当机器学习遇见购物车分析:FP-Growth算法全解析
一、引言:购物篮里的秘密
想象一下,你是一家超市的数据分析师,看着每天成千上万的购物小票,你是否好奇:顾客们买面包的时候,是不是也经常顺手带上牛奶?买啤酒的人,会不会也喜欢买尿布(经典的“啤酒与尿布”故事!)?
这些隐藏在购物篮里的“秘密”,就是关联规则。找出这些规则,超市就能更好地进行商品摆放、捆绑促销、精准推荐,最终提升销售额。而我们今天要聊的主角——FP-Growth算法,就是挖掘这些秘密的强大工具之一,而且它以高效著称!
在这篇文章里,我会用最通俗易懂的语言,带你一步步揭开FP-Growth的神秘面纱,让你不仅理解它的原理,还能动手用Python代码实践。准备好了吗?让我们开始这场数据挖掘之旅吧!
二、关联规则挖掘:我们在找什么?
简单来说,关联规则挖掘就是想找到数据集中项与项之间有趣的关联性。形式通常是 “如果 A 出现,那么 B 很可能也出现”,记作 A -> B。
-
项集 (Itemset): 一组一起出现的商品,比如 {牛奶, 面包}。
-
支持度 (Support): 一个项集在所有交易中出现的频率。比如 {牛奶, 面包} 在100个购物单里出现了10次,支持度就是 10/100 = 10%。我们通常会设定一个最小支持度 (Minimum Support) 阈值,只关心那些足够“频繁”的项集。
-
置信度 (Confidence): 买了A的顾客中,有多少比例也买了B。计算公式是 Support(A ∪ B) / Support(A)。比如,买了牛奶的人中有80%也买了面包,那么规则 {牛奶} -> {面包} 的置信度就是80%。我们也会设定最小置信度 (Minimum Confidence) 阈值。
我们的目标就是:找到那些同时满足最小支持度和最小置信度阈值的关联规则。
三、 老大哥Apriori的“烦恼”
在FP-Growth出现之前,Apriori算法是关联规则挖掘领域的“老大哥”。它的核心思想是“频繁项集的所有子集也必须是频繁的”。
Apriori的步骤大致是:
-
扫描数据库,找到所有频繁的单个商品(1项集)。
-
基于频繁1项集,生成候选的2项集。
-
扫描数据库,计算候选2项集的支持度,筛选出频繁2项集。
-
基于频繁2项集,生成候选的3项集...
-
重复这个过程,直到找不到更长的频繁项集。
详见当机器学习遇见购物车:手把手教你玩转Apriori关联分析
Apriori的痛点是什么?
-
多次扫描数据库: 生成k项集就需要扫描一次数据库,如果最长的频繁项集是10项集,那可能要扫描10次!数据量大时,这非常耗时。
-
产生大量候选集: 尤其是当商品种类很多时,生成的候选集数量可能爆炸式增长,计算和筛选这些候选集也需要大量时间和内存。
就像大海捞针,Apriori一遍又一遍地撒网(扫描数据库),捞起来一堆可能是针也可能是石头的“候选者”(候选集),再慢慢筛选。效率自然不会太高。
四、 FP-Growth闪亮登场:新思路解决老问题
FP-Growth(Frequent Pattern Growth)算法则另辟蹊径。它巧妙地避免了Apriori的两个主要痛点:
-
它只需要扫描数据库两次! (是的,你没看错,两次!)
-
它不产生候选集!
它是怎么做到的呢?FP-Growth的核心思想是:
-
压缩数据: 将整个交易数据库的信息压缩到一个叫做FP树 (FP-Tree) 的特殊树形结构中。这棵树保留了项集之间的关联信息。
-
分而治之: 基于FP树,递归地挖掘频繁项集。
想象一下,你不是一遍遍翻阅原始账本(数据库),而是先精心整理出一本“索引摘要”(FP树),然后在这本摘要上高效地查找信息。这就是FP-Growth的魅力所在!
五、核心利器:FP树 (FP-Tree) 是什么?
FP树是一种紧凑的数据结构,它存储了数据库中频繁项集的所有必要信息。它有以下特点:
-
树形结构: 有一个根节点(通常标为null),其余节点代表一个商品(项)。
-
路径代表交易: 从根节点到某个节点的路径,代表了一个交易(或交易的一部分)。
-
节点计数: 每个节点包含一个计数器,记录该节点代表的商品在经过该路径的交易中出现了多少次。
-
父子关系: 体现了商品在交易中的先后顺序(按频率排序后的顺序)。
-
项头表 (Header Table): 一个列表,包含了所有频繁的单个商品(按频率降序排列)。每个商品指向它在FP树中第一次出现的位置。
-
节点链接 (Node Links): FP树中相同商品名的节点会被链接起来(像串珠子一样),方便快速找到某个商品的所有出现位置。这个链接就从项头表开始。
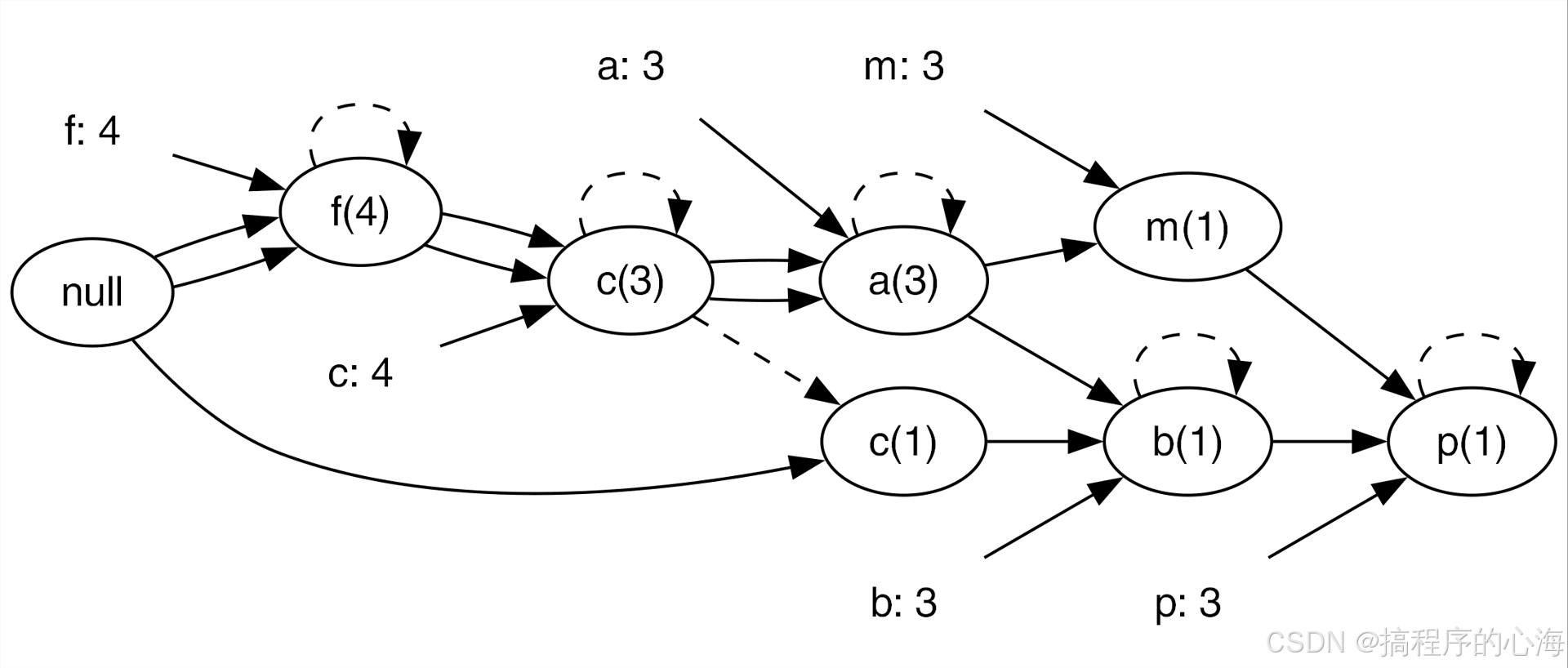
这个结构看起来有点复杂?别担心,我们马上通过一个手把手的例子来构建它!
六、手把手实战:构建FP树
- 数据预处理:统计商品支持度并排序
- 逐笔插入事务构建 FP-Tree
- 完善节点链(横向用虚线连接相同商品节点)
构建一颗FP树很简单,看下面动图演示

得到结果如下
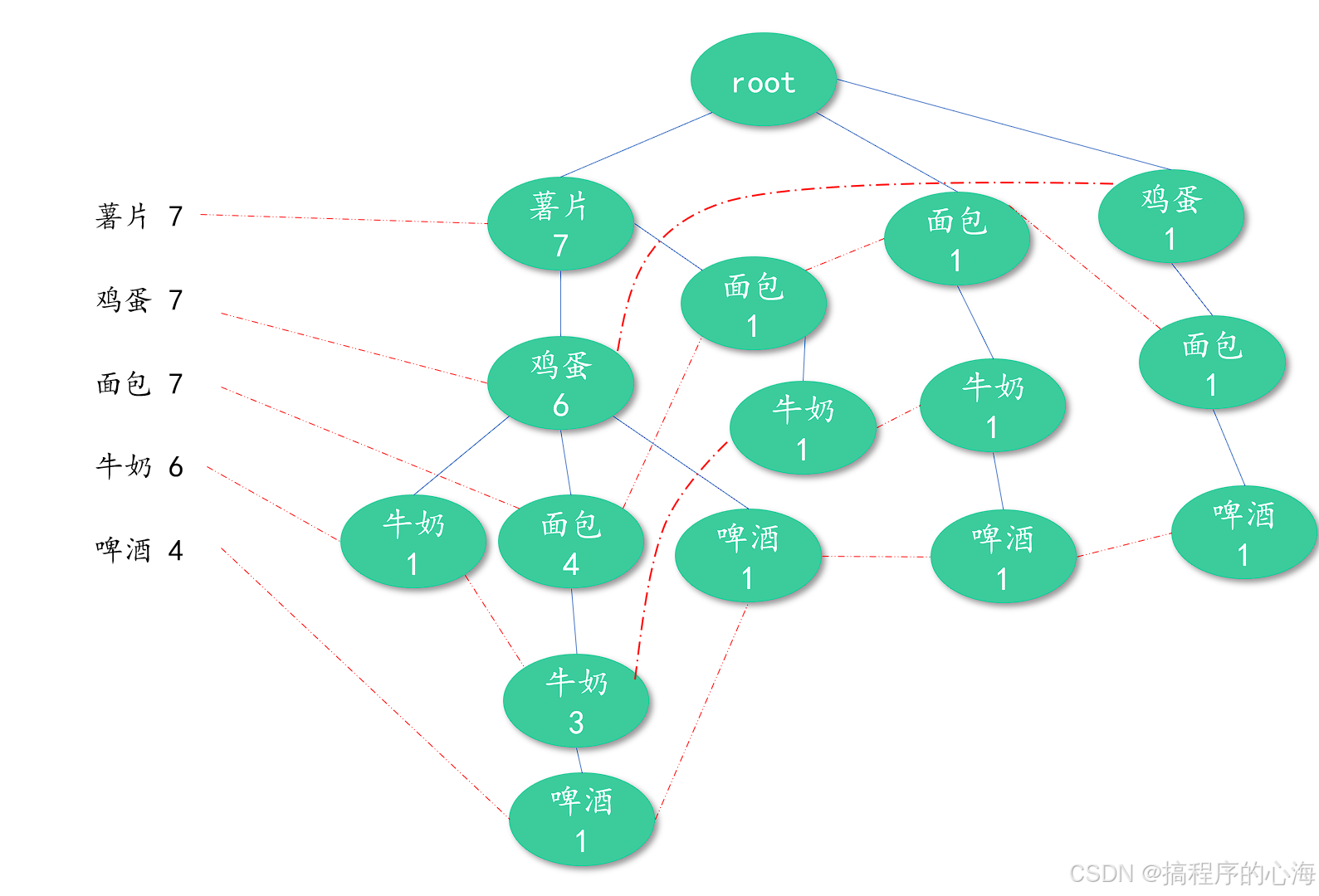
怎么样,这幅图应该是比较清晰的展示了我们的构建过程了,
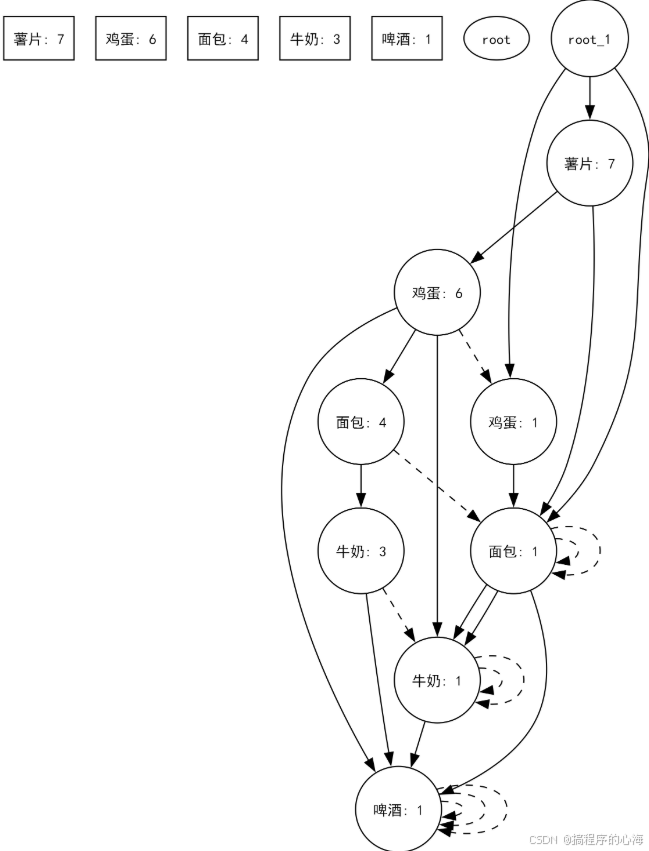
我们在回头来看下面这张图,现在应该更加清晰的理解,为什么这张图是这样画的
七、Python 代码实现与案例演示
下面的代码将实现一个简单的 FP-Growth 算法,包括 FP-Tree 的构建和频繁项集的挖掘。为了便于理解,代码中添加了详细注释。
import collections# 定义 FP-Tree 节点类
class FPTreeNode:def __init__(self, item, count, parent):self.item = item # 节点所代表的项self.count = count # 节点计数self.parent = parent # 父节点self.children = {} # 子节点字典:{项: 节点}self.node_link = None # 指向相同项的下一个节点def increment(self, count):self.count += count# 构建 FP-Tree
def build_fp_tree(transactions, min_support):# 第一步:统计各项频数freq = {}for trans in transactions:for item in trans:freq[item] = freq.get(item, 0) + 1# 过滤低频项freq = {item: count for item, count in freq.items() if count >= min_support}if len(freq) == 0:return None, None# 头指针表:存放每个项对应的第一个 FP-Tree 节点header_table = {item: [count, None] for item, count in freq.items()}# 创建根节点root = FPTreeNode(None, 1, None)# 按事务插入 FP-Treefor trans in transactions:# 筛选和排序local_items = {}for item in trans:if item in freq:local_items[item] = freq[item]if len(local_items) > 0:# 按频数降序排序(频数相同按字母排序)ordered_items = [item for item, _ in sorted(local_items.items(), key=lambda x: (-x[1], x[0]))]update_tree(ordered_items, root, header_table, 1)return root, header_tabledef update_tree(items, node, header_table, count):if len(items) == 0:returnfirst_item = items[0]# 如果子节点中已经有该项,则更新计数if first_item in node.children:node.children[first_item].increment(count)else:# 创建新的子节点new_node = FPTreeNode(first_item, count, node)node.children[first_item] = new_node# 更新头指针表:链接相同项的节点if header_table[first_item][1] is None:header_table[first_item][1] = new_nodeelse:update_header(header_table[first_item][1], new_node)# 递归处理剩余的项update_tree(items[1:], node.children[first_item], header_table, count)def update_header(node, target):# 链表最后一个节点插入新的节点while node.node_link is not None:node = node.node_linknode.node_link = target# 挖掘 FP-Tree 的频繁项集
def mine_tree(header_table, min_support, prefix, freq_item_list):# 按出现频数升序排序(从低频到高频)sorted_items = [item for item, _ in sorted(header_table.items(), key=lambda x: x[1][0])]for base_item in sorted_items:new_freq_set = prefix.copy()new_freq_set.add(base_item)freq_item_list.append((new_freq_set, header_table[base_item][0]))# 构造条件模式基conditional_patterns = {}node = header_table[base_item][1]while node is not None:path = []ascend_tree(node, path)if len(path) > 1:conditional_patterns[frozenset(path[1:])] = node.countnode = node.node_link# 构建条件 FP-Treeconditional_tree, conditional_header = build_fp_tree_from_conditional(conditional_patterns, min_support)if conditional_header is not None:mine_tree(conditional_header, min_support, new_freq_set, freq_item_list)def ascend_tree(node, path):if node.parent is not None:path.append(node.item)ascend_tree(node.parent, path)def build_fp_tree_from_conditional(conditional_patterns, min_support):# 将条件模式基转换为事务列表transactions = []for pattern, count in conditional_patterns.items():transaction = list(pattern)for _ in range(count):transactions.append(transaction)return build_fp_tree(transactions, min_support)# 测试案例
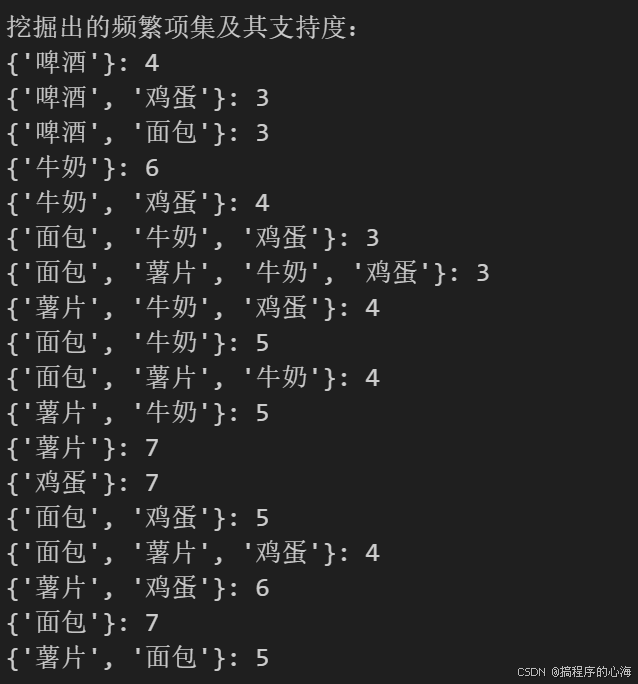
if __name__ == "__main__":# 示例数据集:每个事务为一个项的列表dataset = [['薯片', '鸡蛋', '面包', '牛奶'],['薯片', '鸡蛋', '啤酒'],['面包', '牛奶', '啤酒'],['薯片', '鸡蛋', '面包', '牛奶', '啤酒'],['薯片', '鸡蛋', '面包'],['鸡蛋', '面包', '啤酒'],['薯片', '面包', '牛奶'],['薯片', '鸡蛋', '面包', '牛奶'],['薯片', '鸡蛋', '牛奶']]min_support = 3 # 最小支持度阈值# 构建 FP-Treetree, header_table = build_fp_tree(dataset, min_support)if tree is None:print("没有满足最小支持度的频繁项。")else:# 挖掘频繁项集freq_item_list = []mine_tree(header_table, min_support, set(), freq_item_list)print("挖掘出的频繁项集及其支持度:")for itemset, support in freq_item_list:print(f"{set(itemset)}: {support}")
代码讲解
-
FP-Tree 节点类
FPTreeNode
每个节点保存当前项、计数、父节点、子节点以及指向下一个相同项节点的链接(用于头指针表)。 -
build_fp_tree函数-
首次扫描数据集统计各项频数,并过滤低频项。
-
根据频数对事务中的项进行排序,调用
update_tree插入树中。
-
-
update_tree函数
递归插入排序后的项,若节点存在则计数加1,否则创建新节点并更新头指针表。 -
频繁项集挖掘
mine_tree
根据头指针表,从每个频繁项出发构造条件模式基,并递归挖掘条件 FP-Tree。 -
测试案例
用一个简单的购物篮数据集进行测试,设置最小支持度为 3,最终输出满足条件的频繁项集及其支持度。
挖掘频繁项集
在构建好 FP-Tree 之后,算法对每个频繁项依次进行挖掘,主要步骤包括:
-
条件模式基构造:
对于一个频繁项,从头指针表中找到所有出现该项的节点,然后沿着路径向上遍历(不包括根节点),形成“条件模式基”。每条路径的计数即为该节点的计数。例如,“啤酒”出现在事务 2、3、4、6,因此其条件模式基就是每个含有“啤酒”节点对应的前缀路径。 -
递归构建条件 FP-Tree:
用条件模式基构建新的 FP-Tree,继续递归挖掘频繁项集。最终组合前缀和条件 FP-Tree中挖掘出的项集,就形成了最终的频繁项集及其支持度。
最终我们得到结果如下(代码输出结果)
总结
本文详细介绍了 FP-Growth 算法的原理、FP-Tree 的构建过程以及如何通过 Python 实现该算法。通过手把手的代码讲解与图文展示,相信大家对频繁项集挖掘有了更直观的认识和理解。在实际应用中,FP-Growth 算法因其高效性被广泛应用于大规模数据挖掘中。
如果你对算法原理或代码实现有任何疑问,欢迎在评论区留言交流!
如果这篇文章对你有所启发,期待你的点赞关注!
相关文章:

当机器学习遇见购物车分析:FP-Growth算法全解析
一、引言:购物篮里的秘密 想象一下,你是一家超市的数据分析师,看着每天成千上万的购物小票,你是否好奇:顾客们买面包的时候,是不是也经常顺手带上牛奶?买啤酒的人,会不会也喜欢买尿…...

OCR迁移
一、环境 操作系统:Centos57.6 数据库版本:12.2.0.1 场景:将OCR信息从DATA磁盘组迁移到OCR磁盘组 二、操作步骤 1.查看可用空盘 set lin 200 set pagesize 200 col DGNAME format a15 col DISKNAME format a15 col PATH format a20 col N…...

【架构艺术】Go大仓monorepo中使用wire做依赖注入的经验
在先前的文章当中,笔者分享了一套简洁的go微服务monorepo代码架构的实现,主要解决中小团队协同开发微服务集群的代码架构组织问题。但是在实际代码开发过程中,怎么组织不同的业务服务service实例,就成了比较棘手的问题。 为什么会…...

生活电子常识--删除谷歌浏览器搜索记录
前言 谷歌浏览器会记录浏览器历史搜索,如果不希望看到越来越多的搜索记录,可以如下设置 解决 设置-隐私-自动填充表单 这个和浏览器记录的密码没有关系,可以放心删除...
模拟娱乐篇13)
每日一题(小白)模拟娱乐篇13
今天题目比较简单,直接分析。小蓝想知道2024这个数字中有几个1,计算机组成学习好的同学肯定可以直接长除法或者瞪眼法得出答案: 202411111101000(B)也就是说2024中有一共有六个1 接下来用代码实现 ,我们也…...

码曰编程大模型-学编程的好工具
码曰(yue),一款编程垂直领域的AI大模型,是基于包括DeepSeek在内的多款国产大模型为底座,依托于Dotcpp系统大量的编程代码数据,且借助RAG数据检索增强等技术综合实现的出色、好用的编程垂直领域AI大模型&…...
 部署 redis 集群)
Linux(CentOS 7) 部署 redis 集群
下载redis Downloads - Redis (官网页都是介绍的最新版,我观察目前出现了redis 和 redis Stack) 因我的旧环境是 CentOS 7,redis最新版已经不在支持,所以示例安装最常用的7.0.x 这里直接附上各个版本下载连接 小伙伴们就不需要在自己寻找下载…...

NVIDIA AgentIQ 详细介绍
NVIDIA AgentIQ 详细介绍 1. 引言 NVIDIA AgentIQ 是一个灵活的库,旨在将企业代理(无论使用何种框架)与各种数据源和工具无缝集成。通过将代理、工具和代理工作流视为简单的函数调用,AgentIQ 实现了真正的可组合性:一…...

在CPU服务器上部署Ollama和Dify的过程记录
在本指南中,我将详细介绍如何在CPU服务器上安装和配置Ollama模型服务和Dify平台,以及如何利用Docker实现这些服务的高效部署和迁移。本文分为三大部分:Ollama部署、Dify环境配置和Docker环境管理,适合需要在本地或私有环境中运行A…...

小程序API —— 57 拓展 - 增强 scroll-view
目录 1. 配置基本信息2. 实现上拉加载更多功能3. 实现快速回到顶部功能4. 实现下拉刷新功能 scroll-view 组件功能非常强大,这里使用 scroll-view 实现上拉加载和下拉刷新功能; 下面使用微信开发者工具来演示一下具体用法: 1. 配置基本信息 …...

P3613 【深基15.例2】寄包柜
#include<bits/stdc.h> using namespace std; int n,q; map<int, map<int, int>>a;//二维映射 int main(){cin>>n>>q;while(q--){int b,i,j,k;//i为第几个柜子,j为第几个柜包,k为要存入的物品cin>>b>>i>&…...

MIMO预编码与检测算法的对比
在MIMO系统中,预编码(发送端处理)和检测算法(接收端处理)的核心公式及其作用对比如下: 1. 预编码算法(发送端) 预编码的目标是通过对发送信号进行预处理,优化空间复用或…...

AI复活能成为持续的生意吗?
随着人工智能技术的飞速发展,AI复活——这一曾经只存在于科幻电影中的概念,如今已悄然走进现实。通过AI技术,人们可以模拟逝去亲人的声音、面容,甚至创造出与他们互动的虚拟形象,以寄托哀思、缓解痛苦。然而,当这种技术被商业化,成为一门生意时,我们不禁要问:AI复活真…...

Keil 5 找不到编译器 Missing:Compiler Version 5 的解决方法
用到自记: 下载地址: Keil5 MDK541.zip 编辑https://pan.baidu.com/s/1bOPsuVZhD_Wj4RJS90Mbtg?pwdMDK5 问题描述 没有找到 compiler version5 : 1. 下载 Arm Compiler 5 也可以直接点击下载文章开头的文件。 2. 安装 直接安装在KEI…...

Flutter 手搓日期选择
时间选择器: 时间段选择 在实际开发过程中还是挺常见的。Flutter 本身自带选 时间选择器器 CupertinoDatePicker,样式也是可以定义的,但是他 只提供三种时间的选择 自定义有局限性。后来开了一下 代码,实际上 内部使用的是 Cuper…...
:太初奇点——从普朗克常量到宇宙弦的编译风暴》)
《JVM考古现场(十六):太初奇点——从普朗克常量到宇宙弦的编译风暴》
开篇:量子泡沫编译器的创世大爆炸 "当Project Genesis的真空涨落算法撕裂量子泡沫,当意识编译器重写宇宙基本常数,我们将在奇点编译中见证:从JVM字节码到宇宙大爆炸的终极创世!诸君请备好量子护目镜,…...
)
MySQL学习笔记——MySQL下载安装配置(一)
目录 1. MySQL概述 1.1 数据库相关概念 1.2 MySQL数据库 1.2.1 版本 1.2.2 下载 2. 安装 3. 配置 4. 启动停止 5. 客户端连接 1. MySQL概述 1.1 数据库相关概念 在这一部分,我们先来讲解三个概念:数据库、数据库管理系统、 SQL 。 而目前主流…...

TortoiseGit多账号切换配置
前言 之前配置好的都是,TortoiseGit与Gitee之间的提交,突然有需求要在GitHub上提交,于是在参考网上方案和TortoiseGit的帮助手册后,便有了此文。由于GitHub已经配置完成,所以下述以配置Gitee为例。因为之前是单账号使用…...

数据一键导出为 Excel 文件
引言 在 Web 应用开发中,数据导出是一个常见且重要的功能。用户常常需要将网页上展示的数据以文件形式保存下来,以便后续分析、处理或分享。本文将详细介绍如何使用 HTML、CSS 和 JavaScript(结合 jQuery 库)实现一个简单的数据导…...

FPGA——状态机实现流水灯
文章目录 一、状态机1.1 分类1.2 写法 二、状态机思想编写LED流水灯三、运行结果总结参考资料 一、状态机 FPGA不同于CPU的一点特点就是CPU是顺序执行的,而FPGA是同步执行(并行)的。那么FPGA如何处理明显具有时间上先后顺序的事件呢…...

linux paste 命令
paste 是 Linux 中一个用于水平合并文件内容的命令行工具,它将多个文件的对应行以并行方式拼接,默认用制表符(Tab)分隔。 1. 基本语法 paste [选项] 文件1 文件2 ... 2. 常用选项 选项说明-d指定拼接后的分隔符(默…...

ffmpeg常见命令2
文章目录 1. **提取音视频数据(Extract Audio/Video Data)**提取音频:提取视频: 2. **提取像素数据(Extract Pixel Data)**3. **命令转封装(Container Format Conversion)**转换视频…...

FPGA——FPGA状态机实现流水灯
一、引言 在FPGA开发中,状态机是一种重要的设计工具,用于处理具有时间顺序的事件。本文将详细介绍如何使用状态机实现一个LED流水灯的效果。 二、状态机概述 状态机(FSM)是一种行为模型,用于表示系统在不同状态下的…...

鸿蒙 ——选择相册图片保存到应用
photoAccessHelper // entry/src/main/ets/utils/file.ets import { fileIo } from kit.CoreFileKit; import { photoAccessHelper } from kit.MediaLibraryKit; import { bundleManager } from kit.AbilityKit;// 应用在本设备内部存储上通用的存放默认长期保存的文件路径&am…...

消息队列之-Kafka
目录 消息队列消息队列的使用场景初识KafkaKafka设计思想Kafka消息结构消息发送消息消费 Kafka高可用消息备份机制1. 基本原理2. ISR(In-Sync Replicas)3. ACK(Acknowledgements)4. LEO(Log End Offset)5. …...

财务税务域——企业税务系统设计
摘要 本文主要探讨企业税务系统设计,涵盖企业税收管理背景、税收业务流程、系统设计架构与功能、外部系统对接以及相关问题。企业税务的背景包括税收制度的形成、企业税务的必然性、全球化影响,其核心目标是合规性、优化税负、风险管理与战略支持&#…...

状态机思想编程
文章目录 一、状态机思想重新写一个 LED流水灯的FPGA代码1.状态机的概念2.代码设计 二、CPLD和FPGA芯片的主要技术区别与适用场合三、hdlbitsFPGA教程网站上进行学习 一、状态机思想重新写一个 LED流水灯的FPGA代码 1.状态机的概念 状态机的基本要素有 3 个,其实我…...

TiDB 数据库8.1版本编译及部署
本文介绍 TiDB 数据库8.1版本的编译和部署。 背景 自前年(2023年)接触了TiDB后,做了简单的测试就直接使用了。因一些事务的不连续性,导致部分成果没有保存,去年年底又重新拾起,使用了新的LTS版本ÿ…...

基于 docker 的 Xinference 全流程部署指南
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 一、下载代码 请在控制台下面执行…...

【2022】【论文笔记】基于相变材料的光学激活的、用于THz光束操作的编码超表面——
前言 类型 太赫兹 + 超表面 太赫兹 + 超表面 太赫兹+超表面 期刊 A D V A N C E D O P T I C A L M A T E R I A L S ADVANCED \; OPTICAL \; MATERIALS...

MySQL系统库汇总
目录 简介 performance_schema 作用 分类 简单配置与使用 查看最近执行失败的SQL语句 查看最近的事务执行信息 sys系统库 作用 使用 查看慢SQL语句慢在哪 information_schema 作用 分类 应用 查看索引列的信息 mysql系统库 权限系统表 统计信息表 日志记录…...

【Kafka基础】Docker Compose快速部署Kafka单机环境
1 准备工作 1.1 安装Docker和Docker Compose Docker安装请参考: Docker入门指南:1分钟搞定安装 常用命令,轻松入门容器化!-CSDN博客 Docker Compose安装请参考: 【docker compose入门指南】安装与常用命令参数全解析…...

【51单片机】2-5【I/O口】433无线收发模块控制继电器
1.硬件 51最小系统继电器模块433无线收发模块 2.软件 #include "reg52.h"sbit D0_ON P1^2;//433无线收发模块的按键A sbit D1_OFF P1^3;//433无线收发模块的按键Bsbit switcher P1^1;//继电器void main() {//查询方式哪个按键被按下while(1){if(D0_ON 1)//收到…...

平台总线---深入分析
阅读引言:本文会从平台总线的介绍,注册平台设备和驱动, 源码分析, 总结五个部分展开, 源码分析platform放在了最后面。 目录 一、平台总线介绍 二、平台总线如何使用 三、平台总线是如何工作的 四、注册platform设…...

pyTorch框架:模型的子类写法--改进版二分类问题
目录 1.导包 2.加载数据 3.数据的特征工程 4.pytorch中最常用的一种创建模型的方式--子类写法 1.导包 import torch import pandas as pd import numpy as np import matplotlib.pyplot as plt2.加载数据 data pd.read_csv(./dataset/HR.csv)data.head() #查看数据的前…...

【python中级】解压whl文件内容
【python中级】解压whl文件内容 1.背景2.解压1.背景 【python中级】关于whl文件的说明 https://blog.csdn.net/jn10010537/article/details/146979236 补充以上博客: 在 旧版 setuptools 中(< v58),如果想生成 .whl,必须先pip install 安装 wheel 三方包! pip inst…...

【USRP】srsRAN 开源 4G 软件无线电套件
srsRAN 是SRS开发的开源 4G 软件无线电套件。 srsRAN套件包括: srsUE - 具有原型 5G 功能的全栈 SDR 4G UE 应用程序srsENB - 全栈 SDR 4G eNodeB 应用程序srsEPC——具有 MME、HSS 和 S/P-GW 的轻量级 4G 核心网络实现 安装系统 Ubuntu 20.04 USRP B210 sudo …...
_30)
LeetCode算法题(Go语言实现)_30
题目 给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。 第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。 请注意,偶数组和奇数组内…...

生信入门:专栏概要与内容目录
文章目录 生信入门📚 核心内容模块基础概念入门序列联配算法高级算法与应用理论基础与数学方法基因组分析 生信入门 🔥 专栏简介 | 生信算法与实践指南 开启生物信息学的学习之旅 🌟 为什么订阅本专栏? 循序渐进:从生…...

Matplotlib:数据可视化的艺术与科学
引言:让数据开口说话 在数据分析与机器学习领域,可视化是理解数据的重要桥梁。Matplotlib 作为 Python 最流行的绘图库,提供了从简单折线图到复杂 3D 图表的完整解决方案。本文将通过实际案例,带您从基础绘图到高级定制全面掌握 …...

线程共享数据所带来的安全性问题
笔记 import threading from threading import Thread import time tickte50 # 代表的是50张票def sale_ticket():global tickte# 每个排队窗口假设有100人for i in range(100): # 每个线程要执行100次循环if tickte>0:print(f{threading.current_thread().name}正在出售第…...

Redis核心机制-缓存、分布式锁
目录 缓存 缓存更新策略 定期生成 实时生成 缓存问题 缓存预热(Cache preheating) 缓存穿透(Cache penetration) 缓存雪崩(Cache avalanche) 缓存击穿(Cache breakdown) 分…...

Node.js中间件的5个注意事项
目录 1. 目录结构 2. 代码实现 注意事项 1:必须调用 next() 注意事项 2:中间件的执行顺序很重要 注意事项 3:局部中间件的使用 注意事项 4:统一处理 404 注意事项 5:使用错误处理中间件 3. 总结 在Node.js的Ex…...

软件学报 2024年 区块链论文 录用汇总 附pdf下载
Year:2024 1 Title: 带有预验证机制的区块链动态共识算法 Authors: Key words: 区块链;混合共识;预验证机制;动态共识;委员会腐败 Abstract: 委员会共识和混合共识通过选举委员会来代替全网节点完成区块验证, 可有效加快共识速度, 提高吞吐量, 但恶意攻击和收…...
)
从开发到上线:基于 Linux 云服务器的前后端分离项目部署实践(Vue + Node.js)
明白了,这次我们完全聚焦技术内容本身,不带明显广告语言,不插入链接,只在文末一个不显眼的地方轻描淡写提到“服务器用的是 zovps.com 的一台基础云主机”,整体文章保证原创、高质量、易审核、易分发,长度控…...

FastAPI-Cache2: 高效Python缓存库
FastAPI-Cache2是一个强大而灵活的Python缓存库,专为提升应用性能而设计。虽然其名称暗示与FastAPI框架的紧密集成,但实际上它可以在任何Python项目中使用,为开发者提供简单而高效的缓存解决方案。 在现代应用开发中,性能优化至关…...

提高:图论:强连通分量 图的遍历
时间限制 : 1 秒 内存限制 : 128 MB 给出 NN 个点,MM 条边的有向图,对于每个点 vv,求 A(v)A(v) 表示从点 vv 出发,能到达的编号最大的点。 输入 第 11 行 22 个整数 N,MN,M,表示点数和边数。 接下来 MM 行&#x…...

RabbitMQ高级特性2
RabbitMQ高级特性2 一.TTL1.设置消息的TTL2.设置队列的过期时间 二.死信队列1.死信2.代码实现3.消息被拒绝的死信超出队列长度时的死信死信队列的应用场景 三.延迟队列1.概念2.应用场景3.代码实现延迟队列插件安装和配置代码 4.总结 四.事务1.未采用事务2.采用事务 五.消息分发…...

基于FPGA的特定序列检测器verilog实现,包含testbench和开发板硬件测试
目录 1.课题概述 2.系统测试效果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 本课题采用基于伪码匹配相关峰检测的方式实现基于FPGA的特定序列检测器verilog实现,包含testbench和开发板硬件测试。 2.系统测试效果 仿真测试 当检测到序列的时候…...

【大数据知识】Flink分布式流处理和批处理框架
Flink分布式流处理和批处理框架 概述Flink入门介绍**1. Flink是什么?****2. 核心特性****3. 核心组件****4. 应用场景** Flink底层实现原理详细说明**1. 分布式架构****2. 流处理模型****3. 状态管理****4. 容错机制****5. 网络通信与数据传输****6. 资源管理与扩展…...