DPFunc蛋白质功能预测模型复现报告
模型简介
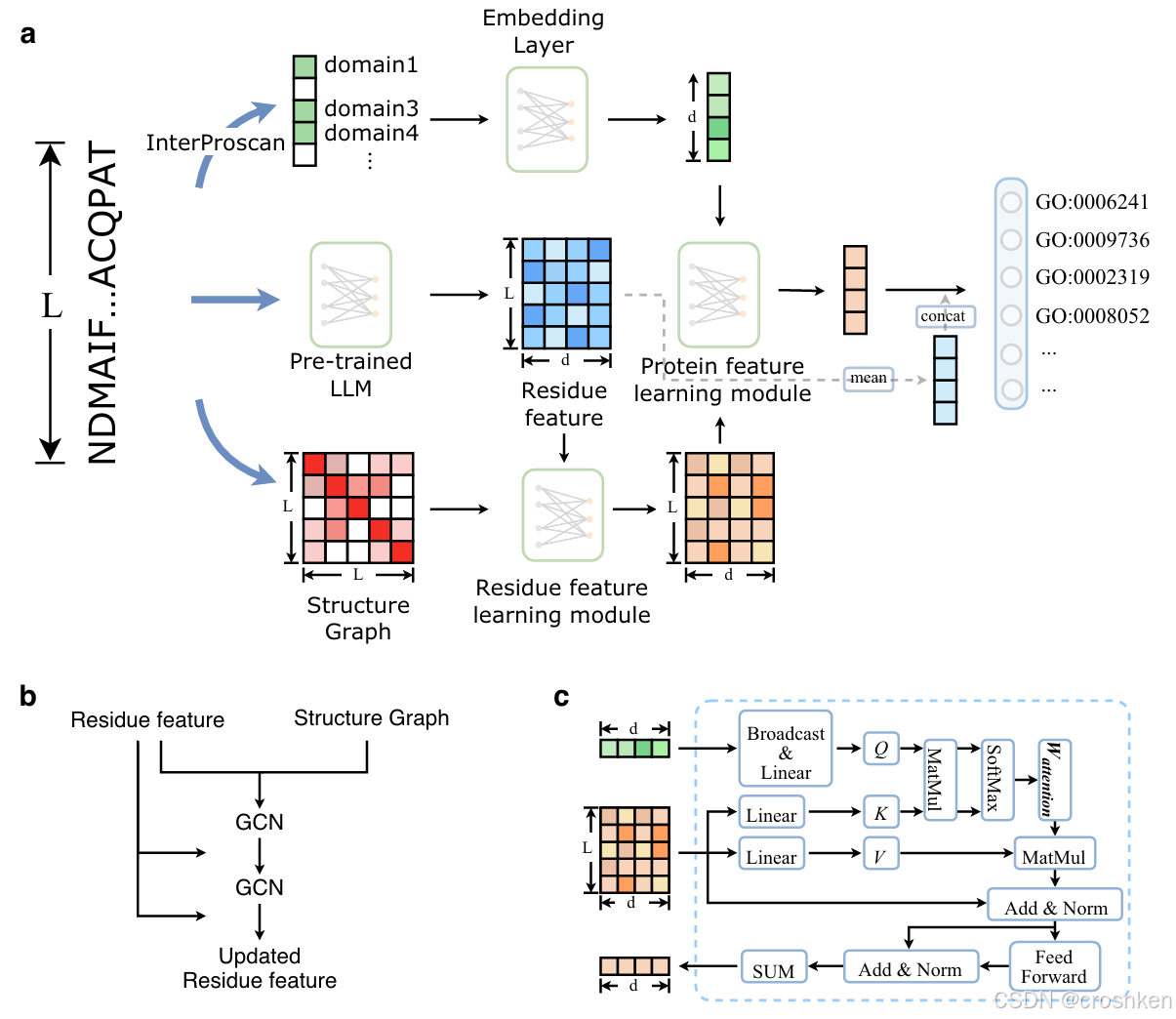
模型的具体介绍见蛋白质功能预测论文阅读记录2025(DPFunc、ProtCLIP)_protein functions-CSDN博客
复现流程
仓库:CSUBioGroup/DPFunc
时间:2025.4.5
环境配置
python 3.9.21 & CUDA 11.6
Pytorch: 1.12.0
DGL: 1.1.0(需要安装cuda版本)
download wheels in this page https://data.dgl.ai/wheels/cu116/repo.html and use
pip install 'dgl-1.1.0-cp39-cp39-manylinux1_x86_64.whl'
一个报错的解决:
OSError: libcusparse.so.11: cannot open shared object file: No such file or directory
在需要使用python的终端中运行下述语句即可
export LD_LIBRARY_PATH="~/miniconda3/envs/xxxxx/lib:$LD_LIBRARY_PATH
数据集准备
首先选好自己的蛋白质集合
先下载pdb和interpro的数据,有数据的就可以跳过了。
下载pdb代码,直接用wget就可以:
import os
import subprocess
from time import sleep
st = set()
file_list = os.listdir("pdb")
for filename in file_list:if filename.startswith("AF"):st.add(filename.split("-")[1])urls = []
# pids.txt保存的是需要下载pdb文件的蛋白质编号(uniprot)
with open(os.path.join("pids.txt"),"r") as f:lines = f.readlines()for line in lines:pid = line.strip()url = "https://alphafold.ebi.ac.uk/files/AF-"+pid+"-F1-model_v4.pdb\n"urls.append(url)for i,url in enumerate(urls):if i < len(file_list):continuepid = url.split("/")[-1].split("-")[1]if pid not in st:print(pid)output_file_path = os.path.join("pdb","AF-"+pid+"-F1-model_v4.pdb")try:result = subprocess.run(["wget", "-O", output_file_path, url.strip()],check=True, # 如果返回值不为 0,将引发异常stdout=subprocess.PIPE, # 捕获标准输出stderr=subprocess.PIPE # 捕获标准错误)print(f"文件下载成功,返回值:{result.returncode}")except subprocess.CalledProcessError as e:print(f"下载失败,返回值:{e.returncode}")print(f"错误信息:{e.stderr.decode()}")os.system("rm %s"%(output_file_path))sleep(1)下载interpro文件的代码:
'''
修改自InterPro官网上的代码
用于读取InterPro上的查找结果 export.tsv 并根据结果下载所有蛋白质的结构域信息
'''
# standard library modules
import sys, errno, re, json, ssl, os
from urllib import request
from urllib.error import HTTPError
from time import sleepdef parse_items(items):if type(items)==list:return ",".join(items)return ""
def parse_member_databases(dbs):if type(dbs)==dict:return ";".join([f"{db}:{','.join(dbs[db])}" for db in dbs.keys()])return ""
def parse_go_terms(gos):if type(gos)==list:return ",".join([go["identifier"] for go in gos])return ""
def parse_locations(locations):if type(locations)==list:return ",".join([",".join([f"{fragment['start']}..{fragment['end']}" for fragment in location["fragments"]])for location in locations])return ""
def parse_group_column(values, selector):return ",".join([parse_column(value, selector) for value in values])def parse_column(value, selector):if value is None:return ""elif "member_databases" in selector:return parse_member_databases(value)elif "go_terms" in selector: return parse_go_terms(value)elif "children" in selector: return parse_items(value)elif "locations" in selector:return parse_locations(value)return str(value)def download_to_file(url, file_path):#disable SSL verification to avoid config issuescontext = ssl._create_unverified_context()next = urllast_page = Falseattempts = 0while next:try:req = request.Request(next, headers={"Accept": "application/json"})res = request.urlopen(req, context=context)# If the API times out due a long running queryif res.status == 408:# wait just over a minutesleep(61)# then continue this loop with the same URLcontinueelif res.status == 204:#no data so leave loopbreakpayload = json.loads(res.read().decode())next = payload["next"]attempts = 0if not next:last_page = Trueexcept HTTPError as e:if e.code == 408:sleep(61)continueelse:# If there is a different HTTP error, it wil re-try 3 times before failingif attempts < 3:attempts += 1sleep(61)continueelse:sys.stderr.write("LAST URL: " + next)raise ewith open(file_path,"w+") as f:for i, item in enumerate(payload["results"]):f.write(parse_column(item["metadata"]["accession"], 'metadata.accession') + "\t")f.write(parse_column(item["metadata"]["name"], 'metadata.name') + "\t")f.write(parse_column(item["metadata"]["source_database"], 'metadata.source_database') + "\t")f.write(parse_column(item["metadata"]["type"], 'metadata.type') + "\t")f.write(parse_column(item["metadata"]["integrated"], 'metadata.integrated') + "\t")f.write(parse_column(item["metadata"]["member_databases"], 'metadata.member_databases') + "\t")f.write(parse_column(item["metadata"]["go_terms"], 'metadata.go_terms') + "\t")f.write(parse_column(item["proteins"][0]["accession"], 'proteins[0].accession') + "\t")f.write(parse_column(item["proteins"][0]["protein_length"], 'proteins[0].protein_length') + "\t")f.write(parse_column(item["proteins"][0]["entry_protein_locations"], 'proteins[0].entry_protein_locations') + "\t")f.write("\n")# Don't overload the server, give it time before asking for moresleep(1)# 先读取之前已经完成的进度
exist_file_list = set()
already_exist_file = os.listdir("interpro")
for file in already_exist_file:if file.endswith(".tsv"):exist_file_list.add(file.split(".")[0])with open(os.path.join("pids.txt"),"r") as f:lines = f.readlines()
cnt = 0
for line in lines:cnt+=1pid = line.strip()# 如果之前完成了,就跳过该条信息# if cnt <= 47:# continueif pid in exist_file_list:print(pid, " exists")continueprint(line," ",cnt,"/",len(lines))url = f"https://www.ebi.ac.uk:443/interpro/api/entry/InterPro/protein/reviewed/{pid}/?page_size=200"download_to_file(url,os.path.join("interpro", pid+'.tsv'))使用ESM-1b-650M跑embedding,并取第31层的embedding进行保留,注意这里不能直接做sum或者mean的readout,需要整个序列的embedding都保存。
ESM1b代码:(直接更换esm.pretrained后面的模型就可以跑其他的esm模型了)
'''
用于生成序列中每个氨基酸的特征向量
'''
import json
import os
import pickle
import tqdm
import pandas as pd
from pandas import DataFrame as dfimport torch
import esm# 设置CUDA设备编号
device = "cuda:2"
# ESM2预训练模型初始化,取消梯度
model, alphabet = esm.pretrained.esm1b_t33_650M_UR50S()
converter = alphabet.get_batch_converter()
model.to(device)
for p in model.parameters():p.requires_grad = False
model.eval()species_name = "xxxx"
# 读取预处理后的文件,这个不重要,只需要根据protein的id来提供序列就可以了
with open(os.path.join(species_name+"_protein_info.json"),'r') as f:protein_info = json.load(f)print("start ESM1b, get sequence embeddings!")
cnt = 0
for uid in protein_info.keys():cnt += 1print(cnt,'/',len(protein_info))val = protein_info[uid]labels, strs, tokens = converter([(uid,val["seq"])])tokens = tokens.to(device)seq_emb = model(tokens, repr_layers=[31])['representations'][31]seq_emb = seq_emb.squeeze(0)seq_emb = seq_emb.cpu().numpy()dir_path = os.path.join("dataset",species_name,uid)os.makedirs(dir_path, exist_ok=True)with open(os.path.join(dir_path,"seq_emb.pkl"), 'wb') as f:pickle.dump(seq_emb, f)del tokens,seq_embtorch.cuda.empty_cache()根据仓库中的需要,导出{bp/cc/mf}_{train/valid/test}_pid_list.pkl和pid2esm.pkl。
这个太简单就不给代码了。
数据处理梳理
这一部分踩了很多坑,改了很多代码才调通。
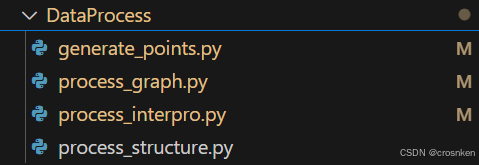
首先generate_points是对所有的数据进行处理的,处理完之后大家都可以读取,所以这里的pid_list.pkl需要包含所有的蛋白质编号。
process_graph需要单独对每一个{bp/cc/mf}_{train/valid/test}_pid_list.pkl做,也就是做出来至少9个文件。大概就是下图所示:
process_interpro,这个可以不用跑,因为在后面的main和pred中它还可以能单独跑,但如果跑了,就需要在yaml配置里面的base填写interpro_whole的路径。
这里因为我们下载下来的interpro是tsv文件,如果直接处理成一行01序列onehot编码会占用很多空间,魔改一下data_utils.py中的get_inter_whole_data函数,让他通过读取标签序列来初始化稀疏矩阵。
def get_inter_whole_data(pid_list, save_file, domain_map, protein_info):rows = []cols = []data = []for i in trange(len(pid_list)):pid = pid_list[i]if pid in protein_info:domain_list = protein_info[pid]['domain']for domain in domain_list:if domain[0] not in domain_map:continuedomain_id = domain_map[domain[0]]rows += [i]cols += [domain_id]data += [1]# col_nodes = np.max(cols) + 1col_nodes = 22369interpro_matrix = csr_matrix((data, (rows, cols)), shape=(len(pid_list), col_nodes))with open(save_file, 'wb') as fw:pkl.dump(interpro_matrix, fw)print(interpro_matrix.shape)return interpro_matrixprocess_structure,这个看起来是作者自用的处理代码,里面都是本地路径,不用管。
另外一个需要注意的事项,提供给DPFunc的go.txt必须是经过传播的go集合,否则训练效果会很差。
跑代码
首先运行:(注意填写正确的esm和pdb的路径)
python DataProcess/generate_points.py -i data/pid_list.pkl -o data/pid_points.pkl
如果只跑test,使用以下流程:
配置填写:(以bp为例)
name: bp
mlb: ./mlb/bp_go.mlb
results: ./resultsbase:pdb_points: ./data/pid_points.pkl
test:name: testpid_list_file: ./data/pid_list.pklpid_go_file: ./data/bp_go.txtpid_pdb_file: ./data/PDB/bp_test_whole_pdb_part0.pklinterpro_file: ./data/bp_interpro.pkl
注意这里跑之前需要把process_graph代码中的输出路径改好
python DataProcess/process_graph.py -d bp
python DataProcess/process_graph.py -d cc
python DataProcess/process_graph.py -d mf
下载已有的DPFunc权重https://drive.google.com/file/d/1V0VTFTiB29ilbAIOZn0okBQWPlbOI3wN/view?usp=drive_link
解压到save_models之后运行预测代码
python DPFunc_pred.py -d bp -n 0 -p DPFunc_model
python DPFunc_pred.py -d cc -n 0 -p DPFunc_model
python DPFunc_pred.py -d mf -n 0 -p DPFunc_model
结果:
bp: Fmax 0.7429, AUPR 0.7608
cc: Fmax 0.8246, AUPR 0.8775
mf: Fmax 0.7238, AUPR 0.7607
跑train+test,使用以下流程:
先要分离train/valid/test的pid_list
填写配置:
name: bp
mlb: ./mlb/bp_go.mlb
results: ./resultsbase:interpro_whole: pdb_points: ./data/pid_points.pkltrain:name: trainpid_list_file: ./data/bp_train_pid_list.pklpid_go_file: ./data/bp_train_go.txtpid_pdb_file: ./data/PDB/bp_train_whole_pdb_part{}.pkltrain_file_count: 1interpro_file: ./data/bp_train_interpro.pklvalid:name: validpid_list_file: ./data/bp_valid_pid_list.pklpid_go_file: ./data/bp_valid_go.txtpid_pdb_file: ./data/PDB/bp_valid_whole_pdb_part0.pklinterpro_file: ./data/bp_valid_interpro.pkltest:name: testpid_list_file: ./data/bp_test_pid_list.pklpid_go_file: ./data/bp_test_go.txtpid_pdb_file: ./data/PDB/bp_test_whole_pdb_part0.pklinterpro_file: ./data/bp_test_interpro.pkl
然后还是需要改process_graph的代码,让他把train/valid/test三个都分别读取对应的文件再输出到对应的路径
重新进行process_graph.py
python DPFunc_main.py -d bp -n 0 -e 15 -p temp_model
python DPFunc_main.py -d cc -n 0 -e 15 -p temp_model
python DPFunc_main.py -d mf -n 0 -e 15 -p temp_model
验证集结果:
bp: AUC 0.9989, Fmax 0.5867, AUPR 0.5913, cut-off: 0.55
cc: AUC 0.9990, Fmax 0.7179, AUPR 0.7711, cut-off: 0.58
mf: AUC 0.9992, Fmax 0.7500, AUPR 0.7826, cut-off: 0.45
python DPFunc_pred.py -d bp -n 0 -p temp_model
python DPFunc_pred.py -d cc -n 0 -p temp_model
python DPFunc_pred.py -d mf -n 0 -p temp_model
测试集结果:
bp: AUC 0.9990, Fmax 0.5867, AUPR 0.5997, cut-off: 0.56
cc: AUC 0.9993, Fmax 0.7238, AUPR 0.7690, cut-off: 0.72
mf: AUC 0.9992, Fmax 0.7500, AUPR 0.7839, cut-off: 0.45
吐槽
整个复现花了5~6天的时间,大部分时间都在数据处理上,模型的效果确实很好,训练也很快,但是中途有一些不太好的设计。
1、冗余的dgl图特征,仅仅只是把esm的特征保存在"x"里面,然后用的时候又是拿出来跑网络,这样一份esm特征我们就需要保存两遍,很占空间。一般没有自定义传播函数的时候,建议dgl图就只保存框架,特征单独拿出来放,大部分DGL自带的GCN都是分离节点特征输入的。
2、路径修改繁琐,几个数据处理文件里面,既有读取配置文件的路径,又有写死的本地路径,改一个路径输入输出需要非常仔细才能不出错,有时候改了这里就忘了改那里。
3、函数不统一,训练代码用的读取函数和输出处理函数的名称相同,但是内容略有差别,调用的是不同位置的函数,改完数据处理函数发现没用,调了半天才发现训练里面的数据处理又是独立的。
4、计算Fmax指标时,有一个对预测结果进行传递的过程:
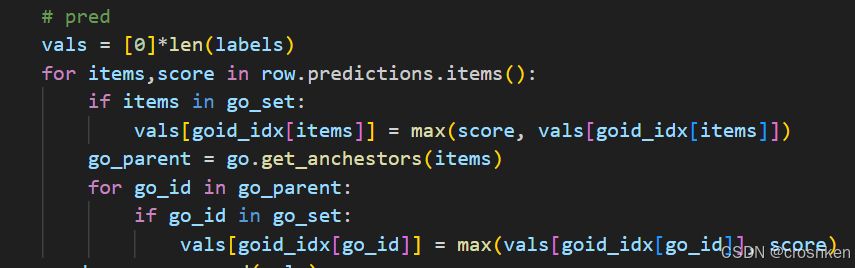
这个非常慢,每一个GO标签都要更新它的传递闭包,并且它是一个一个蛋白质计算的,时间复杂度大概是O(蛋白质个数 * 标签总数 * 平均每个GO标签的传递闭包大小)。
优化的话,可以先求GO图的拓扑序,按照GO拓扑序更新,从具体的GO标签更新到抽象的顶层GO标签,然后预测出来的结果可以作为一个batch更新,而不是一个一个蛋白质更新。
不过我现在还没来得及优化这个,有空再说吧
相关文章:

DPFunc蛋白质功能预测模型复现报告
模型简介 模型的具体介绍见蛋白质功能预测论文阅读记录2025(DPFunc、ProtCLIP)_protein functions-CSDN博客 复现流程 仓库:CSUBioGroup/DPFunc 时间:2025.4.5 环境配置 python 3.9.21 & CUDA 11.6 Pytorch: 1.12.0 DG…...

在 Ubuntu24.04 LTS 上 Docker Compose 部署基于 Dify 重构二开的开源项目 Dify-Plus
一、安装环境信息说明 硬件资源(GB 和 GiB 的主要区别在于它们的换算基数不同,GB 使用十进制,GiB 使用二进制,导致相同数值下 GiB 表示的容量略大于 GB;换算关系:1 GiB ≈ 1.07374 GB ;1 GB ≈ …...

双系统ubuntu20.04不能外接显示器的解决办法
一,更换驱动 首先确定是不是英伟达显卡驱动,如果不是的话,设置里找到附加驱动,更改为NVIdia类型的驱动,更改完成之后重启 这里大部分电脑都可以了,如果不行 二、更改启动方式 重启之后进入BIOS设置&…...

高并发内存池:原理、设计与多线程性能优化实践
高并发内存池是一种专门为多线程环境设计的内存管理机制,其核心目标是通过优化内存分配和释放过程,解决传统内存分配器(如malloc/free)在高并发场景下的性能瓶颈,显著提升多线程程序的内存访问效率。 目录 一、核心设计…...

03.31-04.06 论文速递 聚焦具身智能、复杂场景渲染、电影级对话生成等五大前沿领域
🌟 论文速递 | 2025.03.31-04.06 📢 聚焦具身智能、复杂场景渲染、电影级对话生成等前沿领域 1️⃣ 具身智能体:从脑启发到安全协作系统 论文标题: Advances and Challenges in Foundation Agents: From Brain-Inspired Intellige…...

Django和Celery实现的异步任务案例
推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 先决条件步骤1:安装依赖项步骤2:配置Celery2.1 创建`celery.py`2.2 更新 `__init__.py`步骤3:配置Django设置步骤4:定义Celery任务…...

DAY 38 leetcode 15--哈希表.三数之和
题号15 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 未去重版本 整体思路:先排序再双指针遍…...
)
Java项目之基于ssm的个性化旅游攻略定制系统(源码+文档)
项目简介 个性化旅游攻略定制系统实现了以下功能: 个性化旅游攻略定制系统能够实现对用户上传信息,旅游路线信息,景点项目信息,景点信息,标签分类信息等信息的管理。 💕💕作者:落落…...

链表和数组的效率
访问元素 • 数组:通过索引直接访问元素,时间复杂度为O(1),速度很快。例如arr[5]可以立即访问到数组arr中索引为5的元素。 • 链表:需要从链表头开始逐个遍历节点,直到找到目标元素,平均时间复杂度为O(n)…...

经典回溯问题———组合的输出
题目如下 思路 代码如下...

WPS宏开发手册——附录
目录 系列文章7、附录 系列文章 使用、工程、模块介绍 JSA语法 JSA语法练习题 Excel常用Api Excel实战 常见问题 附录 7、附录 颜色序列:在excel中设置颜色,只能设置颜色序号,不能直接设置rgb颜色 1、黑色 (Black)…...

【leetcode100】买卖股票的最佳时机
1、题目描述 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易中获取的最大利润。如果你…...

uniapp小程序登录失效后操作失灵问题
一开始我在请求返回失效验证时做了登录失效处理然后用uni.switchTab跳转主页的逻辑,结果发现在一天后重新打开小程序或者其他登录挤掉登录验证时有概率导致整个页面失灵无法操作。 经过排查发现,在小程序跳转新页面的时候如果遇到**(过快还是过多&#…...
| LeetCode 513)
找树左下角的值(DFS 深度优先搜索)| LeetCode 513
✨ 题目描述 给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。 提示: 二叉树中至少有一个节点。 📄 示例 示例 1 输入: root [2,1,3] 输出: 1示例 2 输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7ǵ…...
分割回文串)
【力扣hot100题】(060)分割回文串
每次需要判断回文串,这点比之前几题回溯题目复杂一些。 还有我怎么又多写了循环…… class Solution { public:vector<vector<string>> result;string s;bool palindromic(string s){for(int i0;i<s.size()/2;i) if(s[i]!s[s.size()-1-i]) return …...

中国钧瓷收藏市场现状和风险警示
一、数据权威性与综合维度 本榜单由钧瓷联合体、钧瓷频道及钧瓷数据库三方协同制作,通过10项规则综合评估匠人影响力,涵盖知名度、用户评价、平台指数等多元维度,避免单一指标(如拍卖价格)的片面性。榜单每月更新&…...

forms实现任务文档功能
说明: forms实现任务文档功能 效果图: step1:C:\Users\wangrusheng\RiderProjects\WinFormsApp26\WinFormsApp26\Form1.cs using System; using System.Collections.Generic; using System.ComponentModel; using System.Drawing; using System.IO; u…...
方法)
字符串的replace、replaceAll、split()方法
参考 字符串的replace、replaceAll、split()方法_字符串replace-CSDN博客...
)
Kotlin语言进阶:协程、Flow、Channel详解(二)
Kotlin语言进阶:协程、Flow、Channel详解(二) 一、Flow基础 1.1 什么是Flow Flow是Kotlin提供的用于处理异步数据流的解决方案,它建立在协程之上,具有以下特点: 冷流特性:只有在收集时才会开始发射数据背压处理:自动处理生产者和消费者速度不匹配的问题组合操作:提…...

VBA知识学习
文章目录 打开开发工具编写第一个VBA使用VBA调试器 VBA语法 打开开发工具 文件->选项->自定义功能区->开发工具 编写第一个VBA 点击开发工具 ->点击Visual Basic 选择sheet1->右键->插入->模块 Sub 第一个VBA程序()MsgBox "Hello World!&quo…...
)
JAVA EE_多线程-初阶(二)
1.线程安全 1.1.观察线程不安全 实例: package thread; public class text18 {//定义一个成员变量count,初始值为0private static int count0;public static void main(String[] args) throws InterruptedException {Thread t1new Thread(()->{for(int i0;i&l…...

【Linux】进程预备知识——冯诺依曼、操作系统
目录: 一、冯诺依曼体系结构 (一)什么是冯诺依曼 (二)为什么需要冯诺依曼 (三)冯诺依曼如何操作 二、操作系统概念 (一)对下硬件管理 (二)…...

Java入门首周精要:从基础语法到面向对象核心解析
文章目录 Java入门首周精要:从基础语法到面向对象核心解析1.Java类名与文件名的一致性规则2.Java和C语言中char类型的区别3.Java中的注释4.Java中的‘’‘’运算符5.Java的输入输出6.方法(重载&重写)方法的重载方法的重写 7.面向对象&…...

嵌入式AI开源生态指南:从框架到应用的全面解析
嵌入式AI开源生态指南:从框架到应用的全面解析 引言 随着人工智能技术的迅速发展,将AI能力部署到边缘设备上的需求日益增长。嵌入式AI通过在资源受限的微控制器上运行机器学习模型,实现了无需云连接的本地智能处理,大幅降低了延…...

MCP server的stdio和SSE分别是什么?
文章目录 一、Stdio:本地进程间通信的核心二、SSE:远程通信与实时推送的利器三、Stdio vs SSE:关键差异对比四、如何选择?场景驱动的决策指南五、实战建议与避坑指南实际操作结语在AI应用开发中,MCP(Model Context Protocol)协议正成为连接大模型与外部资源的核心桥梁。…...
的实现)
哈希表(闭散列)的实现
目录 概念及定义 闭散列的介绍 闭散列底层实现 哈希表的定义 哈希表的构造 哈希表扩容 哈希表插入 哈希表删除 哈希表查找 概念及定义 哈希表,也成为散列表,在C中unordered_set和unordered_map的底层实现依靠的都是哈希表。 map和set的底层是红…...
:Shiro整合CAS实现单点登录)
Shiro学习(六):Shiro整合CAS实现单点登录
一、单点登录介绍 单点登录(Single Sign On),简称为 SSO,是比较流行的企业业务整合的解决方案之一。 SSO的定义是在多个[应用],用户只需要登录一次就可以访问所有相互信任的应用系统。 一般这种单点登录的实现方案&…...

HAProxy-ACL实战篇
HAProxy-ACL实战篇 IP说明172.25.254.101客户端172.25.254.102haproxy服务器172.25.254.103web1172.25.254.104web2 ACL示例-域名匹配 # 172.25.254.102 [rootRocky ~]# cat /etc/haproxy/conf.d/test.cfg frontend magedu_http_portbind 172.25.254.102:80mode httpbalanc…...

以下是针对该 Ansible 任务的格式检查和优化建议
以下是针对该 Ansible 任务的格式检查和优化建议: 目录 一、格式检查原始代码问题分析修正后的标准格式 二、推荐增强功能1. 添加可执行权限2. 显式指定 Shell 解释器3. 添加错误处理 三、完整 Playbook 示例四、验证脚本兼容性五、常见错误总结 一、格式检查 原始…...

C++语言的测试覆盖率
C语言的测试覆盖率分析与实践 引言 在软件开发过程中,测试覆盖率是一项重要的质量指标,它帮助开发者评估代码的测试效果,确保软件的可靠性与稳定性。尤其在C语言的开发中,由于其复杂的特性和丰富的功能,测试覆盖率的…...

如何使用 DrissionPage 进行网页自动化和爬取
在这个技术博客中,我们将向大家展示如何使用 DrissionPage 进行网页自动化操作与数据爬取。DrissionPage 是一个基于 Playwright 的 Python 自动化工具,它允许我们轻松地控制浏览器进行网页爬取、测试以及自动化操作。与其他工具(如 Selenium…...
详解)
设计模式 Day 3:抽象工厂模式(Abstract Factory Pattern)详解
经过前两天的学习,我们已经掌握了单例模式与工厂方法模式,理解了如何控制实例个数与如何通过子类封装对象的创建逻辑。 今天,我们将进一步深入“工厂”体系,学习抽象工厂模式(Abstract Factory Pattern)&a…...

TensorRT 有什么特殊之处
一、TensorRT的定义与核心功能 TensorRT是NVIDIA推出的高性能深度学习推理优化器和运行时库,专注于将训练好的模型在GPU上实现低延迟、高吞吐量的部署。其主要功能包括: 模型优化:通过算子融合(合并网络层)、消除冗余…...
--SRC获得库名即可)
SQL注入-盲注靶场实战(手写盲注payload)--SRC获得库名即可
布尔盲注 进入页面 注入点 ’ and 11 and 12 得知为布尔盲注 库名长度 and length(database()) 8 抓包(浏览器自动进行了url编码)爆破 得知为 12 库名字符 1 and ascii(substr(database(),1,1))112 – q (这里如果不再次抓包…...

http://noi.openjudge.cn/_2.5基本算法之搜索_1804:小游戏
文章目录 题目深搜代码宽搜代码深搜数据演示图总结 题目 1804:小游戏 总时间限制: 1000ms 内存限制: 65536kB 描述 一天早上,你起床的时候想:“我编程序这么牛,为什么不能靠这个赚点小钱呢?”因此你决定编写一个小游戏。 游戏在一…...

Windows Flip PDF Plus Corporate PDF翻页工具
软件介绍 Flip PDF Plus Corporate是一款功能强大的PDF翻页工具,也被称为名编辑电子杂志大师。这款软件能够迅速将PDF文件转换为具有翻页动画效果的电子书,同时保留原始的超链接和书签。无论是相册、视频、音频,还是Flash、视频和链接&#…...

Java八股文-List
集合的底层是否加锁也就代表是否线程安全 (一)List集合 一、数组 array[1]是如何通过索引找到堆内存中对应的这块数据的呢? (1)数组如何获取其他元素的地址值 (2)为什么数组的索引是从0开始的,不可以从1开始吗 (3)操作数组的时间复杂度 ①查找 根据索引查询 未…...

btrfs , ext4 , jfs , xfs , zfs 对比 笔记250406
btrfs , ext4 , jfs , xfs , zfs 对比 笔记250406 特性Btrfsext4JFSXFSZFS定位现代多功能传统稳定轻量级高性能大文件企业级存储最大文件/分区16EB / 16EB16TB / 1EB4PB / 32PB8EB / 8EB16EB / 25610⁵ ZB快照✅ 支持❌ 不支持❌ 不支持❌ 不支持✅ 支持透明压缩✅ (Zstd/LZO)❌…...

Meta上新Llama 4,到底行不行?
这周AI圈被Meta的“深夜突袭”炸开了锅。 Llama 4家族带着三个新成员,直接杀回开源模型战场,连扎克伯格都亲自站台喊话:“我们要让全世界用上最好的AI!” 但别急着喊“王炸”,先看看它到底强在哪。 这次Meta玩了个狠招…...

显示器工艺简介
华星光电显示器的生产工艺流程介绍,从入厂原料到生产出显示器的整体工艺介绍 华星光电显示器的生产工艺流程主要包括以下几个阶段,从原材料入厂到最终显示器的生产: 原材料准备 玻璃基板:显示器的核心材料,通常采用超…...

音乐软件Pro版!内置音源,听歌自由,一键畅享!
今天给大家介绍一款超实用的音乐软件——LX音乐Pro版。原版LX音乐需要用户自行导入音源才能正常使用,但此次推出的Pro版已经内置了音源,省去了繁琐的操作步骤,使用起来更加便捷 这款软件不仅支持歌曲搜索,还能搜索歌单,…...

Spring 中有哪些设计模式?
🧠 一、Spring 中常见的设计模式 设计模式类型Spring 中的应用场景单例模式创建型默认 Bean 是单例的工厂模式创建型BeanFactory、FactoryBean抽象工厂模式创建型ApplicationContext 提供多个工厂接口代理模式结构型AOP 动态代理(JDK/CGLIB)…...

R语言使用ggplot2作图
在ggplot2中,图是采用串联起来()号函数创建的。每个函数修改属于自己的部分。比如,ggplot()geom()...... aes(x, y, colour a,shape a,size a.......) ggplot2中画图常用的五大块内容 数据(data)及一系列将数据中的变量对应到图…...

GenerationMixin概述
类 类名简单说明GenerateDecoderOnlyOutput继承自 ModelOutput,适用于非束搜索方法的解码器-only模型输出类。GenerateEncoderDecoderOutput继承自 ModelOutput,适用于非束搜索方法的编码器-解码器模型输出类。GenerateBeamDecoderOnlyOutput继承自 Mod…...

文心快码制作微信小程序
AI时代来临,听说Baidu Comate也推出了自家的编程工具Zulu,可以从零到一帮你生成代码,趁着现在还免费,试试效果如何。这里以开发一个敲木鱼的微信小程序为例 一、需求分析 写小程序需求文档 首先,第一步我要准确描述…...

flutter provider状态管理使用
在 Flutter 中,Provider 是一个轻量级且易于使用的状态管理工具,它基于 InheritedWidget,并提供了一种高效的方式来管理和共享应用中的状态。相比其他复杂的状态管理方案(如 Bloc 或 Riverpod),Provider 更…...

C++——静态成员
目录 静态成员的定义 静态成员变量 编程示例 存在的意义 静态成员函数 类内声明 类外定义 编程示例 静态成员的定义 静态成员在C类中是一个重要的概念,它包括静态成员变量和静态成员函数。静态成员的特点和存在的意义如下: 静态成员变量 1…...
UDP 为什么大小不能超过 64KB?)
UDP学习笔记(四)UDP 为什么大小不能超过 64KB?
🌐 UDP 为什么大小不能超过 64KB?TCP 有这个限制吗? 在进行网络编程或者调试网络协议时,我们常常会看到一个说法: “UDP 最大只能发送 64KB 数据。” 这到底是怎么回事?这 64KB 是怎么来的?TCP…...

Linux中用gdb查看coredump文件
查看dump的命令: gdb 可执行文件 dump文件路径查看函数调用栈 (gdb)bt查看反汇编代码 (gdb)disassemble查看寄存器的值 (gdb)info all-registers如果通过上述简单命令无法排查,还是通过-g参数编译带符号表的可执行文件,再用gdb查看...

PyTorch 深度学习 || 7. Unet | Ch7.1 Unet 框架
1. Unet 框架...