如何设计一个本地缓存
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长
Java技术小馆官网![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring
如何设计一个本地缓存
随着系统的复杂性和数据量的增加,如何快速响应用户请求、减少服务器的压力、提高系统的吞吐量,成为了架构设计中的重要挑战。在这种背景下,本地缓存作为一种提高性能的技术手段,受到了广泛的关注和应用。
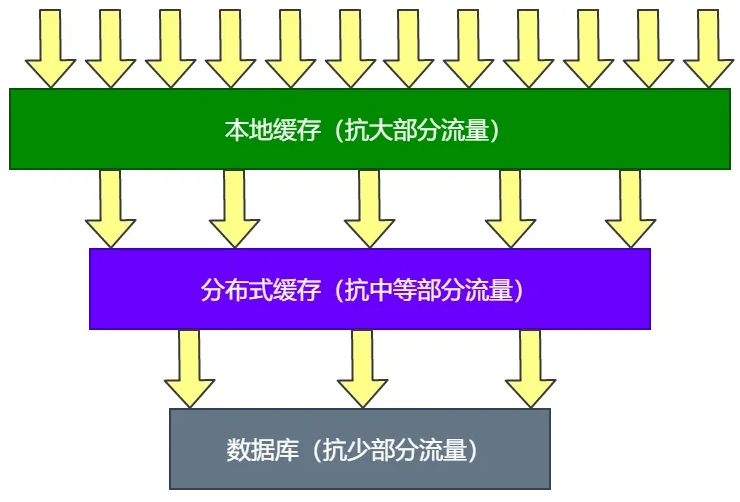
那么,什么是本地缓存呢?简单来说,本地缓存是一种将数据存储在应用程序本地内存中的机制,它能够减少对外部数据源(如数据库、远程服务等)的访问,从而大幅度降低延迟,提升应用程序的响应速度。同时,本地缓存也可以减少对共享资源的竞争,优化服务器的资源利用率。相比分布式缓存,本地缓存的优势在于它的速度更快、实现更简单,不需要考虑网络传输的延迟和分布式一致性的问题。然而,如何设计一个高效的本地缓存并不是一件简单的事情。
本地缓存的基本概念
本地缓存(Local Cache)是一种用于提升应用程序性能的优化技术,它通过在应用程序的本地内存中存储数据,减少对外部数据源(如数据库、远程服务等)的访问频率,从而加快数据的读取速度,降低网络延迟和资源消耗。本地缓存通常被应用于那些需要频繁读取但变化不大的数据场景,例如配置数据、字典数据、热点数据等。
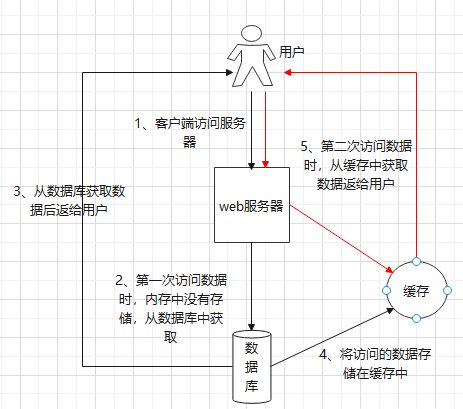
1. 本地缓存的核心思想
本地缓存的核心思想是空间换时间。通过预先将数据加载到本地内存中,避免每次访问都去请求外部数据源,这样可以显著减少访问延迟,尤其是在外部数据源响应较慢或网络不稳定的情况下。本地缓存的这种快速访问特性,使得它非常适合用来优化高频读写场景下的系统性能。
2. 本地缓存的实现方式
- 简单的Map(如HashMap):这是最基本的本地缓存实现,通过使用Java的集合类(如
HashMap或ConcurrentHashMap),将数据存储在内存中。ConcurrentHashMap支持高并发访问,适用于多线程环境。 - LinkedHashMap:通过设置
accessOrder参数,可以利用LinkedHashMap实现一个简单的LRU(Least Recently Used,最近最少使用)缓存。通过覆盖removeEldestEntry()方法,可以自动删除最久未使用的缓存项。 - 缓存框架(如Ehcache, Caffeine):这些框架提供了更丰富的缓存功能,如基于时间的过期策略、基于大小的淘汰策略、缓存统计信息和监控等。它们能够更好地管理缓存的生命周期和性能优化,适用于更加复杂和大型的应用场景。
3. 本地缓存的优势
- 高性能:由于缓存数据存储在本地内存中,访问速度极快,通常只需几个纳秒,这比通过网络请求外部数据源的方式要快得多。
- 简化架构:本地缓存的实现相对简单,不需要考虑分布式一致性、网络延迟等复杂问题,降低了系统的复杂性。
- 减少外部依赖:通过减少对数据库或远程服务的频繁访问,本地缓存可以有效减轻这些外部数据源的负载,提升整个系统的稳定性。
4. 本地缓存的局限性
- 内存消耗:由于本地缓存直接占用应用程序的堆内存,缓存的数据量需要谨慎控制,以免导致内存溢出(OutOfMemoryError)。
- 数据一致性问题:当外部数据源的数据发生变化时,本地缓存中的数据可能会变得过时。如果不能及时更新或刷新缓存,将会导致数据不一致的问题。
- 适用场景受限:本地缓存适用于单机环境下的数据缓存优化,对于分布式系统或多节点应用场景,必须采用更复杂的缓存一致性机制,如分布式缓存(Redis, Memcached等)。
缓存设计的关键要素
在设计一个高效且可靠的本地缓存系统时,必须考虑多个关键要素。这些要素不仅影响缓存的性能,还直接关系到系统的稳定性和数据一致性。
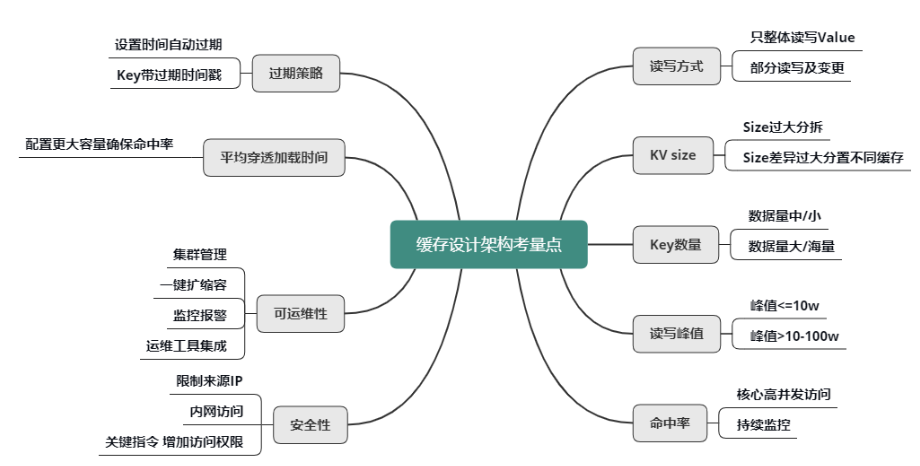
1. 缓存的数据结构选择
数据结构的选择对于缓存的性能至关重要,不同的数据结构适用于不同的应用场景:
- HashMap:最常用的数据结构之一,用于存储键值对。它的查询和插入操作复杂度为O(1),非常适合用于缓存场景。需要注意的是,在多线程环境中,应使用
ConcurrentHashMap来替代HashMap,以避免线程安全问题。 - LinkedHashMap:在
HashMap的基础上,增加了一个双向链表以维护键值对的插入顺序或访问顺序。通过LinkedHashMap可以实现LRU(最近最少使用)缓存策略,只需重写removeEldestEntry方法即可。 - Guava Cache 或 Caffeine:这些是Java社区中常用的缓存库,它们提供了丰富的数据结构和缓存策略(如LRU、LFU、FIFO等),并优化了并发环境下的性能。
2. 缓存的存储策略
缓存的存储策略决定了数据的存放位置和访问方式:
- 堆内存(Heap Memory):大多数本地缓存存储在堆内存中,存取速度快,但受限于JVM的内存大小。如果缓存数据量过大,可能导致
OutOfMemoryError。 - 堆外内存(Off-Heap Memory):一些缓存系统(如Ehcache)支持将数据存储在堆外内存中,这样可以避免占用JVM的堆内存,减少GC(Garbage Collection)对缓存数据的影响,提高系统的稳定性。
- 磁盘存储(Disk Storage):对于需要持久化的数据缓存,磁盘存储是一种选择,虽然访问速度较慢,但可以缓存大规模数据。
3. 缓存的过期策略
缓存的过期策略决定了缓存数据的生命周期,防止缓存过期数据被长期存储在内存中:
- TTL(Time to Live):设定一个固定的时间周期,超过该时间的数据将被自动移除。适合于缓存一些变化频率较低的数据,如配置数据。
- TTI(Time to Idle):如果缓存数据在一段时间内未被访问,则将其移除。适合于缓存一些偶尔被访问的数据。
缓存的淘汰策略
缓存的淘汰策略(Eviction Policy)在缓存设计中扮演着关键角色,特别是在缓存空间有限的情况下,它决定了哪些数据应该被保留,哪些数据应当被移除。合理的淘汰策略可以有效地提升缓存的命中率和系统性能,确保高效地利用缓存资源。
1. LRU(Least Recently Used) - 最近最少使用策略
LRU策略基于一个简单的假设:如果数据在最近一段时间没有被使用,那么它在未来也不太可能被使用。因此,LRU策略会移除最近最少使用的数据。
实现:通常使用双向链表配合哈希表来实现。双向链表维护数据的使用顺序,最近访问的数据被移到链表的头部,而最不常使用的数据位于链表的尾部。哈希表则提供快速的数据访问能力。
优点:
- 能够较好地平衡时间局部性,对于大多数具有局部性访问模式的应用(如Web缓存、数据库缓冲)表现较好。
- 实现简单,且可以达到较高的缓存命中率。
缺点:
- 在高并发场景下维护数据结构(如链表和哈希表)的开销较大,容易成为性能瓶颈。
- 可能会出现“缓存污染”的问题,即频繁访问的大量临时数据可能会迅速填满缓存,从而导致重要的数据被淘汰。
适用场景:适用于访问模式具有时间局部性的场景,如浏览器缓存、数据库缓冲池等。
2. LFU(Least Frequently Used) - 最少使用频率策略
LFU策略基于一个不同的假设:如果一个数据在过去被频繁使用,那么它在未来也有较大的可能继续被使用。因此,LFU策略会移除访问频率最低的数据。
实现:可以使用一个计数器来记录每个数据的访问次数。每次访问时,计数器加一。当需要淘汰数据时,选择计数器最小的数据进行移除。
优点:
- 对于访问模式具有稳定性的数据集(如热点数据少且固定),LFU策略能够提供较高的缓存命中率。
- 能够有效防止“缓存污染”,因为临时访问的热点数据不会频繁填充缓存。
缺点:
- 实现复杂度较高,需要额外的存储空间来维护访问计数器。
- 不适用于访问模式变化较快的场景,因为它无法快速反应访问模式的变化。
适用场景:适用于访问频率相对稳定且变化较少的场景,如用户个性化推荐缓存。
3. FIFO(First In, First Out) - 先进先出策略
FIFO策略是最简单的一种淘汰策略,基于数据进入缓存的顺序来进行淘汰。最早进入缓存的数据会被最先移除。
实现:通常使用队列来实现,数据按插入顺序进入队列,当缓存容量达到上限时,从队列头部开始淘汰数据。
优点:
- 实现简单,无需复杂的数据结构和算法。
- 对所有数据一视同仁,不存在任何特殊的权重或计数器,适合简单的缓存场景。
缺点:
- 无法考虑数据的访问频率和时间局部性,可能导致重要数据被不恰当地淘汰,缓存命中率较低。
- 不适用于访问模式复杂的场景,缓存的效率可能较差。
适用场景:适用于数据生命周期短暂、访问频率随机的场景,如简单的队列缓存、消息缓冲等。
4. ARC(Adaptive Replacement Cache) - 自适应替换缓存策略
ARC是一种更为复杂且自适应的缓存淘汰策略,结合了LRU和LFU的思想。ARC维护了两个LRU队列:一个用于存储最近被访问的数据(LRU),另一个用于存储频繁访问的数据(LFU)。通过动态调整这两个队列的大小,ARC能够自适应不同的访问模式。
实现:ARC会同时维护两个LRU队列和两个“幽灵”缓存(Ghost Cache)队列,这些队列分别用于记录曾经进入缓存但已经被移除的数据。通过分析这些队列的状态,ARC能够动态调整LRU和LFU队列的大小比例。
优点:
- 自适应能力强,能够根据实时访问模式自动调整策略,提供较高的缓存命中率。
- 同时兼顾时间局部性和频率局部性,适用性广泛。
缺点:
- 实现复杂度高,涉及多个数据结构的管理和调整。
- 内存和计算开销较大,不适用于内存资源受限的场景。
适用场景:适用于访问模式复杂且多变的场景,如混合型工作负载缓存。
5. 随机淘汰策略(Random Replacement)
随机淘汰策略并不基于任何特定的访问模式或数据特性,而是简单地随机选择一个数据进行淘汰。
实现:实现简单,通常只需生成一个随机数来决定淘汰的缓存数据。
优点:
- 实现简单且开销极低,几乎不需要额外的存储和计算。
- 在某些特殊场景下,随机淘汰可能会表现出意外的高效性,特别是在缓存污染问题严重的情况下。
缺点:
- 由于不考虑任何数据的使用频率或时间特性,缓存命中率通常较低。
- 在大多数实际应用中表现较差,除非在某些特殊的访问模式下。
适用场景:适用于资源极度受限且缓存数据特性不可预测的场景。
缓存一致性
在分布式系统中,缓存一致性是一个至关重要的问题,尤其是在读写频繁且数据实时性要求较高的场景中。缓存一致性(Cache Consistency)是指缓存中的数据和源数据(如数据库)保持同步的状态,确保客户端从缓存读取的数据是最新的、正确的。这一问题的解决关系到系统的性能、数据的正确性以及用户体验。
1. 缓存一致性的基本概念
缓存一致性要求缓存的数据和底层数据存储(例如数据库)在所有时间点上保持一致。简而言之,当底层数据发生变更时,缓存中相应的数据也应该随之更新或者失效,以避免客户端从缓存中读取到过期或错误的数据。根据不同的应用场景和一致性要求,缓存一致性可以分为以下几种类型:
- 强一致性(Strong Consistency):任何时候从缓存中读取的数据必须是最新的,即缓存数据与底层存储数据始终保持同步。这种一致性要求最严格,但通常会带来较高的性能开销。
- 弱一致性(Weak Consistency):允许缓存中的数据在短时间内与底层存储的数据不一致,只有在一定条件下或者在一定时间后,缓存才会更新。这种策略对性能影响较小,但可能会导致数据不一致。
- 最终一致性(Eventual Consistency):缓存中的数据最终会达到一致,但允许在短时间内存在不一致。对于很多分布式系统来说,这是一个常见的选择,因为它在一致性和性能之间达到了一个较好的平衡。
2. 缓存一致性的挑战
- 数据变更的高频性:如果底层数据存储的变更非常频繁,那么每次变更都要更新缓存或使其失效,这会带来巨大的性能开销和复杂的实现。
- 分布式环境的复杂性:在分布式环境中,缓存可能分布在多个节点上,如何确保所有缓存节点的数据一致性是一个难题。这通常需要一种分布式协议或机制来同步缓存数据。
- 缓存和存储之间的网络延迟:网络延迟可能导致缓存更新的延迟,进一步加剧缓存与底层数据存储之间的不一致性。
- 数据不一致带来的应用逻辑错误:如果缓存数据和底层数据不一致,可能会导致应用逻辑错误,例如库存管理系统中出现超卖或库存不足的情况。
3. 缓存一致性的常见策略
- 写直达(Write-Through)策略:每次数据写入时,先将数据写入缓存,再写入底层存储。这种方式可以保证缓存和存储之间的同步,但是会带来较高的写入延迟。
- 写回(Write-Behind/Write-Back)策略:数据首先写入缓存,再异步写入底层存储。这种方式可以提升写入性能,但存在数据丢失的风险,因为在数据写入存储之前,缓存中的数据可能会丢失。
- 缓存失效(Cache Invalidation)策略:当底层数据发生变更时,通过使缓存数据失效来保证缓存一致性。这种方式常见于缓存层无法感知数据变化的场景,例如数据库中的数据被其他系统更新时。
-
- 被动失效(Passive Invalidation):缓存本身不主动监测数据变化,而是依赖于应用逻辑在数据变更时主动通知缓存进行失效操作。
- 主动失效(Active Invalidation):缓存系统自身具备监控底层数据变化的能力,一旦检测到数据变化,立即使相关缓存数据失效。
- 基于时间的失效(Time-to-Live, TTL)策略:为缓存中的每个数据项设置一个生存时间,超过这个时间,缓存数据会自动失效。TTL策略简单易用,但不能保证严格的一致性,适合对实时性要求不高的场景。
- 双写一致性(Double-Write Consistency):在数据变更时,应用同时更新缓存和底层存储。这种方式在保证一致性方面表现较好,但实现复杂,容易出现数据竞争或写入失败等问题。
- 缓存同步(Cache Synchronization)机制:采用消息队列或者发布订阅模式(Pub/Sub),在底层数据变化时,通过消息通知缓存系统进行同步更新。这种方式适合分布式缓存环境,但需要保证消息的可靠传输和处理顺序。
4. 不同场景下的一致性策略选择
- 高一致性要求的场景:例如金融系统、订单管理系统等,这些场景对数据的准确性要求极高,通常采用写直达策略或者双写一致性策略,来保证数据的强一致性。
- 最终一致性要求的场景:例如社交媒体、推荐系统等,这些场景允许在短时间内存在一定的数据不一致,通常采用写回策略或者TTL策略来平衡性能和一致性。
- 高并发读写场景:例如电商系统中的商品详情缓存,对于读操作频繁且允许短暂数据不一致的场景,可以采用缓存失效策略结合异步更新机制来优化性能。
缓存的监控与管理
在本地缓存设计中,监控与管理是确保缓存高效运行和数据一致性的关键步骤。缓存系统的性能和正确性不仅取决于其设计和实现,还受到监控与管理机制的影响。有效的监控可以帮助发现缓存中的热点数据、识别潜在问题以及优化缓存策略,而合理的管理机制则能够维持缓存的高效性和可靠性。
1. 监控的重要性
本地缓存的监控主要用于实时跟踪缓存的运行状态和性能表现,其重要性体现在以下几个方面:
- 优化性能:通过监控,可以获取缓存命中率、缓存失效率等数据,帮助开发人员评估缓存策略的有效性并进行优化。例如,命中率过低可能意味着缓存数据不够新鲜或没有缓存正确的热点数据。
- 及时检测问题:监控能够实时发现缓存系统中的异常,例如缓存服务的内存泄漏、缓存污染(stale data)、不合理的缓存淘汰等问题。通过及时检测这些问题,能够避免更严重的系统故障或性能下降。
- 提高可靠性和稳定性:监控缓存的状态变化和性能指标,可以为容量规划、缓存扩容和缩容、负载均衡等提供依据,从而提高系统的可靠性和稳定性。
- 数据分析和策略调整:通过分析监控数据,可以了解缓存的使用模式,识别数据的访问频次、热度等特征,从而优化缓存配置和调整缓存策略。
2. 监控的关键指标
- 缓存命中率(Cache Hit Ratio):缓存命中率是衡量缓存有效性的重要指标,表示从缓存中成功读取数据的请求比例。高命中率通常表示缓存数据与用户请求匹配度高,缓存策略合理。命中率过低可能需要调整缓存数据或更新策略。
- 缓存失效率(Cache Miss Ratio):缓存失效率与命中率互为补充,表示未能从缓存中获取数据而需要访问底层存储的请求比例。高失效率可能表明缓存容量不足或缓存数据更新不及时。
- 缓存大小(Cache Size):缓存的当前使用容量和总容量是监控的另一个重要指标。了解缓存使用情况有助于评估是否需要进行缓存扩容或缩容。
- 缓存淘汰率(Cache Eviction Rate):缓存淘汰率表示缓存中数据被替换或删除的频率。这一指标可以反映缓存的压力和淘汰策略的有效性。过高的淘汰率可能意味着缓存容量不足或缓存数据更新频率太高。
- 延迟(Latency):缓存访问的延迟是衡量缓存性能的直接指标,尤其是在低延迟要求高的应用场景中。高延迟可能由网络问题、缓存节点过载或数据复制等原因引起。
- 吞吐量(Throughput):缓存系统的吞吐量是指单位时间内处理的请求数量。高吞吐量要求缓存系统具有高效的数据存取能力和良好的扩展性。
3. 监控工具与实现方式
- 应用内置监控:许多缓存库(如Ehcache、Caffeine、Guava Cache等)内置了监控功能,可以直接通过API获取缓存的各种统计信息,如命中率、失效率、当前缓存大小等。
- 日志分析:通过在缓存访问的关键路径上记录日志,可以分析日志数据来评估缓存的性能表现和使用情况。日志分析工具(如ELK Stack)可以帮助聚合和分析这些日志数据。
- AOP(面向切面编程)拦截:使用AOP技术拦截缓存访问操作,可以在不修改业务代码的情况下采集监控数据。例如,使用Spring AOP或AspectJ拦截缓存的读取、写入和失效操作。
- 性能监控工具:使用性能监控工具(如Prometheus、Grafana、JMX、New Relic等)可以实时监控缓存的各项性能指标,并设置告警机制,当某些指标超过预设阈值时自动发出告警通知。
4. 缓存管理策略
缓存管理策略是缓存系统在运行期间进行自我调整和优化的重要手段,主要包括以下几个方面:
- 动态调整缓存大小:根据缓存的使用情况和应用负载,可以动态调整缓存的大小。对于内存受限的环境,可以通过自动扩展或缩减缓存容量来适应系统需求。
- 缓存淘汰策略调整:根据监控数据,调整缓存的淘汰策略(如LRU、LFU、FIFO等)以适应数据访问模式的变化。例如,在热点数据变化频繁的场景下,可以选择LFU(最少使用)策略来替代LRU(最近最少使用)策略。
- 热点数据预加载:在系统启动时,或者根据历史数据分析结果,预先将热点数据加载到缓存中,以减少缓存冷启动(cold start)时的高失效率。
- 缓存数据更新策略:根据业务需求和数据特性,选择合适的缓存数据更新策略(如TTL、基于事件的失效策略等),以平衡缓存一致性和系统性能。
- 容量规划和扩容策略:通过监控缓存使用情况,提前规划缓存容量,制定合理的扩容策略。在缓存容量逼近上限时,可以触发自动扩容,避免因缓存空间不足导致的频繁淘汰和性能下降。
- 告警和恢复机制:在缓存系统出现异常或性能瓶颈时,能够及时通过告警机制通知相关人员或系统模块,触发自动化恢复策略(如缓存刷新、容量调整等)。
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长
Java技术小馆官网![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring
相关文章:

如何设计一个本地缓存
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring 如何设计一个本地缓存 随着系统的复杂性和数据量的增加,如何快速响应用户请求、减…...

2024版idea使用Lombok时报找不到符号
今天在springboot项目中使用Lombok的Builder注解,启动时居然报了找不到符号的错,如下图 于是开始了漫长的寻找之路,首先去settings->Plugins中看自己的Lombok插件是否启动,发现确实是如此,然后看网上的教程去加上这…...

[Android安卓移动计算]:新建项目和配置环境步骤
文章目录 一:AndroidStudio 创建项目1. New Project2. 选择:Empty Activity 二:配置和下载SDK点击SDK 配置按钮选择API32和Android 9.0(Pie)再点击Apply点击接受条款声明进行安装 安装完后点击NEXT和OK出现:…...

$R^n$平面约束下的向量列
原向量: x → \overset{\rightarrow}{x} x→ 与 x → \overset{\rightarrow}{x} x→法向相同的法向量(与 x → \overset{\rightarrow}{x} x→同向) ( x → ⋅ n → ∣ n → ∣ 2 ) n → (\frac{\overset{\rightarrow}x\cdot\overset{\righta…...

混合编程的架构
在混合使用QML和Qt Widgets的环境中,是否必须严格遵循分层架构需要根据项目规模和复杂度来决定。以下是具体的决策指南和实施建议: 一、分层架构的适用性分析 #mermaid-svg-61Mlp9MrpFOoZPAO {font-family:"trebuchet ms",verdana,arial,sans…...

联网汽车陷入网络安全危机
有人能够入侵并控制汽车这一事实本身就令人恐惧,电影中的场景变成了现实。再加上汽车中的软件会处理和存储我们的个人数据,这种恐惧达到了一个新的高度。 一旦发生安全漏洞,我们的驾驶数据、联系人、通话记录、消息甚至位置信息等信息都可能…...

基于Spark的招聘数据预测分析推荐系统
【Spark】基于Spark的招聘数据预测分析推荐系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统能够高效处理海量招聘数据,利用Spark的强大计算能力实现快速分析和预测。该系…...

基于Spark的酒店数据分析系统
【Spark】基于Spark的酒店数据分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 本项目基于Python语言开发,借助Django进行后台框架的开发,搭建大数据虚拟机集群…...

网络安全L2TP实验
在FW1上,将接口g1/0/0添加进去trust区域 [USG6000V1]firewall zone trust [USG6000V1-zone-trust]add interface GigabitEthernet 1/0/0 在放通安全策略 在FW2上配置ip [USG6000V1]int g1/0/1 [USG6000V1-GigabitEthernet1/0/1]ip address 20.1.1.1 24 [USG6000…...

18.1.go连接redis
开发调试 Tiny RDM:跨平台GUI工具windows版本下载 https://download.csdn.net/download/chxii/90562932 支持多种格式查看:内置高级文本代码编辑器,支持语法高亮/代码折叠/错误提示 便捷搜索过滤:使用正则匹配搜索键后,仍可进行二级过滤,组合筛选数据更方便 调试分析…...

innodb如何实现mvcc的
InnoDB 实现 MVCC(多版本并发控制)的机制主要依赖于 Undo Log(回滚日志)、Read View(读视图) 和 隐藏的事务字段。以下是具体实现步骤和原理: 1. 核心数据结构 InnoDB 的每一行数据(…...
)
递归实现组合型枚举(DFS)
从 1∼n 这 n 个整数中随机选出 m 个,输出所有可能的选择方案。 输入格式 两个整数 n,m,在同一行用空格隔开。 输出格式 按照从小到大的顺序输出所有方案,每行 1 个。 首先,同一行内的数升序排列,相邻两个数用一个空格隔开。…...

【Java学习日记18】:三元运算符和运算符的优先级
一、三元运算符 2. 示例代码 例题1: 例题2: 二、运算符优先级 1. 优先级规则 Java 运算符的执行顺序由优先级决定,优先级高的先执行。 只要记住小括号优先级最大即可,以后就用这玩意 四、总结 运算符优先级:小括号 () 是最高优先级工具...
,源码可白嫖!)
基于springboot放松音乐在线播放系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 本放松音乐在线播放系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Java进行编写,使用了Spring Boot框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。前台主要功能包括:用户注册、登录…...

【Scratch编程系列】Scratch编程软件界面
Scratch是一款由麻省理工学院(MIT) 设计开发的少儿编程工具。其特点是:使用者可以不认识英文单词,也可以不使用键盘,就可以进行编程。构成程序的命令和参数通过积木形状的模块来实现。用鼠标拖动指令模块到脚本区就可以了。 这个软…...

技术驱动革新,强力巨彩LED软模组助力创意显示
随着LED显示技术的不断突破,LED软模组因其独特的柔性特质和个性化显示效果,正逐渐成为各类应用场景的新宠。强力巨彩软模组R3.0H系列具备独特的可塑造型能力与技术创新,为商业展示、数字艺术、建筑装饰等领域开辟全新视觉表达空间。 LED…...
——Nomad Bridge20220801)
历年跨链合约恶意交易详解(三)——Nomad Bridge20220801
漏洞合约函数 /*** notice Given formatted message, attempts to dispatch* message payload to end recipient.* dev Recipient must implement a handle method (refer to IMessageRecipient.sol)* Reverts if formatted messages destination domain is not the Replicas d…...
)
Tensorflow、Pytorch与Python、CUDA版本的对应关系(更新时间:2025年4月)
更新时间:20250405 一、Tensorflow与Python 、CUDA版本对应关系 注意:从 TF 2.11 开始,Windows 不支持 CUDA 构建。要在 Windows 上使用 TensorFlow GPU,您需要在 WSL2 中构建/安装 TensorFlow 或将 tensorflow-cpu 与 TensorFlow-DirectML-Plugin 一起使用 1.1、CPU版本…...

FPGA实现按键切换流水灯不同亮灭模式
本文是一位fpga新手学习fpga的博客,写出这个shi山代码花了3个小时左右,途中学习了按键消抖、状态机等知识... 实现目标:通过按键控制led灯亮的不同模式,将每种模式用状态机表达。 代码如下: module led(input btn1,in…...

SeaTunnel系列之:部署SeaTunnel的Spark和Flink引擎
SeaTunnel系列之:部署SeaTunnel的Spark和Flink引擎 运行 SeaTunnel快速开始使用 Flink快速开始使用 Spark 运行 SeaTunnel 现在您已经下载了 SeaTunnel 二进制包和连接器插件。接下来,您可以选择不同的引擎选项来运行同步任务。 如果您使用 Flink 运行…...

“Pseudo Global Warming”:伪全球变暖PGW
“Pseudo Global Warming”:伪全球变暖PGW PGW方法概述🔍 一、PGW 方法的定义🧠 二、PGW 方法的基本原理🛠️ 三、PGW 方法的主要步骤📈 四、PGW 模拟时常涉及的变量📊 五、PGW 方法的优/缺点📚…...

【Linux学习笔记】初识进程概念和进程PCB
【Linux学习笔记】初识冯诺依曼体系和进程PCB 🔥个人主页:大白的编程日记 🔥专栏:Linux学习笔记 文章目录 【Linux学习笔记】初识冯诺依曼体系和进程PCB前言一. 冯诺依曼体系结构1.1 关于冯诺依曼体系的要点: 二. 操…...

deepseek回答ollama 下载模型的命令
ollama 下载模型的命令 已深度思考(用时 20 秒) 好的,我需要回答用户关于使用Ollama下载模型的命令的问题。首先,我需要回忆Ollama的基本用法。Ollama是一个用于本地运行大型语言模型的工具,支持多种模型如Llama、Mi…...

Kafka 中的生产者分区策略
Kafka 中的 生产者分区策略 是决定消息如何分配到不同分区的机制。这个策略对 Kafka 的性能、负载均衡、消息顺序性等有重要影响。了解它对于高效地使用 Kafka 进行消息生产和消费至关重要。 让我们一起来看 Kafka 中 生产者的分区策略,它如何工作,以及…...

Kafka 如何调优?
Kafka 的调优是个非常实用又容易踩坑的话题,涉及 Producer、Broker、Consumer、硬件、操作系统 等多个层面。我们可以从整体架构角度出发,按模块逐个给你讲清楚 实战建议。 🎯 Kafka 调优主要目标: 提高吞吐量降低延迟保证可靠…...

【机器学习】机器学习工程实战-第4章 特征工程
上一章:第3章 数据收集和准备 文章目录 4.1 为什么要进行特征工程4.2 如何进行特征工程4.2.1 文本的特征工程4.2.2 为什么词袋有用4.2.3 将分类特征转换为数字4.2.4 特征哈希4.2.5 主题建模4.2.6 时间序列的特征4.2.7 发挥你的创造力 特征工程是将原始样本转化为特…...

spring-cloud-alibaba-nacos-config使用说明
一、核心功能与定位 Spring Cloud Alibaba Nacos Config 是 Spring Cloud Alibaba 生态中的核心组件之一,专为微服务架构提供动态配置管理能力。它通过整合 Nacos 的配置中心功能,替代传统的 Spring Cloud Config,提供更高效的配置集中化管理…...

必刷算法100题之计算右侧小于当前元素的个数
题目链接 315. 计算右侧小于当前元素的 个数 - 力扣(LeetCode) 题目解析 计算数组里面所有元素右侧比它小的数的个数, 并且组成一个数组,进行返回 算法原理 归并解法(分治) 当前元素的后面, 有多少个比我小(降序) 我们要找到第一比左边小的元素, 这…...
)
OpenHarmony子系统开发 - DFX(三)
OpenHarmony子系统开发 - DFX(三) 五、HiTraceMeter开发指导 HiTraceMeter概述 简介 HiTraceMeter在OpenHarmony中,为开发者提供业务流程调用链跟踪的维测接口。通过使用该接口所提供的功能,可以帮助开发者迅速获取指定业务流…...

[ctfshow web入门] web6
前置知识 入口点(目录)爆破 还记得之前说过网站的入口的吗,我们输入url/xxx,其中如果url/xxx存在,那么访问成功,证明存在这样一个入口点;如果访问失败则证明不存在此入口点。所以我们可以通过遍历url/xxx,…...
中的历史数据来预测未来G列数字)
完整的Python程序,它能够根据两个Excel表格(假设在同一个Excel文件的不同sheet中)中的历史数据来预测未来G列数字
下面是一个完整的Python程序,它能够根据两个Excel表格(假设在同一个Excel文件的不同sheet中)中的历史数据来预测未来G列数字。此程序采用多模型验证,并且具备自我学习和动态参数调整的功能。最终会输出12个可能的数字范围及其出现…...
设计原则)
设计模式简述(一)设计原则
设计模式简述 6大基本设计原则单一职责原则依赖倒置原则依赖传递方式 里氏替换原则接口隔离原则迪米特法则开闭原则 6大基本设计原则 单一职责原则 一个接口、一个类、一个方法的功能尽量保证原子性。 至于这个度自己把握,没有绝对的标准。 通常可以将同一类、同…...
核心知识点详解)
哈希表(Hashtable)核心知识点详解
1. 基本概念 定义:通过键(Key)直接访问值(Value)的数据结构,基于哈希函数将键映射到存储位置。 核心操作: put(key, value):插入键值对 get(key):获取键对应的值 remo…...
)
论文阅读笔记:Denoising Diffusion Implicit Models (5)
0、快速访问 论文阅读笔记:Denoising Diffusion Implicit Models (1) 论文阅读笔记:Denoising Diffusion Implicit Models (2) 论文阅读笔记:Denoising Diffusion Implicit Models (…...
)
JDK8卸载与安装教程(超详细)
JDK8卸载与安装教程(超详细) 最近学习一个项目,需要使用更高级的JDK,这里记录一下卸载旧版本与安装新版本JDK的过程。 JDK8卸载 以windows10操作系统为例,使用快捷键winR输入cmd,打开控制台窗口…...
(基于gemtc))
R语言网状Meta分析---Meta回归(1)(基于gemtc)
示例: library(gemtc) help(package"gemtc") # Fixed effect meta-regression for heart failure prevention str(hfPrevention) regressor <- list(coefficientshared,variablesecondary,controlcontrol) model <- mtc.model(hfPrevention,type&q…...

通过AOP切面,切点,反射填充公共字段
在项目中,我们通常会实现员工管理和菜品管理等基础服务功能。这些服务在操作数据库时,往往需要记录一些通用字段,比如: 创建人ID(create_user_id) 修改人ID(update_user_id) 创…...

CNN 中感受野/权值共享是什么意思?
这个问题问得非常到位!🌟 在 CNN(卷积神经网络)中,“感受野” 和 “权值共享” 是两个核心概念,它们一起构建了 CNN 在图像处理领域强大能力的基础。 🧠 一句话解释: • 感受野&…...
 + 真题讲解 python)
【蓝桥杯速成】日期问题(填空题) + 真题讲解 python
众所周知,蓝桥杯有两道填空题,还特别喜欢考日期问题 什么?你还在使用计算器手算? 那你将会考虑闰年、大小月等等细节到头昏眼花 最后还比答案大或小1 寄! 接下来我来告诉你正确的做法 基础知识 python自带datetime库…...

C++基础讲解
C基础讲解 序言1 命名空间1.1 命名空间的作用1.2,命名空间的定义1.3 命名空间的使用 2 C输入与输出3 缺省参数4 函数重载5 引用5.1 引用的概念与特性5.2 引用的使用5.2.1 引用传参5.2.2 引用做返回值5.2.2.1采用引用返回:5.2.2.2采用值返回的情形:5.2.2.…...
)
【代码模板】判断C语言中文件是否存在?错误:‘F_OK’未声明如何处理?(access;#include “unistd.h“)
#include "stdio.h" #include "unistd.h"int main(int argc, char *argv[]) {if (access("./1.cpp", F_OK) -1) {printf("not exist\n");} else {printf("exist\n");} }报错 错误:‘F_OK’未声明 需要包含#inc…...

form实现note笔记本新建保存加密功能
说明: 我希望用form实现笔记本新建保存加密功能 笔记管理应用,具备创建、保存、删除笔记的功能,并且有简单的加密保护。 1.笔记管理:1.1新建笔记:清除标题和内容,取消列表选择。1.2保存笔记:验…...
)
【算法竞赛】状态压缩型背包问题经典应用(蓝桥杯2019A4分糖果)
在蓝桥杯中遇到的这道题,看上去比较普通,但其实蕴含了很巧妙的“状态压缩 背包”的思想,本文将从零到一,详细解析这个问题。 目录 一、题目 二、思路分析:状态压缩 最小覆盖 1. 本质:最小集合覆盖问题…...

【C++初阶篇】C++中c_str函数的全面解析
C中c_str函数的全面解析 1. c_str()函数的定义与原型2. c_str()函数的返回值特性3 c_str()函数的使用场景3.1 与C标准库函数交互3.2 文件操作3.3 系统调用 4. c_str()函数的注意事项4.1 返回指针的只读性4.2 生命周期问题4.3 空字符串处理4.4 避免直接赋值给char* 5. c_str()函…...
)
Python 匿名函数(Lambda函数)
什么是匿名函数 匿名函数(也称为lambda函数)是Python中的一种小型匿名函数,它可以接受任意数量的参数,但只能有一个表达式。 语法格式: lambda arguments: expression使用场景 简单函数逻辑:当函数逻辑…...

java高并发------守护线程Daemon Thread
文章目录 1.概念2.生命周期与行为2. 应用场景3. 示例代码4. 注意事项 1.概念 Daemon : 滴门 在Java中,线程分为两类:用户线程(User Thread)和守护线程(Daemon Thread)。 守护线程是后台线程,主要服务于用户线程,当所…...

RocketMQ初认识
ProducerCustomerNameServer: Broker的注册服务发现中心BrokerServer:主要负责消息的存储、投递和查询以及服务高可用保证 RocketMQ的集群部署: 单个master的分支多个Master 模式:集群中有多个 Master 节点,彼此之间相互独立。生产者可以将消…...

K8s的BackUP备份
文章目录 1、kubeadm 安装的单 master 节点数据备份和恢复方式2、Velero 工具3、Velero 服务部署4、备份还原数据 ETCD备份/还原有多种类型,取决于你 k8s 集群的搭建方式 1、kubeadm 安装的单 master 节点数据备份和恢复方式 拷贝 etcdctl 至 master 节点…...

Photoshop 快捷键指南
Photoshop 快捷键指南 放大缩小 按住 Ctrl 鼠标滚轮快捷键 Z 鼠标左键往左往右Ctrl 放大, Ctrl - 缩小 套索工具 快捷键 L鼠标左键绘制按住 ctrl,松开鼠标左键,继续绘制直线绘制完成之后,按住ctrl,鼠标左键继续绘…...

Openlayers:海量图形渲染之图片渲染
最近由于在工作中涉及到了海量图形渲染的问题,因此我开始研究相关的解决方案。在这个过程中我阅读了文章 《Openlayers海量矢量面渲染优化》了解到了利用Canvas在前端生成图片渲染的思路,后来我又从同事那里了解到了后端生成图片渲染的思路。我认为这两种…...