论文阅读笔记:Denoising Diffusion Implicit Models (5)
0、快速访问
论文阅读笔记:Denoising Diffusion Implicit Models (1)
论文阅读笔记:Denoising Diffusion Implicit Models (2)
论文阅读笔记:Denoising Diffusion Implicit Models (3)
论文阅读笔记:Denoising Diffusion Implicit Models (4)
论文阅读笔记:Denoising Diffusion Implicit Models (5)
5、接上文论文阅读笔记:Denoising Diffusion Implicit Models (4)
这里使用中的 σ t \sigma_t σt是可以自己定义的量。有两种特殊的情况:
1、 σ t 2 = 0 \sigma_t^2=0 σt2=0:此时,
x t − 1 x_{t-1} xt−1满足公式(3)
x t − 1 = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + 1 − α t − 1 − σ t 2 ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x 0 + 1 − α t − 1 ⋅ z t \begin{equation} \begin{split} x_{t-1}&=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot x_0+\sqrt{1-\alpha_{t-1}}\cdot z_t \\ \end{split} \end{equation} xt−1=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−σt2⋅zt+σt2ϵt=αt−1⋅x0+1−αt−1⋅zt
x t − n x_{t-n} xt−n满足
x t − n = α t − n ⋅ x t − 1 − α t ⋅ z t α t + 1 − α t − n − σ t 2 ⋅ z t + σ t 2 ϵ t = α t − n ⋅ x 0 + 1 − α t − n ⋅ z t \begin{equation} \begin{split} x_{t-n}&=\sqrt{\alpha_{t-n}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-n}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-n}}\cdot x_0+\sqrt{1-\alpha_{t-n}}\cdot z_t \\ \end{split} \end{equation} xt−n=αt−n⋅αtxt−1−αt⋅zt+1−αt−n−σt2⋅zt+σt2ϵt=αt−n⋅x0+1−αt−n⋅zt
可以看出,此时, x t − 1 x_{t-1} xt−1和 x t − n x_{t-n} xt−n退化成上文论文阅读笔记:Denoising Diffusion Implicit Models (2)中的Lemma 1.
2、 σ t 2 = 1 − α t − 1 1 − α t ⋅ ( 1 − α t α t − 1 ) \sigma_t^2=\frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}}) σt2=1−αt1−αt−1⋅(1−αt−1αt):此时, x t − 1 x_{t-1} xt−1满足公式(4)
x t − 1 = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + 1 − α t − 1 − σ t 2 ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + 1 − α t − 1 − 1 − α t − 1 1 − α t ⋅ ( 1 − α t α t − 1 ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + ( 1 − α t − 1 ) ( 1 − 1 1 − α t ⋅ α t − 1 − α t α t − 1 ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + ( 1 − α t − 1 ) α t − 1 − α t − 1 ⋅ α t − α t − 1 + α t α t − 1 ⋅ ( 1 − α t ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + ( 1 − α t − 1 ) − α t − 1 ⋅ α t + α t α t − 1 ⋅ ( 1 − α t ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t − 1 − α t ⋅ z t α t + ( 1 − α t − 1 ) α t α t − 1 ⋅ ( 1 − α t ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − α t − 1 1 − α t ⋅ z t α t + ( 1 − α t − 1 ) α t α t − 1 ⋅ ( 1 − α t ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − ( α t − 1 1 − α t ⋅ α t − 1 1 − α t − ( 1 − α t − 1 ) ⋅ α t ⋅ α t α t ⋅ α t − 1 ⋅ ( 1 − α t ) ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − ( α t − 1 1 − α t ⋅ α t − 1 1 − α t − ( 1 − α t − 1 ) ⋅ α t ⋅ α t α t ⋅ α t − 1 ⋅ ( 1 − α t ) ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − ( α t − 1 ⋅ ( 1 − α t ) − ( 1 − α t − 1 ) ⋅ α t α t ⋅ α t − 1 ⋅ ( 1 − α t ) ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − ( α t − 1 − α t ⋅ α t − 1 − α t + α t ⋅ α t − 1 α t ⋅ α t − 1 ⋅ ( 1 − α t ) ) ⋅ z t = α t − 1 ⋅ x t α t − ( α t − 1 − α t α t ⋅ α t − 1 ⋅ ( 1 − α t ) ) ⋅ z t + σ t 2 ϵ t = α t − 1 ⋅ x t α t − ( α t − 1 ⋅ ( α t − 1 − α t ) α t − 1 ⋅ α t ⋅ ( 1 − α t ) ) ⋅ z t + σ t 2 ϵ t = α t − 1 α t ( x t − α t − 1 − α t α t − 1 ⋅ 1 − α t ) + σ t 2 ϵ t = α t − 1 α t ( x t − 1 1 − α t ⋅ ( 1 − α t α t − 1 ) ) ⋅ z t + σ t 2 ϵ t = 1 α t ( x t − β t 1 − α ˉ t ) ⋅ z t + σ t 2 ϵ t (换成 D D P M 中的符号) \begin{equation} \begin{split} x_{t-1}&=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}})}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})(1-\frac{1}{1-\alpha_t}\cdot \frac{\alpha_{t-1}-\alpha_t}{\alpha_{t-1}})}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})\frac{\alpha_{t-1}-\alpha_{t-1}\cdot \alpha_{t}-\alpha_{t-1}+\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})\frac{-\alpha_{t-1}\cdot \alpha_{t}+\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+(1-\alpha_{t-1})\sqrt{\frac{\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}}-\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+(1-\alpha_{t-1})\sqrt{\frac{\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}\cdot\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}-(1-\alpha_{t-1})\cdot\sqrt{\alpha_t}\cdot\sqrt{\alpha_t}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t+ \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}\cdot\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}-(1-\alpha_{t-1})\cdot\sqrt{\alpha_t}\cdot\sqrt{\alpha_t}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}}\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}\cdot({1-\alpha_t)}-(1-\alpha_{t-1})\cdot \alpha_t}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}-\bcancel{\alpha_t\cdot \alpha_{t-1}}-\alpha_t+\bcancel{\alpha_t\cdot \alpha_{t-1}}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}-\alpha_t}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}\cdot (\alpha_{t-1}-\alpha_t)}{\alpha_{t-1}\cdot\sqrt{\alpha_t}\cdot \sqrt{(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\frac{\sqrt{\alpha_{t-1}}}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{\alpha_{t-1}-\alpha_t}{\alpha_{t-1}\cdot\ \sqrt{1-\alpha_t}}\Bigg) + \sigma_t^2 \epsilon_t\\ &=\frac{\sqrt{\alpha_{t-1}}}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{1}{\ \sqrt{1-\alpha_t}}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}})\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\frac{1}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{\beta_t}{\ \sqrt{1-\bar\alpha_t}}\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t(换成DDPM中的符号)\\ \end{split} \end{equation} xt−1=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−σt2⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−1−αt1−αt−1⋅(1−αt−1αt)⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)(1−1−αt1⋅αt−1αt−1−αt)⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt−1−αt−1⋅αt−αt−1+αt⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)−αt−1⋅αt+αt⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt⋅zt+σt2ϵt=αt−1⋅αtxt−αtαt−11−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−11−αt⋅αt−11−αt−(1−αt−1)⋅αt⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−11−αt⋅αt−11−αt−(1−αt−1)⋅αt⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1⋅(1−αt)−(1−αt−1)⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1−αt⋅αt−1 −αt+αt⋅αt−1 )⋅zt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1−αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt−1⋅αt⋅(1−αt)αt−1⋅(αt−1−αt))⋅zt+σt2ϵt=αtαt−1(xt−αt−1⋅ 1−αtαt−1−αt)+σt2ϵt=αtαt−1(xt− 1−αt1⋅(1−αt−1αt))⋅zt+σt2ϵt=αt1(xt− 1−αˉtβt)⋅zt+σt2ϵt(换成DDPM中的符号)
可以看出,此时,DDIM退化成了DDPM。
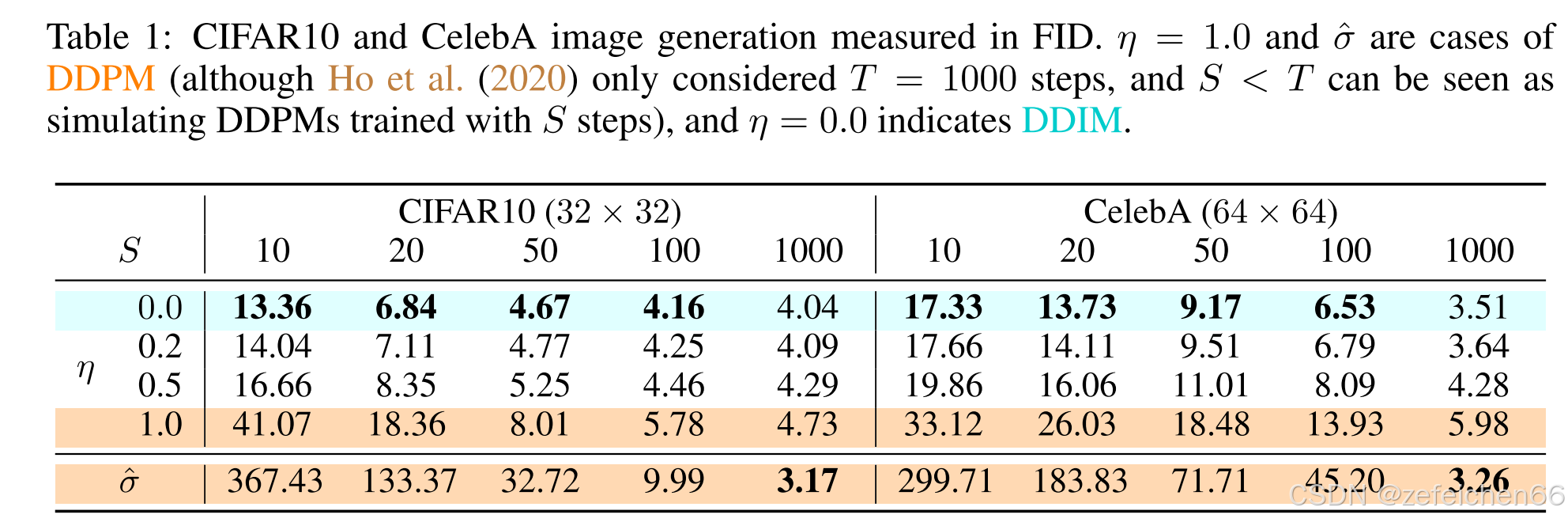
论文讨论了 σ t 2 \sigma_t^2 σt2选取 η ⋅ 1 − α t − 1 1 − α t ⋅ ( 1 − α t α t − 1 ) , η ∈ [ 0 , 1 ] \eta\cdot \frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}}),\eta\in[0,1] η⋅1−αt1−αt−1⋅(1−αt−1αt),η∈[0,1],即在0和DDPM之间变化时。不同 η \eta η以及跳不同步时所对应的表现,如下图所示。
6、代码
class DDIMPipeline(DiffusionPipeline):model_cpu_offload_seq = "unet"def __init__(self, unet, scheduler):super().__init__()# make sure scheduler can always be converted to DDIMscheduler = DDIMScheduler.from_config(scheduler.config)self.register_modules(unet=unet, scheduler=scheduler)@torch.no_grad()def __call__(self,batch_size: int = 1,generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,eta: float = 0.0,num_inference_steps: int = 50,use_clipped_model_output: Optional[bool] = None,output_type: Optional[str] = "pil",return_dict: bool = True,) -> Union[ImagePipelineOutput, Tuple]:# Sample gaussian noise to begin loopif isinstance(self.unet.config.sample_size, int):image_shape = (batch_size,self.unet.config.in_channels,self.unet.config.sample_size,self.unet.config.sample_size,)else:image_shape = (batch_size, self.unet.config.in_channels, *self.unet.config.sample_size)if isinstance(generator, list) and len(generator) != batch_size:raise ValueError(f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"f" size of {batch_size}. Make sure the batch size matches the length of the generators.")# 随即生成噪音image = randn_tensor(image_shape, generator=generator, device=self._execution_device, dtype=self.unet.dtype)# 设置步数间隔。例如num_inference_steps = 50,然而总步长为1000,那么就是每次跳20步,例如在当前时刻, timestep=980, prev_timestep=960self.scheduler.set_timesteps(num_inference_steps)for t in self.progress_bar(self.scheduler.timesteps):# 1. 预测出timestep=980时刻对应噪音model_output = self.unet(image, t).sample# 2. 调用scheduler的方法step,执行公式()得到prev_timestep=960时刻的图像image = self.scheduler.step(model_output, t, image, eta=eta, use_clipped_model_output=use_clipped_model_output, generator=generator).prev_sampleimage = (image / 2 + 0.5).clamp(0, 1)image = image.cpu().permute(0, 2, 3, 1).numpy()if output_type == "pil":image = self.numpy_to_pil(image)if not return_dict:return (image,)return ImagePipelineOutput(images=image)class DDIMScheduler(SchedulerMixin, ConfigMixin):_compatibles = [e.name for e in KarrasDiffusionSchedulers]order = 1@register_to_configdef __init__(self,num_train_timesteps: int = 1000,beta_start: float = 0.0001,beta_end: float = 0.02,beta_schedule: str = "linear",trained_betas: Optional[Union[np.ndarray, List[float]]] = None,clip_sample: bool = True,set_alpha_to_one: bool = True,steps_offset: int = 0,prediction_type: str = "epsilon",thresholding: bool = False,dynamic_thresholding_ratio: float = 0.995,clip_sample_range: float = 1.0,sample_max_value: float = 1.0,timestep_spacing: str = "leading",rescale_betas_zero_snr: bool = False,):if trained_betas is not None:self.betas = torch.tensor(trained_betas, dtype=torch.float32)elif beta_schedule == "linear":self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)elif beta_schedule == "scaled_linear":# this schedule is very specific to the latent diffusion model.self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2elif beta_schedule == "squaredcos_cap_v2":# Glide cosine scheduleself.betas = betas_for_alpha_bar(num_train_timesteps)else:raise NotImplementedError(f"{beta_schedule} is not implemented for {self.__class__}")# Rescale for zero SNRif rescale_betas_zero_snr:self.betas = rescale_zero_terminal_snr(self.betas)self.alphas = 1.0 - self.betasself.alphas_cumprod = torch.cumprod(self.alphas, dim=0)# At every step in ddim, we are looking into the previous alphas_cumprod# For the final step, there is no previous alphas_cumprod because we are already at 0# `set_alpha_to_one` decides whether we set this parameter simply to one or# whether we use the final alpha of the "non-previous" one.self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]# standard deviation of the initial noise distributionself.init_noise_sigma = 1.0# setable valuesself.num_inference_steps = Noneself.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:"""Ensures interchangeability with schedulers that need to scale the denoising model input depending on thecurrent timestep.Args:sample (`torch.Tensor`):The input sample.timestep (`int`, *optional*):The current timestep in the diffusion chain.Returns:`torch.Tensor`:A scaled input sample."""return sampledef _get_variance(self, timestep, prev_timestep):alpha_prod_t = self.alphas_cumprod[timestep]alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprodbeta_prod_t = 1 - alpha_prod_tbeta_prod_t_prev = 1 - alpha_prod_t_prevvariance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)return variance# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sampledef _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:""""Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (theprediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide bys. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventingpixels from saturation at each step. We find that dynamic thresholding results in significantly betterphotorealism as well as better image-text alignment, especially when using very large guidance weights."https://arxiv.org/abs/2205.11487"""dtype = sample.dtypebatch_size, channels, *remaining_dims = sample.shapeif dtype not in (torch.float32, torch.float64):sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half# Flatten sample for doing quantile calculation along each imagesample = sample.reshape(batch_size, channels * np.prod(remaining_dims))abs_sample = sample.abs() # "a certain percentile absolute pixel value"s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)s = torch.clamp(s, min=1, max=self.config.sample_max_value) # When clamped to min=1, equivalent to standard clipping to [-1, 1]s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"sample = sample.reshape(batch_size, channels, *remaining_dims)sample = sample.to(dtype)return sampledef set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):"""Sets the discrete timesteps used for the diffusion chain (to be run before inference).Args:num_inference_steps (`int`):The number of diffusion steps used when generating samples with a pre-trained model."""if num_inference_steps > self.config.num_train_timesteps:raise ValueError(f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"f" maximal {self.config.num_train_timesteps} timesteps.")self.num_inference_steps = num_inference_steps# "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891if self.config.timestep_spacing == "linspace":timesteps = (np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps).round()[::-1].copy().astype(np.int64))elif self.config.timestep_spacing == "leading":step_ratio = self.config.num_train_timesteps // self.num_inference_steps# creates integer timesteps by multiplying by ratio# casting to int to avoid issues when num_inference_step is power of 3timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64)timesteps += self.config.steps_offsetelif self.config.timestep_spacing == "trailing":step_ratio = self.config.num_train_timesteps / self.num_inference_steps# creates integer timesteps by multiplying by ratio# casting to int to avoid issues when num_inference_step is power of 3timesteps = np.round(np.arange(self.config.num_train_timesteps, 0, -step_ratio)).astype(np.int64)timesteps -= 1else:raise ValueError(f"{self.config.timestep_spacing} is not supported. Please make sure to choose one of 'leading' or 'trailing'.")self.timesteps = torch.from_numpy(timesteps).to(device)def step(self,model_output: torch.Tensor,timestep: int,sample: torch.Tensor,eta: float = 0.0,use_clipped_model_output: bool = False,generator=None,variance_noise: Optional[torch.Tensor] = None,return_dict: bool = True,) -> Union[DDIMSchedulerOutput, Tuple]:if self.num_inference_steps is None:raise ValueError("Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler")# 1. get previous step value (=t-1);# timestep=980,self.config.num_train_timesteps=1000, self.num_inference_steps=50# prev_timestep = 960,步数的跳跃间隔为20prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps# 2. compute alphas, betasalpha_prod_t = self.alphas_cumprod[timestep]alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprodbeta_prod_t = 1 - alpha_prod_t# 3. compute predicted original sample from predicted noise also called# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdfif self.config.prediction_type == "epsilon":pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)pred_epsilon = model_outputelif self.config.prediction_type == "sample":pred_original_sample = model_outputpred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)elif self.config.prediction_type == "v_prediction":pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_outputpred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sampleelse:raise ValueError(f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"" `v_prediction`")# 4. Clip or threshold "predicted x_0"if self.config.thresholding:pred_original_sample = self._threshold_sample(pred_original_sample)elif self.config.clip_sample:pred_original_sample = pred_original_sample.clamp(-self.config.clip_sample_range, self.config.clip_sample_range)# 5. compute variance: "sigma_t(η)" -> see formula (16)# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)variance = self._get_variance(timestep, prev_timestep)std_dev_t = eta * variance ** (0.5)if use_clipped_model_output:# the pred_epsilon is always re-derived from the clipped x_0 in Glidepred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)# 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdfpred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon# 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdfprev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_directionif eta > 0:if variance_noise is not None and generator is not None:raise ValueError("Cannot pass both generator and variance_noise. Please make sure that either `generator` or"" `variance_noise` stays `None`.")if variance_noise is None:variance_noise = randn_tensor(model_output.shape, generator=generator, device=model_output.device, dtype=model_output.dtype)variance = std_dev_t * variance_noiseprev_sample = prev_sample + varianceif not return_dict:return (prev_sample,pred_original_sample,)return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noisedef add_noise(self,original_samples: torch.Tensor,noise: torch.Tensor,timesteps: torch.IntTensor,) -> torch.Tensor:# Make sure alphas_cumprod and timestep have same device and dtype as original_samples# Move the self.alphas_cumprod to device to avoid redundant CPU to GPU data movement# for the subsequent add_noise callsself.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device)alphas_cumprod = self.alphas_cumprod.to(dtype=original_samples.dtype)timesteps = timesteps.to(original_samples.device)sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5sqrt_alpha_prod = sqrt_alpha_prod.flatten()while len(sqrt_alpha_prod.shape) < len(original_samples.shape):sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noisereturn noisy_samples# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocitydef get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, timesteps: torch.IntTensor) -> torch.Tensor:# Make sure alphas_cumprod and timestep have same device and dtype as sampleself.alphas_cumprod = self.alphas_cumprod.to(device=sample.device)alphas_cumprod = self.alphas_cumprod.to(dtype=sample.dtype)timesteps = timesteps.to(sample.device)sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5sqrt_alpha_prod = sqrt_alpha_prod.flatten()while len(sqrt_alpha_prod.shape) < len(sample.shape):sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * samplereturn velocitydef __len__(self):return self.config.num_train_timesteps
相关文章:
)
论文阅读笔记:Denoising Diffusion Implicit Models (5)
0、快速访问 论文阅读笔记:Denoising Diffusion Implicit Models (1) 论文阅读笔记:Denoising Diffusion Implicit Models (2) 论文阅读笔记:Denoising Diffusion Implicit Models (…...
)
JDK8卸载与安装教程(超详细)
JDK8卸载与安装教程(超详细) 最近学习一个项目,需要使用更高级的JDK,这里记录一下卸载旧版本与安装新版本JDK的过程。 JDK8卸载 以windows10操作系统为例,使用快捷键winR输入cmd,打开控制台窗口…...
(基于gemtc))
R语言网状Meta分析---Meta回归(1)(基于gemtc)
示例: library(gemtc) help(package"gemtc") # Fixed effect meta-regression for heart failure prevention str(hfPrevention) regressor <- list(coefficientshared,variablesecondary,controlcontrol) model <- mtc.model(hfPrevention,type&q…...

通过AOP切面,切点,反射填充公共字段
在项目中,我们通常会实现员工管理和菜品管理等基础服务功能。这些服务在操作数据库时,往往需要记录一些通用字段,比如: 创建人ID(create_user_id) 修改人ID(update_user_id) 创…...

CNN 中感受野/权值共享是什么意思?
这个问题问得非常到位!🌟 在 CNN(卷积神经网络)中,“感受野” 和 “权值共享” 是两个核心概念,它们一起构建了 CNN 在图像处理领域强大能力的基础。 🧠 一句话解释: • 感受野&…...
 + 真题讲解 python)
【蓝桥杯速成】日期问题(填空题) + 真题讲解 python
众所周知,蓝桥杯有两道填空题,还特别喜欢考日期问题 什么?你还在使用计算器手算? 那你将会考虑闰年、大小月等等细节到头昏眼花 最后还比答案大或小1 寄! 接下来我来告诉你正确的做法 基础知识 python自带datetime库…...

C++基础讲解
C基础讲解 序言1 命名空间1.1 命名空间的作用1.2,命名空间的定义1.3 命名空间的使用 2 C输入与输出3 缺省参数4 函数重载5 引用5.1 引用的概念与特性5.2 引用的使用5.2.1 引用传参5.2.2 引用做返回值5.2.2.1采用引用返回:5.2.2.2采用值返回的情形:5.2.2.…...
)
【代码模板】判断C语言中文件是否存在?错误:‘F_OK’未声明如何处理?(access;#include “unistd.h“)
#include "stdio.h" #include "unistd.h"int main(int argc, char *argv[]) {if (access("./1.cpp", F_OK) -1) {printf("not exist\n");} else {printf("exist\n");} }报错 错误:‘F_OK’未声明 需要包含#inc…...

form实现note笔记本新建保存加密功能
说明: 我希望用form实现笔记本新建保存加密功能 笔记管理应用,具备创建、保存、删除笔记的功能,并且有简单的加密保护。 1.笔记管理:1.1新建笔记:清除标题和内容,取消列表选择。1.2保存笔记:验…...
)
【算法竞赛】状态压缩型背包问题经典应用(蓝桥杯2019A4分糖果)
在蓝桥杯中遇到的这道题,看上去比较普通,但其实蕴含了很巧妙的“状态压缩 背包”的思想,本文将从零到一,详细解析这个问题。 目录 一、题目 二、思路分析:状态压缩 最小覆盖 1. 本质:最小集合覆盖问题…...

【C++初阶篇】C++中c_str函数的全面解析
C中c_str函数的全面解析 1. c_str()函数的定义与原型2. c_str()函数的返回值特性3 c_str()函数的使用场景3.1 与C标准库函数交互3.2 文件操作3.3 系统调用 4. c_str()函数的注意事项4.1 返回指针的只读性4.2 生命周期问题4.3 空字符串处理4.4 避免直接赋值给char* 5. c_str()函…...
)
Python 匿名函数(Lambda函数)
什么是匿名函数 匿名函数(也称为lambda函数)是Python中的一种小型匿名函数,它可以接受任意数量的参数,但只能有一个表达式。 语法格式: lambda arguments: expression使用场景 简单函数逻辑:当函数逻辑…...

java高并发------守护线程Daemon Thread
文章目录 1.概念2.生命周期与行为2. 应用场景3. 示例代码4. 注意事项 1.概念 Daemon : 滴门 在Java中,线程分为两类:用户线程(User Thread)和守护线程(Daemon Thread)。 守护线程是后台线程,主要服务于用户线程,当所…...

RocketMQ初认识
ProducerCustomerNameServer: Broker的注册服务发现中心BrokerServer:主要负责消息的存储、投递和查询以及服务高可用保证 RocketMQ的集群部署: 单个master的分支多个Master 模式:集群中有多个 Master 节点,彼此之间相互独立。生产者可以将消…...

K8s的BackUP备份
文章目录 1、kubeadm 安装的单 master 节点数据备份和恢复方式2、Velero 工具3、Velero 服务部署4、备份还原数据 ETCD备份/还原有多种类型,取决于你 k8s 集群的搭建方式 1、kubeadm 安装的单 master 节点数据备份和恢复方式 拷贝 etcdctl 至 master 节点…...

Photoshop 快捷键指南
Photoshop 快捷键指南 放大缩小 按住 Ctrl 鼠标滚轮快捷键 Z 鼠标左键往左往右Ctrl 放大, Ctrl - 缩小 套索工具 快捷键 L鼠标左键绘制按住 ctrl,松开鼠标左键,继续绘制直线绘制完成之后,按住ctrl,鼠标左键继续绘…...

Openlayers:海量图形渲染之图片渲染
最近由于在工作中涉及到了海量图形渲染的问题,因此我开始研究相关的解决方案。在这个过程中我阅读了文章 《Openlayers海量矢量面渲染优化》了解到了利用Canvas在前端生成图片渲染的思路,后来我又从同事那里了解到了后端生成图片渲染的思路。我认为这两种…...

自定义组件触发饿了么表单校验
饿了么的表单控件,如果存在自定义组件更改了值,例如在el-from中存在原生input组件很有可能没法触发表单校验,下拉框或者弹框组件仍然是报红边框。 这是因为饿了么的输入框或者下拉框更改值的时候会自动触发表单校验,但是封装过后的…...
)
【C++】从零实现Json-Rpc框架(1)
目录 一、项目介绍 二、技术选型 1. RPC的实现方案: 2. 网络传输的参数和返回值怎么映射到对应的RPC 接口上? 3. 网络传输怎么做? 4. 序列化和反序列化? 三、开发环境 四、环境搭建 Ubuntu-22.04 环境搭建 项目汇总&…...

[实战] linux驱动框架与驱动开发实战
linux驱动框架与驱动开发实战 Linux驱动框架与驱动开发实战一、Linux驱动框架概述1.1 Linux驱动的分类1.2 Linux驱动的基本框架 二、Linux驱动关键API详解2.1 模块相关API2.2 字符设备驱动API2.3 内存管理API2.4 中断处理API2.5 PCI设备驱动API 三、Xilinx XDMA驱动开发详解3.1…...
)
【详细】MySQL 8 安装解压即用 (包含MySQL 5 卸载)
卸载MySQL 1.卸载 2.安装目录删除残余文件(当初安装的位置) 3.删除programData下面的mysql数据文件 4.检查mysql服务是否存在,如果存在则删除(先暂停mysql服务) sc delete mysql 5.删除注册表中残留信息 安装MySQL 8&…...
)
Linux:(五种IO模型)
目录 一、对IO的重新认识 二、IO的五种模型 1.阻塞IO 2.非阻塞IO 3.信号驱动IO 4.IO多路转接 5.异步IO 6.一些概念的解释 三、非阻塞IO的代码实现 1.fcntl 2.实现主程序 一、对IO的重新认识 如果有人问你IO是什么,你该怎么回答呢? 你可能会说…...

初识数据结构——Java包装类与泛型:从入门到源码解析
【深入浅出】Java包装类与泛型:从入门到源码解析 🌟 一、开篇一问:为什么我们需要包装类? Java作为一门"面向对象"的语言,却保留了8个"非对象"的基本数据类型(有传言说,是…...

【计算机网络】Linux配置SNAT策略
什么是NAT? NAT 全称是 Network Address Translation(网络地址转换),是一个用来在多个设备共享一个公网 IP上网的技术。 NAT 的核心作用:将一个网络中的私有 IP 地址,转换为公网 IP 地址,从而…...

与 AI 共舞:解锁自我提升的无限可能
与 AI 共舞:解锁自我提升的无限可能 在数字化浪潮的汹涌冲击下,人工智能(AI)正以前所未有的速度重塑着世界的每一个角落。从日常生活的点滴便利到复杂工作的高效推进,AI 的力量无处不在。然而,面对 AI 的强…...
)
Android学习总结之算法篇五(字符串)
字符串求回文字串数目 public class CountPalindromicSubstrings {/*** 此方法用于计算字符串中回文子串的数量* param s 输入的字符串* return 回文子串的数量*/public static int countSubstrings(String s) {// 若输入字符串为空或长度为 0,直接返回 0if (s nu…...

使用人车关系核验API快速核验车辆一致性
一、 引言 随着车辆交易的日益频繁,二手车市场和金融领域的汽车抵押业务蓬勃发展。然而,欺诈和盗窃行为也时有发生,给行业带来了不小的冲击。例如,3月20日央视曝光的“新能源车虚假租赁骗补”产业链,以及某共享汽车平…...

day 8 TIM定时器
一、STM32 定时器概述 1. 定时器的概述定时器的基本功能,但是 STM32 的定时器除了具有定时功能之外,也具有定时器中断功能,还具有输入捕获(检测外部信号)以及输出比较功能(输出不同的脉冲)&…...

硬币找零问题
硬币找零问题:假设需要找零的金额为C,最少要用多少面值为p1<p2<…<pn的硬币(面值种类为n,且假设每种面值的硬币都足够多)? 贪心算法的基本原理是:遵循某种既定原则,不断…...
)
【微机及接口技术】- 第四章 内部存储器及其接口(上)
文章目录 第一节一、存储器的分类二、存储器的层次结构 第二节 半导体存储器一、半导体存储器的基本结构二、半导体存储器的分类1. 只读存储器 ROM2. 随机存储器 RAM 三、内存的主要性能指标1. 存储容量2. 存取时间3. 存取周期4. 可靠性5. 性价比 四、典型的半导体存储器芯片 本…...

tomcat的web三大组件Sciidea搭建web/maven的tomcat项目
文章目录 1. web项目的搭建1. 创建web项目2.修改web.xml版本3.添加servlet、jsp依赖4.servlet示例(使用注解)5.配置tomcat6.添加artifact7.部署8.启动tomcat、访问9.打war包10.部署到tomcat 2.maven的项目搭建1.创建项目图解 2.tomcat启动方式图解idea打…...

《SQL赋能人工智能:解锁特征工程的隐秘力量》
在当今的科技发展进程中,人工智能(AI)已经成为推动各领域变革的核心驱动力。而在人工智能的庞大体系里,特征工程占据着举足轻重的地位,它是将原始数据转化为能够让模型有效学习的特征的关键环节。鲜有人深入探讨的是&a…...

SQLmap工具使用
1. sqlmap介绍 sqlmap是一款自动化的SQL注入工具,用于检测和利用web应用程序中的SQL注入漏洞。不需要我们进行手注,当我们输入url地址后,会自动进行注入指令并将payload返回显示。 在kali中自带。在本机中需要下载,在相应的路径…...

Kubernetes集群管理详解:从入门到精通
1. 引言 Kubernetes(简称k8s)作为当今最流行的容器编排平台,已成为云原生应用部署和管理的事实标准。本文将深入探讨k8s集群管理的各个方面,为运维工程师和开发人员提供一个全面的指南。 2. Kubernetes架构概览 在深入具体的管理任务之前,让我们先回顾一下Kubernetes的基本架…...

【含文档+PPT+源码】基于Python的全国景区数据分析以及可视化实现
项目介绍 本课程演示的是一款基于Python的全国景区数据分析以及可视化实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 带你从零开始部署运行本套系统 该…...

鸿蒙开发者高级认证编程题库
题目一:跨设备分布式数据同步 需求描述 开发一个分布式待办事项应用,要求: 手机与平板登录同一华为账号时,自动同步任务列表任一设备修改任务状态(完成/删除),另一设备实时更新任务数据在设备离线时能本地存储,联网后自动同步实现方案 // 1. 定义分布式数据模型 imp…...

【网络安全】安全的网络设计
网络设计是网络安全的基础,一个好的网络设计可以有效的防止攻击者的入侵。在本篇文章中,我们将详细介绍如何设计一个安全的网络,包括网络架构,网络设备,网络策略,以及如何处理网络安全事件。 一、网络架构…...

基于FLask的重庆市造价工程信息数据可视化分析系统
【FLask】基于FLask的重庆市造价工程信息数据可视化分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 在当今快速发展的建筑工程行业中,造价信息的准确性和时效性对于项目决…...

swift-08-属性、汇编分析inout本质
一、Swift中跟实例相关的属性可以分为2大类 1.1 存储属性( Stored Property) 类似于成员变量这个概念 存储在实例的内存中 结构体、类可以定义存储属性 枚举不可以定义存储属性(因为枚举只存储关联值和case) 1.2 计算属性&am…...
)
Java 大视界 -- Java 大数据在智能医疗远程护理与患者健康管理中的应用与前景(175)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

大数据技术发展与应用趋势分析
大数据技术发展与应用趋势分析 文章目录 大数据技术发展与应用趋势分析1. 大数据概述2 大数据技术架构2.1 数据采集层2.2 数据存储层2.3 数据处理层2.4 数据分析层 3 大数据发展趋势3.1 AI驱动的分析与自动化3.2 隐私保护分析技术3.3 混合云架构的普及3.4 数据网格架构3.5 量子…...

如何在Ubuntu上安装Dify
如何在Ubuntu上安装Dify 如何在Ubuntu上安装docker 使用apt安装 # Add Dockers official GPG key: sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg…...

ffmpeg音频分析
对一个16k 单声道音频,生成频谱图 ./ffmpeg -i input.wav -lavfi "showspectrumpics800x400:modecombined:scalelin:gain1.5" spectrum.png...

每天五分钟深度学习框架pytorch:搭建LSTM完成手写字体识别任务?
本文重点 前面我们学习了LSTM的搭建,我们也学习过很多卷积神经网络关于手写字体的识别,本文我们使用LSTM来完成手写字体的识别。 网络模型的搭建 class RNN(nn.Module):def __init__(self,in_dim,hidden_dim,n_layer,n_class):super(RNN,self).__init__()self.n_layer=n_la…...
——Maven属性)
Maven工具学习使用(七)——Maven属性
内置属性 主要有两个常用的属性${basedir}表示项目的根目录,即包含pom.xml文件的目录;$[version]表示项目版本。 POM属性 使用该类属性引用POM文件中对应元素的值。例如${project.artifactId}就对应了元素的值,常用的POM属性包括: ${project.build.sourceDirectory} 项…...

【Linux网络与网络编程】05.应用层自定义协议序列化和反序列化
前言 本篇博客通过网络计算器的实现来帮助各位理解应用层自定义协议以及序列化和反序列化。 一、认识自定义协议&&序列化和反序列化 我们程序员写的一个个解决我们实际问题,满足我们日常需求的网络程序都是在应用层。前面我们说到:协议是一种…...

搭建K8S-1.23
0、简介 这里只用3台服务器来做一个简单的集群 地址主机名192.168.160.40kuber-master-1192.168.160.41kuber-master-2192.168.160.42kuber-node-1 1、关闭三个服务 (1)防火墙 systemctl stop firewalld (2)Selinux setenf…...

解决Spring Boot Test中的ByteBuddy类缺失问题
目录 解决Spring Boot Test中的ByteBuddy类缺失问题前奏问题描述问题解决第一步:移除ByteBuddy的特定版本号第二步:更新maven-surefire-plugin配置第三步:清理并重新构建项目 结语 解决Spring Boot Test中的ByteBuddy类缺失问题 前奏 今天&…...

npm 项目命名规则
以下是 npm 项目命名规则的详细说明: 一、核心命名规则 必须使用小写字母 名称中不能包含大写字母。原因: 跨平台兼容性(如 Linux 区分大小写,而 Windows 不区分)。避免命令行和 URL 中的大小写冲突(例如包…...
关于 first_match、throughout、within 的用法)
#SVA语法滴水穿石# (012)关于 first_match、throughout、within 的用法
我们今天学习, SystemVerilog 断言(SVA)中 first_match、throughout、within 运算符。 1. first_match 定义与作用 功能:在可能产生 多个匹配结果 的复合序列(如 or 或重复操作符)中,仅选择第…...