AI 数理逻辑基础之统计学基本原理(上)
目录
文章目录
- 目录
- 统计学
- 统计学基本概念
- 描述性统计
- 数据可视化图表工具
- 汇总统计
- 统计数据的分布情况:中位数、众数、平均值
- 统计数据的离散程度:极差、方差、标准差、离散系数
- 相关分析
- Pearson 线性关系相关系数
- Spearman 单调关系相关系数
- 回归分析
- 回归模型
- 一元线性回归模型
- 应用最小二乘法来调整模型参数精度
- 如何评价回归模型的正确性?
- 多元线性回归模型
- 避免过度拟合问题
- 拟线性回归建模方法
- 聚类分析
- 主成分分析
- 判别分析
- 定性和定量分析的关系
统计学
- 定义:是一门关于 “数据资料” 的收集、整理、 描述、分析和解释的学科。
- 目的:探索数据集合的内在特征与规律性。
- 应用:对系统进行深入、全面的认识;对未来作出准确的预测,继而帮助决策。
- 方法:调查研究。
- 路径:数据收集、数据分析、建立概念、描述预测。
掌握统计学的数据科学家或工程师,他们和具体的行业紧密相联,有扎实的统计基础,也有丰富的行业经验。会编程、做数据可视化。通过海量数据进行分析,获得具有巨大价值的产品和服务,或深刻的洞见。
统计学基本概念
使用解字法,我们可以将 “统计学” 拆分为以下基本概念:
数据:英文单词 data,在拉丁文里是 “已知或事实” 的含义。典型的数据类型包括:
- 定性变量数据(Qualitative): 用于描述事物的属性或类别,其值通常是非数值的,无法进行数学运算。
- 名义变量(Nominal Scale):表示无顺序或等级差异的分类数据,仅用于标识或区分不同类别。例如:性别、颜色等。
- 顺序变量(Ordinal Scale):类别具有自然顺序或等级,但类别间的差异无法量化。例如:满意度评分、教育水平等。
- 定量变量数据(Quantitative):以数值形式表示,具有明确的数学意义,可进行算术运算
- 区间变量(Interval Scale):数值具有等距性,但无绝对零点。例如:温度、年份、IQ 分数等。允许加减运算,但不能计算比率,例如:20℃ 不是 10℃ 的两倍热。
- 比率变量(Ratio Scale):具有区间变量的所有特性,且还拥有绝对零点。即:“0” 可以表示 “无”。例如:身高、体重、收入等。可进行乘除运算,例如:身高 180cm 是 90cm 的两倍。
数据化:把现象转变成可以制表分析的量化形式过程。
数据收集:典型的数据来源包括:
- 统计数据:调查数据、实验数据、汇总数据等。
- 传感器记录数据:金融交易、市场价格、生产过程、财务、营销、传感器等。
- 新媒体网络数据:微信、微博、QQ、手机短信、图片、视频、音频等。
数据分析:典型的分析行为包括:
- 描述和分析系统特征,包括:现状、结构、因素之间关系等。
- 分析系统的运行规律与发展趋势,即:动态数据。
- 对系统的未来状态进行预测,例如:建立模型。
描述性统计
描述性统计用于将数据进行可视化展示,是一种将 “抽象思维” 转换为 “形象思维” 的工具和方法论。
把数字置于视觉空间中,读者的大脑就会更容易发现其中隐藏的模式,得出许多出乎意料的结果。—— Nathan Yau
- 目的:通过数据来描述规律、讲述真相、解决问题。
- 思维:问题导向。数据是用来讲故事的,而故事是面向听众的,而听众是带着问题来的,所以数据可视化使用围绕 “问题” 展开。对讲述问题有用的数据应该展示,相反则可以忽略。
- 技巧:用数据说话的强烈意识 对系统特性的深入思考尝试性分析、对信息点敏感,尤其对异常数据点敏感。
- 工具:图表。
- 基本原则:
- 准确:能清晰地表达主题。
- 醒目:信息点特别突出。
- 美观:图形使用应丰富多彩。
- 图、文并茂:文字应与图、表的篇幅平衡。
- 详略得当,防止冗长的流水帐。
数据可视化图表工具
-
柱形图(Bar Chart):用于描述定性数据的分布。适用于定性数据,例如:豆瓣电影评分。包括堆积柱形图、百分比堆积柱形图、瀑布图、漏斗图等变体。

-
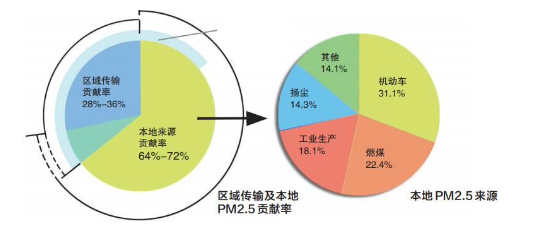
饼图(Pie Chart):用于描述数据的结构性特征。适用于定性数据,例如:北京市空气污染的主要来源。包括子母饼图、旭日图等变体。
-
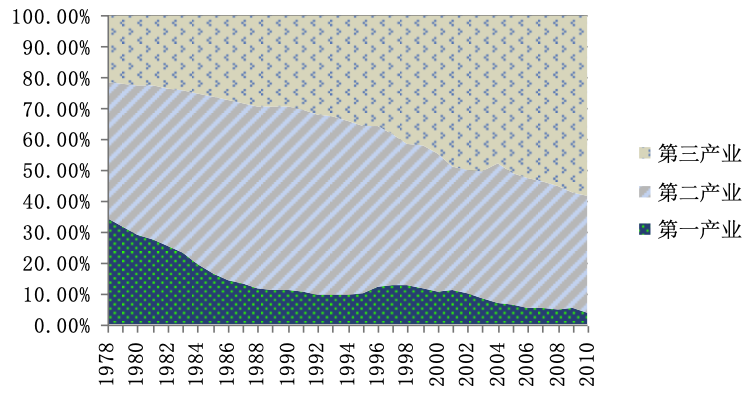
面积图:用于描述数据的动态比率结构。适用于定量数据,例如:上海就业人口的三产构成(1978—2011)。
-
折线图(Line Chart):用于描述数据的动态变化规律。适用于定量数据,例如:城乡居民家庭收入/元(1991~2003)。

-
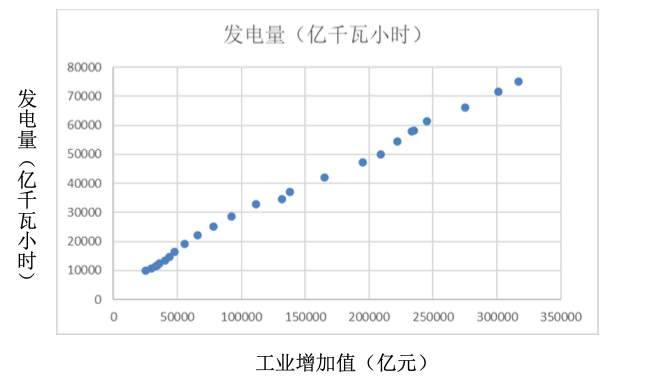
散点图(Scatter Plot):用于描述或反映 2 个定性变量之间的相关关系。例如:发电量与工业增加值的关系(1995~2019)
-
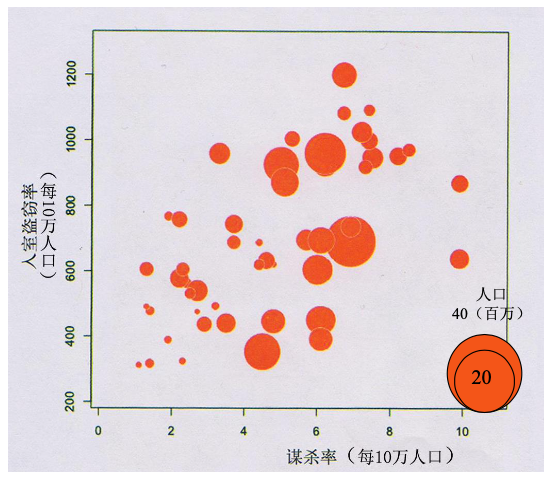
气泡图:用于描述 3 个定性变量的 n 个样本点之间的关系,例如:美国犯罪率气泡图。
-
雷达图(Radar chart):用于描述多个定性变量之间的数量关系,例如:城乡居民家庭平均每人生活消费支出(1997 年)。
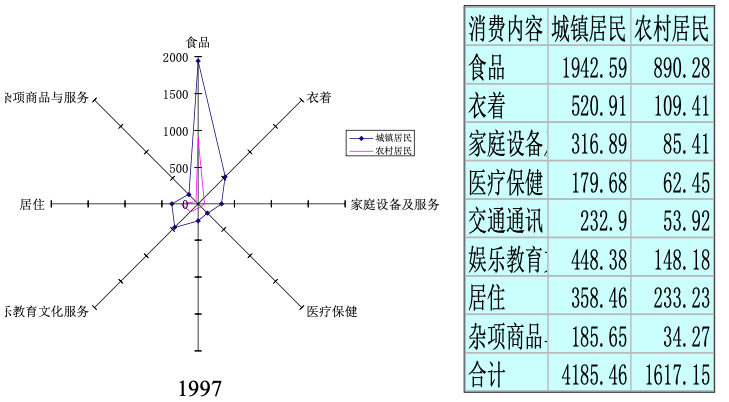
汇总统计
统计数据的分布情况:中位数、众数、平均值
我们通常可以使用 “中位数、众数、均值” 来描述基本的数据分布情况。但因为三者之间有着不同的特性,所以它们也有着不同的应用场景。
中位数(Median):将数据从小到大排序,处于中间位置的观测值(实际数值)。
- 对于一个数据集,中位数经过数值运算后始终是唯一的;
- 定性数据不能数值运算所以没有中位数;
- 只利用了数据集的中间位置数据,所以对两端的极端值不敏感。
- 应用场景:对于名义变量,用于描述集中趋势。
众数(Mode):出现频次最多的观测值。
- 对于一个数据集,众数可以不唯一;
- 众数不需要数值运算得出,所以定性数据有众数;
- 只利用了数据集的一部分数据,所以不容易受到极端值的影响。
- 应用场景:对于顺序变量,用于描述集中趋势。
平均值(Mean):所有数据之和除以数据的个数,反映数据的总体平均水平。
- 对于一个数据集,均值经过数值运算后始终是唯一的;
- 定性数据不能数值运算所以没有均值;
- 利用了数据集的全部数据参与数值运算,所以容易受极端值影响。
- 应用场景:定量变量,一般使用平均值。例如:歌唱比赛,首先应该利用所有评委的评分,其次应该去除最高分和最低分这 2 个极端值。
统计数据的离散程度:极差、方差、标准差、离散系数
所谓离散程度,即:数据集中每 2 个数据之间的差异程度。通常使用极差、方差、标准差、离散系数进行测量。
极差(Rang):最大值与最小值之间的差距,显然容易受到极端值的影响。
- 四分位极差(Interquartile Rang):为了消除极端值的影响。
方差(Variance):以均值为中心,测量所有观测值与均值的平均偏离程度。
-
总体方差(Population Variance):描述整个数据集所有数据与总体均值的偏离程度。“方差” 通常指的就是整体方差。
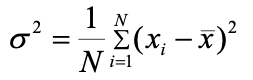
-
样本方差(Sample Variance):描述从整个数据集中抽取的样本数据与样本均值的偏离程度,是总体方差的估计量。当总体方差数据量特别巨大时,可以考虑用样本方差来进行预估。
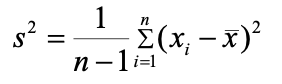
标准差(Standard Deviation):方差的平方根就是标准差。值得注意的是,在一个方差使用平方来表示观测值样本和均值先之间的 “垂直距离”,但平方也放大了数值的量纲。所以标准差就是对方差的平方开根,将结果数值还原为与原样本相同的量纲。
离散系数(Coefficient of Variation):标准差常用于描述一个数据集的离散程度;而离散系数则用于比较 2 个及以上数据集之间的离散程度。离散系数是一种 “无量纲” 的相对度量,公式如下,离散系数等于标准差除以均值,从而消除了量纲的影响,例如:1.4/6=0.23 和 14/60=0.23 之间的 CV 相同,但量纲相差了 10 倍。反之,通常不会使用标准差作为多个数据集之间的离散程度的比较。
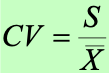
相关分析
线性关系:线性函数 Y=f(X),每一个 X 值都唯一地对应一个 Y 值。
随机关系(Stochastic Relationship):当 X 的值给定时,Y 的取值服从一个分布,而不是一个唯一对应的 Y 值。
相关系数(The Correlation Coefficient):在随机关系场景中,需要引入一个相关系数来描述 “X” 和 “Y 的取值分布” 之间的关联程度的量化指标。简而言之,相关系数描述了 2 个变量 a、b 之间是否存在关系,以及关系是否密切(是否线性相关)。
现如今,根据不同的数据类型和数据分析需求,相关系数有多种定义和计算方法。包括:Pearson、Spearman、Kendall 等相关系数。
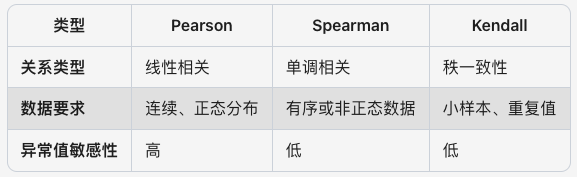
Pearson 线性关系相关系数
Pearson(皮尔逊)相关系数 r(x, y),用于衡量两个连续变量之间的 “线性相关” 程度。
- 存在 2 个连续变量 x 和 y:

- Pearson 系数计算公式:分子为 x 和 y 的样本协方差,分母为 x 和 y 的样本方差的乘积。

r(x, y) 的取值范围诶 [-1, 1],对应的判别性质为:

最佳实践经验值为:

Spearman 单调关系相关系数
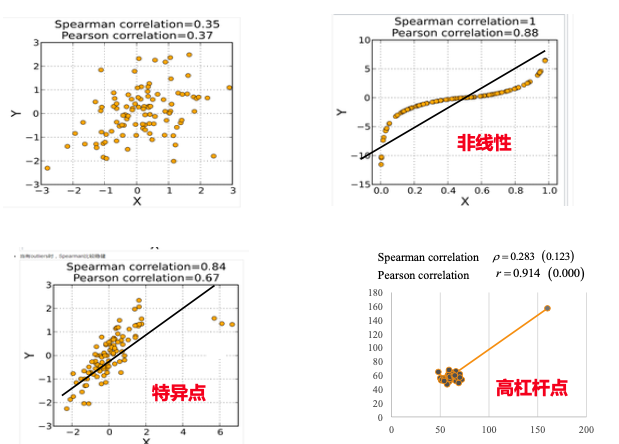
Pearson 用于测量 x 和 y 连续变量之间的线性相关性,但现实中存在大量非线性相关的数据集,但它们之间也会存在某种关联关系,如单调关系。单调关系,即:即一个 x 变量增加时,另一个 y 变量是否倾向于同向或反向的变化,而不会要求严格线性关系。
Spearman 单调关系(正相关、负相关)相关系数,基于 2 个连续变量之间的秩次( Ranks,排序位置)来进行计算。可用于线性或非线性连续变量数据集,尤其适用于顺序连续变量、存在异常值的连续变量、非正态分布连续变量。
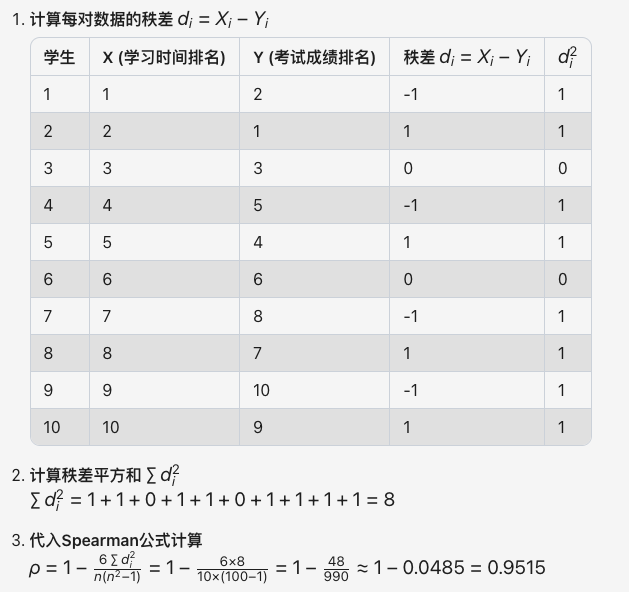
例如:使用 Spearman 来判别某班级 10 名学生按学习时间(小时/周)和考试成绩排名之间的单调关系。如下表。
| 学生 | 学习时长 a | 学习时长排名 x | 考试成绩 b | 考试成绩排名 y |
|---|---|---|---|---|
| A | 十小时 | 1 | 99 | 2 |
| B | 九小时 | 2 | 100 | 1 |
| C | 八小时 | 3 | 98 | 3 |
| D | 七小时 | 4 | 96 | 5 |
| E | 六小时 | 5 | 97 | 4 |
| F | 五小时 | 6 | 95 | 6 |
| G | 四小时 | 7 | 93 | 8 |
| H | 三小时 | 8 | 94 | 7 |
| I | 二小时 | 9 | 91 | 10 |
| J | 一小时 | 10 | 92 | 9 |
显然,以上 a 和 b 两组数据呈现出非线性特征,但这两组数据未必就不存在任何正相关或负相关的关系。同时 a 和 b 两组数据属于顺序变量类型,所以可以采用 Spearman 来测量判别。
从下述计算可知,Spearman 计算过程完全不关心 a 和 b 的实际数据,只会关系 x 和 y 的 ranks 排名关系。计算结果 Spearman 系数 ≈0.952,接近 1,表明学习时间排名与考试成绩排名存在极强的正相关。
回归分析
回归模型
回归模型(regression)的诞生可以追溯到 19 世纪,英国生物统计学家弗朗西斯·高尔顿(Francis Galton)在研究遗传特征时提出。1886 年,高尔顿发表了《遗传的身高向平均数方向的回归》一文,通过分析 1078 对父母与子女的身高数据,发现了一个有趣的现象:
- 身材较高的父母,其子女身高也高于平均身高,但通常不如父母那么高;
- 身材较矮的父母,其子女身高也比平均身高矮,但不如父母那么矮。
高尔顿将这种后代身高 “趋向于平均身高” 的现象称为 “回归”。
高尔顿的学生卡尔·皮尔逊(Karl Pearson)进一步收集了更多数据,证实了这一发现,并建立了第一个数学形式的回归方程:ŷ = 33.73 + 0.516x,其中 x 为父母平均身高,ŷ 为预测的子女身高。这一方程表明父母身高每增加一个单位,其成年子女身高平均增加约 0.516 个单位,体现了 “趋中回归” 的现象。
但需要注意的是,随着研究的发展,“回归” 一词在现代统计学中的含义已经与原始含义不同。现代回归分析主要关注建立自变量 x 和因变量 y 之间的关系模型,即:研究因变量与自变量之间的统计关系。而不再局限于高尔顿发现的 “趋中” 现象。
更具体而言,现代回归模型主要用于解决以下问题:
- 变量关系建模:量化自变量 x 与因变量 y 之间的关系强度与方向。例如:研究广告投入与销售额之间的关系。
- 预测未来数值:基于已知的数据集 x 和 y 求解总体参数 βi 和随机误差 ϵ,继而建立其回归模型(公式),用于预测未来的数值 ŷ。例如:预测房价、股票价格或疾病风险。
- 分类问题处理:虽然回归模型主要用于连续值的预测,但通过逻辑回归等变体,回归模型也能有效解决分类问题。
回归模型的经典方程为:Y=f(X)+ϵ
- Y:因变量
- X:自变量
- f(X):回归函数,如:
- 线性回归函数:一元线性回归模型 Y=β0+β1X 。
- 非线性回归函数:多项式回归模型 Y=β0+β1X+β2X^2
- 逻辑回归函数:如 Sigmoid 函数,用于分类问题。
- ϵ:随机误差
总而言之,回归分析特别适用于需要量化关系、精确预测和分类问题的场景,它通过数学形式明确表达了变量间的关联,比上文中提到的相关分析能提供更多信息。
一元线性回归模型
一元线性回归(Simple Linear Regression Model)用于线性关系预测场景。
数据模型为:
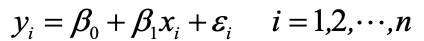
- y:因变量(被预测变量)
- x:自变量(预测变量)
- β0:截距(Y 轴交点)
- β1:斜率(X 每变化 1 单位,Y 的变化量)
- ϵ:随机误差(无法由 X 解释的波动)
在一元线性回归模型的实际应用中,首先需要提供 n 个 (x, y) 的样本数据集,用于反解/估计出模型参数 β0、β1 的估计量 b0、b1,继而得到预测函数。
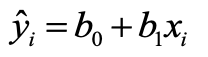
如上图,称为 “一元回归线”。然后,基于一元回归线,对于 n 个新的输入数据 x,可以求解出对应的 ŷ,即:y 的拟合值(预测值)。
应用最小二乘法来调整模型参数精度
上文中,一元回归线函数可以用于预测,但预测的准确度应该如何量化和调整呢?即:模型参数 β0、β1 的估计量 b0、b1 的精度到底是好是坏?这里面显然还需要补充一种 “反馈调整模型参数” 的机制。
最小二乘法(Least Squares Method)就是一种结合了 “预测和反馈调整” 的回归模型,其通过 “最小化残差平方和” 来寻找数据的最佳函数匹配。它在回归分析、曲线拟合、参数估计等领域有广泛应用。
简而言之,最小二乘法的核心思想是最小化 “观测值”与 “模型预测值” 之间的残差平方和,以此来 “自动反馈调整” 预测模型的参数。在一元回归线函数的基础上,在得到拟合值 ŷ 之后,再与观测值 y 计算出残差值。进一步的对于 n 个 (x, y) 的数据集,就可以计算出残差平方和。
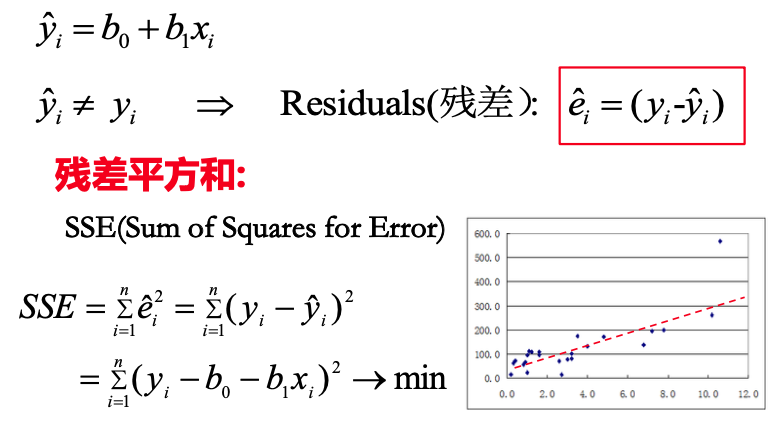
理解 “残差平方和” 的几何意义可以类比 “方差”,即:以预测值为中心,测量所有观测值与预测值的偏离程度,当 SSE 趋于 min 时,一元回归线的模型参数越精确。最小二乘法通过最小化平方残差提供了一种直观且高效的参数估计方法,但其效果依赖于模型假设和数据质量。
如何评价回归模型的正确性?
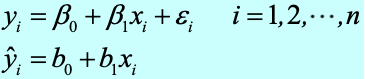
最后,我们还需要解决一个问题,即:如何评价一个线性回归模型的正确性呢?这包含了 3 个层面:
- 该模型能否较好地解释 yi 的取值变化规律?
- x 与 y 是线性关系吗?
- x 在解释 y 时是一个有用的自变量吗?
对应的也有 3 种模型评估方法:
-
R^2 拟合优度判定系数(Coefficient of Determination):公式如下,分子是残差平方和,分母是方差。

-
F-test:检验回归模型的线性关系。当 Significance F < 0.05 时, F-test 通过,X 和 Y 之间存在线性关系。
-
t-test:回归系数的显著性检验。当 P-value < 0.05 时, t-test 通过,X 对 Y 有解析作用。
实际上,在实际应用中,R^2、F-test、t-test 的计算都可以交由现代计算软件完成,如下图所示。我们只需要关注结果继而判断模型质量即可。
多元线性回归模型
多元线性回归模型,顾名思义,相较于一元线性回归模型,拥有多个因变量 Xj,及其对应的模型参数 β0、β1、… 、βk,如下图。
同样的,可以采用最小二乘法来求解模型参数,构建多元线性回归模型,如下图。

也同样的,可以采用 R^2、F-test、t-test 来评价多元线性回归模型的质量好还。
避免过度拟合问题
过度拟合(Overfitting)指回归模型在观测数据(训练样本)上表现优异,例如:R^2 评分特别的高。然而该回归模型在新数据(真实场景数据)上却表现出了精度显著下降的现象,即:泛化能力差(指回归模型对新数据的预测能力)。
如下图所示,图(1)的精度不够,图(3)过度拟合了,而图(2)则是刚好(具有普遍泛化预测能力)。
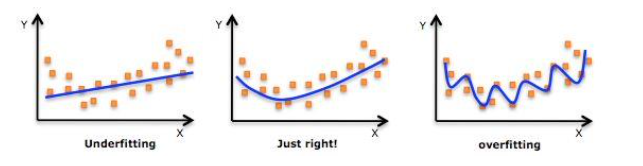
出现过度拟合问题的常见原因有 3 大类型:
- 数据层面:训练样本数量不足,导致模型无法学习到普遍规律。
- 模型层面:模型的参数太多,模型复杂度过高。
- 特征层面:训练样本噪音(异常点)干扰过大,模型误将噪音认为是特征,从而扰乱了模型参数。
对应的也有以下常规解决思路:
- 增加数据量。
- 简化模型。
- 清洗噪音数据。
此外还需要一系列的检测方法来识别过度拟合问题:
- 交叉验证法
- 留一交叉验证法
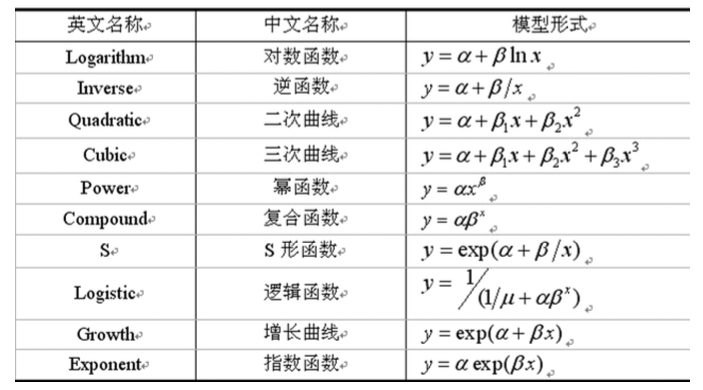
拟线性回归建模方法
上述我们讨论的一元线性回归模型、多元线性回归模型都是线性相关场景的模型建模。但实际生活中还存在大量的非线性相关场景,例如:多项式模型、指数模型等。此时可以采用拟线性回归方法,即:将非线性关系线性化,然后再运用线性模型。如下图所示,将一个 “多项式模型” 转换为了一个 “多元线性模式”。

常用的拟线性回归模型如下表所示。
聚类分析
主成分分析
判别分析
定性和定量分析的关系
相关文章:
)
AI 数理逻辑基础之统计学基本原理(上)
目录 文章目录 目录统计学统计学基本概念描述性统计数据可视化图表工具 汇总统计统计数据的分布情况:中位数、众数、平均值统计数据的离散程度:极差、方差、标准差、离散系数 相关分析Pearson 线性关系相关系数Spearman 单调关系相关系数 回归分析回归模…...

C++容器数据类型定义、测试用例
C11 标准库提供了多种容器类型,每种容器定义了多个成员类型(如 value_type、iterator 等),用于与容器交互。以下详细说明各容器的数据类型定义、测试用例及注意事项。 一、顺序容器 1. std::vector<T> 类型定义࿱…...

bun 版本管理工具 bum 安装与使用
在使用 node 的过程中,我们可能会因为版本更新或者不同项目的要求而频繁切换 node 版本,或者是希望使用更简单的方式安装不同版本的 node,这个时候我们一般会用到 nvm 或者类似的工具。 在我尝试使用 bun 的时候,安装前第一个想到…...

AI——使用numpy
文章目录 一、numpy的介绍1、ndarray介绍2、ndarray使用1、ndarray的属性2、ndarray生成数组的方法 3、修改数组的形状4、修改数组的类型5、数组去重 二、数组的运算1、逻辑运算2、通用判断函数3、三元运算符4、统计运算 三、数组间运算四、数学:矩阵 一、numpy的介…...

在线追思:一个虚拟扫墓平台,让思念不受时空限制
在线追思:一个虚拟扫墓平台,让思念不受时空限制 📢 重要分享 今天想与大家分享一个特别的网站——在线追思平台。这是一个让我们能随时随地表达对逝者思念之情的虚拟扫墓平台。 🌟 为什么需要在线追思? 在现代生活的…...

Visual Basic语言的网络协议栈
Visual Basic语言的网络协议栈 引言 在当今信息技术高速发展的时代,网络通信已经成为各类应用程序中不可或缺的部分。无论是网页浏览、文件传输,还是即时通讯,网络协议的有效实现都是保证数据顺利传输和信息安全的重要基础。在这种背景下&a…...

python速通小笔记-------4.Pandas库
1.pandas介绍 1.一维数组的创建 1.字典创建法-----------pd.Series(字典) 使用pd.Series(),参数为已经创建好了的字典 2.数组创建法-----------pd.Series(列表1,index列表2) 2.一维对象的属性 sr.values----------查看所有的vsr.index----…...

P7453 [THUSC 2017] 大魔法师 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an), b ( b 1 , b 2 , ⋯ , b n ) b(b_1,b_2,\cdots,b_n) b(b1,b2,⋯,bn) 和 c ( c 1 , c 2 , ⋯ , c n ) c(c_1,c_2,\cdots,c_n) c(c1,c2,⋯,cn)&…...

小程序API —— 58 自定义组件 - 创建 - 注册 - 使用组件
目录 1. 基本介绍2. 全局组件3. 页面组件 1. 基本介绍 小程序目前已经支持组件化开发,可以将页面中的功能模块抽取成自定义组件,以便在不同的页面中重复使用;也可以将复杂的页面拆分成多个低耦合的模块,有助于代码维护࿱…...

#Liunx内存管理# 在32bit Linux内核中,用户空间和内核空间的比例通常是3:1,可以修改成2:2吗?
在32位Linux内核中,用户空间和内核空间的3:1默认比例可以修改为2:2,但需要权衡实际需求和潜在影响。以下是具体分析: 一、修改可行性 1.技术实现 通过内核启动参数调整虚拟地址空间划分,例如在GRUB配置中添加mem2G参数,…...

经济统计常见的同比与环比是啥意思?同比和环比有什么区别?
在经济统计领域,其实大家都会经常性看到同比还有环比,可人们对此就会觉得有些疑惑。到底是什么意思?这两者之间又有什么样的区别呢?下面就为大家来详细的介绍一下。 同比与环比是用于衡量数据变化趋势的关键指标,可以给…...
)
前端知识点---本地存储(javascript)
localStorage 是浏览器提供的一个 本地存储 API,可以在用户的浏览器中存储数据,数据不会随页面刷新而丢失。 1. 基本用法 (1) 存储数据(setItem) localStorage.setItem("username", "zhangsan");存储 “use…...
——构建侧边栏以及设置图标字体)
压测工具开发实战篇(二)——构建侧边栏以及设置图标字体
你好,我是安然无虞。 文章目录 构建侧边栏QtAwesome使用调整侧边栏宽度了解: sizePolicy属性伪状态 在阅读本文之前, 有需要的老铁可以先回顾一下上篇文章: 压测工具开发(一)——使用Qt Designer构建简单界面 构建侧边栏 我们要实现类似于下面这样的侧边栏功能: …...

【Java Stream详解】
文章目录 前言一、Stream概述1.1 什么是 Stream?1.2 Stream 和集合的区别 二、Stream的创建方式2.1 基于集合创建2.2 基于数组创建2.3 使用 Stream.generate()2.4 使用 Stream.iterate() 三、Stream常见操作3.1 中间操作(Intermediate)① fil…...

16进制在蓝牙传输中的应用
在蓝牙传输中,16进制(Hexadecimal)是一种常用的数据表示方法。它主要用于描述数据包的内容、地址、命令、参数等信息。以下是16进制在蓝牙传输中的具体应用场景和作用: 1. 数据包的表示 蓝牙通信中,所有数据最终都以二…...

TypeConverter
文章目录 基本描述主要功能接口源码主要实现最佳实践与其他组件的关系常见问题 基本描述 TypeConverter接口是Spring框架中用于在SpEL(Spring表达式语言)中进行类型转换的核心接口,它允许将不同类型的对象相互转换,例如将字符串转…...
)
优化 Web 性能:压缩 CSS 文件(Unminified CSS)
在 Web 开发中,CSS 文件的大小直接影响页面加载速度和用户体验。Google 的 Lighthouse 工具在性能审计中特别关注“未压缩的 CSS 文件”(Unminified CSS),指出未经过压缩的样式表会增加不必要的字节,拖慢页面渲染。本文…...
EnumChildWindows+shellcode)
每日一个小病毒(C++)EnumChildWindows+shellcode
这里写目录标题 1. `EnumChildWindows` 的基本用法2. 如何利用 `EnumChildWindows` 执行 Shellcode?关键点:完整 Shellcode 执行示例3. 为什么 `EnumChildWindows` 能执行 Shellcode?4. 防御方法5. 总结EnumChildWindows 是 Windows API 中的一个函数,通常用于枚举所有子窗…...

leetcode数组-移除元素
题目 题目链接:https://leetcode.cn/problems/remove-element/ 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。 假设 nums 中不等于 val 的元素数量为…...

Git 教程:从 0 到 1 全面指南 教程【全文三万字保姆级详细讲解】
目录 什么是 Git ? Git 与 SVN 区别 Git 安装配置 Linux 平台上安装 Centos/RedHat 源码安装 Windows 平台上安装 使用 winget 工具 Mac 平台上安装 Git 配置 用户信息 文本编辑器 差异分析工具 查看配置信息 生成 SSH 密钥(可选…...

在 Android Studio 中运行安卓应用到 MuMu 模拟器
一、准备工作 1、确保 MuMu 模拟器已正确安装并启动 从官网下载安装最新版 MuMu 模拟器。启动后,建议在设置中调整性能参数(如 CPU 核心数和内存分配),以保证流畅运行。 2、配置 Android Studio 环境(按…...

stable diffusion部署ubuntu
stable-diffusion webui: https://github.com/AUTOMATIC1111/stable-diffusion-webui python3.10 -m venv venv(3.11的下torch会慢得要死) source venv/bin/activate 下载checkpoint模型放入clip_version"/home/chen/软件/stable-diffusion-webu…...

《概率论与数理统计》期末复习笔记_下
目录 第4章 随机变量的数字特征 4.1 数学期望 4.2 方差 4.3 常见分布的期望与方差 4.4 协方差与相关系教 第5章 大数定律和中心极限定理 5.1 大数定律 5.2 中心极限定理 第6章 样本与抽样分布 6.1 数理统汁的基本概念 6.2 抽样分布 6.2.1 卡方分布 6.2.2 t分布 6.…...

Java异步编程实战:线框-管道模型的设计与实现
一、什么是线框-管道模型? 线框-管道模型(Pipeline-Filter Pattern)是一种经典的数据处理架构,其核心思想是将复杂任务拆分为多个独立的处理阶段(Filter),通过管道(Pipe)…...

Linux make与makefile 项目自动化构建工具
本文章将对make与makefile进行一些基础的讲解。 假设我们要建造一座房子,建造过程涉及很多步骤,比如打地基、砌墙、安装门窗、粉刷墙壁等。每个步骤都有先后顺序,并且有些步骤可能依赖于其他步骤的完成。比如,你必须先打好地基才…...

鸿蒙 harmonyOS 网络请求
应用通过HTTP发起一个数据请求,支持常见的GET、POST、OPTIONS、HEAD、PUT、DELETE、TRACE、CONNECT方法。 接口说明 HTTP数据请求功能主要由http模块提供。 使用该功能需要申请ohos.permission.INTERNET权限。 第一步 : 在module.json5文件里面添加网络…...

【Tauri2】014——简单使用listen和emit
前言 【Tauri2】013——前端Window Event与创建Window-CSDN博客https://blog.csdn.net/qq_63401240/article/details/146981362?spm1001.2014.3001.5502【Tauri2】012——on_window_event函数-CSDN博客https://blog.csdn.net/qq_63401240/article/details/146909801?spm1001…...

解锁 C 语言安全新姿势:C11 安全函数全解析
一、开篇:C 语言安全的新护盾 在 C 语言的编程世界里,缓冲区溢出等安全问题犹如潜藏的暗礁,时刻威胁着程序的稳定与安全。为了有效应对这些挑战,C11 标准引入了一系列安全函数,也被称为 “Annex K” 标准库函数。这些…...

【centos】经常使用的脚本
磁盘挂载 yum install wget -y && wget -O auto_disk.sh http://download.bt.cn/tools/auto_disk.sh && bash auto_disk.shYum镜像源更换 bash <(curl -sSL https://linuxmirrors.cn/main.sh)Yum切换安装的java版本 sudo alternatives --config java...

Unity URP渲染管线详解
一、URP概述 Universal Render Pipeline (URP,通用渲染管线)是Unity推出的轻量级、高性能渲染管线解决方案,适用于移动平台、PC和主机等多种平台。 URP核心特点 跨平台支持:针对不同硬件自动优化 模块化设计:可扩展的渲染功能 …...

Python语言的测试用例设计
Python语言的测试用例设计 引言 随着软件开发的不断进步,测试在软件开发生命周期中的重要性日益凸显。测试用例设计是软件测试的核心,它为软件系统的验证和验证提供了实施的基础。在Python语言中,由于其简洁明了的语法和强大的内置库&#…...
)
【记录】kali制作绕过火绒检测的木马(仅通过MSF的方式)
目的:制作一个能够绕过火绒检测的简单木马,熟悉一下怎么使用msfvenom制作木马,因此此处使用的火绒版本较低。 工具准备:火绒安全-3.0.42.0 【点击免费下载工具】 **实验环境:**kali-2019.4 (攻击方&…...

Linux系统进程
Linux系统进程 程序开始 编译链接的引导代码 操作系统下的应用程序在main执行前也需要先执行段引导代码才能去执行main,但写应用程序时不用考虑引导代码的问题,编译连接时(准确说是链接时)由链接器将编译器中事先准备好的引导代码…...

Obsidian按下三个横线不能出现文档属性
解决方案: 需要在标题下方的一行, 按下 键盘数字0后面那个横线(英文横线), 然后回车就可以了 然后点击横线即可...

GitHub 上开源一个小项目的完整指南
GitHub 上开源一个小项目的完整指南 🚀 第一步:准备你的项目 在开源之前,确保项目是可用且有一定结构的: ✅ 最低要求 项目文件清晰、结构合理(比如:src/、README.md、LICENSE)项目能在本地正…...

大模型——MCP 集成至 LlamaIndex 的技术实践
MCP 集成至 LlamaIndex 的技术实践 一、前言 本文主要介绍了如何将 MCP(Model Context Protocol,模型上下文协议)工具转换为可以直接使用的 LlamaIndex 工具,使 LlamaIndex 用户能像使用 Claude, Cursor 等现代 AI 应用一样无缝集成这些服务。 二、技术背景 2.1 什么是…...

leetcode 1123. 最深叶节点的最近公共祖先
给你一个有根节点 root 的二叉树,返回它 最深的叶节点的最近公共祖先 。 回想一下: 叶节点 是二叉树中没有子节点的节点树的根节点的 深度 为 0,如果某一节点的深度为 d,那它的子节点的深度就是 d1如果我们假定 A 是一组节点 S …...

LeetCode热题100记录-【链表】
链表 160.相交链表 思考:只要p1和p2不相等就一直在循环里,因为就算都为null也会走到相等 记录:需要二刷 public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {ListNode p1 headA,p2 headB;whi…...

Python 布尔类型
Python 布尔类型(Boolean) 布尔类型是Python中的基本数据类型之一,用于表示逻辑值。它只有两个值: True - 表示真False - 表示假 1. 布尔值的基本使用 # 定义布尔变量 is_active True is_admin Falseprint(is_active) # 输出: True print(is_admi…...

恒盾C#混淆加密卫士 - 混淆加密保护C#程序
对于大部分C#开发者来说,写完代码点个发布就完事儿了,但你可能不知道——用记事本都能扒开你编译好的程序!像dnSpy这类反编译工具,分分钟能把你的EXE/DLL变回原汁原味的源代码,商业机密赤裸裸曝光不说,竞争…...

Java基础 4.4
1.方法快速入门 public class Method01 {//编写一个main方法public static void main(String[] args) {//方法使用//1.方法写好后,如果不去调用(使用),不会输出Person p1 new Person();p1.speak();//调用方法 p1.cal01();//调用计算方法1p1.cal02(10);…...

黑马点评redis改 part 1
本篇将主要阐述短信登录的相关知识,感谢黑马程序员开源,感谢提供初始源文件(给到的是实战第7集开始的代码)【Redis实战篇】黑马点评学习笔记(16万字超详细、Redis实战项目学习必看、欢迎点赞⭐收藏)-CSDN博…...

降维算法之t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding)算法详解 先说理解: t-SNE(t-distributed Stochastic Neighbor Embedding)是一种用来“可视化高维数据”的降维方法,通俗来说,它就像一个…...

使用 .NET 9 和 Azure 构建云原生应用程序:有什么新功能?
随着 .NET 9 推出一系列以云为中心的增强功能,开发人员拥有比以往更多的工具来在 Azure 上创建可扩展、高性能的云原生应用程序。让我们深入了解 .NET 9 中的一些出色功能,这些功能使构建、部署和优化云应用程序变得更加容易,并附有示例以帮助…...

python基础-10-组织文件
文章目录 【README】【10】组织文件(复制移动删除重命名)【10.1】shutil模块(shell工具)【10.1.1】复制文件和文件夹【10.1.1.1】复制文件夹及其下文件-shutil.copytree 【10.1.2】文件和文件夹的移动与重命名【10.1.3】永久删除文件和文件夹【10.1.4】用…...

从代码学习深度学习 - LSTM PyTorch版
文章目录 前言一、数据加载与预处理1.1 代码实现1.2 功能解析二、LSTM介绍2.1 LSTM原理2.2 模型定义代码解析三、训练与预测3.1 训练逻辑代码解析3.2 可视化工具功能解析功能结果总结前言 深度学习中的循环神经网络(RNN)及其变种长短期记忆网络(LSTM)在处理序列数据(如文…...

linux gcc
一、常用编译选项 基本编译 gcc [input].c -o [output] 示例: gcc hello.c -o hello # 将 hello.c 编译为可执行文件 hello ./hello # 运行程序 分步编译 预处理:-E(生成 .i 文件) gcc -E hello.c -o hello…...

“一路有你”公益行携手《东方星动》走进湖南岳阳岑川镇中心小学
2025年4月2日,“一路有你”公益行携手《东方星动》走进湖南岳阳岑川镇,一场充满爱与温暖的捐赠仪式在岑川镇中心小学隆重举行。这是一场跨越千里的爱心捐赠,也是一场别开生面的国防教育,更是一场赋能提质的文化盛宴。 岑川镇地处湘…...

HTML语言的空值合并
HTML语言的空值合并 引言 在现代Web开发中,HTML(超文本标记语言)是构建网页的基础语言。随着前端技术的快速发展,开发者们面临着大量不同的工具和技术,尤其是在数据处理和用户交互方面。空值合并是一些编程语言中常用…...

并发上传及 JS 的单线程特性
1. JS 的单线程特性 JS 是单线程特性,这意味着所有代码都在一个线程上(即主线程)执行,同一时间只有一个任务在执行,其他任务都在等待。 这意味着即使有多个异步操作,它们的回调函数也会按顺序执行ÿ…...