指针置为空,表示已释放p->trapframe = 0;// 如果该进程的页表存在,则释放该页表所管理的所有用户态内存if(p->pagetable)proc_freepagetable(p->pagetable, p->sz);// 清除种种标志p->pagetable = 0;p->sz = 0;p->pid = 0;p->parent = 0;p->name[0] = 0;p->chan = 0;p->killed = 0;p->xstate = 0;p->state = UNUSED;
}
可以看到,我们首先释放的是trapfram,随后释放所有的用户态内存:
uvmfree(pagetable_t pagetable, uint64 sz)
{if(sz > 0)uvmunmap(pagetable, 0, PGROUNDUP(sz)/PGSIZE, 1);freewalk(pagetable);
}
这个函数会根据地址从低到高释放内存,释放顺序为:data + text段,用户栈+page guard,最后是32页堆内存,此时的空闲页表的顺序为:5页页表,32页页表,用户栈,page guard。
随后再次执行fork,紧接着又是exec系统调用,根据之前的经验,fork会分配10页,而exec分配了9页,释放了9页,数量不变,此时,我通过计算会发现,第17页,就是我们需要寻找的答案:
int main(int argc, char *argv[]) {char *end = sbrk(PGSIZE*32);end = end + 16 * PGSIZE;printf("secret: %s\n", end+32);write(2, end+32, 8);exit(0);
}
这个lab就跟解密一样,确实感觉很有难度,包括分析的视角,深度,感觉都不是一般人能想到的,锻炼了独立思考的能力(虽然我没有),还能够理解xv6的源码,感觉是很棒的lab,就是感觉对我这种人来说,太难了💀,开始担心起之后的lab会有多恐怖了。
写到这里,我又去官网上看了看课程的一些准备工作,包括要去看什么什么源码,我基本只看了手册和课,所以觉得困难也是理所当然的吧。(润去看代码了😡)
我一个人肯定写不出这样的lab了,参考文献:
https://nos-ae.github.io/posts/attack-xv6/
https://blog.csdn.net/weixin_42543071/article/details/143351746
相关文章:

xv6-labs-2024 lab2
lab-2 0. 前置 课程记录 操作系统的隔离性,举例说明就是,当我们的shell,或者qq挂掉了,我们不希望因为他,去影响其他的进程,所以在不同的应用程序之间,需要有隔离性,并且࿰…...

redis导入成功,缺不显示数据
SpringBootTest class SecurityApplicationTests {AutowiredStringRedisTemplate template; //添加这句代码,自动装载,即可解决文章三处代码报错Testvoid contextLoads() {String compact Jwts.builder().signWith(Jwts.SIG.HS512.key().build()).subj…...

Flink对比Spark streaming、Storm
对比Spark streaming、Storm 产品 模型 语义 容错机制 状态管理 延时 吞吐量 Storm native at-least-once ack 无 low low Spark streaming micro-batch exactly-once RDD checkpoint 有 medium high Flink native exactly-once checkpoint 有 low …...

力扣316去除重复字母-单调栈
题目来源: 给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。 示例 1: 输入:s "bcabc" 输出ÿ…...

第421场周赛:数组的最大因子得分、
Q1、数组的最大因子得分 1、题目描述 给你一个整数数组 nums。 因子得分 定义为数组所有元素的最小公倍数(LCM)与最大公约数(GCD)的 乘积。 在 最多 移除一个元素的情况下,返回 nums 的 最大因子得分。 注意&…...

COMSOL 与人工智能融合的多物理场应用:28个案例的思路、方法与工具概述
应用案例概述 基于 COMSOL 与人工智能(AI)结合的应用案例涵盖了 28 个多领域场景,包括工程(如热传导优化、结构力学预测)、能源(如电池热管理、燃料电池性能)、生物医学(如药物传递…...

【算法】插入排序
算法系列五:插入排序 一、直接插入排序 1.原理 2.实现 3.性质 3.1时间复杂度 3.2空间复杂度 3.3稳定性 二、希尔排序 1.原理 1.1优化方向 1.2优化原理 2.设计 2.1比较无序时 2.2比较有序时 3.实现 4.性质 4.1时间复杂度 4.2空间复杂度 4.3稳定性…...

企业展示型网站模板HTML5网站模板下载指南
在当今数字化浪潮中,企业网站已成为企业展示形象、推广产品和服务的重要窗口。一个设计精美、功能完善的企业展示型网站,不仅能提升企业的品牌形象,还能吸引潜在客户,促进业务增长。而HTML5网站模板,凭借其跨平台兼容性…...

C盘清理——快速处理
C盘清理 | 快速处理 软件:小番茄C盘清理 https://ccleancdn.xkbrowser.com/cleanmaster/FanQieClean_13054_st.exe 前言:为什么需要专业的C盘清理工具? 作为一位长期与Windows系统打交道的技术博主,我深知C盘空间不足带来的痛苦…...

什么是模型驱动开发MDD?有哪些应用场景?
模型驱动开发(Model-Driven Development,MDD)是一种以模型为核心的软件开发方法,其核心思想是通过创建高层次的抽象模型来描述系统的结构和行为,而非直接编写代码。这些模型经过自动化工具的转换或生成,最终…...

uniapp小程序生成海报/图片并保存分享
调研结果: 方法一:canvasuni.canvasToTempFilePath耗时太长,现在卡在canvas的绘制有问题,canvas绘制的部分东西不生效但是找不到原因 方法二:使用wxml-to-canvas其实也差不多是用canvas手动绘制,可能会卡在…...

从IoT到AIoT:智能边界的拓展与AI未来趋势预测
文章目录 引言:从连接万物到感知万物1. AIoT的本质:将智能嵌入万物2. AIoT的推动力量与挑战2.1 推动力量2.2 关键挑战 3. 五大AIoT未来趋势预测趋势一:边缘智能将成为主流架构趋势二:AI模型将向自适应与多任务演进趋势三ÿ…...
试题速浏、分类及浅析)
2012年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2012年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激励学生学习数学的积极性,提高学…...

2140 星期计算
2140 星期计算 ⭐️难度:中等 🌟考点:2022、思维、省赛 📖 📚 1️⃣法一: 同余定理, import java.util.Scanner;public class Main2 {public static void main(String[] args) {Scanner sc …...

NVIDIA Jetson 环境安装指导 PyTorch | Conda | cudnn | docker
本文适用于Jetson Nano、TX1/TX2、Xavier 和 Orin系列的设备,供大家参考。 1、PyTorch不同版本安装 这里适用于Jetson Nano、TX1/TX2、Xavier 和 Orin ,需要JetPack 4.2以上。 下载地址:PyTorch for Jetson - Jetson & Embedded System…...

理解 Rust 中的 String 分配机制
在 Rust 中,哪怕是一行再普通不过的代码,也可能暗藏玄机。这次我们就来剖析这样一句看似简单的代码: let s "hello world".to_string();这行代码触发了 只读数据段(.rodata)、堆(heap࿰…...

园区网拓扑练习
1.拓扑图要求 1.按照图示的VLAN及IP地址需求,完成相关配需 2、要求SW1为VLAN 2/3的主根及主网关,SW2为vlan 20/30的主根及主网关,SW1和SW2互为备份 3.上层通过静态路由协议完成数据通信过程 4.AR1为企业出口路由器 5.要求全网可达 2.需求分…...

CentralCache
目录 一、Span和Spanlist 二、CentralCache 一、Span和Spanlist CentralCache其实也是哈希桶结构,只不过他是一个个的Span(Span是管理一定数量的页的结构),而且Span会管理一个freelist,用来挂起一个个的小内存块给Th…...

STM32 基础1
什么是GPIO的上拉和下拉电阻 下拉电阻:把一个不确定的信号通过电阳连接到地,其实就是初始化为低电平。 上拉电阻:把一个不确定的信号通过电连接到高电平,其实就是初始化为高电平。 本质:上拉地注入电流,下…...

Python爬虫第5节-urllib的异常处理、链接解析及 Robots 协议分析
目录 一、处理异常 1.1 URLError 1.2 HTTPError 二、解析链接 2.1 urlparse() 2.2 urlunparse() 2.3 urlsplit() 2.4 urlunsplit() 2.5 urljoin() 2.6 urlencode() 2.7 parse_qs() 2.8 parse_qsl() 2.9 quote() 2.10 unquote() 三、分析网站Robots协议 3.1 R…...

STM32——DAC转换
DAC简介 DAC,全称:Digital-to-Analog Converter,扑指数字/模拟转换器 ADC和DAC是模拟电路与数字电路之间的桥梁 DAC的特性参数 1.分辨率: 表示模拟电压的最小增量,常用二进制位数表示,比如:…...
)
因果推断【Causal Inference】(一)
文章目录 1. 什么是因果推断?2. 为什么要提出因果推断?Motivation:辛普森悖论Scenario 1Scenario 2 3. 【Note】相关性≠因果3.1 混淆(Confounding)——共同原因3.2 样本选择偏差(Selection Bias)——共同结果 4. 潜在结果(Potential Outcome…...
)
人工智能通识速览(Part5. 大语言模型)
五、大语言模型 1.NLP 自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,专注于研究 计算机如何理解、生成和处理人类语言。它的目标是让机器能够像人类一样“读懂”文本或语音,并执 行翻译、问答、摘…...

优化 Django 数据库查询
优化 Django 数据库查询 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 优化 Django 数据库查询**理解 N+1 查询问题****`select_related`:外键的急加载**示例何时使用 `select_re…...
)
MCP AI:下一代智能微服务控制平台 (.NET Core)
平台概述 MCP AI (Microservice Control Platform AI) 是基于.NET Core构建的下一代智能微服务控制平台,旨在为企业级微服务架构提供智能化、自动化的管理和控制能力。 核心特性 智能服务编排 AI驱动的动态服务路由 自适应负载均衡算法 预测性扩展与收缩 统一…...

计算机网络基础:系列教程汇总
计算机网络基础:系列教程汇总 一、前言二、计算机网络基础概要三、计算机网络基础3.1 计算机网络基础:揭开网络世界的神秘面纱3.2 计算机网络基础:剖析网络的构成要素3.3 计算机网络基础:认识网络拓扑结构3.4 计算机网络基础:解析网络协议3.5 计算机网络基础:了解网络类型…...

互联网三高-高性能之JVM调优
1 运行时数据区 JVM运行时数据区是Java虚拟机管理的内存核心模块,主要分为线程共享和线程私有两部分。 (1)线程私有 ① 程序计数器:存储当前线程执行字节码指令的地址,用于分支、循环、异常处理等流程控制 ② 虚拟机…...
:解读GC日志)
学习比较JVM篇(六):解读GC日志
一、前言 在之前的文章中,我们对JVM的结构、垃圾回收算法、垃圾回收器做了一些列的讲解,同时也使用了JVM自带的命令行工具进行了实际操作。今天我们继续讲解JVM。 我们学习JVM的目的是为了了解JVM,然后优化对应的参数。那么如何了解JVM运行…...

说说你对python的理解,有什么特性?
Python是一种高级、解释型、通用的编程语言,由Guido van Rossum于1991年首次发布。经过30多年的发展,Python已成为最受欢迎的编程语言之一,在Web开发、数据分析、人工智能、自动化运维等多个领域都有广泛应用。 Python的核心特性 1. 简洁优…...

【C语言】编译和链接
一、编译环境和运行环境 在ANSI C的任何一种实现中,存在着两个不同的环境: 1、翻译环境:在翻译环境中,其会通过编译和链接两个大的步骤,其中编译又分为了预处理(这 个我们后面还会详细讲解&#x…...

Spark,IDEA编写Maven项目
IDEA中编写Maven项目 1.打开IDEA新建项目 2.选择java语言,构建系统选择Maven 3.IDEA中配置Maven 注:这些文件都是我们老师帮我们在网上找了改动后给我们的,大家可自行在网上查找 编写代码测试HDFS连接 1.在之前创建的pom.xml文件中添加下列…...

【HFP】蓝牙HFP服务层连接与互操作性核心技术研究
目录 一、互操作性设计哲学 二、服务级别连接(SLC)架构设计 2.1 连接建立流程总览 2.2 核心交互时序图 2.3 关键阶段技术实现 2.4 RFCOMM连接:通信的基石 2.5 特征交换与编解码协商 2.6 指示器状态同步 三、状态同步机制深度优化 3…...

VSCode使用Remote-SSH连接服务器时启动失败glibc不符合
问题 远程主机可能不符合glibc和libstdc VS Code服务器的先决条件 原因 VSCode更新后,如果服务端GLIBC低于v2.28.0版本将不再满足需求 查看服务端GLIBC版本: ~$ ldd --version ldd (Ubuntu GLIBC 2.23-0ubuntu11.3) 2.23解决 下载V1.85版本 下载链…...

InceptionNeXt:When Inception Meets ConvNeXt论文翻译
论文名称:InceptionNeXt:WhenInceptionMeetsConvNeXt 论文地址:https://arxiv.org/pdf/2303.16900.pdf 摘要: 受视觉Transformer(ViTs)长距离建模能力的启发,大核卷积因能扩大感受野、提升模型性能而受到广泛研究与应用&#x…...

windows下,cursor连接MCP服务器
1.下载并安装node 安装后,在cmd命令框中,输入命令node -v可以打印版本号,证明安装完成 2.下载MCP服务器项目 在MCP服务器找到对应项目,这里以server-sequential-thinking为例子 在本地cmd命令窗口,使用下面命令下载…...

从零开始:使用 kubeadm 部署 Kubernetes 集群的详细指南
使用kubeadmin 部署k8s集群 目录 硬件要求 前期准备 Master 检查 API 服务器证书 清理并重新初始化 查 kubeadm 初始化日志 配置 crictl 的 endpoint 硬件要求 主机名 ip 硬件最低要求 建议,跑的块 master 10.1.1.7 2核,2G 内存给个6G node2 …...

rancher 采用ingerss ssl 部署nginx+php项目
rancher 采用ingerss ssl 部署nginxphp项目 一、创建nginx dockerfile,上传到阿里云镜像仓库(公有,不需要密码) 二、 创建php7.4 dockerfile,需要必须扩展, 上传到阿里云镜像仓库(公有&#x…...

开源聚合平台 Websoft9:开源创新已成为中小企业数字化转型、数据驱动企业的基础
引言:开源软件正在重塑企业数字化未来 根据2024年OpenLogic报告,94.57%的企业已使用开源软件,其中34.07%的机构加大了对开源技术的投入。开源软件凭借其灵活性、成本优势和生态协作能力,成为中小企业(SMB)数字化转型的…...

IntelliJ IDEA 中通义灵码插件使用指南
IntelliJ IDEA 中通义灵码插件使用指南 通义灵码(TONGYI Lingma)是阿里云推出的一款基于通义大模型的智能编码辅助工具,支持 IntelliJ IDEA 等主流 IDE。它提供了代码补全、自然语言生成代码、单元测试生成、代码注释与解释等功能࿰…...

如何免费使用Meta Llama 4?
周六, Meta发布了全新开源的Llama 4系列模型。 架构介绍查看上篇文章。 作为开源模型,Llama 4存在一个重大限制——庞大的体积。该系列最小的Llama 4 Scout模型就拥有1090亿参数,如此庞大的规模根本无法在本地系统运行。 不过别担心!即使你没有GPU,我们也找到了通过网页…...

introduceHLSL
最近打算好好学习一下ue的shader,跟着下面的视频,打算每天至少更新一集 https://www.youtube.com/watch?vlsXB1PQdGx0&t494s 通过下面的蓝图方式我们就可以得到一个变化的材质 alpha参数的生成实际上就是下面的式子 custom节点允许直接的写入hlsl…...

Module模块化
导出:export关键字 export var color "red"; 重命名导出 在模块中使用as用导出名称表示本地名称。 import { add } from "./05-module-out.js"; 导入: import关键字 导入单个绑定 import { sum } from "./05-module-out.js&…...

使用 Rsync + Lsyncd 实现 CentOS 7 实时文件同步
文章目录 🌀使用 Rsync Lsyncd 实现 CentOS 7 实时文件同步前言介绍架构图🧱系统环境🔧Rsync配置(两台都需安装)关闭SELinux(两台都需) 📦配置目标端(client)…...

软件工程第三章习题
一、选择题 1. (1)答案:D 解析:可行性研究是对项目在技术、经济、操作等多方面进行全面评估论证,也称为项目论证 。技术可行性研究、操作可行性研究、经济可行性研究只是可行性研究的部分内容,不能涵盖整体概念。 2. (2)答案&…...

基于ElasticSearch的向量检索技术实践
基于ElasticSearch的向量检索技术实践 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/620260383 图片、视频、语音、文本等非结构化数据可以通过人工智能技术(深度学习算法)提取特征向量,然后通过对这些特征向量…...

Spring Boot 项目日志系统全攻略:Logback、Log4j2、Log4j与SLF4J整合指南
Spring Boot 项目日志系统全攻略:Logback、Log4j2、Log4j与SLF4J整合指南 日志系统是应用程序不可或缺的组成部分,良好的日志实践能极大提升开发调试和线上问题排查的效率。本文将全面介绍Spring Boot项目中各种日志框架的配置与使用方案,包…...

【设计模式】责任链模式
简介 很多公司都有请假的流程,当员工提交请假申请时,请求会沿着 组长 → 经理 → CEO 的链条传递,直到有对应层级的领导处理。 适用场景 一个请求需要多个对象中的一个或多个处理(如审批流程、过滤器链)。处理对象和…...

智能气候前沿:AI Agent结合机器学习与深度学习在全球气候变化驱动因素预测
全球气候变化已成为21世纪最严峻的环境挑战,其复杂的驱动因素如温室气体排放、气溶胶浓度、野火、海冰融化以及农业和生态系统变化等,交织影响着全球的气候格局。 第一:气候变化驱动因素与数据科学基础 1.1气候变化 全球气候变化 中国碳中…...

es 原生linux部署集群
背景 目的: 1. 理解不同部署方式的架构差异 2. 对比环境配置的复杂度 3. 评估性能与资源管理 4. 探索扩展性与高可用性 5. 学习安全与隔离机制 6. 实践监控与维护 7. 掌握混合部署与云原生场景 实验的最终目标 技能提升: 全面掌握Elasticsear…...

Springboot 同时支持不同的数据库,Oracle,Postgresql
## 关键字 Java,Springboot,Vscode,支持多种数据库 ## 背景环境 我在实际项目开发工程中遇到这样一个问题,用户 A 使用 Oracle 数据库,用户 B 使用 Postgresql 数据库,但是用户 AB 都使用我们的项目。所以…...