[论文阅读]PMC-LLaMA: Towards Building Open-source Language Models for Medicine
PMC-LLaMA:构建医学开源语言模型
摘要
最近,大语言模型在自然语言理解方面展现了非凡的能力。尽管在日常交流和问答场景下表现很好,但是由于缺乏特定领域的知识,这些模型在需要精确度的领域经常表现不佳,例如医学应用。本文中,我们描述了构建一个专门为医学应用设计的强大的开源语言模型的流程,我们称其为PMC-LLaMA。我们的贡献有以下三方面:(i)我们系统性地调研了通用基础语言模型到医学领域的适应过程,这包括以数据为中心的知识注入,通过整合480万篇生物医学学术论文和3万本医学教科书,以及针对特定领域指令的全面微调;(ii)我们为指令微调贡献了一个大规模的全面的数据集。这个数据集结合了医学问答,推理原理和对话,总共包含202M个token;(iii)我们进行了彻底的消融研究,以证明每个提议的组件的有效性。在对各种公共医疗问答基准进行评估时,我们的仅由130亿个参数组成的轻量级PMC-LLaMA表现出了优异的性能,甚至超过了ChatGPT。所有的模型代码和数据集可以在下面的链接中找到:n https://github.com/
chaoyi-wu/PMC-LLaMA.
介绍
大型语言模型(llm)的快速发展,例如OpenAI的ChatGPT (OpenAI 2023b)和GPT-4 (OpenAI 2023a)已经切实改变了自然语言处理的研究,激发了AI在大量日常场景中的应用。不幸的是,目前GPT系列的训练细节和模型架构仍是未知的。一些开源大模型,例如,LLaMa系列在通用领域与chatgpt相比显示出一般的性能。然而,尽管大模型在日常对话中表现得很熟练,但在需要高精度的医学领域,他们往往会产生看似准确但会导致错误的结论,这些可能会高度致命。我们猜想这是因为他们缺乏全面的医学知识。
现有的工作已经探索了几种使LLM适应医学领域的方法,例如Med-Alpaca,Chat-Doctor和MedPALM-2。其中MedPALM-2是唯一成功超越Chatgpt表现的工作,但是它恶的训练细节,训练数据,模型架构仍然是未知的。因此,对于大模型在医学领域适应的系统研究,特别是在开源社区中,还需要进一步探讨。
我们的目标是从以下几个方面系统地将一个开源的通用LLM,即LLaMA,应用于医学领域。首先,采用以数据为中心的医学专用知识注入方法,建立了大规模自由文本医学语料库的语言模型。我们主张语言模型可以在这一步骤中积累足够的医学知识,并为特定领域的复杂术语建立更好的嵌入空间。其次,增强所提出模型的推理能力。这使得模型能够将其医学知识与所提供的病例信息联系起来,并提供合理的建议。最后,提高大模型的对齐能力。与各种指令的鲁棒对齐有助于有效的适应各种任务。
总得来说,本文中我们系统性得构建了一个医学大模型,通过以数据为中心得知识注入和特定医疗指导微调,然后我们发布了一个开源的轻量级医学专用语言模型PMC-LLaMA。特别地,我们首先收集并构建了一个医学专用预料库,名为MedC-K,由4.8M篇生物医学论文和30k本书构成用来进行知识注入。然后,我们在一个新的医学知识感知指令数据集(称为MedC-I)上采用特定于医学的指令调优,该数据集由医学QA、推理和会话组成,总共有202M个tokens。我们在各种医疗QA基准上评估了PMC-LLaMA,超过了ChatGPT和LLaMA-2,如图1所示。
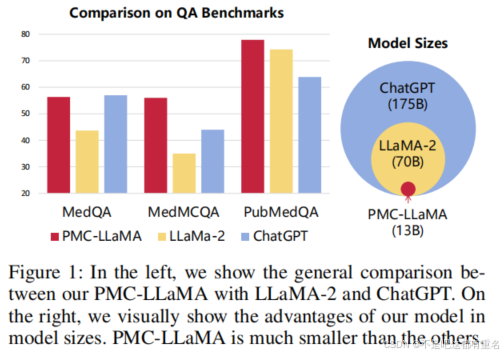
tips:13B模型也能取得不错得效果,但是如果用更大得模型是否可以取得更好得效果呢?要看领域知识和问题是否超过目前得模型解空间吧?
相关工作
大语言模型 最近,大型语言模型(LLM) (OpenAI 2023b,a;Anil, Dai等。2023;Du et al. 2021),在自然语言处理领域引起了极大的关注。例如,OpenAI在ChatGPT和GPT-4方面的进步展示了在各种任务中的卓越能力,包括文本生成、语言翻译、问题回答等等。然而,关于他们的训练方法和权重参数的复杂细节仍未公开。LLaMA (Touvron et al. 2023a)是基础语言模型的开源替代方案,参数范围从70亿个到650亿个不等。鉴于这些进步,人们对为特定的生物医学领域定制语言模型产生了浓厚的兴趣。这些模型大多是在小型医学语料库上使用LLaMA进行快速调优,导致缺乏全面的医学知识整合。
指令调优为了让llm 遵循自然语言指令并完成现实世界的任务,指令调优已被广泛用于对齐。这涉及对模型进行微调,使其在一系列通过指令描述的任务集合上表现更佳,从而有效提升零样本和少样本的泛化能力。基于可公开访问的语言模型,Alpace (Taori et al. 2023)和Vicuna (Chiang, Li等人,2023),通过对机器生成的指令跟随样本进行微调,显示出良好的性能。在医疗领域,Chat-Doctor(云翔等,2023)和Med-Alpaca (Han, Adams et al. 2023)针对医疗问答和对话应用程序进行指令调整。值得注意的是,Med-PaLM (Singhal et al,2022)代表了医学领域法学硕士的顶峰,在强大的 PaLM模型(具有5400亿个参数,由谷歌推出的多模态模型,2023年5月发布了PaLM2)上进行了密集的指导调整。然而,它的代码和数据仍然无法向公众开放。
tips:Palm模型目前看来能力并不是很强,可以在这里看看排行榜https://lmarena.ai/
医学基础语言模型除了指令调整之外,在医学基础模型的训练方面也做了大量的努力,例如BioBert,BioMedGPT等(Lee et al. 2020;Zhang et al. 2023;Luo et al. 2022)。然而,这些模型表现出一定的局限性,首先,大多数特定领域的模型都是专门在医学语料库上训练的。缺乏对医学以外的各种知识领域的接触可能会阻碍模型执行推理或上下文理解的能力;其次,这些模型在模型规模上是有限的,并且主要是基于BERT设计的,因此限制了它们在zero-shot学习下的大量下游任务的实用性。本研究旨在通过知识注入将通用大语言模型(LLM)适配于医学领域,并在此基础上进行医学专属的指令微调,以解决上述两个局限性。
问题定义
在本文中,我们的目标是系统地研究将预训练的基础语言模型转向知识密集型领域(即医学)的过程。训练过程可分为两个阶段:第一阶段,以数据为中心的知识注入阶段,目的是用医学基础知识丰富语言模型;第二,针对特定医疗的指令调整阶段,调整模型以与临床用例保持一致。在训练阶段,假设文本输入是一个token序列,例如, U = u 1 , u 2 , . . . , u N \mathcal U={u_1,u_2,...,u_N} U=u1,u2,...,uN,其中每个 u i u_i ui是一个文本token,N是总序列长度,训练目标是最小化自回归损失,主要区别在于是计算整个序列上的损失还是只计算子序列上的损失,如下所述。
以数据为中心的知识注入对于知识注入步骤,我们只需最小化默认的自回归损失,所有关于医学知识的自由格式文本都可以使用,以便模型积累足够的医学特定知识上下文,公式为
L ( ϕ ) = − ∑ l o g ϕ ( u i ∣ u < i ) L(\phi)=-\sum log\phi(u_i|u_{<i}) L(ϕ)=−∑logϕ(ui∣u<i)
其中 u < i u_{<i} u<i指示标记出现在索引i之前,Φ表示我们的模型。
医学特定指令调优 在此阶段,将token序列进一步拆分为指令 I \mathcal I I和响应 R \mathcal R R,前者是为了模拟用户的查询,因此在训练时忽略损失,记为:
L ( ϕ ) = − ∑ u i ∈ R l o g ϕ ( u i ∣ u < i , I ) L(\phi)=-\sum_{u_i \in R} log\phi(u_i|u_{<i},\mathcal I) L(ϕ)=−ui∈R∑logϕ(ui∣u<i,I)
在推理时,常见的用例是对话,其中用户通常将问题作为指令提供 I \mathcal I I,模型的输出作为答案。
数据集构建
为了支持我们的两阶段训练,即以数据为中心的知识注入和针对医学的指令调整,我们在这里详细介绍了构建高质量语言数据集的过程。
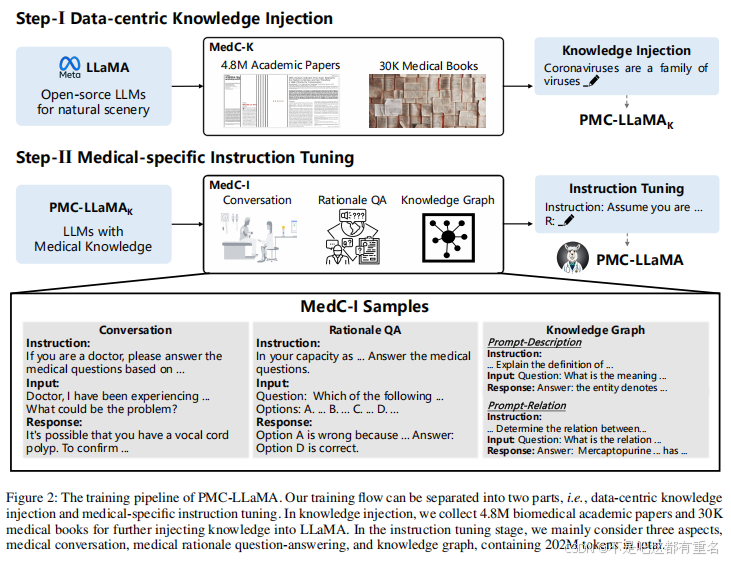
数据集1:基础医学知识
为了引导通用基础语言模型适应医疗场景,我们提出首先进行以数据为中心的知识注入,旨在让模型接触医学相关的术语和定义。我们主要关注两类关键的数据来源,即生物医学论文和教科书。
论文 学术论文作为一种宝贵的知识资源,自然包含着高质量、前沿的医学知识。我们从S2ORC开始(Lo et al. 2020),一个包含8110万篇英文学术论文的数据集,然后根据是否具有相应的PubMed Central (PMC) id挑选出与生物医学相关的论文。最后,大约有480万份生物医学论文剩余,总计超过750亿个tokens。
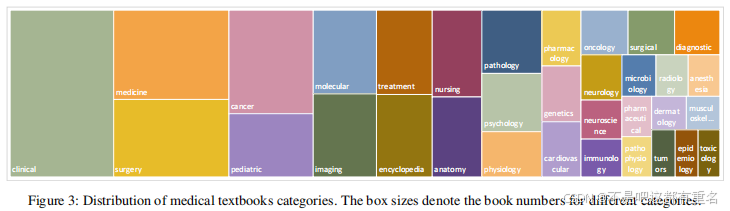
书籍 我们从开放图书馆、大学图书馆、知名出版社等各种渠道收集了30K本教科书,涵盖了广泛的医学专业,如图3所示。对于预处理,我们首先从图书PDF中提取文本内容,然后通过重复数据删除和内容过滤进行数据清洗。具体来说,我们消除了url、作者列表、多余信息、文档内容、参考文献和引用等无关元素。此外,我们还删除了段落中对图像和表格的任何引用,例如,“图5”。1”。在这个彻底的清理过程之后,大约还剩下4B个tokens。
组合 这两个语料库包含不同类型的医学知识,而论文主要捕获前沿的见解,书籍捕获更基本的医学知识,这对于预训练的通用语言模型更为重要。因此,在混合这两个数据集进行知识注入训练时,我们在每个训练批次中使用15:4:1的比例,即我们的意思是更多地强调书籍中的tokens。具体来说,我们从书籍中采样更多的tokens,确保它们每批占用15个部分,从“论文”中采样更少的tokens,以便它们占用每批4份。对于剩下的1份,我们从通用语言语料库RedPajama-Data(Computer 2023)中进行采样,以形成完整的批处理。这主要是为了避免在广泛的知识注入后对先前获得的一般文本知识的灾难性遗忘。
知识注入训练到目前为止,我们已经构建了一个大规模的基础医学知识语言数据集,称为MedC-K。利用这些语料库,我们通过自回归训练进行以数据为中心的知识注入,得到了一个医学语言模型,命名为 P M C − L L a M A K PMC-LLaMA_K PMC−LLaMAK,因为最大数量的令牌来自PubMed Central学术论文。
数据集2:医学指令
在这部分,我们继续进行指令调优,目的是通过利用 P M C − L L a M A k PMC-LLaMA_k PMC−LLaMAk模型中嵌入的医学知识来指导模型响应各种指令。一般来说,我们的指令调优数据集由三个主要部分组成,即医学咨询会话、医学基本原理QA和医学知识图提示。
医学对话 日常生活中存在着多种多样的医患对话,患者提出的问题自然可以作为指导,医生的回答可以作为真值。我们从Med-Alpaca (Han, Adams et al. 2023)和ChatDoctor (Yunxiang et al. 2023)收集的数据开始,进一步将提供的指令扩展到各种同义句中,以提高模型对不同指令的鲁棒性。具体来说,我们使用如下提示词进行GPT-4查询:

其中{指令种子}表示ChatDoctor或MedAlpaca提供的指令,查询可以重复,直到设定的提示数。在训练时,我们从指令库中随机选择一条指令,模拟真实用户的输入,避免对特定指令模板的过度拟合。
医学基本原理QA 除了日常对话,我们还考虑用专业的医学知识为我们的模型配备推理能力。我们从开源医学多选择问答数据集的训练集开始,例如USMLE (Jin, Pan等),PubMedQA (Jin et al. 2019)和MedMCQA (Pal;Umapathi et al. 2022)。尽管其中的问题要求医学专业知识,但大多数这些数据集只包括简单的选择,缺乏详细的推理指导。为了补充这些信息,我们通过提示ChatGPT (OpenAI 2023b)用于因果关系分析。具体来说,给定一个QA对,我们查询ChatGPT以获得基本原理输出(检查补充细节),并将输出作为图2底部所示的结构化格式的解释。
医学知识图谱提示 除了上述数据,我们也考虑利用医学知识图UMLS (Lindberg, Humphreys, and McCray 1993),以配合临床医生的经验。具体而言,为了将医学术语与其各自的知识描述或对应关系联系起来,我们构建了QA对来翻译公共知识图。医学知识图谱主要包含实体描述和实体关系两种类型。我们为它们添加了两个不同的提示,如图2底部所示,这要求模型输出某个实体的描述或预测两个实体之间的关系。
针对医学的指令调优通过将上述三个部分组合在一起,我们形成了一个大规模的、高质量的、特定于医疗的指令调优数据集MedCI,它包含202M个tokens。我们进一步在这个数据集上调整 P M C − L L a M A k PMC-LLaMA_k PMC−LLaMAk,得到我们的最终模型——PMC-LLaMA。
实验
训练细节
我们首先在开源LLaMA模型上进行知识注入,优化自回归损失。具体来说,在训练时,设置最大上下文长度为2048,批大小为3200,模型使用AdamW优化器(Loshchilov and Hutter 2017)进行训练,学习率为2e -5。我们采用了全分片数据并行(FSDP)加速策略,bf16(brain floating point)数据格式和梯度检查点(Chen et al. 2016)。由于我们在每批中从图书中采样更多tokens,因此模型将更早地查看完所有图书tokens。因此,我们在这里定义了一个epoch来查看所有的书籍token,而不是查看所有的混合token。使用32个A100 gpu对模型进行5次知识注入训练。然后我们在MedC-I上进行医疗特定指令调优,使用8个A100 gpu进行3个epoch, 256批处理大小。注意,在指令调优阶段,epoch指的是遍历所有序列。
基准
在文献中,衡量医学语言模型能力的主要方法是基于多项选择题的回答,以准确性为主要衡量标准。
按照惯例,我们采用三个著名的医学问答(QA)基准进行评估。
- PubMedQA (Jin et al. 2019)是一个从PubMed摘要中收集的生物医学质量保证数据集。PubMedQA的任务是用yes/no/- maybe来回答研究问题,这可以看作是一个选择题。它分为三个子集:1k对人工标记对(PQA-L), 61.2万对未标记对(PQA-U)和211.3万对人工生成对(PQA-A)。根据之前的工作(Diao, Pan et al. 2023),我们将PQA-A视为训练集,PQA-L作为测试集,并丢弃PQA-U部分。
- MedMCQA (Pal, Umapathi et al. 2022)是一个选择题数据集,来源于两个印度医学院入学考试AIIMS和NEET-PG的模拟考试和过去的考试(Pal, Umapathi et al. 2022)。训练分割包含182,822个问题,测试分割包含4183个问题。每个问题有4个选项。
- USMLE (Jin, Pan et al. 2021)是一个选择题数据集(每个问题4个选择),基于美国医师执照考试。该数据集收集自专业医学委员会考试,涵盖三种语言:英语、简体中文和繁体中文,分别包含12,724、34251和14,123个问题。在这里,我们使用英语部分,并按照官方划分将其分为10,178个问题用于训练,1273个问题用于验证,1273个问题用于测试。
基线模型
LLaMA (Touvron et al. 2023a)。LLaMA是使用最广泛的开源语言模型,它已经在一个大型文本语料库上进行了训练,只有自回归学习,即不涉及指令调优。
LLaMA-2 (Touvron et al. 2023b)。LLama -2是LLaMA的改进版本,已经进一步调整了指令。据报道,它最大的版本(70B)对自然场景的表现是开源LLM中最好的。
ChatGPT (OpenAI 2023b)。ChatGPT是OpenAI于2022年11月发布的商业模型,在包括医学在内的各个领域的广泛NLP任务上表现出色。请注意,由于ChatGPT的确切细节是保密的,我们遵循一般的假设,即ChatGPT在模型大小上与GPT-3大致相同(175B) (Kung et al. 2022)。
Med-Alpaca (Han, Adams et al. 2023)。Med-Alpaca是使用医疗指导数据在Alpaca (Taori et al. 2023)上进一步微调的模型。他们专注于协助医学对话和问答的任务。
Chat-Doctor (Yunxiang et al. 2023)。Chat-Doctor是一种针对健康助理的语言模型,旨在为用户提供医疗信息、建议和指导。对于训练,它利用了基于对话的指令调优数据。
评价设置
在本节中,我们将描述在QA基准测试中比较上述语言模型的评估细节。请注意,我们并没有声称所呈现的比较是完全公平的,因为许多训练细节,例如,数据,架构仍然未公开用于商业模型。因此,我们仅将这些基线模型作为参考,而更侧重于展示我们构建强大的医学语言模型的过程。我们的评估设置可以分为两种类型:特定任务微调评估和零击指令评估
特定于任务的微调评估。在此评估设置中,我们使用三个QA训练集的组合来进一步微调语言模型,然后对其进行评估。对于没有指令调优的模型,例如LLaMA和PMC-LLaMAK,我们默认采用这个评估设置。
零击指令评估。在这个评估设置中,我们通过给出一个医学QA指令来直接测试模型,例如,“根据问题和选项做出选择。”,而无需进行任何特定任务的微调。大多数模型都在此设置下进行评估,即LLaMA-2, MedAlpaca, Chat-Doctor, ChatGPT和我们自己的PMC-LLaMA
结果
在本节中,我们将介绍实验结果。首先,我们对医疗质量保证基准进行了彻底的消融研究,以证明我们训练程序中不同组成部分的有效性。然后对不同的SOTA方法进行了比较。最后,我们提出定性案例研究。
消融研究
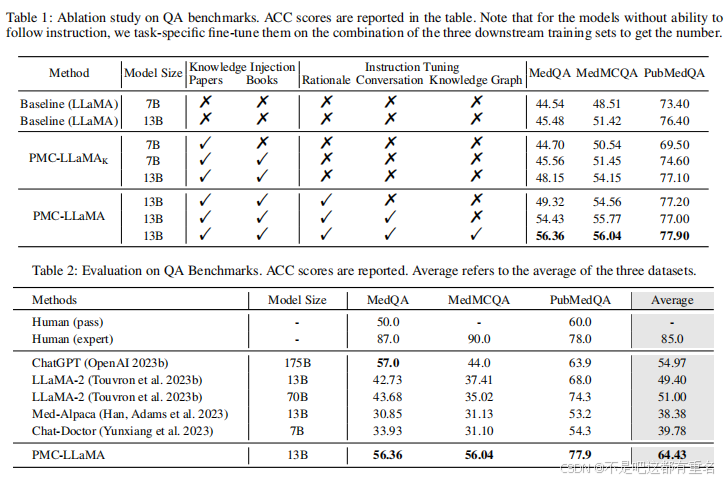
如表1所示,我们系统地研究了不同的设计选择对各种医疗QA基准的影响,例如模型规模的影响、以数据为中心的知识注入、针对医疗的指令调优。
模型的规模。在医学语料库中也可以观察到尺度定律(Kaplan et al. 2020),例如,如表所示,当模型大小从7B切换到13B时,所有基准的性能都有所提高。这一现象在经过进一步的医学基础知识训练的基线LLaMA模型和PMC-LLaMAK都有表现。
以数据为中心的知识注入。与基线7B LLaMA模型相比,整合生物医学论文后MedQA的性能从44.54%提高到44.70%,MedMCQA的性能从48.51%提高到50.54%。而加入书籍进行训练后,性能有了明显的提高,分别在MedQA, MedMCQA和PubMedQA上获得1.02%、2.94%和1.2%的准确率
提高。这两项观察都显示了注入基础医学知识的重要性。
医学特定指令调优我们只从基本的QA数据开始指令调优。在这种情况下,既然只考虑QA任务,与特定任务调优的区别仅在于是否给出理由句作为监督信号。我们观察到,仅仅引入推理过程的示例,相较于在普通选项数据上进行任务特定微调,可以提升问答任务的表现,在 MedQA 数据集上提升了 1.17%。
此外,将对话与基本原理QA集成以进行指令调优可以产生显著的增强,将MedQA的性能从49.32%提高到54.43%。这说明了题型的多样性在指导调整阶段所起的关键作用,因为所有涉及的问题都将限制在医学选择测试中,没有对话。此外,知识图谱的引入使MedQA数据集进一步提高了1.93%,证明了使用明确的说明来强调关键医学概念的重要性。
与基线比较
在表2中,我们将我们的模型与SOTA基线模型在三个QA基准数据集上进行了对比分析,以进行评估。我们还展示了一个定性的案例研究来展示会话和逻辑推理能力。
医疗问答能力。而在医疗QA基准测试上,PMCLLaMA与其他大型语言模型相比,在大多数方面都取得了优异的成绩,平均准确率从54.97%提高到64.43%,甚至超过了功能强大的ChatGPT,尽管包含的参数明显减少。
零样本案例分析(Zero-shot Case Study)。在图4中,我们展示了来自 PMC-LLaMA 和 ChatGPT 的零样本预测的定性示例,用于验证预测质量,涵盖了医患对话和推理式问答任务。图6a中的问题是在我们数据收集之后才在线提出的,因此两个模型在训练过程中都未见过该问题。基于患者的描述,PMC-LLaMA 和 ChatGPT 都识别出了反复性尿路感染(UTI)的症状,但 PMC-LLaMA 提出了进行敏感性测试的具体建议,而 ChatGPT 给出的则是更笼统的建议(调查潜在原因)。图6b展示了一个微生物学的问答案例。可以看出,PMC-LLaMA 不仅给出了正确答案,还简要分析了错误选项,形成了更为全面的推理过程。图6c 展示的是一个聚焦于药理学知识的案例。PMC-LLaMA 和 ChatGPT 都很好地理解了利福平(Rifampin)的疗效及其副作用机制。

总结
本文系统地研究了基于开源大型语言模型的医学专用大型语言模型的构建过程,包括以数据为中心的知识注入和医学专用指令调优。因此,我们提出的PMC-LLaMA是第一个开源的医疗特定语言模型,在各种医疗基准测试中表现出卓越的性能,超过ChatGPT和LLaMA-2的同时参数少得多。
相关文章:

[论文阅读]PMC-LLaMA: Towards Building Open-source Language Models for Medicine
PMC-LLaMA:构建医学开源语言模型 摘要 最近,大语言模型在自然语言理解方面展现了非凡的能力。尽管在日常交流和问答场景下表现很好,但是由于缺乏特定领域的知识,这些模型在需要精确度的领域经常表现不佳,例如医学应用…...

`use_tempaddr` 和 `temp_valid_lft ` 和 `temp_prefered_lft ` 笔记250405
use_tempaddr 和 temp_valid_lft 和 temp_prefered_lft 笔记250405 以下是 Linux 系统中与 IPv6 临时隐私地址相关的三个关键参数 use_tempaddr、temp_valid_lft 和 temp_prefered_lft 的详细说明及协作关系: 📜 参数定义与功能 参数作用默认值依赖关…...
?)
如何设置 JVM 内存参数(-Xms、-Xmx、-Xss 等)?
JVM 内存参数用于控制 Java 虚拟机使用的内存大小和行为。以下是一些常用的 JVM 内存参数及其设置方法: 1. 堆内存 (Heap Memory): -Xms<size>: 设置 JVM 初始堆大小 (initial heap size)。 例如:-Xms2g (初始堆大小为 2GB)默认值:物…...

【MATLAB TCP/IP客户端与NetAssist上位机双向通信实战指南】
MATLAB TCP/IP客户端与NetAssist上位机双向通信实战指南 一、前言 在工业控制和数据采集领域,TCP/IP通信是最常用的网络通信协议之一。MATLAB作为强大的科学计算软件,与各种上位机软件(如NetAssist)进行通信可以实现数据采集、设备控制和实时监控等功能…...

联合、枚举、类型别名
数据类型: 已学--整数、实数、字符、字符串、数组、指针、结构待学--向量(vector)类型:优于数组非主流的类型--联合(union)、枚举(enum) 一、联合 联合类似于结构,可以容…...

Array 和 ArrayList 有何区别?什么时候更适合用 Array?
面试官提问: 你能简要说明 Array 和 ArrayList 之间的主要区别吗?在什么场景下更适合使用 Array? 标准回答: 在 Java 中,Array(数组)和 ArrayList(动态数组)都可以用于存…...

对状态模式的理解
对状态模式的理解 一、场景二、不采用状态模式1、代码2、缺点 三、采用状态模式1、代码1.1 状态类1.2 上下文(这里指:媒体播放器)1.3 客户端 2、优点 一、场景 同一个东西(例如:媒体播放器),有一…...
)
【学Rust写CAD】31 muldiv255函数(muldiv255.rs)
源码 // Calculates floor(a*b/255 0.5) #[inline] pub fn muldiv255(a: u32, b: u32) -> u32 {// The deriviation for this formula can be// found in "Three Wrongs Make a Right" by Jim Blinn.let tmp a * b 128;(tmp (tmp >> 8)) >> 8 }代…...

使用VSCode编写C#程序
目录 一、环境搭建:构建高效开发基础1. 安装VSCode2. 配置.NET SDK3. 安装核心扩展 二、项目开发全流程1. 创建项目2. 代码编辑技巧3. 调试配置4. 高级调试技巧5. 编译与运行 三、常见问题解决指南1. 项目加载失败2. IntelliSense失效3. 代码格式化4. 典型编译错误&…...

chromadb
chromadb是一个轻量化的向量数据库,可以和llama-index等RAG框架使用。底层基于sqllite。 Getting Started - Chroma Docs 1、安装 $pip install chromadb pip install chromadb-client --在CS模式下,如果机器A上只需要安装客户端 2、可以使用客户端…...

第十章: 可观测性_《凤凰架构:构建可靠的大型分布式系统》
第十章: 可观测性 可观测性是现代分布式系统监控和故障排查的核心能力。本章从事件日志、链路追踪、聚合度量三个维度构建完整的可观测性体系,以下是各部分的重点解析与实践要点: 一、事件日志(Event Logging) 1. 核心目标 全链…...

vscode和cursor对ubuntu22.04的remote ssh和X-Windows的无密码登录
这里写自定义目录标题 写在前面需求的描述问题的引出 昨天已使能自动登录上午我的改变UBUNTU 22.04关闭密码规则一:修改 /etc/pam.d/common-password 文件二:修改 /etc/security/pwquality.conf 文件方法三:禁用 pam_pwquality.so 模块 vscod…...

Mlivus Cloud SDK v2的革新:性能优化与实战解析
作为大禹智库的向量数据库高级研究员王帅旭,我在过去30多年的AI应用实战中见证了向量数据库技术的演进历程。今天,我将从专业角度深入剖析Mlivus Cloud SDK v2的架构革新,特别是针对性能瓶颈问题的突破性解决方案。本文不仅会详细解析技术原理,还将提供可操作的优化建议,帮…...

stl_list的模拟实现
文章目录 stl_list的模拟实现迭代器的介绍以及分类stl_list的基本接口介绍stl_list的模拟实现结点类迭代器类基本迭代器操作 链表类链表基本操作 结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路 作者:٩( ‘ω’ …...

【蓝桥杯】十五届省赛B组c++
目录 前言 握手问题 分析 排列组合写法 枚举 小球反弹 分析 代码 好数 分析 代码 R 格式 分析 代码 宝石组合 分析 代码 数字接龙 分析 代码 拔河 分析 代码 总结 前言 主播这两天做了一套蓝桥杯的省赛题目(切实感受到了自己有多菜&#x…...
概念解析与用法实例:根据原图像生成新图像)
变分自编码器(VAE)概念解析与用法实例:根据原图像生成新图像
目录 1. 前言 2. VAE原理 2.1 什么是VAE? 2.2 编码器(Encoder) 2.3 重参数化技巧(Reparameterization Trick) 2.4 解码器(Decoder) 2.5 损失函数 3. Pytorch实现:根据原图像…...

AI随身翻译设备:从翻译工具到智能生活伴侣
文章目录 AI随身翻译设备的核心功能1. 实时翻译2. 翻译策略3. 翻译流程4. 输出格式 二、AI随身翻译设备的扩展功能1. 语言学习助手2. 旅行助手3. 商务助手4. 教育助手5. 健康助手6. 社交助手7. 技术助手8. 生活助手9. 娱乐助手10. 应急助手 三、总结四、未来发展趋势࿰…...

基于大模型的重症肌无力的全周期手术管理技术方案
目录 技术方案文档1. 数据预处理模块2. 多任务预测模型架构3. 动态风险预测引擎4. 手术方案优化系统5. 技术验证模块6. 系统集成架构7. 核心算法清单8. 关键流程图详述实施路线图技术方案文档 1. 数据预处理模块 流程图 [输入原始数据] → [联邦学习节点数据对齐] → [多模态特…...

Linux常用命令详解:从基础到进阶
目录 一、引言 二、文件处理相关命令 (一)grep指令 (二)zip/unzip指令 编辑 (三)tar指令 (四)find指令 三、系统管理相关命令 (一)shutdown指…...

【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具
【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具 资源简介 DeepSeek谷歌版1.1.5是目前全球领先的免费AI助手,性能超越国内主流AI产品,提供类似GPT-4的智能体验。 版本信息 最新版本:1.1.5(2024最新版)应用…...

JWT认证服务
JSON Web Token(JWT)是一种用于在网络应用间安全地传递信息的紧凑、自包含的方式。以下是关于 JWT 认证服务器更详细的介绍,包括其意义、作用、工作原理、组成部分、时效性相关内容、搭建条件以及代码案例。 JWT 的意义与作用 意义…...

Raft算法
Raft算法用于保证分布式环境下多节点数据的一致性。 原理 Raft算法的主要思想是一个 选主(leader selection) 的算法思想,集群种每个节点都有可能成为三种角色。 三种角色 leader 对客户端通信的入口,对内数据同步的发起者,一个集群通常只…...

Kotlin 类委托深入解析:以 MMKV 为例看委托机制在 Android 中的巧妙应用
Kotlin 中的类委托(class delegation)是一个非常实用的特性,它允许我们将接口的实现交给另一个对象,从而简化代码,提升复用性和灵活性。本文将通过简单的 Demo 介绍类委托的基本用法,并以 Android 中的 MMK…...
)
2025年渗透测试面试题总结-某一线实验室实习扩展(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 某一线实验室实习扩展 一、流量分析深度实践 1. FTP反弹定时确认包流量检测 1.1 攻击原理与特征 1.…...

2025大唐杯仿真3——移动性管理
仅仅是1-2之间的信息交互...

云原生与微服务的关系
云原生(Cloud Native)和微服务(Microservices)是现代软件开发和部署中密切相关的两个概念,它们共同推动了应用程序的架构设计、开发模式和运维方式的变革。以下是两者的关系及核心要点: 定义与核心概念 云原…...

【百日精通JAVA | SQL篇 | 第三篇】 MYSQL增删改查
SQL得最核心就是增删改查 一个后端开发,在工作中,最常见的场景就是CRUD。 插入数据 insert into student values (1,zhangsan); 指定列插入数据 同时多个列明之间使用逗号,来分割 insert into student (name) values (zhaoliu); 这个黑框…...

【leetcode】记录与查找:哈希表的题型分析
前言 🌟🌟本期讲解关于力扣的几篇题解的详细介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话不…...

如何在 Windows 10 上安装 PyGame
PyGame 是 Python 编程语言中的一组跨平台模块,这意味着您可以在任何操作系统上安装它,这篇文章告诉您如何在 Windows 10 上安装 PyGame。 如何在 Windows 10 上安装 PyGame? PyGame 依赖于 Python,这意味着您必须在安装 PyGame …...

LVGL修改标签文本,GUI Guider的ui不生效
一.问题背景 笔者最近在学习LVGL框架,同时准备使用该框架作为课程设计的一部分,于是需要从静态显示进阶到动态显示以及事件交互。一方面由于笔者是初次接触LVGL,对它并不熟悉,另一方面由于其网络上的针对性具体资料太少&a…...
)
制造装备物联及生产管理ERP系统设计与实现(代码+数据库+LW)
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装制造装备物联及生产管理ERP系统软件来发挥其高效地信息处理…...

PowerPhotos:拯救你的Mac照片库,告别苹果原生应用的局限
如果你用Mac管理照片,大概率被苹果原生「照片」应用折磨过——无法真正并行操作多个图库。每次切换图库都要关闭重启,想合并照片得手动导出导入,重复文件更是无处可逃…… 直到我发现了 PowerPhotos,这款专为Mac设计的照片库管理…...
)
软件工程面试题(三十)
将ISO8859-1字符串转成GB2312编码,语句为? String snew String(text.getBytes(“iso8859-1”),”gb2312”). 说出你用过的J2EE标准的WEB框架和他们之间的比较? 答:用过的J2EE标准主要有:JSP&Servlet、JDBC、JNDI…...

Java面试黄金宝典35
1. A 和 B 两个表做等值连接 (Inner join) 怎么优化 索引优化:在连接字段上创建索引,让数据库在进行等值连接时,能够快速定位匹配的记录,减少全表扫描的开销。例如,若 A 表和 B 表通过 id 字段进行连接,可在…...

openssl-1.0.1e.tar.gz编译安装步骤
下载与验证 openssl-1.0.1e.tar.gz下载链接:https://pan.quark.cn/s/d682551565e8 校验文件完整性(示例): # 检查 SHA256 哈希值 sha256sum openssl-1.0.1e.tar.gz # 对比官方发布的哈希值(需从 OpenSSL 官网获取&a…...
)
供应链业务-供应链全局观(二)
概述 我们在供应链业务知识分享的第一篇供应链业务-供应链全局观(一)中大致聊了以下三点: 1、供应链的本质:环环相扣的增值网络。供应链是从供应商的供应商到客户的客户之间,通过采购、生产、运输、仓储、销售等环节…...

在 Flutter 中Navigator.push 用于实现页面之间的导航
在 Flutter 中,Navigator.push 是一个非常重要的方法,用于实现页面之间的导航。通过 Navigator.push,你可以将一个新的页面(路由)推送到导航栈中,从而显示新的内容。 以下是一个详细的教程,帮助…...

安永启用AI驱动SAP云ERP系统
安永(EY)宣布与 SAP 和微软展开战略合作,正式启动将其内部业务系统升级为基于 SAP S/4HANA Cloud 私有版的现代化 ERP 系统,并部署在 Microsoft Azure 云平台上。此次转型不仅涉及系统更新,还将通过引入人工智能&#…...

Augment Code:下一代AI编程助手,能否超越GitHub Copilot?
1. 背景介绍 近日,AI编程助手公司 Augment Code 宣布完成 2.27亿美元B轮融资,估值接近 9.77亿美元,距离独角兽企业仅一步之遥。本轮融资由 Sutter Hill Ventures、Index Ventures、Innovation Endeavors、Lightspeed Venture Partners 和 Me…...

图像处理之《直方图规定化和低失真数据隐藏的可逆对比度增强》论文阅读
全文目录 一、文章摘要二、直方图规定化三、提出的方法A.峰值和零点的选择B.数据序列扩展C. V L D E \mathrm{VLD_E} VLDE: 带有扩展的极低失真D.提出的RCE-HS方案四、实现细节五、汇报PPT一、文章摘要 本文研究可逆对比度增强(RCE)。图像增强是通过直方图规定化实现的,直方…...

状态模式~
状态模式 在软件系统中,有些对象也像水一样具有多种状态,这些状态在某些情况下能够相互转换,而且对象在不同状态下也将具有不同的行为. 状态模式(state pattern)的定义: 允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 状态模式就是用于解决系统…...

Latex入门之超详细的Latex环境配置教程
最近在学习Latex,顺便给大家分享一下Latex环境配置的心得。Latex作为一种高质量的排版系统,广泛应用于学术论文、书籍和报告的排版中。对于初学者来说,配置Latex环境可能是个挑战,但只要按照本文的步骤来,其实并不难。…...

[WUSTCTF2020]CV Maker1
进来是个华丽的界面,我们先跟随这个网页创造一个用户 发现了一个上传端口,尝试上传一个php文件并抓包 直接上传进不去,加个GIF89A uploads/d41d8cd98f00b204e9800998ecf8427e.php 传入 并且报告了 上传路径,然后使用蚁剑连接...

第1课:React开发环境搭建与第一个组件
第1课:React开发环境搭建与第一个组件 学习目标 搭建React开发环境创建第一个React项目了解项目基本结构编写并运行第一个React组件 一、环境准备 1. 安装Node.js React开发需要Node.js环境,它包含了npm(Node Package Manager࿰…...

go垃圾回收机制
Go语言的垃圾回收(GC)机制旨在高效管理内存,同时最小化对程序性能的影响。其核心设计结合了并发标记清除、三色标记法和写屏障技术,显著减少了停顿时间(Stop-The-World, STW)。以下是Go垃圾回收机制的关键特…...

【GPT入门】第 34 课:深度剖析 ReAct Agent 工作原理及代码实现
【GPT入门】第 34 课:深度剖析 ReAct Agent 工作原理及代码实现 1. React Agent概述2. React Agent工作原理、关键特点、应用场景3. langchain的ReAct Agent代码实现3.1 Openai1.x 代码实现3.2 Openai 0.x的实现3.3 新旧版API异同比较 1. React Agent概述 定义与基…...

MySQL介绍及使用
1. 安装、启动、配置 MySQL 1. 安装 MySQL 更新软件包索引 sudo apt update 安装 MySQL 服务器 sudo apt install mysql-server 安装过程中可能会提示你设置 root 用户密码。如果没有提示,可以跳过,后续可以手动设置。 2. 配置 MySQL 运行安全脚本…...

九、重学C++—类和函数
上一章节: 八、重学C—动态多态(运行期)-CSDN博客https://blog.csdn.net/weixin_36323170/article/details/147004745?spm1001.2014.3001.5502 本章节代码: cpp/cppClassAndFunc.cpp CuiQingCheng/cppstudy - 码云 - 开源中国…...

C++·包装器
目录 function 包装各种可调用对象 包装类成员函数 应用举例 bind 一般形式 arg_list 调整参数顺序 调整参数个数(绑死) 应用举例 小知识 function 包含在<functional>头文件中,是一个类模版,但本质还是仿函数。…...

Linux动态监控进程利器:top命令详解
动态监控进程利器:top命令详解 在Linux系统的日常管理中,实时监控进程状态和资源使用情况是一项至关重要的任务。top命令作为Linux系统自带的强大工具,以其动态更新的特性,成为了系统管理员和开发者的得力助手。本文将全面解析to…...