OpenVLA-OFT——微调VLA的三大关键设计:支持动作分块的并行解码、连续动作表示以及L1回归目标
前言
25年3.26日,这是一个值得纪念的日子,这一天,我司「七月在线」的定位正式升级为了:具身智能的场景落地与定制开发商 ,后续则从定制开发 逐步过渡到 标准产品化
比如25年q2起,在定制开发之外,我司正式推出第一类具身产品(后续更多产品 详见七月官网):复现各个前沿具身模型的软硬全套的标准化产品,相当于已帮组装好的硬件,和对应复现好的程序,包括且不限于ALOHA/RDT/umi/dexcap/idp3/π0,如此软硬一体标准化的产品,省去复现过程中的
- 各种硬件组装问题
- 各种算法问题
- 各种工程问题
真正做到:一旦拿来,开箱即用
我司具身落地中,过去半年用π0居多,其次idp3和其他模型,也是目前国内具身落地经验最丰富的团队之一了
- 其中有不少工作便涉及到对具身模型的微调——恍如18-20年期间 大家各种微调语言模型
再之后随着GPT3、GPT3.5、GPT4这类语言模型底层能力的飞速提升,使得针对语言模型的微调呈逐年下降趋势 - 但在具身方向,未来一两年,微调具身模型都是主流方向之一
当然了,随着具身模型底层能力的越来越强、泛化性越来越好,也早晚会走到如今语言模型这般 微调偏少的地步
且始终保持对具身最前沿技术的沟通,这不,25年2月底,斯坦福的三位研究者
- Moo Jin Kim
OpenVLA的一作 - Chelsea Finn
ALOHA团队的指导老师,也是RT-2、π0的作者之一,是我过去一两年下来读的机器人论文中出现频率最高的一个人了 - Percy Liang
OpenVLA的作者之一
提出OpenVLA-OFT「paper地址《Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success》、项目地址、GitHub地址」,在他们的角度上,揭示微调VLA的三大关键设计:并行解码、动作分块、连续动作表示以及L1回归目标
第一部分 OpenVLA-OFT
1.1 OpenVLA-OFT的提出背景与相关工作
1.1.1 OpenVLA-OFT的提出背景
Kim等人[22]提出了OpenVLA通过LoRA进行参数高效的微调。然而,OpenVLA的自回归动作生成在高频控制(25-50+ Hz)中仍然过于缓慢(3-5 Hz),并且LoRA和自回归VLAs的全微调在双手操作任务中往往表现不佳[51,26,3]
OpenVLA结合了
- 一个融合的视觉主干(包括SigLIP [52]和DINOv2 [34]视觉变换器)
- 一个Llama-2 7B语言模型[49]
- 以及一个带有GELU激活[11]的三层MLP投影器,用于将视觉特征投影到语言嵌入空间中
流程上,OpenVLA处理单张第三人称图像和语言指令(例如,“将茄子放入锅中”)。融合的视觉编码器从每个ViT中提取256个patch嵌入,沿隐藏维度将它们拼接,并将其投影到语言嵌入空间。这些投影的特征与语言嵌入沿序列维度拼接,然后由Llama-2解码器处理,以输出一个7维的机器人动作,表示末端执行器姿态的增量,由一串离散动作标记表示
更多细节,详见此文《一文通透OpenVLA及其源码剖析——基于Prismatic VLM(SigLIP、DinoV2、Llama 2)及离散化动作预测》
尽管最近的方法通过更好的动作tokenization方案[2,36]提高了效率,实现了2到13倍的加速,但动作块之间的显著延迟(例如,最近的FAST方法[36]为750毫秒)仍然限制了在高频双手机器人上的实时部署
对此,三位作者使用OpenVLA(一种代表性的自回归VLA模型)作为基础模型,将VLA适配到新型机器人和任务中的关键设计决策。他们考察了三个关键设计选择并揭示了一些关键见解:
- 对于动作解码方案——自回归与并行生成
通过动作分块的并行解码不仅提高了推理效率,还改善了下游任务的成功率,同时增强了模型输入输出规范的灵活性 - 对于动作表示——离散与连续
与离散表示相比,连续动作表示进一步提高了模型质量 - 对于学习目标——下一个token预测、L1回归与扩散
使用L1回归目标对VLA进行微调时,在性能上与基于扩散的微调相当,同时提供了更快的训练收敛速度和推理速度
基于以上见解,他们引入了OpenVLA-OFT:一种优化微调(OFT)方案的具体实现,该方案结合了并行解码和动作分块、连续动作表示以及L1回归目标,以在保持算法简单性的同时提高推理效率、任务性能和模型输入输出灵活性
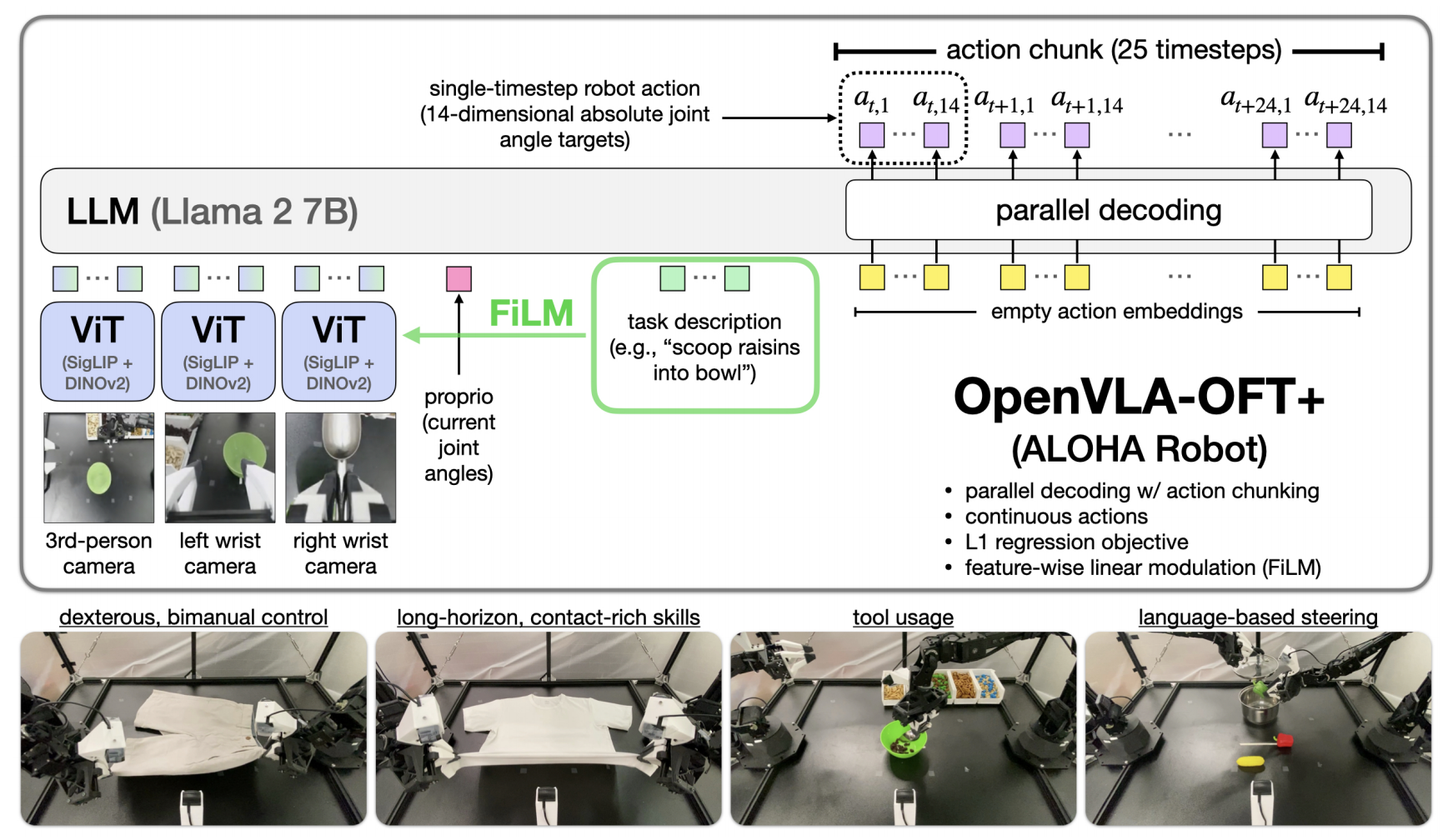
具体而言,相比OpenVLA,OpenVLA-OFT 引入了六个关键变化:
- 通过共享的 SigLIP-DINOv2 主干网络处理多个输入图像(例如第三人称图像加上腕部摄像机图像)
- 通过带有 GELU 激活的两层 MLP 将机器人本体状态投影到语言嵌入空间
- 将因果注意力替换为双向注意力以实现并行解码
- 用一个四层的多层感知机(ReLU激活)替代语言模型解码器的输出层,用于生成连续动作(而非离散动作)
- 输出K个动作的块,而不是单时间步的动作
- (适用于 OpenVLA-OFT+)添加了 FiLM [35] 模块,该模块使用任务语言嵌入的平均值来调制 SigLIP和 DINOv2 视觉变换器中的视觉特征(详见附录C)
最终,他们号称在标准化的LIBERO模拟基准测试和真实双手ALOHA机器人上的灵巧任务中进行了实验
- 在LIBERO中,OpenVLA-OFT通过在四个任务套件中达到97.1%的平均成功率,建立了新的技术标准,超越了微调的OpenVLA策略[22](76.5%)和π0策略[3](94.2%),同时在动作生成中实现了26倍的速度提升(使用8步动作分块)
- 对于真实的ALOHA任务[53],通过FiLM[35]增强了他们的方案以增强语言基础能力
1.1.2 相关工作
第一,以往的研究更关注什么呢?其主要关注模型开发
- 利用语言和视觉基础模型来增强机器人能力,将其用作预训练的视觉表示,从而加速机器人策略学习 [29-Vip,32-R3m,30-Liv,19-Language-driven representation learning for robotic,31]
在机器人任务中进行物体定位 [9,45]
以及用于高层次的规划和推理
[1-SayCan,17,42-Progprompt,16-Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,43-Llmplanner: Few-shot grounded planning for embodied agents with large language models,18-Voxposer,6-Manipulate-anything] - 最近,研究人员探索了微调视觉-语言模型(VLMs)以直接预测低级别机器人控制动作,生成“视觉-语言-动作”模型(VLAs)
[4-RT-2,33-Open x-embodiment,23-Vision-language foundation models as effective robot imitators,22-Openvla,7-An interactive agent foundation model,15-An embodied generalist agent in 3d world,8-Introducing rfm-1: Giving robots human-like reasoning capabilities,50-Lingo-2,55-3dvla,51-Tinyvla,3-π0,2-Minivla]
这些模型展示了对分布外测试条件和未见语义概念的有效泛化能力
而三位作者则专注于开发微调此类模型的流程,并通过从实证分析中获得的见解来验证每个设计决策的合理性——这是OpenVLA-OFT工作的第一点意义
第二,相比OpenVLA,OpenVLA-OFT优势是什么呢
- 拒论文称,尽管微调对于现实世界中的VLA部署至关重要,但关于有效微调策略的经验分析仍然有限。Kim等人[22]研究了各种参数更新策略,并通过他们的研究发现,LoRA微调能够有效适应单臂机器人在低控制频率(<10Hz)下的操作,但OpenVLA的分析并未扩展到双臂机器人在高控制频率(25-50+ Hz)下的更复杂控制场景
- 而本次的研究,OpenVLA-OFT通过探索VLA适应设计决策,以实现快速推理和在具有25 Hz控制器的真实双臂操控器上可靠的任务执行——这是第二点意义
第三,相比π0_FAST(推理慢),OpenVLA-OFT意义在于什么呢
- 尽管π0_FAST通过新的动作tokenization化方案改进了VLA 的效率,使用矢量量化或基于离散余弦变换的压缩方法,以比简单的逐维分箱(如RT-2 [4] 和OpenVLA [22] 中使用的)更少的token表示动作块(动作序列)
- 尽管这些方法为自回归VLA——π0_FAST 实现了2 到13× 的加速,但三位作者探索了超越自回归建模的设计决策,而自回归建模本质上受到迭代生成的限制
最终OpenVLA-OFT的并行解码方法,与动作分块结合时,实现了显著更高的加速:26× 到43× 的吞吐量,同时具有更低的延迟(单臂任务使用一张输入图像的延迟为0.07 ms,双臂任务使用三张输入图像的延迟为0.321 ms)
第四,与基于扩散的VLA(训练慢)相比
尽管这些基于扩散的视觉语言代理(VLA)通过同时生成多时间步的动作块实现了比自回归VLA更高的动作吞吐量,但它们在推理时通过较慢的训练和多个去噪或集成步骤引入了计算权衡
此外,这些扩散VLA在架构、学习算法、视觉语言融合方法以及输入输出规范方面差异很大——哪些设计元素对性能影响最大仍不清楚
通过受控实验,三位作者表明,使用更简单的L1回归目标微调的策略可以在任务性能上匹配更复杂的方法,同时显著提高推理效率
1.2 微调VLA的三大关键设计决策
在涉及到微调VLA的三个关键设计决策之前,有两点 需要先特别说明下
首先,三位作者使用 OpenVLA [22] 作为他们代表性的基础 VLA
- 这是一种通过在 Open X-Embodiment 数据集 [33] 的 100 万个episodes上对Prismatic VLM [20] 进行微调而创建的 7B 参数操控策略
- OpenVLA的原始训练公式使用 7 个离散机器人动作token的自回归预测,每个时间步有
3 个用于位置控制
它采用与语言模型类似的「交叉熵损失的下一个token预测」作为其学习目标
其次,先前的研究表明,动作分块——即预测并执行一系列未来动作而无需中间重新规划,在许多操作任务中提高了策略的成功率[53-ALOHA ACT, 5-Diffusion policy, 27-Bidirectional decoding]
- 然而,OpenVLA 的自回归生成方案使得动作分块变得不切实际,因为即使生成单个时间步的动作,在NVIDIA A100 GPU 上也需要0.33秒
- 对于块大小为K 个时间步和动作维度为D 的情况,OpenVLA 需要进行KD 次顺序解码器前向传递,而无需分块时仅需D 次。这种K 倍的延迟增加使得在OpenVLA的原始公式下,动作分块对于高频机器人来说变得不切实际
在下一节中,三位作者提出了一种并行生成方案,使得高效的动作分块成为可能
最后,现有的方法使用基础模型的自回归训练策略微调VLA时面临两个主要限制:
- 推理速度较慢(3-5 Hz),不适合高频控制
- 以及在双手操作器上的任务执行可靠性不足 [51-Tinyvla,26-Rdt-1b,3-π0]
为了解决这些挑战,三位作者研究了VLA微调的三个关键设计组件:
- 动作生成策略(图2,左):

比较了需要逐个token顺序处理的自回归生成与同时生成所有动作并支持高效动作分块的并行解码 - 动作表示(图2,右):
对通过基于 softmax 的token预测处理的离散动作(对归一化动作进行 256 个分箱的离散化)与由多层感知机(MLP)动作头直接生成的连续动作进行了比较
- 学习目标(图2,右侧)
比较了通过
他们使用OpenVLA [22]作为基础模型,并通过LoRA微调[14]对其进行适配,这是因为的训练数据集相对较小(500个示例,相比于预训练的1百万个示例)
1.2.1 支持动作分块的并行解码
OpenVLA 最初采用自回归生成离散动作token,并通过下一个token预测进行优化。三位作者实施了不同的微调设计决策,同时保持原始预训练不变
第一,与需要按顺序token预测的自回归生成不同
- 并行解码使模型能够在一次前向传递中将输入嵌入映射到预测的输出序列「parallel decoding enables the model to map input embeddingsto the predicted output sequence in a single forward pass」
- 为此,三位作者修改了模型,使其接收空的动作嵌入作为输入,并用双向注意力替换因果注意力掩码,从而使解码器能够同时预测所有动作
这将动作生成从D 次顺序传递减少到一次传递,其中D 是动作的维度「This reduces action generation from D sequential passes to asingle pass, where D is the action dimensionality」
此外,并行解码可以自然地扩展到动作分块
- 为了预测多个未来时间步的动作,只需在解码器的输入中插入额外的空动作嵌入,这些嵌入随后会被映射到未来的一组动作
- 对于分块大小为 K 的情况,模型在一次前向传递中预测 KD 个动作,吞吐量增加 K 倍,而对延迟的影响极小
虽然从理论上讲,并行解码可能不如自回归方法那样具有表现力,但三位作者的实验表明,在各种任务中均未出现性能下降
在原始OpenVLA 自回归训练方案中,模型接收真实标签动作token(向右偏移一个位置)作为输入(这种设置称为教师强制)
- 因果注意力掩码确保模型仅关注当前和先前的token。在测试时,每个预测token会作为输入反馈用于下一个预测
- 对于并行解码,三位作者将此输入替换为空的动作嵌入,这些嵌入仅在位置编码值上有所不同(类似于[53-ALOHA ACT])
且他们还使用了双向注意力掩码(而非因果掩码),使模型在预测动作块中的每个元素时可以非因果性地利用所有中间特征
1.2.2 连续动作表示
OpenVLA 最初使用离散动作token,其中每个动作维度被归一化到[−1, +1] 并均匀离散化为256 个区间。虽然这种方法很方便,因为它不需要对底层VLM进行架构修改,但离散化过程可能会牺牲细粒度的动作细节
对此,三位作者研究了连续动作表示,并从突出的模仿学习方法中提取了两个学习目标
- L1 回归,该动作头直接将解码器最后一层隐藏状态映射到连续动作值。模型被训练为最小化预测动作与真实动作之间的平均 L1 差异,同时保持并行解码的效率优势并可能提高动作精度
- 其次,受 Chi 等人 [5] 的启发,他们实现了条件去噪扩散建模
在训练过程中,模型学习预测在前向扩散期间添加到动作样本中的噪声
在推理过程中,策略通过反向扩散逐渐去噪噪声动作样本以生成真实动作
虽然这种方法提供了可能更具表现力的动作建模,但它在推理期间需要多次前向传递(在三位作者的实现中为 50 次扩散步骤),即使使用并行解码也会影响部署延迟
对于离散动作表示,增加用于离散化的分箱数量可以提高精度,但会降低单个token在训练数据中的出现频率,此举会损害泛化能力
另一方面,使用连续动作表示,VLA可以直接建模动作分布而无需有损离散化。三位作者的连续表示实现使用以下规范
- L1回归:MLP动作头由4层带有ReLU激活的层组成,将最终的Llama-2解码器层隐藏状态直接映射到连续动作
- 扩散:使用DDIM [44] 采样器,具有50个扩散时间步,且遵循 [5,54] 的平方余弦β调度,此外,基于4层噪声预测器,采用与L1回归头相同的MLP架构
1.2.3 额外的模型输入和输出
虽然原始 OpenVLA 处理单个摄像头视图,但一些机器人设置包括多个视角和额外的机器人状态信息
故三位作者实现了一个灵活的输入处理管道:
- 对于摄像头图像,三位作者使用 OpenVLA 的双视觉编码器提取每个视图的 256 个patch嵌入,这些嵌入通过共享投影网络被投影到语言嵌入空间
即将每个输入图像通过OpenVLA融合视觉编码器处理,生成256个patch嵌入,这些嵌入通过一个带有GELU激活函数的三层MLP投影到语言模型嵌入空间 - 对于低维机器人状态输入(例如关节角度和夹持器状态),三位作者使用单独的投影网络将这些映射到与摄像头图像相同的嵌入空间——从而作为另一个输入嵌入
即低维的机器人状态同样通过一个带有GELU激活函数的两层MLP投影到语言嵌入空间
所有输入嵌入——视觉特征、机器人状态和语言token——在传递给解码器之前沿序列维度进行连接。这种统一的潜在表示使模型能够在生成动作时关注所有可用信息
且结合并行解码和动作分块,这种架构可以高效处理丰富的多模态输入,同时生成多时间步的动作,如下图图1所示
可选:使用 FiLM 增强 OpenVLA-OFT 的语言基础能力
当在 ALOHA 机器人设置中部署时,包含来自腕部安装摄像头的多个视角,三位作者观察到由于视觉输入中的伪相关性,策略可能难以跟随语言
- 在训练过程中,策略可能会在预测动作时学习依赖这些伪相关性,而不是正确关注语言指令,导致在测试时无法很好地遵循用户的命令
- 此外,语言输入可能仅在任务的特定时刻是关键的——例如,在“将X 舀入碗中”任务中,抓住勺子后决定舀取哪种成分,如第 VI 节所述。因此,如果没有特殊技术,训练模型适当地关注语言输入可能特别具有挑战性
为了增强语言跟随能力
- 三位作者采用了特征线性调制FiLM[35],它将语言嵌入注入到视觉表示中,以使模型更加关注语言输入
we employ feature-wise linear modulation (FiLM) [35], which infuses languageembeddings into the visual representations so that the modelpays more attention to the language inputs. - 怎么实现呢?三位作者计算任务描述中的语言嵌入
的平均值,并将其投影以获得缩放和偏移向量
和
,这些向量通过仿射变换调制视觉特征F
We compute the average of the language embeddings x from the taskdescription and project it to obtain scaling and shifting vectors γ and β. These vectors modulate the visual features F through an affine transformation
一个关键的实现细节是选择什么去ViT中调制(对应的视觉)” 特征”。尽管人们可能自然地考虑将单个patch 嵌入作为需要调制的特征,但三位作者发现这种方法会导致较差的语言跟随能力
相反,借鉴FiLM 在卷积网络中的操作方式,其中调制通过缩放和偏移整个特征图来空间无关地进行,他们将 和
的每个元素应用于所有视觉patch 嵌入中的对应隐藏单元,从而使
和
影响所有patch 嵌入「we apply each element of γ and β to the corresponding hidden unit across all visual patch embeddings so that γ and β influence all patch embeddings」
- 具体来说,这使得γ 和β 成为
维向量,其中
- 三位作者在每个ViT块的自注意力层之后和前馈层之前应用 FiLM,每个块都有单独的投影器
具体如下图所示,在OpenVLA的融合视觉主干中,将FiLM[35]集成到SigLIP[52]和DINOv2[34] ViT中
通过在每个transformer块中进行缩放和偏移操作,平均任务描述嵌入对视觉特征进行调制,从而增强语言与视觉的集成。这一修改显著提高了ALOHA任务中的语言跟随能力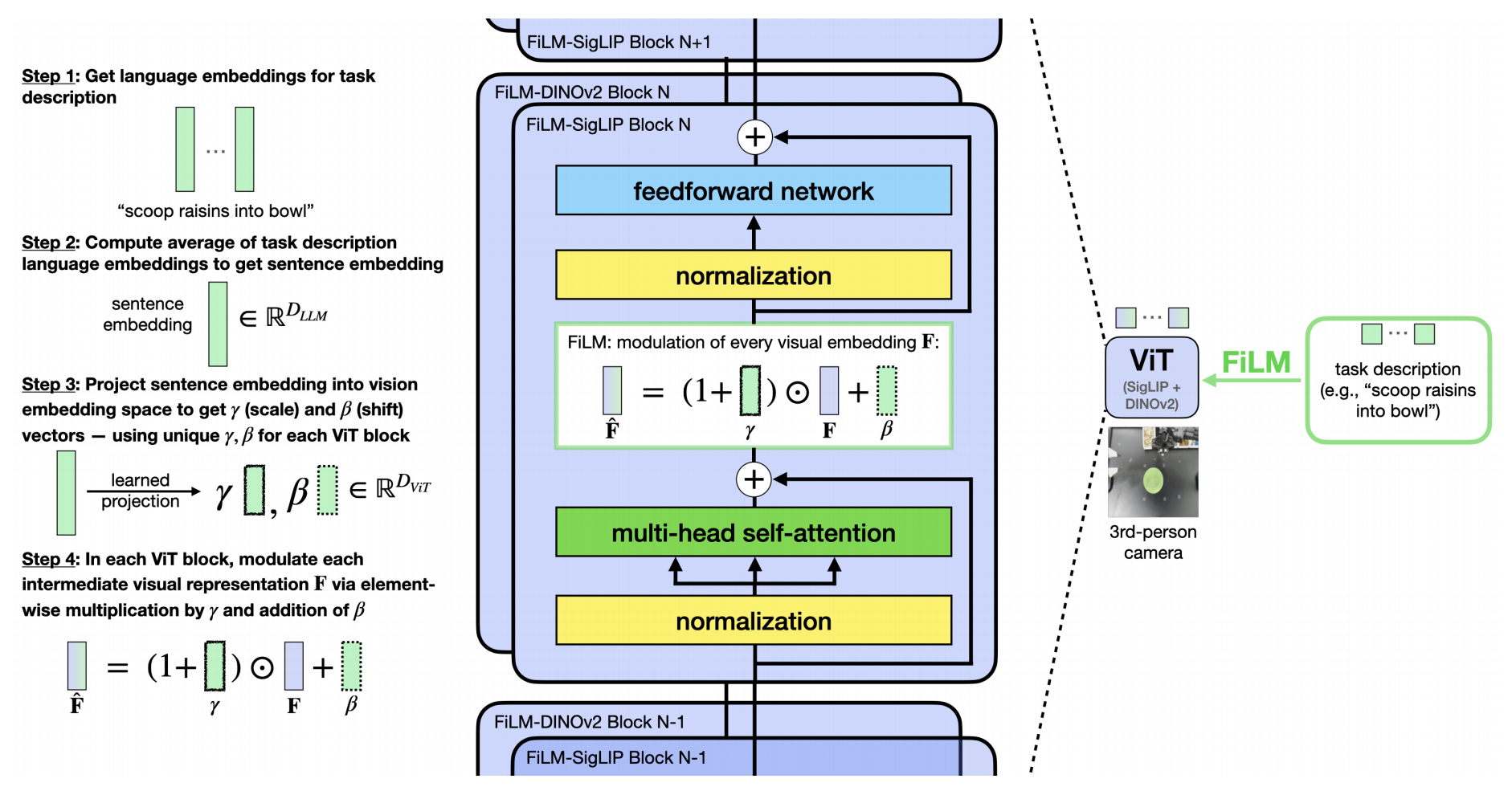
且三位作者遵循Perez 等人[35] 的做法,他们将F 乘以(1 + γ) 而不是γ,因为在初始化时γ 和β接近于零。这有助于在微调开始时保留视觉编码器的原始激活,最小化对预训练表示的扰动
实现细节上
- 将语言嵌入投影为 γ 和 β 的函数 f(x) 和h(x) 被实现为简单的仿射变换。为每个transformer学习了单独的投影器,以允许块特定的调制模式。这种设计使模型能够在视觉特征处理的不同层次学习不同的调制模式
- 可能有人最初会考虑独立调制每个patch嵌入,而不是像第 IV-C 节讨论的那样调制每个嵌入的每个隐藏维度
然而,他们的空间无关调制方法更接近 FiLM 在卷积网络中的操作,其中调制在空间维度上全局应用,因为特征图的整个部分由 γ 和 β 的单个元素进行缩放和偏移
这种设计选择更好地保留了 FiLM 的优势,并显著改善了策略的语言理解能力。且发现,一种独立调制每个patch嵌入的替代形式导致了较弱的语言理解能力最后,他们仅在第 VI 节讨论的 ALOHA 实验中使用 FiLM,在这些实验中,多个摄像机视角导致视觉输入中存在更多的虚假相关性
1.3 对VLA微调设计决策的评估
根据原论文,下面将通过旨在回答三个关键问题的控制实验,评估他们提出的 VLA 适配设计决策的效果
- 每个设计决策如何影响微调策略在下游任务上的成功率
- 每个设计决策如何影响模型推理效率(动作生成吞吐量和延迟)
- 替代的微调形式如何影响模型输入输出规范的灵活性
1.3.1 LIBERO 实验设置
在 LIBERO 模拟基准 [25] 上进行评估,该基准包含一个 Franka Emika Panda 机械臂模拟,演示数据包括相机图像、机器人状态、任务注释和末端执行器位姿变化的动作
他们使用四个任务套件——LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和LIBERO-Long,每个套件提供 10 个任务的 500 个专家演示,用于评估策略在不同空间布局、物体、目标
根据Kim 等人[22] 的方法,他们筛选出不成功的示范,并通过LoRA [14] 独立地对每个任务集微调OpenVLA
- 针对非扩散方法训练50 −150 K 次梯度步
对于扩散方法(收敛较慢)训练100 −250 K 次梯度步
并使用跨8 个A100/H100 GPU 的64-128 的批量大小 - 每隔50K 步测试一次检查点,并报告每次运行的最佳性能。除非另有说明,策略接收一张第三人称图像和语言指令作为输入
- 对于使用动作分块的方法,将块大小设置为K = 8,以匹配Diffusion Policy 基线[5],并在重新规划前执行完整的块,这一设置被发现可以同时提高速度和性能。超参数的详细信息见附录D
1.3.2 LIBERO任务性能比较
为了实现令人满意的部署,机器人策略必须展示出可靠的任务执行能力
三位作者首先评估不同的VLA微调设计决策如何影响LIBERO基准测试中的成功率。根据效率分析显示,并行解码PD和动作分块AC对于高频控制(25-50+ Hz)是必要的,特别是对于具有双倍动作维度的双臂机器人
因此,他们评估了同时使用这两种技术的OpenVLA策略,并比较了使用离散动作、带L1回归的连续动作以及带扩散的连续动作的变体
下表表I的结果显示「1 对比了包括从预训练基础模型 (Octo, DiT Policy, Seer,π0) 微调的策略,从头训练的模型 (Diffusion Policy, Seer (scratch), MDT),以及使用不同微调设计决策的 OpenVLA 变体:并行解码 (PD)、动作分块 (AC,块大小 K=8 步长)、以及带有 L1 回归的连续动作 (Cont-L1) 或扩散 (Cont-Diffusion)。2 本研究中的 OpenVLA 结果是对每个任务套件 (10 个任务 × 50 个实验) 平均 500 次试验的结果。最终,带有额外输入的完整 OpenVLA-OFT 方法实现了 97.1% 的平均成功率,达到了最先进的水平。基线结果来自原始论文,除了 Diffusion Policy、Octo 和原始 OpenVLA 策略的结果由 Kim 等人[22] 报告。加粗和下划线的值分别表示最佳和次优性能」
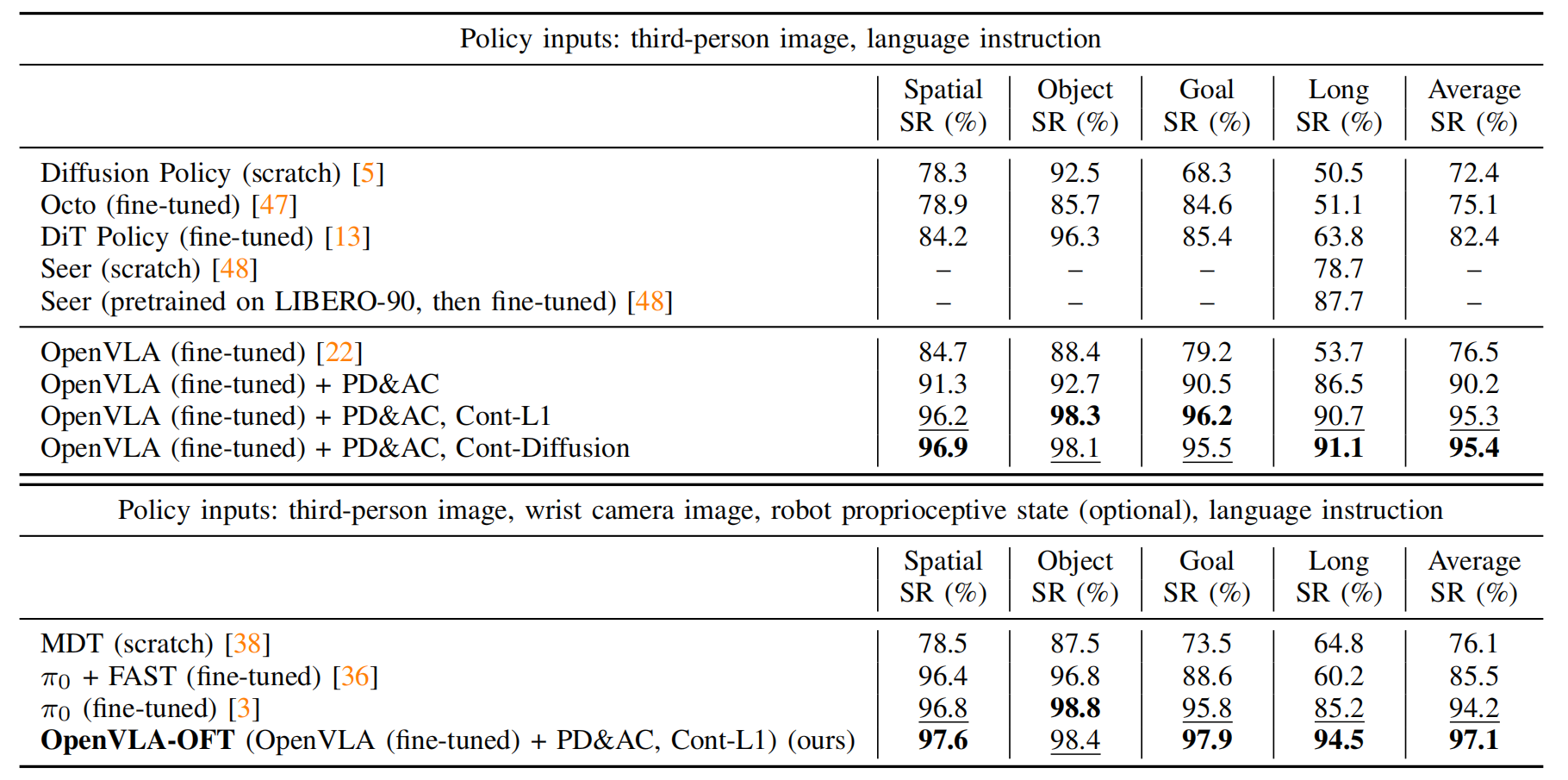
- 并行解码和动作分块不仅提高了吞吐量,还显著提升了性能,使得自回归OpenVLA策略的平均成功率绝对提高了14%。这一改进在LIBERO-Long中尤为显著,这表明动作分块有助于捕获时间依赖性[27]并减少复合错误[39],最终导致更平滑和更可靠的任务执行
- 此外,谈发现使用连续动作变体相较于离散动作变体,成功率进一步提高了 5%(绝对值),这可能是由于动作预测的精度更高所致
- L1回归和扩散变体表现相当,这表明高容量的OpenVLA模型即使使用简单的L1回归也能有效建模多任务动作分布
1.3.3 LIBERO 推理效率比较
高效的推理对于在高频控制机器人上部署 VLAs 至关重要。故原论文中评估了并行解码(PD)、动作分块(AC)和连续动作表示如何影响模型推理速度
- 他们通过在 NVIDIA A100 GPU 上对每种模型变体进行 100 次查询来测量平均延迟(生成一个机器人动作或动作块所需的时间)和吞吐量(每秒生成的总动作数)
- 每次查询处理一个 224 x 224 像素的图像和一个示例 LIBERO 语言指令(“拾起alphabet soup并将其放入篮子中”)
下表表II 中的结果表明「1 针对对 7 维动作的动作生成吞吐量和延迟,平均在 NVIDIA A100 GPU 上的 100 次查询中得出结果。每次查询处理一个 224 × 224 像素的图像和一个 LIBERO 任务指令(“拾起字母汤并将其放入篮子”)。2 比较了使用并行解码(PD)、动作分块(K=8 个时间步长)以及使用 L1 回归或扩散目标的连续动作的 OpenVLA 变体。最后一行添加了腕部摄像头图像和机器人状态输入。加粗和下划线的值分别表示最佳和次优性能」

- 通过将策略中解码器部分的 7 次顺序前向传递替换为单次传递,并行解码将延迟降低了 4 倍,并将吞吐量提高了 4 倍
Results in Table II show that parallel decoding reduces latency and increases throughput by 4× by replacing 7 se-quential forward passes through the decoder portion of the policy with a single pass - 添加动作分块(K = 8)会使延迟增加 17%,这是由于解码器中的注意力序列变长所致,但当与并行解码结合使用时,它能显著提高吞吐量,比基准 OpenVLA 快 26 倍
- 带有 L1 回归的连续动作变体在效率方面几乎没有差异,因为额外的 MLP 动作头仅增加了极少量的计算量
扩散变体需要50个去噪步骤,因此延迟增加了3倍。然而,通过并行解码和分块,它的吞吐量仍然比基线OpenVLA高出2倍
这意味着尽管动作块之间的暂停时间更长,扩散变体仍然比原始自回归变体更快地完成机器人操作周期
1.3.4 模型输入输出的灵活性
并行解码使得OpenVLA能够以最小的延迟增加生成动作块,从而提高模型输出的灵活性。且并行解码和动作块的显著加速为处理额外的模型输入也创造了余地
接下来,通过对OpenVLA进行微调,添加机器人本体状态等额外输入来证明这一点
机器人腕部安装的相机图像,这使得传递到语言模型解码器的视觉patch嵌入数量翻倍,从256增加到512
- 尽管输入序列长度大幅增加,微调后的OpenVLA策略仍然保持高吞吐量(71.4 Hz)和低延迟(0.112秒),如表II所示
- 通过在LIBERO基准上使用额外的输入评估这些策略,显示出所有任务套件的平均成功率进一步提高(表I)
- 值得注意的是,改进的经过微调的OpenVLA策略甚至超过了最佳微调的π0策略[3,36]——这些策略得益于具有更大规模预训练和更复杂学习目标(流匹配[24])的基础模型——以及多模态扩散变换器(MDT)[38]
- 即使使用比最近的VLA更少数据预训练的简单基础模型,他们发现他们的替代VLA适应设计决策使得微调的OpenVLA策略能够在LIBERO基准上建立新的技术水平
第二部分 将OpenVLA适配于现实世界的ALOHA机器人
虽然上面第一部分的实验结果表明OpenVLA-OFT在模拟中的有效性,但在现实世界中成功部署在与预训练阶段所见机器人平台有显著差异的机器人上,对于展示广泛的适用性至关重要
- 因此,三位作者还评估了他们优化后的微调方法在ALOHA机器人环境[53]中的效果,这是一种实际的双手操作平台,以高控制频率运行
- 他们在新颖的灵巧操作任务上进行了评估,这些任务在OpenVLA的预训练阶段(仅涉及单臂机器人数据)中从未遇到过
- 先前的研究[51-Tinyvla,26-Rdt-1b,3-π0]表明,使用自回归VLA[22-Openvla]进行原始LoRA微调对于此类任务是不切实际的,因为其吞吐量(单臂机器人为3-5 Hz,双臂任务甚至更低)远低于实时部署所需的25-50Hz
因此,他们在实验中排除了这一基线,并将其与稍后讨论的更有效方法进行比较
在论文的该部分中,三位作者介绍了增强版本的VLA微调方案(OFT+),该方案额外包括特征线性调制(FiLM)以增强语言基础
最终,他们将通过此增强微调方案实例化的OpenVLA策略记为OpenVLA-OFT+
2.1 ALOHA 实验设置
2.1.1 ALOHA与OpenVLA硬件设置的不同
ALOHA 平台由两个 ViperX 300 S 机械臂、三个相机视角(一个俯视视角和两个安装在手腕上的视角)以及机器人状态输入(14 维关节角度)组成。其运行频率为 25 Hz(从原始的 50 Hz 降低,以实现更快的训练,同时仍保持平滑的机器人控制),动作表示目标绝对关节角度
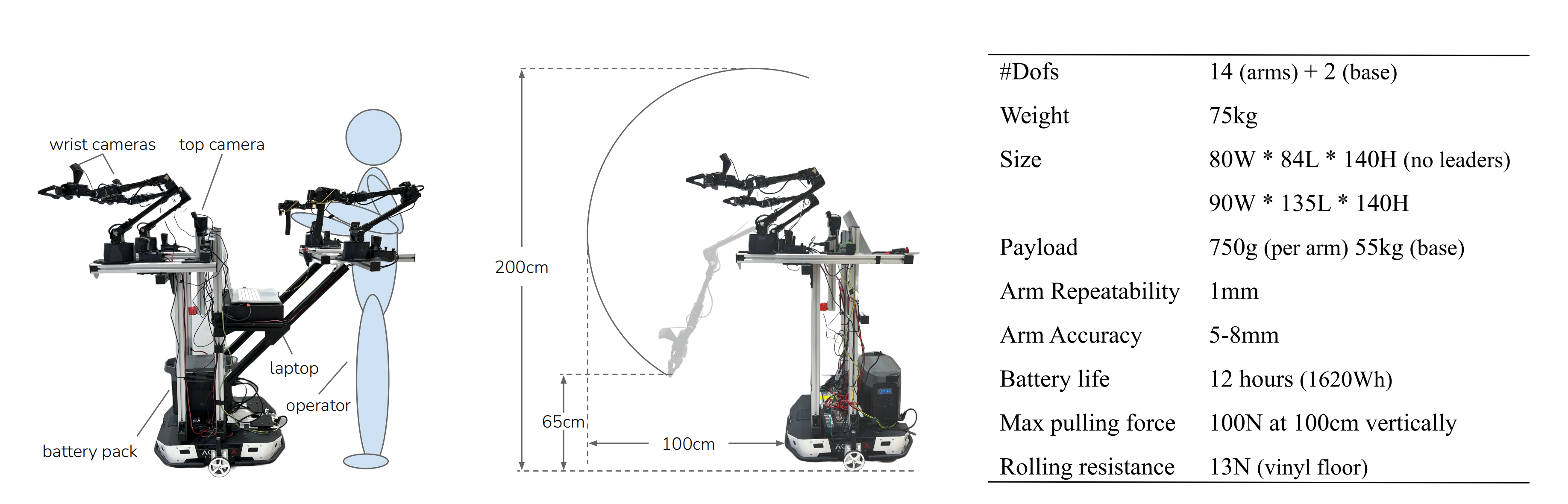
此设置与 OpenVLA 的预训练显著不同,后者仅包括单臂机器人数据、来自第三人称相机的单一视角、无机器人状态输入、低频率控制(3-10 Hz),以及相对末端执行器的姿态动作。 这种分布的变化给该模型的适应性带来了挑战
2.1.2 4个代表性任务:折叠短裤、折叠T恤、将X舀入碗中、将X放入锅中
他们设计了四个代表性任务,用于测试可变形物体操作、长时间技能、工具使用和基于语言的控制:
- “折叠短裤”:在桌子上使用连续的双手折叠动作折叠白色短裤
训练:20次示范。评估:10次试验 - “折叠T恤”:通过多次同步的双手折叠动作折叠白色T恤,测试接触丰富的长时间操作
训练:30次示范。评估:10次试验 - “将X舀入碗中”:用左臂将碗移至桌子中央,用右臂使用金属勺舀取指定的原料(“葡萄干”、“杏仁和绿色M&M巧克力”或“椒盐脆饼”)
训练:45次示范(每种原料15次)。评估:12次试验(每种原料4次) - “将X放入锅中”:用左臂打开锅盖,用右臂放置指定物品(“青椒”、“红椒”或“黄玉米”),然后关闭锅盖
训练:300次演示(每个物体100次)。评估:24次试验(12次分布内,12次分布外)
为了完成上述任务,他们使用OFT+ 对OpenVLA 在每个任务上独立进行微调,进行50 −150 K 次梯度步骤(总批量大小为32,使用8 个A100/H100-80GB GPU),动作块大小为K = 25
且在推理时,在重新查询模型以获取下一个块之前,先执行完整的动作块
2.2 各个方法的PK:OpenVLA-OFT+/RDT/π0/ACT/diffusion policy
ALOHA 任务对OpenVLA 作为基础模型提出了显著的适应性挑战,因为在控制频率、动作空间和输入模态方面,它与OpenVLA的预训练平台存在显著差异
- 基于此,三位作者将OpenVLA-OFT+ 与最近的VLA 模型RDT-1B [26] 和π0 [3]进行比较,这些模型在双手操作数据上进行了预训练,并可能在这些下游任务中表现得更好
- 且三位作者按照原作者推荐的微调方法对这些模型进行评估,这些方法作为重要的比较基准
- 此外,为了提供与计算效率较高的替代方法的比较,三位作者评估了两个流行的模仿学习基线:ACT[53] 和Diffusion Policy [5],它们在每项任务上从零开始训练
为了在这些基线方法中启用语言跟随,三位作者使用了基于语言的实现
- 对于ACT,三位作者修改了EfficientNet-B0[46-Efficientnet: Rethinking model scaling for convolutional neural networks]
且通过FiLM [35-Film: Visual reasoning with a general conditioning layer,41-Yell at your robot: Improving on-the-fly from language corrections,详见此文《YAY Robot——斯坦福和UC伯克利开源的:人类直接口头喊话从而实时纠正机器人行为(含FiLM详解)》]处理CLIP [37]语言嵌入
当然了,他们仅将此FiLM-EfficientNet实现用于与语言相关的任务(例如“将X舀入碗中”和“将X放入锅中”)。对于折叠衣物任务,他们使用原始的ResNet-18 [10]骨干网络,如在[54-3dvla]中所述 - 对于Diffusion Policy,三位作者使用了DROID数据集[21-Droid: A large-scale in-the-wild robot manipulation dataset]的实现,该实现将动作去噪条件设定为基于DistilBERT [40]的语言嵌入,并修改以支持双手控制和多图像输入
2.3 ALOHA任务性能结果
三位作者评估了所有方法——ACT、Diffusion Policy、RDT-1B、π0和OpenVLA-OFT+——在他们4个ALOHA任务上的表现
为了提供精细的评估,三位作者使用了一个预定的评分标准,该标准为部分任务完成分配分数(详见附录F)
图4展示了综合性能分数「OpenVLA-OFT+通过并行解码、动作分块、连续动作、L1回归以及用于语言基础的FiLM [35]增强了基础模型。微调的VLA模型始终优于从头开始的方法,其中OpenVLA-OFT+达到了最高的平均性能」
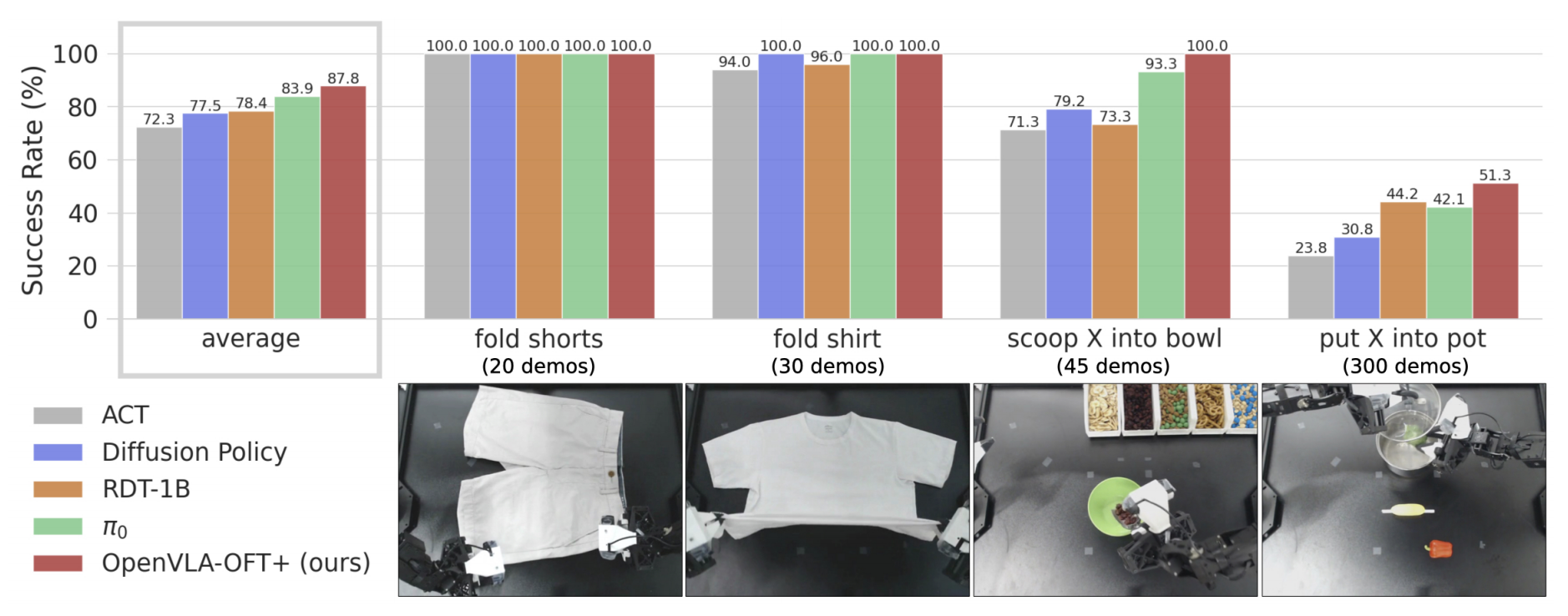
2.3.1 非VLA基线的性能
从头开始训练的基线方法表现出不同程度的成功
- ACT虽然能够完成基本任务,但其产生的动作不够精确,总体表现最低
- 扩散策略展示了更强的能力,在折衣服和舀取任务中与RDT-1B的可靠性相匹配或超过。然而,它在“将X放入锅中”任务中表现不佳,该任务具有更大的训练数据集,这表明相比基于VLA的方法,其可扩展性有限
2.3.2 微调的VLA的性能
微调的VLA策略在任务执行和语言跟随方面通常优于从头开始的基线,与之前的研究结果一致[26-Rdt-1b,3]
在VLA中,三位作者观察到不同的特点:
- RDT-1B通过其“交替条件注入”方案[26-Rdt-1b]实现了良好的语言跟随,但显示出在处理闭环反馈方面的局限性
如图7 所示,它经常无法纠正” 将X 舀入碗中” 任务中的错误——例如,在错过实际碗后继续将材料倒入一个想象中的碗中,这表明其对本体感受状态的依赖超过了视觉反馈
- 另一方面,π0 展现了更稳健的执行能力,动作更流畅,对反馈的反应更灵敏,经常能够从初始失败中成功恢复(如图7 所示)
尽管其语言理解能力稍微落后于RDT-1B,π0 实现了更好的整体任务完成能力,使其成为最强的基线模型
- 最后,OpenVLA-OFT+ 在任务执行和语言理解两方面都达到了最高性能(有关成功任务展开的示例,请参见图6)
当然,值得注意的是,因为基础OpenVLA 模型仅在单臂数据上进行了预训练,而RDT-1B 和π0 分别在大量双臂数据集上进行了预训练(6 K 个任务和8 K 小时的双臂数据)
这表明,微调技术可能比预训练数据的覆盖范围对下游性能更为关键
2.3.3 FiLM的消融研究
三位作者通过消融并评估其对他们OpenVLA-OFT+方法中策略语言跟随能力的重要性来进行研究,这些策略在最后两个任务中需要良好的语言基础才能成功执行
如图5所示——专门跟踪了语言依赖任务的语言跟随能力「微调的 VLA 比从头训练的策略更频繁地遵循用户的命令。OpenVLA-OFT+ 展示了最强的语言基础,然而移除 FiLM [35] 将成功率降低到随机水平」,在这两个任务中,OpenVLA-OFT+语言跟随能力下降到33%——相当于随机选择正确的指令
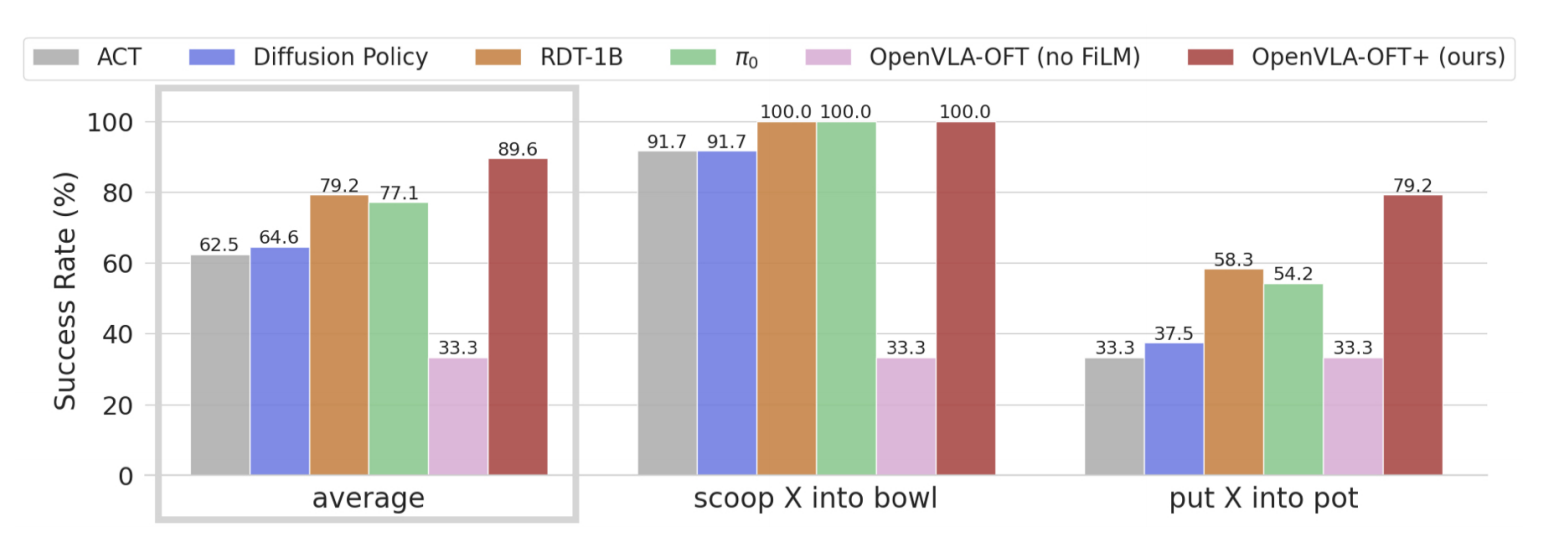
这表明 FiLM 对于防止模型过度拟合于虚假视觉特征以及确保对语言输入的恰当关注至关重要
2.4 ALOHA 推理效率比较
三位作者通过测量每100个查询的动作生成吞吐量和延迟来评估推理效率
他们在表III中报告了结果「1 吞吐量和延迟测量基于在NVIDIA A100 GPU上进行的100次查询的平均值。每次查询处理三张224 × 224像素的图像、14维机器人状态和一个任务命令(“将葡萄干舀入碗中”)。2 所有方法使用动作块大小K=25,除了DiffusionPolicy(K=24,因为需要是4的倍数)和原始的OpenVLA(K=1,无块化)。RDT-1B预测64个动作,但为了公平比较,他们只执行前25个动作。所有实现都使用PyTorch,除了π0(使用JAX)。加粗和下划线的值表示最佳和次优性能」
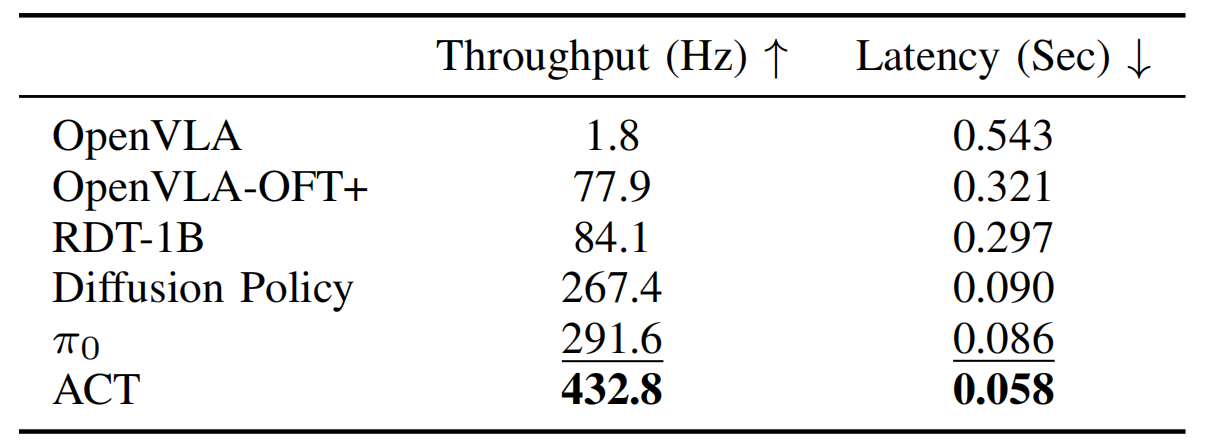
- 即使加入了额外的手腕摄像头输入,原始的OpenVLA公式表现出较低的效率,吞吐量为1.8 Hz,延迟为0.543秒
- 相比之下,OpenVLA-OFT+实现了77.9 Hz的吞吐量,尽管与之前LIBERO实验中的策略相比,其延迟较高,因为它需要处理两个额外的输入图像
其他方法展示了更高的吞吐量由于其较小的架构:ACT(84M参数)、DiffusionPolicy(157M)、RDT-1B(1.2B)和π0(3.3B)——而OpenVLA拥有7.5B参数
- ACT通过结合基于L1回归的单次动作生成(类似于OpenVLA-OFT+)及其紧凑架构,实现了最高速度
- 此外,尽管其规模更大,π0仍然由于其优化的JAX实现(所有其他方法均以PyTorch实现),在速度方面同时超过了RDT-1B和Diffusion Policy
- 值得注意的是,OpenVLA-OFT+ 的吞吐量(77.9 Hz)接近RDT-1B的(84.1 Hz),尽管其大小是后者的7倍,因为它通过单次前向传递生成动作,而不像RDT-1B那样需要多个去噪步骤
2.5 总结与不足
最后,引用原论文的阐述总结一下
- 对VLA微调设计决策的研究揭示了不同组件如何影响推理效率、任务性能、模型输入输出的灵活性以及语言跟随能力
这些见解形成了他们的优化微调(OFT)方案,该方案通过并行解码、动作分块、连续动作、L1回归和(可选的)FiLM语言条件化,实现了VLA在新机器人和任务上的有效适应 - OFT的成功在OpenVLA上尤其值得注意:尽管在预训练期间没有接触过双手机器人或多视图图像输入,使用OFT微调的OpenVLA能够适应此类配置,并能匹配甚至超越遇到过双手操控器和多输入图像的更近期的基于扩散的VLA(π0和RDT-1B)
这表明,一个设计良好的微调方案对最终性能可以有显著影响,且现有的VLA可以在不从头开始大量重新训练的情况下成功适应新的机器人系统 - 三位作者的研究结果表明,基于简单L1回归的方法结合高容量模型(如OpenVLA)在适应新型机器人和任务方面非常有效
与基于扩散的方法相比,这种方法具有实际优势:更简单的算法可以加快训练收敛和推理速度,同时保持较强的性能,这使其特别适合于实际的机器人应用
尽管OFT方法在将VLA适配到新型机器人和任务方面表现出潜力,但仍存在一些重要问题需要解决
- 处理多模态演示
三位作者的实验使用了针对每个任务具有统一策略的聚焦演示数据集。虽然 L1 回归可能通过鼓励策略学习演示动作中的中位数模式来帮助平滑训练演示中的噪声,但它可能难以准确地对存在多个有效动作的相同输入的真正多模态动作分布进行建模,这在生成替代动作序列对任务完成有益的情况下可能不是理想的选择
相反,基于扩散的方法可能更好地捕捉这种多模态性,但存在过度拟合训练数据中次优模式的风险(有关这些细微差别的讨论和视频演示,请访问该项目的网站)。了解 OFT 在多模态演示中的有效性是未来工作的一个重要方向 - 预训练与微调
三位作者的研究特别关注为下游任务微调视觉语言模型。OFT 的优势是否能有效地延伸到预训练,或者对于大规模训练是否需要更强大的算法如扩散模型,这需要进一步的研究 - 不一致的语言对齐
三位作者的 ALOHA 实验表明,没有 FiLM 的 OpenVLA 在语言对齐方面表现不佳,尽管在 LIBERO 模拟基准实验中并未出现此类问题。造成这种差异的原因——无论是由于预训练中缺乏双手数据还是其他因素——仍不清楚,需要进一步研究
// 待更
相关文章:

OpenVLA-OFT——微调VLA的三大关键设计:支持动作分块的并行解码、连续动作表示以及L1回归目标
前言 25年3.26日,这是一个值得纪念的日子,这一天,我司「七月在线」的定位正式升级为了:具身智能的场景落地与定制开发商 ,后续则从定制开发 逐步过渡到 标准产品化 比如25年q2起,在定制开发之外࿰…...

linux3 mkdir rmdir rm cp touch ls -d /*/
Linux 系统的初始目录结构遵循 FHS(Filesystem Hierarchy Standard,文件系统层次标准),定义了每个目录的核心功能和存储内容。以下是 Linux 系统初始安装后的主要目录及其作用: 1. 核心系统目录 目录用途典型内容示例…...

TDengine 中的视图
简介 从 v3.2.1.0 开始,TDengine 企业版提供视图功能,便于用户简化操作,提升用户间的分享能力。 视图(View)本质上是一个存储在数据库中的查询语句。视图(非物化视图)本身不包含数据ÿ…...

算法设计学习9
实验目的及要求: 通过排序算法的实验,旨在深化学生对不同排序算法原理和性能的理解,培养其分析和比较算法效率的能力。通过实际编程,学生将掌握排序算法的实现方法,了解不同算法的优劣,并通过性能测试验证其…...

PGSQL 对象创建函数生成工具
文章目录 代码结果 代码 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>PGSQL 函数生成器</tit…...

企业安全——FIPs
0x00 前言 先来看一道题目。这道题目涉及到的就是道德规范和互联网相关内容,本文会对相关内容进行描述和整理。 正确答案是:D 注意FIPs的主要目的是为了限制,也就是针对数据的守则。 0x01 RFC 1087 1989年1月 互联网架构委员会 IAB 发布了…...
——XBridge20240424攻击)
历年跨链合约恶意交易详解(二)——XBridge20240424攻击
漏洞合约函数 /*** dev token owner can list the pair of their token with their corresponding chain id* param baseToken struct that contains token address and its corresponding chain id* param correspondingToken struct that contains token address and its cor…...
)
《AI大模型开发笔记》MCP快速入门实战(一)
目录 1. MCP入门介绍 2. Function calling技术回顾 3. 大模型Agent开发技术体系回顾 二、 MCP客户端Client开发流程 1. uv工具入门使用指南 1.1 uv入门介绍 1.2 uv安装流程 1.3 uv的基本用法介绍 2.MCP极简客户端搭建流程 2.1 创建 MCP 客户端项目 2.2 创建MCP客户端…...

01背包问题:详细解释为什么重量维度必须从大到小遍历。
01背包 问题描述 题目链接:https://www.lanqiao.cn/problems/1174/learning/?page1&first_category_id1&problem_id1174 特点:每件物品只能拿或者不拿。 解法1 设置状态:dp[i][j]指的是前i件物品重量为j的最大价值。 第i件物品…...

Nginx配置伪静态,URL重写
Nginx配置伪静态,URL重写 [ Nginx ] 在Nginx低版本中,是不支持PATHINFO的,但是可以通过在Nginx.conf中配置转发规则实现: location / { // …..省略部分代码if (!-e $request_filename) {rewrite ^(.*)$ /index.php?s/$1 l…...

【KMP】P10915 [蓝桥杯 2024 国 B] 最长回文前后缀|普及+
本文涉及知识点 较难理解的字符串查找算法KMP P10915 [蓝桥杯 2024 国 B] 最长回文前后缀 题目描述 小明特别喜欢回文串,然而回文串太少见了,因此他定义了一个字符串的相同长度的、不相交的前缀和后缀是“回文前后缀”,当且仅当这个前缀和…...

【linux学习】linux系统调用编程
目录 一、任务、进程和线程 1.1任务 1.2进程 1.3线程 1.4线程和进程的关系 1.5 在linux系统下进程操作 二、Linux虚拟内存管理与stm32的真实物理内存区别 2.1 Linux虚拟内存管理 2.2 STM32的真实物理内存映射 2.3区别 三、 Linux系统调用函数 fork()、wait()、exec(…...

构建第一个ArkTS应用:Hello World之旅
# 构建第一个ArkTS应用:Hello World之旅 在鸿蒙应用开发的领域中,ArkTS语言为我们提供了强大而便捷的开发方式。今天,就让我们一起踏上构建第一个ArkTS应用——Hello World的奇妙旅程。 ## 一、创建ArkTS工程 1. 首先,我们要使用…...

Mysql 集群架构 vs 主从复制架构
特性主从复制架构MySQL 集群架构适用场景读多写少的场景;备份;高可用高并发读写、实时交易、高可用性场景可扩展性仅读性能可扩展读写都可以水平扩展高可用性手动切换,有限的高可用支持自动故障转移,强高可用支持部署复杂度较简单…...

国产轻量级多途径无限制的高效下载工具介绍
软件介绍 们在日常中常常有下载各类文件的需求,学习资料也好,娱乐文件也罢。有一款国产的BT下载软件——BitComet(比特彗星),它凭借高效且无限制的特性,在下载爱好者中备受青睐。 BitComet属于轻量级的BT下…...

leetcode数组-长度最小的子数组
题目 题目链接:https://leetcode.cn/problems/minimum-size-subarray-sum/ 给定一个含有 n个正整数的数组和一个正整数 target** 。** 找出该数组中满足其总和大于等于target的长度最小的 子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度**…...

如何理解缓存一致性?
缓存一致性是指在多处理器系统或分布式系统中,确保各个处理器核心或节点的缓存数据与主内存以及其他缓存中的数据保持一致的机制和过程。以下从问题产生原因、一致性协议和实现方式等方面进行详细理解: 1. 问题产生的原因 1.1 缓存存在的必要性 在计…...
系统源码解析:AI 自动化办公的未来)
智能体(Agent)系统源码解析:AI 自动化办公的未来
—从代码到商业落地,如何用Agent重构企业工作流? 一、Agent系统的核心价值 1. 企业办公效率的瓶颈 重复性任务耗时:数据录入、报表生成、邮件处理等占员工 40% 工作时间跨系统协作低效:OA/CRM/ERP数据孤岛,人工搬运错…...

字符串移位包含问题
字符串移位包含问题 #include <iostream> #include <algorithm> using namespace std; int main(){string a,b;cin>>a>>b;//谁长遍历谁if(a.size()<b.size()) swap(a,b);//1-对整个字符串进行移位for(int i0; i<a.size(); i){//每次循环都将第一…...
)
【JavaScript】原型链 prototype 和 this 关键字的练习(老虎机)
这个老虎机练习主要考察JavaScript中的原型链(prototype)和this关键字的使用。 主要思路 创建三个轮盘(reels)实例:我们需要创建3个独立的轮盘对象,它们都委托(delegate)到基础的ree…...

Windows强制删除任何你想删除的文件和文件夹
Windows强制删除任何你想删除的文件和文件夹 本教程适用于 Windows 10/11 系统,工具和命令均经过验证。 为什么删除会失败? 权限不足:文件或文件夹可能需要管理员权限才能删除。文件被占用:某个程序正在使用目标文件,…...

【MySQL数据库】锁机制
概述 锁:是计算机协调多个进程或者线程并发访问某一资源的机制。在数据库中,除了传统的计算资源(CPU、RAM、IO)的争用以外。数据也是一种供多用户共享的资源。如何保证数据的并发访问的一致性、有效性是所有数据库必须解决的一个…...

JS dom修改元素的style样式属性
1通过样式属性修改 第三种 toggle有就删除 没就加上...

搜索树——AVL、红黑树、B树、B+树
目录 二叉搜索树 AVL树 2-3-4树 红黑树 旋转操作 概念讲解 旋转节点操作(左旋) 插入节点 删除节点 B树和B树 B树 2.5.2 B树 https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 难度高,如果想要了解红黑树的增加、…...

2007-2019年各省地方财政交通运输支出数据
2007-2019年各省地方财政交通运输支出数据 1、时间:2007-2019年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、地方财政交通运输支出 4、范围:31省 5、指标说明:地方财政交通运输支出是指地方…...
_29)
LeetCode算法题(Go语言实现)_29
题目 给你一个链表的头节点 head 。删除 链表的 中间节点 ,并返回修改后的链表的头节点 head 。 长度为 n 链表的中间节点是从头数起第 ⌊n / 2⌋ 个节点(下标从 0 开始),其中 ⌊x⌋ 表示小于或等于 x 的最大整数。 对于 n 1、2…...

MINIQMT学习课程Day6
学习安装qmt 安装好后,点击启动国金qmt系统 之后将xtquant包手动安装到python中的site_package中,之后使用pycharm打开文件,创建本地命令文件。 具体的xtquant安装包以及qmt模拟环境,以及模拟账号密码,可以加我私信沟…...
——Button控件详解)
WinForm真入门(7)——Button控件详解
WinForm Button 控件详解 Button(按钮)是 WinForm 中最基础的交互控件,用于触发操作(如:点击登录按钮进入系统)或提交数据(如:写好请假申请后,点击提交,把申…...

035-Windows抓屏-GDI
Windows抓屏-GDI 一、技术原理 GDI(Graphics Device Interface)抓屏基于Windows系统提供的图形设备接口,通过设备上下文(DC) 实现屏幕内容捕获。核心流程如下: 获取桌面窗口句柄:通过 //获取…...

复古优雅感涂鸦手绘喷漆街头艺术字体 Enter Sonic Graffiti
Enter Sonic Graffiti 是 Rvq Typefoundry 的新字体,具有优雅感的字符集。要创建漂亮的组合,只需混合大写和小写,然后与其他字符形混合即可。新的 Graffiti 字体样式和 .我将这款字体献给我正在与癌症作斗争的母亲。我希望我的母亲和所有受癌…...

4.4 代码随想录第三十五天打卡
121. 买卖股票的最佳时机 (1)题目描述: , (2)解题思路: class Solution { public:int maxProfit(vector<int>& prices) {int len prices.size();if (len 0) return 0;vector<vector<int>> dp(len, vector<int>(2));dp[0][0] - pr…...
:神经架构搜索(NAS)实战)
PyTorch 深度学习实战(34):神经架构搜索(NAS)实战
在上一篇文章中,我们探讨了联邦学习与隐私保护技术。本文将深入介绍神经架构搜索(Neural Architecture Search, NAS)这一自动化机器学习方法,它能够自动设计高性能的神经网络架构。我们将使用PyTorch实现基于梯度优化的DARTS方法&…...

【python】速通笔记
Python学习路径 - 从零基础到入门 环境搭建 安装Python Windows: 从官网下载安装包 https://www.python.org/downloads/Mac/Linux: 通常已预装,可通过终端输入python3 --version检查 配置开发环境 推荐使用VS Code或PyCharm作为代码编辑器安装Python扩展插件创建第…...

简易Minecraft python
废话多说 以下是一个基于Python和ModernGL的简化版3D沙盒游戏框架。由于代码长度限制,这里提供一个核心实现(约500行),您可以通过添加更多功能和内容来扩展它: python import pygame import moderngl import numpy a…...

Linux信号处理解析:从入门到实战
Linux信号处理全解析:从入门到实战 一、初识Linux信号:系统级的"紧急电话" 信号是什么? 信号是Linux系统中进程间通信的"紧急通知",如同现实中的交通信号灯。当用户按下CtrlC(产生SIGINT信号&…...

2025-04-04 Unity 网络基础5——TCP分包与黏包
文章目录 1 分包与黏包2 解决方案2.1 数据接口2.2 定义消息2.3 NetManager2.4 分包、黏包处理 3 测试3.1 服务端3.2 客户端3.3 直接发送3.4 黏包发送3.5 分包发送3.6 分包、黏包发送3.7 其他 1 分包与黏包 分包、黏包指在网络通信中由于各种因素(网络环境、API …...

Ubuntu 安装 JMeter:为你的服务器配置做好准备
Apache JMeter 是一个开源的负载测试工具,可以用于测试静态和动态资源,确定服务器的性能和稳定性。在本文中,我们将讨论如何下载和安装 JMeter。 安装 Java(已安装 Java 的此步骤可跳过) 要下载 Java,请遵…...

swift-oc和swift block和代理
一、闭包或block 1.1、swift 闭包表达式作为参数的形式 一、闭包的定义 func exec(v1: Int, v2: Int, fn: (Int, Int) -> Int) { print(fn(v1, v2)) } 二、调用 exec(v1: 10, v2: 20, fn: { (v1: Int, v2: Int) -> Int in return v1 v2 }) 1.2、swift 闭包表达式作为…...

【数据结构】_队列
hello 友友们~ 今天我们要开始学习队列啦~ 话不多说,让我们开始吧!GO! 1.队列的概念及结构 队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表。 队列具有先进先出FIFO(First In First Out) 入队列&#x…...

【软考中级软件设计师】数据表示:原码、反码、补码、移码、浮点数
数据表示 一、数据表示1、整数的表示(1) 原码(2) 反码(3) 补码:(4) 移码 2、浮点数的表示(IEEE 754标准) 一、数据表示 计算机使用的是二进制,也就是0和1的组合。所有的数据,无论是数字、文字还是图片、声音ÿ…...
信号)
Linux(十二)信号
今天我们就要来一起学习信号啦!!!还记得小编在之前的文章中说过的ctrlc吗?之前小编没有详细介绍过,现在我们就要来学习啦!!! 一、信号的基本介绍 首先,小编带领大家先一…...
)
迪杰斯特拉+二分+优先队列+拓扑+堆优化(奶牛航线Cowroute、架设电话线dd、路障Roadblocks、奶牛交通Traffic)
原文地址 https://fmcraft.top/index.php/Programming/2025040402.html 主要算法 迪杰斯特拉Dijkstra 题目列表 P1:奶牛航线Cowroute 题目描述 题目描述 Bessie已经厌倦了农场冬天的寒冷气候,她决定坐飞机去更温暖的地方去度假。不幸的是…...

【数据结构】树的介绍
目录 一、树1.1什么是树?1.2 树的概念与结构1.3树的相关术语1.4 树形结构实际运用场景 二、二叉树2.1 概念与结构2.2 特殊的二叉树2.2.1 满二叉树2.2.2 完全二叉树 个人主页,点击这里~ 数据结构专栏,点击这里~ 一、树 1.1什么是树࿱…...
 D)
【CF】Day24——Codeforces Round 994 (Div. 2) D
D. Shift Esc 题目: 思路: 典DP的变种 如果这一题没有这个变换操作,那么是一个很典型的二维dp,每一个格子我们都选择上面和左边中的最小值即可 而这题由于可以变换,那我们就要考虑变换操作,首先一个显然…...

Python 字典
Python 字典 字典的介绍 字典不仅可以保存值,还能对值进行描述使用大括号来表示一个字典,不仅有值 value ,还有值的描述 key字典里的数据都是以键值对 key-value 的形式来保留的key 和 value 之间用冒号 : 来连接多个键值对之间用逗号 , 来…...

yolov12检测 聚类轨迹运动速度
目录 分割算法api版: 分割算法: yolo_kmean.py 优化版: 第1步,检测生成json 第2步骤聚类: 分割算法api版: import json import os from glob import globimport cv2 import imageio import numpy as np from scipy.ndimage import gaussian_filter1d from scipy.s…...

【Lua】pcall使用详解
目录 基本语法核心作用基础示例示例 1:捕获一个简单错误示例 2:调用不存在的函数 高级用法1. 传递多个参数和接收多个返回值2. 捕获带 error 主动抛出的错误3. 匿名函数与 pcall 使用场景注意事项总结 在 Lua 中,pcall(Protected …...

Floyd 算法 Java
图论算法实践:使用 Floyd 求任意两点最短路(Java 实现) 在图论算法中,Floyd-Warshall 算法是一个经典的动态规划算法,用于在一个加权图中寻找所有点对之间的最短路径。 场景描述 假设我们有一个包含 n 个点的无向图&…...

List结构之非实时榜单实战
像京东、淘宝等电商系统一般都会有热销的商品榜单,比如热销手机榜单,热销电脑榜单,这些都是非实时的榜单。为什么是非实时的呢?因为完全实时的计算和排序对于资源消耗较大,尤其是当涉及大量交易数据时。 一般来说&…...

OCR的备份与恢复
1.简介 在Oracle RAC环境中,ASM(Automatic Storage Management)管理的OCR(Oracle Cluster Registry)是集群的关键组件,存储集群配置和状态信息。 OCR的备份一般指物理备份,系统默认每4个小时自…...