【爬虫开发】爬虫开发从0到1全知识教程第14篇:scrapy爬虫框架,介绍【附代码文档】

本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:了解 响应内容的分类 Selenium概要 selenium的介绍 知识点: 1. selenium运行效果展示 1.1 chrome浏览器的运行效果 Selenium概要 selenium的其它使用方法 知识点: 1. selenium标签页的切换 知识点:掌握 selenium控制标签页的切换 反爬与反反爬 常见的反爬手段和解决思路 学习目标 1 服务器反爬的原因 2 服务器常反什么样的爬虫 反爬与反反爬 验证码处理 学习目标 1.图片验证码 2.图片识别引擎 反爬与反反爬 JS的解析 学习目标: 1 确定js的位置 1.1 观察按钮的绑定js事件 Mongodb数据库 介绍 内容 mongodb文档 mongodb的简单使用 Mongodb数据库 介绍 内容 mongodb文档 mongodb的聚合操作 Mongodb数据库 介绍 内容 mongodb文档 mongodb和python交互 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的入门使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy管道的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy中间件的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy_redis原理分析并实现断点续爬以及分布式爬虫 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的日志信息与配置 利用appium抓取app中的信息 介绍 内容 appium环境安装 学习目标
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/爬虫/爬虫开发从0到1全知识教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:
scrapy爬虫框架
介绍
我们知道常用的流程web框架有django、flask,那么接下来,我们会来学习一个全世界范围最流行的爬虫框架scrapy
内容
- scrapy的概念作用和工作流程
- scrapy的入门使用
- scrapy构造并发送请求
- scrapy模拟登陆
- scrapy管道的使用
- scrapy中间件的使用
- scrapy_redis概念作用和流程
- scrapy_redis原理分析并实现断点续爬以及分布式爬虫
- scrapy_splash组件的使用
- scrapy的日志信息与配置
- scrapyd部署scrapy项目
scrapy官方文档
[
scrapy中间件的使用
学习目标:
- 应用 scrapy中使用间件使用随机UA的方法
- 应用 scrapy中使用ip的的方法
- 应用 scrapy与selenium配合使用
1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用ip等
- 对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2. 下载中间件的使用方法:
接下来我们对腾讯招聘爬虫进行修改完善,通过下载中间件来学习如何使用中间件 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
-
process_request(self, request, spider):
-
当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
-
返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
process_response(self, request, response, spider):
-
当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
-
返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
在settings.py中配置开启中间件,权重值越小越优先执行
3. 定义实现随机User-Agent的下载中间件
3.1 在middlewares.py中完善代码
import random
from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示class UserAgentMiddleware(object):def process_request(self, request, spider):user_agent = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = user_agent# 不写returnclass CheckUA:def process_response(self,request,response,spider):print(request.headers['User-Agent'])return response # 不能少!
3.2 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {'Tencent.middlewares.UserAgentMiddleware': 543, # 543是权重值'Tencent.middlewares.CheckUA': 600, # 先执行543权重的中间件,再执行600的中间件
}
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = ["Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
运行爬虫观察现象
4. ip的使用
4.1 思路分析
- 添加的位置:request.meta中增加
proxy字段 - 获取一个ip,赋值给
request.meta['proxy'] - 池中随机选择ip
- ip的webapi发送请求获取一个ip
4.2 具体实现
免费ip:
class ProxyMiddleware(object):def process_request(self,request,spider):# proxies可以在settings.py中,也可以来源于ip的webapi# proxy = random.choice(proxies) # 免费的会失效,报 111 connection refused 信息!重找一个ip再试proxy = ' request.meta['proxy'] = proxyreturn None # 可以不写return
收费ip:
# 人民币玩家的代码(使用abuyun提供的ip)import base64# 隧道验证信息 这个是在那个网站上申请的proxyServer = ' # 收费的ip服务器地址,这里是abuyun
proxyUser = 用户名
proxyPass = 密码
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)class ProxyMiddleware(object):def process_request(self, request, spider):# 设置request.meta["proxy"] = proxyServer# 设置认证request.headers["Proxy-Authorization"] = proxyAuth
4.3 检测ip是否可用
在使用了ip的情况下可以在下载中间件的process_response()方法中处理ip的使用情况,如果该ip不能使用可以替换其他ip
class ProxyMiddleware(object):......def process_response(self, request, response, spider):if response.status != '200':request.dont_filter = True # 重新发送的请求对象能够再次进入队列return requst
在settings.py中开启该中间件
5. 在中间件中使用selenium
以github登陆为例
5.1 完成爬虫代码
import scrapyclass Login4Spider(scrapy.Spider):name = 'login4'allowed_domains = ['github.com']start_urls = [' # 直接对验证的url发送请求def parse(self, response):with open('check.html', 'w') as f:f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time
from selenium import webdriverdef getCookies():# 使用selenium模拟登陆,获取并返回cookieusername = input('输入github账号:')password = input('输入github密码:')options = webdriver.ChromeOptions()options.add_argument('--headless')options.add_argument('--disable-gpu')driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver',chrome_options=options)driver.get('time.sleep(1)driver.find_element_by_xpath('//*[@id="login_field"]').send_keys(username)time.sleep(1)driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)time.sleep(1)driver.find_element_by_xpath('//*[@id="login"]/form/div[3]/input[3]').click()time.sleep(2)cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}driver.quit()return cookies_dictclass LoginDownloaderMiddleware(object):def process_request(self, request, spider):cookies_dict = getCookies()print(cookies_dict)request.cookies = cookies_dict # 对请求对象的cookies属性进行替换
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
小结
中间件的使用:
-
完善中间件代码:
-
process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
需要在settings.py中开启中间件 DOWNLOADER_MIDDLEWARES = { 'myspider.middlewares.UserAgentMiddleware': 543, }
scrapy_redis概念作用和流程
学习目标
- 了解 分布式的概念及特点
- 了解 scarpy_redis的概念
- 了解 scrapy_redis的作用
- 了解 scrapy_redis的工作流程
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
1. 分布式是什么
简单的说 分布式就是不同的节点(服务器,ip不同)共同完成一个任务
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬
- 分布式快速抓取
4. scrapy_redis的工作流程
4.1 回顾scrapy的流程
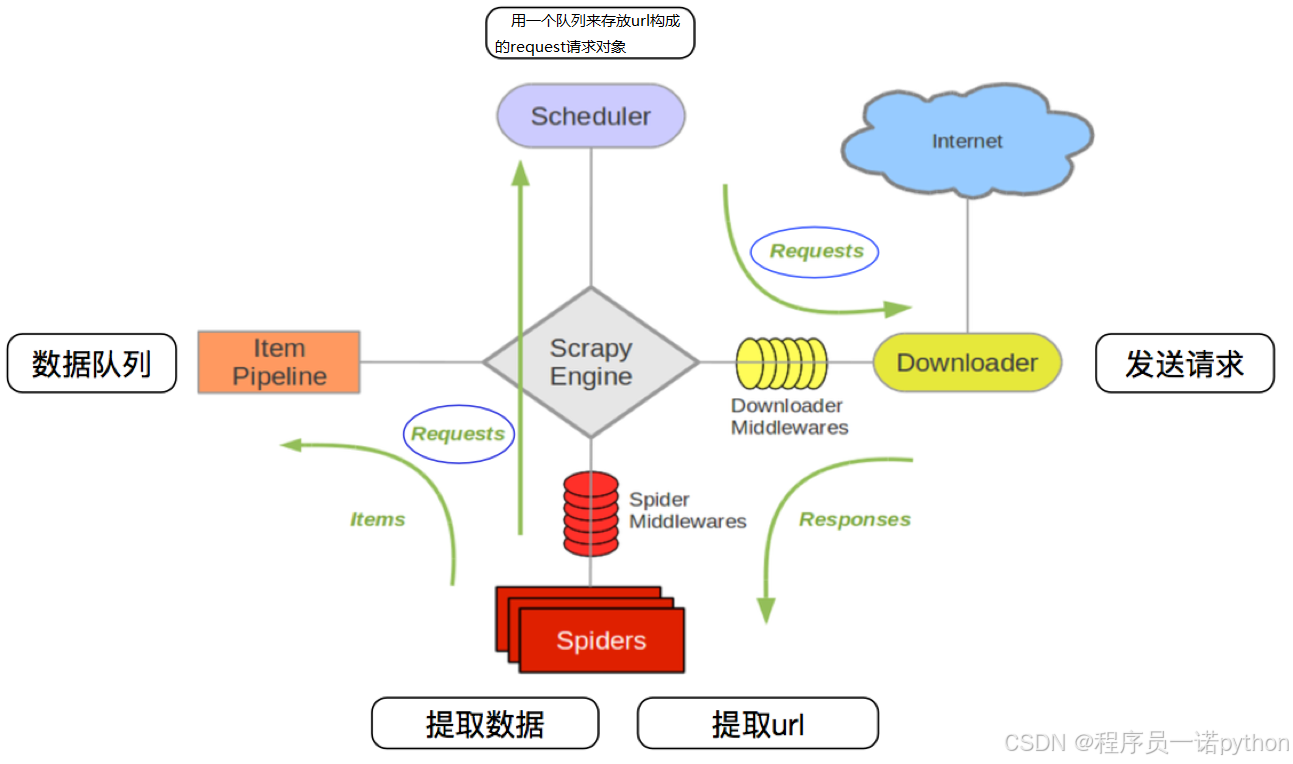
思考:那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
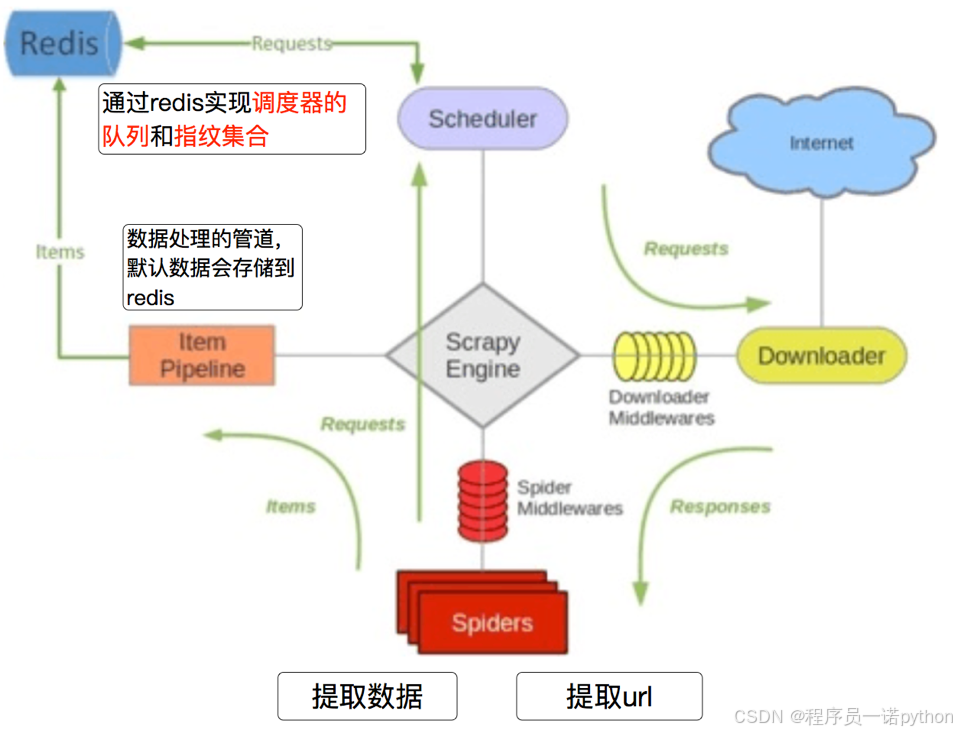
4.2 scrapy_redis的流程
-
在scrapy_redis中,所有的待抓取的request对象和去重的request对象指纹都存在所有的服务器公用的redis中
-
所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
-
所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
-
在默认情况下所有的数据会保存在redis中
具体流程如下:
小结
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的待抓取的对象和去重的指纹都存在公用的redis中
- 所有的服务器公用同一redis中的请求对象的队列
- 所有的request对象存入redis前,都会通过请求对象的指纹进行判断,之前是否已经存入过
相关文章:

【爬虫开发】爬虫开发从0到1全知识教程第14篇:scrapy爬虫框架,介绍【附代码文档】
本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:…...

安装 Microsoft Visual C++ Build Tools
Microsoft Visual C Build Tools下载安装 安装Microsoft Visual C Build Tools是为了在windows系统上编译和运行需要C支持的程序或库(例如某些Python包,Node.js模块等)。 1.下载 打开浏览器,访问 Visual Studio Build Tools下载…...

启服云专利管理系统:铸就知识产权保护的坚固壁垒
在全球竞争日益激烈的今天,知识产权已经成为企业核心竞争力的关键组成部分,而专利作为知识产权的重要体现,其管理和保护显得尤为重要。启服云专利管理系统凭借其卓越的功能和先进的技术,在知识产权保护领域展现出了显著的优势。 高…...
)
树莓派 5 部署 OMV(OpenMediaVault)
我使用Raspberry Pi OS Lite【Debian version: 12 (bookworm)】搭建OMV 换源,换源教程请参考:树莓派 5 换源 加入omv国内清华源 # 创建openmediavault.list文件 touch /etc/apt/sources.list.d/openmediavault.list # 加入内容 echo "deb [signed…...

Opencv之dilib库:表情识别
一、简介 在计算机视觉领域,表情识别是一个既有趣又具有挑战性的任务。它在人机交互、情感分析、安防监控等众多领域都有着广泛的应用前景。本文将详细介绍如何使用 Python 中的 OpenCV 库和 Dlib 库来实现一个简单的实时表情识别系统。 二、实现原理 表情识别系统…...

吾爱置顶软件,吊打电脑自带功能!
今天我给大家带来一款超棒的软件,它来自吾爱论坛的精选推荐,每一款都经过精心挑选,绝对好用! S_Clock 桌面计时软件 这款软件的界面设计特别漂亮,简洁又大方。它是一款功能齐全的时钟计时倒计时软件,既能正…...

深入理解浏览器的事件循环
浏览器的进程模型 浏览器进程:负责子进程的管理和用户交互网络进程:负责加载网络资源渲染进程:浏览器会为每一个标签页开启一个新的渲染进程。 渲染进程中的渲染主线程是我们最关注的,因为浏览器的事件循环就发生在这之中渲染主进…...

分布式锁之redis6
一、分布式锁介绍 之前我们都是使用本地锁(synchronize、lock等)来避免共享资源并发操作导致数据问题,这种是锁在当前进程内。 那么在集群部署下,对于多个节点,我们要使用分布式锁来避免共享资源并发操作导致数据问题…...

数据框的添加
在地图制图中,地图全图显示的同时希望也能够显示局部放大图,以方便查看地物空间位置的同时,也能查看地物具体的相对位置。例如,在一个名为airport的数据集全图制图过程中,希望能附上机场区域范围的局部地图,…...

SQL Server 2022 读写分离问题整合
跟着热点整理一下遇到过的SQL Server的问题,这篇来聊聊读写分离遇到的和听说过的问题。 一、读写分离实现方法 1. 原生高可用方案 1.1 Always On 可用性组(推荐方案) 配置步骤: -- 1. 启用Always On功能 USE [master] GO ALT…...

启服云云端专利管理系统:解锁专利管理新境界
在当今竞争激烈的商业环境中,专利作为企业的核心资产,其管理的重要性不言而喻。启服云云端专利管理系统以其卓越的性能和独特的优势,成为企业专利管理的得力助手,为企业的创新发展保驾护航。 便捷高效,突破时空限制 启…...

记录一下零零散散的的东西-ImageNet
ImageNet 是一个非常著名的大型图像识别数据集, 数据集基本信息 内容说明📸 图像数量超过 1400万张图片(包含各类子集)🏷️ 类别数量常用的是 ImageNet-1K(1000类)🧑Ἶ…...

全连接RNN反向传播梯度计算
全连接RNN反向传播梯度计算 RNN数学表达式BPTT(随时间的反向传播算法)参数关系网络图L对V的梯度L对U的梯度L对W和b的梯度 RNN数学表达式 BPTT(随时间的反向传播算法) 参数关系网络图 L对V的梯度 L对U的梯度 L对W和b的梯度...

基于BusyBox构建ISO镜像
1. 准备 CentOS 7.9 3.10.0-957.el7.x86_64VMware Workstation 建议:系统内核<3.10.0 使用busybox < 1.33.2版本 2. 安装busybox # 安装依赖 yum install syslinux xorriso kernel-devel kernel-headers glibc-static ncurses-devel -y# 下载 wget https://…...

使用python完成手写数字识别
入门图像识别的第一个案例,看到好多小伙伴分享,也把自己当初的思路捋捋,写成一篇博客,作为记录和分享,也欢迎各位交流讨论。 实现思路 数据集:MNIST(包含60,000个训练样本和10,000个测试样本) 深度学习框架:Keras(基于TensorFlow) 模型架构:卷积神经网络(CNN) 实…...

Vue2 过滤器 Filters
提示:Vue 过滤器是用于格式化文本的 JavaScript 函数,通过管道符 | 在模板中使用 文章目录 前言过滤器的核心特性1. 链式调用2. 参数传递3. 纯函数特性 过滤器的常见使用场景1. 文本格式化2. 数字处理3. 日期/时间格式化4. 样式控制(结合组件…...
)
Java 大视界 -- 基于 Java 的大数据分布式存储在视频监控数据管理中的应用优化(170)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
的作用)
c++中cin.ignore()的作用
在 C 中,cin.ignore() 是用于忽略(丢弃)输入流中的字符的函数,通常用来清除输入缓冲区中的残留内容(如换行符、多余输入等),以避免影响后续的输入操作。 基本用法 cin.ignore(n, delim);n&…...
)
讲一下resblock的跳跃连接,以及连接前后的shape保持(通过padding保持shape不变)
ResNet 残差块(ResBlock)的跳跃连接 & 形状保持 ResNet(Residual Network)通过 残差块(Residual Block, ResBlock) 解决了深度网络的梯度消失问题。其核心是跳跃连接(Skip Connection&…...

Unity中优化绘制调用整理
DrawCall 指的是 CPU 向 GPU 发送渲染指令的过程,在 Unity 中,每次渲染一个网格时,CPU 都需要向 GPU 发送一系列的渲染指令,这个过程被称为一次绘制调用(Draw Call)。 1.GPU实例化 使用: 2.绘…...

Coco-AI 支持嵌入,让你的网站拥有 AI 搜索力
在之前的实践中,我们已经成功地把 Hexo、Hugo 等静态博客和 Coco-AI 检索系统打通了:只要完成向量化索引,就可以通过客户端问答界面实现基于内容的智能检索。 这一层已经很好用了,但总觉得少了点什么—— 比如用户还得专门打开一…...

深入解析Java哈希表:从理论到实践
哈希表(Hash Table)是计算机科学中最重要的数据结构之一,也是Java集合框架的核心组件。本文将以HashMap为切入点,深入剖析Java哈希表的实现原理、使用技巧和底层机制。 一、哈希表基础原理 1. 核心概念 键值对存储:通…...

leetcode76.最小覆盖子串
思路源于 【小白都能听懂的算法课】【力扣】【LeetCode 76】最小覆盖子串|滑动窗口|字符串 初始化先创建t的哈希表记录t中的字符以及它出现的次数,t的have记录t中有几种字符 s的哈希表记录窗口中涵盖t的字符以及它出现的次数,初始…...

【HTB】Windwos-easy-Legacy靶机渗透
靶机介绍,一台很简单的WIndows靶机入门 知识点 msfconsole利用 SMB历史漏洞利用 WIndows命令使用,type查看命令 目录标题 一、信息收集二、边界突破三、权限提升 一、信息收集 靶机ip:10.10.10.4攻击机ip:10.10.16.26 扫描TC…...

一问讲透redis持久化机制-rdb aof
一问讲透redis持久化机制-rdb aof 文章目录 一问讲透redis持久化机制-rdb aof前言一、RDB二、AOF二、原理 前言 提示:这里可以添加本文要记录的大概内容: redis作为内存数据库,常常作为系统的缓存使用,但是内存是断电清空数据的…...

【大模型基础_毛玉仁】6.4 生成增强
目录 6.4 生成增强6.4.1 何时增强1)外部观测法2)内部观测法 6.4.2 何处增强6.4.3 多次增强6.4.4 降本增效1)去除冗余文本2)复用计算结果 6.4 生成增强 检索器得到相关信息后,将其传递给大语言模型以期增强模型的生成能…...

4.1-泛型编程深入指南
4.1 泛型编程深入指南 本节将带您深入探索C#泛型机制在游戏开发中的高级应用。通过游戏对象池、数据管理器、事件系统等实际案例,您将学习如何运用泛型构建高效、灵活的游戏系统。掌握这些知识将帮助您开发出性能更好、架构更清晰的游戏。 前置知识 在学习本节内容…...
)
《K230 从熟悉到...》识别机器码(AprilTag)
《K230 从熟悉到...》识别机器码(aprirltag) tag id 《庐山派 K230 从熟悉到...》 识别机器码(AprilTag) AprilTag是一种基于二维码的视觉标记系统,最早是由麻省理工学院(MIT)在2008年开发的。A…...
:实时系统介绍与实例分析)
操作系统(二):实时系统介绍与实例分析
目录 一.概念 1.1 分类 1.2 主要指标 二.实现原理 三.主流实时系统对比 一.概念 实时系统(Real-Time System, RTS)是一类以时间确定性为核心目标的计算机系统,其设计需确保在严格的时间约束内完成任务响应。 1.1 分类 根据时间约束的严…...
话费充值业务回调补偿)
虚拟电商-话费充值业务(六)话费充值业务回调补偿
一、话费充值回调业务补偿 业务需求:供应商对接下单成功后充吧系统将订单状态更改为:等待确认中,此时等待供应商系统进行回调,当供应商系统回调时说明供应商充值成功,供应商回调充吧系统将充吧的订单改为充值成功&…...

加密解密工具箱 - 专业的在线加密解密工具
加密解密工具箱 - 专业的在线加密解密工具 您可以通过以下地址访问该工具: https://toolxq.com/static/hub/secret/index.html 工具简介 加密解密工具箱是一个功能强大的在线加密解密工具,支持多种主流加密算法,包括 Base64、AES、RSA、DES…...

印度股票实时数据API接口选型指南:iTick.org如何成为开发者优选
在全球金融数字化浪潮中,印度股票市场因其高速增长潜力备受关注。对于量化交易开发者、金融科技公司而言,稳定可靠的股票报价API接口是获取市场数据的核心基础设施。本文将深度对比主流印度股票API,并揭示iTick在数据服务领域的独特优势。 一…...
)
使用python实现视频播放器(支持拖动播放位置跳转)
使用python实现视频播放器(支持拖动播放位置跳转) Python实现视频播放器,在我早期的博文中介绍或作为资料记录过 Python实现视频播放器 https://blog.csdn.net/cnds123/article/details/145926189 Python实现本地视频/音频播放器https://bl…...

Python星球日记 - 第2天:数据类型与变量
🌟引言: 上一篇:Python星球日记 - 第1天:欢迎来到Python星球 名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和…...

CyclicBarrier、Semaphore、CountDownLatch的区别,适用场景
CyclicBarrier、Semaphore 和 CountDownLatch 是 Java 并发包中用于线程协作的工具类,它们虽然都与线程同步相关,但设计目的和使用场景有显著差异。以下是它们的核心区别和典型应用场景: 1. CountDownLatch 核心机制 一次性计数器…...

【愚公系列】《高效使用DeepSeek》050-外汇交易辅助
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

java短连接,长连接
在网络通信中,短连接(Short Connection)是指客户端与服务器建立连接后,仅完成一次或几次数据交互就立即断开连接的通信方式。以下是关于短链接的详细说明: 一、短链接的核心特点 连接短暂 数据传输完成后立即关闭连接…...

从零开始训练Codebook:基于ViT的图像重建实践
完整代码在文末,可以一键运行。 1. 核心原理 Codebook是一种离散表征学习方法,其核心思想是将连续特征空间映射到离散的码本空间。我们的实现方案包含三个关键组件: 1.1 ViT编码器 class ViTEncoder(nn.Module):def __init__(self, codebo…...

每日一题洛谷P8664 [蓝桥杯 2018 省 A] 付账问题c++
P8664 [蓝桥杯 2018 省 A] 付账问题 - 洛谷 (luogu.com.cn) 思路:要使方差小,那么钱不能一下付的太多,可以让钱少的全付玩,剩下还需要的钱再让钱多的付(把钱少的补上)。 将钱排序,遍历一遍&…...

蓝桥杯真题——传送阵
原题连接:蓝桥杯2024年第十五届省赛真题-传送阵 - C语言网 知识点:并查集 题目描述 小蓝在环球旅行时来到了一座古代遗迹,里面并排放置了 n 个传送阵,进入第 i 个传送阵会被传送到第 ai 个传送阵前,并且可以随时选择…...

解释回溯算法,如何应用回溯算法解决组合优化问题?
一、回溯算法核心原理 回溯算法本质是暴力穷举的优化版本,采用"试错剪枝"策略解决问题。其核心流程如下: 路径构建:记录当前选择路径选择列表:确定可用候选元素终止条件:确定递归结束时机剪枝优化…...

opencv连接vs2015
需要改的地方: 1.debug x64 2.vc目录 包含目录:D:\softword\opencv\opencv3416\opencv\build\include 3.vc目录 库目录:D:\softword\opencv\opencv3416\opencv\build\x64\vc14\lib 4.链接器——输入:D:\softword\ope…...

用matlab搭建一个简单的图像分类网络
文章目录 1、数据集准备2、网络搭建3、训练网络4、测试神经网络5、进行预测6、完整代码 1、数据集准备 首先准备一个包含十个数字文件夹的DigitsData,每个数字文件夹里包含1000张对应这个数字的图片,图片的尺寸都是 28281 像素的,如下图所示…...

移动端六大语言速记:第6部分 - 错误处理与调试
移动端六大语言速记:第6部分 - 错误处理与调试 本文将对比Java、Kotlin、Flutter(Dart)、Python、ArkTS和Swift这六种移动端开发语言在错误处理与调试方面的特性,帮助开发者理解和掌握各语言的异常处理机制。 6. 错误处理与调试 6.1 异常处理 各语言异常处理的语法对比:…...

【数据库】达梦arm64安装
话不多说,快速开始~ 1.下载 进入官网: 产品下载 | 达梦在线服务平台 下载安装包。 选飞腾、鲲鹏都可以,都是arm架构的。我选择的是: 直接下载地址是https://download.dameng.com/eco/adapter/DM8/202502/dm8_20250117_HWarm920…...
(头插)和 insertRow(rowCount())(尾插)的性能差异)
QTableWidget 中insertRow(0)(头插)和 insertRow(rowCount())(尾插)的性能差异
一、目的 在 Qt 的 QTableWidget 中,insertRow(0) (头插)和 insertRow(rowCount())(尾插)在性能上存在显著差异。 二、QAbstractItemModel:: insertRows 原文解释 QAbstractItemModel Class | Qt Core 5.15.18 AI 解…...
)
使用MFC ActiveX开发KingScada控件(OCX)
最近有个需求,要在KingScada上面开发一个控件。 原来是用的WinCC,WinCC本身是支持调用.net控件,就是winform控件的,winform控件开发简单,相对功能也更丰富。奈何WinCC不是国产的。 话说KingScada,国产组态软…...

大模型学习二:DeepSeek R1+蒸馏模型组本地部署与调用
一、说明 DeepSeek R1蒸馏模型组是基于DeepSeek-R1模型体系,通过知识蒸馏技术优化形成的系列模型,旨在平衡性能与效率。 1、技术路径与核心能力 基础架构与训练方法 DeepSeek-R1-Zero:通过强化学习(RL)训练&…...

通过 Markdown 改进 RAG 文档处理
通过 Markdown 改进 RAG 文档处理 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/29139791931 通过 Markdown 改进 RAG 文档处理https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw 如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果 Mar…...

Java学习总结-IO流
什么IO流? 以内存为主体。input:磁盘向内存输入内容。output:内存向磁盘输入内容。 IO流的分类:...