Flink 1.20 Kafka Connector:新旧 API 深度解析与迁移指南
Flink Kafka Connector 新旧 API 深度解析与迁移指南
一、Flink Kafka Connector 演进背景
Apache Flink 作为实时计算领域的标杆框架,其 Kafka 连接器的迭代始终围绕性能优化、语义增强和API 统一展开。Flink 1.20 版本将彻底弃用基于 FlinkKafkaConsumer/FlinkKafkaProducer 的旧 API(标记为 @Deprecated),全面转向基于新 Source/Sink API(FLIP-27/FLIP-143)的 KafkaSource/KafkaSink。这一变革不仅带来了架构上的革新,更通过流批统一、精确一次语义和动态分区管理等特性,显著提升了用户体验。
二、新旧 API 核心差异对比
Apache Flink 在 1.13+ 版本逐步引入了全新的 Source/Sink API(也称为 FLIP-27 架构),取代了旧的 SourceFunction/SinkFunction 架构。这一变化旨在解决旧架构在扩展性、批流统一、状态管理等方面的局限性。
1. 新架构实现
这里我们从新 Source 举例,来了解新架构及实现原理:
开始了解 - 新 Source 原理 :
Flink 原先数据源一直使用的是 SourceFunction。实现它的 run 方法,使用 SourceContextcollect 数据或者发送 watermark 就实现了一个数据源。但是它有如下问题(来源于FLIP-27: Refactor Source Interface - Apache Flink - Apache Software Foundation翻译):
-
同一类型数据源的批和流模式需要两套不同实现。
-
“work发现”(分片、分区等)和实际 “读取” 数据的逻辑混杂在 SourceFunction 接口和 DataStream API 中,导致实现非常复杂,如 Kafka 和 Kinesis 源等。
-
分区/分片/拆分在接口中不是明确的。这使得以与 source 无关的方式实现某些功能变得困难,例如 event time 对齐、每个分区水印、动态拆分分配、工作窃取。例如,Kafka 和 Kinesis consumer 支持每个分区的 watermark,但从 Flink 1.8.1 开始,只有 Kinesis 消费者支持 event time 对齐(选择性地从拆分中读取以确保我们在事件时间上均匀推进)。
-
Checkpoint 锁由 source function “拥有”。实现必须确保进行元素发送和 state 更新时加锁。 Flink 无法优化它处理该锁的方式。
锁不是公平锁。在锁竞争下,一些线程可能无法获得锁(checkpoint线程)。这也妨碍使用 actor/mailbox 无锁线程模型。 -
没有通用的构建块,这意味着每个源都自己实现了一个复杂的线程模型。这使得实施和测试新 source 变得困难,并增加了对现有 source 的开发贡献的标准。
为了解决这些问题,Flink 引入了新的 Source 架构。
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
-
分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
-
源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
-
分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。
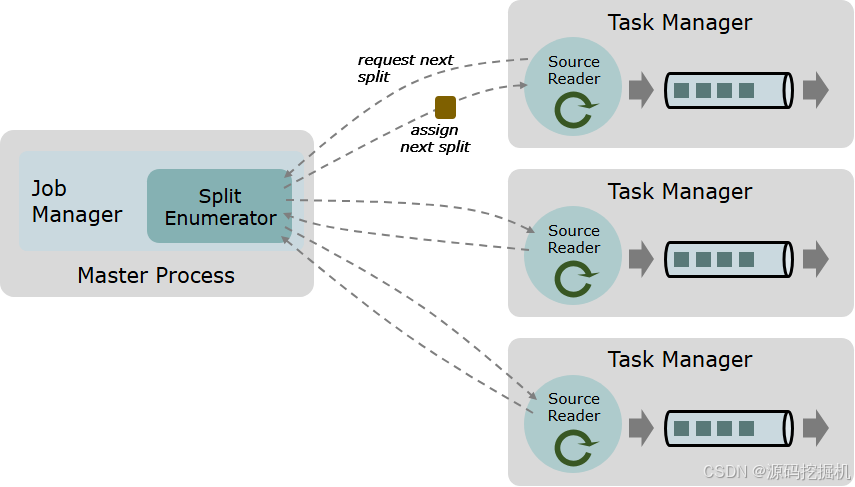
参考原文内容:https://blog.csdn.net/bigdatakenan/article/details/141064429
总的来说,Flink 新 Source/Sink 架构的本质是通过组件解耦和动态分片机制,以实现更加灵活、精细化的资源管理。
2. 核心类与依赖
| 特性 | 旧 API(1.12 之前) | 新 API(1.13+) |
|---|---|---|
| Source 实现类 | FlinkKafkaConsumer | KafkaSource |
| Sink 实现类 | FlinkKafkaProducer | KafkaSink |
| 依赖坐标 示例 | flink-connector-kafka_2.11:1.12 | flink-connector-kafka:1.20 |
| 批流统一 | 需要不同 API | 同一 API 支持流批 |
| 资源效率 | 静态并行度 | 动态分片分配 |
| 并发与锁管理 | 全局锁导致高竞争 | 分片级并发 |
3. 关键功能介绍
(1)动态分区发现
旧 API 通过 flink.partition-discovery.interval-millis 配置分区发现间隔。
新 API 通过 partition.discovery.interval.ms 配置分区发现间隔。
// 设置动态分区发现,间隔为 10 秒
// 旧 API
Properties props = new Properties();
...
props.setProperty("flink.partition-discovery.interval-millis", "10000");
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>("topic-name",new SimpleStringSchema(),props
);// 新 API
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(Config.KAFKA_SERVER).setValueOnlyDeserializer(new SimpleStringSchema())....setProperty("partition.discovery.interval.ms", "10000") .build();
(2)起始偏移量控制
旧 API 通过 auto.offset.reset 参数 或 flinkKafkaConsumer.setStartFromEarliest()的方法配置 offset 。
新 API 提供更细粒度的 offset 控制:
// 旧 API
Properties props = new Properties();
props.setProperty("auto.offset.reset", "earliest");
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>("topic-name",new SimpleStringSchema(),props
);
// 或
flinkKafkaConsumer.setStartFromEarliest();// 新 API
// 从最早可用偏移量(earliest offset)开始消费,忽略消费者组已提交的偏移量。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.earliest()).build();// 优先使用消费者组已提交的偏移量(若存在),如果无提交的偏移量(如首次启动消费者组),则回退到 EARLIEST 偏移量
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST)).build();// 从大于或等于指定时间戳(Unix 毫秒时间戳)的 Kafka 消息开始消费
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.timestamp(1657256257000L)).build();
(3)事务性写入
相较于旧 API ,新 API 配置事务方式更加简洁和易读。
Properties props = new Properties();
...
props.setProperty("enable.idempotence", true);
props.setProperty("transaction.timeout.ms", "900000"); // 旧 API Exactly-Once Sink
FlinkKafkaProducer<String> flinkKafkaProducer = new FlinkKafkaProducer<>("topic",new SimpleStringSchema(),props,FlinkKafkaProducer.Semantic.EXACTLY_ONCE // 旧 API 语义配置)
flinkKafkaProducer.setTransactionalIdPrefix("flink-transactional-id-");// 新 API Exactly-Once Sink
KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers(Config.KAFKA_SERVER).setRecordSerializer(...).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // 新 API 语义配置.setTransactionalIdPrefix("flink-transactional-id-").setKafkaProducerConfig(props).build();
三、迁移实战指南
1. 依赖升级
<!-- 旧 API 依赖 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.12.x</version>
</dependency><!-- 新 API 依赖 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.20.x</version>
</dependency>
2. Source 迁移示例(ConsumerRecord 版)
(1)旧 API 实现
Properties properties = new Properties();
properties.setProperty("consumer.topic", "test_123");
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "group_id_001");
properties.setProperty("auto.offset.reset", "earliest");FlinkKafkaConsumer<ConsumerRecord<byte[], byte[]>> flinkKafkaConsumer = new FlinkKafkaConsumer<>(properties.getProperty("consumer.topic"),new KafkaDeserializationSchema<ConsumerRecord<byte[], byte[]>>(){@Overridepublic TypeInformation getProducedType() {return TypeInformation.of(new TypeHint<ConsumerRecord<byte[], byte[]>>() {});}@Overridepublic ConsumerRecord<byte[], byte[]> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {return new ConsumerRecord<>(record.topic(),record.partition(),record.offset(),record.timestamp(),record.timestampType(),record.checksum(),record.serializedKeySize(),record.serializedValueSize(),record.key(),record.value());}@Overridepublic boolean isEndOfStream(ConsumerRecord<byte[], byte[]> nextElement) {return false;}},properties
);env.addSource(flinkKafkaConsumer);
(2)新 API 实现
KafkaSource<ConsumerRecord<String, String>> source = KafkaSource.<ConsumerRecord<String, String>>builder().setBootstrapServers(Config.KAFKA_SERVER).setTopics(Config.KAFKA_TOPIC).setGroupId(Config.KAFKA_GROUP_ID).setStartingOffsets(OffsetsInitializer.earliest()) .setDeserializer(KafkaRecordDeserializationSchema.of(new KafkaDeserializationSchema<ConsumerRecord<String, String>>() {@Overridepublic TypeInformation<ConsumerRecord<String, String>> getProducedType() {return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>() {});}@Overridepublic boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {return false;}@Overridepublic ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {return new ConsumerRecord<String, String>(record.topic(),record.partition(),record.offset(),record.timestamp(),record.timestampType(),record.checksum(),record.serializedKeySize(),record.serializedValueSize(),record.key() == null ? "" : new String(record.key(), StandardCharsets.UTF_8),record.value() == null ? "" : new String(record.value(), StandardCharsets.UTF_8));}})).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "New Flink Kafka Source");
3. Sink 迁移示例(ProducerRecord 版)
(1)旧 API 实现
Properties props = new Properties();
properties.setProperty("producer.topic", "test_123");
props.setProperty("bootstrap.servers", "localhost:9092");FlinkKafkaProducer<byte[]> flinkKafkaProducer = new FlinkKafkaProducer<>(properties.getProperty("producer.topic"),new KafkaSerializationSchema<byte[]>() {@Overridepublic void open(SerializationSchema.InitializationContext context) throws Exception {KafkaSerializationSchema.super.open(context);}@Overridepublic ProducerRecord<byte[], byte[]> serialize(byte[] element, @Nullable Long timestamp) {return new ProducerRecord<>(properties.getProperty("producer.topic"),"my_key_id".getBytes(StandardCharsets.UTF_8),element);}},properties,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE
);env.fromElements("apple", "banana", "orange").map(i -> i.getBytes(StandardCharsets.UTF_8)).addSink(flinkKafkaProducer);
(2)新 API 实现
KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers(Config.KAFKA_SERVER).setRecordSerializer((KafkaRecordSerializationSchema<String>) (element, context, timestamp) -> {String keyId = "my_key_id";byte[] key = keyId.getBytes(StandardCharsets.UTF_8); // 指定 keybyte[] value = element.getBytes(StandardCharsets.UTF_8); // 指定 valuereturn new ProducerRecord<>(Config.KAFKA_TOPIC, key, value);}).setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();env.fromElements("apple", "banana", "orange").sinkTo(sink);
四、总结与展望
通过Flink KafkaSource/KafkaSink 的连接器 API,用户在使用时不仅获得了更简洁的编程模型,还享受到更便捷的动态分区管理、精确一次语义和性能优化等高级特性。建议用户尽早迁移至新 API,以充分利用 Flink 1.20 的增强功能。
Flink 1.20 版本的发布标志着 Flink 在流批一体和云原生架构方面迈出了重要的一步,进一步巩固了其作为实时流数据处理平台的地位。这一版本在功能上进行了诸多增强,还在性能和易用性方面做出了显著改进,为用户提供了更强大的工具来处理复杂的流批任务。
Flink 1.20 核心改进总结【官宣|Apache Flink 1.20 发布公告】:
-
Flink SQL 物化表(Materialized Table)
- 功能特性
- 通过声明式 SQL 定义动态表结构与数据新鲜度(如
FRESHNESS = INTERVAL '3' MINUTE),引擎自动构建流批统一的数据加工链路。 - 支持流式持续刷新、批式全量刷新、增量刷新三种模式,用户可根据成本灵活切换(如大促时秒级实时,日常天级批处理)。
- 简化运维操作:暂停/恢复数据刷新(
SUSPEND/RESUME)、手动回刷历史分区(REFRESH PARTITION)。
- 通过声明式 SQL 定义动态表结构与数据新鲜度(如
- 价值
- 降低 ETL 开发复杂度,无需分别维护流/批作业,提升实时数仓构建效率。
- 功能特性
-
状态与检查点优化
- 统一检查点文件合并机制
- 将零散小文件合并为大文件,减少元数据压力,需配置
execution.checkpointing.file-merging.enabled=true。 - 支持跨检查点合并(
execution.checkpointing.file-merging.across-checkpoint-boundary=true)及文件池模式选择(阻塞/非阻塞)。
- 将零散小文件合并为大文件,减少元数据压力,需配置
- RocksDB 优化
- 后台自动合并小 SST 文件,避免因文件数量膨胀导致检查点失败。
- 统一检查点文件合并机制
-
批处理容错能力增强
- JobMaster 故障恢复机制
- 通过
JobEventStore持久化执行状态(如任务进度、算子协调器状态),故障后从外部存储恢复进度,避免重跑已完成任务。 - 需启用集群高可用(HA)并配置
execution.batch.job-recovery.enabled=true。
- 通过
- JobMaster 故障恢复机制
-
API 演进
- DataSet API 弃用
- 推荐迁移至 DataStream API 或 Table API/SQL,实现流批统一编程模型。
- DataStream API 增强
- 支持全量分区数据处理(
fullWindowPartition),补齐批处理能力。
- 支持全量分区数据处理(
- DataSet API 弃用
相关文章:

Flink 1.20 Kafka Connector:新旧 API 深度解析与迁移指南
Flink Kafka Connector 新旧 API 深度解析与迁移指南 一、Flink Kafka Connector 演进背景 Apache Flink 作为实时计算领域的标杆框架,其 Kafka 连接器的迭代始终围绕性能优化、语义增强和API 统一展开。Flink 1.20 版本将彻底弃用基于 FlinkKafkaConsumer/FlinkK…...

Vue2 父子组件数据传递与调用:从 ref 到 $emit
提示:https://github.com/jeecgboot/jeecgboot-vue2 文章目录 案例父组件向子组件传递数据的方式父组件调用子组件方法的方式子组件向父组件传递数据的方式流程示意图 案例 提示:以下是本篇文章正文内容,下面案例可供参考 以下是 整合后的关…...

【matplotlib参数调整】
1. 基本绘图函数常用参数 折线图 import matplotlib.pyplot as plt import numpy as npx np.linspace(0, 10, 100) y np.sin(x)plt.plot(x, y, colorred, linestyle--, linewidth2,markero, markersize5, labelsin(x), alpha0.8) plt.title(折线图示例) plt.xlabel(X 轴) p…...
并手动管理依赖(不使用 pom.xml))
如何使用 IntelliJ IDEA 开发命令行程序(或 Swing 程序)并手动管理依赖(不使用 pom.xml)
以下是详细步骤: 1. 创建项目 1.1 打开 IntelliJ IDEA。 1.2 在启动界面,点击 Create New Project(创建新项目)。 1.3 选择 Java,然后点击 Next。 1.4 确保 Project SDK 选择了正确的 JDK 版本&#x…...
配置NTP 时间同步、用户密码策略与使用 autofs 实现 NFS 自动挂载)
Linux红帽:RHCSA认证知识讲解(十 一)配置NTP 时间同步、用户密码策略与使用 autofs 实现 NFS 自动挂载
Linux红帽:RHCSA认证知识讲解(十 一)配置NTP 时间同步、用户密码策略与 NFS 自动挂载 前言一、配置 NTP 时间同步1.1 NTP 简介1.2 安装和配置 NTP 客户端 二、配置新建用户密码过期时间2.1 查看用户密码过期时间2.2 修改密码过期时间 三、使用…...

ffmpeg音视频处理流程
文章目录 FFmpeg 音视频处理流程详细讲解总结音视频处理流程相关的 FFmpeg 工具和命令 FFmpeg 的音视频处理流程涵盖了从输入文件读取数据、编码和解码操作、数据处理、以及最终输出数据的完整过程。为了更好地理解这一流程,我们可以从以下几个关键步骤来分析&#…...

leetcode-代码随想录-链表-移除链表元素
题目 链接:203. 移除链表元素 - 力扣(LeetCode) 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 输入:head [1,2,6,3,4,5,6], val 6 …...

c++与rust的语言区别,rust的主要难点,并举一些例子
C 和 Rust 都是系统级编程语言,它们在设计目标、语法、内存管理等方面存在诸多区别,以下为你详细介绍: 设计目标 C:C 最初是为了给 C 语言添加面向对象编程特性而设计的,之后不断发展,旨在提供高性能、灵…...

从基础算力协作到超智融合,超算互联网助力大语言模型研习
一、背景 大语言模型(LLMs)的快速发展释放出了AI应用领域的巨大潜力。同时,大语言模型作为 AI领域的新兴且关键的技术进展,为 AI 带来了全新的发展方向和应用场景,给 AI 注入了新潜力,这体现在大语言模型独…...

【spring cloud Netflix】Eureka注册中心
1.概念 Eureka就好比是滴滴,负责管理、记录服务提供者的信息。服务调用者无需自己寻找服务,而是把自己的 需求告诉Eureka,然后Eureka会把符合你需求的服务告诉你。同时,服务提供方与Eureka之间通过“心跳” 机制进行监控…...

记录学习的第二十天
今天只做了一道题,有点不在状态。 这道题其实跟昨天的每日一题是差不多的,不过这道题需要进行优化。 根据i小于j,且j小于k,当nums[j]确定时,保证另外两个最大即可得答案。 所以可以使用前缀最大值和后缀最大值。 代…...

7-5 表格输出
作者 乔林 单位 清华大学 本题要求编写程序,按照规定格式输出表格。 输入格式: 本题目没有输入。 输出格式: 要求严格按照给出的格式输出下列表格: ------------------------------------ Province Area(km2) Pop.(…...

【爬虫开发】爬虫开发从0到1全知识教程第14篇:scrapy爬虫框架,介绍【附代码文档】
本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:…...

安装 Microsoft Visual C++ Build Tools
Microsoft Visual C Build Tools下载安装 安装Microsoft Visual C Build Tools是为了在windows系统上编译和运行需要C支持的程序或库(例如某些Python包,Node.js模块等)。 1.下载 打开浏览器,访问 Visual Studio Build Tools下载…...

启服云专利管理系统:铸就知识产权保护的坚固壁垒
在全球竞争日益激烈的今天,知识产权已经成为企业核心竞争力的关键组成部分,而专利作为知识产权的重要体现,其管理和保护显得尤为重要。启服云专利管理系统凭借其卓越的功能和先进的技术,在知识产权保护领域展现出了显著的优势。 高…...
)
树莓派 5 部署 OMV(OpenMediaVault)
我使用Raspberry Pi OS Lite【Debian version: 12 (bookworm)】搭建OMV 换源,换源教程请参考:树莓派 5 换源 加入omv国内清华源 # 创建openmediavault.list文件 touch /etc/apt/sources.list.d/openmediavault.list # 加入内容 echo "deb [signed…...

Opencv之dilib库:表情识别
一、简介 在计算机视觉领域,表情识别是一个既有趣又具有挑战性的任务。它在人机交互、情感分析、安防监控等众多领域都有着广泛的应用前景。本文将详细介绍如何使用 Python 中的 OpenCV 库和 Dlib 库来实现一个简单的实时表情识别系统。 二、实现原理 表情识别系统…...

吾爱置顶软件,吊打电脑自带功能!
今天我给大家带来一款超棒的软件,它来自吾爱论坛的精选推荐,每一款都经过精心挑选,绝对好用! S_Clock 桌面计时软件 这款软件的界面设计特别漂亮,简洁又大方。它是一款功能齐全的时钟计时倒计时软件,既能正…...

深入理解浏览器的事件循环
浏览器的进程模型 浏览器进程:负责子进程的管理和用户交互网络进程:负责加载网络资源渲染进程:浏览器会为每一个标签页开启一个新的渲染进程。 渲染进程中的渲染主线程是我们最关注的,因为浏览器的事件循环就发生在这之中渲染主进…...

分布式锁之redis6
一、分布式锁介绍 之前我们都是使用本地锁(synchronize、lock等)来避免共享资源并发操作导致数据问题,这种是锁在当前进程内。 那么在集群部署下,对于多个节点,我们要使用分布式锁来避免共享资源并发操作导致数据问题…...

数据框的添加
在地图制图中,地图全图显示的同时希望也能够显示局部放大图,以方便查看地物空间位置的同时,也能查看地物具体的相对位置。例如,在一个名为airport的数据集全图制图过程中,希望能附上机场区域范围的局部地图,…...

SQL Server 2022 读写分离问题整合
跟着热点整理一下遇到过的SQL Server的问题,这篇来聊聊读写分离遇到的和听说过的问题。 一、读写分离实现方法 1. 原生高可用方案 1.1 Always On 可用性组(推荐方案) 配置步骤: -- 1. 启用Always On功能 USE [master] GO ALT…...

启服云云端专利管理系统:解锁专利管理新境界
在当今竞争激烈的商业环境中,专利作为企业的核心资产,其管理的重要性不言而喻。启服云云端专利管理系统以其卓越的性能和独特的优势,成为企业专利管理的得力助手,为企业的创新发展保驾护航。 便捷高效,突破时空限制 启…...

记录一下零零散散的的东西-ImageNet
ImageNet 是一个非常著名的大型图像识别数据集, 数据集基本信息 内容说明📸 图像数量超过 1400万张图片(包含各类子集)🏷️ 类别数量常用的是 ImageNet-1K(1000类)🧑Ἶ…...

全连接RNN反向传播梯度计算
全连接RNN反向传播梯度计算 RNN数学表达式BPTT(随时间的反向传播算法)参数关系网络图L对V的梯度L对U的梯度L对W和b的梯度 RNN数学表达式 BPTT(随时间的反向传播算法) 参数关系网络图 L对V的梯度 L对U的梯度 L对W和b的梯度...

基于BusyBox构建ISO镜像
1. 准备 CentOS 7.9 3.10.0-957.el7.x86_64VMware Workstation 建议:系统内核<3.10.0 使用busybox < 1.33.2版本 2. 安装busybox # 安装依赖 yum install syslinux xorriso kernel-devel kernel-headers glibc-static ncurses-devel -y# 下载 wget https://…...

使用python完成手写数字识别
入门图像识别的第一个案例,看到好多小伙伴分享,也把自己当初的思路捋捋,写成一篇博客,作为记录和分享,也欢迎各位交流讨论。 实现思路 数据集:MNIST(包含60,000个训练样本和10,000个测试样本) 深度学习框架:Keras(基于TensorFlow) 模型架构:卷积神经网络(CNN) 实…...

Vue2 过滤器 Filters
提示:Vue 过滤器是用于格式化文本的 JavaScript 函数,通过管道符 | 在模板中使用 文章目录 前言过滤器的核心特性1. 链式调用2. 参数传递3. 纯函数特性 过滤器的常见使用场景1. 文本格式化2. 数字处理3. 日期/时间格式化4. 样式控制(结合组件…...
)
Java 大视界 -- 基于 Java 的大数据分布式存储在视频监控数据管理中的应用优化(170)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
的作用)
c++中cin.ignore()的作用
在 C 中,cin.ignore() 是用于忽略(丢弃)输入流中的字符的函数,通常用来清除输入缓冲区中的残留内容(如换行符、多余输入等),以避免影响后续的输入操作。 基本用法 cin.ignore(n, delim);n&…...
)
讲一下resblock的跳跃连接,以及连接前后的shape保持(通过padding保持shape不变)
ResNet 残差块(ResBlock)的跳跃连接 & 形状保持 ResNet(Residual Network)通过 残差块(Residual Block, ResBlock) 解决了深度网络的梯度消失问题。其核心是跳跃连接(Skip Connection&…...

Unity中优化绘制调用整理
DrawCall 指的是 CPU 向 GPU 发送渲染指令的过程,在 Unity 中,每次渲染一个网格时,CPU 都需要向 GPU 发送一系列的渲染指令,这个过程被称为一次绘制调用(Draw Call)。 1.GPU实例化 使用: 2.绘…...

Coco-AI 支持嵌入,让你的网站拥有 AI 搜索力
在之前的实践中,我们已经成功地把 Hexo、Hugo 等静态博客和 Coco-AI 检索系统打通了:只要完成向量化索引,就可以通过客户端问答界面实现基于内容的智能检索。 这一层已经很好用了,但总觉得少了点什么—— 比如用户还得专门打开一…...

深入解析Java哈希表:从理论到实践
哈希表(Hash Table)是计算机科学中最重要的数据结构之一,也是Java集合框架的核心组件。本文将以HashMap为切入点,深入剖析Java哈希表的实现原理、使用技巧和底层机制。 一、哈希表基础原理 1. 核心概念 键值对存储:通…...

leetcode76.最小覆盖子串
思路源于 【小白都能听懂的算法课】【力扣】【LeetCode 76】最小覆盖子串|滑动窗口|字符串 初始化先创建t的哈希表记录t中的字符以及它出现的次数,t的have记录t中有几种字符 s的哈希表记录窗口中涵盖t的字符以及它出现的次数,初始…...

【HTB】Windwos-easy-Legacy靶机渗透
靶机介绍,一台很简单的WIndows靶机入门 知识点 msfconsole利用 SMB历史漏洞利用 WIndows命令使用,type查看命令 目录标题 一、信息收集二、边界突破三、权限提升 一、信息收集 靶机ip:10.10.10.4攻击机ip:10.10.16.26 扫描TC…...

一问讲透redis持久化机制-rdb aof
一问讲透redis持久化机制-rdb aof 文章目录 一问讲透redis持久化机制-rdb aof前言一、RDB二、AOF二、原理 前言 提示:这里可以添加本文要记录的大概内容: redis作为内存数据库,常常作为系统的缓存使用,但是内存是断电清空数据的…...

【大模型基础_毛玉仁】6.4 生成增强
目录 6.4 生成增强6.4.1 何时增强1)外部观测法2)内部观测法 6.4.2 何处增强6.4.3 多次增强6.4.4 降本增效1)去除冗余文本2)复用计算结果 6.4 生成增强 检索器得到相关信息后,将其传递给大语言模型以期增强模型的生成能…...

4.1-泛型编程深入指南
4.1 泛型编程深入指南 本节将带您深入探索C#泛型机制在游戏开发中的高级应用。通过游戏对象池、数据管理器、事件系统等实际案例,您将学习如何运用泛型构建高效、灵活的游戏系统。掌握这些知识将帮助您开发出性能更好、架构更清晰的游戏。 前置知识 在学习本节内容…...
)
《K230 从熟悉到...》识别机器码(AprilTag)
《K230 从熟悉到...》识别机器码(aprirltag) tag id 《庐山派 K230 从熟悉到...》 识别机器码(AprilTag) AprilTag是一种基于二维码的视觉标记系统,最早是由麻省理工学院(MIT)在2008年开发的。A…...
:实时系统介绍与实例分析)
操作系统(二):实时系统介绍与实例分析
目录 一.概念 1.1 分类 1.2 主要指标 二.实现原理 三.主流实时系统对比 一.概念 实时系统(Real-Time System, RTS)是一类以时间确定性为核心目标的计算机系统,其设计需确保在严格的时间约束内完成任务响应。 1.1 分类 根据时间约束的严…...
话费充值业务回调补偿)
虚拟电商-话费充值业务(六)话费充值业务回调补偿
一、话费充值回调业务补偿 业务需求:供应商对接下单成功后充吧系统将订单状态更改为:等待确认中,此时等待供应商系统进行回调,当供应商系统回调时说明供应商充值成功,供应商回调充吧系统将充吧的订单改为充值成功&…...

加密解密工具箱 - 专业的在线加密解密工具
加密解密工具箱 - 专业的在线加密解密工具 您可以通过以下地址访问该工具: https://toolxq.com/static/hub/secret/index.html 工具简介 加密解密工具箱是一个功能强大的在线加密解密工具,支持多种主流加密算法,包括 Base64、AES、RSA、DES…...

印度股票实时数据API接口选型指南:iTick.org如何成为开发者优选
在全球金融数字化浪潮中,印度股票市场因其高速增长潜力备受关注。对于量化交易开发者、金融科技公司而言,稳定可靠的股票报价API接口是获取市场数据的核心基础设施。本文将深度对比主流印度股票API,并揭示iTick在数据服务领域的独特优势。 一…...
)
使用python实现视频播放器(支持拖动播放位置跳转)
使用python实现视频播放器(支持拖动播放位置跳转) Python实现视频播放器,在我早期的博文中介绍或作为资料记录过 Python实现视频播放器 https://blog.csdn.net/cnds123/article/details/145926189 Python实现本地视频/音频播放器https://bl…...

Python星球日记 - 第2天:数据类型与变量
🌟引言: 上一篇:Python星球日记 - 第1天:欢迎来到Python星球 名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和…...

CyclicBarrier、Semaphore、CountDownLatch的区别,适用场景
CyclicBarrier、Semaphore 和 CountDownLatch 是 Java 并发包中用于线程协作的工具类,它们虽然都与线程同步相关,但设计目的和使用场景有显著差异。以下是它们的核心区别和典型应用场景: 1. CountDownLatch 核心机制 一次性计数器…...

【愚公系列】《高效使用DeepSeek》050-外汇交易辅助
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

java短连接,长连接
在网络通信中,短连接(Short Connection)是指客户端与服务器建立连接后,仅完成一次或几次数据交互就立即断开连接的通信方式。以下是关于短链接的详细说明: 一、短链接的核心特点 连接短暂 数据传输完成后立即关闭连接…...

从零开始训练Codebook:基于ViT的图像重建实践
完整代码在文末,可以一键运行。 1. 核心原理 Codebook是一种离散表征学习方法,其核心思想是将连续特征空间映射到离散的码本空间。我们的实现方案包含三个关键组件: 1.1 ViT编码器 class ViTEncoder(nn.Module):def __init__(self, codebo…...