pyTorch框架使用CNN进行手写数字识别
目录
1.导包
2.torchvision数据处理的方法
3.下载加载手写数字的训练数据集
4.下载加载手写数字的测试数据集
5. 将训练数据与测试数据 转换成dataloader
6.转成迭代器取数据
7.创建模型
8. 把model拷到GPU上面去
9. 定义损失函数
10. 定义优化器
11. 定义训练过程
12.最终运行测试
1.导包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plttorch.__version__'2.4.1+cu121'
# 检查GPU是否可用
torch.cuda.is_available()True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')devicedevice(type='cuda', index=0)
# pytorch中使用GPU进行训练的主要流程注意点:
#1. 把模型转移到GPU上.
#2. 将每一批次的训练数据转移到GPU上.
# torchvision 内置了常用的数据集和常见的模型.
#使用pyTorch框架 整迁移学习时,可以从torchvision中加载出来
2.torchvision数据处理的方法
import torchvisionfrom torchvision import datasets, transforms# transforms.ToTensor 的作用如下:
# 1. 把数据转化为tensor
# 2. 数据的值转化为0到1之间.
# 3. 会把channel放到第一个维度上.
# transforms用来做数据增强, 数据预处理等功能的.
#Compose()可以将很多数据处理的方法组合起来, 用列表来组合
transformation = transforms.Compose([transforms.ToTensor(),])3.下载加载手写数字的训练数据集
#下载获取手写数字数据集MNIST ,获取其中的训练数据集
#train=True表示获取训练数据集
train_ds = datasets.MNIST('./', train=True, transform=transformation, download=True)
datasets<module 'torchvision.datasets' from 'D:\\anaconda3\\lib\\site-packages\\torchvision\\datasets\\__init__.py'>
4.下载加载手写数字的测试数据集
# 下载获取 手写数字的 测试数据集
#train=False表示获取测试数据集
test_ds = datasets.MNIST('./', train=False, transform=transformation, download=True)5. 将训练数据与测试数据 转换成dataloader
# 将训练数据与测试数据 转换成dataloader
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True) #shuffle=True表示打乱数据
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=256) #测试数据时,不需要进行反向传播,可以将batch_size的值给大一些6.转成迭代器取数据
#可迭代对象 与 迭代器 不同
#train_dl是可迭代对象
#iter()将train_dl可迭代对象的数据 变成 迭代器
#next()从迭代器中取出一批数据
images, labels = next(iter(train_dl))#tensorflow中图片的表现形式[batch, hight, width, channel]
# pytorch中图片的表现形式[batch, channel, hight, width]
images.shapetorch.Size([64, 1, 28, 28])
labels #还没有one_hot编码的tensor([1, 1, 2, 3, 2, 1, 8, 4, 5, 8, 4, 3, 0, 0, 4, 8, 2, 3, 3, 7, 3, 0, 5, 5,5, 6, 7, 2, 9, 4, 7, 9, 6, 7, 1, 4, 3, 9, 2, 4, 6, 4, 1, 1, 9, 2, 4, 7,7, 6, 2, 6, 8, 1, 3, 5, 4, 7, 5, 0, 6, 0, 9, 1])
img = images[0] #取一张图的数据img.shape #一张图数据的形状 #三维数据 不方便可视化img = img.numpy() #可以先将数据转成numpy数据类型, 再进行数据降维, 再进行可视化img = np.squeeze(img) #数据降维,降一个维度,把只有1的维度降掉, 将形状变成(28, 28)img.shape(28, 28)
plt.imshow(img, cmap='gray') #图片数据可视化 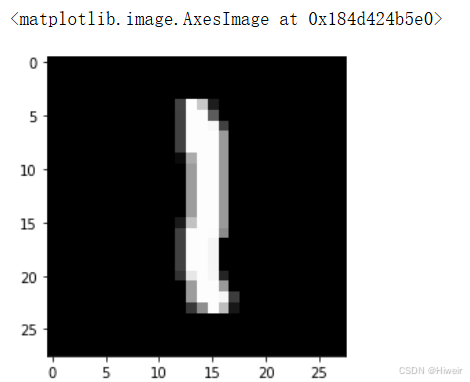
7.创建模型
class Model(nn.Module): #继承nn.Moduledef __init__(self): #重写方法super().__init__() #继承父类的方法#无论经过什么层,batch_size一直保持不变(第一个数)#第一层卷积层#nn.Conv2d(输入的通道数, 自定义输出的通道数=这一层使用的卷积核的个数, 卷积核的大小)#输出的通道数=卷积核的个数(神经元个数)#nn.Conv2d()参数dilation=1(默认值),表示 不膨胀卷积#padding 默认为0#卷积核的大小为奇数时,padding=valid, 图片大小= ((原图片大小w - 卷积核的大小F)+ 1) / 步长s (此时步长默认steps = 1)self.conv1 = nn.Conv2d(1, 32, 3)# in: 64, 1, 28 , 28 -> out: 64, 32, 26, 26#池化层nn.MaxPool2d((卷积核的大小)) ,卷积核的大小可以用元组(2,2)表示,或者直接用一个数2表示 #strip步长默认为2#池化层的数值设置一般都一样,可重复使用,创建一次就行#卷积核的大小为偶数时,padding=same, 图片大小= 原图片大小w / 步长s(此时的步长steps默认为2)#上一句化 等同于 经过一次池化层,原图片大小减半#经过池化层,输入通道数=上一层的输出通道数=上一层使用的卷积核个数self.pool = nn.MaxPool2d((2, 2)) # out: 64, 32, 13, 13
# self.pool = nn.MaxPool2d(2) #等同于上一行代码#第二层卷积核nn.Conv2d(上一层卷积的输出通道数, 自定义在这一层使用的卷积核的个数, 3)self.conv2 = nn.Conv2d(32, 64, 3)# in: 64, 32, 13, 13 -> out: 64, 64, 11, 11# 再加一层池化操作, in: 64, 64, 11, 11 --> out: 64, 64, 5, 5#第一层全连接层(输入通道数=上一层维度形状相乘,自定义输出通道数量=这一层使用的神经元数量)self.linear_1 = nn.Linear(64 * 5 * 5, 256)#第二层全连接层(输入通道数=上一层输出通道数,自定义输出通道数=问题分类数量(数字识别0~9,共10个数字))self.linear_2 = nn.Linear(256, 10)#定义前向传播def forward(self, input):#链式调用 #relu激活函数(第一层卷积层) #调用自定义方法,需要加上self.x = F.relu(self.conv1(input))x = self.pool(x) #第二层:池化层x = F.relu(self.conv2(x)) #第三层:卷积层,然后+ relu激活函数x = self.pool(x) #第四层:池化层# flatten 展平, 进行维度变形x = x.view(-1, 64 * 5 * 5) # (每批次具有64个样本, 特征数量)x = F.relu(self.linear_1(x)) #第五层:全连接层+激活函数relux = self.linear_2(x) #第六层:输出层 #一般会在这一层之后添加一个sigmoid函数,这里没有加,后面需要处理一下return x8. 把model拷到GPU上面去
model = Model()# 把model拷到GPU上面去
model.to(device)Model((conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))(linear_1): Linear(in_features=1600, out_features=256, bias=True)(linear_2): Linear(in_features=256, out_features=10, bias=True) )
9. 定义损失函数
#定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()10. 定义优化器
#定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)11. 定义训练过程
#定义训练过程
def fit(epoch, model, train_loader, test_loader):#声明变量correct = 0 #预测准确的数量total = 0 #总共的样本数量running_loss = 0 #每运行一次的累计损失for x, y in train_loader:# 把CPU上的数据放到GPU上去. x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad(): #不计算梯度求导时#计算预测值 #argmax()是取最大值的索引, y_pred是10个预测数字的概率(包含10个概率数值),是二维数据类型 # dim=1表示取第二个维度上的索引:列上y_pred = torch.argmax(y_pred, dim=1)#计算预测准确的数量, #.item()表示把sum()求和的聚合运算(bool值会直接用1或0表示)之后的 标量(一个具体的数)取出来correct += (y_pred == y).sum().item()total += y.size(0) #总共样本数量running_loss += loss.item() #每运行一次的累计损失epoch_loss = running_loss / len(train_loader.dataset) #计算平均损失epoch_acc = correct / total #计算准确率# 测试过程,不需要计算梯度求导test_correct = 0test_total = 0test_running_loss = 0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()test_epoch_loss = test_running_loss / len(test_loader.dataset)test_epoch_acc = test_correct / test_totalprint('epoch: ', epoch,'loss: ', round(epoch_loss, 3), #3表示三位小数'accuracy: ', round(epoch_acc, 3),'test_loss: ', round(test_epoch_loss, 3),'test_accuracy: ', round(test_epoch_acc))return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc12.最终运行测试
epochs = 20 #指定运行的次数
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc = fit(epoch, model, train_dl, test_dl)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_loss)test_acc.append(epoch_acc)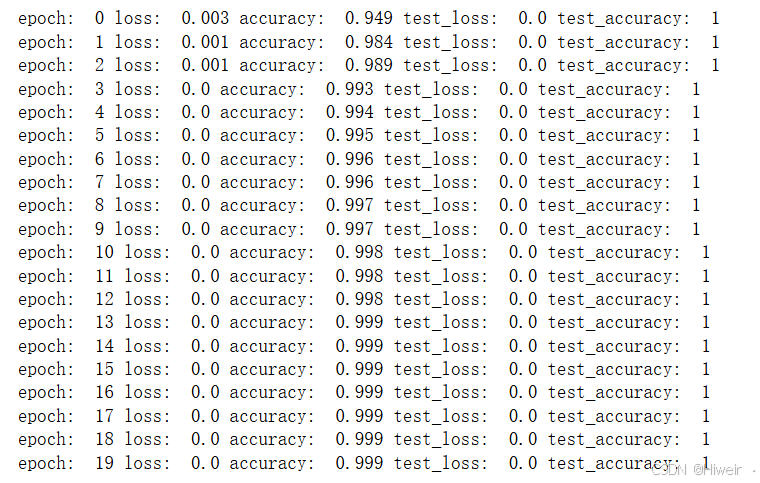
相关文章:

pyTorch框架使用CNN进行手写数字识别
目录 1.导包 2.torchvision数据处理的方法 3.下载加载手写数字的训练数据集 4.下载加载手写数字的测试数据集 5. 将训练数据与测试数据 转换成dataloader 6.转成迭代器取数据 7.创建模型 8. 把model拷到GPU上面去 9. 定义损失函数 10. 定义优化器 11. 定义训练…...

新能源汽车电子电气架构设计中的功能安全
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

使用binance-connector库获取Binance全市场的币种价格,然后选择一个币种进行下单
一个完整的示例,展示如何使用 api 获取Binance全市场的币种价格,然后选择一个最便宜的币种进行下单操作 代码经过修改,亲测可用,目前只可用于现货,合约的待开发 获取市场价格:使用client.ticker_price()获取所有交易对的当前价格 账户检查:获取账户余额,确保有足够的资…...

HikariCP 源码核心设计解析与 ZKmall开源商城场景调优实践
HikariCP 作为 Spring Boot 默认数据库连接池,其高性能源于独特的无锁设计、轻量级数据结构和精细化生命周期管理。以下从源码解析与 ZKmall开源商城性能调优两个维度展开: 一、HikariCP 源码核心设计解析 无锁并发控制与 ConcurrentBag 容器 Concur…...
)
P1036 [NOIP 2002 普及组] 选数(DFS)
题目描述 已知 n 个整数 x1,x2,⋯,xn,以及 1 个整数 k(k<n)。从 n 个整数中任选 k 个整数相加,可分别得到一系列的和。例如当 n4,k3,4 个整数分别为 3,7,12,19 时,可得全部的组合与它…...

自然语言处理
自然语言处理基础 什么是自然语言处理:让计算机来理解人类所说的一种语言。自然语言处理实际就是让计算机理解人类说的话,然后像人一样进行交互,去进行对话,去生成自然语言。 自然语言处理的基本任务 词性标注:把给…...

LeetCode刷题常见的Java排序
1. 字符串排序(字母排序) 首先,你的代码实现了根据字母表顺序对字符串中的字母进行排序,忽略了大小写并且保留了非字母字符的位置。关键点是: 提取和排序字母:通过 Character.isLetter() 判断是否为字母,并利用 Character.toLowerCase() 来忽略大小写进行排序。保留非字…...

# 利用OpenCV和Dlib实现疲劳检测:守护安全与专注
利用OpenCV和Dlib实现疲劳检测:守护安全与专注 在当今快节奏的生活中,疲劳和注意力不集中是许多人面临的常见问题,尤其是在驾驶、学习等需要高度集中精力的场景中。疲劳不仅影响个人的健康和安全,还可能导致严重的事故。为了应对…...

python基础-16-处理csv文件和json数据
文章目录 【README】【16】处理csv文件和json数据【16.1】csv模块【16.1.1】reader对象【16.1.2】在for循环中, 从reader对象读取数据【16.1.3】writer对象【16.1.5】DictReader与DictWriter对象 【16.4】json模块【16.4.1】使用loads()函数读取json字符串并转为jso…...

Mysql 数据库编程技术01
一、数据库基础 1.1 认识数据库 为什么学习数据库 瞬时数据:比如内存中的数据,是不能永久保存的。持久化数据:比如持久化至数据库中或者文档中,能够长久保存。 数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长…...
)
基于SSM的车辆管理系统的设计与实现(代码+数据库+LW)
摘要 当下,正处于信息化的时代,许多行业顺应时代的变化,结合使用计算机技术向数字化、信息化建设迈进。以前企业对于车辆信息的管理和控制,采用人工登记的方式保存相关数据,这种以人力为主的管理模式已然落后。本人结…...

BugKu Simple_SSTI_2
这个题很简单,主要是记录一下,做题的原理: 打开环境,提示我们用flag传参,然后我们需要判断是什么模板: 这里有一张图片,可以帮助我们轻松判断是什么模板类型:这个图片找不到出处了&…...
】)
浙考!【触发器逻辑方程推导(电位运算)】
RS触发器是浙江高考通用技术一大考点。“对角线原则”、“置1置0”、“保持”、“不使用”、“记忆功能”…经常让考生云里雾里,非常反直觉。 这篇文章,我想以高中生的视角诠释一下触发器。 1、触发器逻辑方程推导(以或非门触发器为例&…...

二叉树的前序中序后序遍历
一、前序遍历 144. Binary Tree Preorder Traversal 递归代码实现: /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* …...

es中节点类型有哪些
Elasticsearch 节点类型有哪些 在 Elasticsearch 中,节点类型(或角色)定义了每个节点在集群中的职责。不同版本的 Elasticsearch 对节点角色的定义和管理方式有所不同,尤其在 7.9.0 版本引入 node.roles 后,配置方式更…...

【学习笔记】深度学习环境部署相关
文章目录 [AI硬件科普] 内存/显存带宽,从 NVIDIA 到苹果 M4[工具使用] tmux 会话管理及会话持久性[A100 02] GPU 服务器压力测试,gpu burn,cpu burn,cuda samples[A100 01] A100 服务器开箱,超微平台,gpu、…...

游戏引擎学习第206天
回顾并为当天的工作定下目标 接着回顾了前一天的进展。之前我们做了一些调试功能,并且已经完成了一些基础的工作,但是还有一些功能需要继续完善。其中一个目标是能够展示实体数据,以便在开发游戏逻辑系统时,可以清晰地查看和检查…...

Rust所有权详解
文章目录 Rust所有权所有权规则作用域 内存和分配移动与克隆栈空间堆空间 关于函数的所有权机制作为参数作为返回值 引用与租借垂悬引用 Rust所有权 C/C中我们对于堆内存通常需要自己手动管理,手动申请和释放,即便有了智能指针,对于效率的影…...

贪心算法的使用条件
1. 算法原理 贪心算法是一种在每一步选择中都采取当前状态下最优(局部最优)的策略,从而希望最终得到全局最优解的算法。其核心思想是:“目光短浅” 地选择当前最优解,不回溯、不瞻前顾后。 示例:活动选择问…...

网络性能优化参数关系解读 | TCP Nagle / TCP_NODELAY / TCP_QUICKACK / TCP_CORK
注:本文为 “网路性能优化” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 TCP_NODELAY 详解 lenky0401 发表于 2012-08-25 16:40 在网络拥塞控制领域,Nagle 算法(Nagle algorithm)是一个非常著名的算法&…...

《打破SQL与AI框架对接壁垒,解锁融合新路径》
在当今科技飞速发展的浪潮中,SQL作为管理和处理关系型数据的经典语言,与代表前沿技术的人工智能框架之间的融合,正逐渐成为推动数据驱动型应用发展的重要力量。这种融合所带来的接口实现,不仅是技术上的突破,更是为众多…...

虚拟Ashx页面,在WEB.CONFIG中不添加handlers如何运行
https://localhost:44311/webapi.ashx 虚拟ASHX页面,在WEB.CONFIG中添加handlers,如何不添加节点,直接运行?把页面直接保存ASHX名称?现在是.VB 如果你不想通过在 web.config 里添加 handlers 节点来配置处理程序,而是直接让 .as…...

【ssrf漏洞waf绕过】
SSRF绕过方法 SSRF对于防御方式(waf)绕过方法 SSRF攻击内网的redis 题目一 基于java 的一个 WEBLOGIC 框架 首先我们要知道它内网有什么服务,我们正常给8888端口发送请求是能接受到的,那么我们把8888端口给关闭了,再次请求发现后有一个错误…...
)
BEVFormer v2(CVPR2023)
文章目录 AbstractIntroductionRelated WorksBEV 3D Object DetectorAuxiliary Loss in Camera 3D Object DetectionTwo-stage 3D Object Detector BEVFormer v2Overall ArchitecturePerspective SupervisionPerspective LossRavamped Temporal EncoderTwo-stage BEV DetectorD…...

车载通信架构 --- AUTOSAR 网络管理
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

STM32单片机入门学习——第16节: [6-4] PWM驱动LED呼吸灯PWM驱动舵机PWM驱动直流电机
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.05 STM32开发板学习——第16节: [6-4] PWM驱动LED呼吸灯&PWM驱动舵机&PWM驱…...

RoMo: Robust Motion Segmentation Improves Structure from Motion
前言 看起来像是一篇投稿CVPR的文章,不知道被哪个瞎眼审稿人拒了。同期还有一篇CVPR被接收的工作Segment Any Motion in Videos,看起来不如这篇直白(也可能是因为我先看过spotlesssplats的缘故),后面也应该一并介绍了…...

【AI编程学习之Python】第五天:Python的变量和常量
对象 Python中一切变量的值皆为对象。每个对象由:标识(identity)、类型(type)、value(值)组成。 标识用于唯一标识对象,通常对应于对象在计算机内存中的地址。使用内置函数id(obj)可返回对象obj的标识。 类型用于表示对象存储的“数据”的类型。类型可以限制对象的取值范围以…...

经典算法 约数之和
原题目链接 问题描述 假设现在有两个自然数 A 和 B,设 S 为 A^B 的所有约数之和。 请你计算:S mod 9901 的值。 输入格式 在一行中输入两个用空格隔开的整数 A 和 B。 输出格式 输出一个整数,表示 S mod 9901 的值。 数据范围 0 ≤ A, …...

zookeeper基本概念和核心作用
图片来源: 02-Zookeeper概念_哔哩哔哩_bilibili02-Zookeeper概念是黑马程序员Zookeeper视频教程,快速入门zookeeper技术的第2集视频,该合集共计24集,视频收藏或关注UP主,及时了解更多相关视频内容。https://www.bilib…...

蓝桥杯嵌入式客观题二
十四届模拟一 1. 2.串口通信是一种传输线按位数据顺序传输方式 3.USART_SR是属于STM32微控制器USART的状态寄存器。 4.STM32G431RBT6是32位的ARM微控制器 ARM处理器是英国ARM公司设计的一种低功耗RISC微处理器 5.中断配置EXTI->FTSR(下降沿触发选择寄存器…...

第一章:服务架构演进史_《凤凰架构:构建可靠的大型分布式系统》_Notes
第一章 服务架构演进史 1. 原始分布式时代(1970s-1980s) 核心问题:如何用不可靠的硬件构建可靠的大规模系统? 关键知识点: 技术背景: 硬件限制:微型计算机性能低下(如Intel 8086处…...
)
BUUCTF-web刷题篇(13)
22.NiZhuanSiWei 分析:有三个参数需要以get方式传入,发现有file_get_contents(),所以要使用php伪代码,preg_match("/flag/",$file)说明正则匹配不能含有flag,同时还有反序列化,存在漏洞。 已知前…...

7-9 趣味游戏
题目解析 在某个学校的趣味游戏活动中,N 名同学站成一排,他们的年龄恰好是 1 到 N ,需要注意的是他们并不是按照年龄的大小排列的,而是随机排列的。 游戏的规则是请同学们快速计算出,如果在这 N 名同学的小组中&…...

用 Python 制作仓库自动化指南
1. 环境准备 Python 3.x pip (Python 包管理工具) 文本编辑器或 IDE (如 VS Code、PyCharm) 2. 安装依赖库 pandas: 数据处理 openpyxl: Excel 文件操作 sqlite3: SQLite 数据库交互 smtplib: 邮件发送 bash pip install pandas openpyxl sqlite3 smtplib 3. 功能实现…...

Johnson算法——两阶段流水线调度的最优解法
前言:写这个题目的时候感觉就是说任务a的时候是一定需要的,无法避免,怎么才能节约时间呢,就是进行任务a时候也进行任务b 第一个进行的任务a肯定时间越短越好,因为这样b的等待时间越短 最后一个进行的任务b的时候越短越…...

反向查询详解以Django为例
以下给出两张表格 class User(AbstractUser):mobilemodels.CharField(max_length11,default0,uniqueTrue,verbose_name手机号)email_activemodels.BooleanField(defaultFalse,verbose_name邮箱验证状态)default_address models.ForeignKey(Address, related_nameusers, nullT…...

PDP动物性格测试:趣味性格分析工具
PDP动物性格测试:趣味性格分析工具 📝 简介 大家好!今天我想向大家推荐一个有趣且实用的在线工具 —— PDP动物性格测试。这是一个基于PDP(Process Dynamic Pattern)理论的性格测试工具,通过将性格特征与…...

蓝桥杯 完全平方数 刷题笔记
关键分析 --- ### **完全平方数的质因数指数特性** **核心结论**: 一个数是完全平方数,当且仅当它的所有质因数的指数均为偶数。 --- #include <bits/stdc.h> using namespace std; #define int long long int n;signed main(){cin >>…...

C++自学笔记---数组和指针的异同点
数组和指针的异同点 0. 复习一下:指针运算符 * 和 & 我们前两篇有讲过这两个运算符,& 是取地址运算符,* 是解引用运算符。这两个运算符是理解指针的关键,因为它们分别代表了获取变量地址和访问指针指向的值这两个基本操…...

【学习笔记】pytorch强化学习
https://www.bilibili.com/video/BV1zC411h7B8 文章目录 [mcts] 01 mcts 基本概念基本原理(UCB)及两个示例[mcts] 02 mcts from scartch(UCTNode,uct_search, pUCT,树的可视化) [mcts] 01 mcts 基本概念基本…...

C++学习之线程同步
目录 1.线程同步相关概念 2.锁属性-建议锁 3.Mutex互斥锁操作 4.互斥锁使用注意事项 5.互斥量的初始化方法 6.死锁 7.读写锁特性 8.读写锁操作函数 9.读写锁使用示例 10.条件变量操作函数 11.生产者消费者模型简单分析 12.条件变量实现生产者消费者模型代码预览 13…...
)
定积分的应用(4.39-4.48)
battle cry 前言4.394.404.414.424.434.444.454.464.474.48 前言 题目确实比较多。slow down and take your time. 4.39 狂算了一遍,然后发现不是计算出问题了,是积分上下限写错了。还有把函数代进去也出了一点问题。 点火公式一家人我不记得&#x…...
)
Java EE期末总结(第三章)
目录 一、JavaBean 1、规范与定义 2、与JavaBean相关的JSP动作标签 二、MV开发模式(JSPJavaBean) 三、Servlet组件 1、Servlet定义 2、基于HTTP请求的Servlet开发 3、Sevlet执行原理 4、控制器程序的分层设计(DAO)模式 5、…...

Data_Socket和UDP_Socket
Data_Socket 和 UDP_Socket 是两种不同类型的网络套接字,它们用于不同的协议和应用场景。以下是它们的主要区别: 协议类型: UDP_Socket:使用的是 UDP(User Datagram Protocol) 协议,这是一种无连…...
)
6547网:蓝桥STEMA考试 Scratch 试卷(2025年3月)
『STEMA考试是蓝桥青少教育理念的一部分,旨在培养学生的知识广度和独立思考能力。考试内容主要考察学生的未来STEM素养、计算思维能力和创意编程实践能力。』 一、选择题 第一题 运行下列哪个程序后,飞机会向左移动? ( ) A. …...

使用MATIO库读取Matlab数据文件中的多维数组
使用MATIO库读取Matlab数据文件中的多维数组 MATIO是一个用于读写Matlab数据文件(.mat)的开源C库。下面是一个完整的示例程序,展示如何使用MATIO库读取Matlab数据文件中的多维数组。 示例程序 #include <stdio.h> #include <stdlib.h> #include <…...
Spring @Transactional 注解是如何工作的?
Transactional 注解是 Spring 框架中用于声明式事务管理的核心注解。它可以应用于类或方法,用于指定事务的属性,例如传播行为、隔离级别、超时时间、只读标志等。下面详细解释 Transactional 注解的工作原理: 1. 启用事务管理: …...

spring security 过滤器链使用
Spring Security 的过滤器链提供了灵活的安全控制机制,以下是其在实际开发中的 常见用法 及对应的过滤器配置示例: 一、认证方式配置 1. 表单登录认证 • 过滤器:UsernamePasswordAuthenticationFilter • 配置: http.formLogi…...

k8s 自动伸缩的场景与工作原理
k8s 自动伸缩的场景与工作原理 在现代云原生架构中,应用的访问量和资源需求常常存在波动。为了解决高峰时资源不足、低谷时资源浪费的问题,Kubernetes 提供了自动伸缩功能。自动伸缩可以根据预设的指标(如 CPU 利用率、内存占用、网络流量等…...