InceptionNeXt:When Inception Meets ConvNeXt论文翻译
论文名称:InceptionNeXt:WhenInceptionMeetsConvNeXt
论文地址:https://arxiv.org/pdf/2303.16900.pdf
摘要:
受视觉Transformer(ViTs)长距离建模能力的启发,大核卷积因能扩大感受野、提升模型性能而受到广泛研究与应用,例如采用7×7深度卷积的杰出工作ConvNeXt。尽管此类深度算子仅消耗少量浮点运算(FLOPs),但由于高内存访问成本,其在强算力设备上的实际效率显著降低。例如,ConvNeXt-T与ResNet-50的FLOPs相近,但在A100 GPU全精度训练时吞吐量仅为后者的60%。虽然减小卷积核尺寸可提升速度,但会导致显著的性能下降,这提出了一个关键挑战:如何在保持大核CNN模型性能的同时提升其速度?为此,受Inception网络启发,我们提出将大核深度卷积沿通道维度分解为四个并行分支——小方形核、两个正交带状核和恒等映射。基于这一创新的Inception深度卷积,我们构建了InceptionNeXt系列网络,其不仅具有高吞吐量,同时保持卓越性能。例如,InceptionNeXt-T的训练吞吐量较ConvNeXt-T提升1.6倍,并在ImageNet-1K上实现0.2%的top-1准确率提升。我们期待InceptionNeXt能成为未来架构设计的经济型基线,助力减少碳足迹。
1 Introduction
回顾深度学习的发展史[35],卷积神经网络(CNN)[33, 34]无疑是计算机视觉领域最受欢迎的模型。2012年AlexNet[32]在ImageNet竞赛中取得历史性突破,这一分水岭事件标志着CNN在计算机视觉领域开启了新纪元[11, 32, 54]。此后,大量具有影响力的CNN模型相继涌现,如Network In Network[37]、VGG[56]、Inception网络[58]、ResNe(X)t[22, 74]、DenseNet[27]以及其他高效模型[25, 55, 61, 62, 84]。
受到Transformer在NLP领域巨大成就的激励,研究者们尝试将其模块或块集成到视觉CNN模型中[2,4,28,70],如Non-local Neural Networks[70]、DETR[4]等代表作品,甚至将自注意作为独立的原语[50,85]。 此外,受语言生成预训练[46]的启发,Image GPT (iGPT)[6]将像素作为token,采用纯Transformer进行视觉自监督学习。 然而,由于计算成本的限制,iGPT在处理高分辨率图像时面临限制。 Vision Transformer (ViT)[16]实现了突破,该算法将图像patch作为token,利用纯Transformer作为主干,经过大规模监督图像预训练,在图像分类方面表现出了显著的性能。
显然,ViT[16]的成功进一步点燃了人们对Transformer在计算机视觉领域应用的热情。 许多ViT变体[15,36,39,64,67,75,79],如DeiT[64]和Swin[39],被提出并在广泛的视觉任务中取得了显着的性能。 类维特模型优于传统cnn的表现(例如,swun - t的81.2% vs . ResNet-50在ImageNet上的76.1%[11,22,39,54])使许多研究人员相信变形金刚最终将取代cnn并主导计算机视觉领域。
现在是CNN反击的时候了。 通过DeiT[64]和Swin[39]中先进的训练技术,“ResNet反击”[72]的工作表明,ResNet50的性能可以提高2.3%,达到78.4%。 此外,ConvNeXt[40]表明,使用像GELU[23]激活这样的现代模块和类似于注意力窗口大小[39]的大内核大小,CNN模型可以在各种设置和任务中始终优于Swin Transformer[39]。 ConvNeXt并不孤单:越来越多的研究也显示了类似的观察结果[14,18,24,38,51,68,76,78],如RepLKNet[14]和SLaK[38]。 在这些现代CNN模型中,共同的关键特征是大的接受场,通常通过大核尺寸(例如7 × 7)的深度卷积[7,43]来实现。
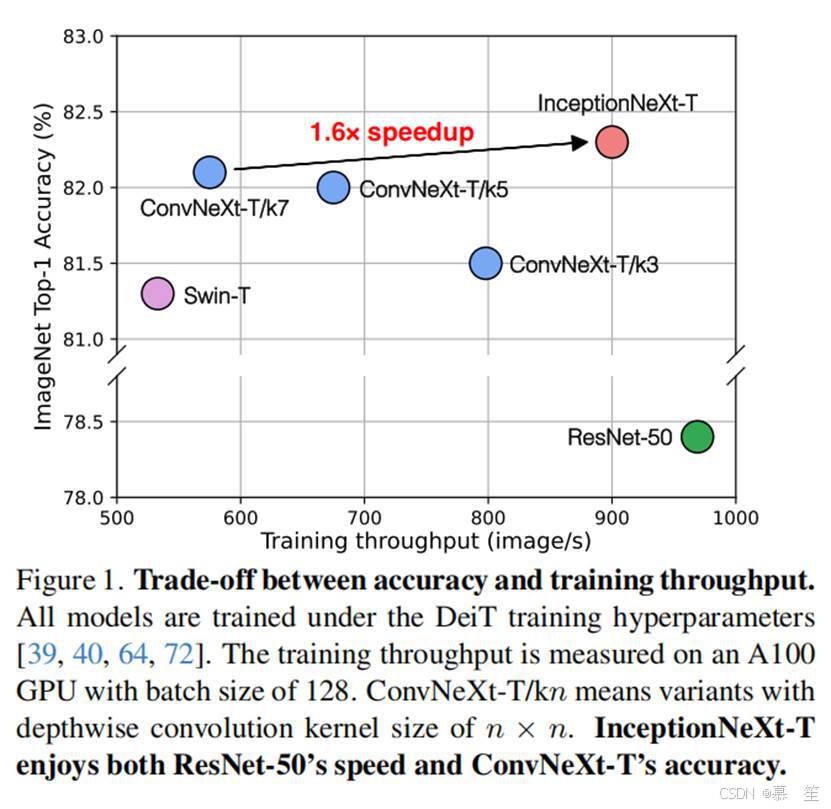
然而,尽管它的flop很小,深度卷积实际上是一个“昂贵的”运算符,因为它带来了很高的内存访问成本,并且可能成为强大的计算设备(如gpu[42])的瓶颈。 此外,正如在[14]中所观察到的那样,更大的内核大小会显著降低速度。 如图1所示,默认内核大小为7 × 7的ConvNeXt-T比内核大小较小的3×3慢1.4倍,比ResNet-50慢1.8倍,尽管它们具有相似的flop。 然而,使用较小的内核大小限制了接受域,这可能导致性能下降。 例如,在ImageNet-1K数据集上,与ConvNeXt-T/k7相比,ConvNeXt-T/k3的性能下降了0.6%,其中kn表示内核大小为n × n。
这就提出了一个具有挑战性的问题:如何在保持大内核CNN性能的同时加速它们? 在本文中,我们的目标是通过以ConvNeXt为基础并改进深度卷积模块来解决这个问题。 通过我们基于ConvNeXt的初步实验(见表1),我们发现并不是所有的输入通道都需要进行计算代价高昂的深度卷积运算[42]。 因此,我们建议保留一些通道不变,只对部分通道进行深度卷积操作。 接下来,我们提出将深度卷积的大核以Inception的方式分解成几组小核[58-60]。 具体来说,对于处理通道,1/3的通道以3×3内核进行处理,1/3的通道以1×k内核进行处理,1/3的通道以k×1内核进行处理。 有了这个新的简单而廉价的运算符,称为“Inception深度卷积”,我们构建的模型InceptionNeXt在准确性和速度之间实现了更好的权衡。 例如,如图1所示,InceptionNeXt-T实现了比ConvNeXtT更高的准确率,同时享有与ResNet-50相似的1.6倍的训练吞吐量加速。
本文的贡献是双重的。 首先,我们确定了ConvNeXt的速度瓶颈,如图1所示。 为了在保证精度的同时解决这一速度瓶颈,我们提出了Inception深度卷积,它将代价高昂的深度卷积分解为三个小核卷积分支和一个恒等映射分支。 其次,大量的图像分类和语义分割实验表明,我们的模型InceptionNeXt比ConvNeXt具有更好的速度和精度权衡。 我们希望InceptionNeXt可以作为一个新的CNN基线来加速神经架构设计的研究。
2 Related work
2.1 Transformer v.s. CNN
Transformer[66]于2017年被引入NLP任务,因为它具有并行训练和比LSTM更好的性能。 然后在Transformer上建立了许多著名的NLP模型,包括GPT系列[3,44,46,47],BERT [12], T5[49]和OPT[83]。 对于Transformer在视觉任务中的应用,vision Transformer (ViT)绝对是开创性的工作,它表明Transformer在经过大规模监督训练后可以取得令人印象深刻的性能。 Swin[39]等后续工作[20,52,53,64,67,69,79]不断提高模型性能,在各种视觉任务上取得了新的进展。 这些结果似乎告诉我们“注意力是你所需要的”[66]。
但事情并没有那么简单。 像DeiT这样的ViT变体通常采用现代训练程序,包括各种先进的数据增强技术[9,10,80,82,86]、正则化[26,59]和优化器[30,41]。 Wightman等人发现,通过类似的训练程序,ResNet的性能可以得到很大的提高。 此外,Yu等人[77]认为在模型性能中起关键作用的是通用架构而不是注意力。 Han等人发现,通过用规则或动态深度卷积代替Swin中的注意力,模型也可以获得相当的性能。 ConvNeXt[40]是一项了不起的工作,它利用vit的一些设计将ResNet现代化为高级版本,并且由此产生的模型始终优于Swin[39]。 其他诸如RepLKNet[14]、VAN[18]、FocalNets[76]、HorNet[51]、SLKNet[38]、ConvFormer[78]、Conv2Former[24]和InternImage[68]等工作不断提高CNN的性能。 尽管这些模型获得了很高的性能,但忽略了效率,表现出比ConvNeXt更低的速度。 实际上,与ResNet相比,ConvNeXt也不是一个高效的模型。 我们认为CNN模型应该保持原有的效率优势。 因此,在本文中,我们的目标是在保持高性能的同时提高cnn的模型效率。
2.2 Convolution with large kernel
知名的作品,如AlexNet[32]和Inception v1[58]已经分别使用了高达11×11和7×7的大型内核。 为了提高大核的效率,VGG[56]提出对3×3卷积进行大量叠加,而Inception v3[59]则将k × k卷积依次分解为1 × k和k × 1卷积。 对于深度卷积,MixConv[63]将核分成3 × 3到k × k的几组。此外,Peng等人发现大核对于语义分割很重要,他们分解的大核类似于Inception v3[59]。 目睹了Transformer在视觉任务中的成功[16,39,67],大核卷积得到了更多的重视,因为它可以为模仿注意力提供一个大的接受场[21,40]。 例如,ConvNeXt默认采用深度卷积的内核大小为7×7。 为了使用更大的内核,RepLKNet[14]建议利用结构重新参数化技术[13,81]将内核大小扩展到31×31; VAN[18]将大核深度卷积(DW-Conv)和深度扩展卷积依次叠加,得到21 × 21的接受域; FocalNets[76]采用门控机制从深度卷积叠加中融合多层特征; SegNeXt[17]通过下注1 × k和k × 1的多个分支学习多尺度特征。 最近,SLaK[38]将大内核k ×k分解为两个小的非平方内核(k × s和s×k,其中s < k)。与这些工作不同,我们的目标不是扩展更大的内核。 相反,我们的目标是提高效率,并以一种简单且对速度友好的方式分解大型内核,同时保持相当的性能。
3 Method
3.1 MetaNeXt
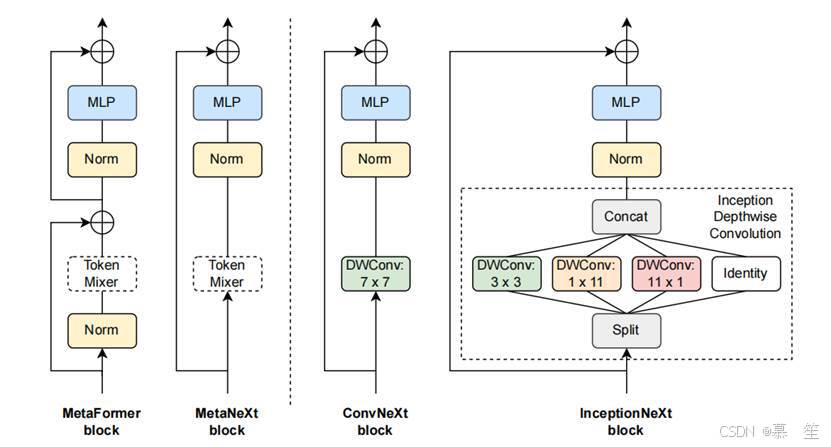
图2。 MetaFormer, MetaNext, ConvNeXt和InceptionNeXt的框图。 类似于MetaFormer块[77],MetaNeXt是从ConvNeXt[40]抽象出来的通用块。 MetaNeXt可以看作是MetaFormer通过合并两个剩余子块而获得的一个更简单的版本。 值得注意的是,MetaNeXt中使用的令牌混合器不能太复杂(例如,自关注[66]),否则它可能无法训练收敛。 通过将令牌混合器指定为深度卷积或Inception深度卷积,模型被实例化为ConvNeXt或InceptionNeXt块。 与ConvNeXt相比,InceptionNeXt更高效,因为它将昂贵的大核深度卷积分解为四个高效的并行分支。
MetaNeXt块的配方。 在ConvNeXt[40]中,对于它的每个ConvNeXt块,首先对输入X进行深度卷积处理,沿空间维度传播信息。 我们遵循MetaFormer[77]将深度卷积抽象为负责空间信息交互的令牌混合器。 因此,如图2中的第二个子图所示,ConvNeXt被抽象为MetaNeXt块。 形式上,在MetaNeXt块中,它的输入X首先被处理为

式中,X,X′∈RB×C×H×W,其中B, C, H, W分别表示批量大小,通道号,高度和宽度。 然后将令牌混频器的输出归一化:
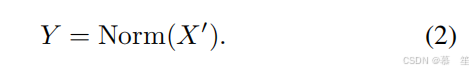
归一化后[1,29],将特征输入到一个MLP模块中,该模块由两个完全连接的层组成,层之间有一个激活函数,与Transformer[66]中的前馈网络相同。 两个完全连接的层也可以通过1 × 1的卷积来实现。 也采用快捷连接方式[22,57]。 这个过程可以表示为:
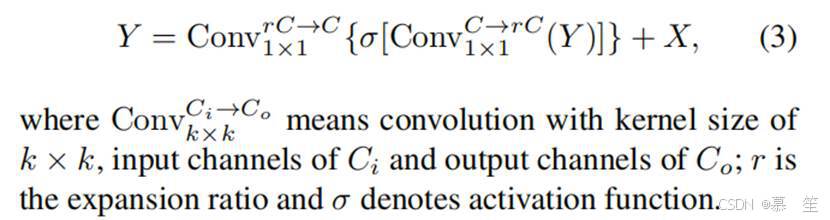
与MetaFormer块的比较。 如图2所示,可以发现MetaNeXt块与MetaFormer块[77]有相似的模块,如token mixer和MLP。 然而,两种模型之间的关键区别在于快捷连接的数量[22,57]。 MetaNeXt块实现一个快捷连接,而MetaFormer块包含两个,一个用于令牌混合器,另一个用于MLP。 从这个角度来看,MetaNeXt块可以看作是合并了MetaFormer的两个剩余子块的结果,从而简化了整个体系结构。 因此,与MetaFormer相比,MetaNeXt架构表现出更高的速度。 然而,这种简单的设计有一个限制:MetaNeXt中的令牌混频器组件不能复杂(例如,Attention),如我们的实验(表5)所示。
实例化到ConvNeXt。 如图2所示,在ConvNeXt中,令牌混频器仅通过深度卷积实现:
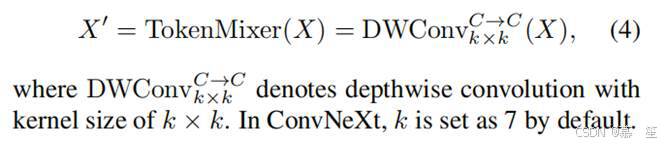
3.2 Inception depthwise convolution
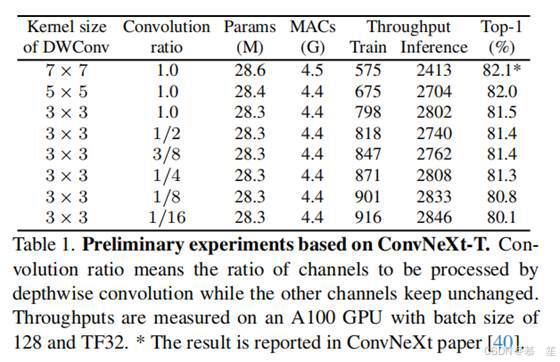
ConvNeXt-T的初步实验。 我们首先基于ConvNeXt-T进行了初步实验,结果如表1所示。 首先,将深度卷积的核大小从7×7减小到3×3。 与内核大小为7 × 7的模型相比,内核大小为3 × 3的模型的训练吞吐量提高了1.4倍,但性能从82.1%下降到81.5%。 接下来,受ShuffleNet V2[42]的启发,我们只将部分输入通道馈送到深度卷积中,其余通道保持不变。 处理的输入通道的数量由一个比率控制。 研究发现,当比值从1降低到1/4时,在性能基本保持不变的情况下,可以进一步提高训练吞吐量。 总之,这些初步实验传达了ConvNeXt的两个发现。 发现1:大核深度卷积是速度瓶颈。 发现2:在单深度卷积层[42]中处理部分通道已经足够好了。
公式化表达。基于上述发现,我们提出一种新型卷积结构以兼顾精度与效率。根据发现2,我们保留部分通道不作处理,将其设为恒等映射分支;受发现1启发,对需要处理的通道,我们采用Inception风格[58-60]的深度可分离卷积分解方案。Inception网络[58]原本采用多分支结构并行处理不同尺寸卷积核(如3×3和5×5),我们同样保留3×3分支,但鉴于大尺寸方形核的实际运行效率较低,转而借鉴Inception v3[59]的分解策略,将kh×kw大核分解为1×kw和kh×1两个正交带状核。具体实现上,对于输入特征图X,我们沿通道维度将其划分为四组:
具体来说,对于输入X,我们沿着通道维度将其分成四组,
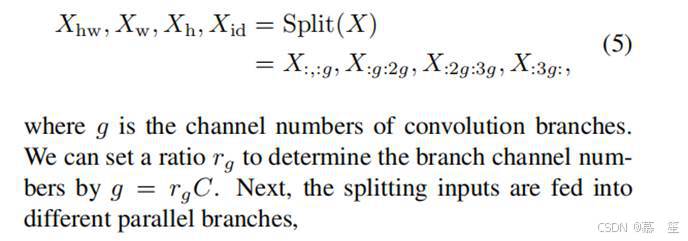

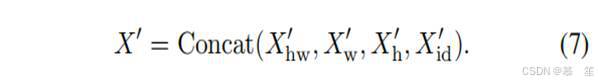
InceptionNeXt块的示例如图2所示。 此外,其PyTorch[45]代码在算法1中进行了总结。

3.3 InceptionNeXt
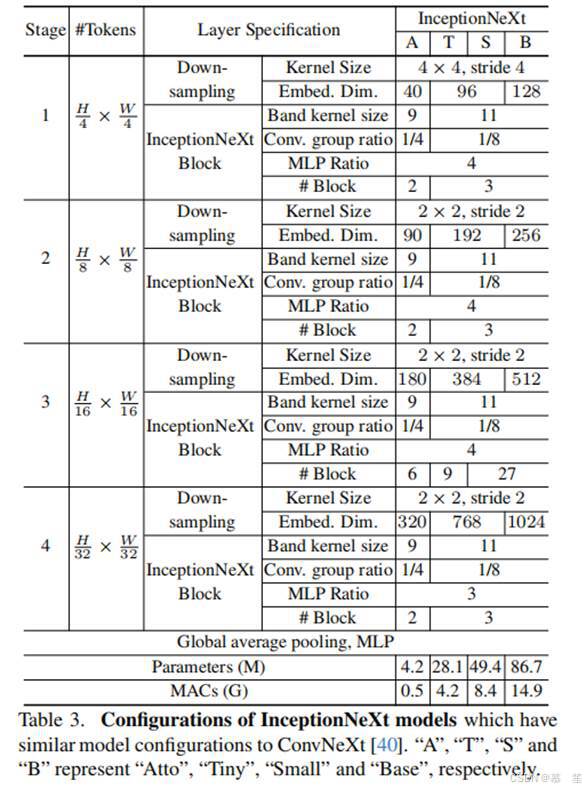
基于InceptionNeXt块,我们可以构建一系列名为InceptionNeXt的模型。 由于ConvNeXt[40]是我们主要的比较基线,所以我们主要按照它来构建几种尺寸的模型[71]。 具体来说,与ResNet[22]和ConvNeXt类似,InceptionNeXt也采用了4stage框架。 与ConvNeXt相同,大尺寸的4个级的编号为[2,2,6,2],小尺寸的编号为[3,3,9,3],基本尺寸的编号为[3,3,27,3]。 我们采用批归一化,因为本文强调速度。 与ConvNeXt的另一个区别是,InceptionNeXt在第4阶段使用3的MLP比率,并将保存的参数移动到分类器,这可以帮助减少一些FLOPs(例如,3%的基本大小)。 详细的模型配置如表3所示。
4 Experiment
4.1 ImageNet classification
设置:在图像分类任务中,ImageNet-1K[11,54]是最常用的基准数据集之一,其训练集包含约130万张图像,验证集包含5万张图像。为了与广泛使用的基线模型(如Swin[39]和ConvNeXt[40])进行公平比较,我们主要遵循DeiT[65]的训练超参数,不使用蒸馏。具体来说,模型通过AdamW[41]优化器训练,学习率为lr = 0.001×batchsize/1024(本文中使用lr = 4e-3和batchsize=4096,与ConvNeXt相同)。遵循DeiT,数据增强包括标准随机裁剪、水平翻转、RandAugment[10]、Mixup[83]、CutMix[81]、随机擦除[87]和颜色抖动。正则化方法采用标签平滑[60]、随机深度[26]和权重衰减。与ConvNeXt类似,我们还使用LayerScale[66]技术来帮助训练深层模型。我们的代码基于PyTorch[45]和timm[72]。
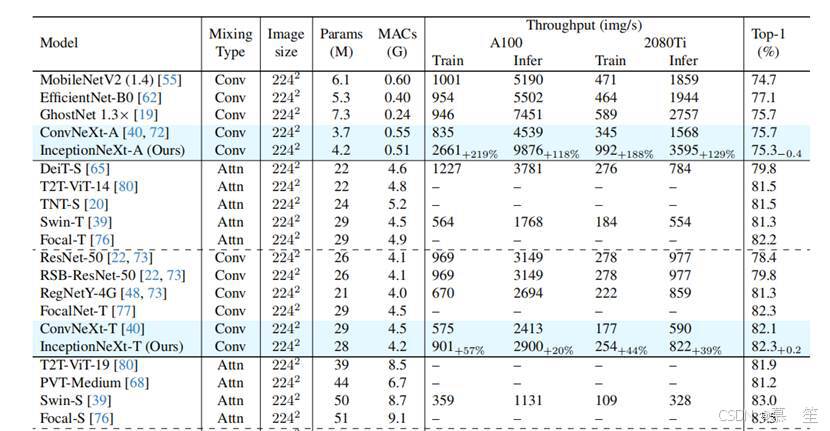
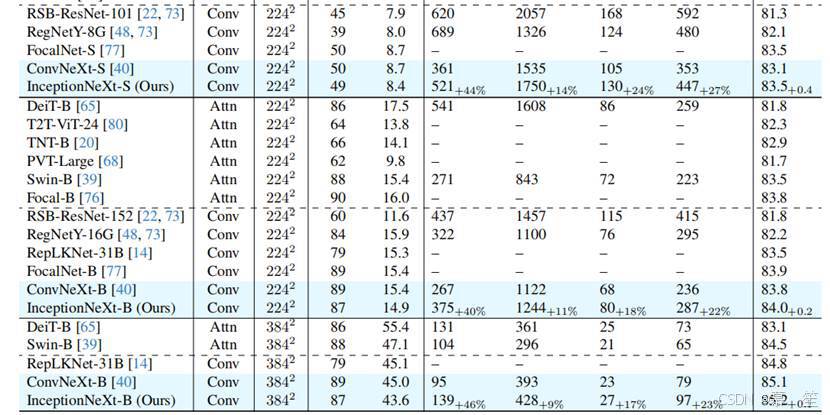
表4. 在ImageNet-1K上训练的模型性能。吞吐量在配备TF32(TensorFloat-32)的A100 GPU(PyTorch 1.13.0和CUDA 11.7.1)以及配备FP32的2080Ti GPU(PyTorch 1.8.1和CUDA 10.2)上测量。吞吐量基准测试的批量大小初始设为128,并逐步减小直至GPU能够承载。报告了“通道优先”和“通道最后”内存布局的较优结果。
结果:我们将InceptionNeXt与各种最先进的模型进行比较,包括基于注意力和基于卷积的模型。如表4所示,InceptionNeXt在取得极具竞争力性能的同时,还具有更高的速度。InceptionNeXt始终比ConvNeXt[40]拥有更好的精度-速度权衡。例如,InceptionNeXt-T不仅比ConvNeXt-T的准确率高0.2%,而且在A100上的训练/推理吞吐量分别是ConvNeXt-T的1.6倍/1.2倍,与ResNet-50相近。也就是说,InceptionNeXt-T兼具ResNet-50的速度和ConvNeXt-T的精度。此外,遵循Swin和ConvNeXt的做法,我们将在224×224分辨率下训练的InceptionNeXt-B微调至384×384分辨率,训练30个 epoch。可以看到,InceptionNeXt-B在保持竞争力精度的同时,训练和推理吞吐量均高于ConvNeXt-B。
值得注意的是,轻量级模型的速度提升更为显著,而随着模型规模增大,提升幅度逐渐减小。原因在于深度wise卷积和Inception深度wise卷积的计算复杂度与通道数呈线性关系(即O(C),其中C为通道数),而MLP的计算复杂度为O(C^2)。对于更大的模型(更大的C),其计算主要由MLP主导。由于仅改进了深度wise卷积,当模型规模增大时,速度提升幅度会变小。
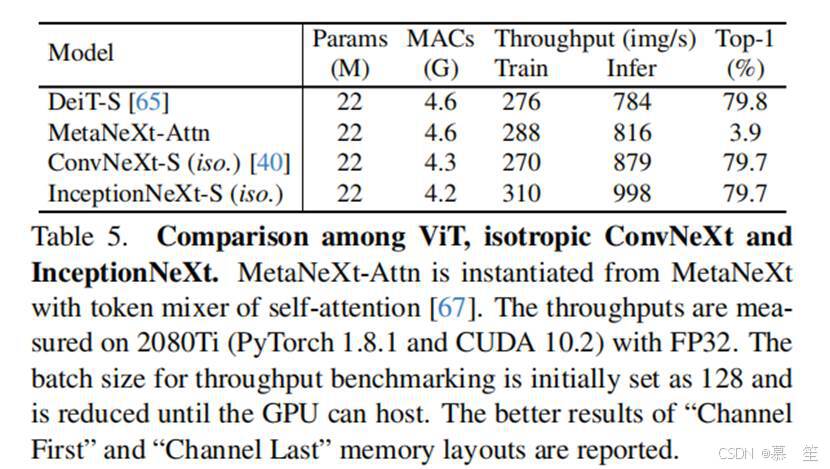
除了4阶段框架[22,39,57],另一个值得注意的是ViT风格[16]的各向同性架构(仅包含一个阶段)。为了匹配DeiT-S的参数和MACs,我们按照ConvNeXt-S(iso.)[40]构建了InceptionNeXt-S(iso.)。具体来说,将嵌入维度设置为384,块数设置为18。此外,我们构建了一个名为MetaNeXt-Attn的模型,该模型通过将自注意力指定为Token Mixer从MetaNeXt块实例化而来,目的是研究是否可以将Transformer块的两个残差子块合并为一个。实验结果如表5所示,可以看到InceptionNeXt在各向同性架构下也能表现良好,表明InceptionNeXt在不同框架下具有良好的泛化能力。值得注意的是,MetaNeXt-Attn无法训练收敛,仅取得3.9%的准确率。这一结果表明,与MetaFormer中的Token Mixer不同,MetaNeXt中的Token Mixer不能过于复杂,否则模型可能无法训练。
4.2 Semantic Segmentation
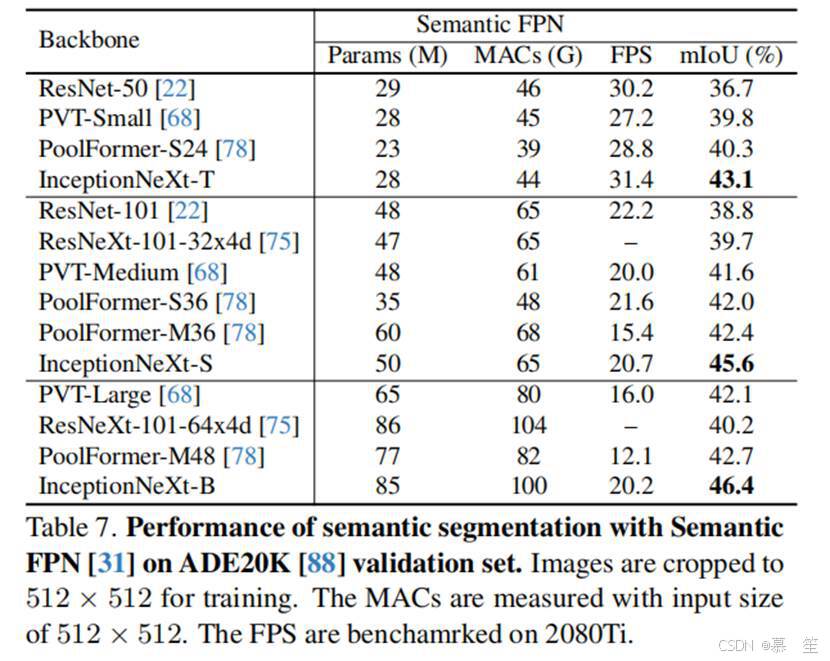
设置:我们使用ADE20K[88](一个常用的场景解析基准数据集)来评估模型在语义分割任务上的表现。ADE20K包含150个细粒度语义类别,训练集和验证集分别包含2万和2千张图像。在ImageNet-1K[11]上以224分辨率训练的检查点用于初始化骨干网络。遵循Swin[39]和ConvNeXt[40],我们首先使用UperNet[74]评估InceptionNeXt。模型通过AdamW[41]优化器训练,学习率为6e-5,批量大小为16,训练16万次迭代。遵循PVT[68]和PoolFormer[78],InceptionNeXt也通过Semantic FPN[31]进行评估。在常规实践[5,31]中,8万次迭代的设置下批量大小为16。遵循PoolFormer[78],我们将批量大小增加到32并将迭代次数减少到4万次以加快训练速度。采用AdamW[30,41]优化器,学习率为2e-4,使用幂次为0.9的多项式衰减策略。我们的代码基于PyTorch[45]和mmsegmentation[8]。
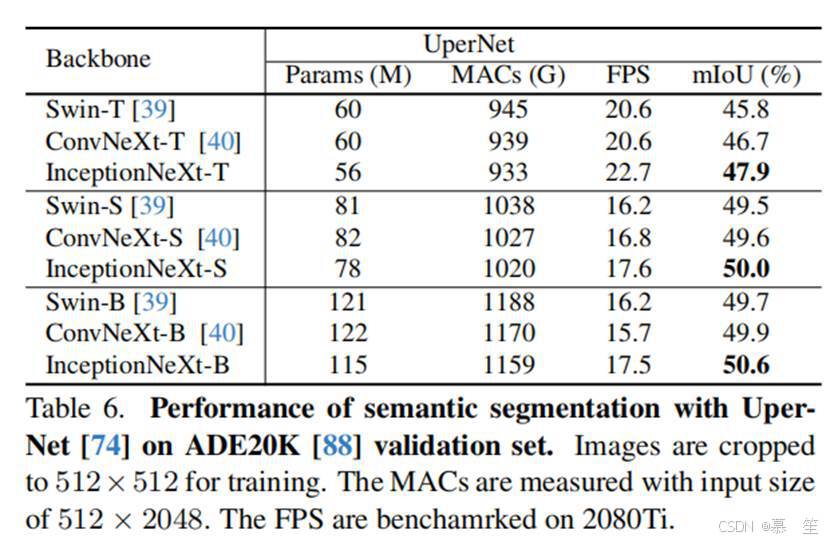
结果:使用UperNet[74]进行分割的结果如表6所示。可以看出,对于不同模型规模,InceptionNeXt始终优于Swin[39]和ConvNeXt[40]。在Semantic FPN[31]方法中(如表7所示),InceptionNeXt显著超越了其他骨干网络,如PVT[68]和PoolFormer[78]。这些结果表明,InceptionNeXt在密集预测任务上也具有很高的潜力。
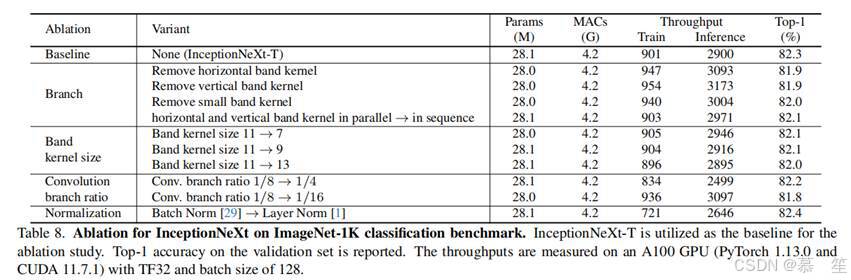
4.3 Ablation Studies
我们以InceptionNeXt-T为基线,在ImageNet-1K[11,54]上从以下方面进行消融研究。
分支:Inception深度wise卷积包含四个分支:三个卷积分支和一个恒等映射分支。当移除水平或垂直带状核的任何一个分支时,性能从82.3%显著下降到81.9%,证明了这两个分支的重要性。这是因为这两个带状核分支可以扩大模型的感受野。对于3×3小方形核分支,移除它仍能达到82.0%的top-1准确率,并带来更高的吞吐量。这启示我们,如果更注重模型速度,可以采用不含3×3方形核的简化版InceptionNeXt。对于带状核,Inception v3大多采用顺序排列方式。我们发现这种组合方式也能获得相似性能,甚至略微提升模型速度。可能的原因是PyTorch/CUDA对顺序卷积进行了良好优化,而我们仅在高层实现了并行分支(见Algorithm 1)。我们相信,当并行方法得到更好优化时会更快,因此默认采用带状核的并行方法。
带状核大小:实验发现,当核大小从7增加到11时性能提升,但增加到13时性能下降。这种现象可能由优化问题导致,可通过结构重参数化[13,14]等方法解决。为简单起见,除Atto尺寸外,默认将核大小设置为11。
卷积分支比例:当比例从1/8增加到1/4时,性能未观察到提升。Ma等人[42]也指出,并非所有通道都需要进行卷积。但当比例降低到1/16时,性能严重下降,因为较小的比例会限制Token混合程度,导致性能下降。因此,除Atto尺寸外,默认将卷积分支比例设置为1/8。
归一化:当将Batch Normalization[29]替换为Layer Normalization[1]时,性能提升0.1%,但训练和推理吞吐量均下降。由于本文关注效率,InceptionNeXt采用Batch Normalization。
5 Conclusion and future work
在这项工作中,我们提出了一种高效的CNN架构InceptionNeXt,其在实际速度和性能之间的权衡优于以往的网络架构。InceptionNeXt将大核深度wise卷积沿通道维度分解为四个并行分支,包括恒等映射、小方形核和两个正交带状核。这四个分支在实际计算中都比大核深度wise卷积高效得多,且能共同提供大的空间感受野以实现良好性能。大量实验结果证明了InceptionNeXt的优越性能和高实用效率。
补充材料
A. 超参数
A.1 ImageNet-1K图像分类
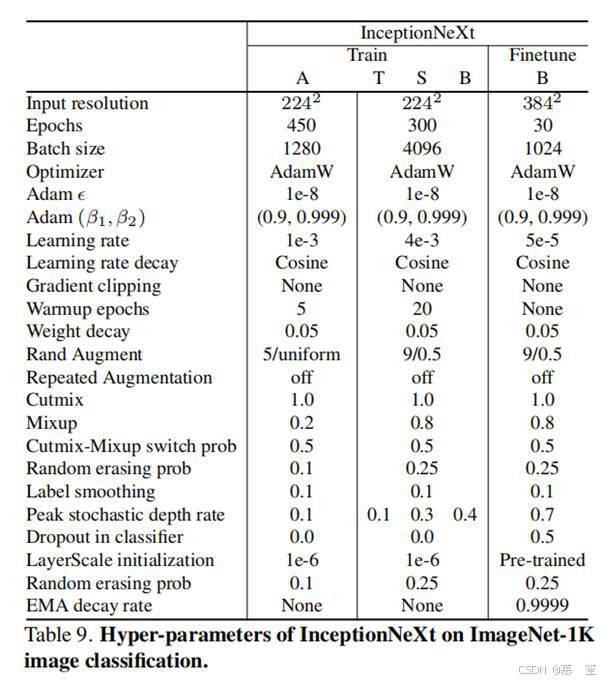
在ImageNet-1K[11,54]分类基准上,遵循ConvNeXt[40]和通过timm[72]训练的ConvNeXt-A,我们采用表9所示的超参数在224²输入分辨率下训练InceptionNeXt,并在384²分辨率下对其进行微调。我们的代码基于PyTorch[45]和timm库[72]实现。
A.2 语义分割
对于ADE20K[88]语义分割任务,我们以ConvNeXt为骨干网络,使用UperNet[74](遵循Swin[39]的配置)和FPN[31](遵循PVT[68]和PoolFormer[78]的配置)。骨干网络通过在ImageNet-1K上以224²分辨率预训练的检查点进行初始化。InceptionNeXt骨干网络的峰值随机深度率如表10所示。我们的实现基于PyTorch[45]和mmsegmentation库[8]。
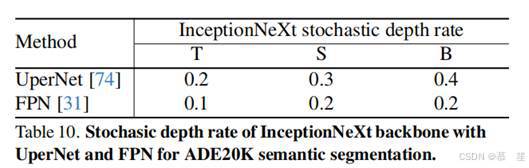
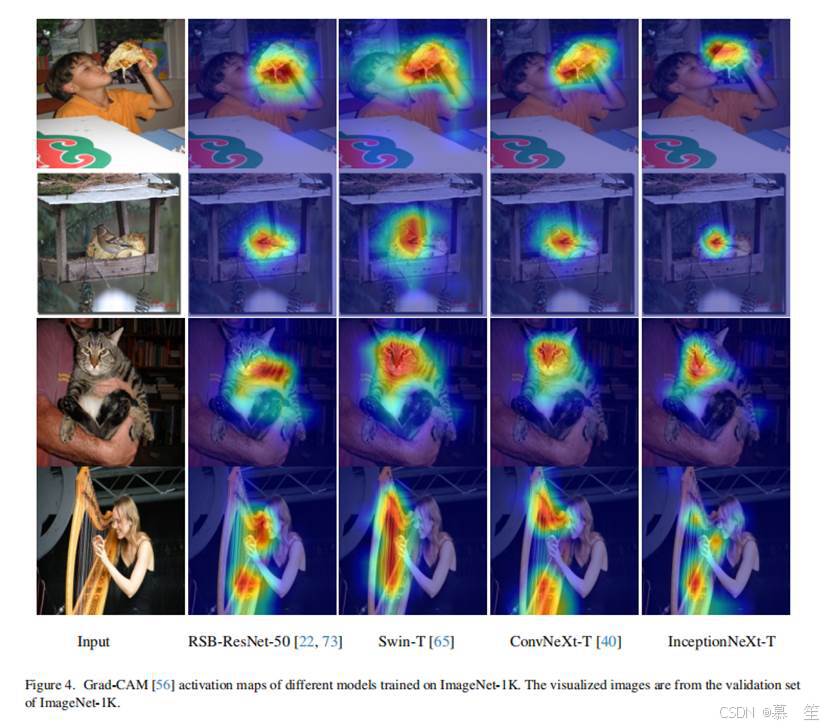
B. 定性结果
使用Grad-CAM[56]可视化在ImageNet-1K上训练的不同模型的激活图,包括RSB-ResNet-50[22,73]、Swin-T[39]、ConvNeXt-T[40]和我们的InceptionNeXt-T。结果如图4所示。与其他模型相比,InceptionNeXt-T能更准确地定位关键部分,且激活区域更小。
相关文章:

InceptionNeXt:When Inception Meets ConvNeXt论文翻译
论文名称:InceptionNeXt:WhenInceptionMeetsConvNeXt 论文地址:https://arxiv.org/pdf/2303.16900.pdf 摘要: 受视觉Transformer(ViTs)长距离建模能力的启发,大核卷积因能扩大感受野、提升模型性能而受到广泛研究与应用&#x…...

windows下,cursor连接MCP服务器
1.下载并安装node 安装后,在cmd命令框中,输入命令node -v可以打印版本号,证明安装完成 2.下载MCP服务器项目 在MCP服务器找到对应项目,这里以server-sequential-thinking为例子 在本地cmd命令窗口,使用下面命令下载…...

从零开始:使用 kubeadm 部署 Kubernetes 集群的详细指南
使用kubeadmin 部署k8s集群 目录 硬件要求 前期准备 Master 检查 API 服务器证书 清理并重新初始化 查 kubeadm 初始化日志 配置 crictl 的 endpoint 硬件要求 主机名 ip 硬件最低要求 建议,跑的块 master 10.1.1.7 2核,2G 内存给个6G node2 …...

rancher 采用ingerss ssl 部署nginx+php项目
rancher 采用ingerss ssl 部署nginxphp项目 一、创建nginx dockerfile,上传到阿里云镜像仓库(公有,不需要密码) 二、 创建php7.4 dockerfile,需要必须扩展, 上传到阿里云镜像仓库(公有&#x…...

开源聚合平台 Websoft9:开源创新已成为中小企业数字化转型、数据驱动企业的基础
引言:开源软件正在重塑企业数字化未来 根据2024年OpenLogic报告,94.57%的企业已使用开源软件,其中34.07%的机构加大了对开源技术的投入。开源软件凭借其灵活性、成本优势和生态协作能力,成为中小企业(SMB)数字化转型的…...

IntelliJ IDEA 中通义灵码插件使用指南
IntelliJ IDEA 中通义灵码插件使用指南 通义灵码(TONGYI Lingma)是阿里云推出的一款基于通义大模型的智能编码辅助工具,支持 IntelliJ IDEA 等主流 IDE。它提供了代码补全、自然语言生成代码、单元测试生成、代码注释与解释等功能࿰…...

如何免费使用Meta Llama 4?
周六, Meta发布了全新开源的Llama 4系列模型。 架构介绍查看上篇文章。 作为开源模型,Llama 4存在一个重大限制——庞大的体积。该系列最小的Llama 4 Scout模型就拥有1090亿参数,如此庞大的规模根本无法在本地系统运行。 不过别担心!即使你没有GPU,我们也找到了通过网页…...

introduceHLSL
最近打算好好学习一下ue的shader,跟着下面的视频,打算每天至少更新一集 https://www.youtube.com/watch?vlsXB1PQdGx0&t494s 通过下面的蓝图方式我们就可以得到一个变化的材质 alpha参数的生成实际上就是下面的式子 custom节点允许直接的写入hlsl…...

Module模块化
导出:export关键字 export var color "red"; 重命名导出 在模块中使用as用导出名称表示本地名称。 import { add } from "./05-module-out.js"; 导入: import关键字 导入单个绑定 import { sum } from "./05-module-out.js&…...

使用 Rsync + Lsyncd 实现 CentOS 7 实时文件同步
文章目录 🌀使用 Rsync Lsyncd 实现 CentOS 7 实时文件同步前言介绍架构图🧱系统环境🔧Rsync配置(两台都需安装)关闭SELinux(两台都需) 📦配置目标端(client)…...

软件工程第三章习题
一、选择题 1. (1)答案:D 解析:可行性研究是对项目在技术、经济、操作等多方面进行全面评估论证,也称为项目论证 。技术可行性研究、操作可行性研究、经济可行性研究只是可行性研究的部分内容,不能涵盖整体概念。 2. (2)答案&…...

基于ElasticSearch的向量检索技术实践
基于ElasticSearch的向量检索技术实践 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/620260383 图片、视频、语音、文本等非结构化数据可以通过人工智能技术(深度学习算法)提取特征向量,然后通过对这些特征向量…...

Spring Boot 项目日志系统全攻略:Logback、Log4j2、Log4j与SLF4J整合指南
Spring Boot 项目日志系统全攻略:Logback、Log4j2、Log4j与SLF4J整合指南 日志系统是应用程序不可或缺的组成部分,良好的日志实践能极大提升开发调试和线上问题排查的效率。本文将全面介绍Spring Boot项目中各种日志框架的配置与使用方案,包…...

【设计模式】责任链模式
简介 很多公司都有请假的流程,当员工提交请假申请时,请求会沿着 组长 → 经理 → CEO 的链条传递,直到有对应层级的领导处理。 适用场景 一个请求需要多个对象中的一个或多个处理(如审批流程、过滤器链)。处理对象和…...

智能气候前沿:AI Agent结合机器学习与深度学习在全球气候变化驱动因素预测
全球气候变化已成为21世纪最严峻的环境挑战,其复杂的驱动因素如温室气体排放、气溶胶浓度、野火、海冰融化以及农业和生态系统变化等,交织影响着全球的气候格局。 第一:气候变化驱动因素与数据科学基础 1.1气候变化 全球气候变化 中国碳中…...

es 原生linux部署集群
背景 目的: 1. 理解不同部署方式的架构差异 2. 对比环境配置的复杂度 3. 评估性能与资源管理 4. 探索扩展性与高可用性 5. 学习安全与隔离机制 6. 实践监控与维护 7. 掌握混合部署与云原生场景 实验的最终目标 技能提升: 全面掌握Elasticsear…...

Springboot 同时支持不同的数据库,Oracle,Postgresql
## 关键字 Java,Springboot,Vscode,支持多种数据库 ## 背景环境 我在实际项目开发工程中遇到这样一个问题,用户 A 使用 Oracle 数据库,用户 B 使用 Postgresql 数据库,但是用户 AB 都使用我们的项目。所以…...

go --- go run main.go 和 go run .
目录 go run main.gogo run .示例 go run main.go 功能:只编译和运行指定的文件(main.go),忽略同目录下的其他文件。适用场景: 当你只需要运行一个独立的文件,且该文件不依赖其他文件时。适合单文件程序或…...

关于Spring MVC中@RequestMapping注解的详细解析,涵盖其核心功能、属性、使用场景及最佳实践
以下是关于Spring MVC中RequestMapping注解的详细解析,涵盖其核心功能、属性、使用场景及最佳实践: 1. 基础概念 RequestMapping是Spring MVC的核心注解,用于将HTTP请求映射到控制器(Controller)的方法上。它支持类级…...

deepseek使用记录26——从体力异化到脑力异化
我们的一切发现和进步,似乎结果是使物质力量具有理智生命,而人的生命则化为愚钝的物质力量。AI快速发展的现实中,人面临着比工业革命更深刻的异化。在工业革命中,人的身躯沦为了机器的一部分,而现在人的脑袋沦为了AI的…...

Ubertool 的详细介绍、安装指南及使用说明
Ubertool:多协议网络分析与调试平台 一、Ubertool 简介 Ubertool 是一款开源的 多协议网络分析工具,专为物联网(IoT)、嵌入式系统和工业自动化领域设计。它支持蓝牙、Wi-Fi、LoRa、CAN总线等多种通信协议的实时监控、数据包捕获…...

用 HTML、CSS 和 jQuery 打造多页输入框验证功能
在网页开发中,输入框验证是至关重要的一环,它能确保用户输入的数据符合特定要求,提升交互的准确性与流畅性。今天,我们就来深入剖析一个运用 HTML、CSS 和 jQuery 实现多页输入框验证的精彩实例,带你领略前端开发中表单…...

在CentOS上安装Docker需要注意的事项
文章目录 前言Docker Engine如何设置仓库设置镜像加速器获取镜像加速器地址 写在前面:大家好!我是晴空๓。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的唯一博客更新地址是:https://ac-…...

Chrome 135 版本新特性
Chrome 135 版本新特性 一、Chrome 135 版本浏览器更新 ** 1. 第三方托管账户注册迁移到 OIDC 授权码流程** Chrome 135 将账户注册的登录页面从营销网站迁移到动态网站,同时也将 OpenID Connect (OIDC) 的隐式流程迁移到授权码流程。这样做的目的是进一步提升第…...

CMake实战指南一:add_custom_command
CMake 进阶:add_custom_command 用法详解与实战指南 在 CMake 构建系统中,add_custom_command 是一个灵活且强大的工具,允许开发者在构建流程中插入自定义操作。无论是生成中间文件、执行预处理脚本,还是在目标构建前后触发额外逻…...

K8S学习之基础七十五:istio实现灰度发布
istio实现灰度发布 上传镜像到harbor 创建两个版本的pod vi deployment-v1.yaml apiVersion: apps/v1 kind: Deployment metadata:name: appv1labels:app: v1 spec:replicas: 1selector:matchLabels:app: v1apply: canarytemplate:metadata:labels:app: v1apply: canaryspec…...

7-1 列出连通集
作者 陈越 单位 浙江大学 给定一个有 n 个顶点和 m 条边的无向图,请用深度优先遍历(DFS)和广度优先遍历(BFS)分别列出其所有的连通集。假设顶点从 0 到 n−1 编号。进行搜索时,假设我们总是从编号最小的顶点…...

XML Schema 指示器
XML Schema 指示器 引言 XML Schema 是一种用于定义 XML 文档结构的语言,它能够确保 XML 文档的合法性。在 XML 文档的解析和应用中,XML Schema 指示器(XML Schema Indicator)扮演着至关重要的角色。本文将详细介绍 XML Schema 指示器的概念、作用、应用场景以及如何使用…...

Linux内核中TCP协议栈的实现:tcp_close函数的深度剖析
引言 TCP(传输控制协议)作为互联网协议族中的核心协议之一,负责在不可靠的网络层之上提供可靠的、面向连接的字节流服务。Linux内核中的TCP协议栈实现了TCP协议的全部功能,包括连接建立、数据传输、流量控制、拥塞控制以及连接关闭等。本文将深入分析Linux内核中tcp_close…...

17-产品经理-创建发布
点击“发布”-“创建发布”。 填写发布名称,选择测试的版本。还可以设置此次发布是否为“里程碑”。 点击“保存”后,进入该发布详情页面。需要为此次发布关联需求、已解决BUG、以及遗留BUG。可以通过设置条件,进行“搜索”,然后批…...

了解Spring的统一功能
目录 一、统一数据返回格式 1.引入统一数据返回格式 2.学习使用统一数据返回格式 support方法 beforeBodyWrite方法 统一数据返回格式具体逻辑 使用统一数据返回格式存在的问题 解决方法: 统一数据返回格式的优点 统一数据返回格式代码实现(包含了…...

123213
根据道路在道路网的地位、交通功能、对沿线的服务功能划分可分为快速路、主干路、次干路及支路 快速路完全为交通功能服务, 主干路以交通功能为主, 次干路是城市区域性的交通干道,为区域交通集散服务,兼有服务功能,结合主干路组成干路网 …...

通过 axios 请求回来的 HTML 字符串渲染到 Vue 界面上并添加样式
1. 通过 axios 获取数据 使用 axios 发起请求,获取返回的 HTML 字符串数据。 2. 在 Vue 中处理和渲染数据 由于 HTML 字符串中可能包含一些标签和样式,直接插入到 Vue 的模板中可能会导致样式问题。可以通过以下方式处理: 方法一…...
)
P1162 填涂颜色(BFS)
题目描述 由数字 0 组成的方阵中,有一任意形状的由数字 1 构成的闭合圈。现要求把闭合圈内的所有空间都填写成 2。例如:66 的方阵(n6),涂色前和涂色后的方阵如下: 如果从某个 0 出发,只向上下…...

【笔记】VS中C#类库项目引用另一个类库项目的方法
VS中C#类库项目引用另一个类库项目的方法 在 C# 开发中,有时我们需要在一个类库项目中引用另一个类库项目,但另一个项目可能尚未编译成 DLL。在这种情况下,我们仍然可以通过 Visual Studio 提供的项目引用功能进行依赖管理。 🎯 …...

进程内存分布--之smaps呈现memory-layout.cpp内存分布
上一篇介绍了:进程内存分布--之单线程代码来内存分布呈现memory-layout.cpp 这里我们使用smaps将更加形象的的体现内存分布,smaps文件是Linux的proc文件系统提供的一种可以查看内存资源使用情况的方法,Linux系统中运行的库、堆、栈等信息都可在smaps中查…...

再看自适应RAG方法:SEAKR|PIKE-RAG|DeepRAG
当大语言模型开始"怀疑人生":一场关于知识检索的AI内心戏 各位看官,今天我们要聊一个AI界的"哲学难题"——当大语言模型突然意识到自己可能是个"半瓶子醋",会发生什么奇妙反应? 想象一下这个场景:某天深夜,ChatGPT正对着用户提问"如…...
)
DNS服务(Linux)
DNS 介绍 dns,Domain Name Server,它的作用是将域名解析为 IP 地址,或者将IP地址解析为域名。 这需要运行在三层和四层,也就是说它需要使用 TCP 或 UDP 协议,并且需要绑定端口,53。在使用时先通过 UDP 去…...

探秘PythonJSON解析深度剖析json.loads处理嵌套JSON字符串的奥秘
哈喽,大家好,我是木头左! 在当今数字化时代,数据以各种格式呈现,而JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,在众多领域广泛应用。Python作为一门强大的编程语言,其内置的json模块为处理JSON数据提供了便捷的方法。然而,当遇到像{"name&q…...

Day7 FIFO与鼠标控制
文章目录 1. harib04a例程(获取按键编码)2. harib04b例程(加快中断处理)3. harib04c例程(FIFO缓冲区)4. harib04d例程(改善FIFO缓冲区)5. harib04e例程(整理FIFO缓冲区&a…...

软件工程第一章习题
第1章软件与软件工程 1.选择题 (1)下列说法中正确的是( )o A.20世纪50年代提出了软件工程的概念 B.20世纪60年代提出了软件工程的概念 C.20世纪70年代出现了客户机/服务器技术 D.20世纪80年代软件工程学科达到成熟 (2)软件危机的主要原因是( Do B.软件生产…...

Ollama 手动高速下载Win/Linux/Mac安装包及安装方法
前言 Ollama下载速度太慢,按这个方式,速度嘎嘎的快----下载地址 手动安装 如果要从以前的版本升级,则应删除旧库。比如:sudo rm -rf /usr/lib/ollama 解压 tar -C /usr -xzf ollama-linux-amd64.tgz # 解压到/usr文件夹# 如…...

Jmeter+Jenkins+Ant自动化持续集成环境搭建
一、安装准备 1.JDK:jdk-8u121-windows-x64 2.jmeter工具:apache-jmeter-2.13 3.ANT工具:apache-ant-1.9.7-bin 4.jenkins工具:jenkins-2.32.2 二、软件安装 1.JDK的安装 >双击JDK安装包,选择安装路径(本人是…...

【11】Redis快速安装与Golang实战指南
文章目录 1 Redis 基础与安装部署1.1 Redis 核心特性解析1.2 Docker Compose 快速部署1.3 Redis 本地快速部署 2 Golang 与 Redis 集成实战2.1 环境准备与依赖安装2.2 核心操作与数据结构实践2.2.1 基础键值操作2.2.2 哈希结构存储用户信息 3 生产级应用场景实战3.1 分布式锁实…...

ISP算法.红外图像增强
在图像处理领域,常见的图像处理一般都是白光相机,实际红外相机也是常见的一种相机,它可以用来对发热的东西进行成像,也可以作为白光相机夜晚不可见的一种辅助手段,为白光相机赋能夜视能力。 红外相机的成像原理在于辐射…...

Spring Boot中使用RedisTemplate操作Redis的几种数据类型详解
Redis作为高性能的键值存储系统,在现代Java应用中扮演着重要角色。Spring Boot通过RedisTemplate为开发者提供了便捷的Redis操作方式。本文将详细介绍如何使用RedisTemplate操作Redis的五种主要数据类型。 一、RedisTemplate简介 RedisTemplate是Spring Data Redi…...
)
大数据与人工智能之大数据架构(Hadoop、Spark、Flink)
一、核心特性与架构设计 1. Hadoop:分布式批处理的基石 核心组件: HDFS:分布式文件系统,支持大规模数据存储。MapReduce:基于“分而治之”的批处理模型,适合离线分析。 架构特点: 批处理主导&…...

VSCode中Marp插件
VSCode神级插件Marp,用Markdown来做PPT 优秀教程:https://zhuanlan.zhihu.com/p/582872955...

C++20 数学常数:<numbers> 头文件的革新
文章目录 一、<numbers> 头文件中的数学常数二、使用示例三、优势与应用场景(一)提高代码可读性(二)提高精度(三)适用于多种数据类型(四)简化数学计算 四、总结 C20 标准引入了…...

OpenCV--图像平滑处理
在数字图像处理领域,图像平滑处理是一项极为重要的技术,广泛应用于计算机视觉、医学影像分析、安防监控等多个领域。在 OpenCV 这一强大的计算机视觉库的助力下,我们能便捷地实现多种图像平滑算法。本文将深入探讨图像平滑的原理,…...