[项目总结] 在线OJ刷题系统项目技术应用(下)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(96平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(93平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 10. 阿里云短信服务
- 11. 阿里云OSS对象存储
- 12. docker代码沙箱
- 13. xxl-job定时任务
- 13.1 历史竞赛与完赛的竞赛
- 13.2 竞赛结束之后发送站内信
- 14. OpenFeign
- 15. TransmittableThreadLocal
- 15.1 技术原理
- 15.2 项目应用
- 16. RabbitMQ异步通信
- 17. 数据库表设计
- 18. Gateway网关
10. 阿里云短信服务
首先我们需要对阿里云的短信服务进行配置,我们需要配置调用发送短信API的必要数据,accessKeyId,accessKeySecret,这连个是每个用户有且仅有一个,用来拿到阿里云账号的用户权限.之后配置的是endpoint,即要发送短信的地域集群(这封短信从那个城市集群发出).
@Configuration
public class AliSmsConfig {@Value("${sms.aliyun.accessKeyId:}")private String accessKeyId;@Value("${sms.aliyun.accessKeySecret:}")private String accessKeySecret;@Value("${sms.aliyun.endpoint:}")private String endpoint;@Bean("aliClient")public Client client() throws Exception {Config config = new Config().setAccessKeyId(accessKeyId).setAccessKeySecret(accessKeySecret).setEndpoint(endpoint);return new Client(config);}
}
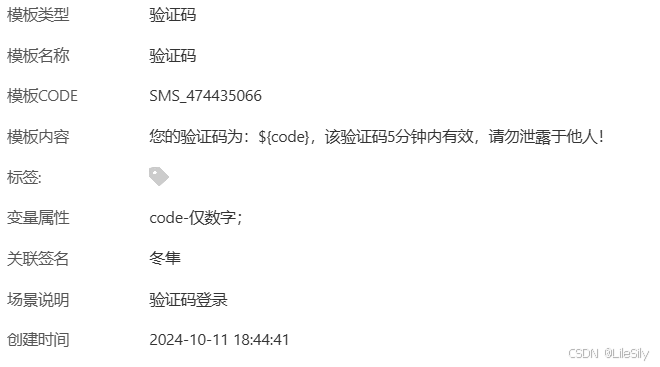
我们调用短信服务主要用来发送验证码,在发送验证码的方法中,我们在SendSmsRequest中定义了要发送的手机号phone,使用的签名,即在短信头的中括号中显示的签名singName,之后就是我们需要使用的短信模版idtemplateCode,之后就是我们需要往短信中填充的内容,短信的模版中有一些内容是可变的,即${ }中的内容,这个Map中就修改的是这其中的内容.
@Component
@Slf4j
public class AliSmsService {@Autowiredprivate Client aliClient;//业务配置@Value("${sms.aliyun.templateCode:}")private String templateCode;@Value("${sms.aliyun.sing-name:}")private String singName;public boolean sendMobileCode(String phone, String code) {Map<String, String> params = new HashMap<>();params.put("code", code);return sendTempMessage(phone, singName, templateCode, params);}public boolean sendTempMessage(String phone, String singName, String templateCode,Map<String, String> params) {SendSmsRequest sendSmsRequest = new SendSmsRequest();sendSmsRequest.setPhoneNumbers(phone);sendSmsRequest.setSignName(singName);sendSmsRequest.setTemplateCode(templateCode);sendSmsRequest.setTemplateParam(JSON.toJSONString(params));try {SendSmsResponse sendSmsResponse = aliClient.sendSms(sendSmsRequest);SendSmsResponseBody responseBody = sendSmsResponse.getBody();if (!"OK".equalsIgnoreCase(responseBody.getCode())) {log.error("短信{} 发送失败,失败原因:{}.... ", JSON.toJSONString(sendSmsRequest), responseBody.getMessage());return false;}return true;} catch (Exception e) {log.error("短信{} 发送失败,失败原因:{}.... ", JSON.toJSONString(sendSmsRequest), e.getMessage());return false;}}
}
11. 阿里云OSS对象存储
从OSS配置的属性中,我们就可以看出OSS对象存储服务需要的字段,和上面的短信服务一样,我们仍然需要endpoint城市集群结点URL,用户唯一的权限校验id和密钥accessKeyId和accessKeySecret,其次,我们的配置还需要比短信服务多出了bucketNameOSS对象存储的存储空间,即存储对象的容器.其次就是pathPrefix,表示的是对象在bucket中的存储路径.最后是region,表示的是对象存储的城市服务器集群.我们需要首先在DefaultCredentialProvider把accessKeyId和accessKeySecret两个属性配置好.之后配置进OSSClientBuilder即可,之后我们还需要配置endpoint和Region,即城市集群URL和城市集群地域信息.由于OSS对象存储服务是以数据流的方式对数据进行上上传的,所以我们在上传完成之后需要对数据流进行关闭closeOSSClient().
@Slf4j
@Configuration
public class OSSConfig {@Autowiredprivate OSSProperties prop;public OSS ossClient;@Beanpublic OSS ossClient() throws ClientException {DefaultCredentialProvider credentialsProvider = CredentialsProviderFactory.newDefaultCredentialProvider(prop.getAccessKeyId(), prop.getAccessKeySecret());// 创建ClientBuilderConfigurationClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);// 使用内网endpoint进行上传ossClient = OSSClientBuilder.create().endpoint(prop.getEndpoint()).credentialsProvider(credentialsProvider).clientConfiguration(clientBuilderConfiguration).region(prop.getRegion()).build();return ossClient;}@PreDestroypublic void closeOSSClient() {ossClient.shutdown();}
}
@Data
@Component
@ConfigurationProperties(prefix = "file.oss")
public class OSSProperties {private String endpoint;private String region;private String accessKeyId;private String accessKeySecret;private String bucketName;private String pathPrefix;
}
我们在配置好属性之后,我们就可以对外提供一个用于向OSS上传文件的Service方法了, 在一个c端的用户想要对头像进行修改的时候,为了保证某些恶意用户浪费系统资源,我们对每个用户单日上传头像的此处做了一定的限制,把每个用户上传头像的次数保存在Redis中,在上传头像之前先去Redis中查询当前用户上传头像的次数,如果超过了一定的次数限制,那么直接限制,如果没有超过,直接对Redis中的当前缓存的Value++.同时在每天的凌晨1点的时候对缓存进行刷新.进行检查之后,就可以对文件进行上传了,首先需要指定好文件路径与文件名,也就是在OSS的bucket中,我们需要把文件上传到哪个路径之下,之后我们可以使用InputStream输入流对文件进行上传,最后记得在finally方法中关闭输入流.
public OSSResult uploadFile(MultipartFile file) throws Exception {if (!test) {checkUploadCount();}InputStream inputStream = null;try {String fileName;if (file.getOriginalFilename() != null) {fileName = file.getOriginalFilename().toLowerCase();} else {fileName = "a.png";}String extName = fileName.substring(fileName.lastIndexOf(".") + 1);inputStream = file.getInputStream();return upload(extName, inputStream);} catch (Exception e) {log.error("OSS upload file error", e);throw new ServiceException(ResultCode.FAILED_FILE_UPLOAD);} finally {if (inputStream != null) {inputStream.close();}}
}
private void checkUploadCount() {Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);Long times = redisService.getCacheMapValue(CacheConstants.USER_UPLOAD_TIMES_KEY, String.valueOf(userId), Long.class);if (times != null && times >= maxTime) {throw new ServiceException(ResultCode.FAILED_FILE_UPLOAD_TIME_LIMIT);}redisService.incrementHashValue(CacheConstants.USER_UPLOAD_TIMES_KEY, String.valueOf(userId), 1);if (times == null || times == 0) {long seconds = ChronoUnit.SECONDS.between(LocalDateTime.now(),LocalDateTime.now().plusDays(1).withHour(0).withMinute(0).withSecond(0).withNano(0));redisService.expire(CacheConstants.USER_UPLOAD_TIMES_KEY, seconds, TimeUnit.SECONDS);}
}
12. docker代码沙箱
在用户的id和用户的代码被提交到java判题功能的时候,首先需要根据用户提交的代码进行用户代码文件的构建,即createUserCodeFile,就是把用户提交的代码和主方法拼接起来,之后使用FileUtil工具类在指定的目录之下创建一个用户代码文件.之后就是初始化代码沙箱,在初始化代码沙箱的时候,我们使用的是容器池的技术,即池化技术,避免每一次提交代码都在创建容器上产生不必要的开销,直接从容器池中获取到一个docker容器并启动docker容器.创建并启动完成之后,把我们之前创建好的用户代码提交到docker容器中进行编译,如果编译不通过直接返回编译错误,并删除之前创建的docker容器和用户代码文件避免资源的浪费,如果编译通过,则把测试用例的输入带入到用户提交的代码中进行执行并得到返回结果.
@Override
public SandBoxExecuteResult exeJavaCode(Long userId, String userCode, List<String> inputList) {containerId = sandBoxPool.getContainer();//创建用户代码文件createUserCodeFile(userCode);//编译代码CompileResult compileResult = compileCodeByDocker();//编译是否通过,如果不通过,直接把容器归还给容器池,并删除用户代码路径if (!compileResult.isCompiled()) {sandBoxPool.returnContainer(containerId);deleteUserCodeFile();//返回一个失败的结果return SandBoxExecuteResult.fail(CodeRunStatus.COMPILE_FAILED, compileResult.getExeMessage());}//如果编译通过,则执行代码return executeJavaCodeByDocker(inputList);
}
//创建并返回用户代码的文件
private void createUserCodeFile(Long userId, String userCode) {//创建存放用户代码的目录String examCodeDir = System.getProperty("user.dir") + File.separator + JudgeConstants.EXAM_CODE_DIR;if (!FileUtil.exist(examCodeDir)) {FileUtil.mkdir(examCodeDir);}String time = LocalDateTimeUtil.format(LocalDateTime.now(), DateTimeFormatter.ofPattern("yyyyMMddHHmmss"));//拼接用户代码文件格式userCodeDir = examCodeDir + File.separator + userId + Constant.UNDERLINE_SEPARATOR + time;userCodeFileName = userCodeDir + File.separator + JudgeConstants.USER_CODE_JAVA_CLASS_NAME;FileUtil.writeString(userCode, userCodeFileName, Constant.UTF8);
}
在创建一个docker容器的时候,需要对当前的docker容器进行配置,首先就是创建DefaultDockerClientConfig配置类,采用其中的createDefaultConfigBuilder()docker默认配置即可,之后为配置类指定要创建在哪个端口上,即withDockerHost.创建好配置类之后,使用DockerClientBuilder为我们需要创建的docker容器指定配置.之后拉取镜像.之后为当前容器指定其他的一些核心配置,比如限制最大内存,限制内存最大交换次数,限制cpu可以使用的核心,禁用网络等.之后为我们要创建的容器指定一个名称,之后就可以为容器传入配置正式创建容器,拿到创建好的容器id就可以正式启动容器了.
private void initDockerSanBox(){//创建一个docker客户端配置,采用默认配置,并设置端口号DefaultDockerClientConfig clientConfig = DefaultDockerClientConfig.createDefaultConfigBuilder().withDockerHost(dockerHost).build();//构建docker容器dockerClient = DockerClientBuilder.getInstance(clientConfig) //传入docker配置.withDockerCmdExecFactory(new NettyDockerCmdExecFactory()).build();//拉取镜像pullJavaEnvImage();//获取到容器的配置HostConfig hostConfig = getHostConfig();//创建容器并指定容器的名称CreateContainerCmd containerCmd = dockerClient.createContainerCmd(JudgeConstants.JAVA_ENV_IMAGE).withName(JudgeConstants.JAVA_CONTAINER_NAME);//配置容器参数CreateContainerResponse createContainerResponse = containerCmd.withHostConfig(hostConfig)//使用之前获取到的配置.withAttachStderr(true).withAttachStdout(true).withTty(true).exec();//记录容器idcontainerId = createContainerResponse.getId();//启动容器dockerClient.startContainerCmd(containerId).exec();
}
private HostConfig getHostConfig() {HostConfig hostConfig = new HostConfig();//设置挂载目录,指定用户代码路径,这是为了让容器可以访问用户代码,同时限制容器只能访问这个特定目录hostConfig.setBinds(new Bind(userCodeDir, new Volume(JudgeConstants.DOCKER_USER_CODE_DIR)));//限制docker容器使用资源//限制内存资源hostConfig.withMemory(memoryLimit);//限制最大内存hostConfig.withMemorySwap(memorySwapLimit);//限制内存最大交换次数hostConfig.withCpuCount(cpuLimit);//限制cpu可以使用的核心hostConfig.withNetworkMode("none"); //禁用网络hostConfig.withReadonlyRootfs(true); //禁止在root目录写文件return hostConfig;
}
docker容器池的创建其实和线程池的原理差不多,都是一种池化技术,首先我们在构造方法中指定该docker容器池的配置,包括容器客户端,代码沙箱镜像,挂载目录,最大内存限制,最大内存交换次数限制,使用的最大的cpu核心数,容器池中的最大容器数量,容器前缀名,归还与获取容器的阻塞队列,initDockerPool就是使用我们前面提到的创建容器的方法,为当前容器池中创建容器.getContainer方法是从docker容器池的阻塞队列中获取到docker容器,returnContainer是把docker容器归还到阻塞队列中.
/*** 实现容器池,避免因为创建容器而产生的开销*/
@Slf4j
public class DockerSandBoxPool {private DockerClient dockerClient;//容器客户端private String sandboxImage;//代码沙箱镜像private String volumeDir;//挂载目录,与宿主机中的目录进行关联private Long memoryLimit;//最大内存限制private Long memorySwapLimit;//最大内存交换次数限制private Long cpuLimit;//使用的最大的cpu核心数private int poolSize;//容器池中的最大容器数量private String containerNamePrefix;//容器前缀名private BlockingQueue<String> containerQueue;//归还与获取容器的阻塞队列private Map<String, String> containerNameMap;public DockerSandBoxPool(DockerClient dockerClient,String sandboxImage,String volumeDir, Long memoryLimit,Long memorySwapLimit, Long cpuLimit,int poolSize, String containerNamePrefix) {this.dockerClient = dockerClient;this.sandboxImage = sandboxImage;this.volumeDir = volumeDir;this.memoryLimit = memoryLimit;this.memorySwapLimit = memorySwapLimit;this.cpuLimit = cpuLimit;this.poolSize = poolSize;this.containerQueue = new ArrayBlockingQueue<>(poolSize);this.containerNamePrefix = containerNamePrefix;this.containerNameMap = new HashMap<>();}public void initDockerPool() {log.info("------ 创建容器开始 -----");for(int i = 0; i < poolSize; i++) {createContainer(containerNamePrefix + "-" + i);}log.info("------ 创建容器结束 -----");}public String getContainer() {try {return containerQueue.take();} catch (InterruptedException e) {throw new RuntimeException(e);}}public void returnContainer(String containerId) {containerQueue.add(containerId);}
13. xxl-job定时任务
13.1 历史竞赛与完赛的竞赛
在每天的凌晨一点,都需要对竞赛的列表进行刷新,我们需要先从数据库中查询到结束时间早于当前时间的竞赛和晚于当前时间的竞赛,由于c端用户获取到竞赛列表的时候是首先从Redis中拿到的,所以我们需要对缓存中的竞赛列表进行刷新,即refreshCache(unFinishList, CacheConstants.EXAM_UNFINISHED_LIST);和refreshCache(historyList, CacheConstants.EXAM_HISTORY_LIST);.
@XxlJob("examListOrganizeHandler")
public void examListOrganizeHandler() {log.info("*** examListOrganizeHandler ***");List<Exam> unFinishList = examMapper.selectList(new LambdaQueryWrapper<Exam>().select(Exam::getExamId, Exam::getTitle, Exam::getStartTime, Exam::getEndTime).gt(Exam::getEndTime, LocalDateTime.now()).eq(Exam::getStatus, Constants.TRUE).orderByDesc(Exam::getCreateTime));refreshCache(unFinishList, CacheConstants.EXAM_UNFINISHED_LIST);List<Exam> historyList = examMapper.selectList(new LambdaQueryWrapper<Exam>().select(Exam::getExamId, Exam::getTitle, Exam::getStartTime, Exam::getEndTime).le(Exam::getEndTime, LocalDateTime.now()).eq(Exam::getStatus, Constants.TRUE).orderByDesc(Exam::getCreateTime));refreshCache(historyList, CacheConstants.EXAM_HISTORY_LIST);log.info("*** examListOrganizeHandler 统计结束 ***");
}
13.2 竞赛结束之后发送站内信
还是在每天的固定时间,从数据库中查询当天结束的竞赛,针对参加这些竞赛的用户创建站内信,通知用户竞赛结束并公布排名.
@XxlJob("examResultHandler")
public void examResultHandler() {LocalDateTime now = LocalDateTime.now();LocalDateTime minusDateTime = now.minusDays(1);//从当前时间中减去一天List<Exam> examList = examMapper.selectList(new LambdaQueryWrapper<Exam>().select(Exam::getExamId, Exam::getTitle).eq(Exam::getStatus, Constants.TRUE).ge(Exam::getEndTime, minusDateTime)// 结束时间 >= minusDateTime(前一天).le(Exam::getEndTime, now));// 结束时间 <= now(当前时间)if (CollectionUtil.isEmpty(examList)) {return;}Set<Long> examIdSet = examList.stream().map(Exam::getExamId).collect(Collectors.toSet());List<UserScore> userScoreList = userSubmitMapper.selectUserScoreList(examIdSet);Map<Long, List<UserScore>> userScoreMap = userScoreList.stream().collect(Collectors.groupingBy(UserScore::getExamId));createMessage(examList, userScoreMap);
}
14. OpenFeign
用户在c端调用Submit接口提交代码的时候,由于判题服务和代码提交服务是在两个不同的服务当中,需要通过OpenFeign的方式来把friend服务构造好的JudgeSubmitDTO参数(其中包含用户提交的代码)提交到判题服务中,由代码沙箱进行代码运行之后,得到判题的结果.
@FeignClient(contextId = "RemoteJudgeService",value = Constant.JUDGE_SERVICE)
public interface RemoteJudgeService {@PostMapping("/judge/doJudgeJavaCode")R<UserQuestionResultVO> doJudgeJavaCode(@RequestBody JudgeSubmitDTO judgeSubmitDTO);
}
15. TransmittableThreadLocal
15.1 技术原理
见线程与网络专栏"线程池,定时器,ThreadLocal".需要注意的一点是,之所以在当前项目中不直接使用ThreadLocal,是因为,ThreadLocal在一些场景下会出现问题,比如在线程池进行线程复用的时候会出现上下文污染,上一个线程中的信息回被下一个线程读取到,在消息异步处理的时候可能会导致子线程无法拿到在父线程中设置的信息.
15.2 项目应用
由于我们在某些时候需要在程序中用到当前用户的信息,所以我们需要在ThreadLocal中设置当前用户的userId以及userKey,但是需要注意的是,我们不可以在网关的服务中对ThreadLocal的信息进行设置,因为网关属于一个单独的服务,与其他的服务属于不同的进程,在网关设置的信息无法在其他的服务拿到,所以我们需要在拦截器中对其进行设置.拦截器与网关不同,只要那个服务调用了拦截器,当前拦截器就属于这个服务.
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String token = getToken(request); //请求头中获取tokenif (StrUtil.isEmpty(token)) {return true;}Claims claims = tokenService.getClaims(token, secret);Long userId = tokenService.getUserId(claims);String userKey = tokenService.getUserKey(claims);ThreadLocalUtil.set(Constants.USER_ID, userId);ThreadLocalUtil.set(Constants.USER_KEY, userKey);tokenService.extendToken(claims);return true;
}
16. RabbitMQ异步通信
在提交用户代码的时候,我们除了使用OpenFeign,最优的方案还是使用RabbitMQ进行异步通信.
还是在提交功能和判题功能的交互中,可能同时会有很多用户提交代码,而且判题功能逻辑较为复杂,这时候我们就需要用到消息队列来对消息进行削峰处理和异步处理,保证消息准确从提交功能到达判题功能.
在提交功能中,我们把构造好的JudgeSubmitDTO提交到消息队列中.
@Override
public boolean rabbitSubmit(UserSubmitDTO submitDTO) {Integer programType = submitDTO.getProgramType();if (ProgramType.JAVA.getValue().equals(programType)) {//按照java逻辑处理JudgeSubmitDTO judgeSubmitDTO = assembleJudgeSubmitDTO(submitDTO);judgeProducer.produceMsg(judgeSubmitDTO);return true;}throw new ServiceException(ResultCode.FAILED_NOT_SUPPORT_PROGRAM);
}
在判题功能中,我们设置一个Listener对消息进行监听,确保判题服务可以拿到JudgeSubmitDTO.
@Slf4j
@Component
public class JudgeConsumer {@Autowiredprivate IJudgeService judgeService;@RabbitListener(queues = RabbitMQConstants.OJ_WORK_QUEUE)public void consume(JudgeSubmitDTO judgeSubmitDTO) {log.info("收到消息为: {}", judgeSubmitDTO);judgeService.doJudgeJavaCode(judgeSubmitDTO);}
}
但是这里有一个问题,由于我们是通过消息队列来把代码提交给另一个服务的,所以我们无法从判题服务中把判题的结果再次返回到friend服务中,所以我们只能在数据库中再维护一张表tb_user_submit用来保存判题的结果,在判题服务中,我们把判题的结果保存到表中,在friend服务中,从数据库中获取到判题的结果即可.
private void saveUserSubmit(JudgeSubmitDTO judgeSubmitDTO, UserQuestionResultVO userQuestionResultVO) {UserSubmit userSubmit = new UserSubmit();BeanUtil.copyProperties(userQuestionResultVO, userSubmit);userSubmit.setUserId(judgeSubmitDTO.getUserId());userSubmit.setQuestionId(judgeSubmitDTO.getQuestionId());userSubmit.setExamId(judgeSubmitDTO.getExamId());userSubmit.setProgramType(judgeSubmitDTO.getProgramType());userSubmit.setUserCode(judgeSubmitDTO.getUserCode());userSubmit.setCaseJudgeRes(JSON.toJSONString(userQuestionResultVO.getUserExeResultList()));userSubmit.setCreateBy(judgeSubmitDTO.getUserId());userSubmitMapper.delete(new LambdaQueryWrapper<UserSubmit>().eq(UserSubmit::getUserId, judgeSubmitDTO.getUserId()).eq(UserSubmit::getQuestionId, judgeSubmitDTO.getQuestionId()).isNull(judgeSubmitDTO.getExamId() == null, UserSubmit::getExamId).eq(judgeSubmitDTO.getExamId() != null, UserSubmit::getExamId, judgeSubmitDTO.getExamId()));userSubmitMapper.insert(userSubmit);
}
@Override
public UserQuestionResultVO exeResult(Long examId, Long questionId, String currentTime) {Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);UserSubmit userSubmit = userSubmitMapper.selectCurrentUserSubmit(userId, examId, questionId, currentTime);UserQuestionResultVO resultVO = new UserQuestionResultVO();if (userSubmit == null) {resultVO.setPass(QuestionResType.IN_JUDGE.getValue());} else {resultVO.setPass(userSubmit.getPass());resultVO.setExeMessage(userSubmit.getExeMessage());if (StrUtil.isNotEmpty(userSubmit.getCaseJudgeRes())) {resultVO.setUserExeResultList(JSON.parseArray(userSubmit.getCaseJudgeRes(), UserExeResult.class));}}return resultVO;
}
17. 数据库表设计
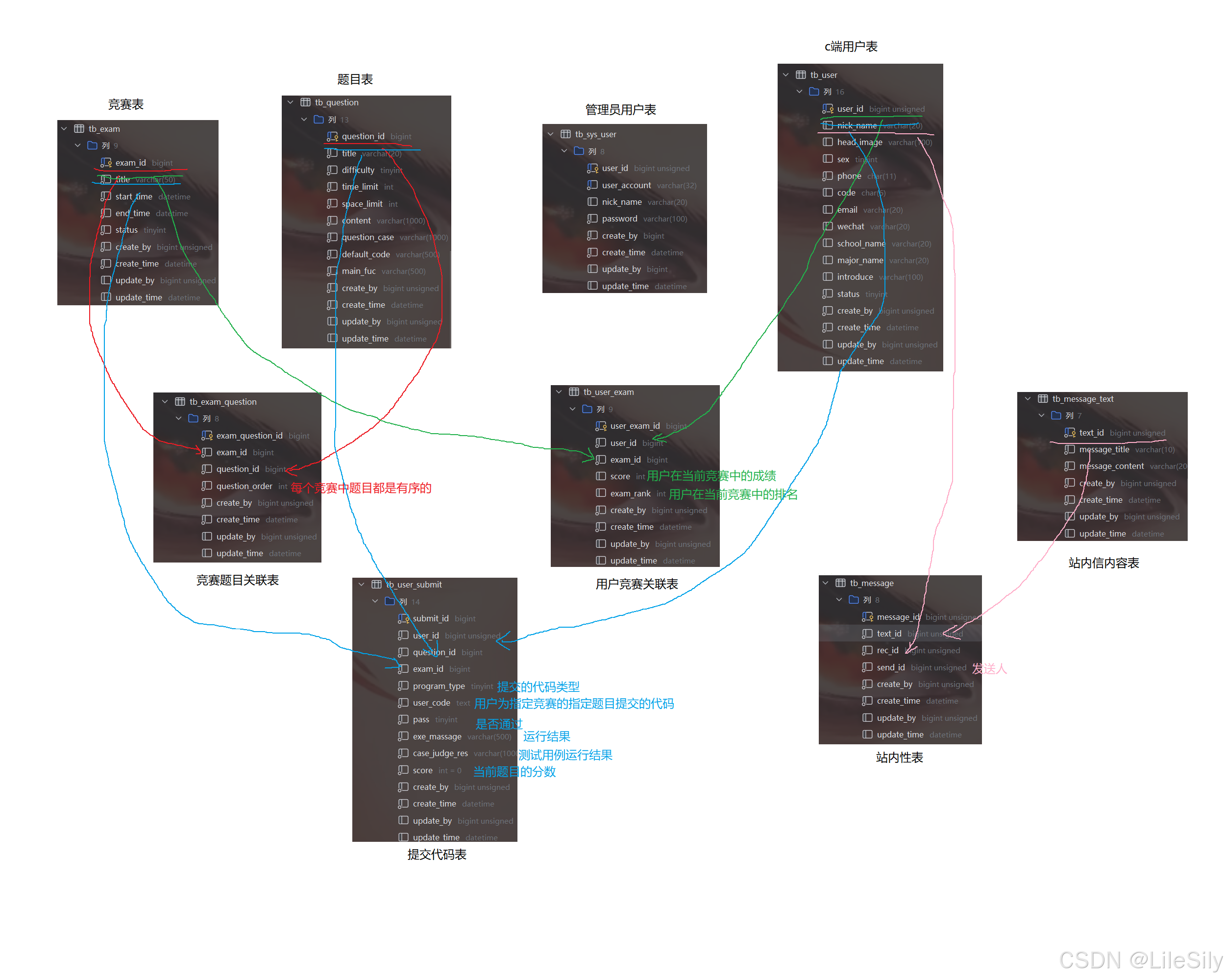
我们在涉及站内信的数据库表设计的时候,我们设计的是分开两张表的方式,之所以我们需要这样设计,是因为我们向不同的用户发送的消息可能是相同的,如果全部存在一张表中,会浪费很大的空间,所以我们选择把消息内容和发送人接收人内容分开存储.
18. Gateway网关
网关主要是对用户的权限做一些校验,我们采用了自定义过滤器的方式,其中自定义过滤器类中实现了GlobalFilter接口,证明是全局过滤器,会应用到所有路由请求上,实现Order用于指定过滤器的优先级.想要从网络请求中获取到相关的请求信息,首先我们需要从ServerWebExchange获取到网络请求.
ServerHttpRequest request = exchange.getRequest();
当然我们有一些接口是不需要经过网关权限验证的,比如用户登录功能,用户注册功能,游客可浏览页面,我们可以配置一个白名单,对白名单中的值不进行权限校验.继续执行下一个过滤器.由于网关中只有这一个自定义过滤器,所以相当于直接进入了后端服务中.
其中,白名单类IgnoreWhiteProperties中,我们使用@RefreshScope热更新,当Nacos中的配置更新之后,不需要重新读取配置,会立即进行配置更新,使用@ConfigurationProperties注解从配置文件中直接读取配置相关信息,对类中的属性进行注入.无需使用@Value注入.其中private List<String> whites = new ArrayList<>();中存放的就是从Nacos中读取出来的白名单路由信息.
@Autowired
private IgnoreWhiteProperties ignoreWhite;
// 跳过不需要验证的路径(白名单中的路径,比如登录功能)
if (matches(url, ignoreWhite.getWhites())) {return chain.filter(exchange);
}@Configuration
@RefreshScope //配置热更新,无需刷新,配置更新之后自动更新
@ConfigurationProperties(prefix = "security.ignore")//在配置文件中找到security.ignore,为响应属性注入值
public class IgnoreWhiteProperties {/*** 放行白名单配置,网关不校验此处的白名单,比如登录接口*/private List<String> whites = new ArrayList<>();public List<String> getWhites() {return whites;}public void setWhites(List<String> whites) {this.whites = whites;}
}
我们在if条件中使用match函数对请求的路径进行校验,ignoreWhite.getWhites()是我们从Nacos中获取到的白名单配置,如果url中符合白名单中的通配符表达式,那么就返回一个true,证明这个URL无需进行校验.其中AntPathMatcher.match方法就是专门用来做通配符校验的.
private boolean matches(String url, List<String> patternList) {if (StrUtil.isEmpty(url) || patternList.isEmpty()) {return false;}for (String pattern : patternList) {if (isMatch(pattern, url)) {return true;}}return false;
}
private boolean isMatch(String pattern, String url) {AntPathMatcher matcher = new AntPathMatcher();return matcher.match(pattern, url);
}
由于我们的用户token是保存在header中的,所以我们需要从header中获取到用户的token信息.由于Header中是一些key-value形式的信息,其中HttpConstants.AUTHENTICATION是我们在header中保存用户token的key,拿着这个key,就可以获取到value,即用户令牌.*由于OAuth 2.0和JWT规范,Authorization头的Token通常以Bearer开头,所以如果字符串中有Bearer前缀,我们需要把这个前缀去掉,获取到纯净的token信息.
//从http请求头中获取token
String token = getToken(request);
if (StrUtil.isEmpty(token)) {return unauthorizedResponse(exchange, "令牌不能为空");
}
/*** 从请求头中获取请求token*/
private String getToken(ServerHttpRequest request) {String token =request.getHeaders().getFirst(HttpConstants.AUTHENTICATION);// 如果前端设置了令牌前缀,则裁剪掉前缀if (StrUtil.isNotEmpty(token) &&token.startsWith(HttpConstants.PREFIX)) {token = token.replaceFirst(HttpConstants.PREFIX, StrUtil.EMPTY);}return token;
}
之后我们就可以从获取到的token信息中解析用户详细信息.其中我们需要传入我们在Nacos中配置好的签名密钥.
在解析JWT的方法中.我们传入用户令牌和签名密钥,我们就可以拿到Body信息.即用户信息.如果没有解析出用户的详细信息,即if (claims == null),我们就判断用户传入的令牌不正确或者已经过期.
判断令牌不正确之后,我们就需要给前端返回一个错误信息,其中webFluxResponseWriter方法封装一个JSON类型的响应数据,其中包括设置http请求的状态码,设置header,设置返回结果,并通过response.writeWith封装进入Mono(异步的、零或一个结果的流式数据)异步返回.
Claims claims;
try {claims = JWTUtils.parseToken(token, secret); //获取令牌中信息 解析payload中信息if (claims == null) {return unauthorizedResponse(exchange, "令牌已过期或验证不正确!");}
} catch (Exception e) {return unauthorizedResponse(exchange, "令牌已过期或验证不正确!");
}
public static Claims parseToken(String token, String secret) {return Jwts.parser().setSigningKey(secret).parseClaimsJws(token).getBody();
}
private Mono<Void> unauthorizedResponse(ServerWebExchange exchange, Stringmsg) {log.error("[鉴权异常处理]请求路径:{}", exchange.getRequest().getPath());return webFluxResponseWriter(exchange.getResponse(), msg,ResultCode.FAILED_UNAUTHORIZED.getCode());
}
//拼装webflux模型响应
private Mono<Void> webFluxResponseWriter(ServerHttpResponse response,String msg, int code) {response.setStatusCode(HttpStatus.OK);//设置http响应的状态码response.getHeaders().add(HttpHeaders.CONTENT_TYPE,MediaType.APPLICATION_JSON_VALUE);//设置headerR<?> result = R.fail(code, msg);DataBuffer dataBuffer =response.bufferFactory().wrap(JSON.toJSONString(result).getBytes());return response.writeWith(Mono.just(dataBuffer));//异步返回result
}
之后我们就可以从解析出的用户信息Claims中获取到UserKey,之后从redis查询当前的userKey是否存在,如果不存在,则证明登录状态已经过期.和上面一样,校验不同过之后,我们就构造一个http响应数据(JSON响应数据),使用Mono进行异步返回.
String userKey = JWTUtils.getUserKey(claims); //获取jwt中的key
boolean isLogin = redisService.hasKey(getTokenKey(userKey));//判断Redis中是否还存在当前用户的UserKey
if (!isLogin) {return unauthorizedResponse(exchange, "登录状态已过期");
}
之后需要校验Claim数据的完整性,确保userId也存在,方便我们进行之后的操作.
String userId = JWTUtils.getUserId(claims); //判断jwt中的信息是否完整
if (StrUtil.isEmpty(userId)) {return unauthorizedResponse(exchange, "令牌验证失败");
}
如果进行了上面的校验之后,均没有返回错误信息,则证明redis中的token信息是正确的,我们就根据UserKey把用户信息从redis中拿出来(即拿出UserKey的value信息),之后我们需要对当前用户的身份进行校验,看看当前用户是管理员还是普通用户,如果身份对不上,还是和上面一样,通过Mono异步方式返回错误信息.
具体的校验方式,是首先拿到我们之前的从ServerWebExchange获取到的URL信息,看看URL中包含/system还是/friend,如果是/system,则只有管理员才可以访问,如果是/friend,只有普通用户才可以访问,我们可以从redis中获取到的用户信息中获取到用户的身份信息,以此来作比较.
LoginUser user = redisService.getCacheObject(getTokenKey(userKey),LoginUser.class);//把该用户的身份信息从Redis中拿出来
if (url.contains(HttpConstants.SYSTEM_URL_PREFIX) &&!UserIdentity.ADMIN.getValue().equals(user.getIdentity())) {//如果获取URL中的前缀发现是system前缀,但是当前用户的身份不是管理员return unauthorizedResponse(exchange, "令牌验证失败");
}
if (url.contains(HttpConstants.FRIEND_URL_PREFIX) &&!UserIdentity.ORDINARY.getValue().equals(user.getIdentity())) {//从URL中获取前缀发现是friend,但是当前用户不是普通用户return unauthorizedResponse(exchange, "令牌验证失败");
}
最后进行返回,把当前请求交给下一个过滤器.
return chain.filter(exchange);
相关文章:
)
[项目总结] 在线OJ刷题系统项目技术应用(下)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

链表算法中常用操作和技巧
目 1.常用技巧 1.1.画图 1.2.添加虚拟头节点 1.3.大胆引入中间变量 1.4.快慢双指针 1.4.1判断链表是否有环 1.4.2找链表中环的入口 2.常用操作 2.1. 创建一个新节点 2.2.尾插 2.3.头插 1.常用技巧 1.1.画图 画图可以让一些抽象的文字语言更加形象生动 画图&#…...

MySQL基础 [二] - 数据库基础
目录 库的增删查改 查看数据库 创建数据库 删除数据库 修改数据库 认识系统编码(字符集和校验规则) 查看系统默认字符集以及校验规则 查看数据库支持的字符集和字符集校验规则 验证不同校验码编码的影响 校验规则对数据库的影响 数据库的备份…...

【Linux篇】基础IO - 文件描述符的引入
📌 个人主页: 孙同学_ 🔧 文章专栏:Liunx 💡 关注我,分享经验,助你少走弯路! 文章目录 一. 理解文件1.1 侠义理解1.2 广义理解1.3 文件操作的归类认知1.4 系统角度 二. 回顾C语言文件…...

13.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--微服务基础工具与技术--Refit
在微服务架构中,不同服务之间经常需要相互调用以完成复杂业务流程,而 Refit 能让这种“跨服务调用”变得简洁又可靠。开发者只需将对外暴露的 REST 接口抽象成 C# 接口,并通过共享库或内部 NuGet 包在各服务中引用,这种契约优先的…...

C++ 并发性能优化实战:提升多线程应用的效率与稳定性
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,获得2024年博客之星荣誉证书,高级开发工程师,数学专业,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开发技术,…...

前端性能优化的全方位方案【待进一步结合项目】
以下是前端性能优化的全方位方案,结合代码配置和最佳实践,涵盖从代码编写到部署的全流程优化: 一、代码层面优化 1. HTML结构优化 <!-- 语义化标签减少嵌套 --> <header><nav>...</nav> </header> <main&…...
 并行计算 CS149 Lecture3 (现代多核处理器2 + ISPC编程抽象))
(undone) 并行计算 CS149 Lecture3 (现代多核处理器2 + ISPC编程抽象)
url: https://www.bilibili.com/video/BV1du17YfE5G?spm_id_from333.788.videopod.sections&vd_source7a1a0bc74158c6993c7355c5490fc600&p3 如上堂课,超线程技术通过储存不同线程的 execution context,能够在一个线程等待 IO 的时候低成本切换…...

DiffAD:自动驾驶的统一扩散建模方法
25年3月来自新加坡公司 Carion 和北航的论文“DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving”。 端到端自动驾驶 (E2E-AD) 已迅速成为实现完全自动驾驶的一种有前途的方法。然而,现有的 E2E-AD 系统通常采用传统的多任务框架,…...

QScrollArea 内部滚动条 QSS 样式失效问题及解决方案
在使用 Qt 进行 UI 开发时,我们经常希望通过 QSS(Qt Style Sheets)自定义控件的外观,比如为 QScrollArea 的内部滚动条设置特定的样式。然而,有开发者遇到了这样的问题:在 UI 设计器中预览 QSS 显示效果正常,但程序运行时却显示为系统默认样式。经过反复测试和调试,最终…...

换脸视频FaceFusion3.1.0-附整合包
2025版最强换脸软件FaceFusion来了(附整合包)超变态的AI换脸教程 2025版最强换脸软件FaceFusion来了(附整合包)超变态的AI换脸教程 整合包地址: 「Facefusion_V3.1.0」 链接:https://pan.quark.cn/s/f71601…...

Qt 入门 1 之第一个程序 Hello World
Qt 入门1之第一个程序 Hello World 直接上操作步骤从头开始认识,打开Qt Creator,创建一个新项目,并依次执行以下操作 在Qt Creator中,一个Kits 表示一个完整的构建环境,包括编译器、Qt版本、调试器等。在上图中可以直…...

无锁队列简介与实现示例
1. 简介 无锁队列是一种数据结构,旨在在多线程环境中实现高效的并发访问,而无需使用传统的锁机制(如互斥锁)。无锁队列通过使用原子操作(如CAS,Compare-And-Swap)来确保线程安全,从…...

SpringMVC与SpringCloud的区别
SpringMVC与SpringCloud的核心区别 功能定位 • SpringMVC: 基于Spring框架的Web层开发模块,采用MVC(Model-View-Controller)模式,专注于处理HTTP请求、路由分发(如DispatcherServlet)和视图…...
)
STM32F103C8T6单片机开发:简单说说单片机的外部GPIO中断(标准库)
目录 前言 如何使用STM32F1系列的标准库完成外部中断的抽象 初始化我们的GPIO为输入的一个模式 初识GPIO复用,开启GPIO的复用功能时钟 GPIO_EXTILineConfig和EXTI_Init配置外部中断参数 插入一个小知识——如何正确的配置结构体? 初始化中断&#…...

Python urllib3 全面指南:从基础到实战应用
欢迎来到涛涛的频道,今天用到了urllib3,和大家分享下。 1、介绍 urllib3 urllib3 是 Python 中一个功能强大且用户友好的 HTTP 客户端库,它提供了许多标准库 urllib 所不具备的高级特性。作为 Python 生态中最受欢迎的 HTTP 库之一…...

25.5 GLM-4优化RAG实战:0.1%参数实现准确率飙升30%,成本直降90%!
使用 GLM-4 优化 RAG 程序:基于标注数据的 Adapter 训练实战 关键词:GLM-4 优化, RAG 增强, 数据标注, Adapter 训练, 检索增强生成 1. RAG 系统的核心挑战与优化方向 传统 RAG(Retrieval-Augmented Generation)系统常面临以下瓶颈: graph LR A[用户提问] --> B[检…...
)
OrangePi入门教程(待更新)
快速上手指南 https://www.hiascend.com/developer/techArticles/20240301-1?envFlag1 教学课程(含开发板配置和推理应用开发) https://www.hiascend.com/developer/devboard 开发推理应用 https://www.hiascend.com/developer/techArticles/20240326-1?envFlag1...

基于SpringBoot+Vue实现的二手交易市场平台功能一
一、前言介绍: 1.1 项目摘要 随着社会的发展和人们生活水平的提高,消费者购买能力的提升导致产生了大量的闲置物品,这些闲置物品具有一定的经济价值。特别是在高校环境中,学生群体作为一个具有一定消费水平的群体,每…...

TC3xx芯片的UCB介绍
文章目录 前言一、UCB的定义及其功能简介二、UCB_BMHDx_ORIG and UCB_BMHDx_COPY (x 0 - 3)2.1 BMHD(Boot Mode Head) 三、UCB_SSW四、UCB_PFLASH_ORIG and UCB_PFLASH_COPY4.1 Password4.2 UCB Confirmation 前言 缩写全称UCBUser Configuration BlockBMHDBoot Mode Headers…...

Airflow量化入门系列:第四章 A股数据处理与存储优化
Airflow量化入门系列:第四章 A股数据处理与存储优化 本教程系统性地讲解了 Apache Airflow 在 A 股量化交易中的应用,覆盖从基础安装到高级功能的完整知识体系。通过八章内容,读者将掌握 Airflow 的核心概念、任务调度、数据处理、技术指标计…...
)
《海空重力测量理论方法及应用》之一重力仪系统组成及工作原理(下)
2、三轴稳定平台型 稳定平台的作用是隔离测量载体角运动对重力观测量的影响,确保重力传感器的敏感轴方向始终与重向保持一致。 当前主流的海空重力仪使用的稳定平台方案主要有4种: ①双轴阻尼陀螺平台: ②)双轴惯导加捷联方位平台: ③三轴惯导平台; ④捷联惯导…...

C++模板递归结构详解和使用
示例代码 template<typename _SourceIterator, typename _DestT> struct convert_pointer {typedef typename convert_pointer<typename _SourceIterator::pointer, _DestT>::type type; };1. 模板参数 _SourceIterator 是输入的类型,通常表示迭代器类…...
PMSM驱动控制学习---无感控制之滑膜观测器)
(八)PMSM驱动控制学习---无感控制之滑膜观测器
在FOC矢量控制中,我们需要实时得到转子的转速和位置 ,但在考虑到成本和使用场合的情况下,往往使用无感控制,因为无位置传感器克服了传统机械式传感器的很多缺点和不足。比如,机械式传感器对环境要求比较严格࿰…...

蓝桥杯真题-分糖果-题解
链接:https://www.lanqiao.cn/problems/4124/learning/ 题目 复述:两种糖果,分别有9和16,分给7人,每个人得到的最少2,最多5,必需全部分完,几种分法? 复习-深度优先搜索 …...
:基于MaskNet和WideDeep的商品推荐CTR模型实现)
推荐系统(二十二):基于MaskNet和WideDeep的商品推荐CTR模型实现
在上一篇文章《推荐系统(二十一):基于MaskNet的商品推荐CTR模型实现》中,笔者基于 MaskNet 构建了一个简单的模型。笔者所经历的工业级实践证明,将 MaskNet 和 Wide&Deep 结合应用,可以取得不错的效果&…...

辅助查询是根据查询到的文档片段再去生成新的查询问题
💡 辅助查询是怎么来的? 它是基于你当前查询(query)检索到的某个文档片段(chunk_result),再去“反推”出新的相关问题(utility queries),这些问题的作用是&a…...

Spring Cloud 框架为什么能处理高并发
Spring Cloud框架能够有效处理高并发场景,核心在于其微服务架构设计及多组件的协同作用,具体机制如下: 一、分布式架构设计支撑高扩展性 服务拆分与集群部署 Spring Cloud通过微服务拆分将单体系统解耦为独立子服务,每个服务可独…...
)
Pseduo LiDAR(CVPR2019)
文章目录 AbstractIntroductionRelated WorkLiDAR-based 3D object detectionStereo- and monocular-based depth estimationImage-based 3D object detection MethodDepth estimationPseudo-LiDAR generationLiDAR vs. pseudo-LiDAR3D object detectionData representation ma…...
introduction to RL)
强化学习课程:stanford_cs234 学习笔记(3)introduction to RL
文章目录 前言7 markov 实践7.1 markov 过程再叙7.2 markov 奖励过程 MRP(markov reward process)7.3 markov 价值函数与贝尔曼方程7.4 markov 决策过程MDP(markov decision process)的 状态价值函数7.4.1 状态价值函数7.4.2 状态…...

前端精度计算:Decimal.js 基本用法与详解
一、Decimal.js 简介 decimal.js 是一个用于任意精度算术运算的 JavaScript 库,它可以完美解决浮点数计算中的精度丢失问题。 官方API文档:Decimal.js 特性: 任意精度计算:支持大数、小数的高精度运算。 链式调用:…...

来聊聊C++中的vector
一.vector简介 vector是什么 C 中的 vector 是一种序列容器,它允许你在运行时动态地插入和删除元素。 vector 是基于数组的数据结构,但它可以自动管理内存,这意味着你不需要手动分配和释放内存。 与 C 数组相比,vector 具有更多的…...
和InfoNCE(SimCLR)损失函数+案例(附SimSiam分析))
对比学习中的NCE(Noise-Contrastive Estimation)和InfoNCE(SimCLR)损失函数+案例(附SimSiam分析)
在对比学习(Contrastive Learning)中,NCE(Noise-Contrastive Estimation)和InfoNCE是两种常见的目标函数,它们都用于通过区分正样本和负样本来学习高质量的表示。 1. NCE(Noise-Contrastive Est…...

基于FAN网络的图像识别系统设计与实现
基于FAN网络的图像识别系统设计与实现 一、系统概述 本系统旨在利用FAN(Fourier Analysis Networks)网络架构实现高效的图像识别功能,并通过Python语言设计一个直观的用户界面,方便用户操作与使用。FAN网络在处理周期性特征方面具有独特优势,有望提升图像识别在复杂场景…...

【瑞萨 RA-Eco-RA2E1-48PIN-V1.0 开发板测评】PWM
【瑞萨 RA-Eco-RA2E1-48PIN-V1.0 开发板测评】PWM 本文介绍了瑞萨 RA2E1 开发板使用内置时钟和定时器实现 PWM 输出以及呼吸灯的项目设计。 项目介绍 介绍了 PWM 和 RA2E1 的 PWM 资源。 PWM 脉冲宽度调制(Pulse Width Modulation, PWM)是一种对模拟…...

NDK开发:开发环境
NDK开发环境 一、NDK简介 1.1 什么是NDK NDK(Native Development Kit)是Android提供的一套工具集,允许开发者在Android应用中使用C/C++代码。它包含了: 交叉编译器构建工具调试器系统头文件和库示例代码和文档1.2 NDK的优势 性能优化:直接使用底层代码,提高性能代码保…...
工厂模式)
设计模式简述(三)工厂模式
工厂模式 描述简单工厂(静态工厂)工厂方法模式 抽象工厂增加工厂管理类使用 描述 工厂模式用以封装复杂的实例初始化过程,供外部统一调用 简单工厂(静态工厂) 如果对象创建逻辑简单且一致,可以使用简单工…...

通过Postman和OAuth 2.0连接Dynamics 365 Online的详细步骤
🌟 引言 在企业应用开发中,Dynamics 365 Online作为微软的核心CRM平台,提供了强大的Web API接口。本文将教你如何通过Postman和OAuth 2.0认证实现与Dynamics 365的安全连接,轻松调用数据接口。 📝 准备工作 工具安装…...

LlamaIndex实现RAG增强:上下文增强检索/重排序
面向文档检索的上下文增强技术 文章目录 面向文档检索的上下文增强技术概述技术背景核心组件方法详解文档预处理向量存储创建上下文增强检索检索对比技术优势结论导入库和环境变量读取文档创建向量存储和检索器数据摄取管道使用句子分割器的摄取管道使用句子窗口的摄取管道查询…...

AI比人脑更强,因为被植入思维模型【43】蝴蝶效应思维模型
giszz的理解:蝴蝶效应我们都熟知,就是说一个微小的变化,能带动整个系统甚至系统的空间和时间的远端,产生巨大的链式反应。我学习后的启迪,简单的说,就是不要忽视任何微小的问题,更多时候&#x…...
:DSP系统的媒体与PDB投放设置探秘)
程序化广告行业(62/89):DSP系统的媒体与PDB投放设置探秘
程序化广告行业(62/89):DSP系统的媒体与PDB投放设置探秘 大家好!在之前的学习中,我们对程序化广告的DSP系统有了一定了解。今天还是带着和大家共同进步的想法,深入探索DSP系统中媒体设置以及PDB投放设置的…...
)
Java项目之基于ssm的怀旧唱片售卖系统(源码+文档)
项目简介 怀旧唱片售卖系统实现了以下功能: 用户信息管理: 用户信息新增:添加新用户的信息。 用户信息修改:对现有用户信息进行修改。 商品信息管理: 商品信息添加:增加新的商品(唱片&#x…...
:DSP系统活动设置深度剖析)
程序化广告行业(61/89):DSP系统活动设置深度剖析
程序化广告行业(61/89):DSP系统活动设置深度剖析 大家好!在程序化广告的学习道路上,我们已经探索了不少重要内容。今天依旧本着和大家一起学习进步的想法,深入解析DSP系统中活动设置的相关知识。这部分内容…...

Altshuller矛盾矩阵查询:基于python和streamlit
基于python和streamlit实现的Altshuller矛盾矩阵查询 import streamlit as st import json# 加载数据 st.cache_resource def load_data():with open(parameter.json, encodingutf-8) as f:parameters json.load(f)with open(way.json, encodingutf-8) as f:contradictions …...

FreeRTOS的空闲任务
在 FreeRTOS 中,空闲任务(Idle Task) 是操作系统自动创建的一个特殊任务,其作用和管理方式如下: 1. 空闲任务创建 FreeRTOS 内核自动创建:当调用 vTaskStartScheduler() 启动调度器时,内核会自…...

【代码模板】如何用FILE操作符打开文件?fopen、fclose
#include "stdio.h" #include "unistd.h"int main(int argc, char *argv[]) {FILE *fp fopen("1.log", "wb");if (!fp) {perror("Failed open 1.log");return -1;}fclose(fp); }关于权限部分参考兄弟篇【代码模板】C语言中…...

[特殊字符] Pandas 常用操作对比:Python 运算符 vs Pandas 函数
在 Pandas 中,许多操作可以直接使用 Python 的比较运算符(如 、!、>、< 等),而不需要调用 Pandas 的专门函数(如 eq()、ne()、gt() 等)。这些运算符在 Pandas 中已经被重载,代码更简洁。以…...

I.MX6ULL开发板与linux互传文件的方法--NFS,SCP,mount
1、内存卡或者U盘 方法比较简单,首先在linux系统中找到u盘对应的文件夹,随后使用cp指令将文件拷贝进u盘。 随后将u盘插入开发板中,找到u盘对应的设备文件。一般u盘对应的设备文件在/dev下,以sda开头,可以使用命令列出所…...

图解AUTOSAR_SWS_FlashEEPROMEmulation
AUTOSAR Flash EEPROM Emulation (FEE) 详解 基于AUTOSAR规范的Flash EEPROM Emulation模块分析 目录 1. 概述2. 架构设计 2.1 模块位置与接口2.2 内部状态管理2.3 配置结构3. API接口 3.1 接口功能分类3.2 错误管理4. 操作流程 4.1 写入操作序列5. 总结1. 概述 Flash EEPROM …...
)
Unity:Simple Follow Camera(简单相机跟随)
为什么需要Simple Follow Camera? 在游戏开发中,相机(Camera)是玩家的“眼睛”。它的作用是决定玩家看到游戏世界的哪一部分。很多游戏需要相机自动跟随玩家角色,让玩家始终可以看到角色及其周围的环境,而…...