变分自编码器(VAE)概念解析与用法实例:根据原图像生成新图像
目录
1. 前言
2. VAE原理
2.1 什么是VAE?
2.2 编码器(Encoder)
2.3 重参数化技巧(Reparameterization Trick)
2.4 解码器(Decoder)
2.5 损失函数
3. Pytorch实现:根据原图像生成新图像
3.1 导入库
3.2 定义超参数
3.3 数据预处理
3.4 定义编码器
3.5 定义解码器
3.6 定义VAE
3.7 定义损失函数
3.8 初始化模型和优化器
3.9 训练过程
3.10 生成图像
3.11 开始训练
4. 完整代码案例
5. 总结
1. 前言
变分自编码器(Variational Autoencoder, VAE)是一种强大的生成模型,它结合了自编码器和变分推断的思想,能够有效地学习数据的低维表示并生成新的样本。与传统的自编码器不同,VAE以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值。本文将详细介绍VAE的原理,并通过一个使用Pytorch库构建的完整实例来展示其应用。
自编码器基础可以阅读:
《自编码器(AutoEncoder)概念解析与用法实例:压缩数字图像》
2. VAE原理
2.1 什么是VAE?
VAE是一种生成模型,它通过学习数据的概率分布来生成新的样本。与传统自编码器相比,VAE不仅能够压缩数据,还能生成与训练数据相似的新数据。它的核心思想是将输入数据映射到一个概率分布(通常是高斯分布),然后从该分布中采样并重建数据。
2.2 编码器(Encoder)
编码器是VAE的第一部分,它的任务是将输入数据映射到潜在空间中的概率分布。通常,这个分布是一个高斯分布,编码器会输出潜在变量的均值和方差。
2.3 重参数化技巧(Reparameterization Trick)
为了使模型能够进行反向传播,我们采用重参数化技巧。通过引入一个随机变量,将潜在变量表示为均值和方差的函数。具体来说,潜在变量 z 可以表示为:
![]()
其中 ϵ 是一个标准正态分布的随机变量。
2.4 解码器(Decoder)
解码器是VAE的第二部分,它的任务是将潜在空间中的点映射回数据空间,生成与输入数据相似的新样本。
2.5 损失函数
VAE的损失函数由两部分组成:
-
重构损失(Reconstruction Loss):衡量生成数据与原始数据的差异,通常使用二元交叉熵或均方误差。
-
KL散度(KL Divergence):衡量潜在分布与标准正态分布的差异,用于确保潜在空间的平滑性。
损失函数的公式为:
![]()
其中:
-
BCE 是二元交叉熵
-
KL 是KL散度
3. Pytorch实现:根据原图像生成新图像
3.1 导入库
首先,我们需要导入必要的库:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt3.2 定义超参数
batch_size = 128
epochs = 10
learning_rate = 1e-3
latent_dim = 20 # 潜在空间的维度
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")3.3 数据预处理
我们使用MNIST数据集作为示例:
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)3.4 定义编码器
编码器将输入数据映射到潜在空间中的均值和方差:
class Encoder(nn.Module):def __init__(self, latent_dim):super(Encoder, self).__init__()self.fc1 = nn.Linear(28*28, 400)self.fc21 = nn.Linear(400, latent_dim) # 潜在变量的均值self.fc22 = nn.Linear(400, latent_dim) # 潜在变量的方差def forward(self, x):h1 = torch.relu(self.fc1(x.view(-1, 28*28)))z_mean = self.fc21(h1)z_log_var = self.fc22(h1)return z_mean, z_log_var3.5 定义解码器
解码器将潜在空间中的点映射回数据空间:
class Decoder(nn.Module):def __init__(self, latent_dim):super(Decoder, self).__init__()self.fc3 = nn.Linear(latent_dim, 400)self.fc4 = nn.Linear(400, 28*28)def forward(self, z):h3 = torch.relu(self.fc3(z))reconstruction = torch.sigmoid(self.fc4(h3))return reconstruction3.6 定义VAE
将编码器和解码器组合成一个VAE模型:
class VAE(nn.Module):def __init__(self, latent_dim):super(VAE, self).__init__()self.encoder = Encoder(latent_dim)self.decoder = Decoder(latent_dim)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef forward(self, x):z_mean, z_log_var = self.encoder(x)z = self.reparameterize(z_mean, z_log_var)reconstruction = self.decoder(z)return reconstruction, z_mean, z_log_var-
mu:潜在变量的均值,形状为[batch_size, latent_dim]。 -
logvar:潜在变量的方差的对数,形状为[batch_size, latent_dim]。
3.7 定义损失函数
def loss_function(reconstruction, x, z_mean, z_log_var):# 重构损失BCE = nn.functional.binary_cross_entropy(reconstruction, x.view(-1, 28*28), reduction='sum')# KL散度KL = -0.5 * torch.sum(1 + z_log_var - z_mean.pow(2) - torch.exp(z_log_var))return BCE + KL-
重构损失:衡量生成数据与原始数据的差异。这里使用的是二元交叉熵(Binary Cross-Entropy, BCE)损失函数。
-
KL散度:衡量潜在分布与标准正态分布的差异。它用于正则化潜在空间,确保潜在变量的分布接近标准正态分布。
-
z_mean:潜在变量的均值。 -
z_log_var:潜在变量的方差的对数。
公式如下:
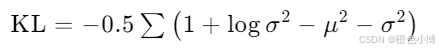
3.8 初始化模型和优化器
model = VAE(latent_dim).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)3.9 训练过程
def train(epoch):model.train()train_loss = 0for batch_idx, (data, _) in enumerate(train_loader):data = data.to(device)optimizer.zero_grad()reconstruction, z_mean, z_log_var = model(data)loss = loss_function(reconstruction, data, z_mean, z_log_var)loss.backward()train_loss += loss.item()optimizer.step()if batch_idx % 100 == 0:print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item() / len(data):.6f}")print(f"====> Epoch: {epoch} Average loss: {train_loss / len(train_loader.dataset):.4f}")3.10 生成图像
训练完成后,我们可以使用解码器生成新的图像:
def generate_images(epoch, num_images=10):model.eval()with torch.no_grad():z = torch.randn(num_images, latent_dim).to(device)sample = model.decoder(z).cpu()sample = sample.view(num_images, 28, 28)fig, axes = plt.subplots(1, num_images, figsize=(15, 15))for i in range(num_images):axes[i].imshow(sample[i], cmap='gray')axes[i].axis('off')plt.savefig(f"generated_images_epoch_{epoch}.png")plt.close()在 VAE 中,潜在空间(latent space)是一个低维空间,它捕捉了数据的主要特征。通过在潜在空间中采样随机噪声,我们可以利用解码器(decoder)将这些随机噪声映射回数据空间,从而生成新的样本。这种方法可以验证模型是否成功地学习了数据的分布,并能够生成与训练数据相似但又不完全相同的新样本。
随机噪声的生成过程如下:
-
使用
torch.randn生成服从标准正态分布的随机噪声。 -
将这些随机噪声输入到解码器中,生成新的图像。
3.11 开始训练
for epoch in range(1, epochs + 1):train(epoch)generate_images(epoch)4. 完整代码案例
完整代码如下:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as pltbatch_size = 128
epochs = 10
learning_rate = 1e-3
latent_dim = 20 # 潜在空间的维度
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)class Encoder(nn.Module):def __init__(self, latent_dim):super(Encoder, self).__init__()self.fc1 = nn.Linear(28*28, 400)self.fc21 = nn.Linear(400, latent_dim) # 潜在变量的均值self.fc22 = nn.Linear(400, latent_dim) # 潜在变量的方差def forward(self, x):h1 = torch.relu(self.fc1(x.view(-1, 28*28)))z_mean = self.fc21(h1)z_log_var = self.fc22(h1)return z_mean, z_log_varclass Decoder(nn.Module):def __init__(self, latent_dim):super(Decoder, self).__init__()self.fc3 = nn.Linear(latent_dim, 400)self.fc4 = nn.Linear(400, 28*28)def forward(self, z):h3 = torch.relu(self.fc3(z))reconstruction = torch.sigmoid(self.fc4(h3))return reconstructionclass VAE(nn.Module):def __init__(self, latent_dim):super(VAE, self).__init__()self.encoder = Encoder(latent_dim)self.decoder = Decoder(latent_dim)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef forward(self, x):z_mean, z_log_var = self.encoder(x)z = self.reparameterize(z_mean, z_log_var)reconstruction = self.decoder(z)return reconstruction, z_mean, z_log_vardef loss_function(reconstruction, x, z_mean, z_log_var):# 重构损失BCE = nn.functional.binary_cross_entropy(reconstruction, x.view(-1, 28*28), reduction='sum')# KL散度KL = -0.5 * torch.sum(1 + z_log_var - z_mean.pow(2) - torch.exp(z_log_var))return BCE + KLmodel = VAE(latent_dim).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)def train(epoch):model.train()train_loss = 0for batch_idx, (data, _) in enumerate(train_loader):data = data.to(device)optimizer.zero_grad()reconstruction, z_mean, z_log_var = model(data)loss = loss_function(reconstruction, data, z_mean, z_log_var)loss.backward()train_loss += loss.item()optimizer.step()if batch_idx % 100 == 0:print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item() / len(data):.6f}")print(f"====> Epoch: {epoch} Average loss: {train_loss / len(train_loader.dataset):.4f}")def generate_images(epoch, num_images=10):model.eval()with torch.no_grad():z = torch.randn(num_images, latent_dim).to(device)sample = model.decoder(z).cpu()sample = sample.view(num_images, 28, 28)fig, axes = plt.subplots(1, num_images, figsize=(15, 15))for i in range(num_images):axes[i].imshow(sample[i], cmap='gray')axes[i].axis('off')plt.show()for epoch in range(1, epochs + 1):train(epoch)generate_images(epoch)5. 总结
通过本文,我们详细介绍了变分自编码器(VAE)的基本原理,并通过一个完整的Pytorch实现展示了其应用。VAE在生成模型领域具有重要的地位,能够有效地学习数据的低维表示并生成新的样本。虽然VAE生成的图像可能不如GAN清晰,但它在潜在空间的平滑性和概率生成方面具有独特的优势。
希望本文能够帮助读者更好地理解VAE的工作原理和实现方法。我是橙色小博,关注我,一起在人工智能领域学习进步。
相关文章:
概念解析与用法实例:根据原图像生成新图像)
变分自编码器(VAE)概念解析与用法实例:根据原图像生成新图像
目录 1. 前言 2. VAE原理 2.1 什么是VAE? 2.2 编码器(Encoder) 2.3 重参数化技巧(Reparameterization Trick) 2.4 解码器(Decoder) 2.5 损失函数 3. Pytorch实现:根据原图像…...

AI随身翻译设备:从翻译工具到智能生活伴侣
文章目录 AI随身翻译设备的核心功能1. 实时翻译2. 翻译策略3. 翻译流程4. 输出格式 二、AI随身翻译设备的扩展功能1. 语言学习助手2. 旅行助手3. 商务助手4. 教育助手5. 健康助手6. 社交助手7. 技术助手8. 生活助手9. 娱乐助手10. 应急助手 三、总结四、未来发展趋势࿰…...

基于大模型的重症肌无力的全周期手术管理技术方案
目录 技术方案文档1. 数据预处理模块2. 多任务预测模型架构3. 动态风险预测引擎4. 手术方案优化系统5. 技术验证模块6. 系统集成架构7. 核心算法清单8. 关键流程图详述实施路线图技术方案文档 1. 数据预处理模块 流程图 [输入原始数据] → [联邦学习节点数据对齐] → [多模态特…...

Linux常用命令详解:从基础到进阶
目录 一、引言 二、文件处理相关命令 (一)grep指令 (二)zip/unzip指令 编辑 (三)tar指令 (四)find指令 三、系统管理相关命令 (一)shutdown指…...

【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具
【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具 资源简介 DeepSeek谷歌版1.1.5是目前全球领先的免费AI助手,性能超越国内主流AI产品,提供类似GPT-4的智能体验。 版本信息 最新版本:1.1.5(2024最新版)应用…...

JWT认证服务
JSON Web Token(JWT)是一种用于在网络应用间安全地传递信息的紧凑、自包含的方式。以下是关于 JWT 认证服务器更详细的介绍,包括其意义、作用、工作原理、组成部分、时效性相关内容、搭建条件以及代码案例。 JWT 的意义与作用 意义…...

Raft算法
Raft算法用于保证分布式环境下多节点数据的一致性。 原理 Raft算法的主要思想是一个 选主(leader selection) 的算法思想,集群种每个节点都有可能成为三种角色。 三种角色 leader 对客户端通信的入口,对内数据同步的发起者,一个集群通常只…...

Kotlin 类委托深入解析:以 MMKV 为例看委托机制在 Android 中的巧妙应用
Kotlin 中的类委托(class delegation)是一个非常实用的特性,它允许我们将接口的实现交给另一个对象,从而简化代码,提升复用性和灵活性。本文将通过简单的 Demo 介绍类委托的基本用法,并以 Android 中的 MMK…...
)
2025年渗透测试面试题总结-某一线实验室实习扩展(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 某一线实验室实习扩展 一、流量分析深度实践 1. FTP反弹定时确认包流量检测 1.1 攻击原理与特征 1.…...

2025大唐杯仿真3——移动性管理
仅仅是1-2之间的信息交互...

云原生与微服务的关系
云原生(Cloud Native)和微服务(Microservices)是现代软件开发和部署中密切相关的两个概念,它们共同推动了应用程序的架构设计、开发模式和运维方式的变革。以下是两者的关系及核心要点: 定义与核心概念 云原…...

【百日精通JAVA | SQL篇 | 第三篇】 MYSQL增删改查
SQL得最核心就是增删改查 一个后端开发,在工作中,最常见的场景就是CRUD。 插入数据 insert into student values (1,zhangsan); 指定列插入数据 同时多个列明之间使用逗号,来分割 insert into student (name) values (zhaoliu); 这个黑框…...

【leetcode】记录与查找:哈希表的题型分析
前言 🌟🌟本期讲解关于力扣的几篇题解的详细介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话不…...

如何在 Windows 10 上安装 PyGame
PyGame 是 Python 编程语言中的一组跨平台模块,这意味着您可以在任何操作系统上安装它,这篇文章告诉您如何在 Windows 10 上安装 PyGame。 如何在 Windows 10 上安装 PyGame? PyGame 依赖于 Python,这意味着您必须在安装 PyGame …...

LVGL修改标签文本,GUI Guider的ui不生效
一.问题背景 笔者最近在学习LVGL框架,同时准备使用该框架作为课程设计的一部分,于是需要从静态显示进阶到动态显示以及事件交互。一方面由于笔者是初次接触LVGL,对它并不熟悉,另一方面由于其网络上的针对性具体资料太少&a…...
)
制造装备物联及生产管理ERP系统设计与实现(代码+数据库+LW)
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装制造装备物联及生产管理ERP系统软件来发挥其高效地信息处理…...

PowerPhotos:拯救你的Mac照片库,告别苹果原生应用的局限
如果你用Mac管理照片,大概率被苹果原生「照片」应用折磨过——无法真正并行操作多个图库。每次切换图库都要关闭重启,想合并照片得手动导出导入,重复文件更是无处可逃…… 直到我发现了 PowerPhotos,这款专为Mac设计的照片库管理…...
)
软件工程面试题(三十)
将ISO8859-1字符串转成GB2312编码,语句为? String snew String(text.getBytes(“iso8859-1”),”gb2312”). 说出你用过的J2EE标准的WEB框架和他们之间的比较? 答:用过的J2EE标准主要有:JSP&Servlet、JDBC、JNDI…...

Java面试黄金宝典35
1. A 和 B 两个表做等值连接 (Inner join) 怎么优化 索引优化:在连接字段上创建索引,让数据库在进行等值连接时,能够快速定位匹配的记录,减少全表扫描的开销。例如,若 A 表和 B 表通过 id 字段进行连接,可在…...

openssl-1.0.1e.tar.gz编译安装步骤
下载与验证 openssl-1.0.1e.tar.gz下载链接:https://pan.quark.cn/s/d682551565e8 校验文件完整性(示例): # 检查 SHA256 哈希值 sha256sum openssl-1.0.1e.tar.gz # 对比官方发布的哈希值(需从 OpenSSL 官网获取&a…...
)
供应链业务-供应链全局观(二)
概述 我们在供应链业务知识分享的第一篇供应链业务-供应链全局观(一)中大致聊了以下三点: 1、供应链的本质:环环相扣的增值网络。供应链是从供应商的供应商到客户的客户之间,通过采购、生产、运输、仓储、销售等环节…...

在 Flutter 中Navigator.push 用于实现页面之间的导航
在 Flutter 中,Navigator.push 是一个非常重要的方法,用于实现页面之间的导航。通过 Navigator.push,你可以将一个新的页面(路由)推送到导航栈中,从而显示新的内容。 以下是一个详细的教程,帮助…...

安永启用AI驱动SAP云ERP系统
安永(EY)宣布与 SAP 和微软展开战略合作,正式启动将其内部业务系统升级为基于 SAP S/4HANA Cloud 私有版的现代化 ERP 系统,并部署在 Microsoft Azure 云平台上。此次转型不仅涉及系统更新,还将通过引入人工智能&#…...

Augment Code:下一代AI编程助手,能否超越GitHub Copilot?
1. 背景介绍 近日,AI编程助手公司 Augment Code 宣布完成 2.27亿美元B轮融资,估值接近 9.77亿美元,距离独角兽企业仅一步之遥。本轮融资由 Sutter Hill Ventures、Index Ventures、Innovation Endeavors、Lightspeed Venture Partners 和 Me…...

图像处理之《直方图规定化和低失真数据隐藏的可逆对比度增强》论文阅读
全文目录 一、文章摘要二、直方图规定化三、提出的方法A.峰值和零点的选择B.数据序列扩展C. V L D E \mathrm{VLD_E} VLDE: 带有扩展的极低失真D.提出的RCE-HS方案四、实现细节五、汇报PPT一、文章摘要 本文研究可逆对比度增强(RCE)。图像增强是通过直方图规定化实现的,直方…...

状态模式~
状态模式 在软件系统中,有些对象也像水一样具有多种状态,这些状态在某些情况下能够相互转换,而且对象在不同状态下也将具有不同的行为. 状态模式(state pattern)的定义: 允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 状态模式就是用于解决系统…...

Latex入门之超详细的Latex环境配置教程
最近在学习Latex,顺便给大家分享一下Latex环境配置的心得。Latex作为一种高质量的排版系统,广泛应用于学术论文、书籍和报告的排版中。对于初学者来说,配置Latex环境可能是个挑战,但只要按照本文的步骤来,其实并不难。…...

[WUSTCTF2020]CV Maker1
进来是个华丽的界面,我们先跟随这个网页创造一个用户 发现了一个上传端口,尝试上传一个php文件并抓包 直接上传进不去,加个GIF89A uploads/d41d8cd98f00b204e9800998ecf8427e.php 传入 并且报告了 上传路径,然后使用蚁剑连接...

第1课:React开发环境搭建与第一个组件
第1课:React开发环境搭建与第一个组件 学习目标 搭建React开发环境创建第一个React项目了解项目基本结构编写并运行第一个React组件 一、环境准备 1. 安装Node.js React开发需要Node.js环境,它包含了npm(Node Package Manager࿰…...

go垃圾回收机制
Go语言的垃圾回收(GC)机制旨在高效管理内存,同时最小化对程序性能的影响。其核心设计结合了并发标记清除、三色标记法和写屏障技术,显著减少了停顿时间(Stop-The-World, STW)。以下是Go垃圾回收机制的关键特…...

【GPT入门】第 34 课:深度剖析 ReAct Agent 工作原理及代码实现
【GPT入门】第 34 课:深度剖析 ReAct Agent 工作原理及代码实现 1. React Agent概述2. React Agent工作原理、关键特点、应用场景3. langchain的ReAct Agent代码实现3.1 Openai1.x 代码实现3.2 Openai 0.x的实现3.3 新旧版API异同比较 1. React Agent概述 定义与基…...

MySQL介绍及使用
1. 安装、启动、配置 MySQL 1. 安装 MySQL 更新软件包索引 sudo apt update 安装 MySQL 服务器 sudo apt install mysql-server 安装过程中可能会提示你设置 root 用户密码。如果没有提示,可以跳过,后续可以手动设置。 2. 配置 MySQL 运行安全脚本…...

九、重学C++—类和函数
上一章节: 八、重学C—动态多态(运行期)-CSDN博客https://blog.csdn.net/weixin_36323170/article/details/147004745?spm1001.2014.3001.5502 本章节代码: cpp/cppClassAndFunc.cpp CuiQingCheng/cppstudy - 码云 - 开源中国…...

C++·包装器
目录 function 包装各种可调用对象 包装类成员函数 应用举例 bind 一般形式 arg_list 调整参数顺序 调整参数个数(绑死) 应用举例 小知识 function 包含在<functional>头文件中,是一个类模版,但本质还是仿函数。…...

Linux动态监控进程利器:top命令详解
动态监控进程利器:top命令详解 在Linux系统的日常管理中,实时监控进程状态和资源使用情况是一项至关重要的任务。top命令作为Linux系统自带的强大工具,以其动态更新的特性,成为了系统管理员和开发者的得力助手。本文将全面解析to…...

家庭路由器wifi设置LAN2LAN和LAN2WAN
一、LAN2LAN 方式:桥接模式,主路由器的LAN口接入子路由器的LAN口 子路由器先重置登录密码(知道密码可以不重置),登录后台 1、设置为动态IP模式 2、找到LAN口设置 1)ip设置和主路由器在一个网段上&#…...

Python实现NOA星雀优化算法优化LightGBM分类模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后关注获取。 1.项目背景 在机器学习领域,分类问题是许多实际应用场景的核心任务之一,例如信用评估、…...

面试顺序优化:基于Matlab的高效决策方案
内容摘要 本文围绕面试顺序问题,通过建立数学模型并利用Matlab编程求解,寻找使面试总时长最短的面试顺序安排。详细介绍问题分析、模型构建及Matlab代码实现过程,为类似的时间优化问题提供参考,助力提升流程效率。 关键词&#x…...
)
【暑期实习之战】2024年美团秋招技术岗第一批笔试(练习)
选择题 6. 在MySQL中可以用来执行预处理语句的是() A execute B prepare C deallocate D using prepare:用于预编译SQL语句(为执行做准备),但并非执行动作本身。execute:专门用于执行已通过 PREPARE 预处理的语句,是运行预编译查询的关键步骤。✔deallocate prepare:…...

VLAN详解
VLAN(虚拟局域网)详解 1. 基本概念 VLAN(Virtual Local Area Network)是一种通过逻辑划分而非物理连接实现的局域网技术,允许在同一物理网络基础设施上创建多个独立的广播域。 2. 核心功能 功能说明广播域隔离不同V…...
)
[leetcode]1786. 从第一个节点出发到最后一个节点的受限路径数(Dijkstra+记忆化搜索/dp)
题目链接 题意 给定一个无向连通图,edges{u,v,w} 表示 u u u和 v v v之间有一条无向边,边权为 w w w n n n个点 [ 1 , n ] [1,n] [1,n] 每个点到 n n n的最短路为 d i s [ i ] dis[i] dis[i] 定义受限路径: 从起点 1 1 1到 n n n,路径上的…...

Ubuntu挂载HDD迁移存储PostgreSQL数据
关联博客:windows通用网线连接ubuntu实现ssh登录、桌面控制、文件共享 背景: 在个人ubuntu机器上安装了pgsql,新建了一张表插入了2000w数据用于模拟大批量数据分页查询用,但是发现查询也不慢(在公司测试环境查询1700…...
建造者模式)
设计模式简述(五)建造者模式
建造者模式 描述基本要素协调类使用 描述 建造者模式属于创造型设计模式。 通常用于构建一系列复杂对象,这些对象有一定的共性。 我们可以通过不同的建造者,组装不同的对象 与工厂模式的区别,建造者模式更侧重与基于基础构件组装而非直接创…...

ARXML文件解析-2
目录 1 摘要2 常见ARXML文件注意事项以及常见问题2.1 注意事项2.2 常见问题2.3 答疑 3 ARXML解读/编辑指南3.1 解读ARXML文件的步骤3.2 编辑ARXML文件的方法3.3 验证与调试 4 总结 1 摘要 本文主要对ARXML文件的注意事项、常见问题以及解读与编辑进行详细介绍。 上文回顾&…...

Docker设置代理
目录 前言创建代理文件重载守护进程并重启Docker检查代理验证 前言 拉取flowable/flowable-ui失败,用DaoCloud源也没拉下来,不知道是不是没同步。索性想用代理拉镜像。在此记录一下。 创建代理文件 创建docker代理配置 sudo mkdir -p /etc/systemd/s…...

ASP.NET Core Web API 参数传递方式
文章目录 前言一、参数传递方式路由参数(Route Parameters)查询字符串参数(Query String Parameters)请求体参数(Request Body)表单数据(Form Data)请求头参数(Header Pa…...

火语言RPA--PgSQL-导入数据表格
【组件功能】:导入特定的表格数据到包含同样字段的数据表 将表格对象数据通过数据库操作对象导入到指定数据库。 配置预览 配置说明 源表格 表格来源有“来自表格对象”和“来自表达式”2种,表达式支持DataTable类型变量。 对象 对应来自表格对象&…...

Spring Cloud 网关及配置管理教学
一、课程目标 深入理解 Spring Cloud 中网关和配置管理的核心概念、原理及应用场景。熟练掌握 Spring Cloud Gateway 的配置与开发,能够实现请求路由、登录校验、用户信息传递等功能。学会使用 Nacos 进行配置管理,包括共享配置、配置热更新和动态路由的…...

202520 | 微服务
微服务 VS 单体架构 单体架构(Monolithic Architecture)和微服务架构(Microservices Architecture)是两种主流的软件设计模式,它们在开发、部署、扩展和维护等方面有显著差异。以下是两者的详细对比: 1. 定…...
)
32信号和槽_信号和槽存在的意义(2)
① 一个学生,可以选择多门课程来学习 一门课程,也可以被多个同学来选择 ② 张三这个同学,可以选 语文和数学 . 李四这个同学可以选 语文 和 英语 语文这门课程,既可以被张三选择,也可以被李四选择~~ ③ 引入第三张表作为关联表 ④一个信号,可以 connect 到多个槽函数上 一个槽…...