分子生成的深层次层次变分自编码器 - DrugHIVE 测评
一、背景介绍
DrugHIVE 来源于南加州大学定量与计算生物学系的 Remo Rohs 为通讯作者的文章:《Structure-Based Drug Design with a Deep Hierarchical Generative Model》。文章链接:https://pubs.acs.org/doi/10.1021/acs.jcim.4c01193。该文章在 2024 年 7 月 26 日发表于 《Journal of Chemical Information and Modeling》 上。

为了应对筛选放面对的计算和类药化合物的搜索限制,作者提出了深度学习方法 DrugHIVE 。该方法是一种深层次层次变分自编码器的生成模型,从现有数据中学习药物-靶标系统中分子内和分子间的关系,以实现对生成分子的精细控制。作者设计了一系列药物设计任务实验,如从头生成分子、分子优化、骨架跃迁、连接体设计和高通量模式替换等展示 DrugHIVE 的性能。作者还在 AlphaFold 预测的受体上进行评估,展示了 DrugHIVE 的高度可拓展性。
二、模型介绍
传统的类药化合物库筛选的药物发现策略受限于化合物库的规模和筛选的成本,难以有效拓展整个类药化合物空间,并且整个过程严重依赖于专家的专业知识和经验。深度学习生成方法可以在受体-配体数据集上学习其相互作用,有效缩小药物搜索的化学空间,并且针对骨架跃迁、片段生长和分子优化等早期药物设计任务显现出有前景的应用潜能。
在本研究中,作者提出了 DrugHIVE ,这是一种基于层次变分层次变分自编码器的深度结构分子生成模型。与传统编码器-解码器模型不同,DrugHIVE 采用了一种更自然地表示分子空间分布的层次先验结构。使用层次先验可以在不同的空间尺度上对分子结构进行编码,并生成具有高空间控制的新分子,这对于许多药物设计任务都是必须的。DrugHIVE 在生成高预测结合亲和力和高药物相似性分子方面优于当前最先进的自回归和基于扩散的方法。并且,DrugHIVE 采用单次生成方式,显著快于其他需要多步推理的方法。
DrugHIVE 能够以多种方式生成分子,可以完成一系列常见的药物设计任务。作者展示了通过进化潜在空间搜索以优化分子类药属性、结合亲和力和选择性的能力。作者还将模型应用于自动替换泛测干扰化合物(PAINS)模式、连接片段筛选实验的活性片段的 linker 设计、子结构修改(骨架跳跃)和分子结构生长(片段生长)等任务。评估试验结果表明,DrugHIVE 能够成功生成并优化与受体结合亲和力预测值更高的配体,利用AlphaFold2 预测的结构,将生成分子设计的界限扩展到当前可用晶体结构之外。
2.1 模型框架
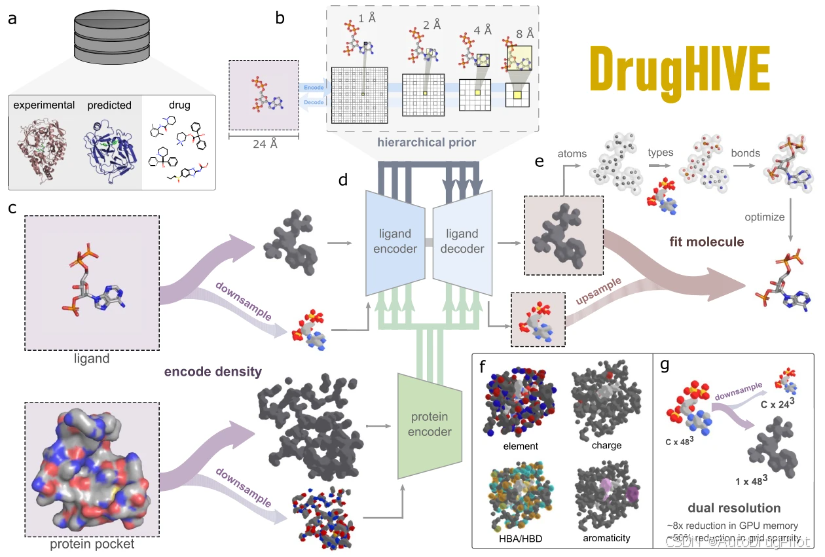
DrugHIVE 模型整体如下图所示。图 a 表示模型的输入数据可以来自于实验结构、预测结构或类药分子库。DrugHIVE 在实验结构和类药分子数据上进行训练,并且可以使用这些来源的数据类型进行分子生成。图 b 展示了先验的层次结构,表示不同的空间尺度。如图 c 中所示,输入分子首先被转换为分子密度网格,其中每个原子通过多通道伪高斯密度表示,每个通道代表不同的原子特征。对于每个原子,相同的原子密度被放置在与其特征相对应的每个网格通道中。
DrugHIVE 使用 15 个特征通道的子集:九种原子元素(C、N、O、F、P、S、Cl、Br、I)和六个其他原子特征(氢键供体、氢键受体、芳香性、正电荷、中性电荷和负电荷)。评估时,使用仅包含九种原子元素的模型版本。
DrugHIVE 由配体编码器、蛋白质编码器和配体解码器组成,如下图d所示。分子网格通过两条路径输入网络一条是全分辨率通道放置在网络层的最上方,一条以2作为因子的下采样通道,输入到网络中下采样层之后。模型使用这种层排列方式的镜像。通过以这种方式将占用率与原子特征分离,我们可以保留原子位置信息,同时显著降低网格稀疏性和内存负载。
DrugHIVE 基于层次变分自编码器(HVAE)架构,是层次贝叶斯方法的深度学习实现。与标准变分自编码器(VAE)类似,其目标是学习将输入数据可逆编码为多维正态分布的潜在空间。标准 VAE 只有一个潜在表示,而 HVAE 具有多个层次,并且较低层次与较高层次之间存在依赖关系。这种结构非常适合具有固有层次关系的数据。在成功训练的模型中,可以通过从这个潜在分布中抽取并解码随机样本来生成新的实例。如图 e 所示,模型输出原子占据率(全分辨率)和原子类型网格(半分辨率),然后与分子结构进行拟合。首先,将原子拟合到原子占据率密度上,并使用上采样的原子类型密度分配原子类型。接下来,应用键连接算法将原子连接起来。最后,使用力场优化放松原子位置和键长。图 f 展示了通过不同网格通道表示的原子性质,如原子序数(元素)、氢键受体(HBA)、氢键供体(HBD)和芳香性。图 g 显示了原子占据率在单个全分辨率通道中表示,而原子性质在半分辨率通道中表示,这有助于减少内存消耗和网格稀疏性。
2.2 数据集和评价指标
作者在 DrugHIVE 的训练和评估中使用了两个数据集:PDBbind(v2020,精炼集)和 ZINC 药物样本集的一个子样本。PDBbind 精炼集提供了一组配体与蛋白受体结合的高质量晶体结构。作者移除了配体过宽(>16 Å)或具有超过阈值原子数量(>43)的结构,从数据集中随机选择了 100 个受体结构作为测试集。为了改进训练并减少由于 PDBbind 数据集中配体样本相对较少而导致的过拟合风险,作者还在未结合的药物分子上使用了 ZINC 数据集的一个子样本。从 ZINC 药物样本集中开始,基于 ALogP(辛醇-水分配系数,衡量疏水性)和重原子数量均匀抽样了约 2700 万个分子,并过滤掉了包含不考虑的原子元素集合中的重原子的结构(Z ∈ {C, N, O, F, P, S, Cl, Br, I})。
为了评估 DrugHIVE 从 AlphaFold2(AF)预测结构生成分子的能力,作者使用了一个包含100 个 AF 结构的数据集,这些结构在数据集中也具有相应的 PDB 结构。为了创建该数据集,作者首先确定了 PDBbind 数据集中所有包含单条蛋白链的受体口袋结构,这些结构也可在 AlphaFold 蛋白结构数据库中找到。接着,使用 PyMOL 的 align 功能对 AF 结构与 PDB 结构进行序列和结构对齐,并过滤掉序列相似度低于 70% 的受体结构,以确保 AF 和 PDB 结合口袋之间的高序列相似性。然后,通过基于序列对齐去除多余残基并移除距离配体超过 24 Å 的所有残基,提取结合口袋。如果任何配体 5 Å 范围内的残基的信心分数(pLDDT)低于 70,则过滤掉相应结构。最后,从剩余的受体中随机抽取 100 个作为 AF 测试集。
作者使用 QuickVina 2 计算生成的每个配体的 Vina 对接评分,并用 ΔVina 表示生成配体与参考配体(如晶体结构中的配体)的 Vina 评分差值。分子相似性通过分子指纹的 Tanimoto 距离来计算,而分子多样性则定义为一组分子中每对分子之间平均 Tanimoto 距离。药物相似性定量估计 (QED) 得分通过结合一组分子属性来估计分子的药物相似性。合成可及性 (SA) 得分估计分子合成的难易程度。为了计算虚拟筛选效率,作者首先过滤出尺寸与晶体配体相等或更小的分子(以纠正尺寸偏差),然后计算 Vina 评分等于或优于晶体配体的分子百分比。解离常数 () 是一种实验性测量配体-蛋白质结合亲和力的指标,值越低表示结合越强。半数抑制浓度 (IC50) 是一种测量配体效力的实验性指标,值越低表示生物效应越强。
2.3 模型性能
2.3.1 大规模测试集上的分子生成
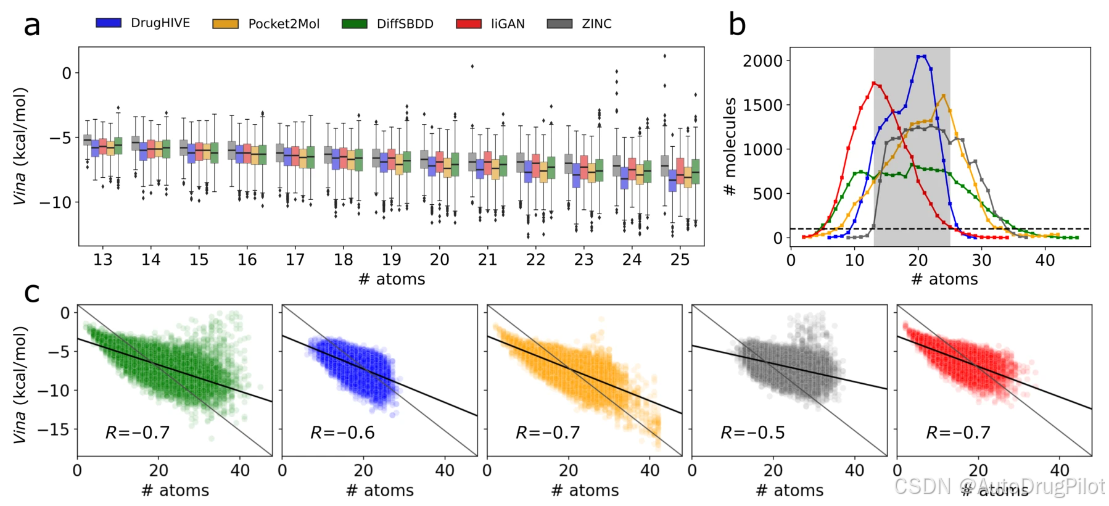
作者在包含 100 个受体的测试集上生成分子,并将结果与 LiGAN、DiffSBDD、Pocket2Mol 以及 ZINC 药物类子集中的随机样本进行比较。如下表所示,DrugHIVE 在生成具有药物类属性和强预测结合亲和力的新分子方面表现出色,超越了扩散和基于图的网络,在生成分子的平均预测结合亲和力和药物类特性上表现更佳。

虽然上述使用的指标常常被用作分子生成性能评估的基准,但这些指标的计算和解释方面存在一些问题。vina 得分和分子大小之间有强相关性,但许多研究并没有考虑这一点,导致倾向于生成大分子量分子的方法从指标上看表现更好。生成分子的多样性也不能一味的追求最大化,基于结构的分子生成可能由于结构的限制无法实现很高的多样性,所以生成分子的多样性不必显著高于 ZINC 中随机类药分子的多样性,只要在合理的范围内即可。下图展示了生成分子结合亲和力和原子数目之间的关系。从图 a 可以看出在生成分子对应的不同的原子数目上,DrugHIVE 的结合亲和力表现都是最好的。从图 b 可以看出,DrugHIVE 生成分子的原子数目和ZINC 中随机类药分子的基本一致。图 c 展示了不同方法分子的原子数目和 vina 打分的相关性,DrugHIVE 基于结构生成的分子很少有大分子数目的,样本点分布相对比较集中。
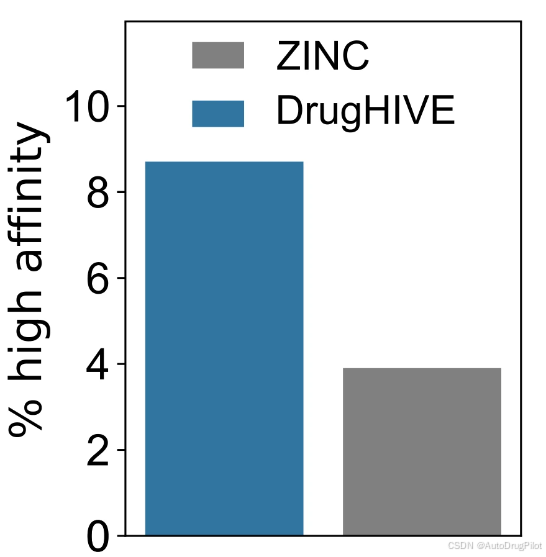
下图展示了 DrugHIVE 生成的分子和 ZINC 类药子集的随机采样分子的高于参考配体亲和力的分子比例。约 8.7% 的 DrugHIVE 生成的分子与参考配体同样大小或更小,其预测亲和力与参考配体相当或更好。这是 ZINC 数据集中随机样本(3.9%)的两倍多,这意味着 DrugHIVE 生成的分子的虚拟筛选效率显著更高。
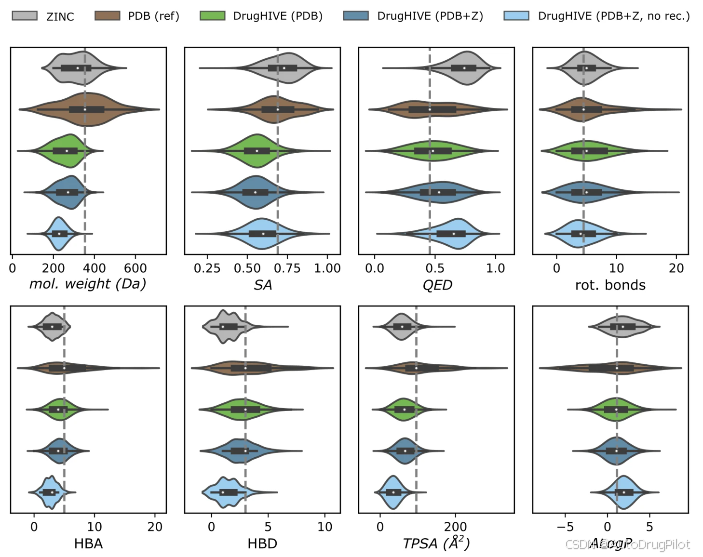
作者分别使用 PDBbind 数据集(PDB)、两者共同的数据(PDB+Z)和不包含受体结构的两者共同的数据(PDB+Z,no rec)训练不同的 DrugHIVE 模型。下图将 PDBbind 数据集中参考配体的属性与 ZINC 数据集中随机样本的分子属性进行了比较,结果显示生成分子的属性很好地落在训练数据集的分布范围内,表明模型有效地学习了训练分布。我们还观察到,生成的分子在有无蛋白质受体的情况下存在显著的分布偏移,这表明模型在生成过程中考虑了受体信息。
2.3.2 药物属性的多目标优化
如下图所示,DrugHIVE 采用先验-后验采样,能够生成与参考分子具有高相似度的新的配体。每个配体-受体复合物在编码的潜在空间中都有独特的表示。
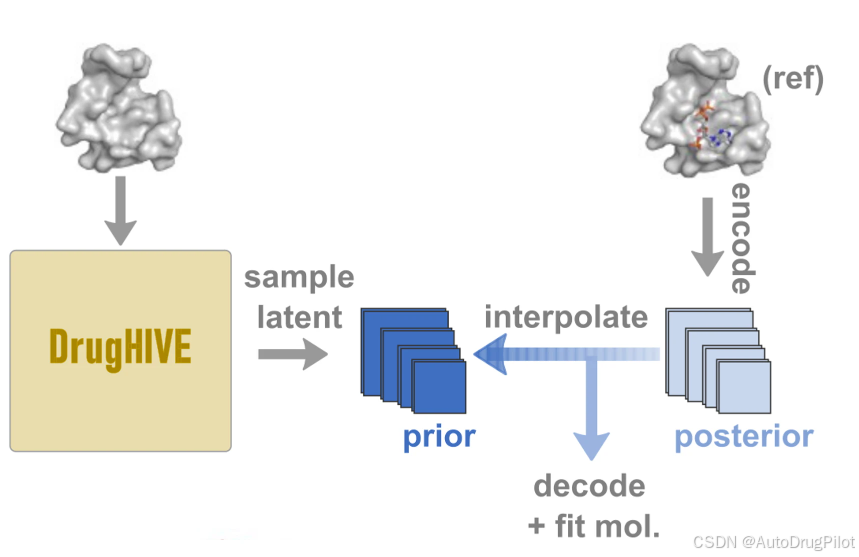
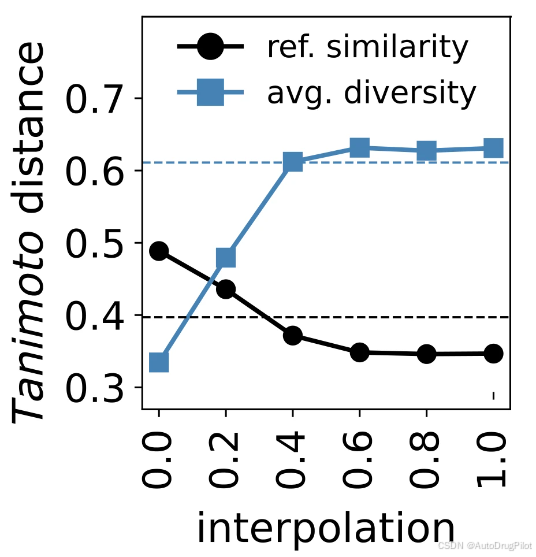
如下图所示,作者从给定的参考配体的潜在表示(后验)开始,并朝向随机采样的点(先验)进行插值,得到的分子在朝向先验采样点插值时会具有更高的平均多样性和较低的与参考的分子相似性。利用这种对变化的高度控制,可以实施一个进化算法来搜索潜在空间,并优化参考分子的属性。
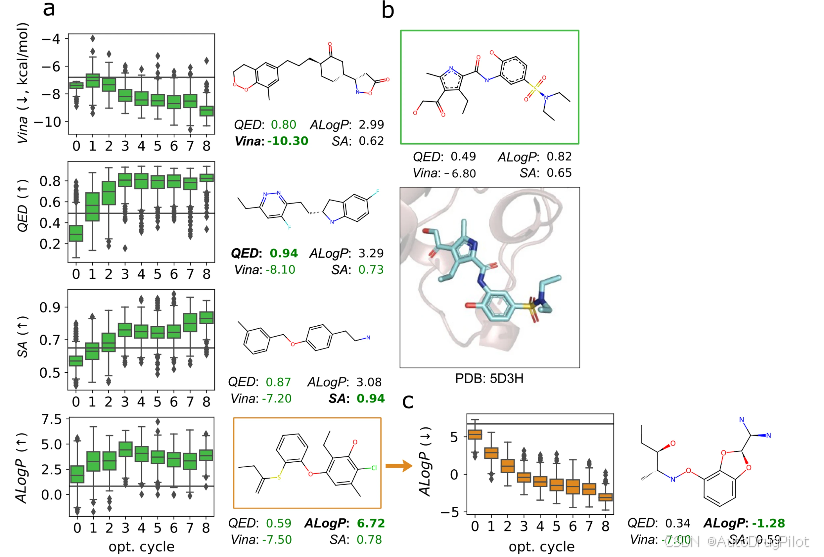
下图 a-c 展示了与人类溴结构域蛋白 4(BRD4)受体(PDB ID 5D3H)结合的配体(57G)的优化过程。图 a 显示了结合亲和力(Vina)、药物相似性(QED)、合成性(SA)和疏水性(ALogP)值的成功优化。对于 QED、SA 和 ALogP,作者通过将结合亲和力作为适应度函数中的次要目标来进行多目标优化。可以看到每个目标属性都有显著改善,其中最佳分子的预测结合亲和力分数提高了 51%,使该配体对目标受体表现出强实验亲和力(Kd = 7.9 μM)。作者成功地将 QED 从 0.49 提高到 0.94,将 SA 从 0.65 提高到 0.94 。在这两种情况下,值从中等提高到高值,同时改善了结合亲和力。图 b 展示初始的配体。在图 c 中,作者首先向上优化 ALogP,从稍微疏水的配体(ALogP = 0.82)开始,最终得到一个非常疏水的分子(ALogP = 6.72)。接下来,向下优化 ALogP 值,反向进行处理,以得到一个亲水分子(ALogP = −1.28)。
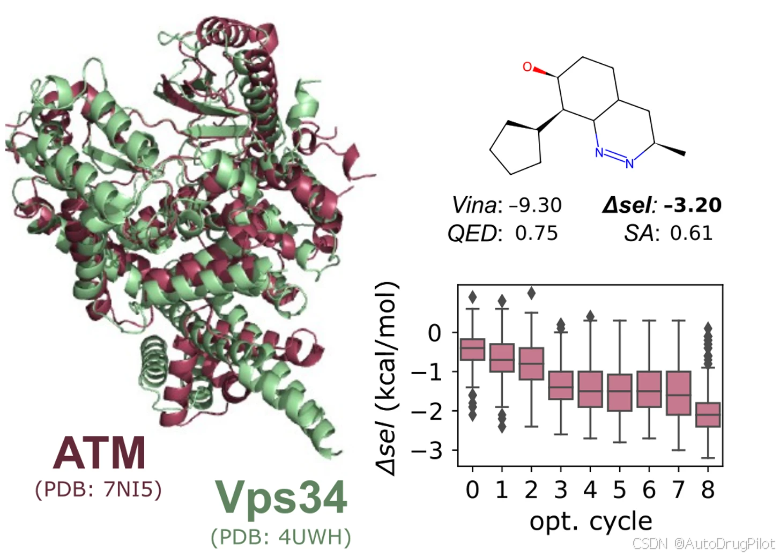
下图展示了针对人类共济失调-扩张血管畸形突变(ATM)激酶选择性和针对人类液泡蛋白分选(Vps34)激酶的配体生成和优化结果。ATM 激酶是亨廷顿病治疗的重要潜在靶点,ATM 抑制剂对 Vps34 表现出高选择性至关重要。作者使用 DrugHIVE 为 ATM 受体(PDB ID 7NI5)生成了一组初始配体,然后针对 Vps34 受体(PDB ID 4UWH)进行选择性优化。结果显示选择性有了显著改善,最佳分子对 ATM 的结合亲和力得分(−9.3 kcal/mol)显著优于对 Vps34 的得分(−6.1 kcal/mol)。这些实验表明,DrugHIVE 学习到的潜在编码是化学空间的强大表示,能够有效进行多目标的分子结构优化,并具有高度的控制能力。
2.3.3 通过空间先验-后验插值进行的药物优化
DrugHIVE 的层次先验结构保留了空间上下文,并通过在潜在表示的空间子集上应用先验-后验采样,允许分子进行空间修改。作者将该方法应用于常见的药物设计问题,如下图所示的连接体设计、子结构修改(骨架跃迁)、片段扩展和分子模式替换等任务。
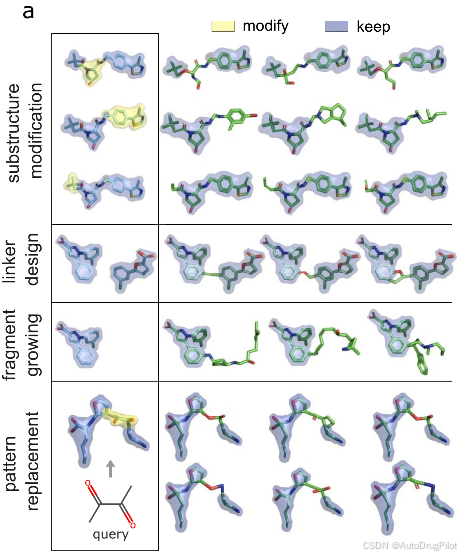
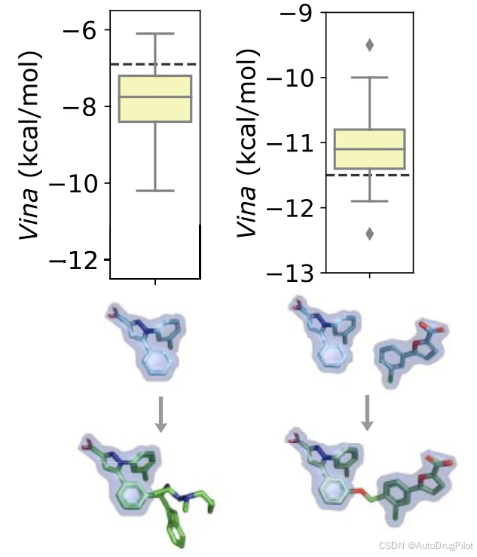
基于片段的筛选是早期药物发现中的常见策略。这种筛选的结果是一组相对较小的分子片段,对目标受体具有适度的亲和力。给定两个或多个这样的片段,挑战在于将单个片段连接成一个连贯的高亲和力药物分子。下图展示了 DrugHIVE 成功连接复制蛋白A(PDB ID 4LUV)筛选实验的单个片段(配体1DZ和1XS)。所有生成的配体的 Vina 得分均优于任何单个片段。相比于设计的连接分子(PDB ID 4LWC 的配体 1XU,实验 Kd = 20 μM),21% 的生成分子具有等于或更好的 Vina 得分,51% 的分子具有等于或更好的 SA 得分。
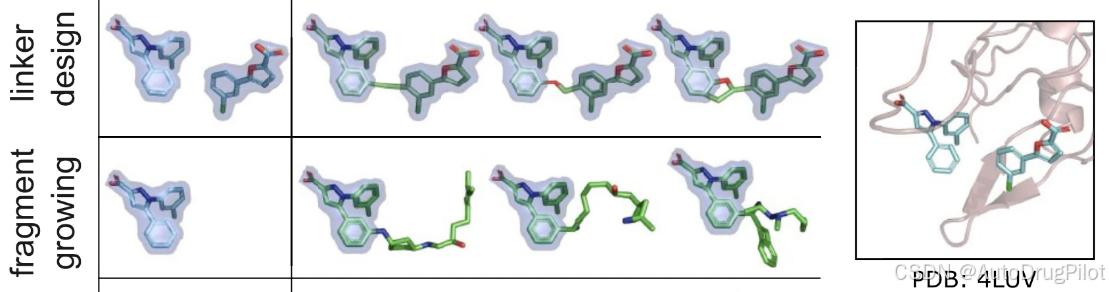
常见的药物设计任务之一是利用已知片段(由于其大小而具有适度结合亲和力)来扩展结构,以提高其对目标的亲和力。下图展示了 DrugHIVE 成功扩展来自同一片段筛选实验的一个片段(配体 1DZ),显著提高了其对目标受体的预测结合亲和力,85% 的生成分子具有改善的 Vina 得分。
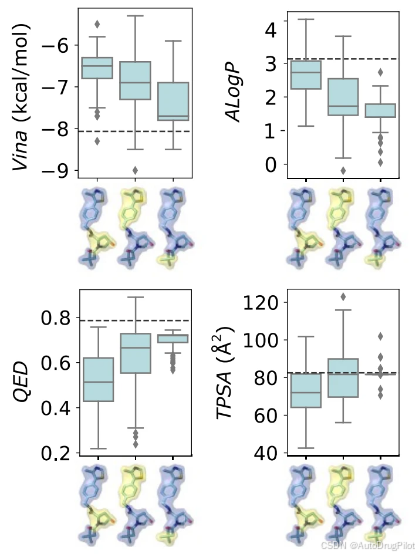
分子优化的一种常用技术是系统地替换候选分子上的化学骨架或 R 基团,以改善其属性或扩展候选集。从与冯-希佩尔-林道肿瘤抑制因子结合的晶体配体(3JU,PDB ID 4W9F)开始,作者展示了如何利用空间先验-后验采样实现自动子结构优化。如下图所示,应用 BRICS 分解将该配体(一个报告 Kd = 3.27 μM 的激动剂)分解为分子片段。对于每个片段,生成一组分子,仅修改片段子结构,其余部分保持不变。
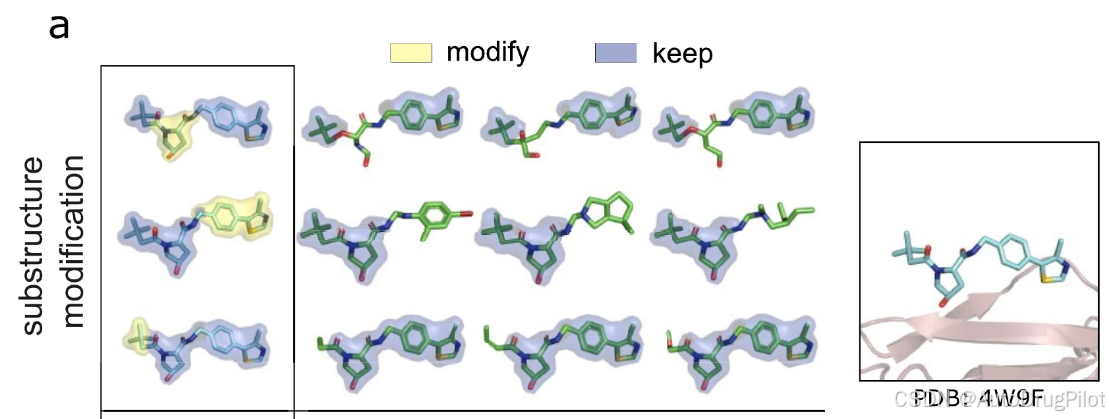
如下图所示,对于每个 BRICS 片段,作者分析生成分子的属性分布,以了解每个片段对每个属性的贡献。根据修改的片段不同,对每个属性(ΔVina、ALogP、TPSA、QED)的影响存在显著差异。例如,只有片段 2 的药物相似性得分得到了改善。片段 3 的修改导致疏水性(ALogP)值的最大下降,而对拓扑极性表面积(TPSA)几乎没有影响。片段 1 的修改导致Vina 得分的最大提高,而片段 3 的影响相对较小。这种方法可以为先导优化和结构-活性关系分析提供有价值的见解。
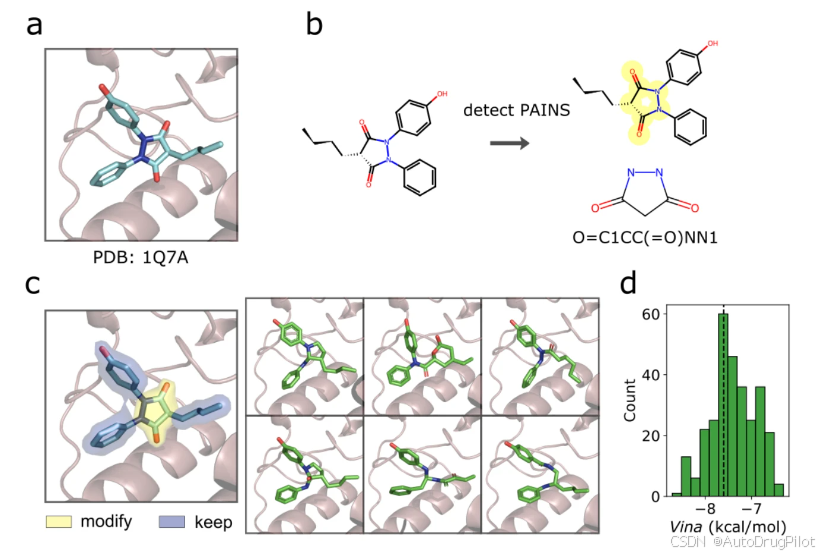
对于模式替换任务,给定分子 SMILES 或 SMARTS 模式,可以修改与该模式对应的单个分子或一组分子的结构,使用 DrugHIVE 生成一组用输入模式替换的新分子。这一功能可以用于修改具有已知毒性、杂交或其他不良属性的片段,减少需要筛除具有其他有希望品质的候选物的必要性。这方面的一个明显应用是替换 PAINS 模式,这是一组与 HTS 实验中假阳性结果相关的分子亚结构。这些分子模式并不总是导致实验干扰,因此筛选决策应谨慎作出。为了避免假阳性实验结果和假阴性筛选决策的风险,可以简单地使用生成的空间修改替换现有集合中的所有 PAINS 模式。作为例子,作者应用一组过滤器来识别数据集中与 PAINS 相关的 PDB 晶体配体,并识别与磷脂酶 A2 结合的配体(PDB ID 1Q7A)作为 PAINS 分子。下图显示了生成 200 个分子的结果,其中 28% 的生成分子表现出改善的结合亲和力得分(图 d )。这种模式替换能力可以扩展到大量分子集合,因为每个分子的运行时间与快速虚拟对接算法相当。
2.3.4 基于预测结构的药物设计
SBDD 方法的一个主要限制是它们依赖于目标受体的高分辨率晶体结构。尽管过去十年中,PDB 中存放的蛋白质晶体数据迅速增加,平均每年超过 9000 个结构,但仍有超过 80% 的人类蛋白组尚未解决。最近,序列到结构的预测模型如 AlphaFold2 获得了生成高置信度预测的能力,填补了大部分人类蛋白组可折叠区域缺失的结构数据。
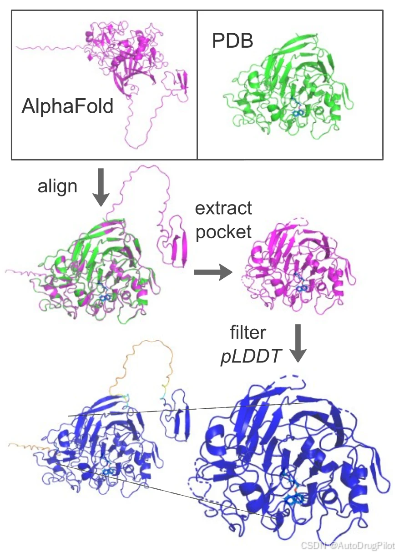
如下图所示,为了测试使用预测结构进行生成药物设计的有效性,作者为测试集中的目标受体生成配体,这些受体同时具有 AF 预测和 PDB 晶体结构。选择 AF 目标时未使用晶体结构对齐信息。过滤仅基于序列对齐,以确保足够的序列相似性,以及 AF 置信分数 pLDDT,以确保高置信度预测。
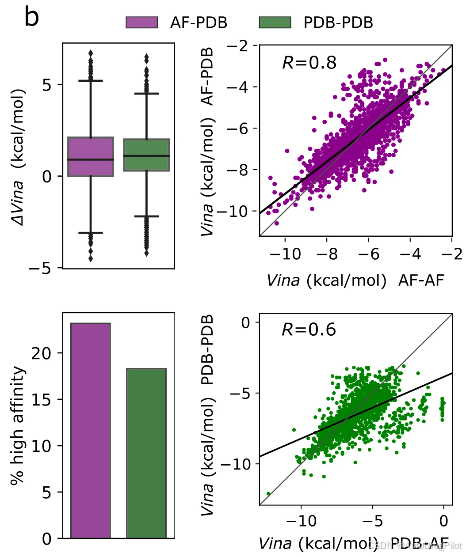
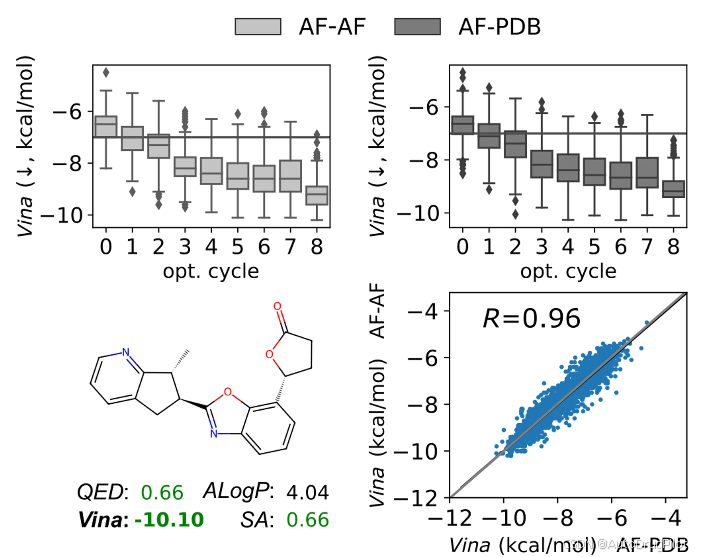
作者将 AF 生成的配体对接到 AF 和晶体解析的受体,并比较对PDB受体生成的配体的结合亲和力预测。下图展示了 AF 和 PDB 生成的配体对接到相应 PDB 受体时 ΔVina 分数的分布。两组之间的亲和力范围非常相似,AF 生成的配体具有稍微更好的中位值。两组中,具有比晶体配体更好对接得分的配体比例约为 20%,AF 生成的配体稍微更好。在对接到PDB 和 AF 受体时,AF 生成的配体之间的 Vina 得分相关性良好(R = 0.8),而 PDB 生成的配体为(R = 0.6)。
如下图所示,DrugHIVE 可以使用 AF 口袋优化配体的预测亲和力。作者从与 PDB ID 5D3H 相对应的 AF 预测结构中的 PDB 晶体配体开始进行优化过程。结果分子的预测结合亲和力与通过相同优化过程获得的 PDB 口袋中的分子相似。然后,将优化过程中生成的所有分子对接到 PDB 口袋,并计算两组亲和力得分的 Pearson 相关系数。得到一个高相关性(R = 0.96),AF 对接得分始终低估 PDB 对接得分——这种偏差在高亲和力配体中被夸大。尽管存在这种低估,高相关性仍然使 DrugHIVE 优化过程显著提高了初始配体的结合亲和力得分。
三、DrugHIVE 评测
3.1 安装环境
复制代码项目:
git clone https://github.com/jssweller/DrugHIVE.git使用项目提供的 requirements.txt 创建 DrugHIVE 环境并安装基础依赖库,命令如下:
conda create -n DrugHIVE -c conda-forge -c pytorch -c nvidia -c rdkit --file requirements.txt
conda activate DrugHIVE安装 qvina,用于生成分子的优化
wget https://github.com/QVina/qvina/raw/master/bin/qvina2.1
chmod +x qvina2.1
mv qvina2.1 /home/wufeil/miniconda3/envs/DrugHIVE/bin下载项目训练好的模型到 ./model_checkpoints 文件夹中,命令如下:
wget -P model_checkpoints/ https://zenodo.org/records/12668687/files/drughive_model_ch9.ckpt
3.2 分子生成案例测试
DrugHIVE 在基于结构进行采样时可以使用力场或者对接优化生成分子。
在对接优化策略的分子生成过程中,生成一批初始分子,通过对接计算分子和蛋白口袋的对接亲和力,选出 Top n 的分子(自定义设置 n 的数目)作为参考分子进行下一轮的分子生成,经过几轮迭代最后保存对接优化后的分子,该策略相对于力场优化的分子生成花费的时间较长。
3.2.1 内置案例
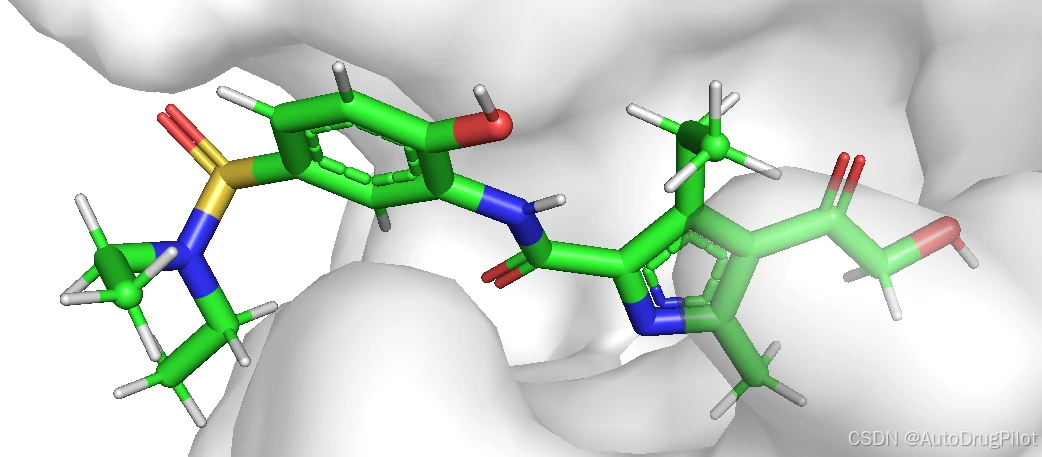
项目提供的基于口袋的分子生成案例使用的是 5D3H 蛋白,原始配体在口袋中的结构如下:
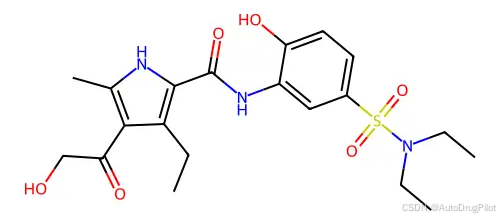
配体的 2D 结构如下:
项目提供分子生成和优化所需的结构文件,在 ./data/example_data/5d3h 文件夹中,文件结构如下所示。其中 5d3h_ligand.sdf 和 5d3h_protein.pdb 分别为配体和蛋白结构,把配体周围 8 Å 的残基作为口袋保存为 5d3h_pocket.pdb,为方便后续分子结构优化和对接,同时转换成 5d3h_pocket.pdbqt 。
.
|-- 5d3h_ligand.sdf
|-- 5d3h_pocket.pdb
|-- 5d3h_pocket.pdbqt
`-- 5d3h_protein.pdb0 directories, 4 files3.2.1.1 分子生成
针对内置案例,根据项目提供的配置文件进行分子生成,命令如下:
python generate_molecules.py config/generate.yml
配置文件中指定参考配体和口袋结构文件以及生成分子的输出文件夹,在 5D3H 蛋白口袋中采样生成 100 个分子,并使用力场优化生成的分子构象。config/generate.yml 的具体配置如下:
ligand_path: data/example_data/5d3h/5d3h_ligand.sdf # .sdf file for posterior ligand molecule
target_path: data/example_data/5d3h/5d3h_pocket.pdb # .pdb file for target structure
pdb_id: 5d3h # PDB ID for target
output: output/generate_example # output directoryn_samples: 100 # number of molecules to generate
random_rotate: true
random_translate: falsezbetas: [0., 0., 0., 0.] # list defining prior-posterior interpolation factor for each latent resolution. Or single value for all resolutions.
temps: [0.5, 0.5, 0.5, 0.5] # list defining temperature factor for each latent resolution. Or single value for all resolution.## model
checkpoint: model_checkpoints/drughive_model_ch9.ckpt # model checkpoint
model_id: c9_pdbzinc # id for model
ffopt_mols: True # run force field optimization on generated molecules注:从先验中采样,在配置文件中设置 zbetas: 1; 要从后验中采样,在配置文件中设置 zbetas: 0; 要在先验和后验之间采样,请将 zbetas 的值设置在 0. 和 1. 之间。
因为 zbetas 参数设置为0,意味着生成分子是从参考分子的隐向量开始,那么生成的分子应该与参考分子很相似,下面的结果中也可以观察出这一点。
运行过程输出如下:
Generating molecules and saving to: output/generate_example
Setting port to: 6004
Loading model...model_checkpoints/drughive_model_ch9.ckptmodel_class: <class 'drughive.lightning.HVAEComplexSplit'>
len log norm: 459
len bn: 308Loading Datasets....done
gen_name: priorsaving generated mols to: output/generate_example/prior
(0): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [08:24<00:00, 504.65s/it]
n_samples_all 100
n_tries_all 102# failed: 2% failed: 2.0FF Optimizing molecules...Searching for ligands..
dirs_process: ['output/generate_example/prior/5d3h']Found 1 set of ligands to process:0%| | 0/1 [00:00<?, ?it/s] Processing files...output/generate_example/prior/5d3h/lig_ref.sdfoutput/generate_example/prior/5d3h/mols_gen.sdfWriting optimized mols to: output/generate_example/prior/5d3h/lig_ref_opt.sdfWriting optimized mols to: output/generate_example/prior/5d3h/mols_gen_opt.sdf
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:31<00:00, 31.41s/it]Total time: 0m 31sdone.
生成的分子保存在 ./output/generate_example/prior/5d3h 中,设置生成 100 个分子,实际生成 100 个分子,生成过程显存占用约 4 GB,用时约 13 分钟。 ./output/generate_example/prior/5d3h的文件目录如下:
.
|-- lig_ref.sdf
|-- lig_ref_ffopt.csv
|-- lig_ref_opt.sdf
|-- mols_gen.sdf
|-- mols_gen_ffopt.csv
`-- mols_gen_opt.sdf0 directories, 6 files其中,lig_ref.sdf,lig_ref_ffopt.csv,lig_ref_opt.sdf 对应的是参考分子。mols_gen.sdf是生成的3D分子,mols_gen_opt.sdf是经过力场优化以后的分子。
接下来,我们使用 qvina 把生成分子对接到蛋白口袋中,创建 ./get_qvina/5d3h/generate_example 文件夹,项目在 ./data/example_data/5d3h 文件夹中提供的处理好的配体结构和蛋白结构对接的相关数据,对接时可以直接使用
创建 ./get_qvina/5d3h/generate_example/1_qvina_docking.ipynb 处理生成分子并生成对接脚本。导入依赖库。创建 ./get_qvina/5d3h/generate_example/pdbqt_mol 文件夹,以便保存转换成 pdbqt 格式的生成分子。
import os
from rdkit import Chem
os.chdir('../../../')
print(os.getcwd())if not os.path.exists('./get_qvina/5d3h/generate_example/pdbqt_mol'):os.makedirs('./get_qvina/5d3h/generate_example/pdbqt_mol')all_mols = Chem.SDMolSupplier('./output/generate_example/prior/5d3h/mols_gen_opt.sdf')for i,mol in enumerate(all_mols):SDWriter = Chem.SDWriter(f'./get_qvina/5d3h/generate_example/pdbqt_mol/{i}.sdf')SDWriter.write(mol)
根据参考配体获取对接中心坐标,通过 openbabel 把生成分子转换成 pdbqt 格式的结构,并生成对接脚本 ./get_qvina/5d3h/generate_example/docking.sh 。
all_sdfs = [f'./get_qvina/5d3h/generate_example/pdbqt_mol/{i}.sdf' for i in range(len(all_mols))]ligand = Chem.SDMolSupplier('./data/example_data/5d3h/5d3h_ligand.sdf')[0]
pos = mol.GetConformer(0).GetPositions()
center = (pos.max(0) + pos.min(0)) / 2with open('./get_qvina/5d3h/generate_example/docking.sh', 'a') as f:for i,sdf in enumerate(all_sdfs):commands = f"""conda activate adtobabel {sdf} -O ./get_qvina/5d3h/generate_example/pdbqt_mol/{i}.pdbqt"""os.system(commands)f.write(f'''qvina2 \--receptor ./data/example_data/5d3h/5d3h_pocket.pdbqt \--ligand ./get_qvina/5d3h/generate_example/pdbqt_mol/{i}.pdbqt \--cpu 60 \--center_x {center[0]} \--center_y {center[1]} \--center_z {center[2]} \--size_x 20 --size_y 20 --size_z 20 \--exhaustiveness 16 \--log ./get_qvina/5d3h/generate_example/pdbqt_mol/{i}.log\n''')
在终端运行对接脚本,具体命令如下:
cd ./get_qvina/5d3h/generate_example
bash docking.sh > docking.log 注意,运行上述第二个命令,不要按回车键,让其自动运行结束。
生成分子对接完成后,根据 qvina 的最好对接打分升序排列,保存到 ./get_qvina/5d3h/generate_example/Generated_molecules_with_qvina_score
.sdf 中。
import os
from rdkit import Chemall_logs = [i for i in os.listdir('./pdbqt_mol') if i.endswith('.log')]# 保存生成的分子
mol_sdfs = []for log in all_logs:with open(f'./pdbqt_mol/{log}') as f:lines = f.readlines()for line in lines:if ' 1 ' in line:aff_num = float([i for i in line.split(' ') if i != ''][1])num = log.split('.')[0]# 保存生成分子的构象mol = Chem.SDMolSupplier(f'./pdbqt_mol/{num}.sdf')[0]# 给分子添加 vina_score 属性qvina_score = aff_nummol.SetProp('qvina_score', str(qvina_score)) mol_sdfs.append(mol)# 每个 mol 对象都有 'vina_score' 属性,按 vina_score 降序排列
sorted_mol_list = sorted(mol_sdfs, key=lambda mol: float(mol.GetProp('qvina_score')), reverse=False)# 把生成分子保存成 sdf 格式
sdf_path = 'Generated_molecules_with_vina_score.sdf'
w = Chem.SDWriter(sdf_path)
for mol in sorted_mol_list:w.write(mol)
w.close()
print('Generated molecules saved as sdf format in {}!'.format(sdf_path))
所有生成的分子如下:
DrugHIVE_generate_5d3h
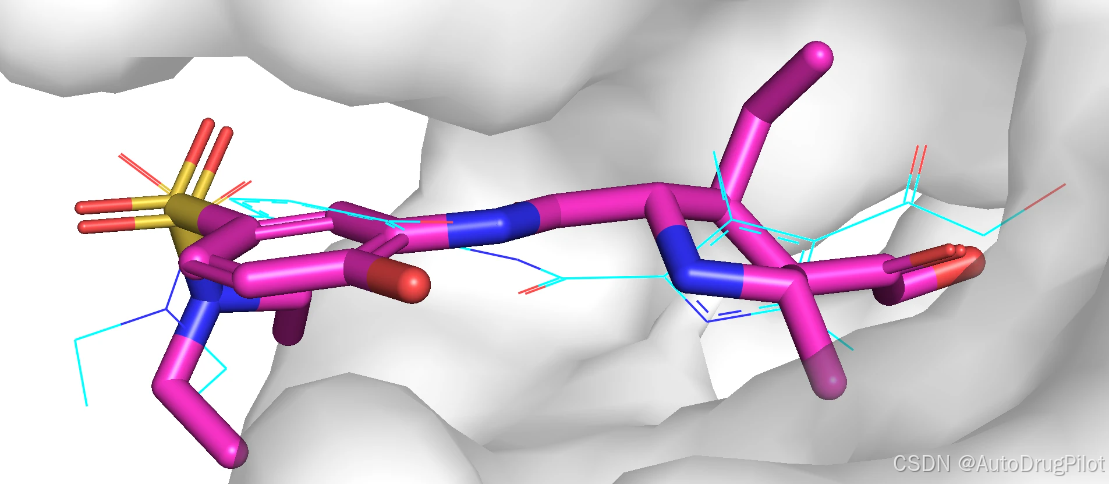
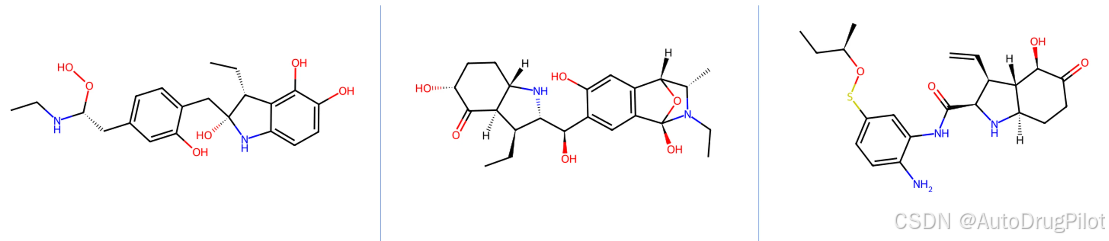
生成分子中包含重复分子,只是分子构象不同。qvina score 排名前 4 的分子是同一个分子,所以我们下面展示第 4-6 的三个分子的2D 结构,对应的 qvina score 分数分别为 -7.1,-7.0, -6.9:

这三个分子在口袋中的 Pose 如下,蓝色的是参考分子,紫红色的是生成分子。正如zbetas: 0参数设置的,生成的分子与参考分子很像。
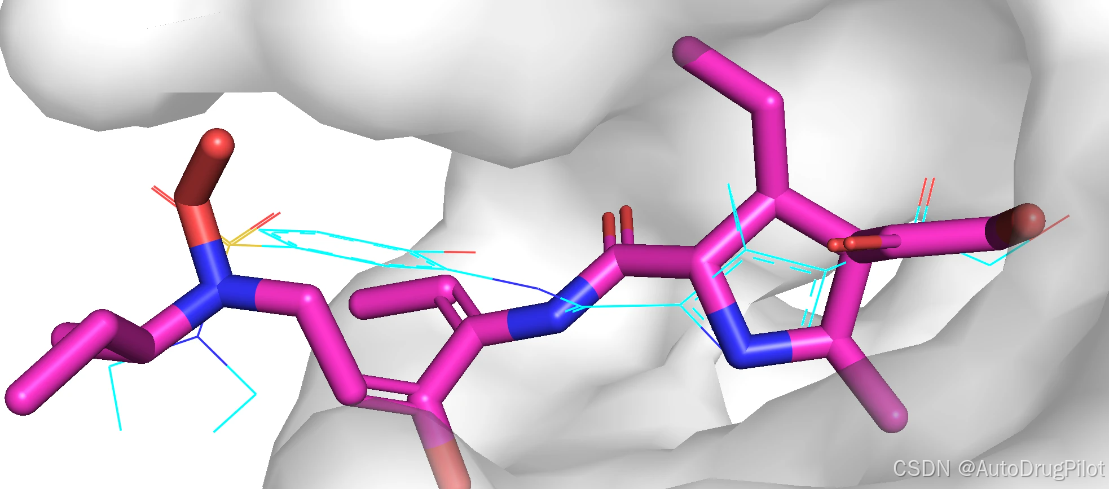
3.2.1.2 分子优化
针对内置案例,通过 qvina 对生成分子进行优化,命令如下:
python generate_optimize.py \config/generate_optimize.yml配置文件中指定配体和口袋结构文件,优化后的输出文件夹等。
其中使用的配置文件指定,使用 qvina 对生成分子的结合亲和力进行优化(注:按照作者的描述也可以使用qed, alogp, or sa作为优化指标)。过滤包含五、六环以外的生成分子,过滤超过三个环以上的生成分子等。生成后的分子会过滤筛选,所以我们设置生成 1000 个分子。config/generate_optimize.yml 的具体配置内容如下:
ligand_path: data/example_data/5d3h/5d3h_ligand.sdf # .sdf file for molecule(s) to optimize
target_path: data/example_data/5d3h/5d3h_pocket.pdb # .pdb file for target structure
target_path_pdbqt: data/example_data/5d3h/5d3h_pocket.pdbqt # .pdbqt file for docking to target structure
pdb_id: 5d3h # PDB ID for target
output: output/optimize_example # output directory## optimization params
key_opt: affinity_qvina # options: affinity_qvina, qed, alogp, or sa
save_name: affinity_qvina_z3-1 # directory name for saving optimization process
opt_increase: false # increase value during optimizationn_cycles: 8 # optimization cycles
n_samples_initial: 1000 # initial population size
n_samples: 20 # number of children per parent
n_best_parents: 20 # number of parents to choose from each pdb_id each next generation
affinity_quantile_thresh: 0.5 # affinity threshold for parent pool (use for non-affinity optimization)
random_rotate: true
random_translate: false
cluster_parents: true # cluster molecules before choosing parents. Up to one parent chosen per cluster.zbetas_initial: 0.3 # prior-posterior interpolation factor for generating initial population
temps_initial: 1. # temperature factor for generating initial population
zbetas: [0.3, 0.3, 0.2, 0.2, 0.2, 0.2, 0.2, 0.1] # list defining prior-posterior interpolation factor for each optimization cycle. Or single value for all cycles.
temps: 1. # temperature factor## filter generated molecules
ring_sizes: [5,6] # only allow rings of this size
ring_system_max: 3 # only allow ring systems up to this size
ring_loops_max: 0 # only allow this many ring loops
dbl_bond_pairs: false # allow consecutive double bonds
n_atoms_min: 0 # minimum number of atoms allowed in each molecule## model
checkpoint: model_checkpoints/drughive_model_ch9.ckpt # model checkpoint
model_id: c9_pdbzinc # id for model## docking
docking_cmd: qvina2.1 # command for docking
protonate: true # protonate molecules before docking
因为在配置文件中,指定分子优化进行了8轮,因此耗时较长,生成过程显存占用约 4 GB,用时约 27 个小时。优化后的分子结构保存在 ./output/optimize_example 文件夹中, 文件目录如下:
|-- affinity_qvina_z3-1
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt1
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt2
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt3
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt4
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt5
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt6
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt7
| |-- c9_pdbzinc_affinity_qvina_z3-1_opt8
| `-- mols_parent
|-- input.txt
`-- pdbzinc_initial`-- posterior_3其中,pdbzinc_initial是最初第一轮生成的分子。c9_pdbzinc_affinity_qvina_z3-1_opt8 则是经过了第8次 qvina score 优化以后的分子。
接下来,我们使用 qvina 把第一轮的生成分子对接到蛋白口袋中,创建 ./get_qvina/5d3h/optimize_example 文件夹。创建 ./get_qvina/5d3h/optimize_example/1_qvina_docking.ipynb 处理生成分子并生成对接脚本。导入依赖库。创建 ./get_qvina/5d3h/optimize_example/pdbqt_mol 文件夹,以便保存转换成 pdbqt 格式的生成分子。
对接脚本和流程可以参考上文分子生成的内容,这里略过。
最初第一轮生成了719个分子,所有生成的分子如下,可以看到最初的分子和参考分子还是很像的:
DrugHIVE_optimize_5d3h_first
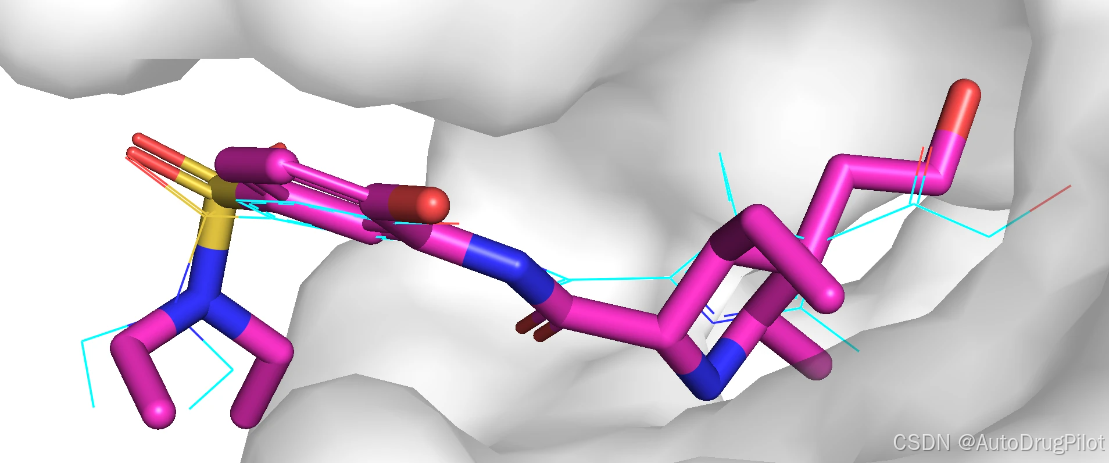
qvina score 排名前 3 的分子的2D 结构如下所示,对应的 qvina score 分数分别为 -8.6,-8.4, -8.4:
这三个分子在口袋中的 Pose 如下,蓝色的是参考分子,橙红色的是生成分子。
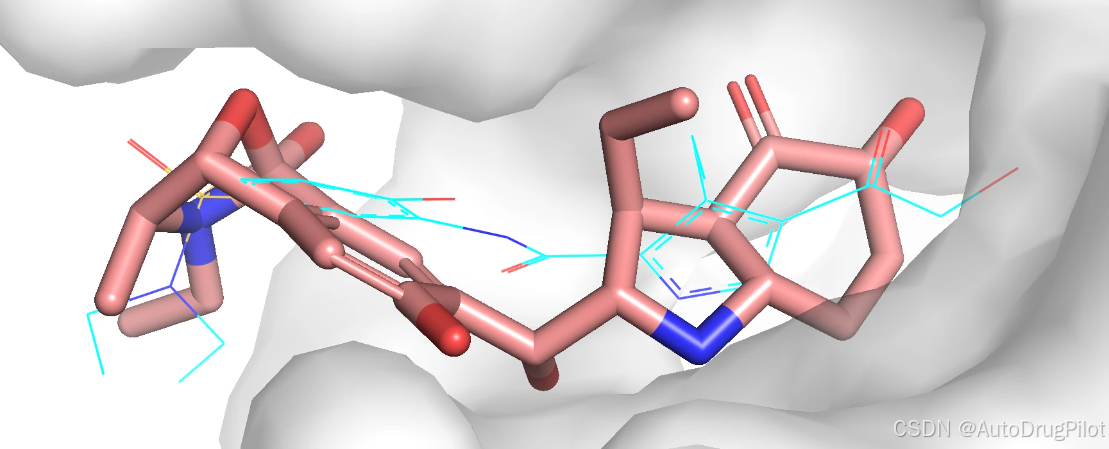
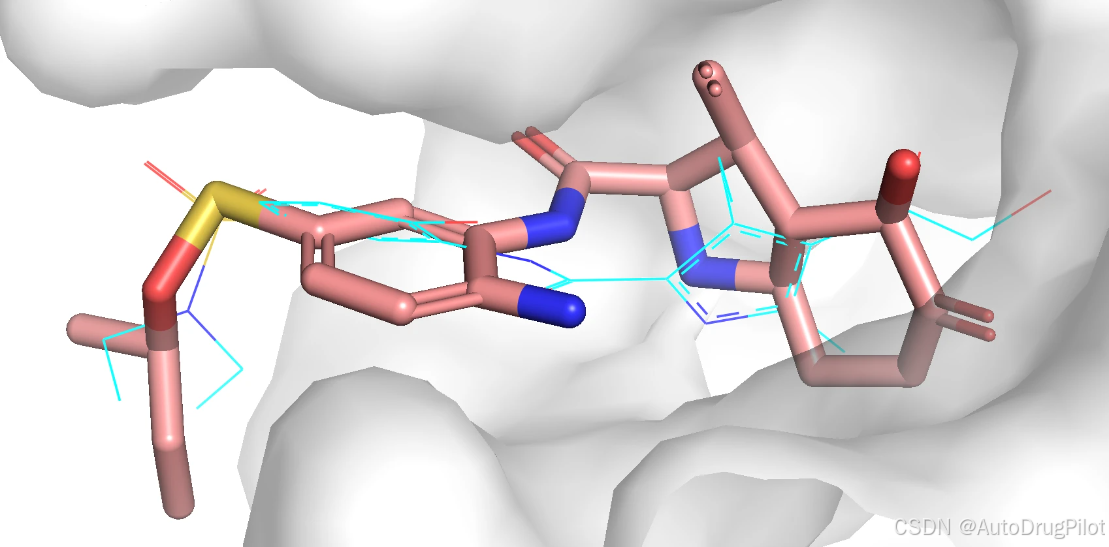
同样的,我们可以对最后一轮(第8轮生成的分子),也进行对接。最后一轮生成的全部分子如下,可以都看到,基本的分子结构发生了变化,但是药效团扔保持的较好。从分子的结构多样性来说,这些分子子结构几乎一样了,重复的分子非常多:
DrugHIVE_5d3h_opt_8_cycles
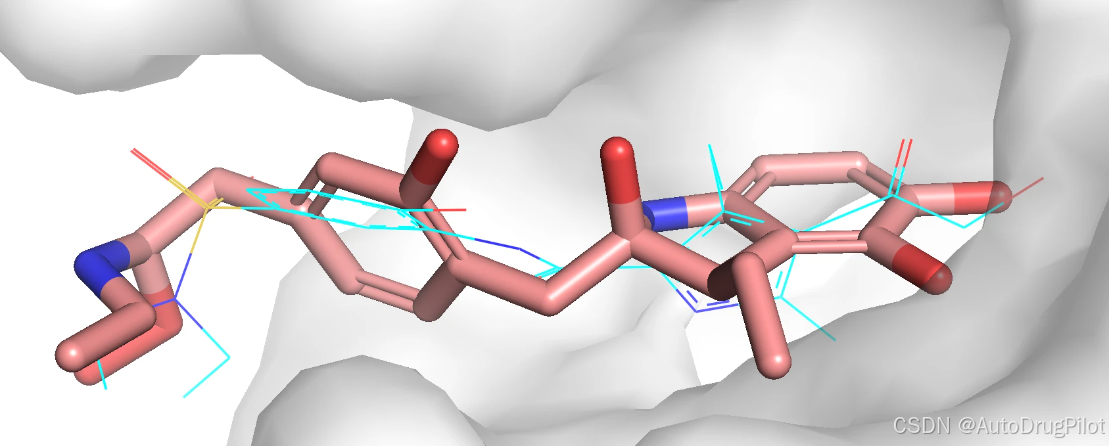
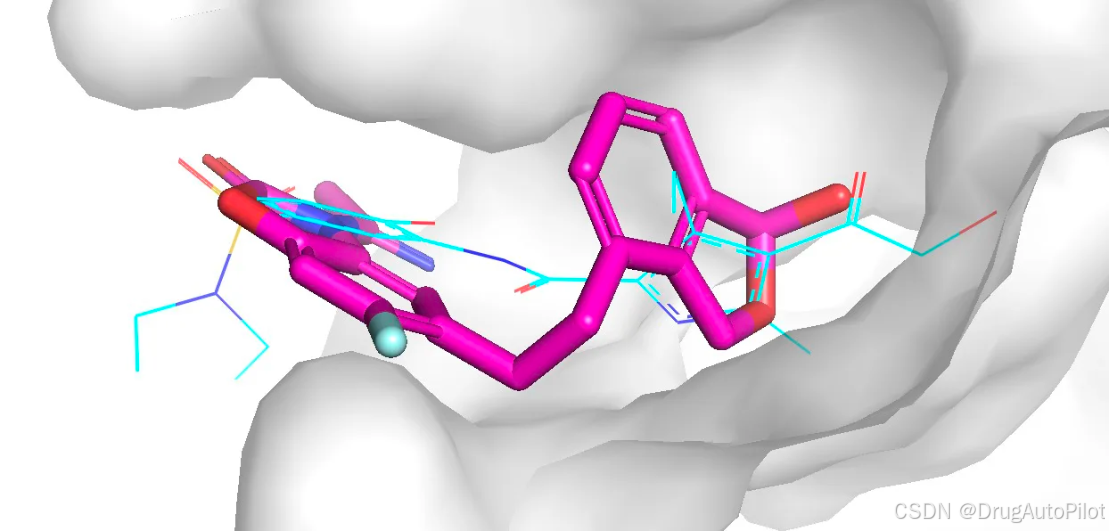
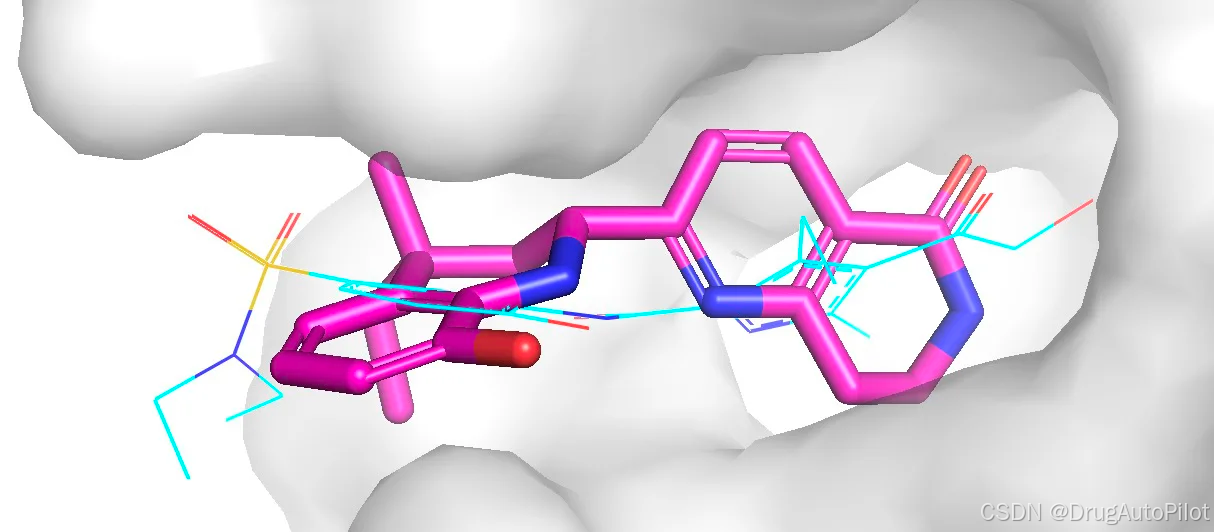
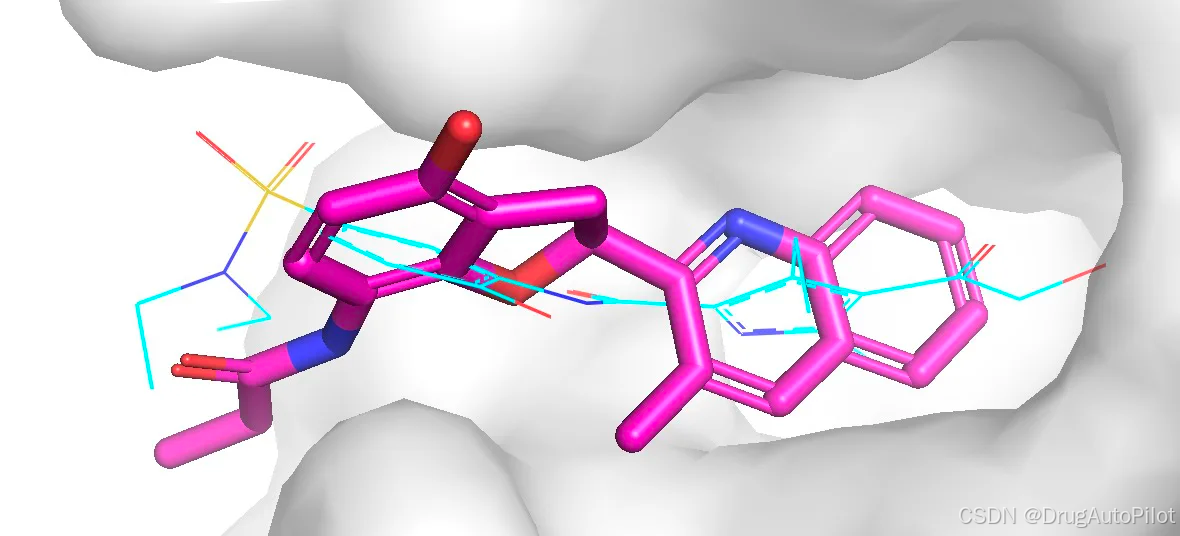
qvina score 排名前 3 的分子的2D 结构如下所示,对应的 qvina score 分数分别为 -10.3,-10.2, -10.2:
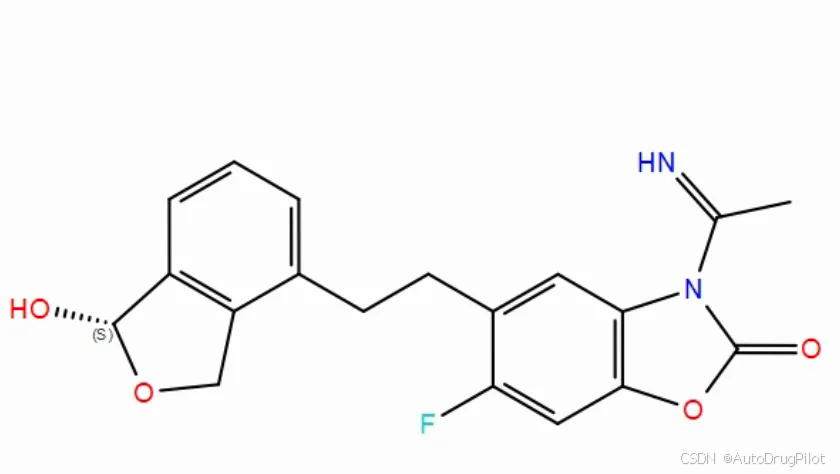
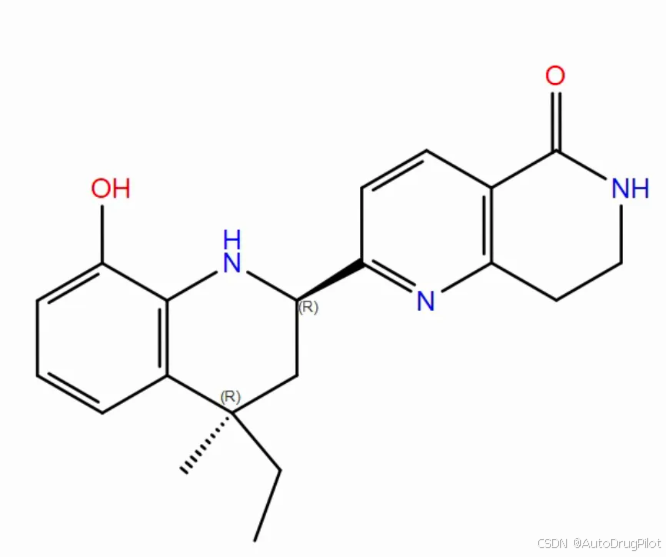
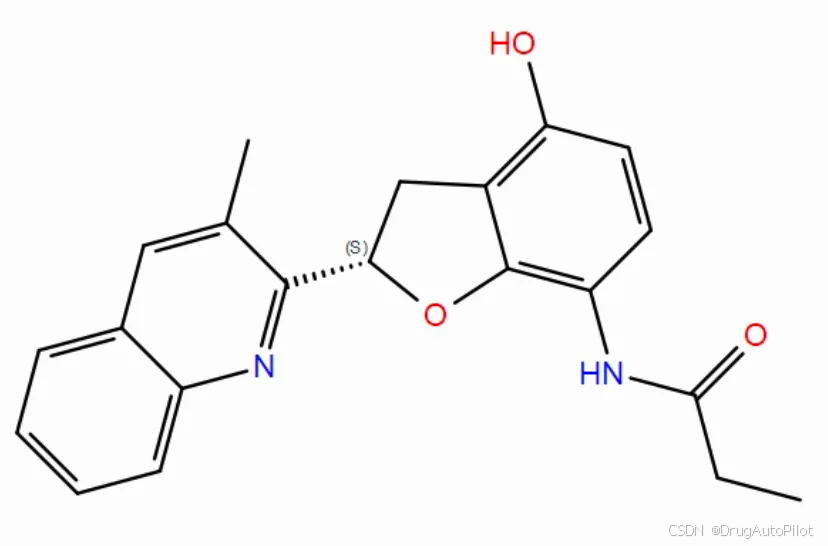
这三个分子在口袋中的 Pose 如下,蓝色的是参考分子。
3.2.2 自定义案例
我们使用 3wze 的蛋白作为自定义测试案例。从 PDB 数据库下载蛋白结构 3wze.pdb 。配体在口袋中的构象如下:
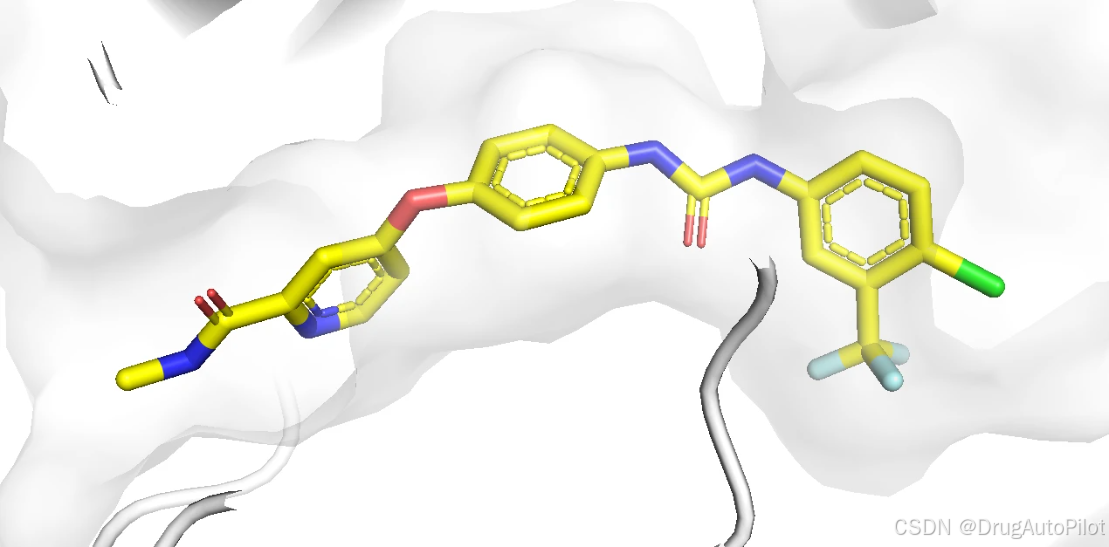
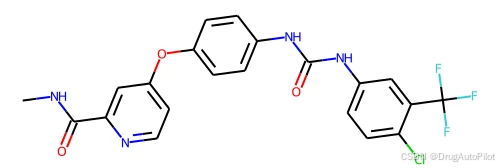
口袋中分子的 2D 结构,如下:
创建 ./3WZE 文件夹。使用 pymol 把配体结构 3wze_ligand.sdf 和蛋白结构3wze_protein.pdb 分别保存到 ./3WZE 文件夹。把配体周围 8 Å 的残基作为口袋,保存为 3wze_pocket.pdb ,同时转换成 3wze_pocket.pdbqt ,以便后续对接使用。至此,./3WZE 文件夹中的文件如下所示:
.
|-- 3wze_ligand.sdf
|-- 3wze_pocket.pdb
|-- 3wze_pocket.pdbqt
`-- 3wze_protein.pdb0 directories, 4 files3.2.2.1 分子生成
使用配置文件对自定义案例进行分子生成,命令如下:
python generate_molecules.py config/generate_3wze.yml配置文件中指定参考配体和口袋结构文件以及生成分子的输出文件夹,在 5D3H 蛋白口袋中采样生成 100 个分子,并使用力场优化生成的分子构象。config/generate_3wze.yml 的具体配置如下:
ligand_path: ./3WZE/3wze_ligand.sdf # .sdf file for posterior ligand molecule
target_path: ./3WZE/3wze_pocket.pdb # .pdb file for target structure
pdb_id: 3wze # PDB ID for target
output: output_3wze/generate_example # output directoryn_samples: 100 # number of molecules to generate
random_rotate: true
random_translate: falsezbetas: [0., 0., 0., 0.] # list defining prior-posterior interpolation factor for each latent resolution. Or single value for all resolutions.
temps: [0.5, 0.5, 0.5, 0.5] # list defining temperature factor for each latent resolution. Or single value for all resolution.# ## filter generated molecules
# ring_sizes: [5,6] # only allow rings of this size
# ring_system_max: 3 # only allow ring systems up to this size
# ring_loops_max: 0 # only allow this many ring loops
# dbl_bond_pairs: false # allow consecutive double bonds
# n_atoms_min: 0 # minimum number of atoms allowed in each molecule## model
checkpoint: model_checkpoints/drughive_model_ch9.ckpt # model checkpoint
model_id: c9_pdbzinc # id for model
ffopt_mols: True # run force field optimization on generated molecules生成的分子保存在 ./output_3wze/generate_example/prior/3wze 中,设置生成 100 个分子,实际生成 100 个分子,生成过程显存占用约 4 GB,用时约 15 分钟。
所有生成的分子如下:
DrugHIVE_genertae_3wze
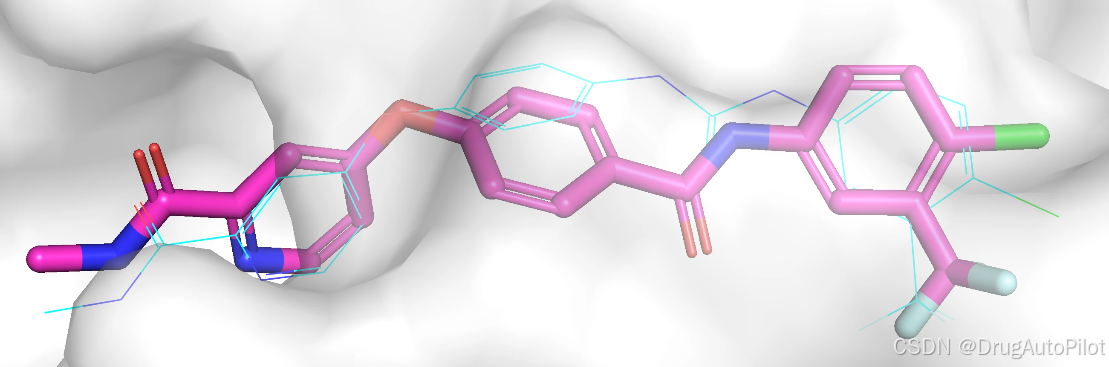
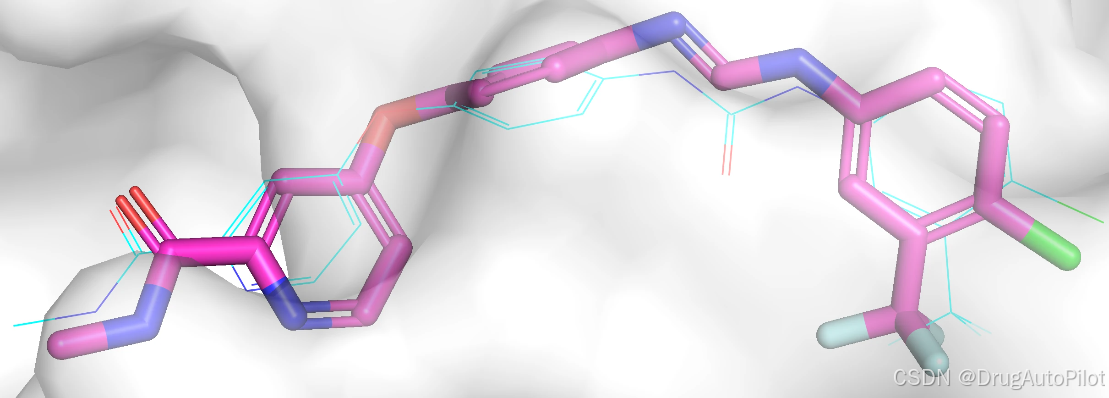
qvina score 排名前 2 和 3 的分子是同一个分子,所以我们下面展示第 1,2,4 的三个分子的2D 结构,对应的 qvina score 分数分别为 -11.5,-11.4, -11.4:

这三个分子在口袋中的 Pose 如下,蓝色的是参考分子,紫红色的是生成分子。这三个分子和参考分子结构十分接近,只是相差了个别原子或键。
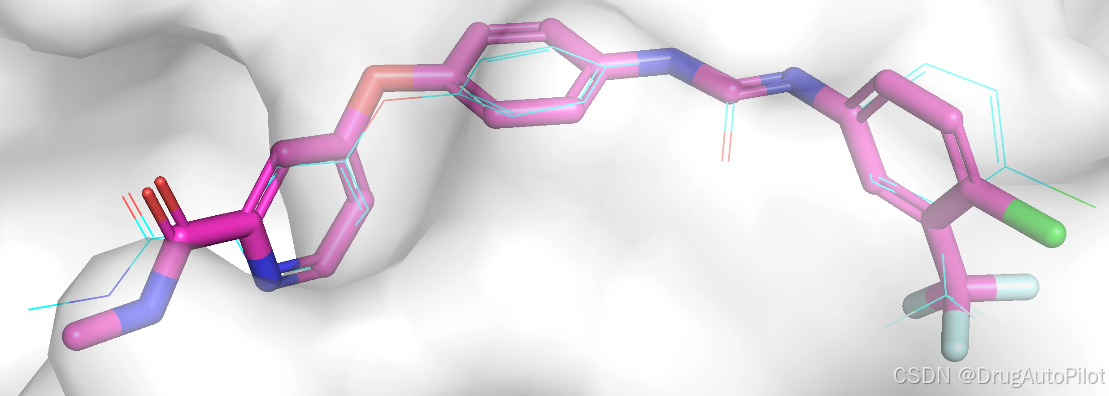
3.2.2.2 分子优化
针对自定义案例,通过 qvina 对生成分子进行优化,命令如下:
time python generate_optimize.py \config/generate_optimize_3wze.yml配置文件中指定配体和口袋结构文件,优化后的输出文件夹。使用 qvina 对生成分子的结合亲和力进行优化。过滤包含五、六环以外的生成分子,过滤超过三个环以上的生成分子等。生成后的分子会过滤筛选后保留 100 个分子。config/generate_optimize_3wze.yml 的具体配置内容如下:
ligand_path: ./3WZE/3wze_ligand.sdf # .sdf file for molecule(s) to optimize
target_path: ./3WZE/3wze_pocket.pdb # .pdb file for target structure
target_path_pdbqt: ./3WZE/3wze_pocket.pdbqt # .pdbqt file for docking to target structure
pdb_id: 3wze # PDB ID for target
output: output_3wze/optimize_example # output directory## optimization params
key_opt: affinity_qvina # options: affinity_qvina, qed, alogp, or sa
save_name: affinity_qvina_z3-1 # directory name for saving optimization process
opt_increase: false # increase value during optimizationn_cycles: 8 # optimization cycles
n_samples_initial: 100 # initial population size
n_samples: 20 # number of children per parent
n_best_parents: 20 # number of parents to choose from each pdb_id each next generation
affinity_quantile_thresh: 0.5 # affinity threshold for parent pool (use for non-affinity optimization)
random_rotate: true
random_translate: false
cluster_parents: true # cluster molecules before choosing parents. Up to one parent chosen per cluster.zbetas_initial: 0.3 # prior-posterior interpolation factor for generating initial population
temps_initial: 1. # temperature factor for generating initial population
zbetas: [0.3, 0.3, 0.2, 0.2, 0.2, 0.2, 0.2, 0.1] # list defining prior-posterior interpolation factor for each optimization cycle. Or single value for all cycles.
temps: 1. # temperature factor## filter generated molecules
ring_sizes: [5,6] # only allow rings of this size
ring_system_max: 3 # only allow ring systems up to this size
ring_loops_max: 0 # only allow this many ring loops
dbl_bond_pairs: false # allow consecutive double bonds
n_atoms_min: 0 # minimum number of atoms allowed in each molecule## model
checkpoint: model_checkpoints/drughive_model_ch9.ckpt # model checkpoint
model_id: c9_pdbzinc # id for model## docking
docking_cmd: qvina2.1 # command for docking
protonate: true # protonate molecules before docking
优化后的分子结构保存在 ./output_3wze/optimize_example 文件夹中,生成过程显存占用约 4 GB,花费时间约 13 个小时。
第8轮,所有生成的分子如下:
DrugHIVE_optimize_3wze
从视频上看,重复的分子比较多,qvina score 排名前1 3 不同的2D 结构,对应的 qvina score 分数分别为 -12.0,-11.9, -11.5:
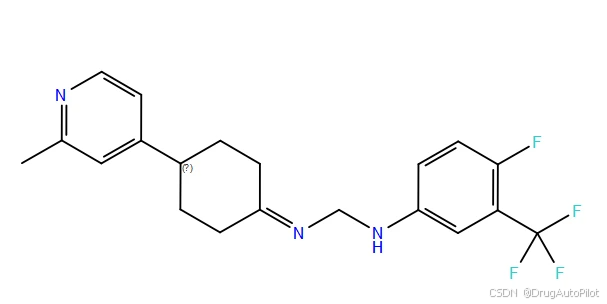
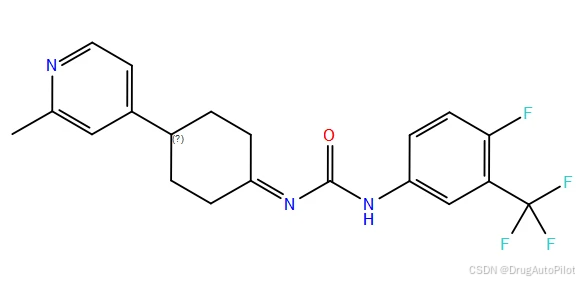
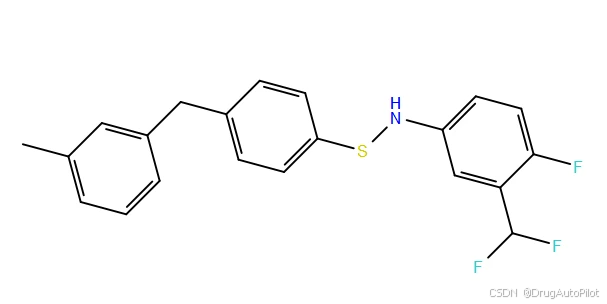
这三个分子在口袋中的 Pose 如下,蓝色的是参考分子,紫色的是生成分子。对接pose 上还是比较接近,但是他们的结构存在明显的差异。
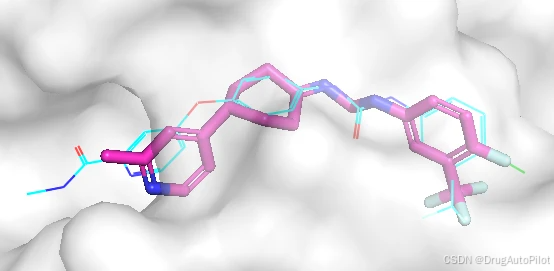
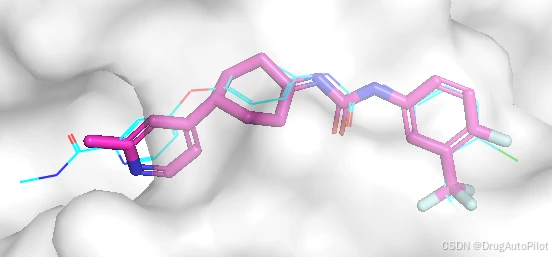
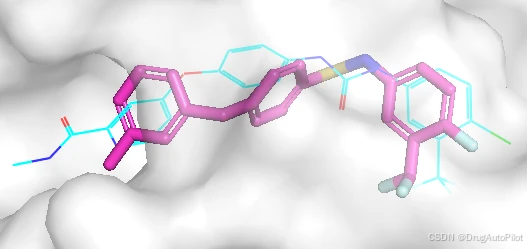
四、总结
作者提出了 DrugHIVE ,这是一种基于深度 HVAE 架构的药物设计方法。模型设计的动机在于捕捉分子系统在不同空间尺度上的结构和属性,更好地学习分子内和分子间关系的分布,可以高度控制地生成高亲和力的类药分子。评估结果显示,DrugHIVE 在连接体设计、骨架跳跃、片段生长和高通量模式替换等任务上均有良好的表现。
相关文章:

分子生成的深层次层次变分自编码器 - DrugHIVE 测评
一、背景介绍 DrugHIVE 来源于南加州大学定量与计算生物学系的 Remo Rohs 为通讯作者的文章:《Structure-Based Drug Design with a Deep Hierarchical Generative Model》。文章链接:https://pubs.acs.org/doi/10.1021/acs.jcim.4c01193。该文章在 202…...
)
54.大学生心理健康管理系统(基于springboot项目)
目录 1.系统的受众说明 2.相关技术 2.1 B/S结构 2.2 MySQL数据库 3.系统分析 3.1可行性分析 3.1.1时间可行性 3.1.2 经济可行性 3.1.3 操作可行性 3.1.4 技术可行性 3.1.5 法律可行性 3.2系统流程分析 3.3系统功能需求分析 3.4 系统非功能需求分析 4.系统设计…...

Linux文件特殊权限管理及进程和线程
acl 权限优先级 拥有者 > 特殊指定用户 > 权限多的组 >权限少的组 > 其他 mask阈值 mask是能够赋予指定用户权限的最大阀值 当设定完毕文件的acl列表之后用chmod缩小了文件拥有组的权力 mask会发生变化 恢复: setfacl -m m: 权限 :rwx 文件/…...

Vue2+Vue3 45-90集学习笔记
Vue2Vue3 45-90集学习笔记 小兔鲜首页 页面开发思路: 分析页面,按模块拆分组件,搭架子(局部注册或全局注册) 局部注册:App.js中 导入(import),注册(compon…...

【Web 服务器】的工作原理
🌐 Web 服务器的工作原理 Web 服务器的主要作用是 接收客户端请求(通常是浏览器发出的 HTTP/HTTPS 请求),处理请求,并返回相应的数据(如网页、图片、API 响应等)。 📌 工作流程 1️…...

LeetCode 5 -- 区间DP | 中心拓展算法
题目描述 最长回文子串 数据规模为 5e5,必须 manacher 算法 1. DP 由于 r e v e r s e ( ) reverse() reverse() 的时间复杂度是 O ( N ) O(N) O(N),因此暴力肯定是不行的。 d p dp dp 的思路:如果 s [ l . . r ] s[l..r] s[l..r] 是一个…...

IntelliJ IDEA中Spring Boot 3.4.x+集成Redis 7.x:最新配置与实战指南
前言 Spring Boot 3.4.x作为当前最新稳定版本,全面支持Java 17与Jakarta EE 10规范。本文以Spring Boot 3.4.1和Redis 7.x为例,详解如何在IDEA中快速接入Redis,涵盖最新依赖配置、数据序列化优化、缓存注解及高…...

数仓建模中计算累计销量
在数仓建模中计算累计销量,通常需要结合时间维度和业务逻辑设计合理的模型与计算逻辑。以下是分步骤的实现思路和示例: 1. 模型设计 累计销量的计算通常基于星型模型或雪花模型,核心结构包括: 事实表:记录每一笔销售…...
 CExercise_05_1函数_1.2计算base的exponent次幂)
(多看) CExercise_05_1函数_1.2计算base的exponent次幂
题目: 键盘录入两个整数:底(base)和幂指数(exponent),计算base的exponent次幂,并打印输出对应的结果。(注意底和幂指数都可能是负数) 提示:求幂运算时,基础的思路就是先无脑把指数转…...

Pollard‘s Rho 算法
Pollard’s Rho 算法:一场数学与计算机科学的巧妙结合 在现代计算机科学中,素数分解、整数因子化问题有着广泛的应用,尤其是在密码学领域。然而,当面对一个大合数时,寻找其因子仍然是一个非常复杂的问题。我们常常依赖…...

8款分形长虹玻璃科幻渐变海报设计JPG背景素材 The Gradient Backgrounds Pack
天空从未如此美好 — 直到有人将日落洒在您的屏幕上。这些渐变是带有心跳的液体颜色,从熔化的金色转变为深紫色,就像地平线一样。 8 个背景中的每一个都以 45003000 像素和 300dpi 的速度脉冲,清晰到足以让您感觉自己可以直接踏入光芒中。但这…...

AIGC9——AIGC时代的用户体验革命:智能交互与隐私保护的平衡术
引言:当AI成为交互主角 2024年,淘宝AI客服"阿里小蜜"日均处理20亿次咨询,日本虚拟偶像"初音未来"演唱会门票3秒售罄——这些现象标志着AIGC已深度融入人机交互场景。但与此同时,过度个性化的推荐引发"信…...

vm虚拟机虚拟出网卡并ping通外网
在 Linux 和 Windows 系统中,即使不使用网络命名空间(namespace),也能实现虚拟网卡上网。以下是不同场景下的实现方法: 一、Linux 系统(不使用网络命名空间) 1. 直接创建虚拟网卡对(…...
)
基于时间卷积网络TCN实现电力负荷多变量时序预测(PyTorch版)
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

ESXi8的部署过程
目录 一、系统安装 二、ESXI8的序列号 三、挂载硬盘和新建VMFS数据分区 四、通过数据存储浏览器上传下载文件 五、Windows远程桌面端口隐射 六、导出虚机 一、系统安装 1、使用UtrIOS系统制作ESXI8的启动盘; 2、服务器启动F8按键进入Popup启动选项,选择U盘启动; 3、安…...

IntelliJ IDEA 2020~2024 创建SpringBoot项目编辑报错: 程序包org.springframework.boot不存在
目录 前奏解决结尾 前奏 哈!今天在处理我的SpringBoot项目时,突然遇到了一些让人摸不着头脑的错误提示: java: 程序包org.junit不存在 java: 程序包org.junit.runner不存在 java: 程序包org.springframework.boot.test.context不存在 java:…...
)
Windows 权限配置文件解析与安全分析(GPP,GPO,LSA)
在 Windows 网络环境中,权限配置文件用于管理用户权限、密码策略和访问控制,涵盖组策略首选项(GPP)、本地安全策略(LSA)、注册表以及 Active Directory 组策略(GPO) 等。这些配置文件…...

【微服务】基础概念
1.什么是微服务 微服务其实就是一种架构风格,他提倡我们在开发的时候,一个应用应该是一组小型服务而组成的,每一个服务都运行在自己的进程中,每一个小服务都通过HTTP的方式进行互通。他更加强调服务的彻底拆分。他并不是仅局限于…...
[NOIP 2004 普及组] FBI 树(二叉树实操,递归提高))
MYOJ_4342:(洛谷P1087)[NOIP 2004 普及组] FBI 树(二叉树实操,递归提高)
题目描述 我们可以把由 “0” 和 “1” 组成的字符串分为三类:全 “0” 串称为 B 串,全 “1” 串称为 I 串,既含 “0” 又含 “1” 的串则称为 F 串。 FBI 树是一种二叉树,它的结点类型也包括 F 结点,B 结点和 I 结点三…...
:词编码后的位置)
LLM(13):词编码后的位置
原则上,token 嵌入是大型语言模型(LLM)的合适输入。然而,LLM 的一个小缺点是它们的自注意力机制无法指导序列中 token 的位置或顺序。在前面介绍的嵌入层的工作方式中,无论 token ID 在输入序列中的位置如何࿰…...

MINIQMT学习课程Day4
聚宽的模拟/实盘跟单系统,已经全部介绍完毕,上传完毕了,相信大家已经可以进行聚宽的miniqmt的交易了。如果还有疑问,私信我进行沟通。 现在开始进入新的课题,如何学习python,我不教那些乱七八糟的ÿ…...

AWS云服务:大数据公司实现技术突破与商业价值的核心引擎
在数据驱动决策的时代,大数据公司面临着海量数据存储、实时计算、复杂分析及安全合规等核心挑战。如何高效构建弹性、可扩展且低成本的技术架构,成为企业能否在竞争中胜出的关键。亚马逊云科技(AWS)作为全球云计算领域的领导者&am…...
)
Openpyxl使用教程(包含处理大数据量案例)
文章目录 一、简介功能特性应用场景使用优势 二、常用方法1、工作簿wb2、工作表ws 三、案例1、创建新工作簿2、将Excel数据存入list中3、按行读取文件(适合大文件)4、按指定行读取文件(适合大文件) 一、简介 在 Python 数据处理领域,openpyxl 凭借其卓越的功能与易…...

蓝桥杯15届 宝石组合
问题描述 在一个神秘的森林里,住着一个小精灵名叫小蓝。有一天,他偶然发现了一个隐藏在树洞里的宝藏,里面装满了闪烁着美丽光芒的宝石。这些宝石都有着不同的颜色和形状,但最引人注目的是它们各自独特的 “闪亮度” 属性。每颗宝…...

THE UNIVERSITY OF MANCHESTER-NUMERICAL ANALYSIS 1-3.4数值积分-复合积分公式
3.4.1 复合梯形法则 梯形法则仅使用两个点来近似积分,显然对于大多数应用来说,这不足够。为了提高精度,有多种方法可以利用更多的点和函数值。正如我们刚才在Newton-Cotes方法和辛普森法则中所看到的,一种方法是使用更高阶的插值函数。另一种方法是将区间划分为更小的区间…...

嵌入式系统应用-拓展-相关开发软件说明
这里以STM32的系列产品为例子,利用MDK的集成开发平台进行开发过程中,所有相关软件安装说明。 1 集成开发环境安装 1.1 MDK 下载 1.1.1 官网下载 官方下载地址: https://www.keil.com/download/product/ 选择MDK-ARM ,填写一些…...
)
react实现上传图片到阿里云OSS以及问题解决(保姆级)
一、优势 提高上传速度:前端直传利用了浏览器与 OSS 之间的直接连接,能够充分利用用户的网络带宽。相比之下,后端传递文件时,文件需要经过后端服务器的中转,可能会受到后端服务器网络环境和处理能力的限制,…...

嵌入式学习笔记——ARM-中断与异常
文章目录 中断与异常的区别中断与 DMA 的区别中断能否睡眠?下半部能否睡眠?1. 中断处理程序不能睡眠2. 下半部(SoftIRQ、Tasklet、Workqueue) 中断处理注意点1. 快进快出2. 避免阻塞3. 正确返回值4. 如何处理大量任务5. 避免竞态问…...
)
OpenHarmony子系统开发 - 安全(十二)
OpenHarmony SELinux开发指导(五) 一、OpenHarmony SELinux常见问题 neverallow编译报错处理 现象描述 编译SELinux时会进行neverallow检查,当配置的策略不合理时,可能出现违反neverallow编译报错。 neverallow check failed…...

深入解析ARM与RISC-V架构的Bring-up核心流程
深入解析ARM与RISC-V架构的Bring-up核心流程 作者:嵌入式架构探索者 | 2023年10月 引言 在嵌入式开发中,处理器的Bring-up(启动初始化)是系统运行的第一道门槛。ARM和RISC-V作为两大主流架构,其Bring-up流程既有共性…...
全排列)
【力扣hot100题】(054)全排列
挺经典的回溯题的。 class Solution { public:vector<vector<int>> result;void recursion(vector<int>& nums,vector<int>& now){if(nums.size()0){result.push_back(now);return ;}for(int i0;i<nums.size();i){now.push_back(nums[i]);…...

vue中如何动态的绑定图片
在项目中遇到需要动态的改变图片路径,图片路径并非是从后台获取过来的数据。 因此在data中必须用require加载,否则会当成字符串来处理。...

湖北师范大学计信学院研究生课程《工程伦理》12.6章节练习
1【单选题】下列哪个不是数字身份的特点? A. 多样性 B. 唯一性 C. 可变性 D. 允许匿名和假名 2【单选题】下列哪项不是现代国家的基本职能。 A. 保护政权统一 B. 保护本国面对其他国家侵犯 C. 保护国内每个人免受他人侵犯 D. 承担发展国民经济 3【单选题】哪个国家在全球率先发…...

prism WPF 登录对话框登录成功后显示主界面
prism WPF 登录对话框登录成功后显示主界面 项目结构 LoginUC.xaml <UserControl x:Class"PrismWpfApp.Views.LoginUC"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml…...

MySQL统计信息
1. 什么是统计信息? 统计信息就像是数据库的"地图",它告诉优化器: 每个表有多大(有多少行数据) 每个索引的"区分度"(有多少不同的值) 数据分布情况(哪些值出…...

Spark,配置hadoop集群2
编写Hadoop集群启停脚本 1.建立新文件,编写脚本程序 在hadoop101中操作,在/root/bin下新建文件:myhadoop,输入如下内容: 2.分发执行权限 保存后退出,然后赋予脚本执行权限 [roothadoop101 ~]$ chmod x /r…...
Reconstruct Itinerary)
⭐算法OJ⭐重建行程【哈密尔顿路径】(C++ 实现)Reconstruct Itinerary
You are given a list of airline tickets where tickets[i] [from_i, to_i] represent the departure and the arrival airports of one flight. Reconstruct the itinerary in order and return it. All of the tickets belong to a man who departs from “JFK”, thus, t…...

大模型如何优化数字人的实时交互与情感表达
标题:大模型如何优化数字人的实时交互与情感表达 内容:1.摘要 随着人工智能技术的飞速发展,数字人在多个领域的应用愈发广泛,其实时交互与情感表达能力成为提升用户体验的关键因素。本文旨在探讨大模型如何优化数字人的实时交互与情感表达。通过分析大模…...

【含文档+PPT+源码】基于SpringBoot+Vue旅游管理网站
项目介绍 本课程演示的是一款 基于SpringBootVue旅游管理网站,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该项目附…...

理解OSPF Stub区域和各类LSA特点
之前学习到OSPF特殊区域和各类类型LSA的分析后,一直很混乱,在网上也难找到详细的解释,在看了 HCNP书本内容后,对这块类容理解更加清晰,本次内容,我们使用实验示例,来对OSPF特殊区域和各 类型LSA…...

AI智算-K8s如何利用GPFS分布式并行文件存储加速训练or推理
文章目录 GPFS简介核心特性存储环境介绍存储软件版本客户端存储RoCEGPFS 管理(GUI)1. 创建 CSI 用户2. 检查GUI与k8s通信文件系统配置1. 开启配额2. 启用filesetdf文件系统3. 验证文件系统配置4. 启用自动inode扩展存储集群配置1. 启用对根文件集(root fileset)配额2. igno…...

Linux如何设置bash为默认shell
大部分情况下,Linux的默认shell是bash,但某些Linux发行版,例如Kali,默认的终端是zsh,本文以Kali为例,将Kali的默认shell从zsh改为bash。 其实Kali早期的shell也是bash,2020 版本之后:…...

leetcode-代码随想录-链表-翻转链表
题目 链接:206. 反转链表 - 力扣(LeetCode) 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]class Solution { public:ListNode* rev…...

CSS快速上手
第一章 CSS基础 首先来回答2个问题。 1.CSS是什么? CSS是用来控制网页外观的一门技术。 2.前端最核心的技术是什么?他们分别是用来干吗的? 前端最核心的技术有:HTML、CSS、JavaScript。 HTML用于控制网页的结构,CSS…...

虚拟现实 UI 设计:打造沉浸式用户体验
VR UI 设计基础与特点 虚拟现实技术近年来发展迅猛,其独特的沉浸式体验吸引了众多领域的关注与应用。在 VR 环境中,UI 设计扮演着至关重要的角色,它是用户与虚拟世界交互的桥梁。与传统 UI 设计相比,VR UI 设计具有显著的特点。传…...

搜索与图论 树的广度优先遍历 图中点的层次
适用性 当边的权值相等时,使用广度优先遍历,往往是求图(树)的最短路径最优方法 抽象理解 伪代码 建立队列 添加第一个起始点到队列,标记其不可访问 while(队列不为空)//开始循环{获取队列中的队首元素,获…...

DHCP之报文格式
字段说明: op (op code): 表示报文的类型,取值为 1 或 2,含义如下 1:客户端请求报 2:服务器响应报文 Secs (seconds):由客户端填充,表示从客户端开始获得 IP 地址或 IP 地址续借后所使用了的秒数,缺省值为 3600s。 F…...

Docker安装、配置Redis
1.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:redis:image: redis:latestcontainer_name: redisports:- "6379:6379"command: redis-server --requirepass "123456"restart: a…...

空中无人机等动态目标识别2025.4.4
* 一.无人机动态数据概述* 1.1 空中动态数据定义 在无人机动态数据的范畴中, 空中动态数据 是一个核心概念。它主要包括无人机在飞行过程中产生的各种实时信息,如 位置、速度、高度、姿态 等[1]。这些数据通过传感器系统采集,并以特定格式存…...

【AI论文】通过R1-Zero类似训练改进视觉空间推理
摘要:人们越来越关注提升多模态大型语言模型(MLLMs)的推理能力。作为在物理领域中运作的人工智能代理的基石,基于视频的视觉空间智能(VSI)成为MLLMs最为关键的推理能力之一。本研究首次深入探讨了通过R1-Ze…...