Boost库搜索引擎项目(版本1)
Boost库搜索引擎
项目开源地址
Github:https://github.com/H0308/BoostSearchingEngine
Gitee:https://gitee.com/EPSDA/BoostSearchingEngine
版本声明
当前为最初版本,后续会根据其他内容对当前项目进行修改,具体见后续版本。
后续版本待更新
前置知识
了解搜索引擎
搜索引擎是一种信息检索系统,它能够自动从互联网或特定数据集合中收集、分析和组织信息,并根据用户的查询需求快速定位和返回相关结果。搜索引擎通常由爬虫、索引器和检索系统三大核心组件构成,实现数据采集、处理和高效查询
一般情况下,搜索引擎分为两种:
- 站内搜索引擎:只在当前网站的内容之上进行搜索,实现难度较为容易
- 全网搜索引擎:在整个互联网的内容之上进行搜索,实现难度大且维护成本高
本次只实现站内搜索,了解站内搜索基本原理再推测全网搜索的原理
分词
分词是将文本切分成有意义的基本单元(词语或词元)的过程,是搜索引擎和自然语言处理的基础环节
一般分词可以分为两种模式:
- 全模式:切分出文本中所有可能成词的单元,不考虑语义合理性,特点是同一个字可能出现在多个词中,产生词语重叠。这种模式适合模糊匹配的需求,但是会产生大量冗余结果
- 精确模式:只切分出最符合语义的词语组合,特点是每个字只会出现在一个词中,无重叠现象。这种模式下分词结果符合人类语义理解,但是依赖高质量词典或训练语料
例如,将“我来到北京清华大学”这段话,通过分词可以分为:
- 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学(全模式)
- 我/ 来到/ 北京/ 清华大学(精确模式)
本次项目中会使用分词技术查找出满足条件的文档
正排索引和倒排索引
正排索引(Forward Index)
正排索引是以文档为中心的索引结构:
- 定义:以文档ID为索引,文档内容为值的数据结构
- 结构:文档ID → 文档内容/词项集合
- 示例:
文档1 → {标题:"Boost库简介", 内容:"Boost是一个C++库集合..."} 文档2 → {标题:"C\+\+编程", 内容:"C\+\+是一种面向对象编程语言..."} - 特点:
- 适合已知文档ID时获取文档内容
- 类似于图书馆中按编号排列的书架
- 不利于根据关键词查找文档
- 构建简单,存储效率低
倒排索引(Inverted Index)
倒排索引是以词项为中心的索引结构:
- 定义:以词项为索引,包含该词项的文档列表为值
- 结构:词项 → 文档ID列表(可能包含位置、频率等信息)
- 示例:
"Boost" → {文档1: [位置1, 位置4], 文档3: [位置2]} "C++" → {文档1: [位置10], 文档2: [位置1, 位置5]} - 特点:
- 适合根据关键词快速查找相关文档
- 类似于图书馆中的关键词目录
- 支持高效的全文检索
- 构建复杂,查询高效
两者对比与应用
| 特性 | 正排索引 | 倒排索引 |
|---|---|---|
| 查询方向 | 文档→词项 | 词项→文档 |
| 适用场景 | 文档展示和获取 | 关键词搜索 |
| 构建复杂度 | 低 | 高 |
| 查询效率 | 特定文档高 | 关键词搜索高 |
| 存储需求 | 大 | 相对小 |
实际搜索引擎通常同时使用两种索引:
- 用倒排索引快速找到匹配查询的文档集合
- 用正排索引获取匹配文档的完整内容以展示给用户
倒排索引是现代搜索引擎的核心数据结构,使得快速全文检索成为可能
项目准备
本次项目会使用到下面的内容:
- 后端:C++、cpp-httplib开源库、Jieba分词、Jsoncpp
- 前端:HTML、CSS和JavaScript
- 搜索内容:1.78版本的Boost库中的
doc/html中的内容 - 日志:在Linux下实现的日志系统
- 操作系统:Ubuntu 24.04(Linux)
- 注意,这里的Boost库不要使用最新的,最新的Boost库中的HTML文件并不存在。另外,官网下载有的时候可能比较慢,可以使用本链接作为替代,这个链接是官方认可的资源站
- 本项目中会用到C++ 17的filesystem和string_view,如果不了解请先看C++ 17 filesystem和C++ 17 string_view
实现思路
根据常见搜素引擎的搜索结果可以看出,一条结果一般包含下面三个内容:
- 内容标题
- 描述内容或者部分主体内容
- 内容网址
但是直接从下载到的Boost库资源中可以看到都是HTML文件,直接从该文件中获取到上面三个内容就需要做最重要的一步:去除HTML文件中的标签留下纯文本内容,这便是本次实现的第一步:数据清洗
完成数据清洗之后就需要对构建搜索引擎做准备,首先需要完成的就是索引的构建,在前面提到了两种索引方式:正排索引和倒排索引,本次实现中也会包含这两种索引,根据两种索引的特点完成索引的构建
构建完成索引后就需要根据用户的输入查找索引给用户返回查找到的内容
最后,编写前端代码,完善服务端模块,客户端请求即可完成搜索
数据清洗
介绍
根据前面提到的一条搜索结果的构成可以分析出需要创建一个结构体包含这三个字段:
// 结果基本内容结构
struct ResultData
{std::string title; // 结构标题std::string body; // 结果内容或描述std::string url; // 网址
};
接着就是将一个正常HTML文件中的内容依次读取到结构体对应的字段中,下面分三步走:
- 读取到源文件目录下所有的HTML文件,将其拼接为一个字符串存储到vector中
- 根据上一步得到的vector中的数据,取出每一个文件中的三个字段:文档标题、文档内容和文档在Boost官网的URL都存放到一个结构化对象中,再将该对象存储到一个vector中
- 根据上一步结果的vector中每一个结构化数据读取并写入到一个文本文档
raw,每一个结构化数据以一个\n分隔,而其中的成员以\3分隔
下面是本次项目的目录结构:
- 根路径- data- source- html // 所有的HTML文件位于这里- raw // 结构化数据存储到这里// 头文件和源文件文件与data目录平级
接着,创建一个DataParse类,用于进行数据清洗:
class DataParse
{
private:};
读取所有HTML路径
本步骤的基本思路就是获取到HTML路径存储到vector中,所以需要使用C++ 17中的filesystem库,也可以使用Boost库中提供的filesystem,二者在使用方式上都是一样的。
首先定义出当前HTML文件所在路径:
// HTML文件路径
const fs::path g_datasource_path = "data/source/html";
接着,实现函数读取到所有的HTML文件,如果不是HTML文件就不统计。因为当前HTML文件路径中存在目录,目录中还存在更多的HTML文件,所以还需要用到递归遍历目录
基于上面的思路,首先需要添加一个vector成员sources和获取HTML文件函数getHtmlSourceFiles:
class DataParse
{
public:// 获取HTML文件路径函数bool getHtmlSourceFiles(){}
private:std::vector<fs::path> sources;
};
读取思路:从g_datasource_path开始遍历,遇到后缀为HTML的文件就添加到sources中,如果遇到的是目录就进入目录继续查找,实现代码如下:
// HTML文件后缀
const std::string g_html_extension = ".html";// 获取HTML文件路径函数
bool getHtmlSourceFiles()
{// 如果路径不存在,直接返回falseif (!fs::exists(g_datasource_path)){ls::LOG(ls::LogLevel::DEBUG) << "不存在指定路径";return false;}// 递归目录结束位置,相当于空指针nullptrfor (const auto &entry : fs::recursive_directory_iterator(g_datasource_path)){// 1. 不是普通文件就是目录,继续遍历if (!fs::is_regular_file(entry))continue;// 2. 是普通文件,但是不是HTML文件,继续遍历if (entry.path().extension() != g_html_extension)continue;// 3. 是普通文件并且是HTML文件,插入结果sources_.push_back(std::move(entry.path()));}// 空结果返回falsereturn !sources_.empty();
}
读取HTML文件内容到结构体字段中
基本逻辑介绍
本部分的思路就是根据HTML文件中的特点提取出对应的内容,因为HTML文件的内容都是由标签和普通文本构成,而需要的内容就是文本,对应的行为就是去标签。本次实现分四步:
- 读取文件
- 截取标题
- 截取主体内容
- 构建URL
对于每一个HTML文件都需要走这四步,所以需要使用一个循环,通过一个函数readInfoFromHtml包裹主体逻辑:
// 读取HTML文件内容
bool readInfoFromHtml()
{// 不存在路径返回falseif (sources_.empty()){ls::LOG(ls::LogLevel::WARNING) << "文件路径不存在";return false;}// 每一个文件都执行四步for (const auto &path : sources_){std::string out; // 存储HTML文件内容struct pd::ResultData rd;// 1. 读取文件if (!readHtmlFile(path, out)){ls::LOG(ls::LogLevel::WARNING) << "打开文件:" << path << "失败";// 读取当前文件失败时继续读取后面的文件continue;}// 2. 获取标题if (!getTitleFromHtml(out, &rd.title)){ls::LOG(ls::LogLevel::WARNING) << "获取文件标题失败";continue;}// 3. 读取文件内容if (!getContentFromHtml(out, &rd.body)){ls::LOG(ls::LogLevel::WARNING) << "获取文件内容失败";continue;}// 4. 构建URLif (!constructHtmlUrl(path, &rd.url)){ls::LOG(ls::LogLevel::WARNING) << "构建文件URL失败";continue;}}return true;
}
最后,四个逻辑全部正常执行完后需要将形成的结构体对象插入到一个vector对象results_,此处需要一个添加类成员results_:
class DataParse
{
public:// ...// 从HTML文件中读取信息bool readInfoFromHtml(){// 不存在路径返回falseif (sources_.empty()){ls::LOG(ls::LogLevel::WARNING) << "文件路径不存在";return false;}for (const auto &path : sources){// ...results_.push_back(std::move(rd));}return true;}private:// ...std::vector<pd::ResultData> results_;
};
接着,根据上面的函数主体,依次实现其中的四个函数
实现读取文件内容readHtmlFile
读取HTML文件内容比较简单,就是简单的读取文件内容操作,参考代码如下:
// 读取HTML文件
bool readHtmlFile(const fs::path &p, std::string &out)
{if (p.empty())return false;std::fstream f(p);if (!f.is_open())return false;// 读取文件std::string buffer;while (getline(f, buffer))out += buffer;f.close();return true;
}
实现读取文件标题getTitleFromHtml
因为一个标准的HTML文件中存在且只存在一个语义化标签<title></title>,所以只需要在文件中找到这个标签,并提取出其中的普通文本即可:
// 读取标题
// &为输入型参数,*为输出型参数
bool getTitleFromHtml(std::string &in, std::string *title)
{if(in.empty())return false;// 找到开始标签<title>auto start = in.find("<title>");if(start == std::string::npos)return false;// 找到终止标签</title>auto end = in.find("</title>");if (end == std::string::npos || start > end)return false;// 截取出其中的内容,左闭右开*title = in.substr(start + std::string("<title>").size(), end - (start + std::string("<title>").size()));return true;
}
实现读取文件内容getContentFromHtml
前面提到一个HTML文件只有两种内容:标签和普通文本,所以可以创建一个简单的状态机:如果当前的内容是标签,状态为Label,否则为OrdinaryContent,所以首先需要一个枚举类型描述这两个状态:
// 内容状态
enum ContentStatus
{Label, // 标签状态OrdinaryContent // 普通文本状态
};
接下来考虑何时进行两种状态的切换,默认从文件开始,读取到的内容就是<,所以默认状态为Label,而读取到>有三种情况:
- 单标签的结尾
- 双标签开始标签的结尾
- 双标签闭合标签的结尾
而对于这三种情况,第三种情况和第一种情况可以归类为一种情况,因为这两种情况下都是作为当前标签的最后一个>,所以现在就变成了两种情况:
- 双标签起始标签的结尾
> - 当前标签的最后一个
>
根据这两个情况以一个HTML内容为例进行分析:
<div>内容1</div>
<img />
内容2
<div>内容3</div>
以双标签为例,起始时,状态为Label,读取到第一个>时,得到一个条件:Label且>,假设此时可以修改状态为OrdinaryContent,那么接下来读取的就是文本内容,接着读取第一个到<时,得到下一个条件:OrdinaryContent且<,假设此时可以修改状态为Label,那么在读取到最后一个>时,状态为Label,即回到默认值Label继续读取后续内容
接着读取到单标签,状态为Label,得到一个条件:Label且<,根据上面的逻辑,不进行状态改变,接着读取到第一个>,得到一个条件:Label且>,根据上面的思路此时修改状态为OrdinaryContent,接下来读取文本内容,当读取到<div>内容3</div>的第一个<时,得到下一个条件:OrdinaryContent且<,根据上面的逻辑可以修改状态为Label,即回到默认值Label继续读取后续内容
所以,综上所述,状态切换时机为:
- 当前状态为
Label且遇到的是>,切换为OrdinaryContent - 当前状态为
OrdinaryContent且遇到的是<,切换为Label
根据上面的逻辑,在函数中判断出状态为OrdinaryContent就可以执行插入内容,需要注意的是,后面需要使用\n作为分隔符,所以为了防止源文件内容中的\n干扰,需要将该\n替换为一个空格字符:
// 读取HTML文件内容
bool getContentFromHtml(std::string &out, std::string *body)
{// 默认状态为标签ContentStatus cs = ContentStatus::Label;// 注意,因为文档没有中文,直接用char没有问题for (char ch : out){switch (cs){// 读取到右尖括号且状态为标签说明接下来为文本内容case ContentStatus::Label:if(ch == '>')cs = ContentStatus::OrdinaryContent; // 切换状态break;case ContentStatus::OrdinaryContent:// 去除\nif (ch == '<')cs = ContentStatus::Label; // 切换状态else{if (ch == '\n')*body += ' ';else *body += ch;}break;default:break;}}return true;
}
实现URL构建constructHtmlUrl
要构建一个有效的URL,就必须要将本地文件的路径和官网的路径进行对比,找出一个固定的值和可以改变的部分,例如以accumulators.html,在本地的路径和官网URL路径分别如下:
本地路径:data/source/html/accumulators.html
官网路径:https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html
从上面的路径可以看出,只需要获取到本地路径中的最后一个文件内容/accumulators.html拼接到https://www.boost.org/doc/libs/1_78_0/doc/html后方即可
基于这个思路,实现下面的函数:
// 构建URL
bool constructHtmlUrl(const fs::path& p, std::string *url)
{// 在本地路径中找到"/文件"std::string t_path = p.string();auto pos = t_path.rfind("/");if(pos == std::string::npos)return false;// 从/开始截取一直到结尾std::string source_path = t_path.substr(pos);*url = g_url_to_concat + source_path;return true;
}
写入结构体对象数据到文本文件中
首先指定好文本文件的位置和分隔符:
// 文本文件路径
const fs::path g_rawfile_path = "data/raw";
// 结构体字段间的分隔符
const std::string g_rd_sep = "\3";
// 不同HTML文件的分隔符
const std::string g_html_sep = "\n";
接着就是基本的文件写入操作,但是为了保证不可打印字符可以正常显示,建议使用二进制写入的方式,函数实现如下:
// 将结构体字段写入文本文件中
bool writeToRawFile()
{// 以二进制形式打开文件std::fstream f(g_rawfile_path);if (!f.is_open()){ls::LOG(ls::LogLevel::WARNING) << "文本文件不存在";return false;}// 写入结构化数据for (auto &rd : results_){std::string temp;temp += rd.title;temp += g_rd_sep;temp += rd.body;temp += g_rd_sep;temp += rd.url;temp += g_html_sep;f.write(temp.c_str(), temp.size());}f.close();return true;
}
构建正排索引和构建倒排索引
基本思路和结构介绍
因为正排索引和倒排索引最后都会筛选出一组数据,这个数据肯定包括前面封装的结构体ResultData;另外,因为不论是正排索引和倒排索引,最后都需要知道当前的文档ID,所以此处需要创建一个结构体,包含这里提到的两个字段:
struct SelectedDocInfo
{struct pd::ResultData rd;uint64_t id;
};
接着,为了创建一个类用于构建正排索引和倒排索引。在这个类中需要有两个成员,一个成员存储正排索引的结果,另外一个成员存储倒排索引的结果
首先考虑正排索引,正排索引只需要根据文档ID查询到文档的信息即可,而因为数组可以通过下标访问元素,这就可以保证文档ID与数组下标进行对应,将来查询时直接使用文档ID即可获取到指定的文章信息,所以存储正排索引的结构可以是一个动态数组,而每一个元素就是SelectedDocInfo结构体对象
接着是倒排索引,倒排索引是根据关键字进行构建的结果,而一个关键字可能对应着多个文章信息,所以这里首先需要一个有关当前关键字和相关文章的对应关系,也就是说,并不是直接通过关键字找出某一个文章信息,而是通过关键字对应的相关属性查询到具体的文章,这个属性包含文档ID、当前关键字和权重信息,通过权重信息筛选出结果后再根据其中的文档ID通过正排索引查询出对应的文章。根据这个思路,首先就需要一个用于保存关键字相关属性的结构:
// 倒排索引时当前关键字的信息
struct BackwardIndexElement
{uint64_t id; // 文档IDstd::string word; // 关键字int weight; // 权重信息
};
接着,因为在查询时肯定需要用到获取方法,可能是获取正排索引,也可能是获取倒排索引,所以在类中需要提供两个函数用于获取当前正排索引的SelectedDocInfo对象和倒排索引中存储BackwardIndexElement对象数组,为了避免结构体对象的频繁拷贝,考虑返回对应节点的指针
考虑如何获取,对于正排索引来说,在前面介绍时已经提到是通过文档ID进行查询,所以获取时需要的参数就是文档ID;对于倒排索引来说,因为一个关键字可能对应着多个关键字信息节点BackwardIndexElement,对应的就需要用一个数组存储所有的信息节点,所以就需要建立一个哈希表用于关键字和关键字信息节点数组之间的映射关系,对应的获取时通过关键字获取到的就是关键字信息节点数组
=== “getForwardIndexDocInfo函数”
SelectedDocInfo *getForwardIndexDocInfo()
{
}
=== “getBackwardIndexElement函数”
// 获取倒排索引结果
std::vector<BackwardIndexElement> *getBackwardIndexElement()
{
}
接着,既然是建立索引,那么少不了的就是构建索引的函数。这个函数并不是只进行正排索引或者倒排索引,而是二者都进行,即当前函数包含着正排索引和倒排索引的主逻辑:
// 构建索引
bool buildIndex()
{}
所以,当前用于构建索引的类的结构如下:
class SearchIndex
{
public:// 获取正排索引结果SelectedDocInfo *getForwardIndexDocInfo(){}// 获取倒排索引结果std::vector<BackwardIndexElement> *getBackwardIndexElement(){}// 构建索引bool buildIndex(){}private:std::vector<SelectedDocInfo> forward_index_; // 正排索引结果std::unordered_map<std::string, std::vector<BackwardIndexElement>> backward_index_; // 倒排索引结果
};
实现构建索引函数
既然要构建索引,那么少不了的就是获取到用于构建索引的内容,而在上一步:数据清洗中已经将清洗后的数据存储到了一个文本文件中,所以当前构建索引函数只需要从该文件中读取数据即可。读取数据时需要根据写入时的格式和方式进行读取,因为当时是使用二进制的方式进行写入,那么读取时就需要使用二进制的方式读取;另外,在构建内容时,每一个ResultData对象之间都是以\n进行的分隔,所以在读取一个ResultData对象数据时就可以直接使用getline函数(该函数不会读取到用于分隔的\n)
接着,根据读取到的数据进行正排索引的构建和倒排索引的构建。这里的设计就涉及到前面提到的思路。首先,构建正排索引需要根据当前读取到的信息构建,所以参数需要传递一个当前读取到的信息,另外当前函数考虑返回一个SelectedDocInfo对象地址,只要这个对象地址不为空,就说明是成功构建一个了SelectedDocInfo对象,否则就不是。接着就是构建倒排索引,根据前面的思路,构建倒排索引需要使用到SelectedDocInfo对象中的文档ID值,所以构建倒排索引的函数需要传递一个SelectedDocInfo对象,而这个函数可以考虑返回一个布尔值
基于上面的思路,所以构建索引函数的基本逻辑如下:
// 构建索引
bool buildIndex()
{// 以二进制方式读取文本文件中的内容std::fstream in(pd::g_rawfile_path, std::ios::in | std::ios::binary);if(!in.is_open()){ls::LOG(ls::LogLevel::WARNING) << "打开文本文件失败";return false;}// 读取每一个ResultData对象std::string line;while(getline(in, line)){// 构建正排索引struct SelectedDocInfo* s = buildForwardIndex(line);if(s == nullptr){ls::LOG(ls::LogLevel::WARNING) << "构建正排索引失败";continue;}// 构建倒排索引bool flag = buildBackwardIndex(*s);if(!flag){ls::LOG(ls::LogLevel::WARNING) << "构建倒排索引失败";continue;}}return true;
}
接下来就是实现构建正排索引函数和构建倒排索引函数
实现构建正排索引buildForwardIndex
构建正排索引函数思路就是根据当前文章的内容填入SelectedDocInfo对象中对应的信息
思路虽然比较简短,但是其中的实现方式其实并不简短。当前buildForwardIndex函数接收到了一行的数据,这个数据不包括结尾的\n,所以在当前函数中要考虑的就是读取到一行数据中以\3分隔的三个字段,这里涉及到了对整体数据按照某一种分隔符进行切割,按照之前的思路就是使用strtok函数,但是这个函数使用起来并不方便,所以本次可以考虑两个思路:
- 使用Boost库中的
split函数 - 使用string_view实现自定义的
split函数
使用Boost库中的split函数:
首先介绍第一种思路,在Boost库中,提供了字符串切割的函数split,这个函数的原型如下:
template<typename SequenceSequenceT, typename RangeT, typename PredicateT>
SequenceSequenceT & split(SequenceSequenceT &, RangeT &&, PredicateT, token_compress_mode_type = token_compress_off);
这个函数的第一个参数是输出型参数,表示切割后的每一段内容的存储位置,第二个参数表示需要切割的内容,第三个参数表示分隔符,第四个参数表示是否需要开启压缩模式,默认为关闭状态,使用示例如下:
#include <boost/algorithm/string.hpp>int main()
{std::string str = "aaaaa\3bbbbb\3ccccc"; // 原始数据std::vector<std::string> out; // 存储切割后的数据// 以\3作为切割符切割,默认不压缩boost::split(out, str, boost::is_any_of("\3"));std::for_each(out.begin(), out.end(), [&out](std::string s){std::cout << s << std::endl;});return 0;
}输出结果:
aaaaa
bbbbb
ccccc
上面使用默认的不压缩,所谓的压缩,就是对于连续出现多次\3时将其压缩为一个\3处理:
#include <boost/algorithm/string.hpp>int main()
{std::string str = "aaaaa\3\3\3\3\3bbbbb\3ccccc"; // 原始数据std::vector<std::string> out; // 存储切割后的数据// 以\3作为切割符切割,压缩boost::split(out, str, boost::is_any_of("\3"), boost::token_compress_on);std::for_each(out.begin(), out.end(), [&out](std::string s){std::cout << s << std::endl;});return 0;
}输出结果:
aaaaa
bbbbb
ccccc
如果上面的代码中不进行压缩,那么默认结果如下:
int main()
{// ...boost::split(out, str, boost::is_any_of("\3"));// ...
}输出结果:
aaaaabbbbb
ccccc
基于上面的使用示例,接下来就是根据\3对读取到的一行内容进行分隔,将分割后的内容存储到一个vector中便于接下来创建ResultData对象可以快速填充字段,为了便于可维护性,将切割逻辑单独作为一个函数抽离:
=== “切割字符串函数”
// boost中的split
void split(std::vector<std::string>& out, std::string& line, std::string sep)
{boost::split(out, line, boost::is_any_of("\3"), boost::token_compress_on);
}
=== “构建正排索引函数”
SelectedDocInfo *buildForwardIndex(std::string &line)
{std::vector<std::string> out;split(out, line, pd::g_rd_sep);if (out.size() != 3){ls::LOG(ls::LogLevel::WARNING) << "无法读取元信息";return nullptr;}SelectedDocInfo sd;// 注意填充顺序sd.rd.title = out[0];sd.rd.body = out[1];sd.rd.url = out[2];// 先设置id时直接使用正排索引数组长度sd.id = forward_index_.size();// 再添加SelectedDocInfo对象forward_index_.push_back(std::move(sd));return &forward_index_.back();
}
使用string_view实现自定义的split函数:
接下来思考第二种方式,使用string_view自主实现一个split函数,实现的基本思路与直接使用string是基本一致的,但是如果直接使用string会出现各种拷贝的情况。而最后在插入到结果集中时需要注意重新转换为string对象,因为参数传递的line属于局部对象,离开了while代码块就会销毁,这就直接导致了vector中存储的数据丢失导致的野指针问题,所以vector需要存储string对象,这里是无法避免的。整体的实现方式如下:
// 使用string_view自主实现split
void split(std::vector<std::string> &out, std::string_view line, std::string_view sep)
{if (line.empty())return;size_t pos = 0;size_t found;while ((found = line.find(sep, pos)) != std::string_view::npos){// 添加当前位置到分隔符之间的子字符串out.push_back(std::string(line.substr(pos, found - pos)));// 更新位置到分隔符之后pos = found + sep.length();}// 添加最后一个分隔符之后的子字符串if (pos < line.length())out.push_back(std::string(line.substr(pos)));
}
构建正排索引的主逻辑代码不需要改变,因为string_view对象可以通过string对象构建
实现构建倒排索引buildBackwardIndex
为了构建倒排索引首先需要知道本次构建倒排索引的思路:
倒排索引本质就是根据已有的关键字筛选出出现该关键字的文章
基于上面这个本质,可以推出两种情况:
- 一个关键字可能对应着多个文档
- 一个文档内可能含有多个关键字
很明显,上面构成的是一种“多对多”的关系
首先从一方面考虑:一个文档中含有多个关键字。根据前面的结构SelectDocInfo中的内容,其中的ResultData结构体中存在着title和content字段,这两个字段都有可能出现某一个关键字,所以二者都需要考虑。再看前面的BackwardIndexElement结构,这个结构中含有关键字、文档ID和文章权重三个字段,既然是一个文档中含有多个关键字,那么对于同一篇文档,多个关键字BackwardIndexElement对象中的文档ID一定是相同的
接下来考虑关键字的问题,关键字既可能出现在title中,也可能出现在content中,那么必然需要对title和content两部分进行分词解析提取出其中的关键字,这里可以为每一个关键字建立一个结构体WordCount,这个结构体中存储着当前关键字在当前文档中的标题和内容部分出现的次数,所以有两个变量title_cnt和body_cnt,而为了建立关键字和对应的关键字出现次数结构体之间的映射关系,就需要用到一个unordered_map<string, WordCount>,分别统计title和content中关键字出现的次数更新对应字段的值即可统计出当前关键字在当前文档中出现的次数
最后,在BackwardIndexElement中还有一个字段:权重,本质上这里需要涉及到相关性分析,但是相关性分析是一套很复杂的过程,所以本次为了简便,考虑一种思路:关键字出现在标题的权重值要大于关键字出现在内容的权重值,所以可以设计权重的计算公式为 t i t l e × 10 + b o d y title \times 10 + body title×10+body,这样就完成了一篇文档内所有关键字的统计
最后,既然是“多对多”的关系,那么除了考虑一个文档内含有多个关键字以外,还需要考虑一个关键字对应多个文档的情况。实际上,因为每一个文档都需要统计当前文档中所有的关键字,而一旦所有的文档全部统计完毕就相当于处理了一个关键字对应多个文档的情况
基于上面的思路,首先需要一个结构体WordCount表示一个关键字分别在标题和文章中出现的频率:
// 频率结构
struct WordCount
{int title_cnt;int body_cnt;
};
接着,还需要一个哈希表用于表示这个关键字和对应词频结构对象之间的映射关系,所以需要在索引类中添加一个哈希表成员:
std::unordered_map<std::string, WordCount> word_cnt_; // 词频统计
根据上面的思路实现buildBackwardIndex函数,但是实现之前首先需要提取出标题和内容中的关键字,这里就需要用到分词工具Jieba:
根据Jieba的操作指示,首先需要将远程的Jieba克隆到本地,具体存放位置自定义:
git clone https://github.com/yanyiwu/cppjieba.git
接着,为了能在项目中使用,考虑在当前路径下建立软链接指向cppjieba文件夹中的include目录,例如:
ln -s /home/epsda/dependencies/cppjieba/include include
创建完成后就可以看到下面的信息:
lrwxrwxrwx 1 epsda epsda 41 Apr 3 09:28 include -> /home/epsda/dependencies/cppjieba/include/
在接下来的项目中使用就可以通过下面的方式引入:
#include "include/cppjieba/Jieba.hpp"
但是,如果执行上面的步骤就会出现丢失文件的问题,本质是因为Jieba.hpp中的QuerySegment.hpp引入了limonp/Logging.hpp,这个文件在新版的Jieba库中并不是直接存储在Jieba仓库中,而是单独在limonp仓库中,所以接下来需要克隆limonp仓库:
git clone https://github.com/yanyiwu/limonp.git
克隆完成后可以在该仓库中的include文件夹下找到limonp文件夹,这个文件夹中就包含了Logging.hpp文件,所以只需要将include/limonp拷贝到cppjieba目录中的include目录中即可,最后的目录结构如下:
/home/epsda/dependencies/cppjieba/include/cppjieba
├── DictTrie.hpp
├── FullSegment.hpp
├── HMMModel.hpp
├── HMMSegment.hpp
├── Jieba.hpp
├── KeywordExtractor.hpp
├── MPSegment.hpp
├── MixSegment.hpp
├── PosTagger.hpp
├── PreFilter.hpp
├── QuerySegment.hpp
├── SegmentBase.hpp
├── SegmentTagged.hpp
├── TextRankExtractor.hpp
├── Trie.hpp
├── Unicode.hpp
└── limonp // limonp文件├── ArgvContext.hpp├── Closure.hpp├── Colors.hpp├── Condition.hpp├── Config.hpp├── ForcePublic.hpp├── LocalVector.hpp├── Logging.hpp├── NonCopyable.hpp├── StdExtension.hpp└── StringUtil.hpp
接着,执行Jieba的测试代码:
#include <iostream>
#include "include/cppjieba/Jieba.hpp"using namespace std;int main(int argc, char **argv)
{cppjieba::Jieba jieba;vector<string> words;vector<cppjieba::Word> jiebawords;string s;string result;s = "他来到了网易杭研大厦";cout << s << endl;cout << "[demo] Cut With HMM" << endl;jieba.Cut(s, words, true);cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Cut Without HMM " << endl;jieba.Cut(s, words, false);cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "我来到北京清华大学";cout << s << endl;cout << "[demo] CutAll" << endl;jieba.CutAll(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造";cout << s << endl;cout << "[demo] CutForSearch" << endl;jieba.CutForSearch(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;return EXIT_SUCCESS;
}
上面的代码相对于原始的
demo.cpp中删除了部分不需要的代码,不影响整体代码运行
这个代码在demo.cpp文件中,demo.cpp可以在此链接处可以找到,但是需要注意,如果直接使用这个文件会出现找不到字典文件的问题,因为该文件中默认初始化Jieba类时使用的是下面的方式:
// ...
int main(int argc, char** argv) {cppjieba::Jieba jieba;// ...
}
但是,在Jieba.hpp中可以看到初始化时默认字典值都是空:
// ...
class Jieba {public:Jieba(const string& dict_path = "", const string& model_path = "",const string& user_dict_path = "", const string& idf_path = "", const string& stop_word_path = "") : dict_trie_(getPath(dict_path, "jieba.dict.utf8"), getPath(user_dict_path, "user.dict.utf8")),model_(getPath(model_path, "hmm_model.utf8")),mp_seg_(&dict_trie_),hmm_seg_(&model_),mix_seg_(&dict_trie_, &model_),full_seg_(&dict_trie_),query_seg_(&dict_trie_, &model_),extractor(&dict_trie_, &model_, getPath(idf_path, "idf.utf8"), getPath(stop_word_path, "stop_words.utf8")) {}// ...static string getPath(const string& path, const string& default_file) {if (path.empty()) {string current_dir = getCurrentDirectory();string parent_dir = current_dir.substr(0, current_dir.find_last_of("/\\"));string grandparent_dir = parent_dir.substr(0, parent_dir.find_last_of("/\\"));return pathJoin(pathJoin(grandparent_dir, "dict"), default_file);}return path;}
}
根据getPath函数的逻辑:如果用户指定的字典文件路径为空,那么就会读取默认路径的值例如如果dict_path为空,jieba.dict.utf8就会作为默认文件路径,在函数内部会调用pathJoin将祖父路径、dict目录和当前jieba.dict.utf8拼接形成一个路径。但是当前因为是软链接,所以实际三个路径获取的结果都是include/cppjieba,此时根据Jieba.hpp的文件位置:include/cppjieba,如果要使用原始文件就需要将cppjieba/dict目录拷贝到cppjieba/include目录中。对于这种情况,使用的目录结构如下:
/home/epsda/dependencies/cppjieba/include
├── cppjieba // Jieba.hpp所在的路径
│ ├── DictTrie.hpp
│ ├── FullSegment.hpp
│ ├── HMMModel.hpp
│ ├── HMMSegment.hpp
│ ├── Jieba.hpp
│ ├── KeywordExtractor.hpp
│ ├── MPSegment.hpp
│ ├── MixSegment.hpp
│ ├── PosTagger.hpp
│ ├── PreFilter.hpp
│ ├── QuerySegment.hpp
│ ├── SegmentBase.hpp
│ ├── SegmentTagged.hpp
│ ├── TextRankExtractor.hpp
│ ├── Trie.hpp
│ ├── Unicode.hpp
│ └── limonp
│ ├── ArgvContext.hpp
│ ├── Closure.hpp
│ ├── Colors.hpp
│ ├── Condition.hpp
│ ├── Config.hpp
│ ├── ForcePublic.hpp
│ ├── LocalVector.hpp
│ ├── Logging.hpp
│ ├── NonCopyable.hpp
│ ├── StdExtension.hpp
│ └── StringUtil.hpp
└── dict // 与cppjieba目录同级的dict目录├── README.md├── hmm_model.utf8├── idf.utf8├── jieba.dict.utf8├── pos_dict│ ├── char_state_tab.utf8│ ├── prob_emit.utf8│ ├── prob_start.utf8│ └── prob_trans.utf8├── stop_words.utf8└── user.dict.utf8
另外还有一种方法,在当前项目路径中创建一个软链接指向cppjieba/dict目录,例如:
ln -s /home/epsda/dependencies/cppjieba/dict dict
再在代码中创建Jieba对象时指定字典文件:
int main(int argc, char **argv)
{cppjieba::Jieba jieba("./dict/jieba.dict.utf8","./dict/hmm_model.utf8","./dict/user.dict.utf8","./dict/idf.utf8","./dict/stop_words.utf8");// ...
}
本次考虑使用第一种方案,运行demo.cpp代码就可以看到下面的结果:
他来到了网易杭研大厦
[demo] Cut With HMM
他/来到/了/网易/杭研/大厦
[demo] Cut Without HMM
他/来到/了/网易/杭/研/大厦
我来到北京清华大学
[demo] CutAll
我/来到/北京/清华/清华大学/华大/大学
小明硕士毕业于中国科学院计算所,后在日本京都大学深造
[demo] CutForSearch
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
在本次使用中,只需要用到其中的CutForSearch方法,其定义如下:
void CutForSearch(const string& sentence, vector<string>& words, bool hmm = true) const;
虽然函数中有三个参数,但是本次只需要考虑前两个参数即可。第一个参数表示待切割的内容,第二个参数表示切割后的结果存放位置
基于上面的介绍,现在继续完成buildBackwardIndex的逻辑。因为需要统计切分后的词在标题和内容中的频次,所以需要对标题和内容分别进行切分,这里分两步走:
- 切分标题统计切分后的词出现的次数
- 切分内容统计切分后的词出现的次数
统计完毕后,接下来需要根据关键字构建对应的倒排索引文章信息节点,这一步只需要创建倒排索引文章信息节点再填入对应的信息即可完成构建
所以,构建倒排索引buildBackwardIndex函数基本逻辑如下:
class SearchIndex
{
private:static const int title_weight_per = 10;static const int body_weight_per = 1;
public:// ...// 构建倒排索引bool buildBackwardIndex(SelectedDocInfo &sd){// 统计标题中关键字出现的次数cppjieba::Jieba jieba;std::vector<std::string> title_words;jieba.CutForSearch(sd.rd.title, title_words);for (auto &tw : title_words)word_cnt_[tw].title_cnt++;// 统计内容中关键字出现的次数std::vector<std::string> body_words;jieba.CutForSearch(sd.rd.body, body_words);for (auto &bw : body_words)word_cnt_[bw].body_cnt++;// 遍历关键字哈希表获取关键字填充对应的倒排索引节点for (auto &word : word_cnt_){BackwardIndexElement b;b.id = sd.id;b.word = word.first;// 权重统计按照公式计算b.weight = word.second.title_cnt * title_weight_per + word.second.body_cnt * body_weight_per;backward_index_[b.word].push_back(std::move(b));}return true;}// ...
private:// ...std::unordered_map<std::string, std::vector<BackwardIndexElement>> backward_index_; // 倒排索引结果std::unordered_map<std::string, WordCount> word_cnt_; // 词频统计
};
实现搜索引擎模块
基本实现
搜索的本质就是根据搜索关键字在已有的关键字中查询出需要的文章,所以这里首先建立一个类用于表示搜索服务:
class SearchEngine
{};
既然是搜索引擎,那么在初始化搜索引擎对象时就需要先构建需要用到的索引,所以考虑搜索引擎的构造函数中完成对索引对象的初始化。所以在搜索引擎类中需要有一个SearchIndex类对象作为成员,接着在SearchEngine的构造函数中初始化这个成员:
class SearchEngine
{
public:SearchEngine(){// 构建索引search_index_.buildIndex();}private:si::SearchIndex search_index_;
};
上面这种创建SearchIndex类成员的方式可以达到需要的效果,但是如果SearchEngine类对象被多次创建就会出现多次构建索引的情况,所以为了避免这个问题,考虑将SearchIndex类设置为单例模式:
class SearchIndex
{
private:// ...// 私有构造函数SearchIndex(){}// 禁用拷贝和赋值SearchIndex(const SearchIndex& si) = delete;SearchIndex& operator=(SearchIndex& si) = delete;SearchIndex(SearchIndex&& si) = delete;static SearchIndex* si;
public:// 获取单例对象static SearchIndex* getSearchIndexInstance(){if(!si){// 加锁mtx.lock();if(!si)si = new SearchIndex();mtx.unlock();}return si;}// ...
private:// ...static std::mutex mtx;
};SearchIndex* SearchIndex::si = nullptr;
std::mutex SearchIndex::mtx;
接着,在SearchEngine对象中通过调用getSearchIndexInstance函数获取SearchIndex类对象:
class SearchEngine
{
public:SearchEngine(): search_index_(si::SearchIndex::getSearchIndexInstance()){// 构建索引search_index_->buildIndex();}~SearchEngine(){}private:si::SearchIndex* search_index_;
};
完成索引的构建之后就需要根据用户输入的关键字查询出对应的结果,这里可以通过一个search函数包裹整体逻辑,这个函数的第一个参数就是用户输入的关键字,第二个参数是查询到的结果。因为后面需要进行网络传输,所以少不了的就是对查询的结果进行协议化,为了保证客户端也可以正常识别当前服务端传送的数据,这里考虑使用JSON字符串作为第二个参数,即:
// 根据关键字进行搜索
void search(std::string& keyword, std::string& json_string)
{}
接下来考虑search函数中的逻辑,因为用户输入的词可能并不是文章中一定存在的某一个关键词,所以此处还需要对用户输入的内容进行分词。对搜索关键字进行分词之后就是在哈希表中查询出相应的结果,这里可以需要考虑将内容存储到一个结构中。这里需要考虑两个问题:
- 前面建立了两个哈希表,具体需要查询哪一个哈希表
- 如何处理分词后的结果
对于第一个问题,两张哈希表分别为unordered_map<string, WordCount>用于统计关键字和对应权重的映射关系以及unordered_map<string, vector<BackwardIndexElement>>用于统计关键字和所有倒排结果的映射关系,考虑到后面需要根据BackwardIndexElement中的文档ID查询正排索引,所以需要查询的哈希表实际上就是unordered_map<string, vector<BackwardIndexElement>>
对于第二个问题,在unordered_map<string, vector<BackwardIndexElement>>中通过关键字查询得到的结果就是出现指定关键字对应的关键字信息节点数组,所以接下来为了在下一步可以对结果进行排序,考虑将查询出的结果存储到一个数组中。注意这个数组中存储的不是vector<BackwardIndexElement>,而是其中的BackwardIndexElement对象,因为获取到所有的结果后实际上就已经不需要再考虑关键字的问题了,接下来考虑的只是权重优先级问题
明确了上面提到的两个问题之后,思考search函数的基本逻辑:首先对用户输入的关键词进行切分。接着,根据切分后的每个词查找倒排索引得到其中存储倒排索引文章信息节点的数组vector<BackwardIndexElement>,将这个数组中的每一个BackwardIndexElement对象存储到一个单独的结构中便于接下来的排序,本次排序的基本思路就是按照倒排信息节点中的权重字段进行降序排序(即权重高的排在前面)
基于上面的思路,首先需要实现SearchIndex类中的getBackwardIndexElement函数:
// 获取倒排索引结果
std::vector<BackwardIndexElement> *getBackwardIndexElement(const std::string &keyword)
{auto pos = backward_index_.find(keyword);if(pos == backward_index_.end()){ls::LOG(ls::LogLevel::WARNING) << "不存在对应的关键字";return nullptr;}return &backward_index_[keyword];
}
接着实现search函数中的逻辑:
// 根据关键字进行搜索
void search(std::string &keyword, std::string &json_string)
{// 对用户输入的关键字进行切分cppjieba::Jieba jieba;std::vector<std::string> keywords;jieba.CutForSearch(keyword, keywords);// 查询哈希表得到结果std::vector<si::BackwardIndexElement> results;for (auto &word : keywords){// 查倒排索引std::vector<si::BackwardIndexElement>* ret_ptr = search_index_->getBackwardIndexElement(word);if(!ret_ptr)continue;// 插入结果results.insert(results.end(), ret_ptr->begin(), ret_ptr->end());}// 按照权重排序std::stable_sort(results.begin(), results.end(), [](si::BackwardIndexElement &b1, si::BackwardIndexElement &b2){ return b1.weight > b2.weight; });
}
虽然上面的过程能实现基本的目标,但是还存在一个问题:如果存在多个关键字对应着同样的文章,例如关键字1和关键字2都对应着文档1和文档2。这种情况下执行上面的逻辑就会出现文档1和文档2的结果被插入两次导致最后的结果存在相同的内容。为了解决这个问题,可以考虑下面的思路:
因为问一个BackwardIndexElement节点都有对应的文档ID,可以根据文档ID是否重复出现判断是否出现了重复插入,所以这里可以建立一张哈希表,这个哈希表的第二个元素类型就是BackwardIndexElement,第一个元素类型就是文档ID:
std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;
接着,在每一次遍历获取倒排索引文章信息节点数组后遍历该数组,判断其中的文章是否已经在select_map出现,没有出现就插入,否则不插入。当遍历完用户输入的所有可能的关键词后将select_map再插入到results即可:
// 根据关键字进行搜索
void search(std::string &keyword, std::string &json_string)
{// ...for (auto &word : keywords){// ...for(auto &bi : *ret_ptr){// 如果文档ID已经存在,说明已经存在,否则不存在if(select_map.find(bi.id) == select_map.end())select_map[bi.id] = bi;}}// 遍历select_map存储结果for(auto &pair : select_map)results.push_back(std::move(pair.second));// ...
}
但是,仅仅有上面的逻辑还不足以完成去重的行为,因为当前只考虑了多个关键字对应同一篇文档的情况,也可能存在文档内部存在多个关键字的情况,对于第二种情况上面的逻辑就只是简单的获取赋值而已,并没有实现去重
解决第二种情况的方式很简单,就是将同一个文档中多个关键字进行累积,但是基于已有的BackwardIndexElement无法做到这一点,因为BackwardIndexElement中只能保存一个关键字,所以考虑创建一个新的节点结构SearchIndexElement,该结构与BackwardIndexElement主要不同点就是std::string word变为std::vector<std::string> words:
// 搜索节点结构
struct SearchIndexElement
{uint64_t id;std::vector<std::string> words;int weight;
};
另外,为了后续计算安全,考虑提供一个构造函数对成员进行初始化:
SearchIndexElement():id(0), weight(0)
{}
接着更改用于去重的哈希表结构:
// std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;
std::unordered_map<uint64_t, SearchIndexElement> select_map;
基于上面的哈希表结构,修改去重逻辑:
// 根据关键字进行搜索
void search(std::string &keyword, std::string &json_string)
{// ...for (auto &word : keywords){// ...for (auto &bi : *ret_ptr){// 如果文档ID已经存在,说明已经存在,否则不存在if (select_map.find(bi.id) == select_map.end()){// 获取当前文档搜索结构节点,不存在自动插入,存在直接获取auto &el = select_map[bi.id];// 如果是新节点,直接赋值;如果是重复出现的节点,覆盖el.id = bi.id;// 如果是新节点,第一次添加;如果是重复节点,追加el.words.push_back(bi.word);// 如果是新节点,直接赋值;如果是重复节点,累加el.weight += bi.weight;}}}// ...
}
接着添加去重后的节点到结果集中便于后续排序,此处需要修改结果集结构:
// std::vector<si::BackwardIndexElement> results;
std::vector<SearchIndexElement> results;
修改排序逻辑:
// std::stable_sort(results.begin(), results.end(), [](const si::BackwardIndexElement &b1, const si::BackwardIndexElement &b2) { return b1.weight > b2.weight; });
std::stable_sort(results.begin(), results.end(), [](const SearchIndexElement &b1, const SearchIndexElement &b2){ return b1.weight > b2.weight; });
完成上面的逻辑之后,最后就是将结果转换为JSON字符串存储到search函数的第二个参数中。因为需要给用户返回的内容时文章标题、文章内容和文章在官网的URL,而此处的SearchIndexElement并没有这三个字段,所以此处还需要借助正排索引,这就是为什么需要同时在正排索引文章信息节点SelectDocInfo和SearchIndexElement设置文档ID字段的原因。一旦获取到文章信息后,就可以将三个字段的内容转换为JSON字符串并赋值给json_string
基于这个逻辑,首先实现获取正排索引文章信息节点函数getForwardIndexDocInfo:
// 获取正排索引结果
SelectedDocInfo *getForwardIndexDocInfo(uint64_t id)
{if(id < 0 || id > forward_index_.size()){ls::LOG(ls::LogLevel::WARNING) << "不存在对应的文档ID";return nullptr;}return &forward_index_[id];
}
接着,实现search最后一部分逻辑。对于一个文档中含有多个关键字的情况,此处为了简便只取出第一个关键词:
// 根据关键字进行搜索
void search(std::string &keyword, std::string &json_string)
{// ...// 转换为JSON字符串Json::Value root;for (auto &el : results){// 通过正排索引获取文章内容si::SelectedDocInfo *sd = search_index_->getForwardIndexDocInfo(el.id);Json::Value item;item["title"] = sd->rd.title;// 取出第一个关键词item["body"] = getPartialBodyWithKeyword(sd->rd.body, el.words[0]);item["url"] = sd->rd.url;// 将item作为一个JSON对象插入到root中作为子JSON对象root.append(item);}json_string = root.toStyledString();
}
搜索关键字查询优化
使用上面实现的搜索引擎会发现一个比较影响体验的问题:大小写问题。在实际生活中使用的搜索引擎实际上都是忽略大小写的,所以为了保证本次实现的搜索引擎符合日常使用,添加忽略大小写的功能到当前项目中
既然要实现忽略大小写,那么必然涉及到两个方面:
- 构建索引时对应的关键字需要忽略大小写
- 获取到用户输入的关键字需要忽略大小写
根据上面两个方面对前面的代码进行修改:
首先是构建索引部分,只有倒排索引需要修改。对于标题和内容都需要忽略大小写,而忽略大小写的时机就在切割关键词之后,统计关键词频次之前,修改如下:
// 构建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{// 统计标题中关键字出现的次数cppjieba::Jieba jieba;std::vector<std::string> title_words;jieba.CutForSearch(sd.rd.title, title_words);for (auto &tw : title_words){// 忽略大小写boost::to_lower(tw);word_cnt_[tw].title_cnt++;}// 统计内容中关键字出现的次数std::vector<std::string> body_words;jieba.CutForSearch(sd.rd.body, body_words);for (auto &bw : body_words){boost::to_lower(bw);word_cnt_[bw].body_cnt++;}// ...
}
接着就是对用户输入的关键字进行大小写忽略,执行的位置就是在分词之后,查找之前:
// 根据关键字进行搜索
void search(std::string &keyword, std::string &json_string)
{// 对用户输入的关键字进行切分cppjieba::Jieba jieba;std::vector<std::string> keywords;jieba.CutForSearch(keyword, keywords);// 查询哈希表得到结果std::vector<si::BackwardIndexElement> results;std::unordered_map<uint64_t, si::BackwardIndexElement> select_map;for (auto &word : keywords){// 忽略大小写boost::to_lower(word);// 查倒排索引// ...}// ...
}
查询结果优化
在上面的代码中可以发现获取到的内容中有些body部分内容特别多,这是因为在写入时直接写入了整个body的内容,这个内容对应的就是去除标签后整个网页的内容,其中还包括了标题,但是在一个搜索引擎结果中,描述性文字实际上只有用户输入的关键字附近的一部分内容,如下图所示:
本次实现同样考虑实现这个方案,实现方式很简单,只需要截取以关键字为中心附近的字符组成一个新字符串再转换为JSON字符串即可。这里实现可以考虑使用string_view,因为涉及到大量的字符串操作
本次实现中考虑取出第一个关键字前50个字符(如果没有就从头开始取)以及后100个字符(如果没有就取到结尾)构成一个新的字符串:
static const int prev_words = 50;
static const int after_words = 100;
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// 找到关键字size_t pos = body.find(keyword);if(pos == std::string_view::npos){ls::LOG(ls::LogLevel::WARNING) << "无法找到关键字,无法截取文章内容";return "Fail to cut body, can't find keyword";}// 默认起始位置为0,终止位置为body字符串最后一个字符int start = 0;int end = static_cast<int>(body.size() - 1);// 如果pos位置前有50个字符,就取前50个字符if(pos - prev_words > start) start = pos - prev_words;// 如果pos位置后有100个字符,就取后100个字符if(pos + static_cast<int>(keyword.size() + after_words) < end)end = pos + static_cast<int>(keyword.size()) + after_words;if(start > end){ls::LOG(ls::LogLevel::WARNING) << "内容不足,无法截取文章内容";return "Fail to cut body, body is not enough";}// 左闭右闭区间return std::string(body.substr(start, end - start + 1));
}
第一阶段问题
构建索引速度慢
在构建索引函数buildIndex中分别添加两条日志:
// 构建索引
bool buildIndex()
{// debugls::LOG(ls::LogLevel::DEBUG) << "开始建立索引";// ..ls::LOG(ls::LogLevel::DEBUG) << "建立索引完成";return true;
}
测试上面的代码可以发现几乎3秒钟执行一次10次构建,而raw文件中的内容有8141行,计算下来需要花费将近40分钟进行构建
出现这个问题的主要原因就是buildBackwardIndex和search两个函数中的Jieba分词对象都是以局部变量的形式创建的,search会在用户搜索时执行,刚开始并没有出现明显的速度拖慢,但是buildBackwardIndex会在每一行内容构建时执行,这就导致了Jieba对象需要创建8141次
解决这个问题的方式就是将Jieba分词对象作为成员变量:
=== “SearchIndex类”
class SearchIndex{// ...public:// ...private:// ...// 构建倒排索引bool buildBackwardIndex(SelectedDocInfo &sd){// ...std::vector<std::string> title_words;jieba_.CutForSearch(sd.rd.title, title_words);// ...}//...private:// ...cppjieba::Jieba jieba_;};
=== “SearchEngine类”
class SearchEngine
{
public:SearchEngine(): search_index_(si::SearchIndex::getSearchIndexInstance()){// 构建索引search_index_->buildIndex();}// 根据关键字进行搜索void search(std::string &keyword, std::string &json_string){// 对用户输入的关键字进行切分std::vector<std::string> keywords;jieba_.CutForSearch(keyword, keywords);// ...}~SearchEngine(){}// ...private:// ...cppjieba::Jieba jieba_;
};
进程占满内存,系统杀死进程
解决第一个问题之后,再次运行代码可以发现建立索引的速度的确变快了,但是同时出现了第二个问题,当前系统的内存为4GB,在建立到五千行时会出现系统杀死进程,本质就是当前进程在运行一段时间后占满了内存,操作系统为了保护自己不得已杀死进程,如下图:
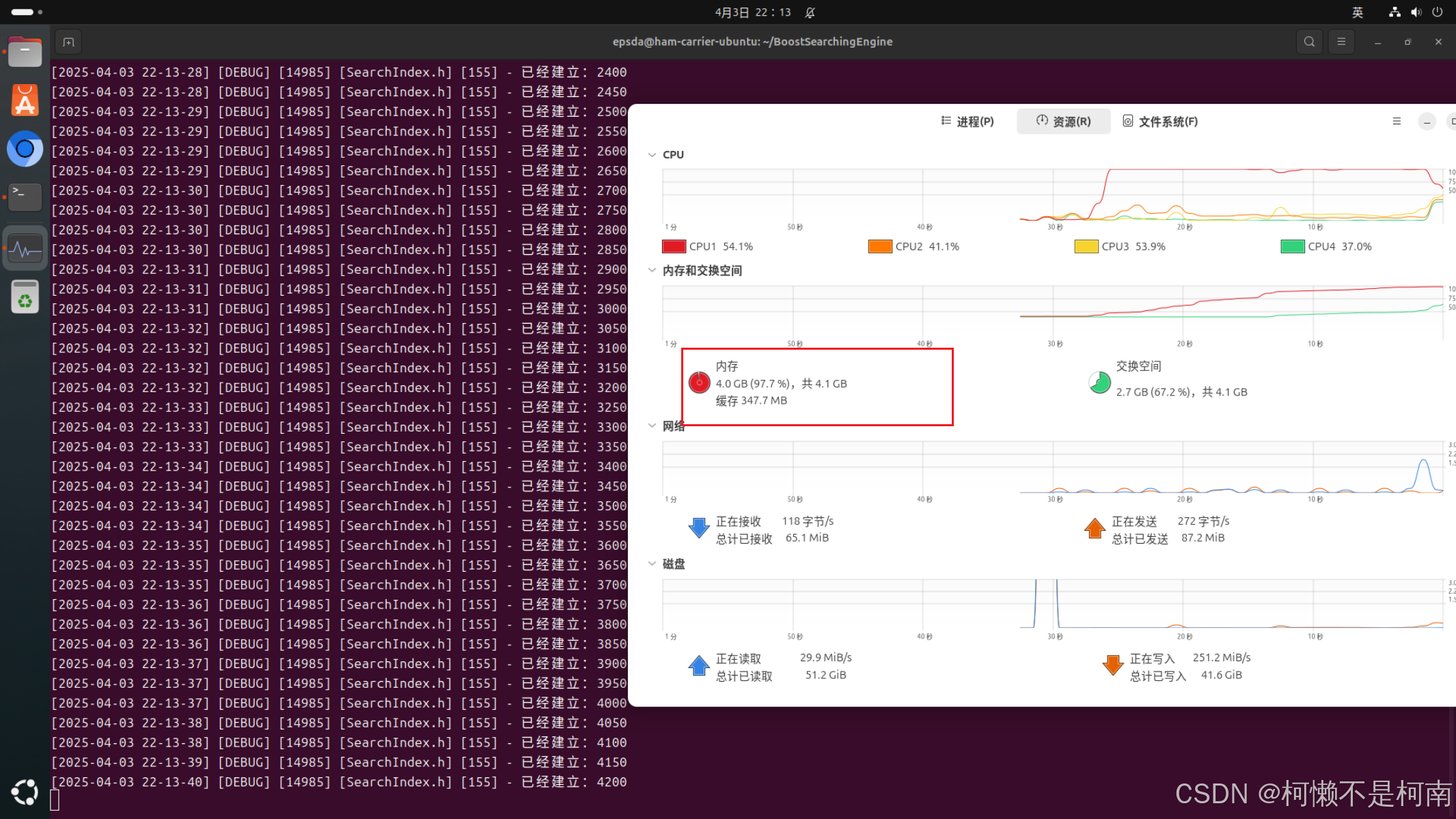
出现这个问题的原因就是用于统计词频的哈希表成员。这张哈希表作为了成员变量,其生命周期随着对象,而当前对象只有在SearchEngine对象销毁时才会销毁,这就导致了word_cnt_成员在8141次构建倒排索引时一直在增长,最后内存无法存储这么大的哈希表不得已杀死进程
但是实际上,word_cnt_只需要统计当前一行的关键字即可,因为在buildBackwardIndex中最后会将词频计算存储到倒排索引信息节点的权重属性,所以执行完这一步,word_cnt_当前的内容就可以不需要了
解决方案有两种:
- 将
word_cnt_作为buildBackwardIndex函数的成员变量 - 在
buildBackwardIndex函数刚开始调用word_cnt_的clear函数清空当前的word_cnt_
本次采用第二种方法,修改如下:
// 构建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{word_cnt_.clear();// ...
}
错误进入本不应该进入的逻辑
进入getPartialBodyWithKeyword中无法找到关键字分支
出现这个问题的本质是在getPartialBodyWithKeyword函数中,因为第一个参数获取到的是文章原始内容,其中的每一个单词包含大写和小写,但是第二个参数是忽略大小写之后的结果,这就导致在查找倒排索引时的确查得到,但是截取时因为可能存在大写字母而没有忽略大小写导致没有截取到对应的关键字
最简单的解决方案就是将内容全部转换为小写,但是这样的成本过高,另外一种方案就是在查找的时候忽略大小写,但是string_view中并没有提供忽略大小写查找的方案,所以需要借助<algorithm>中的search方法解决,该方法的原型如下:
template <class ForwardIterator1, class ForwardIterator2, class BinaryPredicate>
ForwardIterator1 search (ForwardIterator1 first1, ForwardIterator1 last1,ForwardIterator2 first2, ForwardIterator2 last2,BinaryPredicate pred);
该方法的含义是根据pred的比较方式查找第一个容器中是否连续含有第二个容器的内容,因为本次查找就是为了查找出内容中是否含有关键字并且需要忽略大小写,本质就是查找是否在内容中存在连续的字符转换为小写与关键字的每一个字符在转换小写后相同
但是,search函数会返回一个迭代器而不是整数表示第一次出现的位置,所以还需要计算出当前迭代器位置与原始内容字符串开始的距离
这里可以使用<iterator>库中的distance函数,该函数原型如下:
template<class InputIterator>
typename iterator_traits<InputIterator>::difference_type
distance (InputIterator first, InputIterator last);
该函数会返回第一个迭代器和第二个迭代器之间的位置值,如果将迭代器类比为指针,因为当前元素是字符,占用一个字节,那么就可以理解为两个指针直接相减得到的值
基于上面这个解决方案,修改原来的getPartialBodyWithKeyword函数:
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// 找到关键字// size_t pos = body.find(keyword);auto pos_t = std::search(body.begin(), body.end(), keyword.begin(), keyword.end(), [](char c1, char c2){ return std::tolower(c1) == std::tolower(c2); });if (pos_t == body.end()){ls::LOG(ls::LogLevel::WARNING) << "无法找到关键字,无法截取文章内容";return "Fail to cut body, can't find keyword";}int pos = std::distance(body.begin(), pos_t);// ...
}
进入getPartialBodyWithKeyword中内容不足截取不到内容分支
出现这个问题的原因在getPartialBodyWithKeyword中,计算是否可以取出前50个字符时pos并没有转换为int,而是保留了size_t参与运算,这就导致计算pos - prev_words > start是出现了类型提升,即全部以size_t类型进行计算,而此时的pos一旦是size_t就会变成npos的值(即int类型下的-1,size_t下的 2 64 − 1 2^{64} - 1 264−1),因此pos - prev_words始终大于start,因为根本减不到负数。这里条件成立进入分支之后执行start = pos - prev_words;。接着,一旦满足start > end,就会进入到内容不足截取不到内容分支的逻辑
解决方案就是将pos转换为int类型防止出现类型提升:
std::string getPartialBodyWithKeyword(std::string_view body, std::string_view keyword)
{// ...// 如果pos位置前有50个字符,就取前50个字符if (static_cast<int>(pos) - prev_words > start)start = pos - prev_words;// ...
}
构建的URL在官网出现页面不存在
例如下面构建出的URL:
https://www.boost.org/doc/libs/1_78_0/doc/html/some_basic_explanations.html
官网实际的URL为:
https://www.boost.org/doc/libs/1_78_0/doc/html/interprocess/some_basic_explanations.html
首先排除目录路径问题,如下:
epsda@ham-carrier-ubuntu:~/BoostSearchingEngine$ find -name some_basic_explanations.html
./data/source/html/interprocess/some_basic_explanations.html
可以看到在html目录下的确存在interprocess/some_basic_explanations.html,如果按照预期的拼接方式应该为:
https://www.boost.org/doc/libs/1_78_0/doc/html/ + interprocess/some_basic_explanations.html
但是这里的拼接方式为:
https://www.boost.org/doc/libs/1_78_0/doc/html/ + some_basic_explanations.html
这就导致出现了页面不存在(404)的问题
出现这个问题的代码就是constructHtmlUrl中截取本地路径部分。原始的逻辑是找到最后一个/就停止查找,导致截取出的some_basic_explanations.html实际上缺少了其父级目录interprocess/,进而导致构建URL时得到的URL在官网不存在
解决这个问题的思路很简单,只需要查找路径/data/source/html在/data/source/html/interprocess/some_basic_explanations.html出现的起始位置值pos,再从pos + 路径长度开始截取后面的内容即可
基于上面的思路修改代码如下:
// 构建URL
bool constructHtmlUrl(const fs::path &p, std::string *url)
{// 查找/data/source/htmlstd::string t_path = p.string();auto pos = t_path.find(g_datasource_path);// ...std::string source_path = t_path.substr(pos + g_datasource_path.string().size());*url = g_url_to_concat + source_path;return true;
}
权重计算异常
在构建JSON字符串时,添加文档ID、权重和关键字后测试:
void search(std::string &keyword, std::string &json_string)
{// ...// 转换为JSON字符串Json::Value root;for (auto &bi : results){// ...item["id"] = sd->id;item["word"] = bi.word;item["weight"] = bi.weight;// ...}// ...
}
测试结果可以看到,有些权重计算结果存在一定误差,例如搜索split:
{"body" : "Class template split_iteratorHomeLibrariesPeopleFAQMoreClass template split_iteratorboost::algorithm::split_iterator \u2014 ","id" : 6164,"title" : "Class template split_iterator","url" : "https://www.boost.org/doc/libs/1_78_0/doc/html/boost/algorithm/split_iterator.html","weight" : 34,"word" : "split"
},
通过网址到官网启动浏览器搜索可以看到结果总共是25,其中标题中也存在split,按照设定的权重计算公式 t i t l e × 10 + b o d y title \times 10 + body title×10+body应该是35而并非34
为了找出这个问题出现的原因,需要在查询时针对当前文档ID单独打印处理,猜测出现这个问题的原因是分词工具的分词逻辑和浏览器的分词逻辑不同,修改buildBackwardIndex代码如下:
// 构建倒排索引
bool buildBackwardIndex(SelectedDocInfo &sd)
{// ...// 一旦文档ID为6164就打印出标题的所有分词结果if (sd.id == 6164){for (auto &s : title_words){std::cout << "title: " << s << std::endl;}}// ...// 一旦文档ID为6164就打印出所有文档内容的所有分词结果if (sd.id == 6164){for (auto &s : body_words){std::cout << "body: " << s << std::endl;}}// ...
}
再次进行测试,可以发现,标题存在1个split,文章内容中只有24个split,根据前面的计算公式可以得出权重值为34,可以发现代码并没有问题,只是分词的逻辑不同而已
创建服务器
本次创建服务器不直接使用原生的网络接口,而是使用封装后的cpp-httplib库,所以首先需要准备该库:
git clone https://github.com/yhirose/cpp-httplib.git
接着,在当前项目目录下建立一个软链接指向cpp-httplib对应的目录即可,例如:
ln -s /home/epsda/dependencies/cpp-httplib/
完成安装后即可写出对应的服务器代码
关于cpp-httplib的基本使用可以看对应仓库中的介绍,此处不再提及
首先,为了保证客户端可以直接通过IP地址+端口号的方式直接访问到主页,先设置Web根目录为wwwroot,其中含有一个index.html文件作为主页,并在服务器程序中通过cpp-httplib.h中的set_base_dir函数设置:
// 设置网页根路径
httplib::Server s;
s.set_base_dir(pd::root_path);
设置完成后直接访问IP地址+端口号即可访问到主页
接着服务器需要设置对应处理请求的方案,本次考虑用户请求/search服务时调用服务器中的search方法执行搜索,所以实现方式如下:
void run(se::SearchEngine& s_engine, const httplib::Request& req, httplib::Response &resp)
{}int main()
{// ...se::SearchEngine s_engine;s.Get("/search", std::bind(run, std::ref(s_engine), std::placeholders::_1, std::placeholders::_2));// ...
}
接着,本次考虑需要用户按照下面的方式请求才可以获取到内容:
http://IP地址+端口/search?keyword=xxx
所以可以编写出对应的代码为:
void run(se::SearchEngine& s_engine, const httplib::Request& req, httplib::Response &resp)
{// 如果不存在word,说明在请求不存在的页面,返回404if(!req.has_param("keyword")){se::ls::LOG(se::ls::LogLevel::INFO) << "请求不存在的资源";resp.status = httplib::StatusCode::NotFound_404;resp.set_file_content("wwwroot/404.html", "text/html");return;}// 此时说明存在对应的值,获取值auto val = req.get_param_value("keyword");// 执行搜索std::string json_string;s_engine.search(val, json_string);se::ls::LOG(se::ls::LogLevel::INFO) << "搜索关键词: " << val;resp.set_content(json_string, "application/json");
}
最后,为了保证服务器可以正常被客户端访问,服务器还需要启动监听。本次考虑监听端口由启动方设定:
int main(int argc, char* argv[])
{if(argc != 2){se::ls::LOG(se::ls::LogLevel::ERROR) << "启动方式错误";return 1;}// ...// 获取端口int port = std::stoi(argv[1]);// 监听任意端口s.listen("0.0.0.0", port);return 0;
}
相关文章:
)
Boost库搜索引擎项目(版本1)
Boost库搜索引擎 项目开源地址 Github:https://github.com/H0308/BoostSearchingEngine Gitee:https://gitee.com/EPSDA/BoostSearchingEngine 版本声明 当前为最初版本,后续会根据其他内容对当前项目进行修改,具体见后续版本…...

复古千禧Y2风格霓虹发光酸性镀铬金属短片音乐视频文字标题动画AE/PR模板
踏入时光机,重温 21 世纪初大胆、未来主义和超光彩的美学!这是一个动态的 After Effects 模板,旨在重现千禧年的标志性视觉效果——铬反射、霓虹灯发光、闪亮的金属和流畅的动态图形。无论您是在制作时尚宣传片、怀旧音乐视频还是时尚的社交媒…...

如何高效使用 Ubuntu 中文官方网站
Ubuntu 中文官方网站 一、快速导航与核心模块 首页焦点区 顶部菜单栏:快速访问「下载」「文档」「支持」「商店」等核心功能。轮播图区:展示最新版本(如 Ubuntu 24.04 LTS)和特色功能(如 Ubuntu Pro 订阅服务)。搜索框:支持中文关键词搜索(如 "边缘计算"),…...
)
简单多状态dp问题 + 总结(一)
文章目录 按摩师题解代码 打家劫舍II题解代码 删除并获得点数题解代码 粉刷房子题解代码 按摩师 题目链接 题解 1. 细节处理:题目是有没有客人的时候,所有n等于零时返回零 2. 状态表示:到达i位置时的最长预约时长 3. 状态转移方程…...

2022 CCF CSP-S2.假期计划
题目 4732. 假期计划 算法标签: 搜索, 枚举, 贪心 思路 最多转车 k k k次等价于路线长度小于等于 k 1 k 1 k1, 经过的点没有限制, 注意到点的数量 2500 2500 2500, 因此 n 2 n ^ 2 n2的时间复杂度是可以考虑的, 边的数量 10000 10000 10000, n m n \times m nm时间复杂…...
 | 零基础入门STM32第九十三步)
STM32低功耗模式详解:睡眠、停机、待机模式原理与实践(下) | 零基础入门STM32第九十三步
主题内容教学目的/扩展视频低功耗模式什么是低功耗,模式介绍,切换方法。为电池设备开发做准备。 师从洋桃电子,杜洋老师 📑文章目录 一、低功耗模式基本工作原理1.1 功耗层级对比1.2 工作流程 二、睡眠模式实践2.1 测试程序解析2.…...

【Docker】在Orin Nano上使用Docker
1、安装Docker 1)使用 SDKManager 烧写系统时,选择NVIDIA Container Runtime,将会安装Docker, 并将 NVIDIA GPU 暴露给容器中的应用程序,这样可以在Docker中使用GPU等NVIDIA的特性。 2)使用命令安装 添加源 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \…...

C# 程序脱壳,去除强签名StrongNameRemove
由于.net程序的运行机制,利用Reflector,ilspy等反射工具很容易就能看到原代码。很多程序都做了代码混淆,加壳。代码混淆后反编译乱码,不容易理解;加壳使反编译工具不能正常反射,提示无效的程序集。 需要做…...

【mongodb】mongodb和MySQL体系结构的对比
目录 1. 说明2. 数据存储模型2.1 MySQL2.2 MongoDB 3. 扩展性3.1 MySQL3.2 MongoDB 4. 查询语言4.1 MySQL4.2 MongoDB 5. 索引和性能5.1 MySQL5.2 MongoDB 6. 一致性模型6.1 MySQL6.2 MongoDB 7. 架构组件7.1 MySQL7.2 MongoDB 8. 使用场景7.1 MySQL7.2 MongoDB 9. 总结对比表 …...

【深度学习新浪潮】视觉与多模态大模型文字生成技术研究进展与产品实践
一、研究进展 跨模态架构创新 原生多模态模型:微软KOSMOS系列通过统一框架支持文本、图像、语音等多模态输入输出,实现跨模态推理与迁移。例如,KOSMOS-2.5可处理文本密集图像,生成结构化文本描述,并通过重采样模块优化视觉与语言的对齐。混合专家架构:第三代模型(如Deep…...

麒麟系统桌面版本v10安装教程
下载地址 共享文件下载 - Kylin Distro 虚拟机安装教程 选择默认兼容 内核数量选择2个 内存给2g 存储为单个文件的话,占用你内存大,多个文件的话,用多少就占多少内存 打开虚拟机 开机 补充 安装来源 Live 安装:通过镜像文件进行…...

Python-文件操作
1. 文件操作基础 1.1 打开文件 在Python中使用open()函数来打开文件: file open(example.txt, r) # 以只读模式打开文件文件打开模式: r - 只读(默认)w - 写入,会覆盖已有文件a - 追加,写入到文件末尾…...
)
Apache 配置负载均衡详解(含配置示例)
Apache 是互联网上最受欢迎的 Web 服务器之一。除了基本的网页服务,它还能通过模块扩展出丰富的功能。其中一个重要用途就是将 Apache 配置成负载均衡器,用于在多个后端服务器之间分配流量,提升网站的性能和稳定性。Google Gemini中国版调用G…...
)
文章记单词 | 第24篇(六级)
一,单词释义 liner:名词,意为 “班轮;邮轮;衬里;画线者”convention:名词,意为 “大会;会议;习俗;惯例;公约;协定”lavat…...

日本汽车规模性经济计划失败,日产三大品牌的合并合作共赢,还是绝地求生?本田与日产合并确认失败,将成为世界第三大汽车集团愿景失败
本田与日产(含三菱汽车)的合并计划最终因核心矛盾无法调和而宣告失败,这一事件揭示了传统车企在行业变革期的深层困境。以下从合并动机、失败原因、本质判断及未来影响等方面综合分析: 一、合并的初衷:生存压力主导的被动策略 市场危机与财务困境 中国市场溃败:日系品牌在…...

人工智能赋能工业制造:智能制造的未来之路
一、引言 随着人工智能技术的飞速发展,其应用场景不断拓展,从消费电子到医疗健康,从金融科技到交通运输,几乎涵盖了所有行业。而工业制造作为国民经济的支柱产业,也在人工智能的浪潮中迎来了深刻的变革。智能制造&…...

支持selenium的chrome driver更新到135.0.7049.42
最近chrome释放新版本:135.0.7049.42 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

C++/Qt 模拟sensornetwork的工作
C/Qt 可视化模拟sensornetwork的工作 C/Qt 模拟sensornetwork的工作 C/Qt 可视化模拟sensornetwork的工作内容简介(一) 需求和规格说明(1)问题描述(2)设计目的(3)基本要求࿰…...

无状态版的DHCPv6是不是SLAAC? 笔记250405
无状态版的DHCPv6是不是SLAAC? 笔记250405 无状态版 DHCPv6 不是 SLAAC,但二者在 IPv6 网络中可协同工作。以下是核心区别与协作关系: 本质区别 特性SLAAC无状态 DHCPv6主要功能生成 IPv6 地址(基于路由器通告的前缀)分发 DNS、…...

前端判断值相等的方法和区别
1. (宽松相等) 在比较之前会进行类型转换 可能导致一些意外的结果 0 // true 0 0 // true false 0 // true null undefined // true [1,2,3]1,2,3 // true2. (严格相等) 不进行类型转换 类型和值都必须相同 0 // false 0 0 // false false 0 /…...

AWS全球化低延迟架构实战:助力APP快速上架欧美、加拿大、澳大利亚
作者:AWS解决方案架构师 关键词:AWS全球架构、低延迟优化、多区域部署、Serverless、GDPR合规 一、客户需求分析 客户计划将APP上架至欧美(欧盟)、加拿大、澳大利亚等地区,并要求: 全球用户低延迟访问&…...

Maven使用
配置 Maven repository 教学视频 windows环境 idea配置 Maven项目结构 src:主项目文件 main:项目文件,其中java存放java文件,resource存放其他文件如图片文件等;test存放测试文件,如果需要也可以自己创建一个resources文件 target:主要存放我运行后的jar包等,以及一些…...
)
笔试强训题(7)
目录 1. Day371.1 旋转字符串(字符串)1.2 合并k个已排序的链表(链表)1.3 滑雪(记忆化搜索) 2. Day382.1 天使果冻(递推 DP)2.2 dd爱旋转(模拟)2.3 小红取数&…...

2023-2024总结记录
概括经历 这一年算是一个人生节点,2023年花了一整年的时间在准备考研,基本上等于一个人奋战,我不怎么去图书馆,只呆在无人的实验室,还好有对象陪我,不然可能要抑郁了。作息上还是很随意,什么时…...

类初始化、类加载、垃圾回收---JVM
创建对象过程 类加载 一个类从被加载到虚拟机内存中开始,到从内存中卸载,整个生命周期需要经过七个阶段:加载 、验证、准备、解析、初始化、使用和卸载。 类加载过程分为三个主要步骤:加载、链接、初始化 加载:通过…...

交换机与ARP
交换机与 ARP(Address Resolution Protocol,地址解析协议) 的关系主要体现在 局域网(LAN)内设备通信的地址解析与数据帧转发 过程中。以下是二者的核心关联: 1. 基本角色 交换机:工作在 数据链…...

元宇宙概念下,UI 设计如何打造沉浸式体验?
一、元宇宙时代UI设计的核心趋势 在元宇宙概念下,UI设计的核心目标是打造沉浸式体验,让用户在虚拟世界中感受到身临其境的交互效果。以下是元宇宙时代UI设计的几个核心趋势: 沉浸式体验设计 元宇宙的核心是提供沉浸式体验,UI设计…...

pycharm 有智能提示,但是没法自动导包,也就是alt+enter无效果
找到file->settings->editor->inspections 把python勾选上,原来不能用是因为只勾选了一部分。...
)
神经网络与深度学习:案例与实践——第三章(3)
神经网络与深度学习:案例与实践——第三章(3)——基于Softmax回归完成鸢尾花分类任务 实践流程主要包括以下7个步骤:数据处理、模型构建、损失函数定义、优化器构建、模型训练、模型评价和模型预测等, ①数据处理&am…...

LeetCode 249 解法揭秘:如何把“abc”和“bcd”分到一组?
文章目录 摘要描述痛点分析 & 实际应用场景Swift 题解答案可运行 Demo 代码题解代码分析差值是怎么来的?为什么加 26 再 %26? 示例测试及结果时间复杂度分析空间复杂度分析总结 摘要 你有没有遇到过这种情况:有一堆字符串,看…...

【Kafka基础】topic命令行工具kafka-topics.sh:基础操作命令解析
Kafka作为分布式流处理平台的核心组件,其主题管理是每个开发者必须掌握的关键技能。本文将详细解析kafka-topics.sh工具的使用技巧,从基础操作操作开始,助您轻松驾驭Kafka主题管理。 1 创建主题 /export/home/kafka_zk/kafka_2.13-2.7.1/bin/…...
)
C++ 排序(1)
以下是一些插入排序的代码 1.插入排序 1.直接插入排序 // 升序 // 最坏:O(N^2) 逆序 // 最好:O(N) 顺序有序 void InsertSort(vector<int>& a, int n) {for (int i 1; i < n; i){int end i - 1;int tmp a[i];// 将tmp插入到[0,en…...
 高频词汇学习)
Business English Certificates (BEC) 高频词汇学习
Business English Certificates {BEC} 高频词汇 References Cambridge English: Business Certificates, also known as Business English Certificates (BEC), are a suite of three English language qualifications for international business. abandon /əˈbndən/ vt. …...

信息系统项目管理中各个知识领域的概要描述及其管理流程
1. 立项管理 涵义:评估项目可行性,决定是否启动。 流程: 需求分析:识别业务需求或问题。 可行性研究:技术、经济、法律等可行性分析。 项目建议书:提交初步方案。 立项评审:高层审批。 项目…...

OpenAI推出PaperBench
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

基于LSTM的文本分类2——文本数据处理
前言 由于计算机无法认识到文字内容,因此在训练模型时需要将文字映射到计算机能够识别的编码内容。 映射的流程如下: 首先将文字内容按照词表映射到成唯一的数字ID。比如“我爱中国”,将“中”映射为1,将“国”映射到2。再将文…...
)
神经网络与深度学习:案例与实践——第三章(2)
神经网络与深度学习:案例与实践——第三章(2) 基于Softmax回归的多分类任务 Logistic回归可以有效地解决二分类问题,但在分类任务中,还有一类多分类问题,即类别数 C大于2 的分类问题。Softmax回归就是Log…...

Maven/Gradle的讲解
一、为什么需要构建工具? 在理解 Maven/Gradle 之前,先明确它们解决的问题: 依赖管理:项目中可能需要引入第三方库(如 Spring、JUnit 等),手动下载和管理这些库的版本非常麻烦。标…...

常见的HR面问题汇总
⚠️注意:以下仅是个人对问题的参考,具体情况视个人情况而定~ 1. 你觉得你有哪些优点和缺点? 优点:学习能力强,遇到问题会主动思考和查找解决方案;有责任心,对待工作认真负责&#…...

把握数据治理关键,释放企业数据潜能
数据治理是对数据资产管理行使权力和控制的活动集合,以下是关于它的详细介绍: 一、定义 数据治理是指从使用零散数据变为使用统一主数据、从具有很少或没有组织和流程治理到企业范围内的综合数据治理、从尝试处理主数据混乱状况到主数据井井有条的一个…...
)
优化 Web 性能:处理非合成动画(Non-Composited Animations)
在 Web 开发中,动画能够增强用户体验,但低效的动画实现可能导致性能问题。Google 的 Lighthouse 工具在性能审计中特别关注“非合成动画”(Non-Composited Animations),指出这些动画可能增加主线程负担,影响…...

房地产之后:探寻可持续扩张的产业与 GDP 新思
在经济发展的长河中,房地产长期占据着支柱产业的重要地位。其之所以能担当此重任,根源在于它深度嵌入了人们的生活与经济体系。住房,作为人类最基本的需求之一,具有不可替代的刚性。与其他现买按需生产的产业不同,房地产有着独特的消费逻辑。人们为了拥有一个稳定的居住之…...

Chapter02_数字图像处理基础
文章目录 图像的表示⭐模拟图像→数字图像均匀采样和量化均匀采样均匀量化 非均匀采样和量化 数字图像的表示二值图像灰度图像彩色图像 ⭐空间分辨率和灰度分辨率空间分辨率灰度分辨率 ⭐图像视觉效果影响因素采样数变化对图像视觉效果的影响空间分辨率变化对图像视觉效果的影响…...

【Android】UI开发:XML布局与Jetpack Compose的全面对比指南
随着Google推出Jetpack Compose这一现代化工具,我们面临一个关键选择:继续使用传统的XML布局,还是转向Compose? 一、语法对比:两种不同的构建方式 1. XML布局:基于标签的静态结构 XML通过嵌套标签定义UI元…...

浙大:LLM具身推理引擎Embodied-Reasoner
📖标题:Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks 🌐来源:arXiv, 2503.21696 🌟摘要 🔸深度思维模型的最新进展已经证明了数学和编码任务的…...

form+ffmpeg+opus录音压缩音频
说明: formffmpegopus录音压缩音频 效果图: step1:opus格式录音 C:\Users\wangrusheng\RiderProjects\WinFormsApp11\WinFormsApp11\Form1.cs using System; using System.Diagnostics; using System.IO; using System.Windows.Forms;namespace WinFo…...

win10 笔记本电脑安装 pytorch+cuda+gpu 大模型开发环境过程记录
win10 笔记本电脑安装 pytorchcudagpu 大模型开发环境过程记录 文章部分内容参考 deepseek。 以下使用命令行工具 mingw64。 安装 Anaconda 安装位置: /c/DEVPACK/Anaconda3 然后安装 Python 3.10.16 (略) $ conda create -n pytorch_…...

LeetCode 2442:统计反转后的不同整数数量
目录 核心思想:数字的“拆分”与“重组” 分步拆解(以输入 123 为例) 关键操作详解 为什么能处理中间或末尾的0? 数学本质 总结 题目描述 解题思路 代码实现 代码解析 复杂度分析 示例演示 总结 核心思想:…...

获取inode的完整路径包含挂载的路径
一、背景 在之前的博客 缺页异常导致的iowait打印出相关文件的绝对路径-CSDN博客 里的 2.2.3 一节和 关于inode,dentry结合软链接及硬链接的实验-CSDN博客 里,我们讲到了在内核里通过inode获取inode对应的绝对路径的方法。对于根目录下的文件而言&#…...

解决上传PDF、视频、音频等格式文件到FTP站点时报错“将文件复制到FTP服务器时发生错误。请检查是否有权限将文件放到该服务器上”问题
一、问题描述 可以将文本文件(.txt格式),图像文件(.jpg、.png等格式)上传到我们的FTP服务器上;但是上传一些PDF文件、视频等文件时就会报错“ 将文件复制到FTP服务器时发生错误。请检查是否有权限将文件放到该服务器上。 详细信息: 200 Type set to l. 227 Entering Pas…...