使用Scrapy官方开发的爬虫部署、运行、管理工具:Scrapyd
一般情况下,爬虫会使用云服务器来运行,这样可以保证爬虫24h不间断运行。但是如何把爬虫放到云服务器上面去呢?有人说用FTP,有人说用Git,有人说用Docker。但是它们都有很多问题。
FTP:使用FTP来上传代码,不仅非常不方便,而且经常出现把方向搞反,导致本地最新的代码被服务器代码覆盖的问题。
Git:好处是可以进行版本管理,不会出现代码丢失的问题。但操作步骤多,需要先在本地提交,然后登录服务器,再从服务器上面把代码下载下来。如果有很多服务器的话,每个服务器都登录并下载一遍代码是非常浪费时间的事情。
Docker:好处是可以做到所有服务器都有相同的环境,部署非常方便。但需要对Linux有比较深入的了解,对新人不友好,上手难度比较大。
为了简化新人的上手难度,本次将会使用Scrapy官方开发的爬虫部署、运行、管理工具:Scrapyd。
一、Scrapyd介绍与使用
1. Scrapyd的介绍
Scrapyd是Scrapy官方开发的,用来部署、运行和管理Scrapy爬虫的工具。使用Scrapyd,可以实现一键部署Scrapy爬虫,访问一个网址就启动/停止爬虫。Scrapyd自带一个简陋网页,可以通过浏览器看到爬虫当前运行状态或者查阅爬虫Log。Scrapyd提供了官方API,从而可以通过二次开发实现更多更加复杂的功能。
Scrapyd可以同时管理多个Scrapy工程里面的多个爬虫的多个版本。如果在多个云服务器上安装Scrapyd,可以通过Python写一个小程序,来实现批量部署爬虫、批量启动爬虫和批量停止爬虫。
2. 安装Scrapyd
安装Scrapyd就像安装普通的Python第三方库一样容易,直接使用pip安装即可:
pip install scrapyd
由于Scrapyd所依赖的其他第三方库在安装Scrapy的时候都已经安装过了,所以安装Scrapyd会非常快。
Scrapyd需要安装到云服务器上,如果读者没有云服务器,或者想在本地测试,那么可以在本地也安装一个。
接下来需要安装scrapyd-client,这是用来上传Scrapy爬虫的工具,也是Python的一个第三方库,使用pip安装即可:
pip install scrapyd-client这个工具只需要安装到本地计算机上,不需要安装到云服务器上。
3. 启动Scrapyd
接下来需要在云服务器上启动Scrapyd。在默认情况下,Scrapyd不能从外网访问,为了让它能够被外网访问,需要创建一个配置文件。
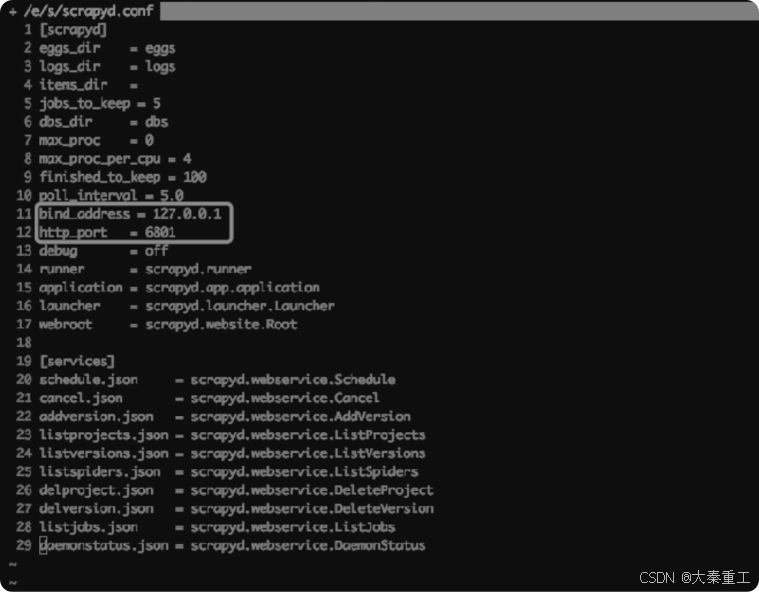
对于Mac OS和Linux系统,在/etc下创建文件夹scrapyd,进入scrapyd,创建scrapyd.conf文件。对于Windows系统,在C盘创建scrapyd文件夹,在文件夹中创建scrapyd.conf文件,文件内容如下:

除了bind_address这一项外,其他都可以保持默认。bind_address这一项的值设定为当前这台云服务器的外网IP地址。
配置文件放好以后,在终端或者CMD中输入scrapyd并按Enter键,这样Scrapyd就启动了。此时打开浏览器,输入“http://云服务器IP地址:6800”格式的地址就可以打开Scrapyd自带的简陋网页。
4. 部署爬虫
Scrapyd启动以后,就可以开始部署爬虫了。打开任意一个Scrapy的工程文件,可以看到在工程的根目录中,Scrapy已经自动创建了一个scrapy.cfg文件,打开这个文件,其内容如图所示。
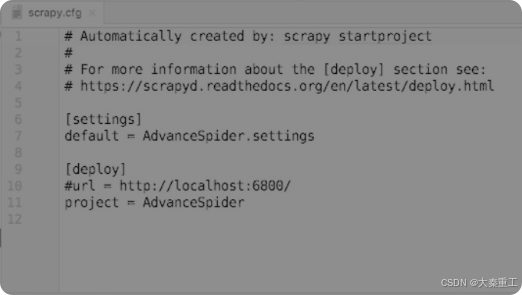
现在需要把第10行的注释符号去掉,并将IP地址改为Scrapyd所在云服务器的IP地址。
最后,使用终端或者CMD进入这个Scrapy工程的根目录,执行下面这一行命令部署爬虫:
scrapyd-deploy命令执行完成后,爬虫代码就已经在服务器上面了;如果服务器上面的Python版本和本地开发环境的Python版本不一致,那么部署的时候需要注意代码是否使用了服务器的Python不支持的语法;最好的办法是使用本地和服务器一样的版本开发环境(推荐使用 Conda)。需要记住,Scrapyd只是一个管理Scrapy爬虫的工具而已,只有能够正常运行的爬虫放到Scrapyd上面,才能够正常工作。
5.启动/停止爬虫
在上传了爬虫以后,就可以启动爬虫了。对于Mac OS和Linux系统,启动和停止爬虫非常简单。要启动爬虫,需要在终端输入下面这一行格式的代码:
curl http://云服务器IP地址:6800/schedule.json-d project=爬虫工程名-d spider=爬虫名 执行完成命令以后,打开Scrapyd的网页,进入Jobs页面,可以看到爬虫正在运行。单击右侧的Log链接,可以看到当前爬虫的Log。需要注意的是,这里显示的Log只能是在爬虫里面使用logging模块输出的内容,而不会显示print函数打印出来的内容。
如果爬虫的运行时间太长,希望提前结束爬虫,那么可以使用下面格式的命令来实现:
x
curl http://云服务器IP地址:6800/schedule.json-d project=爬虫工程名-d spider=爬虫名运行以后,相当于对爬虫按下了Ctrl+C组合键的效果。如果爬虫本身已经运行结束了,那么执行命令以后的返回内容中,“prevstate”这一项的值就为null,如果运行命令的时候爬虫还在运行,那么这一项的值就为“running”。对于Windows系统,启动和停止爬虫稍微麻烦一点,这是由于Windows的CMD功能较弱,没有像Mac OS和Linux的终端一样拥有curl这个发起网络请求的自带工具。但既然是发起网络请求,那么只需要借助Python和requests就可以完成。先来看看启动爬虫的命令:
curl http://192.168.31.210:6800/schedule.json -d project=DeploySpider -d spider=Example显而易见,其中的“http://192.168.31.210:6800/schedule.json”是一个网址,后面的-d中的d对应的是英文data数据的首字母,project=DeploySpider和spider=Example又刚好是Key、Value的形式,这和Python的字典有点像。而requests的POST方法刚好有一个参数也是data,它的值正好也是一个字典,所以使用requests的POST方法就可以实现启动爬虫。由于部署爬虫的时候直接执行scrapyd-deploy命令,所以如何使用Python来自动化部署爬虫呢?其实也非常容易。在Python里面使用os这个自带模块就可以执行系统命令,如图:
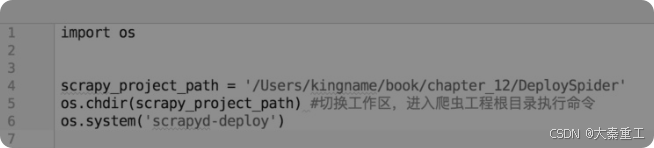
使用Python与requests的好处不仅在于可以帮助Windows实现控制爬虫,还可以用来实现批量部署、批量控制爬虫。假设有一百台云服务器,只要每一台上面都安装了Scrapyd,那么使用Python来批量部署并启动爬虫所需要的时间不超过1min。这里给出一个批量部署并启动爬虫的例子,首先在爬虫的根目录下创建一个scrapy_template.cfg文件,其内容如图所示。
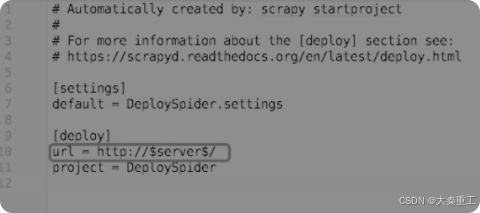
scrapy_template.cfg与scrapy.cfg的唯一不同之处就在于url这一项,其中的IP地址和端口变成了$server$。接下来编写批量部署和运行爬虫的脚本,如图所示。
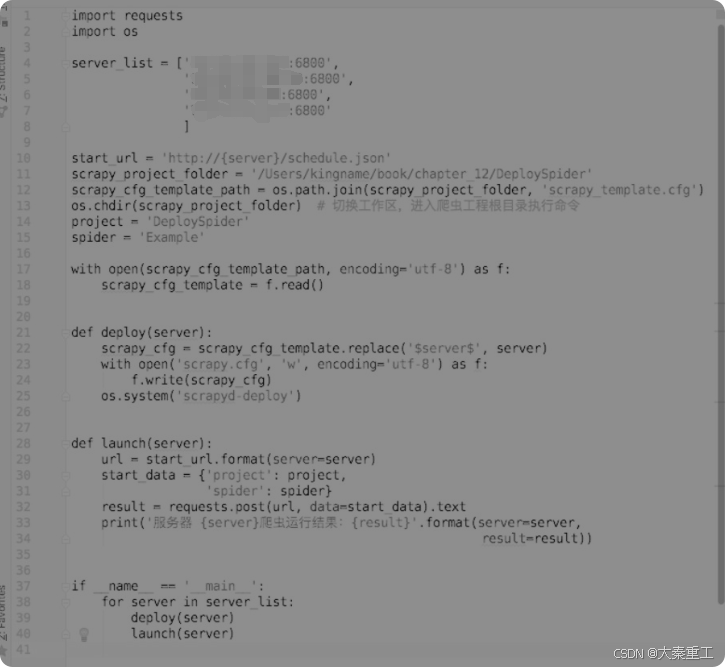
这个脚本的作用是逐一修改scrapy.cfg里面的IP地址和端口,每次修改完成以后就部署并运行爬虫。运行完成以后再使用下一个服务器的IP地址修改scrapy.cfg,再部署再运行,直到把爬虫部署到所有的服务器上并运行。
二、权限管理
在整个使用Scrapyd的过程中,只要知道IP地址和端口就可以操作爬虫。如果IP地址和端口被别人知道了,那岂不是别人也可以随意控制你的爬虫?确实是这样的,因为Scrapyd没有权限管理系统。任何人只要知道了IP地址和端口就可以控制爬虫。为了弥补Scrapyd没有权限管理系统这一短板,就需要借助其他方式来对网络请求进行管控。带权限管理的反向代理就是一种解决办法。能实现反向代理的程序很多,本次以Nginx为例来进行说明。
1. Nginx的介绍
Nginx读作Engine X,是一个轻量级的高性能网络服务器、负载均衡器和反向代理。为了解决Scrapyd的问题,需要用Nginx做反向代理。所谓“反向代理”,是相对于“正向代理”而言的。前面章节所用到的代理是正向代理。正向代理帮助请求者(爬虫)隐藏身份,爬虫通过代理访问服务器,服务器只能看到代理IP,看不到爬虫;反向代理帮助服务器隐藏身份。用户只知道服务器返回的内容,但不知道也不需要知道这个内容是在哪里生成的。使用Nginx反向代理到Scrapyd以后,Scrapyd本身只需要开通内网访问即可。用户访问Nginx, Nginx再访问Scrapyd,然后Scrapyd把结果返回给Nginx, Nginx再把结果返回给用户。这样只要在Nginx上设置登录密码,就可以间接实现Scrapyd的访问管控了,如图所示。

这个过程就好比是家里的保险箱没有锁,如果把保险箱放在大庭广众之下,谁都可以去里面拿钱。但是现在把保险箱放在房间里,房间门有锁,那么即使保险箱没有锁也没关系,只有手里有房间门钥匙的人才能拿到保险箱里面的钱。Scrapyd就相当于这里的“保险箱”,云服务器就相当于这里的“房间”, Nginx就相当于“房间门”,而登录账号和密码就相当于房间门的“钥匙”。为了完成这个目标,需要先安装Nginx。由于这里涉及爬虫的部署和服务器的配置,因此仅以Linux的Ubuntu为例。一般不建议Windows做爬虫服务器,也不建议购买很多台苹果计算机(因为太贵了)来搭建爬虫服务器。
2.Nginx的安装
在Ubuntu中安装Nginx非常简单,使用一行命令即可完成:
sudo apt-get install nginx安装好以后,需要考虑以下两个问题。(1)服务器是否有其他的程序占用了80端口。(2)服务器是否有防火墙。对于第1个问题,如果有其他程序占用了80端口,那么Nginx就无法启动。因为Nginx会默认打开80端口,展示一个安装成功的页面。当其他程序占用了80端口,Nginx就会因为拿不到80端口而报错。要解决这个问题,其办法有两个,关闭占用80端口的程序,或者把Nginx默认开启的端口改为其他端口。如果云服务器为国内的服务器,建议修改Nginx的默认启动端口,无论是否有其他程序占用了80端口。这是因为国内服务器架设网站是需要进行备案的,而80端口一般是给网站用的。如果没有备案就开启了80端口,有可能导致云服务器被运营商停机。
比如,讲监听端口从80修改为81;然后使用下列命令重启Nginx
sudo systemctl restart nginx重启Nginx可以在1~2s内完成。完成以后,使用浏览器访问格式为“服务器IP:81”的地址,如果出现图所示的页面,表示服务器没有防火墙,Nginx架设成功。
如果浏览器提示网页无法访问,那么就可能是服务器有防火墙,因此需要让防火墙对81端口的数据放行。不同的云服务器提供商,其防火墙是不一样的。例如Vultr,它没有默认的防火墙,Nginx运行以后就能用;国内的阿里云,CentOS系统服务器自带的防火墙为firewalld; Ubuntu系统自带的防火墙是Iptables;亚马逊的AWS,需要在网页后台开放端口;而UCloud,服务器自带防火墙的同时,网页控制台上还有对端口的限制。因此,要开放一个端口,最好先看一下云服务器提供商使用的是什么样的防火墙策略,并搜索提供商的文档。如果云服务器提供商没有相关的文档,可以问 AI ,比如:Deepseek 。
开放了端口以后,就可以开始配置环境了。
3.配置反向代理
首先打开/etc/scrapyd/scrapyd.conf,把bind_address这一项重新改为127.0.0.1,并把http_port这一项改为6801,如图所示。
这样修改以后,如果再重新启动Scrapyd,只能在服务器上向127.0.0.1:6801发送请求操作Scrapyd,服务器之外是没有办法连上Scrapyd的。接下来配置Nginx,在/etc/nginx/sites-available文件夹下创建一个scrapyd.conf,其内容为:
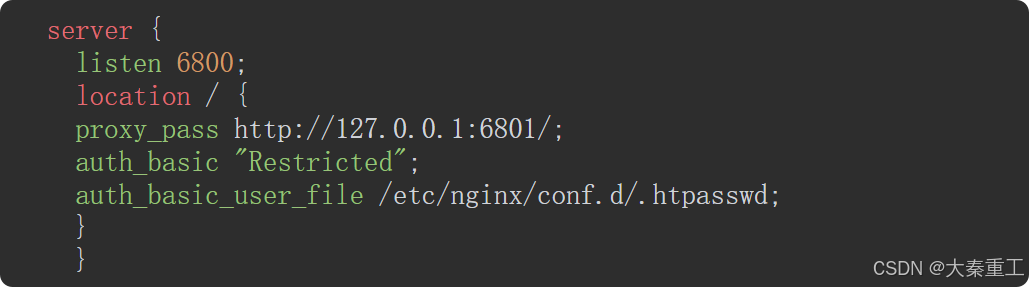
这个配置的意思是说,使用basic auth权限管理方法,对于通过授权的用户,将它对6800端口的请求转到服务器本地的6801端口。需要注意配置里面的记录授权文件的路径这一项:

在后面会将授权信息的记录文件放在/etc/nginx/conf.d/.htpasswd这个文件中。写好这个配置以后,保存。接下来,执行下面的命令,在/etc/nginx/sites-enabled文件夹下创建一个软连接:

软连接创建好以后,需要生成账号和密码的配置文件。
首先安装apache2-utils软件包:

安装完成apache2-utils以后,cd进入/etc/nginx/conf.d文件夹,并执行命令为用户kingname生成密码文件:

屏幕会提示输入密码,与Linux的其他密码输入机制一样,在输入密码的时候屏幕上不会出现*号,所以不用担心,输入完成密码按Enter键即可。
上面的命令会在/etc/nginx/conf.d文件夹下生成一个.htpasswd的隐藏文件。有了这个文件,Nginx就能进行权限验证了。接下来重启Nginx:

重启完成以后,启动Scrapyd,再在浏览器上访问格式为“http://服务器IP:6800”的网址,可以看到图所示的页面。
在这里输入使用htpasswd生成的账号和密码,就可以成功登录Scrapyd。
4.配置Scrapy工程
由于为Scrapyd添加了权限管控,涉及的部署爬虫、启动/停止爬虫的地方都要做一些小修改。首先是部署爬虫,为了让scrapyd-deploy能成功地输入密码,需要修改爬虫根目录的scrapy.cfg文件,添加username和password两项,其中username对应账号,password对应密码,如图所示。
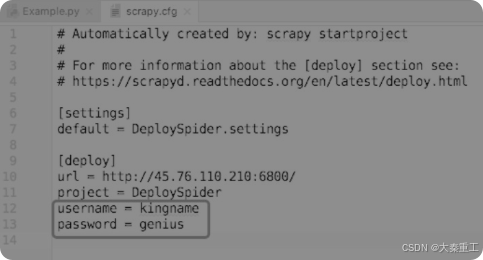
配置好scrapy.cfg以后,部署爬虫的命令不变,还是进入这个Scrapy工程的根目录,执行以下代码即可:
scrapyd-deploy使用curl启动/关闭爬虫,只需要在命令上加上账号参数即可。账号参数为“-u用户名:密码”。所以,启动爬虫的命令为:
curl http://192.168.31.210:6800/schedule.json-d project=工程名-d spider=爬虫名 -u kingname:genius停止爬虫的命令为:
curl http://192.168.31.210:6800/cancel.json-d project=工程名-d job=爬虫JOBID-u kingname:genius如果使用Python与requests编写脚本来控制爬虫,那么账号信息可以作为POST方法的一个参数,参数名为auth,值为一个元组,元组第0项为账号,第1项为密码:
result = requests.post(start_url, data=start_data, auth=('kingname', 'genius')).textresult = requests.post(end_url, data=end_data, auth=('kingname', 'genius')).text三、分布式架构介绍
之前讲到了把目标放到Redis里面,然后让多个爬虫从Redis中读取目标再爬取的架构,这其实就是一种主—从式的分布式架构。使用Scrapy,配合scrapy_redis,再加上Redis,也就实现了一个所谓的分布式爬虫。实际上,这种分布式爬虫的核心概念就是一个中心结点,也叫Master。它上面跑着一个Redis,所有的待爬网站的网址都在里面。其他云服务器上面的爬虫(Slave)就从这个共同的Redis中读取待爬网址。只要能访问这个Master服务器,并读取Redis,那么其他服务器使用什么系统什么提供商都没有关系。例如,使用Ubuntu作为爬虫的Master,用来做任务的派分。使用树莓派、Windows 10 PC和Mac来作为分布式爬虫的Slave,用来爬取网站,并将结果保存到Mac上面运行的MongoDB中。
其中,作为Master的Ubuntu服务器仅需要安装Redis即可,它的作用仅仅是作为一个待爬网址的临时中转,所以甚至不需要安装Python。在Mac、树莓派和Windows PC中,需要安装好Scrapy,并通过Scrapyd管理爬虫。由于爬虫会一直监控Master的Redis,所以在Redis没有数据的时候爬虫处于待命状态。当目标被放进了Redis以后,爬虫就能开始运行了。由于Redis是一个单线程的数据库,因此不会出现多个爬虫拿到同一个网址的情况。
严格来讲,Master只需要能运行Redis并且能被其他爬虫访问即可。但是如果能拥有一个公网IP则更好。这样可以从世界上任何一个能访问互联网的地方访问Master。但如果实在没有云服务器,也并不是说一定得花钱买一个,如果自己有很多台计算机,完全可以用一台计算机来作为Master,其他计算机来做Slave。Master也可以同时是Slave。Scrapy和Redis是安装在同一台计算机中的。这台计算机既是Master又是Slave。Master一定要能够被其他所有的Slave访问。所以,如果所有计算机不在同一个局域网,那么就需要想办法弄到一台具有公网IP的计算机或者云服务器。在中国,大部分情况下,电信运营商分配到的IP是内网IP。在这种情况下,即使知道了IP地址,也没有办法从外面连进来。在局域网里面,因为局域网共用一个出口,局域网内的所有共用同一个公网IP。对网站来说,这个IP地址访问频率太高了,肯定不是人在访问,从而被网站封锁的可能性增大。而使用分布式爬虫,不仅仅是为了提高访问抓取速度,更重要的是降低每一个IP的访问频率,使网站误认为这是人在访问。所以,如果所有的爬虫确实都在同一个局域网共用一个出口的话,建议为每个爬虫加上代理。在实际生产环境中,最理想的情况是每一个Slave的公网IP都不一样,这样才能做到既能快速抓取,又能减小被反爬虫机制封锁的机会。
四、爬虫开发中的法律与道德问题
全国人民代表大会常务委员会在2016年11月7日通过了《中华人民共和国网络安全法》,2017年6月1日正式实施。爬虫从过去游走在法律边缘的灰色产业,变得有法可循。在开发爬虫的过程中,一定要注意一些细节,否则容易在不知不觉中触碰道德甚至是法律的底线。
1. 数据采集的法律问题
如果爬虫爬取的是商业网站,并且目标网站使用了反爬虫机制,那么强行突破反爬虫机制可能构成非法侵入计算机系统罪、非法获取计算机信息系统数据罪。如果目标网站有反爬虫声明,那么对方在被爬虫爬取以后,可以根据服务器日志或者各种记录来起诉使用爬虫的公司。这里有几点需要注意。
(1)目标网站有反爬虫声明。
(2)目标网站能在服务器中找到证据(包括但不限于日志、IP)。
(3)目标网站进行起诉。如果目标网站本身就是提供公众查询服务的网站,那么使用爬虫是合法合规的。但是尽量不要爬取域名包含.gov的网站。
2. 数据的使用
公开的数据并不一定被允许用于第三方盈利目的。例如某网站可以供所有人访问,但是如果一个开发把这个网站的数据爬取下来,然后用于盈利,那么可能会面临法律风险。成熟的大数据公司在爬取并使用一个网站的数据时,一般都需要专业的律师对目标网站进行审核,看是否有禁止爬取或者禁止商业用途的相关规定。
3. 注册及登录可能导致的法律问题
自己能查看的数据,不一定被允许擅自拿给第三方查看。例如登录很多网站以后,用户可以看到“用户自己”的数据。如果开发把自己的数据爬取下来用于盈利,那么可能面临法律风险。因此,如果能在不登录的情况下爬取数据,那么爬虫就绝不应该登录。这一方面是避免反爬虫机制,另一方面也是减小法律风险。如果必须登录,那么需要查看网站的注册协议和条款,检查是否有禁止将用户自己后台数据公开的相关条文。
4. 数据存储
根据《个人信息和重要数据出境安全评估办法(征求意见稿)》第九条的规定,包含或超过50万人的个人信息,或者包含国家关键信息的数据,如果要转移到境外,必须经过主管或者监管部门组织安全评估。
5. 内幕交易
如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好,于是买入该公司股票并赚了一笔钱。这是合法的。如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好。于是将数据或者分析结果出售给某基金公司,从而获得销售收入。这也是合法的。如果开发通过爬虫抓取某公司网站的公开数据,分析以后发现这个公司业绩非常好,于是首先把数据或者分析结果出售给某基金公司,然后自己再买被爬公司的股票。此时,该开发涉嫌内幕交易,属于严重违法行为。之所以出售数据给基金公司以后,开发就不能在基金公司购买股票之前再购买被爬公司股票,这是由于“基金公司将要购买哪一只股票”属于内幕消息,使用内幕消息购买股票将严重损坏市场公平,因此已被定义为非法行为。而开发自身是没有办法证明自己买被爬公司的股票是基于对自己数据的信心,而不是基于知道了某基金公司将要购买该公司股票这一内幕消息的。在金融领域,有一个词叫作“老鼠仓”,与上述情况较为类似。
五、道德协议
在爬虫开发过程中,除了法律限制以外,还有一些需要遵守的道德规范。虽然违反也不会面临法律风险,但是遵守才能让爬虫细水长流。
robots.txt协议robots.txt是一个存放在网站根目录下的ASCII编码的文本文件。爬虫在爬网站之前,需要首先访问并获取这个robots.txt文件的内容,这个文件里面的内容会告诉爬虫哪些数据是可以爬取的,哪些数据是不可以爬取的。要查看一个网站的robots.txt,只需要访问“网站域名/robots.txt”,例如知乎的robots.txt地址为https://www.zhihu.com/robots.txt,访问后的结果如图所示。
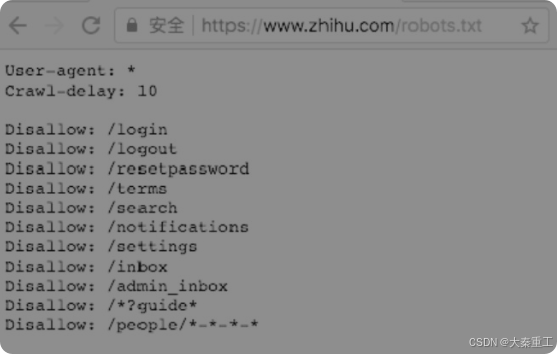
这个robots.txt文件表示,对于任何爬虫,允许爬取除了以Disallow开头的网址以外的其他网址,并且爬取的时间间隔为10s。Disallow在英文中的意思是“不允许”,因此列在这个页面上的网址是不允许爬取的,没有列在这里的网址都是可以爬取的。在Scrapy工程的settings.py文件中,有一个配置项为“ROBOTSTXT_OBEY”,如果设置为True,那么Scrapy就会自动跳过网站不允许爬取的内容。robots.txt并不是一种规范,它只是一种约定,所以即使不遵守也不会受到惩罚。但是从道德上讲,建议遵守。
新手开发在开发爬虫时,往往不限制爬虫的请求频率。这种做法一方面很容易导致爬虫被网站屏蔽,另一方面也会给网站造成一定的负担。如果很多爬虫同时对一个网站全速爬取,那么其实就是对网站进行了DDOS(Distributed Denial-of-Service,分布式拒绝服务)攻击。小型网站是无法承受这样的攻击的,轻者服务器崩溃,重者耗尽服务器流量。而一旦服务器流量被耗尽,网站在一个月内都无法访问了。
开源是一件好事,但不要随便公开爬虫的源代码。因为别有用心的人可能会拿到被公开的爬虫代码而对网站进行攻击或者恶意抓取数据。网站的反爬虫技术也是一种知识产权,而破解了反爬虫机制再开源爬虫代码,其实就相当于把目标网站的反爬虫技术泄漏了。这可能会导致一些不必要的麻烦。
在爬虫开发和数据采集的过程中,阅读网站的协议可以有效发现并规避潜在的法律风险。爬虫在爬取网站的时候控制频率,善待网站,才能让爬虫运行得更长久。
--------------------------------------
没有自由的秩序和没有秩序的自由,同样具有破坏性。

相关文章:

使用Scrapy官方开发的爬虫部署、运行、管理工具:Scrapyd
一般情况下,爬虫会使用云服务器来运行,这样可以保证爬虫24h不间断运行。但是如何把爬虫放到云服务器上面去呢?有人说用FTP,有人说用Git,有人说用Docker。但是它们都有很多问题。 FTP:使用FTP来上传…...

基于51单片机和8X8点阵屏、独立按键的单人弹球小游戏
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、8X8点阵屏2、独立按键3、定时器04、定时器1 四、主函数总结 系列文章目录 前言 用的是普中A2开发板,用到板上的独立按键、8X8点阵屏。 【单片机】STC89C52RC 【频率】12T11.0592MHz 效果查看/操作…...

群体智能避障革命:RVO算法在Unity中的深度实践与优化
引言:游戏群体移动的挑战与进化 在《全面战争》中万人战场恢弘列阵,在《刺客信条》闹市里人群自然涌动,这些令人惊叹的场景背后,都离不开一个关键技术——群体动态避障。传统路径规划算法(如A*)虽能解决单…...

Java 实现选择排序:[通俗易懂的排序算法系列之一]
引言 大家好!从今天开始,我计划写一个关于常见排序算法的系列文章,旨在用通俗易懂的方式,结合 Java 代码实现,帮助大家理解和掌握这些基础但非常重要的数据结构与算法知识。 排序是计算机科学中最基本的操作之一&…...

动画过渡设置
使用Animator的Trigger参数 步骤 1:打开 Animator 窗口 确保你的 Sprite 对象已添加 Animator 组件。 在 Unity 编辑器顶部菜单栏,选择 Window > Animation > Animator,打开 Animator 窗口。 步骤 2:创建 Trigger 参数 在…...

【项目管理-高项】学习方法 整体概览
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 📝 软考高项,全称 信息系统项目管理师 ,是软考高级资格项目之一。 本考试考三门科目:综合知识(上午)、案例分析(下午…...

HarmonyOS应用开发者高级-编程题-001
题目一:跨设备分布式数据同步 需求描述 开发一个分布式待办事项应用,要求: 手机与平板登录同一华为账号时,自动同步任务列表任一设备修改任务状态(完成/删除),另一设备实时更新任务数据在设备…...

HarmonyOS-ArkUI Ability进阶系列-UIAbility与各类Context
UIAbility及相关类关系 一个模块编译的时候会出一个HAP包, 每一个HAP包在运行时都对应一个AbilityStage。 AbilityStage持有一个AbilityStageContext一个APP, 有时候会有很多个HAP包, 至少一个。 一个APP运行时,对应的是我们的App…...

接口并行执行且流式顺序输出的解决方案
接口并行执行且流式顺序输出的解决方案: import asyncio from aiotas_agi2all_llms_utils.output_answer_from_ask_question_results import (reasoning_model_ask_question, ) import os from aiotas_agi2all_llms_utils.logging_utils import create_logger import uuid fr…...

浅谈AI - DeepSpeed - 单卡慎用!
前言 曾在游戏世界挥洒创意,也曾在前端和后端的浪潮间穿梭,如今,而立的我仰望AI的璀璨星空,心潮澎湃,步履不停!愿你我皆乘风破浪,逐梦星辰! 简介 Deepspeed 的 ZeRO(Ze…...
)
Java Web从入门到精通:全面探索与实战(一)
目录 引言:开启 Java Web 之旅 一、Java Web 基础概念大揭秘 1.1 什么是 Java Web 1.2 Java Web 的优势剖析 1.3 Java Web 相关核心概念详解 二、搭建 Java Web 开发环境:步步为营 2.1 所需软件大盘点 2.2 软件安装与配置全流程 三…...

5G从专家到小白
文章目录 第五代移动通信技术(5G)简介应用场景 数据传输率带宽频段频段 VS 带宽中低频(6 GHz以下):覆盖范围广、穿透力强高频(24 GHz以上):满足在热点区域提升容量的需求毫米波热点区…...

leetcode111 二叉树的最小深度
相对于 104.二叉树的最大深度 ,本题还也可以使用层序遍历的方式来解决,思路是一样的。 最小深度的定义:从根节点到最近叶子节点的最短路径上的节点数量。 特别注意: 如果一个子树不存在,就不能用它来计算深度&#x…...

算法设计学习10
实验目的及要求: 本查找实验旨在使学生深入了解不同查找算法的原理、性能特征和适用场景,培养其在实际问题中选择和应用查找算法的能力。通过实验,学生将具体实现多种查找算法,并通过性能测试验证其在不同数据集上的表现ÿ…...

数字统计题解
题目理解 题目要求计算所有不大于 N 的非负整数中数字 D 出现的总次数。例如,当 D1 且 N12 时,数字1出现在1、10、11(两次)、12中,共5次。 输入输出分析 输入格式: 两个正整数 D 和 N,其中1≤…...

eclipse导入工程提示Project has no explicit encoding set
eclipse导入工程提示Project has no explicit encoding set-CSDN博客...

【网络安全论文】筑牢局域网安全防线:策略、技术与实战分析
【网络安全论文】筑牢局域网安全防线:策略、技术与实战分析 简述一、引言1.1 研究背景1.2 研究目的与意义1.3 国内外研究现状1.4 研究方法与创新点二、局域网网络安全基础理论2.1 局域网概述2.1.1 局域网的定义与特点2.1.2 局域网的常见拓扑结构2.2 网络安全基本概念2.2.1 网络…...
:深入理解Java类加载器与类加载机制)
JVM虚拟机篇(五):深入理解Java类加载器与类加载机制
深入理解Java类加载器与类加载机制 深入理解Java类加载器与类加载机制一、引言二、类加载器2.1 类加载器的定义2.2 类加载器的分类2.2.1 启动类加载器(Bootstrap ClassLoader)2.2.2 扩展类加载器(Extension ClassLoader)2.2.3 应用…...
,手打个人理解注释,超全面,且均已验证成功(附带详细手写“模拟流程图”,全网首个)
纯个人整理,蓝桥杯使用的算法模板day4(图论 最小生成树问题),手打个人理解注释,超全面,且均已验证成功(附带详细手写“模拟流程图”,全网首个
目录 最小生成树Prim代码模拟流程图 kruskal代码 代码对应实现案例 最小生成树 最小生成树:在无向图中求一棵树(n-1条边,无环,连通所有点),而且这棵树的边权和最小 (ps:可能结果不止…...

学习笔记,DbContext context 对象是保存了所有用户对象吗
DbContext 并不会将所有用户对象保存在内存中: DbContext 是 Entity Framework Core (EF Core) 的数据库上下文,它是一个数据库访问的抽象层它实际上是与数据库的一个连接会话,而不是数据的内存缓存当您通过 _context.Users 查询数据时&…...

Kafka 和 Flink的讲解
一、Kafka:分布式消息队列 1. 核心概念 角色:Kafka 是一个分布式、高吞吐量的消息队列(Pub-Sub 模型),用于实时传输数据流。关键术语: Producer(生产者&…...

Kafka 高吞吐量的原因是什么?
Kafka 的高吞吐量是它成为“数据中枢”的关键特性之一,这背后是多个技术设计的巧妙配合。下面我给你整理一下 Kafka 高吞吐量的主要原因,通俗又系统。 ✅ 1. 顺序写磁盘(磁盘也能飞) Kafka 的消息写入是追加到日志末尾ÿ…...

基于Python+Flask的服装零售商城APP方案,用到了DeepSeek AI、个性化推荐和AR虚拟试衣功能
首先创建项目结构: fashion_store/ ├── backend/ │ ├── app/ │ │ ├── __init__.py │ │ ├── models/ │ │ ├── routes/ │ │ ├── services/ │ │ └── utils/ │ ├── config.py │ ├── requirements.t…...

26.[MRCTF2020]Transform 1
打开文件是可执行程序.exe,打开看一下,顺便拖入ExeinfoPE 查询一下基本信息。如图。 无壳,且是64-bit,打开执行文件也没有什么特别的信息。那就 IDA-x64 分析吧。 🆗,简单的一个加密,我们直接逆…...

LeetCode-98. 验证二叉搜索树
一、题目 给定一个二叉树,判断其是否是一个有效的二叉搜索树。假设一个二叉搜索树具有如下特征: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的…...

【LeetCode Solutions】LeetCode 146 ~ 150 题解
CONTENTS LeetCode 146. LRU 缓存(中等)LeetCode 147. 对链表进行插入排序(中等)LeetCode 148. 排序链表(中等)LeetCode 149. 直线上最多的点数(困难)LeetCode 150. 逆波兰表达式求值…...

leetcode二叉树刷题调试不方便的解决办法
1. 二叉树不易构建 在leetcode中刷题时,如果没有会员就需要将代码拷贝到本地的编译器进行调试。但是leetcode中有一类题可谓是毒瘤,那就是二叉树的题。 要调试二叉树有关的题需要根据测试用例给出的前序遍历,自己构建一个二叉树,…...
】消息通知系统设计:搭建高效沟通桥梁)
【家政平台开发(16)】消息通知系统设计:搭建高效沟通桥梁
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化…...

AI比人脑更强,因为被植入思维模型【44】成长破圈思维
giszz的理解:芒格说,不懂不投。我们一生都在追求破圈,突破本我,突破舒适圈、恐惧圈、学习圈、成长圈、自在圈,可是我们真正能懂的知识有实际真的太少了。这个思维模型给我的启迪,一是要破圈,二是…...

【JavaWeb-Spring boot】学习笔记
目录 <<回到导览Spring boot1. http协议1.1.请求协议1.2.响应协议 2.Tomcat2.1.请求2.1.1.apifox2.1.2.简单参数2.1.3.实体参数2.1.4.数组集合参数2.1.5.日期参数2.1.6.(重点)JSON参数2.1.7.路径参数 2.2.响应2.3.综合练习 3.三层架构3.1.三层拆分3.2.分层解耦3.3.补充 &…...

基于GitLab+Jenkins的持续集成实践指南
架构设计原则 分层自动化策略 基础层: 代码提交触发自动构建(100%自动化)中间层: 制品生成与验证(自动化+人工审核)发布层: 环境部署(受控手动触发)工具定位矩阵 工具核心职责关键优势GitLab源码管理+MR流程精细的权限控制Jenkins流水线编排+任务调度插件生态丰富Nexus制…...

用HTML.CSS.JavaScript实现一个贪吃蛇小游戏
目录 一、引言二、实现思路1. HTML 结构2. CSS 样式3. JavaScript 逻辑 三、代码实现四、效果展示 一、引言 贪吃蛇是一款经典的小游戏,曾经风靡一时。今天,我们将使用 HTML、CSS 和 JavaScript 来实现一个简单的贪吃蛇小游戏。通过这个项目,…...
)
医疗思维图与数智云融合:从私有云到思维图的AI架构迭代(代码版)
医疗思维图作为AI架构演进的重要方向,其发展路径从传统云计算向融合时空智能、大模型及生态开放的“思维图”架构迭代,体现了技术与场景深度融合的趋势。 以下是其架构迭代的核心路径与关键特征分析: 一、从“智慧云”到“思维图”的架构演进逻辑 以下是针对医疗信息化领域…...

Kafka 中,为什么同一个分区只能由消费者组中的一个消费者消费?
在 Kafka 中,同一个分区只能由消费者组中的一个消费者消费,这是 Kafka 的设计决策之一,目的是保证消息的顺序性和避免重复消费。这背后有几个关键的原因: 1. 保证消息顺序性 Kafka 中的每个 分区(Partitionÿ…...

Kafka 中的批次
在 Kafka 中,批次(Batch) 是生产者发送消息的一个重要概念。它对 Kafka 的性能、吞吐量、延迟等有很大影响。批量处理可以使消息发送更高效,减少网络往返和磁盘写入的开销。 下面我将详细解释 Kafka 中的批次机制,包括…...

《UNIX网络编程卷1:套接字联网API》第7章:套接字选项深度解析
《UNIX网络编程卷1:套接字联网API》第7章:套接字选项深度解析 一、套接字选项核心原理 1.1 选项层级体系 套接字选项按协议层级划分(图1): SOL_SOCKET:通用套接字层选项IPPROTO_IP:IPv4协议层…...

使用 pytest-xdist 进行高效并行自化测试
pytest-xdist 是 pytest 的一个扩展插件,主要用于实现测试用例的并行执行和分布式测试。通过利用多进程或者多机分布式的方式,pytest-xdist 能够显著缩短测试执行时间,提升持续集成(CI)流程的效率。 在自动化测试中&a…...

谈谈策略模式,策略模式的适用场景是什么?
一、什么是策略模式? 策略模式(Strategy Pattern)属于行为型设计模式。核心思路是将一组可替换的算法封装在独立的类中,使它们可以在运行时动态切换,同时使客户端代码与具体算法解耦。它包含三个…...

网络安全防御核心原则与实践指南
一、四大核心防御原则 A. 纵深防御原则(Defense in Depth) 定义:通过在多个层次(如网络、系统、应用、数据)设置互补的安全措施,形成多层次防护体系。 目的:防止单一漏洞导致整体安全失效&…...

动态规划2——斐波那契数列模型——三步问题
1.题目 三步问题。有个小孩正在上楼梯,楼梯有 n 阶台阶,小孩一次可以上 1 阶、2 阶或 3 阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模 1000000007。 示例 1: 输入:n 3 …...
)
周末总结(2024/04/05)
工作 人际关系核心实践: 要学会随时回应别人的善意,执行时间控制在5分钟以内 坚持每天早会打招呼 遇到接不住的话题时拉低自己,抬高别人(无阴阳气息) 朋友圈点赞控制在5min以内,职场社交不要放在5min以外 职场的人际关系在面对利…...

常见的图像生成算法
综合技术原理、优化方向和应用场景,结合经典模型与前沿进展进行分述: 一、经典生成模型 1. 生成对抗网络(GAN) 原理:由生成器(Generator)和判别器(Discriminator)通过…...
系统调用与函数地址动态寻找)
PE结构(十五)系统调用与函数地址动态寻找
双机调试 当需要分析一个程序时,这个程序一定是可以调试的,操作系统也不例外。在调试过程中下断点是很重要的 当我们对一个应用程序下断点时,应用程序是挂起的。但当我们对操作系统的内核程序下断点时,被挂起的不是内核程序而是…...

verilog状态机思想编程流水灯
目录 一、状态机1. 状态机基本概念2. 状态机类型3. Verilog 状态机设计要点 二、状态机实现一个1s流水灯三、DE2-115实物演示 一、状态机 1. 状态机基本概念 状态机(Finite State Machine, FSM)是数字电路设计中用于描述系统状态转换的核心组件&#x…...

Java实现N皇后问题的双路径探索:递归回溯与迭代回溯算法详解
N皇后问题要求在NN的棋盘上放置N个皇后,使得她们无法互相攻击。本文提供递归和循环迭代两种解法,并通过图示解释核心逻辑。 一、算法核心思想 使用回溯法逐行放置皇后,通过冲突检测保证每行、每列、对角线上只有一个皇后。发现无效路径时回退…...
断言基本概念和背景)
#SVA语法滴水穿石# (000)断言基本概念和背景
一、前言 随着数字电路规模越来越大、设计越来越复杂,使得对设计的功能验证越来越重要。首先,我们要明白为什么要对设计进行验证?验证有什么作用?例如,在用FPGA进行设计时,我们并不能确保设计出来的东西没有功能上的漏洞,因此在设计后我们都会对其进行验证仿真。换句话说…...

【Android Studio 下载 Gradle 失败】
路虽远行则将至,事虽难做则必成 一、事故现场 下载Gradle下载不下来,没有Gradle就无法把项目编译为Android应用。 二、问题分析 观察发现下载时长三分钟,进度条半天没动,说明这个是国外的东西,被墙住了,需…...

贪心算法之Huffman编码
1. 算法推理 Huffman 编码的目标是为给定字符构造一种前缀码,使得整体编码长度最短。基本思想是: 贪心选择:每次选择频率最小的两个节点合并。合并后的节点的权值为两个子节点权值之和,代表这部分子树出现的总频率。 局部最优导…...

Flask学习笔记 - 表单
表单处理 基本表单处理:使用 request.form 获取表单数据。使用 Flask-WTF:结合 WTForms 进行表单处理和验证,简化表单操作。表单验证:使用验证器确保表单数据的有效性。文件上传:处理文件上传和保存文件。CSRF 保护&a…...
)
指针的补充(用于学习笔记的记录)
1.指针基础知识 1.1 指针变量的定义和使用 指针也是一种数据类型,指针变量也是一种变量 指针变量指向谁,就把谁的地址赋值给指针变量 #include<stdio.h>int main() {int a 0;char b 100;printf("%p,%p \n", &a,&b); // …...