【Hadoop3.1.4】完全分布式集群搭建
一、虚拟机的建立与连接
1.建立虚拟机
详情见【Linux】虚拟机的安装
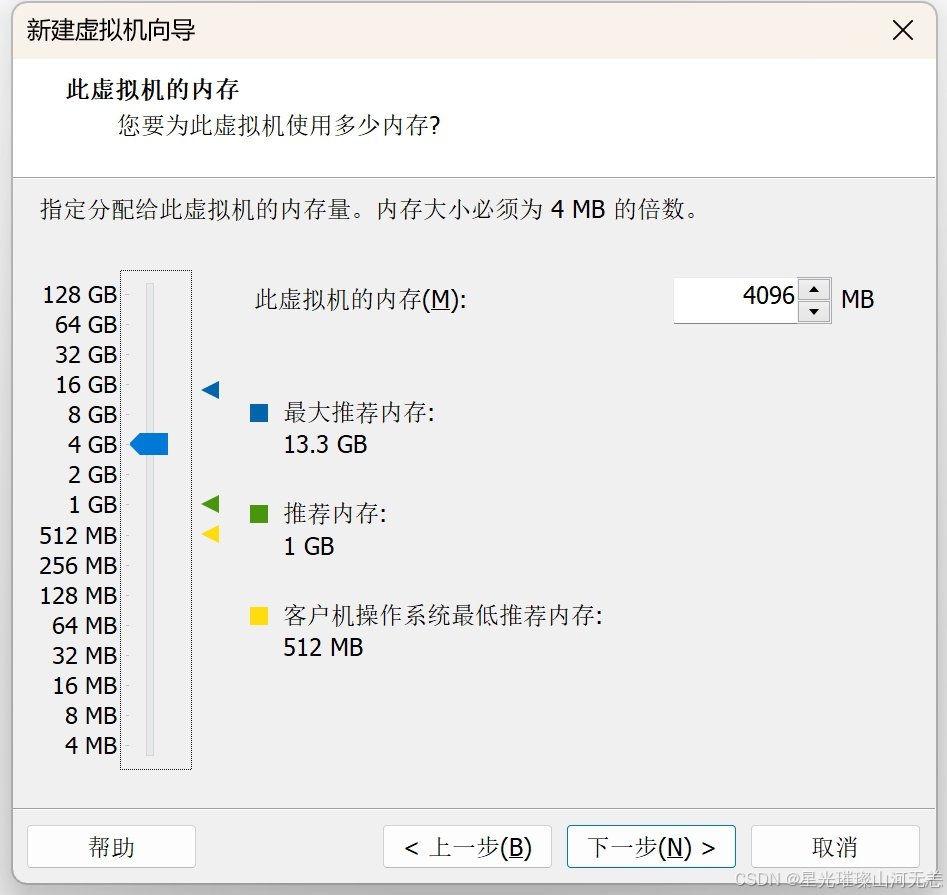
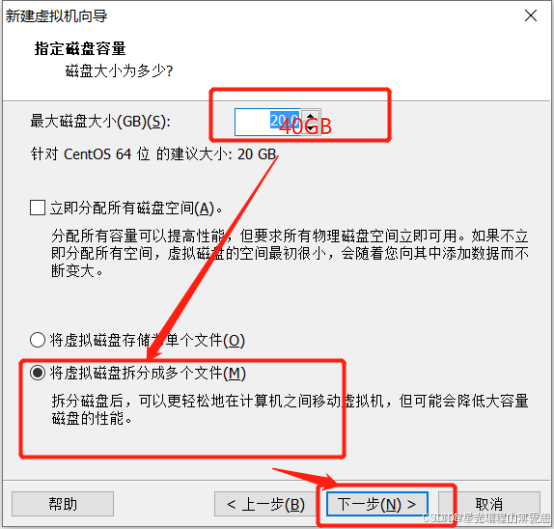
把上面三个参数改掉
2.连接虚拟机
具体见【Linux】远程连接虚拟机+防火墙
二、修改主机名
在Centos7中直接使用root用户执行hostnamectl命令修改,重启(reboot)后永久生效。
hostnamectl set-hostname 新主机名

三、关闭防火墙
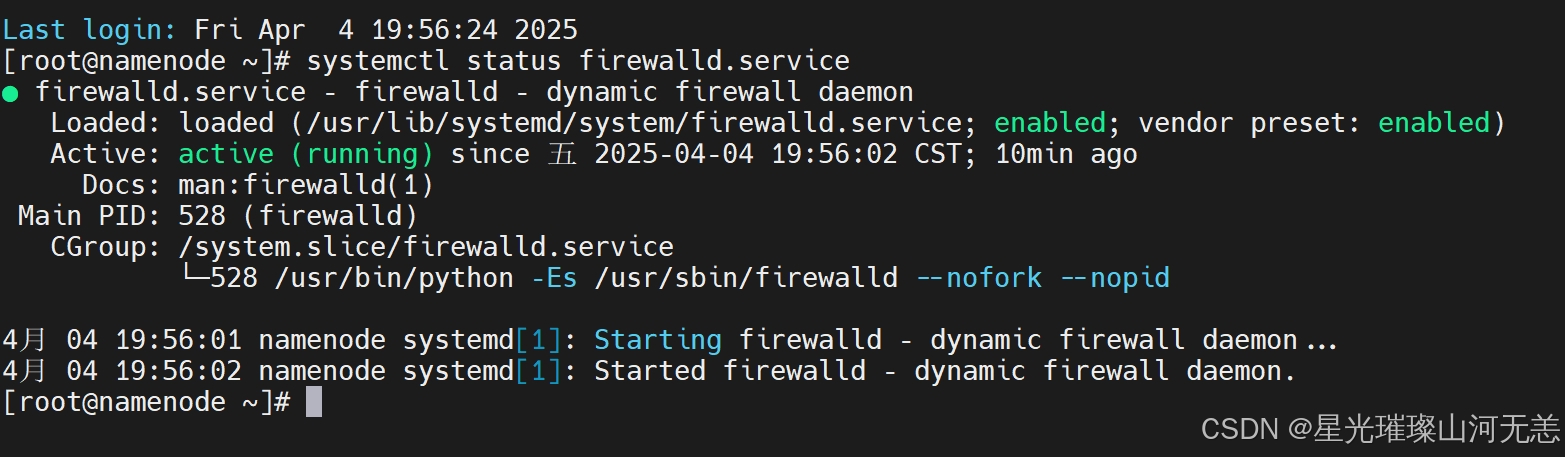
1.查看CentOS 7防火墙状态
systemctl status firewalld.service
2.关闭运行的防火墙
systemctl stop firewalld.service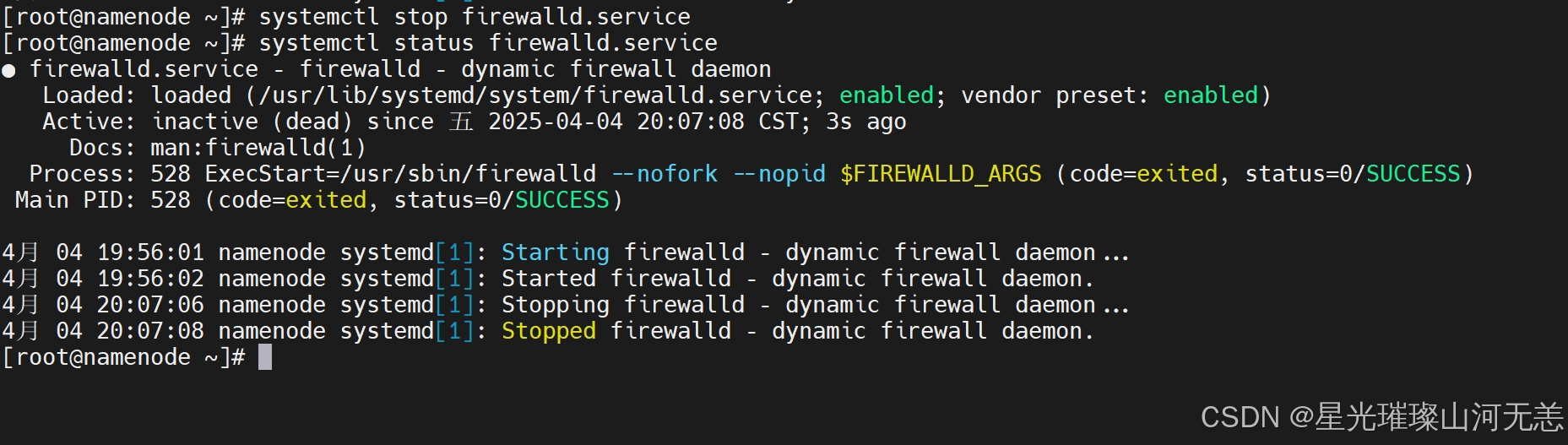
关闭后,可查看防火墙状态,当显示disavtive(dead)的字样,说明CentOS 7防火墙已经关闭。
但要注意的是,上面的命令只是临时关闭了CentOS 7防火墙,当重启操作系统后,防火墙服务还是会再次启动。如果想要永久关闭防火墙则还需要禁用防火墙服务。
3.禁用防火墙服务
systemctl disable firewalld.service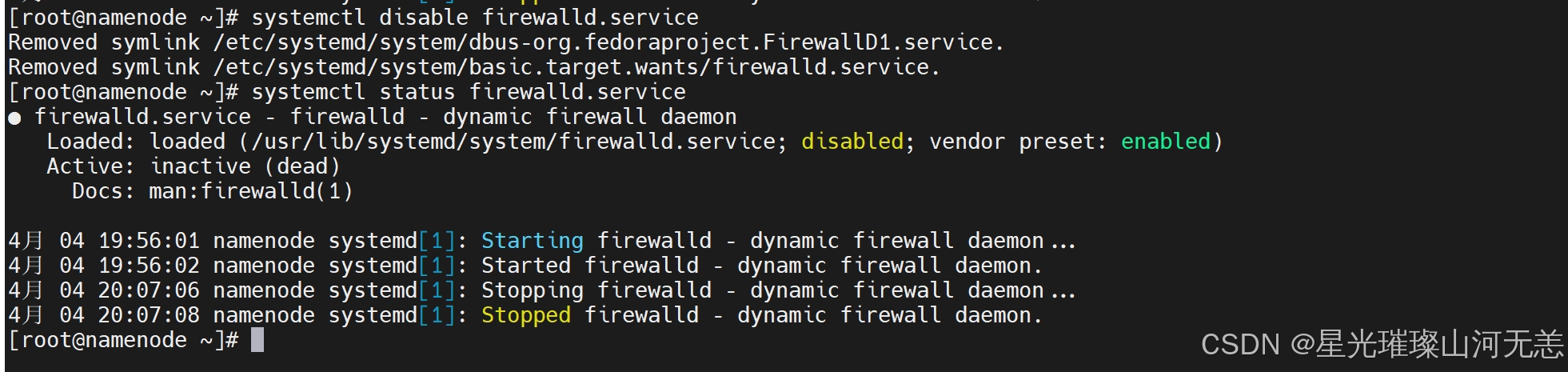
四、关闭NetworkManger服务
NAT模式,修改网卡配置文件后,重启服务出现错误’Job for network.service failed because the control process exited with error code. See “systemctl status network.service” and “journalctl -xe” for details.’
解决方法:
1.和 NetworkManager 服务有冲突,关闭 NetworkManger 服务
systemctl stop NetworkManager2.禁止开机启动NetworkManager 服务
systemctl disable NetworkManager
3.除此以外,其他相关命令如下:
查看# systemctl status NetworkManager开启# systemctl start NetworkManager
可用# systemctl enable NetworkManager
五、配置静态ip
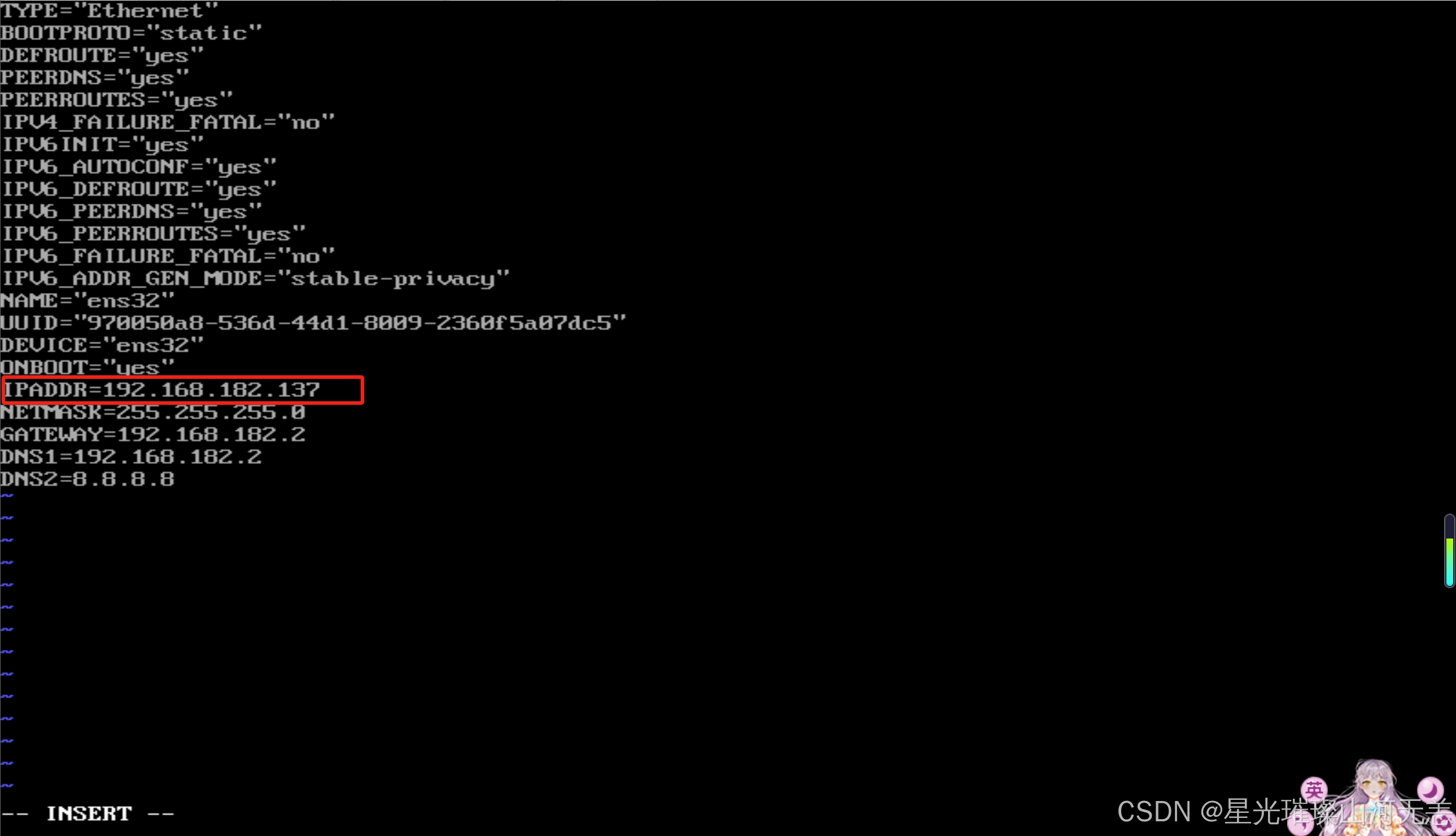
使用root用户修改当前启用的网卡配置文件,所在路径为 /etc/sysconfig/network-scripts ,CentOS 6系统默认为ifcfg-eth0,CentOS 7系统默认为ifcfg-ens32 ,使用vi编辑器编辑ifcfg-ens32文件,所用命令如下:
vi /etc/sysconfig/network-scripts/ifcfg-ens32
三个节点上的这个文件都需要修改,修改的内容基本一致,如下是需要修改和添加的
详情见【Linux】无法连接网络的情况及解决方案里的配置静态IP地址
#原值为dhcp,修改为static
BOOTPROT="static"
# 添加IPADDR,对应的值要与原ip在同一网段
IPADDR=xxx.xxx.xxx.xxx
# 添加NETMASK,指定子网掩码,默认为255.255.255.0
NETMASK=255.255.255.0
# 添加GATEWAY,要与虚拟机网卡的设置一致,默认仅主机模式为1,NAT模式为2
GATEWAY=xxx.xxx.xxx.1/2
# 如果需要连入外网,则可以添加DNS1和DNS2配置,通常会将DNS1指定为网关地址
DNS1=网关地址
DNS2=8.8.8.8
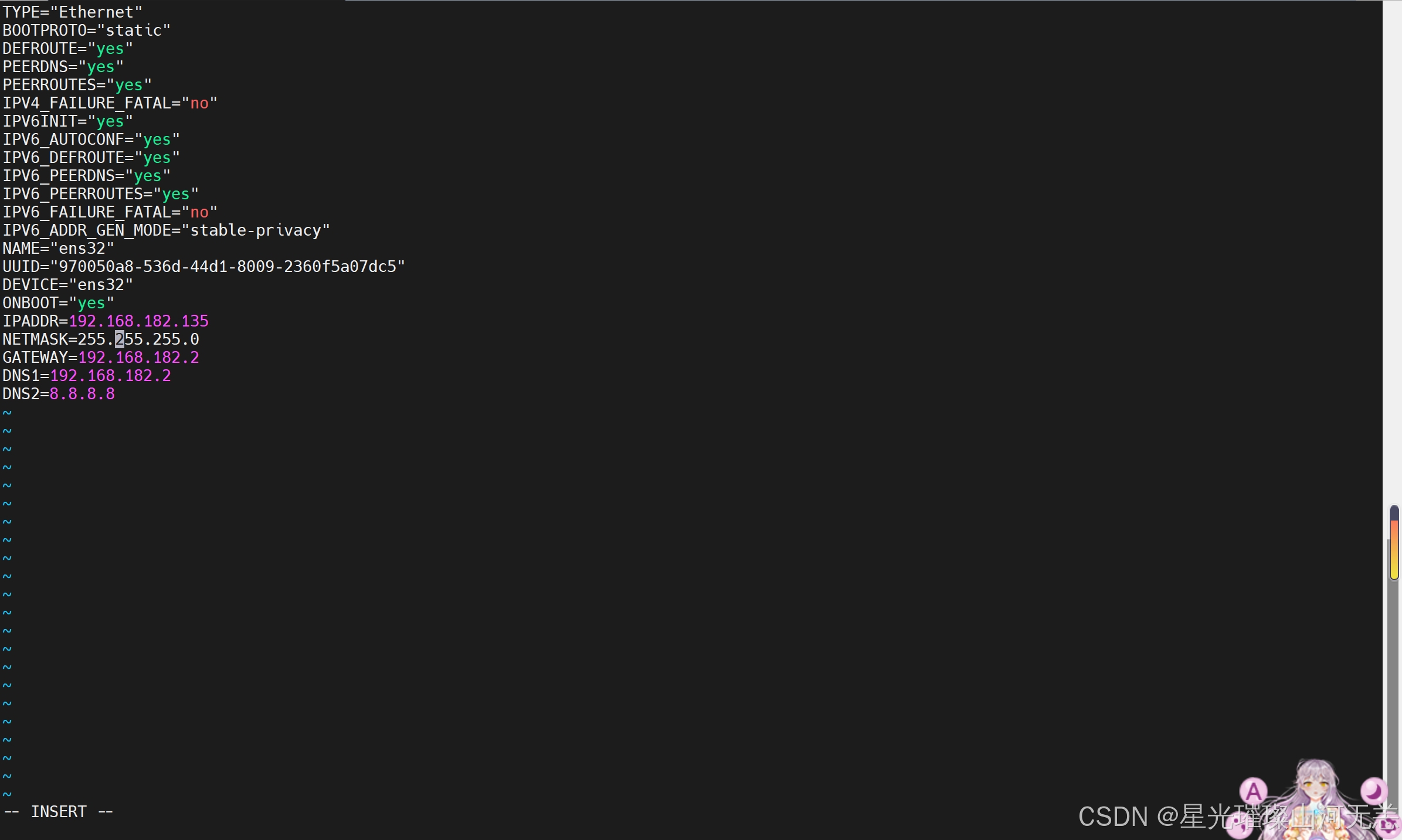
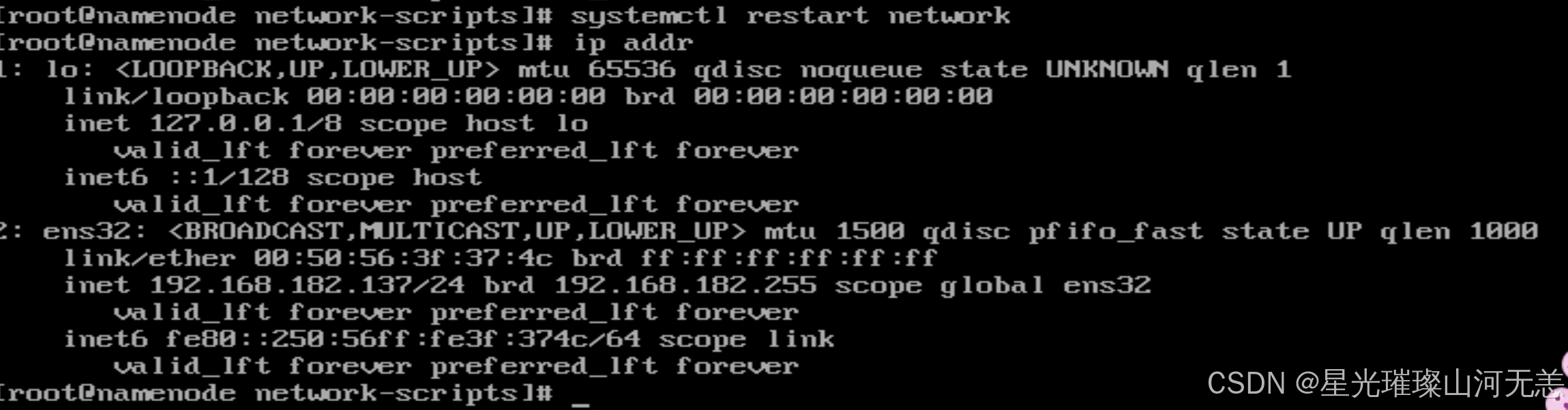
重启网络

注意:
配置完成后保存退出,使用systemctl restart network命令重启网卡服务。(如果使用service network restart命令,则需要编辑/etc/resolv.conf文件,添加对应的如下内容:nameserver 8.8.8.8 )
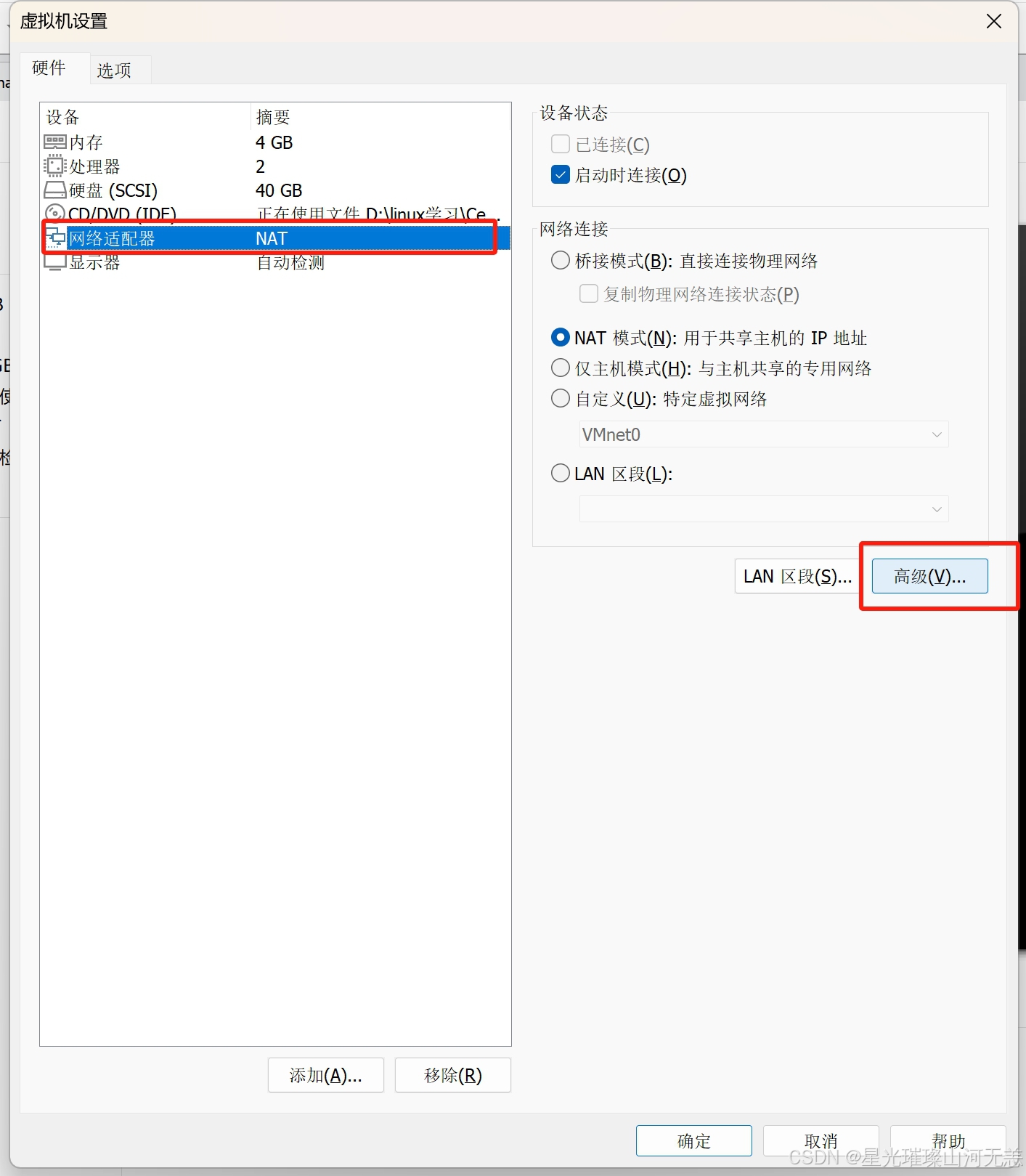
六、克隆虚拟机
克隆时要先关机,这里需要克隆worker1和worker2
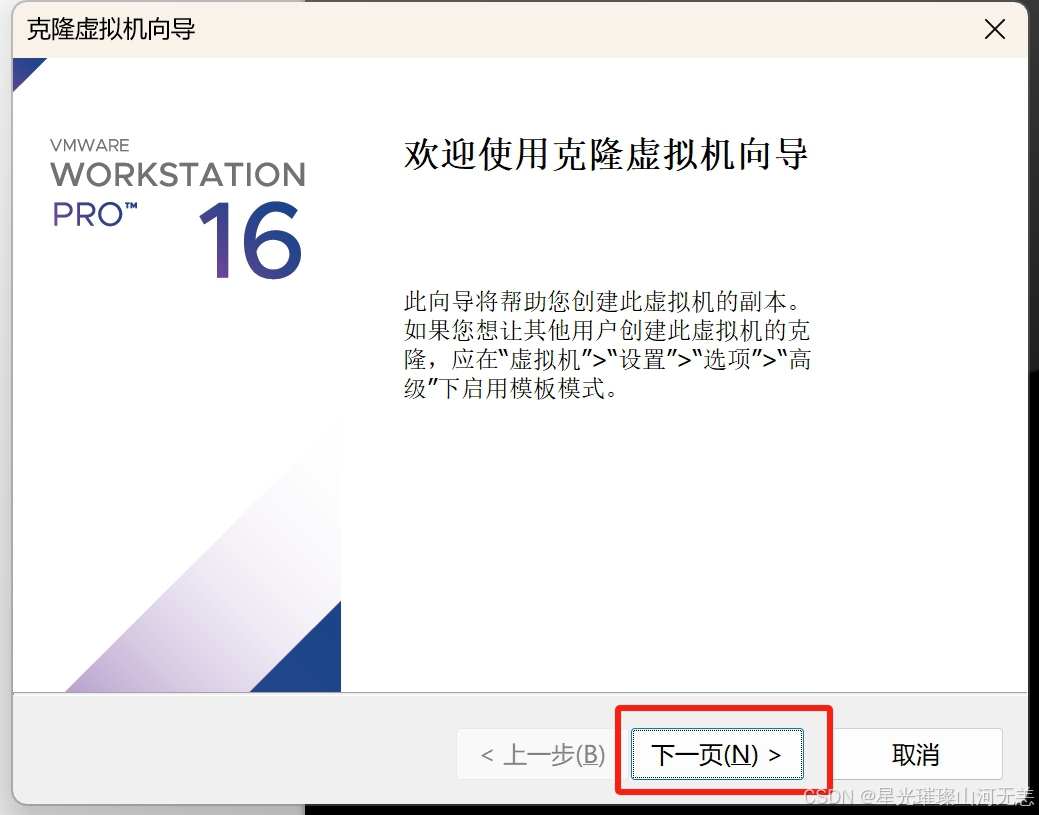
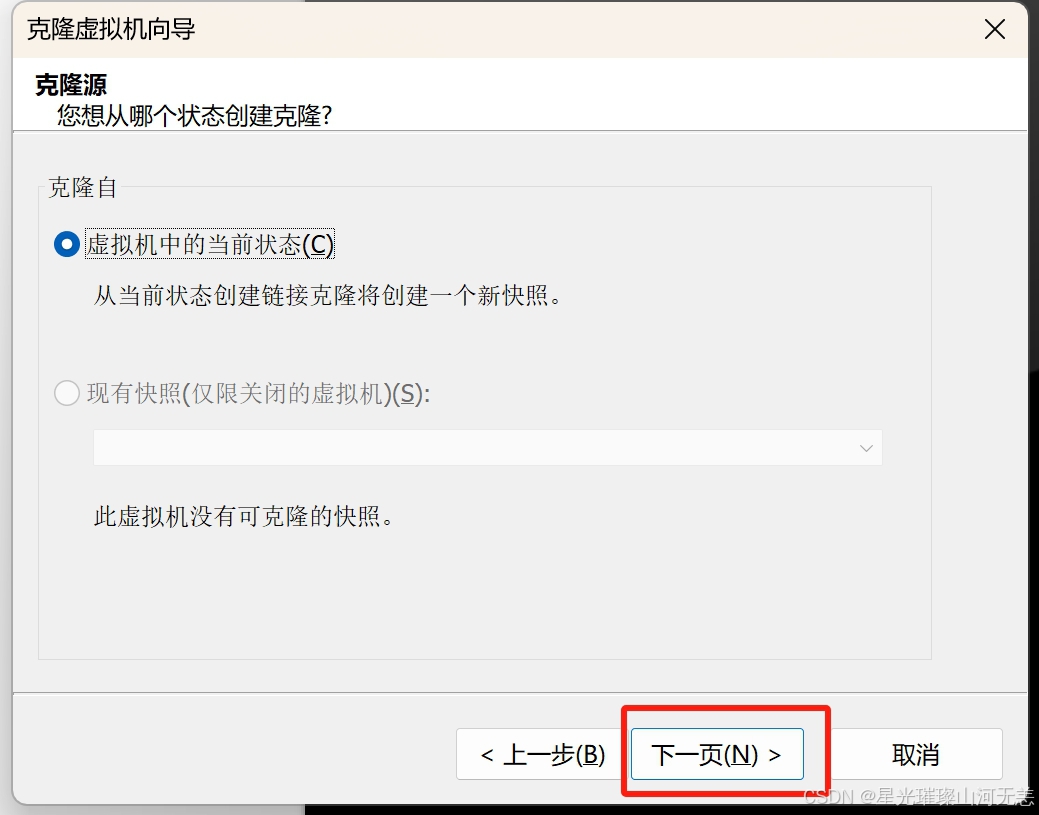
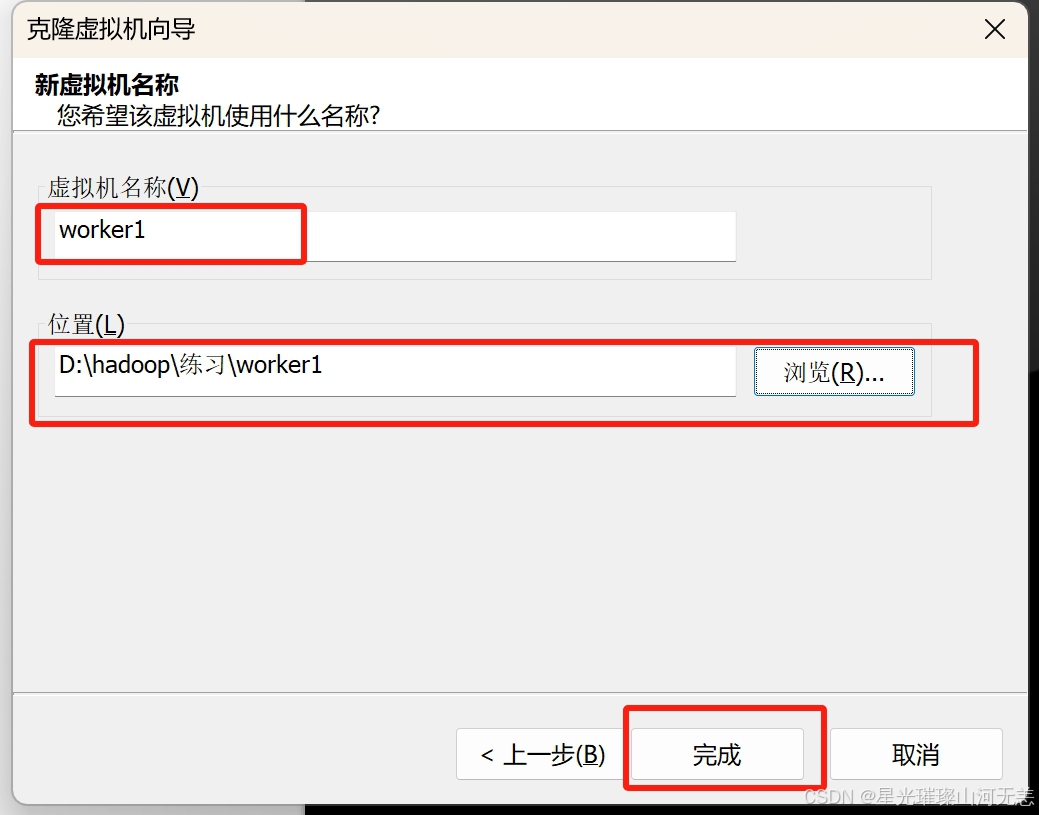
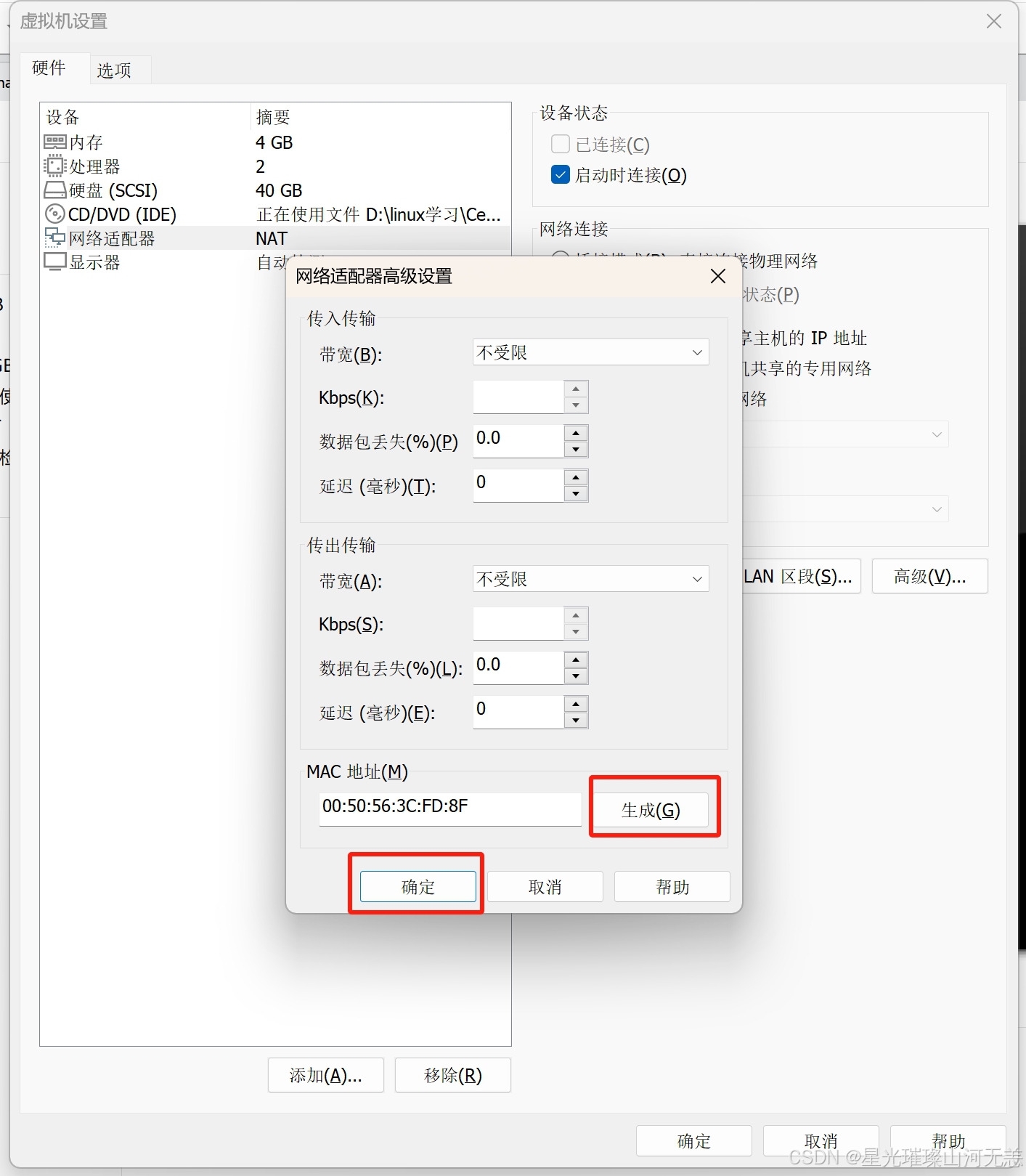
克隆完成后需要重新设置ip地址和mac地址
mac地址的设置如下:
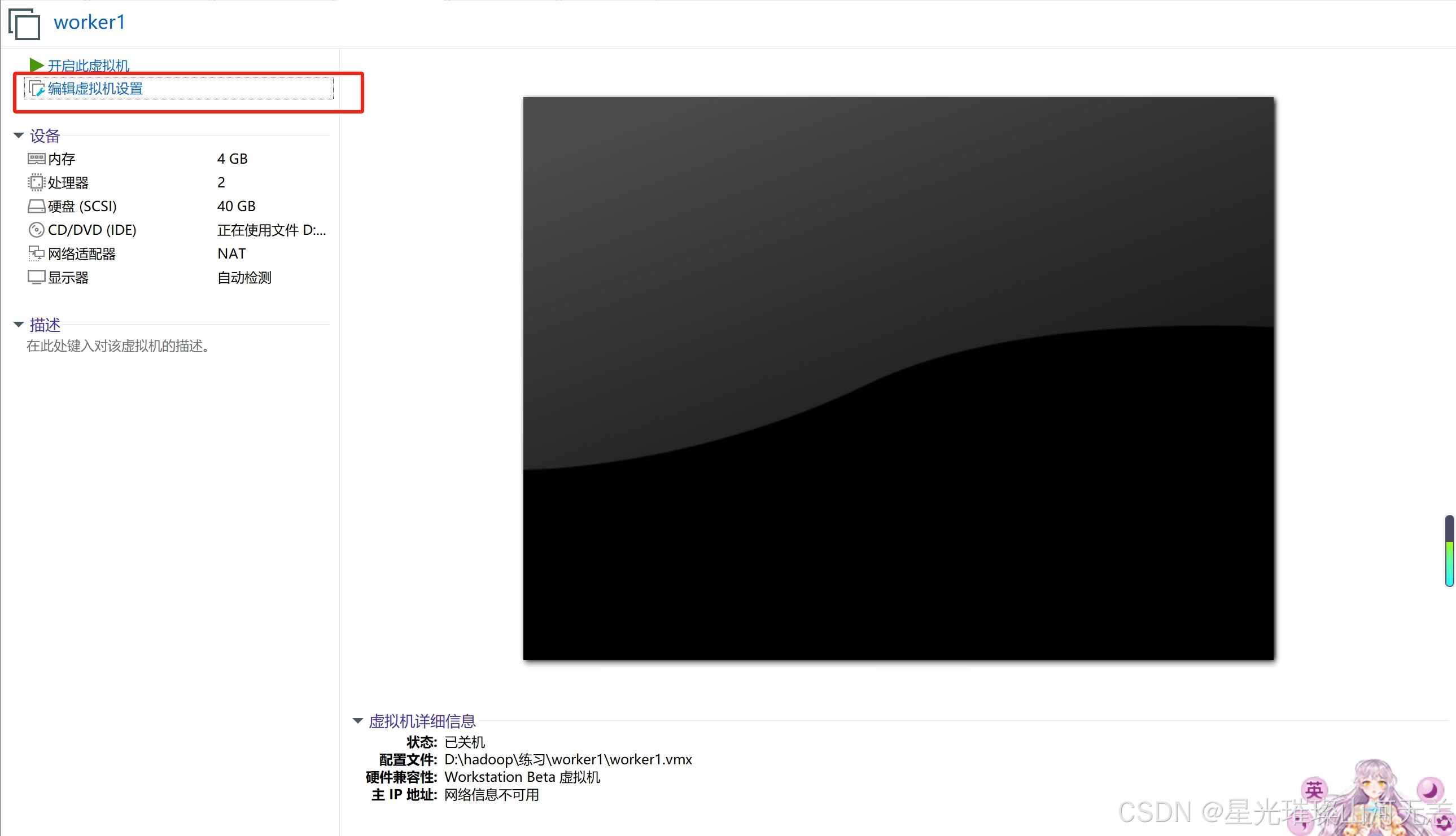
重新设置ip地址如下:

启动虚拟机,连接MobaXterm
注:三个虚拟机的ip地址都是连续的
七、ip地址和主机名的映射
在完全分布式部署的Hadoop平台上,为了方便各节点的交互,也为了尽量减少配置的修改,通常在配置文件中都会使用主机名来访问节点,这就需要正确的建立主机名与ip的映射。我们目前已经有了三台配置好网络的机器。现在我们有这样三台机器(namenode为主节点):
| 主机名称 | IP地址 |
|---|---|
| namenode | 192.168.182.135 |
| worker1 | 192.168.182.136 |
| worker2 | 192.168.182.127 |
1.需要使用root用户修改(用vi修改) /etc/hosts 文件,删除原来的内容,在结尾直接追加内容(每台机器):
用MultiExec可以一起编译3台虚拟机
192.168.182.135 namenode
192.168.182.136 worker1
192.168.182.137 worker2
用dd把里面的内容全删除
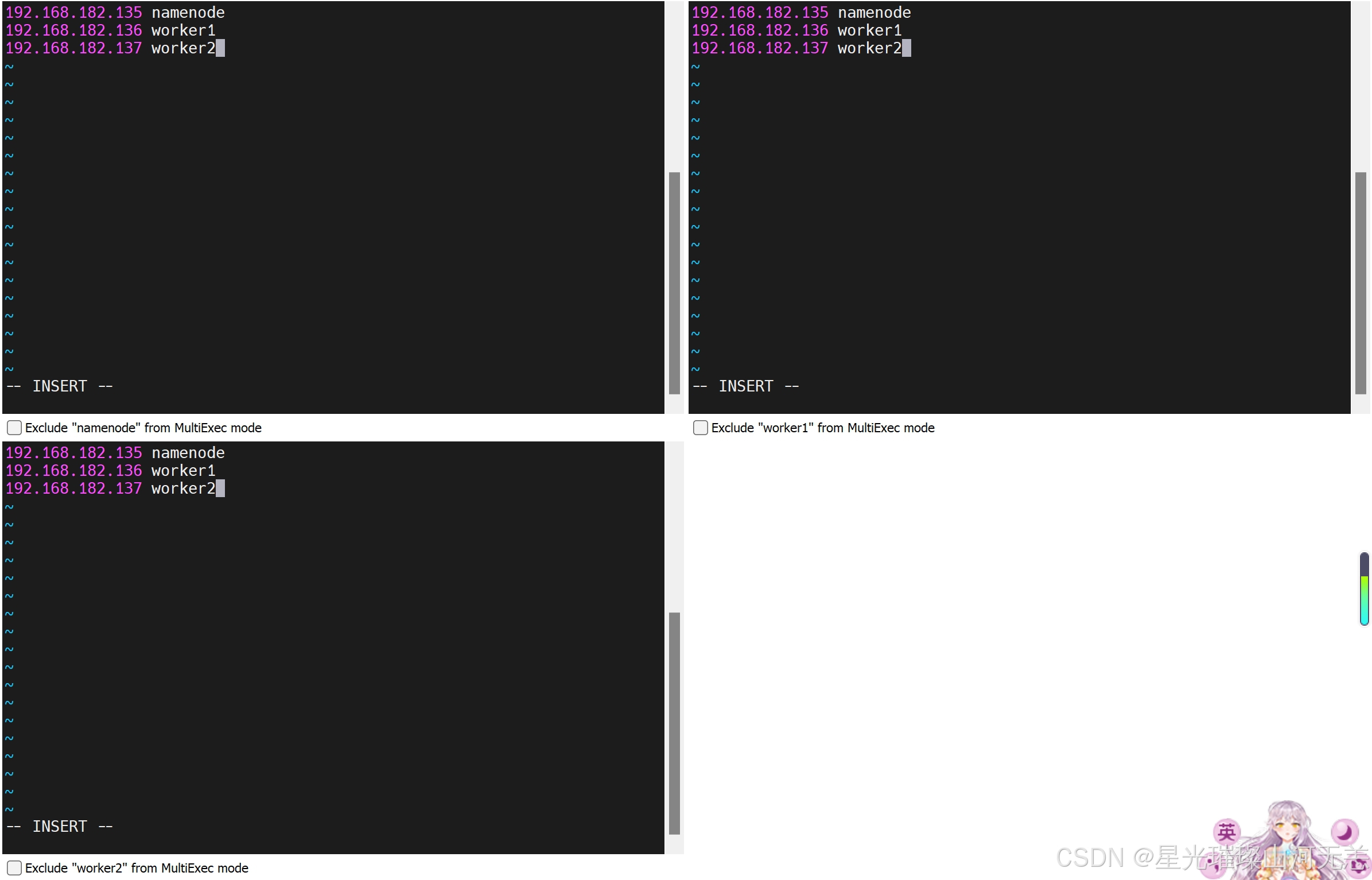
先按etc键,再按:wq(保存并退出)
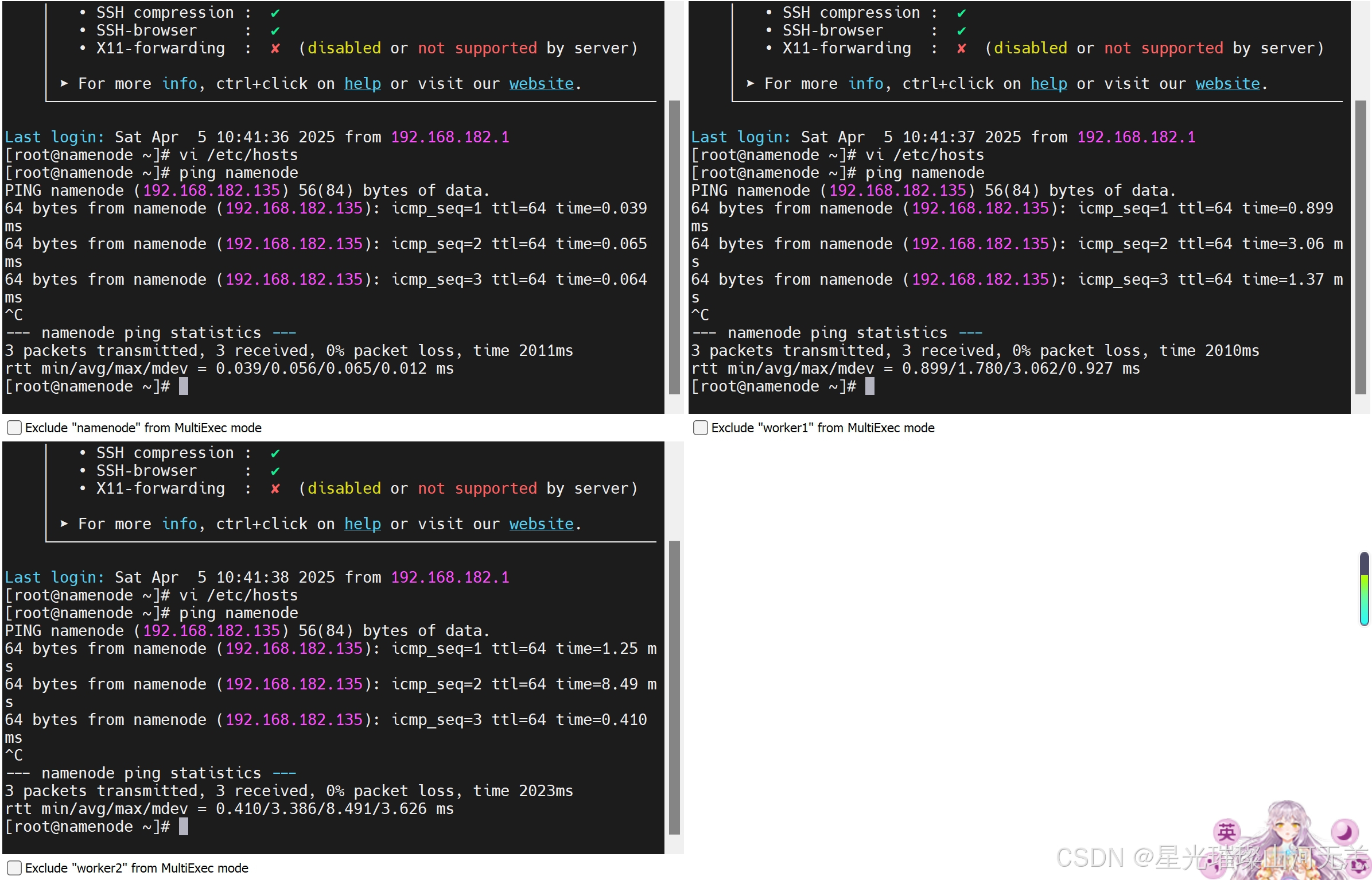
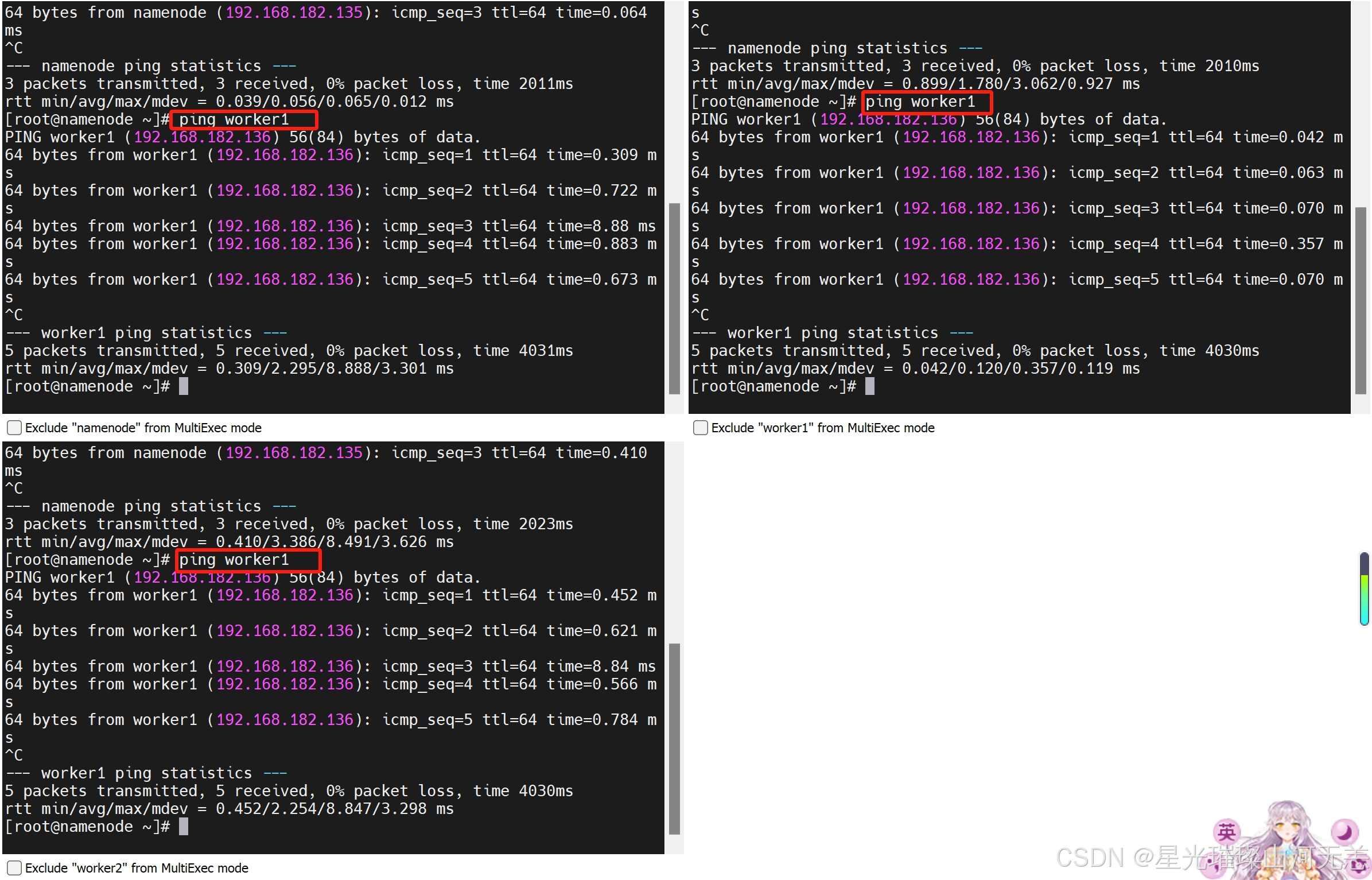
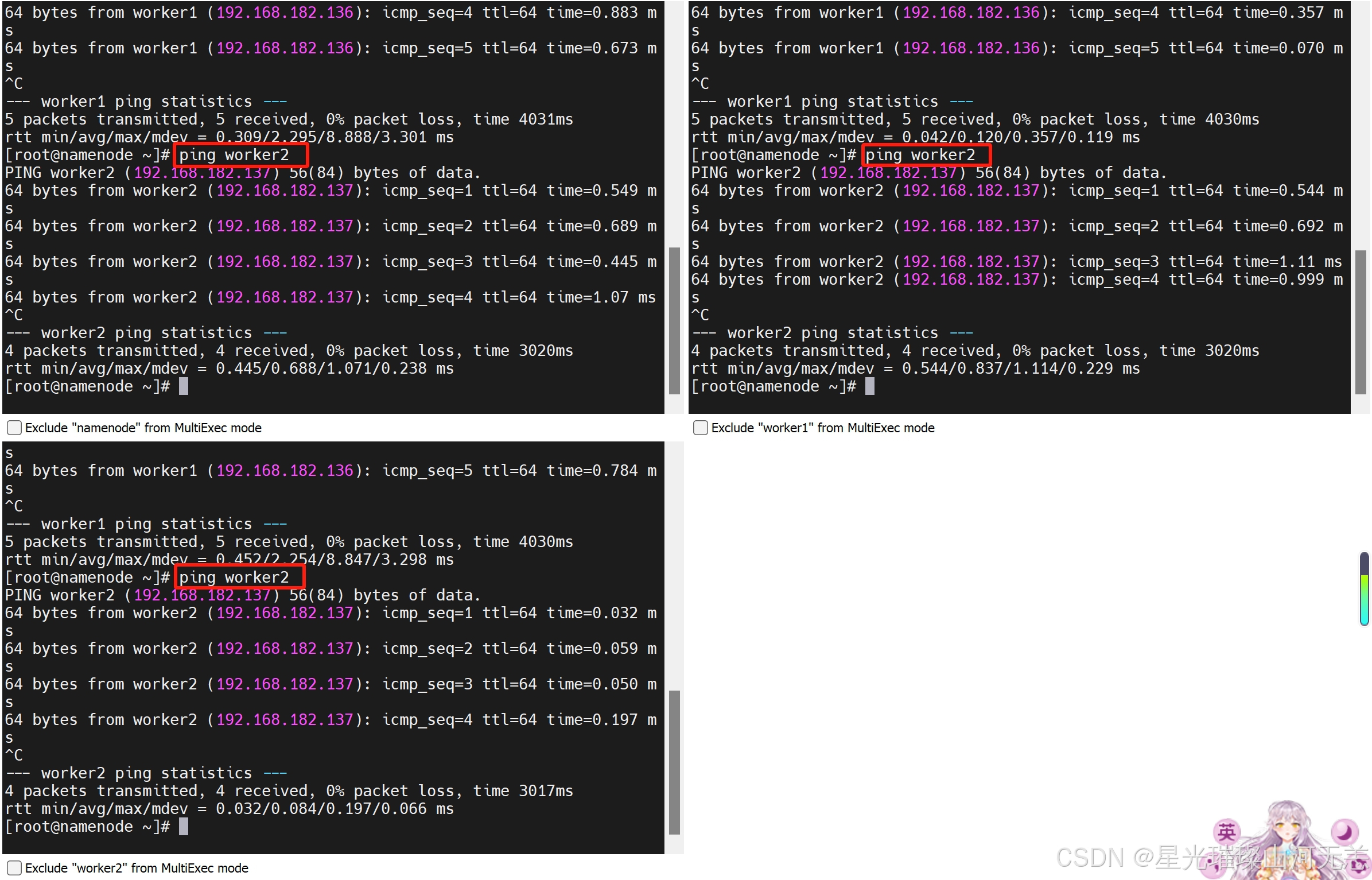
2.配置完成后可以使用ping命令一一测试,看看是够能够正确解析出ip地址,得到目标机器的回应(可以每台机器都测试一下:使用Ctrl + C结束)。
检测在同一个网段内,3个都测试
3.(如果一个个虚拟机操作的)在slave1和slave2 上也修改hosts文件,追加内容和步骤1的内容相同,然后重复步骤2
八、免密登录设置
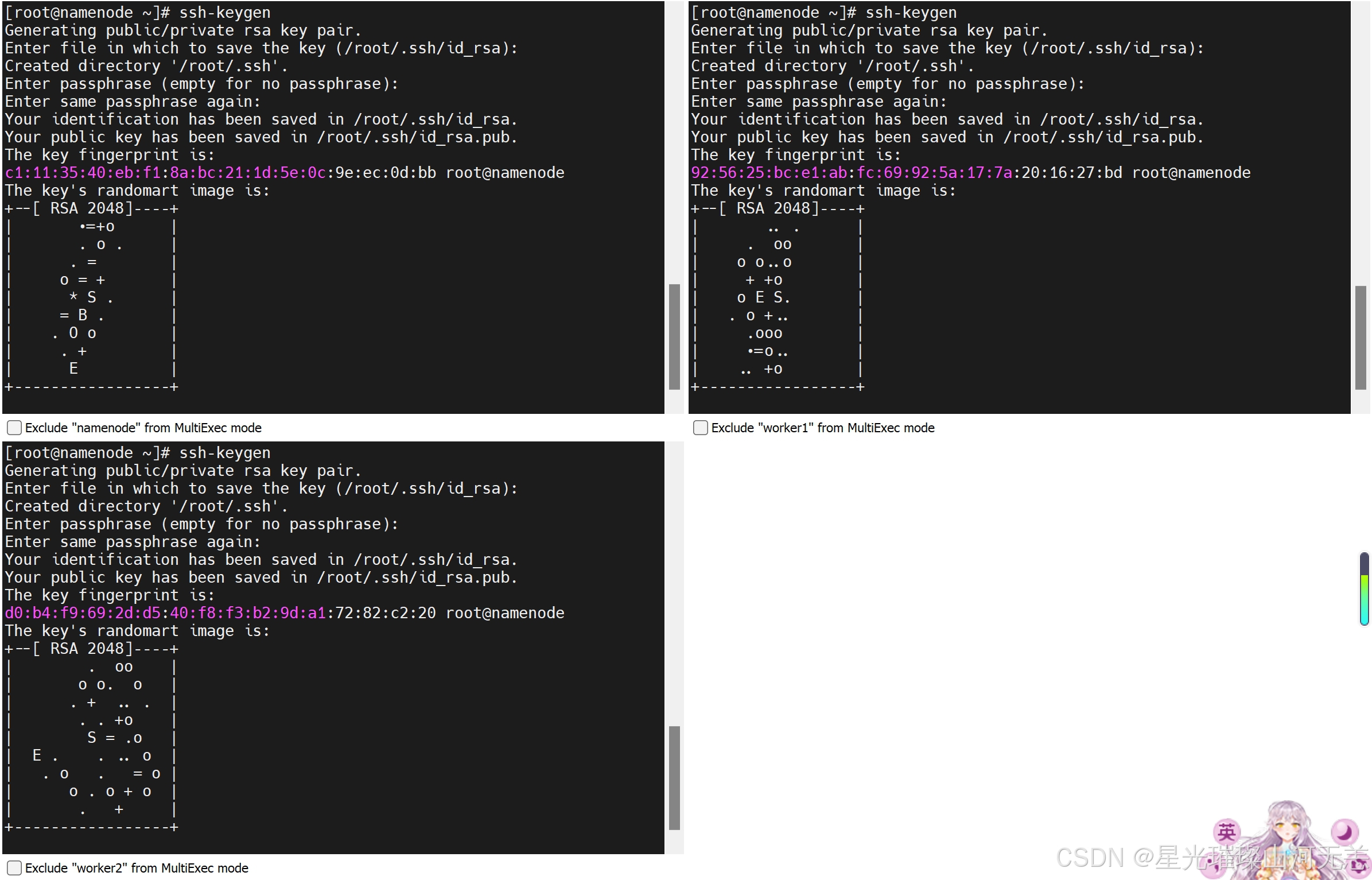
1.生成公钥密钥对
在3个节点上分别都执行如下命令:
ssh-keygen连续按Enter键确认。
在root目录下输入:ll-a 可以查看当前目录下的所有文件(包含隐藏文件)。
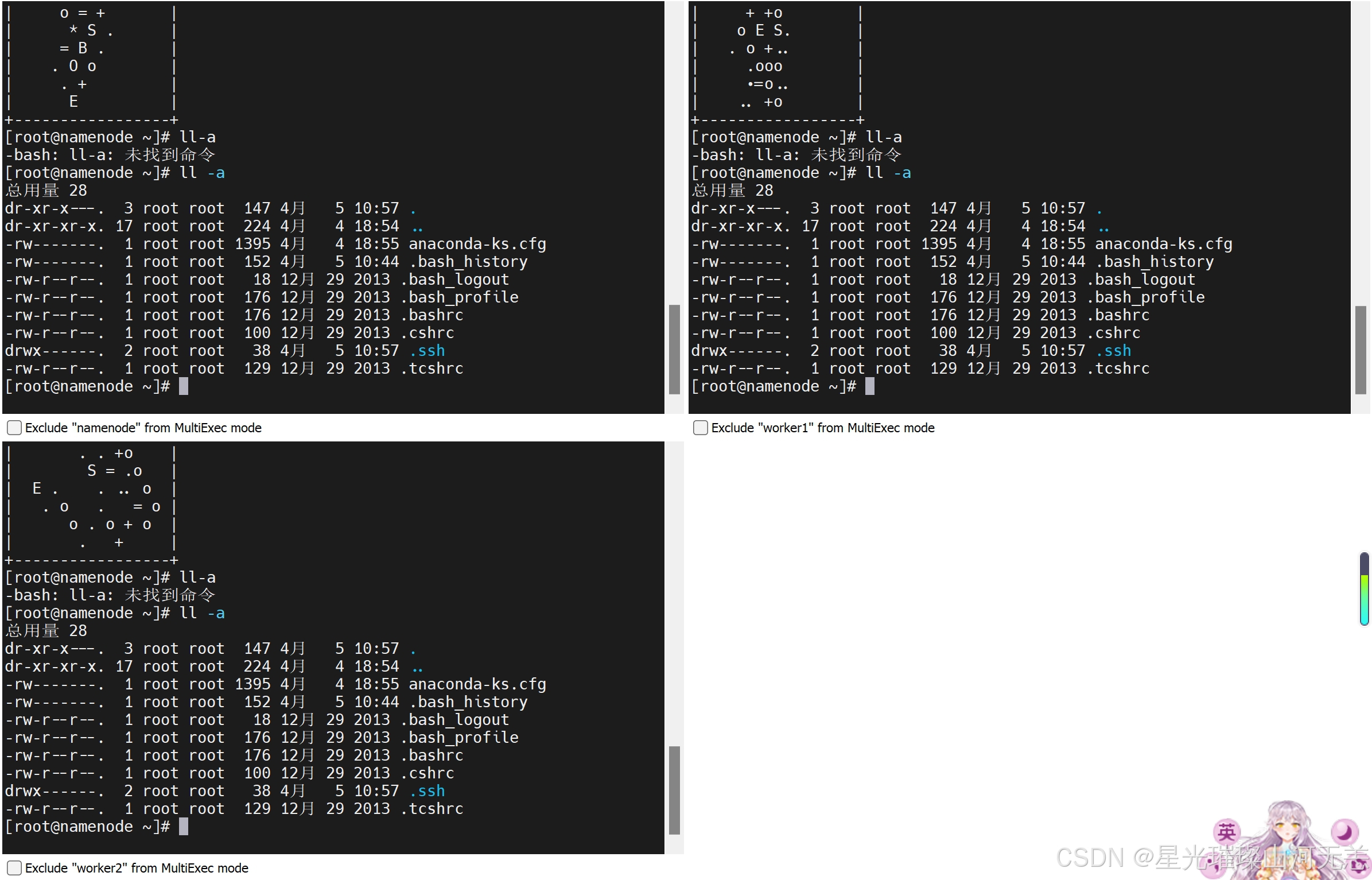
然后进入.ssh隐藏目录,输入ls 命令,如图所示:
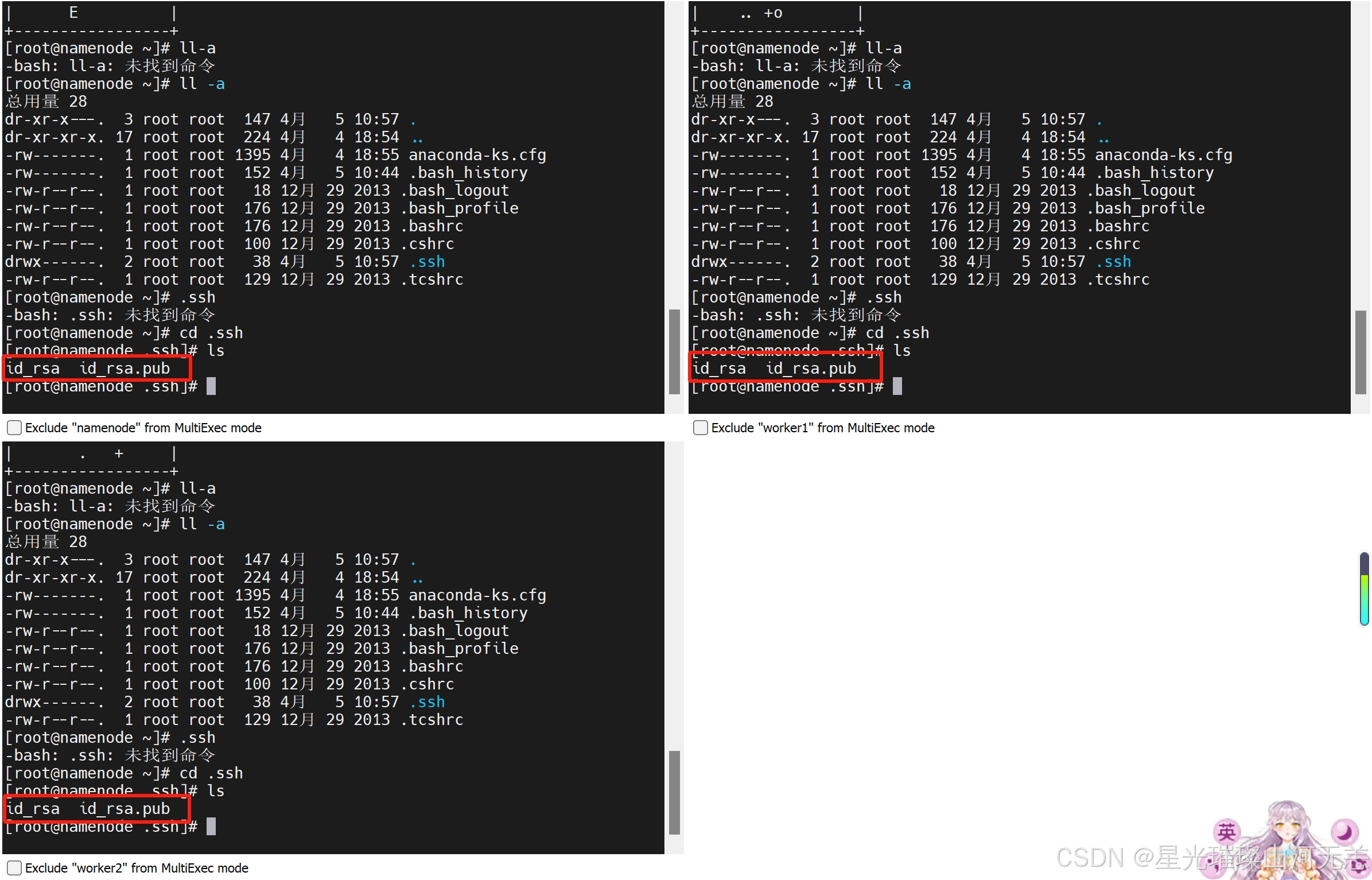
在图中能够看到包含两个文件分别是私钥和公钥,其中id_rsa为生成的私钥,id_rsa.pub为生成的公钥。
2.将子节点的公钥拷贝到主节点并添加进authorized_keys
在namenode节点上执行如下两行命令:
ssh-copy-id namenode
ssh-copy-id worker1
ssh-copy-id worker2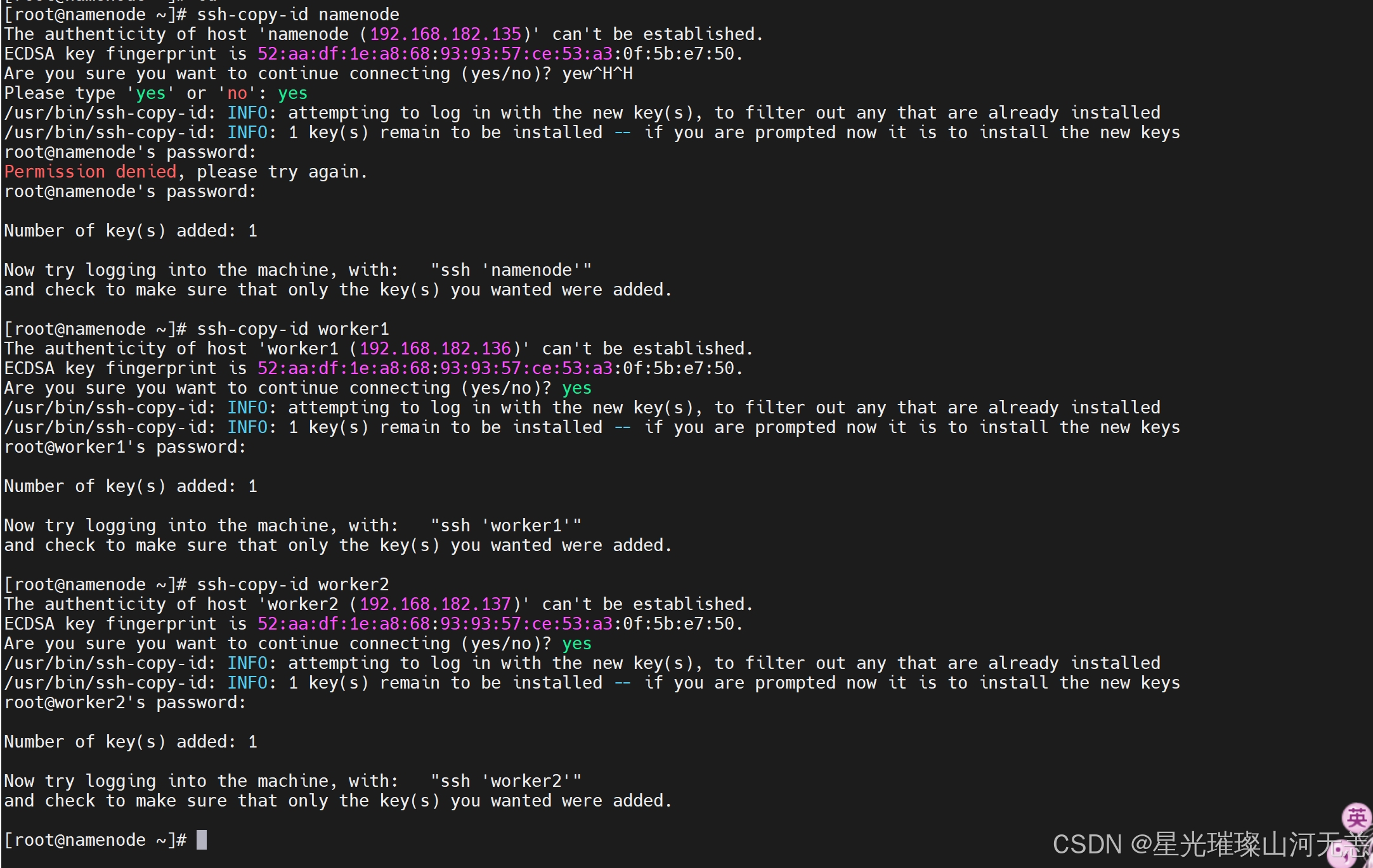
执行时,需要输入yes
3.测试是否成功
为了测试免密设置是否成功,可执行如下命令:
ssh namenode
ssh worker1
ssh worker2结果如图所示:
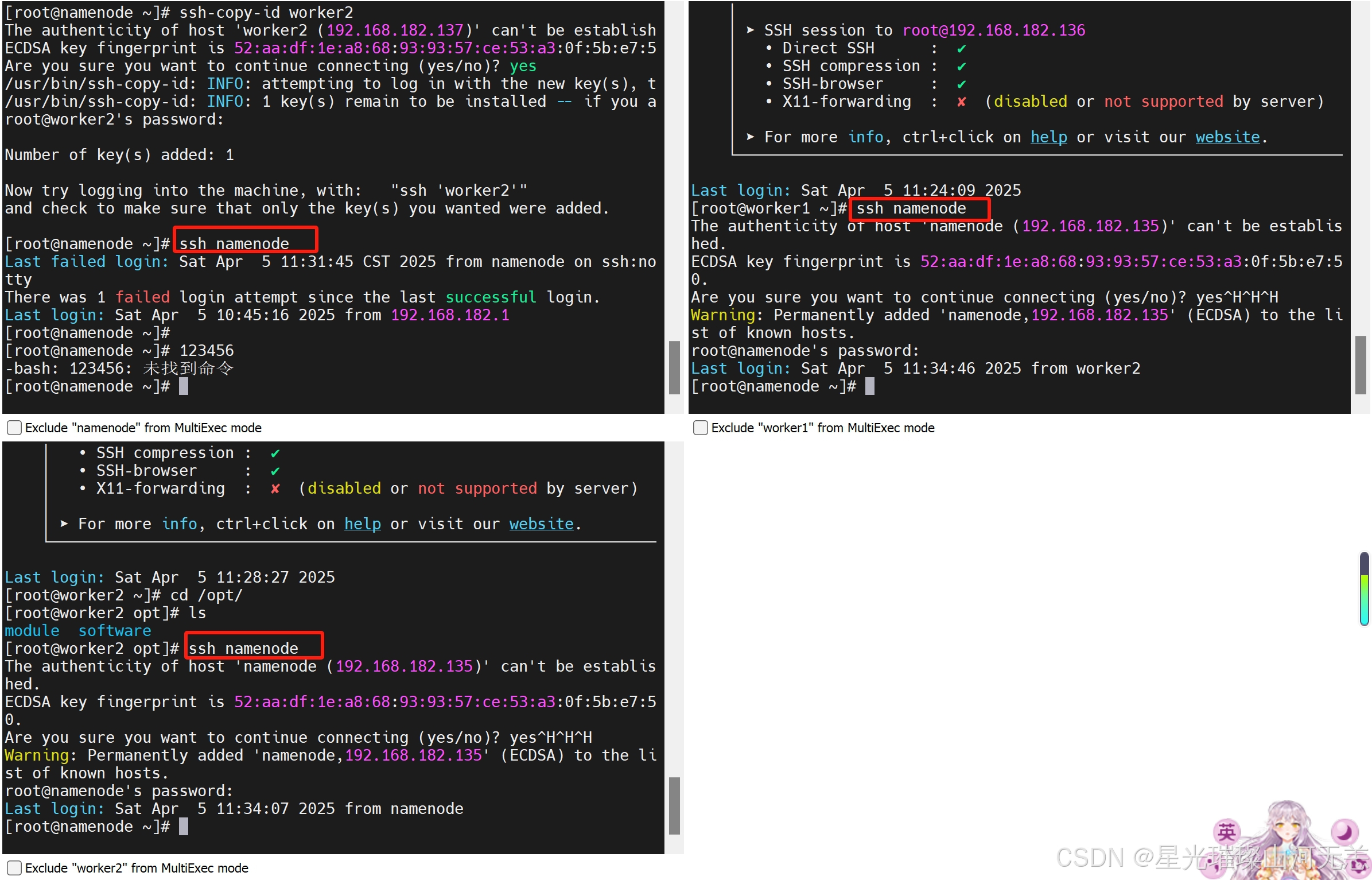
exit登出
九、配置时间同步服务
- 如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
- 如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
- NTP(Network Time Protocol,网络时间协议) 是使计算机时间同步化的一种协议,可以使计算机对其服务器或时钟源进行同步化,提供高精度的时间校正。
- Hadoop集群对时间要求很高,主节点与各从节点的时间必须同步,因此需要配置时间同步服务。
1.下载安装ntp服务
2.设置master节点为ntp服务主节点
3.从节点配置ntp服务
4.启动ntp服务
十、配置jdk、hadoop环境
为了规范后续Hadoop集群相关软件和数据的安装配置,这里在虚拟机的根目录下建一些文件夹作为约定,具体如下:
| 文件夹名 | 作用 |
|---|---|
| /opt/module | 存放软件 |
| /opt/software | 存放安装包压缩包 |
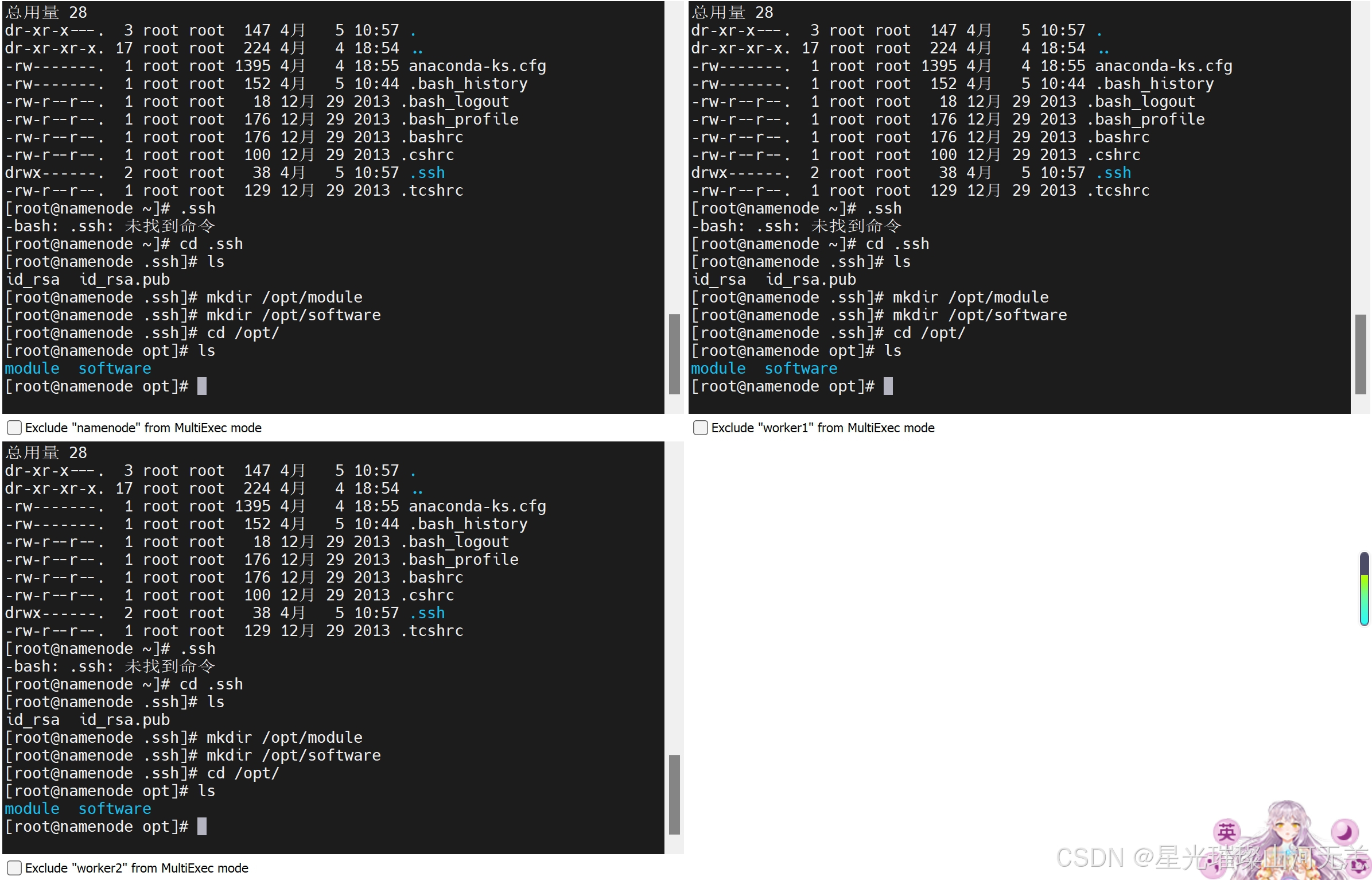
这里忘记改虚拟机名字了


具体需要执行下面3条命令:
mkdir -p /opt/module
mkdir -p /opt/software
进入/opt目录下,执行ls命令,如图所示即为成功。
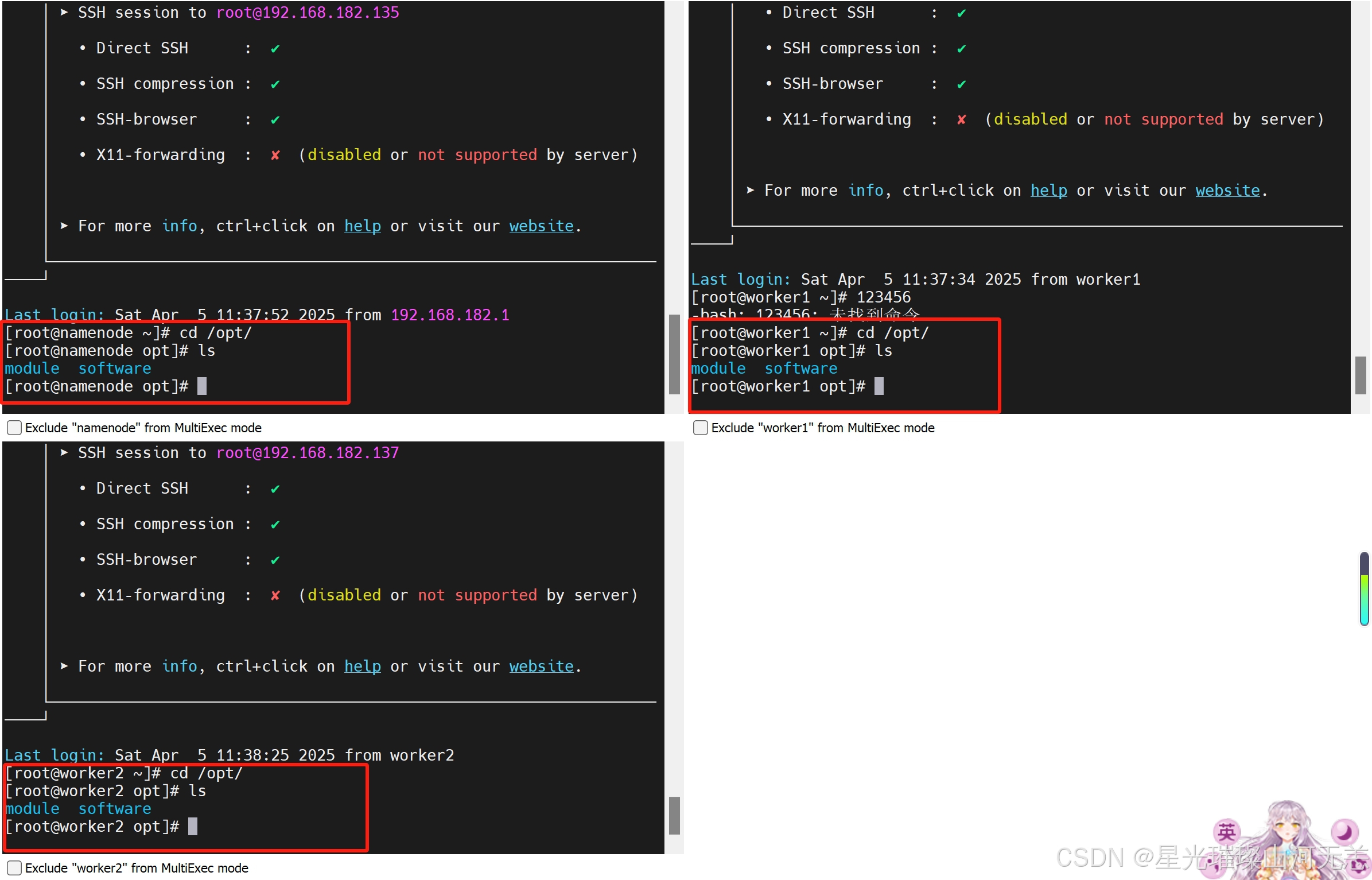
1.下载jdk安装包和hadoop3.1.4
下载JDK地址 : https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2.将本地的jdk、hadoop安装包上传到/opt/software系统中

3.进入/opt/software目录下,解压jdk安装包到/opt/module
执行如下命令:
cd /opt/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module
tar -zxvf hadoop-3.1.4.tar.gz -C /opt/module/
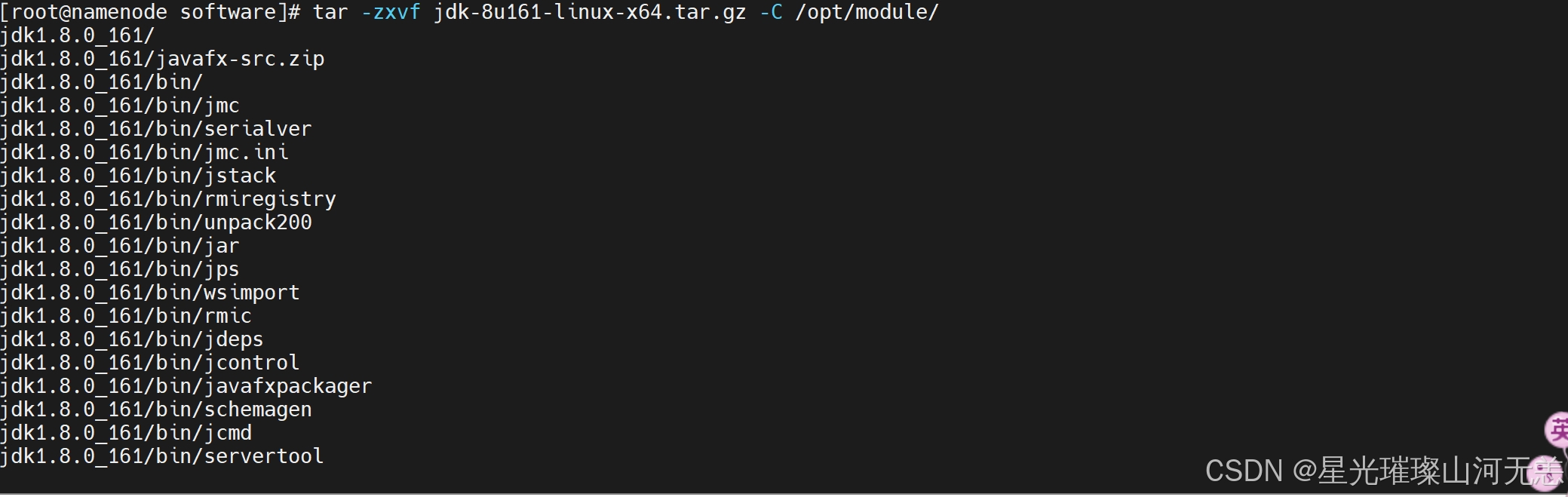
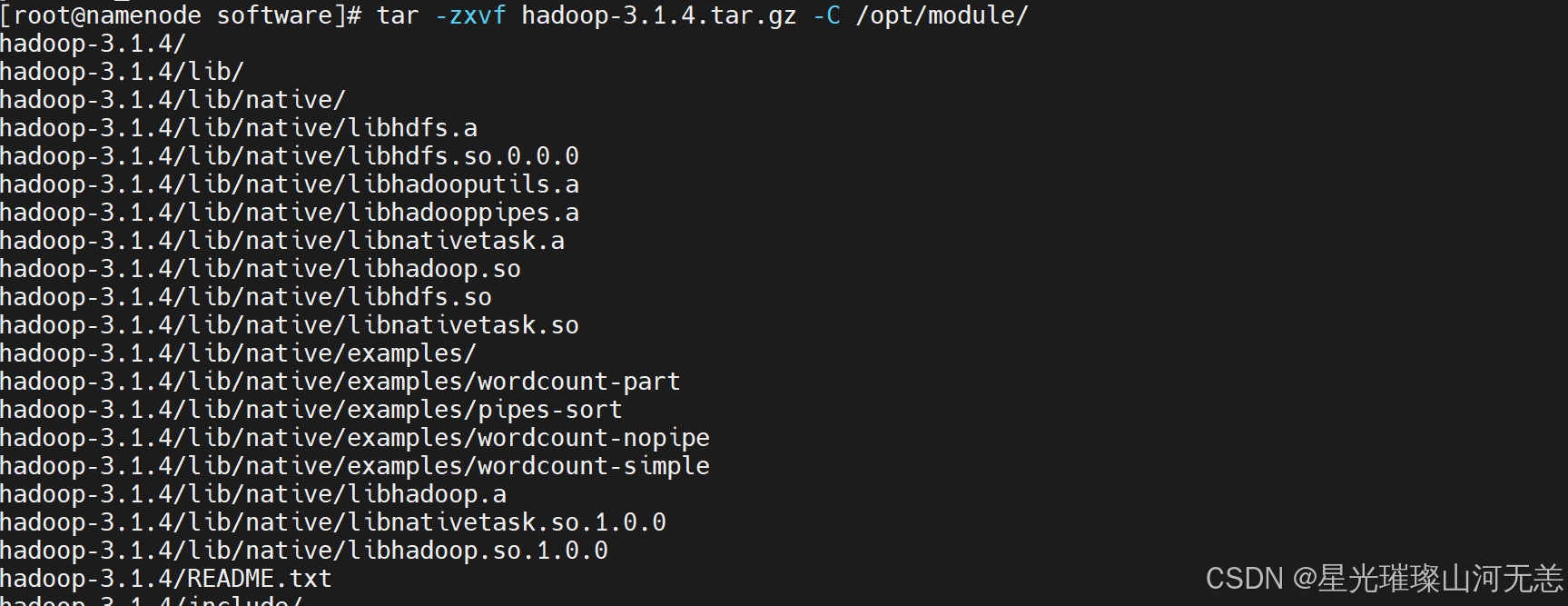
解压后在/opt/module目录下使用ll命令查看:

4.配置环境变量
使用vi编辑器编辑etc文件夹下的profile文件,键盘按下大写字母G,即可将光标移动到文章的末尾。
vi /etc/profile.d/my_env.sh
将如下内容添加到末尾
#jdk环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
#hadoop环境变量
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH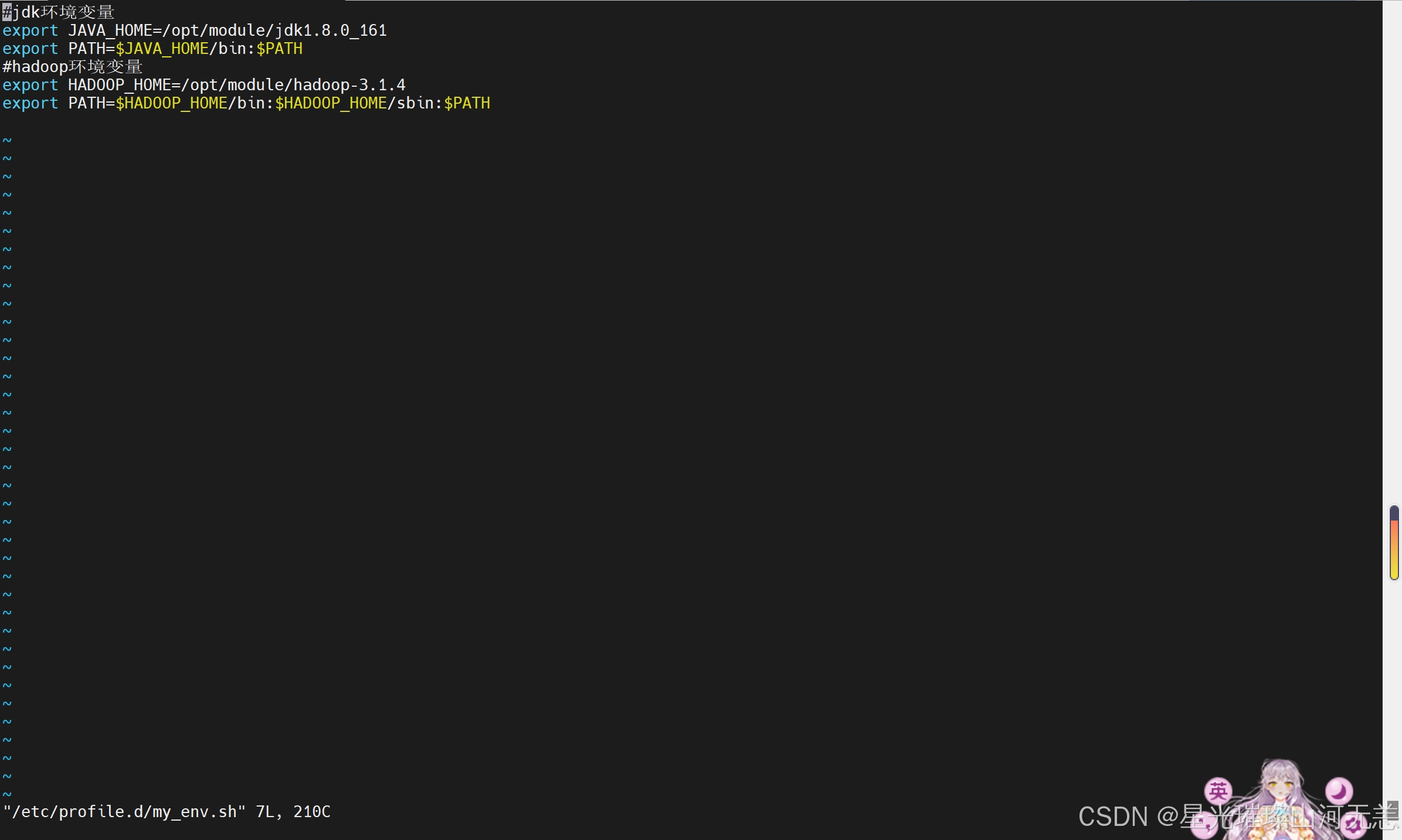
刷新环境变量
source /etc/profile

使用命令测试jdk环境变量的配置
java -version

使用命令测试hadoop环境变量的配置
hadoop version

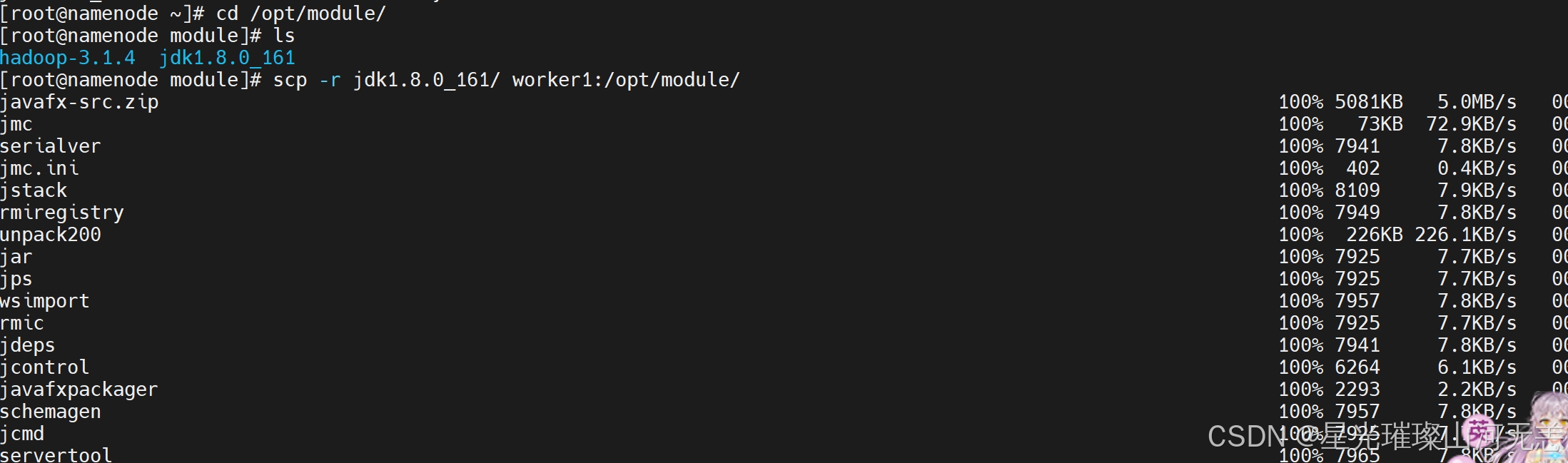
将第一台机子master上的jdk和hadoop的软件包及环境变量配置文件,传给slave1和slave2
scp -r jdk1.8.0_161/ slave1:/opt/module/
scp -r jdk1.8.0_161/ slave2:/opt/module/
scp -r hadoop-3.1.4/ slave1:/opt/module/
scp -r hadoop-3.1.4/ slave2:/opt/module/
scp -r /etc/profile.d/my_env.sh slave1:/etc/profile.d/
scp -r /etc/profile.d/my_env.sh slave2:/etc/profile.d/
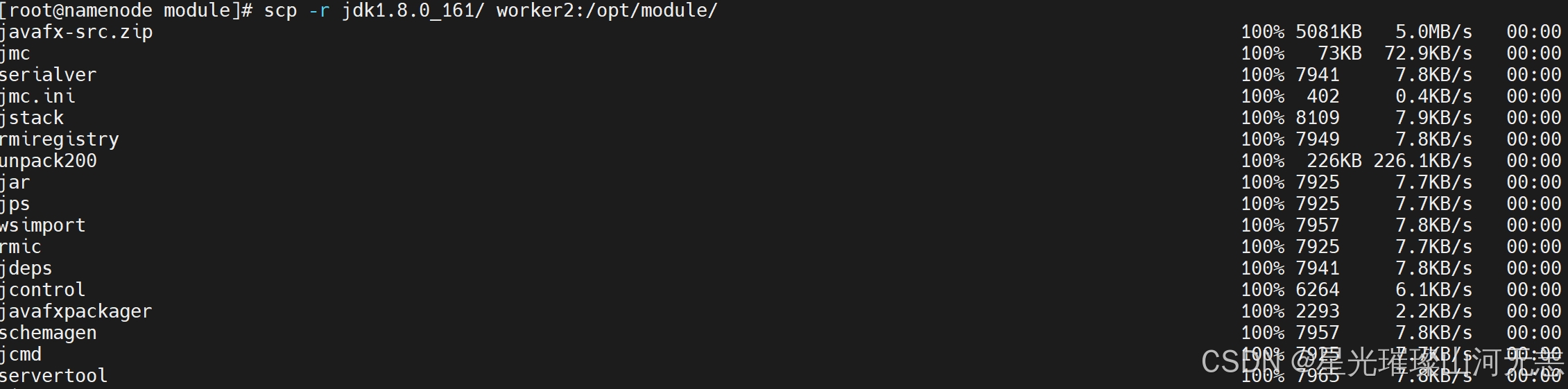



三台机子都需要刷新环境变量生效
source /etc/profile

相关文章:

【Hadoop3.1.4】完全分布式集群搭建
一、虚拟机的建立与连接 1.建立虚拟机 详情见【Linux】虚拟机的安装 把上面三个参数改掉 2.连接虚拟机 具体见【Linux】远程连接虚拟机防火墙 二、修改主机名 在Centos7中直接使用root用户执行hostnamectl命令修改,重启(reboot)后永久生…...

NLP简介及其发展历史
自然语言处理(Natural Language Processing,简称NLP)是人工智能和计算机科学领域中的一个重要分支,致力于实现人与计算机之间自然、高效的语言交流。本文将介绍NLP的基本概念以及其发展历史。 一、什么是自然语言处理?…...

Java异步编程中的CompletableFuture介绍、常见错误及最佳实践
一、Future接口的局限性 Java 5引入的Future接口为异步编程提供了基础支持,但其设计存在明显局限性,导致复杂场景下难以满足需求: 阻塞获取结果 必须通过future.get()阻塞线程等待结果,无法实现真正的非阻塞: Executo…...

基于FLask的共享单车需求数据可视化分析系统
【FLask】基于FLask的共享单车需求数据可视化分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统能够整合并处理大量共享单车使用数据,通过直观的可视化手段࿰…...

vue2项目中,多个固定的请求域名 和 通过url动态获取到的ip域名 封装 axios
vue2 使用场景:项目中,有固定的请求域名,而有某些接口是其他域名 /utils/request.js 固定请求域名 import axios from axios import Vue from vuelet baseURL switch (window.location.hostname) {case localhost: // 本地case 127.0.0.1…...

【嵌入式学习3】基于python的tcp客户端、服务器
目录 1、tcp客户端 2、tcp服务器 3、服务器多次连接客户端、多次接收信息 1、tcp客户端 """ tcp:客户端 1. 导入socket模块 2. 创建socket套接字 3. 建立tcp连接(和服务端建立连接) 4. 开始发送数据(到服务端) 5. 关闭套接字 """ import soc…...

tomcat构建源码环境
一. IDEA运行Tomcat8源码 参考网址:https://blog.csdn.net/yekong1225/article/details/81000446 Tomcat作为J2EE的开源实现,其代码具有很高的参考价值,我们可以从中汲取很多的知识。作为Java后端程序员,相信有很多人很想了解…...

你用的是Bing吗?!
🔥【深度解析】微软Bing革命性升级!Copilot Search上线:从此搜索≠找链接,而是直接生成答案! 💡 你是否厌倦了这样的搜索体验? 搜索「Python处理JSON」,在10个网页间反复跳转想对比…...

拍摄的婚庆视频有些DAT的视频文件打不开怎么办
3-12 现在的婚庆公司大多提供结婚的拍摄服务,或者有一些第三方公司做这方面业务,对于视频拍摄来说,有时候会遇到这样一种问题,就是拍摄下来的视频文件,然后会有一两个视频文件是损坏的,播放不了࿰…...
 服务器最新控制台启用 IPv6 超详细图文指南(2025最新实践))
Oracle Cloud (OCI) 服务器最新控制台启用 IPv6 超详细图文指南(2025最新实践)
本文为原作者发布到第三方平台,更多内容参考: 🚀 Oracle Cloud (OCI) 服务器最新控制台启用 IPv6 超详细图文指南(2025最新实践) 随着 IPv6 的普及,IPv6的优秀特性能为你的 OCI 云服务器提升网络性能和路由效率,并提升兼容性。本指南将引导你在 Oracle Cloud Infrast…...

YOLO环境搭建,win11+wsl2+ubuntu24+cuda12.6+idea
提示:环境搭建 文章目录 前言一、 win11 gpu 驱动更新1.1 下载驱动3. 验证, 二、配置子系统 ubuntu2.1 安装 cuda 三、配置 anaconda四、idea 配置使用 wsl ubuntu conda 环境 前言 提示:版本 win11 wsl2 ubuntu24 idea 2024 子系统跳过&…...

类 和 对象 的介绍
对象的本质是一种新的数据类型。类是一个模型,对象是类的一个具体化实例。为类创建实例也就是创建对象。 一、类(class) 类决定一个对象将是什么样的(有什么属性、功能)。类和变量一样,有名字。 1.创建类 …...
—线性回归)
机器学习(1)—线性回归
文章目录 1. 算法定义2. 模型形式2.1. 简单线性回归(单变量):2.2. 多元线性回归(多变量): 3. 基本原理3.1. 误差函数:3.2. 求解回归系数 4. 假设条件5. 模型评估6. 优缺点7. 扩展方法8. 应用场景…...

macOS下SourceInsight的替代品
macOS 推荐的几款开源、轻量级、且功能类似于 SourceInsight 的源码阅读工具(排除 VS Code): 1. Zeal(离线文档 简单代码导航) 官网/GitHub: https://zealdocs.org/特点: 轻量级离线文档浏览器࿰…...

form实现pdf文件转换成jpg文件
说明: 我希望将pdf文件转换成jpg文件 请去下载并安装 Ghostscript,gs10050w64.exe 配置环境变量:D:\Program Files\gs\gs10.05.0\bin 本地pdf路径:C:\Users\wangrusheng\Documents\name.pdf 输出文件目录:C:\Users\wan…...

聊天室项目之http知识
一.http的核心组成部分(都分成请求的和响应的) 1.起始行:请求------------------------ 方法(Method):GET、POST、PUT、DELETE 等。 请求目标(Request Target):URL 路径…...
 高可用集群 V1.28.2)
kubeadm部署 Kubernetes(k8s) 高可用集群 V1.28.2
1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 10台机器,操作系统Openeuler22.03 LTS SP4硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多,docker 数据卷单独挂…...
)
BUUCTF-web刷题篇(12)
21.easy_tornado Tornado大致可以分为四个主要组成部分: 一个web框架(包括RequestHandler创建Web应用程序的子类,以及各种支持类)。 HTTPServerHTTP(和AsyncHTTPClient)的客户端和服务器端实现。 一个异…...

基于 Netty 框架的 Java TCP 服务器端实现,用于启动一个 TCP 服务器来处理客户端的连接和数据传输
代码: package com.example.tpson_tcp;import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.ChannelFuture; import io.netty.channel.ChannelInitializer; import io.netty.channel.ChannelOption; import io.netty.channel.EventLoopGroup; imp…...

【Kafka基础】Kafka配置文件关键参数解析与单机生产环境配置指南
1 Kafka配置文件概述 Apache Kafka的配置文件是控制其行为的关键所在,合理的配置能够显著提升性能、可靠性和可维护性。Kafka主要涉及两个核心配置文件: server.properties:Broker主配置文件zookeeper.properties:ZooKeeper配置文…...

Kafka 漏消费和重复消费问题
Kafka 虽然是一个高可靠、高吞吐的消息系统,但如果使用不当,**“漏消费”和“重复消费”**问题是非常容易发生的,尤其在业务系统中会造成数据丢失、重复写库等严重问题。 🎯 一句话理解: Kafka 本身提供 “至多一次”…...

Mysql慢查询设置 和 建立索引
1 .mysql慢查询的设置 slow_query_log ON //或 slow_query_log_file /usr/local/mysql/data/slow.log long_query_time 2 修改后重启动mysql 1.1 查看设置后的参数 mysql> show variables like slow_query%; --------------------------------------------------…...

Windows程序中计时器WM_TIMER消息的使用
本文章是对《Windows程序设计》这本书第八章计时器的总结,如果有时间,可以去看书里的讲解,如果时间不充裕,想马上知道计时器该如何使用,欢迎阅读本文,本文已经将计时器的干货整理完毕! 什么是计…...

关于apple ios苹果mdm监管锁的漏洞与修复
前言 本人从2020年开始接触苹果mdm管理系统的开发 起初只是接触如何利用mdm进行app分发 23年开始开发mdm监管锁业务 随着手机租赁的市场兴起 mdm监管锁系统随即而生 注意 本人只是分享工作过程中遇到的一些问题 不接受苹果手机屏蔽以及解锁的业务 此文章仅做分享使用 MDM监…...

使用Geotools中的原始方法来操作PostGIS空间数据库
目录 前言 一、原生PostGIS连接介绍 1、连接参数说明 2、创建DataStore 二、工程实战 1、Maven Pom.xml定义 2、空间数据库表 3、读取空间表的数据 三、总结 前言 在当今数字化与信息化飞速发展的时代,空间数据的处理与分析已成为众多领域不可或缺的一环。从…...

C-S模式之实现一对一聊天
天天开心!!! 文章目录 一、如何实现一对一聊天?1. 服务器设计2. 客户端设计3. 服务端代码实现4. 客户端代码实现5. 实现说明6.实验结果 二、改进常见的服务器高并发方案1. 多线程/多进程模型2. I/O多路复用3. 异步I/O(…...

Kafka Consumer Group
Kafka 消费者组(Consumer Group) 是 Kafka 的核心机制之一!理解它对你掌握 Kafka 的高可用、高吞吐、负载均衡等能力非常关键。下面我来给你完整讲一讲👇 🧠 什么是 Kafka 消费者组(Consumer Group&#x…...

LangChain vs LlamaIndex:大模型应用开发框架深度对比与实战指南
一、引言:大模型时代的应用开发挑战 随着ChatGPT、LLaMA等大语言模型的爆发式发展,如何高效构建「大模型+垂直领域」的智能应用成为新课题。传统开发模式面临三大痛点: 数据交互复杂:大模型与本地数据的融合缺乏标准化接口功能扩展困难:链式调用、工具集成需要重复造轮子…...

第二章:访问远程服务_《凤凰架构:构建可靠的大型分布式系统》
第二章 访问远程服务 2.1 远程服务调用(RPC) 2.1.1 进程间通信机制 核心方式: 管道(Pipe):单向通信,用于父子进程信号(Signal):异步事件通知,不…...

一键自动备份:数据安全的双重保障
随着数字化时代的到来,数据已成为企业和个人不可或缺的核心资产。在享受数据带来的便捷与高效的同时,数据丢失的风险也随之增加。因此,备份文件的重要性不言而喻。本文将深入探讨备份文件的重要性,并介绍两种实用的自动备份方法&a…...

C++11之std::is_convertible
目录 1.简介 2.实现原理 3.使用场景 4.总结 1.简介 std::is_convertible 是 C 标准库 <type_traits> 头文件中的一个类型特性(type trait),它用于在编译时检查一个类型是否可以隐式转换为另一个类型。下面的原型: temp…...

从零开始:在Qt中使用OpenGL绘制指南
从零开始:在Qt中使用OpenGL绘制指南 本文只介绍基本的 QOpenGLWidget 和 QOpenGLFunctions 的使用,想要学习 OpenGL 的朋友,建议访问经典 OpenGL 学习网站:LearnOpenGL CN 本篇文章,我们将以绘制一个经典的三角形为例&…...

我的购物车设计思考:从个人项目到生产实战思考的蜕变
一、代码初体验:我踩过的那些坑 还记得大二做课程设计时,我写的购物车直接用ArrayList存商品,结果改数量时遍历半天找商品。现在看你这个HashMap实现,确实清爽很多,但有几点让我想起当年惨痛经历: 1. 线程…...

【算法实践】算法面试常见问题——数组的波浪排序
问题描述 给定一个无序整数数组,将其排列成波浪形数组。若数组 arr[0..n-1] 满足以下条件,则称为波浪形: arr[0] > arr[1] < arr[2] > arr[3] < arr[4] > ... 或 arr[0] < arr[1] > arr[2] < arr[3] > arr[4] &l…...

【大模型深度学习】如何估算大模型需要的显存
一、模型参数量 参数量的单位 参数量指的是模型中所有权重和偏置的数量总和。在大模型中,参数量的单位通常以“百万”(M)或“亿”(B,也常说十亿)来表示。 百万(M):表示…...

[论文阅读]PMC-LLaMA: Towards Building Open-source Language Models for Medicine
PMC-LLaMA:构建医学开源语言模型 摘要 最近,大语言模型在自然语言理解方面展现了非凡的能力。尽管在日常交流和问答场景下表现很好,但是由于缺乏特定领域的知识,这些模型在需要精确度的领域经常表现不佳,例如医学应用…...

`use_tempaddr` 和 `temp_valid_lft ` 和 `temp_prefered_lft ` 笔记250405
use_tempaddr 和 temp_valid_lft 和 temp_prefered_lft 笔记250405 以下是 Linux 系统中与 IPv6 临时隐私地址相关的三个关键参数 use_tempaddr、temp_valid_lft 和 temp_prefered_lft 的详细说明及协作关系: 📜 参数定义与功能 参数作用默认值依赖关…...
?)
如何设置 JVM 内存参数(-Xms、-Xmx、-Xss 等)?
JVM 内存参数用于控制 Java 虚拟机使用的内存大小和行为。以下是一些常用的 JVM 内存参数及其设置方法: 1. 堆内存 (Heap Memory): -Xms<size>: 设置 JVM 初始堆大小 (initial heap size)。 例如:-Xms2g (初始堆大小为 2GB)默认值:物…...

【MATLAB TCP/IP客户端与NetAssist上位机双向通信实战指南】
MATLAB TCP/IP客户端与NetAssist上位机双向通信实战指南 一、前言 在工业控制和数据采集领域,TCP/IP通信是最常用的网络通信协议之一。MATLAB作为强大的科学计算软件,与各种上位机软件(如NetAssist)进行通信可以实现数据采集、设备控制和实时监控等功能…...

联合、枚举、类型别名
数据类型: 已学--整数、实数、字符、字符串、数组、指针、结构待学--向量(vector)类型:优于数组非主流的类型--联合(union)、枚举(enum) 一、联合 联合类似于结构,可以容…...

Array 和 ArrayList 有何区别?什么时候更适合用 Array?
面试官提问: 你能简要说明 Array 和 ArrayList 之间的主要区别吗?在什么场景下更适合使用 Array? 标准回答: 在 Java 中,Array(数组)和 ArrayList(动态数组)都可以用于存…...

对状态模式的理解
对状态模式的理解 一、场景二、不采用状态模式1、代码2、缺点 三、采用状态模式1、代码1.1 状态类1.2 上下文(这里指:媒体播放器)1.3 客户端 2、优点 一、场景 同一个东西(例如:媒体播放器),有一…...
)
【学Rust写CAD】31 muldiv255函数(muldiv255.rs)
源码 // Calculates floor(a*b/255 0.5) #[inline] pub fn muldiv255(a: u32, b: u32) -> u32 {// The deriviation for this formula can be// found in "Three Wrongs Make a Right" by Jim Blinn.let tmp a * b 128;(tmp (tmp >> 8)) >> 8 }代…...

使用VSCode编写C#程序
目录 一、环境搭建:构建高效开发基础1. 安装VSCode2. 配置.NET SDK3. 安装核心扩展 二、项目开发全流程1. 创建项目2. 代码编辑技巧3. 调试配置4. 高级调试技巧5. 编译与运行 三、常见问题解决指南1. 项目加载失败2. IntelliSense失效3. 代码格式化4. 典型编译错误&…...

chromadb
chromadb是一个轻量化的向量数据库,可以和llama-index等RAG框架使用。底层基于sqllite。 Getting Started - Chroma Docs 1、安装 $pip install chromadb pip install chromadb-client --在CS模式下,如果机器A上只需要安装客户端 2、可以使用客户端…...

第十章: 可观测性_《凤凰架构:构建可靠的大型分布式系统》
第十章: 可观测性 可观测性是现代分布式系统监控和故障排查的核心能力。本章从事件日志、链路追踪、聚合度量三个维度构建完整的可观测性体系,以下是各部分的重点解析与实践要点: 一、事件日志(Event Logging) 1. 核心目标 全链…...

vscode和cursor对ubuntu22.04的remote ssh和X-Windows的无密码登录
这里写自定义目录标题 写在前面需求的描述问题的引出 昨天已使能自动登录上午我的改变UBUNTU 22.04关闭密码规则一:修改 /etc/pam.d/common-password 文件二:修改 /etc/security/pwquality.conf 文件方法三:禁用 pam_pwquality.so 模块 vscod…...

Mlivus Cloud SDK v2的革新:性能优化与实战解析
作为大禹智库的向量数据库高级研究员王帅旭,我在过去30多年的AI应用实战中见证了向量数据库技术的演进历程。今天,我将从专业角度深入剖析Mlivus Cloud SDK v2的架构革新,特别是针对性能瓶颈问题的突破性解决方案。本文不仅会详细解析技术原理,还将提供可操作的优化建议,帮…...

stl_list的模拟实现
文章目录 stl_list的模拟实现迭代器的介绍以及分类stl_list的基本接口介绍stl_list的模拟实现结点类迭代器类基本迭代器操作 链表类链表基本操作 结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路 作者:٩( ‘ω’ …...

【蓝桥杯】十五届省赛B组c++
目录 前言 握手问题 分析 排列组合写法 枚举 小球反弹 分析 代码 好数 分析 代码 R 格式 分析 代码 宝石组合 分析 代码 数字接龙 分析 代码 拔河 分析 代码 总结 前言 主播这两天做了一套蓝桥杯的省赛题目(切实感受到了自己有多菜&#x…...