【大数据知识】Flink分布式流处理和批处理框架
Flink分布式流处理和批处理框架
- 概述
- Flink入门介绍
- **1. Flink是什么?**
- **2. 核心特性**
- **3. 核心组件**
- **4. 应用场景**
- Flink底层实现原理详细说明
- **1. 分布式架构**
- **2. 流处理模型**
- **3. 状态管理**
- **4. 容错机制**
- **5. 网络通信与数据传输**
- **6. 资源管理与扩展性**
- 总结
- 实现过程
- Flink如何实现高效流式处理及数据处理过程详解
- **一、高效流式处理的核心机制**
- **二、数据处理全流程(附代码示例)**
- **三、性能优化实践**
- **总结**
- 部署与使用
- Flink部署过程及使用说明
- **一、部署方式详解**
- **二、使用步骤(以Standalone模式为例)**
- **三、代码示例(Socket词频统计)**
- **四、部署与使用注意事项**
概述
Flink入门介绍
1. Flink是什么?
Apache Flink 是一个分布式流处理和批处理框架,用于在无界(实时流)和有界(历史数据)数据流上进行有状态计算。它结合了高吞吐量、低延迟和容错能力,适合处理大规模实时数据流。
2. 核心特性
- 流批统一:用同一套API处理流和批数据。
- 事件驱动:支持事件时间(Event Time)和处理时间(Processing Time),解决乱序事件问题。
- 状态管理:提供托管状态(Managed State),支持复杂有状态操作(如窗口计算)。
- Exactly-Once语义:通过检查点(Checkpoint)机制确保数据处理的精确一致性。
- 高扩展性:支持本地、Standalone、YARN、Kubernetes等部署模式。
3. 核心组件
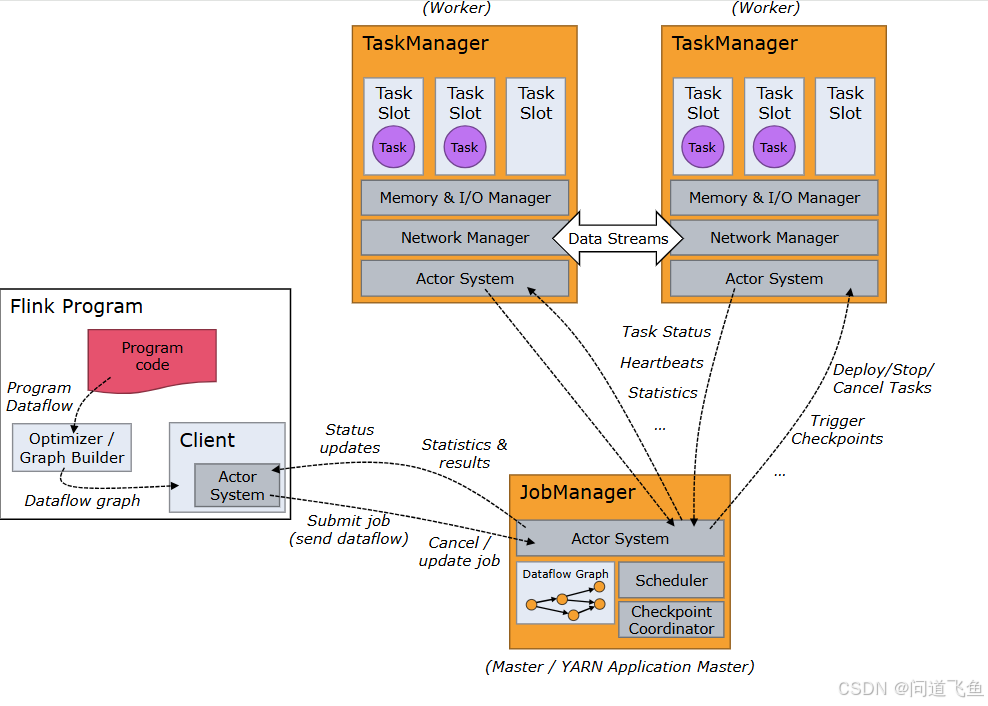
- JobManager:主节点,负责任务调度、资源分配和故障恢复。
- TaskManager:工作节点,执行具体任务(如数据流处理和状态管理)。
- Client:提交作业到集群,生成JobGraph。
- ResourceManager:管理集群资源(如YARN/K8s中的资源分配)。
4. 应用场景
- 实时分析:如实时风控、用户行为分析。
- 事件驱动应用:如实时报警、异常检测。
- ETL流水线:持续数据转换和加载。
- 复杂事件处理(CEP):检测特定事件模式。
Flink底层实现原理详细说明
1. 分布式架构
- Master-Slave架构:
- JobManager:协调任务执行,管理检查点和故障恢复。
- TaskManager:执行具体任务,每个TaskManager包含多个TaskSlot(资源隔离单元)。
- 任务调度:
- JobManager将作业转换为执行图(ExecutionGraph),并分配到TaskManager的Slot上。
- 支持链式任务(Operator Chaining)优化性能。
2. 流处理模型
- 数据流(DataStream):
- 数据以流的形式处理,支持无界和有界流。
- 操作包括Map、Filter、KeyBy、Window等。
- 时间语义:
- 事件时间:基于事件产生的时间戳,解决乱序问题。
- 水位线(Watermark):衡量事件时间进展,触发窗口计算。
- 窗口机制:
- 支持时间窗口、计数窗口、会话窗口等。
- 窗口操作通过状态后端管理中间状态。
3. 状态管理
- 托管状态(Managed State):
- 算子状态(Operator State):与特定算子实例关联。
- 键控状态(Keyed State):按Key分区,支持高效状态访问。
- 状态后端(State Backends):
- MemoryStateBackend:状态存于内存,适合小状态调试。
- FsStateBackend:状态存于文件系统(如HDFS),支持大状态。
- RocksDBStateBackend:状态存于RocksDB,支持增量检查点。
4. 容错机制
- 检查点(Checkpoint):
- 定期保存作业状态到外部存储(如HDFS、S3)。
- 使用**栅栏(Barrier)**机制实现分布式快照。
- 保存点(Savepoint):
- 手动触发的全局一致状态快照,用于作业升级或迁移。
- 故障恢复:
- 从最近检查点恢复状态,重新计算未处理数据。
- 支持Exactly-Once语义,确保数据不丢失、不重复。
5. 网络通信与数据传输
- 数据分区:
- 使用哈希分区或自定义分区策略,将数据分配到不同任务实例。
- 序列化/反序列化:
- 数据传输前序列化为字节流,接收方反序列化后处理。
- 缓冲机制:
- 使用内存缓冲区优化网络传输效率,减少序列化开销。
6. 资源管理与扩展性
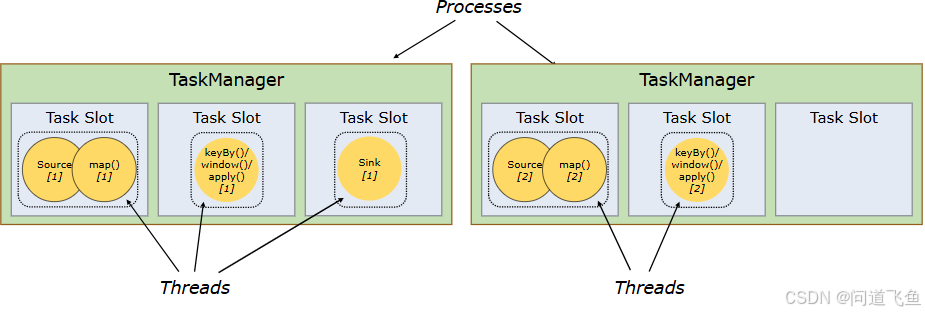
- TaskSlot:
- 每个TaskManager包含多个Slot,每个Slot可运行一个任务子链。
- Slot数量决定并行度上限。
- 动态扩展:
- 支持在YARN/K8s中动态申请和释放资源。
- 通过调整TaskManager数量或Slot数扩展计算能力。
总结
Flink通过分布式架构、流处理模型、状态管理和容错机制实现了高性能、低延迟的流批处理。其底层设计围绕状态一致性、高效资源利用和容错能力展开,适用于实时性要求高、数据规模大的场景。
实现过程
Flink如何实现高效流式处理及数据处理过程详解
一、高效流式处理的核心机制
Flink通过以下机制实现低延迟、高吞吐的流式处理:
-
数据流抽象与算子链优化
DataStream模型:将实时数据抽象为DataStream,支持链式转换操作(如map→filter→keyBy)。- 算子链(Operator Chaining):
- 合并执行:将多个算子合并到同一线程执行,减少序列化/反序列化开销。
- 条件:上下游算子并行度相同、未禁用链、分区策略为
ForwardPartitioner。 - 示例:
inputStream.map(...).filter(...).keyBy(...)可能合并为单个任务。
-
时间语义与窗口机制
- 时间语义:
- 事件时间(Event Time):基于数据生成时间,解决乱序问题。
- 处理时间(Processing Time):依赖系统时钟,低延迟但结果不精确。
- 摄入时间(Ingestion Time):数据进入Flink的时间,平衡延迟与准确性。
- 水位线(Watermark):
- 作用:标记事件时间进展,触发窗口计算。
- 生成规则:
Watermark = maxEventTime - 延迟阈值,确保迟到数据可控。
- 窗口类型:
- 滚动窗口:固定大小、无重叠(如每小时统计)。
- 滑动窗口:固定大小+滑动步长(如每10分钟滑动5分钟)。
- 会话窗口:按活动间隙分组(如用户连续点击行为)。
- 时间语义:
-
状态管理
- 托管状态(Managed State):
- 键值状态(Keyed State):按Key分区,支持高效访问(如
ValueState,ListState)。 - 算子状态(Operator State):与算子实例关联,用于全局统计(如Kafka偏移量)。
- 键值状态(Keyed State):按Key分区,支持高效访问(如
- 状态后端(State Backend):
- MemoryStateBackend:状态存内存,适合调试。
- RocksDBStateBackend:状态存磁盘,支持增量检查点,适合大状态场景。
- 托管状态(Managed State):
-
检查点机制(Checkpointing)
- 作用:定期保存状态,实现故障快速恢复。
- 精确一次(Exactly-Once):
- 两阶段提交(2PC):确保状态与输出的一致性。
- 幂等写入:如Kafka事务性写入,避免重复数据。
- 配置:
env.enableCheckpointing(间隔毫秒),默认关闭,需手动启用。
-
资源调度
- TaskSlot:
- 资源隔离:每个TaskManager划分多个Slot,每个Slot运行一个任务链。
- 动态分配:根据任务需求申请/释放Slot,提升集群利用率。
- 部署模式:
- YARN/K8s:支持弹性扩缩容,适应负载波动。
- TaskSlot:
二、数据处理全流程(附代码示例)
-
数据源接入
// 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 接入Socket数据源(示例) DataStream<String> inputStream = env.socketTextStream("localhost", 9999); -
数据转换
// 自定义分词函数 public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {String[] words = value.split(" ");for (String word : words) {out.collect(new Tuple2<>(word, 1));}} } // 执行转换:分词 → 键控 → 聚合 DataStream<Tuple2<String, Integer>> counts = inputStream.flatMap(new Tokenizer()).keyBy(0) // 按单词键控.sum(1); // 聚合计数 -
状态更新(以窗口统计为例)
// 定义时间窗口(5秒滚动窗口) DataStream<Tuple2<String, Integer>> windowCounts = counts.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum(1); // Flink自动管理窗口状态(存储每个窗口的计数) -
检查点触发
// 启用检查点(间隔1秒) env.enableCheckpointing(1000); // 可选:设置检查点模式(精确一次/至少一次) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); -
结果输出
// 打印到控制台(生产环境可写入数据库/Kafka) windowCounts.print(); // 执行任务 env.execute("Socket Window WordCount");
三、性能优化实践
-
算子链优化
- 避免禁用链:除非需强制拆分任务(如隔离资源)。
- 手动控制链边界:使用
startNewChain()方法。
-
状态后端选择
- 小状态场景:使用
MemoryStateBackend(低延迟)。 - 大状态场景:使用
RocksDBStateBackend(支持增量检查点)。
- 小状态场景:使用
-
资源隔离
- 调整TaskSlot数:根据任务类型分配不同Slot(如计算密集型任务分配更多Slot)。
-
检查点调优
- 调整间隔:频繁检查点影响性能,间隔过长恢复慢。
- 设置超时:
env.getCheckpointConfig().setCheckpointTimeout(60000);
总结
Flink通过数据流抽象、算子链优化、时间语义、状态管理、检查点机制和资源调度实现高效流式处理。其处理流程围绕数据接入→转换→状态更新→检查点→输出展开,结合代码示例可清晰理解各环节。实际生产环境中,需根据场景选择状态后端、调优检查点参数,并合理利用算子链提升性能。
部署与使用
Flink部署过程及使用说明
一、部署方式详解
Flink支持多种部署模式,适应不同场景需求:
-
Standalone模式(独立集群)
- 适用场景:开发测试环境,需快速搭建独立集群。
- 部署步骤:
- 下载与解压:
wget https://flink.apache.org/downloads/1.17.1/flink-1.17.1-bin-scala_2.12.tgz tar -zxvf flink-1.17.1-bin-scala_2.12.tgz cd flink-1.17.1 - 配置环境变量:
echo 'export PATH=$PATH:/path/to/flink/bin' >> ~/.bashrc source ~/.bashrc - 修改配置文件:
flink-conf.yaml:jobmanager.rpc.address: localhost taskmanager.numberOfTaskSlots: 2masters(指定JobManager节点):localhost:8081workers(指定TaskManager节点):localhost
- 启动集群:
./bin/start-cluster.sh - 验证部署:
- 访问Web界面:
http://localhost:8081。 - 提交测试作业:
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
- 访问Web界面:
- 下载与解压:
-
YARN模式(Hadoop资源管理器)
- 适用场景:生产环境,与Hadoop生态(如HDFS)集成。
- 部署步骤:
- 环境准备:
- 确保Hadoop集群已安装并配置。
- 下载Flink的YARN支持版本。
- 配置环境变量:
export HADOOP_CLASSPATH=`hadoop classpath` - 提交作业:
./bin/flink run -m yarn-cluster -yn 2 examples/streaming/SocketWindowWordCount.jar --port 9000
- 环境准备:
-
Kubernetes模式(容器化部署)
- 适用场景:云原生环境,需动态资源分配。
- 部署步骤:
- 部署Kubernetes集群:使用工具如
kubeadm或托管服务(如EKS)。 - 应用Flink配置:
kubectl apply -f https://raw.githubusercontent.com/apache/flink/release-1.17/flink-kubernetes/kubernetes-session.yaml - 提交作业:
./bin/flink run -m kubernetes-session -yk 2 examples/streaming/SocketWindowWordCount.jar --port 9000
- 部署Kubernetes集群:使用工具如
二、使用步骤(以Standalone模式为例)
-
环境准备
- 安装JDK 1.8+,配置
JAVA_HOME。
- 安装JDK 1.8+,配置
-
启动集群
./bin/start-cluster.sh -
提交作业
./bin/flink run -c com.example.YourJobClass /path/to/your-job.jar -
监控与管理
- Web界面:查看作业状态、日志和资源使用情况。
- 命令行:
./bin/flink list # 查看运行中的作业 ./bin/flink cancel <job-id> # 取消作业
三、代码示例(Socket词频统计)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SocketWordCount {public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 接入Socket数据源(本地9999端口)DataStream<String> textStream = env.socketTextStream("localhost", 9999);// 数据处理:分词并计数DataStream<Tuple2<String, Integer>> counts = textStream.flatMap(new Tokenizer()) // 分词.keyBy(value -> value.f0) // 按单词键控.sum(1); // 聚合计数// 输出结果到控制台counts.print();// 执行任务env.execute("Socket WordCount");}// 自定义分词函数public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {String[] words = value.toLowerCase().split(" ");for (String word : words) {if (!word.isEmpty()) {out.collect(new Tuple2<>(word, 1));}}}}
}
四、部署与使用注意事项
-
配置文件调优
- 内存分配:根据集群资源调整
taskmanager.memory.process.size。 - 并行度:设置
parallelism.default控制默认并行度。
- 内存分配:根据集群资源调整
-
高可用性(HA)
- Standalone HA:配置多个JobManager节点并使用ZooKeeper协调。
- YARN HA:依赖YARN的ResourceManager HA机制。
-
日志与调试
- 查看日志:检查
log目录下的日志文件。 - Web界面:通过
http://<JobManager-IP>:8081查看任务日志和指标。
- 查看日志:检查
-
资源隔离
- TaskManager槽位:通过
taskmanager.numberOfTaskSlots控制资源隔离粒度。
- TaskManager槽位:通过
通过以上步骤,您可以在不同环境中快速部署Flink集群并提交作业。实际生产环境中,建议根据需求选择YARN或Kubernetes模式,并充分测试配置参数以优化性能。
相关文章:

【大数据知识】Flink分布式流处理和批处理框架
Flink分布式流处理和批处理框架 概述Flink入门介绍**1. Flink是什么?****2. 核心特性****3. 核心组件****4. 应用场景** Flink底层实现原理详细说明**1. 分布式架构****2. 流处理模型****3. 状态管理****4. 容错机制****5. 网络通信与数据传输****6. 资源管理与扩展…...

Java面试黄金宝典33
1. 什么是存取控制、 触发器、 存储过程 、 游标 存取控制 定义:存取控制是数据库管理系统(DBMS)为保障数据安全性与完整性,对不同用户访问数据库对象(如表、视图等)的权限加以管理的机制。它借助定义用户…...

实战解析:基于AWS Serverless架构的高并发微服务设计与优化
随着云计算进入深水区,Serverless架构正在重塑现代微服务的设计范式。本文将以电商秒杀系统为场景,基于AWS Serverless服务构建高可用架构,并深入探讨性能优化方案。 一、架构设计解析 我们采用分层架构设计,核心组件包括&#…...

Muduo网络库介绍
1.Reactor介绍 1.回调函数 **回调(Callback)**是一种编程技术,允许将一个函数作为参数传递给另一个函数,并在适当的时候调用该函数 1.工作原理 定义回调函数 注册回调函数 触发回调 2.优点 异步编程 回调函数允许在事件发生时…...
)
Cribl 导入文件来检查pipeline 的设定规则(eval 等)
Cribl 导入文件来检查pipeline 的设定规则(eval 等) 从这个页面先下载,或者copy 内容来创建pipeline: Reducing Windows XML Events | Cribl Docs...

2360. 图中的最长环
2360. 图中的最长环 题目链接:2360. 图中的最长环 代码如下: //参考链接:https://leetcode.cn/problems/longest-cycle-in-a-graph/solutions/1710828/nei-xiang-ji-huan-shu-zhao-huan-li-yong-pmqmr class Solution { public:int longest…...
:神经网络的学习)
深度学习入门(三):神经网络的学习
文章目录 前言人类思考 VS 机器学习 VS 深度学习基础术语损失函数常用的损失函数均方误差MSE(Mean Square Error)交叉熵误差(Cross Entropy Error)mini-batch学习 为何要设定损失函数数值微分神经网络学习算法的实现两层神经网络的…...

Python 推导式:简洁高效的数据生成方式
为什么需要推导式? 在Python编程中,我们经常需要对数据进行各种转换和过滤操作。传统的方法是使用循环结构,但这往往会导致代码冗长且不够直观。Python推导式(Comprehensions)应运而生,它提供了一种简洁、…...

HTML5+CSS3+JS小实例:带滑动指示器的导航图标
实例:带滑动指示器的导航图标 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, ini…...

一周学会Pandas2 Python数据处理与分析-Jupyter Notebook安装
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Jupyter (Project Jupyter | Home)项目是一个非营利性开源项目,于2014年由IPython项目中诞生…...

FPGA状态机思想实现流水灯及HDLBits学习
目录 第一章 在DE2-115上用状态机思想实现LED流水灯1.1 状态机设计思路1.2 Verilog代码实现1.3. 仿真测试代码1.4 编译代码与仿真 第二章 CPLD和FPGA芯片的主要技术区别是什么?它们各适用于什么场合?2.1 主要技术区别2.2 适用场合 第三章 HDLBits学习3.1…...

【教程】Windows下 Xshell 连接跳板机和开发机
需求 使用远程连接工具 Xshell 连接跳板机,再从跳板机连接开发机,用户登陆方式为使用密钥。 方法 首先,建立一个会话,用于配置跳板机信息和开发机转跳信息: 在【连接】页面,给跳板机取个名字,…...

Java导出excel,表格插入pdf附件,以及实现过程中遇见的坑
1.不能使用XSSFWorkbook,必须使用HSSFWorkbook,否则导出excel后,不显示插入的图标和内容,如果是读取的已有的excel模板,必须保证excel的格式是xls,如果把xlsx通过重命名的方式改为xls,是不生效的,后面执行下…...

神马系统8.5搭建过程,附源码数据库
项目介绍 神马系统是多年来流行的一款电视端应用,历经多年的发展,在稳定性和易用性方面都比较友好。 十多年前当家里的第一台智能电视买回家,就泡在某论坛,找了很多APP安装在电视上,其中这个神马系统就是用得很久的一…...

cesium 材质 与 交互 以及 性能相关介绍
文章目录 cesium 材质 与 交互 以及 性能相关介绍1. Cesium 材质与着色器简介2. 具体实例应用核心代码及解释3. 代码解释 Cesium 交互1. 常见交互和事件类型2. 示例代码及解释3. 代码解释 cesium 性能优化数据加载与管理渲染优化相机与场景管理代码优化服务器端优化 案例分享1.…...

指令补充+样式绑定+计算属性+监听器
一、指令补充 1. 指令修饰符 1. 作用: 借助指令修饰符, 可以让指令更加强大 2. 分类: 1> 按键修饰符: 用来检测用户的按键, 配合键盘事件使用. keydown 和 keyup 语法: keydown.enter/v-on:keydown.enter 表示当enter按下的时候触发 keyup.enter/v-on:keyup.enter 表示当…...
,源码可白嫖!)
基于Android的病虫害防治技术系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 基于Android的病虫害防治技术系统设计的目的是为用户提供一个病虫害防治技术管理的平台。与PC端应用程序相比,病虫害防治技术管理的设计主要面向于广大用户,旨在为用户提供一个查看科普内容,进行病虫识别、发帖交流的平台。 基于Androi…...

ffmpeg 使用不同编码器编码hevc的速度
1.核显uhd630 编码器hevc_qsv ffmpeg版本2024-03-14 2.73X 转码完成后大小 971mb 2.1680V4 编码器 libx265 ffmpeg版本2025-05-07 1.42x 转码完成后大小 176mb 3.RX588 编码器hevc_amf ffmpeg版本2024-03-14 转码完成后大小 376MB 4.1680v4dg1rx584 编码器hevc_amf ffm…...

【硬件模块】数码管模块
一位数码管 共阳极数码管:8个LED共用一个阳极 数字编码00xC010xF920xA430xB040x9950x9260x8270xF880x8090x90A0x88B0x83C0xC6D0xA1E0x86F0x8E 共阴极数码管:8个LED共用一个阴极 数字编码00x3F10x0620x5B30x4F40x6650x6D60x7D70x0780x7F90x6FA0x77B0x7…...
)
NO.64十六届蓝桥杯备战|基础算法-简单贪心|货仓选址|最大子段和|纪念品分组|排座椅|矩阵消除(C++)
贪⼼算法是两极分化很严重的算法。简单的问题会让你觉得理所应当,难⼀点的问题会让你怀疑⼈⽣ 什么是贪⼼算法? 贪⼼算法,或者说是贪⼼策略:企图⽤局部最优找出全局最优。 把解决问题的过程分成若⼲步;解决每⼀步时…...

ubuntu22.04LTS设置中文输入法
打开搜狗网址直接下载软件,软件下载完成后,会弹出安装教程说明书。 网址:搜狗输入法linux-首页搜狗输入法for linux—支持全拼、简拼、模糊音、云输入、皮肤、中英混输https://shurufa.sogou.com/linux...

基于YOLOv8的热力图生成与可视化-支持自定义模型与置信度阈值的多维度分析
目标检测是计算机视觉领域的重要研究方向,而YOLO(You Only Look Once)系列算法因其高效性和准确性成为该领域的代表性方法。YOLOv8作为YOLO系列的最新版本,在目标检测任务中表现出色。然而,传统的目标检测结果通常以边…...

常见设计系统清单
机构设计系统toB/toC网站GoogleMaterial DesignCm3.material.ioIBM CarbonDesign SystemBcarbondesignsystem.comSalesforceLightning Design SystemBlightningdesignsystem.comMicrosoftFluent Design SystemCfluent2.microsoft.design阿里Ant DesignCant.designSAPFiori Desi…...
)
React编程高级主题:错误处理(Error Handling)
文章目录 **5.2 错误处理(Error Handling)概述****5.2.1 onErrorReturn / onErrorResume(错误回退)****1. onErrorReturn:提供默认值****2. onErrorResume:切换备用数据流** **5.2.2 retry / retryWhen&…...

【设计模式】代理模式
简介 假设你在网上购物时,快递员无法直接将包裹送到你手中(比如你不在家)。 代理模式的解决方案是: 快递员将包裹交给小区代收点(代理),代收点代替你控制和管理包裹的访问。 代收点可以添加额外…...

局域网:电脑或移动设备作为主机实现局域网访问
电脑作为主机 1. 启用电脑的网络发现、SMB功能 2. 将访问设备开启WIFI或热点,用此电脑连接;或多台设备连接到同一WIFI 3. 此电脑打开命令行窗口,查看电脑本地的IP地址 Win系统:输入"ipconfig",回车后如图 4.…...

图论的基础
E - Replace(判环,破环成链) #include <bits/stdc.h> #include <atcoder/dsu>using namespace std; using namespace atcoder;const int C 26;int main() {int n;cin >> n;string s, t;cin >> s >> t;if (s …...

Jetpack Compose CompositionLocal 深入解析:局部参数透传实践
Jetpack Compose CompositionLocal 深入解析:局部参数透传实践 在 Jetpack Compose 中,如何优雅地在组件之间传递数据,而不需要层层传参? CompositionLocal 就是为了解决这个问题的! 1. 什么是 CompositionLocal&#…...

第十五届蓝桥杯大赛软件赛省赛Python 大学 C 组:3.数字诗意
题目1 数字诗意 在诗人的眼中,数字是生活的韵律,也是诗意的表达。 小蓝,当代顶级诗人与数学家,被赋予了”数学诗人”的美誉。他擅长将冰冷的数字与抽象的诗意相融合,并用优雅的文字将数学之美展现于纸上。 某日&…...
对比>)
Oracle数据库数据编程SQL<8 文本编辑器Notepad++和UltraEdit(UE)对比>
首先,用户界面方面。Notepad是开源的,界面看起来比较简洁,可能更适合喜欢轻量级工具的用户。而UltraEdit作为商业软件,界面可能更现代化,功能布局更复杂一些。不过,UltraEdit支持更多的主题和自定义选项&am…...

P12013 [Ynoi April Fool‘s Round 2025] 牢夸 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 个操作分两种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r] 执行 …...

PostgreSQL LIKE 操作符详解
PostgreSQL LIKE 操作符详解 引言 在数据库查询中,LIKE 操作符是一种非常常用的字符串匹配工具。它可以帮助我们实现模糊查询,从而提高查询的灵活性。本文将详细介绍 PostgreSQL 中的 LIKE 操作符,包括其语法、使用方法以及一些注意事项。 LIKE 操作符语法 LIKE 操作符通…...

【前端】【Nuxt3】Nuxt3的生命周期
路由导航和中间件执行顺序 路由导航开始 中间件执行顺序: 全局中间件(middleware/*.global.js)布局中间件(在definePageMeta中定义的布局级中间件)页面中间件(在definePageMeta中定义的页面级中间件&#…...

热更新简介+xLua基础调用
什么是冷更新 开发者将测试好的代码,发布到应用商店的审核平台,平台方会进行稳定性及性能测试。测试成功后,用户即可在AppStore看到应用的更新信息,用户点击应用更新后,需要先关闭应用,再进行更新。 什么是…...

大钲资本押注儒拉玛特全球业务,累计交付超2500条自动化生产线儒拉玛特有望重整雄风,我以为它破产倒闭了,担心很多非标兄弟们失业
1. 交易概况 时间与主体:大钲资本于2025年4月1日正式宣布完成对儒拉玛特自动化技术(苏州)有限公司及其全球子公司和关联企业的收购。交易通过大钲资本旗下美元基金设立的儒拉玛特(新加坡)公司作为控股主体进行,交易金额未披露。 收购范围:包括儒拉玛特亚太、欧洲、北美等…...

FPGA系统开发板调试过程不同芯片的移植步骤介绍
目录 1.我目前使用的开发板 2.不同开发板的移植 步骤一:芯片型号设置 步骤二:约束修改 步骤三、IP核更新 关于FPGA系统开发板调试过程中不同芯片的移植。我需要先理清楚FPGA开发中移植到不同芯片的一般流程。首先,移植通常涉及到更换FPG…...
)
算法设计与分析5(动态规划)
动态规划的基本思想 将一个问题划分为多个不独立的子问题,这些子问题在求解过程中可能会有些数据进行了重复计算。我们可以把计算过的数据保存起来,当下次遇到同样的数据计算时,就可以查表直接得到答案,而不是再次计算 动态规划…...

ModuleNotFoundError: No module named ‘matplotlib_inline‘
ModuleNotFoundError: No module named matplotlib_inline 1. ModuleNotFoundError: No module named matplotlib_inline2. matplotlib-inlineReferences 如果你在普通的 Python 脚本或命令行中运行代码,那么不需要 matplotlib_inline,因为普通的 Python…...

Mysql 中的 B+树 和 B 树在进行数据增删改查后的结构调整过程是怎样的?
B 树的增、删、改、查数据的调整过程 在 MySQL 中,B 树 是一种广泛用于存储引擎(如 InnoDB)中的索引结构。B 树的结构使得它非常适合于处理大量数据的插入、删除和查询等操作。B 树是一种自平衡的树数据结构,其中所有的值都存储在…...

在Rust生态中探索高性能HTTP服务器:Hyperlane初体验
在Rust生态中探索高性能HTTP服务器:Hyperlane初体验 最近在调研Rust的HTTP服务器方案时,发现了一个有趣的新项目——Hyperlane。这个轻量级库宣称在保持简洁API的同时,性能表现可圈可点。作为Rust生态的长期观察者,我决定深入体验…...

AI医疗诊疗系统设计方案
AI医疗诊疗系统设计方案 1. 项目概述 1.1 项目背景 随着人工智能技术的快速发展,将AI技术应用于医疗诊疗领域已成为提升医疗服务效率和质量的重要途径。本系统旨在通过AI技术辅助医生进行诊疗服务,提供智能化的医疗决策支持。 1.2 项目目标 提供全面…...

k8s的StorageClass存储类和pv、pvc、provisioner、物理存储的链路
k8s的StorageClass存储类和pv、pvc、provisioner、物理存储的链路 StorageClass能自动创建pv 在控制器中,直接声明storageClassName,不仅能自动创建pvc,也能自动创建pv stoageclass来自于provisioner,provisioner来自于pod&#x…...

【移动编程技术】作业1 中国现代信息科技发展史、Android 系统概述与程序结构 作业解析
单选题(共 20 题,每题 5 分,满分 100 分) (单选题) 1946 年第一台计算机问世,计算机的发展经历了 4 个时代,它们是()。 选项: A. 模拟计算机、数字计算机、混合计算机、智…...
: 执行超时已过期] 操作超时问题及数据库日志已满的解决方案)
SQL Server数据库异常-[SqlException (0x80131904): 执行超时已过期] 操作超时问题及数据库日志已满的解决方案
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,获得2024年博客之星荣誉证书,高级开发工程师,数学专业,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开发技术,…...
,实现IDEA和VS Code的git commit自动生成)
使用ollama部署本地大模型(没有GPU也可以),实现IDEA和VS Code的git commit自动生成
详情 问豆包,提示词如下:收集下ollama相关信息,包括但不限于:官网地址/GitHub地址/文档地址 官网地址 https://ollama.com/ GitHub 地址 https://github.com/ollama/ollama 文档地址 https://github.com/ollama/ollama/blo…...
)
线程同步与互斥(上)
上一篇:线程概念与控制https://blog.csdn.net/Small_entreprene/article/details/146704881?sharetypeblogdetail&sharerId146704881&sharereferPC&sharesourceSmall_entreprene&sharefrommp_from_link我们学习了线程的控制及其相关概念之后&#…...

ngx_test_full_name
定义在 src\core\ngx_file.c static ngx_int_t ngx_test_full_name(ngx_str_t *name) { #if (NGX_WIN32)u_char c0, c1;c0 name->data[0];if (name->len < 2) {if (c0 /) {return 2;}return NGX_DECLINED;}c1 name->data[1];if (c1 :) {c0 | 0x20;if ((c0 &…...

R 列表:深入解析及其在数据分析中的应用
R 列表:深入解析及其在数据分析中的应用 引言 在R语言中,列表(List)是一种非常重要的数据结构,它允许将不同类型的数据项组合在一起。列表在数据分析、统计建模以及数据可视化中扮演着关键角色。本文将深入探讨R列表…...

智能体中的知识库、数据库与大模型详解
前言 在 LLM(大语言模型)驱动的智能体架构中,知识库(Knowledge Base)、数据库(Database)和大模型(LLM)是关键组成部分,它们共同决定了智能体的理解能力、决策…...

AMD Versal™ AI Core Series VCK190 Evaluation Kit
AMD Versal™ AI Core Series VCK190 Evaluation Kit AMD VCK190 是首款 Versal™ AI Core 系列评估套件,可帮助设计人员使用 AI 和 DSP 引擎开发解决方案,与当前的服务器级 CPU 相比,该引擎能够提供超过 100 倍的计算性能。Versal AI Core …...