【Flink】Flink 作业执行大致流程
Flink 作业执行流程 (Application 模式)
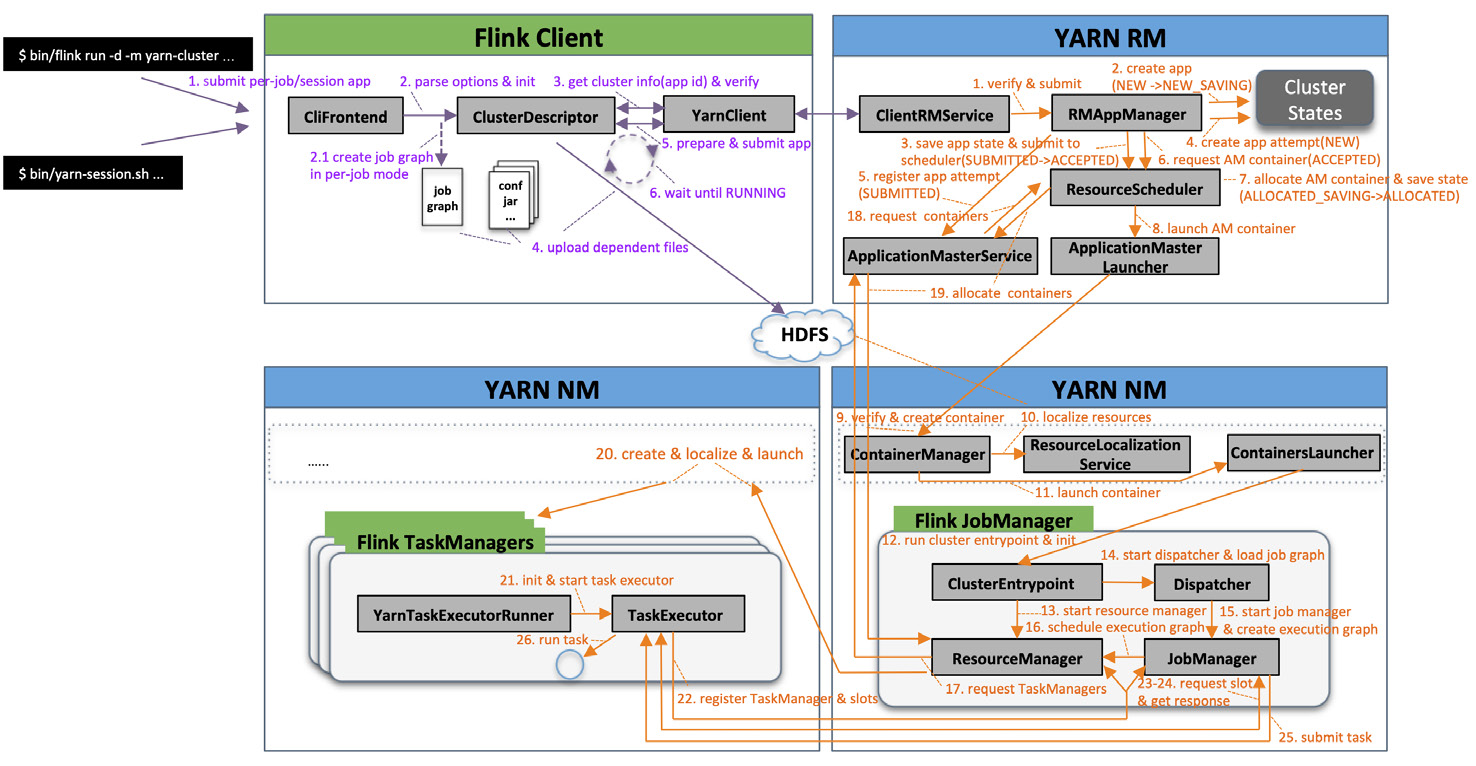
客户端通过 ClusterDescriptor 提交 Application 模式 Sql 任务到服务端,服务端调用作业时 StreamTableEnvironment 使用 FlinkSqlParser 将 SQL 转换为 Operation , StreamTableEnvironment 转换 SQL 过程中使用 CatalogSourceTable 调用 FactoryUtil 的 createDynamicTableSource 方法创建 DynamicTableSource,StreamTableEnvironment 解析完 Sql 后就开始执行 Operation。
StreamTableEnvironment 执行 Operation 过程中, Opeartion 会先被转化为 Transformation,转换过程中也会创建 DynamicTableSink,然后 StreamExecutionEnvironment 会创建并使用 StreamGraphGenerator 通过 Transformation 创建 StreamGraph,然后通过 StreamingJobGraphGenerator 再将 StreamGraph 转换为 JobGraph, 再调用 StreamExecutionEnvironment 执行 JobGraph,也就是将作业提交到 JobManager 上。
StreamTableEnvironment 执行 Operation 过程中,会调用 ExecNodeBase (CommonExecTableSourceScan 和 CommonExecSink) 将 Operation 转换为 Transformation,ExecNodeBase 会从 DynamicTableSource/Sink 中获取 ScanTableSource.ScanRuntimeProvider / Sink / Function / OutputFormat / InputFormat 等数据处理实现类用于创建 Transformation,Transformation 可以理解为对数据流进行处理和转换的操作。
Operation 转换成 Transformation 转换后, StreamTableEnvironment 将通过 Transformation 创建 StreamGraph。
StreamGraph 是一副以 StreamNode 为顶点,StreamEdge 为边连接起来的流图。StreamTableEnvironment 创建 StreamGraph 时会通过 StreamGraphGenerator 使用 Transformation 对应的 TransformationTranslator 将 Transformation 转换成相应的 Operator,然后再使用 Operator 创建 StreamNode 和 StreamEdge。例如在创建过程中 StreamGraphGenerator 会根据 SourceTransformation 创建 SourceOperatorFactory,SourceOperatorFactory 用于创建 SourceOperator 和 SourceCoordinator。StreamNode 代表作业的单个操作,每个操作中包含相关的算子、输入输出类型、资源等配置。可以简单理解为创建 StreamGraph 就是创建算子,以及将所有算子连接起来的操作。
StreamGraph 创建完后,StreamTableEnvironment 还需要将 StreamGraph 转换为 JobGraph。JobGraph 是一副以 JobVertex 为顶点,JobEdge 为边连接起来的作业图, 表示了一个 Flink 作业的逻辑结构,其中包括了任务之间的依赖关系、数据流图、操作符和配置信息等,它定义了整个作业的结构和逻辑,但还没有包括与具体执行相关的信息。JobVertex 表示 Flink 作业中的一个逻辑操作单元,用于描述逻辑任务及其依赖关系,每个 JobVertex 包含一个或多个算子操作。
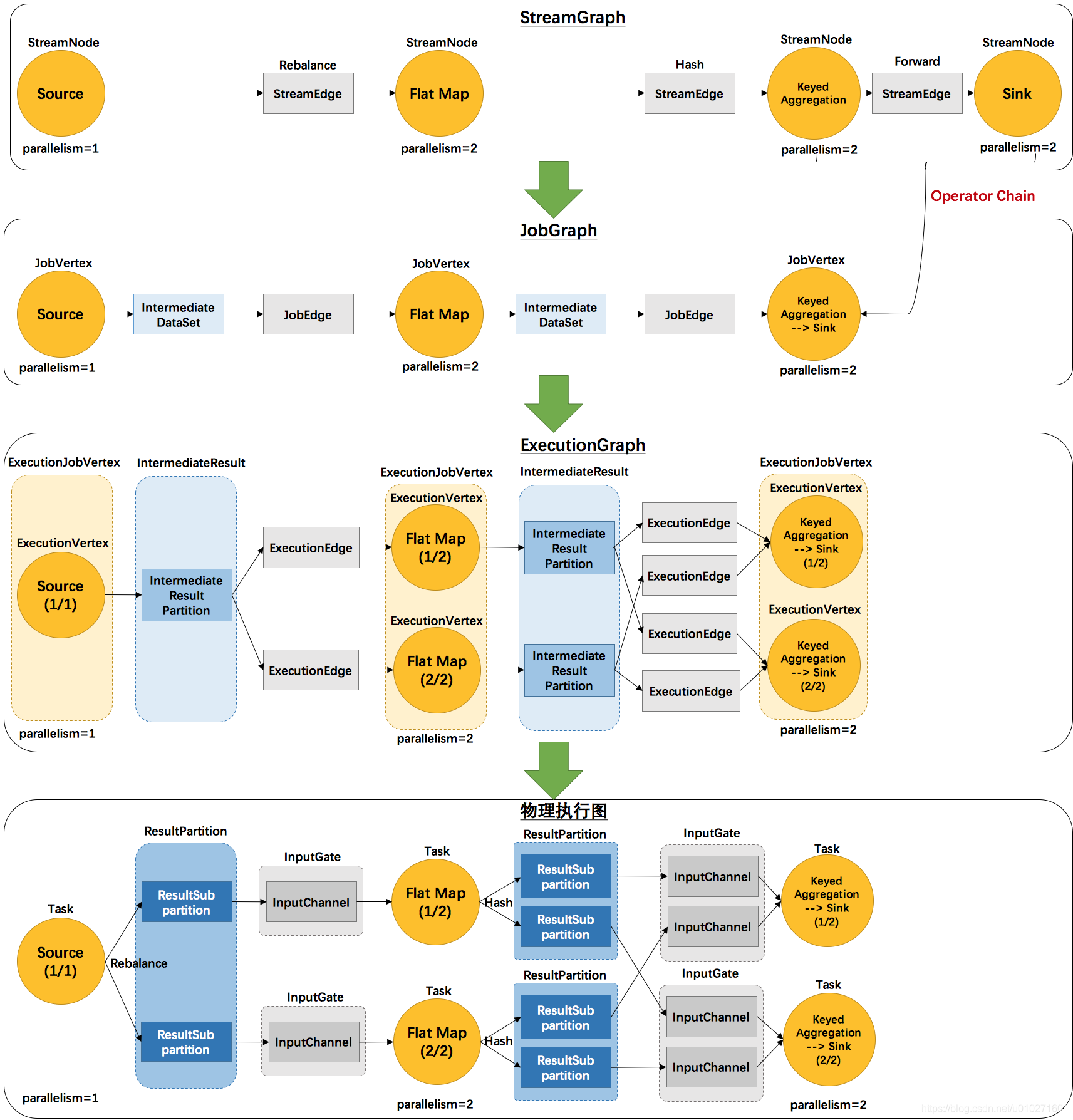
从 StreamGraph 转换到 JobGraph 需要进行 OperatorChain 操作,Chain 的过程就是将相连且只有单个输入源的 StreamNode 合并在一起,组成一个 JobVertex,JobVertex 根据连接的 StreamNode 源端创建。多个输入源的 StreamNode 会作为一个单独的 Vertex 创建成 JobVertex,同理,后面与其相连的单输入源的 StreamNode 会合并到该 JobVertex 里面。JobVertex 创建完后,每个 JobVertex 会通过 JobEdge 连接到一起。简单理解就是如果两个算子的数据是直接Forward,在同一个slot组并且并行度一致,那就可以合并。反过来,如果两个Operator之间有shuffle (比如keyBy)、rebalance (比如并行度不一样) 之类的操作,或者一个Operator有多个上游 (就是有多个operator), 那就不能合并。Chain 的过程中还会调用 OperatorFactory 创建相应的 OperatorCoordinator.Provider 并传递到 JobVertex 中。
JobGraph 创建完后,将提交 JobGraph 到 JobManager 上, 在 Application 模式中,这时需要高可用启动作业管理器 JobManager。JobManager 包含三大组件,资源管理器 (ResourceManager) 、调度器 (Dispatcher) 和相应作业对应的单个作业控制器(JobMaster)。
ResourceManager 将不断与 JobManager 保持通信,并处理 JobManager 的资源请求和分配处理 TaskManager。Dispatcher 负责分发向 JobManager 发送的各种请求、处理作业的提交、管理集群资源,以及协调其他组件的运行。JobMaster 在运行作业时拉起,与其他组件协作通信,负责相应的单个作业的调度、管理和容错。
JobManager 启动完成并接收到 JobGraph 后, 开始通过 JobGraph 创建 JobMaster 然后调度作业,JobMaster 创建过程中会创建重要的作业调度器 SchedulerNG,作业调度器包含作业调度需要的所有信息和策略,它在创建时会通过 JobGraph 创建和恢复作业执行图 ExecutionGraph。
作业执行图 ExecutionGraph 表示了作业的具体执行信息,它包括了具体的任务、任务之间的数据交换通道、部署信息以及与作业的执行相关的所有信息。ExecutionGraph 内部包含 ExecutionJobVertex,如果 ExecutionGraph 表示 JobGraph 执行时的信息,那么 ExecutionJobVertex 就表示 JobGraph 中 JobVertex 的执行节点,不过 ExecutionJobVertex 是并行数量个 JobVertex,它也代表着相关子任务的执行信息,相关的Coordinator 也会在 ExecutionJobVertex 创建时被创建 。
ExecutionGraph 的创建也代表作业需要执行,这时也会创建单次子任务的执行 Execution 以及对应的 ExecutionVertex ,Execution 表示子任务的执行操作,ExecutionVertex 表示子任务的执行信息,每一次任务的执行和重试都需要使用它们。如果开启了Checkpoint,ExecutionGraph 还需要创建状态相关组件以及初始化状态数据信息。
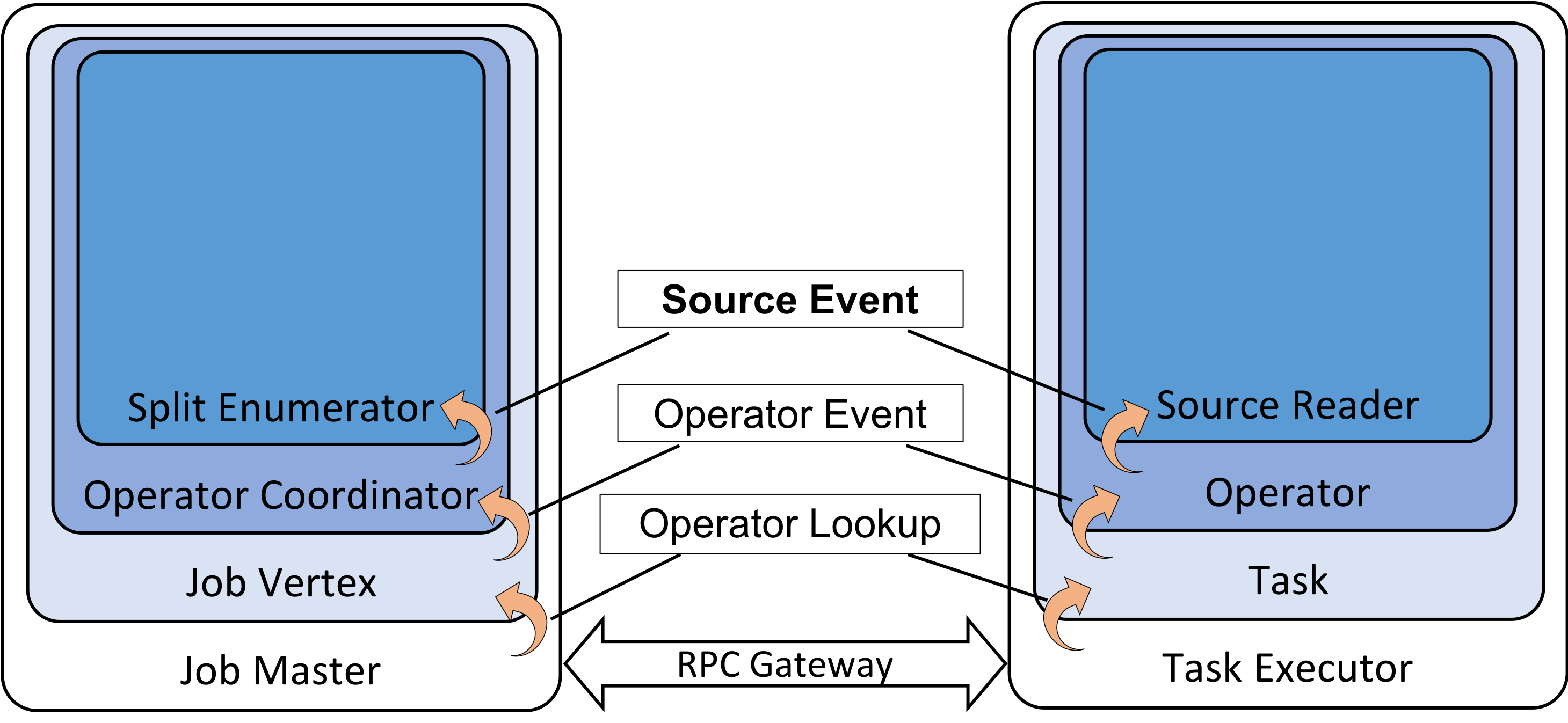
JobManager 调用 SchedulerNG 开始部署任务。作业的部署主要是需要部署所有的子任务,也就是 ExeuctionGraph 中所有的 Execution。不过在部署前,还会先会启动算子的 Coordinator,例如在 Source 端,SourceCoordinator 启动时会调用 Source 的 createEnumerator 方法创建并启动 SplitEnumerator,SplitEnumerator 启动一般用于监听 Split 的改变 ( Kafka Connector 中是使用 Topic Partition 表示 Split 的) 。
SchedulerNG 计算任务需要的资源也就是 Slot 数量,并向 ResourceManager 发送资源请求,ResourceManager 收到资源请求后,如果资源请求合理,则根据需要的 Slot 数量启动 TaskManager (TaskExecutor),TaskManager 启动完后,则将 TaskManager 资源信息发送给 SchedulerNG。
SchedulerNG 接收到资源信息后,调用所有子任务的执行 Execution 将任务部署到 TaskManager 相应的 Slot 上面,Execution 通过ExecutionVertex 获取任务部署描述符 TaskDeploymentDescriptor,然后将任务部署描述符发送给 TaskManager 部署任务。
TaskExecutor 接收到任务信息后创建 Task 启动任务,Task 使用 TaskDeploymentDescriptor 初始化配置并从 Blob 上下载相关的 Jar 包并创建相关的 ClassLoader,然后通过 ClassLoader 和 Configuration 反序列化创建运行时主任务 StreamTask,StreamTask 在创建时会创建 MailboxProcessor、SubtaskCheckpointCoordinator 等重要的组件,StreamTask 创建完后 Task 开始恢复 StreamTask。
StreamTask 的恢复会先创建算子链,算子链创建过程中会先主算子,以及其配置,然后从主算子配置中获取所有相关算子的配置 StreamConfig,再通过 StreamConfig 反序列创建之前 Vertex 中的所有算子工厂,并通过算子工厂创建算子,最后将算子连接起来成为算子链。算子创建过程中还会创建算子数据的输出端 StreamTaskInput 、 输入端 DataOutput 以及输入端处理器 StreamInputProcessor,StreamOneInputProcessor 将 StreamTaskInput 和 DataOutput 连接起来,用于将输入端的数据传输到输出端,是算子之间数据传输的桥梁。
算子链创建完后会先初始化主算子,如果主算子是 SourceOperator 算子,那么算子在初始化时会通过 Source 创建 SourceReader,并通知 SourceCoordinator 注册 SourceReader,然后启动 SourceReader。
**主算子初始化完后,开始恢复所有算子和网关的状态和打开所有算子。**这个过程 TaskManager 将通知 JobMaster 任务已经达到运行状态,JobMaster 开始定期执行 Checkpoint 任务,任务的 ResultPartitionWriter 和 InputGate 将读取任务状态管理器中 Channel 状态 ,InputGate 将会请求相关的子分区,算子将读取恢复 keyed 状态和算子状态, MailboxProcessor 这时也会启动直到状态恢复。
SourceOperator 打开时将会恢复相关的 Reader Split 并添加到 Reader 中,然后异步给 SourceCoordinator 发送 ReaderRegistrationEvent 事件,用于给子任务注册 SourceReader,随后开始启动 SourceReader (SourceReader#start)。
SourceCoordinator 接收到 ReaderRegistrationEvent 事件后, 调用 SplitEnumerator 给子任务添加 Reader,一般来说,SplitEnumerator 会在启动的时候获取 Split 并缓存,或者添加 Reader 时获取 Split, 然后通过 Split 创建 AddSplitEvent 事件,并给 SourceOperator 发送该事件。
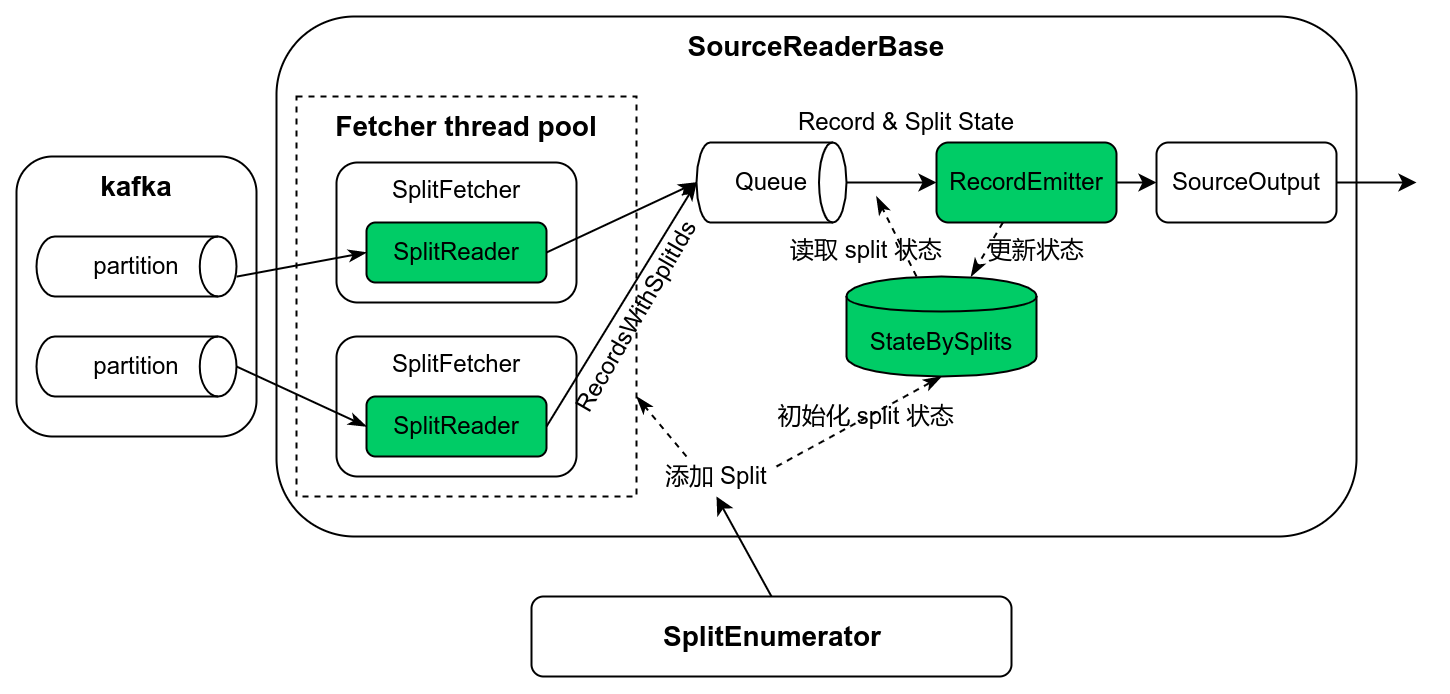
SourceOperator 接受到 AddSplitEvent 后,SourceOperator 需要先使用 Source 通过 getSplitSerializer 创建的 SimpleVersionedSerializer,然后根据 splitId 创建 SourceOutput,随后将 Splits 添加到 Reader 中,最后如果是 SourceReaderBase,则 会调用 SplitFetcherManager 添加 Splits。
SplitFetcherManager 添加 Splits 时,将会创建 SplitReader,然后调用 SplitReader 创建 SplitFetcher,SplitFetch 调用 SplitFetcher 添加 Splits,然后启动 SplitFetcher,用于获取分片数据。
SplitFetcher 创建时也会创建一个"主任务" (FetchTask,用于获取数据) ,而且 SplitFetcher 内部会维护一个任务队列。SplitFetcherManager 给 SplitFetcher 添加 Splits 时,将会创建一个 AddSplitsTask 任务添加到 SplitFetcher 内部的任务队列中。
SplitFetcher 是一个单独的线程,启动后它循环执行内部任务队列中的任务,它将会首先执行队列中已经存在的任务,像前面 SplitFetcherManager 添加的 AddSplitsTask,如果队列中没有任务了,则会执行主任务 FetchTask 去获取数据。
SplitFetcher 的 FetchTask 任务被执行时,会调用 SplitReader 的 fetch 方法真正从 Source 中获取数据,获取后的数据将会与相应的数据 Splits 一起封装成 RecordsWithSplitIds,RecordsWithSplitIds 将会放入 SplitFetcherManager 维护的元素队列中。
SourceTask 恢复完后,开始启动 (SourceTask#invoke),也就是开始运行 MailboxProcessor,MailboxProcessor 会不断同步处理发送过来的 Mail,如果没有需要处理的 Mail, 那么会执行默认动作 (处理输入端数据) (StreamTask#processInput)。
处理输入端动作将会调用 StreamOneInputProcessor 让 StreamTaskInput 将数据发送给 DataOutput (PushingAsyncDataInput#emitNext)。
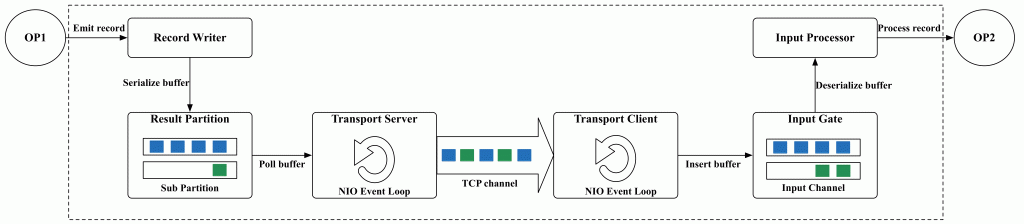
StreamTaskInput 调用内部的 SourceOperator 给 DataOutput 发送已收集的数据, SourceOperator 调用 SourceReader 轮询下一条可用记录到 DataOutput ,SourceReader 不断从 RecordsWithSplitIds 的所有 Split 中获取数据,并调用 RecordEmitter 将数据发送给DataOutput, 然后 DataOutput 将数据发送给下游算子 (SinkOperator#processElement 等),如果我们在 DAG 构建中使用 Partition (将数据分区)相关的操作,比如 DataStream 的 keyBy 或 rescale、SQL 中的 Group By,Flink 会引入一轮 Shuffle。
最后下游算子开始处理数据,这里使用 SinkWriterOperator 来说明,最后 SinkWriterOperator 在 processElement 方法中将调用我们自定义的 SinkWriter 来处理数据。
如果 RecordsWithSplitIds 中分片 Split 的所有数据都处理完成了,那么任务也会自己结束运行。
MailboxProcessor 中途可能会接受到 Checkpoint Mail,那么相关的算子也需要完成 Checkpoint 相关操作。
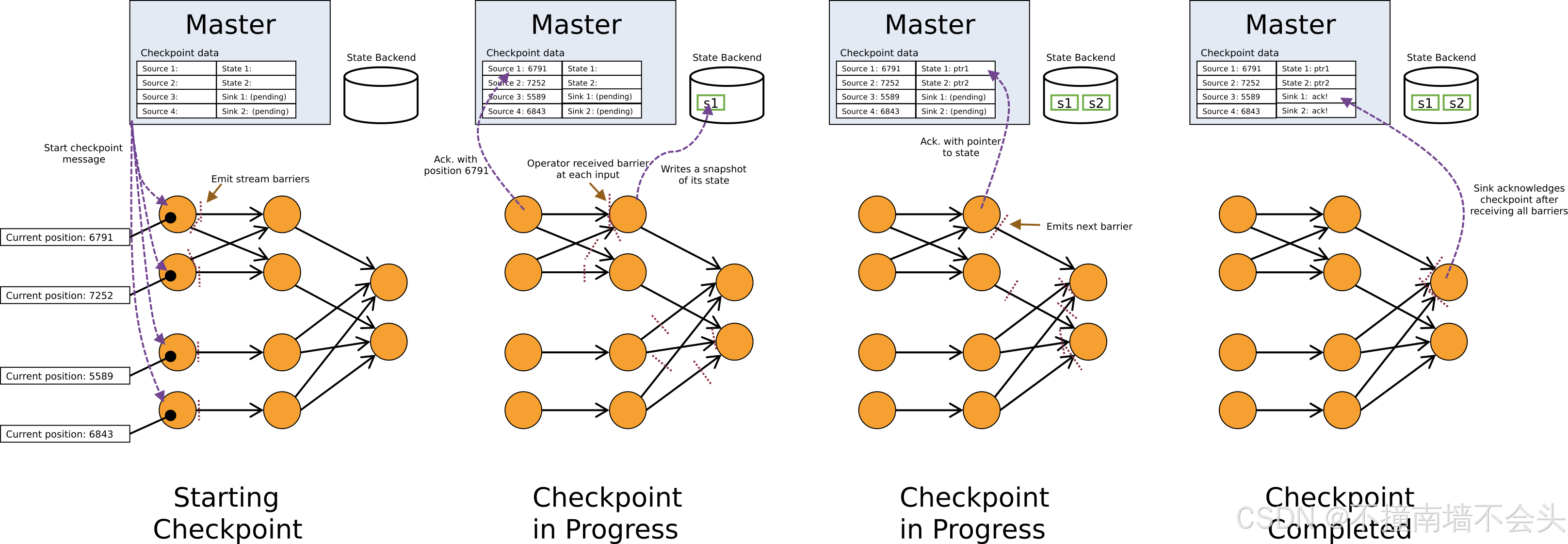
任务运行后 JobMaster 定时执行 Checkpoint,JobMaster 会通过调用 CheckpointCoordinator 对作业进行 Checkpoint。
CheckpointCoordinator 开始进行 Checkpoint,它首先会先创建 PendingCheckpoint,然后开始给 Checkpoint 计时,再关闭网关开始触发 OperatorCoordinator 的 Checkpoint。
如果是 SourceOperatorCoordinator,则这时会调用 Source 的 getSplitSerializer,获取分片序列化器,然后将 SplitAssignmentTracker 中任务运行时分配的分片序列化创建 Snapshot,再将 Snapshot 放入 PendingCheckpoint 中。
OperatorCoordinator 状态触发完后,开始触发 MasterHooks 状态快照,MasterTriggerRestoreHook 由 UDFStreamOperator 内部的实现 WithMasterCheckpointHook 接口的 Function 创建,用于在 Master 触发 Checkpoint 时,Function 需要进行的操作。
MasterHooks 调用完后,CheckpointCoordinator 将给子任务 TaskManager 发送请求,通知它们开始 Checkpoint。
TaskExecutor 获取相应的任务 Task,Task 调用 StreamTask 开始进行 Checkpoint,StreamTask 调用 Mailbox 执行 Checkpoint 事件,Mailbox 执行 Checkpoint 事件时, Source 将不会从数据源读取数据。
Checkpoint 事件开始执行,如果 Checkpoint 需要强制对齐,那么需要异步创建 Channel 和结果分区的数据快照, 随后在执行传播 Barrier 前,SubtaskCheckpointCoordinatorImpl 会调用 OperatorChain 让 Operator 进行 Barrier 前的准备操作,然后开始往下游传播 Barrier。
SubtaskCheckpointCoordinatorImpl 创建 CheckpointBarrier 并将 CheckpointBarrier 发送给 RecordWriterOutput 将 Barrier 传输给下游任务,然后注册 Barrier 对齐超时计时器。
Barrier 传播完后,如果 Checkpoint 需要 Channel 状态 ,那么还需要异步创建 Channel 和 结果分区的数据快照。
最后 SubtaskCheckpointCoordinatorImpl 开始对当前子任务的所有算子进行 Checkpoint,算子将会把状态存储到 OperatorStateBackend 和 KeyedStateBackend,然后 OperatorStateBackend 和 KeyedStateBackend 的状态快照,不过 Operator 的状态一般会存储在 StateSnapshotContext 中。
总的来说,Checkpoint 将创建托管键值状态、托管算子状态、未处理的键值状态、未处理的算子状态、输入通道状态和结果分区状态的快照。
下游任务这时是正常处理上游发送过来的数据的,但是上游正在进行 Checkpoint,数据也是被发送过来的 CheckpointBarrier 分割开了,处理到后面会接收到上游的 CheckpointBarrier,也就表示着当前 Checkpoint 上游快照数据已经处理完,下游也开始进行 Checkpoint 了,下游进行 Checkpoint 的过程也是和上面的一样,继续调用 SubtaskCheckpointCoordinatorImpl 开始进行 Checkpoint。
相关文章:

【Flink】Flink 作业执行大致流程
Flink 作业执行流程 (Application 模式) 客户端通过 ClusterDescriptor 提交 Application 模式 Sql 任务到服务端,服务端调用作业时 StreamTableEnvironment 使用 FlinkSqlParser 将 SQL 转换为 Operation , StreamTableEnvironment 转换 SQL 过程中使用 CatalogSou…...
)
mdf文件数据处理之画图(subplots多信号展示同一张图中)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
)
python基础知识(一)
文章目录 基础语法注释多行语句数字(Number)类型字符串(String)字符串常用方法字符串格式化 import与from...import 基本数据类型多个变量赋值标准数据类型 运算符算术运算符赋值运算符逻辑运算符成员运算符身份运算符 基础语法 注释 python注释可以使用#,或者三个…...

解决 Flutter Dio合并请求多个接口,如果一个接口500,那么导致其他请求不在执行
Flutter Dio如何自定义拦截异常 应用场景 我们一般会统一拦截DioExceptionType 如400,403,500 等错误 但有时候,有个地方合并请求多个接口,如果一个接口500,那么导致其他请求不在执行,因为统一拦截了500&…...

RPC一分钟
概述 微服务治理:Springcloud、Dubbo服务通信:Grpc、Trift Dubbo 参考 Dubbo核心功能,主要提供了:远程方法调用、智能容错和负载均衡、提供服务自动注册、自动发现等高效服务治理功能。 Dubbo协议Dubbo支持dubbo、rmi、http、…...

CentOS 7 docker部署jar包
1、创建Dockerfile vim Dockerfile2、编辑内容 # 基础镜像 FROM openjdk:8 # 作者或联系方式 MAINTAINER wq # test为别名 ADD erp-1.0.jar /test.jar # 容器暴露端口 EXPOSE 8081 ENTRYPOINT ["java","-jar","test.jar"]3、生成镜像 docker …...

高性能mysql 1
高性能mysql 1 参考: 博客 https://segmentfault.com/a/1190000040374142书籍📚’High performance mysql’ I note some hard part ,translating it into Chinese for a better comprehensionsometimes when I have some trouble with reading En…...

QT发布ArcGIS QML项目时遇到的问题
在打包 ArcGIS Runtime SDK for Qt 项目时,如果项目中没有正确显示地图或者图层,且在项目的 DLL 依赖中没有找到与 ArcGIS SDK 相关的依赖,可能是由于以下几种原因导致的: 1. 未正确配置 ArcGIS SDK 的依赖 ArcGIS Runtime SDK …...

高校数字化运营平台解决方案:构建统一的服务大厅、业务平台、办公平台,助力打造智慧校园
教育数字化是建设教育强国的重要基础,利用技术和数据助推高校管理转型,从而更好地支撑教学业务开展。 近年来,国家多次发布政策,驱动教育行业的数字化转型。《“十四五”国家信息化规划》,推进信息技术、智能技术与教育…...

cocotb value cocotb—基础语法对照篇
cocotb—基础语法对照篇 import cocotb from cocotb.triggers import Timer from adder_model import adder_model from cocotb.clock import Clock from cocotb.triggers import RisingEdge import randomcocotb.test() async def adder_basic_test(dut):"""Te…...

LLM与动态符号执行生成测试用例的比较
LLM与动态符号执行生成测试用例的比较 在软件测试领域,生成有效的测试用例是确保软件质量和可靠性的关键步骤。近年来,大型语言模型(Large Language Models,LLM)和动态符号执行(Dynamic Symbolic Executio…...

torchvison.models中包含的哪些模型?
1.模型 Alexnet AlexNet 是一个具有 8 层的深度卷积神经网络,结构上比早期的卷积神经网络(如 LeNet)要深得多。它由 5 个卷积层(conv layers)和 3 个全连接层(fully connected layers)组成。Al…...

安装v2x,使用docker安装deepstream,安装v2x步骤,并使用tritonServer进行推理步骤,以及避坑问题
1,安装步骤 大致分为下面的安装过程: a 安装docker,b 本地安装环境,c 拉取docker镜像,d,本地下载数据 e,移动数据到docker下目录,f,docker下解压数据,g,docker下engine化数据,h,docker下编译v2x并运行离线数据,r,rtsp数据流替换并运行 To install these packages…...

2022 年 6 月青少年软编等考 C 语言三级真题解析
目录 T1. 制作蛋糕思路分析T2. 找和最接近但不超过K的两个元素思路分析T3. 数根思路分析T4. 迷信的病人思路分析T5. 算 24思路分析T1. 制作蛋糕 小 A 擅长制作香蕉蛋糕和巧克力蛋糕。制作一个香蕉蛋糕需要 2 2 2 个单位的香蕉, 250 250 250 个单位的面粉, 75 75 75 个单位的…...

java opcua server服务端开发 设置用户密码访问
前言 关于使用milo开源库,开发opc ua服务器,之前的教程中,都是使用的匿名访问,有网友咨询如何设置服务端使用用户密码访问,于是我完善了这部分的空缺整理整了这篇教程,希望能解决有同样需求,但是遇到困难的网友!因为milo没有官方文档的教程且网上详细的教程很少,本人…...
的基本用法)
SQLite:DDL(数据定义语言)的基本用法
SQLite:DDL(数据定义语言)的基本用法 1 主要内容说明2 相关内容说明2.1 创建表格(create table)2.1.1 SQLite常见的数据类型2.1.1.1 integer(整型)2.1.1.2 text(文本型)2…...

Spring-Smart-DI !动态切换实现类框架
背景 一般我们系统同一个功能可能会对接多个服务商,防止某个服务商的服务不可用快速切换或者收费不同需要切换,那我们一般做快速切换逻辑传统无非就是先将每个服务商实现,然后在配置点(数据库或者nacos)配置当前正在使…...

【SCT71401】3V-40V Vin, 150mA, 2.5uA IQ,低压稳压器,替代SGM2203
SCT71401 3V-40V Vin, 150mA, 2.5uA IQ,低压稳压器,替代SGM2203 描述 SCT71401系列产品是一款低压差线性稳压器,设计用于3 V至40 V (45V瞬态输入电压)的宽输入电压范围和150mA输出电流。SCT71401系列产品使用3.3uF…...

浅谈网络 | 应用层之流媒体与P2P协议
目录 流媒体名词系列视频的本质视频压缩编码过程如何在直播中看到帅哥美女?RTMP 协议 P2PP2P 文件下载种子文件 (.torrent)去中心化网络(DHT)哈希值与 DHT 网络DHT 网络是如何查找 流媒体 直播系统组成与协议 近几年直播比较火,…...
:构建FNN神经网络实战教程 - 用户喜好预测)
Brain.js(六):构建FNN神经网络实战教程 - 用户喜好预测
在前文不同的神经网络类型和对比 针对不同的神经网络类型做了对比,本章将对FNN稍作展开 测试环境: chrome 版本 131.0.6778.86(正式版本) (64 位) 一、引言 Brain.js 是一个简单易用的 JavaScript 神经网…...

重学设计模式-建造者模式
本文介绍一下建造者模式,相对于工厂模式来说,建造者模式更为简单,且用的更少 定义 建造者模式是一种创建型设计模式,它使用多个简单的对象一步一步构建成一个复杂的对象。这种模式的主要目的是将一个复杂对象的构建过程与其表示…...

linux下c++调用opencv3.4.16实战技巧
目录 参考:在图像上绘框在图像上绘圆在图像上绘文字在图像上绘制线灰度图rgb转yuvOpenCV 读取视频,设置起始帧、结束帧及帧率获取(1.1)简介(1.2)Mat类型(1.3)IplImage类型将OpenCV抓拍的图片进行x264编码并保存到文件c++调用opencv,读取rtsp视频流参考: https://blog…...

记录css模糊程度的属性
记录需要模糊以及透明化图片需求: opacity: (0到1之间数字,dom透明程度)。 filter: blur() 括号里需数字,单位为px,值越大模糊程度越大。 关于css中filter属性记录 filter 滤镜属性: blur&…...

K8S的监控与告警配置有哪些最佳实践
在 Kubernetes (K8s) 集群中实现有效的监控与告警是确保集群稳定性、性能以及及时响应潜在问题的关键。以下是 K8s 监控与告警配置的最佳实践,涵盖了监控工具的选择、告警规则的配置、数据存储与可视化等方面。 1. 选择合适的监控工具 Kubernetes 生态系统有多种监…...

如何在Ubuntu 20.04上安装和使用PostgreSQL:一步步指南
如何在Ubuntu 20.04上安装和使用PostgreSQL:一步步指南 在Ubuntu 20.04上安装和使用PostgreSQL数据库包括几个明确的步骤:安装、配置、创建用户和数据库、以及基本的数据库操作。下面,我将详细解释每个步骤,并提供具体的命令行示…...

PostGis学习笔记
– 文本方式查看几何数据 SELECT ST_AsText(geom)FROM nyc_streets WHERE name ‘Avenue O’; – 计算紧邻的街区 SELECT name,ST_GeometryType(geom) FROM nyc_streets WHERE ST_DWithin( geom,ST_GeomFromText(‘LINESTRING(586782 4504202,586864 4504216)’,26918),0.1); …...

JDK17 线程池 ThreadPoolExecutor
文章目录 线程池ThreadPoolExecutor状态向线程池添加任务 executeWorker线程池新建工作线程 addWorker 拒绝策略 线程池 线程池将创建线程和使用线程解耦。优点是 避免重复创建和销毁线程,降低资源消耗。任务不用等待创建线程的时间,提高响应速度。统一…...

Dify+Docker
1. 获取代码 直接下载 (1)访问 langgenius/dify: Dify is an open-source LLM app development platform. Difys intuitive interface combines AI workflow, RAG pipeline, agent capabilities, model management, observability features and more, …...

分布式会话 详解
分布式会话详解 在分布式系统中,用户的会话状态需要在多个服务器或节点之间共享或存储。分布式会话指的是在这种场景下如何管理和存储会话,以便在多个节点上都能正确识别用户状态,从而保证用户体验的一致性。 1. 为什么需要分布式会话 在单…...

Java进阶
Java进阶 java注解 java中注解(Annotation),又称为java标注,是一种特殊的注释,可以添加在包,类,成员变量,方法,参数等内容上面.注解会随同代码编译到字节码文件中,在运行时,可以通过反射机制获取到类中的注解,然后根据不同的注解进行相应的解析. 内置注解 Java 语言中已经定…...

Qt/C++实现帧同步播放器/硬解码GPU绘制/超低资源占用/支持8K16K/支持win/linux/mac/嵌入式/国产OS等
一、前言 首先泼一盆冷水,在不同的电脑上实现完完全全的帧同步理论上是不可能的,市面上所有号称帧同步的播放器,同一台电脑不同拼接视频可以通过合并成一张图片来绘制实现完完全全的帧同步,不同电脑,受限于网络的延迟…...
)
hhdb数据库介绍(10-33)
管理 数据归档 归档记录查询 功能入口:“管理->数据归档->归档记录查询” 需要确保配置的归档用户对数据归档规则所在的逻辑库具备CREATE权限,以及对原数据表具有所有权限。 清理归档数据 (一)功能入口:“…...

UE4_材质节点_有关距离的_流体模拟
一、材质节点介绍: 特别注意:距离场需要独立显卡支持。 1、什么是距离场? 想象一下空间中只有两个实体, 一个球,一个圆柱. 空间由无数个点组成, 取其中任何一个点, 比如,它跟球面的最近距离是3, 跟圆柱面的最近距离是2, 那么这个点的值就…...
)
SpringBoot集成 SpringDoc (SpringFox 和 Swagger 的升级版)
阅读 SpringDoc 官网 - Migrating from SpringFox 只需要导入以下一个依赖即可: <dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>2.7.0</version>…...

分布式推理框架 xDit
1. xDiT 简介 xDiT 是一个为大规模多 GPU 集群上的 Diffusion Transformers(DiTs)设计的可扩展推理引擎。它提供了一套高效的并行方法和 GPU 内核加速技术,以满足实时推理需求。 1.1 DiT 和 LLM DiT(Diffusion Transformers&am…...

《Vue零基础入门教程》第十七课:侦听器
往期内容 《Vue零基础入门教程》第九课:插值语法细节 《Vue零基础入门教程》第十课:属性绑定指令 《Vue零基础入门教程》第十一课:事件绑定指令 《Vue零基础入门教程》第十二课:双向绑定指令 《Vue零基础入门教程》第十三课&…...

【人工智能-基础】SVM中的核函数到底是什么
文章目录 支持向量机(SVM)中的核函数详解1. 什么是核函数?核函数的作用:2. 核技巧:从低维到高维的映射3. 常见的核函数类型3.1 线性核函数3.2 多项式核函数3.3 高斯径向基函数(RBF核)4. 总结支持向量机(SVM)中的核函数详解 支持向量机(SVM,Support Vector Machine)…...

RoBERTa- 稳健优化的 BERT 预训练模型详解
一、引言 自 BERT(Bidirectional Encoder Representations from Transformers)问世,预训练语言模型在自然语言处理(NLP)领域掀起革命浪潮,凭卓越表现大幅刷新诸多任务成绩。RoBERTa 承继 BERT 架构&#x…...
Git上次超过100M单文件)
20.(开发工具篇github)Git上次超过100M单文件
1:安装lfs git lfs install 2: 撤销所有更改(包括未暂存的更改) git reset --hard 3:查找大于100M的文件 find ./ -size 100M 4:加入到 track git lfs track “./data/geo_tif_zzjg/2023年_种植结构影像.tif” git lfs track “./data/geo_tif_zz…...

Redis使用场景-缓存-缓存击穿
前言 之前在针对实习面试的博文中讲到Redis在实际开发中的生产问题,其中缓存穿透、击穿、雪崩在面试中问的最频繁,本文加了图解,希望帮助你更直观的了解缓存击穿😀 (放出之前写的针对实习面试的关于Redis生产问题的博…...

uniapp Electron打包生成桌面应用exe文件
1.uniapp Electron打包生成桌面应用exe文件 随着跨平台开发的需求日益增长,UniApp 成为了开发者们的首选之一。通过 UniApp,你可以使用 Vue.js 的语法结构和组件系统来构建原生应用、Web 应用甚至是桌面应用。本文将详细介绍如何使用 UniApp 将你的项目打包成 Windows 桌面端…...

【机器学习】Sigmoid函数在深层神经网络中存在梯度消失问题,如何设计一种改进的Sigmoid激活函数,既能保持其概率预测优势,又能避免梯度消失?
为了解决 Sigmoid 函数在深层神经网络中的梯度消失问题,可以设计一种改进的 Sigmoid 激活函数,使其同时具备以下特性: 减缓梯度消失问题:避免在输入值远离零时梯度趋于零的问题。保持概率预测能力:保留 Sigmoid 的单调…...
)
SpringBoot中实现EasyExcel实现动态表头导入(完整版)
前言 最近在写项目的时候有一个需求,就是实现动态表头的导入,那时候我自己也不知道动态表头导入是什么,查询了大量的网站和资料,终于了解了动态表头导入是什么。 一、准备工作 确保项目中引入了处理 Excel 文件的相关库ÿ…...

前端用到的一些框架
拖拽框架:Vue.Draggable Vue.Draggable是一款基于Sortable.js拖拽插件 官网:https://github.com/SortableJS/Vue.Draggable 分屏插件:fullPage.js fullPage.js 是一个基于 jQuery 的插件,它能够很方便、很轻松的制作出全屏网站…...

“量子跃迁与数据织网:深入探索K最近邻算法在高维空间中的优化路径、神经网络融合技术及未来机器学习生态系统的构建“
🎼个人主页:【Y小夜】 😎作者简介:一位双非学校的大二学生,编程爱好者, 专注于基础和实战分享,欢迎私信咨询! 🎆入门专栏:🎇【MySQL࿰…...

10个Word自动化办公脚本
在日常工作和学习中,我们常常需要处理Word文档(.docx)。 Python提供了强大的库,如python-docx,使我们能够轻松地进行文档创建、编辑和格式化等操作。本文将分享10个使用Python编写的Word自动化脚本,帮助新…...

【青牛科技】D35摄氏温度传感器芯片,低功耗,静态工作电流小于60 μA
概述: D35是基于模拟电路的一种基本摄氏温度传感器,其作用是将感测的环境温度/物体温度精确的以电压的形式输出,且输出电压与摄氏温度成线性正比关系,转换公式为Vo0 10 mV / ℃*T(℃),0C时输出为…...

无分类编址的IPv4地址
/20含义:前20比特位为网络号,后面32-2012为主机号 路由聚合:找共同前缀 所有可分配地址的主机都能接收广播地址,...

LeetCode - #150 逆波兰表达式求值
文章目录 前言1. 描述2. 示例3. 答案关于我们 前言 我们社区陆续会将顾毅(Netflix 增长黑客,《iOS 面试之道》作者,ACE 职业健身教练。)的 Swift 算法题题解整理为文字版以方便大家学习与阅读。 LeetCode 算法到目前我们已经更新…...

如何避免数据丢失:服务器恢复与预防策略
在当今数字时代,数据对于个人和企业来说都至关重要。数据丢失可能会导致严重的财务损失、业务中断甚至法律责任。因此,采取措施防止数据丢失至关重要。本文将讨论服务器数据丢失的常见原因以及如何防止数据丢失的有效策略。 服务器数据丢失的常见原因 服…...