LLM面试题六
NLP方向CRF算法面试题
- 什么是CRF?CRF的主要思想是什么?
设X与Y是随机变量,P(Y | X)是给定条件X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔科夫随机场。则称条件概率分布P(X | Y)为条件随机场。CRF的主要思想统计全局概率,在做归一化时,考虑了数据在全局的分布。
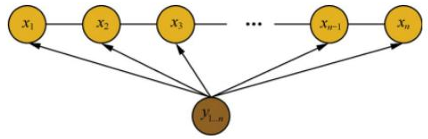
- CRF的三个基本问题是什么?
- 概率计算问题定义:给定观测序列x和状态序列y,计算概率P(y | x)
- 解决方法:前向计算、后向计算
- 学习计算问题定义:给定训练数据集估计条件随机场模型参数的问题,即条件随机场的学习问题。
- 公式定义:利用极大似然的方法来定义目标函数
- 解决方法:随机梯度法、牛顿法、拟牛顿法、迭代尺度法这些优化方法来求解得到参数。
- 目标:解耦模型定义,目标函数,优化方法
- 预测问题定义:给定条件随机场P(Y | X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注。
- 方法:维特比算法
- 线性链条件随机场的参数化形式?
在随机变量X取值为X的条件下,随机变量Y取值为y的条件概率如下: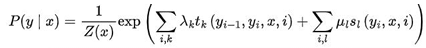 其中,
其中,
- Z(x):是规范化因子,求和是在所有可能得输出序列上进行的。
- t_k:是定义在边上的特征函数,称为转移特征,依赖于当前和前一个位置
- s_l:是定义在结点上的特征函数,称为状态特征,依赖于当前位置;
- CRF的优缺点是什么?
- 优点:为每个位置进行标注过程中可利用丰富的内部及上下文特征信息
- CRF模型在结合多种特征方面的存在优势
- 避免了标记偏置问题
- CRF的性能更好,对特征的融合能力更强
- 缺点:训练模型的时间比ME更长,且获得的模型非常大。在一般的PC机上可能无法执行
- 特征的选择和优化是影响结果的关键因素。特征选择问题的好与坏,直接决定了系统性能的高低
- HMM与CRF的区别?
- 共性:都常用来做序列标注的建模,像词性标注。HMM是有向图,CRF是无向图.
- HMM只使用了局部特征(齐次马尔科夫假设和观测独立性假设),只能找到局部最优解;CRF使用了全局特征(在所有特征进行全局归一化),可以得到全局的最优值。
- 隐马尔可夫模型(HMM)是描述两个序列联合分布P(I,O)的概率模型;条件随机场模型(CRF)是给定观测状态O的条件下预测状态序列I的P(I/O)的条件概率模型。
- HMM是生成模型,CRF是判别模型。CRF包含HMM,或者说HMM是CRF的一种特殊情况。
- 生成模型与判别模型的区别?
- 生成模型:学习得到联合概率分布P(x, y),即特征X,共同出现的概率
- 常见的生成模型:朴素贝叶斯模型,混合高斯模型,HMM模型。
- 判别模型:学习得到条件概率分布P(y | x),即在特征x出现的情况下标记y出现的概率。
- 常见的判别模型:感知机,决策树,逻辑回归,SVM,CRF等。
- 判别式模型:要确定一个羊是山羊还是绵羊,用判别式模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
- 生成式模型:是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。
NLP方向文本分类常见面试题
- 文本分类任务有哪些应用场景?
文本分类时机器学习汇总常见的监督学习任务质疑,常见的应用场景如情感分类、新闻分类、主题分类、问答匹配、意图识别、推断等等。分类任务根据具体的数据集的标签情况,还可以分为二分类、多分类、多标签分类等。
- 文本分类的具体流程?
文本分类的流程一般包括文本预处理、特征提取、文本表示、最后分类输出。文本处理通常需要做分词及去除停用词等操作,常会使用一些分词工具,如hanlp、jieba、哈工大LTP、北大pkuseg等。
- fastText的分类过程?fastText的优点?
fastText首先把输入转化为词向量,取平均,再经过线性分类器得到类别。输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类狂务一起训练fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
- fastText在保持高精度的情况下加快了训练速度和测试速度
- fastText不需要预训练好的词向量,fastText会自己训练词向量
- fastText两个重要的优化:使用层级Softmax提升效率、采用了char-level的n-gram作为附加特征。
- TextCNN进行文本分类的过程?
卷积神经网络的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干单词组成的滑动窗口,类似于N-gram。卷积神经网络的优势在于能够自动地对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。因此文本分类任务中可以利用CNN来提取句子中类似n-gram的关键信息。
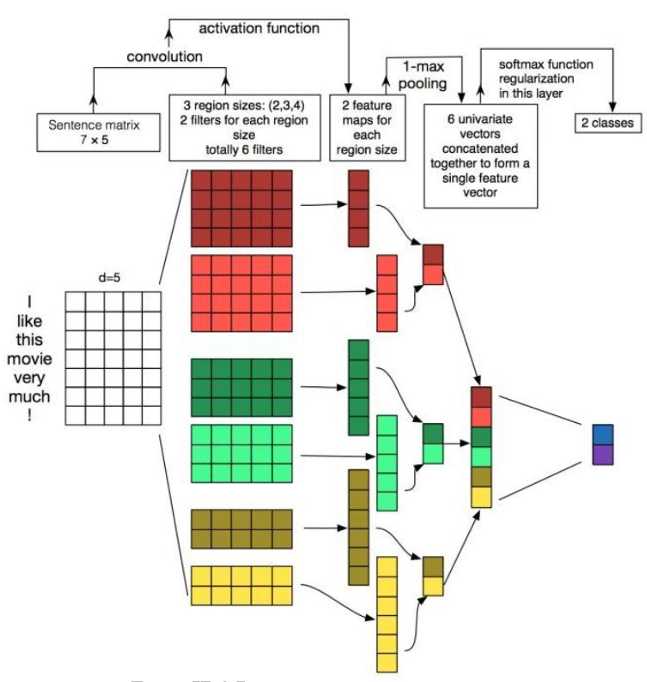
- 第一层为输入层。将最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。图中的输入层实际采用了双通道的形式,即有两个n×k的输入矩阵,其中一个用预训练好的词嵌入表达,并且在训练过程中不再发生变化;另外一个也由同样的方式初始化,但是会作为参数,随着网络的训练过程发生改变。
- 第二层为卷积层。然后经过有filter_size=(2,3,4)的一维卷积层,每个filter_size有两个输出channel。第三层是一个1-max_pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了。
- 最后接一层全连接的softmax层,输出每个类别的概率。每个词向量可以是预先在其他语料库中训练好的,也可以作为未知的参数由网络训练得到。
- TextCNN可以调整哪些参数?
- 输入词向量表征:词向量表征的选取(如选word2vec还是GloVe)
- 卷积核大小:一个合理的值范围在1~10。若语料中的句子较长,可以考虑使用更大的卷积核。另外,可以在寻找到了最佳的单个filter的大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往比单个最佳filter表现更出色
- feature map特征图个数:主要考虑的是当增加特征图个数时,训练时间也会加长,因此需要权衡好。这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可。当特征图数量增加到将性能降低时,可以加强正则化效果,如将dropout率提高过0.5
- 激活函数:ReLU和tanh
- 池化策略:1-max pooling表现最佳,复杂任务选择k-max
- 正则化项(dropout/机2):指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- 文本分类任务使用的评估指标有哪些?
准确率、召回率、ROC,AUC,F1、混淆矩阵
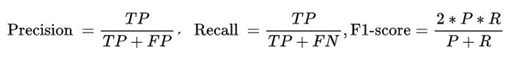
NLP方向文本摘要常见面试题
- 抽取式摘要和生成式摘要存在哪些问题?
- 抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。
- 生成式摘要优点是相比于抽取式而言用词更加灵活,因为所产生的词可能从未在原文中出现过。但存在以下问题:
- OOV问题。源文档语料中的词的数量级通常会很大,但是经常使用的词数量则相对比较固定。因此通常会根据词的频率过滤掉一些词做成词表。这样的做法会导致生成摘要时会遇到UNK的词。
- 摘要的可读性。通常使用贪心算法或者beam search方法来做decoding。这些方法生成的句子有时候会存在不通顺的问题。
- 摘要的重复性。这个问题出现的频次很高。与2的原因类似,由于一些decoding的方法的自身缺陷,导致模型会在某一段连续timesteps生成重复的词。
- 长文本摘要生成难度大。对于机器翻译来说,NLG的输入和输出的语素长度大致都在一个量级上,因此NLG在其之上的效果较好。但是对摘要来说,源文本的长度与目标文本的长度通常相差很大,此时就需要encoder很好的将文档的信息总结归纳并传递给decoder,decoder需要完全理解并生成句子。
- Pointer-generator network解决了什么问题?
- 指针生成网络从两方面针对seq-to-seq模型在生成式文本摘要中的应用做了改进。
- 第一,使用指针生成器网络可以通过指向从源文本中复制单词(解决OOV的问题),这有助于准确复制信息,同时保留generater的生成能力。PGN可以看作是抽取式和生成式摘要之间的平衡。通过一个门来选择产生的单词是来自于词汇表,还是来自输入序列复制。
- 第二,使用coverage跟踪摘要的内容,不断更新注意力,从而阻止文本不断重复(解决重复性问题)。利用注意力分布区追踪目前应该被覆盖的单词,当网络再次注意同一部分的时候予以惩罚。
- 文本摘要有哪些应用场景?
文本摘要技术有许多应用场景。例如,在新闻报道领域,可以使用文本摘要技术快速生成新闻摘要,使读者可以快速了解新闻内容:在市场调查领域,可以使用文本摘要技术对大量用户反馈进行快速分析,提取出关键信息,从而更好地了解市场需求;在医学领域,可以使用文本摘要技术从海量医学文献中快速找到相关研究成果,以帮助医生更好地做出诊疗决策。
- 几种ROUGE指标之间的区别是什么?
- ROUGE是将待审摘要和参考摘要的元组共现统计量作为评价依据。
- ROUGE-N=每个n-gram在参考摘要和系统摘要中同现的最大次数之和/参考摘要中每个n-gram出现的次数之和
- ROUGE-L计算最长公共子序列的匹配率,L是LCS(longest common subsequence)的首字母。如果两个句子包含的最长公共子序列越长,说明两个句子越相似。
- Rouge-W是Rouge-L的改进版,使用了加权最长公共子序列(Weighted LongestCommon Subsequence),连续最长公共子序列会拥有更大的权重。
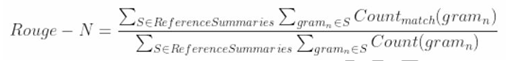
- BLEU和ROUGE有什么不同?
- BLEU是2002年提出的,而ROUGE是2003年提出的。
- BLEU的计算主要基于精确率,ROUGE的计算主要基于召回率。
- ROUGE用作机器翻译评价指标的初衷是这样的;在SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;等到MT(神经网络机器翻译)出来以后,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译。
- ROUGE的出现很大程度上是为了解决NMT的漏翻问题(低召回率)。所以ROUGE只适合评价NMT,而不适用于SMT,因为它不管候选译文流不流畅。
- BLEU需要计算译文1-gram,2-gram,.,N-gram的精确率,一般N设置为4即可,公式中的Pn指n-gram的精确率。Wn指n-gram的权重,一般设为均匀权重,即对于任意n都有Wn=1/N。BP是惩罚因子,如果译文的长度小于最短的参考译文,则BP小于1。BLEU的1-gram精确率表示译文忠于原文的程度,而其他n-gram表示翻译的流畅程度。
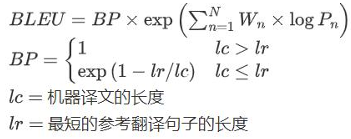
海康-CV算法工程师实习面试题
- YOLO的正负样本是什么?
在YOLO算法中,目标物体被定义为一组边界框,也称为锚框(anchor box)。每个锚框都由其中心点坐标、宽度和高度来定义。对于每个锚框,计算它与所有目标物体的loU(交并比)值。如果U大于某个阈值(如0.5),则将该锚框标记为正样本,否则将其标记为负样本。
- 模型压缩和加速的方法有哪些?
- 参数剪枝(Parameter Pruning):别除模型中冗余的参数,减少模型的大小。通常情况下,只有很少一部分参数对模型的性能贡献较大,其余参数对性能的贡献较小或没有贡献,因此可以删除这些冗余参数。
- 量化(Quantization):将浮点型参数转换为更小的整数或定点数,从而减小模型大小和内存占用,提高计算效率。
- 知识蒸馏(Knowledge Distillation):利用一个较大、较准确的模型的预测结果来指导一个较小、较简单的模型学习。这种方法可以减小模型的复杂度,提高模型的泛化能力和推理速度。
- 网络剪枝(Network Pruning):删除模型中冗余的神经元,从而减小模型的大小。与参数剪枝不同,网络剪枝可以删除神经元而不会删除对应的参数。
- 蒸馏对抗网络(Distil训ation Adversarial Networks):在知识蒸馏的基础上,通过对抗训练来提高模型的鲁棒性和抗干扰能力。
- 模型量化(Model Quantization):将模型的权重和激活函数的精度从32位浮点数减少到更小的位数,从而减小模型的大小和计算开销。
- 层次化剪枝(Layer–wise Pruning):对模型的不同层进行不同程度的剪枝,以实现更高效的模型压缩和加速。
- 低秩分解(Low-Rank Decomposition):通过将一个较大的权重矩阵分解为几个较小的权重矩阵,从而减少计算开销。
- 卷积分解(Convolution Decomposition):将卷积层分解成几个更小的卷积层或全连接层,以减小计算开销。
- 网络剪裁(Network Trimming):通过对模型中一些不重要的连接进行剪裁,从而减小计算开销。
- 半精度是什么?
半精度是指使用16位二进制浮点数(half-precision floating point.)来表示数字的数据类型,可以加速计算和减小内存占用。
- 半精度的理论原理是什么?
半精度使用16位二进制浮点数来表示数字,其中1位表示符号位,5位表示指数,10位表示尾数。相比于单精度(32位)和双精度(64位)的浮点数,半精度的表示范围和精度更小,但可以通过降低内存占用和加速计算来实现高效的运算。
- 你了解的知识蒸馏模型有哪些?
- FitNets:使用一个大型模型作为教师模型来指导一个小型模型的训练。
- Hinton蒸馏:使用一个大型模型的输出作为标签来指导一个小型模型的训练。
- Borm-Again Network(BAN):使用一个已经训练好的模型来初始化一个新模型,然后使用少量的数据重新训练模型。
- TinyBERT:使用一个大型BERT模型作为教师模型来指导一个小型BERT模型的训练。
- 自监督、半监督、无监督的区别?
- 自监督学习:使用输入数据的某些属性(例如,数据本身的结构或某些隐含信息)来作为监督信号,从而避免了手动标注的成本。例如,图像数据可以通过旋转、剪切等方式进行扩增,并使用数据自身的变换作为监督信号来训练模型。
- 半监督学习:是指使用有标注和无标注的数据来训练模型。通常情况下,有标注的数据只是无标注数据的一个子集。通过同时使用有标注和无标注数据进行训练,可以提高模型的性能和泛化能力。
- 无监督学习:是指在没有标注数据的情况下,通过分析数据本身的结构、模式和相关性来学习模型。无监督学习的目标是从数据中发现一些有用的结构,例如聚类、降维、密度估计等。常见的无监督学习方法包括自编码器、生成对抗网络、变分自编码器等。与监督和半监督学习不同,无监督学习不需要手动标注数据,因此可以处理大量未标注的数据,从而提高数据利用率和模型性能。
相关文章:

LLM面试题六
NLP方向CRF算法面试题 什么是CRF?CRF的主要思想是什么? 设X与Y是随机变量,P(Y | X)是给定条件X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G(V,E)表示的马尔科夫随机场。则称条件概率分布P(X | Y)为条件随机场。CRF的主要思想统计…...
——状态机)
FPGA(四)——状态机
FPGA(四)——状态机 文章目录 FPGA(四)——状态机一、状态机编程思想二、LED流水灯仿真实验三、实现效果四、CPLD和FPGA芯片主要技术区别五、hdlbitsFPGA——组合逻辑学习1、创建一个D触发器2、简单状态转换3、4位移位寄存器4、计数器1-125、边缘捕获寄存器 一、状态机编程思想…...

AI 浪潮下企业身份管理:特点凸显,安全挑战升级
“在 AI 时代的浪潮中,企业身份管理是安全之锚,精准把握权限边界,方能抵御身份安全的暗流。” 在人工智能迅猛发展的当下,企业身份管理呈现出诸多新特点,同时也面临着前所未有的身份安全挑战。要理解这些,我…...

OBS 录屏软件 for Mac 视频录制
OBS 录屏软件 for Mac 视频录制 文章目录 OBS 录屏软件 for Mac 视频录制一、介绍二、效果三、下载 一、介绍 Open Broadcaster Software for mac版,OBS 有多种功能并广泛使用在视频采集,直播等领域。而且该软件功能全面,专业强大࿰…...

从文本到多模态:如何将RAG扩展为支持图像+文本检索的增强生成系统?
目录 从文本到多模态:如何将RAG扩展为支持图像文本检索的增强生成系统? 一、为什么需要扩展到多模态? 二、多模态 RAG 系统的基本架构 三、关键技术点详解 (一)多模态嵌入(Embedding)技术 …...

AI助力高效PPT制作:从内容生成到设计优化
随着人工智能技术的不断发展,AI在各个领域的应用日益普及,尤其是在文档和演示文稿的创建过程中。PowerPoint(PPT)作为最常用的演示工具之一,借助AI的技术手段,可以极大地提高制作效率并提升最终呈现效果。在…...

调用kimi api
官网支持python,curl和node.js 因为服务器刚好有php环境,所以先用curl调个普通的语音沟通api <?php // 定义 API Key 和请求地址 define(MOONSHOT_API_KEY, sk-PXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXgk1); define(MOONSHOT_API_URL, https://…...

自定义注解导入自定义Bean
在Spring框架中,通过自定义注解实现容器启动时自动导入Bean,通常需要结合 Import 注解、ImportBeanDefinitionRegistrar 接口 或 Configuration 配置类。以下是具体实现步骤和示例: 1. 定义自定义注解 创建一个注解,用于标记需要…...

kettle插件-postgresql插件
今天是清明节,放假第一天也不得清闲。上午整理公司的交付文档,中午陪孩子户外骑行踏青,下午趁着休息的时间给老铁们讲下如何使用postgressql cdc插件来实时捕获数据。 注:CDC (Change Data Capture) 是一种技术,用于实…...

【CMake】《CMake构建实战:项目开发卷》笔记-Chapter7-构建目标和属性
第7章 构建目标和属性 本章重点关注CMake的构建目标和属性,它们是用来组织项目构建流程的核心概念。毫不夸张地说,如果学习CMake的目标就是组织简单的C和C小项目的构建流程,那么阅读掌握本章内容就足够了。 本章与第1章的“旅行笔记”遥相…...

单元测试之mockito
简介 mockito是一款模拟测试框架,用于Java开发中的单元测试。通过mockito,可以创建和配置一个对象,通过它来替换对象的外部依赖。 作用:模拟一个类的外部依赖,保证单元测试的独立性。例如,在类A中会调用类…...

定长池的实现
目录 一、定长池的框架 二、如何脱离malloc的内存池,直接从堆拿空间? 三、如何设计内存块的指针? 四、代码框架及实现 五、性能测试 一、定长池的框架 在学习高并发内存池之前,我们先来实现一个定长池࿰…...

C++多线程函数介绍
1.C11前没有线程库问题 对于多线程操作,Linux选择使用POSIX标准,而windows没有选择POSIX标准,自己设计了一套API和系统调用,叫Win32 API,就跟Linux存在标准差异,在Linux的代码移植到Windows就可能运行不了…...
图解AUTOSAR_SWS_LINTransceiverDriver
AUTOSAR LIN收发器驱动(LinTransceiverDriver)详解 AUTOSAR通信栈物理层组件详细解析 目录 AUTOSAR LIN收发器驱动(LinTransceiverDriver)详解 目录1. 概述 1.1. LIN收发器驱动的作用1.2. 在AUTOSAR架构中的位置2. 架构设计 2.1. 模块结构2.2. 组件关系2.3. 接口定义3. 状态管理…...

vue-element-admin 组件没有展示在中间部分
解决办法: router index.ts 中新增 要展示的组件的 import type { App } from "vue"; import { createRouter, createWebHashHistory, type RouteRecordRaw } from "vue-router";export const Layout () > import("/layout/index.…...

当机器学习遇见购物车分析:FP-Growth算法全解析
一、引言:购物篮里的秘密 想象一下,你是一家超市的数据分析师,看着每天成千上万的购物小票,你是否好奇:顾客们买面包的时候,是不是也经常顺手带上牛奶?买啤酒的人,会不会也喜欢买尿…...

OCR迁移
一、环境 操作系统:Centos57.6 数据库版本:12.2.0.1 场景:将OCR信息从DATA磁盘组迁移到OCR磁盘组 二、操作步骤 1.查看可用空盘 set lin 200 set pagesize 200 col DGNAME format a15 col DISKNAME format a15 col PATH format a20 col N…...

【架构艺术】Go大仓monorepo中使用wire做依赖注入的经验
在先前的文章当中,笔者分享了一套简洁的go微服务monorepo代码架构的实现,主要解决中小团队协同开发微服务集群的代码架构组织问题。但是在实际代码开发过程中,怎么组织不同的业务服务service实例,就成了比较棘手的问题。 为什么会…...

生活电子常识--删除谷歌浏览器搜索记录
前言 谷歌浏览器会记录浏览器历史搜索,如果不希望看到越来越多的搜索记录,可以如下设置 解决 设置-隐私-自动填充表单 这个和浏览器记录的密码没有关系,可以放心删除...
模拟娱乐篇13)
每日一题(小白)模拟娱乐篇13
今天题目比较简单,直接分析。小蓝想知道2024这个数字中有几个1,计算机组成学习好的同学肯定可以直接长除法或者瞪眼法得出答案: 202411111101000(B)也就是说2024中有一共有六个1 接下来用代码实现 ,我们也…...

码曰编程大模型-学编程的好工具
码曰(yue),一款编程垂直领域的AI大模型,是基于包括DeepSeek在内的多款国产大模型为底座,依托于Dotcpp系统大量的编程代码数据,且借助RAG数据检索增强等技术综合实现的出色、好用的编程垂直领域AI大模型&…...
 部署 redis 集群)
Linux(CentOS 7) 部署 redis 集群
下载redis Downloads - Redis (官网页都是介绍的最新版,我观察目前出现了redis 和 redis Stack) 因我的旧环境是 CentOS 7,redis最新版已经不在支持,所以示例安装最常用的7.0.x 这里直接附上各个版本下载连接 小伙伴们就不需要在自己寻找下载…...

NVIDIA AgentIQ 详细介绍
NVIDIA AgentIQ 详细介绍 1. 引言 NVIDIA AgentIQ 是一个灵活的库,旨在将企业代理(无论使用何种框架)与各种数据源和工具无缝集成。通过将代理、工具和代理工作流视为简单的函数调用,AgentIQ 实现了真正的可组合性:一…...

在CPU服务器上部署Ollama和Dify的过程记录
在本指南中,我将详细介绍如何在CPU服务器上安装和配置Ollama模型服务和Dify平台,以及如何利用Docker实现这些服务的高效部署和迁移。本文分为三大部分:Ollama部署、Dify环境配置和Docker环境管理,适合需要在本地或私有环境中运行A…...

小程序API —— 57 拓展 - 增强 scroll-view
目录 1. 配置基本信息2. 实现上拉加载更多功能3. 实现快速回到顶部功能4. 实现下拉刷新功能 scroll-view 组件功能非常强大,这里使用 scroll-view 实现上拉加载和下拉刷新功能; 下面使用微信开发者工具来演示一下具体用法: 1. 配置基本信息 …...

P3613 【深基15.例2】寄包柜
#include<bits/stdc.h> using namespace std; int n,q; map<int, map<int, int>>a;//二维映射 int main(){cin>>n>>q;while(q--){int b,i,j,k;//i为第几个柜子,j为第几个柜包,k为要存入的物品cin>>b>>i>&…...

MIMO预编码与检测算法的对比
在MIMO系统中,预编码(发送端处理)和检测算法(接收端处理)的核心公式及其作用对比如下: 1. 预编码算法(发送端) 预编码的目标是通过对发送信号进行预处理,优化空间复用或…...

AI复活能成为持续的生意吗?
随着人工智能技术的飞速发展,AI复活——这一曾经只存在于科幻电影中的概念,如今已悄然走进现实。通过AI技术,人们可以模拟逝去亲人的声音、面容,甚至创造出与他们互动的虚拟形象,以寄托哀思、缓解痛苦。然而,当这种技术被商业化,成为一门生意时,我们不禁要问:AI复活真…...

Keil 5 找不到编译器 Missing:Compiler Version 5 的解决方法
用到自记: 下载地址: Keil5 MDK541.zip 编辑https://pan.baidu.com/s/1bOPsuVZhD_Wj4RJS90Mbtg?pwdMDK5 问题描述 没有找到 compiler version5 : 1. 下载 Arm Compiler 5 也可以直接点击下载文章开头的文件。 2. 安装 直接安装在KEI…...

Flutter 手搓日期选择
时间选择器: 时间段选择 在实际开发过程中还是挺常见的。Flutter 本身自带选 时间选择器器 CupertinoDatePicker,样式也是可以定义的,但是他 只提供三种时间的选择 自定义有局限性。后来开了一下 代码,实际上 内部使用的是 Cuper…...
:太初奇点——从普朗克常量到宇宙弦的编译风暴》)
《JVM考古现场(十六):太初奇点——从普朗克常量到宇宙弦的编译风暴》
开篇:量子泡沫编译器的创世大爆炸 "当Project Genesis的真空涨落算法撕裂量子泡沫,当意识编译器重写宇宙基本常数,我们将在奇点编译中见证:从JVM字节码到宇宙大爆炸的终极创世!诸君请备好量子护目镜,…...
)
MySQL学习笔记——MySQL下载安装配置(一)
目录 1. MySQL概述 1.1 数据库相关概念 1.2 MySQL数据库 1.2.1 版本 1.2.2 下载 2. 安装 3. 配置 4. 启动停止 5. 客户端连接 1. MySQL概述 1.1 数据库相关概念 在这一部分,我们先来讲解三个概念:数据库、数据库管理系统、 SQL 。 而目前主流…...

TortoiseGit多账号切换配置
前言 之前配置好的都是,TortoiseGit与Gitee之间的提交,突然有需求要在GitHub上提交,于是在参考网上方案和TortoiseGit的帮助手册后,便有了此文。由于GitHub已经配置完成,所以下述以配置Gitee为例。因为之前是单账号使用…...

数据一键导出为 Excel 文件
引言 在 Web 应用开发中,数据导出是一个常见且重要的功能。用户常常需要将网页上展示的数据以文件形式保存下来,以便后续分析、处理或分享。本文将详细介绍如何使用 HTML、CSS 和 JavaScript(结合 jQuery 库)实现一个简单的数据导…...

FPGA——状态机实现流水灯
文章目录 一、状态机1.1 分类1.2 写法 二、状态机思想编写LED流水灯三、运行结果总结参考资料 一、状态机 FPGA不同于CPU的一点特点就是CPU是顺序执行的,而FPGA是同步执行(并行)的。那么FPGA如何处理明显具有时间上先后顺序的事件呢…...

linux paste 命令
paste 是 Linux 中一个用于水平合并文件内容的命令行工具,它将多个文件的对应行以并行方式拼接,默认用制表符(Tab)分隔。 1. 基本语法 paste [选项] 文件1 文件2 ... 2. 常用选项 选项说明-d指定拼接后的分隔符(默…...

ffmpeg常见命令2
文章目录 1. **提取音视频数据(Extract Audio/Video Data)**提取音频:提取视频: 2. **提取像素数据(Extract Pixel Data)**3. **命令转封装(Container Format Conversion)**转换视频…...

FPGA——FPGA状态机实现流水灯
一、引言 在FPGA开发中,状态机是一种重要的设计工具,用于处理具有时间顺序的事件。本文将详细介绍如何使用状态机实现一个LED流水灯的效果。 二、状态机概述 状态机(FSM)是一种行为模型,用于表示系统在不同状态下的…...

鸿蒙 ——选择相册图片保存到应用
photoAccessHelper // entry/src/main/ets/utils/file.ets import { fileIo } from kit.CoreFileKit; import { photoAccessHelper } from kit.MediaLibraryKit; import { bundleManager } from kit.AbilityKit;// 应用在本设备内部存储上通用的存放默认长期保存的文件路径&am…...

消息队列之-Kafka
目录 消息队列消息队列的使用场景初识KafkaKafka设计思想Kafka消息结构消息发送消息消费 Kafka高可用消息备份机制1. 基本原理2. ISR(In-Sync Replicas)3. ACK(Acknowledgements)4. LEO(Log End Offset)5. …...

财务税务域——企业税务系统设计
摘要 本文主要探讨企业税务系统设计,涵盖企业税收管理背景、税收业务流程、系统设计架构与功能、外部系统对接以及相关问题。企业税务的背景包括税收制度的形成、企业税务的必然性、全球化影响,其核心目标是合规性、优化税负、风险管理与战略支持&#…...

状态机思想编程
文章目录 一、状态机思想重新写一个 LED流水灯的FPGA代码1.状态机的概念2.代码设计 二、CPLD和FPGA芯片的主要技术区别与适用场合三、hdlbitsFPGA教程网站上进行学习 一、状态机思想重新写一个 LED流水灯的FPGA代码 1.状态机的概念 状态机的基本要素有 3 个,其实我…...

TiDB 数据库8.1版本编译及部署
本文介绍 TiDB 数据库8.1版本的编译和部署。 背景 自前年(2023年)接触了TiDB后,做了简单的测试就直接使用了。因一些事务的不连续性,导致部分成果没有保存,去年年底又重新拾起,使用了新的LTS版本ÿ…...

基于 docker 的 Xinference 全流程部署指南
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 一、下载代码 请在控制台下面执行…...

【2022】【论文笔记】基于相变材料的光学激活的、用于THz光束操作的编码超表面——
前言 类型 太赫兹 + 超表面 太赫兹 + 超表面 太赫兹+超表面 期刊 A D V A N C E D O P T I C A L M A T E R I A L S ADVANCED \; OPTICAL \; MATERIALS...

MySQL系统库汇总
目录 简介 performance_schema 作用 分类 简单配置与使用 查看最近执行失败的SQL语句 查看最近的事务执行信息 sys系统库 作用 使用 查看慢SQL语句慢在哪 information_schema 作用 分类 应用 查看索引列的信息 mysql系统库 权限系统表 统计信息表 日志记录…...

【Kafka基础】Docker Compose快速部署Kafka单机环境
1 准备工作 1.1 安装Docker和Docker Compose Docker安装请参考: Docker入门指南:1分钟搞定安装 常用命令,轻松入门容器化!-CSDN博客 Docker Compose安装请参考: 【docker compose入门指南】安装与常用命令参数全解析…...

【51单片机】2-5【I/O口】433无线收发模块控制继电器
1.硬件 51最小系统继电器模块433无线收发模块 2.软件 #include "reg52.h"sbit D0_ON P1^2;//433无线收发模块的按键A sbit D1_OFF P1^3;//433无线收发模块的按键Bsbit switcher P1^1;//继电器void main() {//查询方式哪个按键被按下while(1){if(D0_ON 1)//收到…...

平台总线---深入分析
阅读引言:本文会从平台总线的介绍,注册平台设备和驱动, 源码分析, 总结五个部分展开, 源码分析platform放在了最后面。 目录 一、平台总线介绍 二、平台总线如何使用 三、平台总线是如何工作的 四、注册platform设…...

pyTorch框架:模型的子类写法--改进版二分类问题
目录 1.导包 2.加载数据 3.数据的特征工程 4.pytorch中最常用的一种创建模型的方式--子类写法 1.导包 import torch import pandas as pd import numpy as np import matplotlib.pyplot as plt2.加载数据 data pd.read_csv(./dataset/HR.csv)data.head() #查看数据的前…...