Pseduo LiDAR(CVPR2019)

文章目录
- Abstract
- Introduction
- Related Work
- LiDAR-based 3D object detection
- Stereo- and monocular-based depth estimation
- Image-based 3D object detection
- Method
- Depth estimation
- Pseudo-LiDAR generation
- LiDAR vs. pseudo-LiDAR
- 3D object detection
- Data representation matters
- Discussion and Conclusion
- Future work
paper
Abstract
三维目标检测是自动驾驶中的一项重要任务。如果3D输入数据是从精确但昂贵的激光雷达技术获得的,那么最新的技术具有高精度的检测率。到目前为止,基于更便宜的单眼或立体图像数据的方法导致精度大大降低——这一差距通常归因于基于图像的深度估计不佳。然而,在本文中,我们认为这不是数据的质量,而是它的表示,占大部分的差异。考虑到卷积神经网络的内部工作原理,我们建议将基于图像的深度图转换为伪激光雷达表示-本质上模仿激光雷达信号。利用这种表示,我们可以应用不同的现有的基于激光雷达的检测算法。在流行的KITTI基准测试中,我们的方法在基于图像的性能方面取得了令人印象深刻的改进——将30米范围内物体的检测精度从以前的22%提高到前所未有的74%。在提交时,我们的算法在基于立体图像的方法的KITTI 3D物体检测排行榜上排名最高。
Introduction
可靠和鲁棒的三维目标检测是自动驾驶的基本要求之一。毕竟,为了避免与行人、骑自行车的人和汽车发生碰撞,车辆必须能够在第一时间检测到它们。现有的算法很大程度上依赖于激光雷达(光探测和测距),它提供了周围环境的精确3D点云。虽然高度精确,但出于多种原因,激光雷达的替代品是可取的。首先,激光雷达价格昂贵,这给自动驾驶硬件带来了高昂的成本。其次,过度依赖单一传感器是一种固有的安全风险,如果有第二个传感器,在发生意外时可以依靠,这将是有利的。一个自然的候选是来自立体或单目相机的图像。光学相机价格非常便宜(比Li- DAR便宜几个数量级),以高帧速率运行,并提供密集的深度图,而不是激光雷达信号固有的64或128个稀疏旋转激光束。
最近的一些出版物探讨了使用单眼和立体深度(视差)估计[13,19,32]用于3D目标检测[5,6,22,30]。然而,到目前为止,主要的成功主要是在补充激光雷达方法。例如,KITTI基准上领先的算法之一[17][11,12]使用传感器融合将汽车的3D平均精度(AP)从激光雷达的66%提高到激光雷达和单目图像的73%。相比之下,在仅使用图像的算法中,最先进的算法仅实现了10%的AP[30]。
一个直观和流行的解释,这种较差的性能是基于图像的深度估计精度差。与激光雷达相比,立体深度估计的误差随深度呈二次增长。然而,激光雷达和最先进的立体深度估计器[3]生成的3D点云的视觉比较显示,两种数据模式之间的高质量匹配(参见图1)-即使对于遥远的物体也是如此。

伪激光雷达信号的视觉深度估计。左上:一幅KITTI街景,用激光雷达(红色)和伪激光雷达(绿色)在汽车周围叠加了边界框。左下:估计的视差图。右:伪激光雷达(蓝色)vs。LiDAR(黄色)-伪LiDAR点与LiDAR点对齐得非常好。以彩色观看效果最佳(放大查看细节)。
在本文中,我们提供了一种具有重要性能影响的替代解释。我们认为,立体和激光雷达之间性能差距的主要原因不是深度精度的差异,而是基于convnet的三维目标检测系统在立体上运行时对3D信息表示的糟糕选择。具体来说,激光雷达信号通常表示为3D点云[23]或从自上而下的“鸟瞰”视角[33],并进行相应的处理。在这两种情况下,对象的形状和大小随深度而变化。相比之下,基于图像的深度对每个像素进行密集估计,通常表示为额外的图像通道[6,22,30],使远处的物体更小,更难检测。更糟糕的是,这种表示中的像素邻域将来自3D空间中遥远区域的点聚集在一起。这使得依赖于这些通道上的2D卷积的卷积网络很难在3D中推理和精确定位物体。
为了评估我们的主张,我们介绍了一种基于立体的3D物体检测的两步方法。我们首先将估计的深度图从立体或单目图像转换为3d点云,我们称之为伪激光雷达,因为它模拟了激光雷达信号。然后,我们利用现有的基于激光雷达的3D目标检测管道[16,23],我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,我们获得了基于图像的三维目标检测算法精度的前所未有的提高。具体来说,在“中等难度”汽车实例(官方排行榜中使用的指标)的IoU为0.7的KITTI基准上,我们在验证集上实现了45.3%的3D AP:比之前最先进的基于图像的方法提高了近350%。此外,我们将基于立体和基于激光雷达的系统之间的差距缩小了一半。
我们评估了立体深度估计和三维目标检测算法的多种组合,并得出了非常一致的结果。这表明我们观察到的增益是由于伪激光雷达表示,并且较少依赖于3D目标检测架构或深度估计技术的创新。总之,这篇论文的贡献是双重的。首先,我们的经验表明,基于立体和基于激光雷达的3D物体检测之间性能差距的主要原因不是估计深度的质量,而是其表示。其次,我们提出了伪激光雷达作为3D目标检测估计深度的新推荐表示,并表明它导致了最先进的基于立体的3D目标检测,有效地将现有技术提高了两倍。我们的研究结果表明,在自动驾驶汽车中使用立体摄像头是可能的,这可能会大幅降低成本,并/或提高安全性。
Related Work
LiDAR-based 3D object detection
我们的工作受到3D视觉和基于激光雷达的3D物体检测的最新进展的启发。许多最新的技术使用了这样一个事实,即激光雷达自然地表示为3D点云。例如,截锥体PointNet[23]对来自2D目标检测网络的每个截锥体提议应用PointNet[24]。MV3D[7]将激光雷达点投射到鸟瞰图(BEV)和正面视图中,以获得多视图特征。Vox- elNet[34]将三维点编码为体素,并通过三维卷积提取特征。UberATG-ContFuse[17]是KITTI基准[12]上的领先算法之一,它通过形成连续卷积[27]来融合视觉和BEV激光雷达特征。所有这些算法都以给定精确的三维点坐标为前提。因此,主要的挑战是在3D中预测点标签或绘制边界框来定位对象。
Stereo- and monocular-based depth estimation
基于图像的三维目标检测方法的关键是一种可靠的深度估计方法来取代激光雷达。这些可以通过单目视觉[10,13]或立体视觉[3,19]获得。自早期的单目深度估计工作以来,这些系统的精度急剧提高[8,15,26]。最近的算法,如DORN [10]com,将多尺度特征与有序回归相结合,以非常低的误差预测像素深度。对于立体视觉,PSMNet[3]应用Siamese网络进行视差估计,然后使用3D卷积进行细化,导致离群率低于2%。最近的工作已经使这些方法模式高效,能够在移动设备上以30 FPS运行精确的视差估计。
Image-based 3D object detection
立体和单目深度估计的快速发展表明,它们可以作为激光雷达在基于图像的三维目标检测算法中的替代品。这种风格的现有算法主要是建立在二维目标检测[25]上,增加了额外的几何约束[2,4,21,29]来创建三维提案。[5,6,22,30]应用基于立体的深度估计来获得每个像素的真实三维坐标。这些3D坐标要么作为额外的输入通道输入到2D检测管道中,要么用于提取手工制作的特征。尽管这些方法已经取得了显著的进步,但三维物体检测性能的最新技术仍落后于基于激光雷达的方法。正如我们在第3节中讨论的那样,这可能是因为这些方法使用的深度表示。
Method
尽管基于图像的3D物体识别具有许多优势,但在最先进的图像和基于激光雷达的方法的检测率之间仍然存在明显差距(见第4.3节中的表1)。人们很容易将这种差距归因于激光雷达和相机技术之间明显的物理差异及其影响。例如,基于立体的3D深度估计的误差随着物体的深度呈二次增长,而对于飞行时间(ToF)方法,如LiDAR,这种关系近似为线性。
提出了基于图像的三维目标检测管道。给定立体或单目图像,我们首先预测深度图,然后将其反向投影到激光雷达坐标系统中的3D点云中。我们将这种表示称为伪激光雷达,并完全像激光雷达一样处理它-任何基于激光雷达的检测算法都可以应用。
虽然这些物理差异中的一些确实可能导致准确性差距,但在本文中,我们声称大部分差异可以通过数据表示来解释,而不是数据质量或与数据收集相关的潜在物理特性。事实上,最近的立体深度估计算法可以生成非常精确的深度图[3](见图1)。因此,我们“缩小差距”的方法是仔细消除两种数据模式之间的差异,并尽可能地对齐两个识别管道。为此,我们提出了一种两步方法,首先从立体(甚至单眼)图像中估计密集像素深度,然后将像素反向投影到3D点云中。通过将这种表示视为伪激光雷达信号,我们可以应用任何现有的基于激光雷达的3D物体检测算法。图2描述了我们的管道。
Depth estimation
我们的方法不受不同深度估计算法的影响。我们主要使用立体视差估计算法[3,19],尽管我们的方法可以很容易地使用单目深度估计方法。Astereo视差估计算法以水平偏移量(即基线)b的一对摄像机拍摄的一对左右图像Il和Ir作为输入,输出与两幅输入图像中任意一幅大小相同的视差图Y。在不失一般性的前提下,我们假设深度估计算法将左侧图像Il作为参考,并在Y中记录每个像素到Ir的水平视差。结合左相机的水平焦距fU,我们可以通过以下变换得到深度图D:
Pseudo-LiDAR generation
不像[30]那样,将深度D作为多个额外通道合并到RGB图像中,我们可以在左侧相机坐标系中导出每个像素(u, v)的3D位置(x, y, z),如下所示:

式中(cU,cV)为相机中心对应的像素位置,fV为垂直焦距。
通过将所有像素反向投影到3D坐标中,我们得到一个3D点云{(x(n),y(n),z(n))}Nn=1,其中n是像素数。在给定参考视点和观察方向的情况下,这种点云可以转换成任意的坐标系。我们将得到的点云称为伪激光雷达信号。
LiDAR vs. pseudo-LiDAR
为了最大限度地与现有的LiDAR检测管道兼容,我们对伪LiDAR数据进行了一些额外的后处理步骤。由于真正的激光雷达信号只存在于一定的高度范围内,我们忽略了超出该范围的伪激光雷达点。例如,在KITTI基准测试中,在[33]之后,我们移除虚拟LiDAR源(位于自动驾驶车辆顶部)上方1米以上的所有点。由于大多数感兴趣的物体(如汽车和行人)不会超过这个高度范围,因此几乎没有信息丢失。除了深度,LiDAR还返回任何测量像素的反射率(在[0,1]内)。由于我们没有这样的信息,我们简单地将每个伪lidar点的反射率设置为1.0。
图1描绘了来自KITTI数据集的同一场景的ground-truth LiDAR和pseudo- LiDAR点[11,12]。利用金字塔立体匹配网络(PSMNet)[3]进行深度估计。令人惊讶的是,伪激光雷达点(蓝色)与真激光雷达点(黄色)对齐得非常好,这与人们普遍认为的基于图像的低精度深度是劣质3D物体检测的主要原因形成鲜明对比。我们注意到,激光雷达可以为一个场景捕获100万个点,这与像素计数是相同的数量级。然而,激光雷达点分布在几个(通常是64或128)水平波束上,仅稀疏地占据3D空间。
3D object detection
利用估计的伪激光雷达点,我们可以将任何现有的基于激光雷达的3D物体探测器应用于自动驾驶。在这项工作中,我们考虑了那些基于多模态信息的方法(即单图像+激光雷达),因为将原始视觉信息与伪激光雷达数据结合在一起是很自然的。具体来说,我们在AVOD[16]和frustum PointNet[23]上进行了实验,这两种算法在KITTI基准上的开源代码排名靠前。一般来说,我们区分两种不同的设置:
a)在第一个设置中,我们将伪lidar信息视为三维点云。在这里,我们使用截锥体Point- Net[23],将二维目标检测[18]投影到三维截锥体上,然后使用PointNet[24]提取每个三维截锥体上的点集特征。b)在第二种设置中,我们从鸟瞰(BEV)中查看伪激光雷达信息。特别是,从自上而下的角度将三维信息转换为二维图像,宽度和深度成为spa尺寸,高度记录在通道中。AVOD将视觉特征和BEV激光雷达特征连接到3D盒子提案,然后融合两者进行盒子分类和回归。
Data representation matters
虽然伪激光雷达传达的信息与深度图相同,但我们声称它更适合基于深度卷积网络的3D物体检测管道。要了解这一点,请考虑卷积网络的核心模块:2D卷积。在图像或深度图上操作的卷积网络在图像/深度图上执行一系列2D卷积。虽然卷积的过滤器可以学习,但中心假设是双重的:(a)图像中的局部邻域有意义,网络应该查看局部补丁,(b)所有邻域都可以以相同的方式操作。这些只是不完美的假设。首先,二维图像上的局部斑块只有在完全包含在单个物体中时才具有物理相干性。如果它们跨越对象边界,那么两个像素可以在深度图中彼此相邻,但在3D空间中可能非常遥远。其次,出现在多个深度的对象在深度图中以不同的比例尺投影。同样大小的贴片可能只捕获附近汽车的侧视镜或远处汽车的整个车身。现有的二维目标检测方法与这种假设的分解作斗争,必须设计新的技术,如特征金字塔b[18]来应对这一挑战。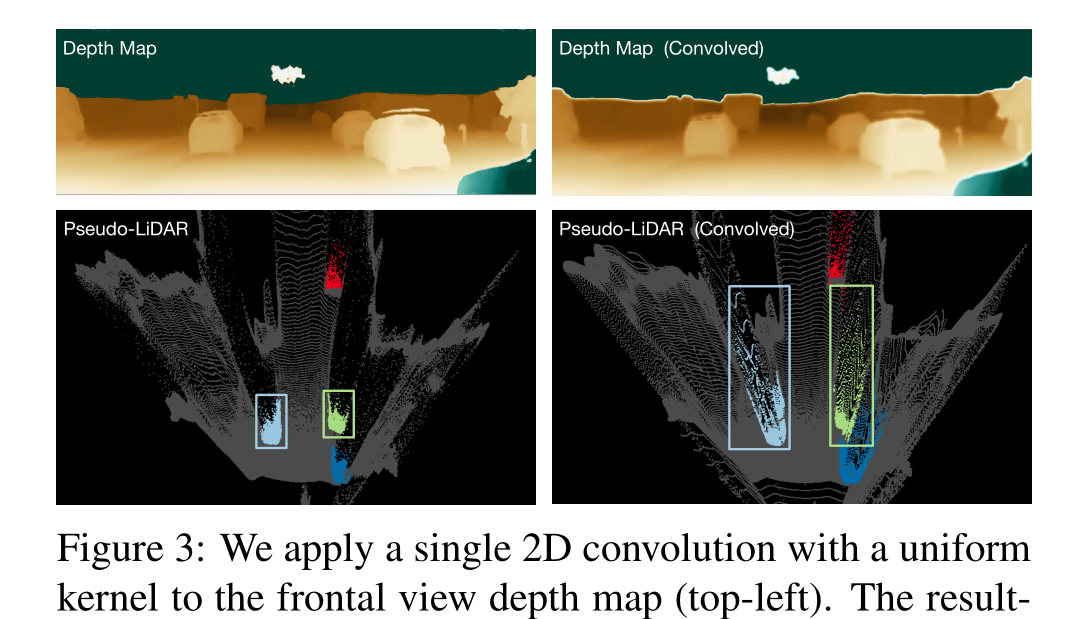
我们对正面视图深度图(左上)应用一个具有统一内核的单一2D卷积。结果深度图(右上),在反向投影到伪激光雷达并从鸟瞰图(右下)显示后,与原始伪激光雷达表示(左下)相比,显示出很大的深度失真,特别是对于远处的物体。我们用一种颜色标记每辆车的位置。这些盒子是叠加的,分别包含了绿色和青色汽车的所有点。
相比之下,点云上的3D卷积或鸟瞰切片中的2D卷积对物理上靠近的像素进行操作(尽管后者确实将来自不同高度的像素拉到一起,但世界的物理意味着在特定空间位置上不同高度的像素通常属于同一对象)。此外,远处的物体和附近的物体的处理方式完全相同。因此,这些操作本质上更有物理意义,因此应该导致更好的学习和更准确的模型。
为了进一步说明这一点,在图3中,我们进行了一个简单的实验。在左列中,我们展示了原始深度图和图像场景的伪激光雷达表示。场景中的四辆车用颜色突出显示。然后,我们在深度图(右上)上使用box filter执行单个11 × 11卷积,该卷积匹配5层3 × 3卷积的接受域。然后我们将得到的(模糊的)深度图转换为伪激光雷达表示(右下)。从图中可以明显看出,这种新的伪激光雷达表示深受模糊效应的影响。这些汽车被拉伸得远远超出了它们的实际物理比例,因此基本上不可能精确定位它们。为了更好的可视化,我们添加了包含绿色和青色汽车的所有点的矩形。经过卷积后,两个边界框都捕获了高度错误的区域。当然,2D卷积网络将学习使用比框过滤器更智能的过滤器,但是这个例子显示了卷积网络可能执行的一些操作可能接近荒谬。
Discussion and Conclusion
有时候,正是一些简单的发现带来了最大的不同。在本文中,我们已经证明了缩小基于图像和基于激光雷达的3D物体检测之间差距的关键组成部分可能只是3D信息的表示。把这些结果看作是对系统效率低下的纠正,而不是一种新的算法,这可能是公平的,然而,这并不会降低它的重要性。我们的发现与我们对卷积神经网络的理解一致,并通过实证结果得到证实。事实上,我们从这次修正中得到的改进是前所未有的,而且对所有方法都有影响。有了这一巨大的飞跃,基于图像的自动驾驶汽车3D目标检测在不久的将来可能成为现实。这种前景的影响是巨大的。目前,激光雷达硬件可以说是自动驾驶所需的最昂贵的附加组件。没有它,自动驾驶的额外硬件成本就变得相对较小。此外,即使在激光雷达设备存在的情况下,基于图像的目标检测也将是有益的。可以想象这样一种场景:激光雷达数据被用于持续训练和微调基于图像的分类器。在我们的传感器中断的情况下,基于图像的分类器可能会作为一个非常可靠的备份。类似地,我们可以想象这样一种场景:高端汽车配备了激光雷达硬件,并不断训练用于廉价车型的基于图像的分类器。
Future work
在未来的工作中,我们可以沿着多个直接的方向改进我们的结果:首先,更高分辨率的立体图像可能会显著提高远距离物体的精度。我们的结果是用40万像素获得的-与最先进的相机技术相去甚远。其次,在这篇论文中,我们没有关注实时图像处理,并且在一张图像中对所有物体进行分类需要15秒的时间。然而,有可能将这些速度提高几个数量级。最近对实时多分辨率深度估计的改进表明,一种有效的加速深度估计的方法是先在低分辨率下计算深度图,然后在公司高分辨率下对先前的结果进行细化。从深度图到伪激光雷达的转换非常快,应该可以通过模型蒸馏[1]或随时预测[14]来大大加快检测流程。最后,未来的工作可能会通过激光雷达和伪激光雷达的传感器融合来提高3D目标检测的最新水平。伪激光雷达的优点是其信号密度比激光雷达大得多,两种数据模式可以互补。我们希望我们的发现将引起基于图像的3D物体识别的复兴,我们的进展将激励计算机视觉社区在不久的将来完全缩小图像/激光雷达的差距。
相关文章:
)
Pseduo LiDAR(CVPR2019)
文章目录 AbstractIntroductionRelated WorkLiDAR-based 3D object detectionStereo- and monocular-based depth estimationImage-based 3D object detection MethodDepth estimationPseudo-LiDAR generationLiDAR vs. pseudo-LiDAR3D object detectionData representation ma…...
introduction to RL)
强化学习课程:stanford_cs234 学习笔记(3)introduction to RL
文章目录 前言7 markov 实践7.1 markov 过程再叙7.2 markov 奖励过程 MRP(markov reward process)7.3 markov 价值函数与贝尔曼方程7.4 markov 决策过程MDP(markov decision process)的 状态价值函数7.4.1 状态价值函数7.4.2 状态…...

前端精度计算:Decimal.js 基本用法与详解
一、Decimal.js 简介 decimal.js 是一个用于任意精度算术运算的 JavaScript 库,它可以完美解决浮点数计算中的精度丢失问题。 官方API文档:Decimal.js 特性: 任意精度计算:支持大数、小数的高精度运算。 链式调用:…...

来聊聊C++中的vector
一.vector简介 vector是什么 C 中的 vector 是一种序列容器,它允许你在运行时动态地插入和删除元素。 vector 是基于数组的数据结构,但它可以自动管理内存,这意味着你不需要手动分配和释放内存。 与 C 数组相比,vector 具有更多的…...
和InfoNCE(SimCLR)损失函数+案例(附SimSiam分析))
对比学习中的NCE(Noise-Contrastive Estimation)和InfoNCE(SimCLR)损失函数+案例(附SimSiam分析)
在对比学习(Contrastive Learning)中,NCE(Noise-Contrastive Estimation)和InfoNCE是两种常见的目标函数,它们都用于通过区分正样本和负样本来学习高质量的表示。 1. NCE(Noise-Contrastive Est…...

基于FAN网络的图像识别系统设计与实现
基于FAN网络的图像识别系统设计与实现 一、系统概述 本系统旨在利用FAN(Fourier Analysis Networks)网络架构实现高效的图像识别功能,并通过Python语言设计一个直观的用户界面,方便用户操作与使用。FAN网络在处理周期性特征方面具有独特优势,有望提升图像识别在复杂场景…...

【瑞萨 RA-Eco-RA2E1-48PIN-V1.0 开发板测评】PWM
【瑞萨 RA-Eco-RA2E1-48PIN-V1.0 开发板测评】PWM 本文介绍了瑞萨 RA2E1 开发板使用内置时钟和定时器实现 PWM 输出以及呼吸灯的项目设计。 项目介绍 介绍了 PWM 和 RA2E1 的 PWM 资源。 PWM 脉冲宽度调制(Pulse Width Modulation, PWM)是一种对模拟…...

NDK开发:开发环境
NDK开发环境 一、NDK简介 1.1 什么是NDK NDK(Native Development Kit)是Android提供的一套工具集,允许开发者在Android应用中使用C/C++代码。它包含了: 交叉编译器构建工具调试器系统头文件和库示例代码和文档1.2 NDK的优势 性能优化:直接使用底层代码,提高性能代码保…...
工厂模式)
设计模式简述(三)工厂模式
工厂模式 描述简单工厂(静态工厂)工厂方法模式 抽象工厂增加工厂管理类使用 描述 工厂模式用以封装复杂的实例初始化过程,供外部统一调用 简单工厂(静态工厂) 如果对象创建逻辑简单且一致,可以使用简单工…...

通过Postman和OAuth 2.0连接Dynamics 365 Online的详细步骤
🌟 引言 在企业应用开发中,Dynamics 365 Online作为微软的核心CRM平台,提供了强大的Web API接口。本文将教你如何通过Postman和OAuth 2.0认证实现与Dynamics 365的安全连接,轻松调用数据接口。 📝 准备工作 工具安装…...

LlamaIndex实现RAG增强:上下文增强检索/重排序
面向文档检索的上下文增强技术 文章目录 面向文档检索的上下文增强技术概述技术背景核心组件方法详解文档预处理向量存储创建上下文增强检索检索对比技术优势结论导入库和环境变量读取文档创建向量存储和检索器数据摄取管道使用句子分割器的摄取管道使用句子窗口的摄取管道查询…...

AI比人脑更强,因为被植入思维模型【43】蝴蝶效应思维模型
giszz的理解:蝴蝶效应我们都熟知,就是说一个微小的变化,能带动整个系统甚至系统的空间和时间的远端,产生巨大的链式反应。我学习后的启迪,简单的说,就是不要忽视任何微小的问题,更多时候&#x…...
:DSP系统的媒体与PDB投放设置探秘)
程序化广告行业(62/89):DSP系统的媒体与PDB投放设置探秘
程序化广告行业(62/89):DSP系统的媒体与PDB投放设置探秘 大家好!在之前的学习中,我们对程序化广告的DSP系统有了一定了解。今天还是带着和大家共同进步的想法,深入探索DSP系统中媒体设置以及PDB投放设置的…...
)
Java项目之基于ssm的怀旧唱片售卖系统(源码+文档)
项目简介 怀旧唱片售卖系统实现了以下功能: 用户信息管理: 用户信息新增:添加新用户的信息。 用户信息修改:对现有用户信息进行修改。 商品信息管理: 商品信息添加:增加新的商品(唱片&#x…...
:DSP系统活动设置深度剖析)
程序化广告行业(61/89):DSP系统活动设置深度剖析
程序化广告行业(61/89):DSP系统活动设置深度剖析 大家好!在程序化广告的学习道路上,我们已经探索了不少重要内容。今天依旧本着和大家一起学习进步的想法,深入解析DSP系统中活动设置的相关知识。这部分内容…...

Altshuller矛盾矩阵查询:基于python和streamlit
基于python和streamlit实现的Altshuller矛盾矩阵查询 import streamlit as st import json# 加载数据 st.cache_resource def load_data():with open(parameter.json, encodingutf-8) as f:parameters json.load(f)with open(way.json, encodingutf-8) as f:contradictions …...

FreeRTOS的空闲任务
在 FreeRTOS 中,空闲任务(Idle Task) 是操作系统自动创建的一个特殊任务,其作用和管理方式如下: 1. 空闲任务创建 FreeRTOS 内核自动创建:当调用 vTaskStartScheduler() 启动调度器时,内核会自…...

【代码模板】如何用FILE操作符打开文件?fopen、fclose
#include "stdio.h" #include "unistd.h"int main(int argc, char *argv[]) {FILE *fp fopen("1.log", "wb");if (!fp) {perror("Failed open 1.log");return -1;}fclose(fp); }关于权限部分参考兄弟篇【代码模板】C语言中…...

[特殊字符] Pandas 常用操作对比:Python 运算符 vs Pandas 函数
在 Pandas 中,许多操作可以直接使用 Python 的比较运算符(如 、!、>、< 等),而不需要调用 Pandas 的专门函数(如 eq()、ne()、gt() 等)。这些运算符在 Pandas 中已经被重载,代码更简洁。以…...

I.MX6ULL开发板与linux互传文件的方法--NFS,SCP,mount
1、内存卡或者U盘 方法比较简单,首先在linux系统中找到u盘对应的文件夹,随后使用cp指令将文件拷贝进u盘。 随后将u盘插入开发板中,找到u盘对应的设备文件。一般u盘对应的设备文件在/dev下,以sda开头,可以使用命令列出所…...

图解AUTOSAR_SWS_FlashEEPROMEmulation
AUTOSAR Flash EEPROM Emulation (FEE) 详解 基于AUTOSAR规范的Flash EEPROM Emulation模块分析 目录 1. 概述2. 架构设计 2.1 模块位置与接口2.2 内部状态管理2.3 配置结构3. API接口 3.1 接口功能分类3.2 错误管理4. 操作流程 4.1 写入操作序列5. 总结1. 概述 Flash EEPROM …...
)
Unity:Simple Follow Camera(简单相机跟随)
为什么需要Simple Follow Camera? 在游戏开发中,相机(Camera)是玩家的“眼睛”。它的作用是决定玩家看到游戏世界的哪一部分。很多游戏需要相机自动跟随玩家角色,让玩家始终可以看到角色及其周围的环境,而…...
: 技术应用(上))
[项目总结] 在线OJ刷题系统项目总结与分析(二): 技术应用(上)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

针对Ansible执行脚本时报错“可执行文件格式错误”,以下是详细的解决步骤和示例
针对Ansible执行脚本时报错“可执行文件格式错误”,以下是详细的解决步骤和示例: 目录 一、错误原因分析二、解决方案1. 检查并添加可执行权限2. 修复Shebang行3. 转换文件格式(Windows → Unix)4. 检查脚本内容兼容性5. 显式指定…...

从 Dense LLM 到 MoE LLM:以 DeepSeek MoE 为例讲解 MoE 的基本原理
写在前面 大多数 LLM 均采用 Dense(密集) 架构。这意味着,在处理每一个输入 Token 时,模型所有的参数都会被激活和计算。想象一下,为了回答一个简单的问题,你需要阅读整部大英百科全书的每一个字——这显然效率低下。 为了突破 Dense 模型的瓶颈,一种名为 Mixture of …...

未来已来:探索AI驱动的HMI设计新方向
在科技浪潮的持续冲击下,人工智能(AI)正以势不可挡的姿态重塑各个领域的格局,其中人机交互(HMI,Human - Machine Interaction)设计领域深受其影响,正经历着深刻的变革。AI 技术的融入…...
)
5天速成ai agent智能体camel-ai之第1天:camel-ai安装和智能体交流消息讲解(附源码,零基础可学习运行)
嗨,朋友们!👋 是不是感觉AI浪潮铺天盖地,身边的人都在谈论AI Agent、大模型,而你看着那些密密麻麻的代码,感觉像在读天书?🤯 别焦虑!你不是一个人。很多人都想抓住AI的风…...

Unity UGUI使用手册
概述 UGUI(Unity Graphical User Interface) :Unity 图像用户界面 在游戏开发中,我们经常需要搭建一些图形用户界面。Unity内置的UGUI可以帮助开发者可视化地拼接界面,提高开发效率。UGUI提供不同样式的UI组件,并且封装了对应功能的API&am…...
输入输出处理——打造智能对话的灵魂)
(二)输入输出处理——打造智能对话的灵魂
上一篇:(一)从零开始:用 LangChain 和 ZhipuAI 搭建简单对话 在上一篇文章中,我们成功搭建了一个基于 LangChain 和 ZhipuAI 的智能对话系统的基础环境。今天,我们将深入探讨输入输出处理的细节࿰…...

beego文件上传
1file.go 2html代码 3路由设置 beego.Router("/file/Upload", &controllers.FileUploadController{}, "post:Upload") 注意 1,得新建个upload文件夹 2,路由设置严格区分大小写。 biiego文件下载上传代码 github 觉得不错Star下...
)
代码随想录回溯算法01(递归)
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。 回溯是递归的副产品,只要有递归就会有回溯。 所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。 组合问题:N个数里面按一定规则找出k个数的集合切割问题&am…...

分治-归并排序-逆序对问题
目录 1.升序(以右边的合并组为基准) 2.降序(以左边的合并组为基准) 3.逆对序--固定下标 1.升序(以右边的合并组为基准) 找出左边有多少个数比我(nums[right])大 应该在每一次合并之前,进行…...

mysql-getshell的几种方法
mysql_getshell的几种方法 mysql_getshell 一、mysql的–os-shell 利用原理 –os-shell就是使用udf提权获取WebShell。也是通过into oufile向服务器写入两个文件,一个可以直接执行系统命令,一个进行上传文件。此为sqlmap的一个命令,利用这…...

初阶数据结构--树
1. 树的概念与结构 树是⼀种⾮线性的数据结构,它是由 n(n>0) 个有限结点组成⼀个具有层次关系的集合。把它叫做 树是因为它看起来像⼀棵倒挂的树,也就是说它是根朝上,⽽叶朝下的。 有⼀个特殊的结点,称…...
)
搭建redis主从同步实现读写分离(原理剖析)
搭建redis主从同步实现读写分离(原理剖析) 文章目录 搭建redis主从同步实现读写分离(原理剖析)前言一、搭建主从同步二、同步原理 前言 为什么要学习redis主从同步,实现读写分析。因为单机的redis虽然是基于内存,单机并发已经能支撑很高。但是随着业务量…...

Python3 学习笔记
Python3 简介 | 菜鸟教程 一 Python3 简介 Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色…...

kmpmanacher
KMP 理论 KMP算法的核心是构建一个部分匹配表,也称为前缀表。这个表记录了模式串中每个位置之前的最长公共前缀和后缀的长度。例如,对于模式串"ababaca",其部分匹配表如下: 位置0123456字符ababaca最长公共前后缀长度…...

ts基础知识总结
TypeScript(简称TS)是JavaScript(简称JS)的一个超集,它在JS的基础上增加了静态类型检查、类、模块等特性。 TypeScript 与 JavaScript 的不同及好处 不同点 类型系统 JavaScript 是一种弱类型语言,这意味…...

操作系统内存管理
为什么要有虚拟内存 单片机的CPU直接操作内存的物理地址,这就导致在内存中同时运行两个程序是不可能的,有可能会出现第一个程序在2000的位置写入新的值将会擦掉第二个程序存放在相同位置上的内容。 出现这个问题的根本原因是两个程序引用了绝对物理地址。…...

M芯片,能运行普通应用程序的原架构虚拟机
在我们使用搭载了Apple芯片的Mac时,很多时候会用到windows虚拟机来使用windows应用程序 但是Apple芯片是ARM架构,如果运行原价构的虚拟机,很多64位的普通应用程序就无法运行,如果使用UTM来安装64位的跨架构虚拟机,就会非常卡慢 但实际上使用一种特殊的系统镜像,就可以使用ARM…...

多功能指示牌的主要功能有哪些?
哇哦!咱们的多功能指示牌可有着超多超厉害的主要功能哦,简直就是生活中的超级小助手,涵盖了方方面面呢! 指示导向功能 道路指引:不管是在繁华热闹的城市道路,还是车水马龙的高速公路,亦或是风…...

Superset 问题
和nginx结合使用,如果不是配置到根路径,会比较麻烦,我试了很多种方法,也就 这个 靠谱点,不过,我最后还是选择的部署在根路径,先探索一番再说默认不能选择mysql数据库,需要安装mysql客…...

安装gpu版本的dgl
1.先去网址,找到对应版本的dgl,然后下载到本地。 dgl-whl下载地址 我的是python 3.8 ,cuda 11.6. windows 2.在虚拟环境里 输入 pip install E:\dgl-1.0.2cu116-cp38-cp38-win_amd64.whl (因为我下载到E盘里了) 这样GPU版本的d…...

vue watch和 watchEffect
在 Vue 3 中,watch 和 watchEffect 是两个用于响应式地监听数据变化并执行副作用的 API。它们在功能上有一些相似之处,但用途和行为有所不同。以下是对 watch 和 watchEffect 的详细对比和解释: 1. watch watch 是一个更通用的 API…...

JavaScript基础--03-变量的数据类型:基本数据类型和引用数据类型
JavaScript基础--03-变量的数据类型:基本数据类型和引用数据类型 前言变量的数据类型为什么需要数据类型JS中一共有六种数据类型 一个经典的例子栈内存和堆内存 前言 我们接着上一篇文章 JavaScript基础–02-变量 来讲。 下一篇文章 JavaScript基础–04-基本数据类…...

WindowsPE文件格式入门05.PE加载器LoadPE
https://bpsend.net/thread-316-1-1.html LoadPE - pe 加载器 壳的前身 如果想访问一个程序运行起来的内存,一种方法就是跨进程读写内存,但是跨进程读写内存需要来回调用api,不如直接访问地址来得方便,那么如果我们需要直接访问地址,该怎么做呢?.需要把dll注进程,注进去的代码…...

【Redis】通用命令
使用者通过redis-cli客户端和redis服务器交互,涉及到很多的redis命令,redis的命令非常多,我们需要多练习常用的命令,以及学会使用redis的文档。 一、get和set命令(最核心的命令) Redis中最核心的两个命令&…...

Android学习总结之service篇
引言 在 Android 开发里,Service 与 IntentService 是非常关键的组件,它们能够让应用在后台开展长时间运行的操作。不过,很多开发者仅仅停留在使用这两个组件的层面,对其内部的源码实现了解甚少。本文将深入剖析 Service 和 Inte…...

基于CATIA产品结构树智能排序的二次开发技术解析——深度定制BOM层级管理系统的Pycatia实践
引言 在航空制造与汽车装配领域,CATIA产品结构树(Product Tree)的规范性直接影响MBOM管理效率。传统手动排序存在两大痛点: 多级编号混乱:混合零件号(PartNumber)与实例名(Insta…...

机器人轨迹跟踪控制——CLF-CBF-QP
本次使用MATLAB复现CLF-CBF-QP算法,以实现机器人轨迹跟踪同时保证安全性能 模型 使用自行车模型来进行模拟机器人的移动动态,具体的模型推导参考车辆运动学模型-自行车模型 采用偏差变量 p ~ = p − p r e f u ~ = u − u r e f \tilde{p} = p - p_{ref} \\ \tilde{u} = …...